The atmospheric environment is the natural space in which human beings live, and it is also the physical space in which human production and life directly interact [
1]. While the atmospheric environment has improved in recent years, its real situation still worries us [
2,
3,
4,
5]. While resolving this kind of problem, we also found that the “environmental panic” [
6] problem caused by the atmospheric pollution problem is becoming more and more serious [
7,
8,
9]. For example, when there is smog, the public shows a negative attitude towards work and life and reduces going out. The public has different “emotions” to the environment because of various “situations” of the environment. This environmental mood is formed by public subjective consciousness and interferes with our thinking and behaviors [
10]. It can also affect our social emotions. However, the implementation of some government policies and the organization of events have not received the expected good results due to the impact of public environmental sentiments [
11,
12,
13,
14,
15]. Therefore, public environmental sentiment prediction is of great significance. This article will carry out a deep research over whether the public environmental emotion can be predicted, and how we should capture and collect the public environmental emotion [
16]. Can public environmental sentiments be predicted? If they can be predicted, how will we predict them? In the study of this paper, we put forward the hypothesis that we believe that the relationship between atmospheric environmental factors and public environmental emotions can be used to predict the public environmental emotions. Then, what is the relationship between public environmental emotions and atmospheric environment? Yu Guoming, Professor of Beijing Normal University, said that the quality of the atmospheric environment affects the normal life and work of the public all the time. It is an important proposition related to social stability to study the impact of the atmospheric environment on the public emotion [
17,
18,
19,
20]. Many studies are also trying to prove the relationship between weather and human emotions. Most of them use questionnaires, telephone access, public datasets or crawling micro blog data to obtain public environmental emotions [
21]. For example, in 2006–2007, taking the information release of world earth day as an example, the survey information of the public’s perception of the ecological environment shows that everyone is basically in an ecological environment prone to negative emotions [
22]; for example, Li Junzhi and others take Xi’an city and Shanghai city as an example, using micro blog big data to carry out the method of emotional analysis and correlation analysis, to carry out a comparative analysis of residents’ emotional data and air quality data in the two cities [
23]. In summary, we believe that the atmospheric environment is related to the public’s emotions, and we can use atmospheric environmental factors to predict the public’s environmental emotions. However, from the perspective of data acquisition, there are obvious deficiencies in the way of obtaining public environmental emotions compared with the way of public participatory perception [
24,
25,
26,
27,
28]. For example, in the way of questionnaire surveys and telephone interviews, the respondents often fail to fully reflect the time of the survey due to time constraints and subjective guidance factors of the investigators, which often results in the collection of data samples without great randomness and this has a great impact on the results [
29]. For the way of crawling microblog data, the data is generally collected by searching for topics. The data is often user comments [
30,
31,
32]. When studying the environment and public environmental emotions, it is necessary to quantify these microblog data and use the quantified microblog data for correlation analysis [
33]. However, there are also microblog comments that are not only published for environmental factors. Comments are quantified to have a greater impact on the results.
Most of the existing domestic and international research on the prediction of environmental factors predict some factors of air quality itself. For example, Huang Jie and others adopted the stacking integration strategy to integrate RNN (Recurrent Neural Network) and CNN (Convolutional Neural Network), and put forward the RNN-CNN integrated deep learning prediction model, aiming at the air quality of 1466 monitoring stations in mainland China in 2016. Data are samples of instance validation [
30]. Another example is Li Dong et al. In order to solve the problem of low precision in PM
2.5 concentration prediction, this paper proposes an online PM
2.5 daily concentration hybrid prediction model based on correlation analysis, autoregressive distribution lag model, Drosophila optimization algorithm and nuclear limit learning machine, and applies the model to five cities in the Guanzhong region, and verifies the model with the monitoring data from January 2016 to May 2017 [
34]. Another example is Mahajan sachit et al. who developed a prediction method, which uses exponential smoothing with drift and real-time PM
2.5 data obtained from large-scale deployment of Internet of things devices in Taichung, Taiwan, for experiment and evaluation. These studies tend to improve the existing prediction model for application research, and the influencing factors of application research are mostly used: PM
2.5, PM
10 [
35]. However, how to learn and analyze the public’s cognition, understanding and behavior characteristics of environmental change through the data of atmospheric environmental factors, to guide the formulation of environmental management policies, to form correct environmental awareness and environmental public opinion, is the starting point and foothold of public environmental behavior, so it is of far-reaching significance to predict public environmental emotion through the existing environmental data.
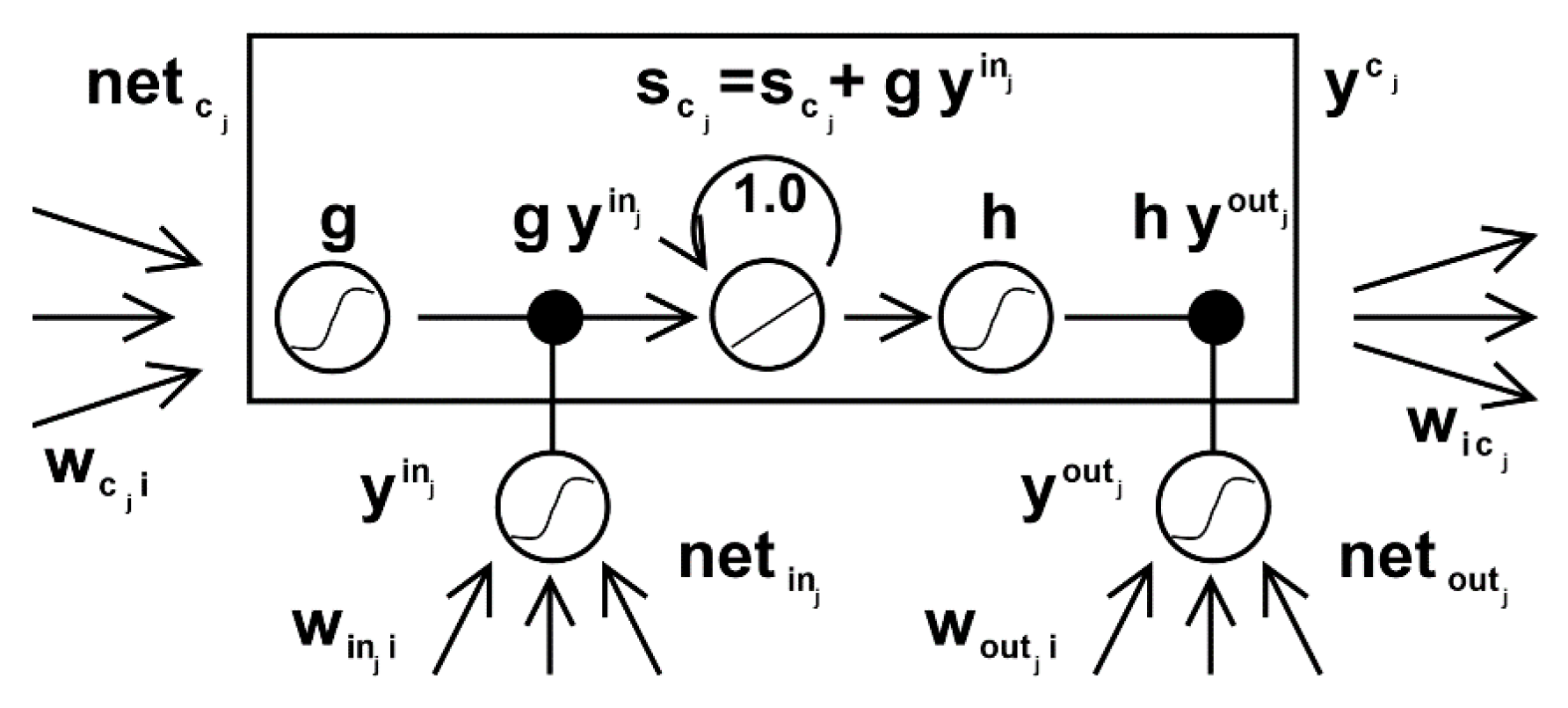
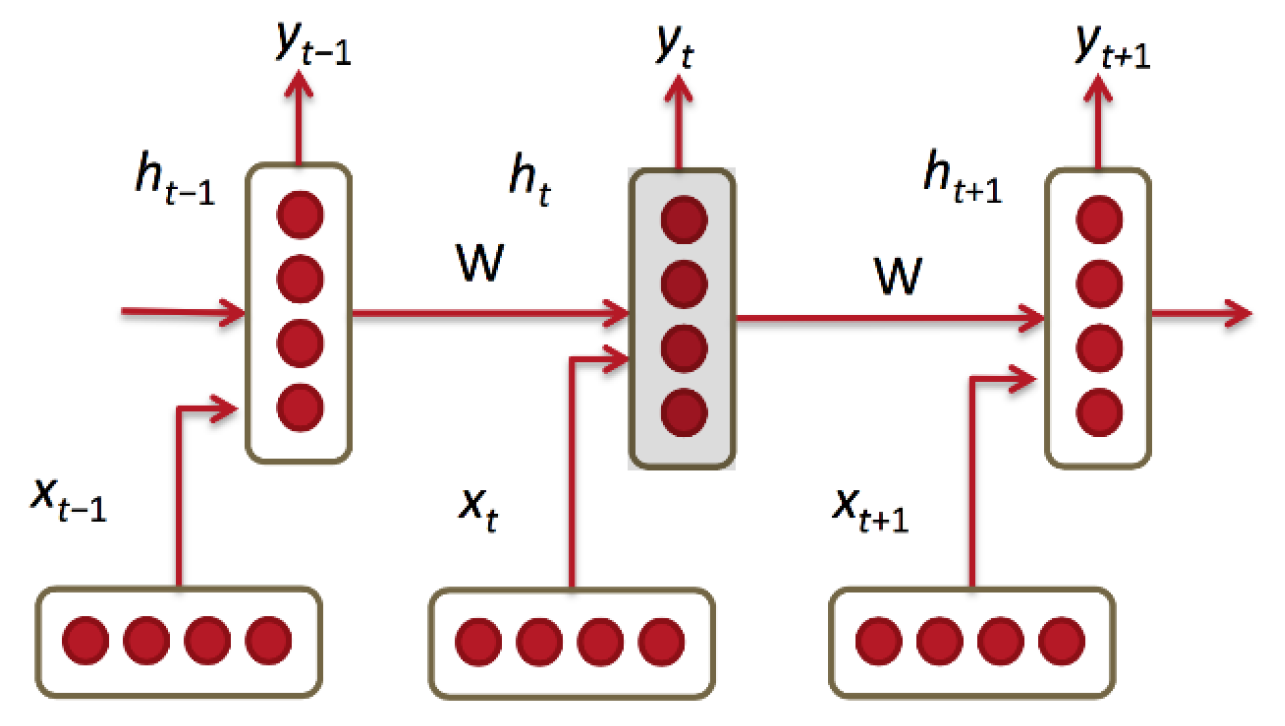
This paper focuses on the study of the relationship between atmospheric environment and public environmental emotion and the application of the public environmental emotion prediction model. First of all, using the atmospheric environment data and public environmental sentiment data on time series, and using the vector autoregressive model (VAR) to analyze the influencing factors of “public environmental perception satisfaction”, the result is one or more influencing factors, which paves the way for the construction of a public environmental sentiment prediction model. In this paper, the LSTM neural network model and RNN neural network model will be used to predict the public environmental sentiment, and the “public environmental sentiment prediction model” will be determined by referring to the prediction accuracy and error analysis between the two models.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}