1. Introduction
Energy is vital for the sustainable development of any country. Over the past decade, global energy demand has grown exponentially. Accurate energy forecasting is crucial for sustainable economic prosperity and environmental security. Energy is correlated with industrial production, agricultural production, nutrition, water access, economy, employment, quality of life, etc. Energy demand forecasting is required for the proper allocation of available resources. Over the last decade, several new techniques have been used for energy forecasting to accurately predict future energy needs. Energy demand management involves effective utilization and management of energy resources, reliability of the supply, energy conservation, combined heat and power systems, renewable and integrated energy systems, independent power delivery systems, etc. Demand management has to consider a series of technical, organizational, or behavioral solutions to decrease energy consumption and demand. Cost-effective options, commercially viable alternatives, and environmentally friendly solutions need to be explored.
Energy demand is closely linked to the price of energy, gross domestic product, and population, among other aspects. Managing energy demand would help to achieve self-sufficiency and cost efficiency in order to ensure sustainable economic growth. Energy demand management should thus help in planning for future requirements, identifying conservation measures, identifying and prioritizing energy resources, optimizing energy utilization, formulating strategies for improved energy efficiency, framing policy decisions, and identifying strategies for reduced emissions. Energy models are developed using macroeconomic variables to forecast energy demand. They assist in the preparation and design of energy management strategies on the demand side [
1].
Cyprus has one of Europe’s highest electricity prices, caused by high dependence on liquid fuel for electricity generation. Nevertheless, a significant change in the electricity supply is imminent. On the one hand, indigenous natural gas discoveries are to be developed in the near future. On the other hand, the cost of renewable energy options has dropped significantly, and in the meantime, concerns about greenhouse gas emissions and regional pollutants have increased, reflecting strict EU regulations. A key challenge for Cyprus is its high dependence on fossil fuels for energy, which is actually the largest share in the EU, making it vital for the country to develop both its hydrocarbon and renewable energy sources. Cyprus is reliant on fossil fuel imports for its electricity needs, and spends over 8% of its gross domestic product to cover the costs. The country has witnessed the highest increase in energy consumption in the EU28, from 1.6 million tons of oil equivalent in 1990 to 2.3 million tons in 2015, a 41% increase. However, Cyprus is determined to find a cleaner solution until it can exploit its own reserves. The energy industry is changing rapidly, challenging long-term estimates. Long-term demand for natural gas is expected to rise before 2050 and decrease over time. This is not something that will happen suddenly. In fact, most of the forecasts predict growth in global gas demand over the next 20 years or so, followed by a gradual decline [
2].
It is a challenging task to predict power demand with high precision. An electricity time series is complex, with nonlinear dependencies, and contains both periodic and random components. The periodic components are due to nested intervals on a weekly and daily basis. The random components are due to the inherent fluctuations in household electricity usage, changes in industry usage (e.g., big consumers with unknown hours of operation), and variations due to weather changes, special events, calendar and economic factors, and malfunctioning of measuring devices [
3].
Electricity load forecasting is crucially important for proper operation, maintenance, and planning of the electric power system. Electricity load forecasting can be classified into four categories, according to the time period: long-term: 1–50 years; mid-term: one month to one year; short-term: estimates of the day or week ahead; and very short-term: a few minutes to an hour ahead of electricity consumption. Both long- and mid-term forecasts are important for strategic planning in the development of electric power systems. This includes scheduling of construction of new generation or transmission facilities, maintenance scheduling, and long-term demand-side measurement and management planning [
4].
Zachariadis [
5] provided a forecast of electricity consumption in Cyprus up to 2030, based on an econometric analysis of energy use as a function of macroeconomic variables, prices, and weather conditions. If past trends continue, electricity use is expected to triple in the next 20–25 years, with the residential and commercial sectors increasing their already high shares of total consumption [
5]. Zachariadis assessed the additional peak electricity load requirements in the future due to climate change, and claimed that the extra load could amount to 65–75 megawatts in 2020 and 85–95 megawatts in 2030. Zachariadis [
6] also presented an energy outlook for Cyprus up to 2020, quantifying the energy savings that could be attained depending on the degree of implementation of policies on energy efficiency and the use of natural gas for energy generation.
Accurate load forecasting is essential for effective power system operation, but electricity load is nonlinear with a high level of volatility. Predicting such complex signals requires suitable prediction tools. The general techniques applied for forecasting can be divided into artificial intelligence (AI) and statistics-based approaches. Energy forecasting models can be categorized into three basic parts: gray box, white box, and black box [
7]. When sufficient climate and energy consumption data are accessible, data-driven black-box and gray-box algorithms consider an exceptional part. The black-box algorithms are further categorized, such as linear autoregressive algorithms (ARAs), as shown in [
8]. Touretzky and Patil proposed an ARA to predict the energy required for energy management in the building sector, specifically demand response and supervisory control [
9]. Ferracuti et al. assessed various complex algorithms to precisely estimate hourly energy usage requirements for district energy management [
10]. Comprehensive studies of information-driven and wide-scale methods for energy prediction and management, future load requests, and short-, medium-, and long-term energy estimation were conducted [
11,
12,
13].
Wan [
14] considered load forecasting as an autoregressive process and used iteratively reweighted least-squares procedures to estimate model parameters. Hamlich [
15] presented a regression-based method with a transformation technique to predict the load of each hour of the day. Stochastic time series models have also been employed, since the list of power load data is actually a time series. Shilpa [
16] developed an adaptive autoregressive moving-average model to conduct for Karnataka electrical load pattern forecasts. Dash [
17] used the new hybrid adaptive autoregressive moving-average model for forecasting day-ahead mixed short-term demand and electricity prices in smart grids. Yu [
18] proposed the usage of a support vector machine and the model is created by using the categories of the forecast day membership. Slama [
19] used a random forest to integrate various features such as customer behaviors, load profiles, and special holidays in one-day-ahead load prediction. Wavelet Recurrent Neural Networks and neuro-wavelet based approaches [
20,
21] have also been introduced in energy and load forecasting.
The AI-based approaches include ANN, SVM, genetic models, and fuzzy logic; however, statistical forecasting model techniques are used to compare the energy required for their causal impact on mathematical algorithms. Examples of such algorithms are Kalman filters, multiple regression approaches, and autoregressive moving-average [
22,
23,
24]. The nature of electricity load is well suited to machine learning (ML) algorithms, as they can model complex nonlinear relationships through a learning process involving historical data trends. Recently, many researchers have utilized ML for energy forecasting. AI methods have recently been proposed for load forecasting, including artificial neural networks expert systems [
25], fuzzy inference methods [
26,
27], genetic programming [
28], evolutionary computation [
29], support vector regression (SVR) [
30], etc. These studies highlight the recent progress in the application of approaches used to predict future energy usage and requirements. Recently, several ML methods have been used for predicting energy demand, such as support vector machine (SVM) [
31], multiple regression [
32,
33], and neural network-based methods [
34,
35].
Table 1 shows a general review of models for forecasting electricity consumption in Cyprus.
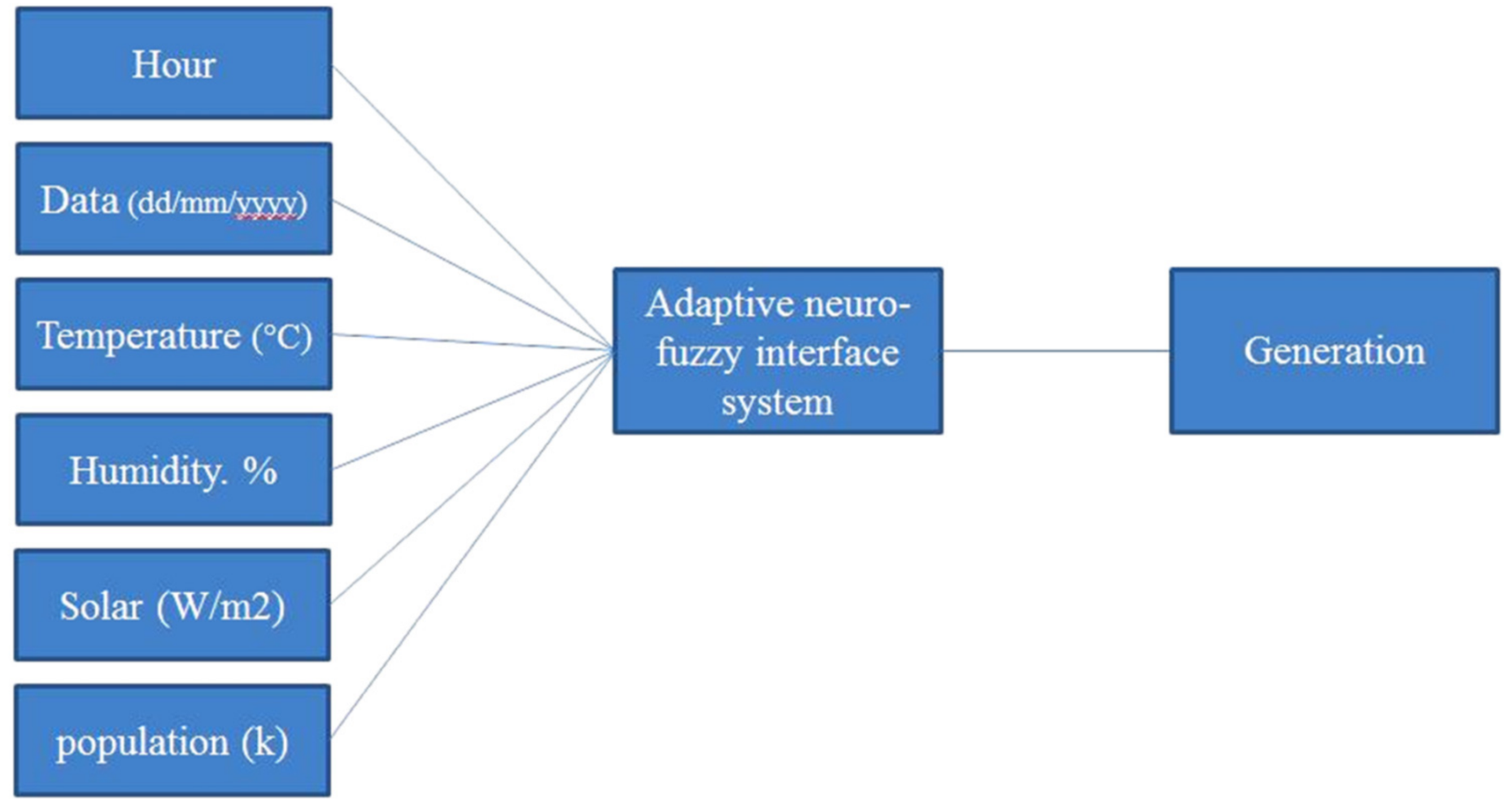
In this paper, machine learning approaches including artificial neural network (ANN), multiple linear regression (MLR), adaptive neuro-fuzzy inference system (ANFIS), and support vector regression (SVR) were applied to forecast electricity load requirements in Cyprus with long-term and short-term analysis. The control variables used for forecasting electricity load are time, temperature, humidity, solar irradiation, population GNI per capita ($), and electricity price per kWh (Euro-cent). The aim of this paper is to develop mathematical models for energy forecasting in Cyprus and comparing the performance of the models for long term and short term forecasting.
3. Machine Learning Algorithms
Machine learning is a branch of artificial intelligence. It is an approach that teaches computers to do something that comes naturally to humans and learn from experience. As the number of samples for learning increases, the performance of the algorithm adaptively improves [
40]. Since 2006, deep learning has emerged as a growing research field exploring performance in a wide range of areas such as machine translation, image segmentation, speech recognition, and object recognition. Deep learning began from ANN as a branch of machine learning. Most deep learning methods imply a neural network architecture, which is why sometimes they are represented as deep neural networks. Deep learning exploits the technique of multiple nonlinear processing of layers for supervised or unsupervised learning and tries to learn from hierarchical descriptions of data. Deep learning has been applied to industries from automated driving to medical devices [
41]. Wuest et al. distinguished supervised and unsupervised machine learning algorithms. Supervised machine learning was found to be good for most manufacturing applications because most of these applications provide labeled data [
42].
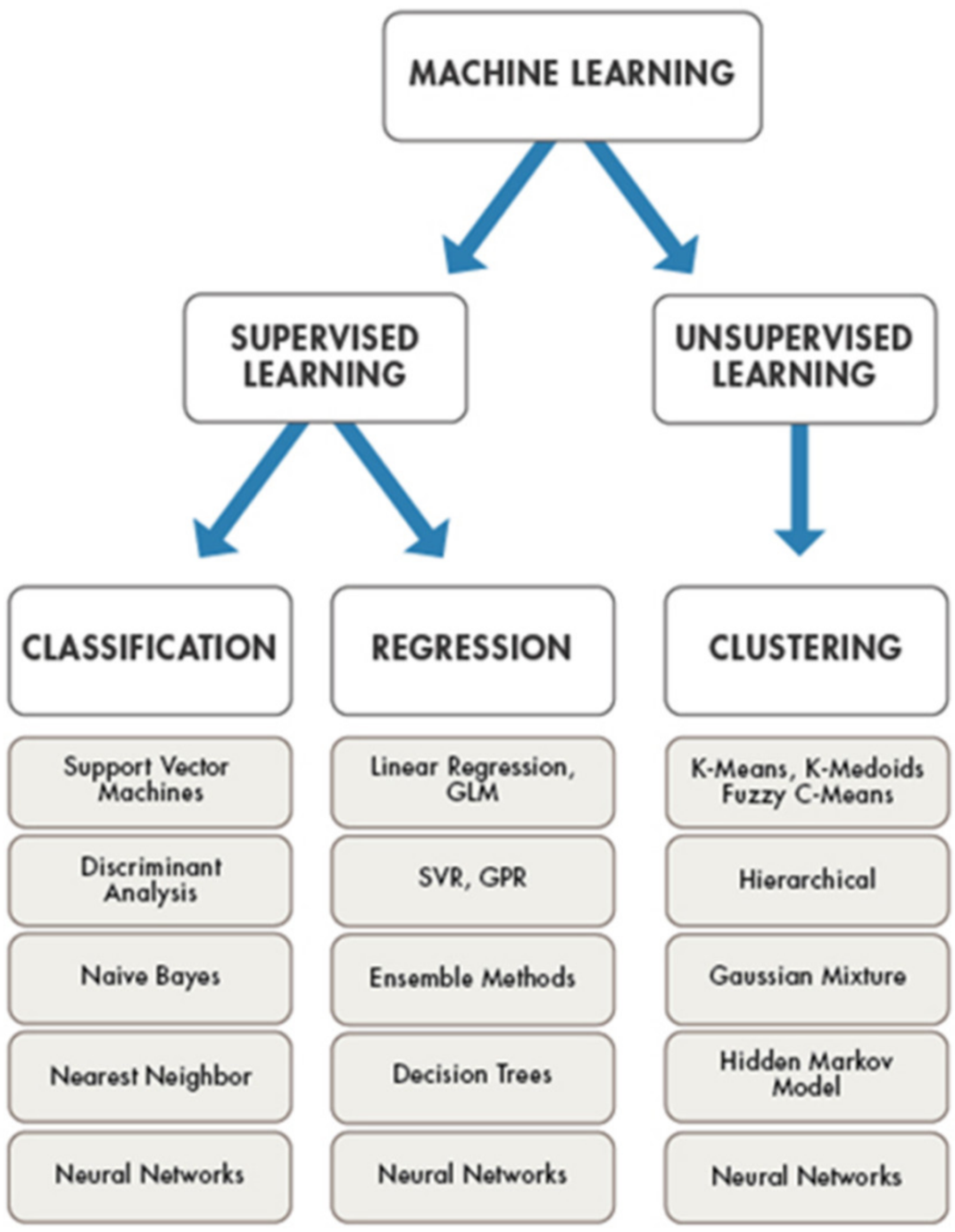
Figure 1 shows a simplified classification diagram of machine learning algorithms including generalized linear model (GLM), support Vector Regression (SVR) and gaussian process regression (GPR).
In manufacturing, SVM is the most commonly used algorithm in supervised machine learning. Machine learning is a powerful tool and its value will increase in the coming days. Machine learning is finding applications in many fields; some commercial fields are face recognition, image processing, manufacturing, and medical areas.
Machine learning (ML) can be applied in the domains of all industries. Machine learning approaches are implemented in procedural compliance, documentation of processes and orientation, and risk and quality frameworks of the manufacturing industry. The ability of machine learning to predict failure before it occurs is a useful feature, and some manufacturing firms are already using it in production to minimize financial losses and reduce risk [
43].
Prediction error which is shown in Equation (1) is a principal tool that processes the performance of a training model, in which the estimation model is confirmed with new data that were not used earlier to examine the model. This tool was used to define the error percentage of the training models. Additionally, Root Mean Square Error (RMSE) is a common method of measuring a model’s error in numerical information estimation. It is described formally as follows Equation (2):
where
N is the complete training data,
pi is the estimation of the deliberate information, and
qi is the actual value. RMSE method has been applied to evaluate the prediction performance of this study.
3.1. Artificial Neural Network
Neural network (NN) technology is an important branch of statistical machine learning and has been frequently used in various kinds of forecasting tasks. Artificial neural networks (ANNs) are the most widely used AI models; they simulate the ability of brain neurons to process information. The use of ANNs to solve forecasting problems has recently attracted considerable research attention because they substantially outperform previously implemented techniques for forecasting based on nonlinear input variables. ANNs are extremely good at modeling the nonlinearities in data in many fields and have theoretically proven capability to approximate any complex function with arbitrary precision. ANNs are inspired by natural neural networks and are computer programs developed to obtain information in a manner similar to the human brain. Artificial intelligence is a combination of neural networks that were developed based on research on cognitive talent and machinery design. ANN is a tool commonly used for prediction and categorization in data processing inspired by the attributes of biological neuron systems that learn by experience. It has many features that make it attractive for problems such as pricing options, with the capability of developing nonlinear model relationships that do not depend on the restrictive assumptions implied in the parametric approach, or on the specification of the theory that connects the prices of underlying assets to the prices of options. The implementation of an ANN model is considered successful when it has the ability to learn from the provided data and use the data in a new way [
44,
45,
46,
47,
48].
The ANN’s model strength lies in the relationship between the input and output variables, which can be complex and difficult to get from mathematical formulation [
49]. Staub et al. explored the features that make ANN the most important tool to solve complex nonlinear problems [
50]. ANNs modify their own values and are able to adapt to the exact solution of the problem. During the training process, ANNs are able to create the desired response. In the past, expert systems and neural networks were used extensively for electricity load forecasting. In the past, professional models and neural networks were commonly used to predict power loads. In recent times, they are also being used to estimate long-term energy demand, taking into account macroeconomic variables. Neural networks are used to model the energy consumption of appliances, lighting, and space cooling in the Canadian residential sector [
51]. Kandananond applied artificial neural networks to forecast electricity demand in Thailand [
44]. In this study, an ANN prediction model is trained for each component using the Levenberg–Marquardt algorithm, which shows stable and fast convergence.
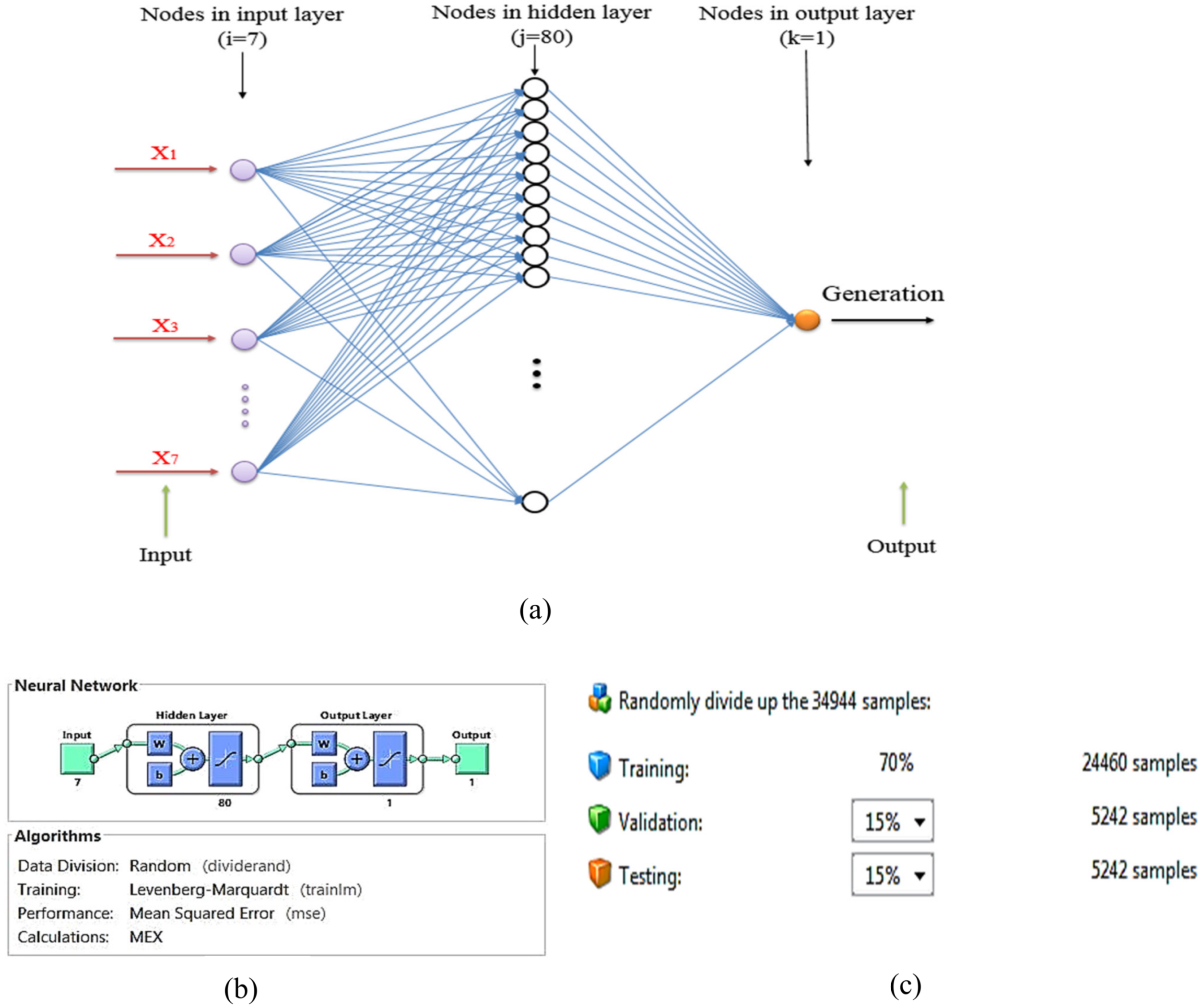
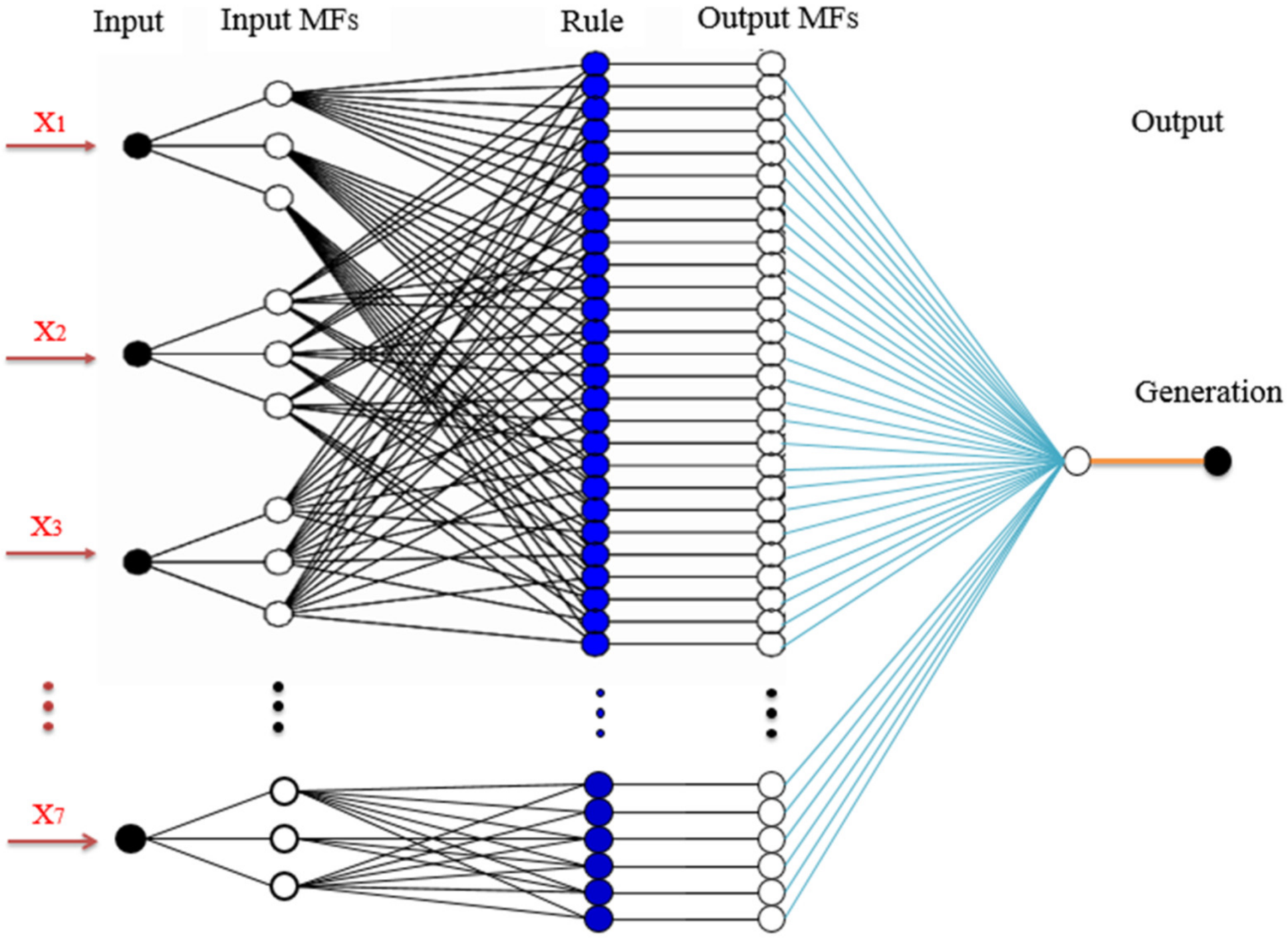
Figure 2 shows the design of this ANN: three layers with full connection and seven input nodes are logged into the input layer to describe one output. Input nodes (X) include time, temperature, humidity, solar irradiation, population, GNI, and electricity price per kWh. The output of this design is electricity generation.
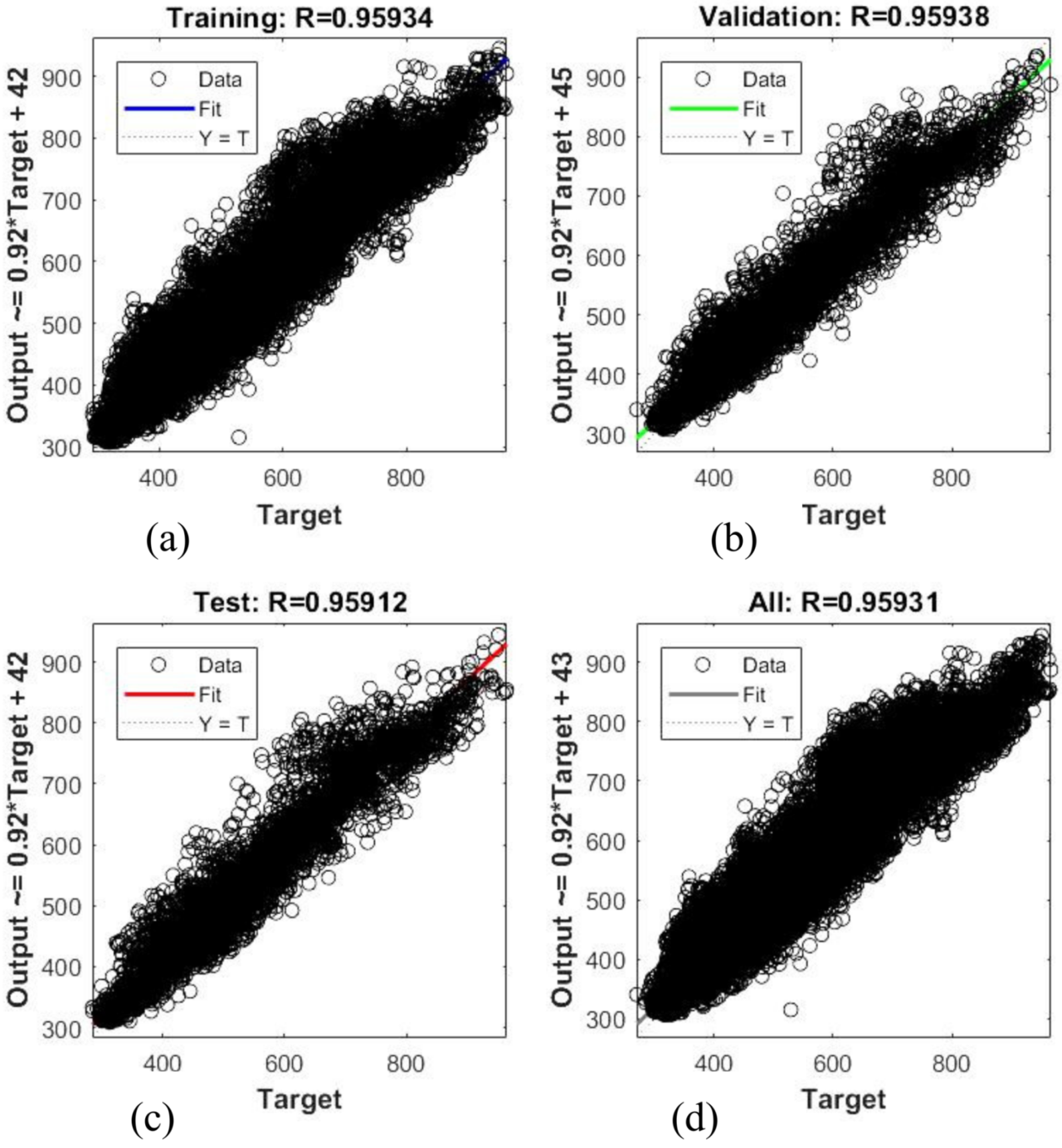
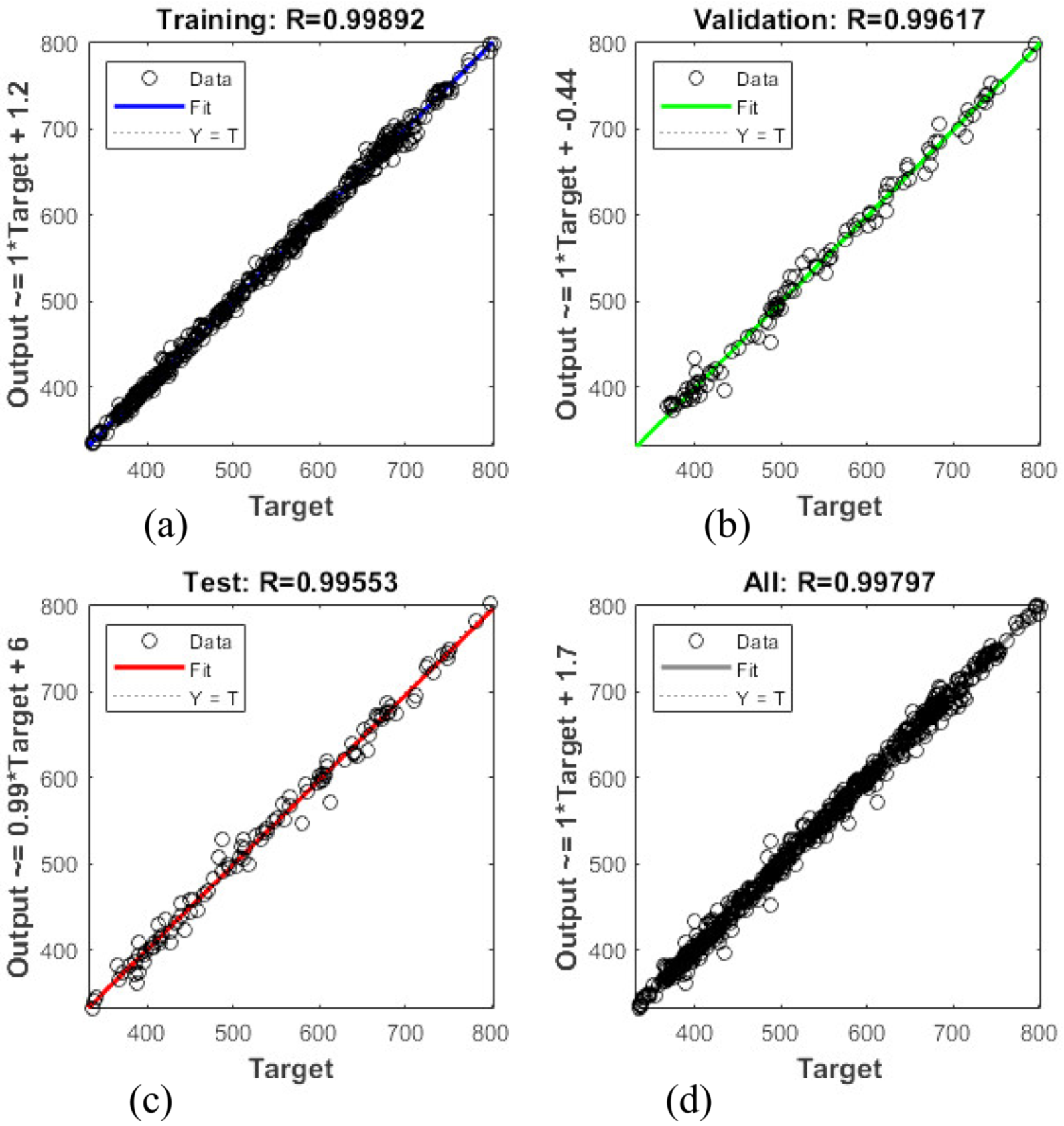
Figure 3 and
Figure 4 show the schemes of long-term record regressions for all datasets for 2016 and 2017, respectively. This figures explain the correlation between the target (experimental data) and the ANN model output. The dashed line in each figure represents the targeted values. The best-fit linear regression line between the outputs and targets is represented by a solid line.
The regression coefficient of both ANN models is very close to one, which is satisfactory. The average error of the training model for 2016 and 2017 is 5.57% and 5.28%, respectively. Additionally,
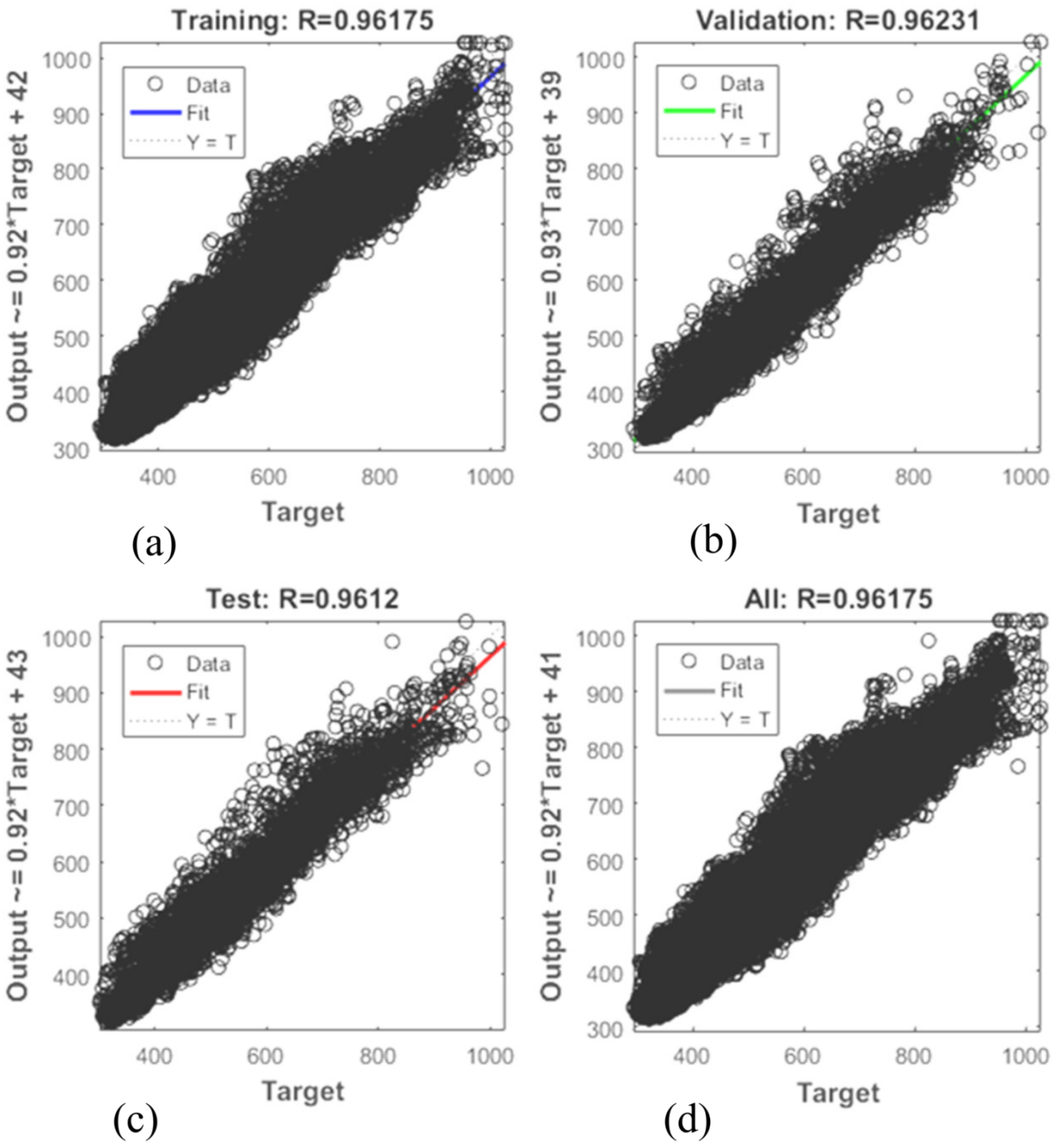
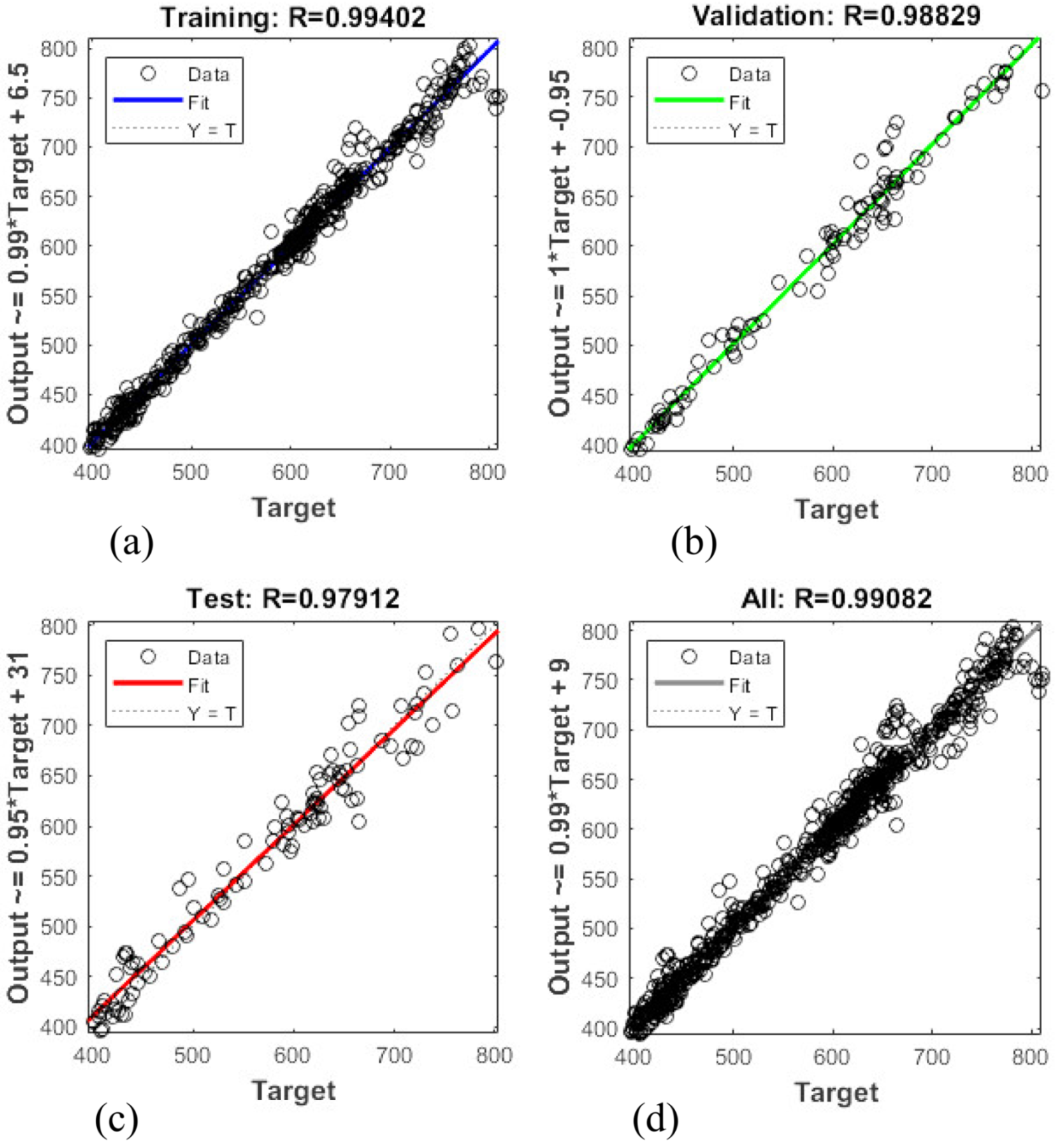
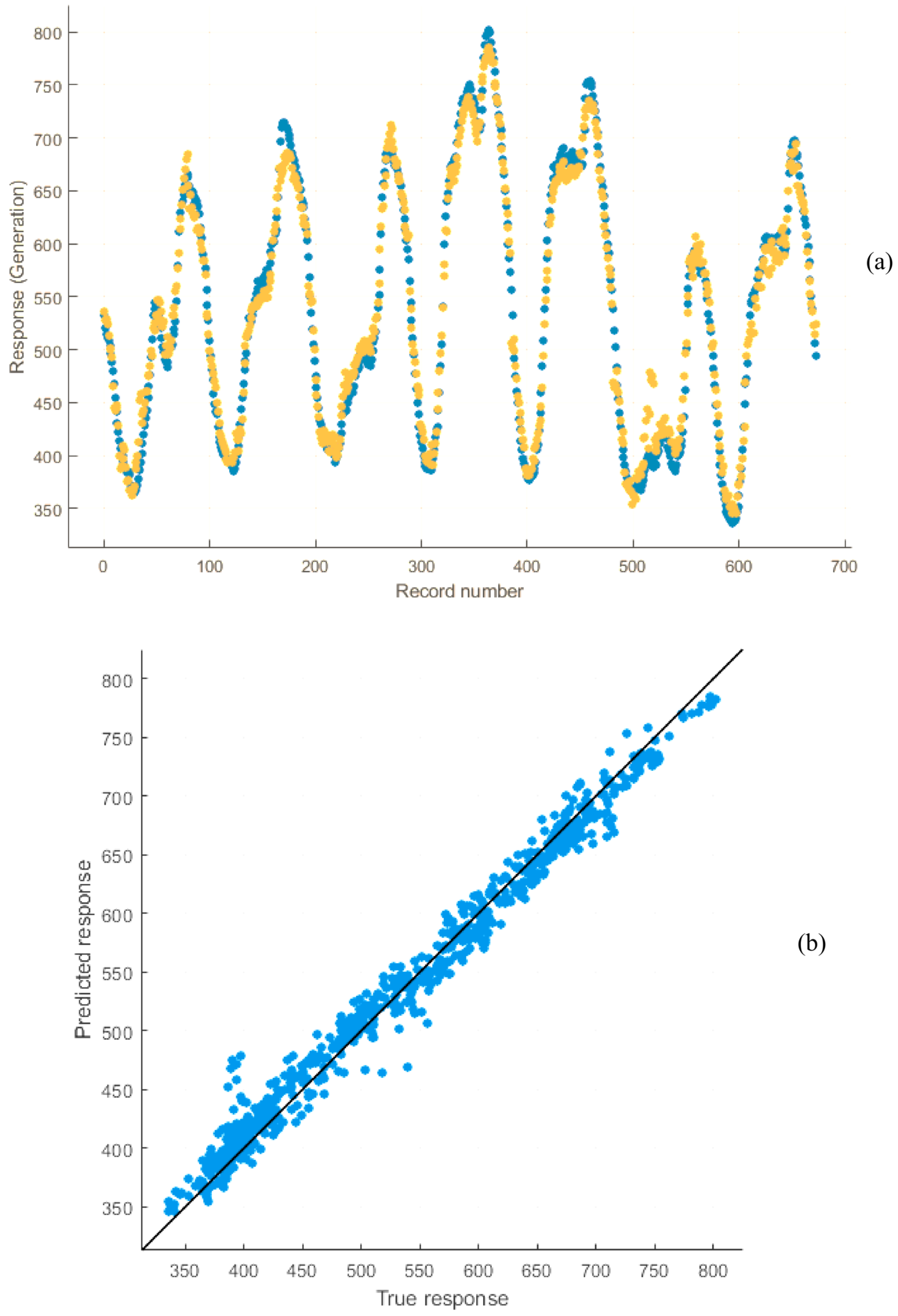
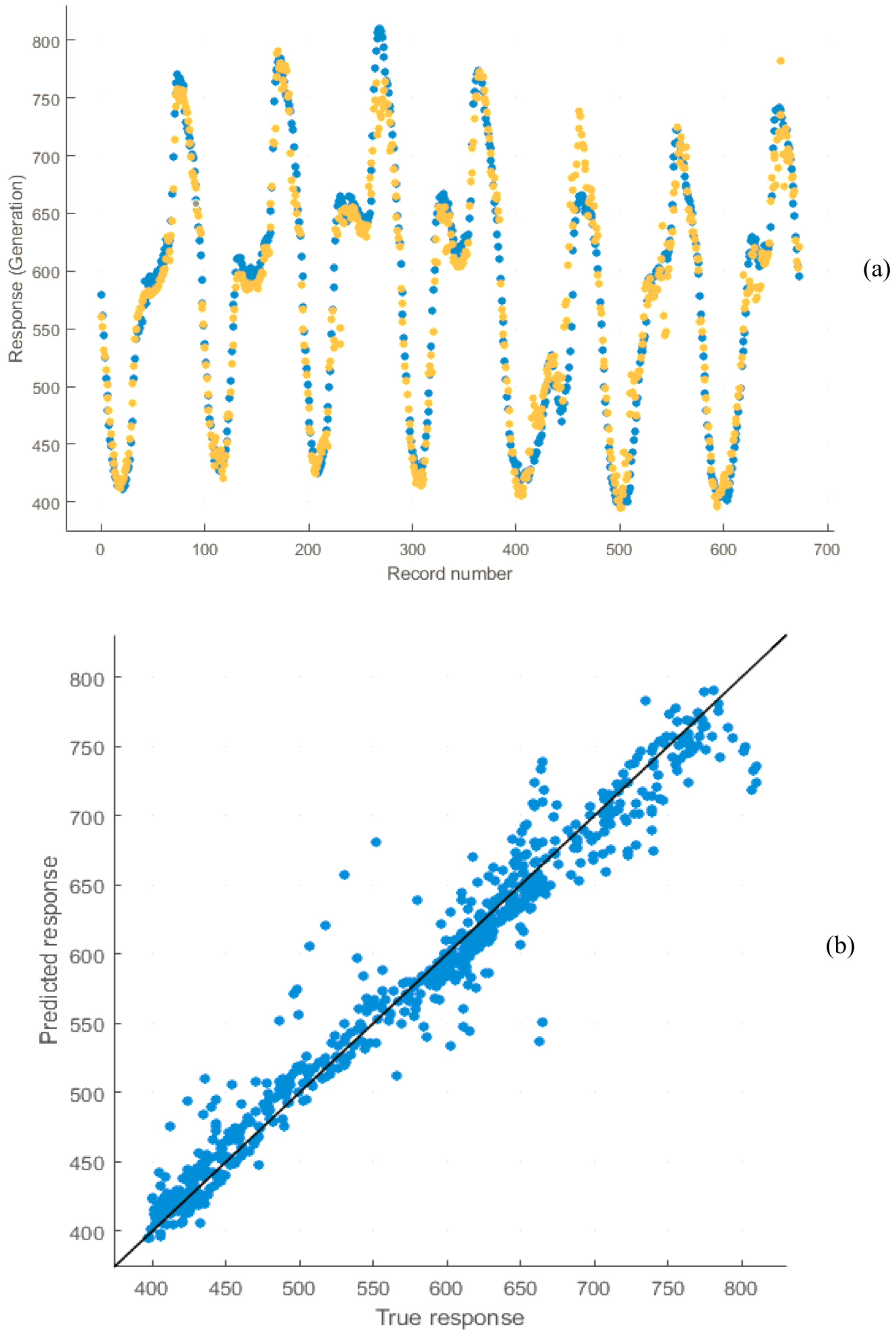
Figure 5 and
Figure 6 show outlines of short-term record regressions for all datasets for 2016 and 2017, respectively. Similarly, the regression coefficient of ANN models for short-term analysis is near one, which is desired. The average prediction error of short-term analysis for 2016 and 2017 is 0.97% and 1.67%, respectively.
3.2. Adaptive Neural Fuzzy Inference System
ANFIS stands for adaptive neuro-fuzzy inference system. The ANFIS toolbox feature forms a fuzzy inference system whose membership structure parameters are calibrated (adjusted) either using a backpropagation method or in combination with a least-squares-type method. This adjustment allows the fuzzy systems to learn from the data they are modeling. Neuro-adaptive training strategies provide a mechanism for fuzzy modeling to learn details about a dataset. The Mamdani fuzzy inference system’s basic structure is a framework that maps input features to input membership functions, input membership features to rules, rules to a series of output features, output characteristics to output membership features, and output membership functions to a single-valued output or a decision associated with the output. Such a system uses fixed membership functions that are chosen arbitrarily and a rule structure that is essentially predetermined by the user’s interpretation of the characteristics of the variables in the model. The fuzzy inference style utilized in this paper contains seven inputs, three membership functions for every input. The Sugeno fuzzy design is made consistent with two IF rules, which are established as follows [
52]. The ANFIS utilized in this investigation was settled with MATLAB.
Figure 7 demonstrates the developed ANFIS model.
The planned ANFIS design for the generation is shown in
Figure 8. It includes seven nodes in the input layer, 100 nodes in the hidden layer, and one node (generation) in the output layer.
Figure 9 and
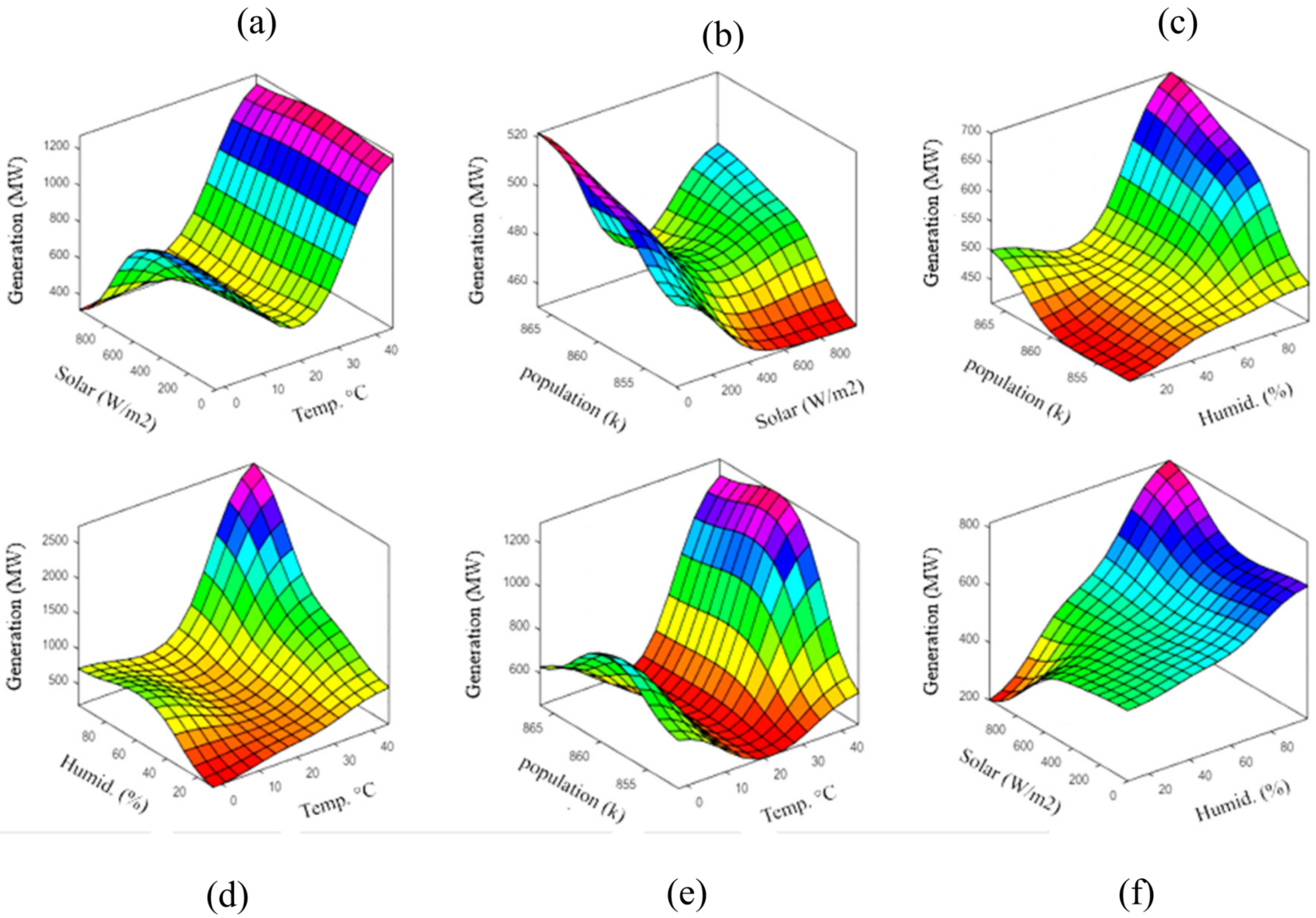
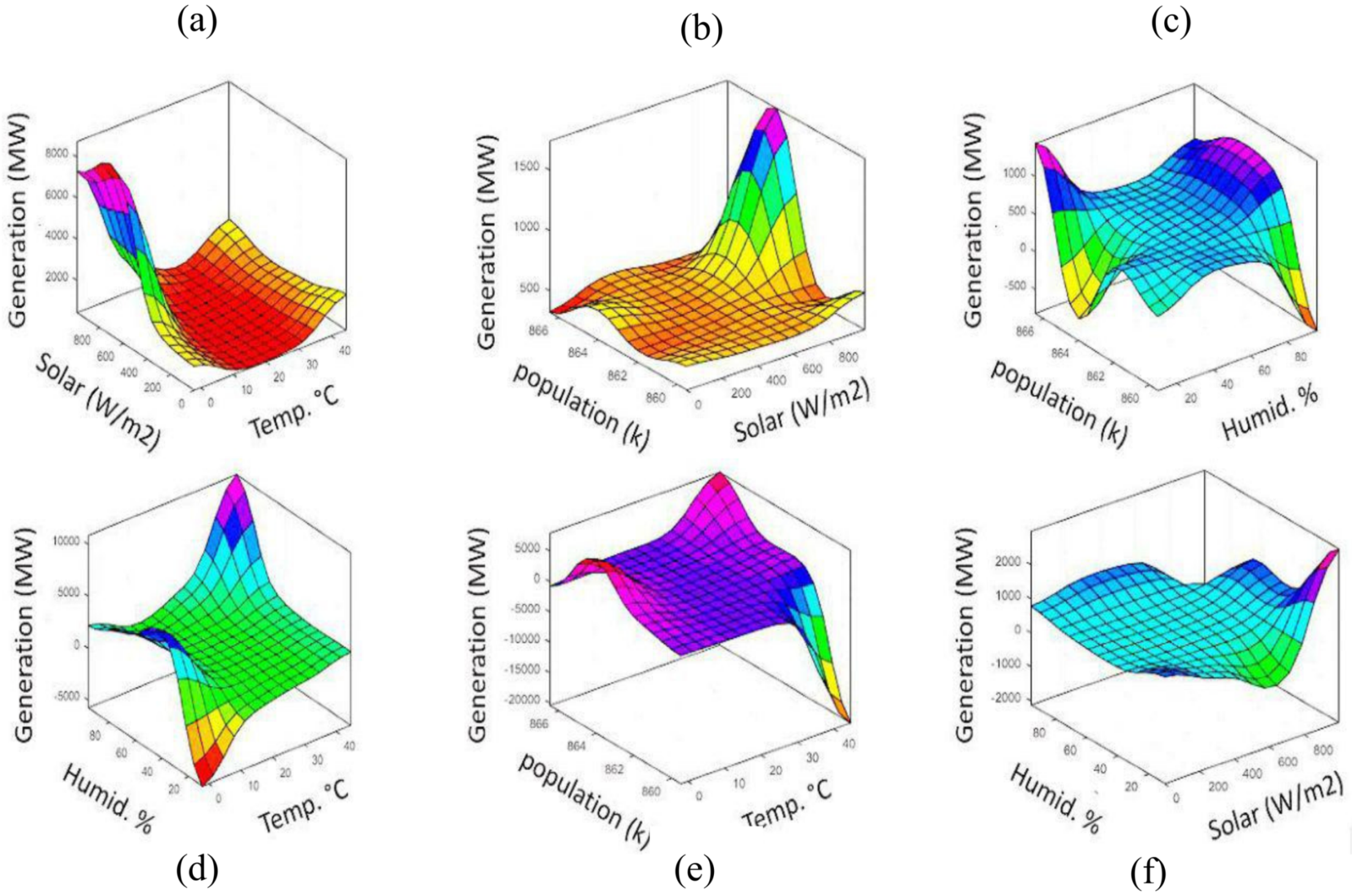
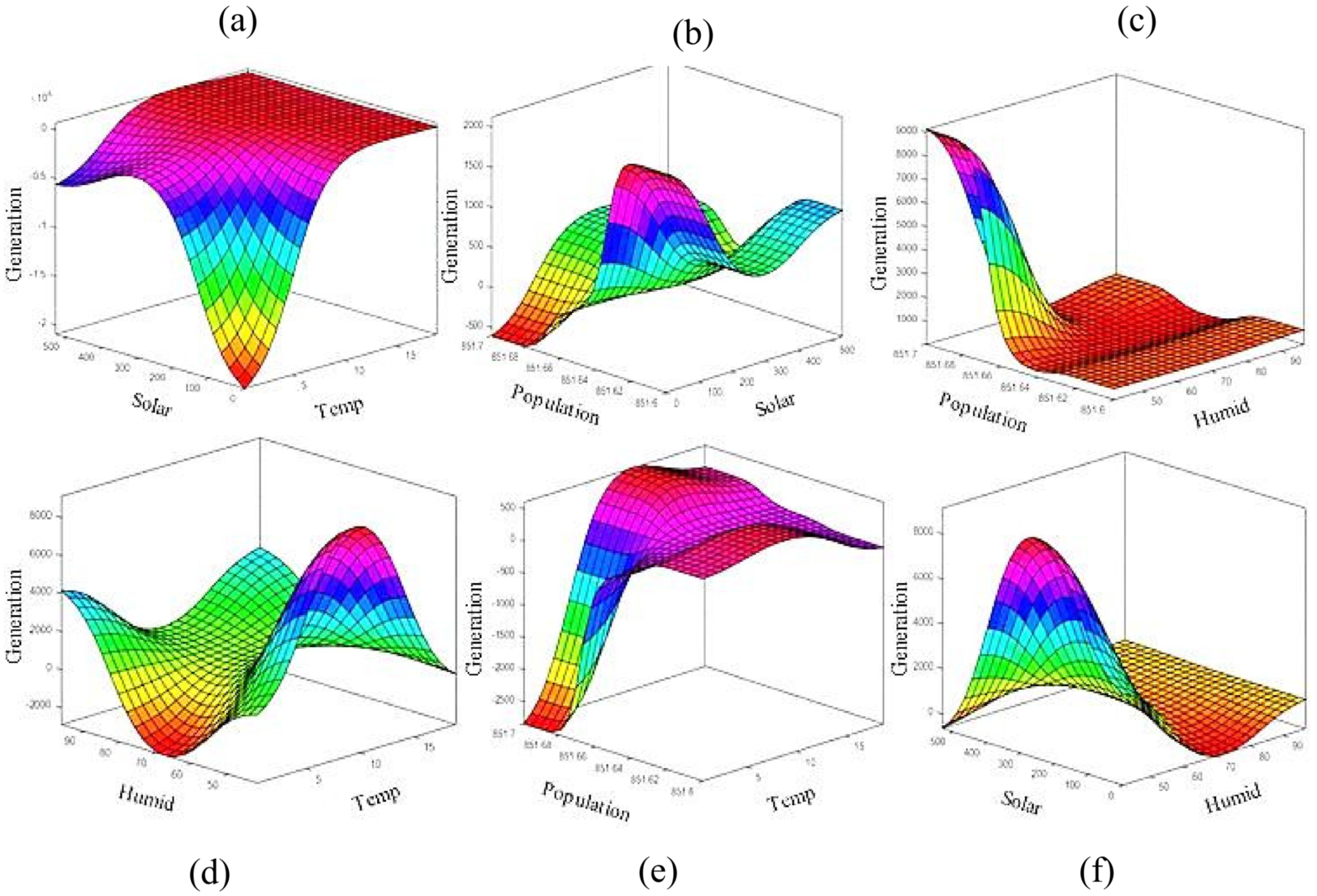
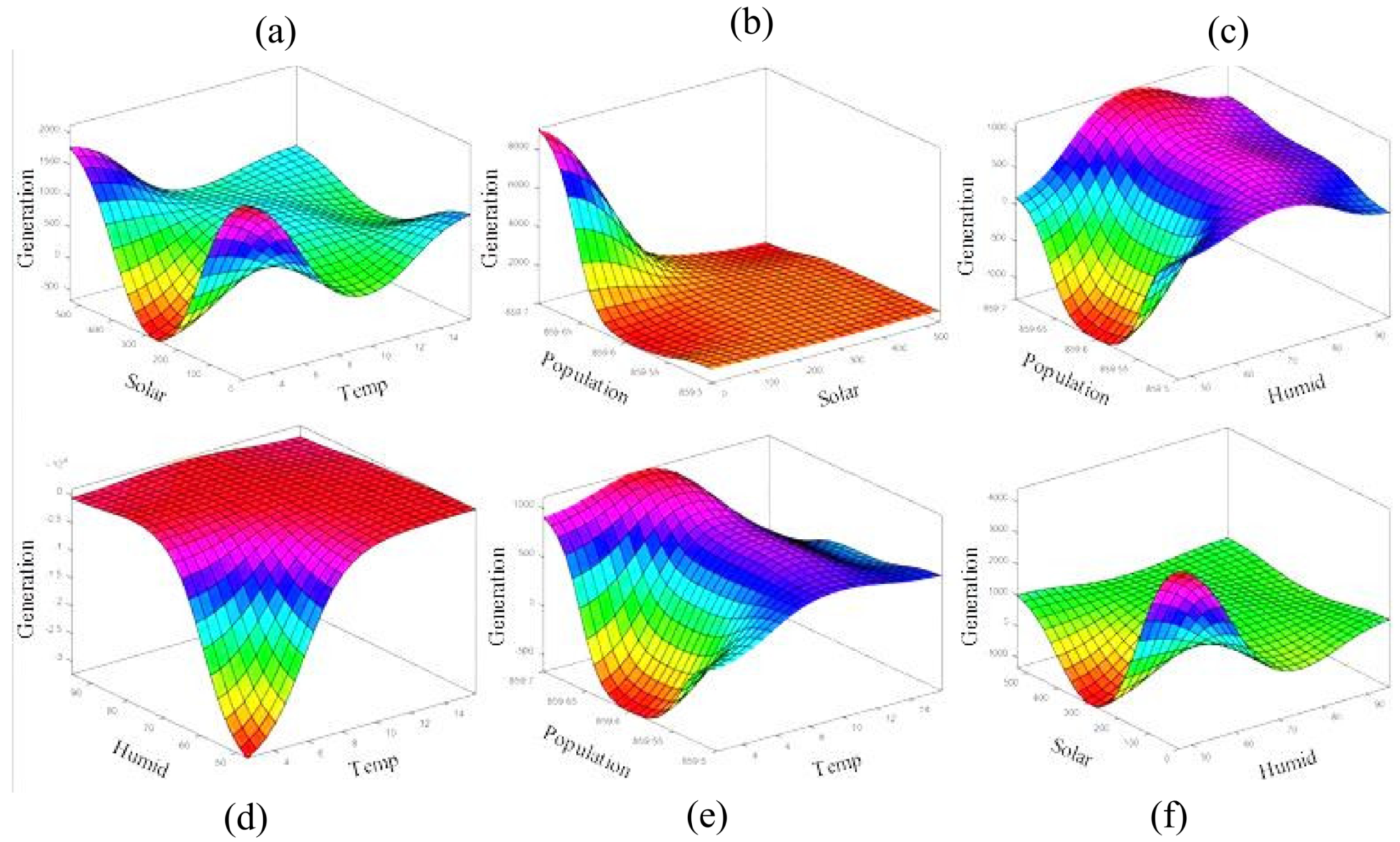
Figure 10 show the contour and 3D graphs of generation values with different input parameters for long-term analysis.
Figure 11 and
Figure 12 show the contour and 3D graphs of generation values for short-term analysis. The results of the graphs show that generation increases with increased humidity, solar irradiation, and temperature. On the other hand, generation decreases with decreased humidity and population.
Figure 13 and
Figure 14 show graphs of estimated versus actual values of long-term study for 2016 and 2017, respectively.
Figure 15 and
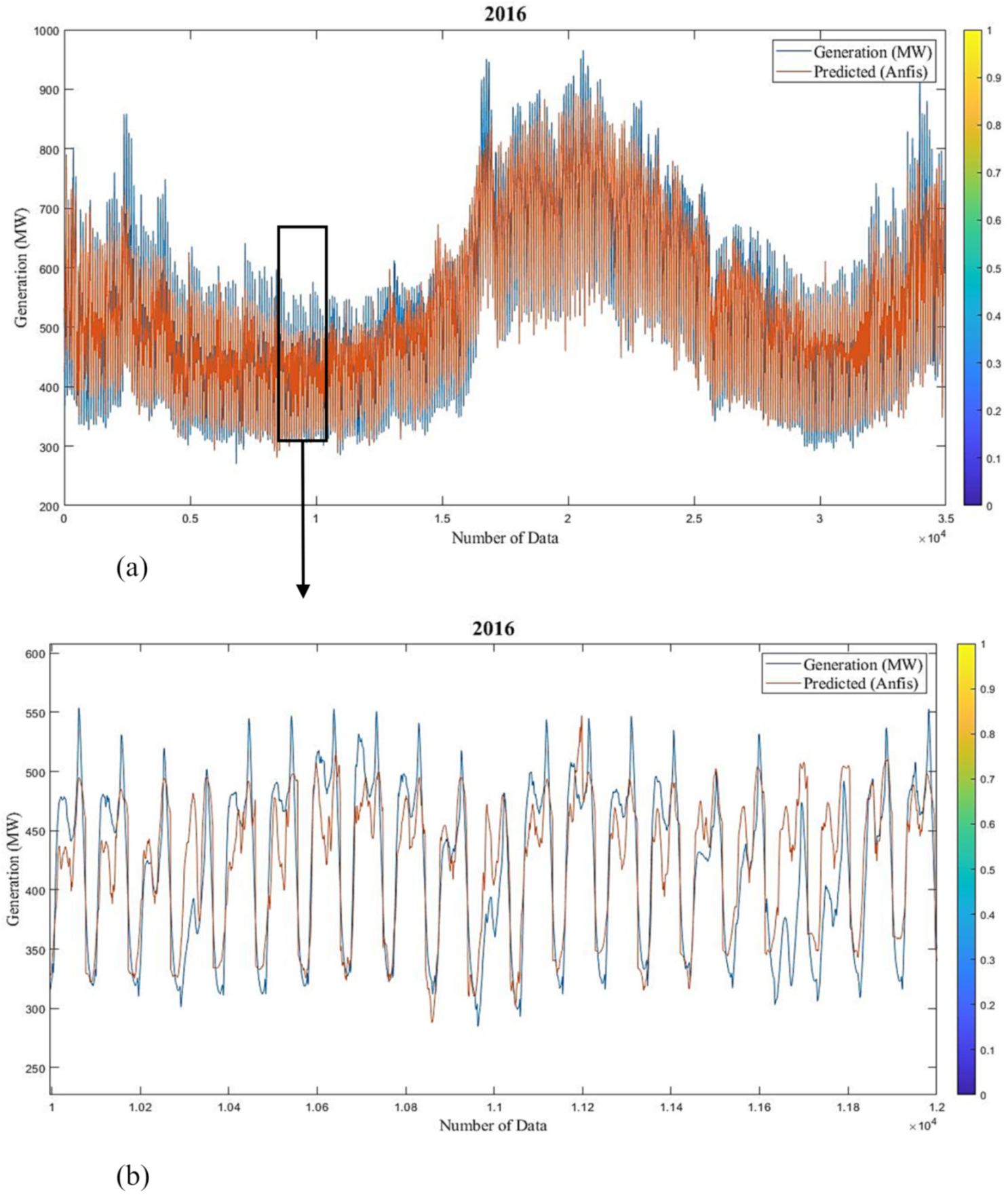
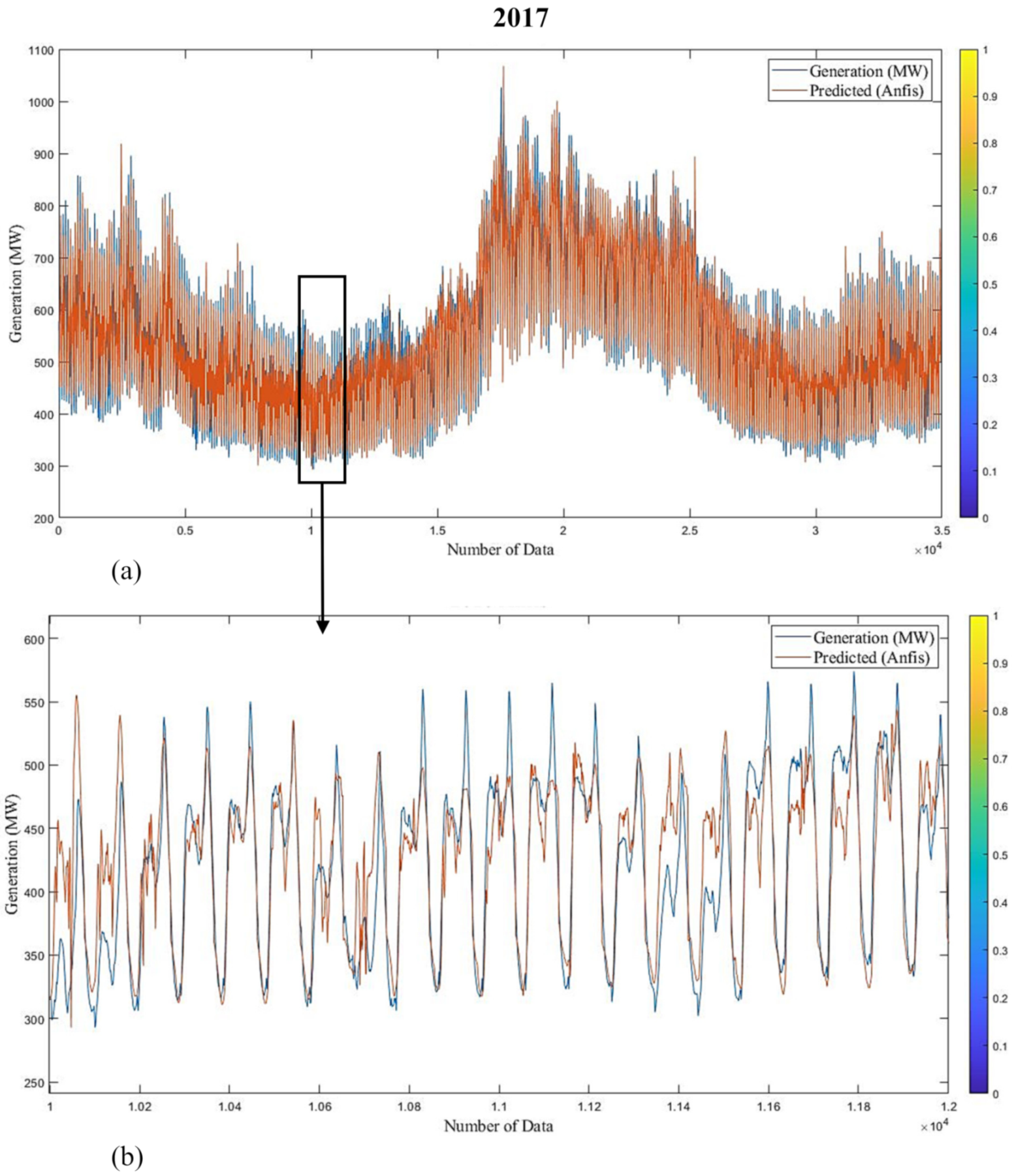
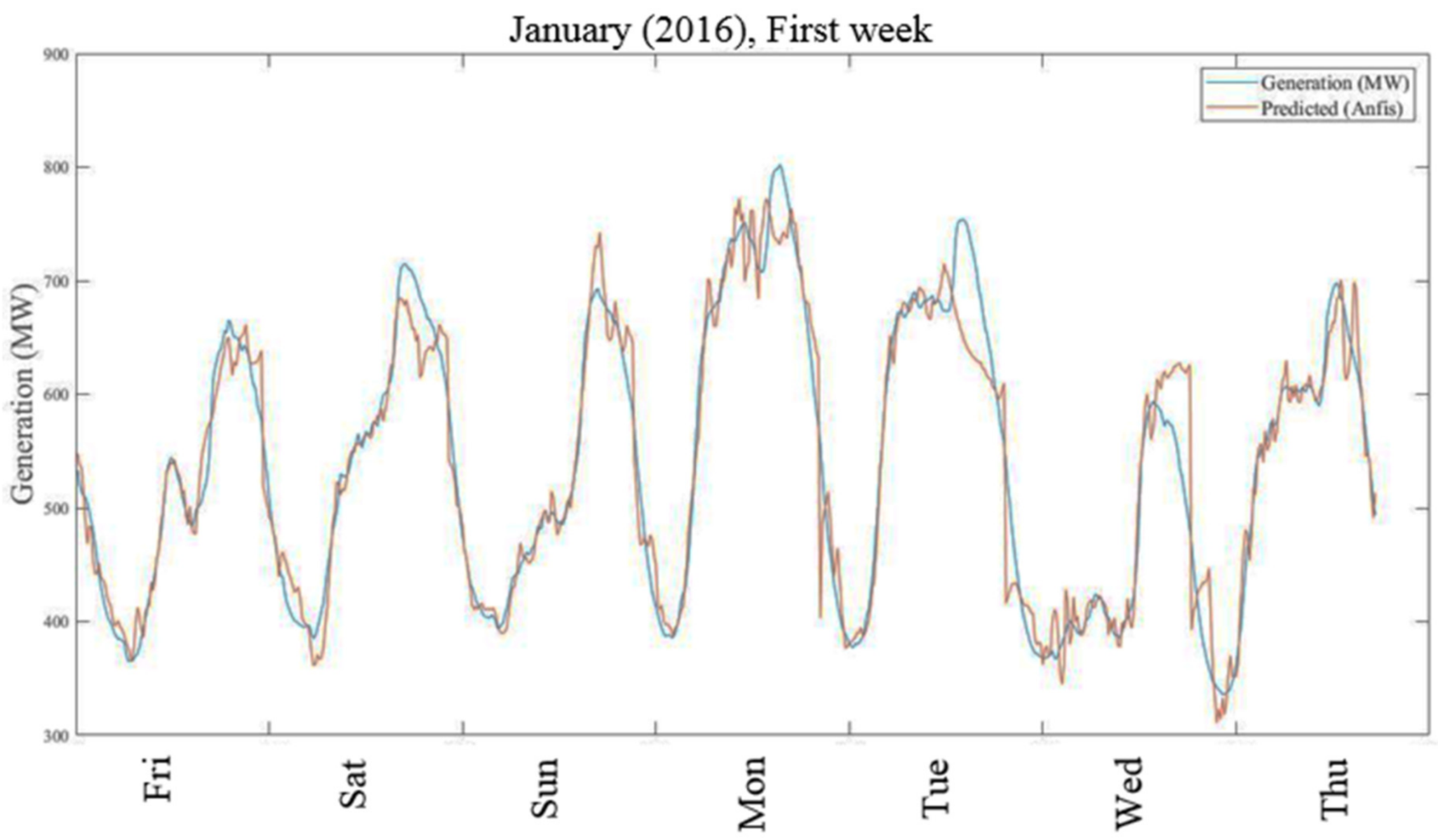
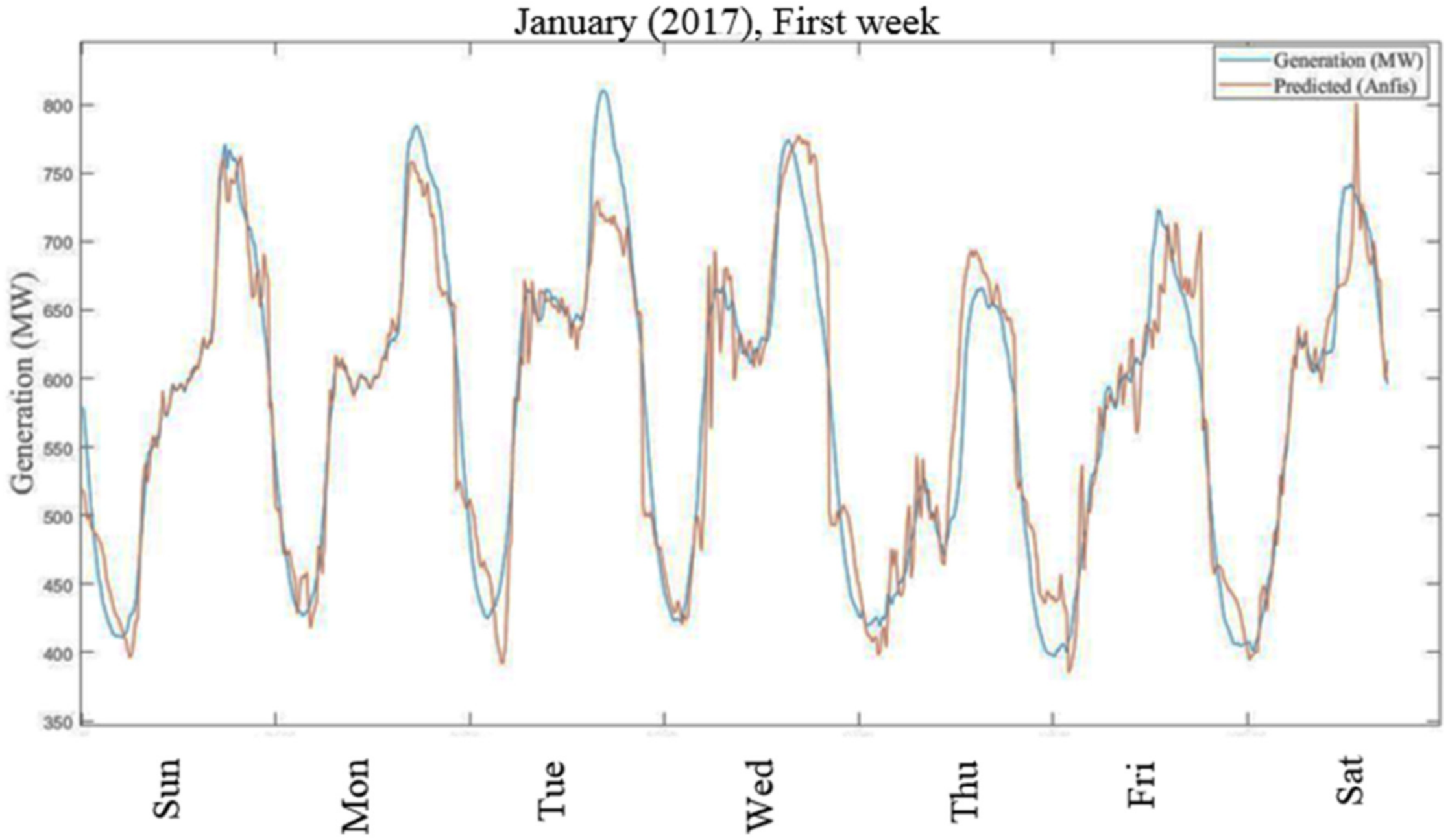
Figure 16 show graphs of predicted versus actual values of short-term study for 2016 and 2017, respectively. Results show that estimated values are in good agreement with the actual responses. The average prediction errors of the long- and short-term ANFIS training models for 2016 and 2017 are 7.69% and 6.11%, and 3.75% and 3.89%, respectively.
3.3. Multiple Linear Regression
Regression analysis is one of the most commonly used traditional forecasting/prediction techniques to identify causality between dependent and independent (explanatory) variables. The association between dependent and predictor variables is formulated as a linear model in Equation (3):
In this formula, β0–βp are the regression coefficients to be estimated according to observations. To avoid multicollinearity problems, correlations between predictors should be controlled (the correlation coefficient of the explanatory variables should not exceed 0.7) [
53]. The last term in the formula, ε, denotes the random error and is referred to as the residual to check the overall significance of the model and each regression coefficient [
54]. The error term is independently and normally distributed, with a mean of zero and a constant variance of σ2 [
55]. Regression models describe the relationships between output values and one or more input values. A multiple regression model is a parametric model. There are many statistical and machine learning methods to generate results, such as linear, generalized, and nonlinear regression models, containing mixed effects and stepwise models. The relationship between the numeric predictor and the continuous target is approximated by simple linear regression by using a straight line. The relationship between a set of
p > 1 predictors and a single continuous target approximates multiple regression modeling using a P-dimensional plane [
56]. One of the main objectives of regression modeling is to select the best suitable regression that can develop an accurate response variable. Regression trees (RTs) and ANNs are ambitious techniques for modeling regression problems. Multiple linear regression (MLR) is a classic technique that delivers many benefits: clarity, interpretability, the potential to be modified over parametric transformations, and reasoning, assuming the normality hypothesis, homoscedasticity, and inter-correlation between the error ε and the predictor variables.
Figure 17 and
Figure 18 show outcomes of MLR numerical investigation of estimated versus actual responses of long-term examination, with scaled coefficients, where the solid line symbolizes the fitting line.
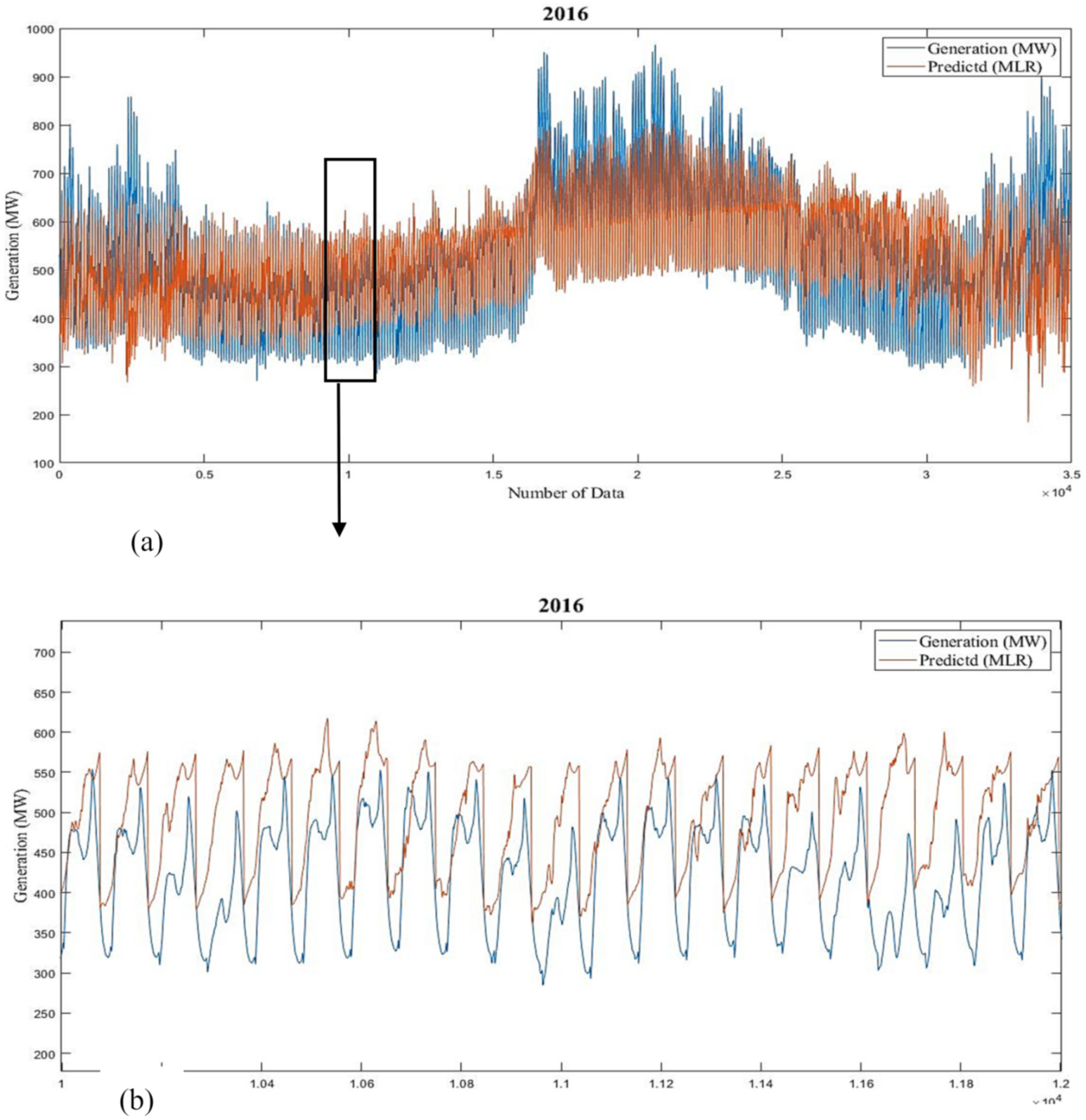
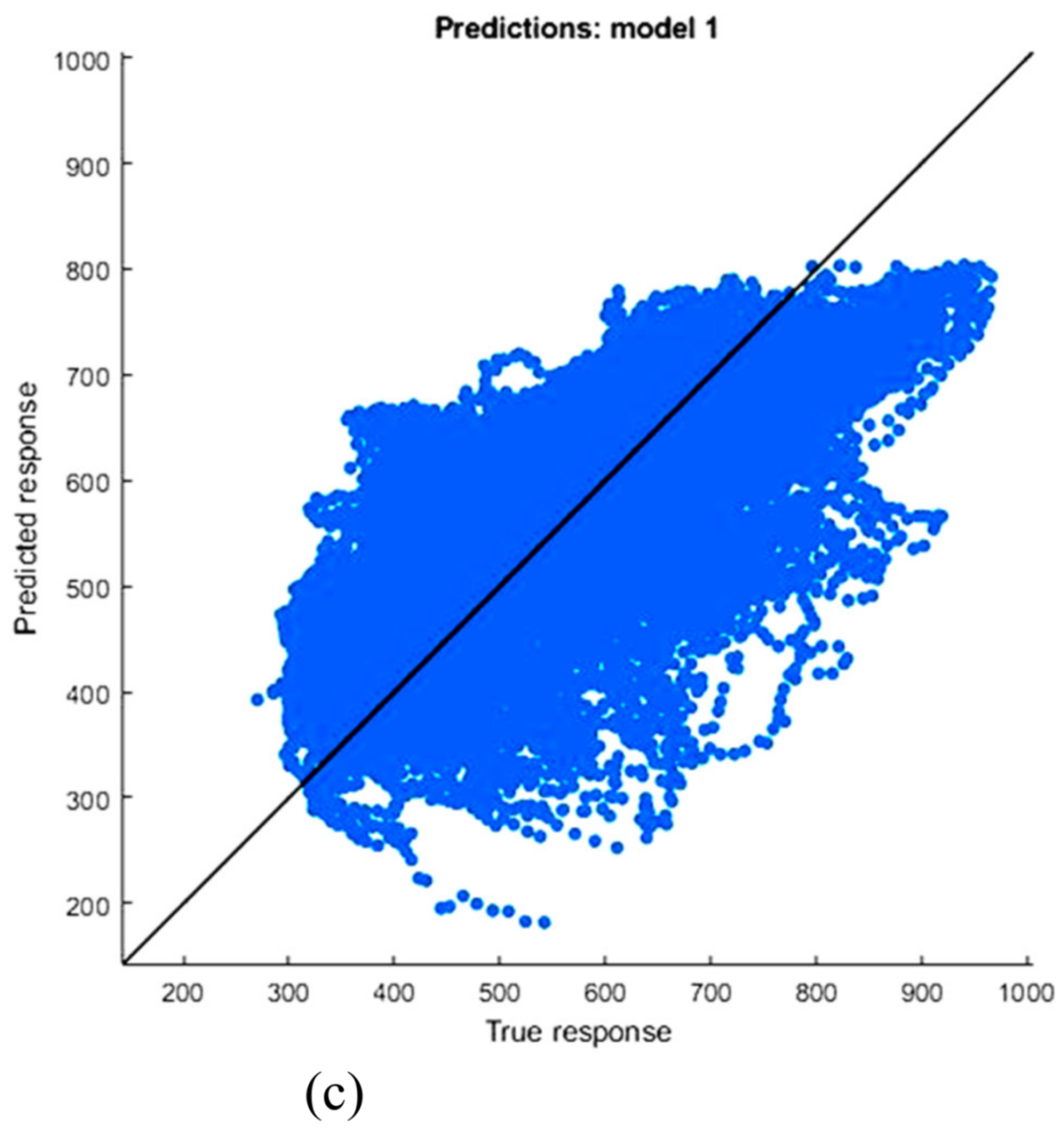
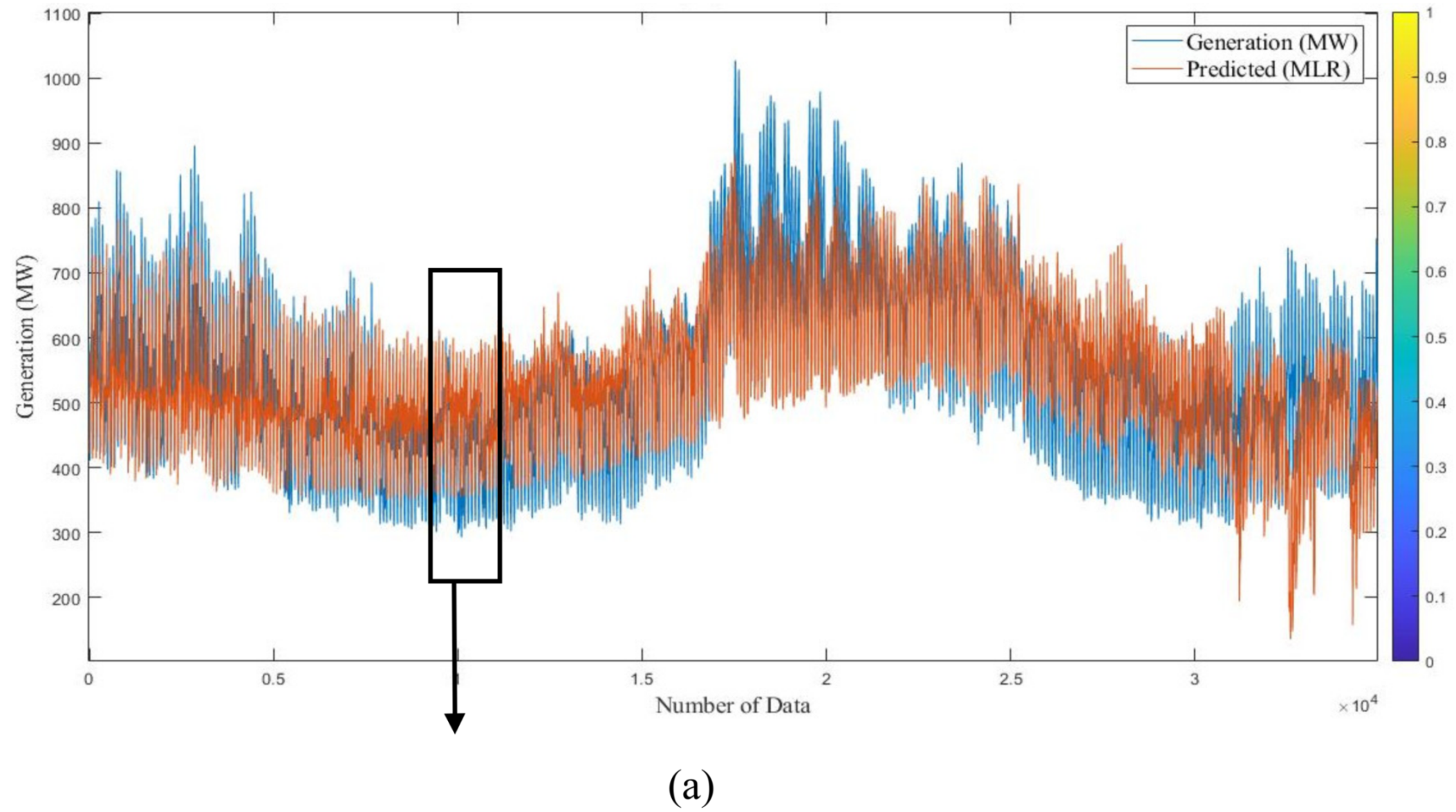
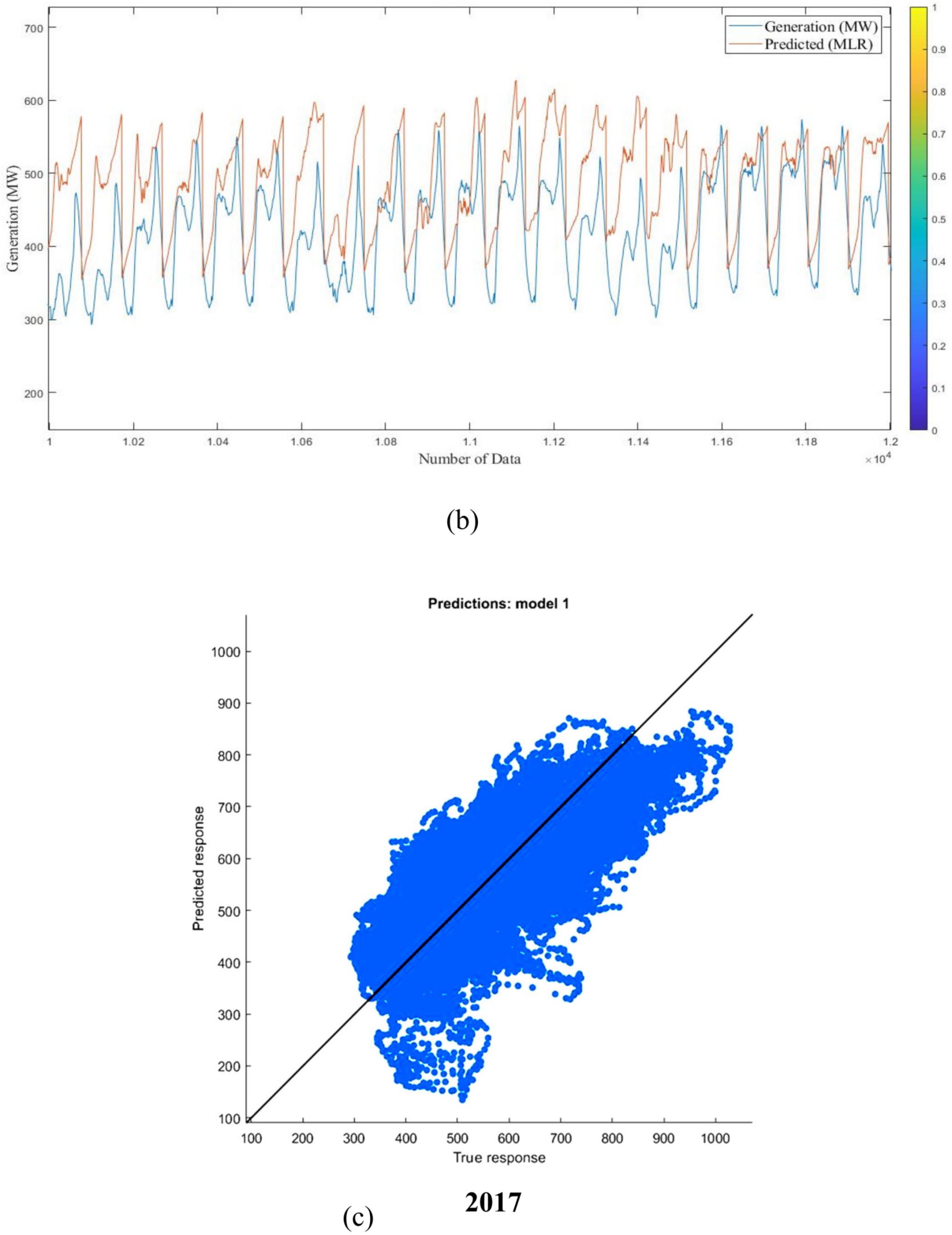
Figure 19 and
Figure 20 demonstrate the results of the MLR numerical study of predicted versus actual responses of short-term examination. The graphs show that estimated and actual data are not well matched. The average prediction errors of long-term and short-term MLR models for 2016 and 2017 are 15.18% and 13.4%, and 10.44% and 9.08%, respectively.
3.4. Support Vector Machine
Support vector machines are used in many machine learning tasks, such as pattern recognition, object classification, and time series prediction, including especially the forecasting of energy consumption. Support vector regression (SVR) is an SVN method specifically for regressions. SVMs are based on the principle of structural risk minimization. The SVM constructs one or more hyperplanes in a high dimensional space. The objective of SVR is to minimize the probability that the model generated from the input dataset will make an error on an unseen data instance. The objective is achieved by finding a solution that best generalizes the training examples. Ma et al. (2018) applied SVM to predict building energy consumption in China [
57]. The SVM algorithm was used to find a hyperplane with N-dimensional space (where N means number of characteristics) that clearly segregate the data points, and many possible hyperplanes were used to separate the two classes of data points. Finding a maximum margin plane is the main objective, for example, the utmost distance between data points of both classes. Overestimating the margin distance provides some support so that future classification of data points can be done with greater confidence [
58,
59].
Guo et al. and Fu used a support vector model for electricity load [
60,
61]. Kavaklioglu et al. derived electricity consumption as a function of socioeconomic indicators such as population, gross national product, and imports and exports [
39]. This method was constructed on the structural possibility of minimization standard.
Figure 21 and
Figure 22 show the output generated via regression investigation for the training and testing datasets for long-term study.
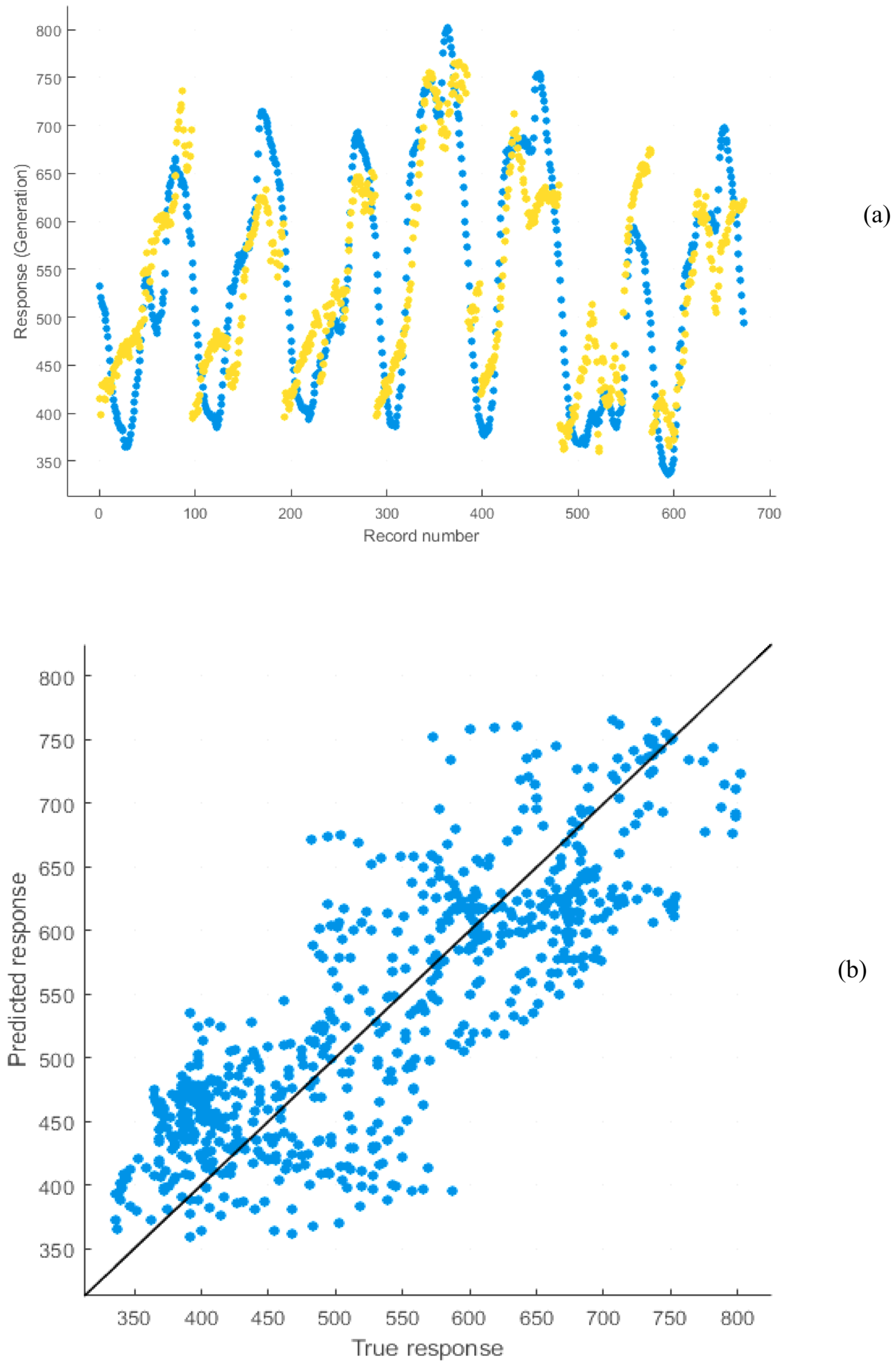
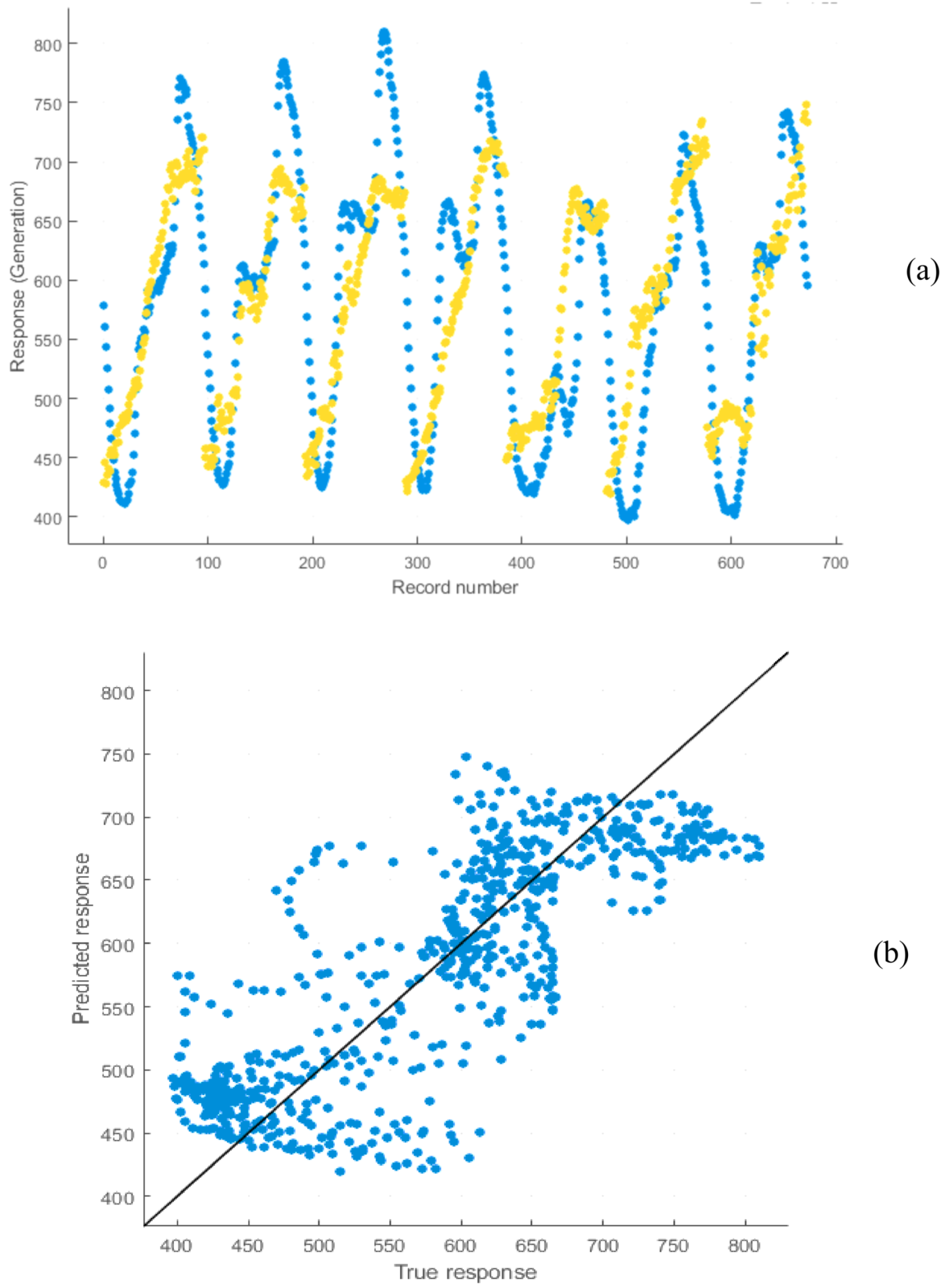
Figure 23 and
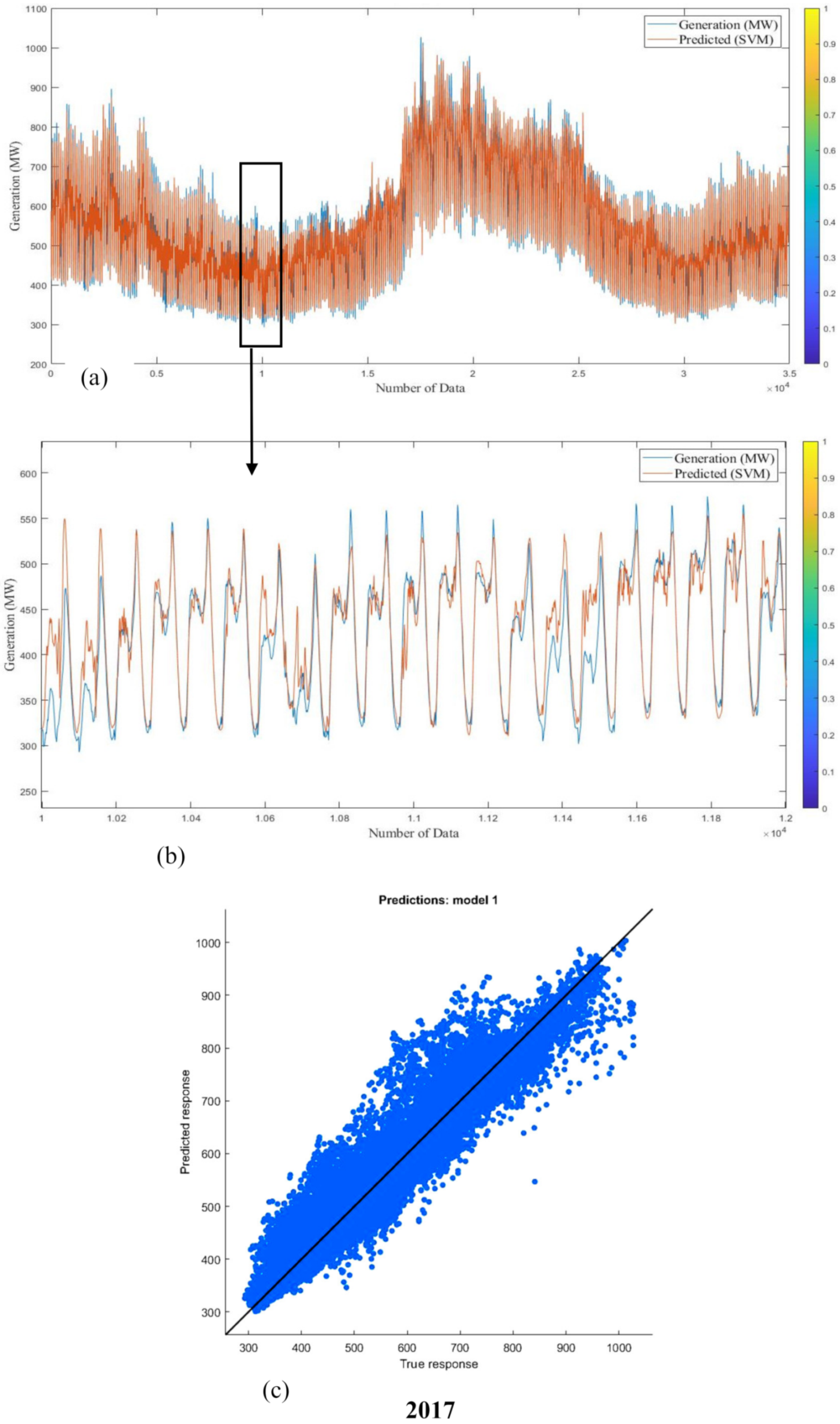
Figure 24 show the output created by regression analysis for training and testing datasets for short-term training. The model responses (estimated) are designed against the targets (actual response). The greatest linear fitting is designated by the diagonal line. The results of the graphs show that predicted responses are not in good agreement with actual responses. It is concluded that the SVM method is not acceptable for this training. The average prediction errors of the SVM long-term model for 2016 and 2017 are 4.34% and 4.49%, and for the short-term model are 2.24% and 2.12%, respectively.
5. Results and Discussion
In the current investigation, four models (artificial neural network (ANN), adaptive neuro-fuzzy inference system (ANFIS), support vector machine (SVM), and multiple linear regression (MLR)) are used to estimate electricity generation in Cyprus for the planning of power generation systems and the efficient operation and sustainable growth of modern electricity networks as long-term and short-term analysis. An ANN model for seven inputs and one output with a hidden layer including 80 nodes beginning from one node was fabricated and evaluated by utilizing the LM procedure. The model parameters were used for long-term and short-term analysis. For the 7-80-1 network with 1000 epochs, the model presented an optimal outcome. With additional nodes in the hidden layer and epochs, the result remained the same or somewhat expanded. Data division was random and Levenberg–Marquardt used as a training function.
In the ANFIS model, the gradient descent and least-squares algorithms are utilized for an operational examination of the optimal factors to achieve good outcomes. With respect to this cross method, connections of training and testing are improved. The Sugeno fuzzy design was made consistent with two IF rules. The ANFIS utilized in this investigation was settled with MATLAB. The ANFIS model includes 2160 fuzzy rules for long-term and 243 rules for short-term study. Furthermore, three generalized Gauss membership algorithms are utilized that diminish the handling time and provide improved outcomes for the estimation of electricity generation.
The SVM model is trained by utilizing the sequential optimization algorithm function and the kernel function utilized is the radial basis function. The MLR model was achieved from the repeated random subsampling procedure with 20 runs. Then, the MLR model with many iterations (1000) reached the ultimate forecast outcomes, and was used for the persistence of outcome assessment.
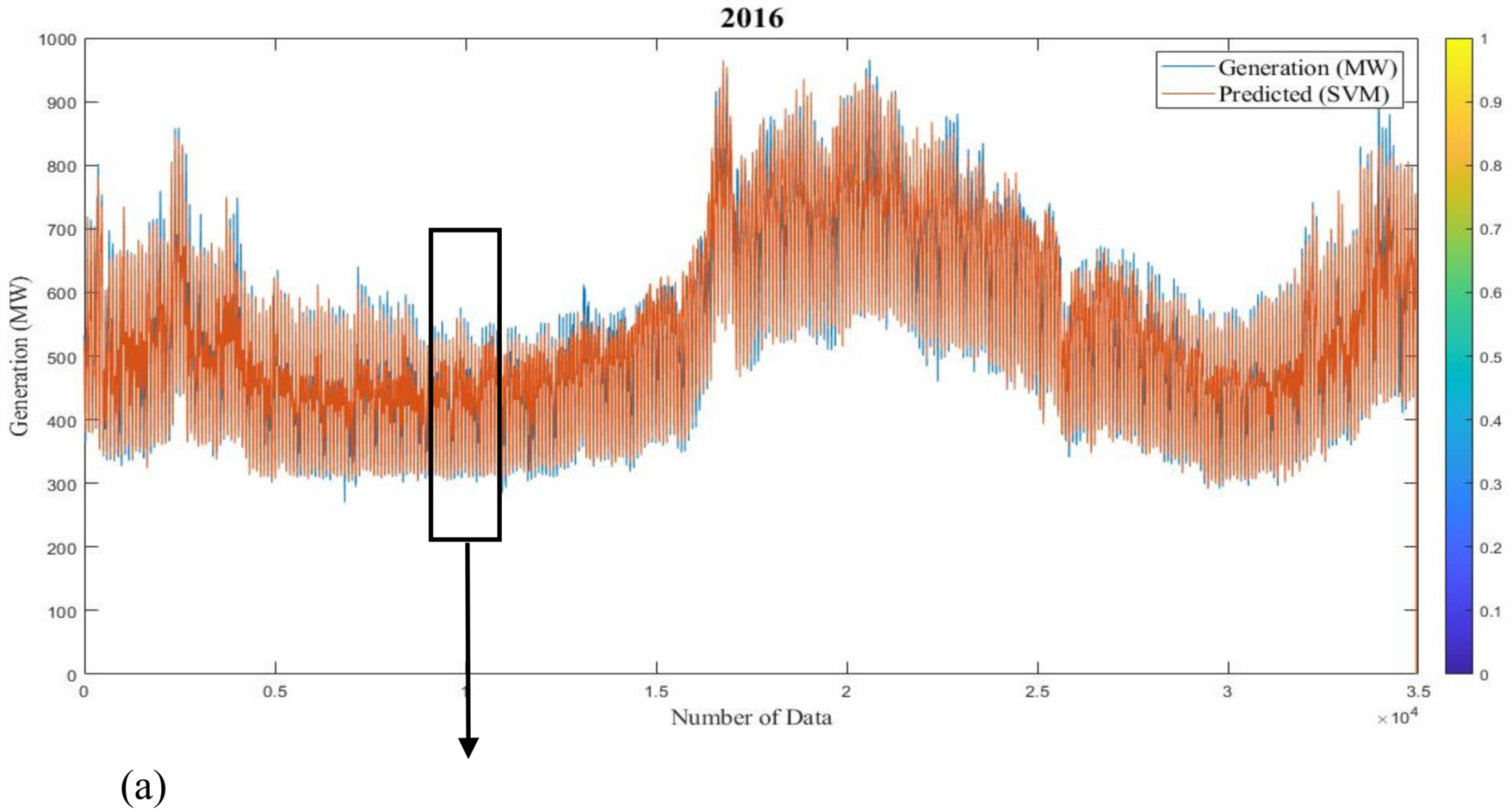
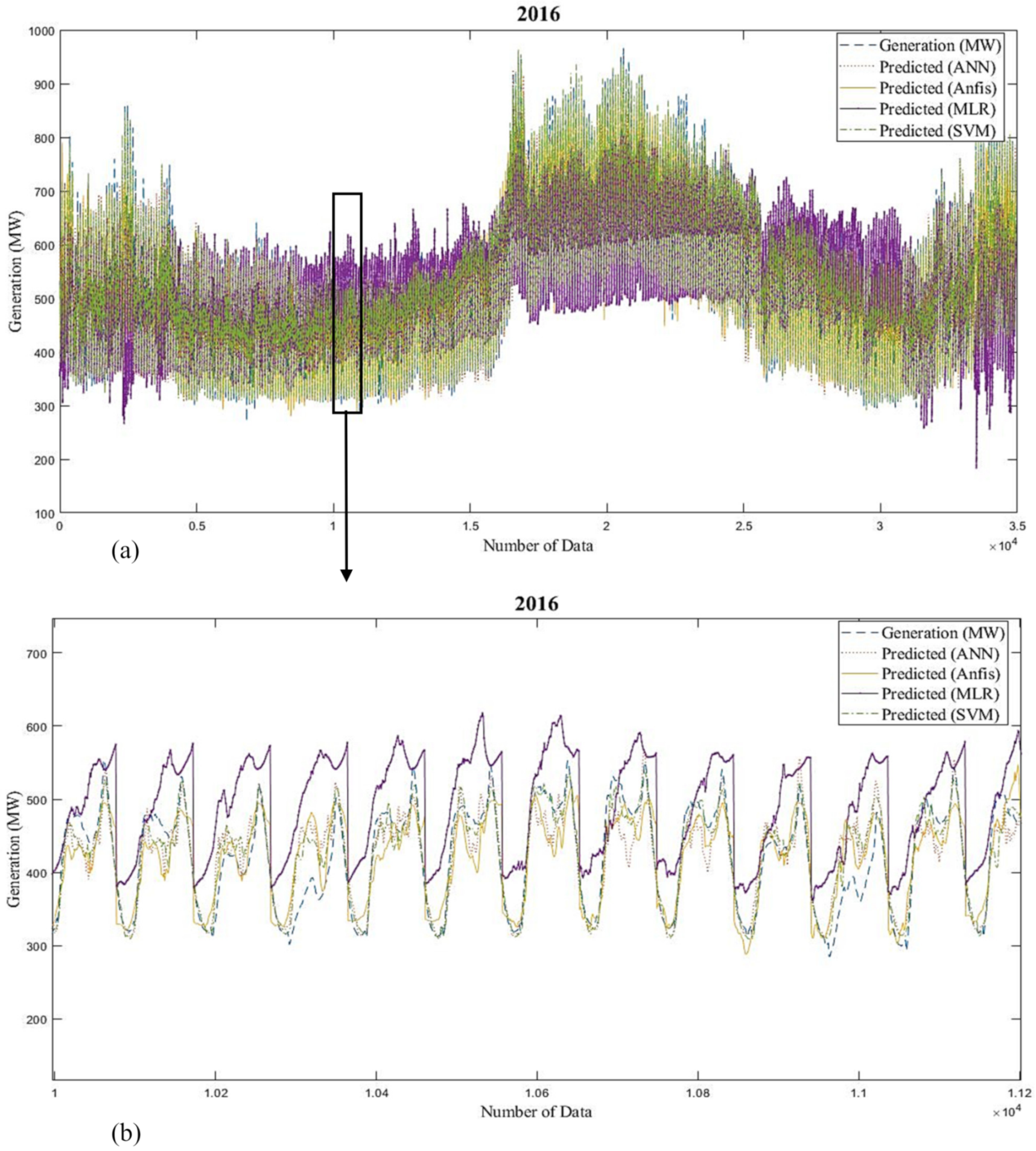
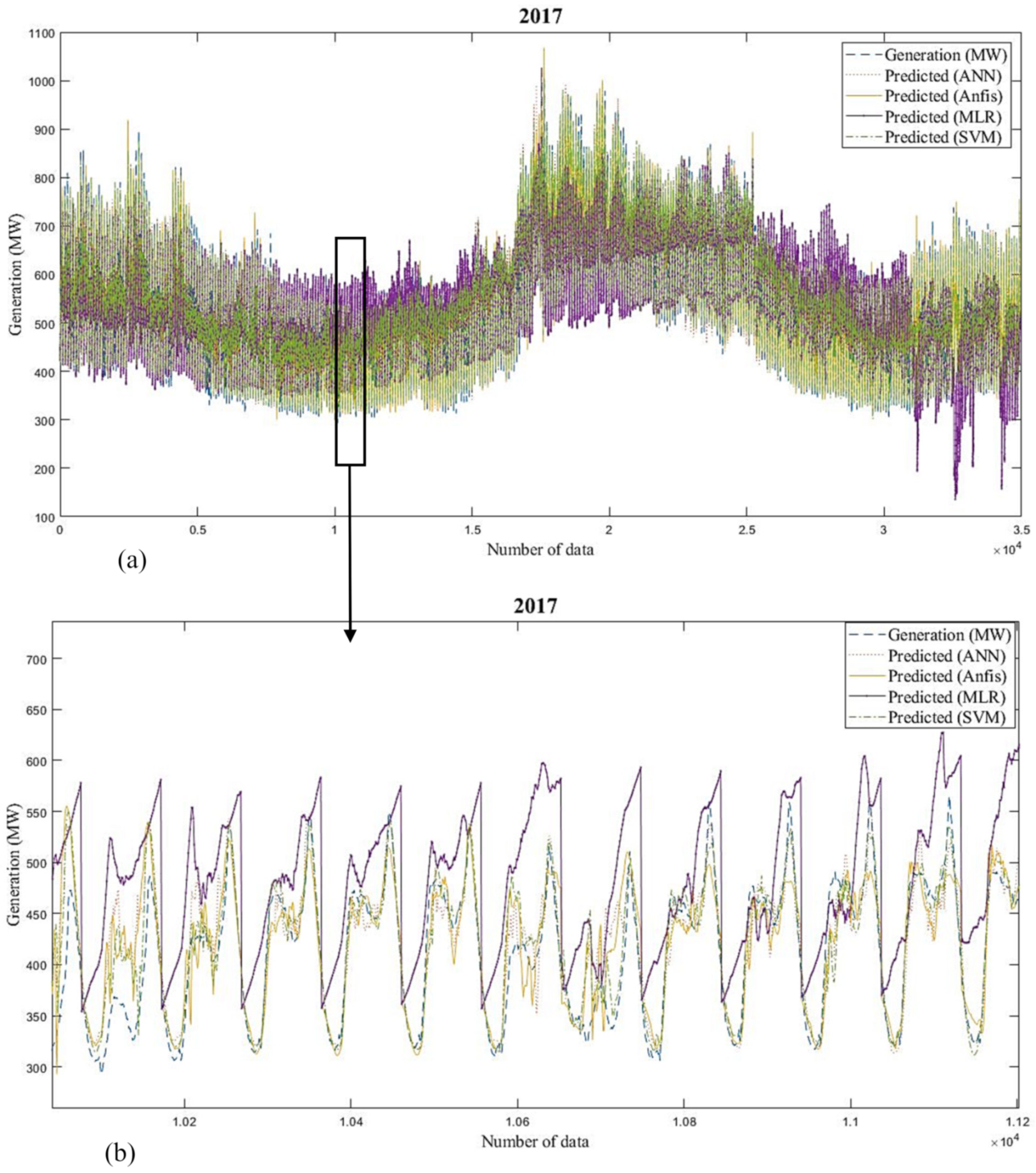
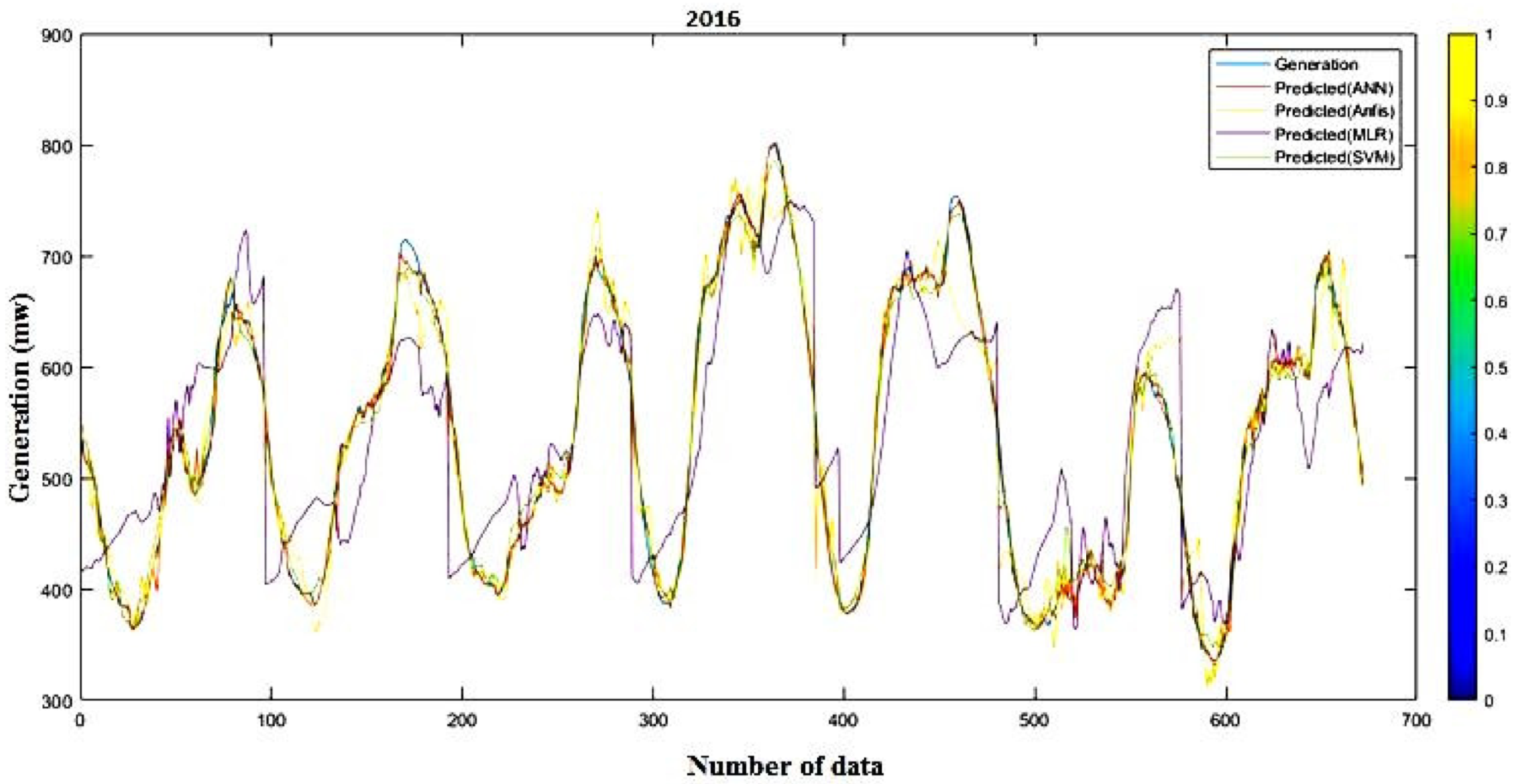
Figure 25 and
Figure 26 and
Table 3;
Table 4 show the predicted generation responses from ANN, ANFIS, MLR, and SVM models and the real responses in variable investigational situations for 2016 and 2017 (long-term).
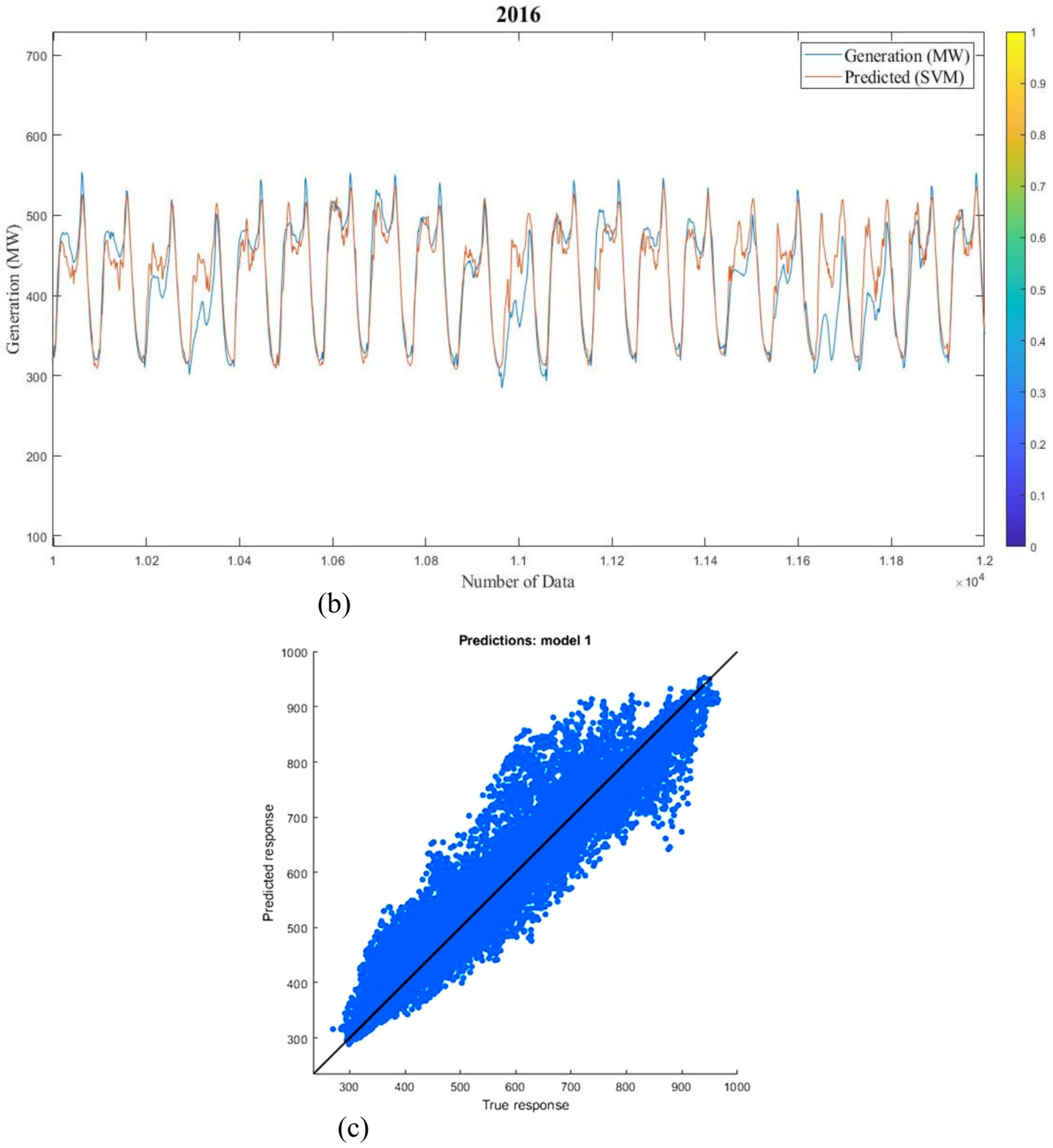
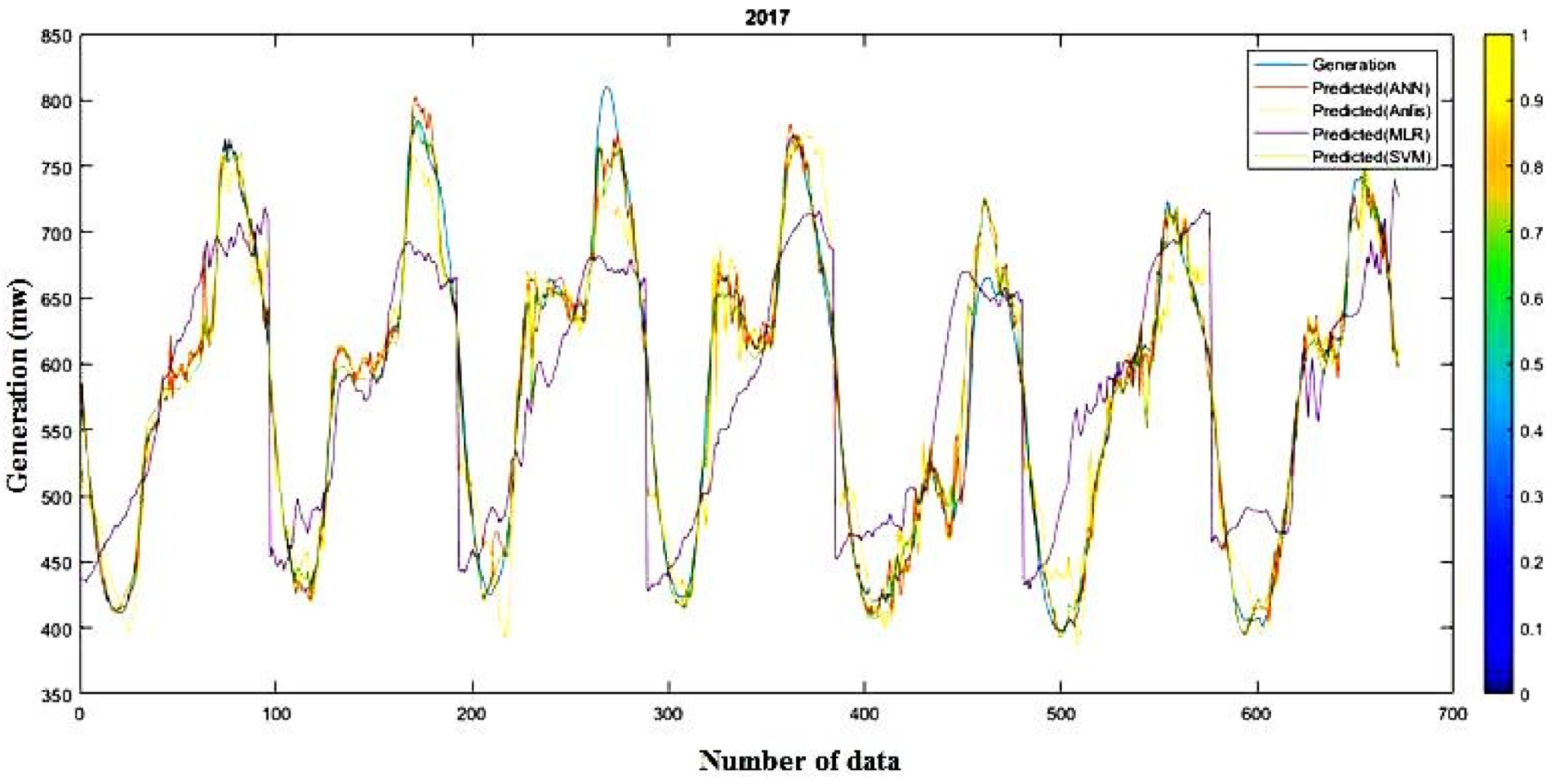
Figure 27 and
Figure 28 and
Table 5 and
Table 6 show the forecast generation results from the mentioned models and the actual outcomes in adaptable investigational conditions for 2016 and 2017 (short-term). Outcomes show that the actual responses are in near agreement with the predicted responses. The average prediction errors of ANN, ANFIS, MLR, and SVM models for long-term analysis are 5.57%, 7.69%, 15.18%, and 4.34% for 2016 and 5.28%, 6.11%, 13.4%, and 4.49% for 2017, which proves that the SVM and ANN models are relatively superior to other ML techniques. Additionally, Root Mean Square Error of the models proves the same result. Likewise, the defined errors of ANN, ANFIS, MLR, and SVM models for short-term study are 0.97%, 3.75%, 10.44%, and 2.24% for 2016 and 1.67%, 3.89%, 9.08%, and 2.12% for 2017, which shows that the ANN and SVM models are preferable over the other methods. Correspondingly, RMSE of the models proves that ANN is more superior to the other methods. The summery performance of all models are presented in
Table 7.
6. Conclusions and Future Work
Load prediction has become increasingly important with the growth of the smart grid. It is a difficult task to predict the electricity load with high precision. The nonlinearity and volatility of real-time energy usage create difficulties in predicting energy demand and consumption. Precise load forecasting is crucial for the planning of power systems and operational decision making. In this study, machine learning approaches including artificial neural network (ANN), multiple linear regression (MLR), adaptive neuro-fuzzy inference system (ANFIS), and support vector machine (SVM) are applied to forecast the electricity load requirements in Cyprus.
It has been observed that electricity load is a function of temperature, humidity, solar irradiation, population, GNI per capita ($), and electricity price per kilowatt-hour; therefore, those were selected as the input parameters for the ML algorithms. The performance of the ML algorithms was comprehensively evaluated using electricity load data in Cyprus. A performance comparison among machine learning methods and identification of the importance of model input variables were carried out. Both the models’ accuracy of prediction and suitability for use were considered to support the forecast. The results indicate that SVM is relatively superior to other ML techniques, providing more reliable and accurate results in terms of lower prediction errors (4.34%, 4.49%) and Root Mean Square Error (25.43, 26.44) for long-term forecasting of energy generation requirements in Cyprus. The ANN model is better than other techniques for short-term analysis, providing lower prediction errors (0.97%, 1.67%) and RMSE (7.67, 14.91).
It is concluded that there is a strong link between energy demand, i.e., electricity load, economy, and environment, and predicting and forecasting electricity load is critical for planning future energy utilization in a sustainable manner.
It is anticipated that the results from this research can open roads toward future implementation of advanced calculation methods regarding energy demand and consumption. It is expected that such models will help energy planners to accurately plan for the future and utilize sustainable and renewable energy resources to a greater extent. The models will help policymakers and administrators to make decisions for a greener tomorrow. As for future work, LSTM and GRU methods can be applied to the time series existing in this research, meanwhile, this approach has achieved good outcomes in other time series forecasting problems.


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}