
A Pro-Environmental Method of Sample Size Determination to Predict the Quality Level of Products Considering Current Customers’ Expectations



Abstract
:1. Introduction
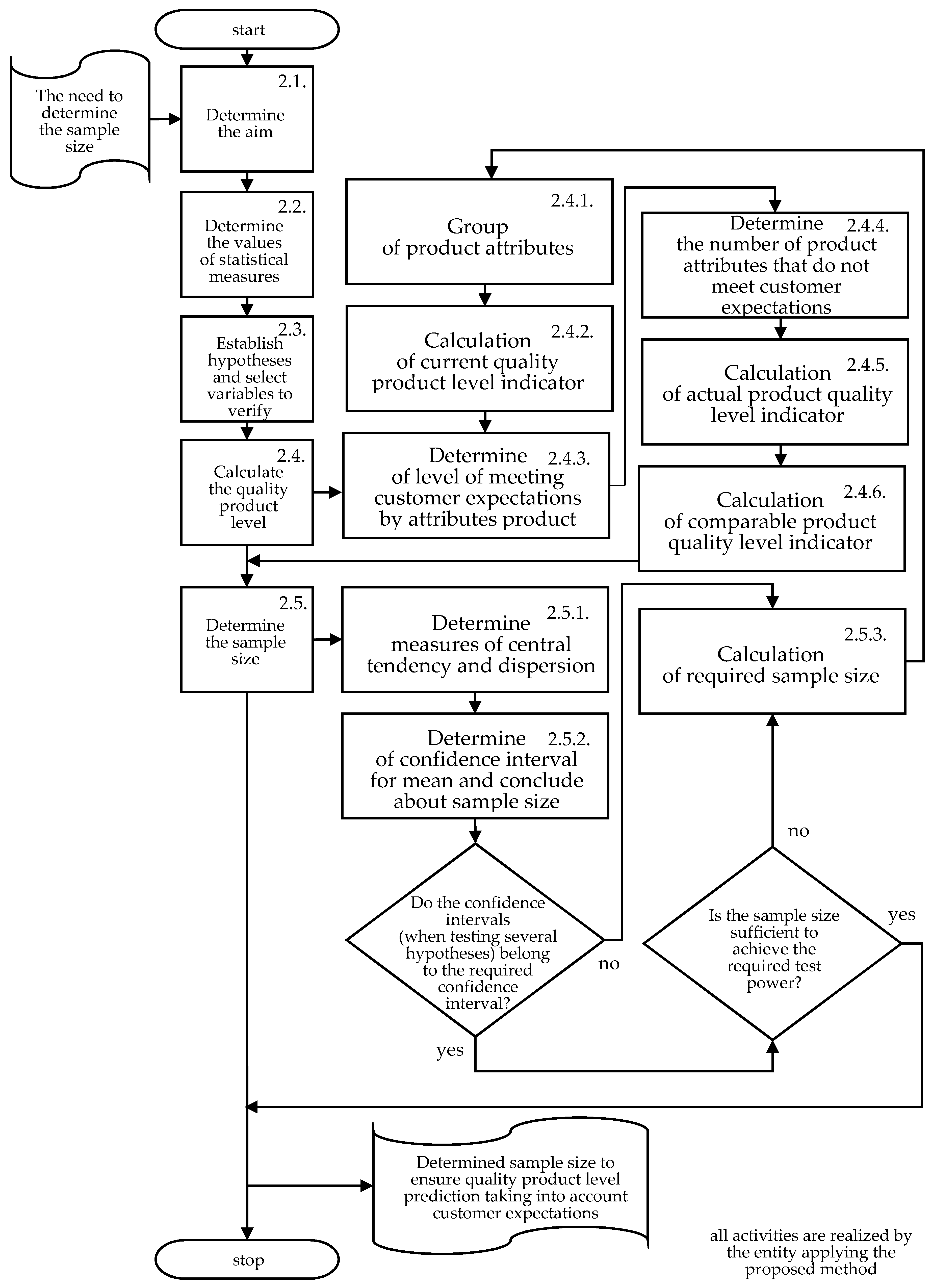
2. Methods
2.1. Determine the Aim
2.2. Determine the Values of Statistical Measures
- The significance level (α) (the probability of making a type I error);
- The probability of making a type II error (β);
- The power of the statistical test (µ = 1 − β);
- The accuracy of analysis results (the so-called error of respect) (d).
- The confidence level (p = α − 1);
- The critical values of the normal standardized distribution (αu);
- t-statistics with Student’s t-distribution and n-1 degrees of freedom (αt);
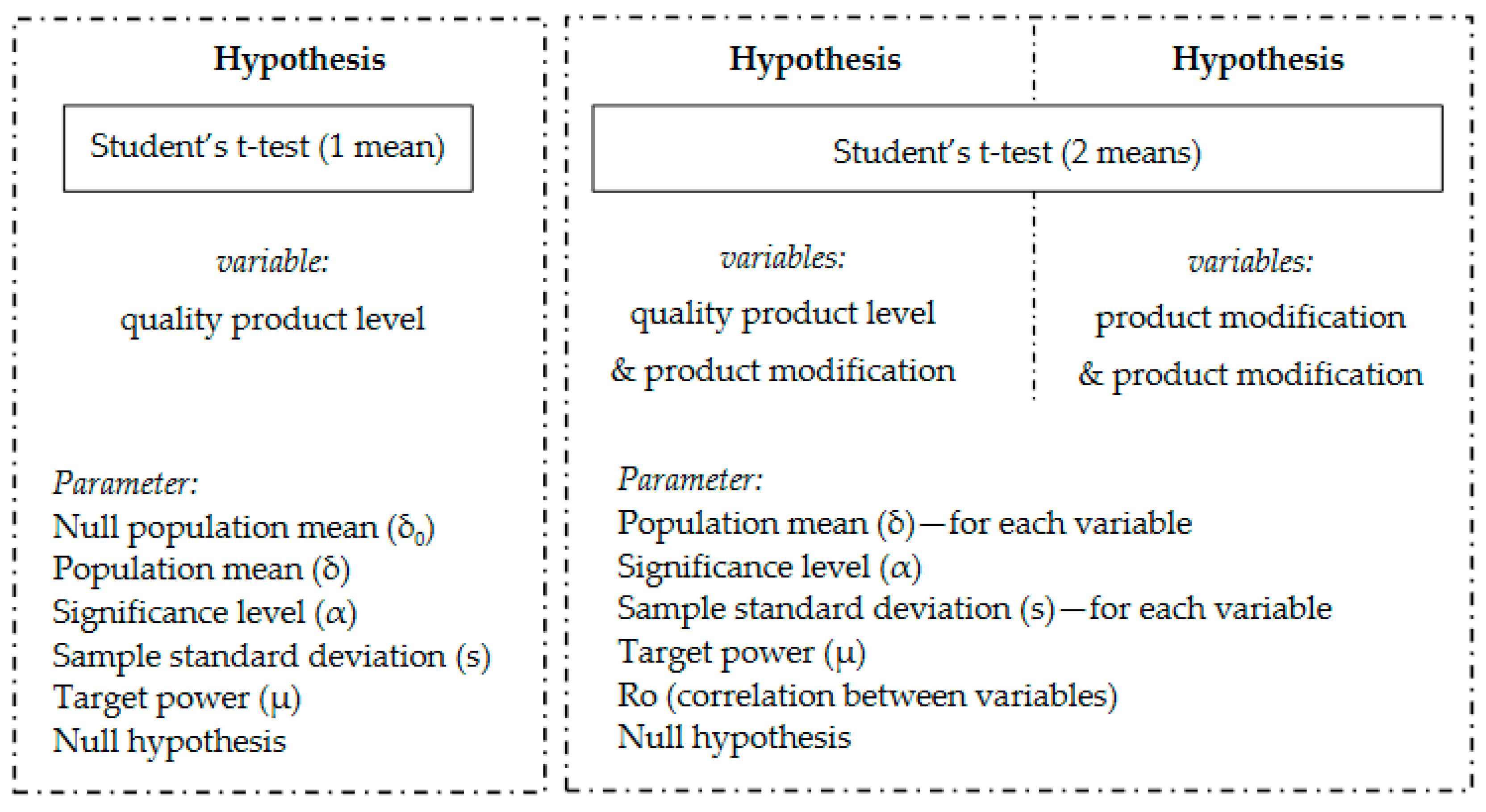
2.3. Establish Hypotheses and Select Variables to Verify Hypotheses
- H0: There is no difference in the quality product level when the product is modified.
- H1: There is a difference in the quality product level when the product is modified.
- H0: There is no difference in the evaluation of product modification.
- H1: There is a difference in the evaluation of product modification.
- H0: There is no difference in the actual and required number of observations to ensure the accepted accuracy of the product quality level and the test power.
- H1: There is a difference in the actual and required number of observations to ensure the accepted accuracy of the product quality level and the test power.
2.4. Calculate the Quality Product Level
2.4.1. Group of Product Attributes
2.4.2. Calculation of Current Quality Product Level Indicator
2.4.3. Determine of Level of Meeting Customer Expectations by Product Attributes
2.4.4. Determine the Number of Product Attributes that Do Not Meet Customer Expectations
2.4.5. Calculation of Actual Product Quality Level Indicator
2.4.6. Calculation of Comparable Product Quality Level Indicator
2.5. Determine the Sample Size
2.5.1. Determine Measures of Central Tendency and Dispersion
- The current sample size (n);
- The sample mean ();
- The sample variance (s2);
- The sample standard deviation (s).
2.5.2. Determine the Confidence Interval for Mean and Determine the Sample Size
2.5.3. Calculation of Required Sample Size
Procedure for the Occurrence of the First Case:
Procedure for the Occurrence of the Second Case:
- Student’s t-test for one mean: H0: δ = δ0 and H1: δ ≠ δ0;
- Student’s t-test for two means, dependent samples: H0: δ1 = δ2 and H1: δ1 ≠ δ2;
- δ, δ1, δ2 is the population mean;
- δ0 is the null population mean.
- If the current sample size is greater or equal to each of the obtained sample sizes, it can be concluded that the current sample size achieves the assumed test power for verifying the research hypotheses. This sample size is sufficient to predict the product quality level taking into account customers’ expectations; thus, the process of determination of the sample size can be stopped (19) [17]:where:n is the current sample size;n0 is the required number of observations in sample.
- If the current sample size is less than at least one of the obtained sample sizes, it can be concluded that current sample size does not allow the assumed test power to be to achieved for verifying the research hypotheses. Then, the required sample size (n0) that allows the established research hypotheses to be verified is the maximum sample size (nmax) among all of those analyzed (20):where:n0 is the required number of observations in sample;nmax is the maximum sample size among all sample sizes;n is the current sample size;n1, n2,…, nn is the required sample size as part of the verification of the adopted research hypotheses.
3. Results
4. Discussion
- Determination of the number of customers to test research hypotheses as part of the prediction of the product quality level (as shown in Section 2.3);
- Determination of the number of customers while ensuring the test power for this sample size, and detection of statistically significant differences between several relationships for this sample size and test power, as shown in Section 2.3, i.e., product quality level, the modified product, and two different product modifications;
- Use of the method in the context of predicting customers’ expectations about the quality of any product.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alt, R.; Ehmke, J.F.; Haux, R.; Henke, T.; Mattfeld, D.C.; Oberweis, A.; Paech, B.; Winter, A. Towards customer-induced service orchestration-requirements for the next step of customer orientation. Electron. Mark. 2019, 29, 79–91. [Google Scholar] [CrossRef]
- Zheng, P.; Xu, X.; Xie, S.Q. A weighted interval rough number based method to determine relative importance ratings of customer requirements in QFD product planning. J. Intell. Manuf. 2019, 30, 3–16. [Google Scholar] [CrossRef]
- Wang, P.; Gong, Y.; Xie, H.; Liu, Y.; Nee, A.Y. Applying CBR to machine tool product configuration design oriented to customer requirements. Chin. J. Mech. Eng. 2017, 30, 60–76. [Google Scholar] [CrossRef]
- Ostasz, G.; Czerwińska, K.; Pacana, A. Quality management of aluminum pistons with the use of quality control points. Manag. Syst. Eng. 2020, 28, 771–773. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Ramirez-Serrano, A.; Yin, G. An optimum design selection approach for product customization development. J. Intell. Manuf. 2010, 23, 1433–1443. [Google Scholar] [CrossRef]
- Huang, H.-Z.; Li, Y.; Liu, W.; Liu, Y.; Wang, Z. Evaluation and decision of products conceptual design schemes based on customer requirements. J. Mech. Sci. Technol. 2011, 25, 2413–2425. [Google Scholar] [CrossRef]
- Stylidis, K.; Rossi, M.; Wickman, C.; Söderberg, R. The Communication Strategies and Customer’s Requirements Definition at the Early Design Stages: An Empirical Study on Italian Luxury Automotive Brands. Procedia CIRP 2016, 50, 553–558. [Google Scholar] [CrossRef] [Green Version]
- Madzik, P.; Chocholakova, A. Structured Transfer of Customer’s Requirements into Product Quality Attributes-A University Case Study. Qual. Access Success 2016, 17, 38–45. [Google Scholar]
- Pacana, A.; Pasternak-Malicka, M.; Zawada, M.; Radon-Cholewa, A. Decision support in the production of packaging films by cost-quality analysis. Przemysł Chem. 2016, 95, 1042–1044. [Google Scholar] [CrossRef]
- Koomsap, P. Design by customer: Concept and applications. J. Intell. Manuf. 2013, 24, 295–311. [Google Scholar] [CrossRef]
- Gupta, M.; Shri, C. Understanding customer requirements of corrugated industry using Kano model. Int. J. Qual. Reliab. Manag. 2018, 35, 1653–1670. [Google Scholar] [CrossRef]
- Li, Y.L.; Du, Y.F.; Chin, K.S. Determining the importance ratings of customer requirements in quality function deployment based on interval linguistic information. Int. J. Prod. Res. 2018, 56, 4692–4708. [Google Scholar] [CrossRef]
- Madzík, P.; Budaj, P.; Mikuláš, D.; Zimon, D. Application of the Kano Model for a Better Understanding of Customer Requirements in Higher Education—A Pilot Study. Adm. Sci. 2019, 9, 11. [Google Scholar] [CrossRef] [Green Version]
- Esser, C.; Refflinghaus, R. Optimizing the evaluation of eye tracking data to validate requirements in virtual space to improve customer satisfaction. Acta Tech. Napoc. Ser. Appl. Math. Mech. Eng. 2018, 61, 459–468. [Google Scholar]
- Chena, C.-H.; Yan, W. An in-process customer utility prediction system for product conceptualisation. Expert Syst. Appl. 2008, 34, 2555–2567. [Google Scholar] [CrossRef]
- Song, W.Y.; Ming, X.G.; Xu, Z.T. Integrating Kano model and grey-Markov chain to predict customer requirement states. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2013, 227, 1232–1244. [Google Scholar] [CrossRef]
- Tadeusiewicz, R.; Izworski, A.; Majewski, J. Biometria; AGH: Cracow, Poland, 1993; pp. 1–379. Available online: http://winntbg.bg.agh.edu.pl/skrypty2/0086/main.html (accessed on 9 December 2020).
- Ruta, R. Wykorzystanie analizy mocy testów do wyznaczenia liczności próby w badaniach tribologicznych. Tribologia 2012, 6, 147–159. [Google Scholar]
- Szymczak, W. Pojęcie wielkości efektu na tle teorii Neymana-Pearsona testowania hipotez statystycznych. Acta Universistatis Lodz. Folia Psychol. 2015, 19, 5–41. [Google Scholar] [CrossRef]
- Harańczyk, G.; Gurycz, J. Analiza Mocy Testu i Jej Znaczenie w Badaniach Empirycznych; StatSoft Polska: Kraków, Poland, 2006; pp. 59–70. [Google Scholar]
- Mishra, P.; Pandey, C.; Keshri, A.; Sabaretnam, M. Selection of Appropriate Statistical Methods for Data Analysis. Ann. Card. Anaesth. 2019, 22, 297–301. [Google Scholar] [CrossRef]
- Chittaranjan, A. The P Value and Statistical Significance: Misunderstandings, Explanations, Challenges, and Alternatives. Indian J. Psychol. Med. 2019, 41, 210–215. [Google Scholar] [CrossRef]
- Schmidt, S.; Lo, S.; Hollestein, L. Research Techniques Made Simple: Sample Size Estimation and Power Calculation. J. Investig. Dermatol. 2018, 138, 1678–1682. [Google Scholar] [CrossRef] [Green Version]
- Altuntas, S.; Özsoy, E.B.; Mor, Ş. Innovative new product development: A case study. Procedia Comput. Sci. 2019, 158, 214–221. [Google Scholar] [CrossRef]
- International Standard Organization. ISO 16355-1:2015. Application of Statistical and Related Methods to New Technology and Product Development Process. Part 1: General Principles and Perspectives of Quality Function Deployment (QFD); International Standard Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Chen, C.H.; Khoo, L.P.; Yan, W. Evaluation of multicultural factors from elicited customer requirements for new product development. Res. Eng. Des. Theory Appl. Concurr. Eng. 2003, 14, 119–130. [Google Scholar] [CrossRef]
- Wang, Y.; Yseng, M.M. Integrating comprehensive customer requirements into product design. CIRP Ann. 2011, 60, 175–178. [Google Scholar] [CrossRef]
- Sun, N.; Mei, X.; Zhang, Y. A simplified systematic method of acquiring design specifications from customer requirements. J. Comput. Inf. Sci. Eng. 2009, 9, 44105. [Google Scholar] [CrossRef]
- Borgianni, Y. Verifying dynamic Kano’s model to support new product/service development. J. Ind. Eng. Manag. 2018, 11, 569–587. [Google Scholar] [CrossRef]
- Yamagishi, K.; Seki, K.; Nishimura, H. Requirement analysis considering uncertain customer preference for Kansei quality of product. J. Adv. Mech. Des. Syst. Manuf. 2018, 12. [Google Scholar] [CrossRef] [Green Version]
- Ginting, R.; Ali, A.Y. Improved Kansei Engineering with Quality Function Deployment Integration: A Comparative Case Study. Mater. Sci. Eng. 2019, 505. [Google Scholar] [CrossRef] [Green Version]
- Syaifoelida, F.; Megat Hamdan, M.; Murrad, M.; Aminuddin, H. The Qualitative Measurement towards Emotional Feeling of Design for Product Development. Mater. Sci. Eng. 2018, 344. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.L.; Peng, Q.J. A spectral clustering method to improve importance rating accuracy of customer requirements in QFD. Int. J. Adv. Manuf. Technol. 2020, 107, 2579–2596. [Google Scholar] [CrossRef]
- Lee, C.H.; Chen, C.H.; Lin, C.Y.; Li, F.; Zhao, X.J. Developing a Quick Response Product Configuration System under Industry 4.0 Based on Customer Requirement Modelling and Optimization Method. Appl. Sci. 2019, 9, 5004. [Google Scholar] [CrossRef] [Green Version]
- Kwong, C.K.; Bai, H. A fuzzy AHP approach to the determination of importance weights of customer requirements in quality function deployment. J. Intell. Manuf. 2002, 13, 367–377. [Google Scholar] [CrossRef]
- Wu, H.H.; Shieh, J.I. Using a Markov chain model in quality function deployment to analyse customer requirements. Int. J. Adv. Manuf. Technol. 2006, 30, 141–146. [Google Scholar] [CrossRef]
- Tontini, G. Identification of customer attractive and must-be requirements using a modified Kano’s method: Guidelines and case study. In Proceedings of the Annual Quality Congress Proceedings-American Society for Quality Control, Anaheim, CA, USA, 8–10 May 2000; pp. 728–734. [Google Scholar]
- Li, Y.L.; Tang, J.F.; Luo, X.G.; Xu, J. An integrated method of rough set, Kano’s model and AHP for rating customer requirements’ final importance. Expert Syst. Appl. 2009, 36, 7045–7053. [Google Scholar] [CrossRef]
- Yang, Q.; Li, Z.; Jiao, H.; Zhang, Z.; Chang, W.; Wei, D. Bayesian Network Approach to Customer Requirements to Customized Product Model. Discret. Dyn. Nat. Soc. 2019. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Tseng, M.M. Identifying Emerging Customer Requirements in an Early Design Stage by Applying Bayes Factor-Based Sequential Analysis. IEEE Trans. Eng. Manag. 2014, 61, 129–137. [Google Scholar] [CrossRef]
- Jiao, Y.; Yang, Y.; Zhong, J.; Zhang, H.S. A Comparative Analysis of Intelligent Classifiers for Mapping Customer Requirements to Product Configurations. In Proceedings of the 2017 International Conference On Big Data Research, Boston, MA, USA, 11–14 December 2017; pp. 72–77. [Google Scholar]
- Yang, Q.; Bian, X.J.; Stark, R.; Fresemann, C.; Song, F. Configuration Equilibrium Model of Product Variant Design Driven by Customer Requirements. Symmetry 2019, 11, 508. [Google Scholar] [CrossRef] [Green Version]
- Jiao, Y.; Yang, Y.; Zhang, H.S. Mapping High Dimensional Sparse Customer Requirements into Product Configurations. In Proceedings of the International Conference on Artificial Intelligence Applications and Technologies (AIAAT 2017), Hawaii, HI, USA, 30 August–2 September 2017; Volume 261. [Google Scholar] [CrossRef]
- Geng, L.S.; Geng, L.X. Analyzing and Dealing with the Distortions in Customer Requirements Transmission Process of QFD. Math. Probl. Eng. 2018. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; Zhang, Q.; Peng, Z.L.; Fan, Y. Integrating customer requirements into customized product configuration design based on Kano’s model. J. Intell. Manuf. 2020, 31, 597–613. [Google Scholar] [CrossRef]
- He, Z.; Wang, S. Mapping customer requirements to product performance index based on data fusion by vague set. J. Comput. Inf. Syst. 2009, 5, 1679–1686. [Google Scholar]
- Pacana, A.; Siwiec, D.; Bednárová, L. Method of Choice: A Fluorescent Penetrant Taking into Account Sustainability Criteria. Sustainability 2020, 12, 5854. [Google Scholar] [CrossRef]
- Confidence Intervals for the Mean and Variance. Available online: http://zsi.ii.us.edu.pl/~nowak/bios/owd/17042011_b.pdf (accessed on 9 December 2020).
- Winiarski, J. Ryzyko w projektach informatycznych–statystyczne narzędzia oceny. Contemporart Economy. Electron. Sci. J. 2012, 3, 35–42. [Google Scholar]
- Lawlor, K.B.; Hornyak, M.J. Smart Goals: How The Application Of Smart Goals Can Contribute To Achievement Of Student Learning Outcomes. Dev. Bus. Simul. Exp. Learn. 2012, 39, 259–267. [Google Scholar]
- Smukavec, A. Precision of Statistical Estimates. General Methodological Explanation 2020. Available online: https://www.stat.si/dokument/8885/PrecisionOfStatisticalEstimatesMEgeneral.pdf (accessed on 19 December 2020).
- Statistical Tables. Available online: https://home.ubalt.edu/ntsbarsh/business-stat/StatistialTables.pdf (accessed on 19 December 2020).
- Statistical Tables. Available online: https://www.alacero.org/sites/default/files/u16/ci_23_-_41_cumulative_distribution_table.pdf (accessed on 19 December 2020).
- Shankar, S.; Singh, R. Demystifying statistics: How to choose a statistical test? Indian J. Rheumatol. 2014, 1–5. [Google Scholar] [CrossRef]
- Siwiec, D.; Bednarova, L.; Pacana, A.; Zawada, M.; Rusko, M. Wspomaganie decyzji w procesie doboru penetrantów fluore-scencyjnych do przemysłowych badan nieniszczących. Przemysł Chem 2019, 98, 1594–1596. [Google Scholar] [CrossRef]
- Pacana, A.; et al. Discrepancies analysis of casts of diesel engine piston. Metalurgija 2018, 57, 324–326. [Google Scholar]
- Kolman, R.R. Quality Engineering; PWE: Warsaw, Poland, 1992; pp. 1–292. [Google Scholar]
- Pacana, A.; Siwiec, D.; Bednarova, L. Analysis of the incompatibility of the product with fluorescent method. Metalurgija 2019, 58, 337–340. [Google Scholar]
- Gajewska, T. Wybrane metody i wskaźniki pomiaru jakości usług logistycznych. Autobusy Tech. Eksploat. Syst. Transp. 2016, 17, 1320–1326. [Google Scholar]
- Joshi, A.; Kale, S.; Chandel, S.; Pal, D.K. Likert Scale: Explored and Explained. Curr. J. Appl. Sci. Technol. 2015, 7, 396–403. [Google Scholar] [CrossRef]
- Budzicz, Ł. Interpretacja statystyk w artykułach naukowych—wskazówki dla praktyków. Psychol. Zesz. Nauk. 2017, 1, 143–157. [Google Scholar]
- Khusainova, R.M.; Shilova, Z.V.; Curteva, O.V. Selection of Appropriate Statistical Methods for Research Results Processing. Math. Educ. 2016, 11, 303–315. [Google Scholar] [CrossRef]
- Turisova, R.; Sinay, J.; Pacaiova, H.; Kotianova, Z.; Glatz, J. Application of the EFQM Model to Assess the Readiness and Sustainability of the Implementation of I4.0 in Slovakian Companies. Sustainability 2020, 12, 5591. [Google Scholar] [CrossRef]
- Olkiewicz, M.; Bober, B.; Wolniak, R. Innowacje w przemyśle farmaceutycznym jako determinanta procesu kształtowania jakości życia. Przemysł Chem. 2017, 96, 2199–2201. [Google Scholar] [CrossRef]
- Pacana, A.; Ulewicz, R. Analysis of causes and effects of implementation of the quality management system compliant with ISO 9001. Pol. J. Manag. Stud. 2020, 21, 283–296. [Google Scholar] [CrossRef]
- Dwornicka, R.; Radek, N.; Pietraszek, J. The Bootstrap Method As A Tool To Improve The Design Of Experiments System Safety. Hum. Tech. Facil. Environ. 2019, 3, 724–729. [Google Scholar] [CrossRef] [Green Version]
- Dolgun, L.; Koksal, G. Effective use of quality function deployment and Kansei engineering for product planning with sensory customer requirements: A plain yogurt case. Qual. Eng. 2018, 30, 569–582. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Hypothesis—Probability | |||
|---|---|---|---|
| H0 | H1 | ||
| Decision about choice of hypothesis | H0 | Correct acceptance H0 1-β | Type II error β |
| H1 | Type I error α | Correct rejection H0 1- α | |
| Interpretation of the Product Quality Compliance Level | Numerical Range of the Quality Level | |
|---|---|---|
| Verbal Interpretation | Numerical Interpretation | |
| Bad | 9 | <0; 0.1) |
| Critical | 8 | <0.1; 0.2) |
| Unfavorable | 7 | <0.2; 0.3) |
| Unsatisfactory | 6 | <0.3; 0.4) |
| Sufficient | 5 | <0.4; 0.5) |
| Moderate | 4 | <0.5; 0.6) |
| Satisfactory | 3 | <0.6; 0.7) |
| Beneficial | 2 | <0.7; 0.8) |
| Distinctive | 1 | <0.8; 0.9) |
| Excellent | 0 | <0.9; 1> |
| Mark | Statistical Measure | Value |
|---|---|---|
| α | the significance level (α) (the probability of making a type I error) | 0.05 |
| α − 1 | the confidence interval | 0.95 |
| αu | the critical value to normal standardized distribution which meets the condition: | 1.960 |
| αt | value of t-statistics with t-Student distribution and n-1 degrees of freedom | 1.960 |
| d1 | the accuracy (so-called error of respect) for quality product level | 0.05 |
| d2 | the accuracy (so-called error of respect) for assessments product attributes | 0.5 |
| β | the probability of making a type II error | ≤0.2 |
| µ = 1 − β | the power of statistical test | ≥0.8 |
| Attribute | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A10 | A11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4.07 | 4.04 | 4.21 | 3.73 | 4.13 | 2.89 | 3.40 | 3.68 | 3.79 | 3.27 | 3.10 | |
| Attribute | A12 | A13 | A14 | A15 | A16 | A17 | A18 | A19 | A20 | A21 | A22 |
| 2.45 | 2.99 | 3.20 | 3.35 | 2.86 | 2.62 | 3.78 | 3.47 | 3.75 | 4.06 | 2.66 |
| Marks and Weights of Attributes Product | the Number of Attributes in Groups | ||
|---|---|---|---|
| mark | description | weight | number |
| nw | number of product attributes in important group | 50 | 5 |
| ns | number of product attributes in moderately important group | 10 | 11 |
| nm | number of product attributes in not very important group | 1 | 6 |
| Observation Number | mw | ms | mm | Qi | qi |
|---|---|---|---|---|---|
| 1 | 0 | 2 | 1 | 345 | 0.94 |
| 2 | 1 | 1 | 0 | 306 | 0.84 |
| 3 | 0 | 0 | 0 | 366 | 1.00 |
| 4 | 0 | 3 | 0 | 336 | 0.92 |
| 5 | 1 | 4 | 3 | 273 | 0.75 |
| 6 | 0 | 0 | 1 | 365 | 1.00 |
| 7 | 0 | 0 | 2 | 364 | 0.99 |
| 8 | 0 | 0 | 1 | 365 | 1.00 |
| 9 | 0 | 2 | 0 | 346 | 0.95 |
| 10 | 1 | 2 | 2 | 294 | 0.80 |
| 157 | 0 | 0 | 1 | 365 | 1.00 |
| Measure | Quality Product Level | Modification 1 | Modification 2 |
|---|---|---|---|
| the sample size (n) | 157 | 157 | 157 |
| the sample mean ( | 0.88 | 3.60 | 4.45 |
| the sample variance (s2) | 0.04 | 2.23 | 1.08 |
| the sample standard deviation (s) | 0.19 | 1.50 | 1.04 |
| Parameter | Quality Product Level |
|---|---|
| Null population mean (δ0) | 0.00 |
| Population mean (δ) | 0.04 |
| Standard deviation in population (σ) | 0.19 |
| Standardized effect (Es) | 0.21 |
| The probability of making a type I error (α) | 0.05 |
| Target power | 0.80 |
| Power for the required sample size | 0.80 |
| Sample size required (n0) | 180.00 |
| Parameter | Quality Product Level and Modification of 1 Product | Modification of 1 Product and Modification of 2 Product |
|---|---|---|
| Average in population (δ1) | 1.80 | 2.23 |
| Average in population (δ2) | 0.04 | 1.80 |
| Standard deviation in population (σ1) | 1.50 | 1.04 |
| Standard deviation in population (σ2) | 0.19 | 1.50 |
| Correlation between groups | 0.33 | 0.35 |
| Error std. for the difference of means | 1.45 | 1.50 |
| Standardized effect (Es) | 1.21 | 0.29 |
| The probability of making a type I error (α) | 0.05 | 0.05 |
| The critical value of t | 2.36 | 1.98 |
| Target power | 0.80 | 0.80 |
| Power for the required sample size | 0.84 | 0.80 |
| Sample size required (n0) | 8.00 | 98.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siwiec, D.; Pacana, A. A Pro-Environmental Method of Sample Size Determination to Predict the Quality Level of Products Considering Current Customers’ Expectations. Sustainability 2021, 13, 5542. https://doi.org/10.3390/su13105542
Siwiec D, Pacana A. A Pro-Environmental Method of Sample Size Determination to Predict the Quality Level of Products Considering Current Customers’ Expectations. Sustainability. 2021; 13(10):5542. https://doi.org/10.3390/su13105542
Chicago/Turabian StyleSiwiec, Dominika, and Andrzej Pacana. 2021. "A Pro-Environmental Method of Sample Size Determination to Predict the Quality Level of Products Considering Current Customers’ Expectations" Sustainability 13, no. 10: 5542. https://doi.org/10.3390/su13105542
APA StyleSiwiec, D., & Pacana, A. (2021). A Pro-Environmental Method of Sample Size Determination to Predict the Quality Level of Products Considering Current Customers’ Expectations. Sustainability, 13(10), 5542. https://doi.org/10.3390/su13105542