
Improving Production Efficiency with a Digital Twin Based on Anomaly Detection



Abstract
:1. Introduction
- DTs are virtual dynamic representations of physical systems.
- DTs exchange data with the physical system automatically and bidirectionally.
- DTs cover the entire product lifecycle.
2. Materials and Methods
2.1. Case Study Partner
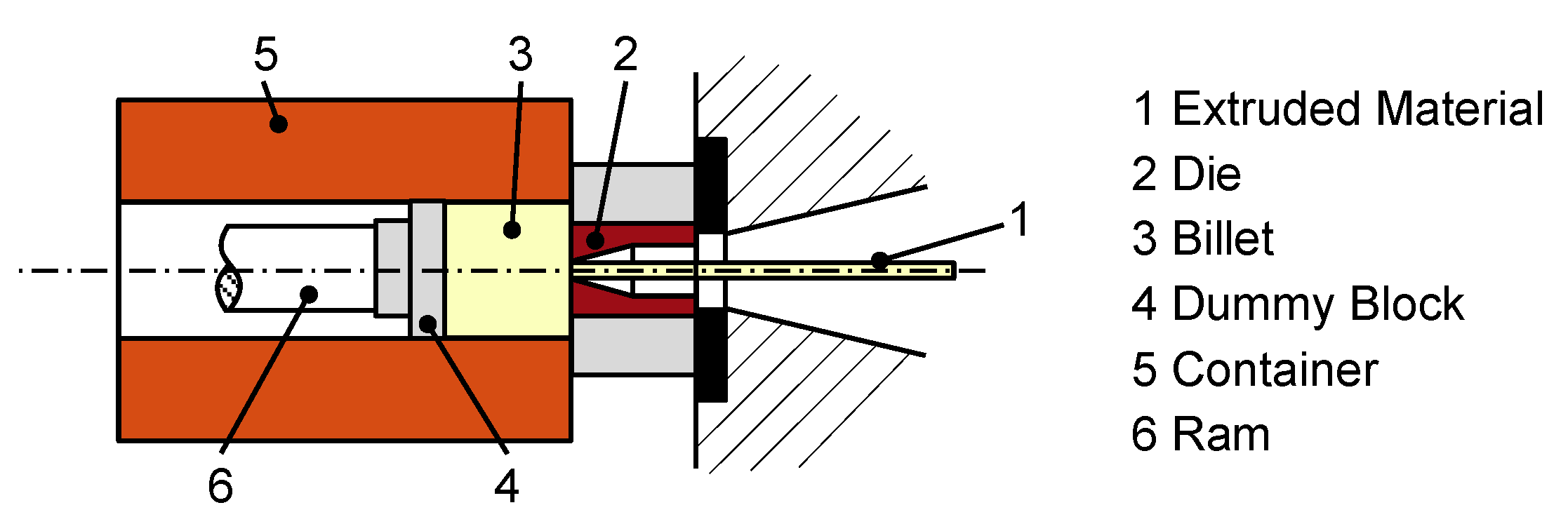
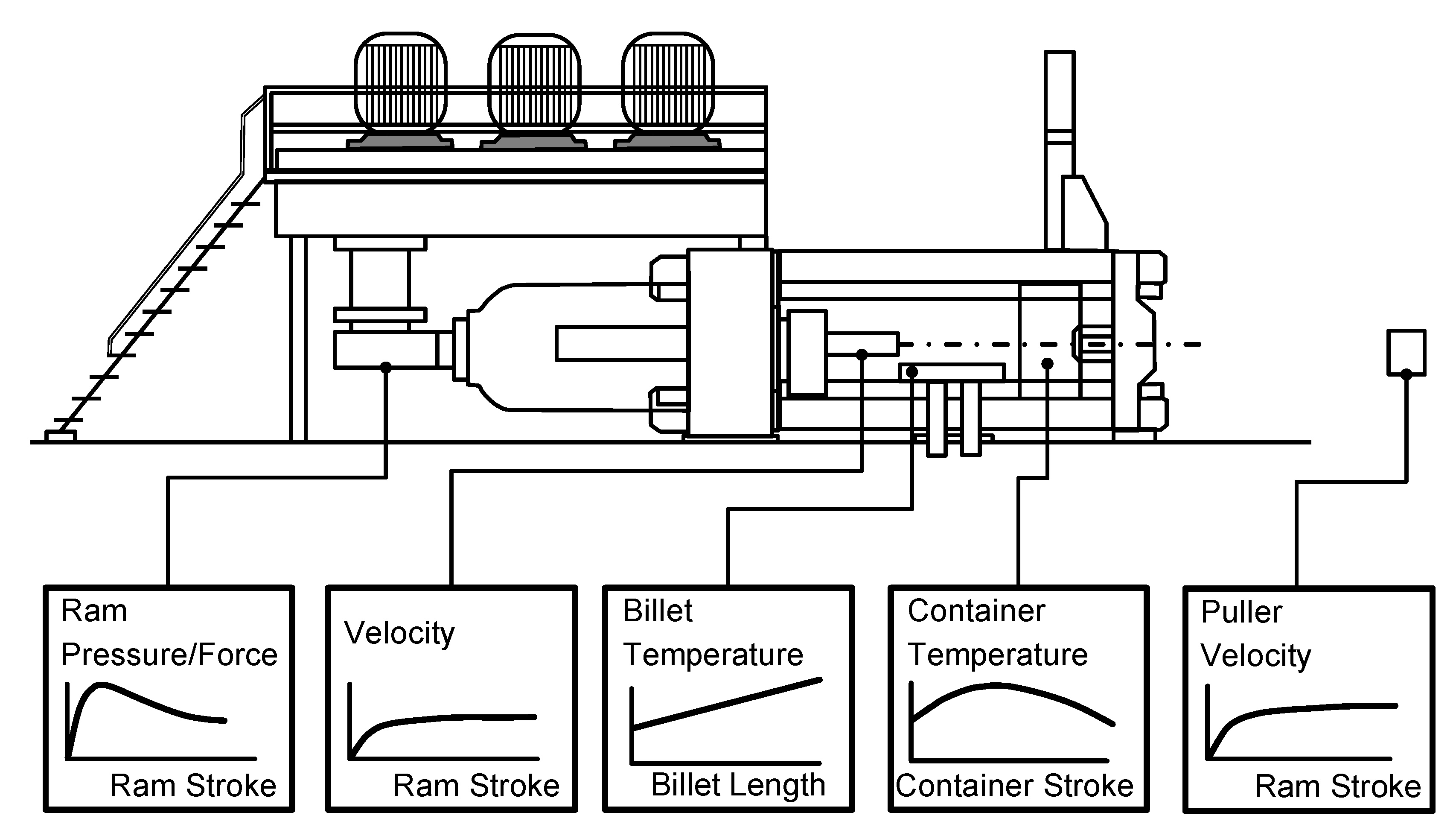
2.2. Aluminum Extrusion Processes
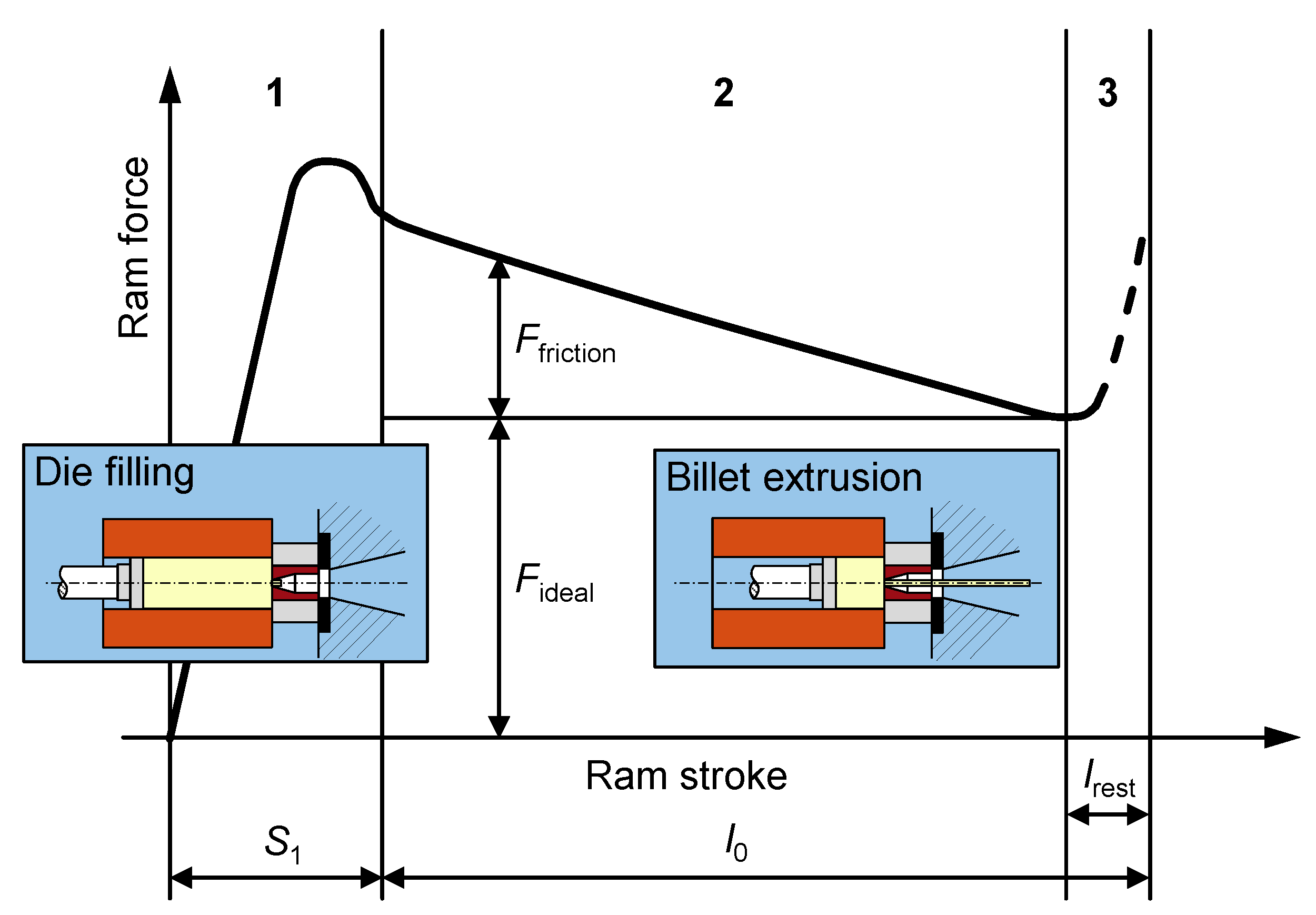
- The billet is filled in and compressed against the die until the maximum force is reached.
- While the billet is pushed through the die, pressure decreases, and “steady-state” extrusion proceeds.
- After the minimum pressure is reached, the ram force again increases rapidly, as the discarded material is compressed. Most commonly, the process is interrupted at this point and the remaining material is discarded and recycled.
2.3. Procedure Model for the Conception and Implementation of Digital Twins
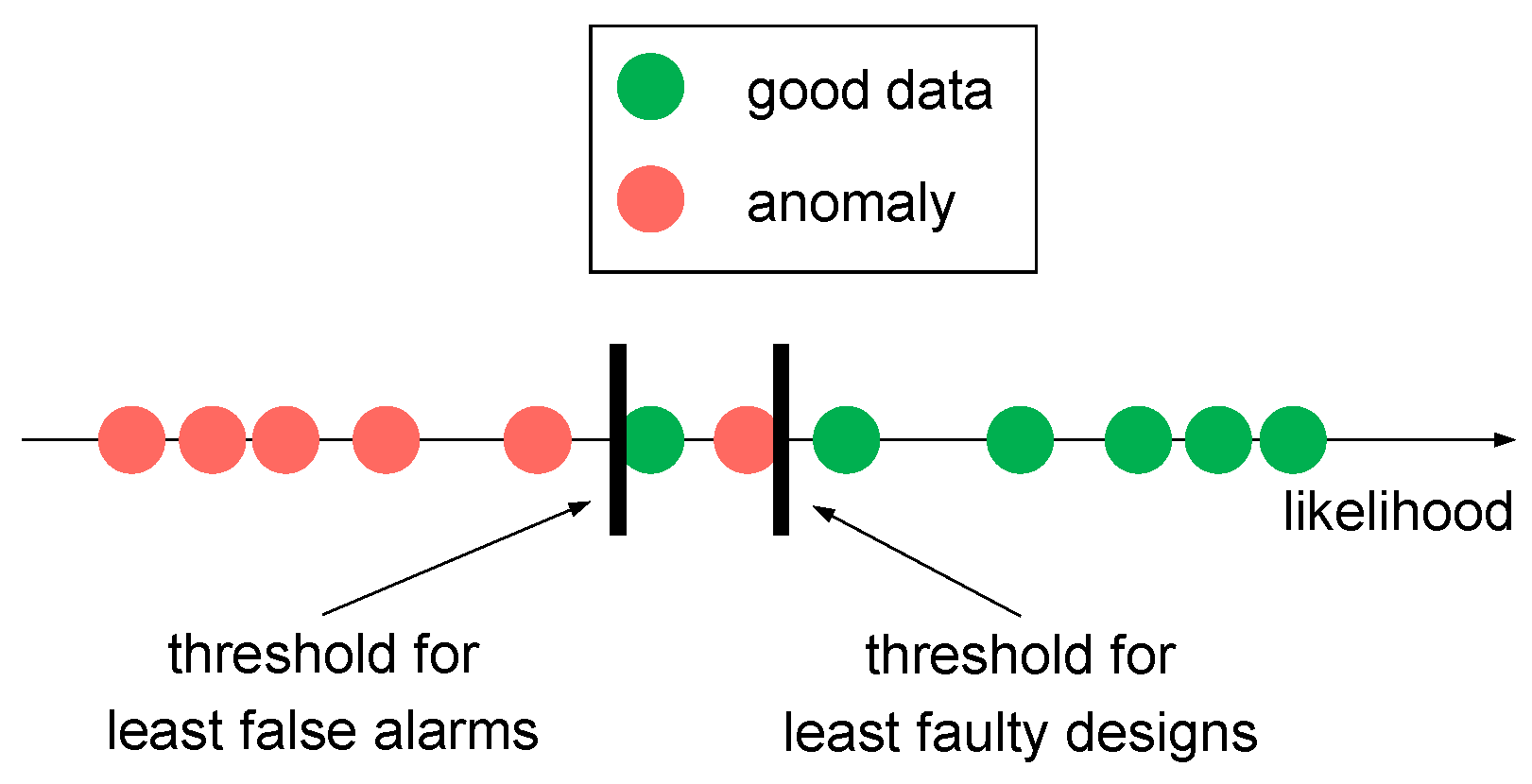
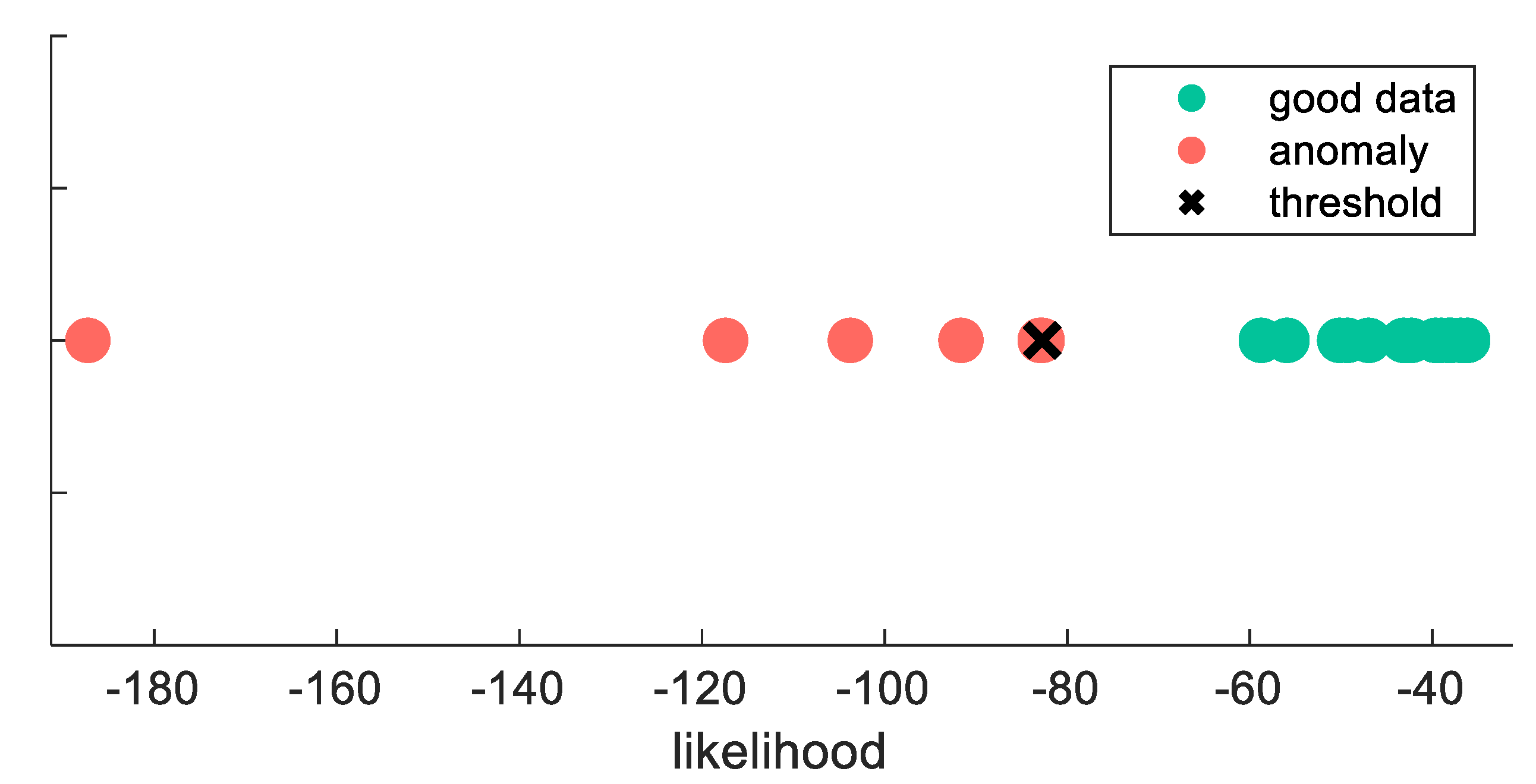
2.4. Anomaly Detection
- Training set with only good data → probability density function.
- Validation set with good and anomalous data → likelihood threshold.
- Training set with good and anomalous data → evaluate model.
- TPR: the rate of anomalies that are correctly declared as anomalies.
- FNR: the rate of anomalies that are wrongly declared as good data.
- TNR: the rate of good data that is correctly declared as good data.
- FPR: the rate of good data that is wrongly declared as anomalies.
3. Application and Results
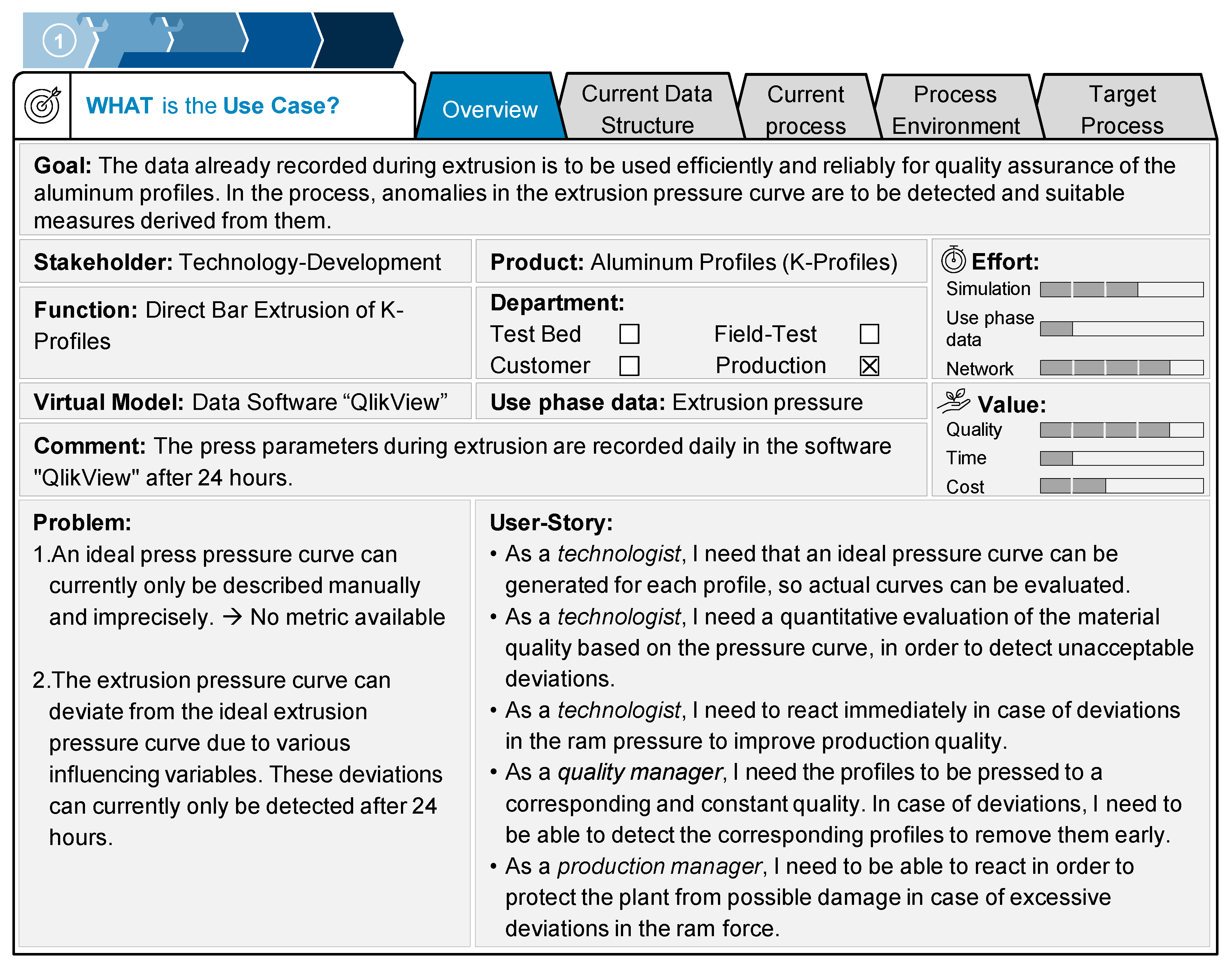
3.1. Application of the DT Procedure Model and the Use Case Template
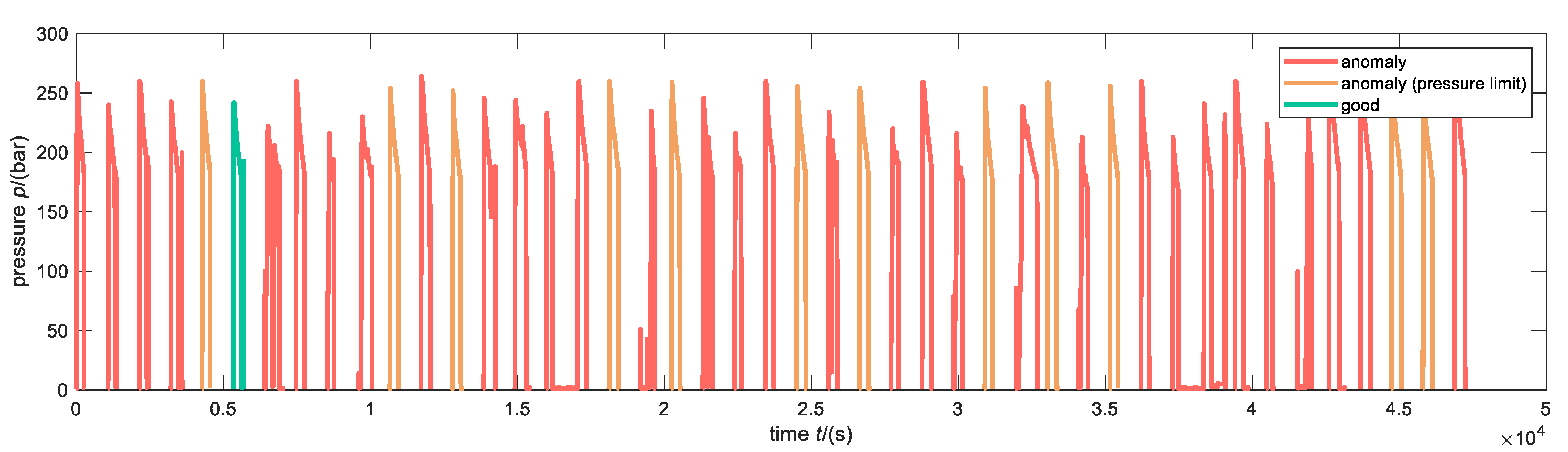
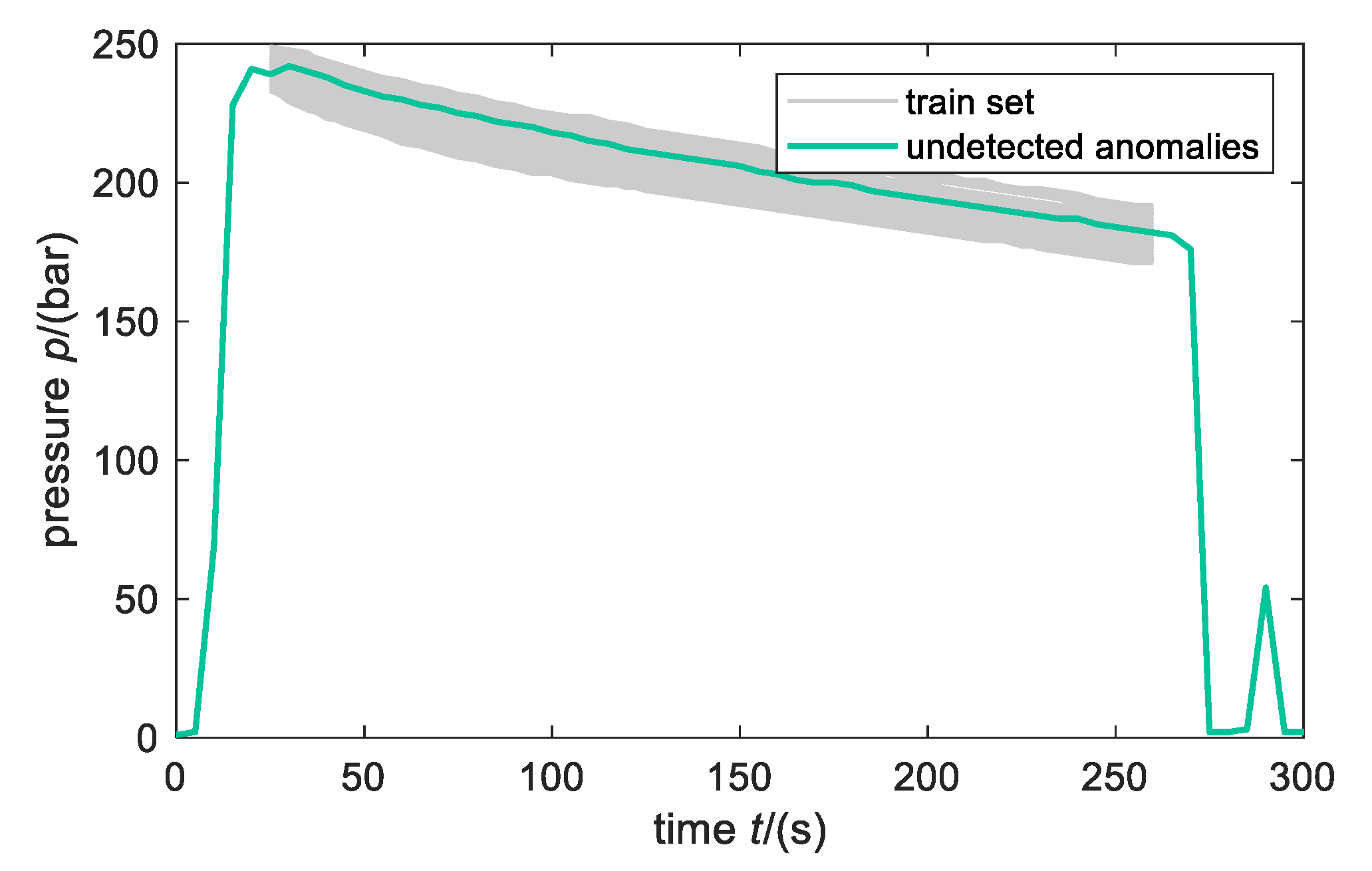
3.2. Application of Anomaly Detection Algorithm
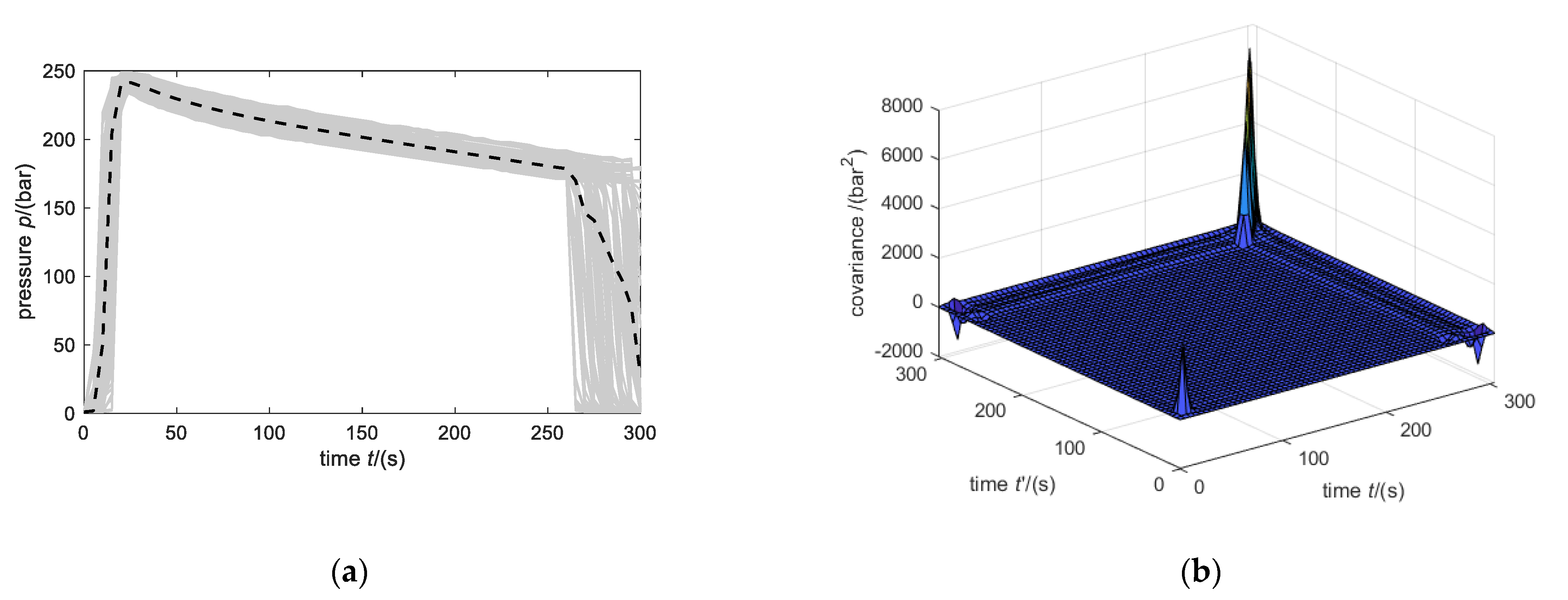
- The pressure lines are not manipulated, and missing data of incomplete vectors are ignored for computing the mean and variance (Figure 11a).
- The first values smaller than 5 bar and values after 260 s are erased. Additionally, missing data of incomplete vectors are ignored for computing the mean and variance (Figure 11c).
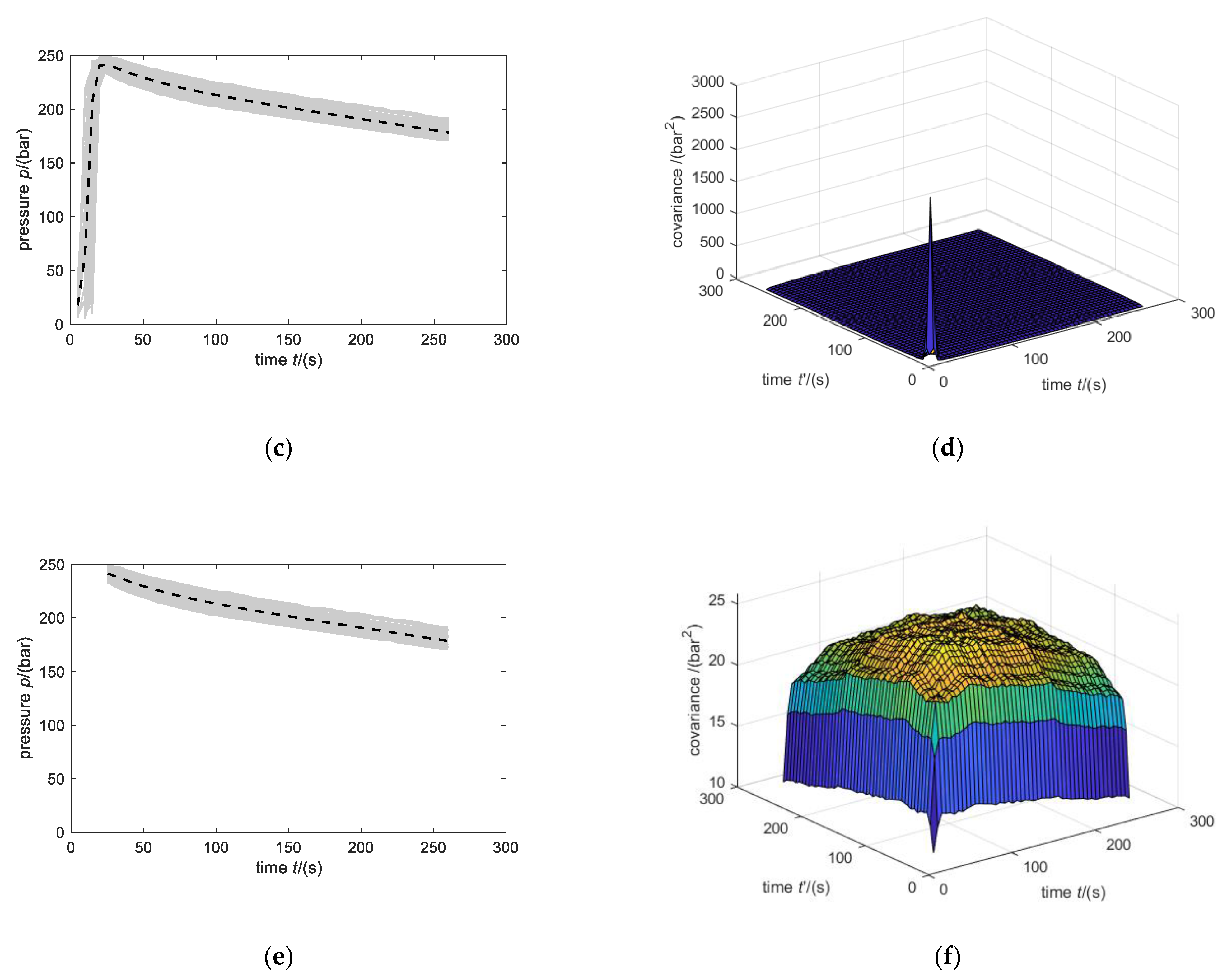
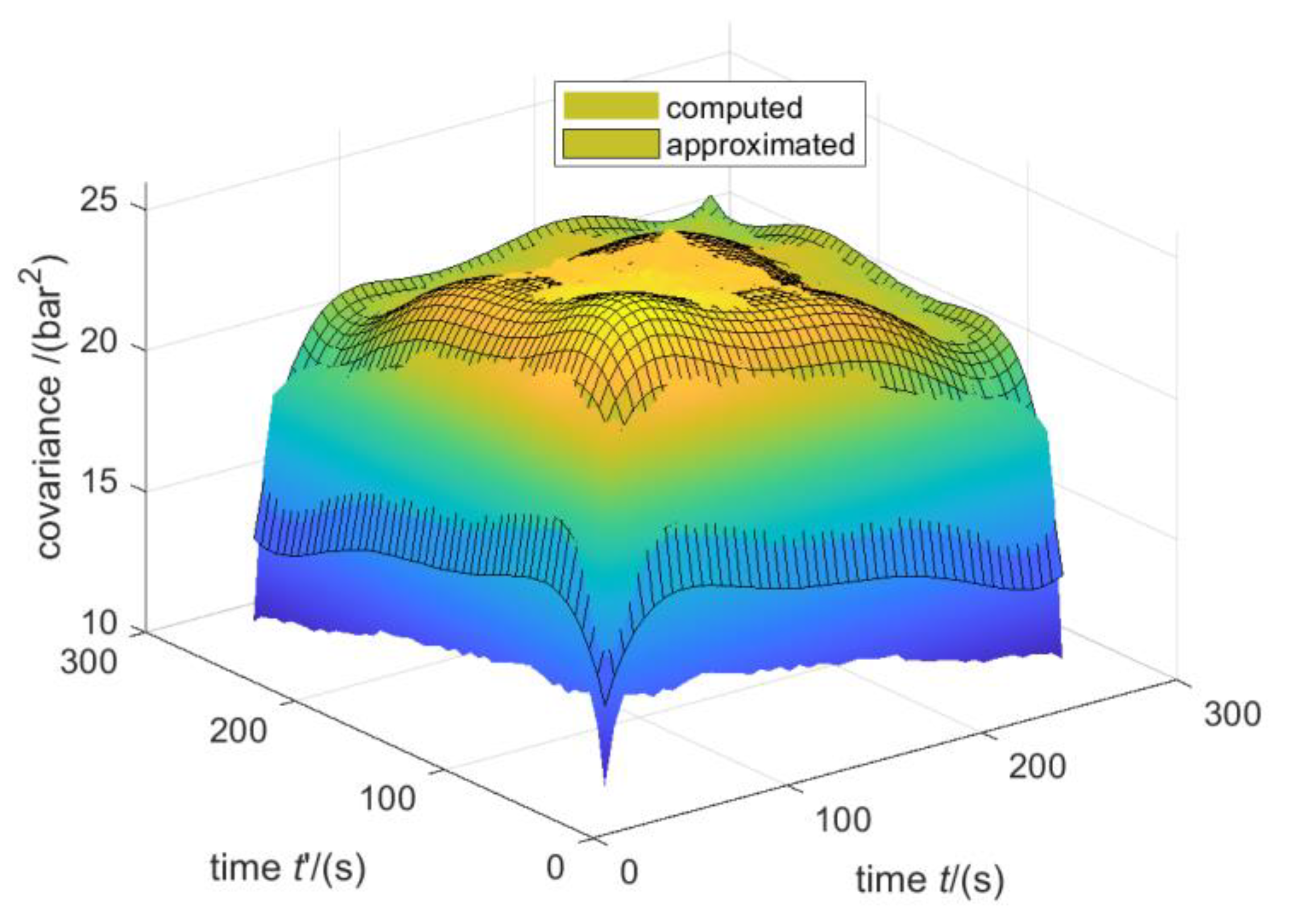
- Values before 25 s and after 260 s are erased (Figure 11e).
3.3. Evaluation of the Success of the Developed Solution
4. Discussion
- What might be a promising use case?
- Who needs to contribute to the use case?
- What is the goal?
- Why is it worth doing?
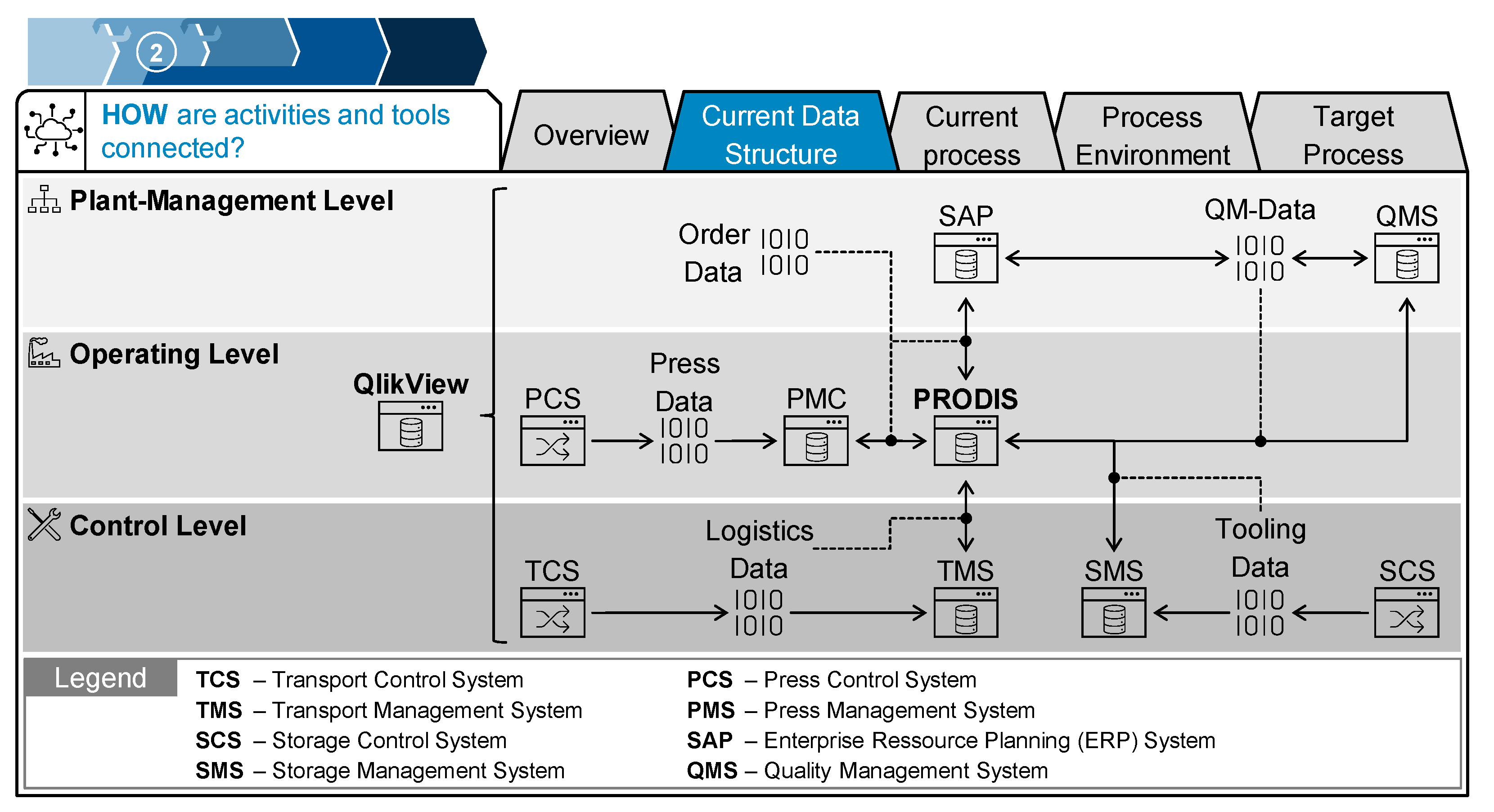
- Where in the current data structure is an appropriate interface?
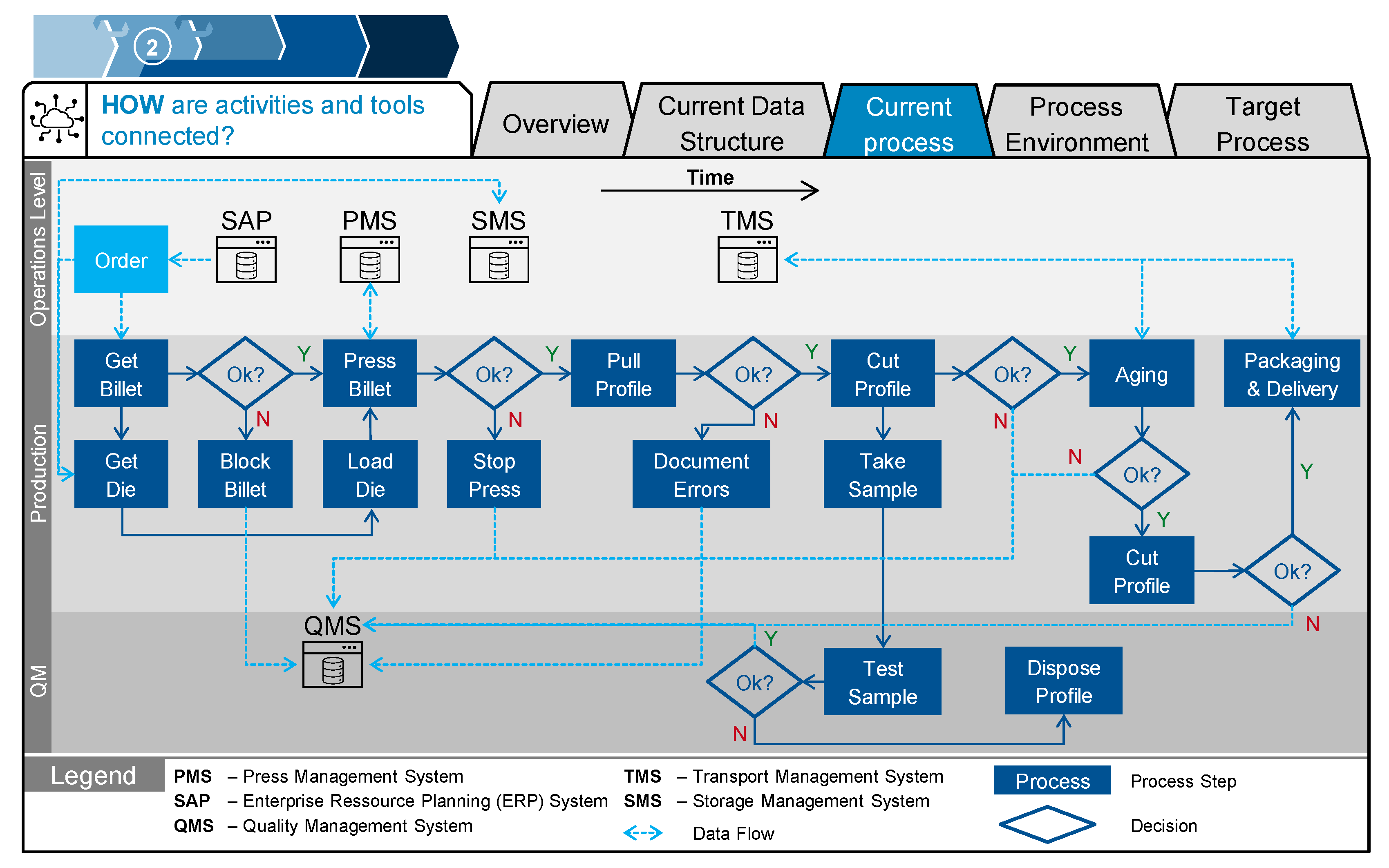
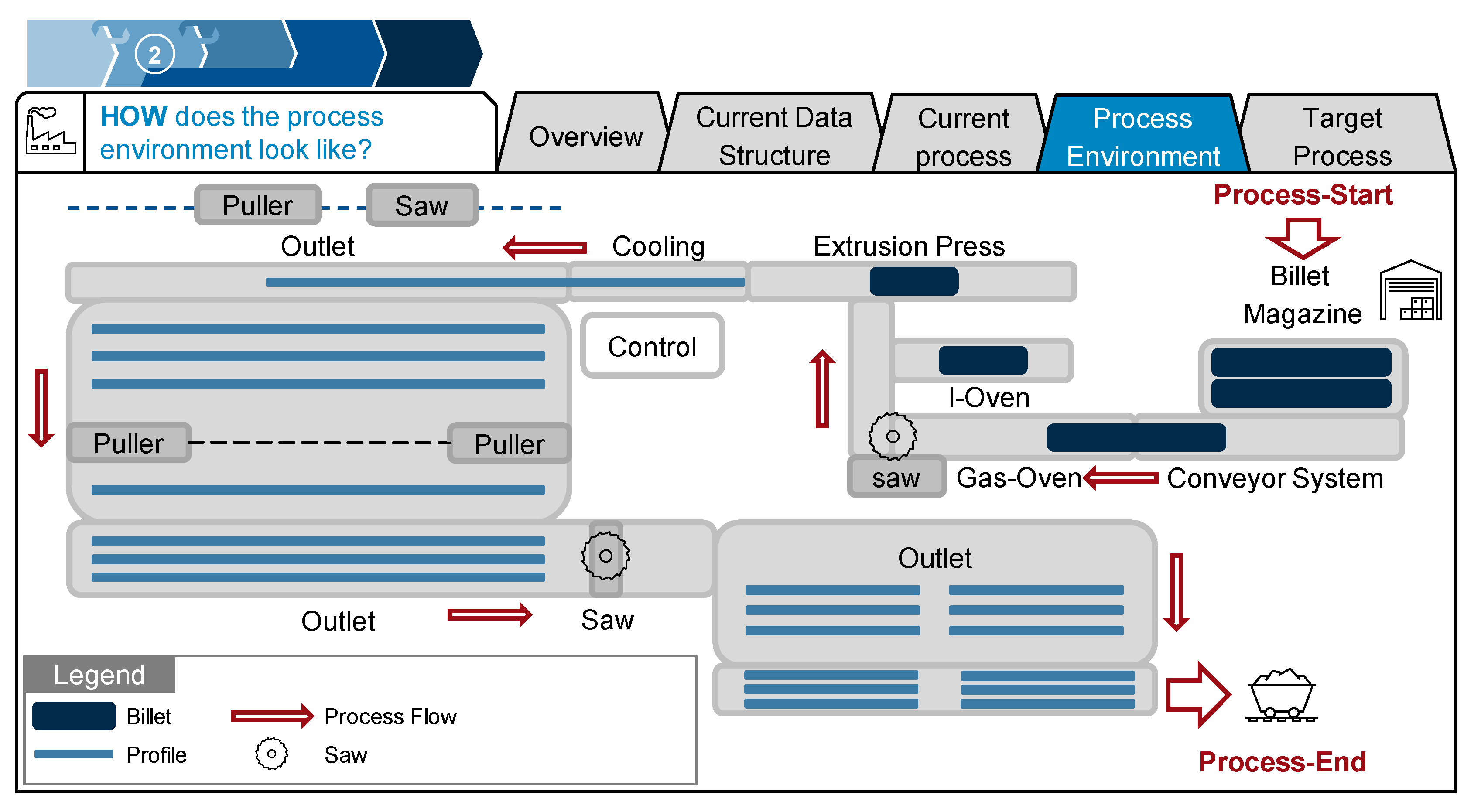
- Where in the current process does a DT provide the most benefit? How can it be incorporated into the current process structure?
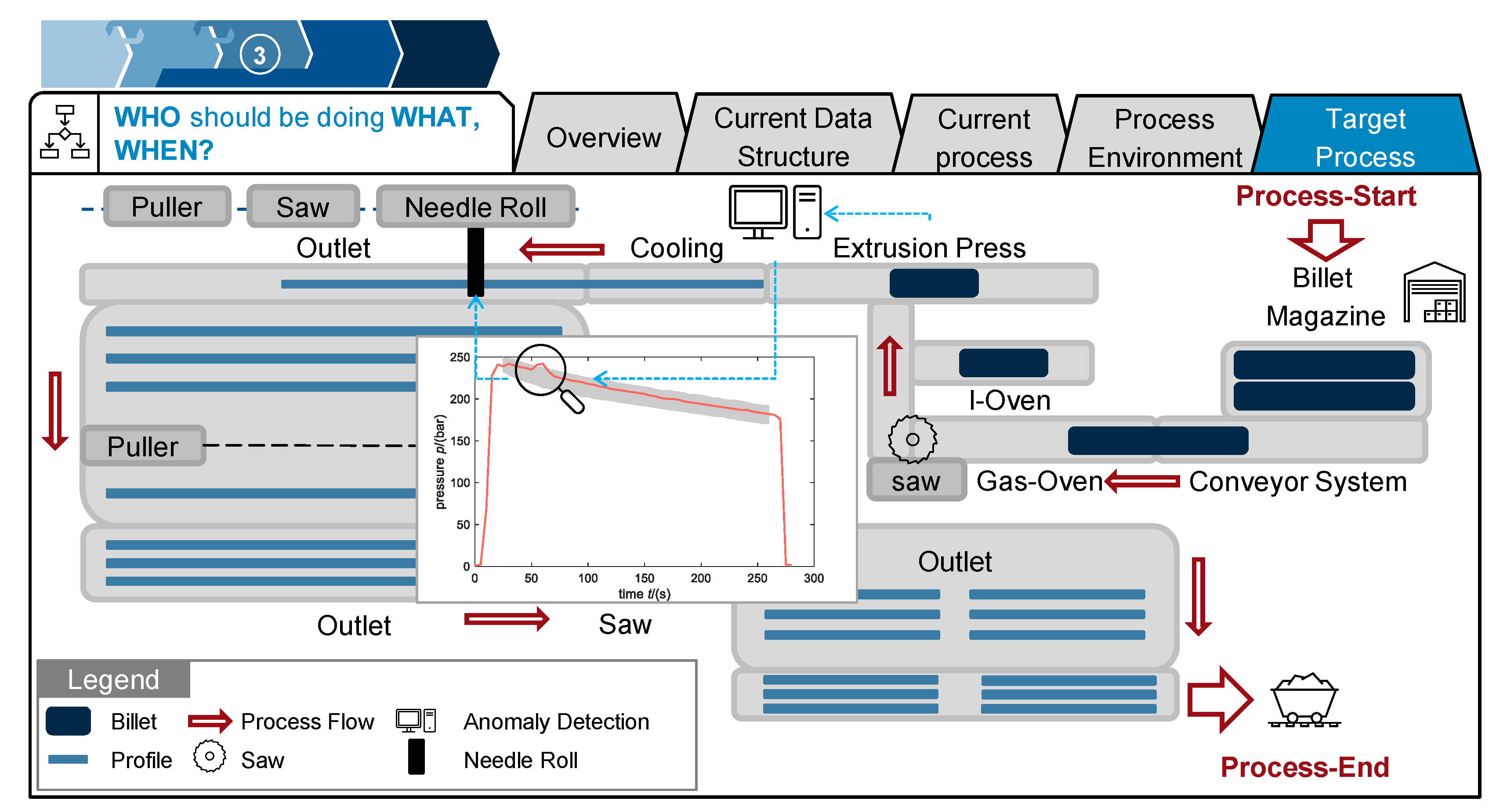
- How should the target process look? How does this DT module affect following process steps?
5. Conclusions
5.1. Summary
5.2. Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- De Mauro, A.; Greco, M.; Grimaldi, M. A formal definition of Big Data based on its essential features. Libr. Rev. 2016, 65, 122–135. [Google Scholar] [CrossRef]
- World Economic Forum. The World’s Data Explained: How Much We’re Producing and Where It’s All Stored. Available online: https://www.weforum.org/agenda/2021/05/world-data-produced-stored-global-gb-tb-zb (accessed on 18 May 2021).
- Lee, E.A. Cyber Physical Systems: Design Challenges. In Proceedings of the 2008 11th IEEE International Symposium on Object and Component-Oriented Real-Time Distributed Computing (ISORC), Orlando, FL, USA, 5 May–5 July 2008; IEEE: New York, NY, USA, 2008; pp. 363–369, ISBN 978-0-7695-3132-8. [Google Scholar]
- Rajkumar, R.; Lee, I.; Sha, L.; Stankovic, J. Cyber-physical systems. In Proceedings of the 47th Design Automation Conference, Anaheim, CA, USA, 13–18 June 2010; Sapatnekar, S.S., Ed.; IEEE: Piscataway, NJ, USA, 2010; p. 731, ISBN 9781450300025. [Google Scholar]
- Wilberg, J.; Fahrmeier, L.; Hollauer, C.; Omer, M. Deriving a Use Phase Data Strategy for Connected Products: A Process Model. In Proceedings of the 15th International Design Conference, Dubrovnik, Croatia, 21–24 May 2018; Faculty of Mechanical Engineering and Naval Architecture, University of Zagreb: Zagreb, Croatia; The Design Society: Glasgow, UK, 2018; pp. 1441–1452. [Google Scholar]
- Eckert, C.; Isaksson, O.; Hallstedt, S.; Malmqvist, J.; Öhrwall Rönnbäck, A.; Panarotto, M. Industry Trends to 2040. Proc. Int. Conf. Eng. Des. 2019, 1, 2121–2128. [Google Scholar] [CrossRef] [Green Version]
- Wilberg, J.; Triep, I.; Hollauer, C.; Omer, M. Big Data in Product Development: Need for a Data Strategy. In Proceedings of the PICMET ‘17, 2017Portland International Conference on Management of Engineering and Technology (PICMET), Portland, OR, USA, 9–13 July 2017; Kocaoglu, D.F., Anderson, T.R., Eds.; PICMET, Department of Engineering and Technology Management, Portland State University: Portland, OR, USA, 2017; pp. 1–10, ISBN 978-1-890843-36-6. [Google Scholar]
- Davenport, T.H. Big Data at Work: Dispelling the Myths, Uncovering the Opportunities; Data mining; Harvard Business Review Press: Boston, MA, USA, 2014; ISBN 9781422168172. [Google Scholar]
- Tavares-Lehmann, A.T.; Varum, C. Industry 4.0 and Sustainability: A Bibliometric Literature Review. Sustainability 2021, 13, 3493. [Google Scholar] [CrossRef]
- Barricelli, B.R.; Casiraghi, E.; Fogli, D. A Survey on Digital Twin: Definitions, Characteristics, Applications, and Design Implications. IEEE Access 2019, 7, 167653–167671. [Google Scholar] [CrossRef]
- Grieves, M.; Vickers, J. Digital Twin: Mitigating Unpredictable, Undesirable Emergent Behavior in Complex Systems. In Transdisciplinary Perspectives on Complex Systems: New Findings and Approaches, 1st ed.; Kahlen, F.-J., Flumerfelt, S., Alves, A., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 85–113. ISBN 978-3-319-38756-7. [Google Scholar]
- Trauer, J.; Schweigert-Recksiek, S.; Engel, C.; Spreitzer, K.; Zimmermann, M. What is a Digital Twin?—Definitions and Insights from an Industrial Case Study in Technical Product Development. Proc. Des. Soc. Des. Conf. 2020, 1, 757–766. [Google Scholar] [CrossRef]
- Pires, F.; Cachada, A.; Barbosa, J.; Moreira, A.P.; Leitao, P. Digital Twin in Industry 4.0: Technologies, Applications and Challenges. In 2019 IEEE 17th International Conference on Industrial Informatics (INDIN), Aalto University, Helsinki-Espoo, Finland, 22–25 July, 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 721–726. ISBN 978-1-7281-2927-3. [Google Scholar]
- Jones, D.; Snider, C.; Nassehi, A.; Yon, J.; Hicks, B. Characterising the Digital Twin: A systematic literature review. Cirp J. Manuf. Sci. Technol. 2020, 29, 36–52. [Google Scholar] [CrossRef]
- Hinduja, H.; Kekkar, S.; Chourasia, S.; Chakrapani, H.B. Industry 4.0: Digital Twin and its Industrial Applications. Riet Ijset Int. J. Sci. Eng. Technol. 2020, 8, 1–7. [Google Scholar]
- Neto, A.A.; Deschamps, F.; da Silva, E.R.; de Lima, E.P. Digital twins in manufacturing: An assessment of drivers, enablers and barriers to implementation. Procedia Cirp 2020, 93, 210–215. [Google Scholar] [CrossRef]
- Schweigert-Recksiek, S.; Trauer, J.; Engel, C.; Spreitzer, K.; Zimmermann, M. Conception of a Digital Twin in Mechanical Engineering—A Case Study in Technical Product Development. Proc. Des. Soc. Des. Conf. 2020, 1, 383–392. [Google Scholar] [CrossRef]
- Hammerer Aluminium Industries. Hammerer Aluminium Industries. Available online: https://www.hai-aluminium.com/en/ (accessed on 14 June 2021).
- Stojanovic, B.; Bukvic, M.; Epler, I. Application of Aluminum and Aluminum Alloys in Engineering. Appl. Eng. Lett. 2018, 3, 52–62. [Google Scholar] [CrossRef]
- Saha, P.K. Aluminum Extrusion Technology; ASM International: Materials Park, OH, Canada, 2000; ISBN 1615032452. [Google Scholar]
- Tekkaya, A.E.; Chatti, S. Bar Extrusion. In CIRP Encyclopedia of Production Engineering, 2nd ed.; Chatti, S., Laperrière, L., Reinhart, G., Tolio, T., Eds.; Springer: Berlin, Germany, 2019; pp. 115–118. ISBN 978-3-662-53119-8. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Goldstein, M.; Uchida, S. A Comparative Evaluation of Unsupervised Anomaly Detection Algorithms for Multivariate Data. PLoS ONE 2016, 11, e0152173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Braei, M.; Wagner, S. Anomaly Detection in Univariate Time-Series: A Survey on the State-of-the-Art. 2020. Available online: https://arxiv.org/abs/2004.00433 (accessed on 18 August 2021).
- Pfingstl, S.; Steiner, M.; Tusch, O.; Zimmermann, M. Crack Detection Zones: Computation and Validation. Sensor 2020, 20, 2568. [Google Scholar] [CrossRef]
- Pfingstl, S.; Zimmermann, M. Strain-based Structural Health Monitoring: Computing Regions for Critical Crack Detection. In Structural Health Monitoring 2019, Enabling Intelligent Life-Cycle Health Management for Industry Internet of Things (IIOT), Lancaster, PA.; Chang, F.-K., Güemes, A., Kopsaftopoulos, F., Eds.; DEStech Publications, Inc.: Lancaster, PA, USA, 2019; ISBN 9781605956015. [Google Scholar]
- Fawcett, T.; Provost, F. Activity monitoring: Noticing interesting changes in behavior. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 53–62. [Google Scholar]
- MacDonald, J.W.; Ghosh, D. COPA--cancer outlier profile analysis. Bioinformatics 2006, 22, 2950–2951. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Hansman, R.J.; Palacios, R.; Welsch, R. Anomaly detection via a Gaussian Mixture Model for flight operation and safety monitoring. Transp. Res. Part C Emerg. Technol. 2016, 64, 45–57. [Google Scholar] [CrossRef]
- Liu, L.; Liu, D.; Zhang, Y.; Peng, Y. Effective Sensor Selection and Data Anomaly Detection for Condition Monitoring of Aircraft Engines. Sensor 2016, 16, 623. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pandit, R.K.; Infield, D. SCADA-based wind turbine anomaly detection using Gaussian process models for wind turbine condition monitoring purposes. IET Renew. Power Gener. 2018, 12, 1249–1255. [Google Scholar] [CrossRef] [Green Version]
- Markou, M.; Singh, S. Novelty detection: A review—part 1: Statistical approaches. Signal Process. 2003, 83, 2481–2497. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning, 3rd ed.; MIT Press: Cambridge, MA, USA, 2008; ISBN 9780262182539. [Google Scholar]
- Garnett, R.; Osborne, M.A.; Reece, S.; Rogers, A.; Roberts, S.J. Sequential Bayesian Prediction in the Presence of Changepoints and Faults. Comput. J. 2010, 53, 1430–1446. [Google Scholar] [CrossRef]
- Gu, M.; Fei, J.; Sun, S. Online anomaly detection with sparse Gaussian processes. Neurocomputing 2020, 403, 383–399. [Google Scholar] [CrossRef]
- Beecks, C.; Schmidt, K.W.; Berns, F.; Graß, A.; Papotti, P. Gaussian Processes for Anomaly Description in Production Environments. In Proceedings of the Workshops of the EDBT/ICDT 2019 Joint Conference (EDBT/ICDT 2019), Lisbon, Portugal, 26 March 2019; Papotti, P., Ed.; 2019. Available online: http://ceur-ws.org/vol-2322/dsi4-4.pdf (accessed on 18 August 2021).
- Aye, S.A.; Heyns, P.S. An integrated Gaussian process regression for prediction of remaining useful life of slow speed bearings based on acoustic emission. Mech. Syst. Signal Process. 2017, 84, 485–498. [Google Scholar] [CrossRef]
- Pfingstl, S.; Rios, J.I.; Baier, H.; Zimmermann, M. Predicting Crack Growth and Fatigue Life with Surrogate Models. arXiv 2020, arXiv:2008.02324. [Google Scholar]
- Pfingstl, S.; Zimmermann, M. On Integrating Prior Knowledge into Gaussian Processes (Submitted). 2021. Available online:. (accessed on 30 July 2021).
- Boschert, S.; Rosen, R. Digital Twin—The Simulation Aspect. In Mechatronic Futures; Hehenberger, P., Bradley, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 59–74. ISBN 978-3-319-32154-7. [Google Scholar]
- Omar, S.; Ngadi, A.; Jebur, H.H. Machine learning techniques for anomaly detection: An overview. Int. J. Comput. Appl. 2013. [Google Scholar] [CrossRef]
- Malkauthekar, M.D. Analysis of euclidean distance and manhattan distance measure in face recognition. In Proceedings of the Third International Conference on Computational Intelligence and Information Technology, 2013. CIIT 2013, Mumbai, India, 18–19 October 2013; The Institution of Engineering and Technology: Stevenage, UK, 2013. ISBN 9781849198592. [Google Scholar]
- Vadivel, A.; Majumdar, A.K.; Sural, S. Performance Comparison of Distance Metrics in Content-Based Image Retrieval Applications; Proc. of Internat. Conf. on Information Technology; Orissa Information Technology Society (OITS): Bhubaneswar, India, 2003. [Google Scholar]
- Grundlagen des Strangpressens: Mit 74 Literaturstellen; Müller, K.; Majumdar, A.K.; Sural, S. (Eds.) Expert-Verl.: Renningen-Malmsheim, Germany, 1995; ISBN 3-8169-1071-8. [Google Scholar]
- Mankins, J.C. Technology readiness assessments: A retrospective. Acta Astronaut. 2009, 65, 1216–1223. [Google Scholar] [CrossRef]
- Ghafoorpoor Yazdi, P.; Azizi, A.; Hashemipour, M. An Empirical Investigation of the Relationship between Overall Equipment Efficiency (OEE) and Manufacturing Sustainability in Industry 4.0 with Time Study Approach. Sustainability 2018, 10, 3031. [Google Scholar] [CrossRef] [Green Version]
- Pfingstl, S.; Schoebel, Y.N.; Zimmermann, M. Reinforcement Learning for Structural Health Monitoring based on Inspection Data. Mater. Res. Proc. 2021, 18, 203–210. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Category | Training Lines | Validation Lines | Test Lines |
|---|---|---|---|
| Good | 533 | 14 | 57 |
| Anomalous | 0 | 14 | 45 |
| Scheme | TPR | FNR | TNR | FPR | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | 43/45 | 95.6% | 2/45 | 4.44% | 40/57 | 70.2% | 17/57 | 29.8% |
| 2 | 44/45 | 97.8% | 1/45 | 2.22% | 53/57 | 93.0% | 4/57 | 7.02% |
| 3 | 44/45 | 97.8% | 1/45 | 2.22% | 57/57 | 100% | 0/57 | 0.00% |
| 3 * | 43/45 | 95.6% | 2/45 | 4.44% | 57/57 | 100% | 0/57 | 0.00% |
| Scenario | Category | Pressing | Intermediate Storage | Artificial Aging | Packaging | Total (∑MHR + ∑PE) |
|---|---|---|---|---|---|---|
| Idealistic | MHR | - | - | 1.71 EUR/B | 2.99 EUR/B | 35.21 EUR/B |
| PE | 1.30 EUR/B | 8.31 EUR/B | - | 20.90 EUR/B | ||
| Realistic | MHR | - | - | - | 2.99 EUR/B | 23.89 EUR/B |
| PE | - | - | - | 20.90 EUR/B |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trauer, J.; Pfingstl, S.; Finsterer, M.; Zimmermann, M. Improving Production Efficiency with a Digital Twin Based on Anomaly Detection. Sustainability 2021, 13, 10155. https://doi.org/10.3390/su131810155
Trauer J, Pfingstl S, Finsterer M, Zimmermann M. Improving Production Efficiency with a Digital Twin Based on Anomaly Detection. Sustainability. 2021; 13(18):10155. https://doi.org/10.3390/su131810155
Chicago/Turabian StyleTrauer, Jakob, Simon Pfingstl, Markus Finsterer, and Markus Zimmermann. 2021. "Improving Production Efficiency with a Digital Twin Based on Anomaly Detection" Sustainability 13, no. 18: 10155. https://doi.org/10.3390/su131810155
APA StyleTrauer, J., Pfingstl, S., Finsterer, M., & Zimmermann, M. (2021). Improving Production Efficiency with a Digital Twin Based on Anomaly Detection. Sustainability, 13(18), 10155. https://doi.org/10.3390/su131810155