
Ensuring Sustainable Evaluation: How to Improve Quality of Evaluating Grant Proposals?


Abstract
:1. Introduction
1.1. Evaluation Process
1.2. Activating Reference Pattern
1.3. Calibration
1.4. Rating Style
1.5. Single Versus Multiple Evaluation
2. Methodology
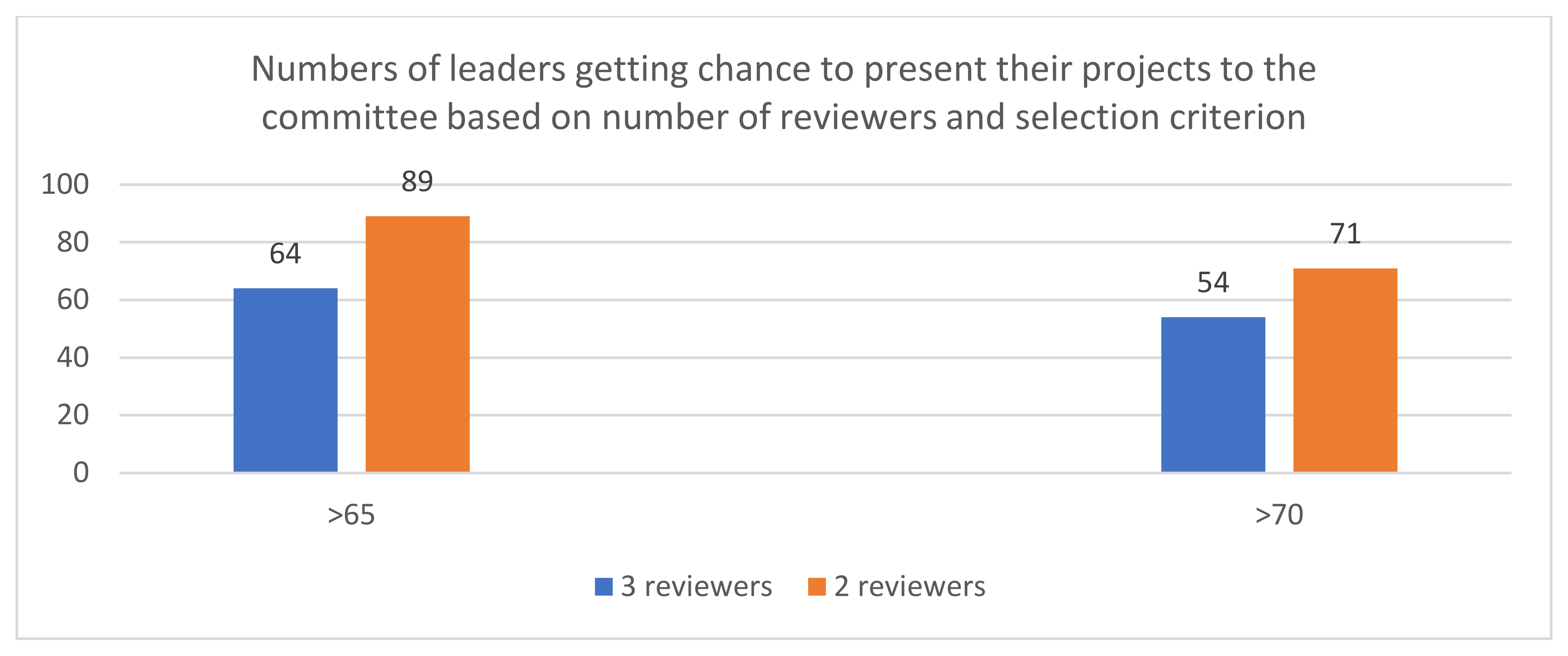
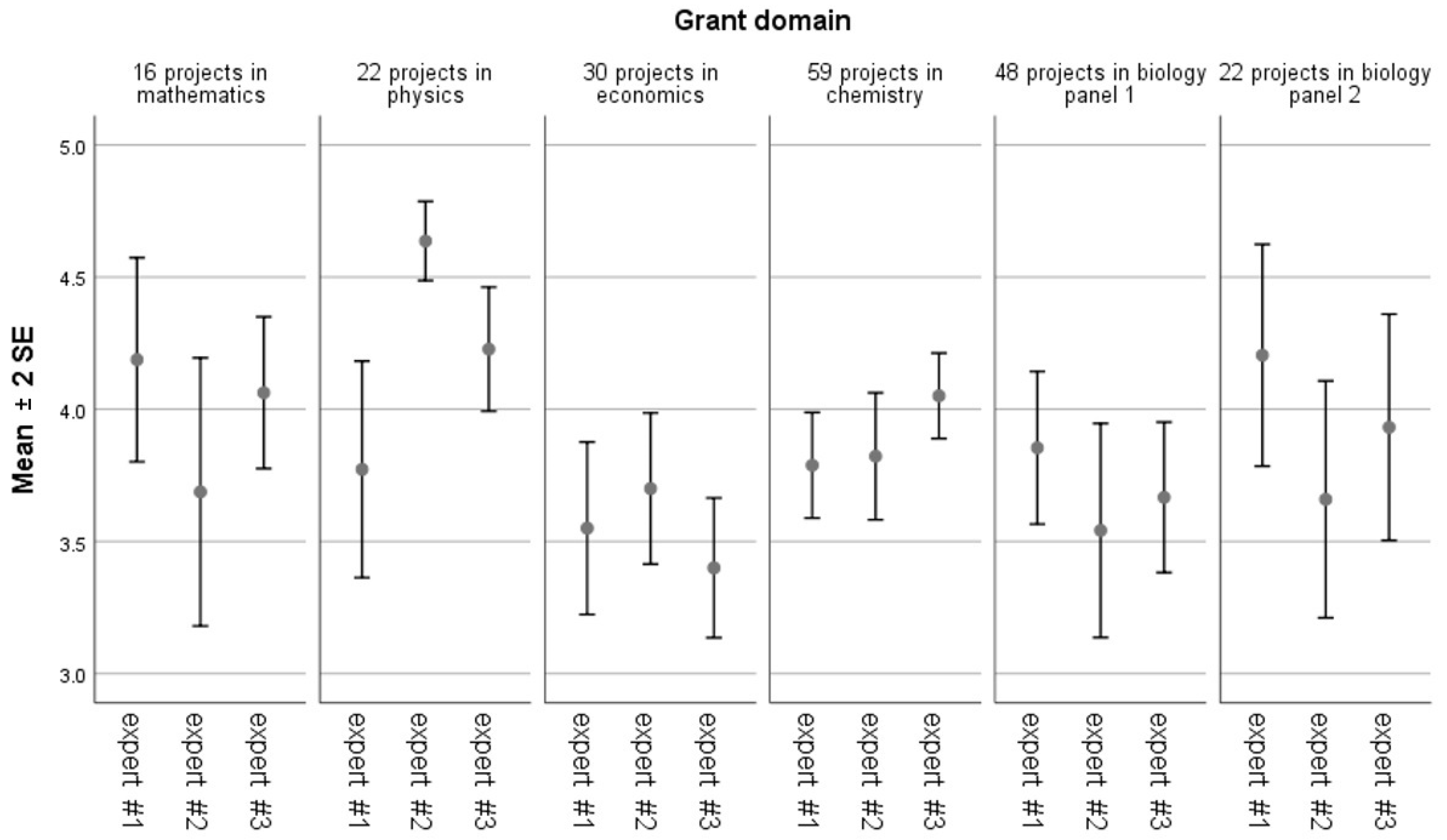
2.1. Study 1: Comparison of Two Evaluation Systems
- (1)
- The National Centre for Research and Development awards grants within the LEADER programme of up to half a million dollars per project ($13 million in total).
- (2)
- The Foundation for Polish Science grants one-year scholarships to young researchers within the START 100 programme, amounting to around $8500 per project.
2.1.1. START Programme
2.1.2. LEADER Programme
2.2. Study 2: Experimental Research on Serial Position Effect
2.2.1. Participants
2.2.2. Procedure and Materials
2.2.3. Results
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wager, E.; Godlee, F.; Jefferson, T. How to Survive Peer Review; BMJ Books: London, UK, 2002. [Google Scholar]
- Jefferson, T.; Rudin, M.; Folse, S.B.; Davidoff, F. Editorial Peer Review for Improving the Quality of Reports of Biomedical Studies. Cochrane Database Syst. Rev. 2006. [Google Scholar] [CrossRef]
- Bornmann, L.; Daniel, H.-D. The Effectiveness of the Peer Review Process: Inter-Referee Agreement and Predictive Validity of Manuscript Refereeing at Angewandte Chemie. Angew. Chem. Int. Ed. 2008, 47, 7173–7178. [Google Scholar] [CrossRef] [PubMed]
- Bornmann, L.; Mutz, R.; Daniel, H.-D. A Reliability-Generalization Study of Journal Peer Reviews: A Multilevel Meta-Analysis of Inter-Rater Reliability and Its Determinants. PLoS ONE 2010, 5, e14331. [Google Scholar] [CrossRef] [Green Version]
- Guthrie, S.; Guerin, B.; Wu, H.; Ismail, S.; Wooding, S. Alternatives to Peer Review in Research Project Funding: 2013 Update; RAND Corporation: Santa Monica, CA, USA, 2013. [Google Scholar]
- Clair, J.A. Procedural Injustice in the System of Peer Review and Scientific Misconduct. Acad. Manag. Learn. Educ. 2015, 14, 159–172. [Google Scholar] [CrossRef]
- Robson, K.; Pitt, L.; West, D.C. Navigating the Peer-Review Process: Reviewers’ Suggestions for a Manuscript: Factors Considered before a Paper Is Accepted or Rejected for the Journal of Advertising Research. J. Advert. Res. 2015, 55, 9–17. [Google Scholar] [CrossRef]
- Demicheli, V.; Di Pietrantonj, C. Peer Review for Improving the Quality of Grant Applications. Cochrane Database Syst. Rev. 2007. [Google Scholar] [CrossRef] [PubMed]
- Guthrie, S.; Ghiga, I.; Wooding, S. What Do We Know about Grant Peer Review in the Health Sciences? F1000Research 2018, 6, 1335. [Google Scholar] [CrossRef] [PubMed]
- Tennant, J.P.; Ross-Hellauer, T. The Limitations to Our Understanding of Peer Review. Res. Integr. Peer Rev. 2020, 5, 6. [Google Scholar] [CrossRef]
- Abdoul, H.; Perrey, C.; Tubach, F.; Amiel, P.; Durand-Zaleski, I.; Alberti, C. Non-Financial Conflicts of Interest in Academic Grant Evaluation: A Qualitative Study of Multiple Stakeholders in France. PLoS ONE 2012, 7, e35247. [Google Scholar] [CrossRef] [Green Version]
- Boudreau, K.J.; Guinan, E.; Lakhani, K.R.; Riedl, C. The Novelty Paradox & Bias for Normal Science: Evidence from Randomized Medical Grant Proposal Evaluations. SSRN Electron. J. 2012. [Google Scholar] [CrossRef] [Green Version]
- Laine, C. Scientific Misconduct Hurts. Ann. Intern. Med. 2016, 166, 148–149. [Google Scholar] [CrossRef] [Green Version]
- Murray, D.L.; Morris, D.; Lavoie, C.; Leavitt, P.R.; MacIsaac, H.; Masson, M.E.J.; Villard, M.-A. Bias in Research Grant Evaluation Has Dire Consequences for Small Universities. PLoS ONE 2016, 11, e0155876. [Google Scholar] [CrossRef] [PubMed]
- Brundtland, G. Our Common Future: Report of the World Commission on Environment and Development; UN-Dokument A/42/427; UN: Geneva, Switzerland, 1987. [Google Scholar]
- Dewberry, C.; Davies-Muir, A.; Newell, S. Impact and Causes of Rater Severity/Leniency in Appraisals without Postevaluation Communication Between Raters and Ratees. Int. J. Sel. Assess. 2013, 21, 286–293. [Google Scholar] [CrossRef]
- Tamblyn, R.; Girard, N.; Qian, C.J.; Hanley, J. Assessment of Potential Bias in Research Grant Peer Review in Canada. CMAJ Can. Med. Assoc. J. 2018, 190, E489–E499. [Google Scholar] [CrossRef] [Green Version]
- DeNisi, A.S.; Murphy, K.R. Performance Appraisal and Performance Management: 100 Years of Progress? J. Appl. Psychol. 2017, 102, 421–433. [Google Scholar] [CrossRef] [PubMed]
- Graves, N.; Barnett, A.G.; Clarke, P. Funding Grant Proposals for Scientific Research: Retrospective Analysis of Scores by Members of Grant Review Panel. BMJ 2011, 343, d4797. [Google Scholar] [CrossRef] [Green Version]
- Król, G.; Kowalczyk, K. Evaluation of Grant Proposals and Abstracts—The Influence of Individual Evaluation Style on Ratings. Probl. Zarz. 2014, 12, 137–155. [Google Scholar] [CrossRef]
- Forgas, J.P.; Laham, S.M.; Vargas, P.T. Mood Effects on Eyewitness Memory: Affective Influences on Susceptibility to Misinformation. J. Exp. Soc. Psychol. 2005, 41, 574–588. [Google Scholar] [CrossRef]
- Cole, S.; Balcetis, E. Sources of Resources: Bioenergetic and Psychoenergetic Resources Influence Distance Perception. Soc. Cogn. 2013, 31, 721–732. [Google Scholar] [CrossRef]
- Memmert, D.; Unkelbach, C. Serial Position Effects in Evaluative Judgments. Current Directions in Psychology Science. Curr. Dir. Psychol. Sci. 2014, 23, 195–200. [Google Scholar] [CrossRef]
- Galinsky, A.D.; Mussweiler, T. First Offers as Anchors: The Role of Perspective-Taking and Negotiator Focus. J. Pers. Soc. Psychol. 2001, 81, 657–669. [Google Scholar] [CrossRef]
- Furnham, A.; Boo, H.C. A Literature Review of the Anchoring Effect. J. Socio-Econ. 2011, 40, 35–42. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow, 1st ed.; Farrar, Straus and Giroux: New York, NY, USA, 2013. [Google Scholar]
- Unkelbach, C.; Memmert, D. Game Management, Context Effects, and Calibration: The Case of Yellow Cards in Soccer. J. Sport Exerc. Psychol. 2008, 30, 95–109. [Google Scholar] [CrossRef] [PubMed]
- Fasold, F.; Memmert, D.; Unkelbach, C. Extreme Judgments Depend on the Expectation of Following Judgments: A Calibration Analysis. Psychol. Sport Exerc. 2012, 13, 197–200. [Google Scholar] [CrossRef]
- Page, K.; Page, L. Alone against the Crowd: Individual Differences in Referees’ Ability to Cope under Pressure. J. Econ. Psychol. 2010, 31, 192–199. [Google Scholar] [CrossRef]
- Hoyt, W.T. Rater Bias in Psychological Research: When Is It a Problem and What Can We Do about It? Psychol. Methods 2000, 5, 64–86. [Google Scholar] [CrossRef] [PubMed]
- Landy, F.J.; Vance, R.J.; Barnes-Farrell, J.L.; Steele, J.W. Statistical Control of Halo Error in Performance Ratings. J. Appl. Psychol. 1980, 65, 501–506. [Google Scholar] [CrossRef]
- Cook, G.I.; Marsh, R.L.; Hicks, J.L. Halo and Devil Effects Demonstrate Valenced-Based Influences on Source-Monitoring Decisions. Conscious. Cogn. 2003, 12, 257–278. [Google Scholar] [CrossRef]
- Dennis, I. Halo Effects in Grading Student Projects. J. Appl. Psychol. 2007, 92, 1169–1176. [Google Scholar] [CrossRef]
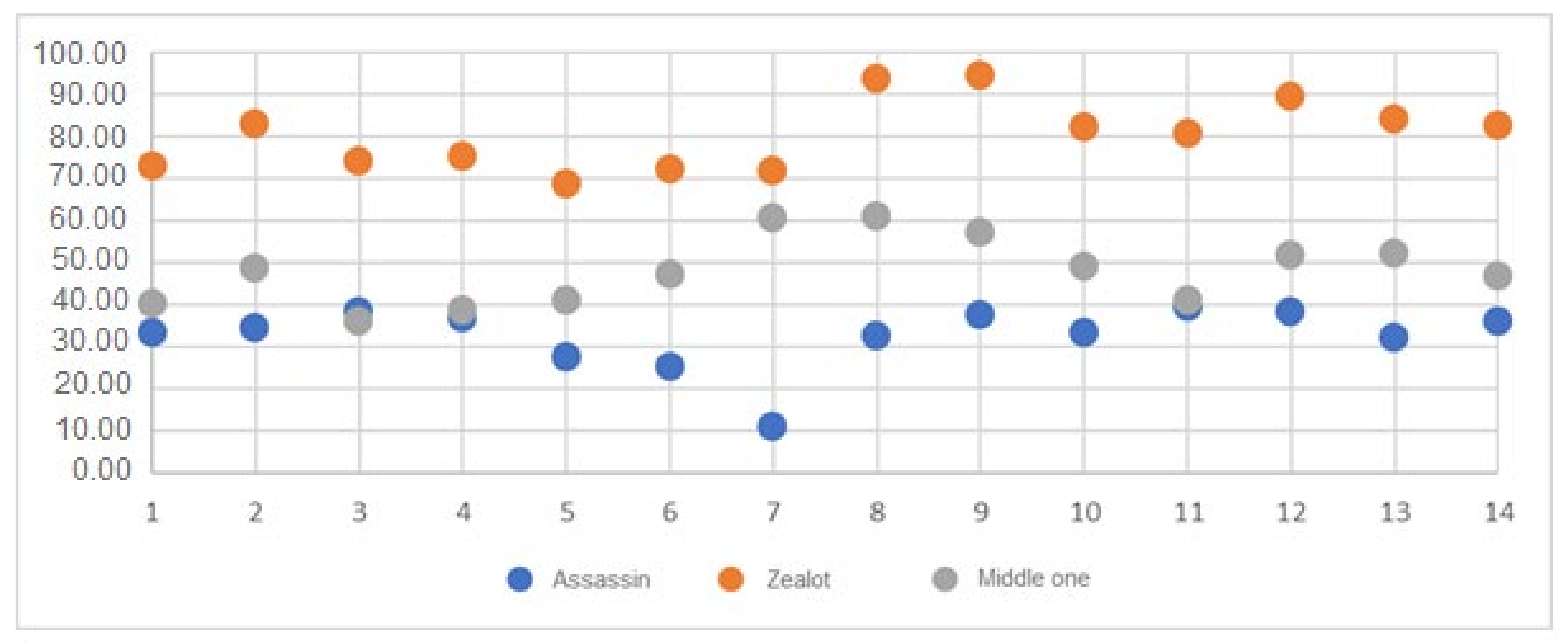
- Siegelman, S.S. Assassins and Zealots: Variations in Peer Review. Special Report. Radiology 1991, 178, 637–642. [Google Scholar] [CrossRef] [PubMed]
- Kane, J.S.; Bernardin, H.J.; Villanova, P.; Peyrefitte, J. Stability of Rater Leniency: Three Studies. Acad. Manag. J. 1995, 38, 1036–1051. [Google Scholar] [CrossRef]
- Borman, W.C.; Hallam, G.L. Observation Accuracy for Assessors of Work-Sample Performance: Consistency across Task and Individual-Differences Correlates. J. Appl. Psychol. 1991, 76, 11–18. [Google Scholar] [CrossRef]
- Marsh, H.W.; Jayasinghe, U.W.; Bond, N.W. Improving the Peer-Review Process for Grant Applications: Reliability, Validity, Bias, and Generalizability. Am. Psychol. 2008, 63, 160–168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- García, J.A.; Rodriguez-Sánchez, R.; Fdez-Valdivia, J. Adverse Selection of Reviewers. J. Assoc. Inf. Sci. Technol. 2015, 66, 1252–1262. [Google Scholar] [CrossRef]
- Bruine de Bruin, W. Save the Last Dance II: Unwanted Serial Position Effects in Figure Skating Judgments. Acta Psychol. (Amst.) 2006, 123, 299–311. [Google Scholar] [CrossRef] [PubMed]
- Unkelbach, C.; Ostheimer, V.; Fasold, F.; Memmert, D. A Calibration Explanation of Serial Position Effects in Evaluative Judgments. Organ. Behav. Hum. Decis. Process. 2012, 119, 103–113. [Google Scholar] [CrossRef]
- Antipov, E.A.; Pokryshevskaya, E.B. Order Effects in the Results of Song Contests: Evidence from the Eurovision and the New Wave. Judgm. Decis. Mak. 2017, 12, 415–419. [Google Scholar]
- Chamorro-Padial, J.; Rodriguez-Sánchez, R.; Fdez-Valdivia, J.; Garcia, J.A. An Evolutionary Explanation of Assassins and Zealots in Peer Review. Scientometrics 2019, 120, 1373–1385. [Google Scholar] [CrossRef]
- Schroter, S.; Black, N.; Evans, S.; Carpenter, J.; Godlee, F.; Smith, R. Effects of Training on Quality of Peer Review: Randomised Controlled Trial. BMJ 2004, 328, 673. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giraudeau, B.; Leyrat, C.; Le Gouge, A.; Léger, J.; Caille, A. Peer Review of Grant Applications: A Simple Method to Identify Proposals with Discordant Reviews. PLoS ONE 2011, 6, e27557. [Google Scholar] [CrossRef] [Green Version]
- Czarniawska, B.; Löfgren, O. (Eds.) Managing Overflow in Affluent Societies, 1st ed.; Routledge: New York, NY, USA, 2012. [Google Scholar]
- Landhuis, E. Scientific Literature: Information Overload. Nature 2016, 535, 457–458. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carr, N. The Shallows: What the Internet Is Doing to Our Brains; W.W. Norton: New York, NY, USA, 2010. [Google Scholar]
- Silvius, A.J.G.; Schipper, R.P.J. Sustainability in Project Management: A Literature Review and Impact Analysis. Soc. Bus. 2014, 4, 63–96. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| E1 | Good | Average | X | Poor |
| E2 | Poor | Average | X | Good |
| E3 | Poor | Average | BREAK TASK | Good |
| SS | df | MS | F | p | Partial Eta Squared | Power | |
|---|---|---|---|---|---|---|---|
| Within | 15.24 | 55 | 0.28 | ||||
| position (first, last) | 12.96 | 1 | 12.96 | 20.42 | 0.001 | 0.271 | 0.993 |
| Abstract quality (weak, good) | 34.18 | 1 | 34.18 | 123.31 | 0.001 | 0.692 | 1.000 |
| Abstract × order | 2.86 | 1 | 2.86 | 10.32 | 0.02 | 0.158 | 0.884 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wieczorkowska, G.; Kowalczyk, K. Ensuring Sustainable Evaluation: How to Improve Quality of Evaluating Grant Proposals? Sustainability 2021, 13, 2842. https://doi.org/10.3390/su13052842
Wieczorkowska G, Kowalczyk K. Ensuring Sustainable Evaluation: How to Improve Quality of Evaluating Grant Proposals? Sustainability. 2021; 13(5):2842. https://doi.org/10.3390/su13052842
Chicago/Turabian StyleWieczorkowska, Grażyna, and Katarzyna Kowalczyk. 2021. "Ensuring Sustainable Evaluation: How to Improve Quality of Evaluating Grant Proposals?" Sustainability 13, no. 5: 2842. https://doi.org/10.3390/su13052842
APA StyleWieczorkowska, G., & Kowalczyk, K. (2021). Ensuring Sustainable Evaluation: How to Improve Quality of Evaluating Grant Proposals? Sustainability, 13(5), 2842. https://doi.org/10.3390/su13052842