1. Introduction
The design process is recognized as a complex system. Since there are several interdependent and highly coupled activities during the process, iterative schedules occur. Over the years, several scheduling methods have been developed in the industries. Gantt Charts is a graphical way of showing task durations and task schedule. Network techniques (like PERT and CPM) represent a project (set of activities) as a network using the graph theory. These scheduling algorithms fail to deal with the iterative schedules. To overcome the limitations of the traditional scheduling algorithms, the dependency structure matrix (DSM) is proposed to deal with iterative tasks. Based on the concept of DSM, research has been developed to manage iterative process to reduce completion time by rearranging the sequence of the activities (known as sequencing). Previous research applied fewer feedback dependencies concepts in sequencing to achieve minimum completion time. The concept mainly focuses on the number of feedback dependencies, since it is believed that possibility that the tasks have to be iterated is proportional to the number of feedback dependencies. The fewer feedback dependencies, the smaller the possibility that some tasks will be reworked, resulting in a shorter completion time.
Classical DSM generally follows the assumption that the least iteration occurs to achieve the shortest completion time. Nevertheless, the assumption may not hold because tasks ought to be re-visited several times if the design qualities do not meet the requirements. In coupled tasks, this may result in several design iterations. Moreover, the other assumption underlying classical DSM is that resources are unlimited. Given the constraints of resource availability, the scheduler must take account of the trade-off between available resources and activity durations from time to time. This calls for resource-constrained scheduling. In this study, quality equations are employed in the classical DSM model to determine the number of tasks that ought to be re-visited. The trade-off between the number of feedback dependencies and the fulfillment of the design requirements under resource constraints could offer a better solution to the practical implementation.
This paper is organized as follows. First, literature studies of iterative scheduling algorithms and their limitations are reviewed. Second, the DSM, mainly activity-based DSM, is presented. Next, a new DSM algorithm combining the quality equations and resource constraints is presented. Finally, a building design process at an engineering consultant company is analyzed as a real case study to demonstrate the application of the new method.
2. Literature Review
Iterative scheduling may occur during the design process and the concurrent projects. DSM is a useful tool to perform both the analysis and the management of iterative schedules. DSM was first proposed by Steward to denote a generic matrix-based model for project information flow analysis [
1,
2]. A primary goal in basic DSM analysis is to minimize the number of feedbacks and their scope by restructuring or re-architecting the process. Since then, several DSM software systems have been proposed for practical implementation, such as DeMaid/GA and ADePT [
3,
4]. However, most classical DSM-based models do not: (1) obtain an optimum activity sequence; (2) tolerate uncertainty of activity time and cost; (3) consider resource constraints; or (4) consider the number of task iterations (i.e., the number of tasks to be re-visited during the design process).
Some research has been conducted to overcome some limitations of classical DSM. Smith and Eppinger [
5] refined the DSM concept to include the stochastic nature of task iteration by adding probabilities to the off-diagonal entries, and deterministic task completion times to the diagonal entries of the matrix. Hisham and Bao [
6] presented a simulation-based optimization framework that determines the optimal sequence of activities execution within a product development project to minimize the project’s total iterative time given stochastic activity durations. Hejducki and Rogalska [
7] proposed a time coupling method to determine the optimal schedule under resource constraints. Although the research mentioned above overcome some limitations of classical DSM, the number of tasks that need revisiting based on feedback dependency is generally assumed to be fixed or ignored. Additionally, the issue of resource constraints is generally not included in these models.
This research proposes a new concept, quality equations, to solve the problem. Quality equations are proposed to determine the iteration number for each task along with the design process. Furthermore, physical resource constraints are also considered in the model to determine the optimal iterative project schedules. These considerations are generally essential to the practical concurrent process.
3. Methodologies
To address the aforementioned objectives, a modified DSM is proposed to analyze iterative project schedules by considering the number of task iterations and resource availability. DSM is first used to highlight the overall relationships among coupled activities. Quality equations are then applied to capture the logic of the number of the tasks that ought to be re-visited based on the design qualities of the tasks. The equations are used to determine the iteration number for each task based on the design quality and its improvement. Finally, a genetic algorithm (GA) is used to explore the optimum solution under resource constraints.
3.1. Design Structure Matrix (DSM)
DSM is a matrix which represents forward and backward relationships of activities in an iterative project. The basic representation of the DSM is a square matrix with each row and column indicating one activity of a project [
1,
8,
9,
10]. There are four types of DSM: (1) component-based or architecture DSM; (2) team-based or organization DSM; (3) activity-based or schedule DSM; and (4) parameter-based DSM. The first two applications are classified as static DSM, and the other two are known as time-based DSM. Static DSM is usually analyzed with clustering algorithms. Time-based DSM uses sequencing algorithms instead. Our study is one kind of activity-based DSM.
Activity-based DSM is used to describe the input/output relationship between activities and highlights iteration and coupled activities during the design process. There are three basic building blocks for describing the relationship between system activities: parallel (or concurrent), sequential (or dependent), and coupled (or interdependent), as depicted in
Table 1.
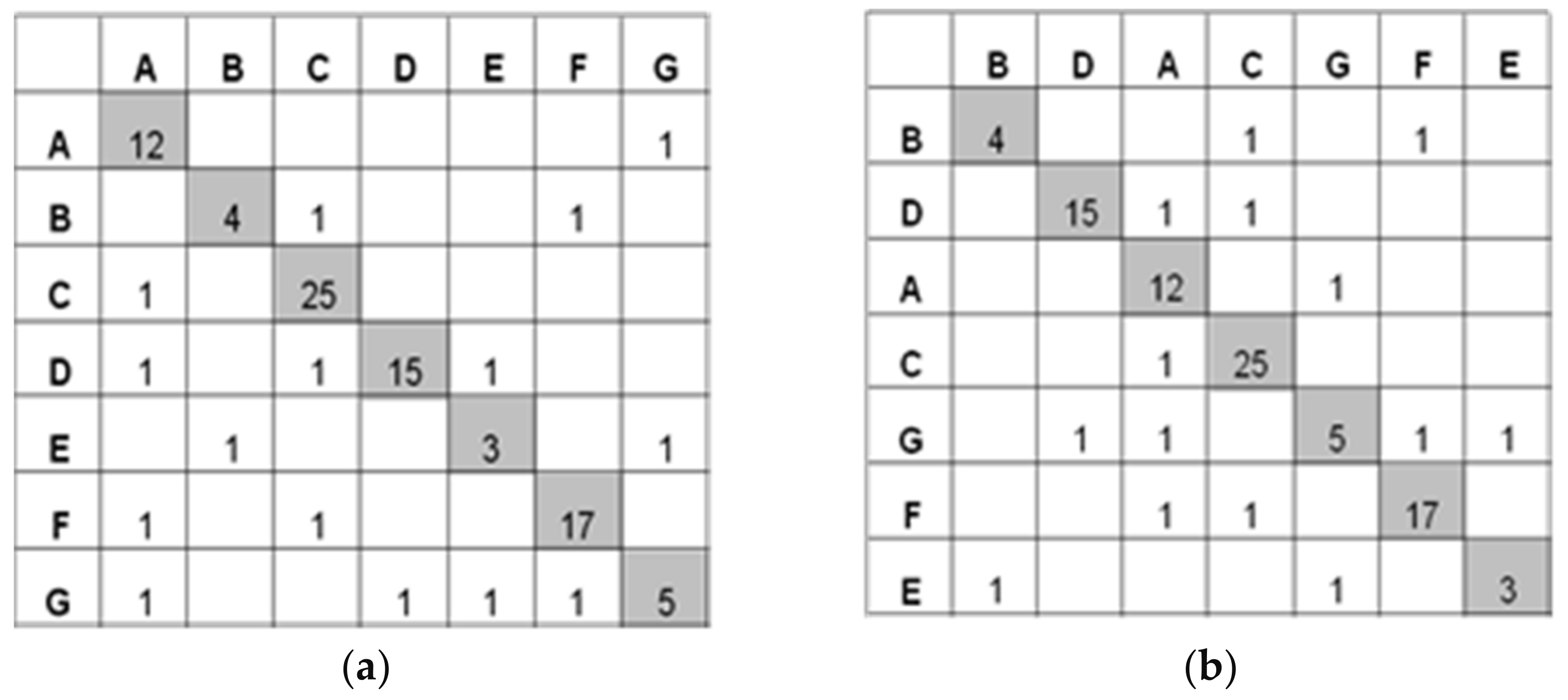
Figure 1 depicts an example of the basic DSM for seven activities. If there is no dependency, nothing (a zero) is recorded in the entry. The activities’ relationships have to be read along the columns as “provide information to” and along the rows as “need information from”. The marks in the sub-diagonal matrix show feedforward information, while in those in the super-diagonal matrix indicate feedback information, the potential for iteration, and rework in the process. Based on the concept of sequencing, the arrangement of the rows and columns in DSM can be re-arranged without losing structural information. For example, the orderings of activities in
Figure 1a can be randomly rearranged while keeping the same dependencies.
Figure 1b shows the rearranged DSM. As shown in
Figure 1b, the ordering of activities is rearranged to hopefully minimize the number of feedbacks.
3.2. Quality Equations
Quality equations are used to determine the number of tasks that need revisiting during the design process and to ensure the required quality. Each task is able to jump out from the coupling block if its output quality has fulfilled the requirement. Once the design converges to the acceptable multi-attribute performance level, the iteration could jump out from the coupling block. By adding these quality equations into DSM, this not only ensures the quality fulfillment of the task, but also decreases the risk of project duration delay due to poor work outputs. The design of the quality equations follows the logic of multiple attribute decision making (MADM). In practice, by collecting and plotting performance scores in terms of iteration steps based on historical performance data, the quality equation can be established. There are two main constitutes in the equation: performance rating and quality improvement [
11].
3.2.1. Performance Rating
Performance rating is used as the measurement of the quality level for each task. Performance refers to the degree of accomplishment of the tasks. It reflects how well the design fulfills the requirements, such as customer’s demand and industrial standards. Performance rating can be gained using some MADM methodologies, such as the analytical hierarchy process (AHP). Using MADM methods, a design project manager can check the level of performance of each design task. Instead of focusing on sort of methodologies to gain performance rating value, this research mainly concentrates on how to use the performance rating as a tool to determine the number of iterations for each task.
3.2.2. Quality Improvement
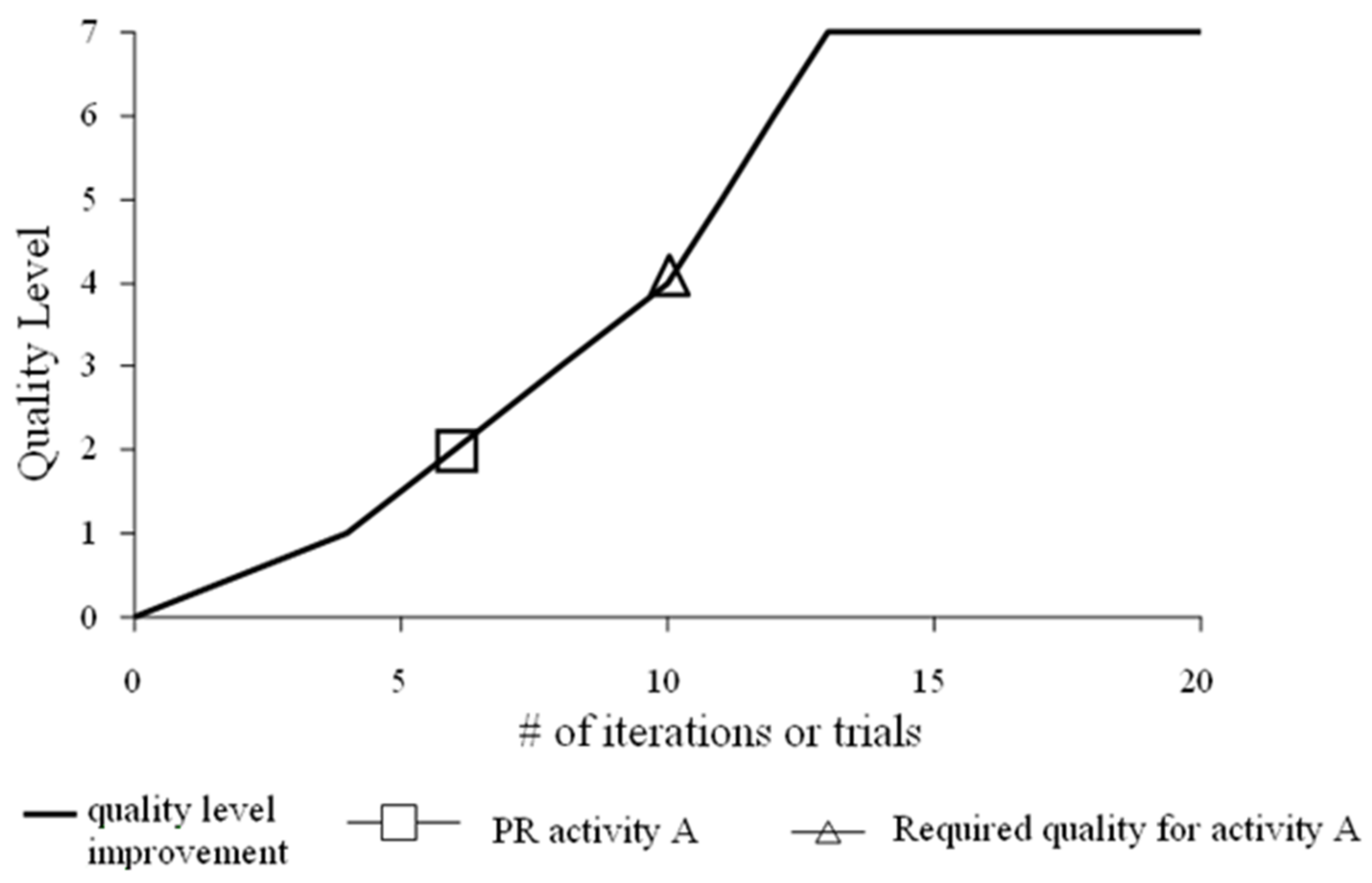
It is reasonable to assume that an improvement in design performance occurs as the task is repeated a number of times. The increase in the number of trials or iterations generally leads to the improvement of the design quality. When more iterations occur, a higher quality level is achieved. Once the quality rating value goes beyond the satisfactory level, the iteration is able to jump out from the coupling block. This research uses the concept of quality improvement to determine the number of iterations needed for each task to achieve the requirements (required quality level). In concept, the quality equation is expressed as a curve in which the performance score on the Y axis is in accordance with iteration step on the X axis. The difference between the values in the X axis for the required quality and performance rate in Y will become the number of iterations needed for each activity to fulfill the requirement.
Figure 2 depicts an example of the quality equation for an activity. Originally, the activity has a quality level of 2 and the requirement is to achieve the quality level of 4. The activity has to be iterated at least 4 times to achieve the required quality, which is yielded from 10 minus 6 on the X axis.
3.3. Resource Constraints
Resources for project activities are always limited in the real world. The unlimited resources assumption in the classical DSM technique may not be feasible. To avoid the waste and shortage of resources in a project, scheduling must take resource allocation into consideration based on the project characteristics. In a design project, engineers and project manager are the main manpower resources. Each design task has its own type and number of required manpower. The number and the type of the manpower are generally more than one and limited in a design project. In this study, all of the engineer’s time must be devoted to a task until it is completed (i.e., no preemption is allowed in this study).
3.4. Genetic Algorithm for DSM
Genetic algorithms (GA) have been popularly used in many areas: scheduling and sequencing, transportation, reliability optimization, constrained or unconstrained optimization, artificial intelligence (AI), and many others [
12]. Significant research has been done in the optimization of construction scheduling using genetic algorithms [
13,
14,
15]. The improved DSM in this study aims to determine the scheduling order of the individual activities with the consideration of design quality and resource constraints during the iterative design process. A GA is used to re-organize and optimize the task flow for the iterative design project to achieve the minimum project duration [
16]. There are four main GA steps: initialization, evaluation, selection, and crossover and mutation. Each step is further explained as follows.
3.4.1. Initialization
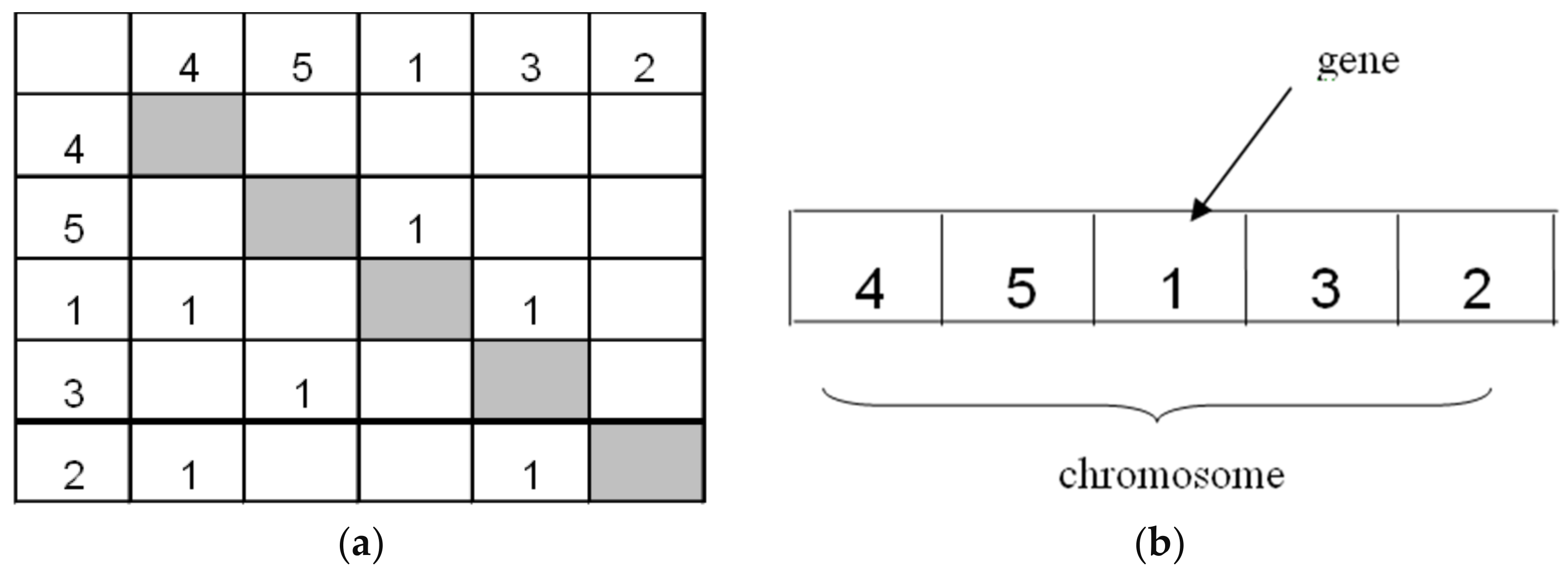
The first step in GA is to generate the initial population. A population (N) is a set of chromosomes, and it serves as a group of candidates or potential solutions. This research used integer form to represent the chromosome in GA.
Figure 3a depicts a DSM example with five activities and
Figure 3b describes its corresponding GA chromosome. A chromosome (also known as a string) in the population represents a possible sequence of activities and each gene (also known as a character) in the chromosome stands for an activity ID (or name). Each gene in a chromosome is selected randomly and only can be picked exactly once. Precedence relationship does not have to be considered when choosing sequence of the gene, since in DSM, feedback dependency is allowed in estimating the project completion time.
3.4.2. Evaluation (Fitness Function Calculation)
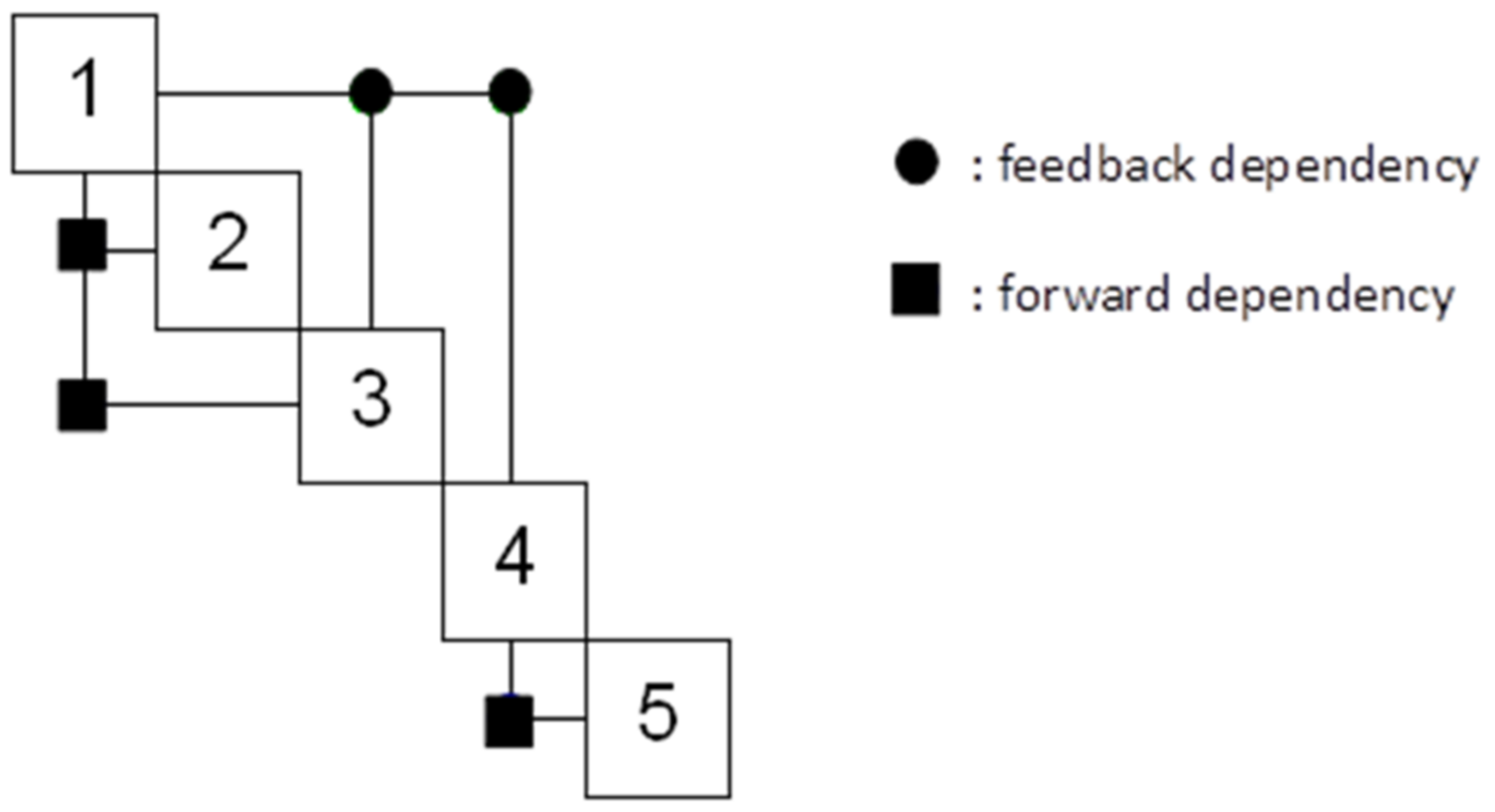
After a set of chromosomes is generated for potential solutions, each of them is assessed based on the fitness function defined. The fitness function shown below is to evaluate the quality (or fitness) of every chromosome in the population by calculating the fitness value. An example of time calculation for iterative design flow is depicted in
Figure 4. The iteration for every feedback is assumed to occur once it causes the process to repeat the tasks in the feedback loop. The time for repeated tasks should be included as parts of the project duration. Task 2 is not included in the time calculation because Task 2 and Task 3 can be undertaken concurrently, so that the shorter of these two tasks (i.e., Task 2) is dropped from the total time calculation. Based on the method proposed by Mazur et al. [
17], the total time period is T1 + T3 + (T1 + T3) + T4 + (T1 + T3 + T4) + T5.
3.4.3. Selection
There are many kinds of selection methods and generally the concepts of roulette wheel and elitism are used. The roulette wheel simulates the behavior of a roulette wheel, where each chromosome has a slot on the wheel. The size of each slot is proportional to the fitness of the corresponding chromosome. To select an individual, a random number is generated and the individual whose segment spans the random number is selected. In the roulette wheel selection, the fittest individual occupies the largest interval, whereas the least fit individual takes correspondingly smaller intervals.
The second selection method is elitism, which is an extension of the selection process that guarantees the survival of the fittest chromosome. Using elitism, the simple solution is only copied from the fittest chromosome(s) from one generation to the next. The elitism operator has proved to increase the speed of convergence of the GA because it ensures that the best solution found in each generation is retained and guarantees that the final result will not become worse.
3.4.4. Crossover and Mutation
A special crossover method, a partially mapped crossover, is undertaken in this study. It passes ordering and value information from the parent to the offspring. A portion of one parent’s string is mapped onto a portion of the other parent string and the remaining information is exchanged. For mutation, a swapping algorithm was used in this research. It only swaps two different numbers and exchanges both of them. Mutation is an auxiliary function of GA to prevent the genetic search from trapping at local optima. In the mutation operation, an appropriate mutation rate (generally around 0.01) is defined so that there is a low disruptive effect on the fitness of the overall population.
4. Case Study and Sensitivity Analysis
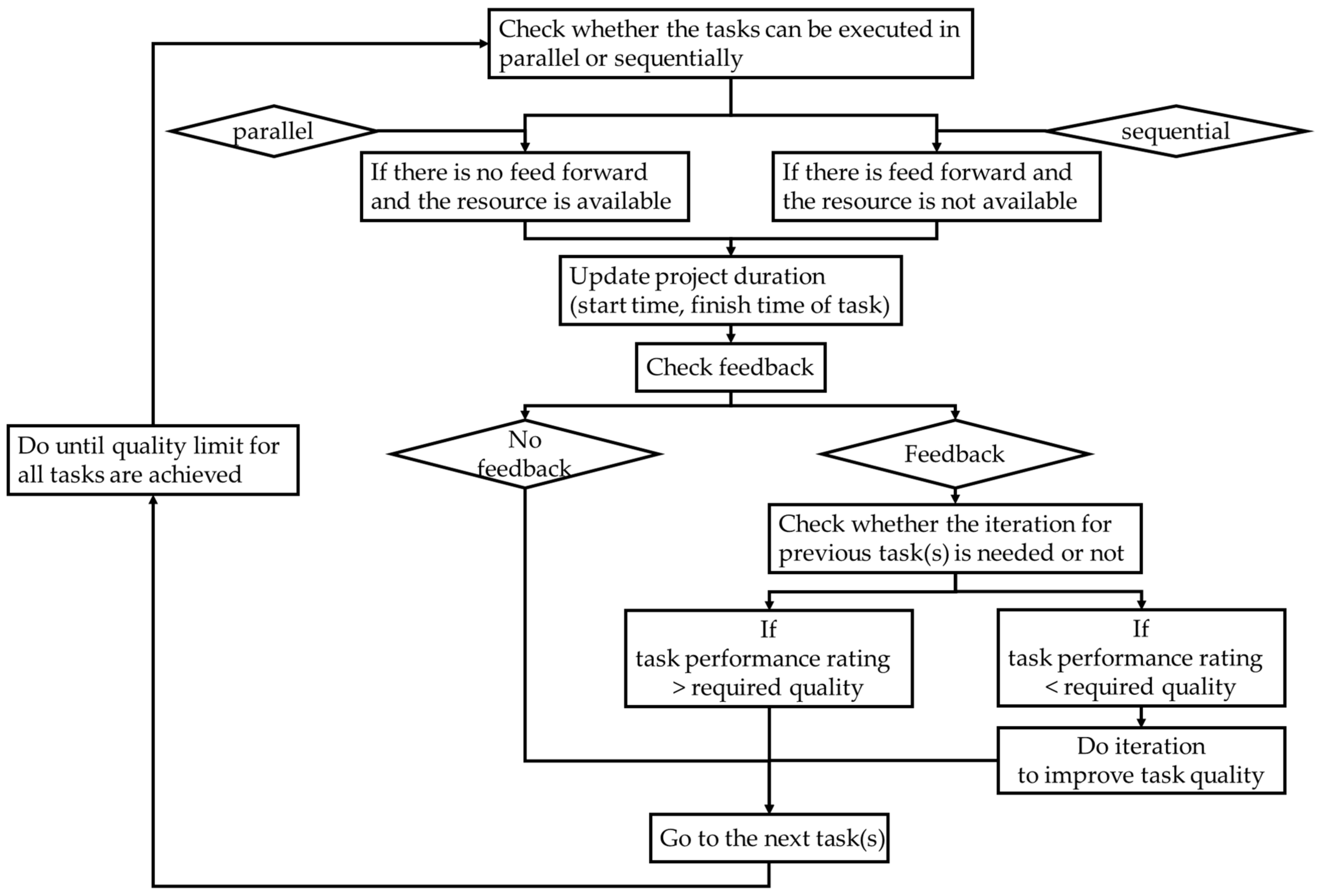
The overall flowchart for DSM fitness function calculation in this study is depicted in
Figure 5. The GA search algorithm consists of two loops. The inner loop is developed to deal with iterative scheduling with the consideration of quality equations. The outer loop is for the optimal solution exploration under rare resource constraints. The model was first verified against Mazur et al. [
17]. DSM data were adopted from Mazur et al. [
17] and the functions of quality equations and resource constraints in our model were temporarily terminated. Comparing the project durations from both models, their values are identical (i.e., 19,824 days). This reveals that the logic and the codes of our model are accurate.
Furthermore, a new set of DSM data used as the case study was taken from an engineering consultant company in Taiwan. The company was a building design project with a 1.5-year construction duration and the design fee was around USD
$430,000. There are 45 activities which are part of the design process. The descriptions of the activity durations and their relationships are shown in
Figure 6. The values in the diagonal line indicate the duration for each design task (in days). Thirteen kinds of engineer are required as resources in the project. Their demands and the upper limits are listed in
Table 2. For ease in the simulation, performance ratings and the quality level improvement curves used in this case study were previously assumed and are depicted in
Table 3. The quality equations used in this case study are assumed to be linear. In the practical implementation, such quality equations can be acquired based on real exercise and data plotting.
The GA convergence is generally reached before the 100th iteration. The basic reason is that the elitism method is used in the selection process. The survival of the fittest chromosomes in a generation are kept into to the next generation. There are two optimum sequences that have the same project duration:
| I. | 1 2 3 4 5 6 7 8 11 10 12 18 13 14 15 16 19 22 23 24 25 26 28 27 29 30 31 32 33 36 37 35 34 38 40 39 41 42 43 44 45 |
| II. | 1 2 3 4 5 6 7 8 11 10 12 18 13 14 15 16 17 19 9 20 21 22 23 24 25 26 28 27 29 30 31 32 33 36 37 35 34 38 40 39 41 42 43 44 45 |
The minimum project duration is 185.4 days and there are five feedback dependencies. It is still 2.3 days faster than the original DSM/DSM data (187.7 days), although there are more feedback dependencies compared to the original DSM. More feedback dependencies do not always increase project duration. The duration may occasionally be shortened due to less forward dependencies, and hence more activities can be done in parallel. Moreover, accelerating project duration by moving the dependency (forward to feedback) becomes more reliable if the iteration number for each feedback dependency can be determined.
A small iterative schedule with three activities is illustrated below as an explanation example (as shown in
Figure 7). In
Figure 7a, all the dependencies are forward dependencies, while in
Figure 7b,c, they are all feedback dependencies. The total duration is 18 days when all the dependencies are forward dependencies because activities B and C can only be executed after activity A is finished. Comparatively, if the relationships have some feedback dependencies, the total duration may be shorter or longer. It becomes shorter if no iteration occurs and it turns out to be longer if activities B and C have to be iterated once or more. If activities B and C are required to be iterated at least once based on the quality equation, then the sequence of activity in
Figure 7a is preferred with a shorter duration. On the other hand, if activities B and C do not have to be iterated, the sequence of activity in
Figure 7b provides a better outcome.
4.1. Sensitivity Analysis and Discussion
There are four sensitive factors in the proposed DSM: activity dependencies, activity duration, resource constraints, and quality equations. Generally, activity dependencies and activity duration are defined and fixed based on the design project characteristics. The sensitivity analysis is conducted based on the variables of resource constraints and quality equations.
4.1.1. Quality Equations
Quality equations have two major parameters: performance rating and quality improvement. The sensitivity analysis was conducted to identify their impact.
Table 4 summarizes the results of the sensitivity test. In Scenario 1, the equation is assumed to be linear as the baseline. In Scenario 2, the performance rating values of all tasks are adjusted to have a maximum value of 5; i.e., no quality improvement is needed since the qualities of all tasks have already achieved the highest level. In Scenario 3, the quality improvement curve is assumed to have a higher curvature, i.e., less iteration is needed for quality improvement. As no quality improvement in Scenario 2 is needed, the project duration is much less than in Scenario 1 (129 days compared to 185.4 days). Meanwhile, one iteration for quality improvement in Scenario 3 is required; as a result, the project durations are still less than Scenario 1 (140.9 days compared to 185.4 days). This means that performance rating and quality improvement iteration greatly influence the DSM sequences to get the optimal values. It is observed that more feedback dependencies tend to occur by raising performance rating values and reducing quality improvement iterations. As previously discussed, if more forward dependencies are switched into feedback dependencies, the related activities can be done in parallel. That causes the project duration to be shorter (coupled activities are an exception).
4.1.2. Resource Constraints
Resources for design activities are limited in the real world. To avoid the waste and shortage of resources on a design project, scheduling must include resource allocation. In general, the construction project regards the amount of resources as the resource constraints. Nevertheless, in the design phase, the resource types and amount are limited and may not be critical. The resource types and their time availability, especially rare resources, play an important role in the completion of design tasks. For example, outsourcing experts, who usually have high credibility, cannot be able to stand idle. Additionally, engineers are often appointed by serval projects simultaneously in real practice. They are not always available to a single design project. The scheduler has to match the sequence of the design project with the available time of the rare resources. The task under wait will proceed right after the due rare resources have finished their tasks on hand.
In the tested design case, the mapping engineer is regarded as the rare resource. Their stay period and arrival time are two major parameters. Rare resources usually stay within the limited design period. Practically, the shorter the stay time of a rare resource is, the more the rarer resources are needed. This study mainly focused on the arrival time plan with a fixed rare resource. Different arrival time is set as a control parameter to conduct sensitivity analysis. The GA search algorithm consists of two loops. The inner loop is developed to deal with iterative scheduling, with the consideration of quality equations. The outer loop is for the optimal solution exploration under rare resource constraints; i.e., the different arrival time of the mapping engineer in our case.
Table 5 depicts the result of sensitivity analysis. The basic findings are concluded as follows. First of all, the optimal search algorithm tends to rearrange related activities into the chain block to achieve minimum project duration; nevertheless, that could cause the increment of feedback. In our case, activities 31, 37, 36, 33, 32, 34, and 28 need the support of the mapping engineer. The final project duration is 186.4 and the best arrival time of the mapping engineer is at 100th. The sequence of design activities is listed below.
| III. | 1 2 3 4 5 6 7 8 11 10 2 18 13 14 15 16 19 17 9 20 21 22 23 24 25 26 27 29 30 31 37 36 33 32 34 28 35 38 40 39 41 42 43 44 45 |
Secondly, as shown in
Table 5, it is found that the different arrival time of rare resources (the mapping engineer in our case) affects the project completion time and also the stay time period of rare resources. The basic reason is that by moving expert arrival time, the sequence in the system will change accordingly, and it will also alter dependencies between activities. Because of that, the rare resource may need to be re-invited to the project several times. This means that the stay time period of the rare resource could increase to fulfill the project requirements (quality requirements, in our case). Moreover, project durations for some scenarios are less than the original DSM and defined by a two-loop GA algorithm, but some are longer. This result is highly affected by the feedback dependency. As mentioned before, feedback dependency can extend or reduce project duration. The different arrival time largely changes feedback dependency.
5. Conclusions and Further Directions
Classical DSM mainly focuses on the number of feedback dependencies. It is believed that the fewer the feedback dependencies, the shorter the completion time. Nevertheless, the assumption may not hold because tasks ought to be re-visited several times if the required qualities do not meet the requirements. Moreover, resources for iterative design projects are generally limited in practice. This paper proposes a novel DSM algorithm combining the classical DSM concepts with quality equations. The quality equations were used to determine the number of tasks that ought to be re-visited during the iterative process for fulfilling the design requirements. It was proven that quality equations greatly influence the sequence of activities and the project duration of iterative schedules. Finally, resource constraints were considered to determine their effects. Resource constraints (rare resources, in our study) strongly influence the stay time period of rare resources and project durations.
While this study is exploratory in nature, further research is needed, especially in establishing procedures to develop practical quality equations. Furthermore, efficiently solving iterative schedules for rare resources is required. The case of rare resources may happen in the iterative schedules, due to some project resources that have fixed arrival times and limited durations in the project. Finally, risks frequently occur during projects, especially in complex concurrent projects. It is necessary to explore the logic and the effects of risk factors on DSM.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





