
Soybean Cultivars Identification Using Remotely Sensed Image and Machine Learning Models

 ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
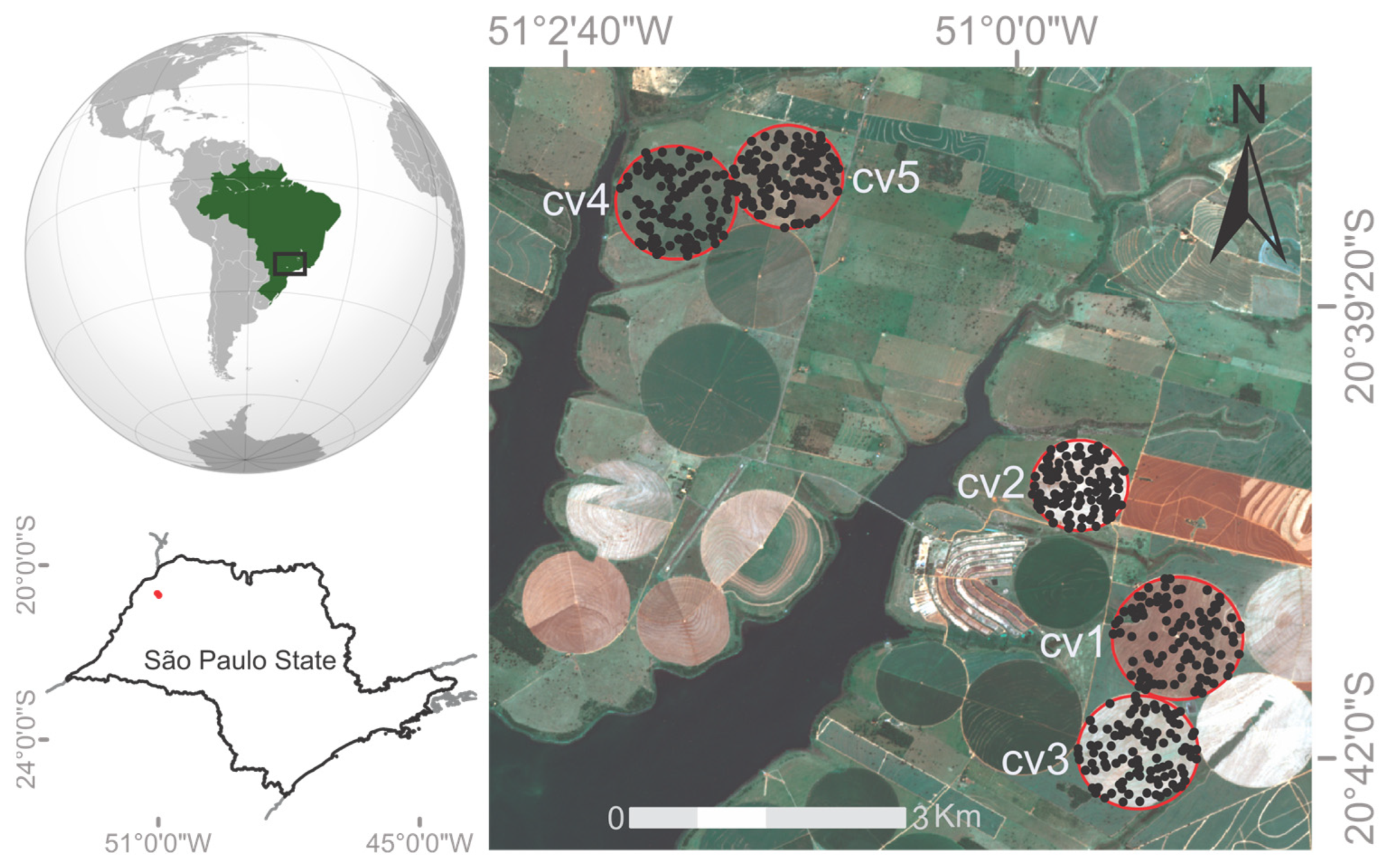
2.1. Experimental Area and Treatments Evaluated
2.2. Image Acquisition and Multispectral Models
2.3. Using Machine Learning Models
2.4. Statistical Analysis
3. Results
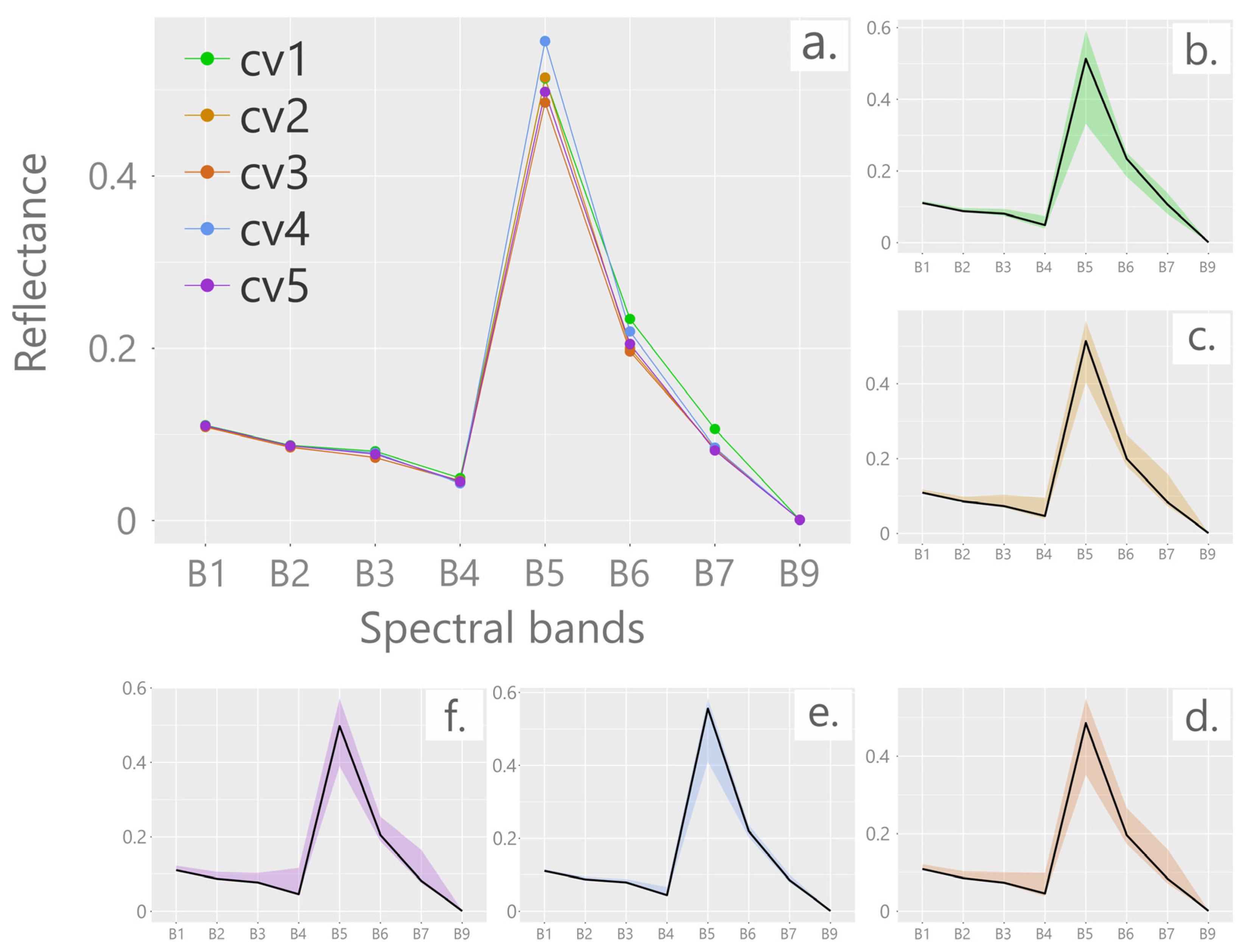
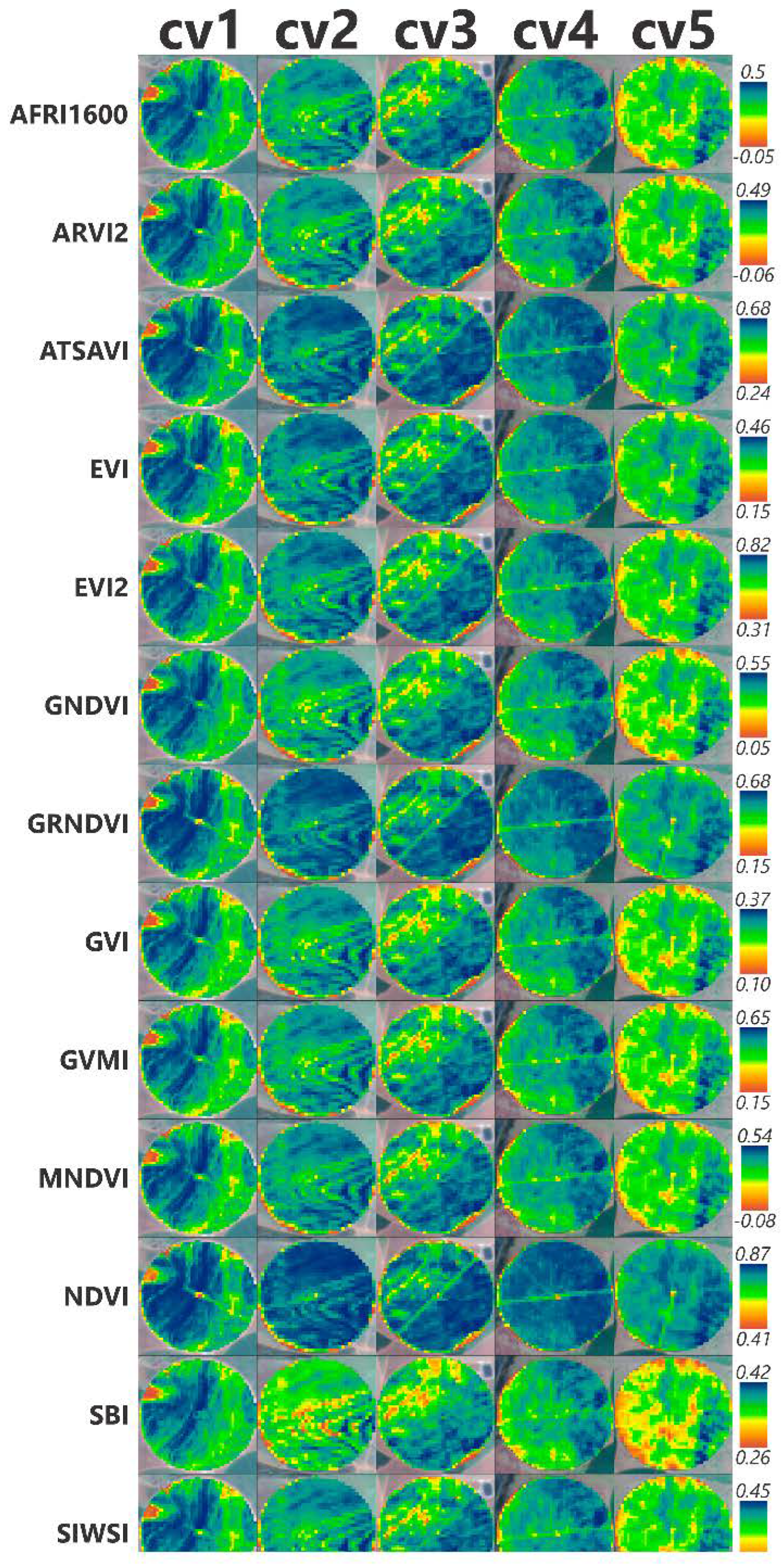
3.1. Spectral Signature of Cultivars
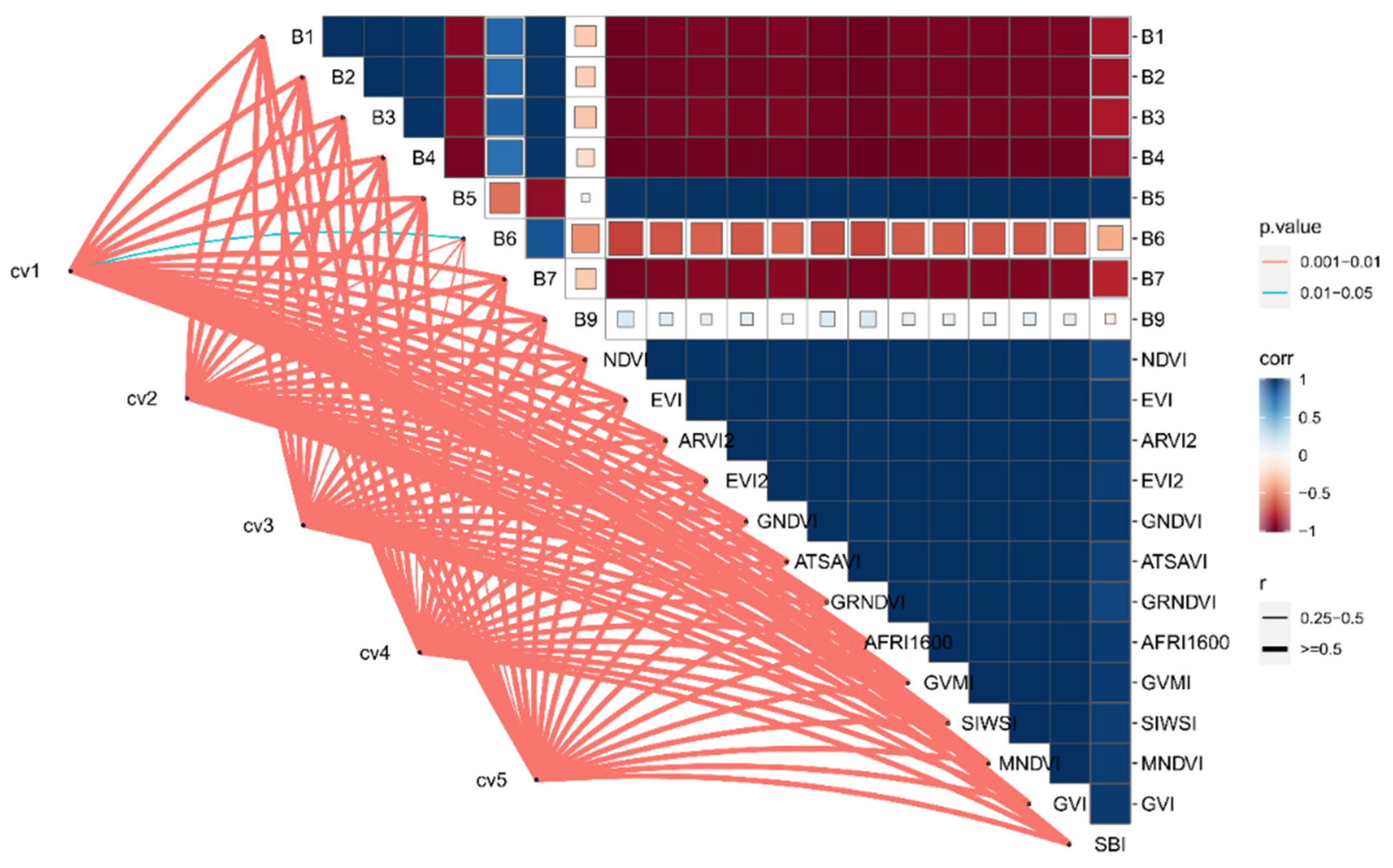
3.2. Correlation between Variables
3.3. Scattering between Variables
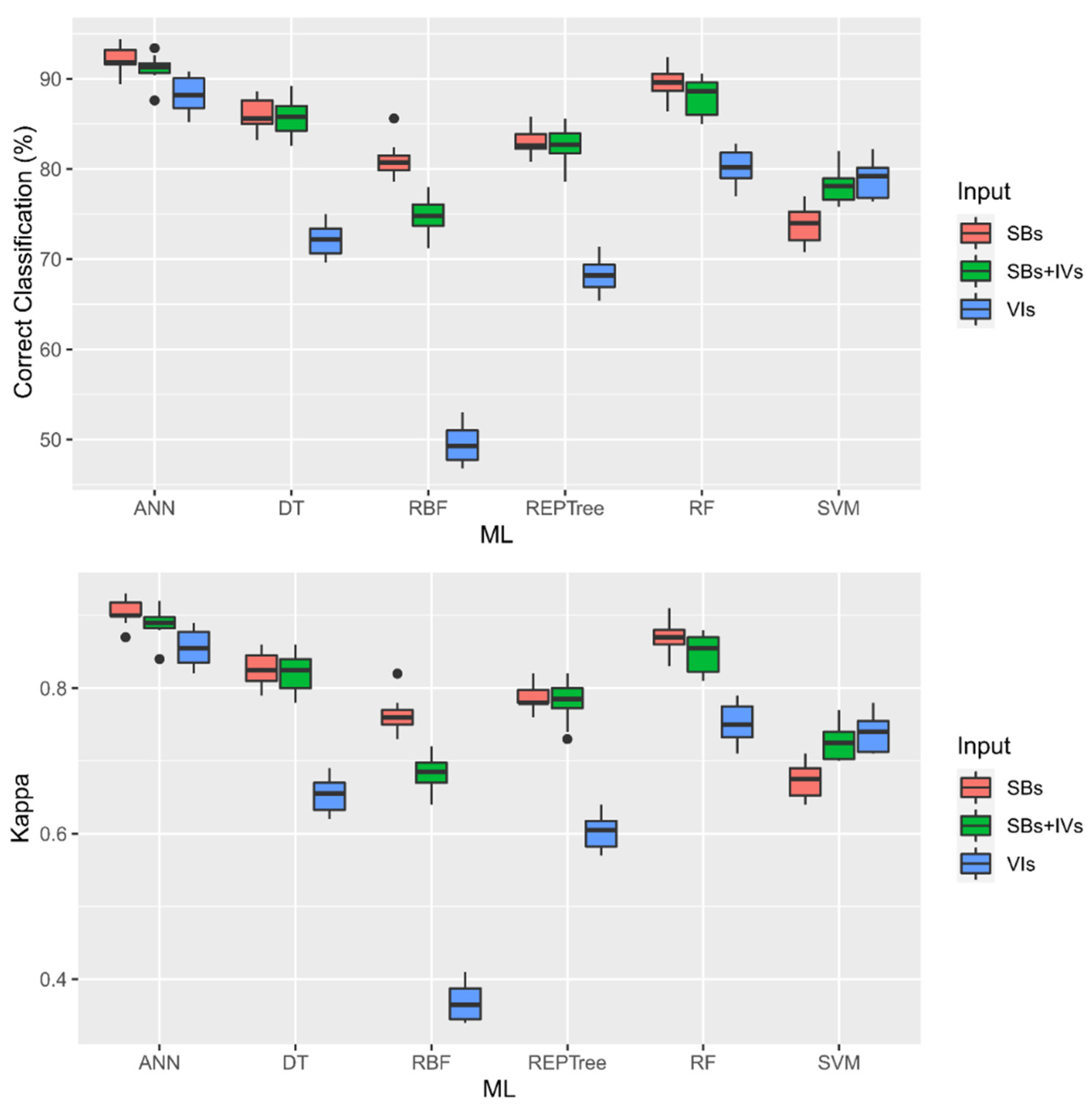
3.4. Choosing the Best Model and Best Input
3.5. Confusion Matrix Using ANN’s
4. Discussion
4.1. Tested Models
4.2. Tested Inputs
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Maher, T.M.; Spagnolo, P. Perspectives for the Future. ERS Monogr. 2016, 2016, 260–274. [Google Scholar] [CrossRef]
- Dukhnytskyi, B. World Agricultural Production. Ekon. APK 2019, 7, 59–65. [Google Scholar] [CrossRef]
- SojaMaps: Monitoring of Soybean Areas through Satellite Imagery. Available online: https://pesquisa.unemat.br/gaaf/plataformas/sojamaps (accessed on 15 May 2022).
- da Silva Junior, C.A.; Leonel-Junior, A.H.S.; Rossi, F.S.; Correia Filho, W.L.F.; de Barros Santiago, D.; de Oliveira-Júnior, J.F.; Teodoro, P.E.; Lima, M.; Capristo-Silva, G.F. Mapping Soybean Planting Area in Midwest Brazil with Remotely Sensed Images and Phenology-Based Algorithm Using the Google Earth Engine Platform. Comput. Electron. Agric. 2020, 169, 105194. [Google Scholar] [CrossRef]
- Zhou, S.; Mou, H.; Zhou, J.; Zhou, J.; Ye, H.; Nguyen, H.T. Development of an Automated Plant Phenotyping System for Evaluation of Salt Tolerance in Soybean. Comput. Electron. Agric. 2021, 182, 106001. [Google Scholar] [CrossRef]
- Diao, C. Remote Sensing Phenological Monitoring Framework to Characterize Corn and Soybean Physiological Growing Stages. Remote Sens. Environ. 2020, 248, 111960. [Google Scholar] [CrossRef]
- da Silva Junior, C.A.; Nanni, M.R.; Shakir, M.; Teodoro, P.E.; de Oliveira-Júnior, J.F.; Cezar, E.; de Gois, G.; Lima, M.; Wojciechowski, J.C.; Shiratsuchi, L.S. Soybean Varieties Discrimination Using Non-Imaging Hyperspectral Sensor. Infrared Phys. Technol. 2018, 89, 338–350. [Google Scholar] [CrossRef]
- Santana, D.C.; Cotrim, M.F.; Flores, M.S.; Rojo Baio, F.H.; Shiratsuchi, L.S.; da Silva Junior, C.A.; Teodoro, L.P.R.; Teodoro, P.E. UAV-Based Multispectral Sensor to Measure Variations in Corn as a Function of Nitrogen Topdressing. Remote Sens. Appl. Soc. Environ. 2021, 23, 100534. [Google Scholar] [CrossRef]
- Feng, L.; Chen, S.; Zhang, C.; Zhang, Y.; He, Y. A Comprehensive Review on Recent Applications of Unmanned Aerial Vehicle Remote Sensing with Various Sensors for High-Throughput Plant Phenotyping. Comput. Electron. Agric. 2021, 182, 106033. [Google Scholar] [CrossRef]
- Zhou, J.; Zhou, J.; Ye, H.; Ali, M.L.; Chen, P.; Nguyen, H.T. Yield Estimation of Soybean Breeding Lines under Drought Stress Using Unmanned Aerial Vehicle-Based Imagery and Convolutional Neural Network. Biosyst. Eng. 2021, 204, 90–103. [Google Scholar] [CrossRef]
- van Dijk, A.D.J.; Kootstra, G.; Kruijer, W.; de Ridder, D. Machine Learning in Plant Science and Plant Breeding. iScience 2021, 24, 101890. [Google Scholar] [CrossRef]
- Marques Ramos, A.P.; Prado Osco, L.; Elis Garcia Furuya, D.; Nunes Gonçalves, W.; Cordeiro Santana, D.; Pereira Ribeiro Teodoro, L.; Antonio da Silva Junior, C.; Fernando Capristo-Silva, G.; Li, J.; Henrique Rojo Baio, F.; et al. A Random Forest Ranking Approach to Predict Yield in Maize with Uav-Based Vegetation Spectral Indices. Comput. Electron. Agric. 2020, 178, 105791. [Google Scholar] [CrossRef]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.V.V.; Ciampitti, I.A. Satellite-Based Soybean Yield Forecast: Integrating Machine Learning and Weather Data for Improving Crop Yield Prediction in Southern Brazil. Agric. For. Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Alvares, C.A.; Stape, J.L.; Sentelhas, P.C.; De Moraes Gonçalves, J.L.; Sparovek, G. Köppen’s Climate Classification Map for Brazil. Meteorol. Z. 2013, 22, 711–728. [Google Scholar] [CrossRef]
- Chander, G.; Markham, B.L.; Helder, D.L. Summary of Current Radiometric Calibration Coefficients for Landsat MSS, TM, ETM+, and EO-1 ALI Sensors. Remote Sens. Environ. 2009, 113, 893–903. [Google Scholar] [CrossRef]
- Wu, Q. Geemap: A Python Package for Interactive Mapping with Google Earth Engine. J. Open Source Softw. 2020, 5, 2305. [Google Scholar] [CrossRef]
- Al Snousy, M.B.; El-Deeb, H.M.; Badran, K.; Khlil, I.A. Al Suite of Decision Tree-Based Classification Algorithms on Cancer Gene Expression Data. Egypt. Inform. J. 2011, 12, 73–82. [Google Scholar] [CrossRef] [Green Version]
- da Silva, C.A., Jr.; Nanni, M.R.; de Oliveira-Júnior, J.F.; Cezar, E.; Teodoro, P.E.; Delgado, R.C.; Shiratsuchi, L.S.; Shakir, M.; Chicati, M.L. Object-Based Image Analysis Supported by Data Mining to Discriminate Large Areas of Soybean. Int. J. Digit. Earth 2018, 12, 270–292. [Google Scholar] [CrossRef]
- Soni, R.; Kumar, B.; Chand, S. Optimal Feature and Classifier Selection for Text Region Classification in Natural Scene Images Using Weka Tool. Multimed. Tools Appl. 2019, 78, 31757–31791. [Google Scholar] [CrossRef]
- Kalmegh, S.R. Analysis of WEKA Data Mining Algorithm REPTree, Simple Cart and RandomTree for Classification of Indian News. Int. J. Innov. Sci. Eng. Technol. 2015, 2, 438–446. [Google Scholar]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Nitin Rajvanshi, K.R. Chowdhary, Comparison of SVM and Naïve Bayes Text Classification Algorithms Using WEKA. Int. J. Eng. Res. 2017, V6, 141–143. [Google Scholar] [CrossRef]
- Bouckaert, R.R.; Frank, E.; Hall, M.A.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. WEKA—Experiences with a Java Open-Source Project. J. Mach. Learn. Res. 2010, 11, 2533–2541. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: http://softlibre.unizar.es/manuales/aplicaciones/r/fullrefman.pdf (accessed on 16 May 2022).
- Montesinos-López, O.A.; Montesinos-López, A.; Pérez-Rodríguez, P.; Barrón-López, J.A.; Martini, J.W.R.; Fajardo-Flores, S.B.; Gaytan-Lugo, L.S.; Santana-Mancilla, P.C.; Crossa, J. A Review of Deep Learning Applications for Genomic Selection. BMC Genom. 2021, 22, 19. [Google Scholar] [CrossRef] [PubMed]
- Eugenio, F.C.; Grohs, M.; Venancio, L.P.; Schuh, M.; Bottega, E.L.; Ruoso, R.; Schons, C.; Mallmann, C.L.; Badin, T.L.; Fernandes, P. Estimation of Soybean Yield from Machine Learning Techniques and Multispectral RPAS Imagery. Remote Sens. Appl. Soc. Environ. 2020, 20, 100397. [Google Scholar] [CrossRef]
- Moradi, G.R.; Dehghani, S.; Khosravian, F.; Arjmandzadeh, A. The Optimized Operational Conditions for Biodiesel Production from Soybean Oil and Application of Artificial Neural Networks for Estimation of the Biodiesel Yield. Renew. Energy 2013, 50, 915–920. [Google Scholar] [CrossRef]
- Badura, A.; Krysiński, J.; Nowaczyk, A.; Buciński, A. Prediction of the Antimicrobial Activity of Quaternary Ammonium Salts against Staphylococcus Aureus Using Artificial Neural Networks. Arab. J. Chem. 2021, 14, 103233. [Google Scholar] [CrossRef]
- Ghasemi, G.; Nemati-Rashtehroodi, A. QSAR Modellemesi Ile Benzimidazole Türevlerinin Trikomoniasis Için Etkili Inhibitörler Olarak Kullanılması. Turk. J. Biochem. 2015, 40, 492–499. [Google Scholar] [CrossRef]
- Basir, M.S.; Chowdhury, M.; Islam, M.N.; Ashik-E-Rabbani, M. Artificial Neural Network Model in Predicting Yield of Mechanically Transplanted Rice from Transplanting Parameters in Bangladesh. J. Agric. Food Res. 2021, 5, 100186. [Google Scholar] [CrossRef]
- Taratuhin, O.D.; Novikova, L.Y.; Seferova, I.V.; Kozlov, K.N. Simulation of Soybean Phenology with the Use of Artificial Neural Networks. Biophysics 2019, 64, 440–447. [Google Scholar] [CrossRef]
- Taratuhin, O.D.; Novikova, L.Y.; Seferova, I.V.; Gerasimova, T.V.; Nuzhdin, S.V.; Samsonova, M.G.; Kozlov, K.N. An Artificial Neural Network Model to Predict the Phenology of Early-Maturing Soybean Varieties from Climatic Factors. Biophysics 2020, 65, 106–117. [Google Scholar] [CrossRef]
- de Freitas, E.C.S.; de Paiva, H.N.; Neves, J.C.L.; Marcatti, G.E.; Leite, H.G. Modeling of Eucalyptus Productivity with Artificial Neural Networks. Ind. Crops Prod. 2020, 146, 112149. [Google Scholar] [CrossRef]
- Borges, M.V.V.; de Oliveira Garcia, J.; Batista, T.S.; Silva, A.N.M.; Baio, F.H.R.; da Silva Junior, C.A.; de Azevedo, G.B.; de Oliveira Sousa Azevedo, G.T.; Teodoro, L.P.R.; Teodoro, P.E. High-Throughput Phenotyping of Two Plant-Size Traits of Eucalyptus Species Using Neural Networks. J. For. Res. 2022, 33, 591–599. [Google Scholar] [CrossRef]
- Singh, A.; Jones, S.; Ganapathysubramanian, B.; Sarkar, S.; Mueller, D.; Sandhu, K.; Nagasubramanian, K. Challenges and Opportunities in Machine-Augmented Plant Stress Phenotyping. Trends Plant Sci. 2021, 26, 53–69. [Google Scholar] [CrossRef] [PubMed]
- da Silva Junior, C.A.; Teodoro, L.P.R.; Teodoro, P.E.; Baio, F.H.R.; de Andrea Pantaleão, A.; Capristo-Silva, G.F.; Facco, C.U.; de Oliveira-Júnior, J.F.; Shiratsuchi, L.S.; Skripachev, V.; et al. Simulating Multispectral MSI Bandsets (Sentinel-2) from Hyperspectral Observations via Spectroradiometer for Identifying Soybean Cultivars. Remote Sens. Appl. Soc. Environ. 2020, 19, 100328. [Google Scholar] [CrossRef]
- Houborg, R.; Boegh, E. Mapping Leaf Chlorophyll and Leaf Area Index Using Inverse and Forward Canopy Reflectance Modeling and SPOT Reflectance Data. Remote Sens. Environ. 2008, 112, 186–202. [Google Scholar] [CrossRef]
- da Silva Junior, C.A.; Teodoro, P.E.; Teodoro, L.P.R.; Della-Silva, J.L.; Shiratsuchi, L.S.; Baio, F.H.R.; Boechat, C.L.; Capristo-Silva, G.F. Is It Possible to Detect Boron Deficiency in Eucalyptus Using Hyper and Multispectral Sensors? Infrared Phys. Technol. 2021, 116, 103810. [Google Scholar] [CrossRef]
- Ravikanth, L.; Jayas, D.S.; White, N.D.G.; Fields, P.G.; Sun, D.-W. Extraction of Spectral Information from Hyperspectral Data and Application of Hyperspectral Imaging for Food and Agricultural Products. Food Bioprocess Technol. 2017, 10, 1–33. [Google Scholar] [CrossRef]
- Jung, J.; Maeda, M.; Chang, A.; Bhandari, M.; Ashapure, A.; Landivar-Bowles, J. The Potential of Remote Sensing and Artificial Intelligence as Tools to Improve the Resilience of Agriculture Production Systems. Curr. Opin. Biotechnol. 2021, 70, 15–22. [Google Scholar] [CrossRef]
- USGS. Landsat 9 Data Users Handbook. Landsat 9 Data Users Handb. 2022, 107, 102689. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vegetation Indices | Equations |
|---|---|
| AFRI1600 (Aerosol Free Vegetation Index 1600) | |
| ARVI2 (Atmospherically Resistant Vegetation Index 2) | |
| ATSAVI (Ajusted Transformed Soil-Ajusted VI) | |
| EVI (Enhanced Vegetation Index) | |
| EVI2 (Enhanced Vegetation Index 2) | |
| GNDVI (Green Normalized Difference Vegetation Index) | |
| GRNDVI (Green-Red NDVI) | |
| GVI (Tasselled Capvegetation) | |
| GVMI (Global Vegetation Moisture Index) | |
| MNDVI (Modified Normalized Difference Vegetation Index) | |
| NDVI (Normalized Difference Vegetation Index) | |
| SBI (Tasselled Cap—brightness) | |
| SIWSI (Normalized Difference 860/1640) |
| Model | SBs * | VIs | SBs + VIs |
|---|---|---|---|
| ANN | 92.18 Aa | 88.30 Ba | 91.12 Aa |
| DT | 85.88 Ac | 72.24 Bc | 85.72 Ac |
| RBF | 80.94 Ab | 49.50 Be | 74.88 Af |
| REPTree | 82.92 Ad | 68.32 Bd | 82.46 Ad |
| RF | 89.62 Ae | 80.22 Bb | 87.94 Ab |
| SVM | 73.82 Bf | 78.86 Ab | 78.24 Ae |
| Model | SBs * | VIs | SBs + VIs |
|---|---|---|---|
| ANN | 0.91 Aa | 0.86 Ba | 0.89 Aa |
| DT | 0.82 Ac | 0.66 Bc | 0.82 Ac |
| RBF | 0.76 Ae | 0.37 Ce | 0.68 Bf |
| REPTree | 0.79 Ad | 0.60 Bd | 0.78 Ad |
| RF | 0.87 Ab | 0.75 Bb | 0.85 Ab |
| SVM | 0.67 Bf | 0.73 Ab | 0.74 Ae |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gava, R.; Santana, D.C.; Cotrim, M.F.; Rossi, F.S.; Teodoro, L.P.R.; da Silva Junior, C.A.; Teodoro, P.E. Soybean Cultivars Identification Using Remotely Sensed Image and Machine Learning Models. Sustainability 2022, 14, 7125. https://doi.org/10.3390/su14127125
Gava R, Santana DC, Cotrim MF, Rossi FS, Teodoro LPR, da Silva Junior CA, Teodoro PE. Soybean Cultivars Identification Using Remotely Sensed Image and Machine Learning Models. Sustainability. 2022; 14(12):7125. https://doi.org/10.3390/su14127125
Chicago/Turabian StyleGava, Ricardo, Dthenifer Cordeiro Santana, Mayara Favero Cotrim, Fernando Saragosa Rossi, Larissa Pereira Ribeiro Teodoro, Carlos Antonio da Silva Junior, and Paulo Eduardo Teodoro. 2022. "Soybean Cultivars Identification Using Remotely Sensed Image and Machine Learning Models" Sustainability 14, no. 12: 7125. https://doi.org/10.3390/su14127125
APA StyleGava, R., Santana, D. C., Cotrim, M. F., Rossi, F. S., Teodoro, L. P. R., da Silva Junior, C. A., & Teodoro, P. E. (2022). Soybean Cultivars Identification Using Remotely Sensed Image and Machine Learning Models. Sustainability, 14(12), 7125. https://doi.org/10.3390/su14127125