
Crack Detection in Concrete Structures Using Deep Learning



Abstract
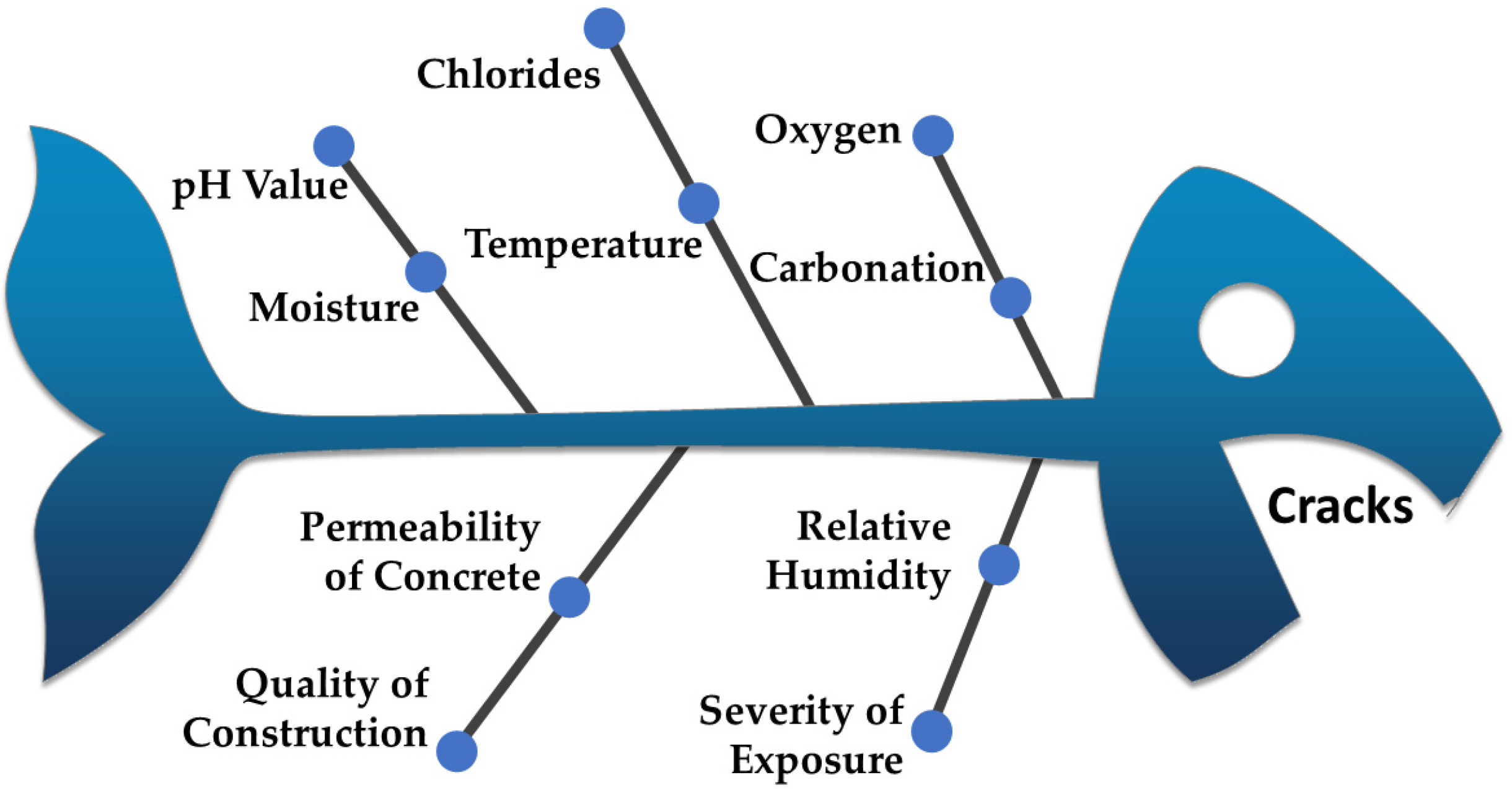
:1. Introduction
- (i)
- To develop and validate a CNN suitable for crack detection;
- (ii)
- To train the developed CNN using processed or unprocessed images, creating different models;
- (iii)
- To analyse relative performance between the trained models in crack detection.
2. Background Literature
2.1. Literature Retrieval
- Published between 2010 and 2020;
- English language only;
- Article type must be a research article, review, or book chapter (letters, abstracts, and comments were not required);
- No duplicates.
2.2. Image Processing Methods
2.2.1. Grayscaling and Thresholding
2.2.2. Edge Detection
2.3. Traditional Machine Learning (ML) Methods
2.4. Deep Learning-Convolutional Neural Network (CNN)
2.5. Evaluating Classification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error | Method | Type | Preprocessing | Reference |
|---|---|---|---|---|
| 1~2% (Crack length/width) | CNN | Deep learning (R-CNN) | None | [1] |
| <11% length | NiBlack, Sauvola, Wolf, NICK, Bernsen | Image processing | Grayscale | [17] |
| <10% width | Global analysis + binarization | Image processing | Terrestrial laser scanning (TLS), orthorectification | [3] |
| mAP 95.54% | CNN | Deep learning (R-CNN) | Thermally excited infrared images | [33] |
| Sensitivity: 93% | Random forest | Traditional machine learning | Binarization | [34] |
| F1:73–99% | CNN (7 pretrained CNNs) | Deep learning | None | [35] |
| F1: 91.9% | FCN crack segmentation | Deep learning (VGG16 pretrained) | None | [36] |
| False discovery rate: 3.86% | Template matching and threshold | Image processing | Convert to 3D with fast average reconstruction | [37] |
| F1: >87% | CNN (multiscale fusion) | Deep learning (SegNet pretrained) | None | [38] |
| AUC: 96.8% | Naive Bayes data fusion scheme CNN | Deep learning and traditional machine learning | None | [39] |
| F1: >80% | CNN | Deep learning (AlexNet pretrained) | Edge detection | [9] |
| F1: >0.79, length range: 221.82% | FCN crack segmentation | Deep learning (VGG19 pretrained) | None | [33] |
| F1: 91.7% | FCN pixel detection | Deep learning (VGG16 pretrained) | Pixels annotated (crack) | [27] |
| F1: 90% | FCN | Deep learning (U-Net pretrained) | Crack-labelled, Adam optimization | [40] |
| Best F1: 92.6%, others: >72.3% | Faster R-CNN, DCNN, and Bayesian probability | Deep learning (VGG16 and ResNet101) and traditional machine learning | Semiautomatic crack annotation | [41] |
| F1: 88.86% | CNN | Deep learning (CrackNet CNN) | Line filters (“feature extractor”) | [42] |
| ACC: >87.9% | CNN | Deep learning (deep CNN) | Image annotation | [43] |
| Realization of automated system | Agglomerative hierarchical clustering | Traditional machine learning | Removal of distortion, thresholding | [44] |
| F1: >89%, Pr: >91%, | CNN | Deep learning | Increase ratio of sample (1:3) | [45] |
| Distance Error: 7.5%–8.5% | Gaussian colour distribution | Traditional machine learning | Particle filtering | [46] |
| F1: 97%, Pr: 95.5% | Various parametric, nonparametric, clustering, one-class classifiers | Traditional machine learning and image processing | Smoothing, white lane line detection, image normalization, saturation | [18] |
3. Methodology
3.1. Dataset Collection
3.2. Image Processing
3.2.1. Control (RGB)
3.2.2. Grayscale (Luminance)
3.2.3. Edge Detection (Sobel Filter)
3.2.4. Thresholding/Binarization (Otsu Method)
3.3. The Proposed CNN Model
3.3.1. Model Development
3.3.2. Model Analysis
4. Results
4.1. 10-Epoch Training
4.2. 20-Epoch Training
4.3. Comparison of the Epochs
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, I.-H.; Jeon, H.; Baetk, S.-C.; Hong, W.-H.; Jung, H.-J. Application of crack identification techniques for an aging concrete bridge inspection using an unmanned aerial vehicle. Sensors 2018, 18, 1881. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Munawar, H.S.; Aggarwal, R.; Qadir, Z.; Khan, S.; Kouzani, A.; Malhmud, M. A gabor filter-based protocol for automated image-based building detection. Buildings 2021, 11, 302. [Google Scholar] [CrossRef]
- Valença, J.; Puente, I.; Júlio, E.; González-Jorge, H.; Alrias-Sánchez, P. Assessment of cracks on concrete bridges using image processing supported by laser scanning survey. Constr. Build. Mater. 2017, 146, 668–678. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khan, S.I.; Qadir, Z.; Kiani, Y.S.; Kouzani, A.Z.; Mahmud, M.A.P. Insights into the Mobility Pattern of Australians during COVID-19. Sustainability 2021, 13, 9611. [Google Scholar] [CrossRef]
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khan, S.; Qadir, Z.; Kouzani, A.; Mahmud, M. Insight into the impact of COVID-19 on Australian transportation sector: An economic and community-based perspective. Sustainability 2021, 13, 1276. [Google Scholar] [CrossRef]
- Hsieh, Y.-A.; Tsai, Y.J. Machine learning for crack detection: Review and model performance comparison. J. Comput. Civ. Eng. 2020, 34, 04020038. [Google Scholar] [CrossRef]
- Khan, S.I.; Qadir, Z.; Munawar, H.S.; Nayak, S.R.; Budati, A.K.; Verma, K.; Prakash, D. UAVs path planning architecture for effective medical emergency response in future networks. Phys. Commun. 2021, 47, 101337. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Benchmarking image processing algorithms for unmanned aerial system-assisted crack detection in concrete structures. Infrastructures 2019, 4, 19. [Google Scholar] [CrossRef] [Green Version]
- Liaquat, M.U.; Munawar, H.S.; Rahman, A.; Qadir, Z.; Kouzani, A.Z.; Mahmud, M.A.P. Sound localization for ad-hoc microphone arrays. Energies 2021, 14, 3446. [Google Scholar] [CrossRef]
- Xie, Y.; Richmond, D. Pre-training on grayscale imagenet improves medical image classification. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bui, H.M.; Lech, M.; Cheng, E.; Neville, K.; Burnett, I.S. Using Grayscale Images for Object Recognition with Convolutional-Recursive Neural Network; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Shahriar, M.T.; Li, H. A Study of Image Pre-processing for Faster Object Recognition. arXiv 2020, arXiv:Preprint/2011.06928. [Google Scholar]
- Pranno, A.; Greco, F.; Lonetti, P.; Luciano, R.; De Maio, U. An improved fracture approach to investigate the degradation of vibration characteristics for reinforced concrete beams under progressive damage. Int. J. Fatigue 2022, 163, 107032. [Google Scholar] [CrossRef]
- De Maio, U.; Greco, F.; Leonetti, L.; Blasi, P.N.; Pranno, A. A cohesive fracture model for predicting crack spacing and crack width in reinforced concrete structures. Eng. Fail. Anal. 2022, 139, 106452. [Google Scholar] [CrossRef]
- Wang, G.; Peter, W.T.; Yuan, M. Automatic internal crack detection from a sequence of infrared images with a triple-threshold Canny edge detector. Meas. Sci. Technol. 2018, 29, 025403. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Cho, S.; Shin, M.; Sim, S.-H. Comparative analysis of image binarization methods for crack identification in concrete structures. Cem. Concr. Res. 2017, 99, 53–61. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. CrackIT An image processing toolbox for crack detection and characterization. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 798–802. [Google Scholar]
- Akram, J.; Munawar, H.S.; Kouzani, A.Z.; Mahmud, M.A.P. Using Adaptive Sensors for Optimised Target Coverage in Wireless Sensor Networks. Sensors 2022, 22, 1083. [Google Scholar] [CrossRef]
- Akram, J.; Tahir, A.; Munawar, H.S.; Akram, A.; Kouzani, A.Z.; Mahmud, M.A.P. Cloud-and Fog-Integrated Smart Grid Model for Efficient Resource Utilisation. Sensors 2021, 21, 7846. [Google Scholar] [CrossRef]
- Qadir, Z.; Munir, A.; Ashfaq, T.; Munawar, H.S.; Khan, M.A.; Le, K. A prototype of an energy-efficient MAGLEV train: A step towards cleaner train transport. Clean. Eng. Technol. 2021, 4, 100217. [Google Scholar] [CrossRef]
- Poynton, C. Frequently asked questions about color. Retrieved June 1997, 19, 2004. [Google Scholar]
- Dorafshan, S.; Maguire, M.; Chang, M. Comparing automated image-based crack detection techniques in the spatial and frequency domains. In Proceedings of the 26th ASNT Research Symposium, Jacksonville, FL, USA, 13–16 March 2017. [Google Scholar]
- Nigam, R.; Singh, S.K. Crack Detection in a Beam Using Wavelet Transform and Photographic Measurements. Structures 2020, 25, 436–447. [Google Scholar] [CrossRef]
- Kumar, N. Gradient Based Techniques for the Avoidance of Oversegmentation. In Proceedings of the BEATS 2010, Jalandhar, India, 7–9 June 2010. [Google Scholar]
- Tahir, A.; Munawar, H.S.; Akram, J.; Adil, M.; Ali, S.; Kouzani, A.Z.; Mahmud, M.A.P. Automatic Target Detection from Satellite Imagery Using Machine Learning. Sensors 2022, 22, 1147. [Google Scholar] [CrossRef] [PubMed]
- Alipour, M.; Harris, D.K.; Miller, G.R. Robust pixel-level crack detection using deep fully convolutional neural networks. J. Comput. Civ. Eng. 2019, 33, 04019040. [Google Scholar] [CrossRef]
- Shaukat, M.A.; Shaukat, H.; Qadir, Z.; Munawar, H.; Kouzani, A.; Mahmud, M. Cluster analysis and model comparison using smart meter data. Sensors 2021, 21, 3157. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Munawar, H.S.; Hammad, A.W.A.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-based crack detection methods: A review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.; Waller, S.T. Disaster Region Coverage Using Drones: Maximum Area Coverage and Minimum Resource Utilisation. Drones 2022, 6, 96. [Google Scholar] [CrossRef]
- Munawar, H.S.; Mojtahedi, M.; Hammad, A.W.; Kouzani, A.; Mahmud, M.P. Disruptive technologies as a solution for disaster risk management: A review. Sci. Total Environ. 2022, 806, 151351. [Google Scholar] [CrossRef]
- Yang, J.; Wang, W.; Lin, G.; Li, Q.; Sun, Y.; Sun, Y. Infrared thermal imaging-based crack detection using deep learning. IEEE Access 2019, 7, 182060–182077. [Google Scholar] [CrossRef]
- Luo, Q.; Ge, B.; Tian, Q. A fast adaptive crack detection algorithm based on a double-edge extraction operator of FSM. Constr. Build. Mater. 2019, 204, 244–254. [Google Scholar] [CrossRef]
- Özgenel, Ç.F.; Sorguç, A.G. Performance comparison of pretrained convolutional neural networks on crack detection in buildings. In Proceedings of the International Symposium on Automation and Robotics in Construction, Berlin, Germany, 20–25 July 2018. [Google Scholar]
- Dung, C.V. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Moosavi, R.; Grunwald, M.; Redmer, B. Crack detection in reinforced concrete. NDT E Int. 2020, 109, 102190. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans Image Process 2018, 28, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Chen, F.-C.; Jahanshahi, M.R. NB-CNN: Deep learning-based crack detection using convolutional neural network and Naïve Bayes data fusion. IEEE Trans. Ind. Electron. 2017, 65, 4392–4400. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Fang, F.; Li, L.; Gu, Y.; Zhu, H.; Lim, J.-H. A novel hybrid approach for crack detection. Pattern Recognit. 2020, 107, 107474. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Pauly, L.; Peel, H.; Luo, S.; Hogg, D.; Fuentes, R. Deeper networks for pavement crack detection. In Proceedings of the 34th ISARC, Taipei, Taiwan, 28 June–1 July 2017. [Google Scholar]
- Rimkus, A.; Podviezko, A.; Gribniak, V. Processing digital images for crack localization in reinforced concrete members. Procedia Eng. 2015, 122, 239–243. [Google Scholar] [CrossRef]
- Fan, Z.; Wu, Y.; Lu, J.; Li, W. Automatic pavement crack detection based on structured prediction with the convolutional neural network. arXiv 2018, arXiv:Preprint/1802.02208. [Google Scholar]
- Lins, R.G.; Givigi, S.N. Automatic crack detection and measurement based on image analysis. IEEE Trans. Instrum. Meas. 2016, 65, 583–590. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.; Waller, S.T. Remote Sensing Methods for Flood Prediction: A Review. Sensors 2022, 22, 960. [Google Scholar] [CrossRef]
- Özgenel, Ç.F. Concrete crack images for classification. Mendeley Data 2018, 1. [Google Scholar]
- Munawar, H.S.; Hammad, A.; Waller, S.; Thaheem, M.; Shrestha, A. An integrated approach for post-disaster flood management via the use of cutting-edge technologies and UAVs: A review. Sustainability 2021, 13, 7925. [Google Scholar] [CrossRef]
- Talab, A.M.A.; Huang, Z.; Xi, F.; HaiMing, L. Detection crack in image using Otsu method and multiple filtering in image processing techniques. Optik 2016, 127, 1030–1033. [Google Scholar] [CrossRef]
- Munawar, H.S.; Awan, A.A.; Khalid, U.; Maqsood, A. Revolutionizing Telemedicine by Instilling H. 265. Int. J. Image Graph. Signal Processing 2017, 9, 20–27. [Google Scholar] [CrossRef] [Green Version]
- Munawar, H.S.; Maqsood, A.; Mustansar, Z. Isotropic surround suppression and Hough transform based target recognition from aerial images. Int. J. Adv. Appl. Sci. 2017, 4, 37–42. [Google Scholar] [CrossRef]
- Akram, J.; Javed, A.; Khan, S.; Akram, A.; Munawar, H.S.; Ahmad, W. Swarm intelligence based localization in wireless sensor networks. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, New York, NY, USA, 22–26 March 2021; pp. 1906–1914. [Google Scholar]
- Ke, L.; Liu, Z.; Yu, H. Characterization of a Patch Antenna Sensor’s Resonant Frequency Response in Identifying the Notch-Shaped Cracks on Metal Structure. Sensors 2018, 19, 110. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:Preprint/1409.1556. [Google Scholar]
- Vedaldi, A.; Lenc, K. Matconvnet: Convolutional neural networks for matlab. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015. [Google Scholar]
- Fawcett, T. ROC graphs: Notes and practical considerations for researchers. Mach. Learn. 2004, 31, 1–38. [Google Scholar]
















| Edge Detector | Method | Advantages | Limitations | Reference |
|---|---|---|---|---|
| Roberts | Gradient-Based |
|
| [23] |
| Sobel | ||||
| Prewitt | ||||
| Canny | Gaussian-Based |
|
| [16] |
| LoG | Gradient-Based |
|
| [9] |
| DWT | Wavelet-Based |
|
| [24] |
| Watershed | Gradient-Based |
|
| [25] |
| Factors | CNN | NLP | RNN |
|---|---|---|---|
| Parameter-Sharing | Yes | No | Yes |
| Recurrent Connections | No | No | Yes |
| Data | Image Data | Tabular Data | Sequence Data (Timeseries, Text, Audio) |
| Vanishing and Exploding Gradient | Yes | Yes | Yes |
| Spatial Relationship | Yes | No | No |
| Metric | 10-Epoch Pretrained | Difference to RGB | |||||
|---|---|---|---|---|---|---|---|
| RGB | Grayscale | Otsu Method | Sobel Filter | Grayscale | Otsu Method | Sobel Filter | |
| ACC | 99.433% | 99.333% | 98.850% | 99.067% | −0.100% | −0.583% | −0.367% |
| TRP | 99.233% | 99.000% | 98.367% | 98.533% | −0.233% | −0.867% | −0.700% |
| TNR | 99.633% | 99.667% | 99.333% | 99.600% | 0.033% | −0.300% | −0.033% |
| PPV | 99.632% | 99.664% | 99.327% | 99.596% | 0.033% | −0.305% | −0.036% |
| NPV | 99.236% | 99.007% | 98.382% | 98.549% | −0.230% | −0.854% | −0.688% |
| F1 | 99.432% | 99.331% | 98.844% | 99.062% | −0.101% | −0.588% | −0.371% |
| Metric | 20-Epoch Pretrained | Difference to RGB | |||||
|---|---|---|---|---|---|---|---|
| RGB | Grayscale | Otsu Method | Sobel Filter | Grayscale | Otsu Method | Sobel Filter | |
| ACC | 99.533% | 99.550% | 98.817% | 99.133% | 0.017% | −0.717% | −0.400% |
| TRP | 99.367% | 99.367% | 98.200% | 98.767% | 0.000% | −1.167% | −0.600% |
| TNR | 99.700% | 99.733% | 99.433% | 99.500% | 0.033% | −0.267% | −0.200% |
| PPV | 99.699% | 99.732% | 99.426% | 99.496% | 0.033% | −0.273 | −0.203% |
| NPV | 99.369% | 99.369% | 98.222% | 98.776% | 0.000% | −1.147% | −0.593% |
| F1 | 99.533% | 99.549% | 98.809% | 99.130% | 0.017% | −0.723% | −0.402% |
| Metric | Difference from 10 to 20 Epochs | Increase Compared to RGB | |||||
|---|---|---|---|---|---|---|---|
| RGB | Grayscale | Otsu Method | Sobel Filter | Grayscale | Otsu Method | Sobel Filter | |
| ACC | 0.100% | 0.217% | −0.33% | 0.067% | 0.117% | −0.133% | −0.033% |
| TRP | 0.133% | 0.367% | −0.167% | 0.233% | 0.233% | −0.300% | 0.100% |
| TNR | 0.067% | 0.067% | 0.100% | −0.100% | 0.000% | 0.033% | −0.167% |
| PPV | 0.067% | 0.068% | 0.099% | −0.099% | 0.001% | 0.032% | −0.167% |
| NPV | 0.132% | 0.362% | −0.160% | 0.227% | 0.230% | −0.293% | 0.094% |
| F1 | 0.100% | 0.218% | −0.035% | 0.068% | 0.118% | −0.135% | −0.032% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Golding, V.P.; Gharineiat, Z.; Munawar, H.S.; Ullah, F. Crack Detection in Concrete Structures Using Deep Learning. Sustainability 2022, 14, 8117. https://doi.org/10.3390/su14138117
Golding VP, Gharineiat Z, Munawar HS, Ullah F. Crack Detection in Concrete Structures Using Deep Learning. Sustainability. 2022; 14(13):8117. https://doi.org/10.3390/su14138117
Chicago/Turabian StyleGolding, Vaughn Peter, Zahra Gharineiat, Hafiz Suliman Munawar, and Fahim Ullah. 2022. "Crack Detection in Concrete Structures Using Deep Learning" Sustainability 14, no. 13: 8117. https://doi.org/10.3390/su14138117
APA StyleGolding, V. P., Gharineiat, Z., Munawar, H. S., & Ullah, F. (2022). Crack Detection in Concrete Structures Using Deep Learning. Sustainability, 14(13), 8117. https://doi.org/10.3390/su14138117