To build an environmental impact assessment model, we applied supervised machine learning techniques on a classification problem. Supervised machine learning involves training and learning a model from patterns that can be identified in a dataset with training examples that are pairs consisting of an input object and an output variable, so that the learned model can predict the output variable for new input data (see, e.g., [
23]). The obtained model is often evaluated using input–output pairs that were not used for training the model, by comparing the outputs from the model to the desired outputs. We more particularly tackled a classification problem. In a classification problem, the output variable is categorical, and the obtained model attempts to predict how a new input object should be labeled.
In
Section 2.1, we present the dataset assembled based on previously conducted LCA studies, containing clothing products (observations), their life cycle characteristics (independent input variables or features), and the corresponding total environmental impact (dependent output variable or outcome variable). We applied a stratified 5-fold cross-validation procedure, i.e., we divided the dataset into five nonoverlapping folds, and used each fold (20% of the data) once as a held back test set whilst all other folds collectively (80% of the data) were used as training set. We thus fitted and evaluated a model on five different data subsets for each machine learning algorithm and reported the average performance over the five iterations to estimate the overall performance of the algorithm (see, e.g., [
23]). In
Section 2.2, we present the nine machine learning algorithms applied to training data to find a function or set of rules that models the data with the least error. The metrics used for assessing the models and algorithms are presented in
Section 2.3. Each machine learning algorithm includes one or more hyperparameters that allow the algorithm behavior to be tailored to the specificities of a dataset. To configure the hyperparameters to our dataset, a grid search optimization procedure with crossvalidation is used. Consequently, we applied a double crossvalidation: we used one crossvalidation procedure to estimate and compare the performance of different machine learning models, and one to evaluate and compare the performance of sets of model hyperparameters. To overcome the problem of overfitting, we nested the (inner) hyperparameter optimization procedure under the (outer) model selection procedure, as suggested by [
23].
2.1. Data Collection and Pretreatment
Building the dataset required (1) selecting a meaningful set of product attributes as features, (2) collecting previously life-cycle-analyzed clothing products, and (3) defining the outcome variable, as detailed in this section.
2.1.1. Selection of the Features
The selected life cycle characteristics inputs should logically and statistically be linked to environmental impact data but should also be product attributes accessible to online retailers, so that they can apply the model to their product catalog. Therefore, we first formed a set of candidate product attributes based upon the literature and the experience of experts regarding the clothing supply chain, which we then refined using different criteria, to create a set of meaningful features. The main criteria used for selecting product attributes to use as features are their relationship to various factors impacting the environment (e.g., energy consumption, garment recyclability, etc.) and their accessibility to online retailers.
The clothing supply chain begins with the production of fibers, followed by spinning to produce yarn. Fabrics are manufactured from yarns through knitting or weaving. After bleaching and dyeing, the garment is manufactured by cutting, sewing, and adding trims. After manufacturing, the garments are shipped to central distribution centers and eventually to smaller retailers. The garments are used, and, at the end of their life, they are incinerated, transported to landfills or developing countries, and few are recycled. As shown in [
3], a garment has an impact on the environment at each stage of its supply chain. According to [
24], most of the life cycle impacts of apparel products occur in the use and production phases. The impacts on water resources, carbon emissions, waste, and chemical pollution vary by garment type as those with higher mass or volume require more resources, for instance (see, e.g., [
3]). However, these impacts vary even for the same garment type, depending on different choices made throughout the life cycle, such as the fiber chosen, which has an impact on the natural resources, water, energy, and chemicals used throughout the manufacturing phase but also on the biodegradability and recyclability of the garment at its end-of-life. According to the sustainable brand Reformation [
25], the raw materials could determine up to two-thirds of the impact of a garment. As also shown by [
26], the process technology and equipment used during the cultivation and manufacturing phases also have an impact on the amount of waste produced and on the amount of energy, water, and chemicals used. Where the garment is manufactured is also determinant, as some countries have better environmental regulations and rely on more renewable energy sources. The location of the garment production also influences the distance the garment travels around the globe and can indirectly impact the transportation means, which in turn influence carbon emissions. The impact of the use phase varies depending on factors such as consumer behavior, the technologies used, and the geographical zone in which the product is used. The type of washing and drying required by the garment during its use-time, which partly depends on the type of fiber used, also has an impact on the water and energy required during the use phase. Finally, specific end-of-life instructions might impact the decision to dispose of the garment in a landfill or to recycle or reuse it. The impacts of the waste treatment and recycling depend on the mechanical and chemical methods used. In a nutshell, textile production is resource intensive and gives rise to substantial environmental impacts due to carbon emissions, energy and water consumption, chemicals, microplastics, and waste. These environmental impacts are determined by the garment and raw material type, the manufacturing processes, by where the garment is produced and how it is transported, how the garment should be taken care of prior to disposal, and the product’s end-of-life.
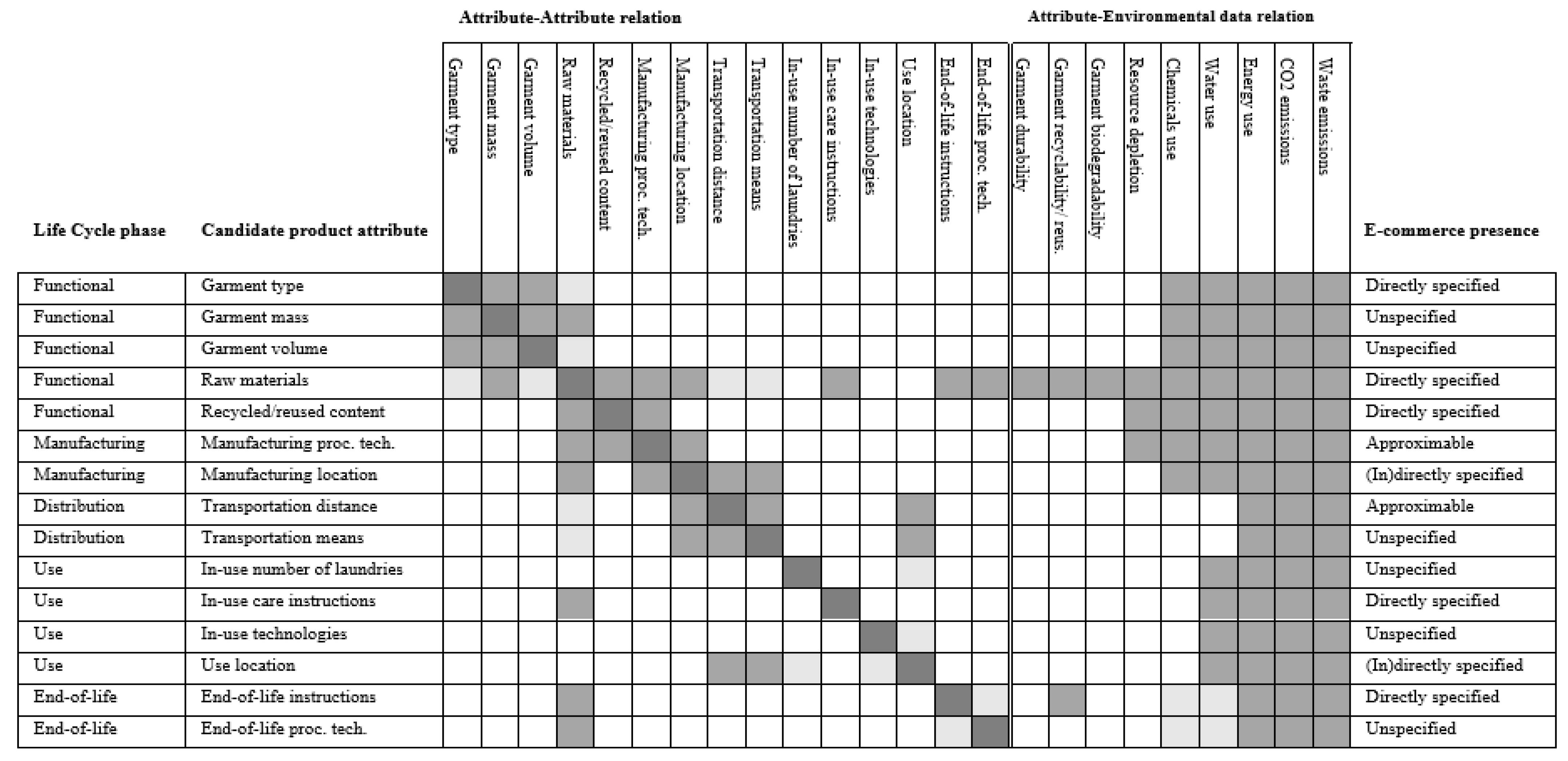
The candidate product attributes identified based on the literature are listed in
Figure 1 and are grouped according to the life cycle phases to which they may be assigned, to verify the coverage of the entire life cycle. The grouped candidate attributes are also provided with efforts to qualitatively identify potential linkages between attributes and to review the relationship between the attributes and environmental impact data. Based on a screening of five e-commerce sites, the candidate product attributes are also assigned a label indicating how they are present on e-commerce sites, which led to the refinement of the set of candidate attributes to arrive at the list of product attributes in
Table 1, which is now described. The garment type, the raw materials it is made of, and the fraction recycled or reused content in the garment, are readily available functional product attributes that directly influence the environmental impact of a garment. It is often not possible to know the exact process technology applied during manufacturing, but labels or explanations often indicate whether a company applies particular production processes to reduce the amount of water and energy used and waste produced during the manufacturing phase, whether it controls the use of chemicals and harmful substances and whether it sources raw materials responsibly. We consequently took as (binary) variables the presence of labels related to material sourcing, chemical use, and production in general. Although the manufacturing location is not always known, we retained this feature and considered the absence of indications regarding the origin of the product as a penalizing element. The use location is often known, especially in online shopping. If the manufacturing and use locations are known, the distance (in km) over which a garment needs to be transported to reach the end-consumer departing from the manufacturing site can be approximated. The transportation means and the transportation of raw materials to the production factories and between the manufacturing locations are excluded as this information is often not known by an online retailer. It did not seem relevant to consider the choices a user could make relative to the garment during the use phase, such as the number of laundries they choose to do and the machines they choose to use to wash, dry, and iron their clothes. Consequently, we only considered the type of washing and drying a garment requires based on the instructions given to the users. It is not possible to consider the process technology used to treat a clothing product at its end-of-life, but it is possible to know whether a product is more likely to be thrown away or to have a second life based on the presence of recyclable-friendly labels and reusable-friendly labels. Finally, it should be noted that packaging and other distributor’s choices are not considered as these elements are specific to the company and not the product. Another notable exclusion is the manufacturing of trims, such as zippers, buttons, and fasteners, but previous studies have shown that these elements are negligible in the total environmental impact of a garment.
2.1.2. Collection of the Observations
The dataset must contain a representative sample of clothing products with complete data on product attributes and corresponding environmental impact. The sustainable and fair-trade certified denim brand “MUD Jeans”, based in the Netherlands, agreed to share the results of LCAs conducted for 75 of its products. We also took 45 clothing products whose LCA results are freely available in the database of The International EPD System. In addition to these 120 products, we included data for 27 other products from studies provided by different researchers and organizations. Finally, using the Python Beautiful Soup library (see, e.g., [
27]), we extracted 159 and 830 clothing products, respectively—with their attributes and environmental impact—from the e-commerce site “Reformation” and a second popular online retailer. When values for some products were missing for some variables, we inferred the missing values from observations with similar values for the other variables or we did not fill in the gap, depending on the missing data. As for use location for a product, we randomly selected a country being part of the retail market of the product’s online retailer, to generate a variety of transportation distances that are representative of reality. This resulted in a dataset containing 1136 clothing products with complete product attribute data and corresponding environmental impact data.
Because the data came from different sources, the data on the environmental impact of the products did however not have a uniform structure. For some products, we had the amount of water (in l) and energy (in MJ) used, the carbon emissions (in kg CO2 eq.), and other less commonly used indicators, from resource extraction (cradle) to the factory gate before it is transported to the consumer (gate), or from resource extraction (cradle) to the final disposal of the product (grave). For other products, the environmental information of a product was expressed in terms of water and carbon emission savings compared to a product made of the same materials without sustainable sourcing and production processes. For most products, calculations were made using data from databases such as Ecoinvent and Agri-footprint modeled with SimaPro and GaBi softwares. However, Reformation sustainability team uses its own LCA tool, called RefScale. The scope of this tool is a cradle-to-grave assessment; the impacts from cradle-to-gate are measured using the Higg materials sustainability index (Higg MSI) developed by the Sustainable Apparel Coalition (SAC), and impact calculations for the following life cycle stages are based on a mix of primary and secondary data, including other LCAs, material databases, and the scientific literature reviews. The Higg MSI, together with the textile exchange’s preferred fibers and materials list, are also used by the second online retailer. Consequently, given that the products’ environmental impacts were expressed in a variety of ways, we defined a common environmental outcome variable.
2.1.3. Definition of the Outcome Variable
Since reducing life cycle environmental impact data to a single score facilitates communication and is more useful for comparative assessments, we chose to use such a score—simultaneously considering different factors impacting the environment related to the life cycle stages of a garment (e.g., water consumption, energy consumption, carbon emissions, etc.)—as our environmental impact output. Therefore, we first defined the factors to be considered and then aggregated the different impact factors to obtain a single score that could be used as a basis to form classification labels for supervised learning models.
Environmental Indicators
References [
24,
26] suggest using the following indicators for the environmental classification and labeling of textile products: carbon and waste emissions to air and water, the energy, water, and harmful substances used during production, working conditions, emissions caused by transportation, product quality and suitability for sustainable use, recyclability and reusability of the textile product, and renewability or depletion of raw materials resources. As it can also be seen in the study of [
3], the factors most regularly considered to assess the environmental impact of a garment are energy consumption, water consumption, carbon emissions, and chemicals, microplastics, and waste released in the environment. The durability of the garment is often not considered as a garment’s lifetime depends more on consumer habits than on the product composition itself. Consequently, we decided to use the following list of environmental indicators to evaluate the total environmental performance of the products in the dataset: energy, water, chemicals used, and waste and carbon emissions during production, environmental costs of transport, suitability of the product for sustainable use and sustainable end-of-life, and depletion of raw materials resources. By not considering the working conditions, our model focuses on the environmental sustainability of clothing products and does not take social and ethical considerations into account. For the products we collected, we often had the amount of water (in l) and energy (in MJ) used and the carbon emissions (in CO
2 eq.) from the extraction of raw materials to the end of the production process. However, unlike for the manufacturing phase, we gathered few detailed data on the environmental impact of the distribution, use, and end-of-life phases, i.e., the amounts of waste generated, water and energy used, and carbon emissions for a product during these phases. Since the added value of having this detailed information for those phases was low compared to the costs of collecting it, we did not take these individual environmental factors into account. We did, however, consider the relative overall environmental costs of distribution, the product’s suitability for sustainable use and sustainable end-of-life, and the risk of resource depletion. We used the Higg MSI and secondary data from other materials and LCA databases, existing LCA studies, and the literature reviews, to fill in missing data.
Aggregation of Indicators
Different methods have been introduced to normalize and weight several non-normalized and unweighted LCA indicators, to obtain a single overall environmental performance indicator or single score. As explained in [
28], most single scores are currently estimated using the ReCiPe method based on a linear weighted sum (LWS), but there are a multitude of methods for the calculation of a single score based on environmental indicators, which are referred to as multiple attribute decision making (MADM) methods. For example, there is the technique for order preference by similarity to ideal solutions (TOPSIS), a distance-based MADM method that consists of multiplying normalized indicators by weighting factors and calculating the single score for each observation in terms of relative closeness to an ideal and nonideal solution. The weighting factors can be based on experts’ opinion on the relative importance of the indicators, which is referred to as panel weighting. In the present study, we used a method close to TOPSIS to estimate single scores from the values of the selected environmental indicators. This method is now described.
If there are m observations in a dataset and n environmental indicators, and xij represents the value of the ith observation for the jth factor, X ([X]ij = xij) represents the decision matrix to use for the calculation of a single score as the aim is to find a single environmental score for each observation based on its values for the environmental indicators. In the present study, we have 1136 clothing products and nine environmental indicators; therefore, the size of our decision matrix is 1136 × 9.
Definition of Ideal and Nonideal Solutions
The first step of the TOPSIS method consists in defining an ideal and a nonideal solution for the observations, i.e., vectors of size n containing, respectively, the ideal and nonideal values for each environmental indicator, and to add these solutions to the decision matrix. In this way, we defined ideal and nonideal solutions for our clothing products. As expected, in our dataset, the values of some environmental indicators were considerably lower for lightweight products, such as T-shirts, blouses, and shirts. We therefore formulated an ideal solution and a nonideal solution for both lightweight and heavyweight products, given that we are more interested in evaluating the environmental sustainability of clothing products compared to close alternatives. Assuming that our dataset contains products representative of what is the most sustainable and least sustainable currently sold, we took, as the ideal value for a cost-type indicator, the smallest existing value (minimum) for it in the dataset, and for a benefit-type indicator, the largest existing value (maximum) for this indicator. Benefit-type indicators are indicators for which greater values are preferred (e.g., fitness for sustainable use and end-of-life), and cost-type indicators are indicators for which lower values are preferred (e.g., water use and energy use). The maximum and minimum values were established after removing and reassigning new highs to outlier values in the dataset. The decision matrix size became 1140 × 9 after adding the four vectors of the two ideal solutions and the two nonideal solutions.
Normalization of Indicators
The second step consists of normalizing the indicators because they have numerical values in several dimensions with significant differences in sizes. We applied the linear min-max normalization to normalize all numerical values between 0 and 1 and to bring the indicators to a common scale. In particular, each element r
ij of the normalized matrix
R ([
R]
ij = r
ij) is computed by:
Lightweight products were normalized to the minimum and maximum values of the lightweight products, and heavyweight products to the minimum and maximum values of the heavyweight products. After normalization, the ideal and nonideal solutions could therefore each be represented by a single vector consisting of only 0’s and 1’s (r+ and r−).
Weighting of Indicators
Environmental indicators can be weighted if they are not equally important. As the different stages of a garment’s life cycle do not contribute equally to a garment’s total environmental impact, we weighted the selected indicators. According to [
29], what happens during the end-of-life and distribution phases appears to be almost negligible when calculating the total environmental impact of a product, regardless of the selected indicators. Combining data from various sources (see, e.g., [
30,
31,
32]), the production phase contributes approximately 4 and 5 times more to the total environmental impact of a product than the end-of-life and distribution phases. Therefore, we assigned a weighting factor of 5 to the five indicators for the production phase. If vector
wj contains the weights assigned to each indicator j, each element of the weighted normalized matrix
V ([
V]
ij = v
ij) is obtained by:
Computation of the Final Scores and Labels
The distance of each observation i to the ideal and nonideal solutions, now represented by vectors
v+ and
v−, is then estimated as in (3) and (4).
Finally, the single score of a product
i (s
i), in terms of relative closeness to the ideal and nonideal solutions, is estimated by:
The values of s
i range between 0 and 1, and the closer the s
i of a product is to 1, the closer the product is to an ideal solution and the further it is from a nonideal garment solution.
In accordance with the tackled problem, i.e., a classification problem, we then used the calculated scores as a basis for five classification labels: extra sustainable (XS), sustainable (S), medium (M), nonsustainable (NS), and extra nonsustainable (XNS).
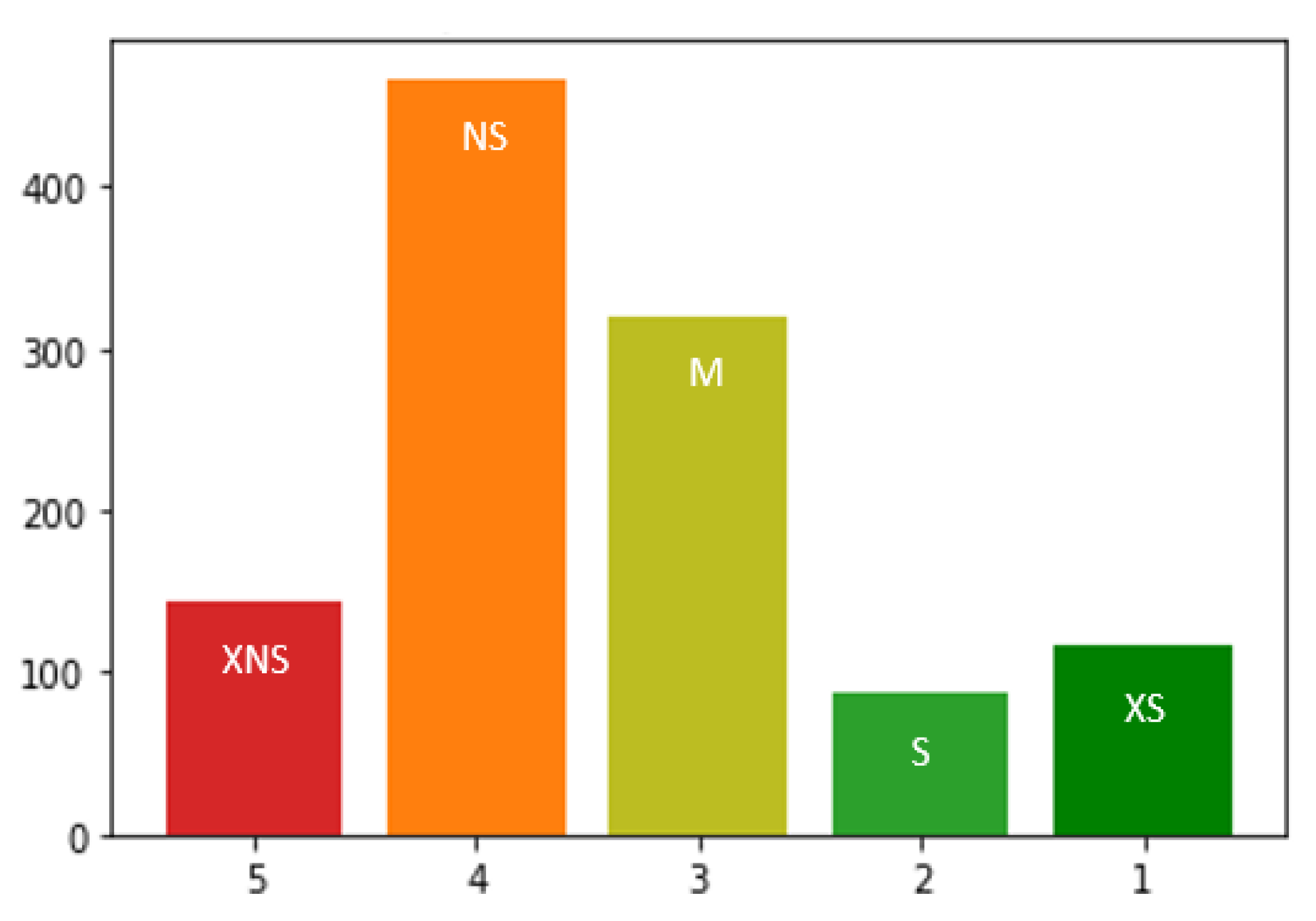
Table 2 shows the five labels with the score range we used to define each label. The method we used to calculate the single scores has the particularity of providing many scores around 0.5, but few scores at the extremes, i.e., close to 0 or 1. Therefore, it was preferable not to use constant score intervals to define the labels. We chose the score range for each label in order to assign the products to a class close to their current “environmental status” on the market, to have a distribution of products on the classes close to reality (considering that sustainable products are likely over-represented in the dataset), and to avoid having poorly represented classes.
2.1.4. Pretreatment of the Data
Univariate Statistical Analysis
The final dataset contains a wide variety of garment types, made from a variety of textile fibers and even recycled materials or deadstock fabrics, i.e., the leftover fabrics from fashion houses that overestimated their needs. Almost one out of every two garments contains some cotton or polyester, but cotton and polyester are seldom simultaneously present in a garment. However, products containing more organic cotton also tend to contain more recycled material, and the more lyocell a product contains, the more likely it is to carry a responsibly sourced material label, while the more polyester a product contains, the less likely it is to carry a material label. The garments come from all over the world, but the majority were made in Southeast Asia. Notably, 33% of the garments carry a label certifying the raw materials were responsibly sourced, 100 products (9% of the total) underwent a manufacturing process aiming to reduce the amount of water and energy used and waste produced in production, and 4% of the products carry a label certifying that the use of chemicals was controlled during production. From a birds-eye view, products travel between 5000 and 20,000 km—and more particularly, on average, 11,570 km—before reaching a consumer, starting from the manufacturing location and passing through the distributor’s warehouse. In total, 68% of the garments can be machine washed with cold water, 16% require to be washed with warm water, but only a few garments in the dataset require washing in hot water, hand washing, or dry cleaning. Line drying is recommended for over 80% of the products, while tumble drying at low and medium temperatures is recommended for few products. There is a strong relationship between washing and drying instructions, as products that can be dry cleaned do not need to be dried, and products that can be washed in warm water can often be tumble dried. Finally, 7% of products come with end-of-life instructions so that the product can be recycled or reused. Products with a reuse label also tend to have a recyclability label. As expected and as can be seen in
Figure 2, since the number of sustainable products on the market is currently still significantly lower than the number of nonsustainable products, we have slightly imbalanced classes: few products are extremely nonsustainable (XNS) or sustainable (S-XS) and most products are nonsustainable (NS), although there is an increase in products with medium sustainability (M). After this univariate statistical analysis, we already reduced our feature set by merging some poorly represented variables (e.g., by merging the variables “%Linen”, “%Jute”, and “%Hemp” under a single variable “%Other plant”).
Bivariate Statistical Analysis
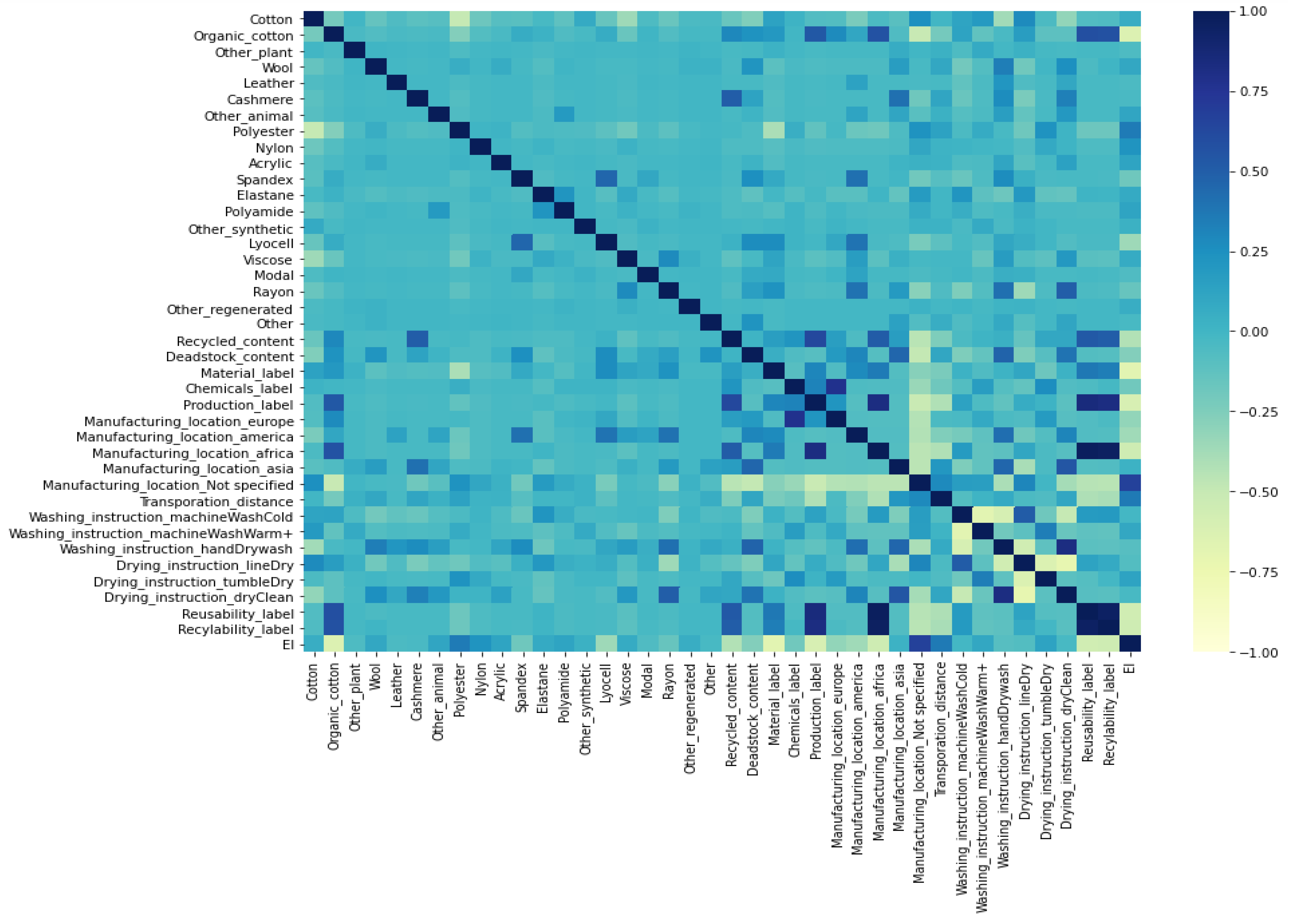
Figure 3 shows the correlation between the remaining features after univariate analysis and after data transformation, as well as the correlation between the features and the outcome variable (EI). After analyzing the correlation between the features using Spearman’s correlation coefficient for correlation between quantitative variables, Pearson’s chi-squared test with 95% statistical significance for correlation between categorical or dichotomous variables, ANOVA and eta correlation for correlation between numerical and categorical variables, and point-biserial correlation for correlation between numerical and dichotomous variables as suggested by [
33], we eliminated some additional features from the feature set to avoid highly correlated features and to reduce the total number of features. When two variables were strongly correlated, we removed the feature that initially contained the most missing values. After eliminating correlated variables, 32 variables remained for model building.
The analysis of the correlation between features and the total environmental impact of the products indicates a strong relationship between the outcome variable and the 32 retained features. The eta squared correlation ratio indicates a strong interaction effect between the amount of cotton, organic cotton, polyester, and recycled content in a garment and its environmental impact. There is also a strong interaction between the outcome variable and the presence of labels related to material sourcing, production, and recyclability.
Dimensionality Reduction and Visualization
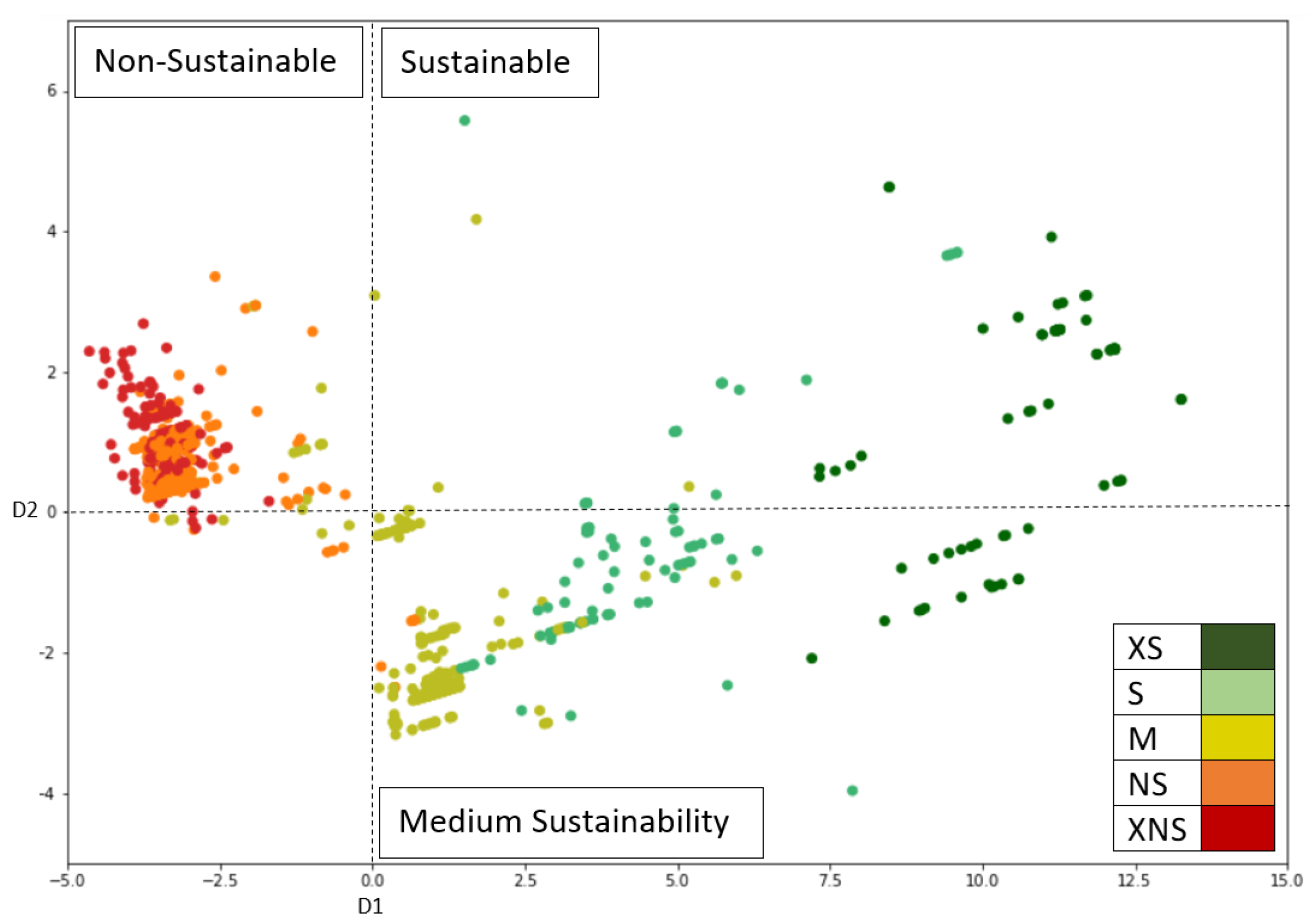
The best visualization of our data was obtained with linear discriminant analysis (LDA) as a dimensionality reduction technique. The two dimensions formed after LDA explain 95% of the variance in the data. As shown in
Figure 4, the first dimension separates relatively sustainable products (M-S-XS) from nonsustainable products (XNS-NS), and the second dimension separates extremely sustainable or nonsustainable products (XS-XNS) from those with medium sustainability (S-M-NS). Thus, highly sustainable products are predominantly present in the upper right-hand area, nonsustainable products in the upper left-hand area, and products with medium sustainability in the lower right-hand area. However, the XNS and NS classes tend to overlap, as products of these classes tend to be similar and have few elements that distinguish them, indicating a risk of misclassification.
We performed principal component analysis (PCA) and factor analysis (FA) on our rescaled features to analyze the potential of reducing the dimensionality of our data prior to modeling, but the results indicated that more than 24 factors are needed to explain at least 90% of the variance. In view of these results and given the recommended decision rules for choosing the number of components after PCA and FA (see, e.g., [
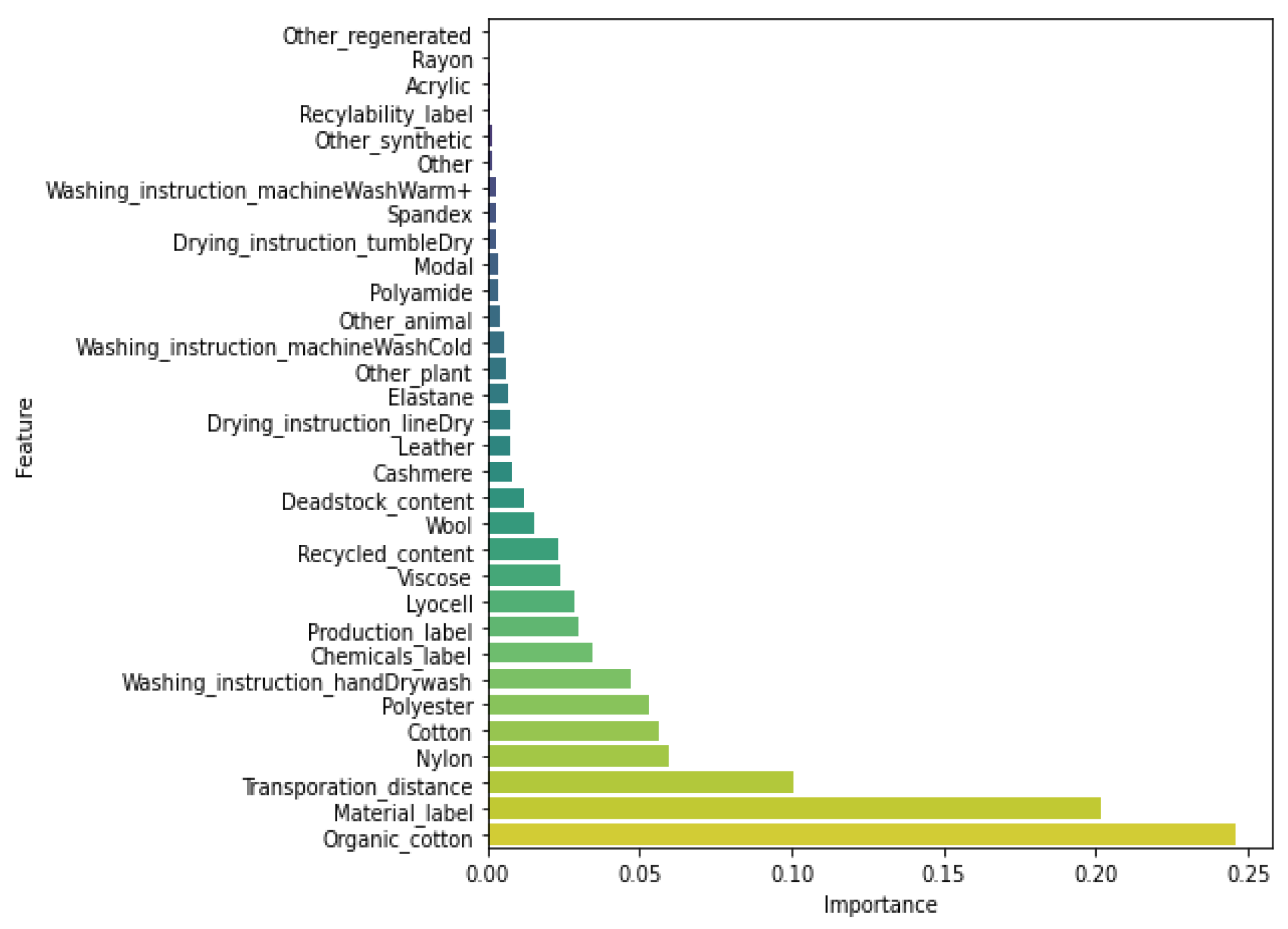
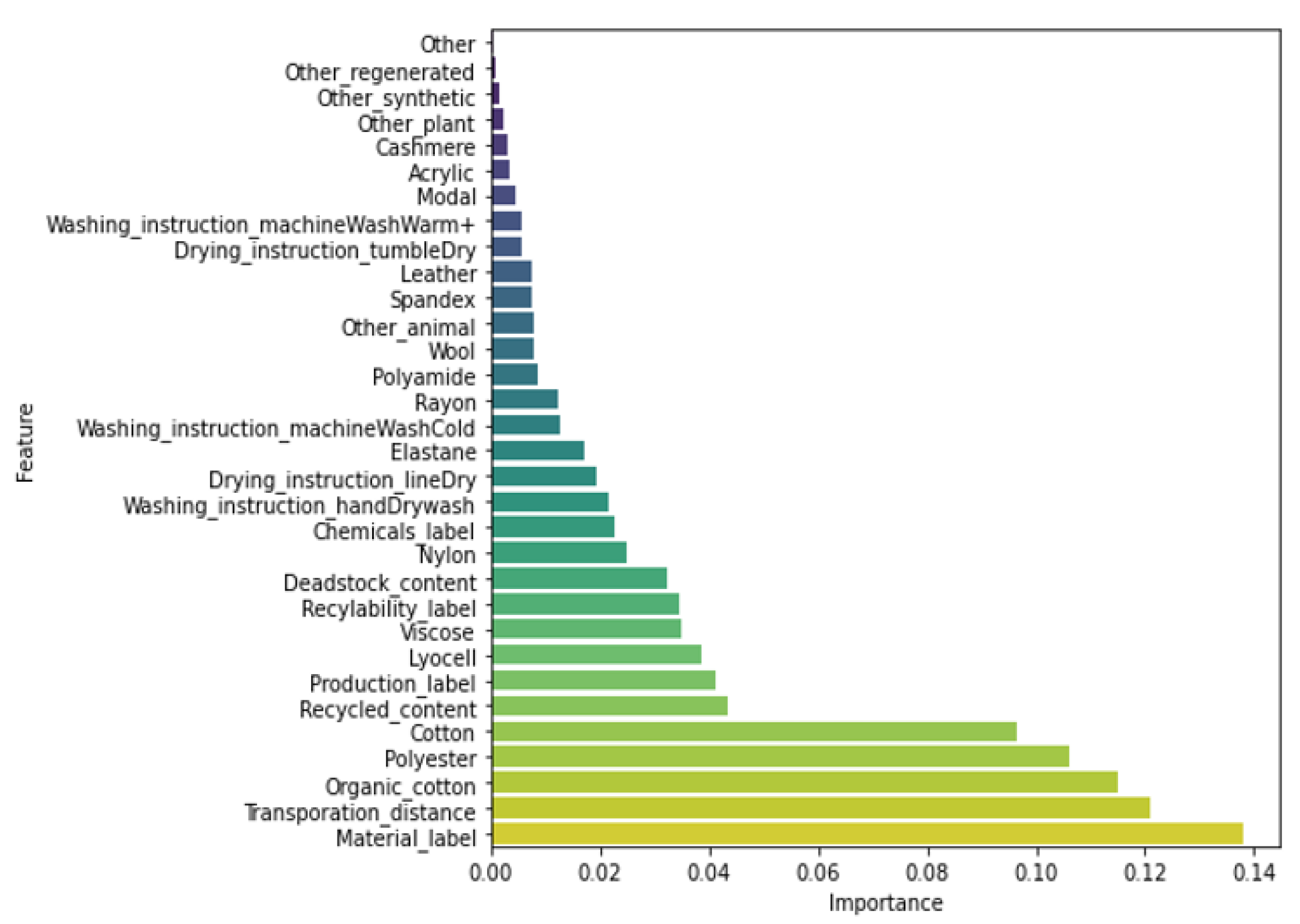
34]), it seemed wise to keep the 32 features retained so far for model building. To increase the quality of the models and avoid the dimensionality curse, we eliminate the remaining variables providing little information when building the models, i.e., with embedded feature selection methods.
2.2. Model Construction
We tested nine supervised machine learning tools to classify clothing products based on their sustainability level: a k-nearest neighbors algorithm (k-NN), a logistic regression (LR), a support vector machine (SVM), an artificial neural network (ANN) with single hidden layer, a decision tree (DT), and ensemble methods such as bagging, random forest, boosting, and gradient boosting. A description of all these algorithms is available in
Appendix A, while this section details how we applied the algorithms in our experiment. We implemented the machine learning tools in Python with the Scikit-learn library (see, e.g., [
35]).
Table 3 shows the nine machine learning algorithms tested, along with the hyperparameters for these algorithms that we tuned using Python grid search with crossvalidation and the values tested for these hyperparameters.
k-nearest neighbors algorithm (k-NN). We implemented a k-NN algorithm using Euclidian distance to find the nearest neighbors and weighting the neighbors by the inverse of their distance to the new observation for class prediction. For each iteration of the outer crossvalidation, we configured the algorithm with the optimal value of k (representing the number of neighbors to be considered) given the data for that iteration. With the inner crossvalidation procedure on the training set of the iteration, we ran and evaluated the performance of the algorithm on the data several times for different values of k, i.e., for values of k ranging from 2 to 10, to find the value of k reducing the number of prediction errors.
Logistic regression (LR). We implemented an elastic-net regularized multinomial logistic regression using the SAGA solver, a variant of the stochastic average gradient (SAG) solver that also supports l1 regularization. In the current Skicit-learn version, elastic-net regularization is only supported by the SAGA solver, and SAGA is the solver of choice for sparse multinomial logistic regression (see [
35]). For each iteration of the outer crossvalidation, we used an automatic model setting procedure to configure the model with the optimal values of the hyperparameters α (the total penalty strength) and λ (the strength of each penalty term relative to the other) given the data for that iteration. With the inner crossvalidation procedure, different values for α i.e., values between 0 and 1, and different values for λ i.e., ten values in the range from 1 to 1000 on a log scale, were tested for each iteration, and the best hyperparameters combination was selected. Relatively similar hyperparameters were found in each iteration; the models seem to perform better with a high penalty, especially a high l1 penalty.
Support vector machine (SVM). We implemented a support vector classifier with LIBSVM, which changes the optimization problem to train the SVM into a quadratic programming (QP) problem and uses the sequential minimal optimization (SMO) method to solve it. With this implementation, the one-vs-one scheme is used to handle multiple classes (see [
35]). For each iteration of the outer cross-validation, we used an automatic model configuration procedure to configure the model with the best-fitting kernel function and the optimal value of C (the regularization strength) given the data for that iteration. For each iteration, ten values in the range from 1 to 1000 on a log scale were tested for the hyperparameter C, and four kernels were tested: the basic linear kernel, the polynomial kernel (tested multiple times with different degrees), the radial kernel, and the sigmoid kernel. The value to be used for gamma in the polynomial, radial, and sigmoid kernels was also tuned. Using the kernel trick with the radial kernel seems to be the best fit for our data. However, different optimal values for the hyperparameter C were found in each iteration, showing that this machine learning model is more dependent on the specifics of the dataset.
Artificial neural network (ANN). In this study, we used a multiple-input, multiple-output, feed-forward single hidden layer ANN with the softmax activation function for the output neurons. We used an adaptive mini-batch gradient descent algorithm, in particular the Adam-optimizer, for the learning process. Categorical cross-entropy and back-propagation were used for the error function, with regularization. The universal approximation theorem states that a feed-forward network with a linear output layer and at least one hidden layer with any “squashing” activation function and enough hidden units can approximate any required function to create desired classification regions (see, e.g., [
36,
37]). We therefore decided to use an ANN with a single hidden layer but to test different numbers of units in the hidden layer and different squashing activation functions for these units (i.e., logistic sigmoid, hyperbolic tangent (tanh), and rectified linear unit (ReLU) activation function) with an automatic grid search using the inner crossvalidation procedure. A hidden layer composed of about 11 neurons seems to be the ideal neural network configuration for our data. The Adam-optimizer is the most popular and widely used gradient descent optimizer for neural network training because it performs well on a wide range of problems and because it is adaptive, i.e., it adjusts the relative learning rates of different parameters during training (see, e.g., [
36]). For each iteration of the outer crossvalidation, we optimized the initial learning rate of the Adam-optimizer, the batch size, and number of epochs simultaneously, as there is a dependency between these hyperparameters.
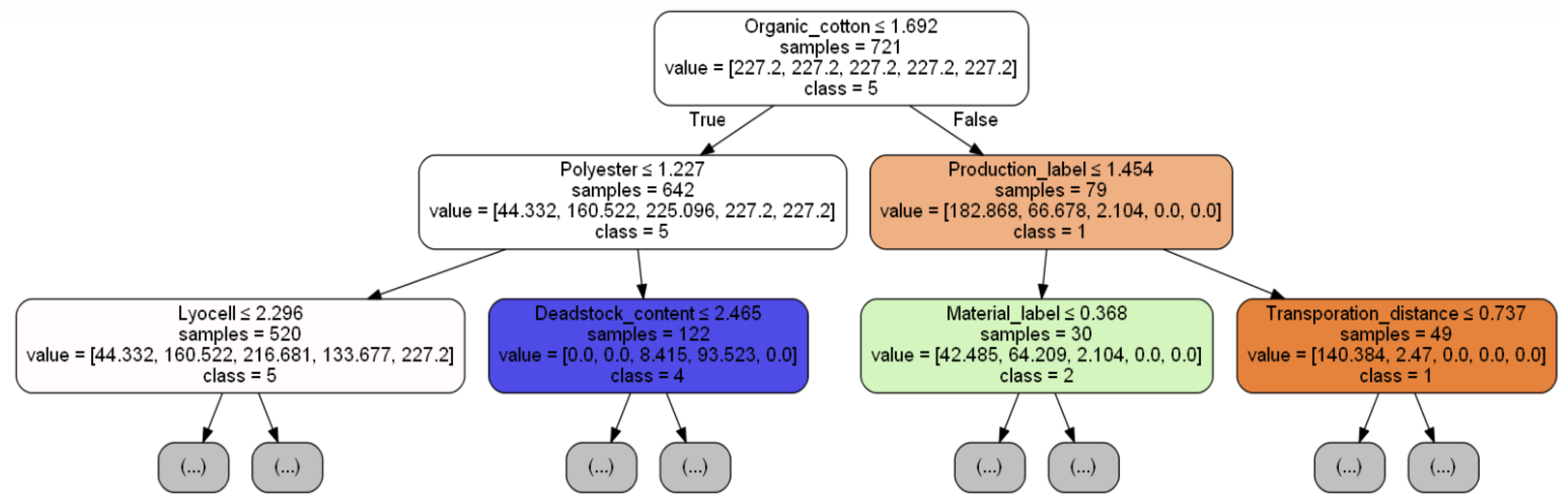
Decision tree (DT). We implemented a decision tree algorithm using the Gini index to measure the quality of a split and always selecting the best split at each node. We expanded the nodes until all leaves contained less than a minimum number of samples, with the minimum number of samples being tuned to the dataset.
Lastly, we tested four ensemble methods: bagging (Bag. DT), a random forest (RF), boosting (Boost. DT), and gradient boosting (GBoost. DT). The number of trees to be included is a hyperparameter that was tuned with the inner crossvalidation procedure for each of these methods. For bagging and the random forest, the trees were grown deep. We used the square root of the total number of features as the number of features that the random forest algorithm can search from at each split point of a tree. For boosting and gradient boosting, we used decision trees with three levels. For gradient boosting, we additionally tuned the learning rate of the boosting algorithm and the number of instances required at each leaf node to accept a new split point.
2.3. Model Assessment
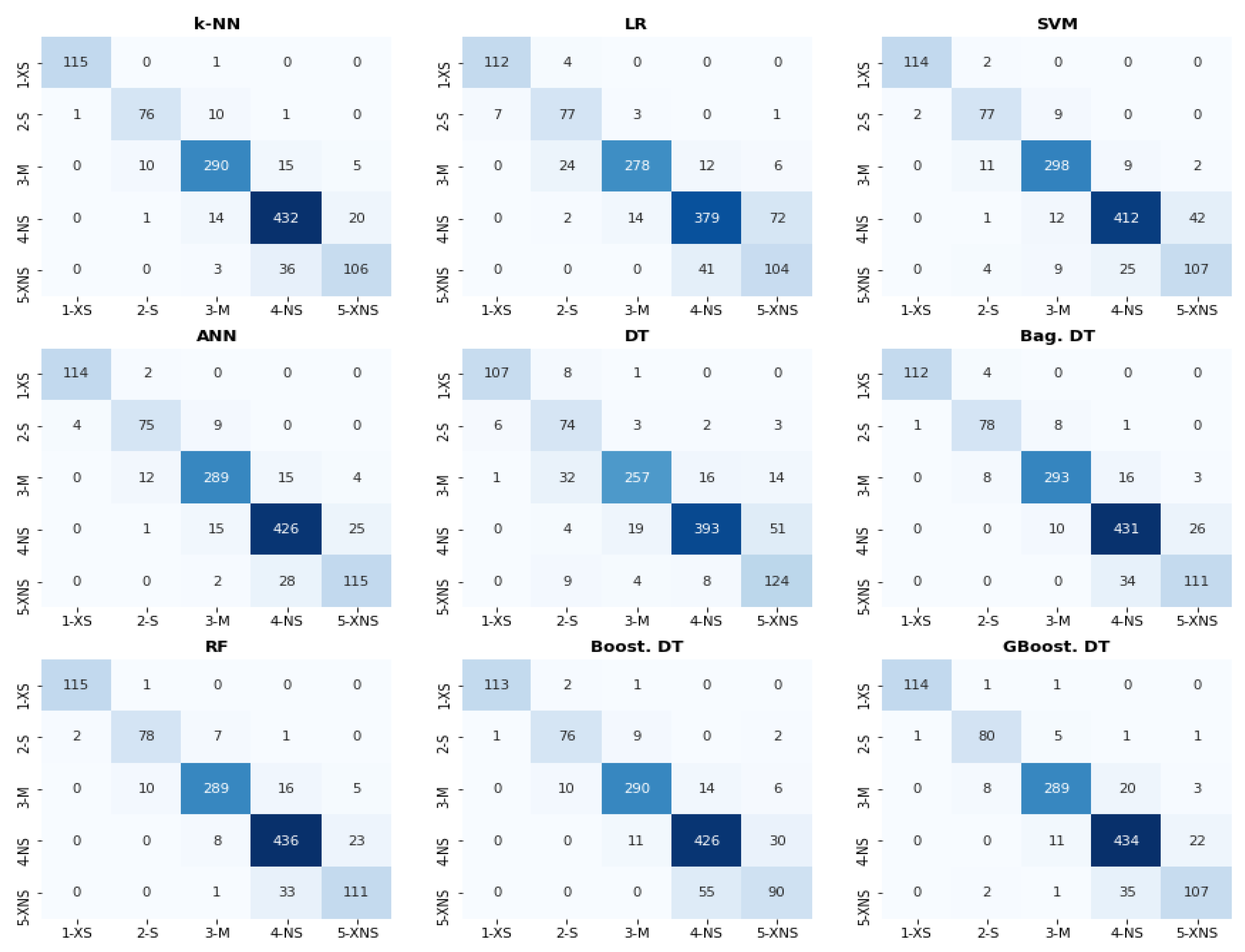
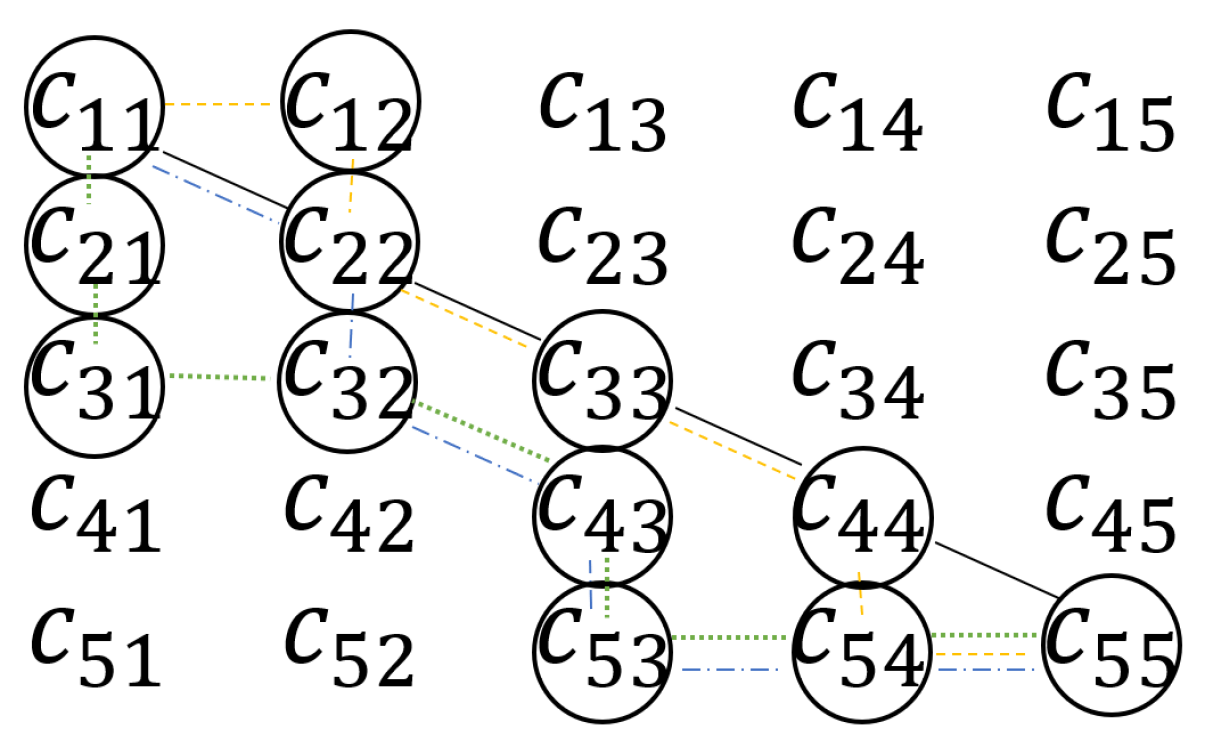
To assess their ability to generalize trends to new data, the trained models were evaluated each time using the products with known environmental impact on which they had not been trained. More precisely, for each model, we computed the confusion matrix
C, whose elements c
ij correspond to the number of products belonging to class i and classified by the model as belonging to class j. The metrics used to measure the performance of each model are accuracy, weighted macro average precision, and weighted macro average recall. All are computed from the confusion matrix as shown in
Appendix B.
As we tackled an ordinal classification problem, i.e., a multiclass classification problem for which there is an inherent order between classes, we further assessed the quality of each classifier by calculating the mean squared error (MSE) defined from the overall confusion matrix, Kendall’s Tau-b rank correlation coefficient (Tau-b) and the ordinal classification index (OCI) developed by [
38]. The MSE captures the extent to which a classifier’s predictions diverge from the true classes. Kendall’s Tau-b captures the (in)consistency between the relative class order given by a classifier and the true relative class order. Finally, the index developed by Cardoso and Sousa captures both the degree of divergence between predictions and actual results and the inconsistency of a classifier with respect to the relative order of classes. Further explanation on how these measures are computed is available in
Appendix B.
Finally, we compared the decision functions and rules of our classifiers with the characteristics of sustainable clothing products currently mentioned in the scientific literature. We also compared the computational complexity of the algorithms to consider more criteria for model selection.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}