
Promoting Sustainability through Next-Generation Biologics Drug Development

 , ,
, ,  , and
, and 
Abstract
:1. Introduction
1.1. Objective and Significance of Work
1.2. Structure of the Work
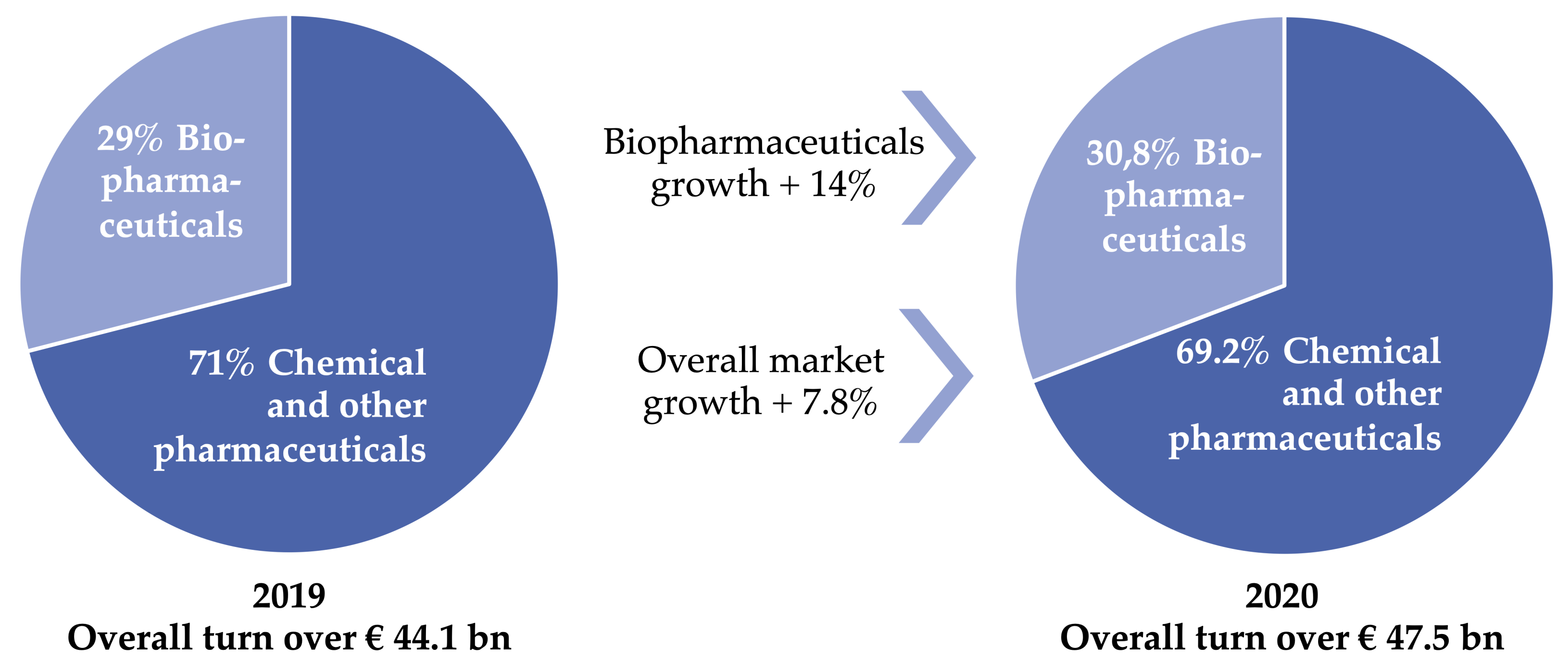
1.3. Economic Significance and Current Challenges in the Pharmaceutical Industry
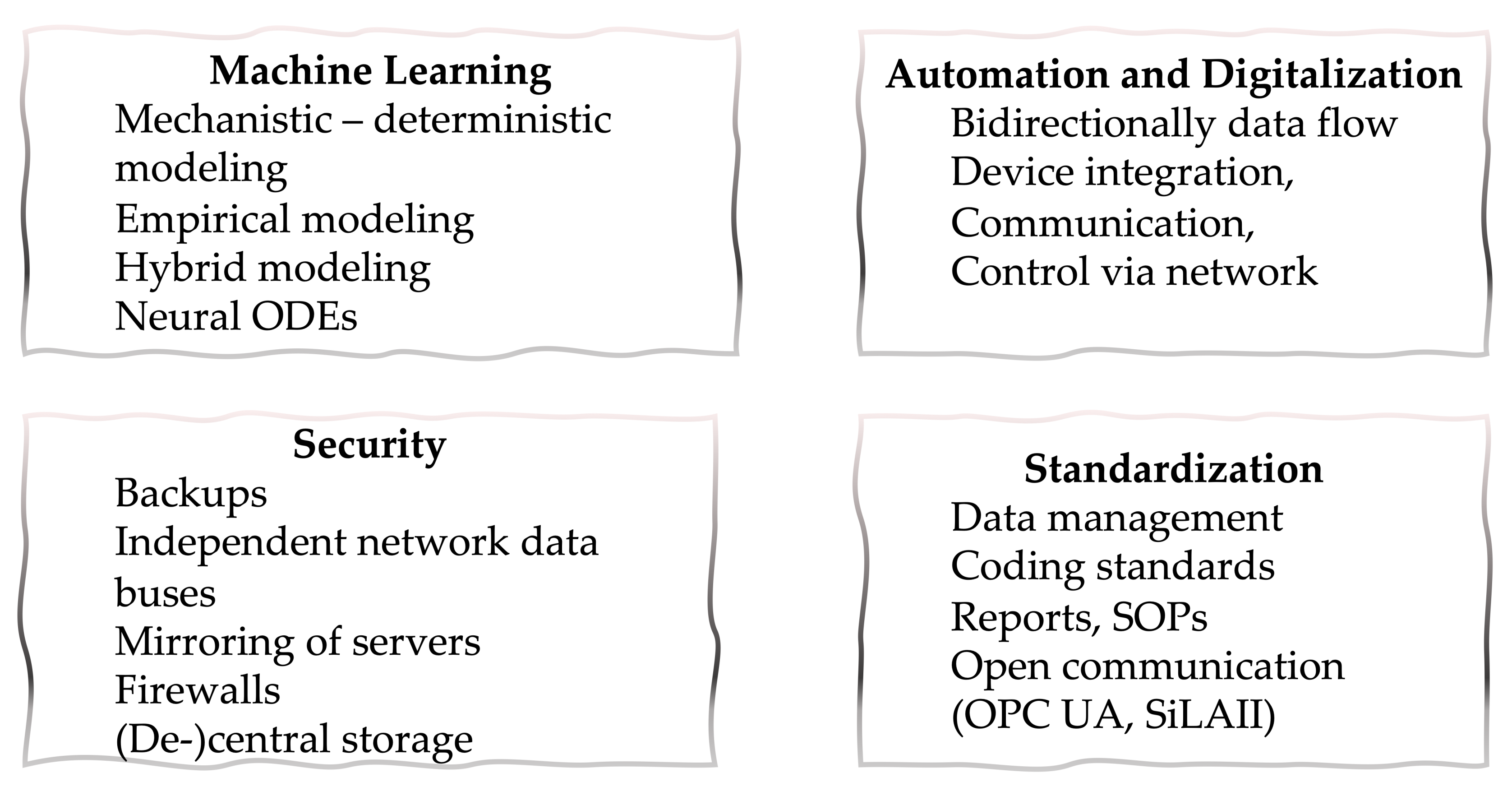
1.4. Current Status of Digitalization
1.5. State of Research: Industry 4.0 and Sustainability
2. Materials and Methods
2.1. Concept
2.2. Theoretical Basics and Definitions
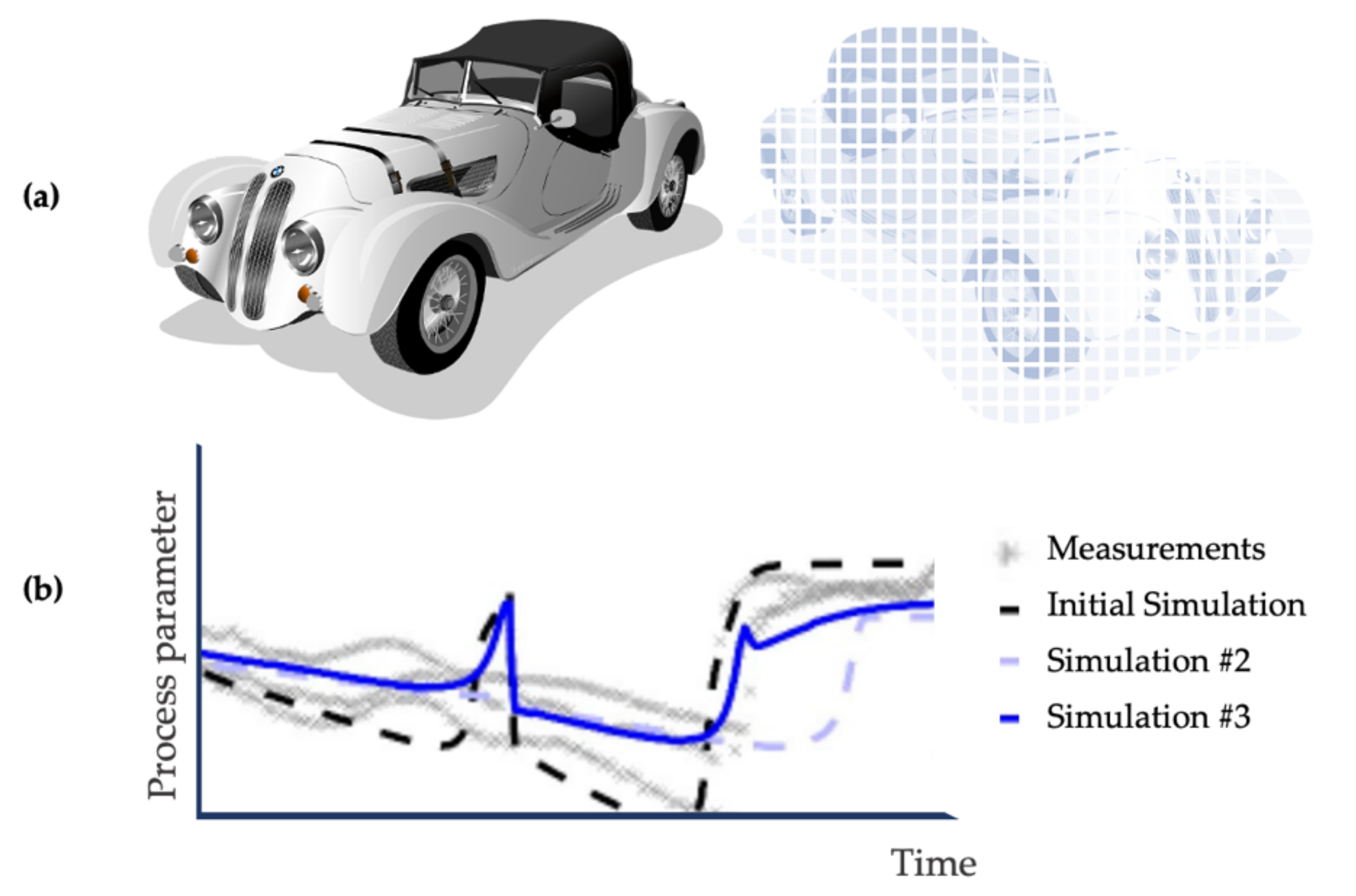
2.3. Validating Machine Learning Models
2.4. Methodologies
3. Results
3.1. Challenges in the Pharmaceutical Industry Require Innovation and Data Science
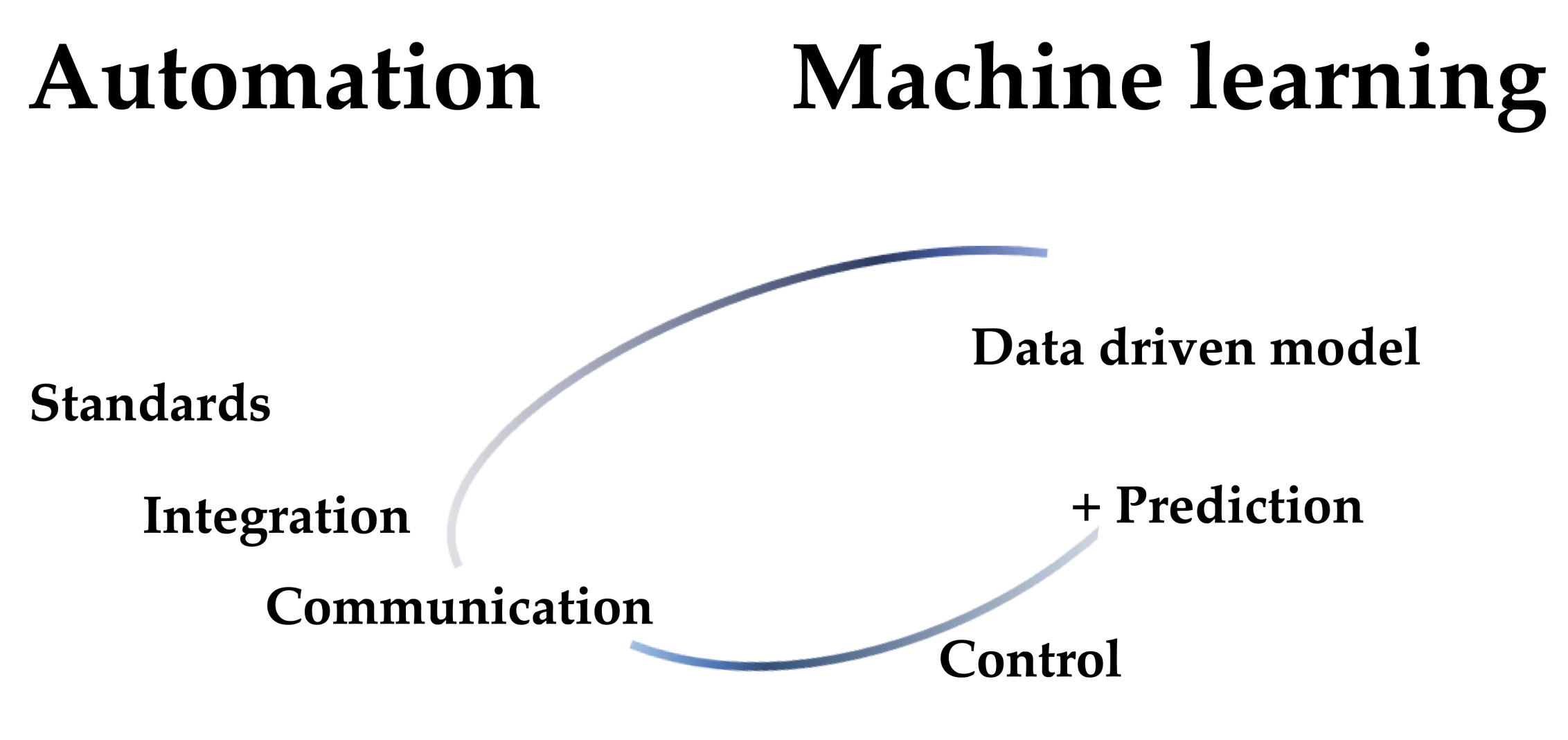
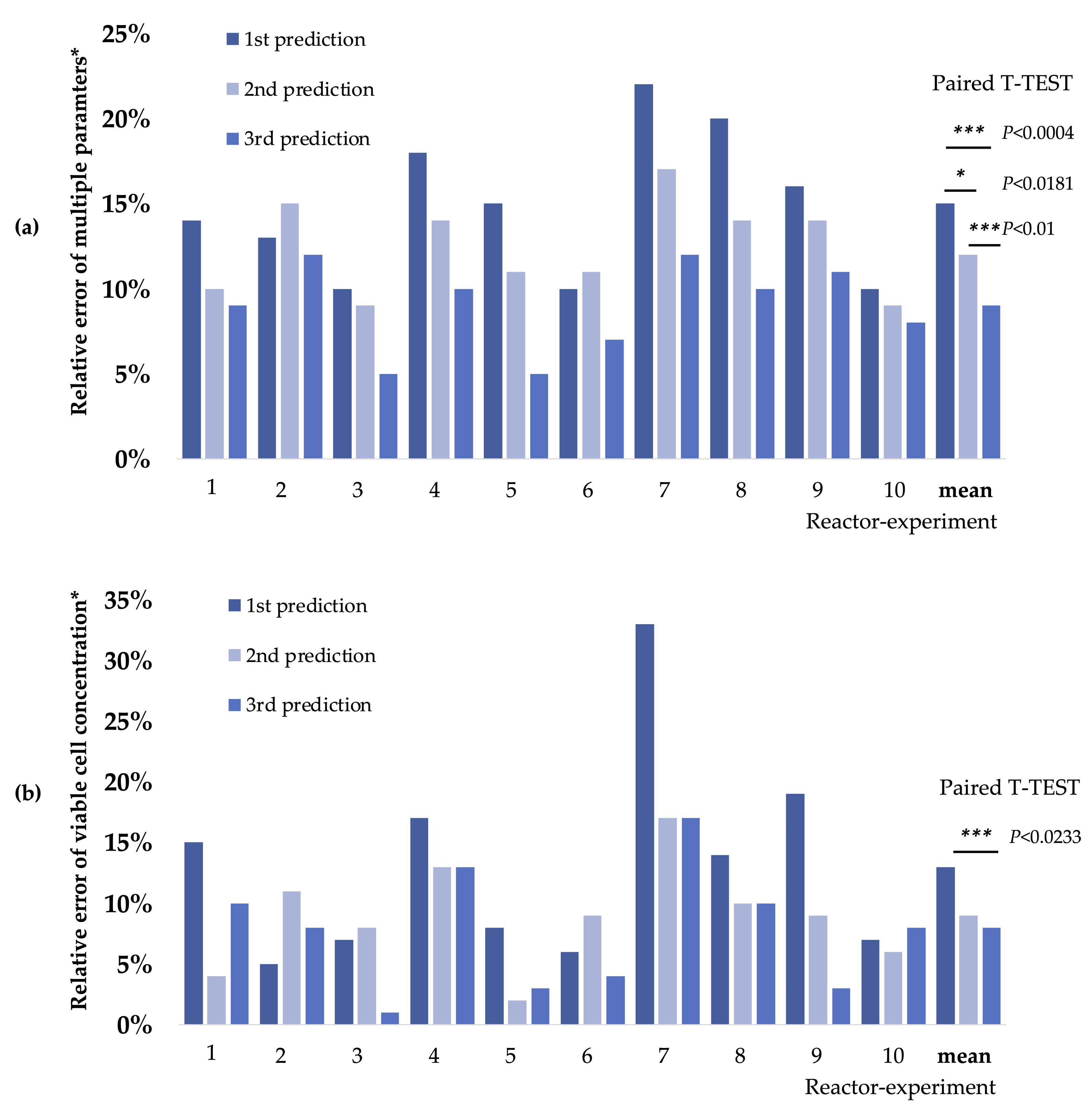
3.2. Machine Learning and Laboratory Automation in Line with the Idea of Industry 4.0 Promotes Process Efficiency
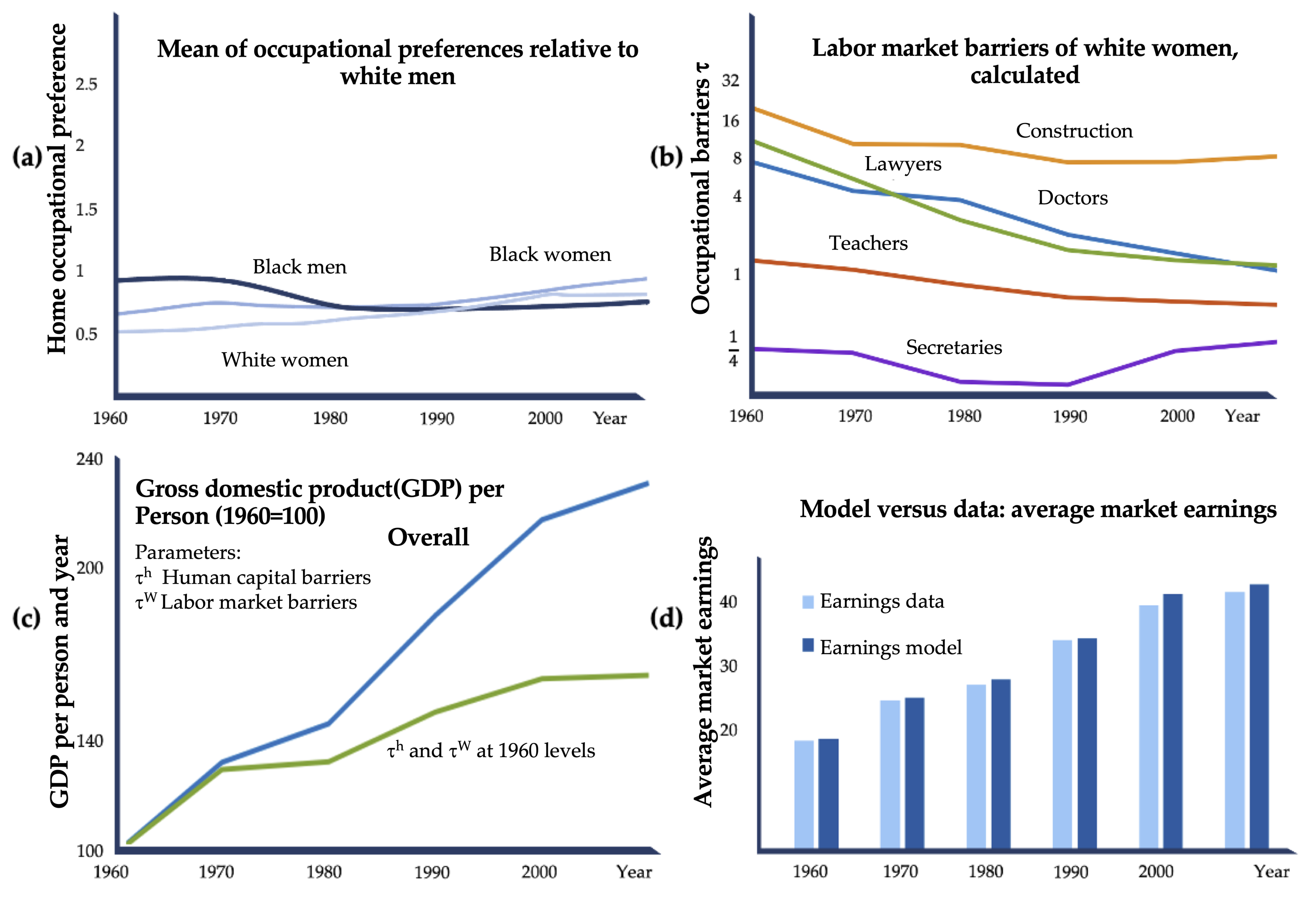
3.3. Economic Efficiency through Diversity and Equality
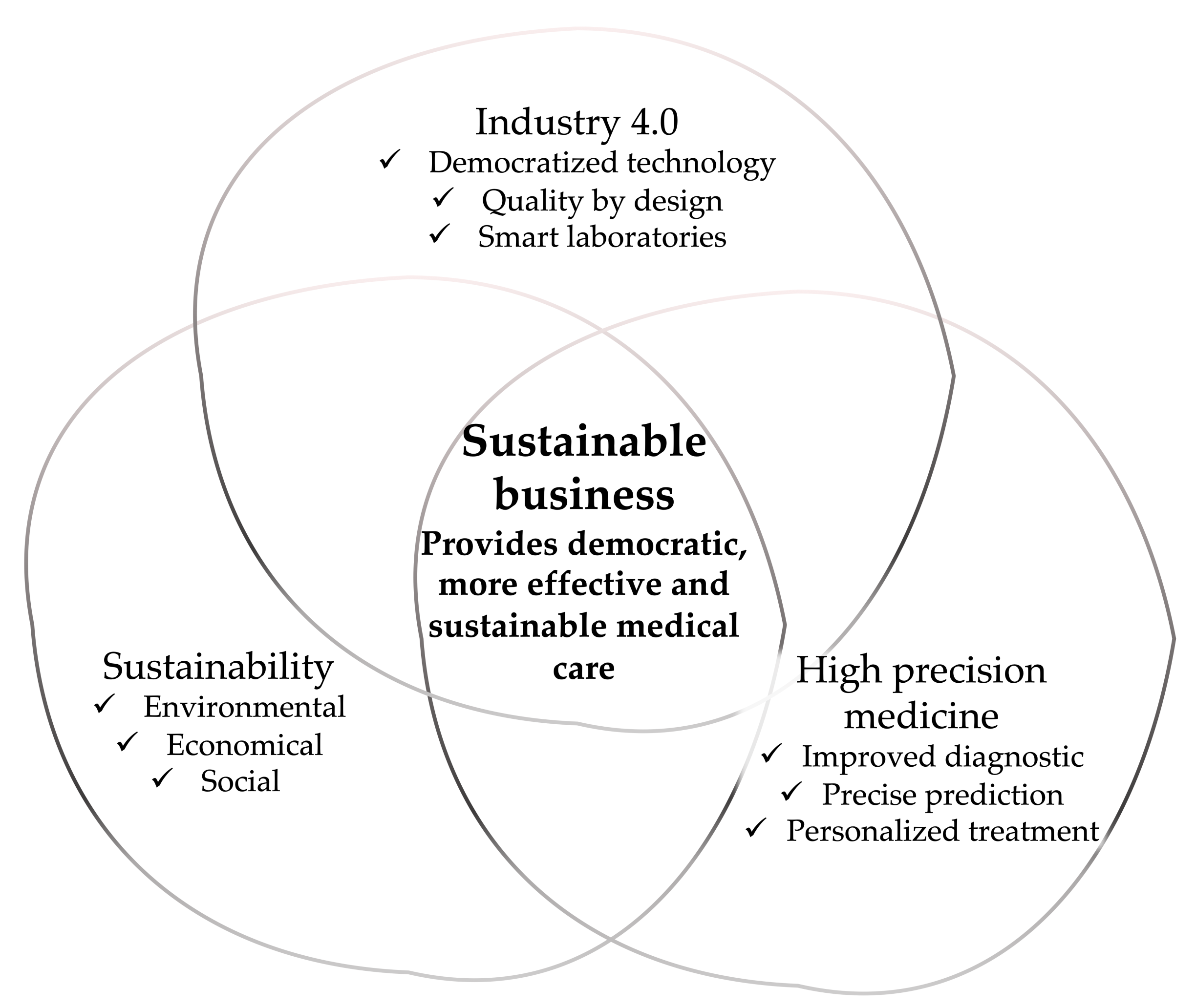
3.4. Industry 4.0 Is in Line with the Sustainability Goals
3.5. Next-Generation Drug Development will Combine the Best Therapies, Data Science, and Sustainability
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| ANN | artificial neural network |
| CAR T-cell | chimeric antigen receptor T-cell |
| CMC | chemistry, manufacturing, and control |
| CO | Carbon Dioxide |
| CRM | Customer relationship management |
| CV | coefficient of variation |
| DoE | Design of experiments |
| DOT | dissolved oxygen tension |
| E. coli | Escherichia coli |
| ECM | Eco-Care Matrix |
| EMA | European Medicines Agency |
| EU | European Union |
| FDA | Food and Drug Administration |
| GMP | good manufacturing practice |
| IoT | Internet of Things |
| M2M | machine to machine |
| MELLODDY | MachinE Learning Ledger Orchestration for Drug DiscoverY |
| mRNA | messenger ribonucleic acid |
| Neural ODEs | neural ordinary differential equations |
| OVAT | one-variable-at-a-time |
| PAT | process analytical technologies |
| PCA | Principal Component Analysis |
| QbD | Quality by Design |
| QSAR | quantitative structure–activity relationship |
| RNN | Recurrent Neural Networks |
| TU Berlin | Technische Universität Berlin |
| U. S. | United States |
| UN | United Nations |
| vfa bio | Die forschenden Pharma-Unternehmen bio |
References
- Wouters, O.J.; McKee, M.; Luyten, J. Estimated Research and Development Investment Needed to Bring a New Medicine to Market, 2009–2018. JAMA 2020, 323, 844. [Google Scholar] [CrossRef]
- World Health Organization. E4As Guide for Advancing Health and Sustainable Development. Resources and Tools for Policy Development and Implementation, 1st ed.; WHO Regional Office for Europe: Copenhagen, Denmark, 2021. [Google Scholar]
- World Health Organization. Report of the Regional Director: The Work of the WHO Regional Office for Europe in 2020–2021; Technical Report; WHO Regional Office for Europe: Copenhagen, Denmark, 2021. [Google Scholar]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D. Bevorzugte Report Items für systematische Übersichten und Meta-Analysen: Das PRISMA-Statement. Dmw-Dtsch. Med. Wochenschr. 2011, 136, e9–e15. [Google Scholar] [CrossRef]
- 17 Goals for a Sustainable Future by the Welthungerhilfe.de. Available online: https://www.welthungerhilfe.org/our-work/focus-areas/civil-society-and-advocacy/sustainable-development-goals/ (accessed on 10 September 2021).
- United Nations General Assembly. Transforming Our World: The 2030 Agenda for Sustainable Development; United Nations: New York, NY, USA, 2015. [Google Scholar]
- Lücke, J.; Bädeker, M.; Hildinger, M.; The Boston Consulting Group, München. Medizinische Biotechnologie in Deuschland 2021; Vfa-Publikationen, Deutschland, The Boston Consulting Group: München, Germany, 2021. [Google Scholar]
- European Federation of Pharmaceutical Industries and Associations. The Pharmaceutical Industry in Figures. Available online: https://www.efpia.eu/media/554521/efpia_pharmafigures_2020_web.pdf (accessed on 15 February 2022).
- KPMG. Digitalization in Life Sciences; KPMG International: Birmingham, UK; Berlin, Germany, 2018; p. 48. [Google Scholar]
- D/A/CH Affiliate: Containment Manual (English Translation). International Society for Pharmaceutical Engineering. 2017. Available online: https://ispe.org/publications/guidance-documents/dach-affiliate-containment-manual-english-translation/ (accessed on 22 March 2022).
- Kaplan, W.; Laing, R. Local Production of Pharmaceuticals: Industrial Policy and Access to Medicines, an Overview of Key Concepts, Issues and Opportunities for Future Research; World Bank: Washington, DC, USA, 2005. [Google Scholar]
- Die forschenden Pharmaunternehmen|vfa. Was Digitalisierung für die Pharma-Industrie bedeutet. Available online: https://www.vfa.de/de/wirtschaft-politik/pharma-digital (accessed on 10 September 2021).
- Die forschenden Pharmaunternehmen| vfa. Big Data und KI in der Pharma-Industrie. Available online: https://www.vfa.de/de/wirtschaft-politik/pharma-digital/zukunft-und-debatte/big-data-und-ki-fuer-die-pharmaindustrie (accessed on 9 September 2021).
- Rifaioglu, A.S.; Atas, H.; Martin, M.J.; Cetin-Atalay, R.; Atalay, V.; Doğan, T. Recent applications of deep learning and machine intelligence on in silico drug discovery: Methods, tools and databases. Briefings Bioinform. 2019, 20, 1878–1912. [Google Scholar] [CrossRef]
- Merck KGaA SYNTHIA™, die KI-Software für die Wirkstoffentwicklung. Available online: https://www.merckgroup.com/de/research/science-space/envisioning-tomorrow/future-of-scientific-work/synthia.html (accessed on 9 September 2021).
- Silver, L.; Smith, A.; Johnson, C.; Taylor, K.; Jiang, J.; Anderson, M.; Rainie, L. Mobile connectivity in emerging economies. Pew Res. Cent. 2019, 7, 72. [Google Scholar]
- Poushter, J. Smartphone ownership and internet usage continues to climb in emerging economies. Pew Res. Cent. 2016, 22, 1–44. [Google Scholar]
- Kay, M.; Santos, J.; Takane, M. mHealth: New Horizons for Health through Mobile Technologies; World Health Organization: Geneva, Switzerland, 2011. [Google Scholar]
- Smyth, P.; de Lannoy, G.; Stosch, M.V.; Pysik, A.; Khan, A. Machine learning in research and development of new vaccines products: Opportunities and challenges. Comput. Intell. 2019, 6. [Google Scholar]
- Subramanian, A.; Narayan, R.; Corsello, S.M.; Peck, D.D.; Natoli, T.E.; Lu, X.; Gould, J.; Davis, J.F.; Tubelli, A.A.; Asiedu, J.K.; et al. A Next Generation Connectivity Map: L1000 Platform and the First 1,000,000 Profiles. Cell 2017, 171, 1437–1452.e17. [Google Scholar] [CrossRef]
- Purdie, F.P. Data Integrity and Compliance with CGMP Guidance for Industry; FDA: Rockville, MD, USA, 2016; p. 13. [Google Scholar]
- Cauchon, N.S.; Oghamian, S.; Hassanpour, S.; Abernathy, M. Innovation in Chemistry, Manufacturing, and Controls—A Regulatory Perspective from Industry. J. Pharm. Sci. 2019, 108, 2207–2237. [Google Scholar] [CrossRef] [Green Version]
- Free Image on Pixabay—Caffeine, Molecule. Available online: https://pixabay.com/vectors/caffeine-molecule-chemical-structure-148821/ (accessed on 21 September 2021).
- Free Image on Pixabay—Vaccine, Cure, Medicine, Virus. Available online: https://pixabay.com/photos/vaccine-cure-medicine-virus-5897391/ (accessed on 21 September 2021).
- Free Image on Pixabay—Blood Cells, Cells, Biology, Liquid. Available online: https://pixabay.com/illustrations/blood-cells-cells-biology-liquid-2177469/ (accessed on 21 September 2021).
- Buchholz, H.; Eberle, T.; Klevesath, M.; Jürgens, A.; Beal, D.; Baic, A.; Radeke, J. Forward Thinking for Sustainable Business Value: A New Method for Impact Valuation. Sustainability 2020, 12, 8420. [Google Scholar] [CrossRef]
- Geissdoerfer, M.; Vladimirova, D.; Evans, S. Sustainable business model innovation: A review. J. Clean. Prod. 2018, 198, 401–416. [Google Scholar] [CrossRef]
- Ram Nidumolu, C.K.P. Why Sustainability Is Now the Key Driver of Innovation. Harv. Bus. Rev. 2009, 87, 56–64. [Google Scholar]
- Schaltegger, S.; Hansen, E.G.; Lüdeke-Freund, F. Business Models for Sustainability: Origins, Present Research, and Future Avenues. Organ. Environ. 2016, 29, 3–10. [Google Scholar] [CrossRef]
- Business Perspectives. Environmental Economics; LLC Consulting Publishing Company “Business Perspectives”: Sumy, Ukraine, 2021. [Google Scholar]
- Mowbray, M.; Savage, T.; Wu, C.; Song, Z.; Cho, B.A.; Del Rio-Chanona, E.A.; Zhang, D. Machine learning for biochemical engineering: A review. Biochem. Eng. J. 2021, 172, 108054. [Google Scholar] [CrossRef]
- Smiatek, J.; Jung, A.; Bluhmki, E. Towards a Digital Bioprocess Replica: Computational Approaches in Biopharmaceutical Development and Manufacturing. Trends Biotechnol. 2020, 38, 1141–1153. [Google Scholar] [CrossRef]
- Radivojević, T.; Costello, Z.; Workman, K.; Garcia Martin, H. A machine learning Automated Recommendation Tool for synthetic biology. Nat. Commun. 2020, 11, 4879. [Google Scholar] [CrossRef]
- Vinuesa, R.; Azizpour, H.; Leite, I.; Balaam, M.; Dignum, V.; Domisch, S.; Felländer, A.; Langhans, S.D.; Tegmark, M.; Fuso Nerini, F. The role of artificial intelligence in achieving the Sustainable Development Goals. Nat. Commun. 2020, 11, 233. [Google Scholar] [CrossRef] [Green Version]
- Hejnaes, K.R.; Ransohoff, T.C. Chemistry, Manufacture and Control. In Biopharmaceutical Processing; Elsevier: London, UK, 2018; pp. 1105–1136. [Google Scholar] [CrossRef]
- U.S. Food and Drug Administration, Office of the Commissioner U.S. 2021. Available online: https://www.fda.gov/home (accessed on 9 September 2021).
- European Medicines Agency. Detailed Guidance on the Electronic Submission of Information on Medicinal Products for Human Use by Marketing Authorisation Holders to the European Medicines Agency in Accordance with Article 57(2), Second Subparagraph of Regulation (EC) No. 726/2004. 2012. Available online: https://www.ema.europa.eu/en/documents/other/chapter-3ii-xevprm-user-guidance-detailed-guidance-electronic-submission-information-medicinal_en.pdf (accessed on 9 September 2021).
- EUR-Lex. Council Conclusions on Personalised Medicine for Patients; Doc ID: 52015XG1217(01); European Union: Brussels, Belgium, 2015. [Google Scholar]
- International Consortium for Personalised Medicine|ICPerMed. What Is Personalised Medicine? International Consortium for Personalised Medicine|ICPerMed: Bonn, Germany, 2021; Available online: https://www.icpermed.eu/en/icpermed-medicine.php (accessed on 10 September 2021).
- Jones, D.; Snider, C.; Nassehi, A.; Yon, J.; Hicks, B. Characterising the Digital Twin: A systematic literature review. CIRP J. Manuf. Sci. Technol. 2020, 29, 36–52. [Google Scholar] [CrossRef]
- Hans, S.; Haby, B.; Krausch, N.; Barz, T.; Neubauer, P.; Cruz-Bournazou, M.N. Automated Conditional Screening of Multiple Escherichia coli Strains in Parallel Adaptive Fed-Batch Cultivations. Bioengineering 2020, 7, 145. [Google Scholar] [CrossRef]
- Free Image on Pixabay—Bmw, Car, Roadster, Sports Car. Available online: https://pixabay.com/vectors/bmw-car-roadster-sports-car-158703/ (accessed on 21 September 2021).
- Bowden, G.D.; Pichler, B.J.; Maurer, A. A Design of Experiments (DoE) Approach Accelerates the Optimization of Copper-Mediated 18F-Fluorination Reactions of Arylstannanes. Sci. Rep. 2019, 9, 11370. [Google Scholar] [CrossRef]
- Anane, E.; García, Á.C.; Haby, B.; Hans, S.; Krausch, N.; Krewinkel, M.; Hauptmann, P.; Neubauer, P.; Cruz Bournazou, M.N. A model-based framework for parallel scale-down fed-batch cultivations in mini-bioreactors for accelerated phenotyping. Biotechnol. Bioeng. 2019, 116, 2906–2918. [Google Scholar] [CrossRef] [Green Version]
- Cruz Bournazou, M.; Barz, T.; Nickel, D.; Lopez Cárdenas, D.; Glauche, F.; Knepper, A.; Neubauer, P. Online optimal experimental re-design in robotic parallel fed-batch cultivation facilities: Online Optimal Experimental Re-Design in Robotic. Biotechnol. Bioeng. 2017, 114, 610–619. [Google Scholar] [CrossRef] [PubMed]
- Sawatzki, A.; Narayanan, H.; Haby, B.; Krausch, N. 2 Accelerated Bioprocess Development 3 of Endopolygalacturonase-Production with 4 Saccharomyces cerevisiae using Multivariate 5 Prediction in a 48 Mini-Bioreactor Automated 6 Platform. Bioengineering 2018, 5, 101. [Google Scholar]
- Freedman, L.P.; Cockburn, I.M.; Simcoe, T.S. The Economics of Reproducibility in Preclinical Research. PLoS Biol. 2015, 13, e1002165. [Google Scholar] [CrossRef] [PubMed]
- The ENCODE Project Consortium; Moore, J.E.; Purcaro, M.J.; Pratt, H.E.; Epstein, C.B.; Shoresh, N.; Adrian, J.; Kawli, T.; Davis, C.A.; Dobin, A.; et al. Expanded encyclopaedias of DNA elements in the human and mouse genomes. Nature 2020, 583, 699–710. [Google Scholar] [CrossRef]
- von Stosch, M.; Hamelink, J.M.; Oliveira, R. Hybrid modeling as a QbD/PAT tool in process development: An industrial E. coli case study. Bioprocess Biosyst. Eng. 2016, 39, 773–784. [Google Scholar] [CrossRef] [Green Version]
- Narayanan, H.; Luna, M.F.; Stosch, M.; Cruz Bournazou, M.N.; Polotti, G.; Morbidelli, M.; Butté, A.; Sokolov, M. Bioprocessing in the Digital Age: The Role of Process Models. Biotechnol. J. 2020, 15, 1900172. [Google Scholar] [CrossRef]
- Narayanan, H.; Cruz Bournazou, M.N.; Guillén Gosálbez, G.; Butté, A. Functional-Hybrid modeling through automated adaptive symbolic regression for interpretable mathematical expressions. Chem. Eng. J. 2022, 430, 133032. [Google Scholar] [CrossRef]
- Lagergren, J.H.; Nardini, J.T.; Baker, R.E.; Simpson, M.J.; Flores, K.B. Biologically-informed neural networks guide mechanistic modeling from sparse experimental data. PLoS Comput. Biol. 2020, 16, e1008462. [Google Scholar] [CrossRef]
- Yazdani, A.; Lu, L.; Raissi, M.; Karniadakis, G.E. Systems biology informed deep learning for inferring parameters and hidden dynamics. PLoS Comput. Biol. 2020, 16, e1007575. [Google Scholar] [CrossRef]
- Chen, R.T.Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D. Neural Ordinary Differential Equations. arXiv 2019, arXiv:1806.07366. [Google Scholar]
- Lever, J.; Krzywinski, M.; Altman, N. Points of significance: Model selection and overfitting. Nat. Methods 2016, 13, 703–705. [Google Scholar] [CrossRef]
- Walsh, I.; Fishman, D.; Garcia-Gasulla, D.; Titma, T.; Pollastri, G.; ELIXIR Machine Learning Focus Group; Harrow, J.; Psomopoulos, F.E.; Tosatto, S.C.E. DOME: Recommendations for supervised machine learning validation in biology. Nat. Methods 2021, 18, 1122–1127. [Google Scholar] [CrossRef] [PubMed]
- Smiatek, J.; Jung, A.; Bluhmki, E. Validation Is Not Verification: Precise Terminology and Scientific Methods in Bioprocess Modeling. Trends Biotechnol. 2021, 39, 1117–1119. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D. Ten quick tips for machine learning in computational biology. Biodata Min. 2017, 10, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Bishop, D. Rein in the four horsemen of irreproducibility. Nature 2019, 568, 435–436. [Google Scholar] [CrossRef] [PubMed]
- Rajamanickam, V.; Babel, H.; Montano-Herrera, L.; Ehsani, A.; Stiefel, F.; Haider, S.; Presser, B.; Knapp, B. About Model Validation in Bioprocessing. Processes 2021, 9, 961. [Google Scholar] [CrossRef]
- Guisasola, A.; Baeza, J.; Carrera, J.; Sin, G.; Vanrolleghem, P.; Lafuente, J. The Influence of Experimental Data Quality and Quantity on Parameter Estimation Accuracy: Andrews Inhibition Model as a Case Study. Educ. Chem. Eng. 2006, 1, 139–145. [Google Scholar] [CrossRef]
- Anane, E.; Barz, T.; Sin, G.; Gernaey, K.V.; Neubauer, P.; Bournazou, M.N.C. Output uncertainty of dynamic growth models: Effect of uncertain parameter estimates on model reliability. Biochem. Eng. J. 2019, 150, 107247. [Google Scholar] [CrossRef]
- Franceschini, G.; Macchietto, S. Model-based design of experiments for parameter precision: State of the art. Chem. Eng. Sci. 2008, 63, 4846–4872. [Google Scholar] [CrossRef]
- Baier, A. Education for Sustainable Development within the Engineering Sciences-Design of Learning Outcomes and a Subsequent Course Evaluation; Technische Universitaet Berlin: Berlin, Germany, 2019. [Google Scholar]
- Holland, M. Deepmind: KI schafft Durchbruch bei der Proteinfaltung; Heise Medien: Hannover, Germany, 2020; Available online: https://www.heise.de/news/Deepmind-KI-schafft-Durchbruch-bei-der-Proteinfaltung-4975964.html (accessed on 21 September 2021).
- Bystrzanowska, M.; Tobiszewski, M. Chemometrics for selection, prediction, and classification of sustainable solutions for green chemistry—A review. Symmetry 2020, 12, 2055. [Google Scholar] [CrossRef]
- Tong, W.; Hong, H.; Xie, Q.; Shi, L.; Fang, H.; Perkins, R. Assessing QSAR limitations—A regulatory perspective. Curr.-Comput.-Aided Drug Des. 2005, 1, 195–205. [Google Scholar] [CrossRef] [Green Version]
- Korany, M.A.; Gazy, A.A.; Khamis, E.F.; Ragab, M.A.; Kamal, M.F. Analysis of closely related antioxidant nutraceuticals using the green analytical methodology of ANN and smart spectrophotometric methods. J. Aoac Int. 2017, 100, 8–17. [Google Scholar] [CrossRef] [PubMed]
- Damerval, M.; Fagnoni-Legat, C.; Louvrier, A.; Fischer, S.; Clairet, A.L.; Limat, S.; Nerich, V.; Madeleine, I.; Kroemer, M. ATMP environmental exposure assessment in European healthcare settings, a systematic review of the literature. Front. Med. 2021, 2162. [Google Scholar] [CrossRef]
- Christopher, J.S.; Boatright, M. Challenges of ATMP Commercial Production: Facility Design for Newcomers; ISPE | International Society for Pharmaceutical Engineering: Tampa, FL, USA, 2020. [Google Scholar]
- Byrne, J. Lonza Hails ‘Significant Milestone’ as First Lymphoma Patient Treated with Cocoon CAR-T System; BioPharma Reporter: Rochdale, UK, 2020. [Google Scholar]
- Kim, K.; Yuraszeck, C.; O’Connor, J. When using a closed and automated manufacturing platform, is there an option to maintain flexibility? Cell Gene Ther. Insights 2021, 7, 857–869. [Google Scholar] [CrossRef]
- Neo, B.H.; Bandapalle, S.; O’Connor, J.; Lin, K.; Daita, K.; Sei, J.; Zander, M.; Gleissner, T.; Schroeder, J.; Abraham, E.; et al. The Cocoon® Platform Combined with the 4D-Nucleofector™ LV Unit A Non-Viral Workflow for Modifying Primary T-Cells; LONZA: Basel, Switzerland, 2020; p. 7. [Google Scholar]
- Roth, T.L.; Puig-Saus, C.; Yu, R.; Shifrut, E.; Carnevale, J.; Li, P.J.; Hiatt, J.; Saco, J.; Krystofinski, P.; Li, H.; et al. Reprogramming human T cell function and specificity with non-viral genome targeting. Nature 2018, 559, 405–409. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Mcafee, E.; Banda-Palle, S.; Siehoff, A.; Gleissner, T.; O’Connor, J.; Abraham, E.; Purpura, K.; Trainor, N.; Smith, T. End-to-End Cell Therapy Automation. WO 2019/046766 A2, 7 March 2019. [Google Scholar]
- Baidak, B.; Hussain, Y.; Kelminson, E.; Jones, T.R.; Franke, L.; Haehn, D. CellProfiler Analyst Web (CPAW) - Exploration, analysis, and classification of biological images on the web. In Proceedings of the IEEE Visualization Short Paper (IEEE VIS), New Orleans, LA, USA, 24–29 October 2021. [Google Scholar]
- Haby, B.; Hans, S.; Anane, E.; Sawatzki, A.; Krausch, N.; Neubauer, P.; Cruz Bournazou, M.N. Integrated Robotic Mini Bioreactor Platform for Automated, Parallel Microbial Cultivation With Online Data Handling and Process Control. Slas Technol. Transl. Life Sci. Innov. 2019, 24, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Food and Drug Administration. Guidance for Industry PAT—A Framework for Innovative Pharmaceutical Development, manufacturing, and Quality Assurance. 2004; p. 19. Available online: http://www.fda.gov/cder/guidance/published.html (accessed on 23 March 2021).
- Kögler, M.; Itkonen, J.; Viitala, T.; Casteleijn, M.G. Assessment of recombinant protein production in E. coli with Time-Gated Surface Enhanced Raman Spectroscopy (TG-SERS). Sci. Rep. 2020, 10, 2472. [Google Scholar] [CrossRef]
- Schlappa, S.; Brenker, L.J.; Bressel, L.; Hass, R.; Münzberg, M. Process Characterization of Polyvinyl Acetate Emulsions Applying Inline Photon Density Wave Spectroscopy at High Solid Contents. Polymers 2021, 13, 669. [Google Scholar] [CrossRef]
- Krämer, D.; King, R. A hybrid approach for bioprocess state estimation using NIR spectroscopy and a sigma-point Kalman filter. J. Process. Control. 2019, 82, 91–104. [Google Scholar] [CrossRef]
- Auer, J.; Bey, N.; Schäfer, J.M. Combined Life Cycle Assessment and Life Cycle Costing in the Eco-Care-Matrix: A case study on the performance of a modernized manufacturing system for glass containers. J. Clean. Prod. 2017, 141, 99–109. [Google Scholar] [CrossRef] [Green Version]
- Moore, M. What Is Industry 4.0? Everything You Need to Know. 2019. Available online: https://www.techradar.com/news/what-is-industry-40-everything-you-need-to-know (accessed on 23 March 2021).
- Parsad, B. The engineer’s perspective: Evolution in cell therapy bioprocess automation. Cell Gene Ther. Insights 2020, 6, 1615–1621. [Google Scholar] [CrossRef]
- Häse, F.; Roch, L.M.; Aspuru-Guzik, A. Next-generation experimentation with self-driving laboratories. Trends Chem. 2019, 1, 282–291. [Google Scholar] [CrossRef]
- Neubauer, P.; Cruz, N.; Glauche, F.; Junne, S.; Knepper, A.; Raven, M. Consistent development of bioprocesses from microliter cultures to the industrial scale. Eng. Life Sci. 2013, 13, 224–238. [Google Scholar] [CrossRef]
- Neubauer, P.; Glauche, F.; Cruz-Bournazou, M.N. Editorial: Bioprocess Development in the era of digitalization. Eng. Life Sci. 2017, 17, 1140–1141. [Google Scholar] [CrossRef] [Green Version]
- Neubauer, P.; Lin, H.Y.; Mathiszik, B. Metabolic load of recombinant protein production: Inhibition of cellular capacities for glucose uptake and respiration after induction of a heterologous gene in Escherichia coli. Biotechnol. Bioeng. 2003, 83, 53–64. [Google Scholar] [CrossRef]
- Hernández Rodríguez, T.; Posch, C.; Schmutzhard, J.; Stettner, J.; Weihs, C.; Pörtner, R.; Frahm, B. Predicting industrial-scale cell culture seed trains—A Bayesian framework for model fitting and parameter estimation, dealing with uncertainty in measurements and model parameters, applied to a nonlinear kinetic cell culture model, using an MCMC method. Biotechnol. Bioeng. 2019, 116, 2944–2959. [Google Scholar] [CrossRef] [Green Version]
- Shook, E.; Sweet, J. When She Rises, We All Rise. Accenture 2018, 1–23. [Google Scholar]
- Shook, E.; Sweet, J. Equality = Innovation. Accenture 2019, 1–36. [Google Scholar]
- Hsieh, C.-T.; Hurst, E.; Jones, C.I.; Klenow, P.J. The allocation of talent and U.S. economic growth. Econometrica 2019, 87, 1439–1474. [Google Scholar] [CrossRef] [Green Version]
- Roy, A.D. Some thoughts on the distribution of earnings 1. Oxf. Econ. Pap. 1951, 3, 135–146. [Google Scholar] [CrossRef]
- Dohmeyer, M.; Dittrich, C. Vielfalt 2020-Die truffls Studie zur Wahrnehmung von Diversity in deutschen Unternehmen; Handelsblatt: Düsseldorf, Germany, 2020. [Google Scholar]
- Kewes, T. Studie zu Diversity: Gerade in Krisen profitieren Unternehmen von Vielfalt; Handelsblatt GmbH—ein Unternehmen der Handelsblatt Media Group GmbH & Co. KG: Duesseldorf, Germany, 2020; ISSN 0017-7296. [Google Scholar]
- Allam, M.; Cai, S.; Coskun, A.F. Multiplex bioimaging of single-cell spatial profiles for precision cancer diagnostics and therapeutics. Npj Precis. Oncol. 2020, 4, 11. [Google Scholar] [CrossRef]
- Blasiak, A.; Khong, J.; Kee, T. CURATE.AI: Optimizing Personalized Medicine with Artificial Intelligence. Slas Technol. Transl. Life Sci. Innov. 2020, 25, 95–105. [Google Scholar] [CrossRef]
- Möller, J.; Kuchemüller, K.B.; Steinmetz, T.; Koopmann, K.S.; Pörtner, R. Model-assisted Design of Experiments as a concept for knowledge-based bioprocess development. Bioprocess Biosyst. Eng. 2019, 42, 867–882. [Google Scholar] [CrossRef]
- ISPE | International Society for Pharmaceutical Engineering GAMP RDI Good Practice Guide: Data Integrity by Design, U.S. 2020. Available online: https://ispe.org/publications/guidance-documents/gamp-rdi-good-practice-guide-data-integrity-design (accessed on 9 September 2021).
- Neubauer, P. This Is the KIWI-Biolab, a BMBF KI Future Lab! Available online: https://kiwi-biolab.de (accessed on 23 March 2021).
- Ho, C.F.; Hsieh, P.H.; Hung, W.H. Enablers and processes for effective knowledge management. Ind. Manag. Data Syst. 2014, 114, 734–754. [Google Scholar] [CrossRef]
- Stauffer, B. What Are the 4 C’s of 21st Century Skills? Available online: https://www.aeseducation.com/blog/four-cs-21st-century-skills (accessed on 8 September 2021).
- International Ergonomics Association|IEA Human Factors; IEA: Geneva, Switzerland, 2021; Available online: https://iea.cc/what-is-ergonomics/ (accessed on 10 September 2021).
- Bridger, R. Introduction to Human Factors and Ergonomics, 4th ed.; CRC Press: Portsmouth, Hampshire, UK, 2017; ISBN 9781498795944. [Google Scholar]
- Scheper, T.; Beutel, S.; McGuinness, N.; Heiden, S.; Oldiges, M.; Lammers, F.; Reardon, K.F. Digitalization and Bioprocessing: Promises and Challenges. In Digital Twins; Herwig, C., Pörtner, R., Möller, J., Eds.; Advances in Biochemical Engineering/Biotechnology; Springer International Publishing: Cham, Switzerland, 2020; Volume 176, pp. 57–69. [Google Scholar] [CrossRef]
- June, C.H.; O’Connor, R.S.; Kawalekar, O.U.; Ghassemi, S.; Milone, M.C. CAR T cell immunotherapy for human cancer. Science 2018, 359, 1361–1365. [Google Scholar] [CrossRef] [Green Version]
- These Are the World’s 10 Most Sustainably Managed Companies. Wall Street Journal. 13 October 2020, p. 1. Available online: https://www.wsj.com/articles/these-are-the-worlds-10-most-sustainable-companies-11602624830 (accessed on 22 March 2022).
- Kundu, S. Mathematical Modeling As A Tool For Sustainable Development. J. Artic. Math. Educ. 2018, 5, 348–350. [Google Scholar]
- Coeckelbergh, M. AI for climate: Freedom, justice, and other ethical and political challenges. AI Ethics 2021, 1, 67–72. [Google Scholar] [CrossRef]
- France, O. Melloddy, MachinE Learning Ledger Orchestration for Drug DiscoverY. Available online: https://cordis.europa.eu/project/id/831472/de (accessed on 23 March 2021).
- Benjamens, S.; Dhunnoo, P.; Meskó, B. The state of artificial intelligence-based FDA-approved medical devices and algorithms: An online database. NPJ Digit. Med. 2020, 3, 118. [Google Scholar] [CrossRef]
- Food and Drug Administration. Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD); Food and Drug Administration: Silver Spring, MD, USA, 2019. [Google Scholar]
- Food and Drug Administration. The FDA’s Officeof Science and Engineering Laboratories. Available online: https://www.fda.gov/about-fda/cdrh-offices/office-science-and-engineering-laboratories (accessed on 23 March 2021).
- Morrison, T.M.; Hariharan, P.; Funkhouser, C.M.; Afshari, P.; Goodin, M.; Horner, M. Assessing computational model credibility using a risk-based framework: Application to hemolysis in centrifugal blood pumps. Asaio J. 2019, 65, 349. [Google Scholar] [CrossRef]
- Bideault, G.; Scaccia, A.; Zahel, T.; Landertinger, R.W.; Daluwatte, C. Verification and validation of computational models used in biopharmaceutical manufacturing: Potential application of the ASME verification and validation 40 standard and FDA proposed AI/ML model life cycle management framework. J. Pharm. Sci. 2021, 110, 1540–1544. [Google Scholar] [CrossRef]
- Evans, J.L.; Hillyer, C.D. Introduction to Quality Systems and Quality Management. In Transfusion Medicine and Hemostasis; Elsevier: London, UK, 2009; pp. 13–18. [Google Scholar]
- FDA. Guidance for Industry, Q8, Q9, Q10 Questions and Answers. Available online: https://www.fda.gov/media/83904/download (accessed on 23 March 2021).
- Food and Drug Administration. Analytical Procedures and Methods Validation for Drugs and Biologics; US Department of Health and Human Services: Washington, DC, USA, 2015. [Google Scholar]
- Food and Drug Administration Reporting of Computational Modeling Studies in Medical Device Submissions—Guidance for Industry and Food and Drug Administration Staff; Food and Drug Administration: White Oak, MD, USA, 2016.
- Food and Drug Administration. General Principles of Software Validation: Final Guidance for Industry and FDA Staff; Tech. Rep.; Center for Devices and Radiological Health: Washington, DC, USA, 2002. [Google Scholar]
- Blaschke, T.F.; Lumpkin, M.; Hartman, D. The World Health Organization prequalification program and clinical pharmacology in 2030. Clin. Pharmacol. Ther. 2020, 107, 68. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
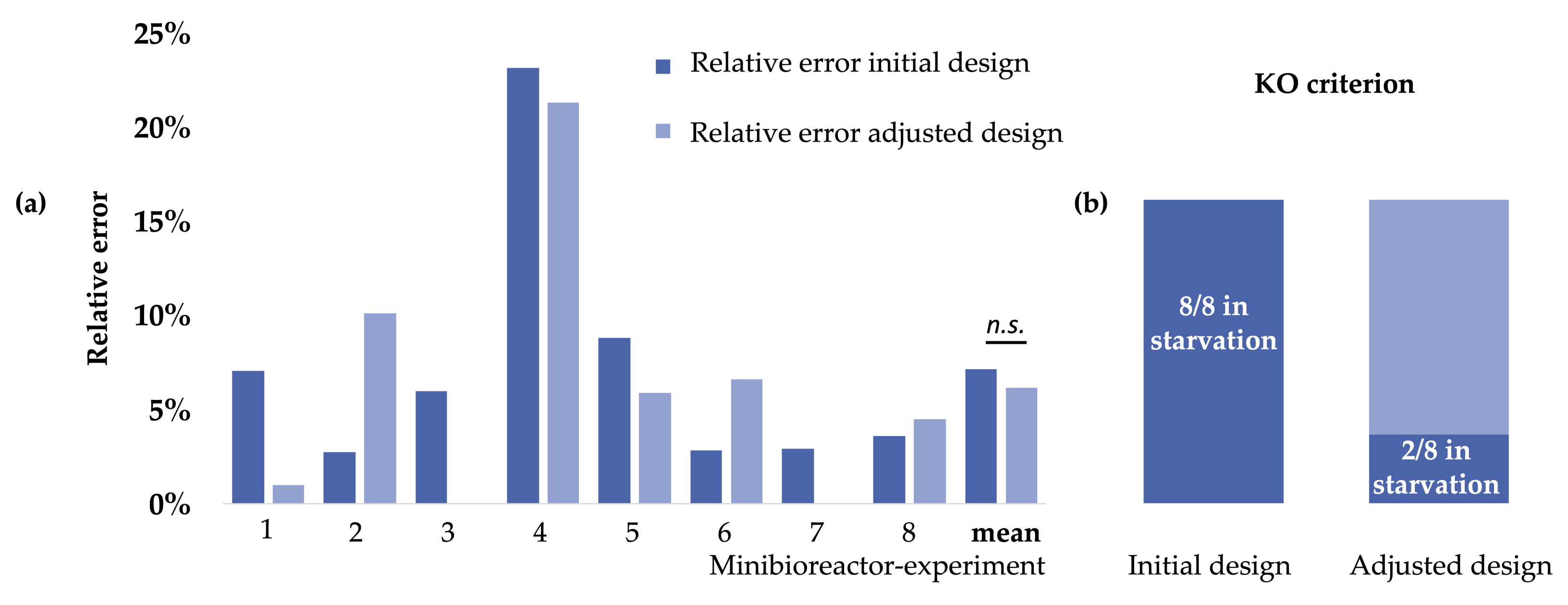
| Strain/Glucose Consumption (min) | Initial Design | Adjusted Design | Observed Glucose Depletion | Deviation Initial | Deviation Adjusted | Relative Error Intitial Design | Relative Error Adjusted Design |
|---|---|---|---|---|---|---|---|
| E. coli clone 1 | 106 | 100 | 99 | −7 | −1 | 7.07% | 1.01% |
| E. coli clone 2 | 112 | 98 | 109 | −3 | 11 | 2.75% | 10.09% |
| E. coli clone 3 | 106 | 100 | 100 | −6 | 0 | 6.00% | 0.00% |
| E. coli clone 4 | 133 | 131 | 108 | −25 | −23 | 23.15% | 21.30% |
| E. coli clone 5 | 111 | 96 | 102 | −9 | 6 | 8.82% | 5.88% |
| E. coli clone 6 | 109 | 99 | 106 | −3 | 7 | 2.83% | 6.60% |
| E. coli clone 7 | 106 | 103 | 103 | −3 | 0 | 2.91% | 0.00% |
| E. coli clone 8 | 115 | 116 | 111 | −4 | −5 | 3.60% | 4.50% |
| Mean relative error (Glucose consumption, low number desired) | 7.14% | 6.17% | |||||
| Amount of cultures in starvation (low number desired) | all | 2 | |||||
| Paired T-TEST of relative errors initial vs. adjusted design | p-value = 0.578 | ||||||
| Technology and Methods | Good Health | Gender Equality | Decent Work, Economic Growth | Industry, Innovation, and Infrastructure | Reduced Inequality | Responsible Consumption and Production | Climate Action | Partnership for the Goals |
|---|---|---|---|---|---|---|---|---|
| High precision medicine [48,76,96,97] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Innovations in CMC [22] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Diversity [92] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Bioprocess: Automation [46] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Design of Experiments [43] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Model-based DoE [98] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Knowledge management [99] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Wet lab PAT [78] | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Soft sensors [81] | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Modeling [77] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Hybrid models [50] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Online re-design [41,45] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| KIWI-biolab [100] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paulick, K.; Seidel, S.; Lange, C.; Kemmer, A.; Cruz-Bournazou, M.N.; Baier, A.; Haehn, D. Promoting Sustainability through Next-Generation Biologics Drug Development. Sustainability 2022, 14, 4401. https://doi.org/10.3390/su14084401
Paulick K, Seidel S, Lange C, Kemmer A, Cruz-Bournazou MN, Baier A, Haehn D. Promoting Sustainability through Next-Generation Biologics Drug Development. Sustainability. 2022; 14(8):4401. https://doi.org/10.3390/su14084401
Chicago/Turabian StylePaulick, Katharina, Simon Seidel, Christoph Lange, Annina Kemmer, Mariano Nicolas Cruz-Bournazou, André Baier, and Daniel Haehn. 2022. "Promoting Sustainability through Next-Generation Biologics Drug Development" Sustainability 14, no. 8: 4401. https://doi.org/10.3390/su14084401
APA StylePaulick, K., Seidel, S., Lange, C., Kemmer, A., Cruz-Bournazou, M. N., Baier, A., & Haehn, D. (2022). Promoting Sustainability through Next-Generation Biologics Drug Development. Sustainability, 14(8), 4401. https://doi.org/10.3390/su14084401