

Prediction of Losses Due to Dust in PV Using Hybrid LSTM-KNN Algorithm: The Case of Saruhanlı


Abstract
:1. Introduction
- -
- The hybrid LSTM-KNN algorithm has not been used in the literature to estimate losses due to dust in PV panels.
- -
- The hybrid LSTM-KNN algorithm was used to improve the performance of LSTM and KNN algorithms. A better prediction was achieved with the hybrid LSTM-KNN algorithm than with the LSTM and KNN algorithm. However, the prediction time of the hybrid LSTM-KNN algorithm was longer than that of the LSTM and KNN algorithms.
- -
- Hybrid LSTM-KNN, LSTM and KNN algorithms were implemented in the same simulation and with the same data. Since algorithms use random values in the different simulations, different data sets may occur. This may cause comparison results to be inaccurate.
- -
- Dust loss in PV panels is affected by meteorological data. In this context, the most important factor affecting dust loss in PV panels was determined to be solar radiation. This is a factor that increases the efficiency of the solar panel during the installation phase.
- -
- The power losses of PV panels due to dust were calculated using different algorithms in the literature. In this context, Pavan et. al. predicted 99.92% of the power loss due to dust using the BNN model. This estimate is the best performance in the literature. In this study, the Hybrid LSTM-KNN algorithm predicted 98.22% of the loss due to dust in PV panels. In this respect, a better result was obtained in this study than many other studies in the literature.
- -
- In our previous studies, the dust loss of PV panels was estimated with hybrid LSTM-SVM, hybrid LSTM-tree, and hybrid LSTM-ensemble. However, the results obtained from other hybrid algorithms were below the values obtained from the hybrid algorithm used in this study.
- -
- Among the algorithms that estimate the power losses of PV panels due to dust, the hybrid algorithm has not been used much in the literature. Therefore, a hybrid algorithm was used in this study.
2. Materials and Methods
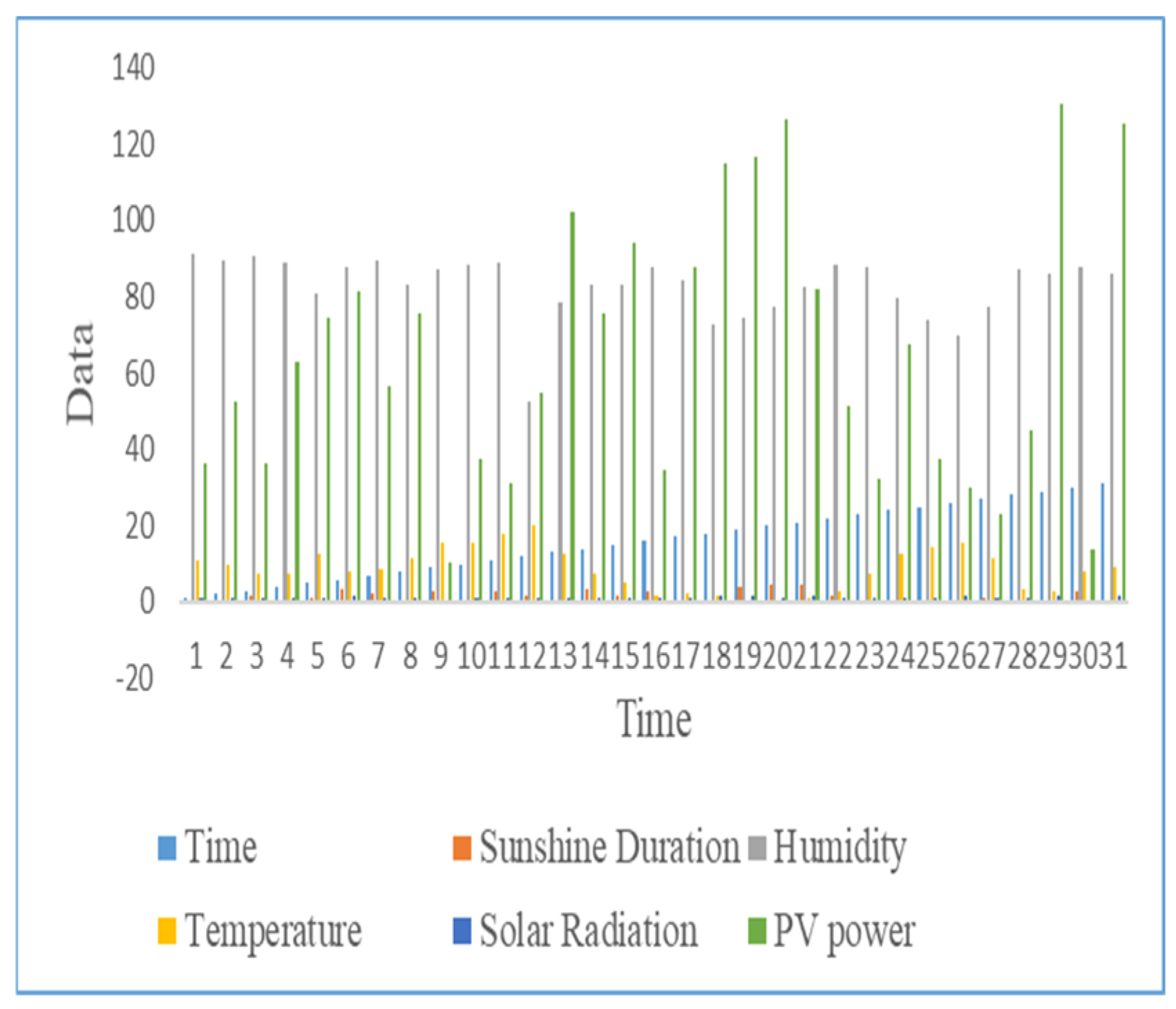
2.1. Data
2.2. Sensitivity Analysis
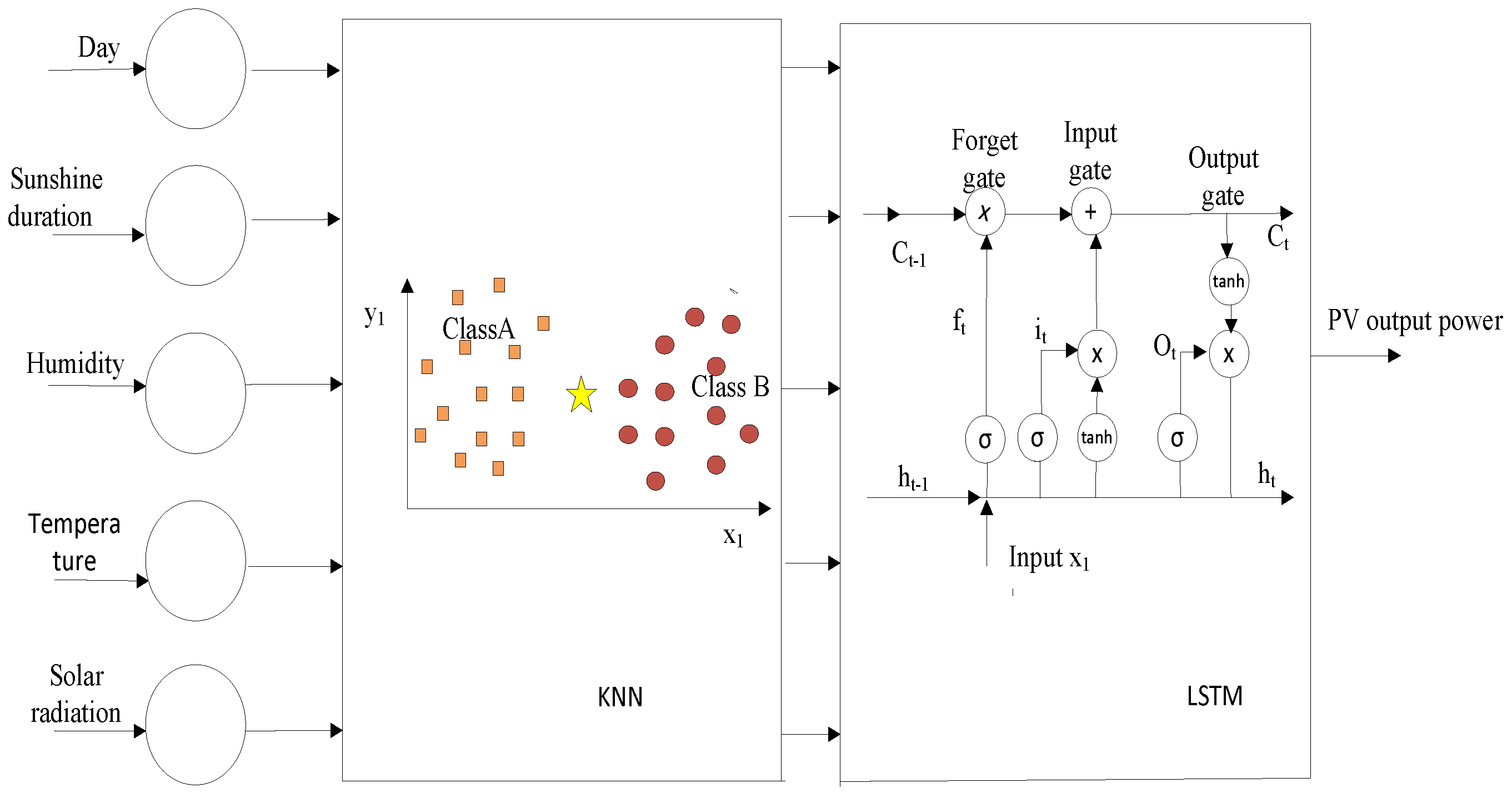
2.3. K-Nearest Neighbor Algorithm
- Feature Vector: This refers to the current model state and past information. To create a feature vector under the KNN procedure, a trade-off between accuracy and runtime is required.
- Distance Metric: This refers to the Euclidean distance used to measure the distance between a feature vector and a subset of it.
- The number of Nearest Neighbors (K): The datasets are arranged according to their Euclidean distances and K-nearest neighbors are selected. If a higher K value is picked, this leads to data redundancy in prediction, whereas if a lower value is chosen, this leads to a loss of information in historical datasets [27].
2.4. Long Short-Term Memory
2.5. Hybrid LSTM-KNN Algorithm
2.6. Performance Metrics
3. Results and Discussions
3.1. The Sensitivity Analysis of Results
3.2. K-Nearest Neighbors of Results
3.3. Long Short-Term Memory of Results
3.4. Hybrid LSTM-KNN of Results
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sampaio, P.G.V.; González, M.O.A. Photovoltaic solar energy: Conceptual framework. Renew. Sustain. Energy Rev. 2017, 74, 590–601. [Google Scholar] [CrossRef]
- Ganti, P.K.; Naik, H.; Barada, M.K. Environmental impact analysis and enhancement of factors affecting the photovoltaic (PV) energy utilization in mining industry by sparrow search optimization based gradient boosting decision tree approach. Energy 2022, 244, 122561. [Google Scholar] [CrossRef]
- Siecker, J.; Kusakana, K.; Numbi, E.B. A review of solar photovoltaic systems cooling technologies. Renew. Sustain. Energy Rev. 2017, 79, 192–203. [Google Scholar] [CrossRef]
- Fan, S.; Wang, Y.; Cao, S.; Zhao, B.; Sun, T.; Liu, P. A deep residual neural network identification method for uneven dust accumulation on photovoltaic (PV) panels. Energy 2022, 239, 122302. [Google Scholar] [CrossRef]
- Sayyah, A.; Horenstein, M.N.; Mazumder, M.K. Energy yield loss caused by dust deposition on photovoltaic panels. Solar Energy 2014, 107, 576–604. [Google Scholar] [CrossRef]
- Fan, S.; Wang, Y.; Cao, S.; Sun, T.; Liu, P. A novel method for analyzing the effect of dust accumulation on energy efficiency loss in photovoltaic (PV) system. Energy 2021, 234, 121112. [Google Scholar] [CrossRef]
- Hussain, A.; Batra, A.; Pachauri, R. An experimental study on effect of dust on power loss in solar photovoltaic module. Renew. Wind. Water Sol. 2017, 4, 9. [Google Scholar] [CrossRef]
- Chen, J.; Pan, G.; Ouyang, J.; Ma, J.; Fu, L.; Zhang, L. Study on impacts of dust accumulation and rainfall on PV power reduction in East China. Energy 2020, 194, 116915. [Google Scholar] [CrossRef]
- Al-Kouz, W.; Al-Dahidi, S.; Hammad, B.; Al-Abed, M. Modeling and analysis framework for investigating the impact of dust and temperature on PV systems’ performance and optimum cleaning frequency. Appl. Sci. 2019, 9, 1397. [Google Scholar] [CrossRef]
- Hammad, B.; Al-Abed, M.; Al-Ghandoor, A.; Al-Sardeah, A.; Al-Bashir, A. Modeling and analysis of dust and temperature effects on photovoltaic systems’ performance and optimal cleaning frequency: Jordan case study. Renew. Sustain. Energy Rev. 2018, 82, 2218–2234. [Google Scholar] [CrossRef]
- Adıgüzel, E.; Özer, E.; Akgündoğdu, A.; Yılmaz, A.E. Prediction of dust particle size effect on efficiency of photovoltaic modules with ANFIS: An experimental study in Aegean region, Turkey. Solar Energy 2019, 177, 690–702. [Google Scholar] [CrossRef]
- Javed, W.; Guo, B.; Figgis, B. Modeling of photovoltaic soiling loss as a function of environmental variables. Solar Energy 2017, 157, 397–407. [Google Scholar] [CrossRef]
- Simal Pérez, N.; Alonso-Montesinos, J.; Batlles, F.J. Estimation of soiling losses from an experimental photovoltaic plant using artificial intelligence techniques. Appl. Sci. 2021, 11, 1516. [Google Scholar] [CrossRef]
- Zitouni, H.; Azouzoute, A.; Hajjaj, C.; El Ydrissi, M.; Regragui, M.; Polo, J.; Oufadel, A.; Bouaichi, A.; Ghennioui, A. Experimental investigation and modeling of photovoltaic soiling loss as a function of environmental variables: A case study of semi-arid climate. Solar Energy Mater. Sol. Cells 2021, 221, 110874. [Google Scholar] [CrossRef]
- Jamil, I.; Lucheng, H.; Iqbal, S.; Aurangzaib, M.; Jamil, R.; Kotb, H.; Alkuhayli, A.; AboRas, K.M. Predictive evaluation of solar energy variables for a large-scale solar power plant based on triple deep learning forecast models. Alex. Eng. J. 2023, 76, 51–73. [Google Scholar] [CrossRef]
- Pavan, A.M.; Mellit, A.; De Pieri, D.; Kalogirou, S.A. A comparison between BNN and regression polynomial methods for the evaluation of the effect of soiling in large scale photovoltaic plants. Appl. Energy 2013, 108, 392–401. [Google Scholar] [CrossRef]
- Velásquez, R.M.A.; Ezcurra, T.T.P. Dust analysis in photo-voltaic solar plants with satellite data. Ain Shams Eng. J. 2023, 15, 102314. [Google Scholar] [CrossRef]
- Available online: https://www.saruhanli.bel.tr/saruhanli-icerik.php?icerik_id=52 (accessed on 15 September 2023).
- Available online: https://tr.weatherspark.com/y/94309/Saruhanl%C4%B1-T%C3%BCrkiye-Ortalama-Hava-Durumu-Y%C4%B1l-Boyunca (accessed on 25 September 2023).
- Available online: https://saruhanli.bel.tr/senar/production/upload/752276338.pdf (accessed on 25 September 2023).
- Available online: https://www.mgm.gov.tr/kurumsal/istasyonlarimiz.aspx (accessed on 1 October 2023).
- Available online: https://csb.gov.tr/sss/hava-yonetimi (accessed on 14 October 2023).
- Moeinossadat, S.R.; Ahangari, K.; Shahriar, K. Calculation of maximum surface settlement induced by EPB shield tunnelling and introducing most effective parameter. J. Cent. South Univ. 2016, 23, 3273–3283. [Google Scholar] [CrossRef]
- Moeinossadat, S.R.; Ahangari, K.; Shahriar, K. Control of ground settlements caused by EPBS tunneling using an intelligent predictive model. Indian Geotech. J. 2018, 48, 420–429. [Google Scholar] [CrossRef]
- Adithiyaa, T.; Chandramohan, D.; Sathish, T. Optimal prediction of process parameters by GWO-KNN in stirring-squeeze casting of AA2219 reinforced metal matrix composites. Mater. Today Proc. 2020, 21, 1000–1007. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, T.; Li, S.; Yang, Y. Automated feature learning for nonlinear process monitoring–An approach using stacked denoising autoencoder and k-nearest neighbor rule. J. Process Control 2018, 64, 49–61. [Google Scholar] [CrossRef]
- Liu, K.; Li, Z.; Yao, C.; Chen, J.; Zhang, K.; Saifullah, M. Coupling the k-nearest neighbor procedure with the Kalman filter for real-time updating of the hydraulic model in flood forecasting. Int. J. Sediment Res. 2016, 31, 149–158. [Google Scholar] [CrossRef]
- Yamaç, S.S.; Todorovic, M. Estimation of daily potato crop evapotranspiration using three different machine learning algorithms and four scenarios of available meteorological data. Agric. Water Manag. 2020, 228, 105875. [Google Scholar] [CrossRef]
- Song, X.; Liu, Y.; Xue, L.; Wang, J.; Zhang, J.; Wang, J.; Jiang, L.; Cheng, Z. Time-series well performance prediction based on Long Short-Term Memory (LSTM) neural network model. J. Pet. Sci. Eng. 2020, 186, 106682. [Google Scholar] [CrossRef]
- Fan, D.; Sun, H.; Yao, J.; Zhang, K.; Yan, X.; Sun, Z. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 2021, 220, 119708. [Google Scholar] [CrossRef]
- Nguyen, H.D.; Tran, K.P.; Thomassey, S.; Hamad, M. Forecasting and Anomaly Detection approaches using LSTM and LSTM Autoencoder techniques with the applications in supply chain management. Int. J. Inf. Manag. 2021, 57, 102282. [Google Scholar] [CrossRef]
- Liang, X.; Xie, Y.; Day, R.; Meng, X.; Wu, H. A data driven deep neural network model for predicting boiling heat transfer in helical coils under high gravity. Int. J. Heat Mass Transf. 2021, 166, 120743. [Google Scholar] [CrossRef]
- Karaman, Ö.A.; Ağır, T.T.; Arsel, İ. Estimation of solar radiation using modern methods. Alex. Eng. J. 2021, 60, 2447–2455. [Google Scholar] [CrossRef]
- Karaman, Ö.A. Prediction of Wind Power with Machine Learning Models. Appl. Sci. 2023, 13, 11455. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Niu, X.; Ma, J.; Wang, Y.; Zhang, J.; Chen, H.; Tang, H. A novel decomposition-ensemble learning model based on ensemble empirical mode decomposition and recurrent neural network for landslide displacement prediction. Appl. Sci. 2021, 11, 4684. [Google Scholar] [CrossRef]
- Tanyildizi, H. Prediction of compressive strength of nano-silica modified engineering cementitious composites exposed to high temperatures using hybrid deep learning models. Expert Syst. Appl. 2023, 241, 122474. [Google Scholar] [CrossRef]
- Simão, M.L.; Videiro, P.M.; Silva PB, A.; de Freitas Assad, L.P.; Sagrilo, L.V.S. Application of Taylor diagram in the evaluation of joint environmental distributions’ performances. Mar. Syst. Ocean. Technol. 2020, 15, 151–159. [Google Scholar] [CrossRef]
- Sharma, S.; Joshua Thomas, J.; Vasant, P. Performance Analysis and Effects of Dust & Temperature on Solar PV Module System by Using Multivariate Linear Regression Model. In Artificial Intelligence for Renewable Energy and Climate Change; Wiley: Hoboken, NJ, USA, 2022; pp. 217–275. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Days | Sunshine Duration (Hours) | Humidity | Temperature (°C) | Solar Radiation | P(kW) |
|---|---|---|---|---|---|
| 1 | 0.3 | 91.3 | 11.2 | 0.9 | 51.28 |
| 2 | 0.6 | 89.3 | 9.7 | 1.3 | 72.22 |
| 3 | 1.7 | 90.6 | 7.2 | 1 | 43.16 |
| 4 | 0 | 89.1 | 7.5 | 1.3 | 102.4 |
| 5 | 1.3 | 80.7 | 12.5 | 1.1 | 123.95 |
| 6 | 3.2 | 88 | 8.3 | 1.4 | 118.6 |
| 7 | 2.1 | 89.5 | 8.4 | 1.3 | 79.65 |
| 8 | 0.6 | 83 | 11.7 | 1.3 | 115,55 |
| 9 | 3 | 77 | 15.7 | 0.6 | 11.13 |
| 10 | 0.6 | 83.8 | 15.7 | 1.3 | 41.17 |
| 11 | 3 | 71.3 | 18 | 1.2 | 19.36 |
| 12 | 1.5 | 52.8 | 20.2 | 1.1 | 69.23 |
| 13 | 0 | 78.8 | 12.8 | 1.2 | 144.93 |
| 14 | 3.2 | 82.9 | 7.6 | 1.2 | 101.27 |
| 15 | 1.9 | 83.1 | 5.1 | 1.3 | 124.53 |
| 16 | 3.1 | 87.5 | 1.4 | 0.9 | 45.43 |
| 17 | 0.3 | 84.2 | 2 | 1.3 | 124.59 |
| 18 | 0.6 | 72.7 | 1.6 | 1.4 | 153.84 |
| 19 | 4.2 | 74.2 | −0.3 | 1.5 | 163.03 |
| 20 | 4.5 | 77.6 | −0.6 | 1.3 | 176.26 |
| 21 | 4.6 | 82.3 | 1 | 1.5 | 109,5 |
| 22 | 1.7 | 88.2 | 3 | 1 | 63.15 |
| 23 | 0 | 87.7 | 7.3 | 1.2 | 40.82 |
| 24 | 0 | 79.9 | 12.9 | 1.3 | 82.9 |
| 25 | 0 | 73.8 | 14.5 | 0.9 | 44.07 |
| 26 | 0 | 69.8 | 15.5 | 1.8 | 37.77 |
| 27 | 1 | 77.4 | 11.5 | 0.9 | 27.04 |
| 28 | 0.4 | 87 | 3.4 | 1.3 | 56.56 |
| 29 | 0.2 | 86.1 | 2.6 | 1.4 | 145.34 |
| 30 | 2.8 | 87.9 | 8.1 | 0.8 | 9.07 |
| 31 | 0.3 | 86.2 | 9.4 | 1.6 | 128.87 |
| NumNeighbors(K) | Distance |
|---|---|
| 10 | Seuclidean |
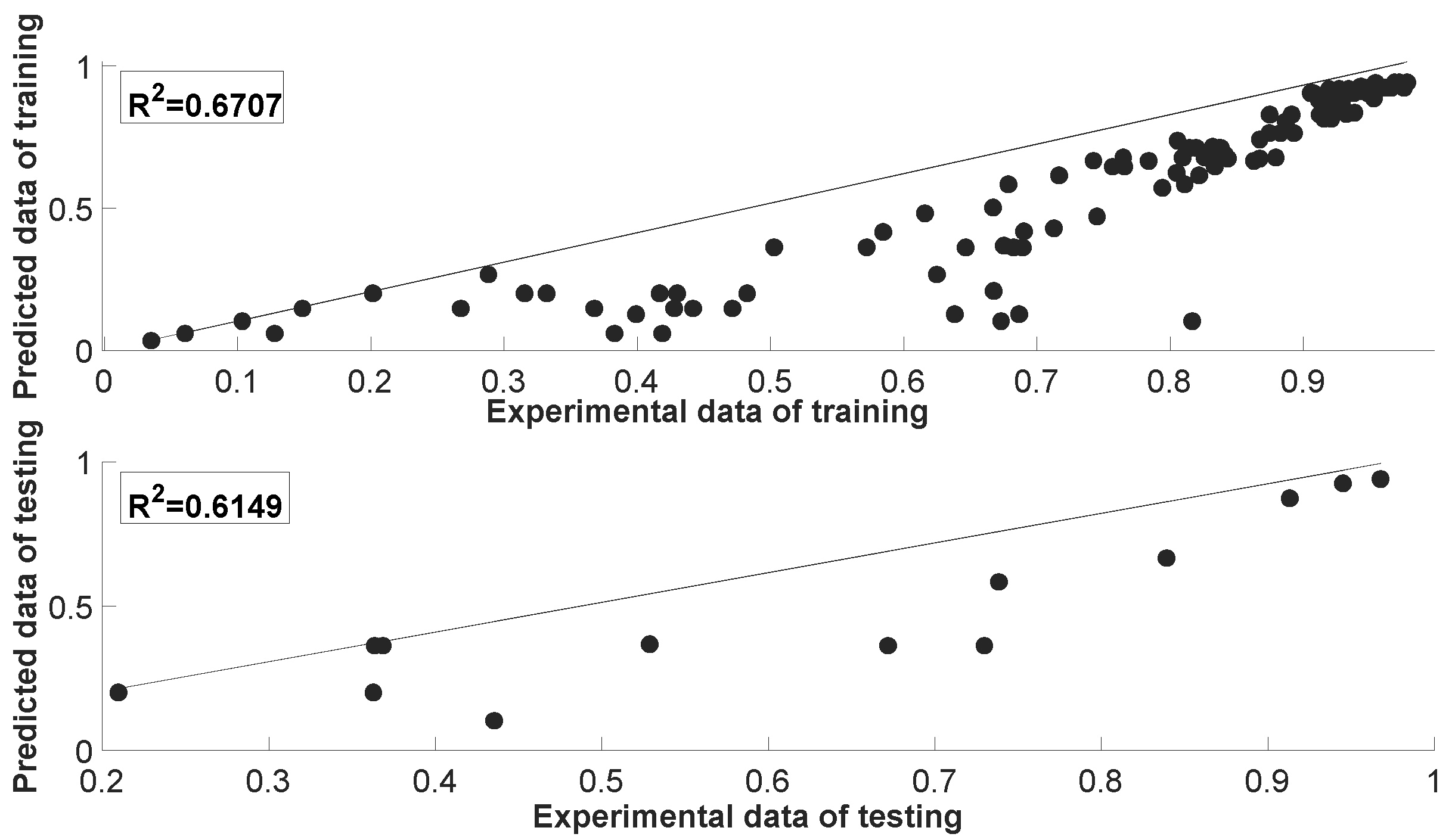
| Performance Metrics | Training | Testing |
|---|---|---|
| MSE | 0.0344 | 0.0344 |
| PSNR | 14.6327 | 14.6394 |
| RMSE | 0.1855 | 0.1854 |
| NRMSE | 0.1968 | 0.2446 |
| MAPE | 20.6954 | 23.2731 |
| 0.6707 | 0.6149 |
| Performance Metrics | Training | Testing |
|---|---|---|
| MSE | 0.0011 | 0.0015 |
| PSNR | 29.7727 | 28.2251 |
| RMSE | 0.0325 | 0.0388 |
| NRMSE | 0.0344 | 0.0512 |
| MAPE | 6.4598 | 6.9112 |
| 0.9639 | 0.9551 |
| Elapsed Time | Epoch | Iteration | Frequency | Hardware Resource | Learning Rate Schedule | Learning Rate |
|---|---|---|---|---|---|---|
| 28 Sec | 2000 | 2000 | 50 Iterations | Single GPU | Piecewise | 2 × 10−6 |
| Performance Metrics | Training | Testing |
|---|---|---|
| MSE | 1.7915 × 10−4 | 5.6199 × 10−4 |
| PSNR | 37.4679 | 32.5027 |
| RMSE | 0.0134 | 0.0237 |
| NRMSE | 0.0142 | 0.0313 |
| MAPE | 2.7509 | 4.3873 |
| 0.9963 | 0.9822 |
| Reference | Model | MSE | RMSE | R | NRMSE | MAPE | |
|---|---|---|---|---|---|---|---|
| Kouz et al. [9] | ELM | 91.42% | 0.0462 | - | - | - | |
| Hammad et al. [10] | ANN | 90.0% | 5.7 | - | - | - | |
| Adıgüzel et al. [11] | ANFIS | 99.803% | - | 0.87098 | - | - | |
| Javed et al. [12] | ANN | 53.7% | 0.0038 | - | - | - | |
| Perez et al. [13] | ANN | - | - | - | 91% | 6.79 | |
| Zitouni et al. [14] | ANN | 81.3% | - | 0.026 | - | - | |
| Jamil et al. [15] | Hybrid CNN-LSTM | - | - | 0.00385 | - | - | 0.28478 |
| Pavan et al. [16] | BNN | 99.92% | - | 0.22 | 99.96% | - | 2.3 |
| Valasquezand Ezcurra [17] | Random forest | 0.88% | 0.07 | - | - | - | - |
| Sharma et al. [39] | MLR | 91% | - | - | - | - | - |
| Presend study | Hybrid LSTM-KNN | 98.22% | 5.6199 × 10−4 | 0.0237 | 99.10% | 0.0313 | 4.3873 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanyıldızı Ağır, T. Prediction of Losses Due to Dust in PV Using Hybrid LSTM-KNN Algorithm: The Case of Saruhanlı. Sustainability 2024, 16, 3581. https://doi.org/10.3390/su16093581
Tanyıldızı Ağır T. Prediction of Losses Due to Dust in PV Using Hybrid LSTM-KNN Algorithm: The Case of Saruhanlı. Sustainability. 2024; 16(9):3581. https://doi.org/10.3390/su16093581
Chicago/Turabian StyleTanyıldızı Ağır, Tuba. 2024. "Prediction of Losses Due to Dust in PV Using Hybrid LSTM-KNN Algorithm: The Case of Saruhanlı" Sustainability 16, no. 9: 3581. https://doi.org/10.3390/su16093581
APA StyleTanyıldızı Ağır, T. (2024). Prediction of Losses Due to Dust in PV Using Hybrid LSTM-KNN Algorithm: The Case of Saruhanlı. Sustainability, 16(9), 3581. https://doi.org/10.3390/su16093581