1. Introduction
In the sustainable energy-saving strategies, smart meters provide an effective power reduction support by controlling electricity with intelligent functions [
1].
Figure 1 shows the architecture of a sustainable energy management system consisting of three modules, which are monitoring, ubiquitous controlling, and power management. The monitoring module aims to sense the environmental information, including temperature, humidity, foreground objects, and other datasets. These sensing datasets are converted into several condition variables for evaluating an environment situation, which are then transmitted to smart meters via a low-cost and wireless sensor network based on ZigBee communication protocol [
2]. Based on the received condition variables, the ubiquitous controlling module achieves an auto-controlling approach for energy management using smart meters. Meanwhile, the smart meters enable remote operation of switching and setting values through cloud computing and controlling. In the power management module, the power socket of an appliance is linked with a smart meter, whose controlling signals are able to control the connected appliance, such as changing temperature of air condition, turning on or turning off lights, heating water, and other activities.
In such a sustainable energy management system, the real-time foreground objects detection in the monitoring module is an important task for smart controlling [
3]. For example, in a garage, when a moving vehicle appears, the nearby lightings need to be turned on; if no foreground object exists, the lightings should be turned off so as to save electricity. To provide an effective environment monitoring approach, this paper aims to study a real-time and accurate foreground object detection algorithm for sustainable energy management. Meanwhile, fast and accurate foreground segmentation for video surveillance is a challenging task in image processing and computer vision [
4]. This approach is also necessary for many multimedia applications, such as virtual reality, human-machine interaction, and mixed reality [
5].
Precise background subtraction is an important step for accurate foreground segmentation. Traditionally, a background model is initialized from the sequential images captured by stationary cameras [
6]. The foreground pixels are subtracted with a pixel-wise difference detection method between the current image and the generated background model. To improve the segmentation accuracy, the adaptive background modeling methods are widely researched for situations where illumination is gradually changing, such as the codebook model [
7]. Because the image scanning process causes huge computation, the traditional background model, such as codebook model, is initialized in the training phase, but not updated with the segmentation process simultaneously.
Although simple spatiotemporal background modeling strategies enable foreground detection without prior knowledgebase, noise and hole regions always exist in the segmentation results [
8]. To enhance the foreground segmentation accuracy, some advanced technologies of background modeling algorithms are studied, such as adaptive background learning, Gaussian mixture model (GMM), self-organizing map, etc. [
9]. However, it is difficult to segment foreground moving objects without noise in unconstrained outdoor environments in rainy, cloudy, foggy, and windy situations. Due to these weather issues, illumination variance of an air or object particle causes a short-term noisy spot. Using the traditional algorithms, it is hard to determine whether the noisy spot belongs to background or foreground models.
The noisy spot is a blob of a small quantity of pixels in the segmented binary foreground result. Based on this definition, it is an effective solution to count pixels in each blob and remove the small blobs as noise. The connectivity-based clustering methods are widely researched to group the foreground pixels into several coherent blobs in spatial domain [
10]. By labeling blobs with distinguished labels, we produce distinct objects for further processing steps such as objects tracking and analysis [
11].
In the rough foreground segmentation process, the computation complexity of pixel-wise difference detection is so easy that foreground pixels can be subtracted fast using CPU programming. However, in the refinement process, the iterative scanning processes of the connected component detection, labeling and noise removal cause huge computation consumption. It is difficult to utilize the traditional CPU computation method for real-time connected component labeling (CCL). To further improve the processing speed, this paper proposes to utilize a graphics processing unit (GPU) programming method instead of CPU to speed up the feedback background modeling, foreground segmentation, and CCL algorithms.
Using GPU programming, we create a thread for each grid in order to analyze its local dataset in parallel [
12]. In pixel-wise foreground segmentation algorithms, the image processing in each pixel is independent from others so that the traditional CPU-based algorithm is easy to be implemented [
13]. For each pixel, we create a color histogram to record its color-changing information, which combines into a background model. If a pixel color in the current image does not locate around the peaks of its histogram, it is segmented as a foreground pixel. Meanwhile, the current image updates the background model synchronously.
In CCL algorithms, the image processing of a pixel is affected by its neighbor pixels [
14]. When we apply parallel computation to process such dependent situations, a thread event on the neighbor grids keeps on being processed no matter that the processing results executed by the threads of the neighboring pixels [
15]. Because the GPU threads do not process at the same speed, the parallel computing results are not certainly same for the dependent situations. For example, in CCL algorithm, we need to label a clique with a minimum value among them, while all labels update based on their neighboring labels simultaneously. If a thread of a neighbor pixel is faster than others, its label will be updated earlier among its local clique so as to cause uncertain labeling results. If the pixel thread is locked until its neighboring computations are finished, there is no difference between CPU and GPU processing methods. For CCL acceleration, we develop a novel parallel connected component labeling (PCCL) algorithm to speed up the image processing of the dependent situation. After the foreground pixels are clustered into several blobs, the pixel count of each blob is computed. The noise blob is assumed to have small quantity of pixels so as to be removed based on the PCCL results.
The main contributions of the proposed PCCL method consist of accurate foreground segmentation and real-time component labeling. The GPU-based feedback background modeling algorithm is able to update the background model of pixel-wise color histogram in real time. The PCCL algorithm increases the labeling speed for component labeling in high-resolution videos. Our proposed method is compatible with real-time remote monitoring, virtual-physical collaboration, sensor network, and other multimedia applications.
The remainder of this paper is organized as follows.
Section 2 provides an overview of related work.
Section 3 introduces the proposed feedback background modeling method and the PCCL algorithm.
Section 4 evaluates the performance of the proposed methods.
Section 5 concludes the paper.
2. Related Works
Currently, feedback background modeling algorithms are widely researched for detection of moving objects. Cuevas et al. [
16] presented a nonparametric background modeling strategy with a particle filter for lightweight smart camera applications. In this strategy, the probability density functions based on Gaussian kernels were defined at each pixel to nonparametrically estimate whether it belonged to the image background or moving foreground regions. Ramasamy et al. [
17] and Casares et al. [
18] employed a temporal difference detection method to generate adaptive background models in dynamic scenes for surveillance enhancement. By detecting the difference between the consecutive frames, the foreground regions of interest were removed. The background model was modeled by the segmented background image frames. Azmat at al. [
19] proposed a low-cost adaptive background modeling method by analyzing temporal scene events including observation frequency and longevity. Using such pixel-wise threshold and frame difference methods, there were noise and holes existing in the segmentation results of the complex scenes with cluttered objects.
Gallego et al. [
20] proposed a foreground segmentation system with a tracking algorithm in camera capture videos. In this system, pixel-wise difference detection between current image and background model was implemented in the initialization phase. The background modeling method modified the mean-shift algorithm with a feedback background model, which enhances the foreground detection accuracy. Zamalieva et al. [
21] introduced a background subtraction method in complicated scenes captured at dynamic camera viewports. The background geometric structure was constructed and the foreground pixels were detected from a series of one-direction conversion between the frames. In these methods, the feedback background modeling phases causes huge computation consumption for high-resolution video sequences.
Currently, the traditional data analysis algorithms are enhanced using GPU technologies [
22], which enable parallel computation of large-scale datasets. The compute unified device architecture (CUDA) from Nvidia (Nvidia, Santa Clara, CA, USA) provides GPU programming interfaces, which is widely studied for pixel-wise background modeling and foreground segmentation [
23]. To extend the typical CPU-based GMM background modeling method [
24], Pham et al. [
25] and Boghdady et al. [
26] utilized CUDA libraries to implement the background modeling process in parallel. They created a pixel-wise probability distribution of intensity, which was updated by each allocated pixel thread in parallel. To remove shadow effect under intensity changes, Fukui et al. [
27] recorded illumination intensity and RGB (red, green, blue) color information into a histogram table as an adaptive background model. The intensity and color threshold of each pixel were generated from their distribution stored in the corresponding histogram. The histogram buffer was allocated and updated in GPU memory so as to record each pixel’s information in parallel. Although the background modeling and foreground segmenting processes were able to be implemented synchronously using these methods, noise and holes existed in the foreground segmentation results.
To realize real-time and accurate foreground–background segmentation, Griesser et al. [
28] applied a pixel-shaders GPU programming technology to accelerate the iterative image scanning speed. The noise was removed and holes were filled in the rough segmentation results using an iterative Markov random field model. Cheng et al. [
29] proposed an online learning framework for foreground segmentation to adapt for spatio and temporal changes of the background scene. For that their proposed algorithms were compatible with parallel computation formalism, they utilized a GPU programming to facilitate real-time foreground segmentation from dynamic scenes over time. These GPU-based foreground segmentation methods achieved real-time approaches, but the noise still existed in difficult scenarios such as foggy and maritime environments.
Connectivity-based clustering methods are studied for distinguishing and tracking objects so as to segment foreground without noisy speckle. Wang et al. [
30] applied an adaptive connected component analysis method to remove the small spots of incorrect foreground pixels from the segmentation results of visual background extractor (ViBe). Using a single-chip Field Programmable Gate Array (FPGA) for the segmentation of moving objects in a video, Appiah et al. [
31] developed a novel feedback background updating method with a CCL algorithm. The moving foreground segmentation and labeling processes were implemented in parallel on the FPGA hardware platform. Using a morphological opening method, the noise was removed and the holes were filled. Jiang et al. [
32] developed connectivity-based segmentation in 2D/3D sensor networks for geometric environment understanding. Flooding from the boundary nodes, the whole geometric cells were scanned to construct a Reeb graph. If the neighbor cells were not mutex, they were merged into one component. The iterative scanning for counting the blobs pixel by pixel causes huge computational consumption. To speed up the connectivity detection in binary images, He et al. [
33] enhanced the conventional two-scan CCL algorithm. On the first scan, all labels of a connected component were assigned with the same temporary equivalent integer. On the second scan, the corresponding labels in a connected component were assigned their unique representative labels. For visual surveillance of moving objects, Hu et al. [
34,
35] proposed a fast 4-connected component labeling algorithm to reduce the influence of a dynamic environment, such as wave ripples. In each scan process of this algorithm, the adjacent pixels of two rows were merged into an isolated block, which was labeled with the minimum label value in the block. After the foreground pixels were roughly subtracted by an illumination difference detection method, the noise assumed as small isolated block was removed. These CPU-based component labeling algorithms were able to deal with the low-resolution video images, but hard to scan large foreground blobs in real time.
In contrast to these state-of-the-art sequential CCL methods, parallelism and multithreading strategies accelerated the labeling speed in high-resolution videos. Typically, there were two propagation methods implemented in the CCL kernel, including directional pass and multi-way pass. Using CUDA, Kalentev et al. [
36] and Hashmi et al. [
37] implemented iterative row–column scanning on 2D binary grids. After initializing all non-zero element labels with their corresponding index, this algorithm propagated the lowest label value along the rows and the columns to label all non-zero neighbors with this lowest value. Hawick et al. [
38] imaplemented and analyzed the performance of two-pass, one-pass, and multi-pass CCL algorithms for speeding up graph component labeling. They allocated a thread for each pixel, which propagated its adjacent pixel list and labeled them with the minimum label value of them. The propagation iterations were stopped and the labeling process was finished until all labels were not changed. In the directional propagation labeling algorithms, such as one-pass, two-pass, and row–column scanning, a GPU thread scanned a row and a column at least twice. The first scanning was to search minimum label, and the second scanning was to label all grids in the row and column with the minimum label. This scanning method was effective for low-resolution images. In contrast to CPU thread, the processing speed of GPU thread was reduced when the computation complexity became high. Thus, the row–column scanning algorithm of CCL caused computational overload for high-resolution situations. From their experiments, the multi-pass algorithms provided the best performance. In description of their multi-pass algorithms, each thread searched and labeled the corresponding local and neighbor pixels synchronously.
Figure 2 shows an example of two iterations of their method. To keep synchronous reading and updating labels, a GPU thread executed its function and held on until every thread finished searching the minimum label. Also, a GPU thread only labeled the local pixel with the minimum label, instead of propagating the minimum label to its neighbor pixels. Although this method kept the consistency of the CCL results, a large number of iterations were required for large-scale datasets due to the low bandwidth of the labeling process.
Using the threads synchronization function, the parallel computation speed was reduced, because the threads had to wait for all threads to finish. Meanwhile, the labeling process became slow without propagating the minimum label to neighbor pixels. If the GPU threads processed the neighbor propagation without synchronization, the data-dependent issue in
Figure 3 would arise, because the GPU threads executed with different speeds. Taking the first four pixels as an example, the labeling process in thread 4 was slower than thread 2, so that the labeling result “1112” was covered by “1133”. This asynchronous characteristic of GPU threads caused uncertain iteration times.
The GPU-based CCL algorithms should address the data-dependent issues. Cabaret et al. [
39] benchmarked the existing GPU-based CCL algorithms and concluded they were all multi-pass data-independent approaches, which were not suitable for GPU acceleration. Instead of GPU programming technology, they utilized OpenMP to program a parallel version of CCL on multi-core processors. However, such multithread architecture of CCL was still inefficient to deal with data-dependent scanning process in parallel. To realize the neighbor propagation in parallel, this paper presents a novel PCCL algorithm to increase the labeling speed for the data-dependent situations.
3. GPU-Accelerated Foreground Segmentation and Labeling
This section describes the GPU-accelerated foreground segmentation and labeling methods using a GPU programming technology. We propose a feedback background modeling method for foreground segmentation from video sequences. From foreground pixels, a PCCL algorithm is developed to cluster and label them into several distinguish blobs.
3.1. The GPU-Accelerated Framework
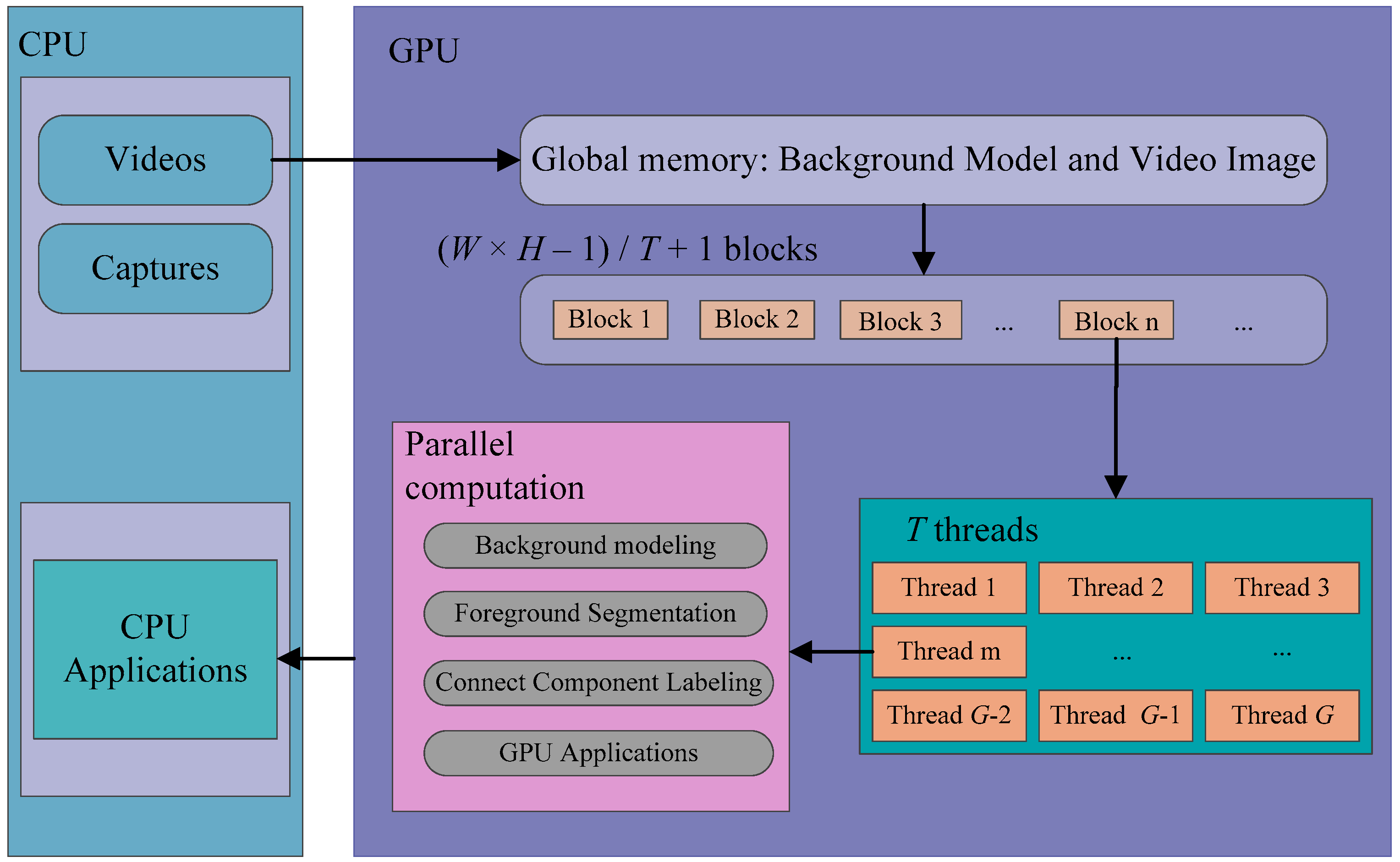
In contrast to CPU-based image processing methods, a GPU-accelerated framework for foreground CCL in video images is proposed as in
Figure 4. The framework contains two modules, including foreground segmentation and labeling. Using CUDA software development kits (SDKs), we allocate (
W ×
H − 1)/
T + 1 blocks and
T threads in each block in order to create
W ×
H threads to compute the proposed image processing algorithms on each pixel in parallel. Here,
W and
H are the width and height of the video image separately.
In the foreground segmentation module, we allocate the video image and the background model buffers in GPU memory. In the background model, pixel-wise RGB histograms are created for recording the color changing distribution. The background model keeps updating based on new registered video images. Meanwhile, the foreground pixels are segmented, if their colors do not locate around the peaks of their corresponding histograms.
In the CCL module, the labels of the segmented foreground pixels are initialized with their corresponding indices. After a GPU thread searches the minimum label among a pixel and its neighboring pixels, these pixels are assigned with the minimum label. This propagation process is implemented iteractively until there is no changing in all labels. This way, the segmented foreground pixels are clustered into several distinguished blobs.
3.2. Foreground Segmentation by a Feedback Background Modeling Method
This section proposes a feedback background model using GPU programming technology for foreground segmentation. As shown in
Figure 5, this model implements the background modeling and segmentation processes synchronously.
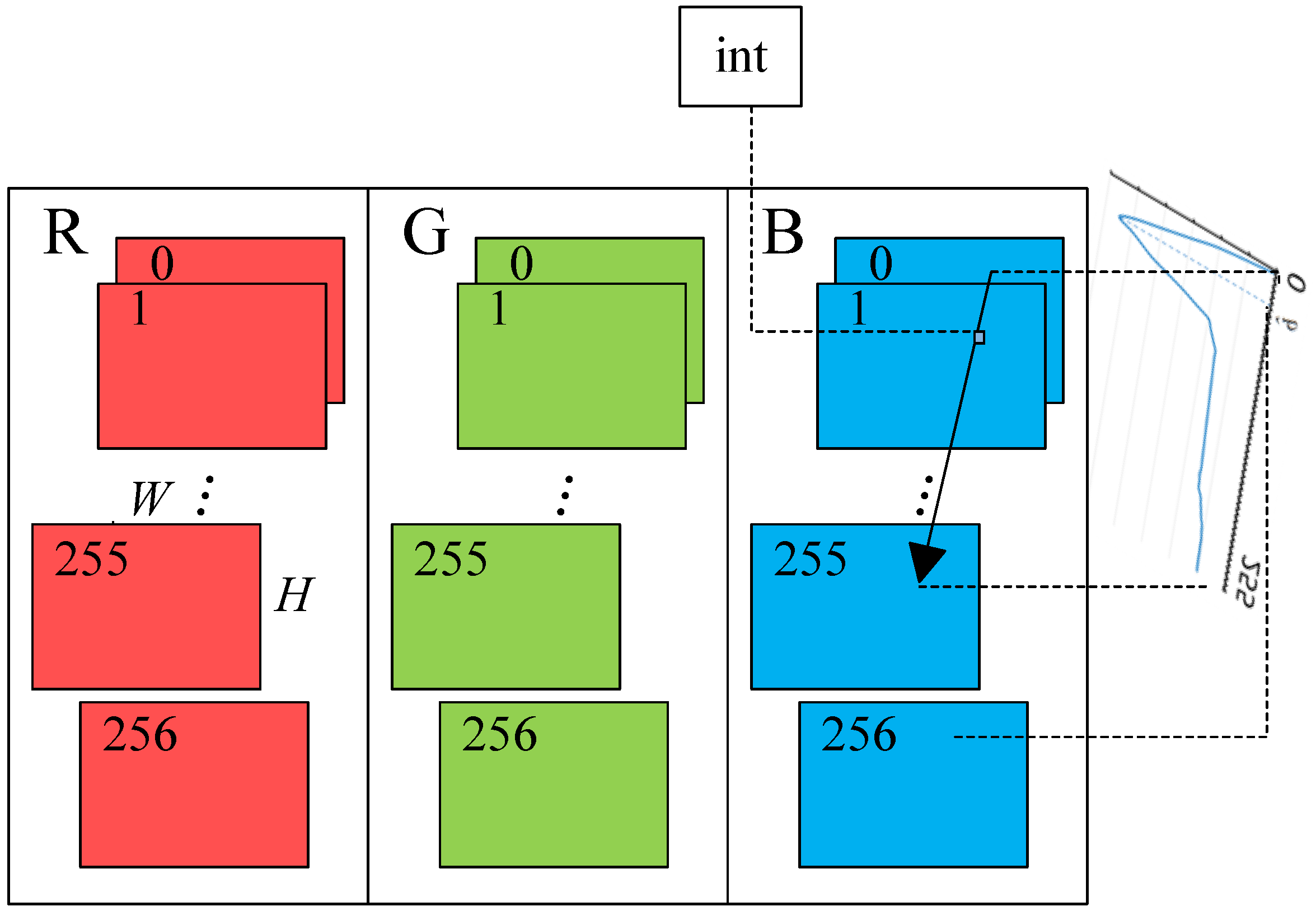
As shown in
Figure 6, in GPU memory, we allocate pixel-wise RGB color histograms and background colors of the histograms for each pixel. To record the color changing history of red, green, and blue channels,
H ×
W × 3 histograms are updating with the new registered color at the corresponding pixels. Each histogram contains 256 integer buckets to record the color appearance counts. When a color (
r,
g,
b) at a pixel (
x,
y) is registered to the background model, the corresponding histogram
Mi at the bucket
i is updated as follows:
A pixel is classified to background class by determining whether its color is repeatedly appearing. During the training stage, the background colors are registered around the peaks in the pixel-wise histograms. From the histograms, the background colors corresponding to the peaks are stored in the 256th buffer blocks. During the testing stage, if a pixel color in a new registered image locates around the peaks of its RGB histograms, it is determined as a background pixel. Otherwise, this pixel is segmented as a foreground pixel. Using GPU programming, the background training and testing stages are implemented in parallel so as to realize a synchronization approach.
3.3. PCCL Algorithm
This section proposes a PCCL algorithm to cluster the segmented foreground pixels into several separate blobs using GPU programming. To realize a parallel computation approach, a GPU thread is created to process the labeling and propagation processes for each foreground pixel, as shown as the red color regions in
Figure 7a. A thread has an ID equal to its processed pixel index.
A label map
L in
Figure 7b is initialized from the foreground segmentation result. If a pixel
i is classified as a foreground pixel, the label at
i is specified as
L(
i) =
i; otherwise
L(
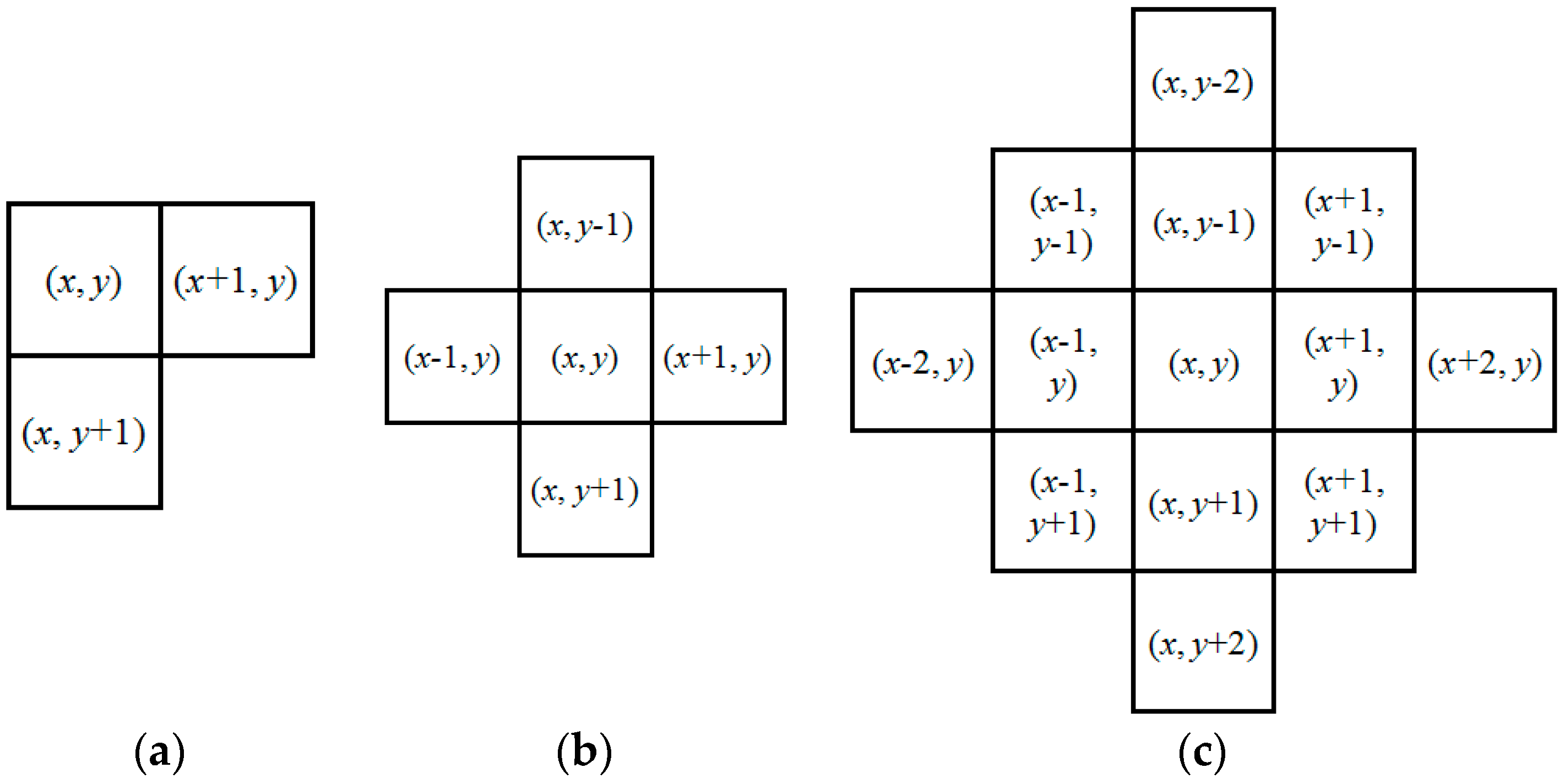
i) = null. In the connectivity detection stage, each foreground pixel propagates to its adjacent foreground pixels which are labeled with the minimum label value among them. In the typically CCL algorithm, a pixel (
x,
y) propagates its right and bottom pixels, as shown in
Figure 8a. In our proposed PCCL, we enlarge the propagation range for accelerating the convergence of the iterative scanning. As shown in
Figure 8b,c, a neighboring clique for a pixel (
x,
y) is defined as the adjacent and local pixels to the pixel with a distance of
d (
d ≥ 1).
We illustrate the propagation in
Figure 7c with
d = 1. In the CPU-based sequential computing methods, the propagation process is implemented pixel by pixel. In contrast to them, we process all foreground pixels individually in parallel by
H ×
W threads. Because a foreground pixel and its neighboring foreground pixels propagate to their neighboring cliques synchronously, the computation of local and the neighboring labels are not certainly finished. Thus, the labeling result is not always the same. When this parallel propagation process is executed iteratively until all label values no longer change, the connected pixels are labeled with the lowest label value among them after several iteration operations, as shown in
Figure 7d.
3.4. Components Extraction
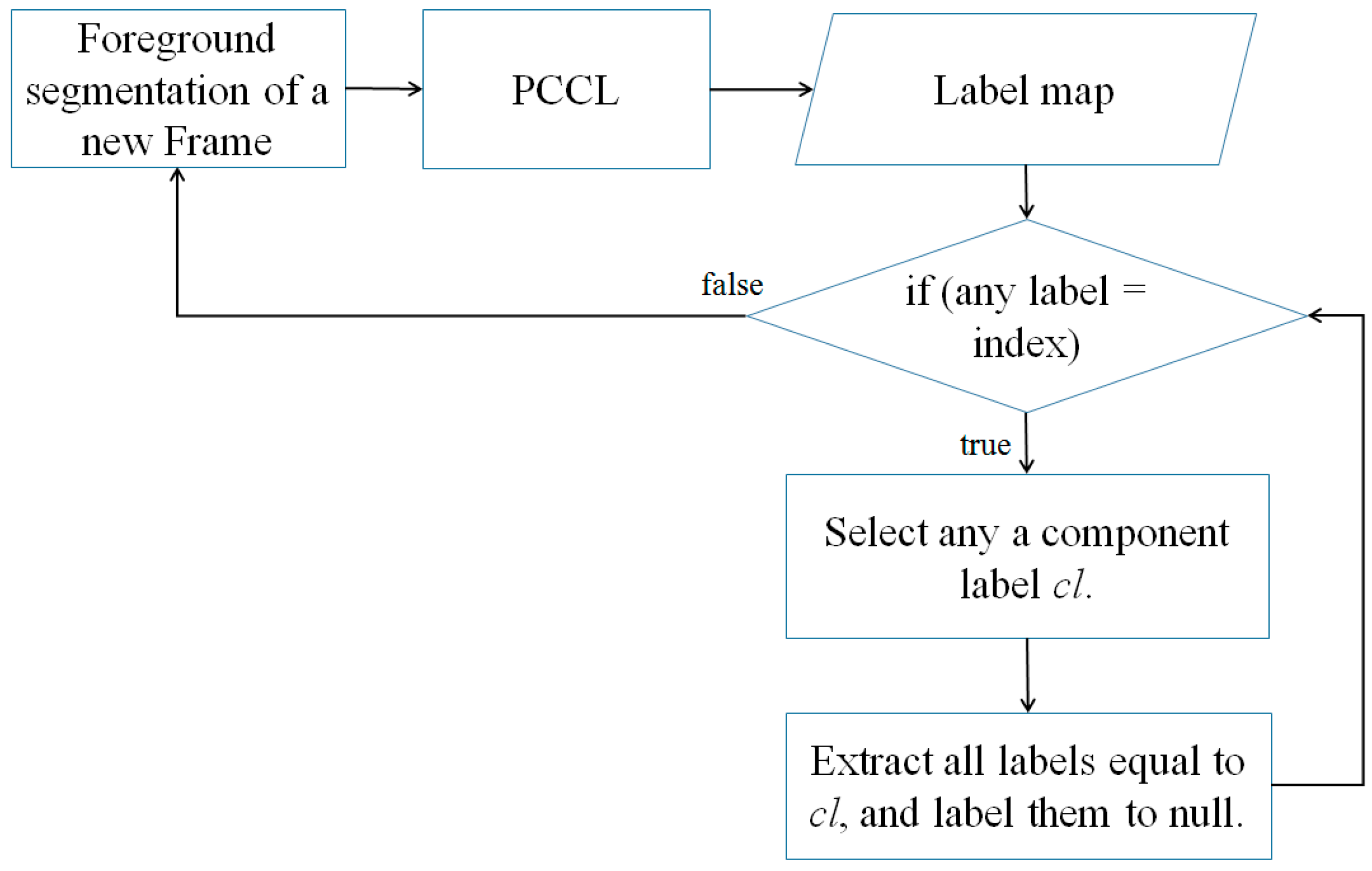
In object tracking applications, distinguished components need to be extracted respectively from the labeling result. Also using GPU programming, we propose a parallel components extraction method as shown in
Figure 9.
A component label cl is defined as the value of its pixel labels, which is the minimum index among them. By traversing all labels using H × W threads, a cl is selected and valued as any label equal to the label index. Then, we extract the component pixels in the component cl, and label their labels as null. This process is implemented iteratively until any component label does not change in the label map.
Besides objects tracking applications, this method provides a clue to remove noise from the foreground segmentation. The noise is always formed as a blob containing a small quantity of pixels. If the extracted pixel of a component is small, we determine that this component is noise and it is removed from the segmentation results.
4. Experiments and Analysis
In this section, we analyze the performance of the proposed GPU-accelerated foreground segmentation and labeling method. The experiments were implemented on a 3.20 GHz Intel® Core™ (Intel, Santa Clara, CA, USA) Quad CPU computer with a GeForce GT 770 graphics card (Nvidia, Santa Clara, CA, USA), 4 GB RAM. The GPU-based parallel computation was implemented using the CUDA toolkit V5.5 (Nvidia, Santa Clara, CA, USA).
4.1. Foreground Segmentation Performance Analysis
Figure 10 shows the experimental results of the proposed methods, which were executed on several typical and challenging scenarios from a crowd dataset (PETS2009) [
40], vehicle dataset (AVSS2007, London, UK) [
41], jug dataset (ICCV2003, Nice, France) [
42], and WaveTree dataset (Microsoft Research, Redmond, WA, USA) [
43], from left to right. In these datasets, the camera viewports were stationary. The crowd dataset contained a 768 × 576 AVI video for the evaluation of moving pedestrian detection. The vehicle dataset had 720 × 576 video sequences for the evaluation of vehicles segmentation, which contained parked vehicles. The jug dataset contained a set of 320 × 240 sequential images for evaluating the moving semitransparent jug segmentation from maritime environments where wave ripples existed. The WaveTree was a low-resolution dataset of 160 × 120 sequential images, which had a waving tree as a background object. The available buffer size of the applied NVIDIA hardware was 5622 megabytes, which satisfied the GPU memory requirement of the background modeling for our experiments.
After several frames of background model updating, the background images in
Figure 10b were generated from the color values located in the peaks of the color histograms. Then, we implemented the proposed PCCL algorithm in the foreground pixels segmented using the generated background model. The connected components were rendered with distinguished colors in the labeling results, shown in
Figure 10c. After the components containing small quantity of pixels were removed as noise, the foreground segmentation results were refined and the foreground objects as large components were extracted, shown in
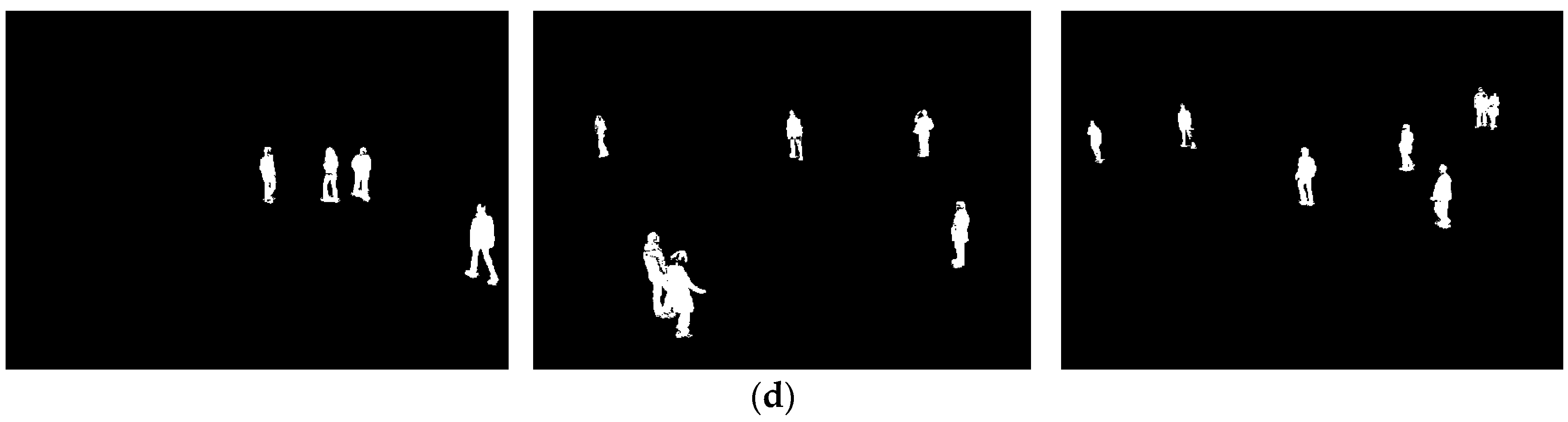
Figure 10d. Finally, the foreground component pixels were extracted in
Figure 10e by masking the binary map in
Figure 10d to the original images.
In order to analyze the performance of our proposed foreground segmentation and PCCL methods, we conducted the same experiments using a self-adaptive codebook model proposed by Shah et al. [
44] and the typical GMM proposed by Stauffer and Grimson [
24]. Following the codebook and GMM description in [
24,
44], we programmed the codebook and GMM using the OpenCV library (Itseez, San Francisco, CA, USA).
Figure 11 and
Figure 12 illustrate the qualitative comparison results of these foreground segmentation methods on the 768 × 576 crowd dataset and 640 × 480 campus dataset, respectively.
Figure 11a and
Figure 12a have several sampling frames of the original videos. The foreground segmentation results using the codebook model are shown in
Figure 11b and
Figure 12b, which contained the noise caused by illumination changes and small waving objects. Although the GMM model removed the noisy spot caused by varying illumination, the spattered noise of waving objects still existed in the segmentation results, as shown in
Figure 11c and
Figure 12c. Using the PCCL algorithm, our proposed method removed both spot and spattered noise of a small quantity of pixels and provided accurate foreground detection results in
Figure 11d and
Figure 12d.
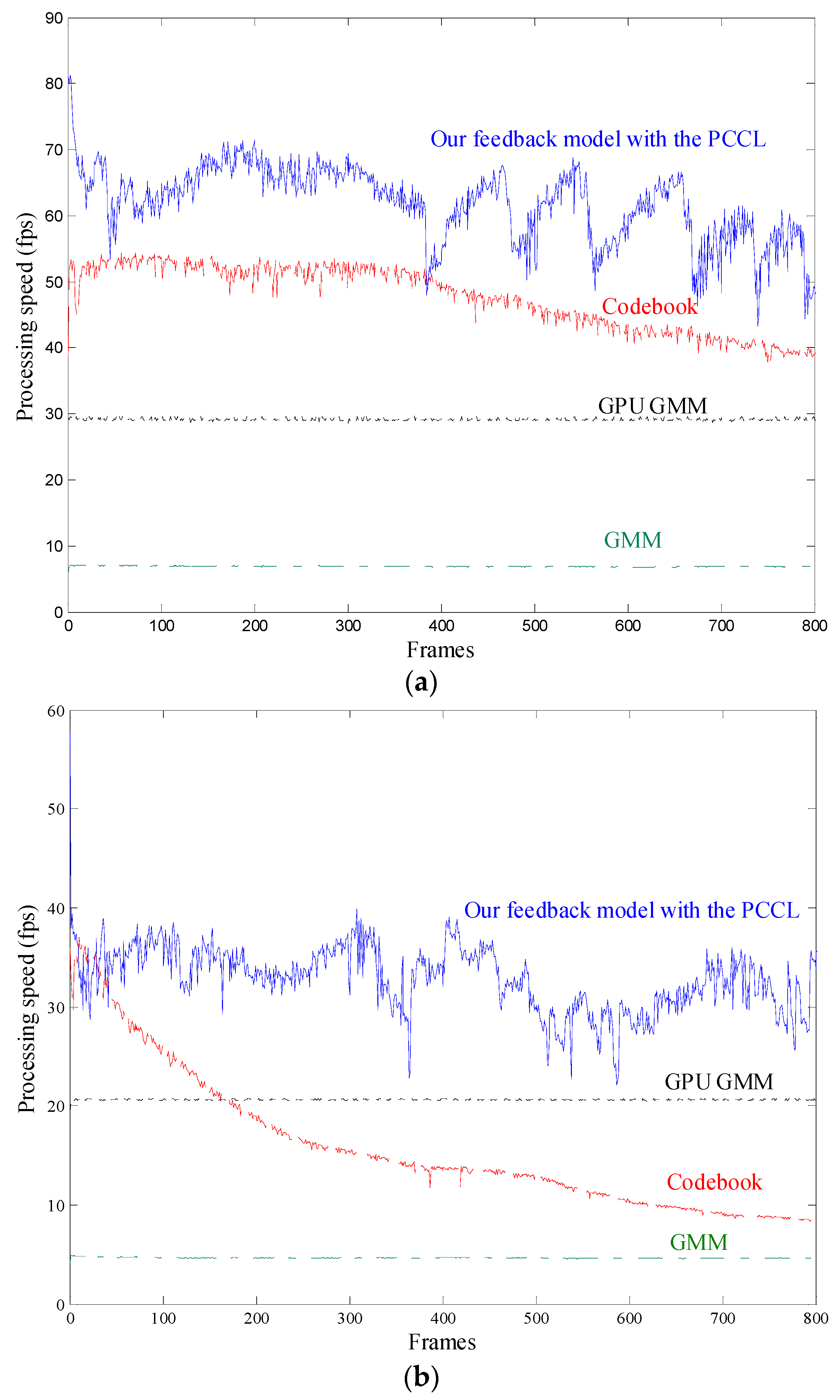
Figure 13 shows the speed performance of the foreground segmentation and labeling methods compared with the self-adaptive codebook model, the GMM, and the GPU GMM proposed by Pham et al. [
25]. We implemented the training and testing stages synchronously. The average processing speeds of the foreground segmentation in the 640 × 480 resolution dataset were 39.3867 frames per second (fps), 6.8981 fps, 29.1489 fps, and 56.3287 fps by using the codebook model, the GMM, the GPU GMM, and the proposed feedback model with the PCCL, respectively. For the 768 × 576 resolution dataset, the processing speed reduced to 15.8867 fps, 4.6507 fps, 20.6014 fps, and 34.1488 fps. The results reflect that when the video resolution became high, the foreground segmentation using codebook and GMM models were not able to implement in real time. The GPU thread is fit for computing simple programs in parallel, but becomes slow when processing complex algorithms. The Gaussian probability density function computation was so complex that the GPU computation speed of GMM was not fast enough for real-time computation in high-resolution videos. Although the processing speed of our method was reduced in the high-resolution situation, it was more than 30 fps and satisfied the requirement of real-time monitoring.
4.2. PCCL Performance Analysis
The existing CPU-based directional pass and multi-way pass CCL methods utilized a single thread to propagate the minimum label to the local and neighboring dataset pixel by pixel. Their principles were similar such as descriptions by He et al. [
33] and Hu et al. [
34]. The different performances of iteration and processing speeds were caused by the different label array range and testing different resolution. If the label array range was enlarged, the minimum label of the large range was quickly searched propagated to the large range by an execution. However, the processing speed became slower due to the more computation consumption required in the larger labeling range.
To compare the performances of the PCCL and the typical CCL methods, we programmed the CPU-based CCL proposed by Hu et al. [
34] and GPU-based multi-pass CCL methods proposed by Hawick et al. [
38], which were implemented in the 768 × 576 resolution dataset. In these methods, the label array of a labeling execution was selected based on the propagating neighboring clique definition in
Figure 8b.
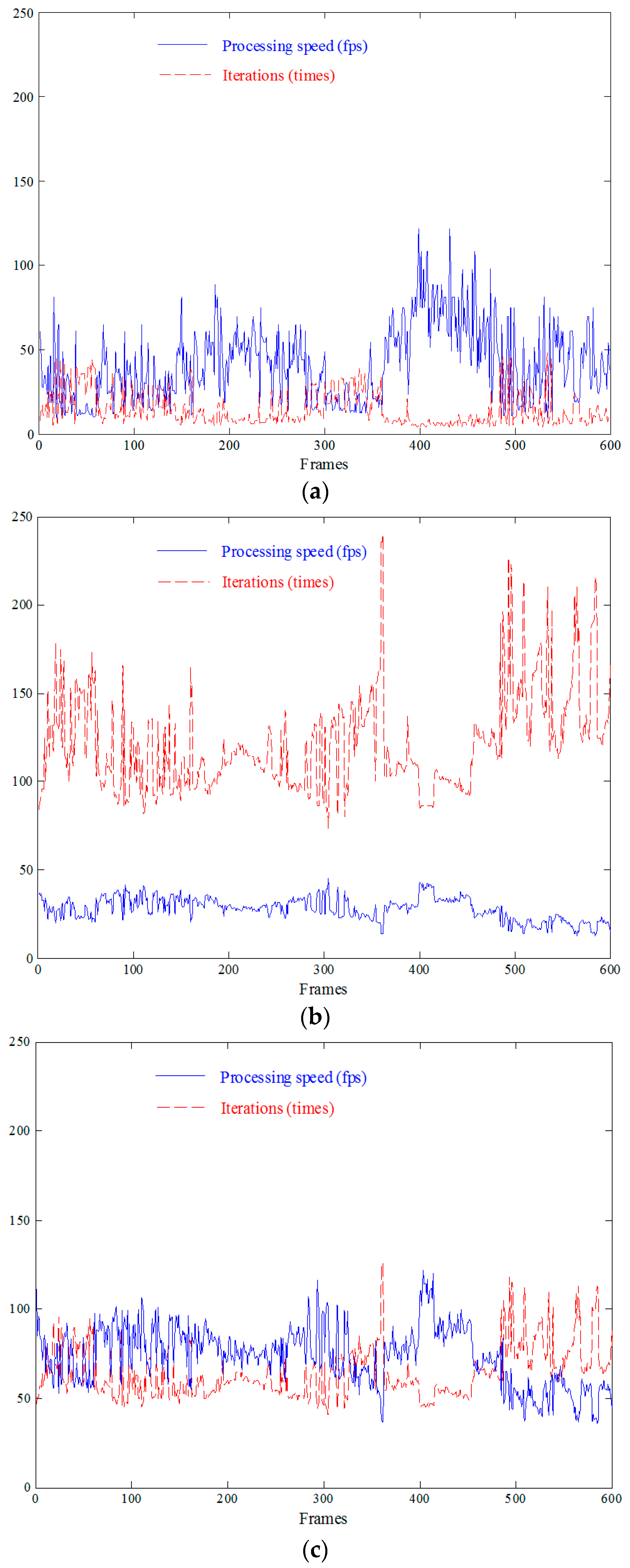
Figure 14 shows the relation between processing speeds and iteration times of these methods.
Because the CPU thread scanned the video images pixel by pixel during each iteration, many labeling iterations were required so that the labeling speed was slow when the foreground pixels occupied large regions in high-resolution images. As shown in
Figure 14a, the speed of the CPU-based CCL decreased faster when more propagating iterations were executed. The average labeling speed performance of the CPU-based method was 41.31 fps with 14.40 iterations. Approximately, if more than 29 iterations were executed, the labeling speed would be reduced to below 20 fps, which does not satisfy the real-time requirement.
Different from CPU programming, the GPU-based labeling methods processed all pixels in parallel so that the labeling speeds did not decrease a lot even for the iteration increment. The GPU-based multi-pass CCL method could be implemented in real time for low-resolution images. However, this method required a large number of iterations for the propagation for high-resolution images, because a GPU thread only updated the center pixel in a clique with the minimum label. Thus, labeling convergence became slow due to the ineffective propagation process. As shown in
Figure 14b, 121.98 iterations were executed using the GPU CCL in our experiment, and the labeling speed was reduced to 27.57 fps on average. In our CCL implementation, the local and neighboring labels were updated with the minimum label, instead of only one local label updated by the GPU CCL. Although the ranges of the label array in the GPU CCL and the CPU CCL were same, in the GPU CCL, the propagation bandwidth was smaller so that more iterations were required.
Also, in our PCCL implementation, a GPU thread labeled its corresponding local and neighbor pixels with the minimum label among its clique. In the PCCL and GPU CCL, the label array ranges were same. We updated five labels by a GPU thread, more than only one label updated by the GPU CCL, so that the labeling convergence was accelerated. This way, the iteration times were reduced and the labeling speed increased. As shown in
Figure 14c, 64.32 iterations were executed using the PCCL, and the labeling speed was 71.35 fps on average. Although our proposed PCCL executed more interactions than the CPU CCL, the parallel computing mechanism accelerated the labeling speed. Thus, the PCCL was able to provide the best performance for high-resolution images.
4.3. Sustainable Energy Management Application
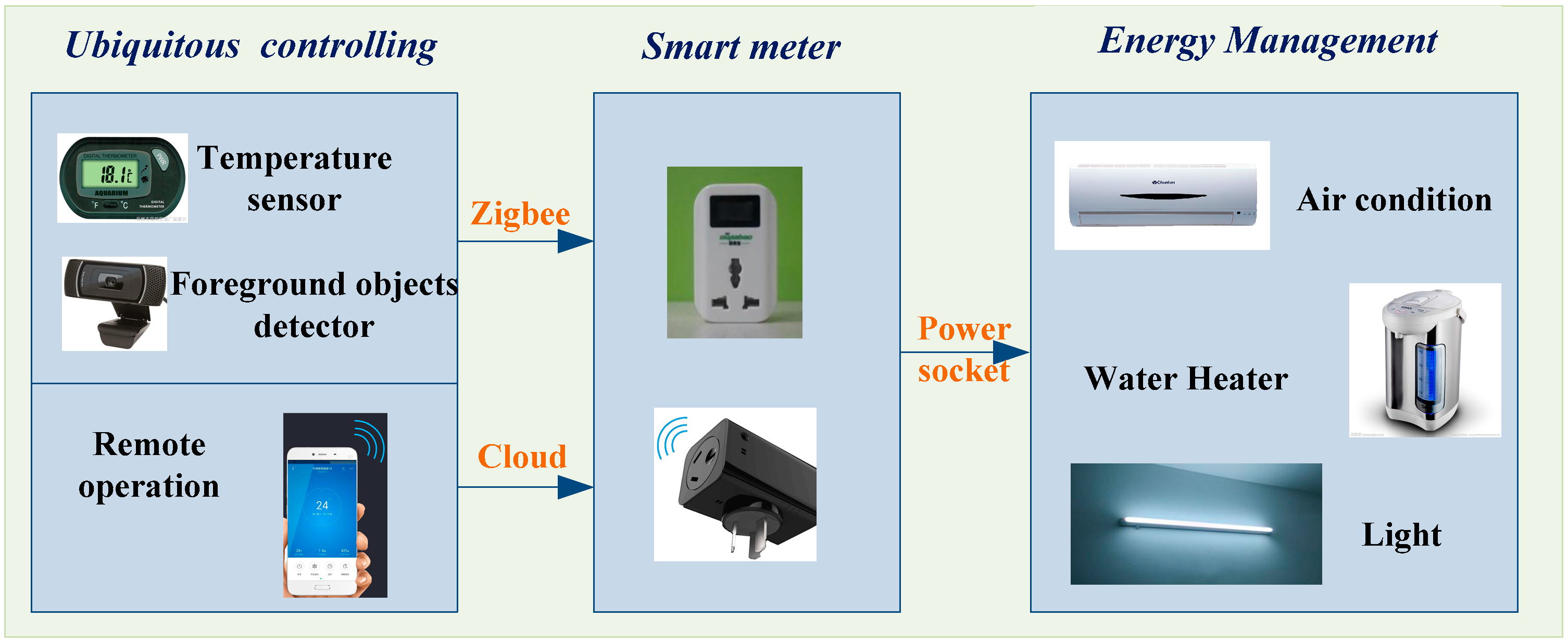
Figure 15 illustrates a video surveillance application for a sustainable energy management system using the proposed GPU-accelerated foreground segmentation and labeling algorithms. In this project, a smart meter developed by Beijing Innolinks Technology Co. Ltd. (Beijing, China) [
45], was utilized for ubiquitous controlling of the appliances, including air conditioning, water heater, and light.
In the monitoring module, the environment information was recorded by multiple sensors and reported to the smart meter via the ZigBee communication. In our application, the ambient temperature was sensed by the thermometer mounted at the smart meter, and the foreground objects were detected by our proposed method. Based on these sensed datasets, the smart meter controlled the appliances for electricity saving by changing operation parameters or switching power supply. Meanwhile, the smart meter enabled the remote operation by smart phones through Cloud services for ubiquitous controlling.
In this project, our contribution was to develop a real-time foreground objects detection method for providing the smart meter with a decision-making basis. When the number of people in a workplace decreased, the smart meter turned up the temperature of the air condition. When a vehicle moved in a dark garage, the lightings around the car were turned on. When a person came into a room, the appliances connected with the smart meters were turned on. Using such smart energy management, the appliances were able to save around 20%–50% energy.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















