
Exploring Spatial-Temporal Patterns of Urban Human Mobility Hotspots


Abstract
:1. Introduction
- (1)
- We develop a methodological workflow to identify human mobility hotspots, including convergent and dispersive hotspots. These hotspots can give insight into where, when and to what extent human convergence or dispersion occurs in urban areas, which allows us to observe the city from a dynamic perspective.
- (2)
- Based on mobile phone location data from Shenzhen, China, we extract six spatial-temporal patterns of human convergent and dispersive hotspots and discuss the relationship between these patterns and urban function areas. The contribution could deepen our understanding about human mobility patterns in Shenzhen, which can serve as references for administrative departments to implement the corresponding policy to satisfy the movements of citizens.
2. Literature Review
2.1. Understanding Human Mobility Patterns
2.2. Hotspots Detection
3. Methodology
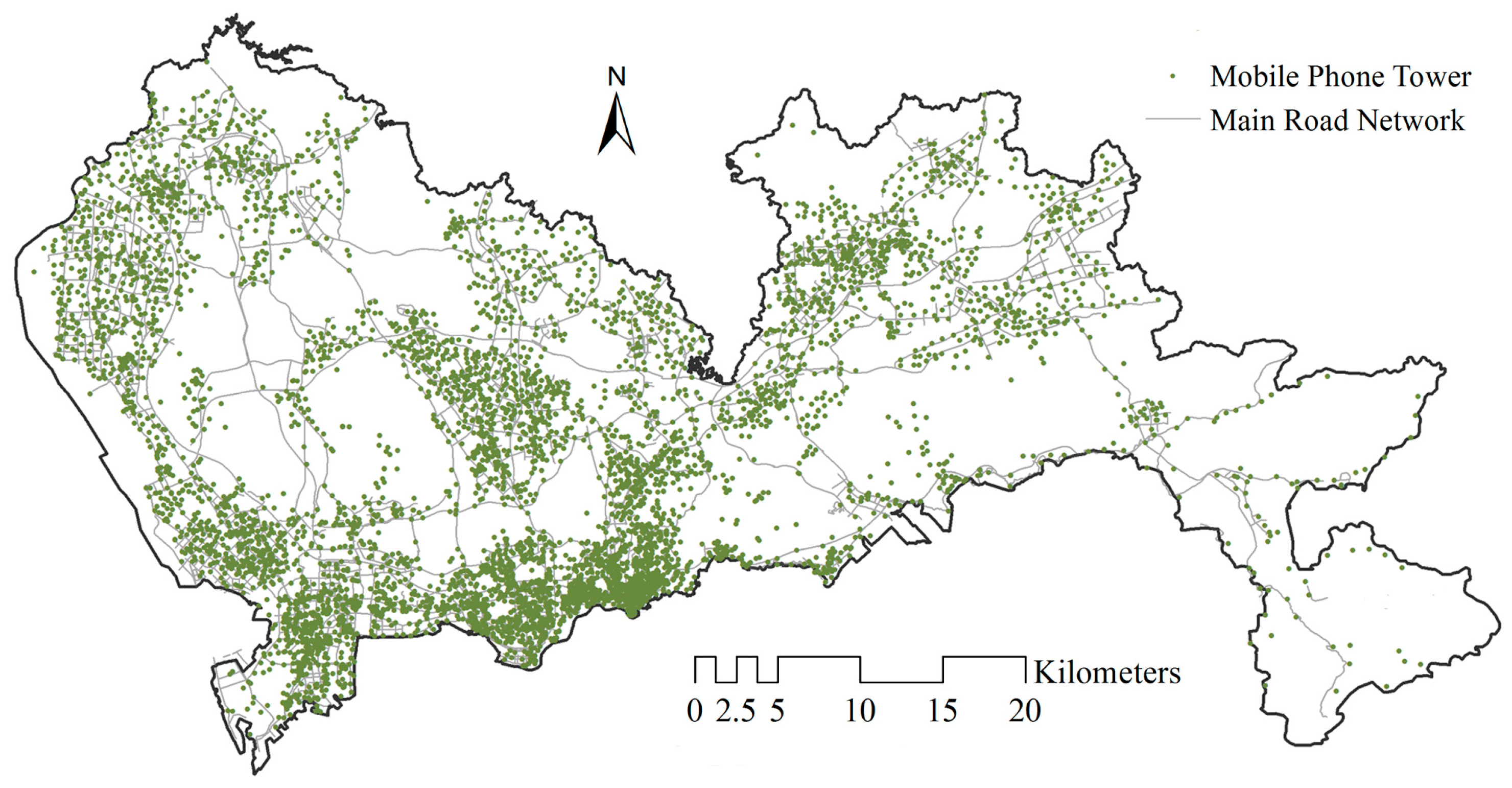
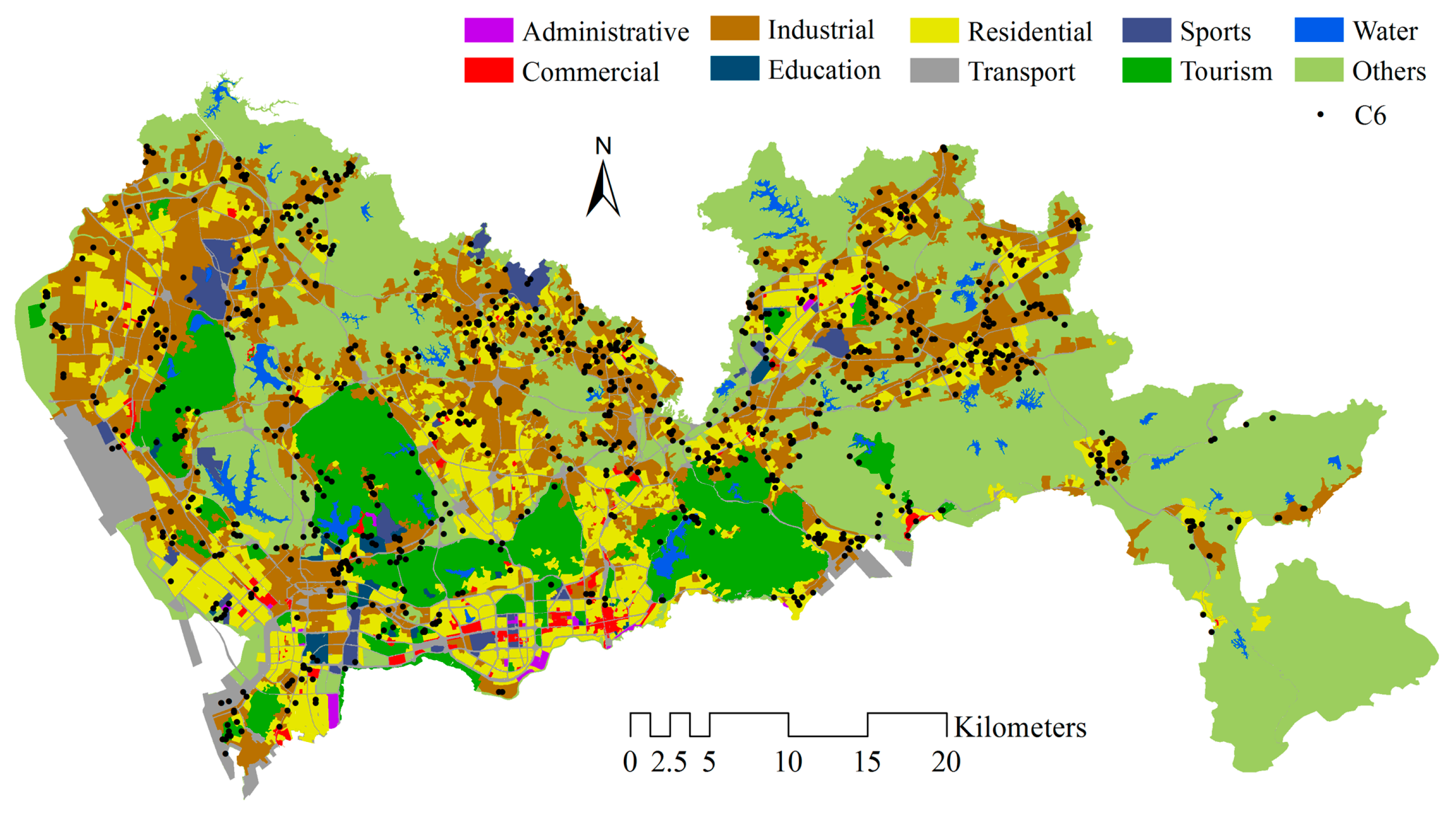
3.1. Dataset and Study Area
3.2. Extracting the Spatial-Temporal Patterns of Human Mobility Hotspots
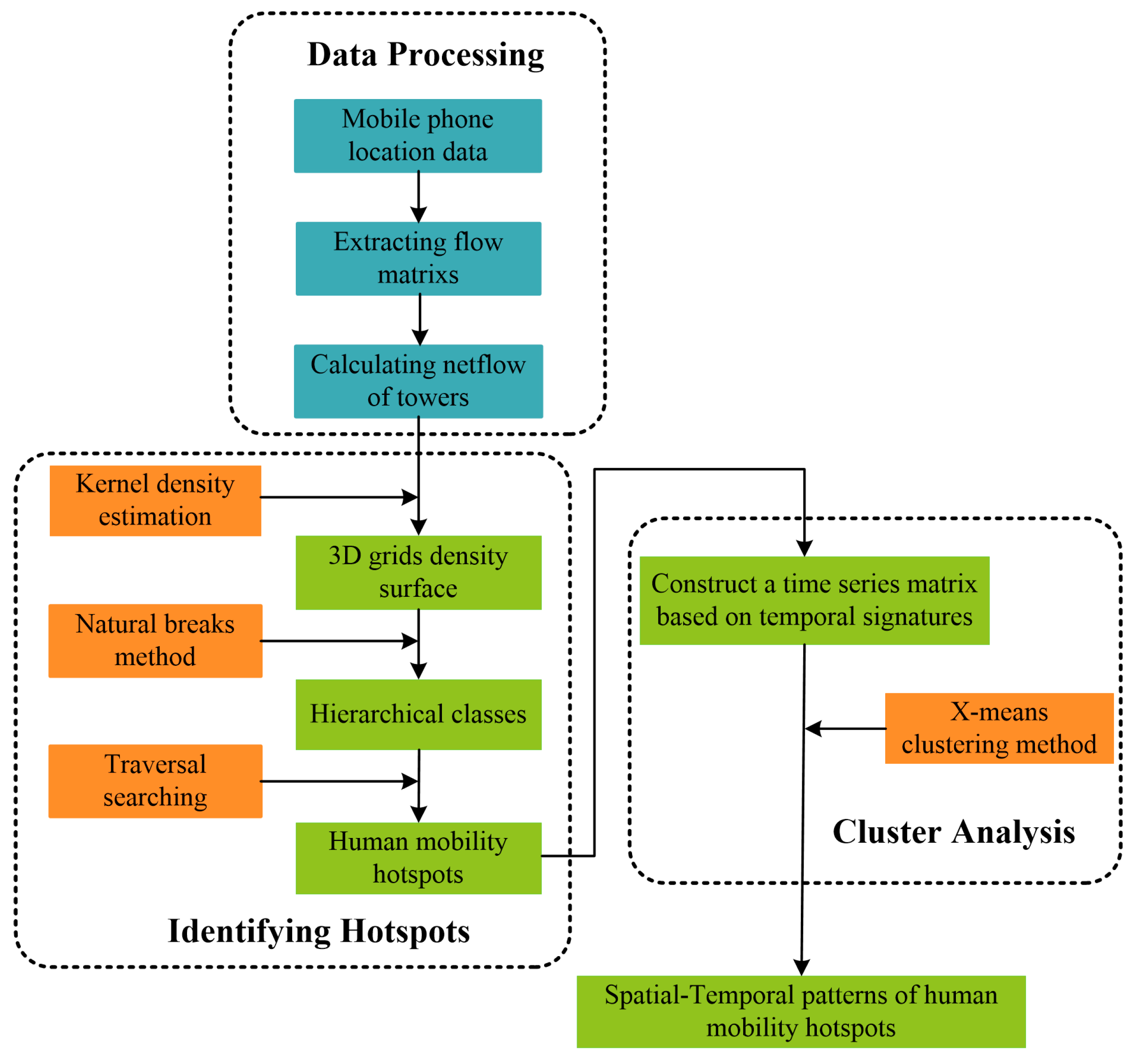
3.2.1. Data Preprocessing
3.2.2. Identifying Human Convergent and Dispersive Hotspots
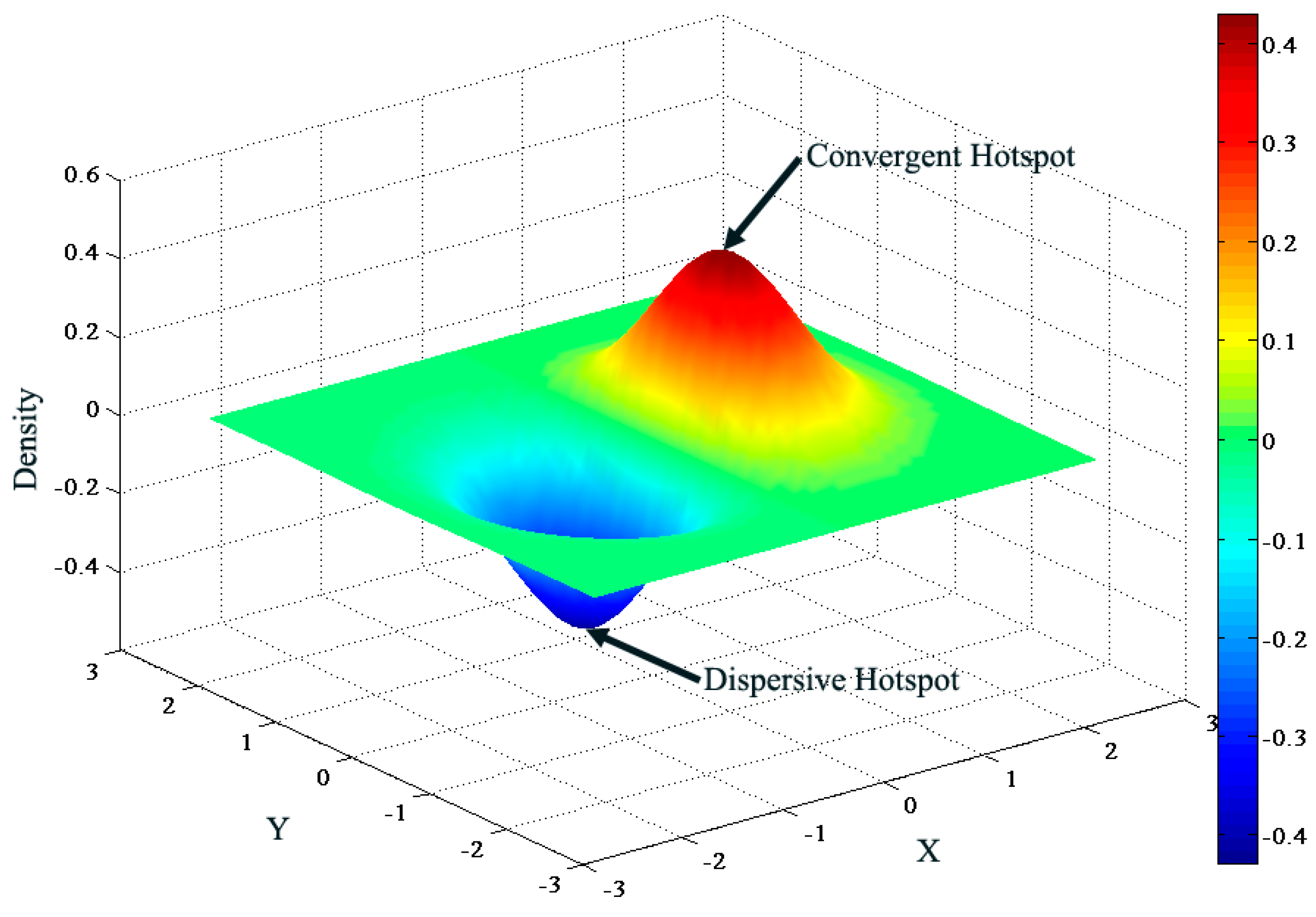
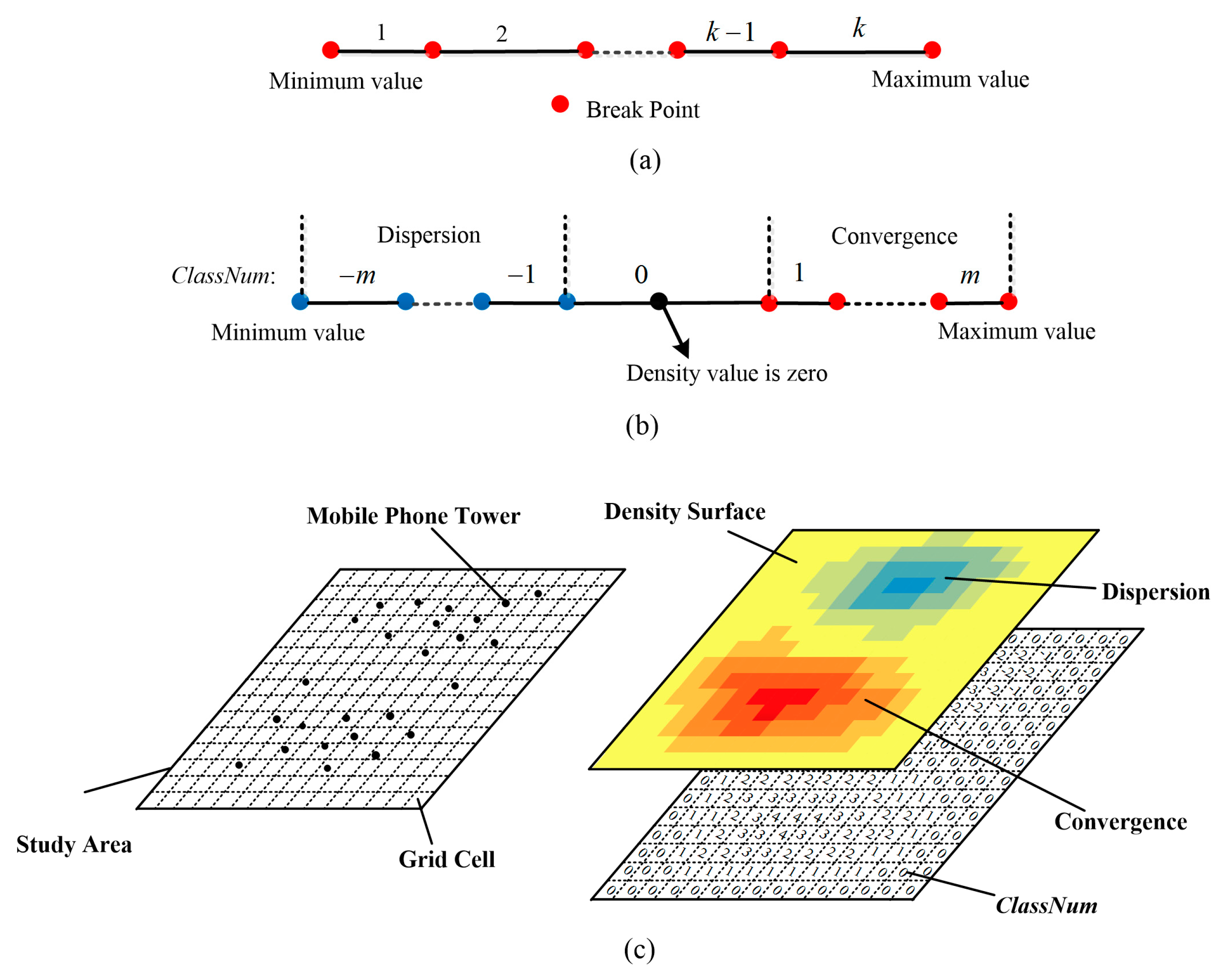
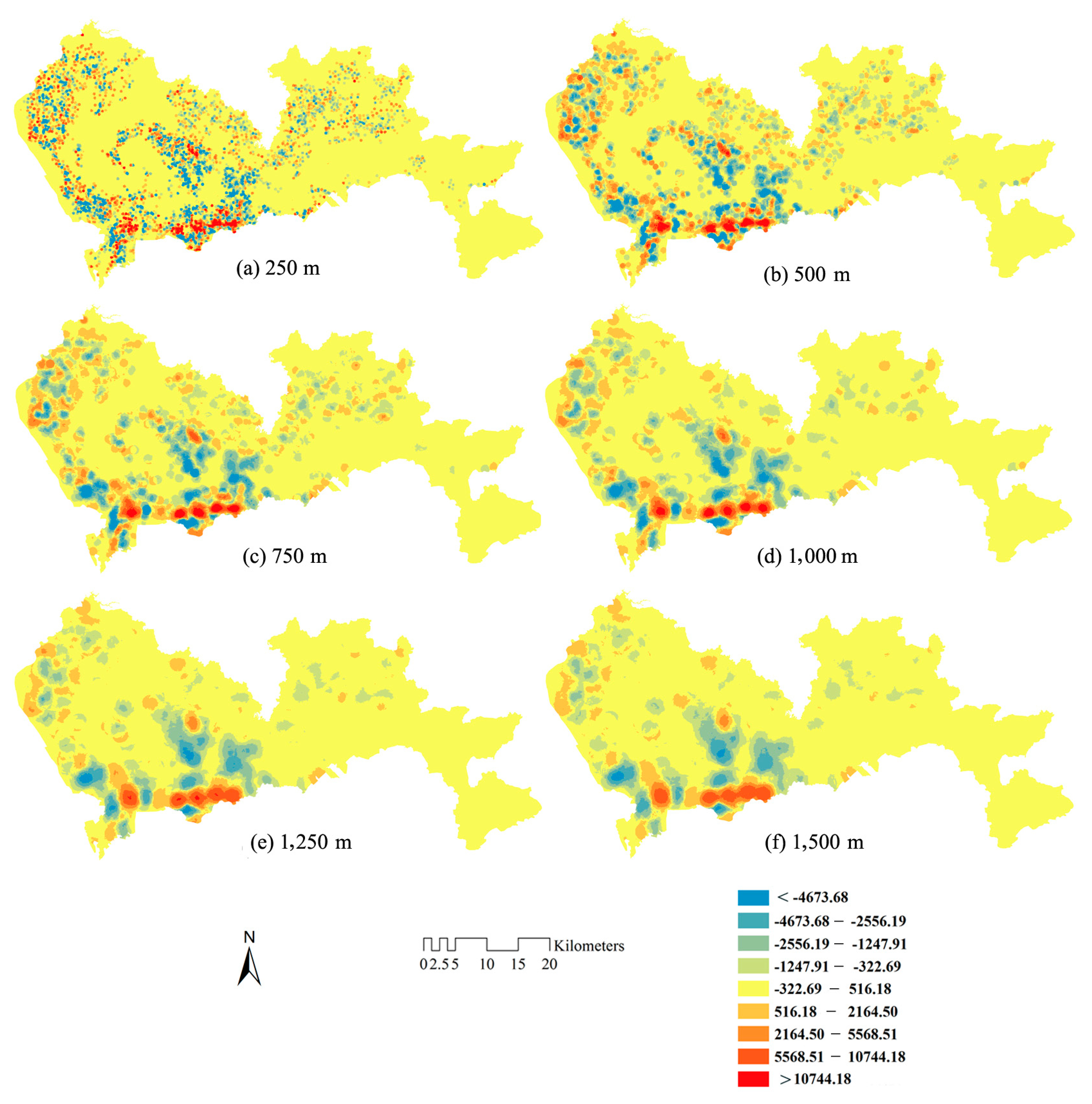
Kernel Density Estimation
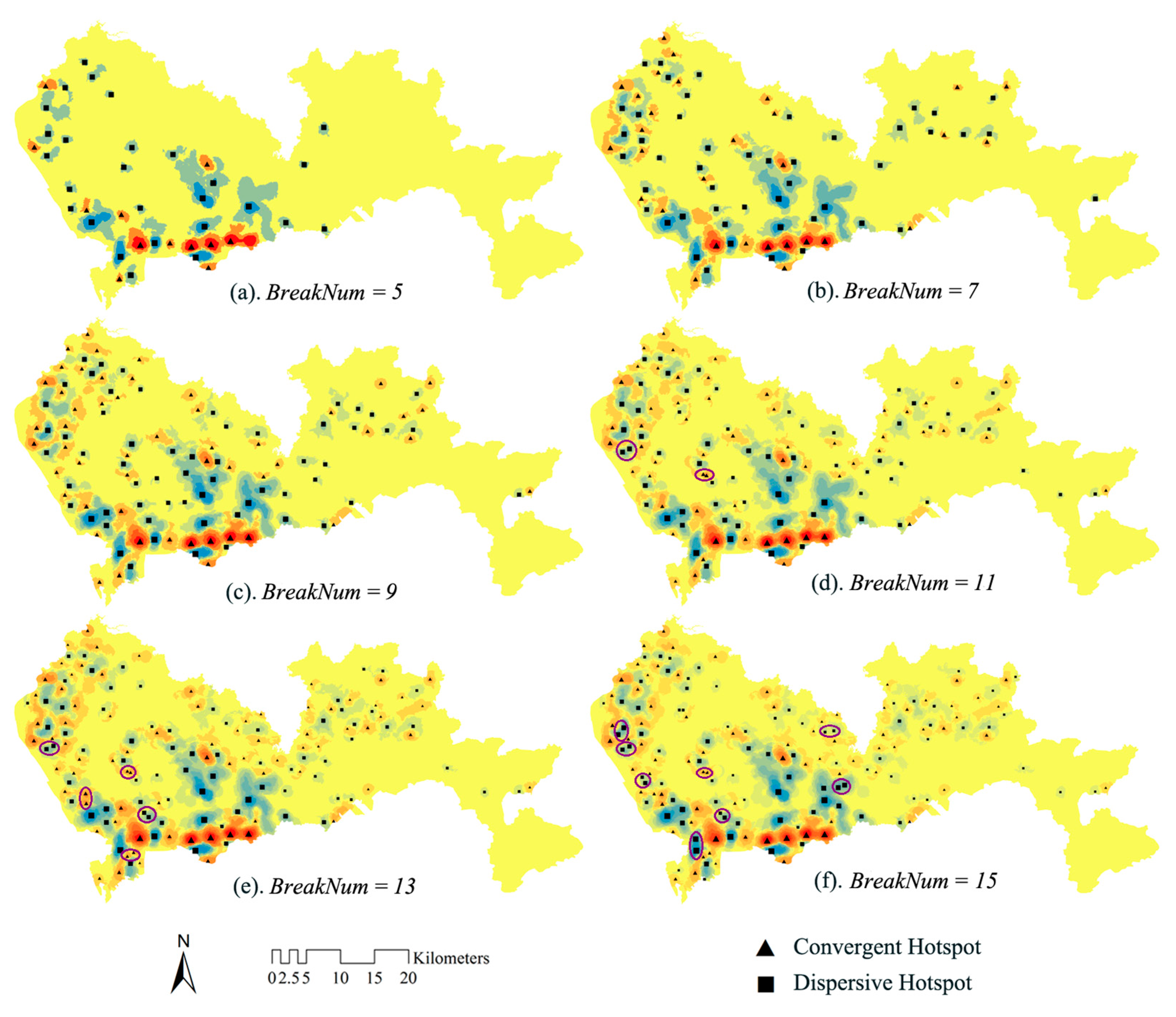
Natural Breaks
Traversal Searching
- Step 1.
- Initializing two temporary empty sets and , which will be used to store grid cells during the traversal searching process.
- Step 2.
- Selecting the grid cell , for which both |Density| and |ClassNum| are maximum from , where represents the absolute value. The grid cell can be regarded as a local extreme point (peak or pit); we add to and remove it from .
- Step 3.
- Let be the expansion origin. We search its 8 neighboring grid cells from . If the ClassNum of the neighboring grid cell has the same sign as and the |ClassNum| of the neighboring grid cell is less than or equal to , then add the grid cell to and remove it from .
- Step 4.
- For each grid cell in , search its 8 neighboring grid cells in the set according to the rule of Step 3, add the grid cells that satisfy the rule to , and remove them from . Clear set , and transfer all grid cells from set to set . If set is empty, go to Step 1. Otherwise, repeat Step 4.
- Step 5.
- Repeat these steps until set is empty.
3.2.3. Clustering of Hotspots Based on Their Temporal Signatures
4. Experiment and Discussion
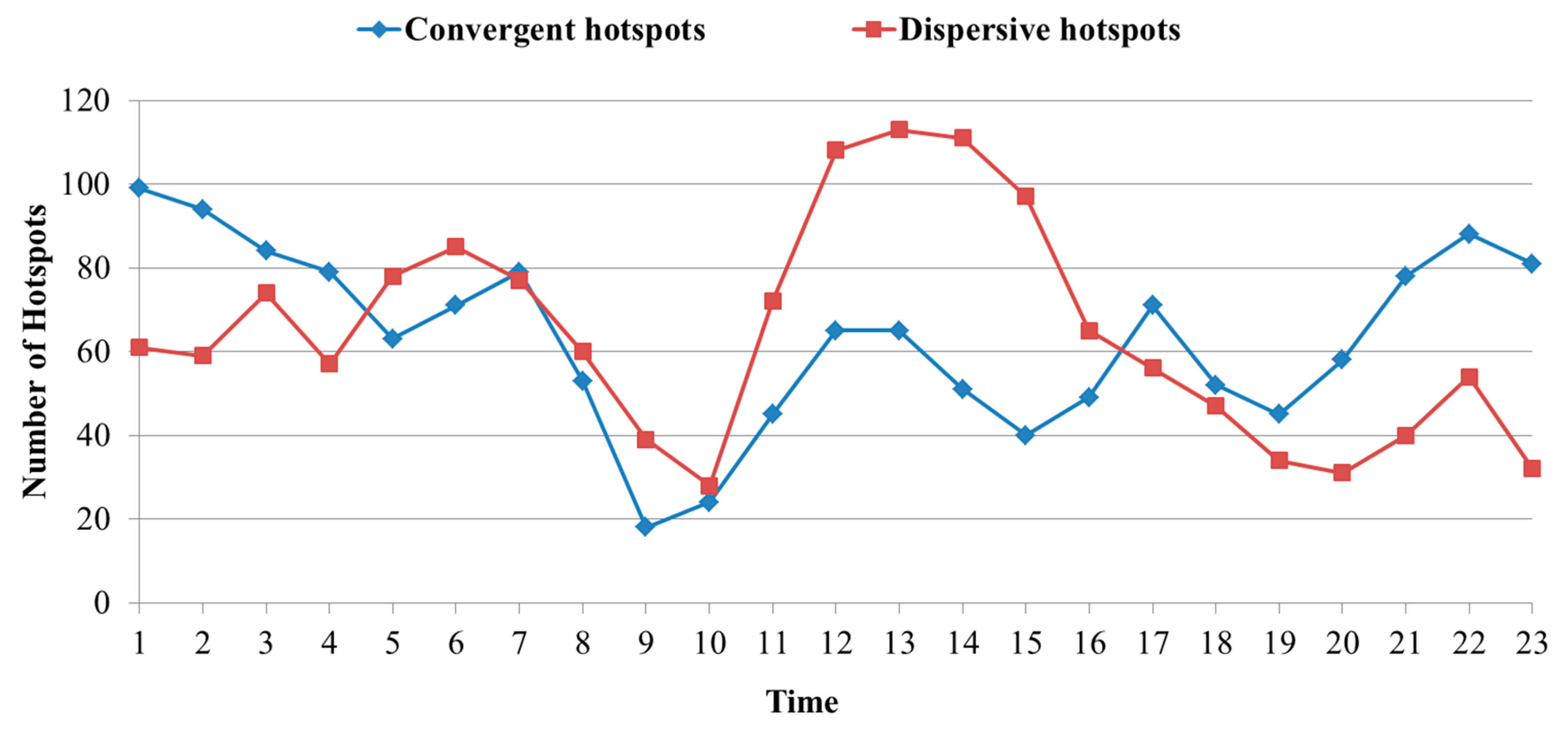
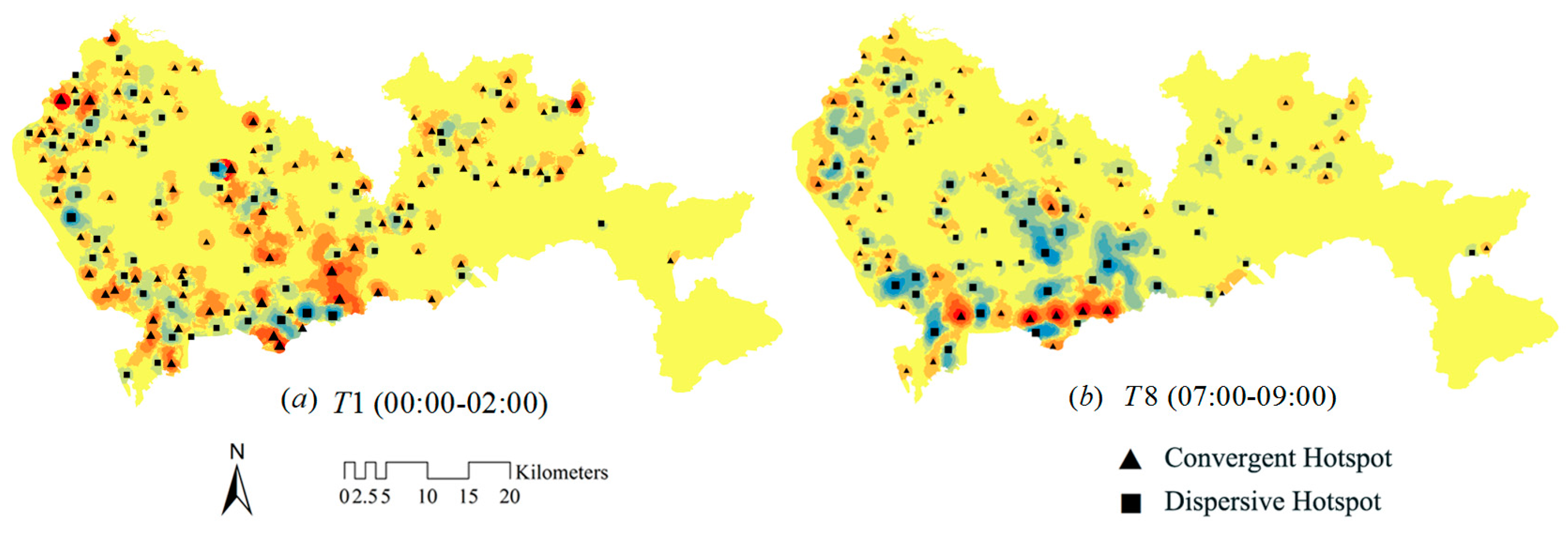
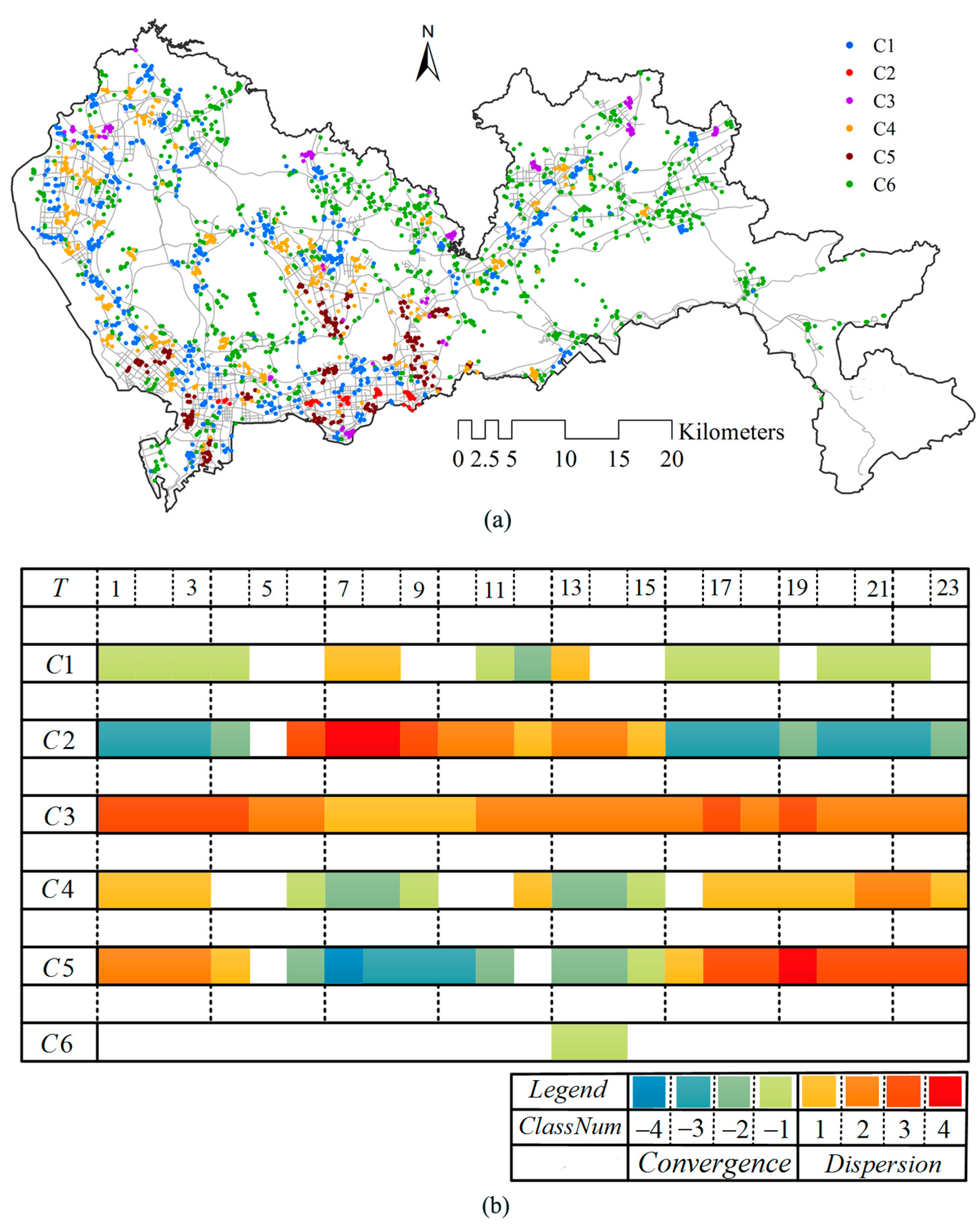
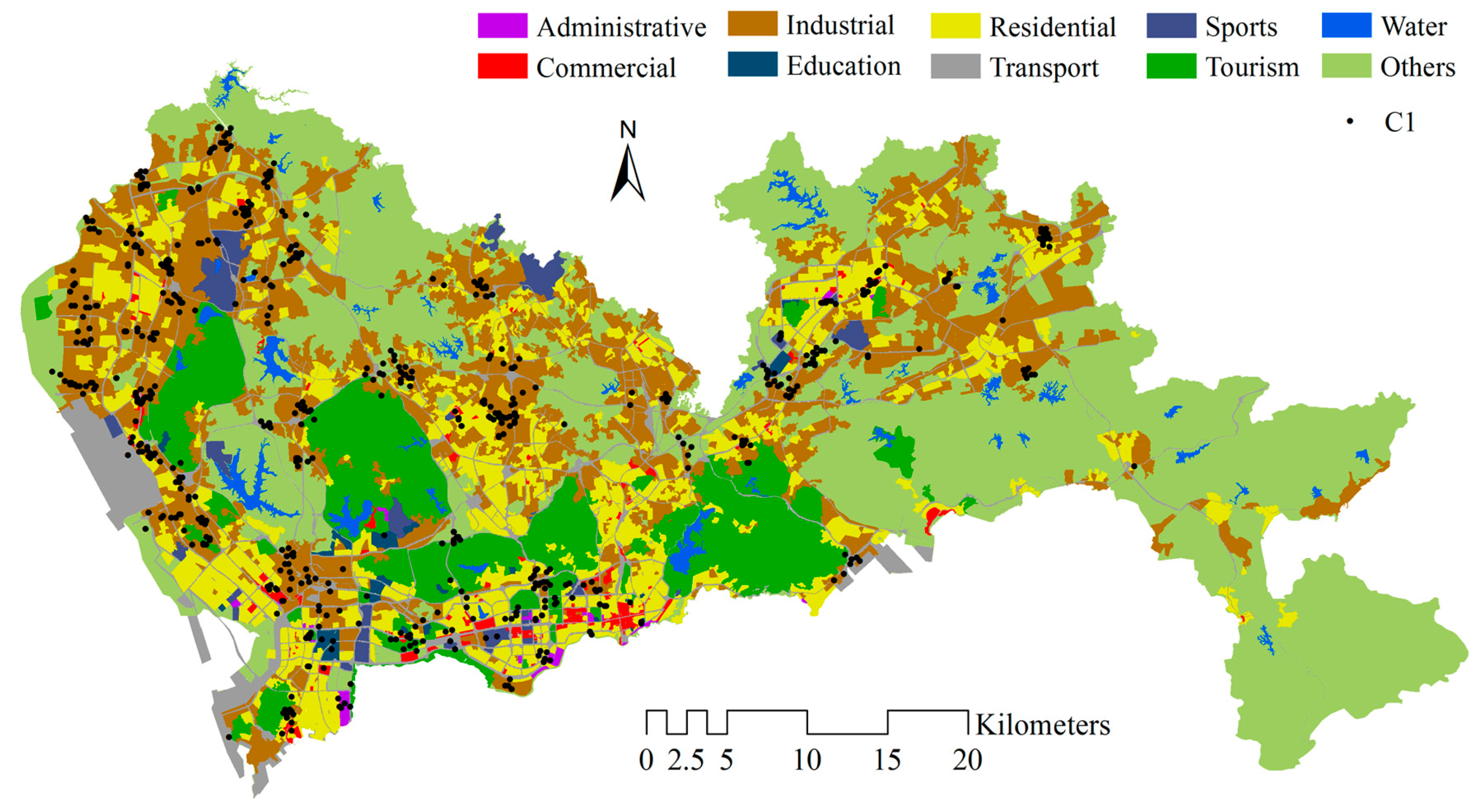
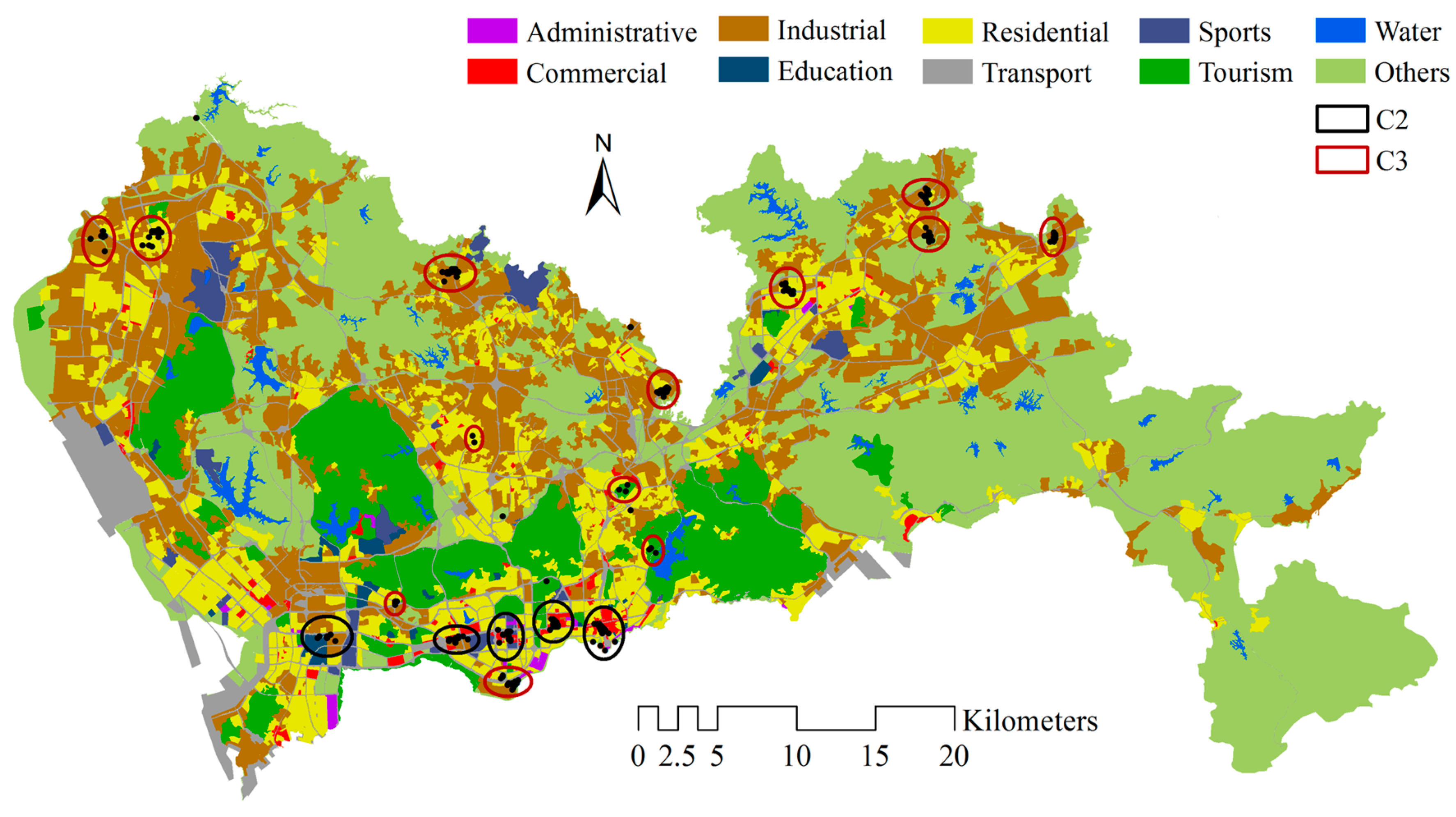
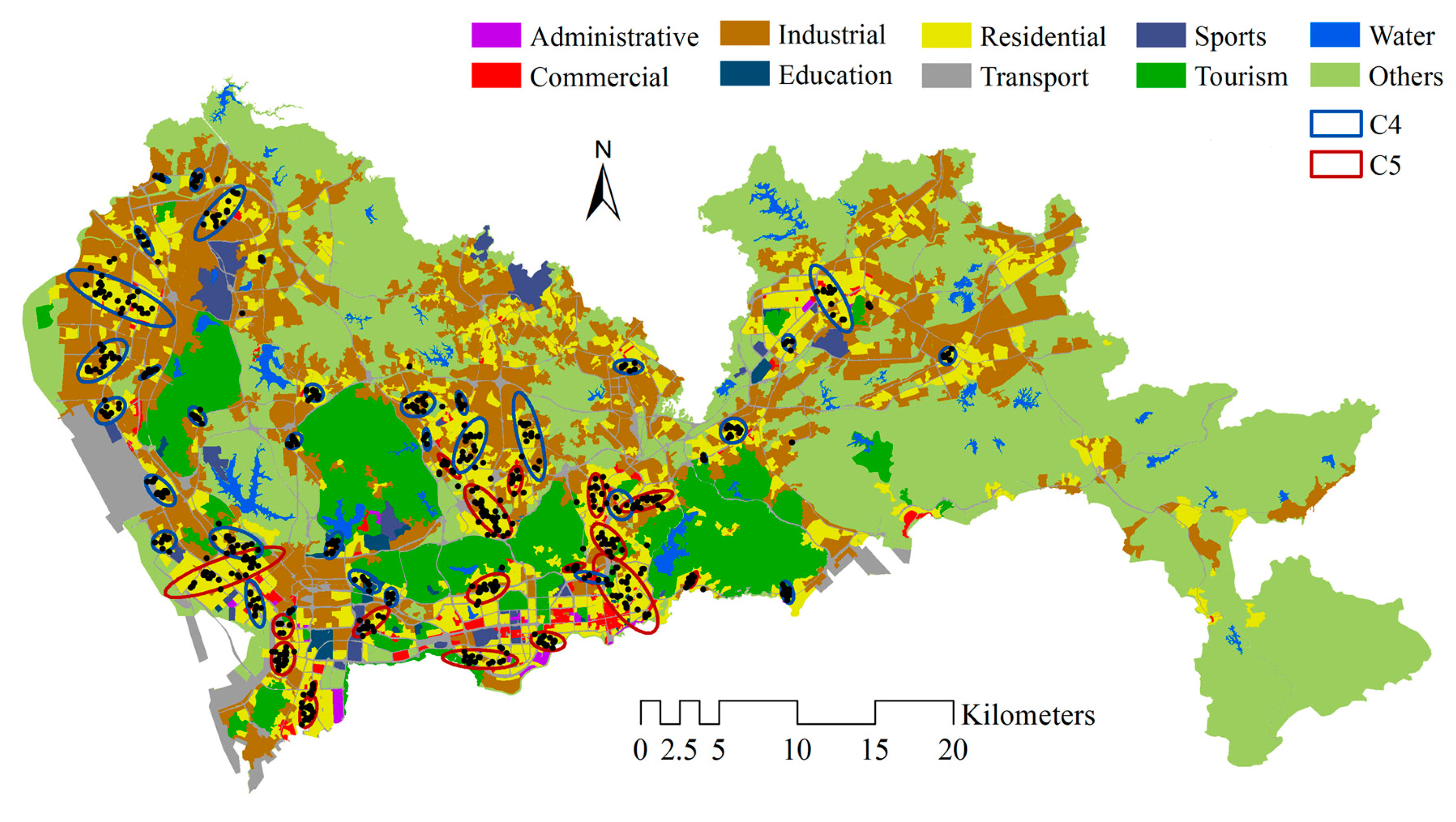
4.1. Identifying Local Human Mobility Hotspots
4.2. Spatial-Temporal Convergent and Dispersive Patterns in the Urban Area
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Armah, F.A.; Yawson, D.O.; Pappoe, A.A. A systems dynamics approach to explore traffic congestion and air pollution link in the city of Accra, Ghana. Sustainability 2010, 2, 252–265. [Google Scholar] [CrossRef]
- Li, S.; Ma, Y. Urbanization, economic development and environmental change. Sustainability 2014, 6, 5143–5161. [Google Scholar] [CrossRef]
- Yuan, Y.; Raubal, M. Extracting dynamic urban mobility patterns from mobile phone data. In Geographic Information Science; Springer: Berlin, Germany, 2012; pp. 354–367. [Google Scholar]
- Fang, Z.; Tu, W.; Li, Q.; Li, Q. A multi-objective approach to scheduling joint participation with variable space and time preferences and opportunities. J. Transp. Geogr. 2011, 19, 623–634. [Google Scholar] [CrossRef]
- Yue, Y.; Lan, T.; Yeh, A.G.; Li, Q.-Q. Zooming into individuals to understand the collective: A review of trajectory-based travel behaviour studies. Travel Behav. Soc. 2014, 1, 69–78. [Google Scholar] [CrossRef]
- Gao, S. Spatio-temporal analytics for exploring human mobility patterns and urban dynamics in the mobile age. Spat. Cogn. Comput. 2015, 15, 86–114. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.-L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Shaw, S.-L.; Yu, H. A gis-based time-geographic approach of studying individual activities and interactions in a hybrid physical-virtual space. J. Transp. Geogr. 2009, 17, 141–149. [Google Scholar] [CrossRef]
- Calabrese, F.; di Lorenzo, G.; Liu, L.; Ratti, C. Estimating origin-destination flows using mobile phone location data. IEEE Pervasive Comput. 2011, 10, 36–44. [Google Scholar] [CrossRef]
- Hasan, S.; Schneider, C.M.; Ukkusuri, S.V.; González, M.C. Spatiotemporal patterns of urban human mobility. J. Stat. Phys. 2013, 151, 304–318. [Google Scholar] [CrossRef]
- Kang, C.; Ma, X.; Tong, D.; Liu, Y. Intra-urban human mobility patterns: An urban morphology perspective. Phys. A Stat. Mech. Appl. 2012, 391, 1702–1717. [Google Scholar] [CrossRef]
- Xu, Y.; Shaw, S.-L.; Zhao, Z.; Yin, L.; Fang, Z.; Li, Q. Understanding aggregate human mobility patterns using passive mobile phone location data: A home-based approach. Transportation 2015, 42, 625–646. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, F.; Xiao, Y.; Gao, S. Urban land uses and traffic ‘source-sink areas’: Evidence from GPS-enabled taxi data in shanghai. Landsc. Urban Plan. 2012, 106, 73–87. [Google Scholar] [CrossRef]
- Bengtsson, L.; Gaudart, J.; Lu, X.; Moore, S.; Wetter, E.; Sallah, K.; Rebaudet, S.; Piarroux, R. Using mobile phone data to predict the spatial spread of cholera. Sci. Rep. 2015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brimicombe, A.J. Cluster detection in point event data having tendency towards spatially repetitive events. In Proceedings of the 8th International Conference on GeoComputation, Ann Arbor, MI, USA, 1–3 August 2005.
- Steenbruggen, J.; Tranos, E.; Nijkamp, P. Data from mobile phone operators: A tool for smarter cities? Telecommun. Policy 2015, 39, 335–346. [Google Scholar] [CrossRef]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.-L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]
- Brockmann, D.; Hufnagel, L.; Geisel, T. The scaling laws of human travel. Nature 2006, 439, 462–465. [Google Scholar] [CrossRef] [PubMed]
- Schneider, C.M.; Belik, V.; Couronné, T.; Smoreda, Z.; González, M.C. Unravelling daily human mobility motifs. J. R. Soc. Interface 2013. [Google Scholar] [CrossRef] [PubMed]
- De Montjoye, Y.-A.; Hidalgo, C.A.; Verleysen, M.; Blondel, V.D. Unique in the crowd: The privacy bounds of human mobility. Sci. Rep. 2013. [Google Scholar] [CrossRef] [PubMed]
- Yin, L.; Wang, Q.; Shaw, S.-L.; Fang, Z.; Hu, J.; Tao, Y.; Wang, W. Re-identification risk versus data utility for aggregated mobility research using mobile phone location data. PLoS ONE 2015, 10, e0140589. [Google Scholar] [CrossRef] [PubMed]
- Ahas, R.; Silm, S.; Järv, O.; Saluveer, E.; Tiru, M. Using mobile positioning data to model locations meaningful to users of mobile phones. J. Urban Technol. 2010, 17, 3–27. [Google Scholar] [CrossRef]
- Kung, K.S.; Greco, K.; Sobolevsky, S.; Ratti, C. Exploring universal patterns in human home-work commuting from mobile phone data. PLoS ONE 2014, 9, e96180. [Google Scholar] [CrossRef] [PubMed]
- Alexander, L.; Jiang, S.; Murga, M.; González, M.C. Origin-destination trips by purpose and time of day inferred from mobile phone data. Transp. Res. Part C Emerg. Technol. 2015, 58, 240–250. [Google Scholar] [CrossRef]
- Ratti, C.; Frenchman, D.; Pulselli, R.M.; Williams, S. Mobile landscapes: Using location data from cell phones for urban analysis. Environ. Plan. B Plan. Des. 2006, 33, 727–748. [Google Scholar] [CrossRef]
- Calabrese, F.; Colonna, M.; Lovisolo, P.; Parata, D.; Ratti, C. Real-time urban monitoring using cell phones: A case study in rome. IEEE Trans. Intell. Transp. Syst. 2011, 12, 141–151. [Google Scholar] [CrossRef]
- Kang, C.; Liu, Y.; Ma, X.; Wu, L. Towards estimating urban population distributions from mobile call data. J. Urban Technol. 2012, 19, 3–21. [Google Scholar] [CrossRef]
- Deville, P.; Linard, C.; Martin, S.; Gilbert, M.; Stevens, F.R.; Gaughan, A.E.; Blondel, V.D.; Tatem, A.J. Dynamic population mapping using mobile phone data. Proc. Natl. Acad. Sci. USA 2014, 111, 15888–15893. [Google Scholar] [CrossRef] [PubMed]
- Hoteit, S.; Secci, S.; Sobolevsky, S.; Ratti, C.; Pujolle, G. Estimating human trajectories and hotspots through mobile phone data. Compu. Netw. 2014, 64, 296–307. [Google Scholar] [CrossRef]
- Yuan, Y.; Raubal, M. Measuring similarity of mobile phone user trajectories—A spatio-temporal edit distance method. Int. J. Geogr. Inf. Sci. 2014, 28, 496–520. [Google Scholar] [CrossRef]
- Sagl, G.; Delmelle, E.; Delmelle, E. Mapping collective human activity in an urban environment based on mobile phone data. Cartogr. Geogr. Inf. Sci. 2014, 41, 272–285. [Google Scholar] [CrossRef]
- Toole, J.L.; Ulm, M.; González, M.C.; Bauer, D. Inferring land use from mobile phone activity. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12 August 2012; ACM: New York, NY, USA; pp. 1–8.
- Pei, T.; Sobolevsky, S.; Ratti, C.; Shaw, S.-L.; Li, T.; Zhou, C. A new insight into land use classification based on aggregated mobile phone data. Int. J. Geogr. Inf. Sci. 2014, 28, 1988–2007. [Google Scholar] [CrossRef]
- Ratti, C.; Sobolevsky, S.; Calabrese, F.; Andris, C.; Reades, J.; Martino, M.; Claxton, R.; Strogatz, S.H. Redrawing the map of great britain from a network of human interactions. PLoS ONE 2010, 5, e14248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, S.; Liu, Y.; Wang, Y.; Ma, X. Discovering spatial interaction communities from mobile phone data. Trans. GIS 2013, 17, 463–481. [Google Scholar] [CrossRef]
- Grauwin, S.; Sobolevsky, S.; Moritz, S.; Gódor, I.; Ratti, C. Towards a comparative science of cities: Using mobile traffic records in New York, London, and Hong Kong. In Computational Approaches for Urban Environments; Springer: Berlin, Germany, 2015; pp. 363–387. [Google Scholar]
- Ahas, R.; Aasa, A.; Yuan, Y.; Raubal, M.; Smoreda, Z.; Liu, Y.; Ziemlicki, C.; Tiru, M.; Zook, M. Everyday space-time geographies: Using mobile phone-based sensor data to monitor urban activity in Harbin, Paris, and Tallinn. Int. J. Geogr. Inf. Sci. 2015, 29, 2017–2039. [Google Scholar] [CrossRef]
- Sherman, L.W.; Gartin, P.R.; Buerger, M.E. Hot spots of predatory crime: Routine activities and the criminology of place. Criminology 1989, 27, 27–56. [Google Scholar] [CrossRef]
- Nie, K.; Wang, Z.; Du, Q.; Ren, F.; Tian, Q. A network-constrained integrated method for detecting spatial cluster and risk location of traffic crash: A case study from Wuhan, China. Sustainability 2015, 7, 2662–2677. [Google Scholar] [CrossRef]
- Yamada, I.; Thill, J.-C. Comparison of planar and network k-functions in traffic accident analysis. J. Transp. Geogr. 2004, 12, 149–158. [Google Scholar] [CrossRef]
- Tiwari, N.; Adhikari, C.; Tewari, A.; Kandpal, V. Investigation of geo-spatial hotspots for the occurrence of tuberculosis in almora district, India, using GIS and spatial scan statistic. Int. J. Health Geogr. 2006. [Google Scholar] [CrossRef] [PubMed]
- Getis, A.; Ord, J.K. The analysis of spatial association by use of distance statistics. Geogr. Anal. 1992, 24, 189–206. [Google Scholar] [CrossRef]
- Anselin, L. Local indicators of spatial association—Lisa. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Nelson, T.A.; Boots, B. Detecting spatial hot spots in landscape ecology. Ecography 2008, 31, 556–566. [Google Scholar] [CrossRef]
- Scholz, R.W.; Lu, Y. Detection of dynamic activity patterns at a collective level from large-volume trajectory data. Int. J. Geogr. Inf. Sci. 2014, 28, 1–18. [Google Scholar] [CrossRef]
- Hu, Y.; Miller, H.J.; Li, X. Detecting and analyzing mobility hotspots using surface networks. Trans. GIS 2014, 18, 911–935. [Google Scholar] [CrossRef]
- Chainey, S.; Ratcliffe, J. Gis and Crime Mapping; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Hasan, S.; Zhan, X.; Ukkusuri, S.V. Understanding urban human activity and mobility patterns using large-scale location-based data from online social media. In Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing, Chicago, IL, USA, 11–14 August 2013; ACM: New York, NY, USA, 2013; p. 6. [Google Scholar]
- Lichman, M.; Smyth, P. Modeling human location data with mixtures of kernel densities. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 35–44. [Google Scholar]
- Zhou, Y.; Fang, Z.; Thill, J.-C.; Li, Q.; Li, Y. Functionally critical locations in an urban transportation network: Identification and space-time analysis using taxi trajectories. Comput. Environ. Urban Syst. 2015, 52, 34–47. [Google Scholar] [CrossRef]
- Shenzhen Statistical Yearbook 2013. Available online: http://www.sztj.gov.cn/nj2014/indexeh.htm (accessed on 25 April 2016).
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; CRC Press: Boca Raton, FL, USA, 1986. [Google Scholar]
- Takahashi, S.; Ikeda, T.; Shinagawa, Y.; Kunii, T.L.; Ueda, M. Algorithms for extracting correct critical points and constructing topological graphs from discrete geographical elevation data. Comput. Graph. Forum 1995. [Google Scholar] [CrossRef]
- Jenks, G.F. The data model concept in statistical mapping. Int. Yearb. Cartogr. 1967, 7, 186–190. [Google Scholar]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.; Zhi, Y.; Chi, G.; Shi, L. Social sensing: A new approach to understanding our socioeconomic environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The weka data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GridID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2169 | 0 | 0 | 0 | −1 | −1 | −2 | −m | −m | −1 | 0 | 1 | −1 | 0 | 0 | 0 | 1 | 2 | 2 | m | m−1 | 1 | 0 | 0 |
| 6054 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | m − 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | −2 | −m | −m + 1 | −1 | −1 | −1 | 0 |
| …… | |||||||||||||||||||||||
| 16254 | −1 | −1 | 0 | 0 | 0 | 0 | 1 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | −1 | −1 | −1 | −1 | −1 | 0 | 0 |
| BreakNum | 5 | 7 | 9 | 11 | 13 | 15 |
|---|---|---|---|---|---|---|
| Convergent hotspots | 12 | 30 | 53 | 59 | 79 | 78 |
| Dispersive hotspots | 27 | 48 | 60 | 65 | 75 | 88 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Zhao, Z.; Lu, S. Exploring Spatial-Temporal Patterns of Urban Human Mobility Hotspots. Sustainability 2016, 8, 674. https://doi.org/10.3390/su8070674
Yang X, Zhao Z, Lu S. Exploring Spatial-Temporal Patterns of Urban Human Mobility Hotspots. Sustainability. 2016; 8(7):674. https://doi.org/10.3390/su8070674
Chicago/Turabian StyleYang, Xiping, Zhiyuan Zhao, and Shiwei Lu. 2016. "Exploring Spatial-Temporal Patterns of Urban Human Mobility Hotspots" Sustainability 8, no. 7: 674. https://doi.org/10.3390/su8070674
APA StyleYang, X., Zhao, Z., & Lu, S. (2016). Exploring Spatial-Temporal Patterns of Urban Human Mobility Hotspots. Sustainability, 8(7), 674. https://doi.org/10.3390/su8070674