A Zipf’s Law-Based Method for Mapping Urban Areas Using NPP-VIIRS Nighttime Light Data

Abstract
:
1. Introduction
2. Study Area and Data
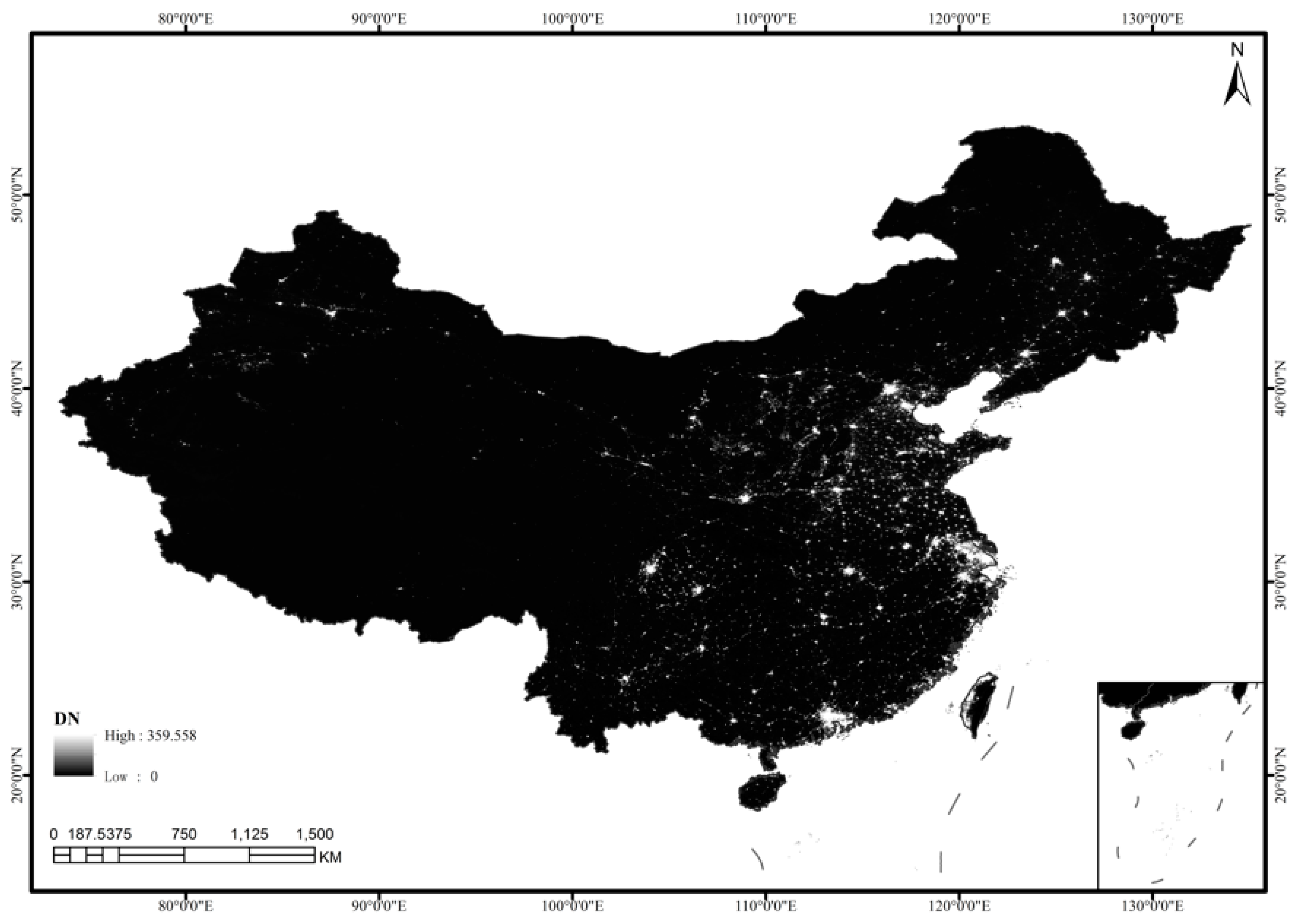
2.1. Study Area: China
2.2. NPP-VIIRS NTL Composite Data
2.3. Other Datasets
3. Methodology
3.1. Correction of the NPP-VIIRS NTL Data
3.2. Estimating Zipf’s Law of NTL Clusters from NPP-VIIRS Data
3.2.1. Zipf’s Law Model for NTL Clusters
3.2.2. Estimating the Parameters in the Zipf’s Law Model
3.3. Zipf’s Law-Based Threshold Estimation Method
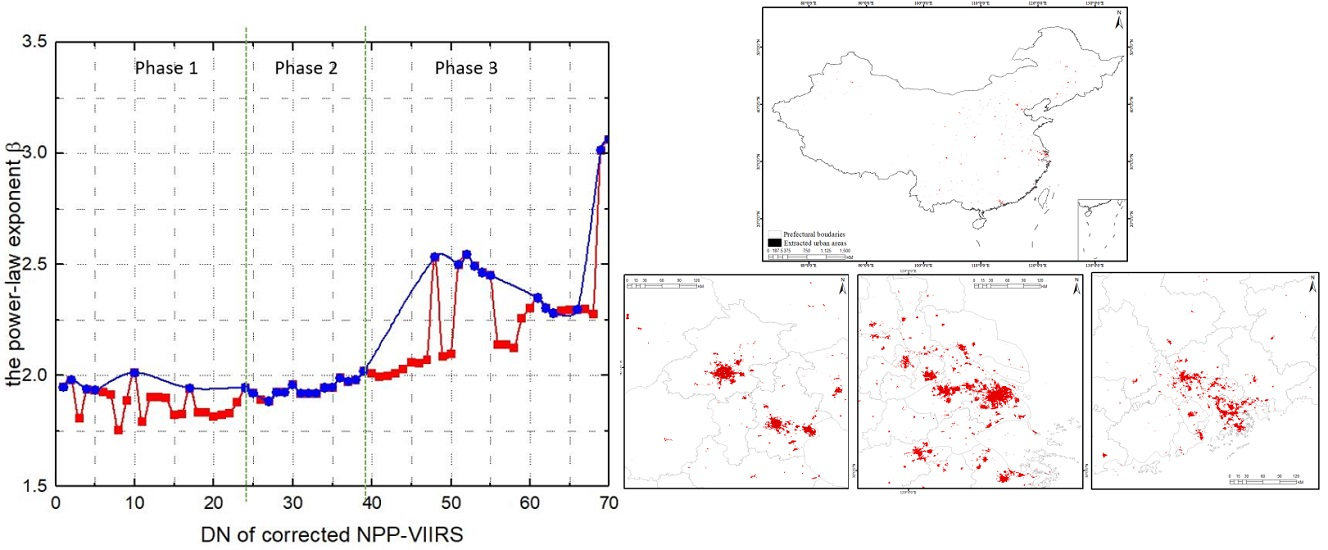
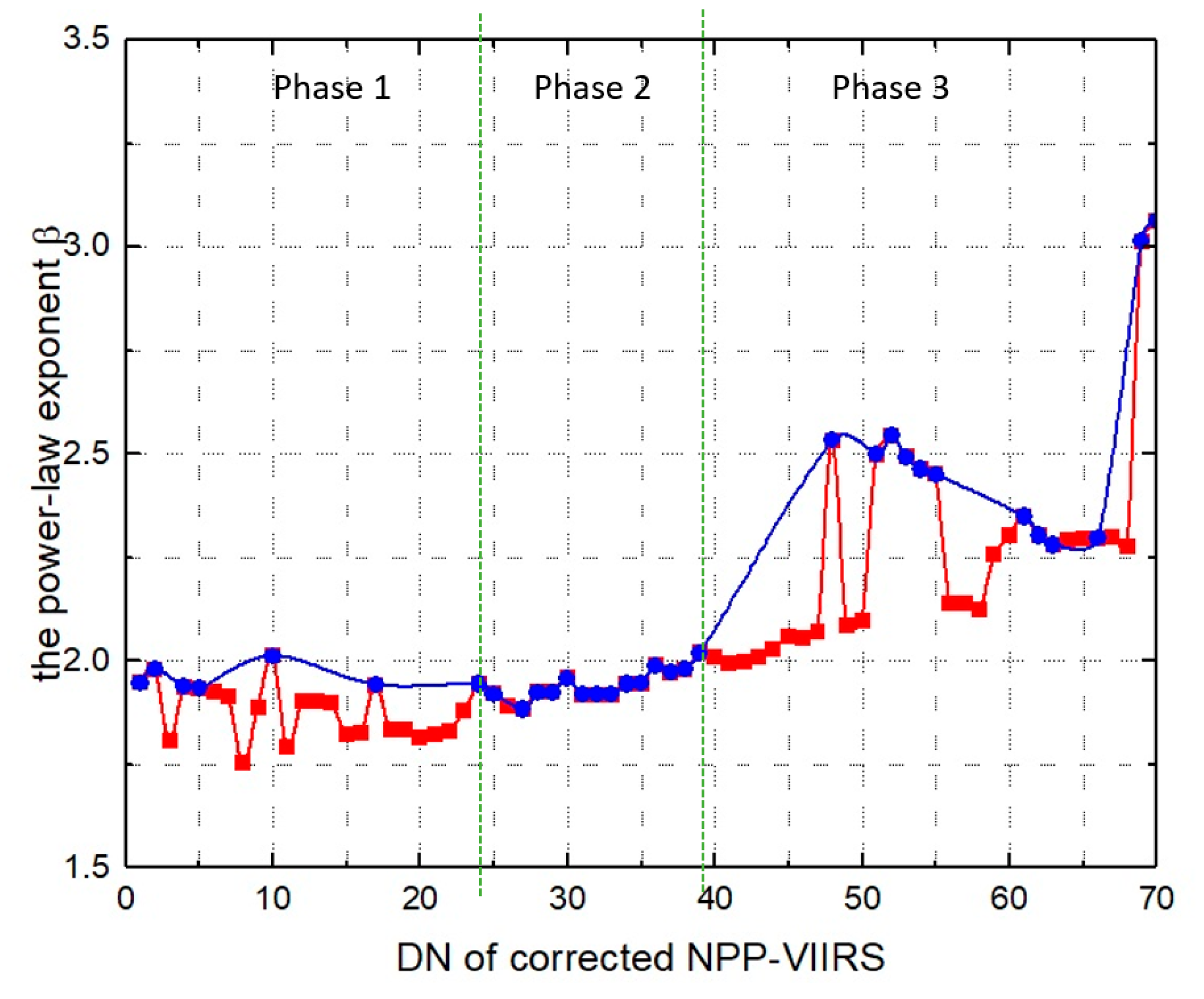
3.3.1. Estimating the Three-Phase Model Based on the Statistical Properties of the Zipf’s Law Model on Continuous Thresholds
3.3.2. Threshold Estimation
| Algorithm 1 Algorithm for optimizing the threshold |
| Inputs: The corrected NTL data on the NPP-VIIRS data. The step size . Outputs: 1. Set the step size as the potential threshold . 2. While do 3. Set the pixels—values less than the threshold —to zero. 4. Segment the data into extracted extents and non-urban extents. 5. Calculate the power-law exponent and the GFI p-value of the size distribution of the extracted area. 6. as the new potential threshold 7. End while 8. Develop the three-phase model. |
| 9. Obtain the optimized threshold |
3.4. Urban Areas Mapping
4. Results and Discussion
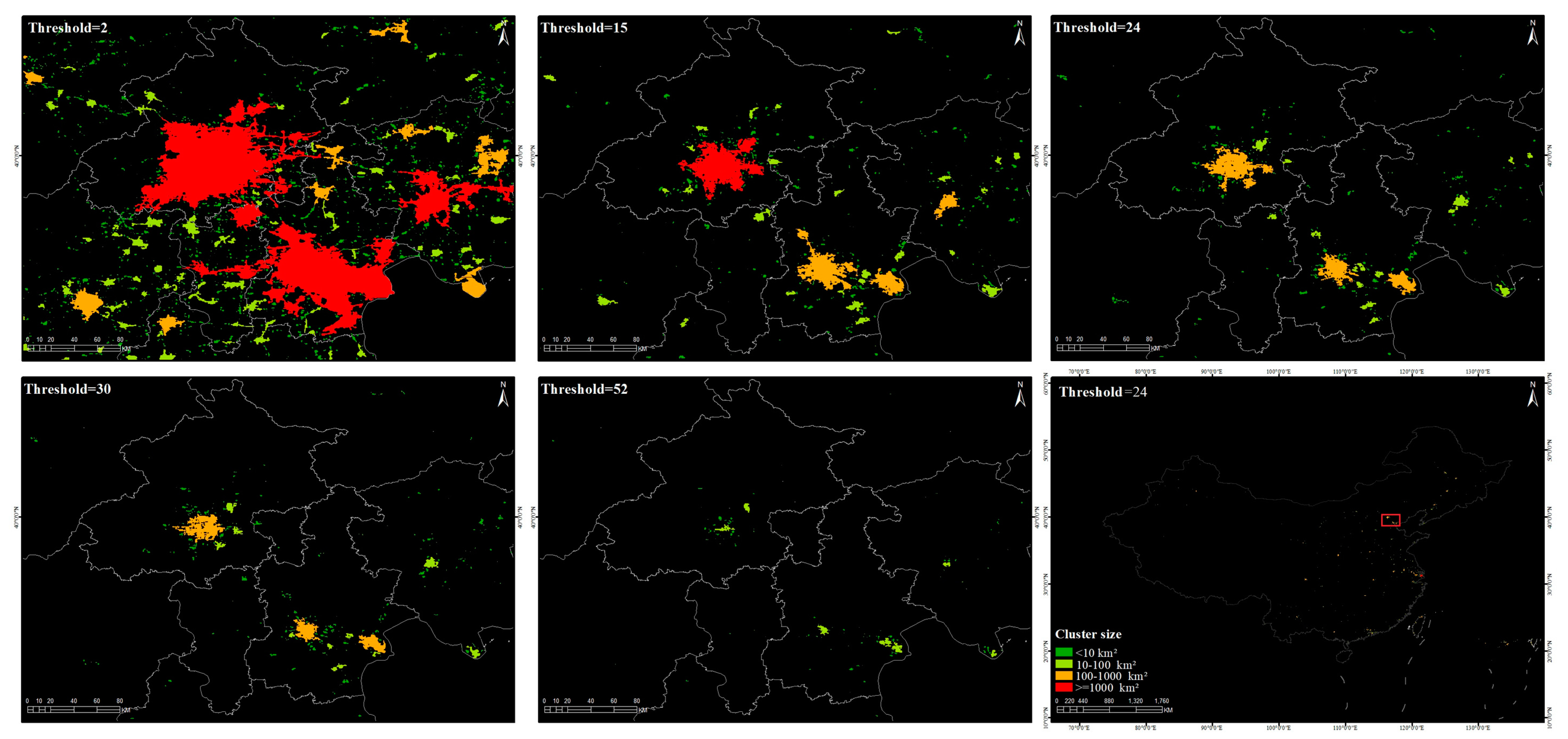
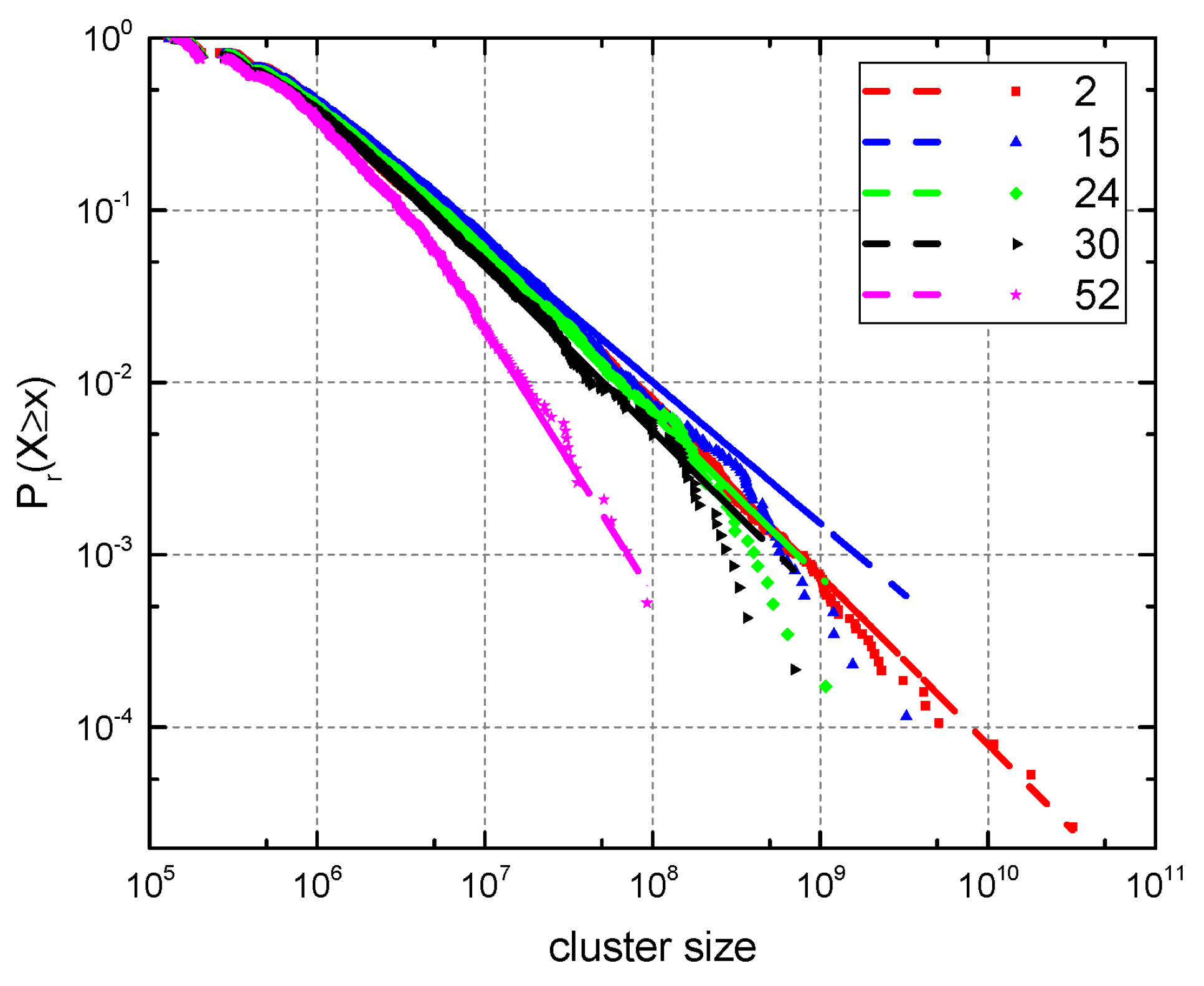
4.1. Threshold Estimation from the Statistical Properties of Zipf’s Law Model on Continuous Thresholds
4.2. The Cluster Dynamics in Three Phases
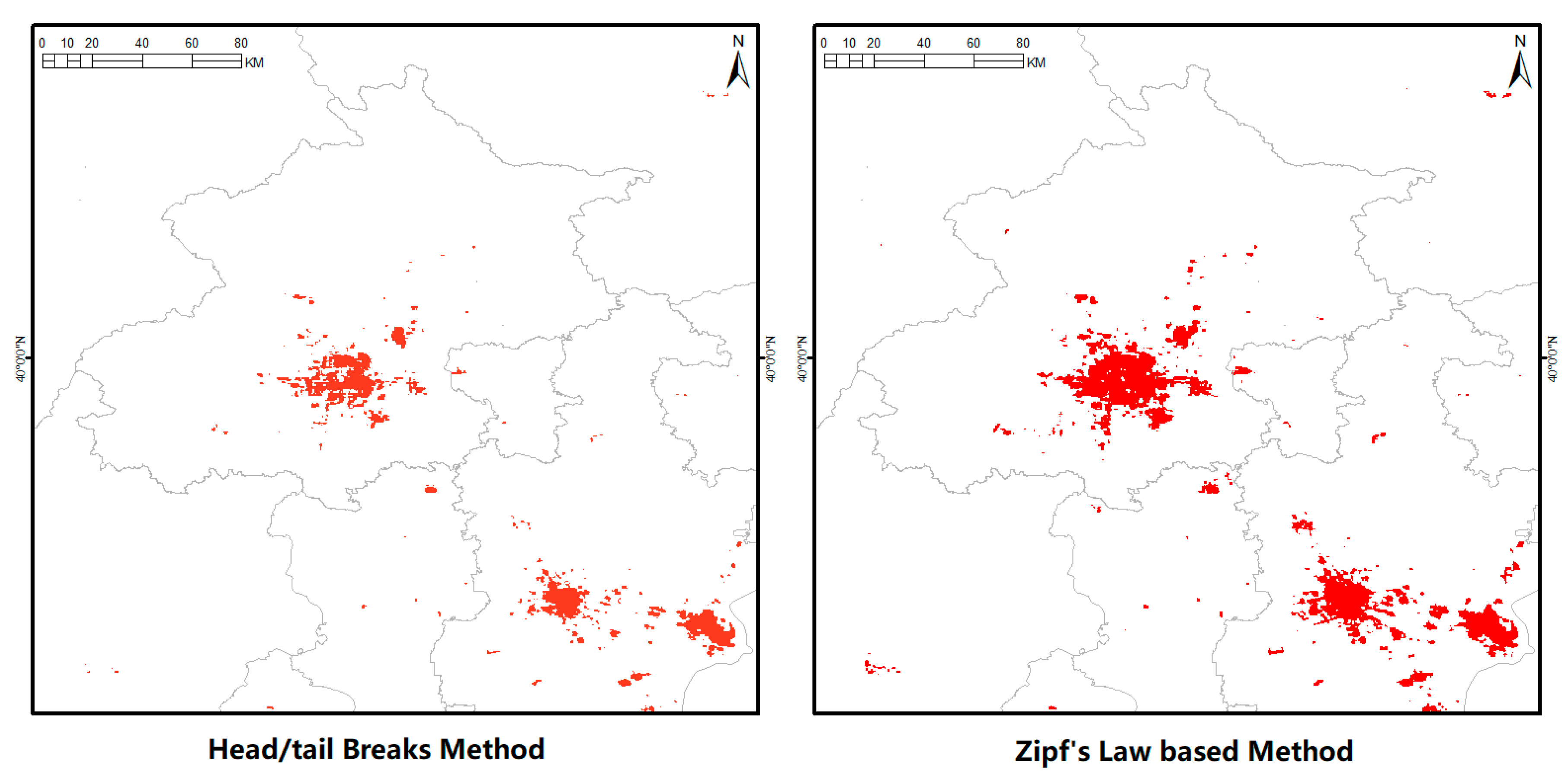
4.3. Comparison with the Head/Tail Breaks Method [8]
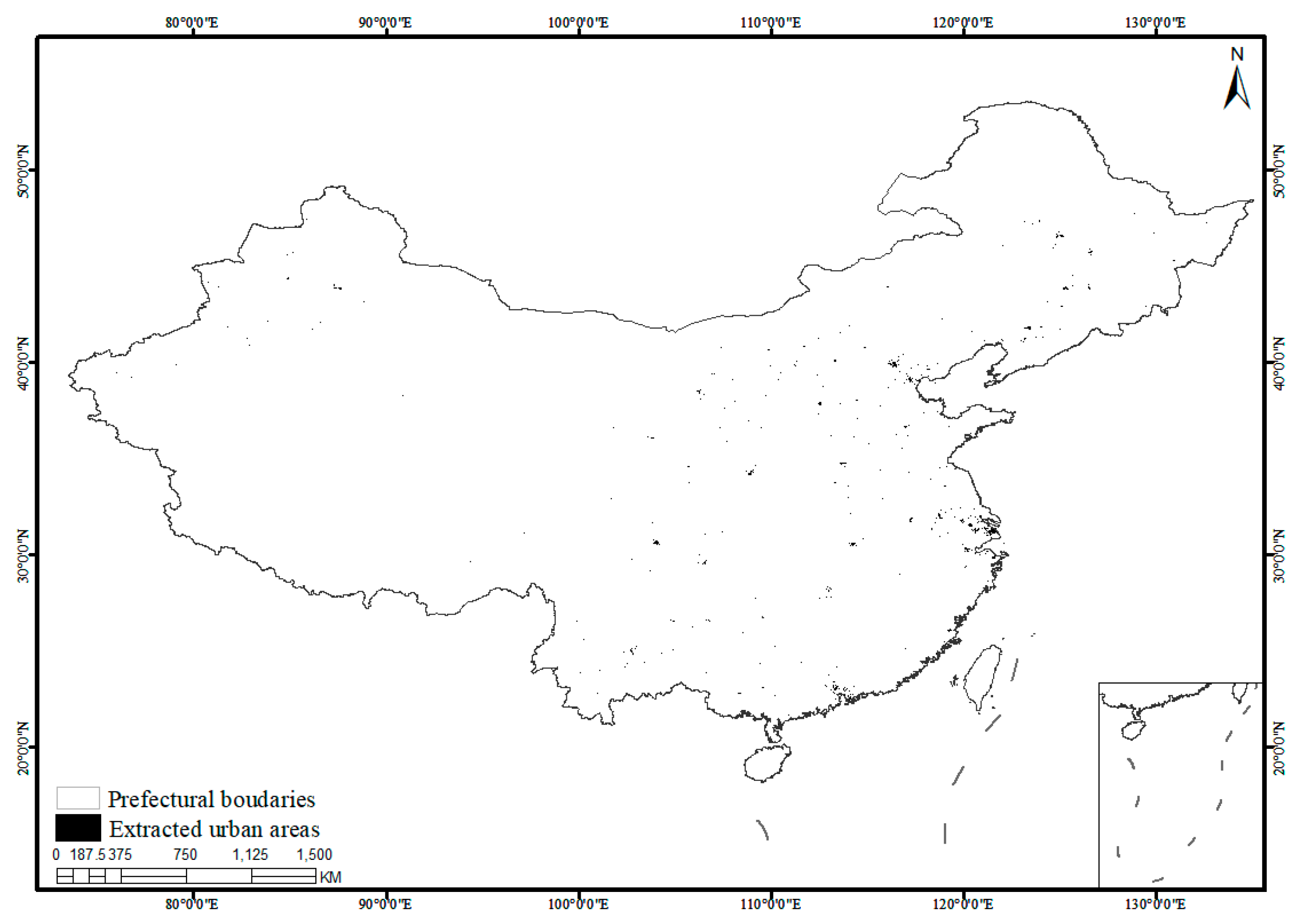
4.4. Urban Area and Accuracy Evaluation
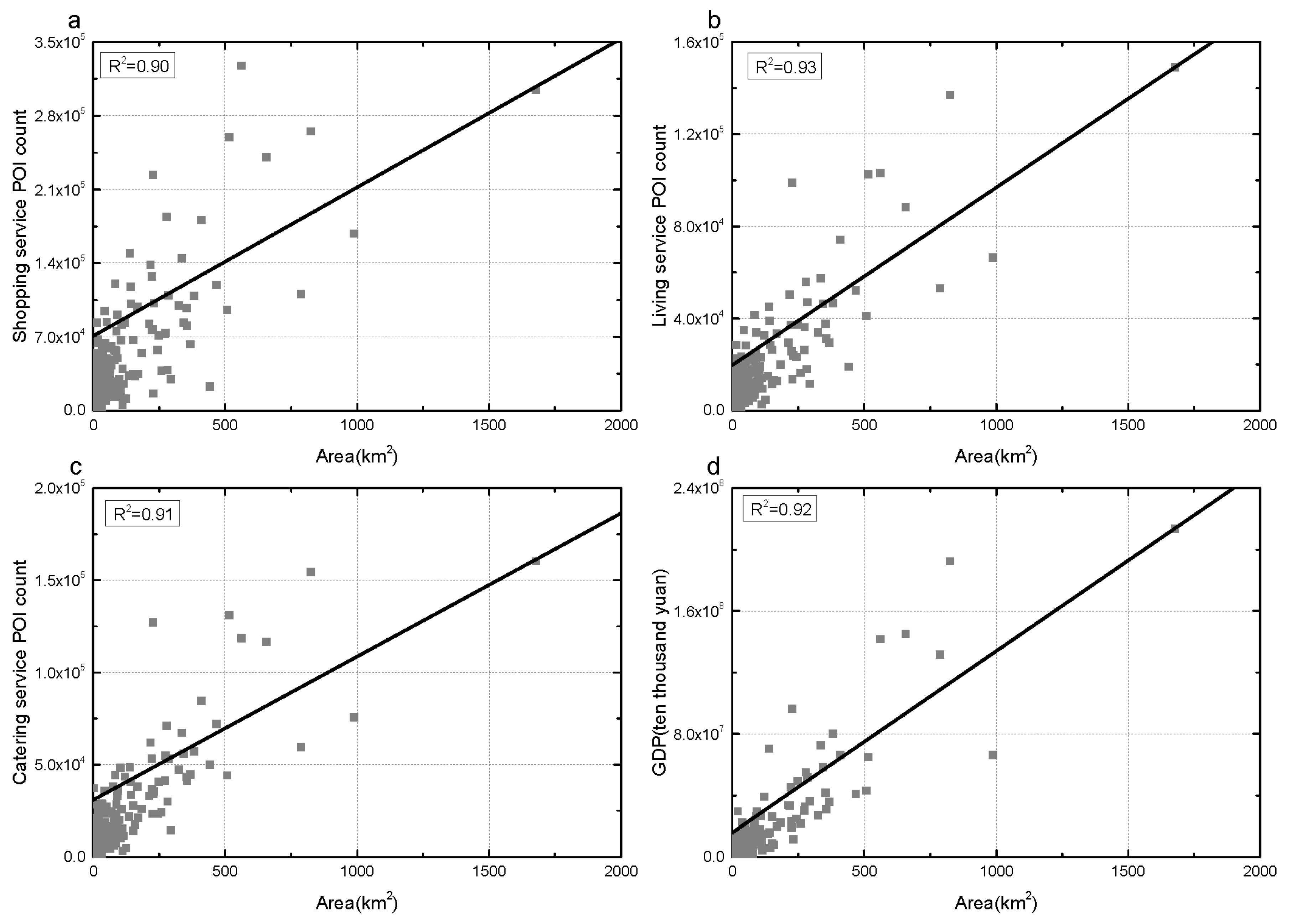
4.5. Validation of Urban Area with POI Data
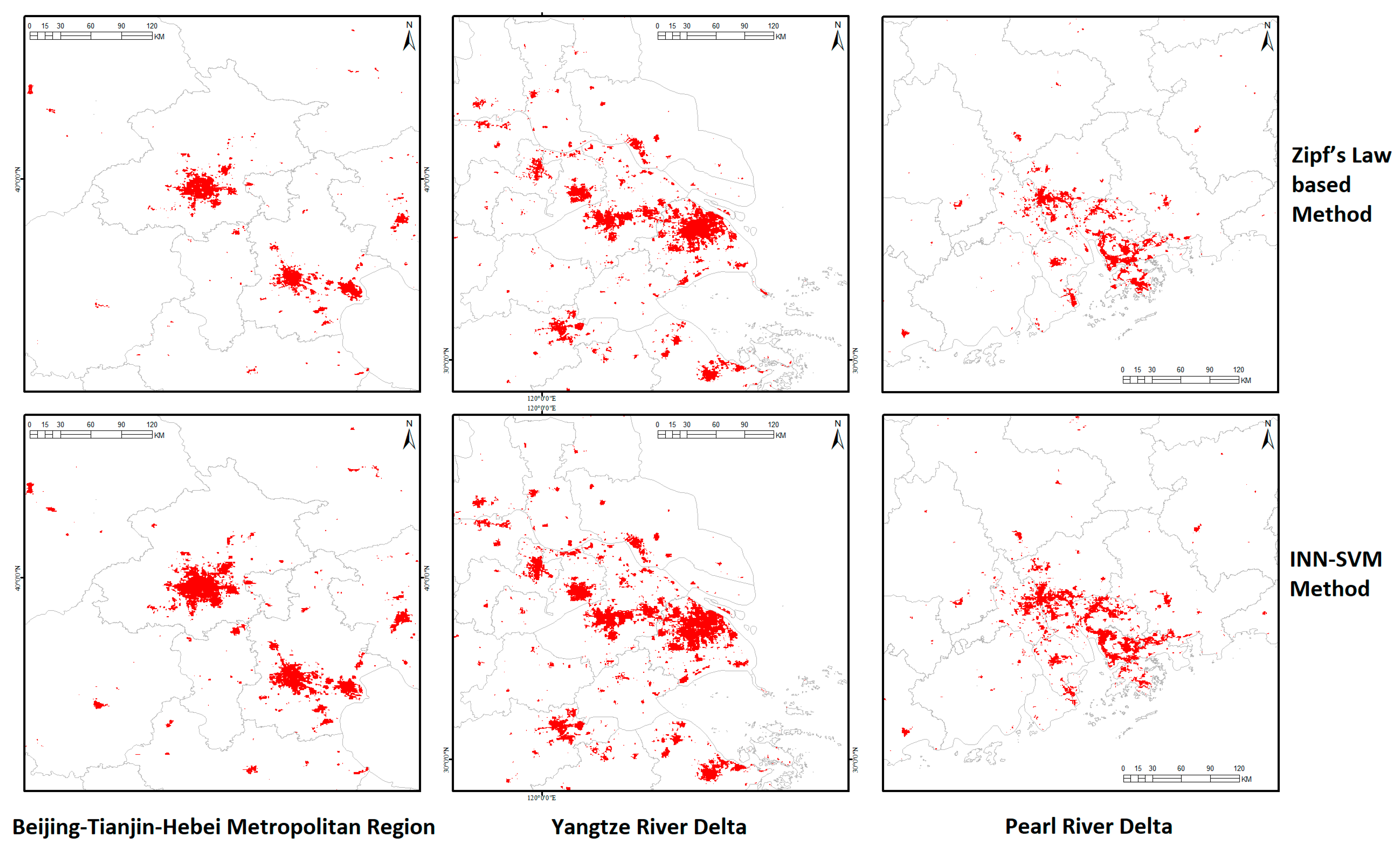
4.6. Comparison with the INN-SVM Method [30]
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bettencourt, L.M.; Lobo, J.; Helbing, D.; Kühnert, C.; West, G.B. Growth, innovation, scaling, and the pace of life in cities. Proc. Natl. Acad. Sci. USA 2007, 104, 7301–7306. [Google Scholar] [CrossRef] [PubMed]
- Batty, M. The New Science of Cities; The MIT Press: Cambridge, MA, USA, 2013; pp. 123–126. [Google Scholar]
- Pumain, D. Scaling Laws and Urban Systems; Santa Fe Institute: Santa Fe, NM, USA, 2004. [Google Scholar]
- Portugali, J. Self-Organization and the City; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Bettencourt, L.M. The origins of scaling in cities. Science 2013, 340, 1438–1441. [Google Scholar] [CrossRef] [PubMed]
- Arcaute, E.; Hatna, E.; Ferguson, P.; Youn, H.; Johansson, A.; Batty, M. Constructing cities, deconstructing scaling laws. J. R. Soc. Interface 2015, 12, 20140745. [Google Scholar] [CrossRef] [PubMed]
- Louf, R. Wandering in Cities: A Statistical Physics Approach to Urban Theory. Ph.D. Thesis, Cornell University, Ithaca, New York, 25 November 2015. [Google Scholar]
- Jiang, B. Head/tail breaks for visualization of city structure and dynamics. Cities 2015, 43, 69–77. [Google Scholar] [CrossRef]
- Jiang, B.; Miao, Y. The evolution of natural cities from the perspective of location-based social media. Prof. Geogr. 2014, 67, 295–306. [Google Scholar] [CrossRef]
- Long, Y. Redefining chinese city system with emerging new data. Appl. Geogr. 2016, 75, 36–48. [Google Scholar] [CrossRef]
- Berry, B.J.L.; Okulicz-Kozaryn, A. The city size distribution debate: Resolution for us urban regions and megalopolitan areas. Cities 2012, 29, S17–S23. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.; Zhang, J.; Wu, L. Allometric scaling, size distribution and pattern formation of natural cities. Palgrave Commun. 2015, 1, 15017. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Kihn, E.A.; Kroehl, H.W.; Davis, E.R. Mapping city lights with nighttime data from the dmsp operational linescan system. Photogramm. Eng. Remote Sens. 1997, 63, 727–734. [Google Scholar]
- Small, C.; Elvidge, C.D.; Balk, D.; Montgomery, M. Spatial scaling of stable night lights. Remote Sens. Environ. 2011, 115, 269–280. [Google Scholar] [CrossRef]
- Yu, B.; Shu, S.; Liu, H.; Song, W.; Wu, J.; Wang, L.; Chen, Z. Object-based spatial cluster analysis of urban landscape pattern using nighttime light satellite images: A case study of china. Int. J. Geogr. Inf. Sci. 2014, 28, 2328–2355. [Google Scholar] [CrossRef]
- Ma, T.; Yin, Z.; Li, B.; Zhou, C.; Haynie, S. Quantitative estimation of the velocity of urbanization in China using nighttime luminosity data. Remote Sens. 2016, 8, 94. [Google Scholar] [CrossRef]
- Yu, B.; Shi, K.; Hu, Y.; Huang, C.; Chen, Z.; Wu, J. Poverty evaluation using npp-viirs nighttime light composite data at the county level in china. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 8, 1217–1229. [Google Scholar] [CrossRef]
- He, C.; Liu, Z.; Tian, J.; Ma, Q. Urban expansion dynamics and natural habitat loss in china: A multiscale landscape perspective. Glob. Chang. Biol. 2014, 20, 2886–2902. [Google Scholar] [CrossRef] [PubMed]
- Dou, Y.; Liu, Z.; He, C.; Yue, H. Urban land extraction using viirs nighttime light data: An evaluation of three popular methods. Remote Sens. 2017, 9, 175. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.; Zhizhin, M.; Hsu, F.C.; Ghosh, T. Viirs night-time lights. Int. J. Remote Sens. 2017, 38, 5860–5879. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Zhizhin, M.; Hsu, F.-C. Why viirs data are superior to DMSP for mapping nighttime lights. Proc. Asia-Pac. Adv. Netw. 2013, 35, 62–69. [Google Scholar] [CrossRef]
- Li, X.; Zhou, Y. Urban mapping using DMSP/OLS stable night-time light: A review. Int. J. Remote Sens. 2017, 1–17. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Ai, B.; Li, X.; Shi, Q. A normalized urban areas composite index (nuaci) based on combination of dmsp-ols and modis for mapping impervious surface area. Remote Sens. 2015, 7, 17168–17189. [Google Scholar] [CrossRef]
- Xie, Y.; Weng, Q. Updating urban extents with nighttime light imagery by using an object-based thresholding method. Remote Sens. Environ. 2016, 187, 1–13. [Google Scholar] [CrossRef]
- Zhou, Y.; Smith, S.J.; Elvidge, C.D.; Zhao, K.; Thomson, A.; Imhoff, M. A cluster-based method to map urban area from DMSP/OLS nightlights. Remote Sens. Environ. 2014, 147, 173–185. [Google Scholar] [CrossRef]
- Shi, K.; Yu, B.; Huang, Y.; Hu, Y.; Yin, B.; Chen, Z.; Chen, L.; Wu, J. Evaluating the ability of npp-viirs nighttime light data to estimate the gross domestic product and the electric power consumption of china at multiple scales: A comparison with dmsp-ols data. Remote Sens. 2014, 6, 1705–1724. [Google Scholar] [CrossRef]
- Sharma, R.C.; Tateishi, R.; Hara, K.; Gharechelou, S.; Iizuka, K. Global mapping of urban built-up areas of year 2014 by combining modis multispectral data with viirs nighttime light data. Int. J. Dig. Earth 2016, 9, 1004–1020. [Google Scholar] [CrossRef]
- Li, Q.; Lu, L.; Weng, Q.; Xie, Y.; Guo, H. Monitoring urban dynamics in the southeast USA using time-series dmsp/ols nightlight imagery. Remote Sens. 2016, 8, 578. [Google Scholar] [CrossRef]
- Jing, W.; Yang, Y.; Yue, X.; Zhao, X. Mapping urban areas with integration of DMSP/OLS nighttime light and modis data using machine learning techniques. Remote Sens. 2015, 7, 12419–12439. [Google Scholar] [CrossRef]
- Yang, Y.; He, C.Y.; Zhang, Q.F.; Han, L.J.; Du, S.Q. Timely and accurate national-scale mapping of urban land in china using defense meteorological satellite program’s operational linescan system nighttime stable light data. J. Appl. Remote Sens. 2013, 7, 073535. [Google Scholar] [CrossRef]
- Sutton, P. Modeling population density with night-time satellite imagery and gis. Comput. Environ. Urban Syst. 1997, 21, 227–244. [Google Scholar] [CrossRef]
- Imhoff, M.L.; Lawrence, W.T.; Stutzer, D.C.; Elvidge, C.D. A technique for using composite dmsp/ols “city lights” satellite data to map urban area. Remote Sens. Environ. 1997, 61, 361–370. [Google Scholar] [CrossRef]
- Ma, T.; Zhou, Y.; Zhou, C.; Haynie, S.; Pei, T.; Xu, T. Night-time light derived estimation of spatio-temporal characteristics of urbanization dynamics using DMSP/OLS satellite data. Remote Sens. Environ. 2015, 158, 453–464. [Google Scholar] [CrossRef]
- He, C.; Shi, P.; Li, J.; Chen, J.; Pan, Y.; Li, J.; Zhuo, L.; Ichinose, T. Restoring urbanization process in china in the 1990s by using non-radiance-calibrated DMSP/OLS nighttime light imagery and statistical data. Chin. Sci. Bull. 2006, 51, 1614–1620. [Google Scholar] [CrossRef]
- Milesi, C.; Elvidge, C.D.; Nemani, R.R.; Running, S.W. Assessing the impact of urban land development on net primary productivity in the southeastern united states. Remote Sens. Environ. 2003, 86, 401–410. [Google Scholar] [CrossRef]
- Henderson, M.; Yeh, E.T.; Gong, P.; Elvidge, C.; Baugh, K. Validation of urban boundaries derived from global night-time satellite imagery. Int. J. Remote Sens. 2003, 24, 595–609. [Google Scholar] [CrossRef]
- Li, X.; Gong, P.; Liang, L. A 30-year (1984–2013) record of annual urban dynamics of beijing city derived from landsat data. Remote Sens. Environ. 2015, 166, 78–90. [Google Scholar] [CrossRef]
- Liu, Z.; He, C.; Zhang, Q.; Huang, Q.; Yang, Y. Extracting the dynamics of urban expansion in china using dmsp-ols nighttime light data from 1992 to 2008. Landsc. Urban Plan. 2012, 106, 62–72. [Google Scholar] [CrossRef]
- Zhou, Y.; Smith, S.J.; Zhao, K.; Imhoff, M.; Thomson, A.; Bond-Lamberty, B.; Asrar, G.R.; Zhang, X.; He, C.; Elvidge, C.D. A global map of urban extent from nightlights. Environ. Res. Lett. 2015, 10, 054011. [Google Scholar] [CrossRef]
- Dennett, D.C. Real patterns. J. Philos. 1991, 88, 27–51. [Google Scholar] [CrossRef]
- Berry, B.J.L. Cities as systems within systems of cities. Pap. Reg. Sci. 1964, 13, 146–163. [Google Scholar] [CrossRef]
- Cristelli, M.; Batty, M.; Pietronero, L. There is more than a power law in zipf. Sci. Rep. 2012, 2, 812. [Google Scholar] [CrossRef] [PubMed]
- Zipf, G.K. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology; Martino Publishing: Eastford, CT, USA, 2012. [Google Scholar]
- Gabaix, X. Zipf’s law for cities: An explanation. Q. J. Econ. 1999, 114, 739–767. [Google Scholar] [CrossRef]
- Jiang, B.; Yin, J.; Liu, Q. Zipf’s law for all the natural cities around the world. Int. J. Geogr. Inf. Sci. 2015, 29, 498–522. [Google Scholar] [CrossRef]
- Soo, K.T. Zipf’s law for cities: A cross-country investigation. Reg. Sci. Urban Econ. 2005, 35, 239–263. [Google Scholar] [CrossRef]
- Batty, M.; Longley, P.A. Fractal Cities—A Geometry of Form and Function; Academic Press Professional, Inc.: Cambridge, MA, USA, 1994. [Google Scholar]
- Version 1 VIIRS Day/Night Band Nighttime Lights. Available online: https://www.ngdc.noaa.gov/eog/viirs/download_dnb_composites.html (accessed on 17 May 2017).
- Goodchild, M.F. Citizens as voluntary sensors: Spatial data infrastructure in the world of web 2.0. Int. J. Spat. Data Infrastruct. Res. 2007, 2, 24–32. [Google Scholar]
- Point of Interest (POI) Data in China in 2014. Available online: https://geohey.com/ (accessed on 15 June 2016).
- National Geomatics Center of China. Available online: http://www.globallandcover.com (accessed on 17 May 2017).
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A pok-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Shi, K.; Huang, C.; Yu, B.; Yin, B.; Huang, Y.; Wu, J. Evaluation of npp-viirs night-time light composite data for extracting built-up urban areas. Remote Sens. Lett. 2014, 5, 358–366. [Google Scholar] [CrossRef]
- Newman, M.E. Power laws, pareto distributions and Zipf’s law. Contemp. Phys. 2005, 46, 323–351. [Google Scholar] [CrossRef]
- Clauset, A.; Shalizi, C.R.; Newman, M.E.J. Power-law distributions in empirical data. Siam Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Goldstein, M.L.; Morris, S.A.; Yen, G.G. Problems with fitting to the power-law distribution. Eur. Phys. J. B-Condens. Matter Complex Syst. 2004, 41, 255–258. [Google Scholar] [CrossRef]
- Rozenfeld, H.D.; Rybski, D.; Andrade, J.S., Jr.; Batty, M.; Stanley, H.E.; Makse, H.A. Laws of population growth. Proc. Natl. Acad. Sci. USA 2008, 105, 18702. [Google Scholar] [CrossRef] [PubMed]
- Long, Y.; Shen, Y.; Jin, X. Mapping block-level urban areas for all chinese cities. Ann. Am. Assoc. Geogr. 2016, 106, 96–113. [Google Scholar] [CrossRef]
- Ma, D.; Sandberg, M.; Jiang, B. Characterizing the heterogeneity of the openstreetmap data and community. ISPRS Int. J. Geo-Inf. 2015, 4, 535–550. [Google Scholar] [CrossRef]
- Ontoy, D.S.; Padua, R.N. Measuring species diversity for conservation biology: Incorpo-rating social and ecological importance of species. Biodivers. J. 2014, 5, 387–390. [Google Scholar]
- Gao, P.; Liu, Z.; Liu, G.; Zhao, H.; Xie, X. Unified metrics for characterizing the fractal nature of geographic features. Ann. Am. Assoc. Geogr. 2017, 1315–1331. [Google Scholar] [CrossRef]
- Jiang, B.; Yin, J. Ht-index for quantifying the fractal or scaling structure of geographic features. Ann. Assoc. Am. Geogr. 2014, 104, 530–540. [Google Scholar] [CrossRef]
- Shu, S.; Yu, B.; Wu, J.; Liu, H. Methods for deriving urban built-up area using night-light data: Assessment and application. Remote Sens. Technol. Appl. 2011, 26, 169–176. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Month | January | February | March | April | September | October | November | December |
|---|---|---|---|---|---|---|---|---|
| Maximum value | 337.589 | 309.868 | 341.728 | 253.113 | 300.827 | 299.849 | 607.028 | 426.462 |
| Light | Number of Pixels | Mean Value | Count of Head | Percentage of Head | Count of Tail | Percentage of Tail | p-Value | |
|---|---|---|---|---|---|---|---|---|
| 0.00–359.59 | 55,548,465 | 0.26 | 9,171,200 | 16.51 | 46,377,265 | 83.49 | ||
| 0.26–359.59 | 9,171,200 | 1.73 | 1,685,716 | 18.38 | 7,485,484 | 81.62 | 2.07 | 0.00 |
| 1.73–359.59 | 1,685,716 | 8.23 | 519,035 | 30.79 | 1,166,681 | 69.21 | 1.98 | 0.48 |
| 8.23–359.59 | 519,035 | 19.87 | 191,648 | 36.92 | 327,387 | 63.08 | 1.76 | 0.00 |
| 19.87–359.59 | 191,648 | 33.14 | 70,202 | 36.63 | 121,446 | 63.37 | 1.83 | 0.01 |
| 33.14–359.59 | 70,202 | 47.71 | 29,265 | 41.69 | 40,937 | 58.31 | 1.94 | 0.26 |
| 47.71–359.59 | 29,265 | 66.13 | 23,514 | 79.37 | 5751 | 20.63 | 2.08 | 0.00 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Zhao, H.; Jiang, S. A Zipf’s Law-Based Method for Mapping Urban Areas Using NPP-VIIRS Nighttime Light Data. Remote Sens. 2018, 10, 130. https://doi.org/10.3390/rs10010130
Wu W, Zhao H, Jiang S. A Zipf’s Law-Based Method for Mapping Urban Areas Using NPP-VIIRS Nighttime Light Data. Remote Sensing. 2018; 10(1):130. https://doi.org/10.3390/rs10010130
Chicago/Turabian StyleWu, Wenjia, Hongrui Zhao, and Shulong Jiang. 2018. "A Zipf’s Law-Based Method for Mapping Urban Areas Using NPP-VIIRS Nighttime Light Data" Remote Sensing 10, no. 1: 130. https://doi.org/10.3390/rs10010130
APA StyleWu, W., Zhao, H., & Jiang, S. (2018). A Zipf’s Law-Based Method for Mapping Urban Areas Using NPP-VIIRS Nighttime Light Data. Remote Sensing, 10(1), 130. https://doi.org/10.3390/rs10010130