Identifying Forest Impacted by Development in the Commonwealth of Virginia through the Use of Landsat and Known Change Indicators



Abstract
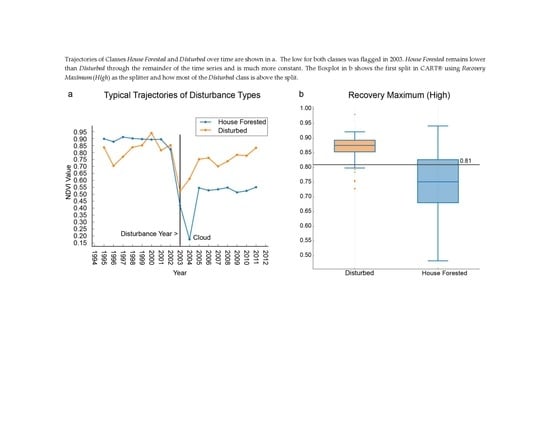
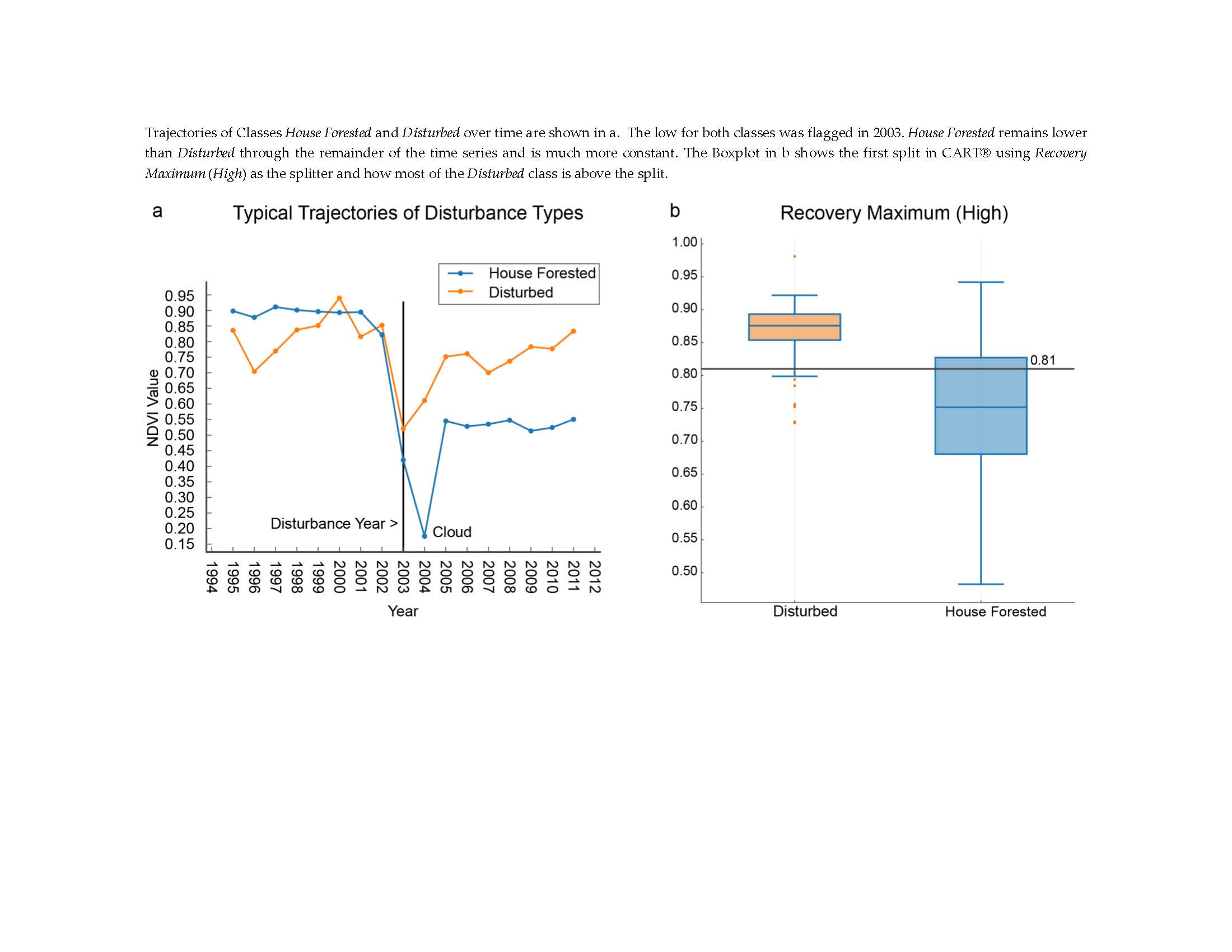
:
1. Introduction
2. Materials and Methods
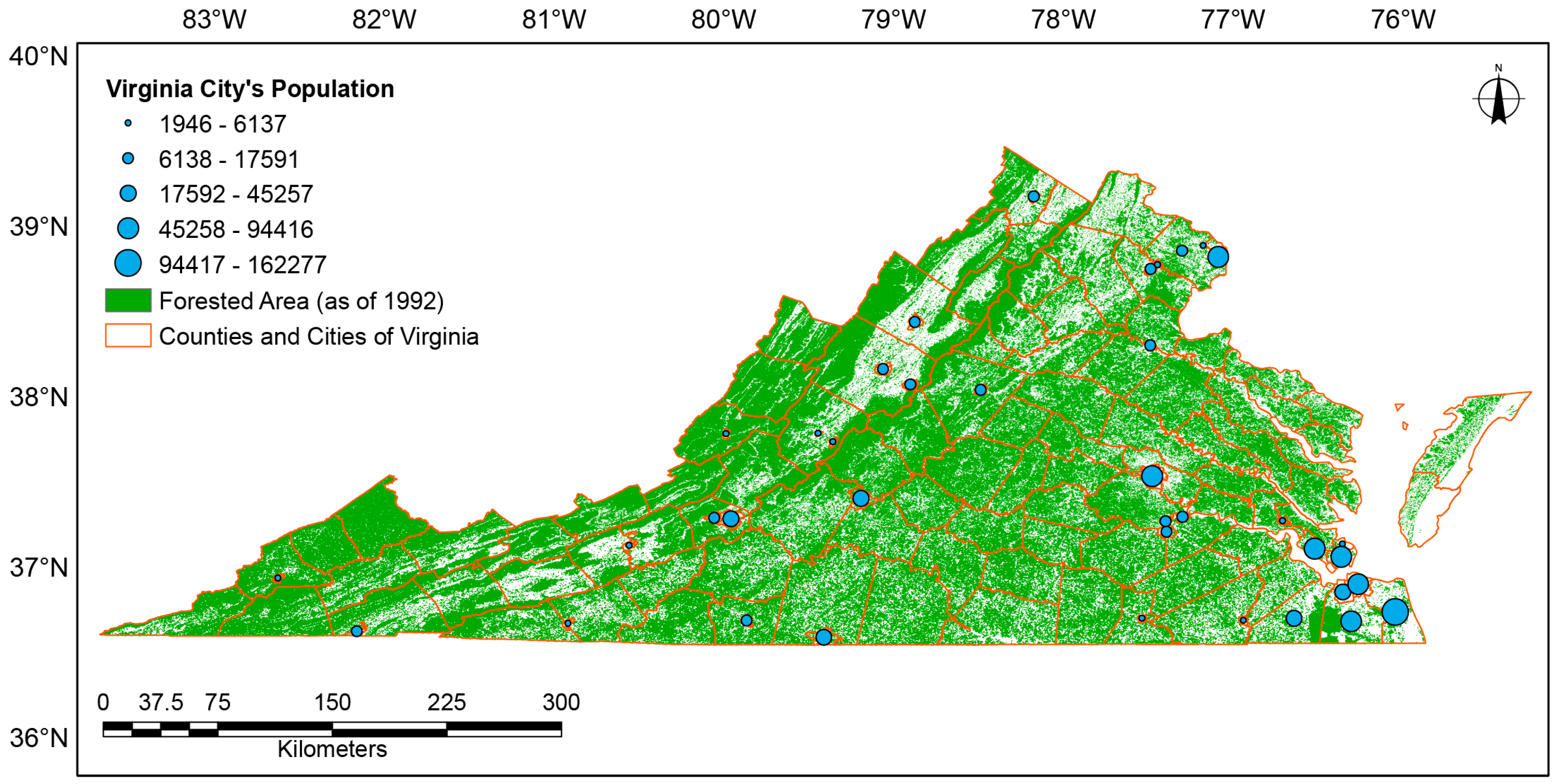
2.1. Study Area
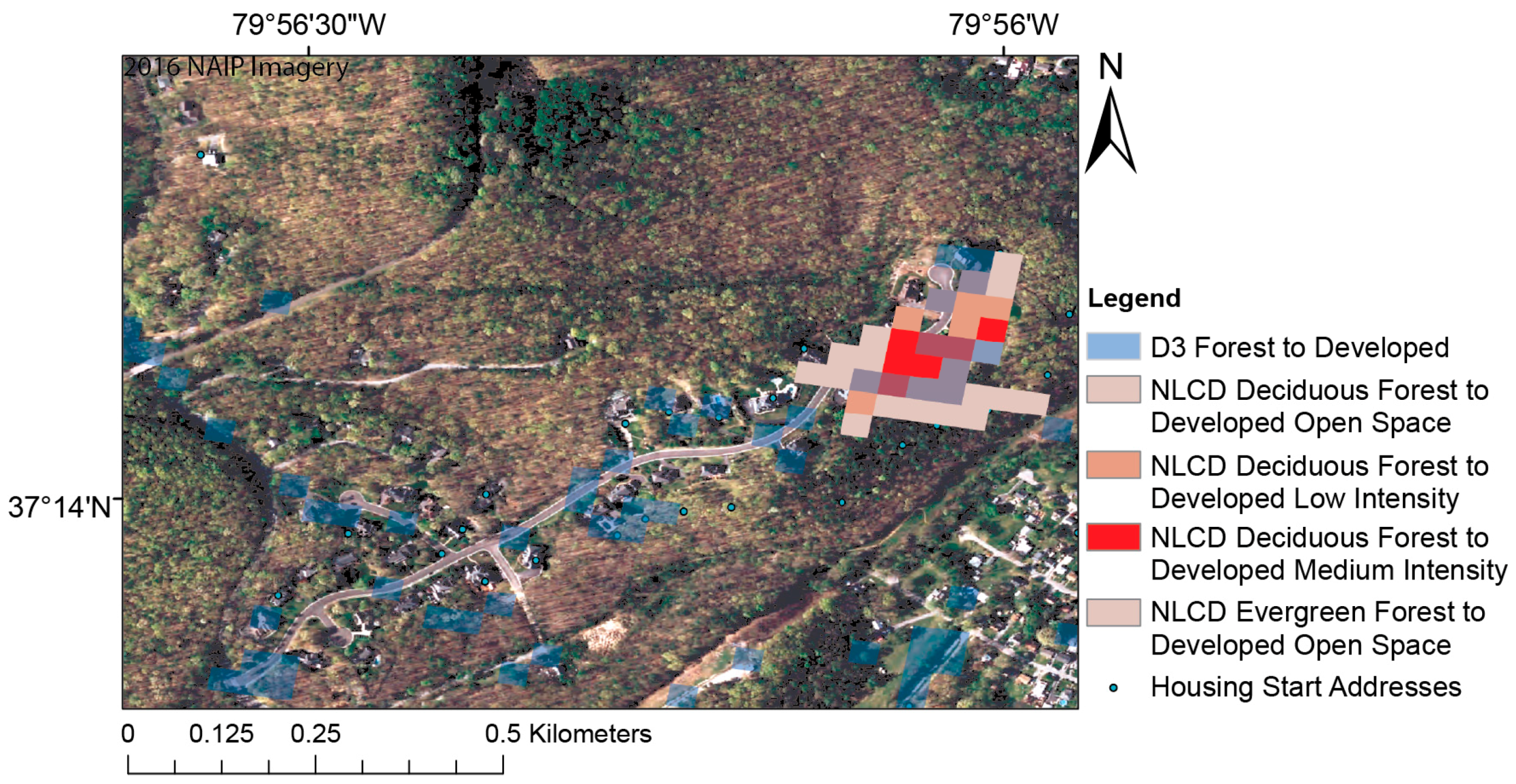
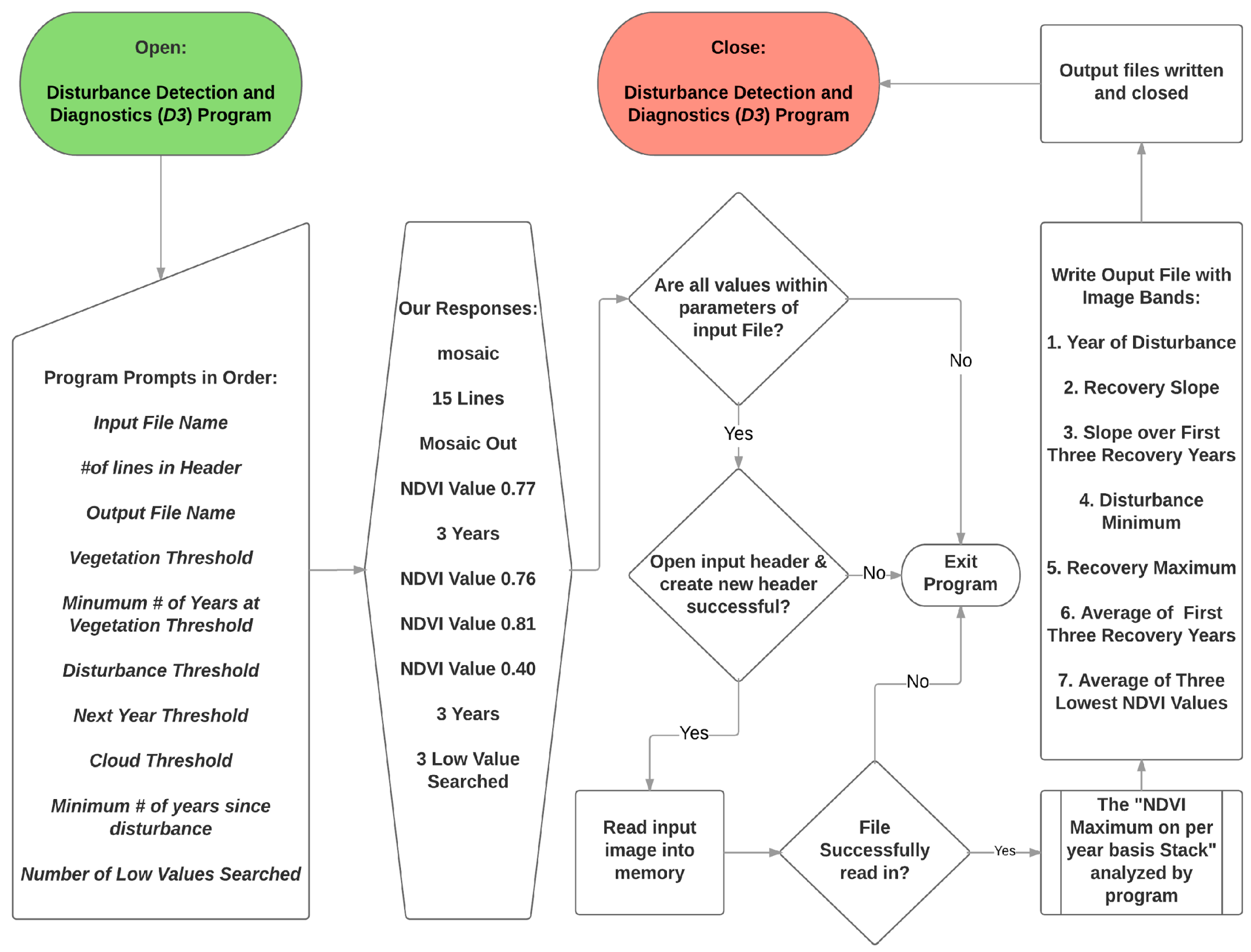
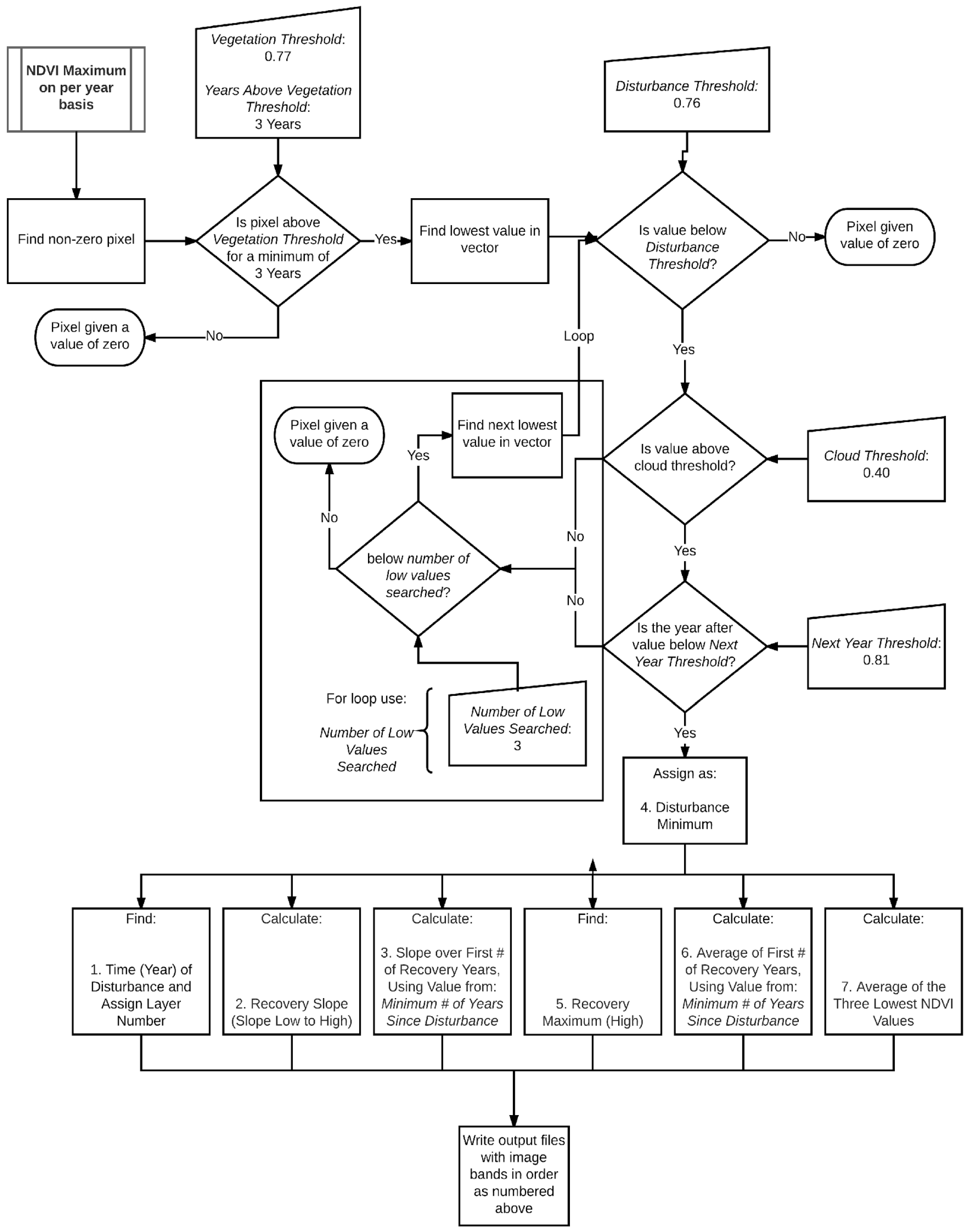
2.2. Automated Disturbance Detection and Diagnostics (D3) Program Development
2.3. Landsat Data
2.4. Initial Satellite Data Processing
2.5. Classification Scheme
2.6. Training Dataset
2.7. Implementation of D3 to Detect Forest Disturbance
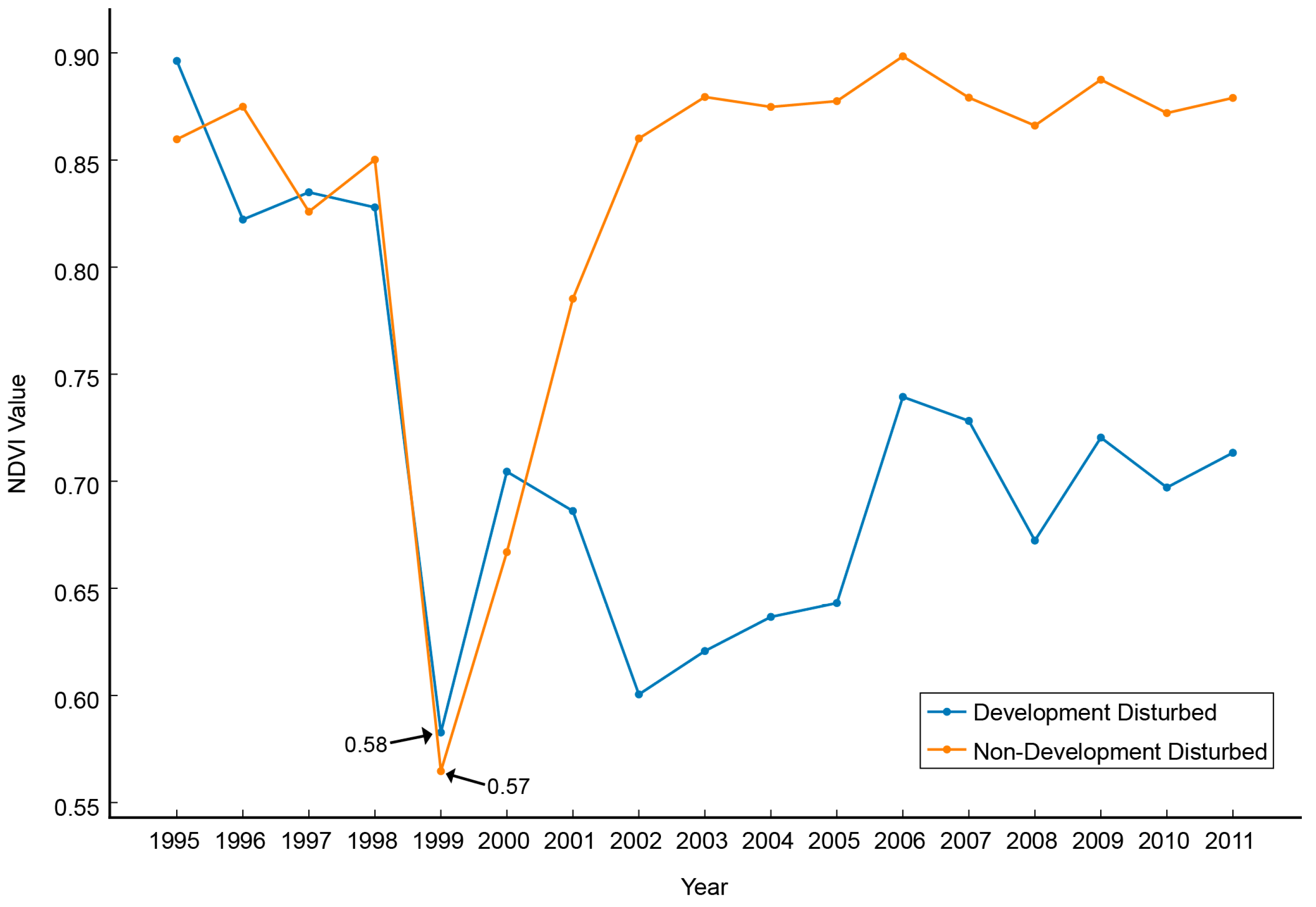
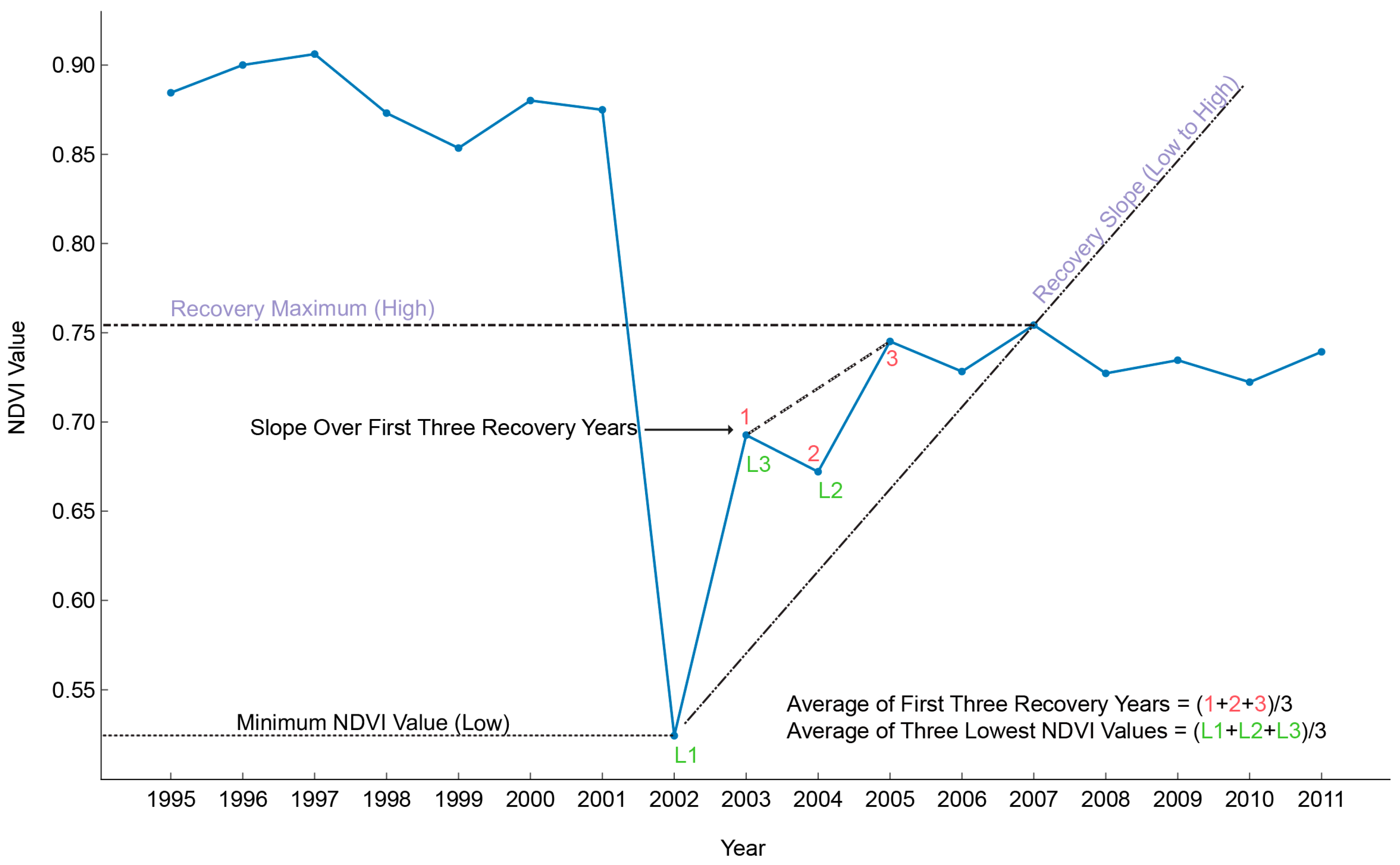
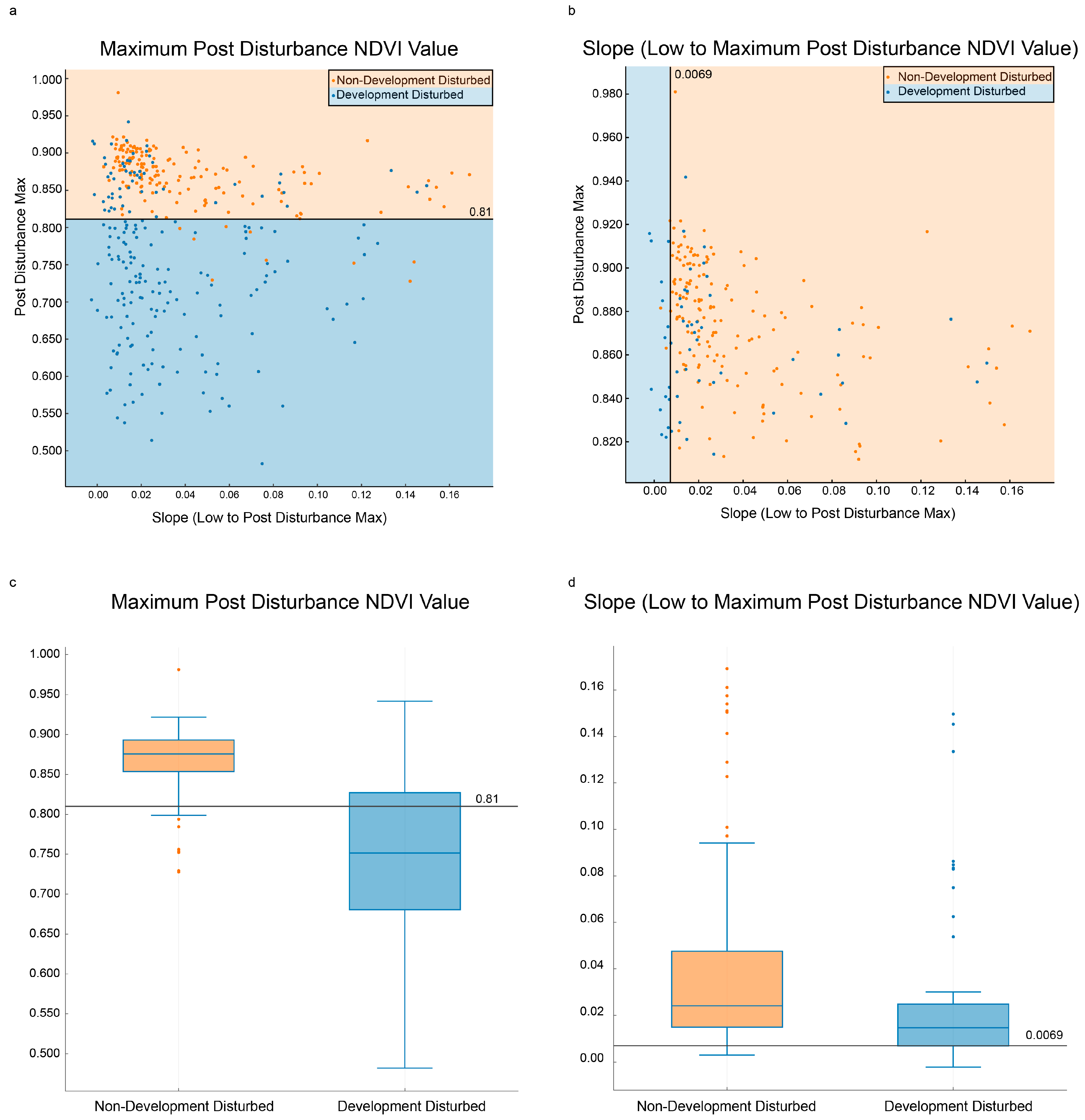
2.8. Interclass Differences in Disturbance and Recovery Dynamics
2.9. Developing a CART Model from the D3 Program Output
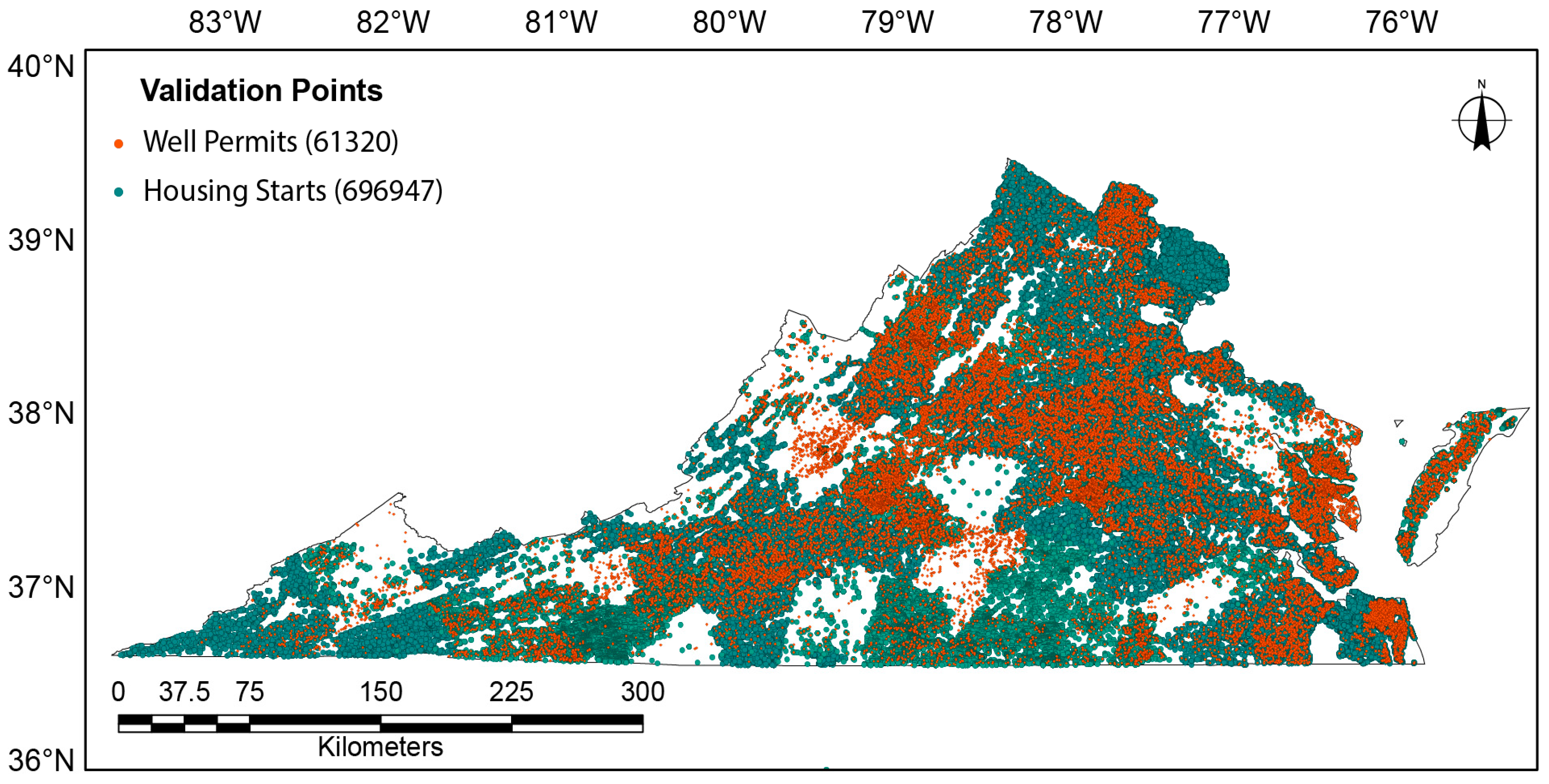
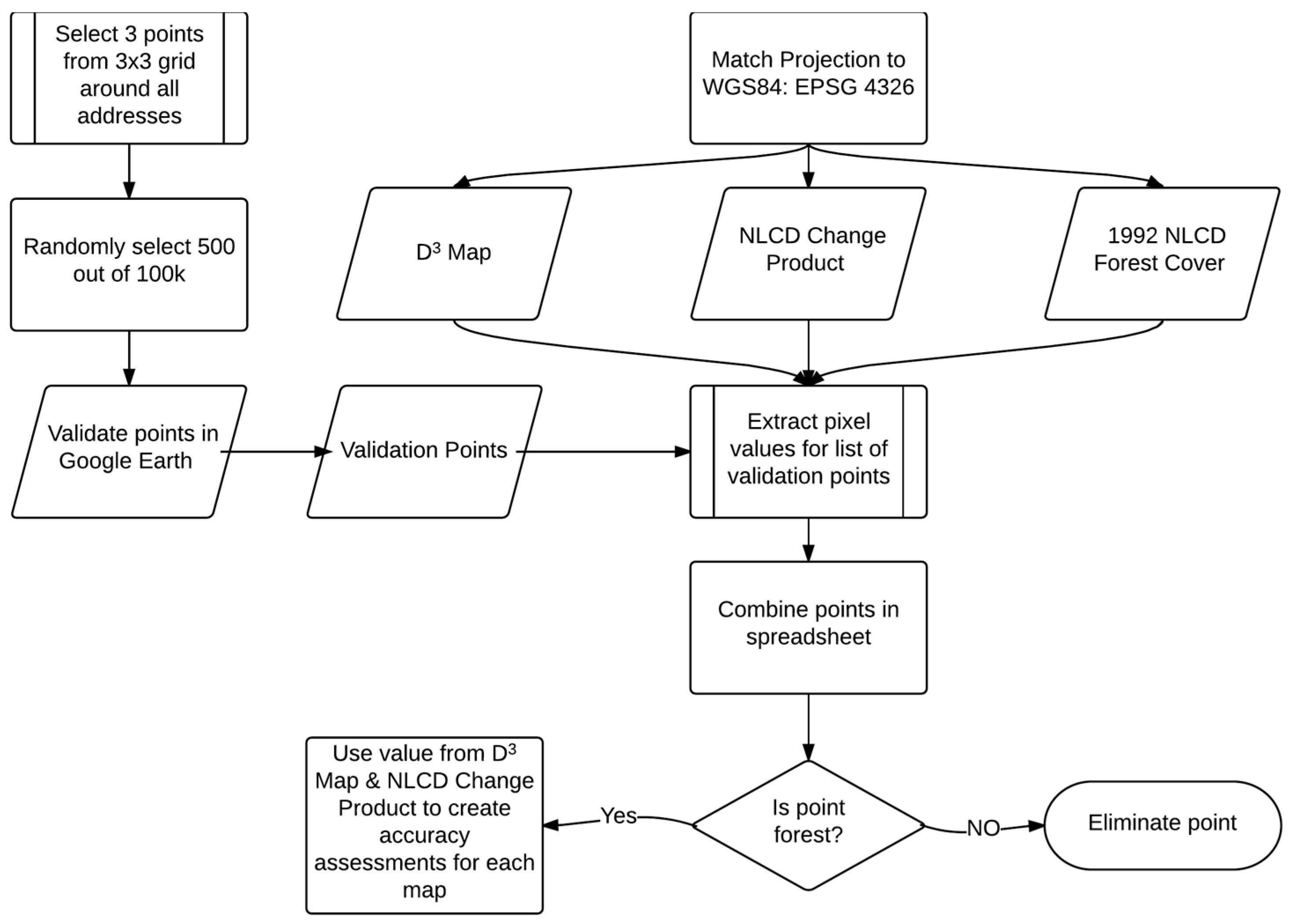
2.10. Validation
3. Results
3.1. Training Dataset
3.2. Classification Accuracy
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Automated Disturbance Detection and Diagnostics (Description and Process Flow Charts)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D3 Input Prompts | Definition and Use |
|---|---|
| Vegetation Threshold | Pixels above this value are labeled forest/vegetation. |
| Minimum # of Years at Vegetation Threshold | A pixel must exceed the vegetation threshold a minimum of 3 years. |
| Disturbance Threshold | A pixel is considered disturbed for a year if its value falls below this threshold |
| Next Year Threshold | The pixel value for the year immediately following the identified low is used to separate false lows from a true disturbance. If the value is above the threshold the identified low is discarded and the next lowest value is considered. |
| Cloud Threshold | The identified low value cannot be below this threshold. Values below this predominantly indicate (and are assumed to be) clouds. |
| Minimum # of Years Since Disturbance | This is the number of years over which the static average and slope are computed |
| Number of Low Values Searched | This is the number of times D3 searches for a low value in a pixel time series vector. |

| Output Layers of D3 | |
|---|---|
| 1 | Year of Disturbance |
| 2 | Slope Low to High |
| 3 | Slope over First x Post Disturbance Years |
| 4 | Low (value when first fell below threshold) |
| 5 | Recovery Maximum (Highest NDVI Value after Low) |
| 6 | Average (of x Post Disturbance Years) |
| 7 | Average of Lowest Three Values in Entire Time series |

Appendix B. Fortran Code for Virginia Tech Disturbance Program (D3)
References
- Berube, A.; Singer, A.; Wilson, J.H.; Frey, W.H. Finding Exurbia: America’s Changing Landscape at the Metropolitan Fringe; The Brookings Institution: Washington, DC, USA, 2006. [Google Scholar]
- Johnson, K.M.; Beale, C.L. The recent revival of widespread population growth in nonmetropolitan areas of the United States. Rural Sociol. 1994, 59, 655–667. [Google Scholar] [CrossRef]
- Johnson, K.M.; Cromartie, J.B. The rural rebound and its aftermath. Popul. Chang. Rural Soc. 2006, 25–49. [Google Scholar] [CrossRef]
- Perry, M.J.; Mackun, P.J.; Joyce, C.D.; Lollock, L.R.; Pearson, L.S. Population change and distribution. Montana 2001, 799, 103–130. [Google Scholar]
- Helms, J.A. The Dictionary of Forestry, 2nd ed.; Society of American Foresters: Bethesda, MD, USA, 1998; ISBN 978-0939970735. [Google Scholar]
- Glickman, D.; Babbitt, B. Urban wildland interface communities within the vicinity of federal lands that are at high risk from wildfire. Fed. Regist. 2001, 66, 751–777. [Google Scholar]
- Cohen, J.D. The wildland-urban interface fire problem: A consequence of the fire exclusion paradigm. In Forest History Today; U.S. Forest Service: Washington, DC, USA, 2008; pp. 20–26. [Google Scholar]
- Zoonoses in Merriam-Webster. 2017. Available online: https://www.merriam-webster.com/dictionary/zoonoses (accessed on 7 July 2017).
- Radeloff, V.C.; Hammer, R.B.; Stewart, S.I.; Fried, J.S.; Holcomb, S.S.; McKeefry, J.F. The wildland-urban interface in the United States. Ecol. Appl. 2005, 15, 799–805. [Google Scholar] [CrossRef]
- Stein, S.M.; McRoberts, R.E.; Alig, R.J.; Nelson, M.D.; Theobald, D.M.; Eley, M.; Dechter, M.; Carr, M. Forests on the Edge: Housing Development on America’s Private Forests; United States Department of Agriculture: Washington, DC, USA, 2005.
- Brown, D.G.; Johnson, K.M.; Loveland, T.R.; Theobald, D.M. Rural land-use trends in the conterminous United States, 1950–2000. Ecol. Appl. 2005, 15, 1851–1863. [Google Scholar] [CrossRef]
- Homer, C.H.; Fry, J.A.; Barnes, C.A. The National Land Cover Database; US Geological Survey: Reston, VS, USA, 2012; pp. 2327–6932.
- Xian, G.; Homer, C.; Fry, J. Updating the 2001 National Land Cover Database land cover classification to 2006 by using Landsat imagery change detection methods. Remote Sens. Environ. 2009, 113, 1133–1147. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. Landtrendr—Temporal segmentation algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Sexton, J.O.; Song, X.-P.; Huang, C.; Channan, S.; Baker, M.E.; Townshend, J.R. Urban growth of the Washington, D.C.—Baltimore, MD metropolitan region from 1984 to 2010 by annual, Landsat-based estimates of impervious cover. Remote Sens. Environ. 2013, 129, 42–53. [Google Scholar] [CrossRef]
- Zhang, L.; Weng, Q. Annual dynamics of impervious surface in the Pearl River delta, China, from 1988 to 2013, using time series landsat imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 86–96. [Google Scholar] [CrossRef]
- Powell, S.; Cohen, W.; Yang, Z.; Pierce, J.; Alberti, M. Quantification of impervious surface in the Snohomish water resources inventory area of western Washington from 1972–2006. Remote Sens. Environ. 2008, 112, 1895–1908. [Google Scholar] [CrossRef]
- USGS 2003. Landsat: A Global Land-Observing Program; US Geological Survey: Reston, VS, USA, 2003.
- Moisen, G.G.; Meyer, M.C.; Schroeder, T.A.; Liao, X.; Schleeweis, K.G.; Freeman, E.A.; Toney, C. Shape selection in Landsat time series: A tool for monitoring forest dynamics. Glob. Chang. Biol. 2016, 22, 3518–3528. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Goward, S.N.; Schleeweis, K.; Thomas, N.; Masek, J.G.; Zhu, Z. Dynamics of national forests assessed using the Landsat record: Case studies in eastern United States. Remote Sens. Environ. 2009, 113, 1430–1442. [Google Scholar] [CrossRef]
- Sen, S.; Zipper, C.E.; Wynne, R.H.; Donovan, P.F. Identifying revegetated mines as disturbance/recovery trajectories using an interannual Landsat chronosequence. Photogramm. Eng. Remote Sens. 2012, 78, 223–235. [Google Scholar] [CrossRef]
- Yang, L.; Homer, C.; Hegge, K.; Huang, C.; Wylie, B.; Reed, B. A Landsat 7 scene selection strategy for a National Land Cover Database. In Proceedings of the IEEE 2001 International Geoscience and Remote Sensing Symposium, Sydney, Australia, 9–13 July 2001; pp. 1123–1125. [Google Scholar]
- Yang, L.; Huang, C.; Homer, C.G.; Wylie, B.K.; Coan, M.J. An approach for mapping large-area impervious surfaces: Synergistic use of Landsat-7 ETM+ and high spatial resolution imagery. Can. J. Remote Sens. 2003, 29, 230–240. [Google Scholar] [CrossRef]
- Huang, C.; Goward, S.N.; Masek, J.G.; Thomas, N.; Zhu, Z.; Vogelmann, J.E. An automated approach for reconstructing recent forest disturbance history using dense Landsat time series stacks. Remote Sens. Environ. 2010, 114, 183–198. [Google Scholar] [CrossRef]
- Brooks, E.B.; Wynne, R.H.; Thomas, V.A.; Blinn, C.E.; Coulston, J.W. On-the-fly massively multitemporal change detection using statistical quality control charts and Landsat data. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3316–3332. [Google Scholar] [CrossRef]
- Buma, B. Evaluating the utility and seasonality of NDVI values for assessing post-disturbance recovery in a subalpine forest. Environ. Monit. Assess. 2012, 184, 3849–3860. [Google Scholar] [CrossRef] [PubMed]
- Van Leeuwen, W.J. Monitoring the effects of forest restoration treatments on post-fire vegetation recovery with MODIS multitemporal data. Sensors 2008, 8, 2017–2042. [Google Scholar] [CrossRef] [PubMed]
- Hirschmugl, M.; Steinegger, M.; Gallaun, H.; Schardt, M. Mapping forest degradation due to selective logging by means of time series analysis: Case studies in Central Africa. Remote Sens. 2014, 6, 756–775. [Google Scholar] [CrossRef]
- Mackun, P.J.; Wilson, S.; Fischetti, T.R.; Goworowska, J. Population Distribution and Change: 2000 to 2010; US Department of Commerce, Economics and Statistics Administration, US Census Bureau: Washington, DC, USA, 2011.
- Rose, A.K. Virginia’s Forests, 2011; U.S. Forest Service: Washington, DC, USA, 2013; p. 92.
- Masek, J.G.; Vermote, E.F.; Saleous, N.E.; Wolfe, R.; Hall, F.G.; Huemmrich, K.F.; Gao, F.; Kutler, J.; Lim, T.-K. A Landsat surface reflectance dataset for North America, 1990–2000. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Department of Health, Agency 5. The Virginia Administrative Code. 2014; pp. 71–104. Available online: http://www.vdh.virginia.gov/EnvironmentalHealth/ONSITE/regulations/documents/2012/pdf/12%20VAC%205%20610.pdf (accessed on 1 December 2016).
- Vogelmann, J.E.; Howard, S.M.; Yang, L.; Larson, C.R.; Wylie, B.K.; Van Driel, N. Completion of the 1990s national land cover data set for the conterminous United States from Landsat Thematic Mapper data and ancillary data sources. Photogramm. Eng. Remote Sens. 2001, 67. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009; Chapter 4. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Australian Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4304, pp. 1015–1021. [Google Scholar]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing, 5th ed.; The Guilford Press: New York, NY, USA, 2011. [Google Scholar]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Linke, J.; McDermid, G.; Masek, J.G.; Gao, F.; White, J.C. A new data fusion model for high spatial-and temporal-resolution mapping of forest disturbance based on Landsat and MODIS. Remote Sens. Environ. 2009, 113, 1613–1627. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E.; Olofsson, P. Continuous monitoring of forest disturbance using all available Landsat imagery. Remote Sens. Environ. 2012, 122, 75–91. [Google Scholar] [CrossRef]
- Schroeder, T.A.; Schleeweis, K.G.; Moisen, G.G.; Toney, C.; Cohen, W.B.; Freeman, E.A.; Yang, Z.; Huang, C. Testing a Landsat-based approach for mapping disturbance causality in U.S. forests. Remote Sens. Environ. 2017, 195, 230–243. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Kennedy, R.E.; Yang, Z.; Braaten, J.; Krankina, O.N.; Friedl, M.A. Detecting forest disturbance in the pacific northwest from MODIS time series using temporal segmentation. Remote Sens. Environ. 2014, 151, 114–123. [Google Scholar] [CrossRef]
- Poirot, M.; Lakel, B.; Muncy, J.; Campbell, J. Virginia’s Forestry Best Management Practices for Water Quality Technical Manual, 5th ed.; Virginia Department of Forestry: Charlottesville, VA, USA, 2011.
- Muncy, J. Virginia’s Forestry Best Management Practices for Water Quality Field Guide; Virginia Department of Forestry: Charlottesville, VA, USA, 2009.
- Masek, J.G.; Goward, S.N.; Kennedy, R.E.; Cohen, W.B.; Moisen, G.G.; Schleweiss, K.; Huang, C. United States forest disturbance trends observed with Landsat time series. Ecosystems 2013, 16, 1087–1104. [Google Scholar] [CrossRef]








| FROM | Deciduous Forest | Evergreen Forest | Mixed Forest | Woody Wetlands |
|---|---|---|---|---|
| TO | Developed-Open Space | Developed-Open Space | Developed-Open Space | Developed-Open Space |
| Developed-Low Intensity | Developed-Low Intensity | Developed-Low Intensity | Developed-Low Intensity | |
| Developed-Medium Intensity | Developed-Medium Intensity | Developed-Medium Intensity | Developed-Medium Intensity | |
| Developed-High Intensity | Developed-High Intensity | Developed-High Intensity | Developed-High Intensity |
| Reference Data | |||||
|---|---|---|---|---|---|
| Combined Forest | Development Disturbed | Total | UA (%) | ||
| Classified Data | Combined Forest | 153 | 28 | 181 | 84.5 |
| Development Disturbed | 33 | 60 | 93 | 64.5 | |
| Total | 186 | 88 | |||
| PA (%) | 82.3 | 68.2 | |||
| Reference Data | |||||
|---|---|---|---|---|---|
| Combined Forest | Development Disturbed | Total | UA (%) | ||
| Classified Data | Combined Forest | 186 | 88 | 274 | 67.9 |
| Development Disturbed | 0 | 0 | 0 | 0 | |
| Total | 186 | 88 | |||
| PA (%) | 100 | 0 | |||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
House, M.N.; Wynne, R.H. Identifying Forest Impacted by Development in the Commonwealth of Virginia through the Use of Landsat and Known Change Indicators. Remote Sens. 2018, 10, 135. https://doi.org/10.3390/rs10010135
House MN, Wynne RH. Identifying Forest Impacted by Development in the Commonwealth of Virginia through the Use of Landsat and Known Change Indicators. Remote Sensing. 2018; 10(1):135. https://doi.org/10.3390/rs10010135
Chicago/Turabian StyleHouse, Matthew N., and Randolph H. Wynne. 2018. "Identifying Forest Impacted by Development in the Commonwealth of Virginia through the Use of Landsat and Known Change Indicators" Remote Sensing 10, no. 1: 135. https://doi.org/10.3390/rs10010135
APA StyleHouse, M. N., & Wynne, R. H. (2018). Identifying Forest Impacted by Development in the Commonwealth of Virginia through the Use of Landsat and Known Change Indicators. Remote Sensing, 10(1), 135. https://doi.org/10.3390/rs10010135