1. Introduction
The rapid development of remote sensing technologies has created a large amount of high-quality satellite and aerial images for research and investigation. High resolution satellite (HRS) images, compared to ordinary low- and medium-resolution images, have some special properties: (1) the structure of geospatial objects is clear; (2) the spatial layout is distinct; and (3) the entire image is a collection of multi-scale objects [
1]. Automated object detection in HRS images is a core requirement for large range scene understanding and semantic information extraction [
2]. Over the past decades, considerable efforts have been made to develop various methods for the detection of different types of objects in satellite and aerial images [
3], such as buildings [
4,
5], storage tanks [
6,
7], vehicles [
8,
9], and airplanes [
10,
11,
12]. Object detection in HRS images determines whether there are one or more objects belonging to the classes we are looking for and locates the position of each object using a bounding box. Learning efficient image representations is the core task for object detection [
13]. To solve the object detection problem, the traditional methods based on either coding of handcrafted features or unsupervised feature learning can only generate shallow to middle features with limited representative ability [
14,
15]. Recently, with the rapid development of convolutional neural network (CNN), several design variations using region based CNN have generated the state-of-the-art performance against traditional multi-class object detection benchmarks [
16,
17,
18,
19,
20]. These benchmark datasets typically present target objects with “friendly” or dominant scales because those images in a large pool of available images and objects with significant scales, could be more easily selected [
21]. Unlike objects on these benchmark datasets, objects on HRS images are much smaller, including fixed shape objects (e.g., airplanes, ships, vehicles, etc.) and diverse shape objects (e.g., harbors, bridges, etc.) that have vastly different scales, which makes object detection in HRS images a very difficult problem. Besides, large variations in the visual appearance of objects caused by viewpoint variation, resolution variation, occlusion, background clutter, illumination, shadow, etc., cause much larger challenges for object detection in HRS images [
3].
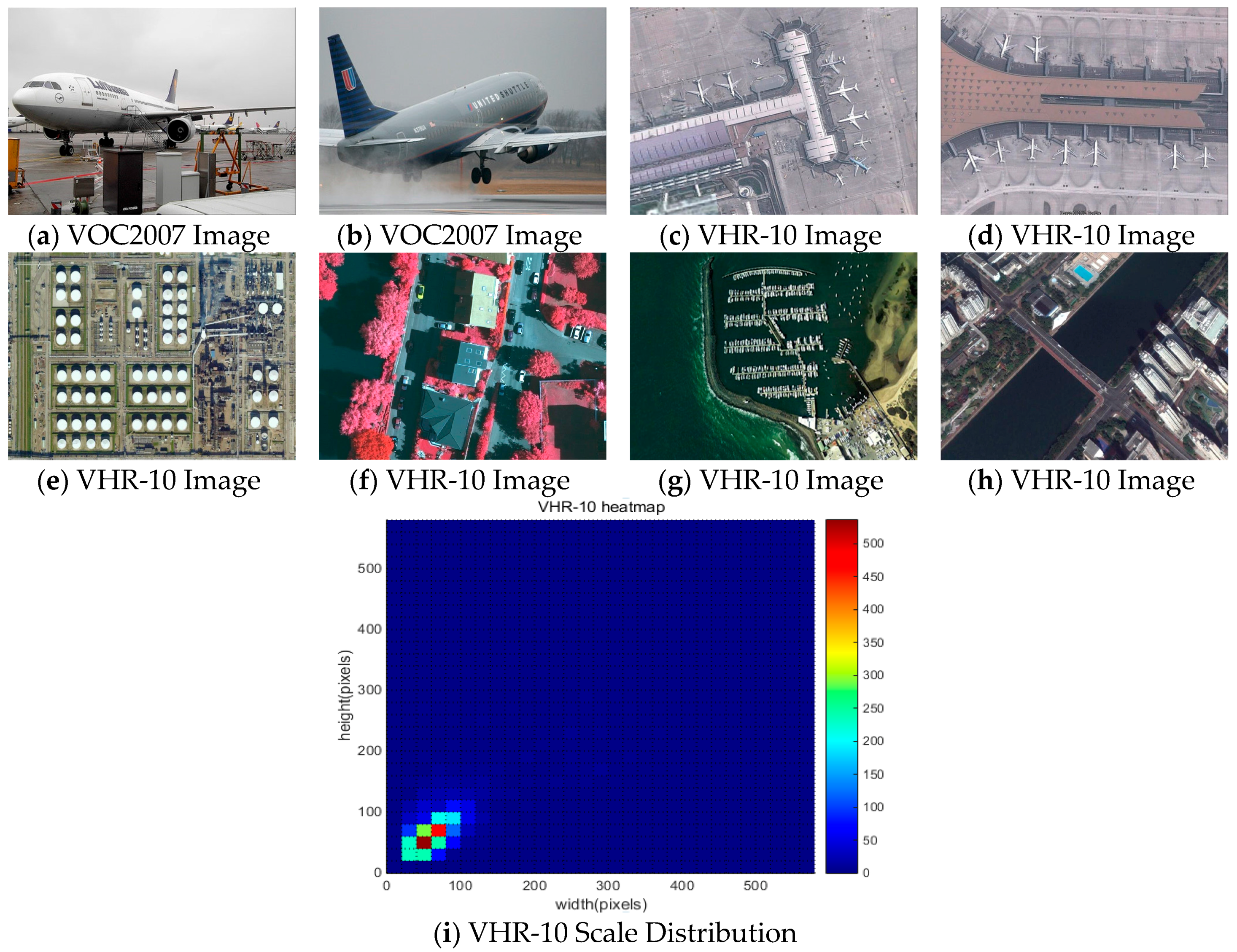
Figure 1 gives the object scale comparison of the Pascal Visual Object Classes 2007 (VOC2007) benchmark with Northwestern Polytechnical University very-high-resolution 10-class (NWPU VHR-10) benchmark and the scale distribution of NWPU VHR-10 benchmarks. We can find that airplanes on the VOC2007 images occupy a dominant position, while objects on the VHR-10 benchmark images are much smaller, with significant differences among them. In fact, most objects have sizes less than 150 pixels, while very small objects such as vehicles as well as large objects such as track fields make up a large proportion of objects. Despite the progress made in traditional many-class object detection benchmarks, the complex object distribution makes it difficult to directly deal with the object detection task in HRS images [
22].
Object detection in HRS images has been extensively studied over recent years [
23]. The existing methods can be generally divided into four main categories: template matching-based methods, knowledge-based methods, object based image analysis (OBIA)-based methods, and machine learning-based methods [
3]. Template matching-based methods can be further divided into two classes, i.e., rigid template matching and deformable template matching. Such types of methods usually have two steps: template generation and similarity measure [
4,
24]. For knowledge-based methods, the most widely leveraged types of knowledge are geometric and context [
25,
26,
27]. OBIA-based methods mainly involve two steps: image segmentation and object classification [
28]. For machine learning-based methods, three processing steps are needed: feature extraction, feature fusion dimension reduction, and classifier training [
29,
30]. Taking the advantages of the powerful feature extraction and classification techniques in machine learning area, object detection tasks have been formulated as feature extraction and classification problems, whose results have been shown to be promising. In the past decade, various feature extraction approaches have been developed for the representation of objects [
31]. Among them, histogram of oriented gradients (HOG) feature, local binary pattern (LBP) feature, bag of words (BoW) feature and sparse coding based features are four widely used features and have greatly advanced the development of object detection. HOG feature was first proposed by Dalal and Triggs, since its edges or gradient structure describes the characteristics of local shape and is very appropriate for human detection [
32]. LBP is an operator used to describe the local texture features of an image [
33]. It has remarkable advantages such as rotation invariance and gray scale invariance. Face recognition with LBP features has shown superiority and efficiency over some other methods [
34]. BoW feature represents the image of a scene by a collection of local regions, denoted as code-words obtained by unsupervised learning, and each region is represented as a part of a “theme” [
35,
36]. It has been widely used in geospatial object detection with excellent performance. Sparse coding is a kind of unsupervised method for learning sets of over-completed bases to represent data efficiently. Leveraging the mature theory in compressive sensing, sparse coding has been widely used in remote sensing image analysis, such as image de-noising, image classification and object detection, yielding promising performance [
37,
38,
39,
40]. Besides feature extraction, the subsequent classification is also very important in the process of object detection. A classifier can be trained using many different approaches by minimizing the misclassification error on the training dataset, including support vector machine (SVM), k-nearest neighbors (KNN), random forest (RF) and so on [
41,
42,
43].
With the recent rapid development of deep learning, CNNs have become a new approach for feature representation and greatly improved the performance of object detection [
44]. Current CNN-based object detection algorithms could be roughly divided into two streams: the region-based CNN (R-CNN) methods (e.g., R-CNN, Fast R-CNN and Faster R-CNN) and the region-free methods (e.g., you only look once (YOLO) and single shot multi-box detector (SSD)) [
16,
17,
18,
19,
20]. For each input image, R-CNN firstly extracts around 2000 region proposals using selective search algorithm. Then, it computes features for each proposal using a large CNN, followed by classifying each region using class-specific linear SVMs [
16]. Since CNN could extract deep features, the R-CNN outperforms other handcrafted features-based methods by a large margin on the ImageNet Large Scale Visual Recognition Challenge 2013 (ILSVRC2013). Fast R-CNN builds on R-CNN, but replaces the SVM classifier with a region of interest (RoI) pooling layer and some fully connected (FC) layers to classify region proposals and adjust the position of region proposals, which not only improves training and testing speed, but also increases detection accuracy [
17]. Faster R-CNN uses region proposal network (RPN) to generate high-quality region proposals. Then, these region proposals are used by Fast R-CNN for detection. RPN shares full image convolutional features with the detection network, thus enabling nearly cost-free region proposal generation [
18]. The region-based methods utilize a classifier to perform object detection. By contrast, the region-free methods such as YOLO frame object detection as a regression problem so that a single network could predict bounding boxes and associated classes directly [
19]. This method is extremely fast. SSD also considers object detection as a regression problem, but small convolutional filters are applied to feature maps to predict category scores and box offsets rather than fully connected layers. Besides, feature maps of different scales are used to make predictions of multi-scales, so the detection accuracy is greatly improved compared with YOLO [
20].
It is important to note that these CNN-based object detection methods were designed somewhat specifically for general object detection challenges, which is not suitable for geospatial object detection in HRS images [
45]. Besides, to handle the problem of multi-scale objects and small objects, some methods like Fast R-CNN and Faster R-CNN achieve this by up-sampling the input image at training phase or testing phase. It significantly increases the memory occupation and processing time. In this paper, we propose a multi-scale CNN for geospatial object detection. The main contributions of this paper are summarized as follows:
- (1)
A unified multi-scale CNN is proposed for geospatial object detection in HRS images. Objects with extremely different scales could be more efficiently detected than the state-of-the-art methods.
- (2)
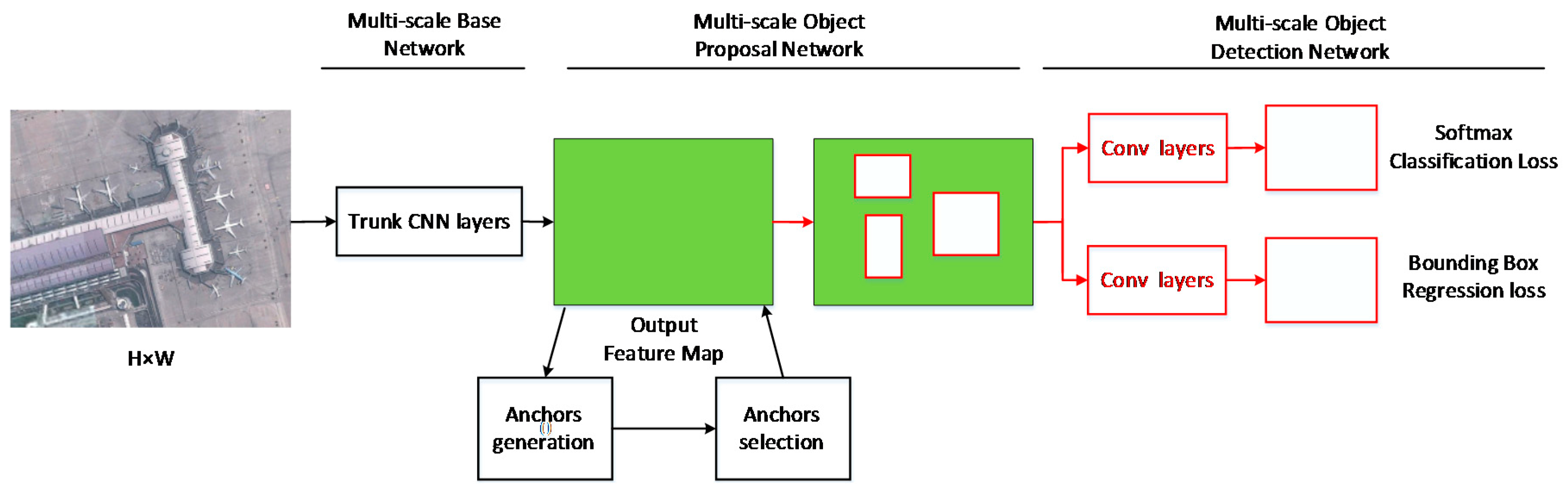
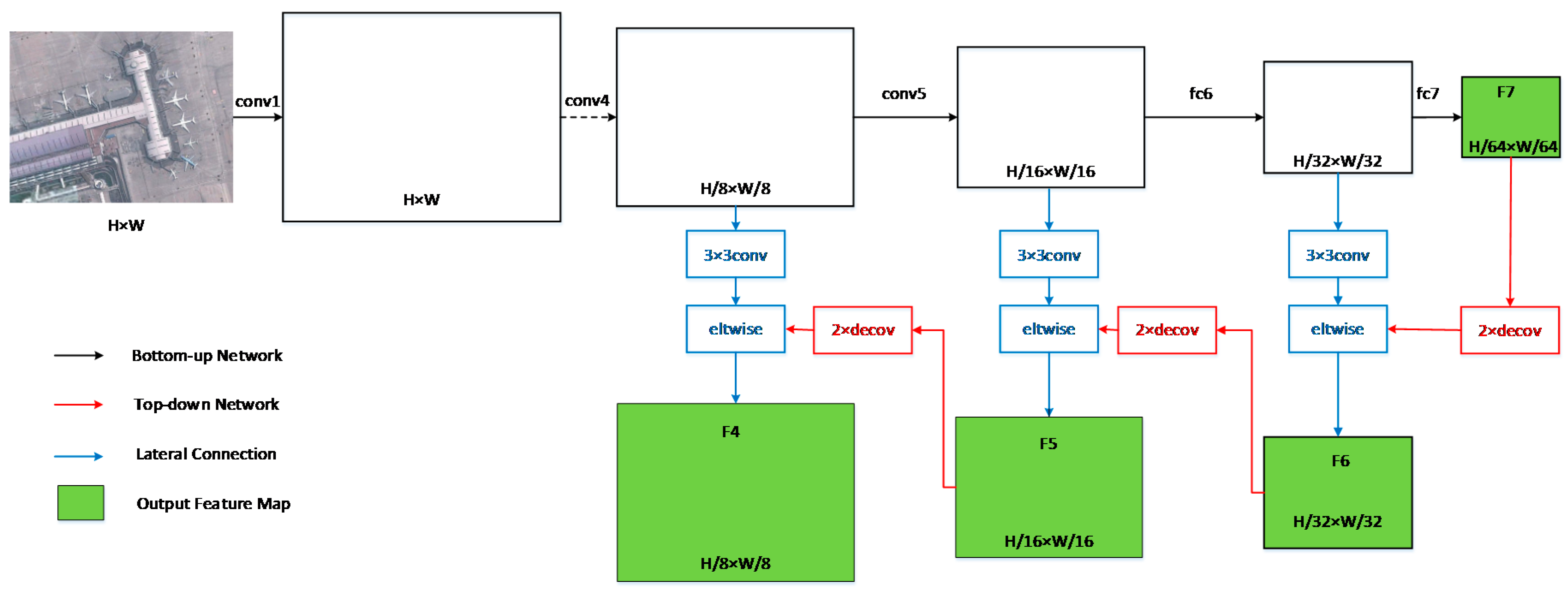
A modified base network is designed to generate feature maps with high semantic information at each layer. Since feature maps of different layers can be assigned to objects of specific scales, the detection performances at all scales are correspondingly improved.
- (3)
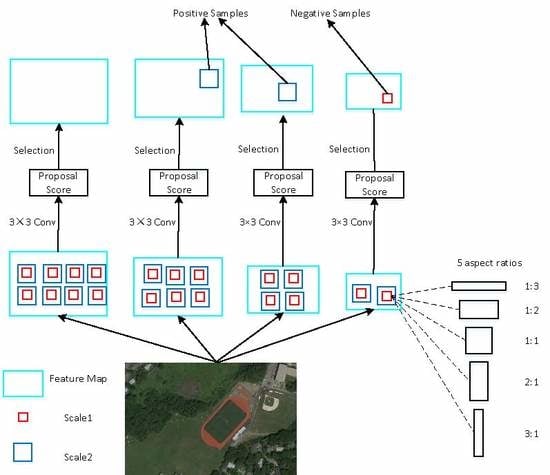
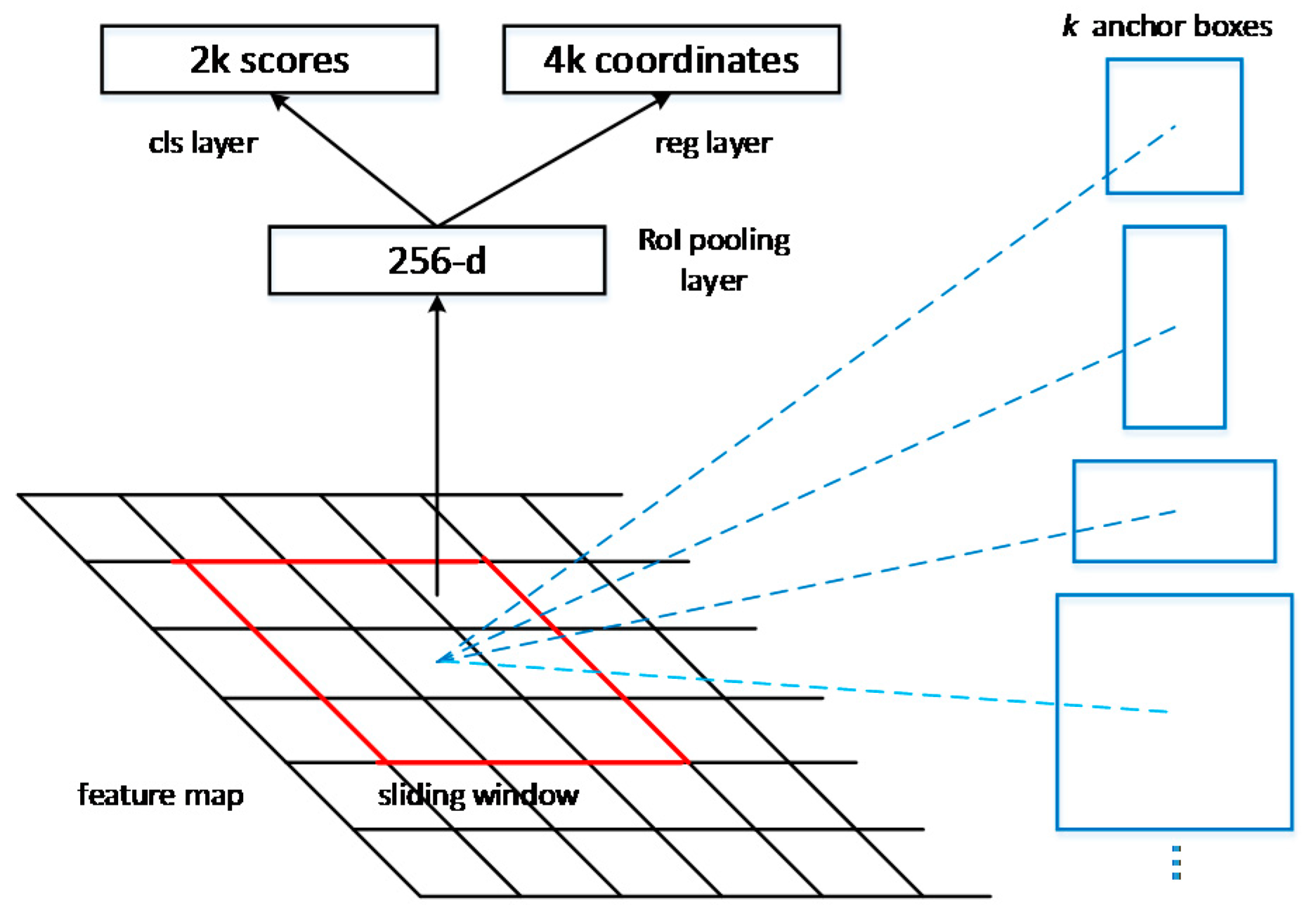
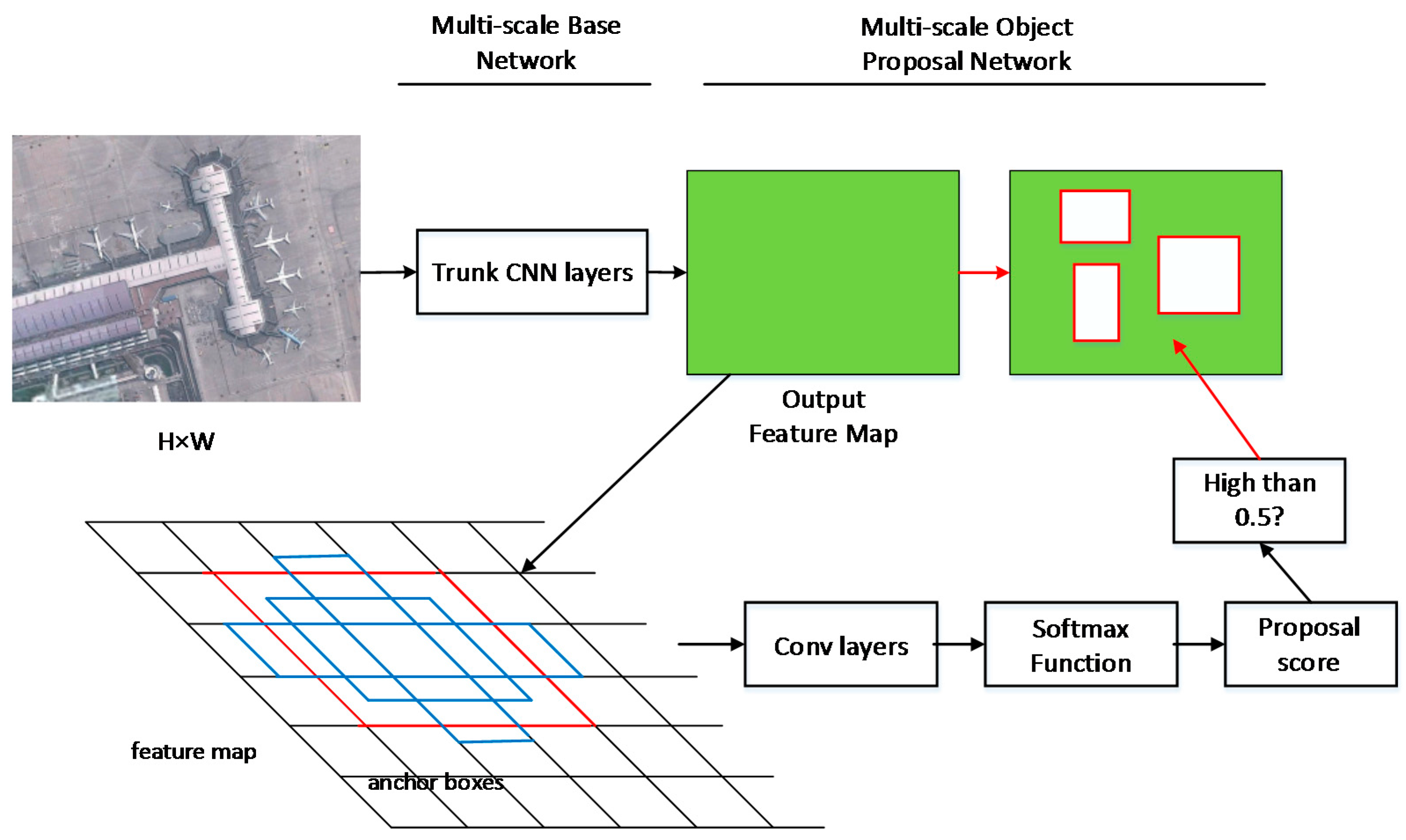
An optimized object proposal network is presented to produce better object proposals. By adding multi-scale anchor boxes to multi-scale feature maps, the network could generate object proposals exhaustively, which could improve the recall rate of the detection. By adding proposal score layers behind the multi-scale feature maps, the network could suppress most of the negative samples, which could improve the precision of the detection.
The proposed method is evaluated on a publicly available remote sensing object detection dataset and then compared with several state-of-the-art approaches. The experimental results demonstrate the effectiveness and superiority of our method.
The rest of this paper is organized as follows.
Section 2 presents the methodology of our multi-scale CNN, which consists of the multi-scale object proposal network and the multi-scale object detection network.
Section 3 presents the dataset description and experimental details.
Section 4 and
Section 5 present the analysis of the experimental results and a discussion of the results, respectively. Finally, the conclusions are drawn in
Section 6. Important terms and their abbreviations are provided in
Table 1.
3. Experiments
Remote Sensing datasets from Google Map have received extensive research attention in the recent years and are recognized as a valid source for remote sensing research [
55]. To evaluate the performance of the proposed multi-scale CNN, we performed ten-class object detection experiments on a publicly available dataset: NWPU VHR-10 dataset acquired from Google Earth [
56]. The dataset description, evaluation metrics, baseline methods and implementation details are described in this section.
3.1. Dataset Description
The NWPU VHR-10 dataset is a ten-class geospatial object detection dataset used for multi-class object detection. This dataset contains airplanes, ships, storage tanks, baseball diamonds, tennis courts, basketball courts, ground track fields, harbors, bridges, and vehicles. It contains a total of 800 very high resolution satellite images, with 715 images acquired from Google Earth with a resolution of 0.5–2.0 m, and 85 pan-sharpened color infrared images with a resolution of 0.08 m. Two image sets are contained in this dataset: a positive dataset, with 650 images each containing at least one target to be detected, and a negative dataset of 150 images, without any targets of the given classes to be detected. From the positive image set, 757 airplanes, 302 ships, 655 storage tanks, 390 baseball diamonds, 524 tennis courts, 150 basketball courts, 163 ground track fields, 224 harbors, 124 bridges, and 477 vehicles were manually annotated with bounding boxes used for ground truth. For the comparison with baseline method, we divide the positive dataset into 20% for training, 20% for validation and 60% for testing, namely 130 images for training, 130 images for validation and 390 images for testing.
3.2. Evaluation Metrics
We incorporate the widely used average precision (AP) and precision-recall curve (PRC) to quantitatively evaluate the performance of the proposed multi-scale CNN. The AP computes the average value of the precision over the interval from recall = 0 to recall = 1, i.e., the area under the PRC; hence, the higher the AP, the better the performance [
8]. In addition, mean AP (mAP) computes the average value of all the AP values for all the classes. The precision metric measures the proportion of detections that are true positives, and the recall metric measures the proportion of positives that are correctly detected. The precision and recall metrics can be formulated as follows:
A detecting anchor box is considered to be true positive (TP) if the area IoU between it and the ground truth is larger than 0.5, otherwise, it will be considered as false positive (FP). In addition, if the area overlap ratio between several detecting anchor boxes and the ground truth are bigger than 0.5, only the bounding box with the largest area IoU is considered as TP, others are considered as FP.
3.3. Baseline Methods
To evaluate the proposed multi-scale CNN quantitatively, we compared it with three state-of-the-art methods and four state-of-the-art CNN-based methods: (1) the BoW feature based method in which each image region is represented as a histogram of visual words generated by the k-means algorithm [
57]; (2) the spatial sparse coding BoW (SSCBoW) feature based model in which visual words are generated by the sparse coding algorithm [
36]; (3) the collection of part detectors (COPD) based method which is composed of 45 seed-based part detectors trained in HOG feature space. Each part detector is a linear SVM classifier corresponding to a particular viewpoint of a particular object class, hence, the collection of them provides an approximate solution for rotation-invariant object detection [
58]; (4) a transferred CNN model fine-tuned from AlexNet, which is used as a universal CNN feature extractor [
59]; (5) a rotation-invariant CNN (RICNN) model which considers rotation-invariant information with a rotation-invariant layer and other fine-tuned layers [
59]; (6) the SSD model with an input image size of
pixels; and (7) the faster R-CNN model with an input image size about
pixels.
3.4. Implementation Details
Our method is trained end-to-end on the NWPU VHR-10 trainval dataset, and tested on NWPU VHR-10 test dataset. To make the model more robust to various input object sizes and shapes, each training image is randomly sampled by one of the following options: (1) using the original/flipped input image; and (2) randomly sampling a patch whose edge length is 0.4, 0.5, 0.6, 0.7, 0.8 or 0.9 of the original image. We keep the patch only if at least one object’s center is in the sampled patch. During the training phase, we initialize the same parameters with VGG-16 by the model pre-trained with ImageNet dataset. For other newly added layers, we initialize the parameters by drawing weights from a zero-mean Gaussian distribution with standard deviation of 0.01. The learning rate is
for the first 30,000 iterations and then decayed to
for other 10,000 iterations. We use a weight decay of 0.0005 and a momentum of 0.9. We resize the input image so that it has an input size of
at the training stage and an input size of
at the testing stage as detection often requires fine-grained visual information [
19]. The hyper-parameters
,
, and
in
Section 2 are set to 1 in all experiments. We adopt stochastic gradient descent with a mini-batch of 10 images.
4. Results
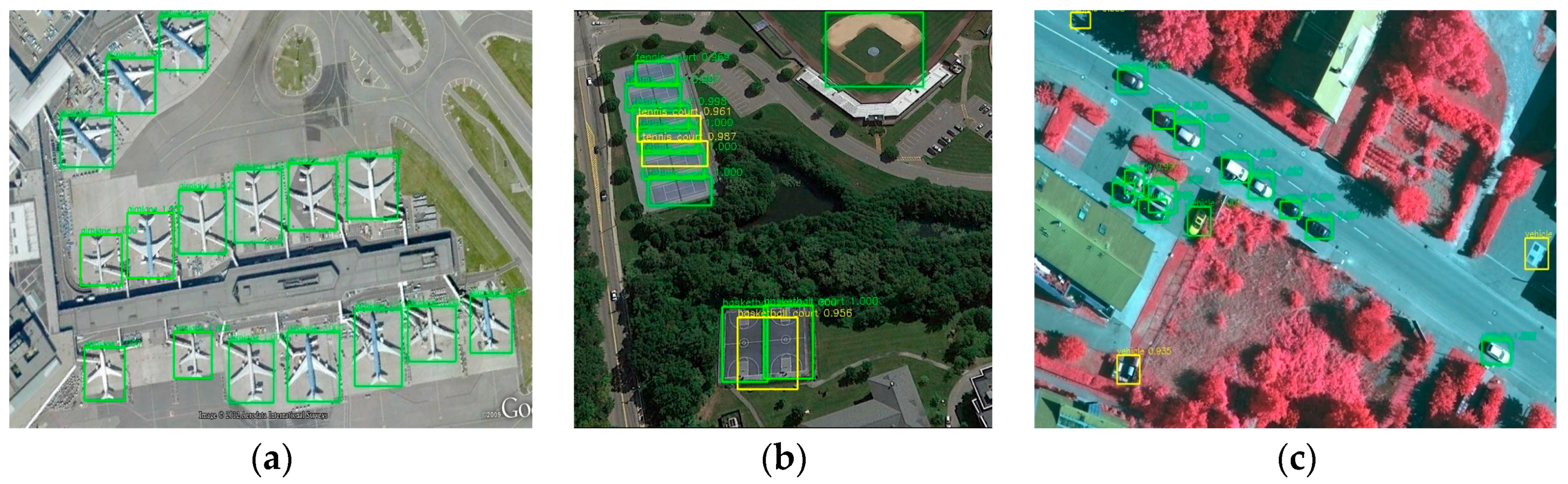
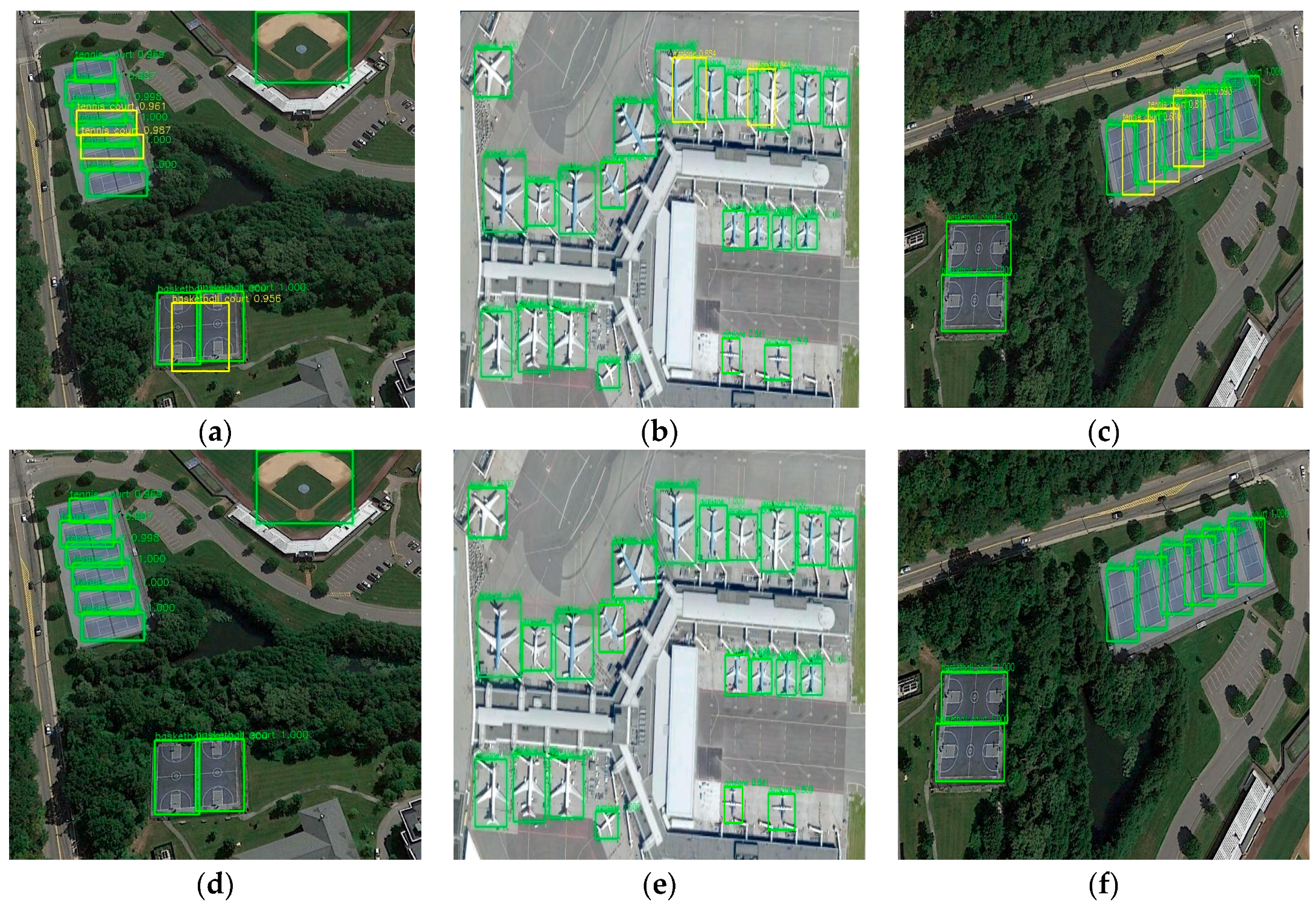
Figure 6 shows airplanes, tennis courts, basketball courts, baseball diamonds and vehicles detected by using our method, Faster R-CNN and SSD. The predicted bounding boxes that match the ground truth bounding boxes with IoU > 0.5 are plotted in green color, while the false alarms and missing targets are plotted in yellow and red color, respectively. Our method is better in the given scenes, since it successfully detects all the objects with a small number of false alarms, while Faster R-CNN detects most of the objects with a small number of false alarms and missing targets, and SSD with many false alarms and missing targets. The detection results for vehicles and tennis courts show that our method could generate better bounding boxes that cover most of the objects even when they are closely aligned and with a small size. The detection results for airplanes and vehicles show that our method could exclude most of the false bounding boxes and detects with a small number of false alarms. This is because our method could generate better bounding boxes that cover most of the objects by using multi-scale base network. Moreover, our method could suppress most of the false alarms by using positive samples selecting.
More results of our method on images from the VHR-10 test dataset are shown in
Figure 7. It can be seen that objects with extremely small scales could also be detected well, e.g., the storage tanks in
Figure 7b and the vehicles in
Figure 7f. Besides, the detection performance for other objects, like airplanes, ships and baseball diamonds are also very promising. However, when objects are small and closely aligned, there may be some false positives, as shown in
Figure 6b and
Figure 7b,g . This is because we add multi-scale anchor boxes to multi-scale feature maps to improve the accuracy of detection. Although our method could cover most objects, there exist a small number of repeated bounding boxes that cannot be suppressed by non-maximum suppression (NMS) operator. If we decrease the threshold of non-maximum suppression operator, more repeated bounding boxes will be restrained, but at the same time, some small objects will also be missed. To solve this problem, we replace the traditional NMS operator by a Soft NMS operator.
Figure 8 shows some detection results using our method with NMS and Soft NMS, respectively. It could be seen that these false alarms are suppressed.
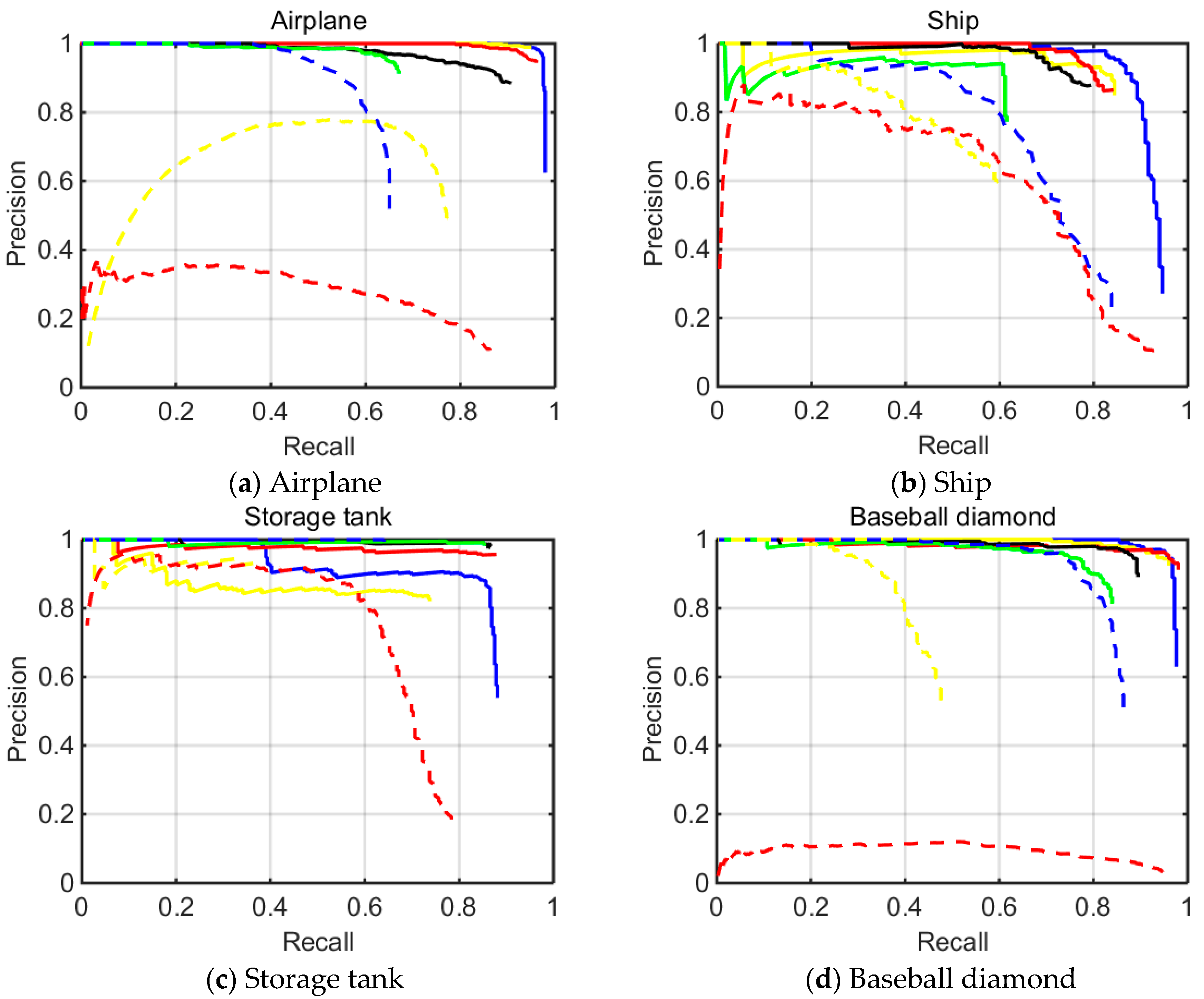
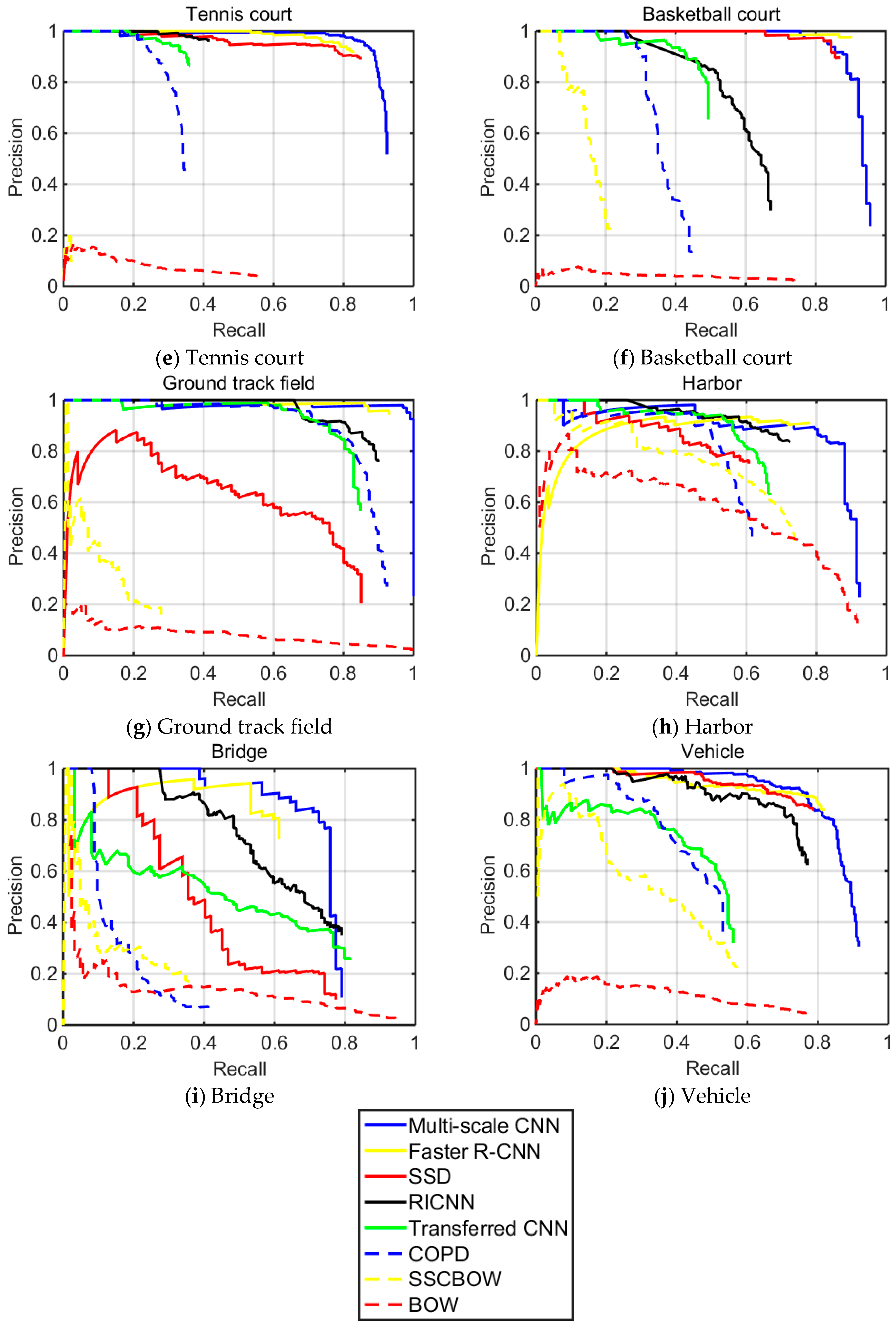
Quantitative comparisons of the eight different methods are shown in
Table 4 and
Table 5, and
Figure 9. The PRC over 10 testing classes are plotted in
Figure 9. The recall ratio evaluates the ability of detecting more targets, while the precision evaluates the quality of detecting correct objects rather than containing many false alarms. In this figure, we can see that our multi-scale CNN achieves the best recall for almost all classes except bridges. It shows that our multi-scale object proposal network could produce anchor boxes which cover most objects. In particular, the recall rates of small objects like storage tanks and vehicles increase more than other objects, which further illustrate the good performance of our methods for small objects detection. On the other hand, it can be seen that our method can usually achieve higher precision than other methods, in detecting airplanes, ships, storage tanks and so on. This is because we have made use of an object proposal score layer to execute positive samples selection, which means that our anchors boxes have a higher probability of predicting the correct bounding boxes. At the same time, it decreases the number of bounding boxes, so the recall rate on bridges decreased.
Table 3 lists the AP and mAP for each method. Based on these statistical data, we can see that the proposed multi-scale CNN obtains the best mAP value of 89.6% among all the object detection methods. In addition, it obtains the highest AP values for almost all classes except storage tanks. Compared with the second best method of Faster R-CNN, there is a 4.97% increase for airplanes, a 11.79% increase for ships, a 42.68% increase for ships, a 1.78% increase for baseball diamonds, a 10.87% increase for tennis courts, a 3.23% increase for basketball courts, a 6.17% increase for ground track fields, a 17.54% increase for harbors, a 25.04% increase for bridges, and a 10.41% increase for vehicles.
Table 4 presents the average testing time per image for each method. It is seen that the computation time needed in our method is a little bit more than SSD, but much less than Faster R-CNN.
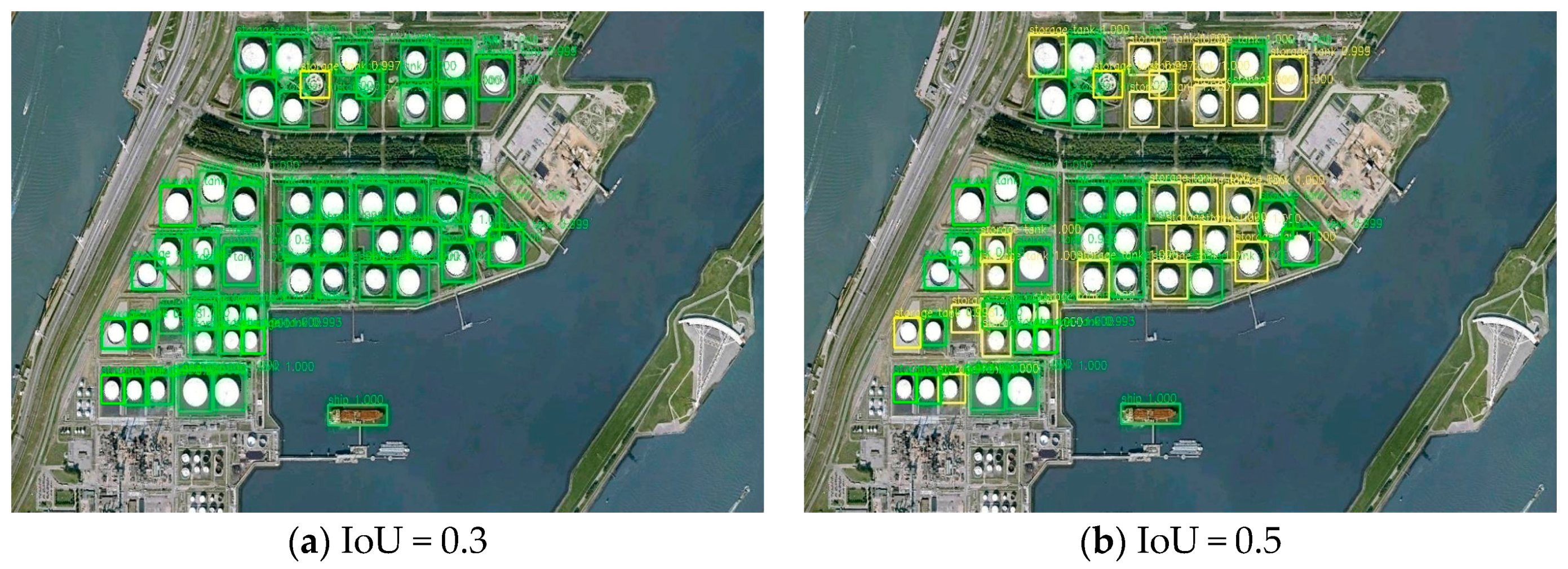
The bounding box quality is evaluated in
Table 6, which lists the AP and mAP for our method, Faster R-CNN and SSD under different IoU for all the test images. It can be easily seen from the table that the AP for each method drops when IoU increases. When IoU is equal to 0.3, we can see that our method obtains mAP value of 92.8%, and it obtains the highest AP values for all classes even for storage tanks.
Figure 10 shows the different detection results of storage tanks using our method when IoU is set as 0.3 and 0.5. We can see that our method obtained a lower AP of storage tanks because many bounding boxes with targets inside it are considered as false alarms. If with a small IoU, the AP increased greatly. For fair comparison, we set IoU as 0.5 in this paper, the same as the IoU values in the baseline methods. However, these baseline methods are not for multi-scale geospatial objects detection in HRS imagery. As it is very important to determine a suitable IoU before detection, we can set a lower IoU in real remote sensing applications.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}