1. Introduction
With continuous development of Synthetic Aperture Radar (SAR) technology, an increasing number of very high resolution (VHR) SAR images have been obtained, providing a new way to strengthen marine monitoring. Different from optical sensors, SAR is capable of working in all-day and all-weather conditions, and it is receiving more and more attention. However, it is very time-consuming to interpret SAR images manually because of speckle noise, false targets, etc. With increasing demand for ocean surveillance in shipping and military sectors, marine target classification and detection has been an important research area in remote sensing with great application prospects. In this work, we will focus on marine target classification on patch level and marine target detection in large-scale SAR images.
Earlier studies on marine target classification were carried out on simulated SAR images due to a lack of real image samples [
1]. In recent years, with the deployment of several spaceborne SAR satellites such as TerraSAR-X, RadarSat-2, and GF-3, a wide variety of SAR images with different resolutions and covering different regions in the world have been obtained. Up to now, researches on marine target classification in SAR images are mainly focused on large ships with distinctive features such as oil tankers, container ships, and cargo ships [
2,
3,
4,
5,
6]. The scattering characteristics of the three kinds of ships have been fully exploited by some initial works [
2,
6]. However, classification of other marine targets such as platform, windmills, and iron towers were not considered. Some studies went further to explore deeper features of different targets combined with classifiers such as sparse representation [
3,
5] and support vector machine (SVM) [
7]. The work in Reference [
5] employed histogram of oriented gradients (HOG) features and dictionary learning to performing classification with an accuracy of 97.5% for the three kinds of ships. While these feature-based classifiers can achieve high performance, the features have to be carefully designed especially when dealing with a wide variety of targets. There are also some works focused on combining the complementary benefits of traditional machine learning classifiers [
4,
8]. However, the classifier-combination strategy increases the computational complexity as it applies the classifiers one by one.
Different from the carefully designed feature-based methods mentioned above, the CNN based methods can extract the deep features of targets automatically, which have made great progress in object classification and recognition in recent years. Some CNN models such as Alexnet [
9], GoogleNet [
10] and ResNet [
11] are capable of working on ImageNet dataset including 1000 classes of images with high accuracy, showing great potential in object classification and recognition. Motivated by previous works in target classification, CNN models have been used in SAR target classification in some earlier studies [
12,
13,
14,
15,
16], most of which used the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset containing 10 classes of military ground targets. Chen et al proposed the ConvNets which consist of five convolutional layers and three pooling layers, without fully connected layers being used [
13]. Its classification accuracy among the ten classes reached 99.13%, which was a great contribution to target classification. Driven by the demand of ocean surveillance, an increasing number of works employed CNN for marine target classification and recognition [
17,
18,
19,
20]. The work in Reference [
19] proposed a simple CNN model with two convolutional layers, two pooling layers and two hidden layers and it was the initial work to perform object classification in oceanographic SAR images. Bentes et al. [
18] built a larger dataset consisting of not only ships, but also manmade platforms and harbors, after which a CNN model with four convolutional layers, four pooling layers, and a fully-connected layers was introduced. It adopts multi-looking images in different channels and achieves 94% accuracy among the five types of marine targets, which is far superior in performance to those of other CNN models and traditional machine learning methods. However, previous studies on marine target classification using CNN algorithms only focus on four or five types of marine targets, limiting their practical applications and the networks adopted over simple structures or inappropriate layer arrangements, failing to fully realize the CNN’s potentials in classifying marine targets in SAR images. To solve this problem, in this work we propose a novel CNN structure to classify eight types of marine targets in SAR images with higher accuracy than the existing methods.
As for the detection task, many algorithms including Constant False Alarm Rate (CFAR) based methods [
21,
22], feature based methods [
23] and CNN based methods [
24,
25] have been developed to detect marine targets in SAR images. Among them, the CFAR based methods are the most widely used ones due to their simplicity. Traditional CFAR based methods determine the detection threshold by estimating the statistical models of the sea clutters, including Rayleigh distribution [
26], Gamma distribution [
27] and K-distribution [
28], etc. Usually, the CFAR based methods are applied after sea-land segmentation to rule out false alarms on land, such as buildings and roads. However, the performance of CFAR based methods is not satisfactory under low-contrast conditions. In addition, they fail to give the labels of different targets because of its lack of classification layers. For feature-based methods, in Reference [
23], an effective and efficient feature extraction strategy based on Haar-like gradient information and a Radon transform is proposed, however, the features have to be designed carefully to achieve a good performance.
In recent years, the region-based CNN networks such as Faster-RCNN [
29], YOLO [
30], and SSD [
31], which can not only generate the coordinates, but also predict the labels of the targets, have shown a great success on the PASCAL VOC dataset [
32]. Faster-RCNN uses a deep convolutional network to extract features and then proposes candidates with different sizes by the Region Proposal Network (RPN) at the last feature map. The candidate regions are normalized through RoI Pooling layer before they are fed into fully connected layers for classification and coordinates regression. This algorithm can detect objects accurately but cannot realize real time detection. YOLO processes images at a faster speed but with lower accuracy than Faster-RCNN. An end-to-end model called SSD was proposed in Reference [
31], which can detect the target at real time with high accuracy. It generates region proposals on several feature maps of different scales while Faster-RCNN proposes region candidates with different sizes on the last feature map provided by the deep convolutional network.
The CNN based methods have been used for target detection in SAR images, e.g., ship detection [
24] and land target detection [
33], and has shown a better performance than the traditional methods. One method splits the images into small patches and then uses the pre-trained CNN model to classify the patches, after which the classification results are mapped onto the original images [
34]. However, this method has a low target location precision because it does not take the edges of target into consideration. Some other works apply the region-based CNN networks to detect ships in SAR images. The study in Reference [
25] adopts the structure of Faster-RCNN and fuses the deep semantic and shallow high-resolution features in both RPN and Region of Interest (RoI) layers, improving the detection performance for small-sized ships. Kang et al. used the Faster-RCNN to carry out the detection task and employed the CFAR method to pick up small targets [
35]. While the modifications to Faster-RCNN could help detect small ships, they introduce false alarms to the detection results. Furthermore, researchers in Reference [
36] applied SSD algorithms to ship detection in SAR images. Apart from comparing the performance of different SSD models, almost no changes are introduced to the SSD structure to improve the performance in terms of marine target detection. To sum up, the previous studies demonstrate that the CNN-based methods can detect the marine targets more accurately than the CFAR methods and feature-based methods. However, among all the detection methods introduced above, they only focus on ship detection in SAR images and are unable to detect other marine targets with classifying the targets at the same time. Moreover, the existing CNN-based methods generate some false alarms and miss the targets due to the complex sea background. To solve the existing problems, a multi-resolution SSD model is proposed to detect marine targets with classification in this work.
Overall, this paper builds a novel CNN structure to recognize eight types of marine targets at patch level and propose an end-to-end algorithm using a modified SSD to realize marine target detection with classification in large-scale SAR images. The main contributions of the work are as follows:
The Marine Target Classification Dataset (MTCD) including eight types of marine targets and the Marine Target Detection Dataset (MTDD) containing six kinds of targets are built on GF-3 SAR images, which provide a benchmark for future study. The features of various targets are analyzed based on their scattering characteristics to generate the ground truths.
A novel CNN structure with six convolutional layers and three max pooling layers is developed to classify different marine targets in SAR images, whose performance is superior to the existing methods.
A modified SSD with multi-resolution input is proposed to detect different targets. This is the first study for detection of different types of marine targets instead of only detecting ships in SAR images, to the best of our knowledge. Then, the framework for detecting marine objects in large-scale SAR images is introduced.
The remainder of this paper is organized as follows: In
Section 2, feature analysis for different targets and the proposed methods are introduced. Experimental results for target classification and detection in comparison with different existing methods are provided in
Section 3.
Section 4 discusses the results of the proposed methods. Finally,
Section 5 concludes this paper.
2. Methods
2.1. Preprocessing of GF-3 Images
The original GF-3 images used in this paper are large-scale single look complex (SLC) images containing many targets, which means it is impossible to use them directly. In this subsection, the preprocessing method is proposed to extract the targets patches automatically and efficiently.
Firstly, the SLC images are transformed into amplitude images using the following formula:
where
is the SLC image while
represents the amplitude image.
Then, a non-linear normalization is applied to the images using Equation (2)
where
is a constant,
is the value of the normalized image at
. The constant
works as a threshold and its value depends on the image. Usually we set
, where
represents the average value of the image.
As it is time-consuming to select the target patches manually, an image segmentation method is proposed here to extract the target patches in the large-scale SAR images. The Otsu method is an effective algorithm to image segmentation, which searches for a threshold that minimizes the intra-class variance [
37].
The proposed method uses the Otsu method to binarize the SAR images, after which the target candidates form the isolated points in the binary images because their pixel values are higher than the Otsu threshold, while the pixel values of sea clutter is lower than the threshold. Then, the algorithm searches for the isolated points and extract the coordinates. Finally, the fixed-size slices are collected according to the coordinates.
2.2. Feature Analysis
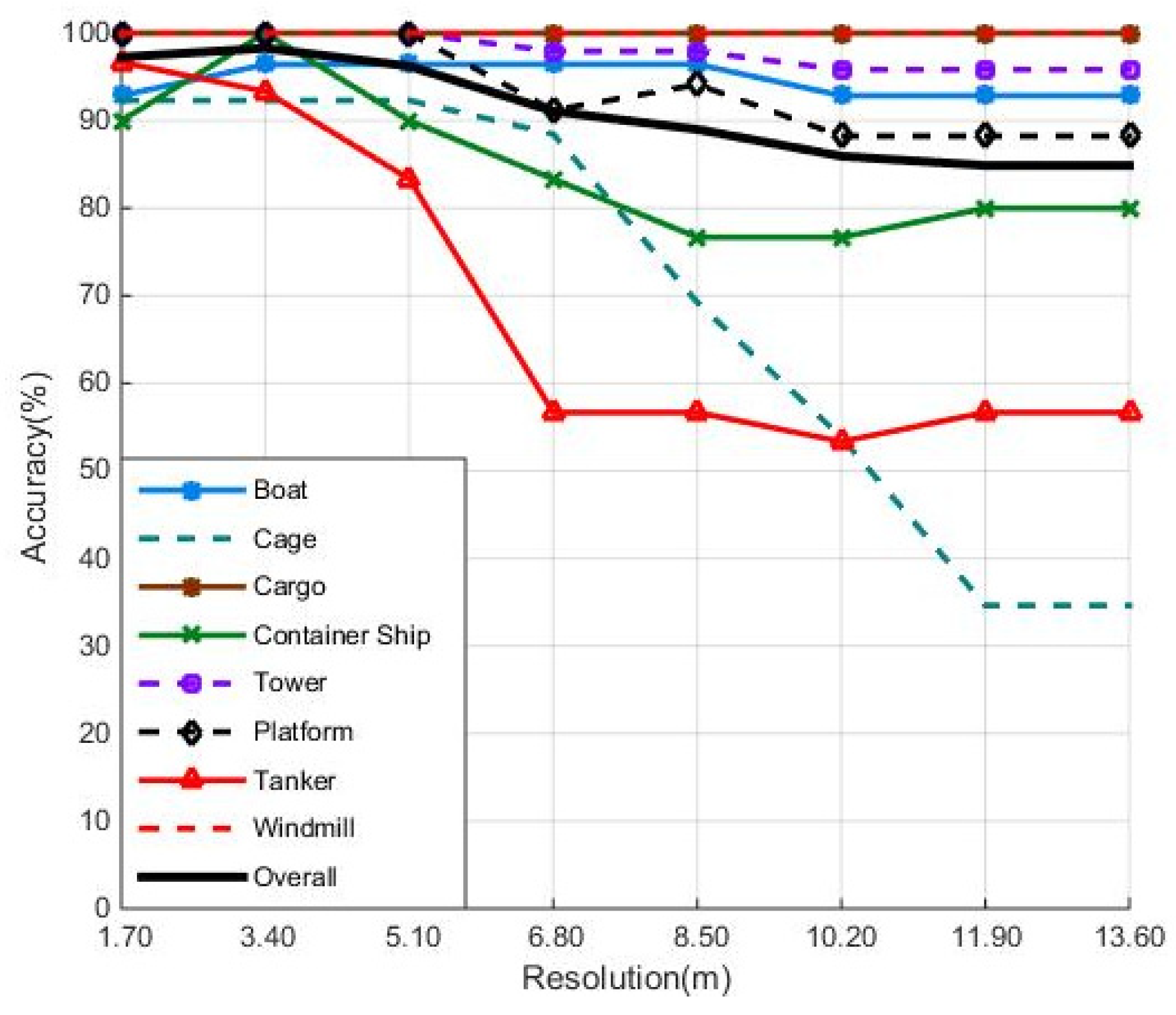
In this paper, eight types of maritime targets: Boat, cargo ship, container ship, tanker ship, cage, iron tower, platform, and windmill are selected and studied. Due to the lack of ground truths of the targets in SAR images, the scattering characteristics of each kind of targets are analyzed to get the label for each target.
Figure 1 presents the eight types of targets in both optical and SAR images. This is the first such explicit analysis on eight types of marine targets to the best of our knowledge.
Boat: Boats have the simplest and smallest structures among the eight targets. As for boats, the hull edges and the engines at the tail generate strong backscattering, which leads to a closed ellipse in SAR images.
Cargo: Due to the existence of several warehouses, there is a strong secondary reflection on the walls of each warehouse, which is where the rectangular shapes come from in the SAR images.
Container ship: Container ships possess the largest hull. When the ships are fully loaded with containers, the container exteriors would produce strong secondary reflections, resulting in the effect of a washboard in the radar images. In addition, the strong reflections at the tail of the ship come from the complex structure of the ship tower.
Oil tanker: In order to transport oil, an oil pipeline is installed in the middle of the tanker. This causes a bright line in the middle of the tanker in the SAR images. Besides, the closed ellipse in the SAR image comes from the hull edges of the ship.
Cage: Cages used in marine aquaculture are concentrated in square grids in offshore areas. The edges of cages can provide strong backscattering, which forms dotted rectangular distribution in the radar image.
Iron tower: When the incident angle is small, the complex structures lead to a strong scattering point. However, when the incident angle is large, the tower target appears as a cone-shaped structure in the radar image. In addition, the transmission lines on the tower produce relatively weak reflection, like a gloomy strip in the image.
Platform: Many offshore countries have built drilling platforms to exploit oil and gas. Usually, they contain support structures, pipelines, and additional combustion towers. The pipelines and combustion towers of the platform result in bright lines, while the support structures produce massive bright spots in SAR images.
Windmill: The strong scatterings of turbines in windmills result in a bright spot. In addition, as the fans rotate, they also produce a bright line that gradually fades toward both ends.
2.3. Marine Target Classification Model Based on CNN
While earlier studies have proposed some CNN models with different structures to classify marine targets, they are employed over simple structures or inappropriate layer arrangements when dealing with small datasets, making it hard to extract distinctive features for marine targets.
In order to solve existing problems, we proposed a CNN structure with six convolutional layers (Conv.1–Conv.6), three max-pooling layers (Pooling1–Pooling3) and two full connection layers, which is shown in
Figure 2. It can be seen that a pyramid structure is adopted, and as the CNN goes deeper, the outputs of each layer are down-sampled by pooling layers and the channel of the feature maps increases at the same time. This kind of structure can extract both low level and high level features.
As the length and width of the marine targets in this study is smaller than 100 pixels, the size of the input patches is set to 128 × 128 pixels to accommodate the objects. At the beginning, 32 convolutional kernels of size 6 × 6 work on the input images to extract features, after which the outputs are down sampled by max-pooling kernels with a size of 3 × 3. Then, the second convolutional layer filters the outputs of the first pooling layer with 128 kernels of size 5 × 5. After that, the convolutional layers are down sampled by the second pooling layer to shrink the feature maps. Then, the CNN network goes deeper with four convolutional layers employing 128 convolutional kernels of size 3 × 3, to generate high-level features, which are transmitted to the third max pooling layer. Finally, two fully-connected layers (FC1 with 1024 output neurons and FC2 with 8 output neurons) take the outputs of the third pooling layers as input and then output the vector to the softmax function to predict the labels of the targets. The strides of all the convolutional layers and all the pooling layers are set to one and two, respectively. Furthermore, the Rectified Linear Units (ReLU) are used for every convolutional layers and full-connected layers to prevent vanishing gradient or exploding gradient.
The training objective is to minimize the cross entropy loss function by forward propagation algorithm and error backpropagation algorithm, which can be written as follows:
where
m represents the total number to training examples and
and
refer to the true label and predicted label of the
th example, respectively.
is the trainable parameter and a regularization term
is added to the loss function to prevent overfitting, where
is the regularization factor.
2.4. A Modified SSD Network for Marine Target Detection
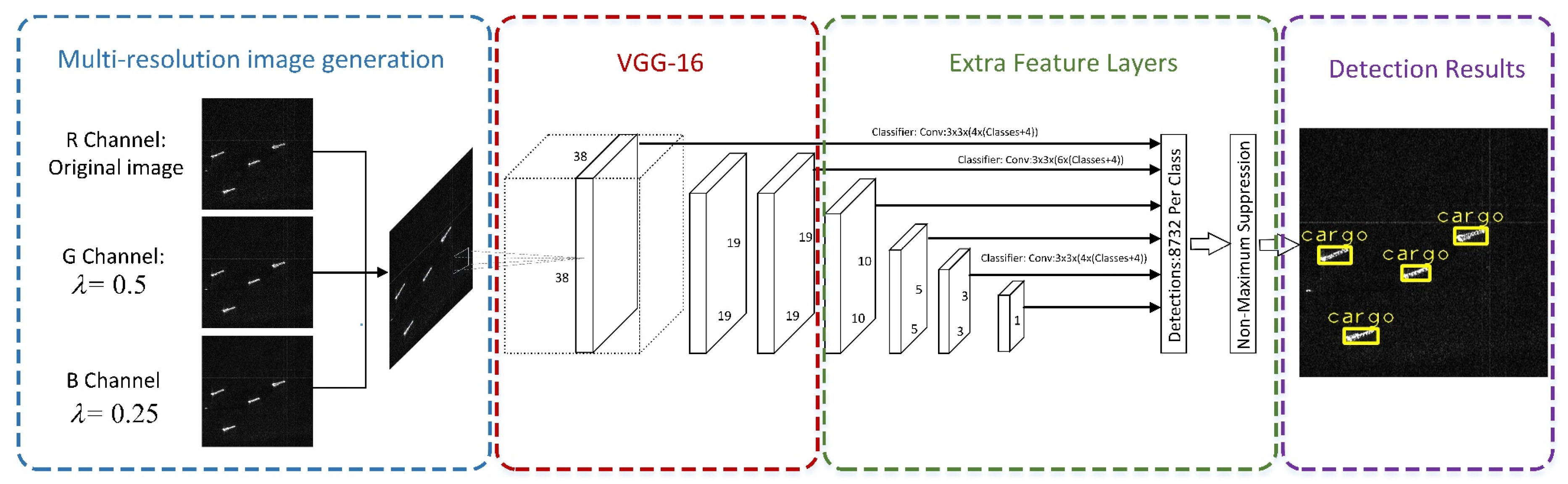
Figure 3 shows the proposed Multi-Resolution Single-Shot Multibox Detector (MR-SSD), which has three parts: The first part is multi-resolution image generation, the second part is a standard CNN architecture used for image classification, and the last part is the auxiliary structure containing multi-scale feature maps, convolutional predictors, and default boxes with different aspect ratios. The MR-SSD is capable of extracting features from different resolution images at the same time, which helps to increase the detection precision.
The input images of traditional SSD have three channels: R, G, and B channels, while the original SAR images only have one channel. Previous practices usually put the same image into the three channels, which causes redundancy in computation and ignore the effects of resolution versions. In this part, a multi-resolution input procedure is designed by adopting images with different resolutions in different channels to extract more features than the traditional SSD. The size of the input images of the MR-SSD is set to 300 × 300. As for the multi-resolution generation part, the images are transformed to the frequency domain using the 2-D Fourier Transformation, and then low-pass filter is used to lower the ground resolution while keeping the image size fixed, described as follows:
where
and
represent the
image’s bandwidth in azimuth direction and range direction, respectively. It can be seen that
is the factor determining the cutoff bandwidth of the filtered images, which is set to 0–1. After that the filtered images in the frequency domain are transformed to the time domain via inverse Fourier Transformation. Finally, the image ground resolution is reduced because of the linear relationship between ground resolution and SAR image bandwidth. For the proposed MR-SSD,
and
are set to 500. Filters with
and
are used to reduce the image resolution, and the images are transmitted to the G channel and B channel, respectively.
The second part of the MR-SSD is a standard CNN architecture, i.e., VGG-16 [
38], including five groups of convolutional layers combined with ReLU and pooling layers. Different from the VGG-16, the last two fully connected layers are replaced with two convolutional layers to extract features.
The extra feature layers allow the detection at multiple-scales. In this part, we adopt the corresponding parameters used in SSD [
31], which proves to be effective in object detection challenges. The extra features layers generate default boxes on each feature map cells with different aspect ratios and then many convolutional filters are used to filter the default boxes to get the class score and offsets. Suppose there are
feature maps in the MR-SSD, the scale of default boxes on different feature maps is defined as follows:
where
,
,
is the scale of
th feature map. The aspect ratios for default boxes are denoted as
. Then, the width (
) and height (
) can be calculated by:
As for , a default box with the scale of is added. As a result, 6 default boxes on each feature map cell are generated and the number of filters for a feature map is , in which is the number of class categories and 4 corresponds to the four offsets. After that, the total number of the default boxes per class is 8732, and non-maximum suppression (NMS) is used to improve the performance of MR-SSD.
When the MR-SSD is trained, it is necessary to determine whether the default box corresponds to a ground truth box or not. For every ground truth box, the default boxes with overlapping rate higher than a threshold (0.5) are selected to match the ground truth boxes. We minimize the loss function as SSD, which is written in Equation (7),
where
is the number of matched default boxes,
and
are the confidence loss and the localization loss, respectively. The confidence loss function employs softmax loss over multiple classes confidences, which is:
where
is an indicator for matching the
th default box to the
th ground truth box of category
. If the two boxes are matched, the indictor will be set to 1, otherwise it will be set to 0.
represents the confidence of the
th default box of category
. The localization loss uses the Smooth L1 loss between the proposed box (
) and the ground truth box (
) parameters, defined as:
The offsets for the center (
;
), width (
) and height (
h) of the default box (
) are regressed by the following formulas:
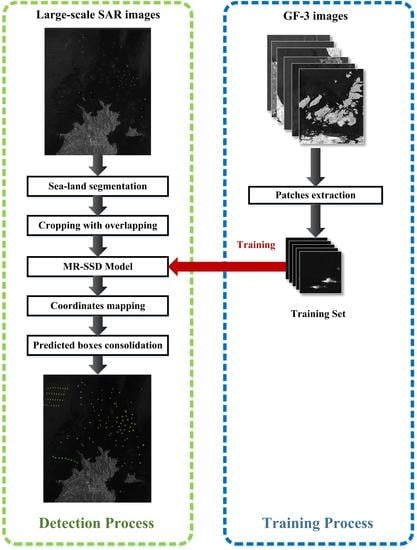
2.5. The Whole Workflow for Marine Target Detection in Large-scale SAR Images
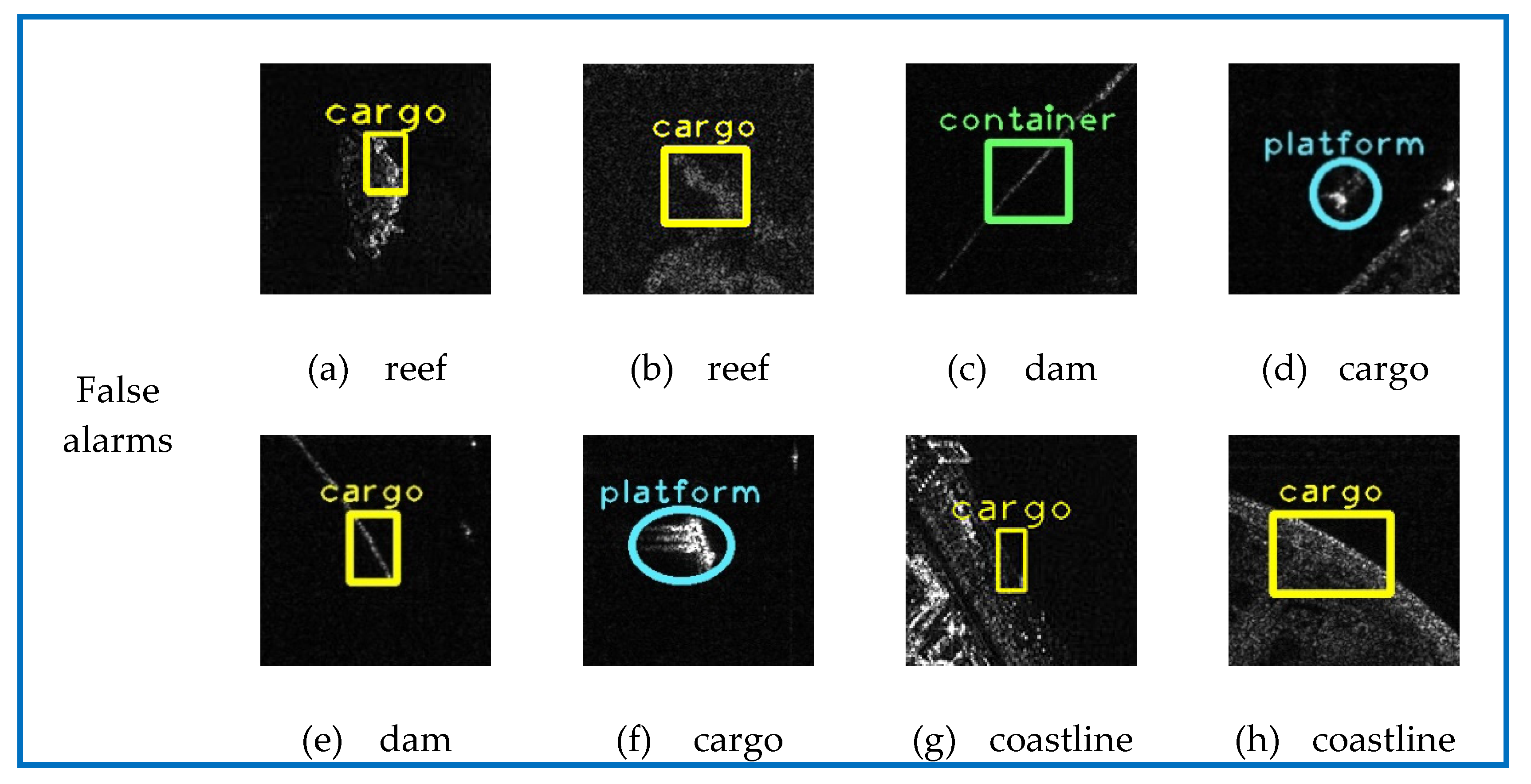
However, target detection in large-scale SAR images (larger than 10,000 × 10,000 pixels) is difficult because some images cover buildings and islands, which would lead to false alarms. Moreover, the CNN based methods can only detect targets at patch level due to the fixed input size. If the large-scale images are resized to a patch size for target detection, it will lose many detail features, making it hard to detect small targets. In order to solve the existing problems, this paper proposes a whole workflow consisting of sea-land segmentation, cropping with overlapping, detection with pre-trained MR-SSD, coordinates mapping and predicted boxes consolidation for marine target detection in large-scale SAR images. It is able to rule out the false alarms on lands, reduce overlapping predicted boxes, and generate accurate coordinates for each marine target.
Figure 4 illustrates the whole procedure in detail.
The whole workflow is divided into two processes: Training process and detection process. As for training process, the patches including marine targets are extracted from SAR images to build the training set and then train the MR-SSD model.
The other one is the detection process for large-scale SAR images. In order to reduce the false alarms on lands, the level-set method [
39] is used to remove land parts, which proves to be effective in image segmentation. Due to the high computation complexity of the level-set method, the images are down-sampled and then the level–set method is employed to generate the land masks, which will be resized to the original scale by interpolation later. After that, the land mask removes all the land objectives.
Usually, the large-scale images cannot feed the MR-SSD model directly because it resizes the large-scale images into 300 × 300, which means that a large number of small targets are hard to be detected. In order to solve this problem, the large-scale images are cropped into overlapping small patches and then the patches are sent to MR-SSD. The purpose of overlapping is to keep the target intact in at least one patch. Given a large-scale SAR image of size
, the total number of patches is
, which can be calculated as follows:
where
and
denotes the width and length of the patches, respectively. In addition,
is the overlap distance between the patches, which can be adjusted according to the image ground resolution.
Then, the patches have to be resized to 300 × 300 to meet the input requirements of MR-SSD. The pre-trained MR-SSD model extract deep features of the objectives to generate targets labels and coordinates for each patch later.
With the preliminary detection results, the coordinates on small patches are projected onto the large-scale images and the final detection results are obtained. For a patch whose index in width is
th and index in height is
th, the coordinate of its
th target can be written as
. The mapping relationship can be calculated as follows:
where
and
are the coordinates of the
th target in two directions in the large-scale SAR images.
However, cropping the SAR images would split the targets in two or more pieces, leading to fragmentary predicted boxes and the overlapping operation could cause overlapped predicted boxes, which can be seen in
Figure 5a. In order to solve the problems, we consolidate the overlapping and fragmentary predicted boxes by searching the box coordinates to find a coordinates group forming the largest box. As a result, the consolidated box is considered as the final predicted box shown in
Figure 5b.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}