1. Introduction
Due to its advantages of all-day, all-weather, and strong penetrating capability, synthetic aperture radar (SAR) has been widely used in military and civil fields. SAR is a kind of active microwave imaging radar, which can obtain two-dimensional (2-D) images with high resolution [
1,
2,
3,
4]. The automatic target recognition (ATR) is for SAR images to extract stable and iconic features based on SAR images, and determine its category attribute and confirm its particular copies of the same class, which can be applied to battlefield monitoring, guidance attack, attack effect assessment, marine resource detection, environmental geomorphology detection, and natural disaster assessment, and has vital research significance. ATR also plays an important role in the electronic warfare (EW) and electronic intelligence (ELINT) systems [
5,
6]. The initial artificial interpretation for SAR images is inefficient and overly dependent on subjective factors. Therefore, in recent years, ATR for SAR images has attracted significant attention from many experts, which is one of the most popular topics in current research [
7,
8,
9].
The generalized ATR for SAR images can be divided into three levels: SAR target discrimination, SAR target classification, and SAR target recognition. SAR target discrimination can only distinguish the difference between SAR targets. SAR target classification predicts the class of a target in the SAR image on the basis of SAR target discrimination. SAR target recognition confirms the specific copies of the same class of targets in SAR images based on target discrimination and target classification. Generally, when we say the target recognition is a narrow sense of target recognition, it only means the highest level of target recognition. This paper mainly identifies target recognition. It mainly includes three steps: target detection, discrimination, and recognition [
8]. Target detection extracts the target region of interest from a SAR image using image segmentation technique to eliminate background clutter and speckle noise, enhance the target region, and weaken the influence of the background on recognition. The process of target discrimination is mainly the process of feature extraction, which extracts and integrates effective information in the SAR image and transforms the image data into feature vectors. Good features have good intra-class aggregation and inter-class difference in the classification space. Pei et al. [
10] extracted SAR image features using 2-D principle component analysis-based 2-D neighborhood virtual points discriminant embedding for SAR ATR. However, when new samples come in, features and models need to be relearned. This method’s universality is low and it is time consuming. To overcome this problem, Dang et al. [
11] used the incremental non-negative matrix decomposition method to study the features online to improve the computational efficiency and the universality of the model. After feature extraction, different classifiers can be designed to classify targets for SAR images. There are three mainstream paradigms of ATR for SAR images: template matching, model-based methods, and machine learning. Template matching is the most common and typical one, which stores the physical features, structural feature, etc., extracted from the training samples in the template data set, and matches the target features of all samples in the template library until matching rules are met to determine the information of the target to be tested [
8,
12]. However, this method requires a large amount of computation and prior information. The extracted features need to be manually designed, and it is difficult to fully explore the mutual relations among the massive amount of data. The basic idea behind the model-based classification method is to replace the target feature templates stored in the target data set with solid model or scattering center model, which could construct a feature template in real time for recognition according to the specific conditions such as target posture. Verly et al. [
13] achieved recognition results by extracting the length, area, location, and other features in control and matching them with the model library. However, this method needs to build the attribute diagram of target size, shape, etc., which is difficult to implement, and only applicable to specific scenarios.
With the rapid development of computer hardware devices, machine learning is widely used in optical image processing [
14], speech recognition [
15], speech separation [
16], etc. In recent years, ATR methods for SAR images based on machine learning have been widely used and achieved very good results. Verly et al. and Zhao et al. classified and recognized the ground vehicles, whose data was from the moving and stationary target acquisition and recognition (MSTAR) [
17], by using AdaBoost and a support vector machine based on a maximized classification boundary [
13,
18]. However, these methods require hand-designed features and empirical information, is heavily dependent on subjective factors, and had low universality. Wang et al. utilized the wavelet scattering network to extract wavelet scattering coefficients as features [
19]. Although the convolutional network was utilized, it also belongs to the traditional methods which contain three steps: feature extraction by hands, dimension reduction, and classification using different classifier. He et al. [
20] utilized convolutional neural network (CNN) to classify SAR images, with a final recognition rate of 99.47%, but only seven categories of targets in the MSTAR data set were classified. With the increase of layers, more and more parameters need to be trained for CNN. Meanwhile, overfitting is occurred easily, which leads to the network’s inability to converge or to converge to the global optimum. To reduce the number of the network parameters, Chen et al. [
21] proposed a SAR image target recognition method based on A-ConvNets, which removed all the fully connected layers and only contained sparse connection layers. A
softmax activation function was utilized at the end of the network to achieve the final classification. This method was verified using MSTAR data set, and the recognition rate got 99%, which was higher than the traditional method. However, the recognition rate of this method for SAR images after segmentation is only 95.04%. Schumacher et al. [
22,
23] pointed out that the radar echo of each type of target in MSTAR data set can only be recorded under a specific background, that is, there is a one-to-one relationship between the target and the background, and the background can also be used as a feature of the target for classification and recognition. Based on this, Zhou et al. [
24] used the traditional CNN to classify the SAR image background in MSTAR, and obtained the recognition rate of 30–40%, which proved that SAR image background can improve the recognition rate. At the same time, Zhou et al. proposed a large-margin
softmax (LM-
softmax) batch-normalization CNN (LM-BN-CNN) method, which had a better recognition rates under both standard operating condition (SOC) and extended operating conditions (EOCs).
However, if the SAR image quality is not good and the resolution is low, it will greatly affect the correct recognition rate of SAR targets. The above methods are all based on the original SAR images, and the image quality is not improved and enhanced. In recent years, some researchers have done a lot of studies on image super-resolution reconstruction [
25,
26]. Image super-resolution reconstruction techniques overcome the disadvantages of imaging equipment’s inherent resolution, breaks the limitation of imaging environment, and can obtain high-quality images, which is higher than the physical resolution of the existing imaging system, at the lowest cost. The existing super-resolution reconstruction technique of a single frame image is mainly divided into three types: an interpolation-based method, reconstruction-based method, and learning-based method. With the help of machine learning techniques, the high frequency information loss of the low-resolution SAR image is estimated by learning the mapping relationship between low-resolution and high-resolution SAR images in order to obtain the detailed information on the clear target, such as edge, contour, texture, etc. Thus, the image features characterization ability is enhanced, and the SAR image correct classification coefficient is improved in this paper. Liu et al. [
27] adopted a joint-learning-based strategy, combined with the characteristics of SAR image, to reconstruct a high-resolution SAR image from low-resolution SAR image to achieve the global minimum of the super-resolution error and reduce speckle noise. Li et al. [
28] utilized a Markov random field and Shearlet transformation to recover a super-resolution SAR image. The result of this method is better than the traditional method, but the detailed texture information of the reconstructed image is still different from the original image in visual effect. The super-resolution reconstruction method based on deep learning uses multi-layer neural network to directly establish the end-to-end nonlinear mapping relationship between low-resolution and high-resolution images. Dong et al. [
29] proposed a nonlinear regression super-resolution reconstruction method using CNN, but this method has fewer layers and a smaller receptive field. To overcome this problem, Kim et al. [
30] achieved better results based on recursive neural network super-resolution technology by adding the number of convolutional layers and reducing the number of network parameters. In recent years, the generative adversarial network (GAN) has been developing rapidly with its unique advantages. It uses the game confrontation process of a generator and a discriminator to realize new image formation [
31,
32]. The MSTAR data set was utilized as training set to generate more realistic SAR images by GAN to expand the SAR image data set. Leding et al. [
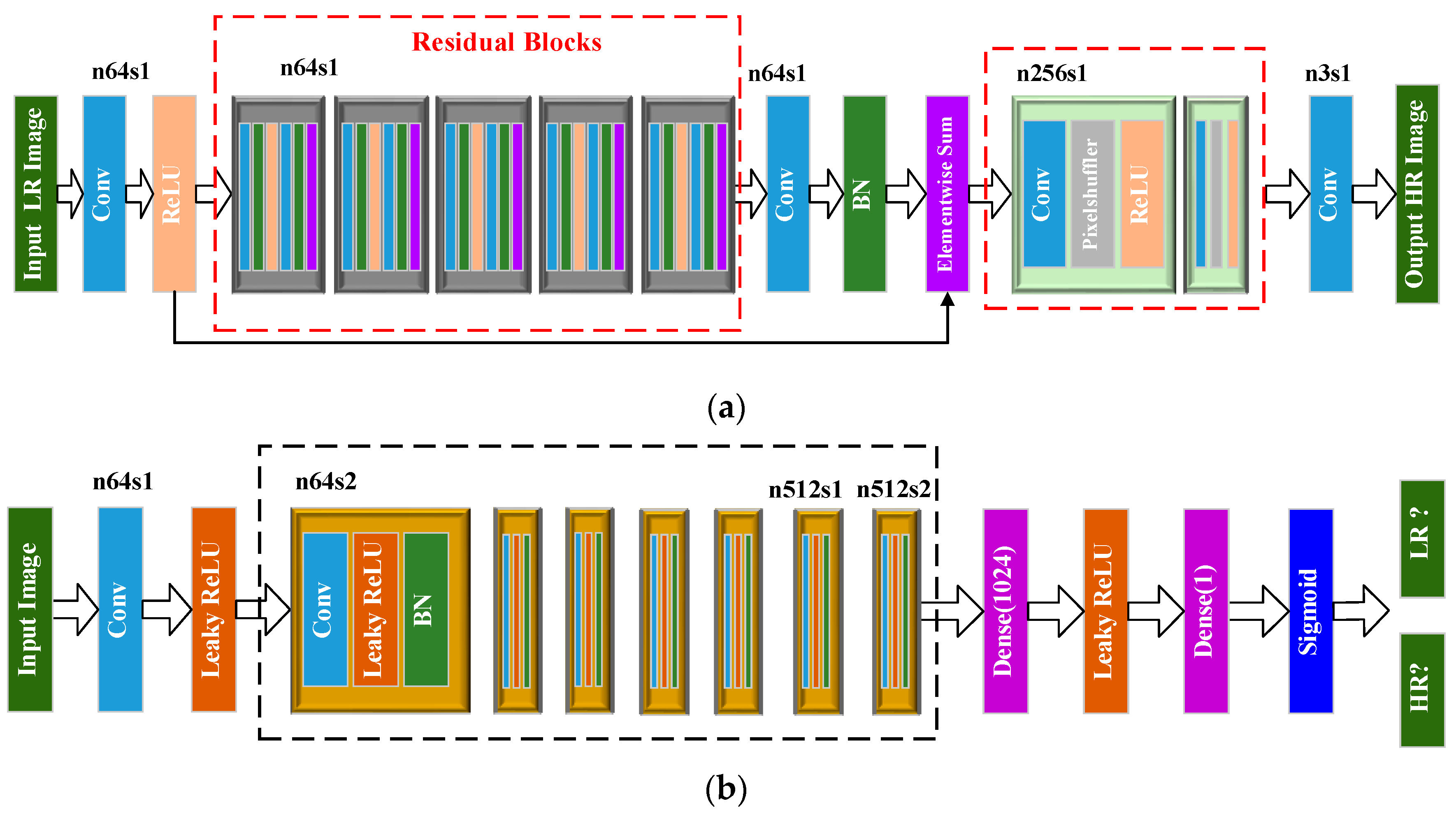
33] improved GAN to obtain super-resolution GAN (SRGAN) by replacing the loss function based on mean square error (MSE) with the the loss function of the feature map of visual geometry group (VGG) network. Under the condition of high magnification, the reconstruction of optical image from low-resolution to high-resolution was realized, and better visual effects were obtained.
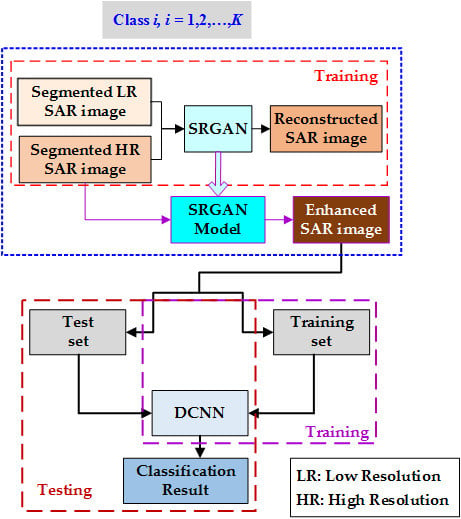
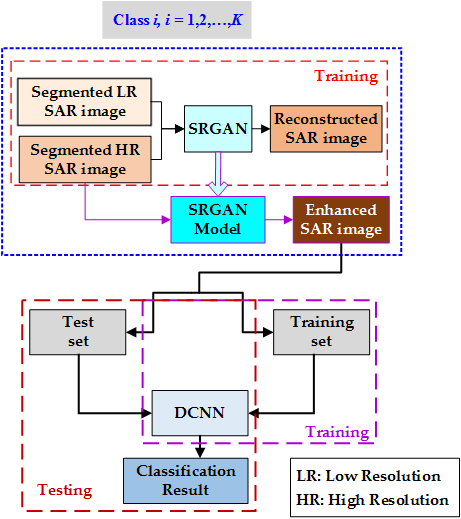
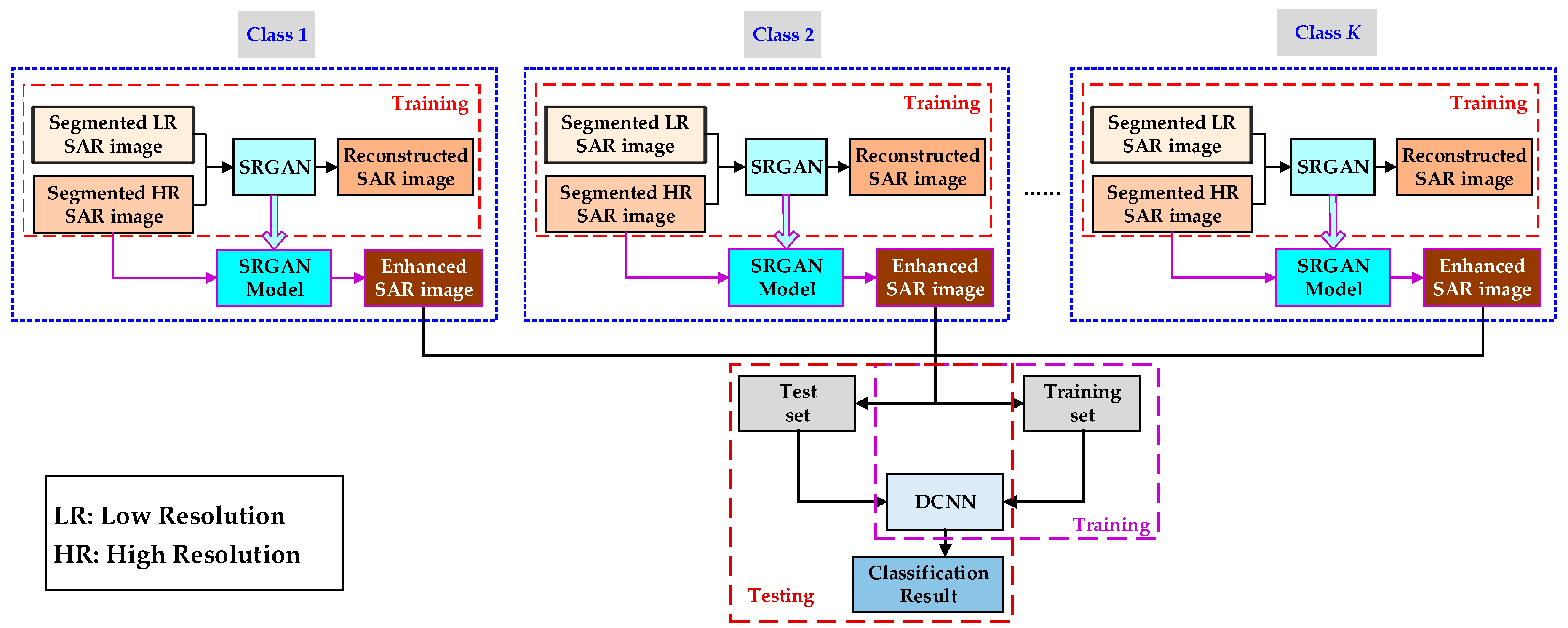
In this paper, a ATR for SAR image based on SRGAN and DCNN is proposed. First, a SAR image preprocessing method based on threshold segmentation is utilized to eliminate the influence of image background on target classification and recognition and extract effective target areas. Second, the SRGAN model is obtained through training to enhance the low-resolution SAR image, improve the visual resolution of the target areas of interest in the SAR image, and improve the feature characterization ability. Finally, DCNN with good generalization is adopted to learn the SAR target’s amplitude, contour, texture, and space information, and achieve the SAR images target classification and recognition.
The remainder of this paper is organized as follows.
Section 2 describes the SAR image preprocessing method based on threshold segmentation and extracts the interested target regions. The architectures of SRGAN’s generator and discriminator and the composition of loss function are introduced in
Section 3. The expression ability of the target features is improved through SRGAN. In
Section 4, the basic modules of DCNN are introduced in detail, which is utilized for feature extraction and classification of targets.
Section 5 provides detailed experimental results in various scenarios.
Section 6 analyzes the computational complexity of the proposed method.
Section 7 gives the conclusion.
2. SAR Image Pre-Processing
Since the target only occupies part of the SAR image, if the whole SAR image is classified as a sample, the background characteristics as a feature that matches the target will affect the recognition result, thus reducing the generalization performance of the ATR algorithm. If the image background noise is too strong, the recognition accuracy will be decreased. Therefore, it is necessary to use the image segmentation technique to pre-process the SAR images and extract target areas of interest in SAR images to improve the recognition accuracy and generalization performance.
The gray histogram of the image represents the statistical distribution of the gray values of image pixels. It arranges the gray values of image pixels in a descending or ascending order and counts the number of occurrences of each gray value. Generally speaking, the grayscale distribution of a SAR image is not uniform, and the image brightness of the same target is changeable under different scenes. If the same threshold value is used for segmentation of all the images, background speckle noise may be left in some images with a small threshold value, or the targets may be excessively segmented, the effective edge information of the targets cannot be retained, and the detailed features of the target may be lost with large threshold value. Therefore, it is necessary to carry out histogram equalization on the SAR image to make the grayscale distribute uniformly, expand the dynamic range of the pixel values, adjust the image contrast, and then select a uniform threshold for image segmentation.
2.1. Histogram Equalization of SAR Image
The purpose of histogram equalization is to find a mapping relation between the original image and the image after histogram equalization, thus achieving the uniform distribution of the grayscale of the transformed image [
34]. Set
be the grayscale of the original SAR image and
is the grayscale of the image after histogram equalization. The transformation function from
to
can be expressed using:
where
is the transformation function. To facilitate discussion, set
,
needs to satisfy the following conditions:
- (i)
When , ;
- (ii)
When , is a monotonically increasing function.
Then, the transformation function from
to
can be written as:
where
is the inverse transformation operator.
In order to satisfy the above conditions (i) and (ii), suppose that
is the probability distribution function of
:
The probability density of the transformed grayscale
can be obtained according to the probability density of the random variable function:
It can be seen that the gray value of SAR image after transformation is evenly distributed.
For the discrete function, the accumulative distribution operator of each grayscale of histogram can be regarded as the transformation function, and the gray value of the transformed image can be written as:
where
,
is the number of the image elements,
is the number of elements of the grayscale
, and
is the probability of the
grayscale.
Then, the gray value of the transformed SAR image is transformed into the range of [0, 255] according to:
It can be seen that the grayscale distribution of SAR image after histogram equalization is close to uniform distribution, and the image contrast is adjusted, which lays a foundation for the following uniform threshold selection in image segmentation.
2.2. Threshold Segmentation
SAR images are normalized after the histogram equalization, and the target regions of interest in SAR images are extracted by selecting uniform thresholds. Suppose that is the SAR image after equilibrium normalization, is any pixel of the image , and is the SAR binary mask image after threshold segmentation. If , then and this pixel is regarded as the background; if , then and this pixel is recognized as the target. is the uniform threshold.
2.3. Morphological Filtering
To reduce the speckle noise and unsmoothness of the target edge in the SAR binary mask image, some filtering operations are needed to smooth and suppress speckle noise. Morphological filtering is utilized here. Set
be the structural element, corrosion and expansion can be defined respectively as [
35]:
where
is the image region corresponding to the structural element
. If the size of
is
, then
,
. Open and closed operations can be defined respectively as:
Open operations can remove isolated points and burrs. Closed operations can fill the small holes in the body, close the small cracks, connect the adjacent objects, and smooth the boundary.
Figure 1 is the flow chart of the SAR image preprocessing using the threshold segmentation method. First, histogram equalization and normalization are adopted to the original SAR image to make the image grayscale distribution close to the uniform distribution. Then use the median filtering to smooth the normalized image. Second, select an appropriate threshold to make the SAR image binary and segment the SAR image background and the target of interest. Third, in order to solve the problem of speckle noise and burrs on the edge of the target in binary images, the closed operation of morphological filtering is utilized to obtain the SAR binary mask image. Finally, the original SAR image is multiplied by the SAR binary mask image to obtain the segmented SAR image.
5. Experiments and Results
This paper utilizes the open data set, MSTAR, for the verification of the effectiveness of the proposed algorithm. The MSTAR data set was gathered in 1995 and 1996 separately by Sandia X-band (9.6 GHz) HH-polarization spotlight SAR and contains ten categories of ground military vehicles. The pitching angles were 15°, 17°, 30°, and 45°. The azimuth angles ranged from 0° to 360°. The original SAR image resolution was 0.3 m × 0.3 m and the image size was 128 × 128. These ten categories of ground military targets include BTR-70, BTR-60, BMP-2, T-72, T-62, 2S1, BRDM-2, D-7, ZIL-131, and ZSU-234.
Figure 6 shows the optical images and the corresponding SAR images of the ten categories of targets. It can be seen that the resolution of SAR images is low, the targets’ edge information is not clear, and it is not easy to extract the detailed information of the images.
Experiments were conducted under SOC and EOCs [
39]. SOC means that the targets of the training set and the test set have the same serial number and target configuration, but they have different azimuth and pitch angles. The differences between the training set and the test set under EOCs were large, and different controlling variables could be set such as pitch angle, configuration variant, and version variant.
5.1. SAR Image Threshold Segmentation Based on Histogram Equilibrium Normalization
Each type of target in the MSTAR data set is collected in a specific environment, and it is pointed out that these background clutter alone has an recognition accuracy of about 30% to 40% [
24]. In view of this situation, the image background improves the recognition accuracy of the target to some extent. However, in the actual situation, the background of the target will vary with the specific environment. Therefore, in order to reduce the interference of the clutter of the target background on the classification results, the image needs to be segmented.
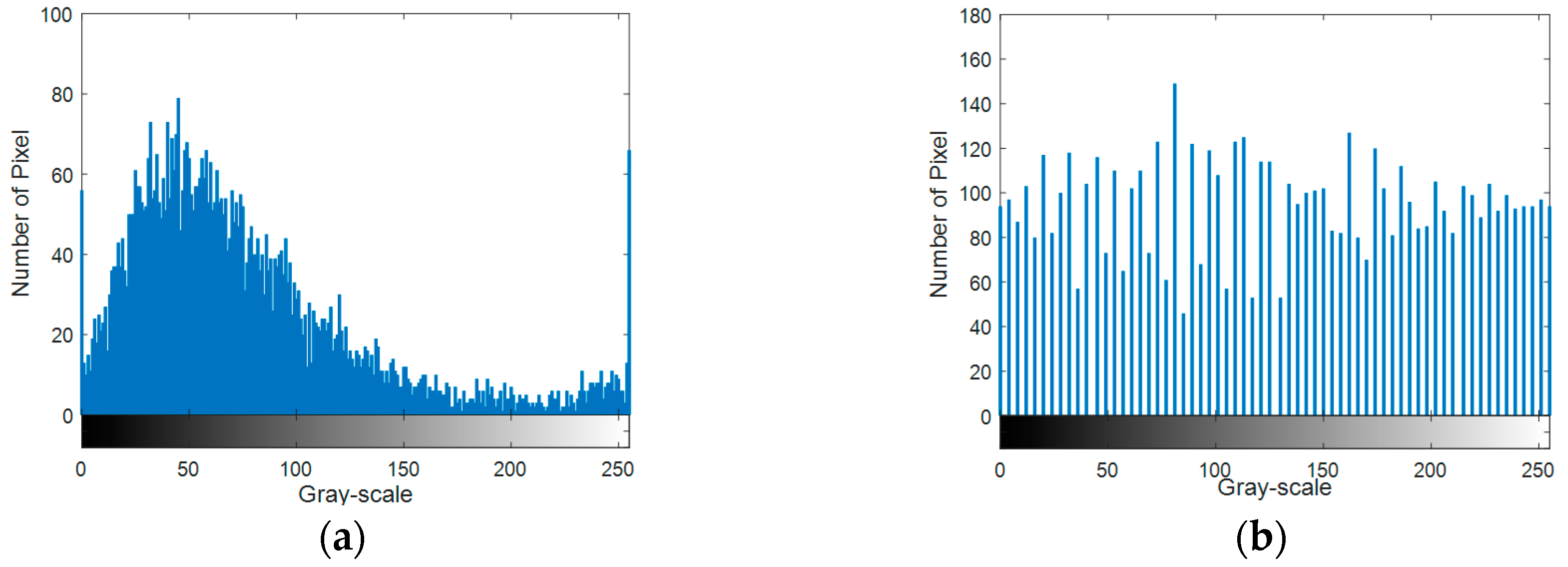
In order to facilitate the determination of the uniform segmentation threshold, first, the histogram equalization for the original SAR image was done, and then the before and after histogram results were compared, as shown in
Figure 7.
Figure 7a is the grayscale histogram distribution of the SAR image before equalization, and
Figure 7b is the grayscale histogram distribution of the SAR image after equalization. From
Figure 7, the grayscale distribution of the original SAR image was not uniform, where most of the pixels were concentrated in the range of 0 to 150, and the grayscale distribution of the SAR image after the histogram equalization was relatively even, facilitating the subsequent fixed threshold segmentation.
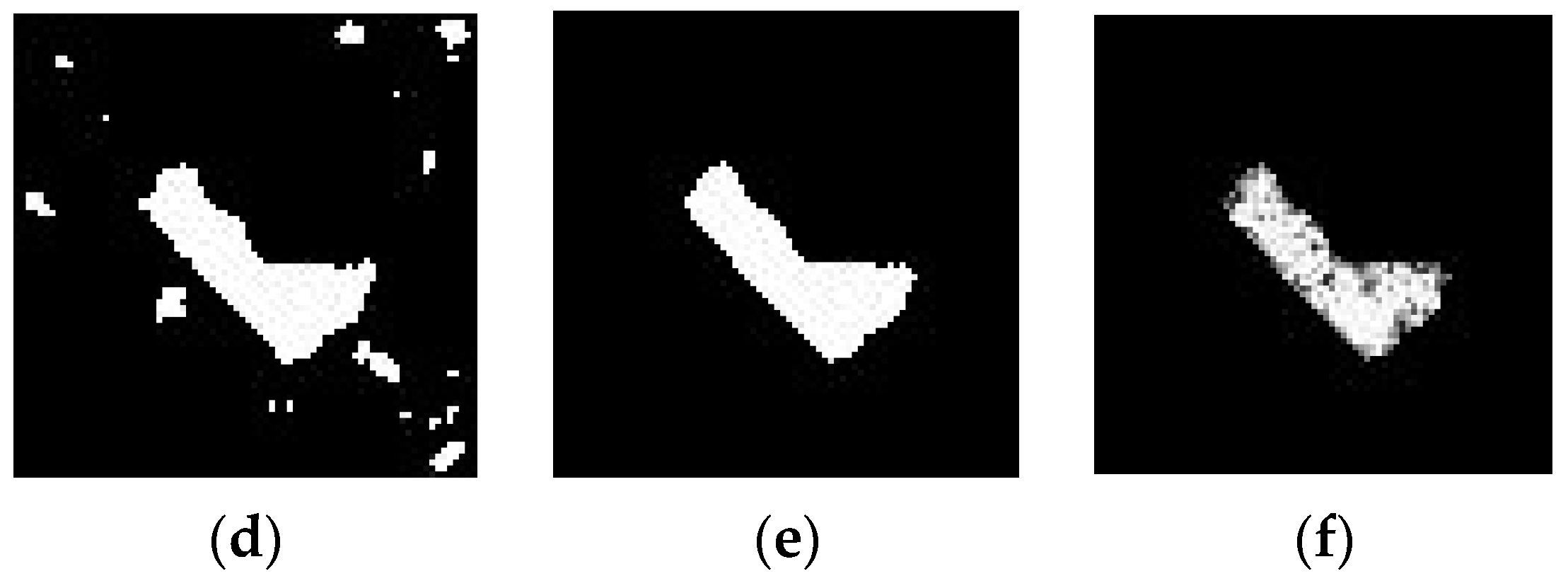
Taking 2S1 for example,
Figure 8 gives the process of the SAR image threshold segmentation.
Figure 8a is the original SAR image before the histogram equalization;
Figure 8b is the SAR image after equilibrium normalization, where it had a more even grayscale distribution;
Figure 8c is the SAR image after median filtering, where the gray value was smoothed;
Figure 8d is the SAR image after threshold segmentation, where it can be seen that there is a lot of speckle noise in the image;
Figure 8e is the SAR image after morphological filtering, where the background speckle noise was well suppressed; and
Figure 8f is the SAR image after segmentation, where the details and edge information of the target were well preserved.
5.2. SAR Image Enhancement Based on SRGAN
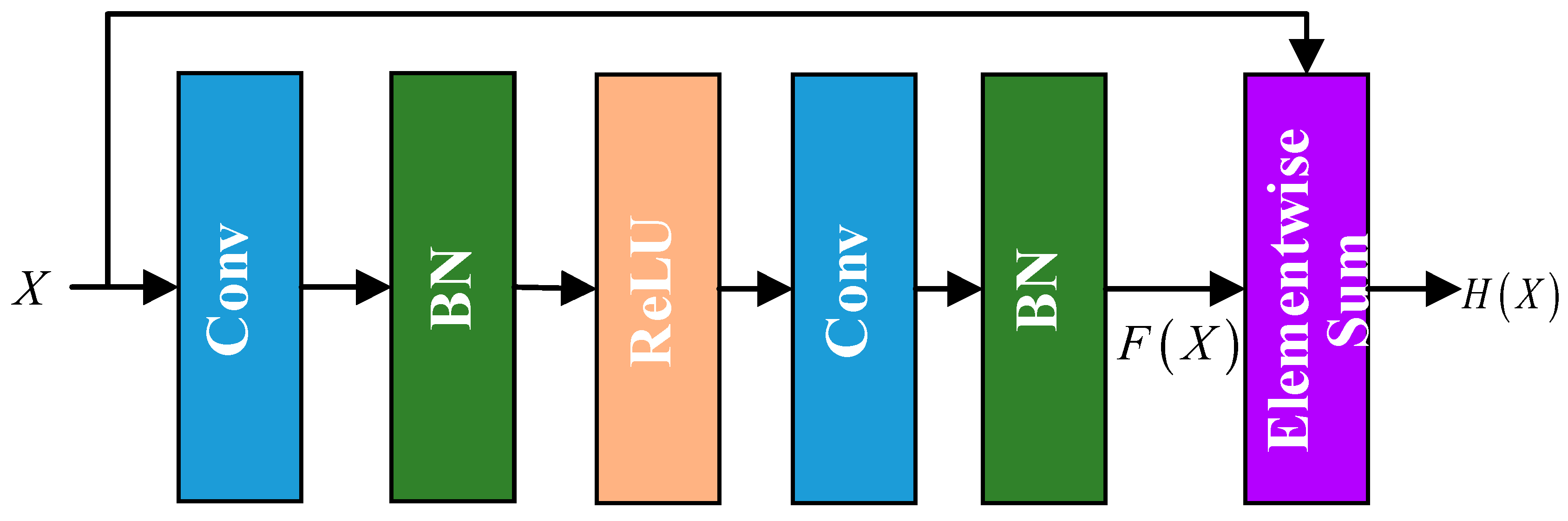
In view of the high acquisition cost of high-resolution SAR images and the inconspicuous target edge features of low-resolution SAR images, an SRGAN-based SAR image enhancement method is proposed in this paper to improve the SAR image feature characterization ability, and then the enhanced SAR image was sent to the classifier to improve the accuracy of target classification. The generator of SRGAN adds the upper sampling layer at the end to keep the image size consistent with the original image.
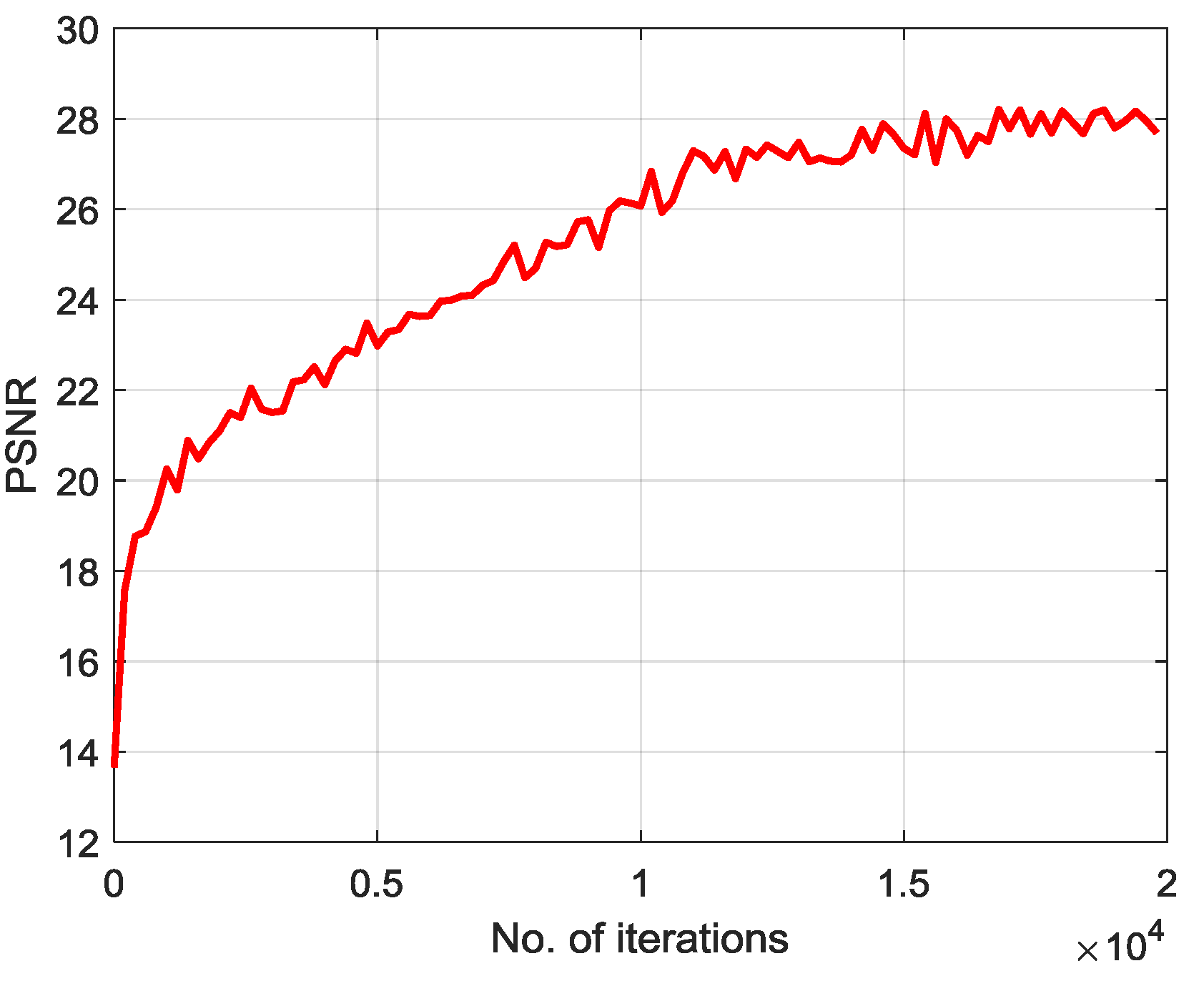
Generally, we use peak signal to noise ratio (PSNR) to measure the quality of reconstructed images.
Figure 9 gives the variation curve of PSNR with number of training epoch during SAR image reconstruction based on SRGAN. From
Figure 9, in the process of network training, the PSNR of the low-resolution SAR image was improved with the training epoch, and the image visual resolution is improved.
Figure 10 expresses the SAR image enhancement through SRGAN.
Figure 10a shows the SAR image after segmentation, where its size was 78 × 78;
Figure 10b is the low-resolution SAR image with quadruplet sampling, where the size became 19 × 19 and the image looks very blurred with a lot of information being lost;
Figure 10c gives the reconstructed SAR image after SRGAN convergence, where the size was restored to 78 × 78. Compared with
Figure 10a, it was very close to the original segmented image in visual sense and visual perception. It proved that SRGAN has learned the features of the original segmented image in the training process. Sending the original segmented SAR image (
Figure 10a) into the trained SRGAN again, the enhanced SAR image was obtained, as shown in
Figure 10d, where the size became 312 × 312. From
Figure 10d, the texture information of the target surface was expressed in detail, the edge features are more obvious, and the visual resolution of the image was improved, which provides strong support for the classification and recognition of the target.
5.3. Experiments and Results under SOC
To verify the effectiveness and robustness of the proposed method, we conducted experiments in two different conditions, SOC and EOCs.
Table 1 is the description of the training set and test set under SOC. The training set contains 10 classes of targets, the pitch angles of targets in the training set were all 17°, the pitch angles of targets in the test set are all 15°. The sample numbers of each class in the training set and test set are shown in
Table 1. The training set is sent into the DCNN to be trained to obtain the stable network parameters. After that, the test set is sent into the trained DCNN to obtain the final classification results.
Figure 11 is the visualization result of the first 16 feature maps of five convolutional layers after sending the enhanced SAR image of 2S1 into DCNN.
Figure 11a shows the feature map of the 1st convolutional layer,
Figure 11b gives the feature map of the 3rd convolutional layer,
Figure 11c is the feature map of the 5th convolutional layer,
Figure 11d shows the feature map of the 8th convolutional layer, and
Figure 11e gives the feature map of the 11th convolutional layer. From
Figure 11, with the deepening of the layers, the SAR image feature characterization ability got stronger and stronger, proving that our network has learned the SAR image features.
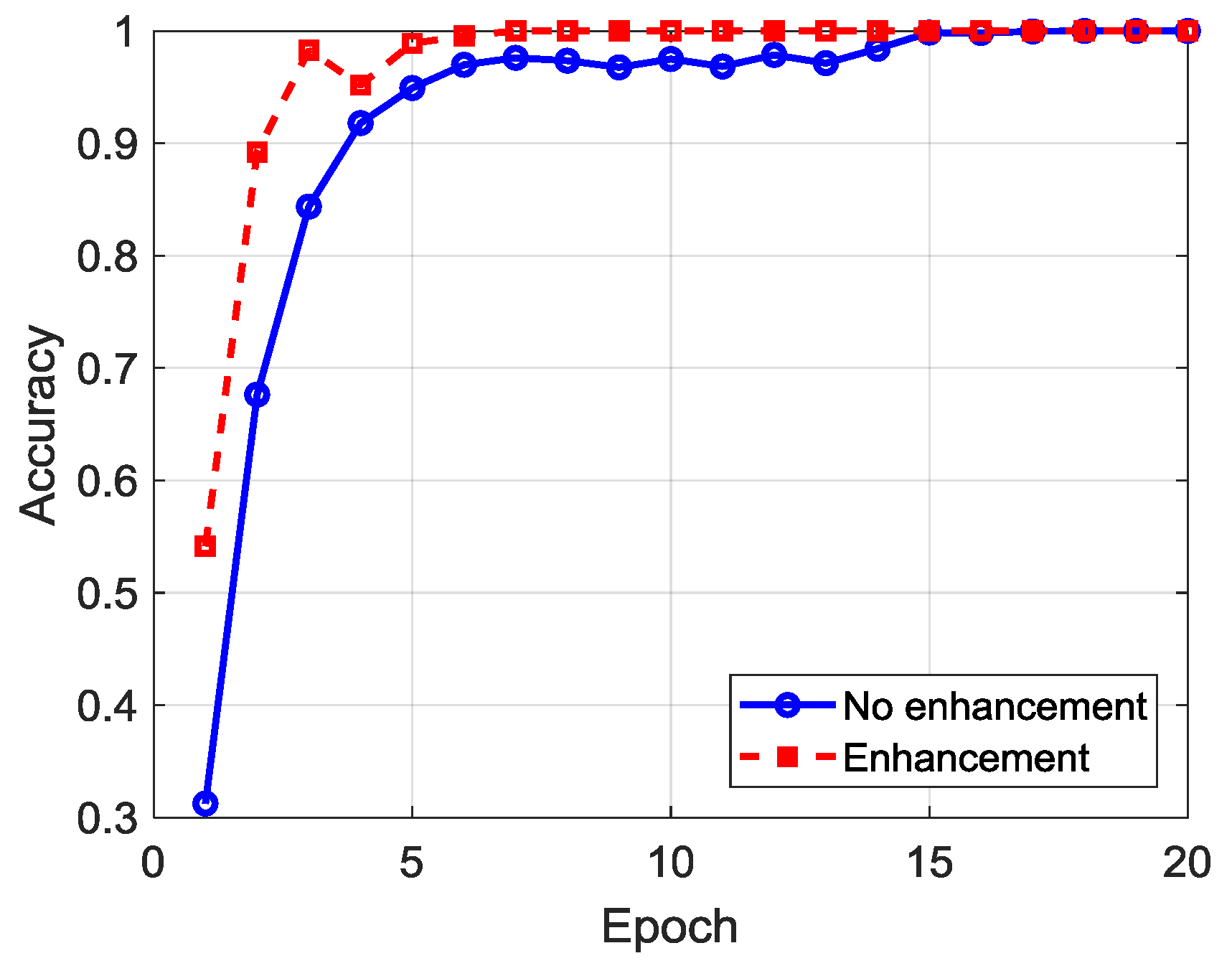
Figure 12 gives the comparison of convergence of DCNN with and without image enhancement. The solid line is the convergence curve of training accuracy with training epoch without image enhancement, and the dashed line denotes the convergence curve of training accuracy with training epoch with image enhancement. From
Figure 12, the training accuracy reached a stable 100% after 15 epochs without SAR image enhancement. The convergence speed became very fast after image enhancement based on SRGAN. The training accuracy reached 100% at the fifth epoch for the first time, and it was stable after the ninth epoch. This fully proves that the features of the SAR image after enhancement were easier to extract and learn than the one without enhancement.
Table 2 is the confusion matrix of the recognition results of 10 classes of targets under SOC. Here, “Acc” is the abbreviation of accuracy. The SAR image average recognition accuracy of the 10 classes using the proposed method was as high as 99.31%, among which, the 2S1, BTR-70, T-72, and ZIL-131 recognition accuracy reached 100%. However, BRT-60 had the lowest recognition accuracy, which was mainly because some samples of BRT-60 were wrongly classified as ZSU-234. When the pitch angle was 17°, these two classes of target images had a great deal of similarity, as shown in
Figure 13.
5.4. Experiments and Results under EOC1
For SOC, the pitch angles of the training set and the test set were different, but the difference was not large. However, the SAR image was very sensitive to many factors, and in order to verify the robustness of the method proposed in this paper, MSTAR data sets were tested in different EOCs. The EOCs need to set three different experimental conditions: different pitch angles (EOC1), and different configurations and different versions (EOC2).
There were four classes of targets in EOC1, including 2S1, BRDM-2, T-72, and ZSU-234. The number of samples of each class and the corresponding pitch angles in the training set and test set are shown in
Table 3. The pitch angles of the training set and test set samples differed by 13°. The postures of the training samples and testing samples were more different than the SOC.
Table 4 is the confusion matrix under EOC1 based on the proposed method. It can be seen from
Table 4, after image enhancement, that the recognition rate of each class of target was above 97%, and the average recognition accuracy reached 99.05%. Although there was a large difference of pitch angles between the training set and test set, the better recognition result under EOC1 was still obtained, which proves the robustness of the propose method.
5.5. Experiments and Results under EOC2
EOC2 is divided into different configurations and different versions. The target type, the number of samples, and the corresponding pitch angles of the training set and test set are shown in
Table 5,
Table 6 and
Table 7, respectively. The training sets are the same for the two EOC2’s, including BMP-2, BRDM-2, BTR-70, and T-72. For the configuration variants, the test samples only included variants of T-72. For version variants, the test samples only included variants of T-72 and BMP-2.
Table 8 shows the confusion matrix under EOC2 (configuration variant) based on the proposed method. Under the configuration variant condition, the final recognition accuracy reached 99.27%, among which the T72/S7 and T72/A32 recognition accuracy reached 100%.
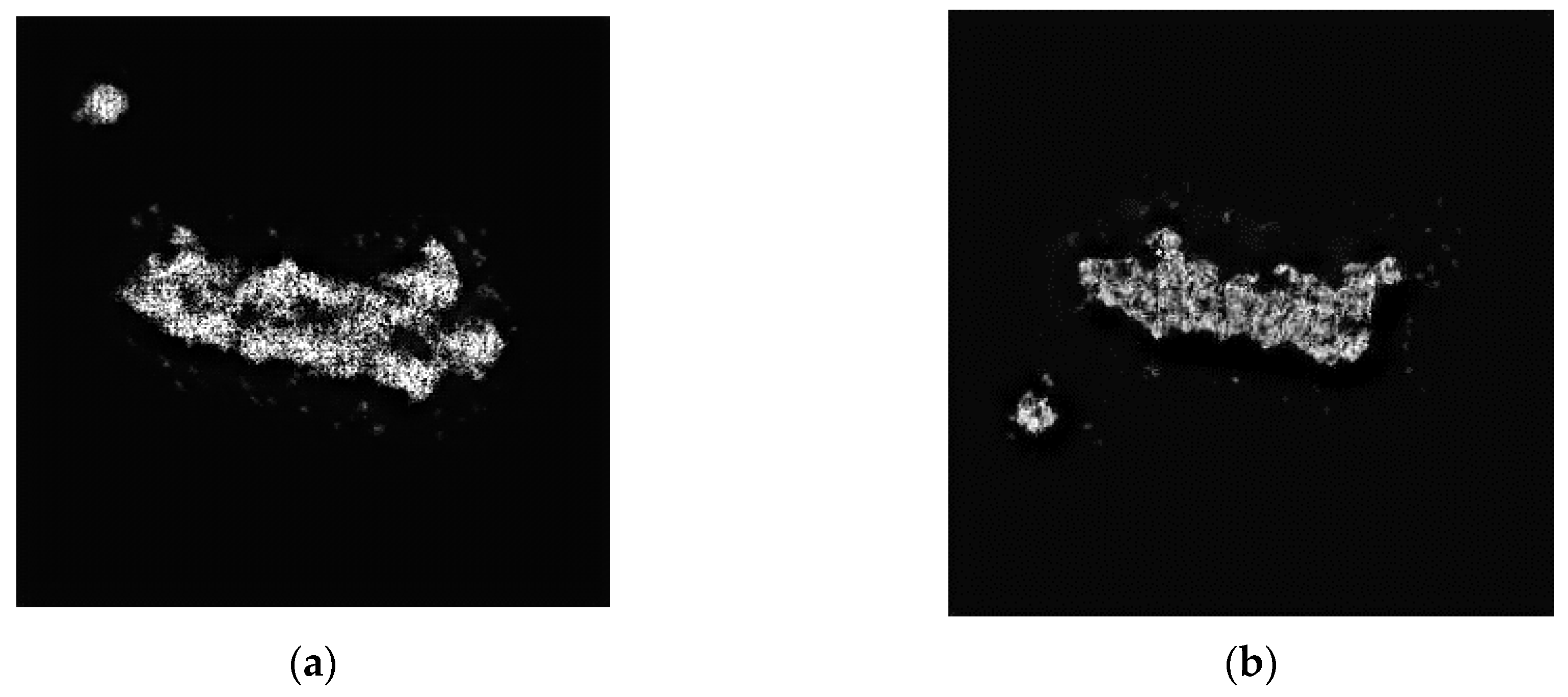
Table 9 is the confusion matrix under EOC2 (version variant) based on the proposed method, and the final average recognition accuracy was 98.92%. Among them, the recognition accuracy of A07 in T-72 was low, which was 96.68%. This was mainly because some T-72/A07 was wrongly classified as BRDM-2.
Figure 14 gives the images of T-72/A07 and BRDM-2. It can be seen that these two classes had similarities in visual scene. There were residual regions due to the insufficient segments.
Table 10 is the comparison of different methods, namely traditional CNN, A-ConvNets, LM-BN-CNN, and the proposed method in this paper. Under SOC, the recognition accuracy of the proposed method was 4.5% higher than the traditional CNN, 4.3% higher than A-ConvNets, and 2.9% higher than LM-BN-CNN. Under EOC1, the recognition accuracy of the proposed method was 10.6% higher than the traditional CNN, 10.0% higher than A-ConvNets, and 7.4% higher than LM-BN-CNN. In the case of EOC2 (configuration variant), the recognition accuracy of the proposed method was 12.6% higher than the traditional CNN, 12.0% higher than A-ConvNets, and 10.1% higher than LM-BN-CNN. In the case of EOC2 (version variant), the recognition accuracy of the proposed method was 12.9% higher than traditional CNN, 11.8% higher than A-ConvNets, and 10.3% higher than LM-BN-CNN. It can be seen that the proposed method had stronger feature expression ability and better generalization performance, and the recognition results were superior to A-ConvNets and LM-BN-CNN. The advantages of the image enhancement are obvious, and it has better classification recognition ability when the number of target categories was fewer.
To sum up, under SOC, EOC1, and EOC2, the recognition accuracies of the proposed method in this paper were all above 98%, showing good feature expression ability and classification ability. The convergence speed of the SAR image with segmentation and enhancement was faster than the SAR image with only segmentation and without enhancement, the network was more stable, and the image features were easier to extract. There were two main reasons: First, the proposed algorithm eliminates the influence of background noise using image segmentation method and decreases the computational complexity. Second, and most importantly, the proposed algorithm adopts a super-resolution technique to improve the visual resolution of the targets in SAR images, where the detailed information becomes more obvious, such that the learning feature ability of the network is improved and the difference between different targets can be captured well, thus the recognition rate is increased. Therefore, the proposed ATR method for SAR images based on SRGAN and DCNN has effectiveness, robustness, and good generalization performance.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}