Combining Multi-Date Airborne Laser Scanning and Digital Aerial Photogrammetric Data for Forest Growth and Yield Modelling

 ,
,  ,
,  ,
,  , and
, and
Abstract
:
1. Introduction
2. Materials
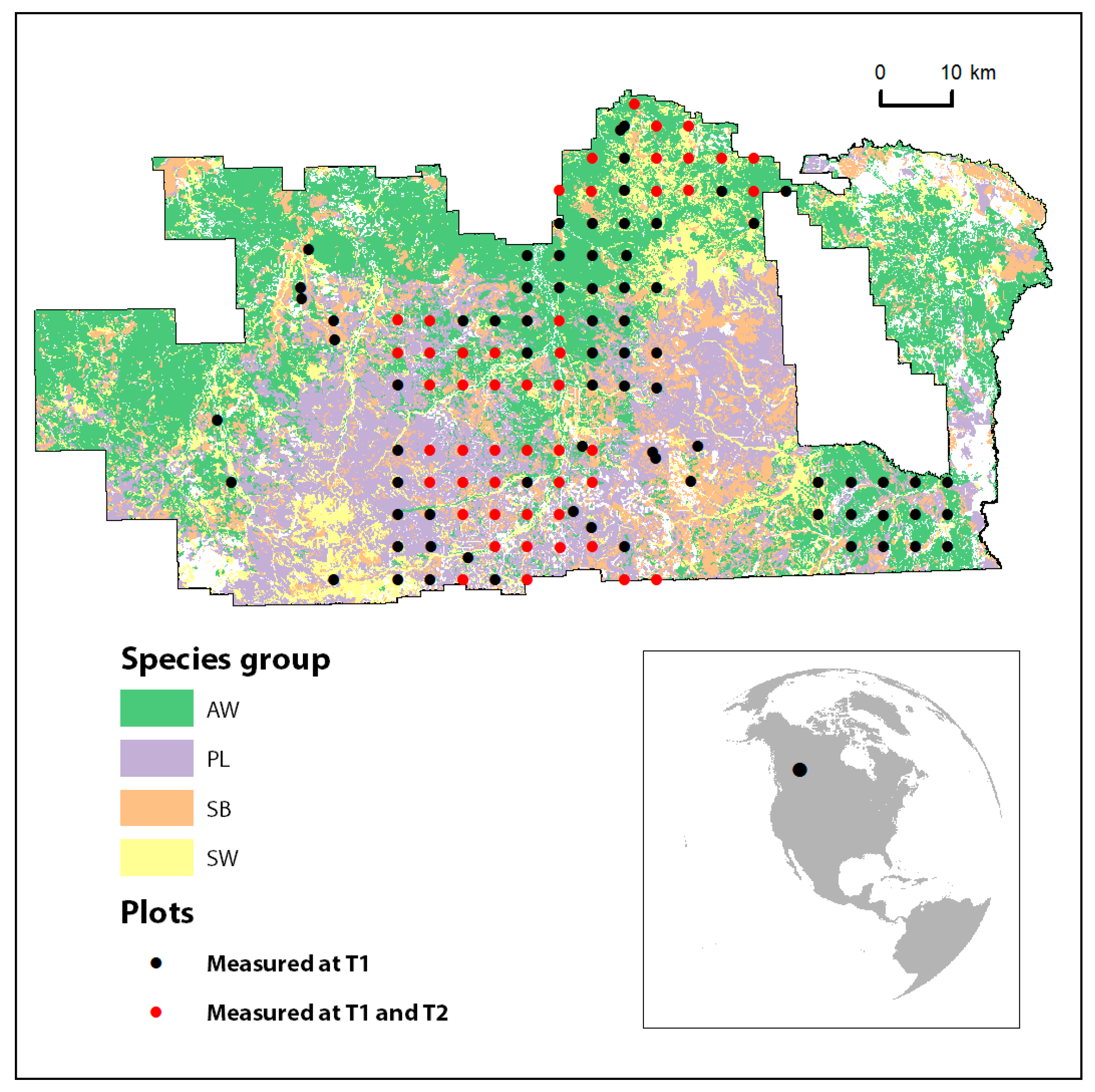
2.1. Study Area
2.2. Forest Inventory Data
2.3. Plot Data
2.4. ALS Data
2.5. DAP Data
2.6. Point Cloud Data Processing
3. Methods
3.1. ABA Modeling
3.2. The Growth and Yield Projection System (GYPSY)
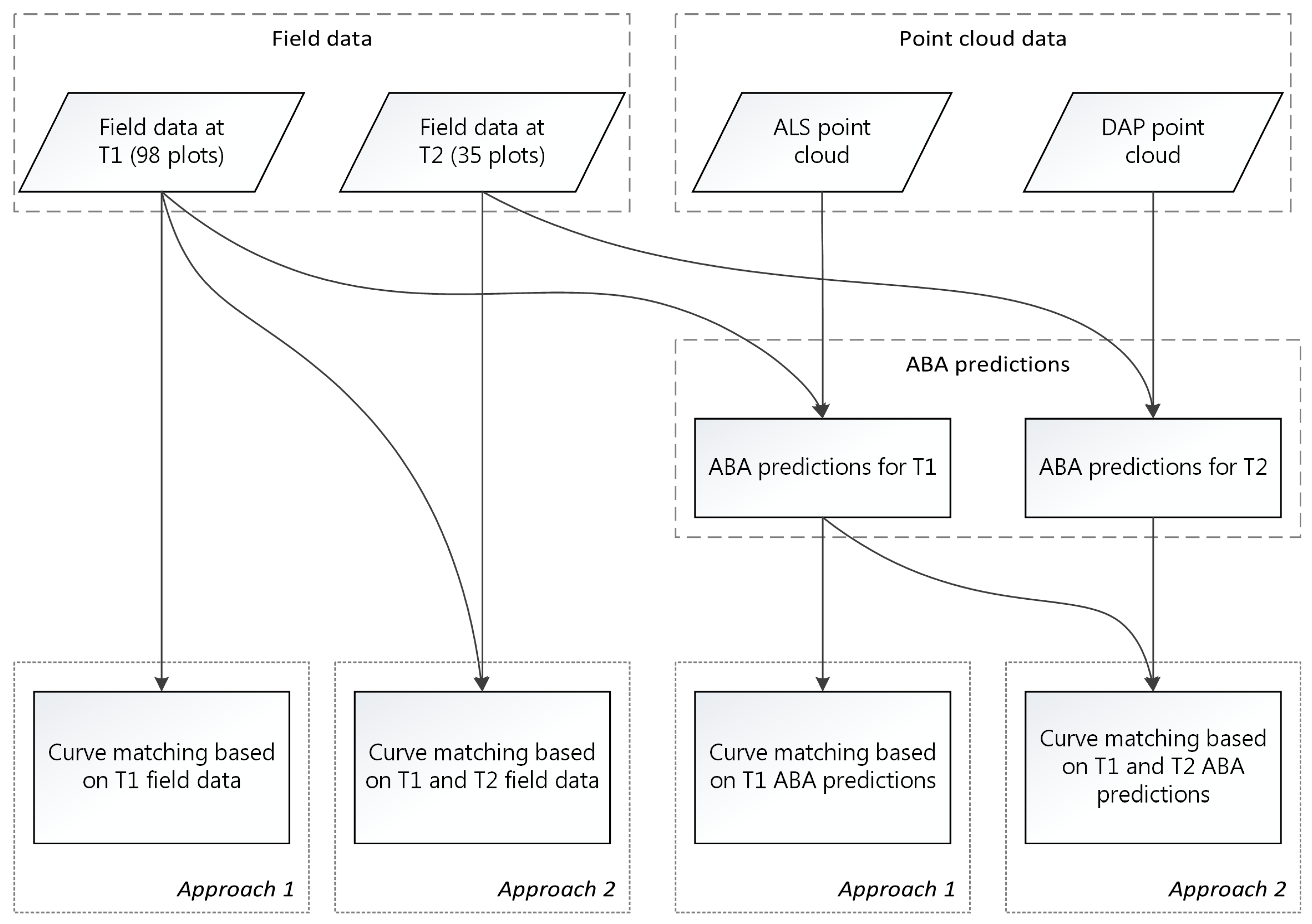
3.3. Yield Curve Matching
3.4. Validation of the Yield Curve Assignment
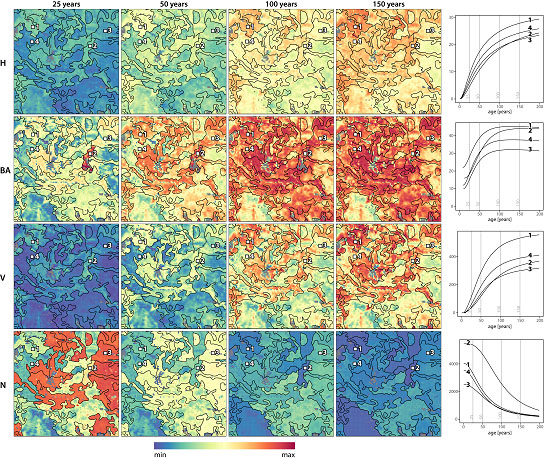
3.5. Wall-to-Wall Growth and Yield Projections
4. Results
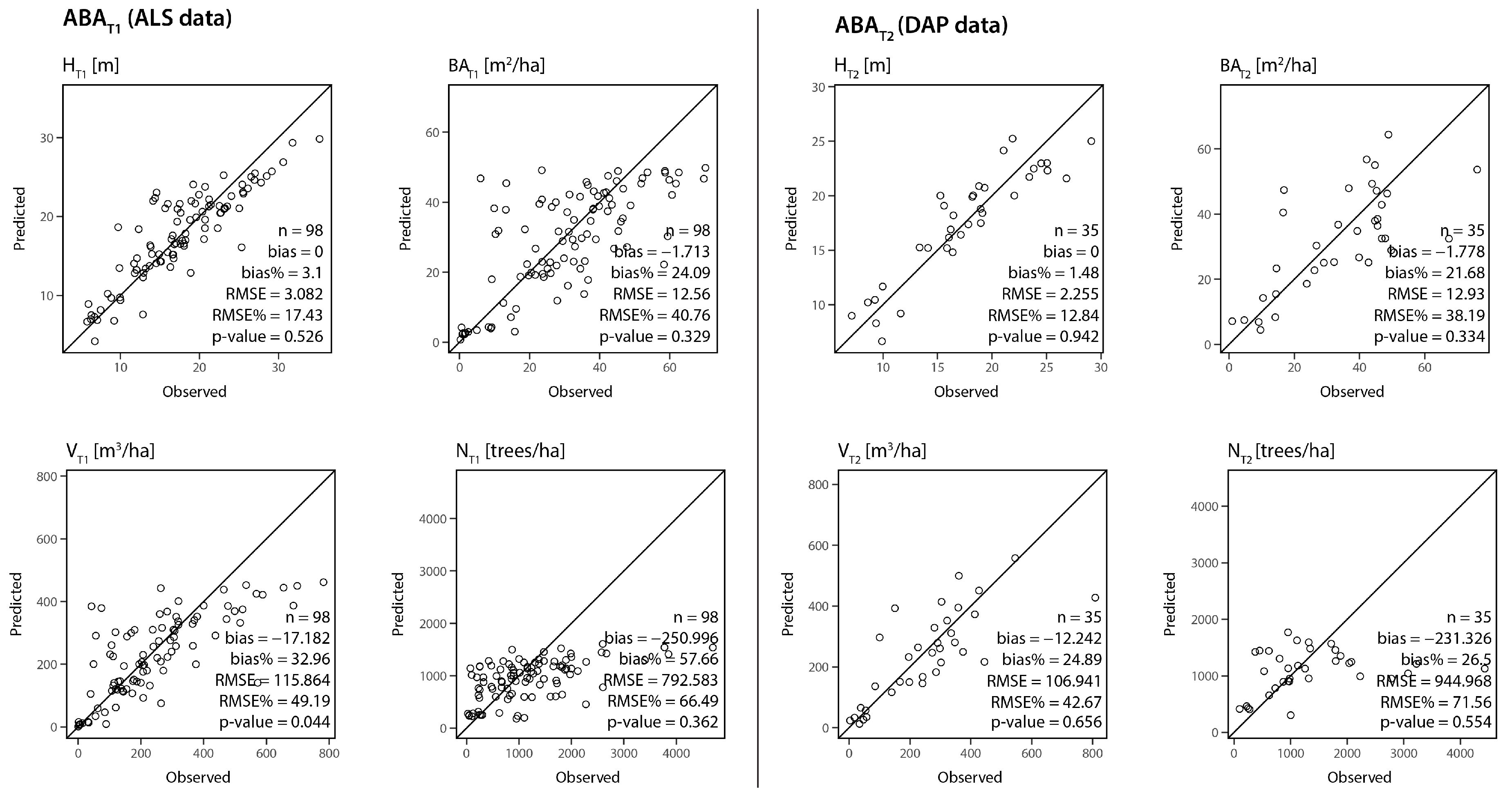
4.1. ABA Modeling Results
4.2. Yield Curve Matching
4.3. Uncertainty in the Yield Curve Matching
4.4. Analysis of the Wall-to-Wall Projections
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Avery, T.E.; Burkhart, H. Forest Measurements; McGraw-Hill: New York, NY, USA, 2002. [Google Scholar]
- Pretzsch, H. Forest Dynamics, Growth and Yield; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–39. [Google Scholar]
- Ministry of Forest Lands and Natural Resource Operations Growth and Yield Modelling. Available online: https://www.for.gov.bc.ca/hts/growth/tipsy/tipsy_description.html (accessed one 10 June 2015).
- Huang, S.; Meng, S.X.; Yang, Y. A Growth and Yield Projection System (GYPSY) for Natural and Post-Harvest Stands in Alberta. 2009. Available online: https://www.agric.gov.ab.ca/app21/forestrypage?cat1=Forest%20Management&cat2=Growth%20%26%20Yield (accessed on 4 December 2017).
- White, J.C.; Wulder, M.A.; Varhola, A.; Vastaranta, M.; Coops, N.C.; Cook, B.D.; Pitt, D.; Woods, M. A best practices guide for generating forest inventory attributes from airborne laser scanning data using an area-based approach. For. Chron. 2013, 89, 722–723. [Google Scholar] [CrossRef]
- Maltamo, M.; Næsset, E.; Vauhkonen, J. Forestry Applications of Airborne Laser Scanning; Springer: Dordrecht, The Netherlands, 2014; Volume 27, pp. 63–88. [Google Scholar]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote Sensing Technologies for Enhancing Forest Inventories: A Review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Coops, N.C.; Hilker, T.; Wulder, M.A.; St-Onge, B.; Newnham, G.J.; Siggins, A.; Trofymow, J.A. Estimating canopy structure of Douglas-fir forest stands from discrete-return LiDAR. Trees Struct. Funct. 2007, 21, 295–310. [Google Scholar] [CrossRef]
- Penner, M.; Pitt, D.G.; Woods, M.E. Parametric vs. nonparametric LiDAR models for operational forest inventory in boreal Ontario. Can. J. Remote Sens. 2013, 39, 426–443. [Google Scholar]
- Næsset, E. Airborne laser scanning as a method in operational forest inventory: Status of accuracy assessments accomplished in Scandinavia. Scand. J. For. Res. 2007, 22, 433–442. [Google Scholar] [CrossRef]
- Hyyppä, J.; Inkinen, M. Detecting and estimating attributes for single trees using laser scanner. Photogramm. J. Finland 1999, 16, 27–42. [Google Scholar]
- Jakubowski, M.; Li, W.; Guo, Q.; Kelly, M. Delineating Individual Trees from Lidar Data: A Comparison of Vector- and Raster-based Segmentation Approaches. Remote Sens. 2013, 5, 4163–4186. [Google Scholar] [CrossRef]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Gobakken, T.; Bollandsås, O.M.; Næsset, E. Comparing biophysical forest characteristics estimated from photogrammetric matching of aerial images and airborne laser scanning data. Scand. J. For. Res. 2015, 30, 73–86. [Google Scholar] [CrossRef]
- Stepper, C.; Straub, C.; Pretzsch, H. Using semi-global matching point clouds to estimate growing stock at the plot and stand levels: Application for a broadleaf-dominated forest in central Europe. Can. J. Remote Sens. 2015, 45, 111–123. [Google Scholar] [CrossRef]
- Balenović, I.; Simic Milas, A.; Marjanović, H. A Comparison of Stand-Level Volume Estimates from Image-Based Canopy Height Models of Different Spatial Resolutions. Remote Sens. 2017, 9, 205. [Google Scholar] [CrossRef]
- Puliti, S.; Gobakken, T.; Ørka, H.O.; Næsset, E. Assessing 3D point clouds from aerial photographs for species-specific forest inventories inventories. Scand. J. For. Res. 2017, 32, 68–79. [Google Scholar] [CrossRef]
- Yu, X.; Hyyppä, J.; Karjalainen, M.; Nurminen, K.; Karila, K.; Kukko, A.; Jaakkola, A.; Liang, X.; Wang, Y.; Hyyppä, H. Comparison of Laser and Stereo Optical, SAR and InSAR Point Clouds from Air- and Space-Borne Sources in the Retrieval of Forest Inventory Attributes. Remote Sens. 2015, 7, 15933–15954. [Google Scholar] [CrossRef]
- White, J.C.; Wulder, M.A.; Vastaranta, M.; Coops, N.C.; Pitt, D.; Woods, M. The Utility of Image-Based Point Clouds for Forest Inventory: A Comparison with Airborne Laser Scanning. Forests 2013, 4, 518–536. [Google Scholar] [CrossRef]
- White, J.C.; Tompalski, P.; Coops, N.C.; Wulder, M.A. Comparison of airborne laser scanning and digital stereo imagery for characterizing forest canopy gaps in coastal temperate rainforests. Remote Sens. Environ. 2018, 208, 1–14. [Google Scholar] [CrossRef]
- Tompalski, P.; Coops, N.; White, J.; Wulder, M. Enhancing Forest Growth and Yield Predictions with Airborne Laser Scanning Data: Increasing Spatial Detail and Optimizing Yield Curve Selection through Template Matching. Forests 2016, 7, 255. [Google Scholar] [CrossRef]
- Yu, X.; Hyyppä, J.; Kaartinen, H.; Maltamo, M. Automatic detection of harvested trees and determination of forest growth using airborne laser scanning. Remote Sens. Environ. 2004, 90, 451–462. [Google Scholar] [CrossRef]
- Hopkinson, C.; Chasmer, L.; Hall, R.J. The uncertainty in conifer plantation growth prediction from multi-temporal lidar datasets. Remote Sens. Environ. 2008, 112, 1168–1180. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T. Estimating forest growth using canopy metrics derived from airborne laser scanner data. Remote Sens. Environ. 2005, 96, 453–465. [Google Scholar] [CrossRef]
- Ali-Sisto, D.; Packalen, P. Forest Change Detection by Using Point Clouds From Dense Image Matching Together With a LiDAR-Derived Terrain Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 1–10. [Google Scholar] [CrossRef]
- Stepper, C.; Straub, C.; Pretzsch, H. Assessing height changes in a highly structured forest using regularly acquired aerial image data. Forestry 2014, 88, 304–316. [Google Scholar] [CrossRef]
- Véga, C.; St-Onge, B. Height growth reconstruction of a boreal forest canopy over a period of 58 years using a combination of photogrammetric and lidar models. Remote Sens. Environ. 2008, 112, 1784–1794. [Google Scholar] [CrossRef] [Green Version]
- Cao, L.; Coops, N.C.; Innes, J.L.; Sheppard, S.R.J.; Fu, L.; Ruan, H.; She, G. Estimation of forest biomass dynamics in subtropical forests using multi-temporal airborne LiDAR data. Remote Sens. Environ. 2016, 178, 158–171. [Google Scholar] [CrossRef]
- Goodbody, T.R.H.; Coops, N.C.; Tompalski, P.; Crawford, P.; Day, K.J.K. Updating residual stem volume estimates using ALS- and UAV-acquired stereo-photogrammetric point clouds. Int. J. Remote Sens. 2016, 38, 2938–2953. [Google Scholar] [CrossRef]
- Socha, J.; Pierzchalski, M.; Bałazy, R.; Ciesielski, M. Modelling top height growth and site index using repeated laser scanning data. For. Ecol. Manag. 2017, 406, 307–317. [Google Scholar] [CrossRef]
- Falkowski, M.J.; Hudak, A.T.; Crookston, N.L.; Gessler, P.E.; Uebler, E.H.; Smith, A.M.S. Landscape-scale parametrization of a tree-level forest growth model: A k-nearest neighbor imputation approach incorporating LiDAR data. Can. J. For. Res. 2010, 40, 184–199. [Google Scholar] [CrossRef]
- Dixon, G. Essential FVS: A User’s Guide to the Forest Vegetation Simulator; Internal Report; USDA Forest Service, Forest Management Service Center: Fort Collins, CO, USA, 2003.
- Lamb, S.M.; MacLean, D.A.; Hennigar, C.R.; Pitt, D.G. Imputing Tree Lists for New Brunswick Spruce Plantations Through Nearest-Neighbor Matching of Airborne Laser Scan and Inventory Plot Data. Can. J. Remote Sens. 2017, 43, 269–285. [Google Scholar] [CrossRef]
- Natural Regions Committee. Natural Regions and Subregions of Alberta; Natural Regions Committee: Edmonton, AB, Canada, 2006. [Google Scholar]
- Alberta Sustainable Resource Development. Alberta Vegetation Inventory Interpretation Standards. 2005. Available online: http://www.srd.gov.ab.ca/index.html (accessed on 4 December 2017).
- Isenburg, M. LAStools. Available online: http://lastools.org (accessed on 1 December 2017).
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 110–117. [Google Scholar]
- McGaughey, R.J. FUSION/LDV: Software for LIDAR Data Analysis and Visualization. 2015. Available online: http://forsys.sefs.uw.edu/fusion.html (accessed on 4 December 2017).
- Bouvier, M.; Durrieu, S.; Fournier, R.A.; Renaud, J.-P. Generalizing predictive models of forest inventory attributes using an area-based approach with airborne LiDAR data. Remote Sens. Environ. 2015, 156, 322–334. [Google Scholar] [CrossRef]
- Sprugel, D. Correcting for bias in log-transformed allometric equations. Ecology 1983, 64, 209–210. [Google Scholar] [CrossRef]
- The Forestry Corporation. Validation Summary of GYPSY Sub-Models; The Forestry Corporation: Edmonton, AB, Canada, 2009. Available online: http://www1.agric.gov.ab.ca/$department/deptdocs.nsf/all/formain15784/$file/GYPSY-ValidationSummary-SubModelsJun16-2009.pdf?OpenElement (accessed on 15 February 2018).
- Bohlin, J.; Wallerman, J.; Fransson, J.E.S.; Bohlin, J.; Wallerman, J.; Forest, J.E.S.F.; Bohlin, J. Forest variable estimation using photogrammetric matching of digital aerial images in combination with a high-resolution DEM. Scand. J. For. Res. 2012, 27, 692–699. [Google Scholar] [CrossRef]
- Hawryło, P.; Tompalski, P.; Wężyk, P. Area-based estimation of growing stock volume in Scots pine stands using ALS and airborne image-based point clouds. Forestry 2017, 90, 685–696. [Google Scholar] [CrossRef]
- White, J.; Stepper, C.; Tompalski, P.; Coops, N.; Wulder, M. Comparing ALS and Image-Based Point Cloud Metrics and Modelled Forest Inventory Attributes in a Complex Coastal Forest Environment. Forests 2015, 6, 3704–3732. [Google Scholar] [CrossRef]
- Vastaranta, M.; Wulder, M.A.; White, J.C.; Pekkarinen, A.; Tuominen, S.; Ginzler, C.; Kankare, V.; Holopainen, M.; Hyyppa, J.; Hyyppa, H. Airborne laser scanning and digital stereo imagery measures of forest structure: Comparative results and implications to forest mapping and inventory update. Can. J. Remote Sens. 2013, 39, 382–395. [Google Scholar] [CrossRef]
- Saad, R.; Eyvindson, K.; Gong, P.; Lämås, T.; Ståhl, G. Potential of using data assimilation to support forest planning. Can. J. For. Res. 2017, 47, 690–695. [Google Scholar] [CrossRef]
- Nyström, M.; Lindgren, N.; Wallerman, J.; Grafström, A.; Muszta, A.; Nyström, K.; Bohlin, J.; Willén, E.; Fransson, J.E.S.; Ehlers, S.; et al. Data assimilation in forest inventory: First empirical results. Forests 2015, 6, 4540–4557. [Google Scholar] [CrossRef]
- Pascual, A.; Pukkala, T.; Rodríguez, F.; de-Miguel, S. Using spatial optimization to create dynamic harvest blocks from LiDAR-based small interpretation units. Forests 2016, 7, 220. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
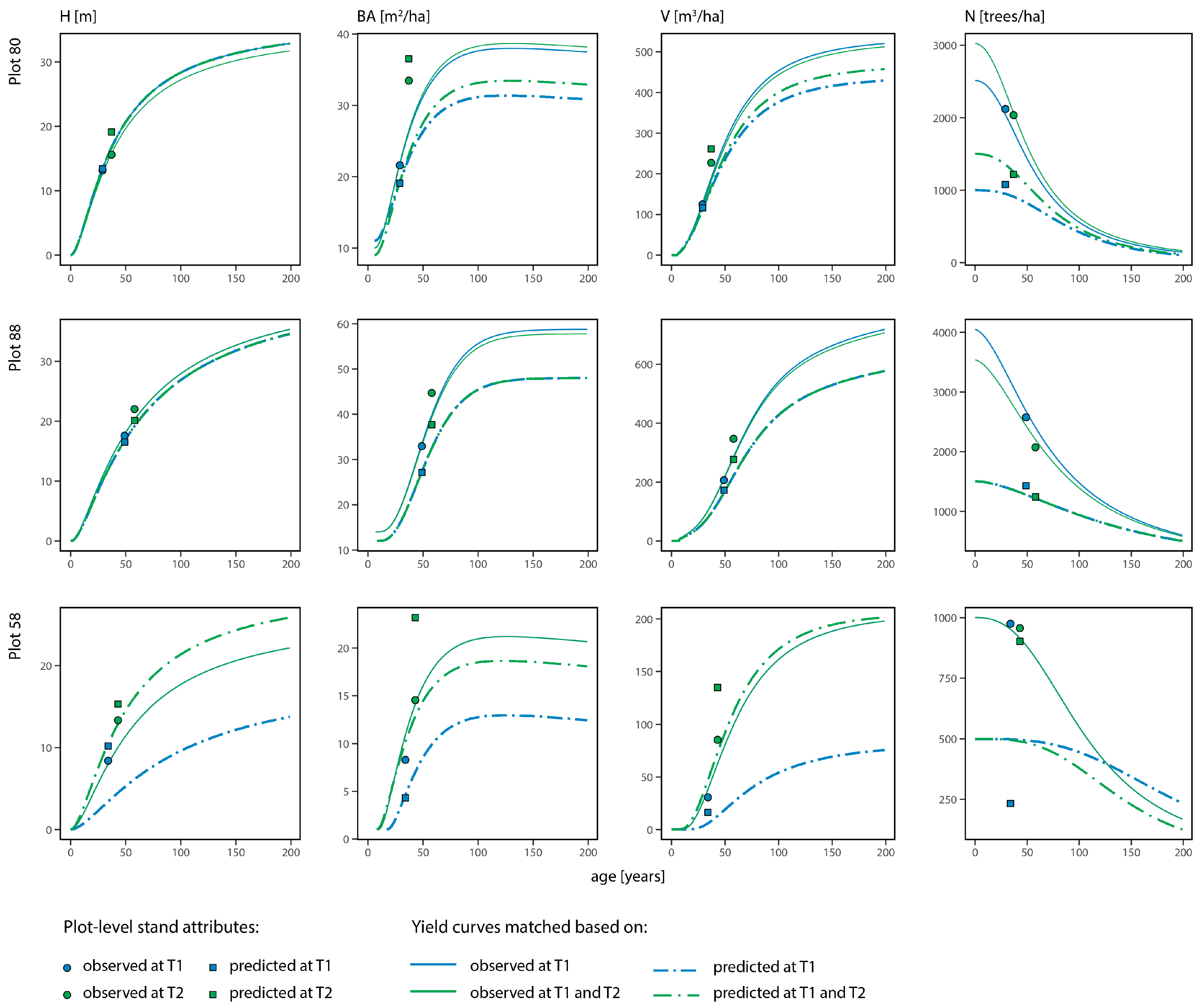{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species Group and Code | Included Dominant Species | Number of Stands | Total Area | Mean Area | Stand Age | |||
|---|---|---|---|---|---|---|---|---|
| # | % | ha | % | ha | Mean | σ | ||
| Aspen group—AW | balsam poplar (Populus balsamifera) trembling aspen (Populus tremuloides) | 17,134 | 36.52 | 250886.20 | 42.68 | 14.64 | 81 | 38 |
| Pine group—PL | jack pine (Pinus banksiana) lodgepole pine (Pinus contorta v. latifolia) tamarack/larch (Larix laricina) | 11,830 | 25.22 | 162834.58 | 27.70 | 13.76 | 112 | 55 |
| Black spruce group—SB | black spruce (Picea mariana) | 9947 | 21.20 | 90498.25 | 15.39 | 9.10 | 117 | 47 |
| White spruce group—SW | alpine fir (Abies lasiocarpa) balsam fir (Abies balsamea) Douglas fir (Pseudotsuga menziesii) Engelmann spruce (Picea englemannii) white spruce (Picea glauca) | 8002 | 17.06 | 83656.40 | 14.23 | 10.45 | 120 | 44 |
| Total | 46,913 | 100.00 | 587875.43 | 100.00 | 12.53 | 103 | 49 | |
| Time | Species Group Code | N | H | BA | V | N | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |||
| T1 | AW | 39 | 19.6 | 5.3 | 32.3 | 15.7 | 269.3 | 179.6 | 1169.5 | 629.9 |
| T1 | PL | 17 | 12.9 | 5.9 | 22.8 | 19.1 | 162.5 | 183.4 | 1166.4 | 1193.8 |
| T1 | SB | 26 | 15.4 | 5.2 | 30.6 | 17.5 | 190.4 | 140.1 | 1438.5 | 1058.3 |
| T1 | SW | 16 | 21.8 | 7.1 | 36.1 | 18.1 | 304.4 | 193.3 | 873.4 | 697.0 |
| T1 | Total | 98 | 17.7 | 6.4 | 30.8 | 17.4 | 235.6 | 178.2 | 1192.0 | 887.5 |
| T2 | AW | 10 | 21.9 | 4.2 | 37.3 | 10.7 | 326.1 | 124.1 | 1102.0 | 454.4 |
| T2 | PL | 9 | 13.8 | 5.7 | 25.6 | 24.0 | 202.1 | 257.4 | 1122.9 | 1061.3 |
| T2 | SB | 11 | 16.2 | 4.0 | 37.5 | 16.8 | 230.2 | 123.7 | 1846.8 | 1171.7 |
| T2 | SW | 5 | 18.7 | 5.7 | 33.7 | 18.5 | 232.2 | 132.7 | 955.7 | 714.5 |
| T2 | Total | 35 | 17.6 | 5.5 | 33.9 | 17.8 | 250.6 | 169.5 | 1320.6 | 957.6 |
| Year of Acquisition | 2006 | 2007 and 2008 |
|---|---|---|
| Sensor | Optech ALTM 3100 | Optech ALTM 3100 |
| Flying height | 1250 m AGL | 1400 m AGL |
| Flight speed | 160 kts | 160 kts |
| Pulse repeatition rate | 50 kHz | 70 kHz |
| Scanning frequency | 30 Hz | 33 Hz |
| Scan angle | 50 deg | 50 deg |
| Beam divergence | 0.3 mrad | 0.3 mrad |
| Average point density | 1.53 | 1.52 (2007)/1.68 (2008) |
| Dependent Variable | Predictive Model | R2 |
|---|---|---|
| HT1 | 3.344 + 0.814 ∗ P99 | 0.76 |
| BAT1 | 0.71 | |
| VT1 | 0.78 | |
| NT1 | 0.26 | |
| HT2 | 0.83 | |
| BAT2 | 0.60 | |
| VT2 | 0.72 | |
| NT2 | 0.25 |
| H | BA | V | N | |||||
|---|---|---|---|---|---|---|---|---|
| Approach | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 |
| R2 | 0.29 | 0.12 | 0.66 | 0.72 | 0.64 | 0.81 | 0.83 | 0.81 |
| model term: | ||||||||
| prediction error | 0.21 | 0.47 * | 0.79 *** | 0.72 *** | 0.88 *** | 0.81 *** | 0.85 *** | 0.85 *** |
| uncertainty | 0 | 0 | −0.01 | −0.03 * | −0.01 | −0.02 | −0.06 | 0.19 |
| age | −0.02 | −0.01 | 0.03 | 0.04 * | 0.26 | 0.11 | 0.3 | 1.7 |
| species-PL | 1.27 | 0.09 | 1.62 | 7.96 ** | 32.56 | 25.38 | 19.14 | 153.8 |
| species-SB | −0.37 | −0.19 | 2.95 | 5.66 * | 17.33 | 35.91 * | −168.11 | −42.93 |
| species-SW | −0.51 | 0.24 | 1.61 | 5.69 * | 12.35 | 16.84 | −320.85* | −196.21 |
| Variable | R | MD | RMSD | RMSD% | p-Value |
|---|---|---|---|---|---|
| H [m] | 0.93 | 0.02 | 2.45 | 14.49 | 0.93 |
| BA [m2/ha] | 0.91 | −1.01 | 3.98 | 13.99 | 0.98 |
| V [m3/ha] | 0.95 | −11.50 | 44.36 | 20.75 | 0.57 |
| N [stems/ha] | 0.89 | −30.72 | 151.96 | 17.67 | 0.31 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tompalski, P.; Coops, N.C.; Marshall, P.L.; White, J.C.; Wulder, M.A.; Bailey, T. Combining Multi-Date Airborne Laser Scanning and Digital Aerial Photogrammetric Data for Forest Growth and Yield Modelling. Remote Sens. 2018, 10, 347. https://doi.org/10.3390/rs10020347
Tompalski P, Coops NC, Marshall PL, White JC, Wulder MA, Bailey T. Combining Multi-Date Airborne Laser Scanning and Digital Aerial Photogrammetric Data for Forest Growth and Yield Modelling. Remote Sensing. 2018; 10(2):347. https://doi.org/10.3390/rs10020347
Chicago/Turabian StyleTompalski, Piotr, Nicholas C. Coops, Peter L. Marshall, Joanne C. White, Michael A. Wulder, and Todd Bailey. 2018. "Combining Multi-Date Airborne Laser Scanning and Digital Aerial Photogrammetric Data for Forest Growth and Yield Modelling" Remote Sensing 10, no. 2: 347. https://doi.org/10.3390/rs10020347
APA StyleTompalski, P., Coops, N. C., Marshall, P. L., White, J. C., Wulder, M. A., & Bailey, T. (2018). Combining Multi-Date Airborne Laser Scanning and Digital Aerial Photogrammetric Data for Forest Growth and Yield Modelling. Remote Sensing, 10(2), 347. https://doi.org/10.3390/rs10020347