Object-Based Features for House Detection from RGB High-Resolution Images



Abstract
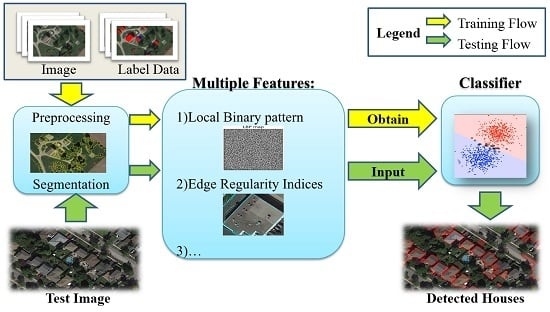
:
1. Introduction
2. Related Works
2.1. Line- or Edge-Based Approaches
2.2. Template Matching Approach
2.3. OBIA Approach
2.4. Knowledge-Based Approach
2.5. Auxiliary Data-Based Approach
2.6. Machine Learning Approach
3. The Proposed Approach
3.1. Overview of the Approach
3.2. Image Segmentation
3.3. Candidate Selection
3.3.1. Vegetation and Shadow Detection
3.3.2. Choosing Candidate Regions
3.4. Feature Descriptors for Regions
3.4.1. Color Descriptors
3.4.2. Texture Descriptors
3.4.3. Geometric Descriptors
- AreaArea is the number of pixels located inside the region boundaries. Here, area is denoted as .
- EccentricityEccentricity is defined as the ratio of the major axis of a region to its minor axis, described as:where and are the length of the major axis and that of the minor axis, respectively.
- SoliditySolidity describes whether the shape is convex or concave, defined as:where is the area of the region and is the convex hull area of the region.
- ConvexityConvexity is defined as the ratio of the perimeter of the convex hull of the given region over that of the original region :
- RectangularityRectangularity represents how rectangular a region is, which can be used to differentiate circles, rectangles and other irregular shapes. Rectangularity is defined as follows:where is the area of the region and is the area of the minimum bounding rectangle of the region. The value of rectangularity varies between 0 and 1.
- CircularityCircularity, also called compactness, is a measure of similarity to a circle about a region or a polygon. Several definitions are described in different studies, one of which is defined as follows:where is the area of the original region and P is the perimeter of the region.
- Shape RoughnessShape roughness is a measure of the smoothness of the boundary of a region and is defined as follows:where is the perimeter of the region and and are the length of the major axis and that of the minor axis, respectively.
3.4.4. Zernike Moments
3.4.5. Edge Regularity Indices
3.4.6. Shadow Line Indices
3.4.7. Hybrid Descriptors
3.5. Training and Testing
3.5.1. Labeling and Training
3.5.2. Testing
4. Experiments
4.1. Introduction of Data
4.2. Evaluation Metrics
4.3. Results and Quality Assessment
4.4. Evaluation of Different Features
4.5. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AdaBoost | adaptive boost |
| AUC | area under the curve |
| CNN | convolutional neural network |
| DSM | digital surface model |
| ERI | edge regularity indices |
| GIS | geographic information systems |
| HMT | hit-or-miss transformation |
| HT | Hough transformation |
| LBP | local binary patterns |
| ML | machine learning |
| OBIA | object-based image analysis |
| RF | random forests |
| RGB | red, green, and blue |
| ROC | receiver operating characteristic |
| SLI | shadow line indices |
| SVM | support vector machine |
| VHR | very high resolution |
| WT | watershed transformation |
References
- Quang, N.T.; Thuy, N.T.; Sang, D.V.; Binh, H.T.T. An efficient framework for pixel-wise building segmentation from aerial images. In Proceedings of the 6th International Symposium on Information and Communication Technology, Hue City, Viet Nam, 3–4 December 2015; pp. 282–287. [Google Scholar]
- Li, E.; Xu, S.; Meng, W.; Zhang, X. Building extraction from remotely sensed images by integrating saliency cue. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 906–919. [Google Scholar] [CrossRef]
- Lin, C.; Huertas, A.; Nevatia, R. Detection of buildings using perceptual grouping and shadows. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 62–69. [Google Scholar]
- Katartzis, A.; Sahli, H. A stochastic framework for the identification of building rooftops using a single remote sensing image. IEEE Trans. Geosci. Remote Sens. 2008, 46, 259–271. [Google Scholar] [CrossRef]
- Kim, T.; Muller, J.P. Development of a graph-based approach for building detection. Image Vis. Comput. 1999, 17, 3–14. [Google Scholar] [CrossRef]
- San, D.K.; Turker, M. Building extraction from high resolution satellite images using Hough transform. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, XXXVIII, 1063–1068. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Lefèvre, S.; Weber, J. Automatic building extraction in VHR images using advanced morphological operators. In Proceedings of the IEEE Urban Remote Sensing Joint Event, Paris, France, 11–13 April 2007; pp. 1–5. [Google Scholar]
- Stankov, K.; He, D.C. Building detection in very high spatial resolution multispectral images using the hit-or-miss transform. IEEE Geosci. Remote Sens. Lett. 2013, 10, 86–90. [Google Scholar] [CrossRef]
- Stankov, K.; He, D.C. Detection of buildings in multispectral very high spatial resolution images using the percentage occupancy hit-or-miss transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4069–4080. [Google Scholar] [CrossRef]
- Peng, J.; Zhang, D.; Liu, Y. An improved snake model for building detection from urban aerial images. Pattern Recognit. Lett. 2005, 26, 587–595. [Google Scholar] [CrossRef]
- Ahmadi, S.; Zoej, M.J.V.; Ebadi, H.; Abrishami, H.; Mohammadzadeh, A. Automatic urban building boundary extraction from high resolution aerial images using an innovative model of active contours. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 150–157. [Google Scholar] [CrossRef]
- Yari, D.; Mokhtarzade, M.; Ebadi, H.; Ahmadi, S. Automatic reconstruction of regular buildings using a shape-based balloon snake model. Photogramm. Rec. 2014, 29, 187–205. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; Tiede, D. Geographic object-based image analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Ziaei, Z.; Pradhan, B.; Mansor, S.B. A rule-based parameter aided with object-based classification approach for extraction of building and roads from WorldView-2 images. Geocarto Int. 2014, 29, 554–569. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Huertas, A.; Nevatia, R. Detecting buildings in aerial images. Comput. Vis. Graph. Image Process. 1988, 41, 131–152. [Google Scholar] [CrossRef]
- Irvin, R.B.; McKeown, D.M. Methods for exploiting the relationship between buildings and their shadows in aerial imagery. IEEE Trans. Syst. Man Cybern. 1989, 19, 1564–1575. [Google Scholar] [CrossRef]
- Liow, Y.T.; Pavlidis, T. Use of shadows for extracting buildings in aerial images. Comput. Vis. Graph. Image Process. 1990, 49, 242–277. [Google Scholar] [CrossRef]
- Sirmacek, B.; Unsalan, C. Building detection from aerial images using invariant color features and shadow information. In Proceedings of the 23rd International Symposium on Computer and Information Sciences, ISCIS 2008, Istanbul, Turkey, 27–29 October 2008; pp. 105–110. [Google Scholar]
- Huang, X.; Zhang, L. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 161–172. [Google Scholar] [CrossRef]
- Benarchid, O.; Raissouni, N.; Adib, S.E.; Abbous, A.; Azyat, A.; Ben, A.N.; Lahraoua, M.; Chahboun, A. Building extraction using object-based classification and shadow information in very high resolution multispectral images, a case study: Tetuan, Morocco. Can. J. Image Process. Comput. Vis. 2013, 4, 1–8. [Google Scholar]
- Chen, D.; Shang, S.; Wu, C. Shadow-based building detection and segmentation in high-resolution remote sensing image. J. Multimedia 2014, 9, 181–188. [Google Scholar] [CrossRef]
- Durieux, L.; Lagabrielle, E.; Nelson, A. A method for monitoring building construction in urban sprawl areas using object-based analysis of Spot 5 images and existing GIS data. ISPRS J. Photogramm. Remote Sens. 2008, 63, 399–408. [Google Scholar] [CrossRef]
- Sahar, L.; Muthukumar, S.; French, S.P. Using aerial imagery and GIS in automated building footprint extraction and shape recognition for earthquake risk assessment of urban inventories. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3511–3520. [Google Scholar] [CrossRef]
- Guo, Z.; Du, S. Mining parameter information for building extraction and change detection with very high-resolution imagery and GIS data. GISci. Remote Sens. 2017, 54, 38–63. [Google Scholar] [CrossRef]
- Sohn, G.; Dowman, I. Data fusion of high-resolution satellite imagery and LiDAR data for automatic building extraction. ISPRS J. Photogramm. Remote Sens. 2007, 62, 43–63. [Google Scholar] [CrossRef]
- Hermosilla, T.; Ruiz, L.A.; Recio, J.A.; Estornell, J. Evaluation of automatic building detection approachs combining high resolution images and LiDAR data. Remote Sens. 2011, 3, 1188–1210. [Google Scholar] [CrossRef]
- Partovi, T.; Bahmanyar, R.; Krauß, T.; Reinartz, P. Building outline extraction using a heuristic approach based on generalization of line segments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 933–947. [Google Scholar] [CrossRef]
- Chai, D. A probabilistic framework for building extraction from airborne color image and DSM. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 948–959. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Guo, Z.; Shao, X.; Xu, Y.; Miyazaki, H.; Ohira, W.; Shibasaki, R. Identification of village building via Google Earth images and supervised machine learning methods. Remote Sens. 2016, 8, 271. [Google Scholar] [CrossRef]
- Cohen, J.P.; Ding, W.; Kuhlman, C.; Chen, A.; Di, L. Rapid building detection using machine learning. Appl. Intell. 2016, 45, 443–457. [Google Scholar] [CrossRef]
- Dornaika, F.; Moujahid, A.; Merabet, Y.E.; Ruichek, Y. Building detection from orthophotos using a machine learning approach: An empirical study on image segmentation and descriptors. Expert Syst. Appl. 2016, 58, 130–142. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Yuan, J.; Cheriyadat, A.M. Learning to count buildings in diverse aerial scenes. In Proceedings of the International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014. [Google Scholar]
- Roerdink, J.B.; Meijster, A. The watershed transform: Definitions, algorithms and parallelization strategies. Fundam. Inform. 2000, 41, 187–228. [Google Scholar]
- Haris, K.; Efstratiadis, S.N.; Maglaveras, N.; Katsaggelos, A.K. Hybrid image segmentation using watersheds and fast region merging. IEEE Trans. Image Process. 1998, 7, 1684–1699. [Google Scholar] [CrossRef] [PubMed]
- Cretu, A.M.; Payeur, P. Building detection in aerial images based on watershed and visual attention feature descriptors. In Proceedings of the International Conference on Computer and Robot Vision, Regina, SK, Canada, 28–31 May 2013; pp. 265–272. [Google Scholar]
- Shorter, N.; Kasparis, T. Automatic vegetation identification and building detection. Remote Sens. 2009, 1, 731–757. [Google Scholar] [CrossRef]
- Gevers, T.; Smeulders, A.W.M. PicToSeek: Combining color and shape invariant features for image retrieval. IEEE Trans. Image Process. 2000, 9, 102–119. [Google Scholar] [CrossRef] [PubMed]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Shahtahmassebi, A.; Yang, N.; Wang, K.; Moore, N.; Shen, Z. Review of shadow detection and de-shadowing methods in remote sensing. Chin. Geogr. Sci. 2013, 23, 403–420. [Google Scholar] [CrossRef]
- Breen, E.J.; Jones, R.; Talbot, H. Mathematical morphology: A useful set of tools for image analysis. Stat. Comput. 2000, 10, 105–120. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Harwood, D. A comparative study of texture measures with classification based on feature distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with Local Binary Pattern. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Teague, M.R. Image Analysis via the general theory of moments. J. Opt. Soc. Am. 1980, 70, 920–930. [Google Scholar] [CrossRef]
- Singh, G.; Jouppi, M.; Zhang, Z.; Zakhor, A. Shadow based building extraction from single satellite image. Proc. SPIE Comput. Imaging XIII 2015, 9401, 94010F. [Google Scholar]
- Potuckova, M.; Hofman, P. Comparison of quality measures for building outline extraction. Photogramm. Rec. 2016, 31, 193–209. [Google Scholar] [CrossRef]
- Powers, D. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Parameters | Description |
|---|---|---|
| AdaBoost | The maximum number of estimator at which boosting is terminated. | |
| Learning rate. | ||
| SVM | Kernel = ‘RBF’ | Ridial basis function is used as the kernal. |
| defines the influence distance of a single example. | ||
| RF | Total number of trees in the random forest. | |
| The number of tried attributes when splitting nodes. |
| Method | Data | Acc. | Prec. | Rec. | Spec. | F1 Score | AUC |
|---|---|---|---|---|---|---|---|
| AdaBoost | test01 | 0.889 | 0.811 | 0.896 | 0.885 | 0.851 | 0.951 |
| test02 | 0.852 | 0.735 | 0.781 | 0.882 | 0.758 | 0.934 | |
| test03 | 0.839 | 0.734 | 0.746 | 0.880 | 0.740 | 0.915 | |
| test04 | 0.833 | 0.831 | 0.673 | 0.923 | 0.744 | 0.918 | |
| test05 | 0.850 | 0.900 | 0.692 | 0.951 | 0.783 | 0.901 | |
| test06 | 0.877 | 0.750 | 0.792 | 0.907 | 0.771 | 0.926 | |
| test07 | 0.774 | 0.792 | 0.514 | 0.923 | 0.623 | 0.870 | |
| test08 | 0.778 | 0.829 | 0.459 | 0.949 | 0.591 | 0.860 | |
| Overall | 0.829 | 0.787 | 0.671 | 0.909 | 0.725 | 0.900 | |
| RF | test01 | 0.926 | 0.879 | 0.906 | 0.936 | 0.892 | 0.965 |
| test02 | 0.898 | 0.825 | 0.825 | 0.928 | 0.825 | 0.953 | |
| test03 | 0.905 | 0.855 | 0.803 | 0.945 | 0.828 | 0.948 | |
| test04 | 0.840 | 0.830 | 0.682 | 0.925 | 0.749 | 0.918 | |
| test05 | 0.902 | 0.953 | 0.788 | 0.975 | 0.863 | 0.934 | |
| test06 | 0.911 | 0.807 | 0.868 | 0.927 | 0.836 | 0.950 | |
| test07 | 0.825 | 0.870 | 0.563 | 0.957 | 0.684 | 0.900 | |
| test08 | 0.821 | 0.816 | 0.593 | 0.934 | 0.687 | 0.883 | |
| Overall | 0.872 | 0.848 | 0.731 | 0.938 | 0.785 | 0.926 | |
| SVM | test01 | 0.926 | 0.903 | 0.875 | 0.952 | 0.889 | 0.966 |
| test02 | 0.907 | 0.821 | 0.873 | 0.922 | 0.846 | 0.958 | |
| test03 | 0.915 | 0.866 | 0.829 | 0.949 | 0.847 | 0.959 | |
| test04 | 0.873 | 0.854 | 0.766 | 0.930 | 0.808 | 0.947 | |
| test05 | 0.910 | 0.900 | 0.865 | 0.938 | 0.882 | 0.958 | |
| test06 | 0.921 | 0.803 | 0.925 | 0.920 | 0.860 | 0.973 | |
| test07 | 0.901 | 0.868 | 0.831 | 0.936 | 0.849 | 0.939 | |
| test08 | 0.867 | 0.824 | 0.763 | 0.919 | 0.792 | 0.929 | |
| Overall | 0.898 | 0.852 | 0.825 | 0.933 | 0.838 | 0.951 |
| Data | Acc. | Prec. | Rec. | Spec. | F1 Score | AUC |
|---|---|---|---|---|---|---|
| test09 | 0.950 | 0.875 | 0.875 | 0.969 | 0.875 | 0.986 |
| test10 | 0.867 | 0.917 | 0.688 | 0.966 | 0.786 | 0.878 |
| test11 | 0.927 | 0.923 | 0.750 | 0.981 | 0.828 | 0.915 |
| test12 | 0.887 | 0.886 | 0.646 | 0.971 | 0.747 | 0.899 |
| Overall | 0.910 | 0.902 | 0.724 | 0.973 | 0.803 | 0.915 |
| Features | Color | LBP | Geometric Indices | Zernike Moments | ERI + SLI | Sum. |
|---|---|---|---|---|---|---|
| Importance | 0.1269 | 0.1845 | 0.2030 | 0.2011 | 0.2845 | 1.0000 |
| Features | Acc. | Prec. | Rec. | Spec. | F1 Score | AUC |
|---|---|---|---|---|---|---|
| all | 0.905 | 0.896 | 0.765 | 0.961 | 0.825 | 0.935 |
| All-(ERI + SLI) | 0.861 | 0.840 | 0.653 | 0.947 | 0.735 | 0.903 |
| ERI + SLI | 0.841 | 0.876 | 0.555 | 0.954 | 0.670 | 0.875 |
| Color | 0.771 | 0.642 | 0.432 | 0.896 | 0.486 | 0.793 |
| LBP | 0.767 | 0.666 | 0.452 | 0.887 | 0.520 | 0.789 |
| Geo | 0.825 | 0.825 | 0.527 | 0.945 | 0.638 | 0.848 |
| Zer | 0.766 | 0.713 | 0.374 | 0.923 | 0.480 | 0.747 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, R.; Li, X.; Li, J. Object-Based Features for House Detection from RGB High-Resolution Images. Remote Sens. 2018, 10, 451. https://doi.org/10.3390/rs10030451
Chen R, Li X, Li J. Object-Based Features for House Detection from RGB High-Resolution Images. Remote Sensing. 2018; 10(3):451. https://doi.org/10.3390/rs10030451
Chicago/Turabian StyleChen, Renxi, Xinhui Li, and Jonathan Li. 2018. "Object-Based Features for House Detection from RGB High-Resolution Images" Remote Sensing 10, no. 3: 451. https://doi.org/10.3390/rs10030451
APA StyleChen, R., Li, X., & Li, J. (2018). Object-Based Features for House Detection from RGB High-Resolution Images. Remote Sensing, 10(3), 451. https://doi.org/10.3390/rs10030451