Data Field-Based K-Means Clustering for Spatio-Temporal Seismicity Analysis and Hazard Assessment



 and
and
Abstract
:
1. Introduction
2. Related Works
3. Preliminary Studies and the Proposed Method
3.1. K-Means Clustering Preliminary Study
3.2. Data Field Theory
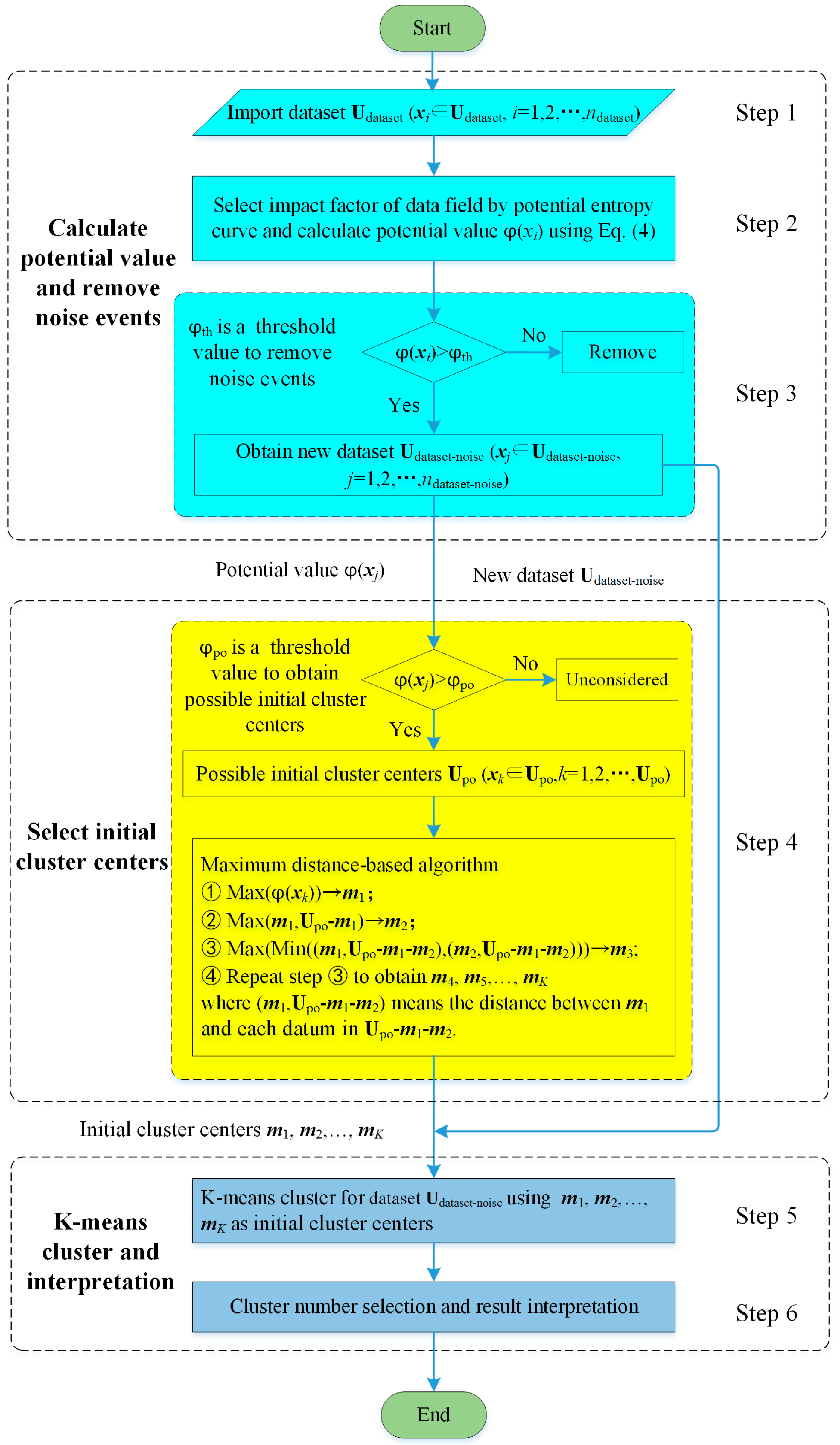
3.3. Data Field-Based K-Means Clustering Procedure
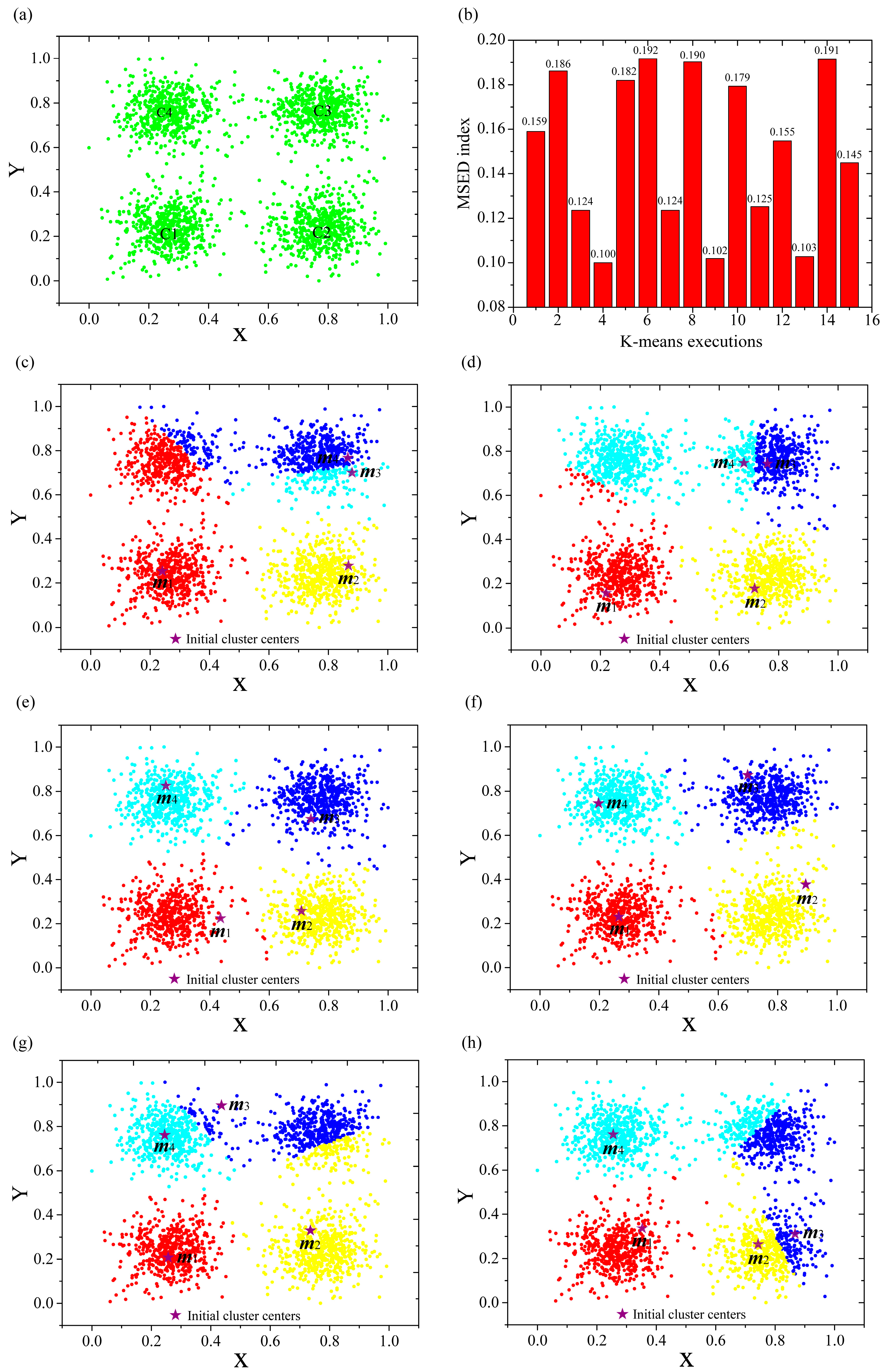
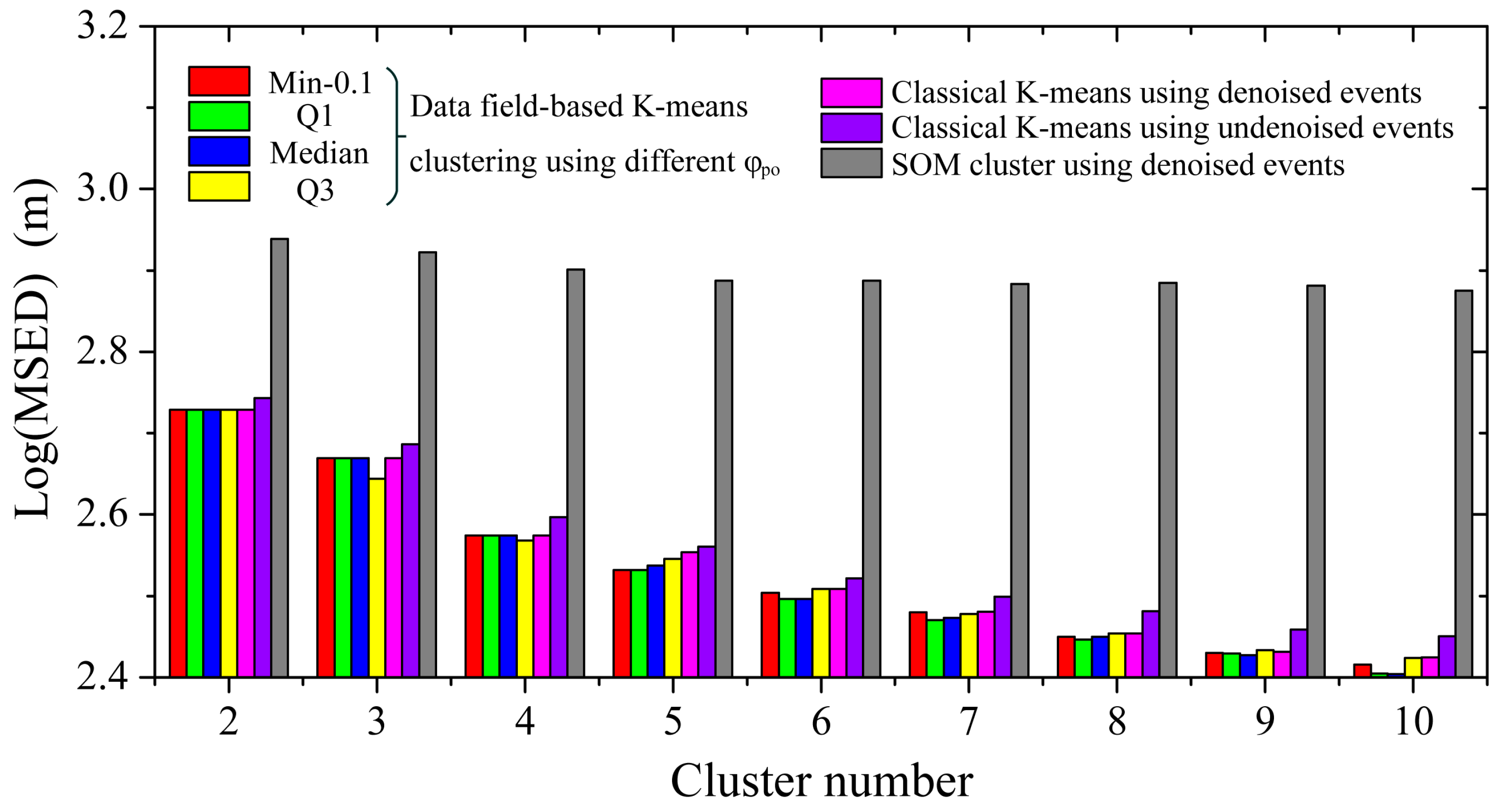
3.4. Application Test
4. Application to Seismic Data
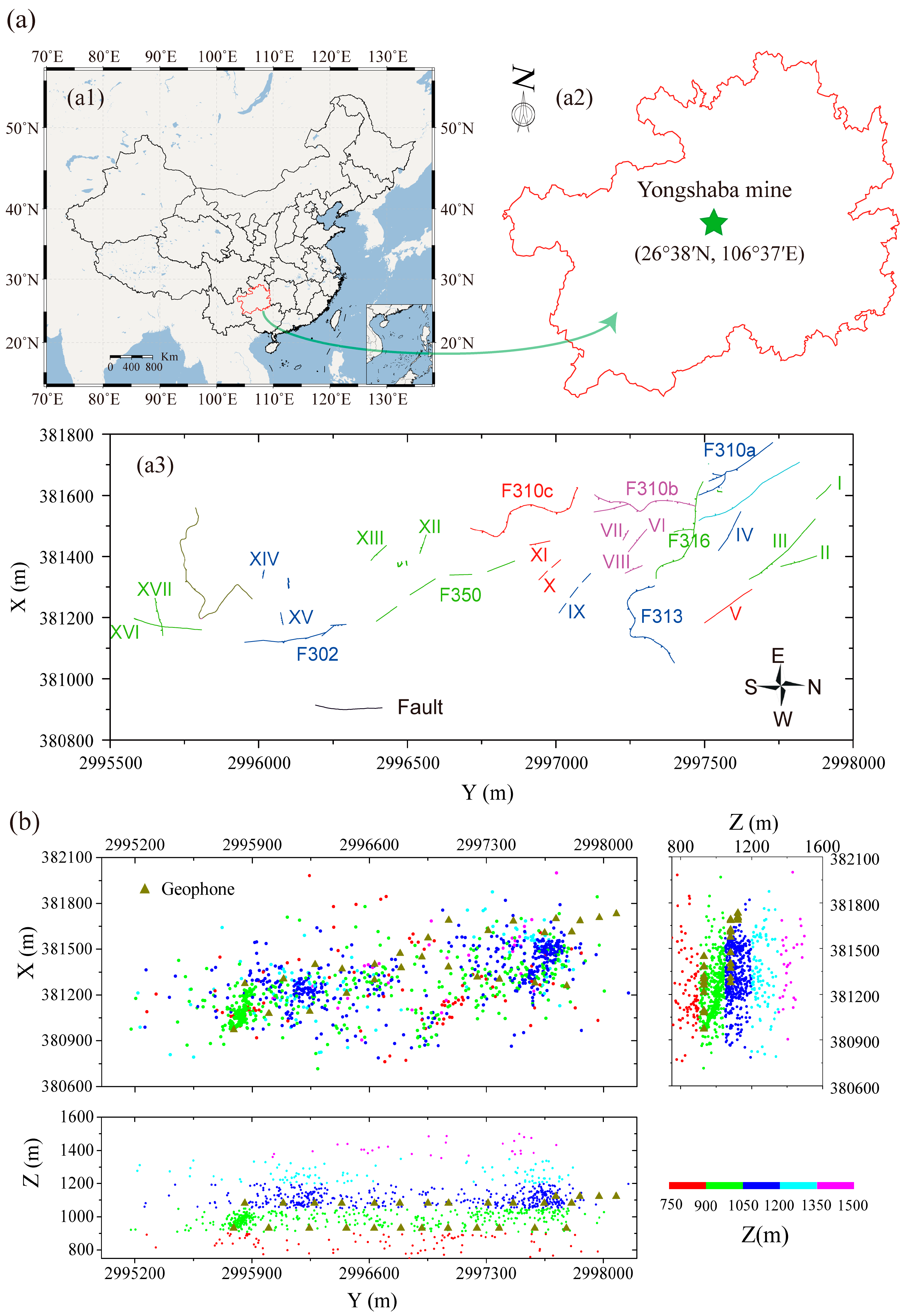
4.1. Seismic Dataset Description
4.2. Noise Event Removing Process
4.3. Seismic Event Clustering Procedure
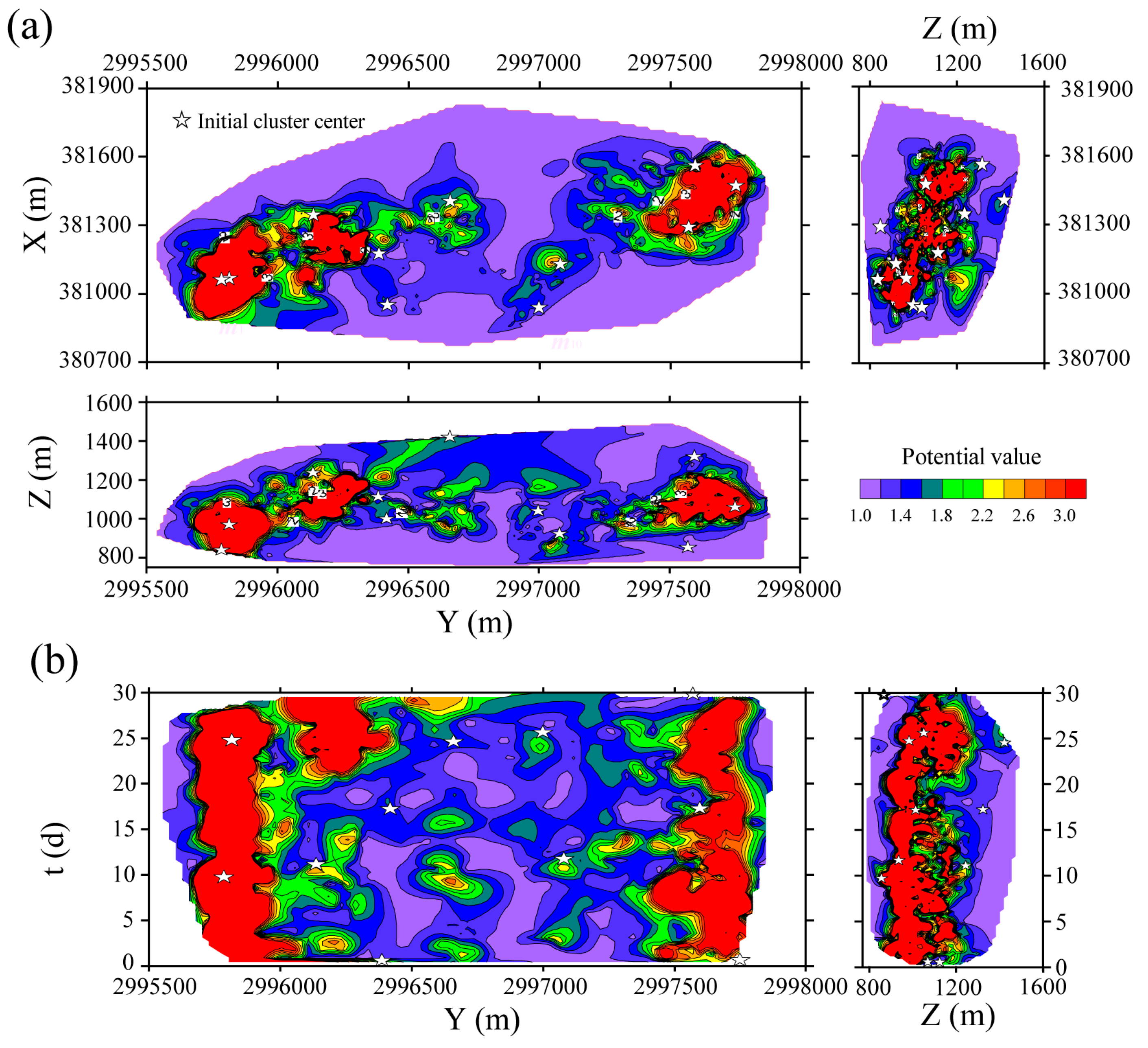
4.3.1. Time-Event Location Distance-Based Data Field
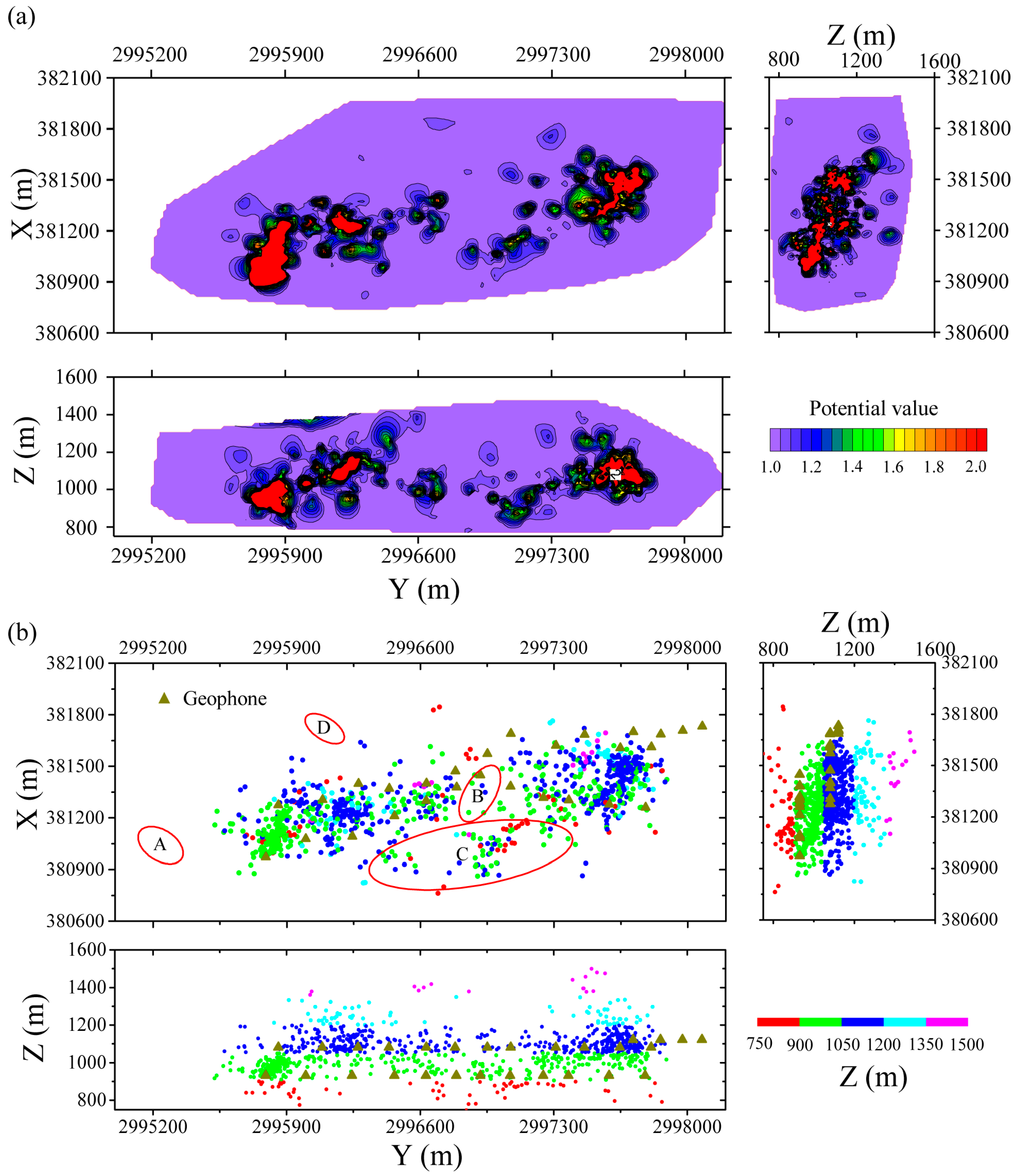
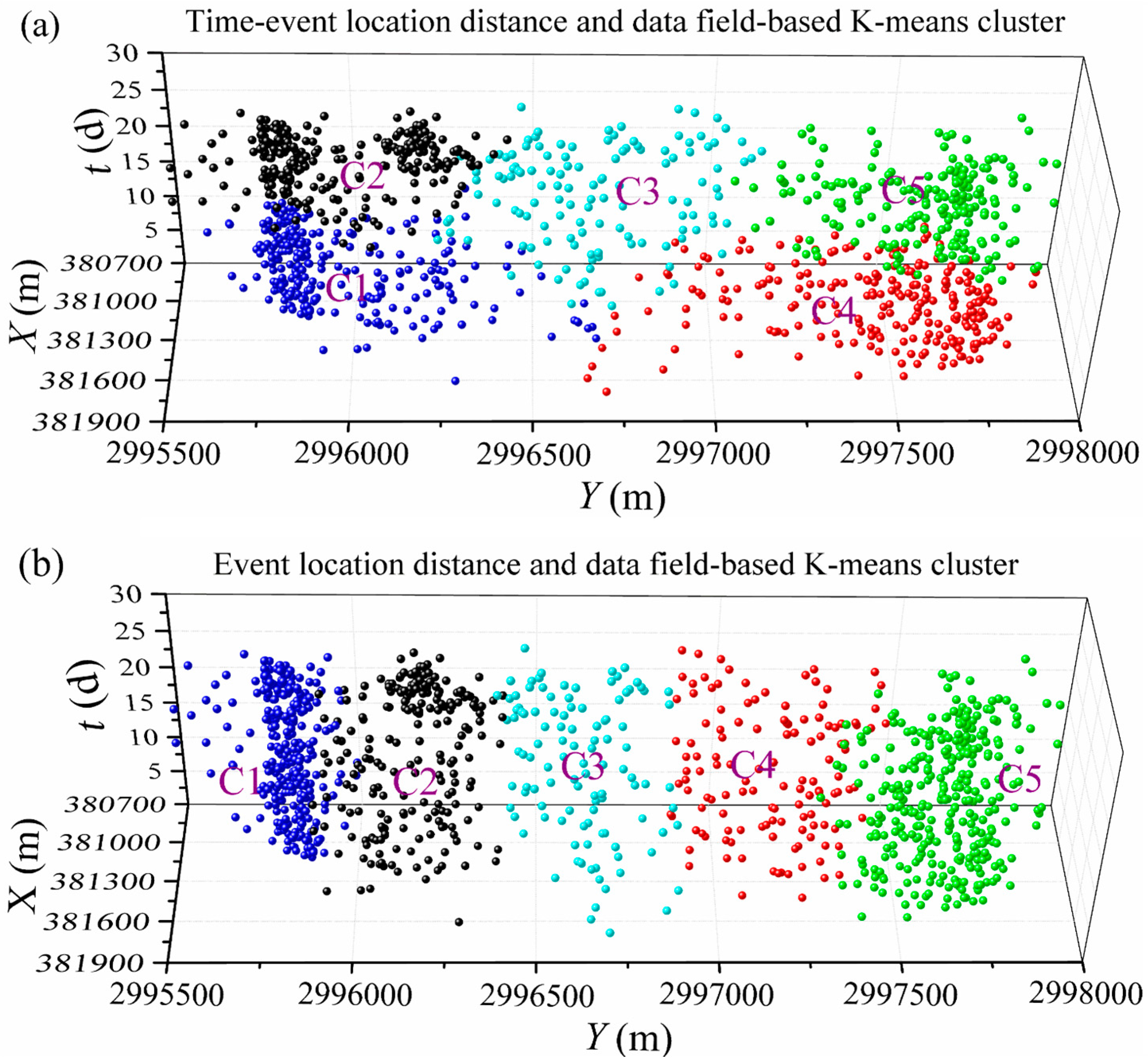
4.3.2. Cluster Results
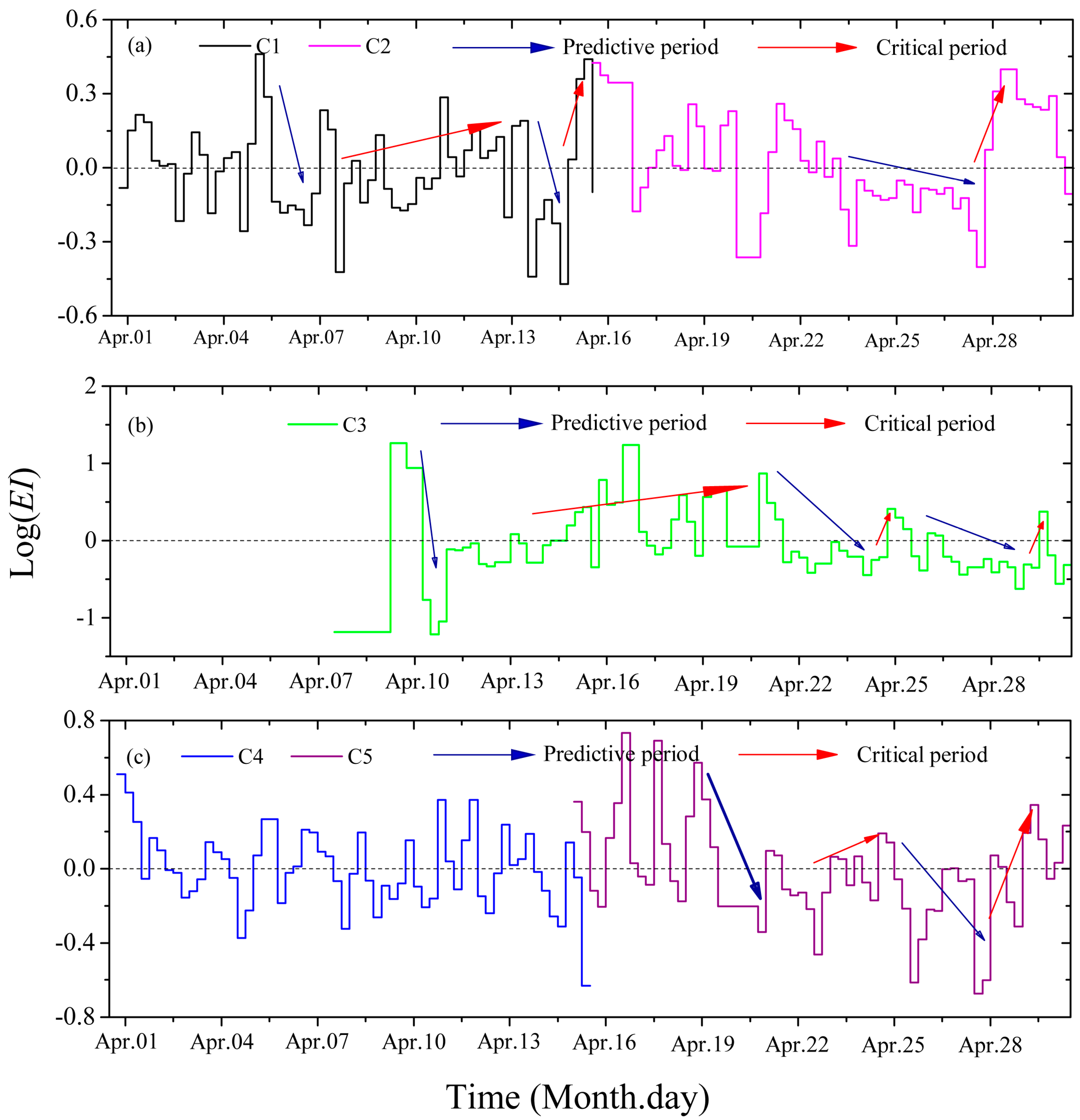
4.3.3. Seismicity Analysis
5. Discussion
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Georgoulas, G.; Konstantaras, A.; Katsifarakis, E.; Stylios, C.D.; Maravelakis, E.; Vachtsevanos, G.J. “Seismic-mass” density-based algorithm for spatio-temporal clustering. Expert Syst. Appl. 2013, 40, 4183–4189. [Google Scholar] [CrossRef]
- Fidani, C.; Battiston, R.; Burger, W.J. A study of the correlation between earthquakes and NOAA satellite energetic particle bursts. Remote Sens. 2010, 2, 2170–2184. [Google Scholar] [CrossRef]
- Zamani, A.; Hashemi, N. Computer-based self-organized tectonic zoning: A tentative pattern recognition for Iran. Comput. Geosci. 2004, 30, 705–718. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means clustering algorithm. J. R. Stat. Soc. C-Appl. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Burton, P.W.; Weatherill, G.; Karnawati, D.; Pramumijoyo, S. Seismic Hazard Assessment and Zoning in Java: New and Alternative Probabilistic Assessment Models. In Proceedings of the International Conference on Earthquake Engineering and Disaster Mitigation, Jakarta, Indonesia, 14–15 April 2008. [Google Scholar]
- Weatherill, G.; Burton, P.W. Delineation of shallow seismic source zones using K-means cluster analysis, with application to the Aegean region. Geophys. J. Int. 2009, 176, 565–588. [Google Scholar] [CrossRef]
- Weatherill, G.; Burton, P.W. An alternative approach to probabilistic seismic hazard analysis in the Aegean region using Monte Carlo simulation. Tectonophysics 2010, 492, 253–278. [Google Scholar] [CrossRef]
- Ramdani, F.; Kettani, O.; Tadili, B. Evidence for subduction beneath Gibraltar Arc and Andean regions from k-means earthquake centroids. J. Seismol. 2015, 19, 41–53. [Google Scholar] [CrossRef]
- Rehman, K.; Burton, P.W.; Weatherill, G.A. K-means cluster analysis and seismicity partitioning for Pakistan. J. Seismol. 2014, 18, 401–419. [Google Scholar] [CrossRef]
- Morales-Esteban, A.; Martinez-Alvarez, F.; Scitovski, S.; Scitovski, R. A fast partitioning algorithm using adaptive Mahalanobis clustering with application to seismic zoning. Comput. Geosci. 2014, 73, 132–141. [Google Scholar] [CrossRef]
- Shang, X.Y.; Li, X.B.; Morales-Esteban, A.; Dong, L.J.; Peng, K. K-Means cluster for seismicity partitioning and geological structure interpretation, with application to the Yongshaba mine (China). Shock Vib. 2017, 1–11. [Google Scholar] [CrossRef]
- Wardlaw, R.L.; Frohlich, C.; Davis, S.D. Evaluation of precursory seismic quiescence in sixteen subduction zones using single-link cluster analysis. Pure Appl. Geophys. 1990, 134, 57–78. [Google Scholar] [CrossRef]
- Frohlich, C.; Davis, S.D. Single-Link cluster analysis as a method to evaluate spatial and temporal properties of earthquake catalogues. Geophys. J. Int. 1990, 100, 19–32. [Google Scholar] [CrossRef]
- Davis, S.D.; Frohlich, C. Single-Link cluster analysis, synthetic earthquake catalogues, and aftershock identification. Geophys. J. Int. 1991, 104, 289–306. [Google Scholar] [CrossRef]
- Hudyma, M.; Potvin, Y.H. An Engineering Approach to Seismic Risk Management in Hardrock Mines. Rock Mech. Rock Eng. 2010, 43, 891–906. [Google Scholar] [CrossRef]
- Hashemi, S.N.; Mehdizadeh, R. Application of hierarchical clustering technique for numerical tectonic regionalization of the Zagros region (Iran). Earth Sci. Inform. 2015, 8, 367–380. [Google Scholar] [CrossRef]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Zamani, A.; Nedaei, M.; Boostani, R. Tectonic zoning of Iran based on self-organizing map. J. Appl. Sci. 2009, 9, 4099–4114. [Google Scholar] [CrossRef]
- Zamani, A.; Khalili, M.; Gerami, A. Computer-based self-organized tectonic zoning revisited: Scientific criterion for determining the optimum number of zones. Tectonophysics 2011, 510, 207–216. [Google Scholar] [CrossRef]
- Mojarab, M.; Memarian, H.; Zare, M.; Morshedy, A.H.; Pishahang, M.H. Modeling of the seismotectonic provinces of Iran using the self-organizing map algorithm. Comput. Geosci. 2014, 67, 150–162. [Google Scholar] [CrossRef]
- Ramezani Besheli, P.; Zare, M.; Ramezani Umali, R.; Nakhaeezadeh, G. Zoning Iran based on earthquake precursor importance and introducing a main zone using a data-mining process. Nat. Hazards 2015, 78, 821–835. [Google Scholar] [CrossRef]
- Martínez-Álvarez, F.; Gutiérrez-Avilés, D.; Morales-Esteban, A.; Reyes, J.; Amaro-Mellado, J.; Rubio-Escudero, C. A novel method for seismogenic zoning based on triclustering: Application to the Iberian Peninsula. Entropy 2015, 17, 5000–5021. [Google Scholar] [CrossRef]
- Ansari, A.; Noorzad, A.; Zafarani, H. Clustering analysis of the seismic catalog of Iran. Comput. Geosci. 2009, 35, 475–486. [Google Scholar] [CrossRef]
- Benitez, H.D.; Florez, J.F.; Duque, D.P.; Benavides, A.; Baquero, O.L.; Quintero, J. Spatial pattern recognition of seismic events in South West Colombia. Comput. Geosci. 2013, 59, 60–77. [Google Scholar] [CrossRef]
- Monem, M.J.; Hashemy, S.M. Extracting physical homogeneous regions out of irrigation networks using fuzzy clustering method: A case study for the Ghazvin canal irrigation network. J. Hydroinform. 2011, 13, 652–660. [Google Scholar] [CrossRef]
- Mukhopadhyay, B.; Fnais, M.; Mukhopadhyay, M.; Dasgupta, S. Seismic cluster analysis for the Burmese-Andaman and West Sunda Arc: Insight into subduction kinematics and seismic potentiality. Geomat. Nat. Hazards Risk 2010, 1, 283–314. [Google Scholar] [CrossRef]
- Nanda, S.J.; Panda, G. Design of computationally efficient density-based clustering algorithms. Data Knowl. Eng. 2015, 95, 23–38. [Google Scholar] [CrossRef]
- Gutiérrez-Avilés, D.; Rubio-Escudero, C. Mining 3D patterns from gene expression temporal data: A new tricluster evaluation measure. Sci. World J. 2014, 624371. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez-Avilés, D.; Rubio-Escudero, C.; Martínez-Álvarez, F.; Riquelme, J.C. TriGen: A genetic algorithm to mine triclusters in temporal gene expression data. Neurocomputing 2014, 132, 42–53. [Google Scholar] [CrossRef]
- Lesniak, A.; Isakow, Z. Space-time clustering of seismic events and hazard assessment in the Zabrze-Bielszowice coal mine, Poland. Int. J. Rock Mech. Min. 2009, 46, 918–928. [Google Scholar] [CrossRef]
- Konstantaras, A.J.; Katsifarakis, E.; Maravelakis, E.; Skounakis, E.; Kokkinos, E.; Karapidakis, E. Intelligent spatial-clustering of seismicity in the vicinity of the Hellenic Seismic Arc. Earth Sci. Res. 2012, 1, 1–10. [Google Scholar] [CrossRef]
- Baiesi, M.; Paczuski, M. Scale-free networks of earthquakes and aftershocks. Phys. Rev. E 2004, 69, 066106. [Google Scholar] [CrossRef] [PubMed]
- Zaliapin, I.; Gabrielov, A.; Keilis-Borok, V.; Wong, H. Clustering analysis of seismicity and aftershock identification. Phys. Rev. Lett. 2008, 101, 018501. [Google Scholar] [CrossRef] [PubMed]
- Zaliapin, I.; Ben-Zion, Y. Asymmetric distribution of aftershocks on large faults in California. Geophys. J. Int. 2011, 185, 1288–1304. [Google Scholar] [CrossRef]
- Zaliapin, I.; Ben-Zion, Y. Earthquake clusters in southern California II: Classification and relation to physical properties of the crust. J. Geophys. Res.-Sol. EA 2013, 118, 2865–2877. [Google Scholar] [CrossRef]
- Zaliapin, I.; Ben-Zion, Y. Earthquake clusters in Southern California I: Identification and stability. J. Geophys. Res.-Sol. EA 2013, 118, 2847–2864. [Google Scholar] [CrossRef]
- Zaliapin, I.; Ben-Zion, Y. A global classification and characterization of earthquake clusters. Geophys. J. Int. 2016, 207, 608–634. [Google Scholar] [CrossRef]
- Zaliapin, I.; Ben-Zion, Y. Discriminating characteristics of tectonic and human-induced seismicity. Bull. Seismol. Soc. Am. 2016, 106, 846–859. [Google Scholar] [CrossRef]
- Wang, S.; Gan, W.; Li, D.; Li, D. Data field for hierarchical clustering. Int. J. Data Warehous. 2011, 7, 43–63. [Google Scholar] [CrossRef]
- Wu, T. Image data field-based framework for image thresholding. Opt. Laser Technol. 2014, 62, 1–11. [Google Scholar] [CrossRef]
- Li, X.B.; Wang, Z.W.; Dong, L.J. Locating single-point sources from arrival times containing large picking errors (LPEs): The virtual field optimization method (VFOM). Sci. Rep. 2016, 6, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Shang, X.Y.; Li, X.B.; Morales-Esteban, A.; Dong, L.J. Enhancing micro-seismic P-phase arrival picking: EMD-cosine function-based denoising with an application to the AIC picker. J. Appl. Geophys 2018, 150, 325–337. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Krzanowski, W.J.; Lai, Y.T. A criterion for determining the number of groups in a data set using sum-of-squares clustering. Biometrics 1988, 44, 23–34. [Google Scholar] [CrossRef]
- Hudyma, M. Analysis and Interpretation of Clusters of Seismic Events in Mines. Ph.D. Thesis, University of Western Australia, Crawley, Australia, 2008. [Google Scholar]
- Aswegen, G.; Butler, A.G. Applications of quantitative seismology in South African gold mines. In Proceedings of the International Symposium on Rockbursts and Seismicity in Mines, Kingston, ON, Canada, 16–18 August 1993. [Google Scholar]
- Mendecki, D.A.J. Seismic Monitoring in Mines; Chapman & Hall: London, UK, 1997; ISBN 0412753006. [Google Scholar]
- Liu, J.P.; Feng, X.T.; Li, Y.H.; Xu, S.D.; Sheng, Y. Studies on temporal and spatial variation of microseismic activities in a deep metal mine. Int. J. Rock Mech. Min. 2013, 60, 171–179. [Google Scholar] [CrossRef]
- Li, Y.; Yang, T.H.; Liu, H.L.; Wang, H.; Hou, X.G.; Zhang, P.H.; Wang, P.T. Real-time microseismic monitoring and its characteristic analysis in working face with high-intensity mining. J. Appl. Geophys. 2016, 132, 152–163. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster Centers | m1 | m2 | m3 | m4 | m5 | m6 | m7 | m8 | m9 | m10 |
|---|---|---|---|---|---|---|---|---|---|---|
| m1 | 0 | |||||||||
| m2 | 2361.34 | 0 | ||||||||
| m3 | 1793.42 | 1590.18 | 0 | |||||||
| m4 | 1422.77 | 1397.01 | 1977.84 | 0 | ||||||
| m5 | 1013.33 | 1719.96 | 1115.39 | 1362.96 | 0 | |||||
| m6 | 1445.11 | 968.44 | 1095.78 | 934.14 | 984.84 | 0 | ||||
| m7 | 1922.17 | 941.06 | 859.61 | 1562.75 | 1031.80 | 834.58 | 0 | |||
| m8 | 812.17 | 2077.43 | 2093.20 | 830.29 | 1356.92 | 1302.51 | 1978.66 | 0 | ||
| m9 | 735.67 | 1682.82 | 1383.36 | 922.88 | 769.68 | 748.29 | 1362.56 | 772.89 | 0 | |
| m10 | 1192.75 | 1621.99 | 731.55 | 1490.57 | 692.52 | 779.04 | 1010.09 | 1497.57 | 734.18 | 0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, X.; Li, X.; Morales-Esteban, A.; Asencio-Cortés, G.; Wang, Z. Data Field-Based K-Means Clustering for Spatio-Temporal Seismicity Analysis and Hazard Assessment. Remote Sens. 2018, 10, 461. https://doi.org/10.3390/rs10030461
Shang X, Li X, Morales-Esteban A, Asencio-Cortés G, Wang Z. Data Field-Based K-Means Clustering for Spatio-Temporal Seismicity Analysis and Hazard Assessment. Remote Sensing. 2018; 10(3):461. https://doi.org/10.3390/rs10030461
Chicago/Turabian StyleShang, Xueyi, Xibing Li, Antonio Morales-Esteban, Gualberto Asencio-Cortés, and Zewei Wang. 2018. "Data Field-Based K-Means Clustering for Spatio-Temporal Seismicity Analysis and Hazard Assessment" Remote Sensing 10, no. 3: 461. https://doi.org/10.3390/rs10030461
APA StyleShang, X., Li, X., Morales-Esteban, A., Asencio-Cortés, G., & Wang, Z. (2018). Data Field-Based K-Means Clustering for Spatio-Temporal Seismicity Analysis and Hazard Assessment. Remote Sensing, 10(3), 461. https://doi.org/10.3390/rs10030461