A Deep-Local-Global Feature Fusion Framework for High Spatial Resolution Imagery Scene Classification



Abstract
:1. Introduction
- (1)
- The DLGFF framework is proposed to discover discriminative information from the HSR imagery. Based on the low-level visual information, three heterogeneous handcrafted features and two deep features are designed to capture the complex geometrical structures and spatial patterns of HSR images. The feature spaces of different types of features are separately mined and effectively fused to circumvent feature interruption in the feature learning process (see also Section 3).
- (2)
- In order to capture representative semantics and spatial structures for the scenes, the low-level based SITI texture, the mid-level based BoVW model, and the high-level based CNN scene classification method are first combined in DLGFF. The spatial information and intrinsic information are acquired from the CNN, whereas the unique characteristics of HSR imagery can be extracted from the handcrafted feature–based methods. The integration of the low-level, mid-level, and deep features provides a multi-level feature description for distinct scenes (see also Section 3.1 and Section 3.2).
- (3)
- Two approaches are proposed in the DLGFF framework, i.e., the local and global features fused with the fully connected features (LGFF) and the local and global features fused with the pooling-stretched convolutional features (LGCF). To make full use of the spatial information and intrinsic information in the intermediate Conv layers and FC layer, the DLGFF framework provides an effective strategy for the BoVW features to complement the deep features from different layers (see also Section 3.3).
2. Background
2.1. Scene Classification Based on the BoVW Model
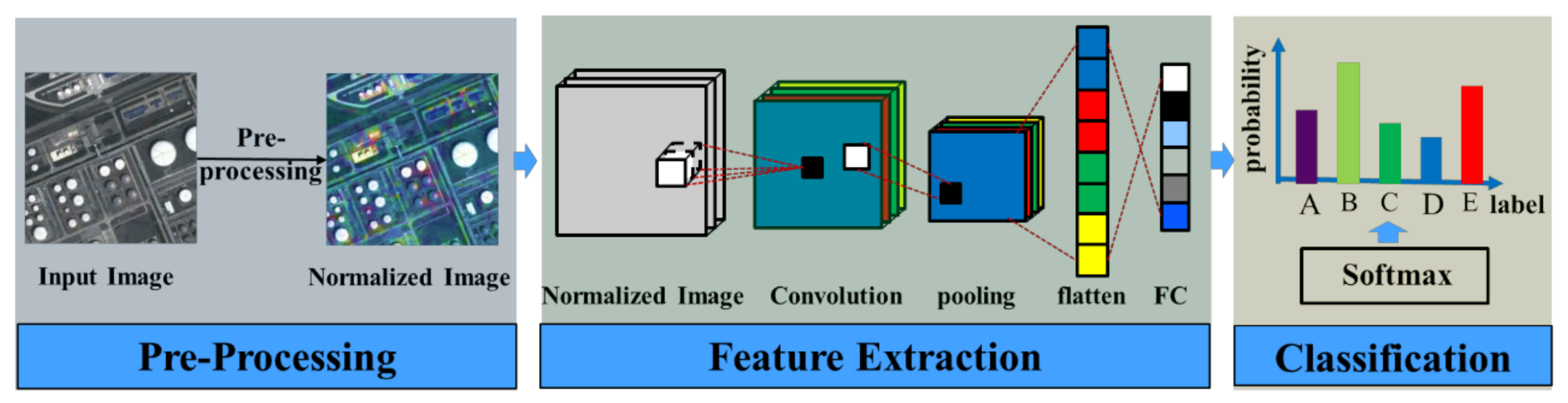
2.2. Scene Classification Based on a CNN
3. The DLGFF Framework for HSR Imagery Scene Classification
3.1. Local and Global Feature Generation
3.2. Conv and FC Feature Generation by CNN
3.3. Feature Fusion and Classification Based on LGCF and LGFF
4. Experiments and Analysis
4.1. Experimental Setup
4.2. Experiment 1: The UC Merced Image Dataset
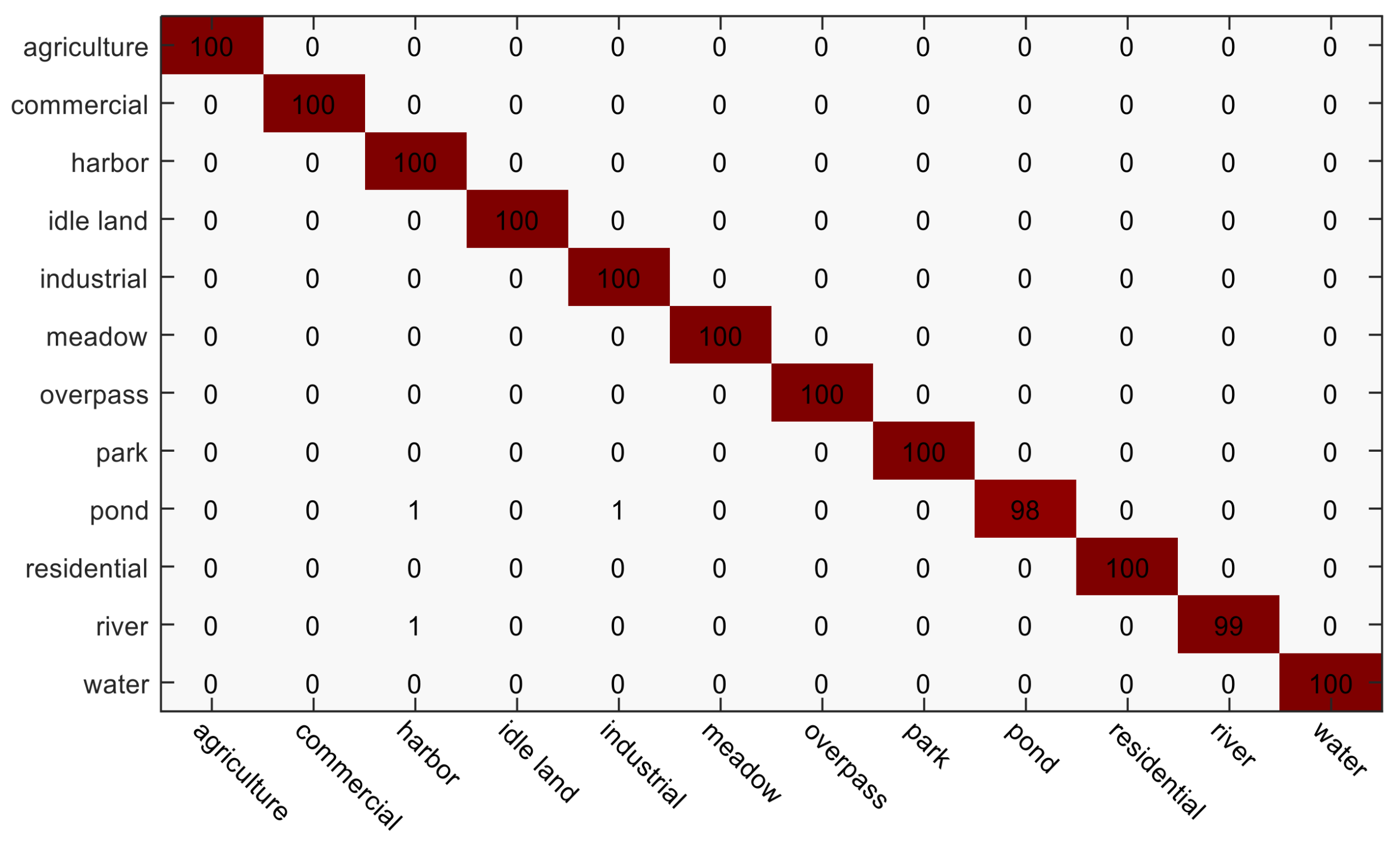
4.3. Experiment 2: The Google Dataset of SIRI-WHU
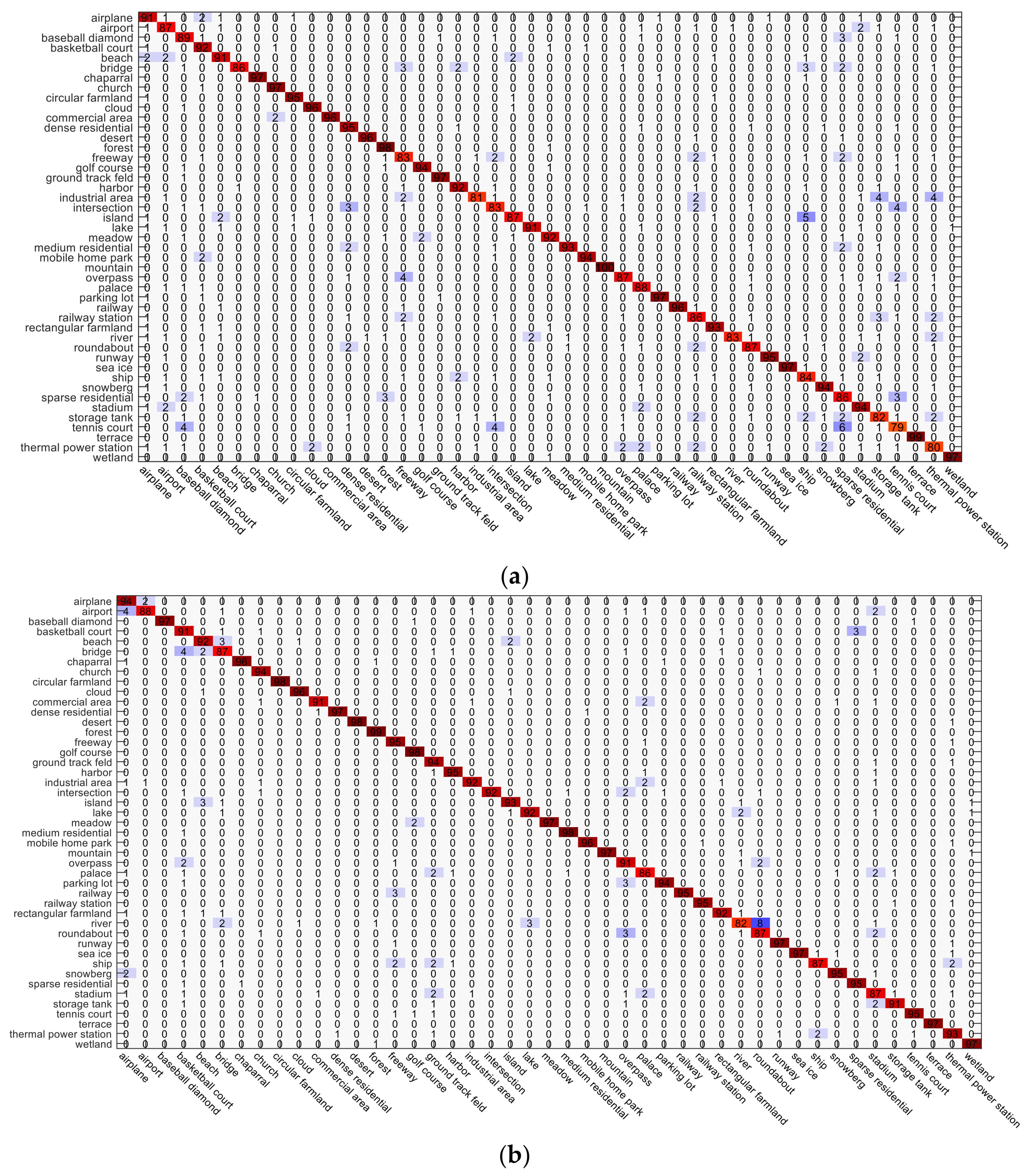
4.4. Experiment 3: The NWPU-RESISC45 Dataset
5. Discussion
- (1)
- The effect of the visual word number V for the LGFBOVW and DLGFF scene classification methods. In the experiments, the visual word number V was varied over the range of [1350,2350,2850,3350] for the UC Merced dataset, the Google dataset of SIRI-WHU, and the NWPU-RESISC45 dataset, under the training sample proportions of 10% and 20%. As shown in Figure 13, with the increase of the visual word number V, the overall accuracy (OA) curves of LGCF and LGFF become higher at the beginning and then fluctuate. For the three datasets, the highest accuracy is acquired when the visual word number is 2350.
- (2)
- The effect of the different Conv layers for the DLGFF framework. In the experiments, the parameter settings of the global SITI feature and the local BoVW-based feature were the same as the settings of the preliminary experiments. The first, third, and fifth Conv layers and the first and second FC layers from the pre-trained CaffeNet were selected for comparison. As shown in Figure 15, the feature from the first FC layer, i.e., Fc6, outperforms the features from the other layers. For the Conv layers, as the depth of the layers increases, the OA also tends to increase. For the FC layers, Fc6 performs better than Fc7. Compared with Fc7, the fifth Conv layer, i.e., Conv5, does not perform as well in distinguishing the images.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| HSR | high spatial resolution |
| LULC | land-cover/land-use |
| LBP | local binary patterns |
| BoVW | bag-of-visual-words |
| CNN | Convolutional neural network |
| FC | fully connected |
| LLC | locality-constrained linear coding |
| VLAD | vector of locally aggregated descriptors |
| IFK | improved fisher kernel |
| DLGFF | deep-local-global feature fusion |
| MSD | mean and standard deviation |
| SIFT | scale-invariant feature transform |
| SITI | shape-based invariant texture index |
| Conv | convolutional |
| SVM | support vector machine |
| HIK | histogram intersection kernel |
| LGFF | local and global features fused with the fully connected features |
| LGCF | local and global features fused with the pooling-stretched convolutional features |
| CpH | compactness histogram |
| EH | elongation histogram |
| CtH | contrast histogram |
| SRH | scale ratio histogram |
| Caffe | Convolutional Architecture for Fast Feature Embedding |
| Conv5 | the last convolutional layer |
| FC6 | the first fully connected layer |
| BoVW-MSD | BoVW-based scene classification utilizing the MSD feature |
| LGFBOVW | the combination of BoVW-based scene classification utilizing the MSD and SIFT features with the global SITI feature |
| CAFFE-CONV5 | pre-trained CaffeNet based scene classification utilizing the last Conv feature |
| CAFFE-FC6 | pre-trained CaffeNet based scene classification utilizing the first FC feature |
| RS_IDEA | Intelligent Data Extraction and Analysis of Remote Sensing |
| SIRI-WHU | scene image dataset designed by the RS_IDEA Group of Wuhan University |
| OA | overall accuracy |
| POI | point of interest |
| VGI | volunteered geographic information |
| OSM | OpenStreetMap |
References
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; van der Meer, F.; van der Werff, H.; van Coillie, F. Geographic object-based image analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Hay, G.J.; Blaschke, T.; Marceau, D.J.; Bouchard, A. A comparison of three image-object methods for the multiscale analysis of landscape structure. ISPRS J. Photogramm. Remote Sens. 2003, 57, 327–345. [Google Scholar] [CrossRef]
- Tilton, J.C.; Tarabalka, Y.; Montesano, P.M.; Gofman, E. Best merge region-growing segmentation with integrated nonadjacent region object aggregation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4454–4467. [Google Scholar] [CrossRef]
- Bratasanu, D.; Nedelcu, I.; Datcu, M. Bridging the semantic gap for satellite image annotation and automatic mapping applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 193–204. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Li, A.; Lu, Z.; Wang, L.; Xiang, T.; Wen, J.-R. Zero-shot scene classification for high spatial resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4157–4167. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Chen, S.; Tian, Y. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1947–1957. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhao, L.-J.; Tang, P.; Huo, L.-Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.-S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Zhang, L. Scene classification via latent Dirichlet allocation using a hybrid generative/discriminative strategy for high spatial resolution remote sensing imagery. Remote Sens. Lett. 2013, 4, 1204–1213. [Google Scholar] [CrossRef]
- Fan, J.; Chen, T.; Lu, S. Unsupervised feature learning for land-use scene recognition. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2250–2261. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Deng, H.; Lu, J.; Huang, H.; Zhang, L.; Liu, J.; Tang, H.; Xing, X. Learning a discriminative distance metric with label consistency for scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4427–4440. [Google Scholar] [CrossRef]
- Zhong, Y.; Cui, M.; Zhu, Q.; Zhang, L. Scene classification based on multifeature probabilistic latent semantic analysis for high spatial resolution remote sensing images. J. Appl. Remote Sens. 2015, 9, 0950640. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhu, Q.; Zhang, L. Scene classification based on the multifeature fusion probabilistic topic model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6207–6222. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhang, L.; Li, D. Scene classification based on the fully sparse semantic topic model. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5525–5538. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Wallach, I.; Dzamba, M.; Heifets, A. Atomnet: A deep convolutional neural network for bioactivity prediction in structure-based drug discovery. arXiv, 2015; arXiv:1510.02855. [Google Scholar]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object detection in optical remote sensing images based on weakly supervised learning and high-level feature learning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3325–3337. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Geng, J. Spectral–spatial classification of hyperspectral image based on deep auto-encoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4073–4085. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database, Computer Vision and Pattern Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Penatti, O.A.; Nogueira, K.; dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–13 December 2015; pp. 44–51. [Google Scholar]
- Liu, Q.; Hang, R.; Song, H.; Zhu, F.; Plaza, J.; Plaza, A. Adaptive deep pyramid matching for remote sensing scene classification. arXiv, 2016; arXiv:1611.03589. [Google Scholar]
- Wang, J.; Luo, C.; Huang, H.; Zhao, H.; Wang, S. Transferring pre-trained deep CNNs for remote scene classification with general features learned from linear PCA network. Remote Sens. 2017, 9, 225. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv, 2015; arXiv:1508.00092. [Google Scholar]
- Liu, Y.; Huang, C. Scene classification via triplet networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 220–237. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote sensing image scene classification using bag of convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating multilayer features of convolutional neural networks for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Xia, G.-S.; Delon, J.; Gousseau, Y. Shape-based invariant texture indexing. Int. J. Comput. Vis. 2010, 88, 382–403. [Google Scholar] [CrossRef]
- Boureau, Y.-L.; Ponce, J.; LeCun, Y. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 111–118. [Google Scholar]
- Nogueira, K.; Penatti, O.A.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Fei-Fei, L.; Perona, P. A Bayesian hierarchical model for learning natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 524–531. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Barla, A.; Odone, F.; Verri, A. Histogram intersection kernel for image classification. In Proceedings of the International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; p. III-513. [Google Scholar]
- Zhao, B.; Zhong, Y.; Xia, G.-S.; Zhang, L. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2108–2123. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Zhang, L. A spectral–structural bag-of-features scene classifier for very high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2016, 116, 73–85. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Classification Accuracy (%) |
|---|---|
| SITI | 81.54 ± 1.46 |
| BoVW-MSD | 85.30 ± 1.67 |
| LGFBOVW | 96.88 ± 1.32 |
| CAFFE-CONV5 | 95.34 ± 0.74 |
| CAFFE-FC6 | 95.89 ± 0.74 |
| Yang and Newsam [10] | 81.19 |
| Chen and Tian [9] | 89.10 |
| Zhao et al. [46] | 92.92 ± 1.23 |
| Zhao et al. [47] | 91.67 ± 1.70 |
| Castelluccio et al. [33] | 97.10 |
| Zhu et al. [18] | 95.71 ± 1.01 |
| Li et al. [37] | 98.81 ± 0.38 |
| Nogueira et al. [40] | 99.47 ± 0.50 |
| LGCF | 99.52 ± 0.38 |
| LGFF | 99.76 ± 0.06 |
| Method | Classification Accuracy (%) |
|---|---|
| SITI | 79.23 ± 1.01 |
| BoVW-MSD | 86.51 ± 0.92 |
| LGFBOVW | 96.96 ± 0.95 |
| CAFFE-CONV5 | 93.14 ± 0.82 |
| CAFFE-FC6 | 91.79 ± 0.75 |
| Zhao et al. [46] | 91.52 ± 0.64 |
| Zhao et al. [47] | 90.86 ± 0.85 |
| Zhu et al. [18] | 97.83 ± 0.93 |
| LGCF | 99.67 ± 0.22 |
| LGFF | 99.75 ± 0.08 |
| Method | Training Sample Proportion | |
|---|---|---|
| 10% | 20% | |
| SITI | 53.26 ± 0.45 | 58.94 ± 1.12 |
| BoVW-MSD | 57.90 ± 0.17 | 63.59 ± 0.18 |
| LGFBOVW | 74.78 ± 0.28 | 81.67 ± 0.22 |
| CAFFE-CONV5 | 76.90 ± 0.22 | 80.19 ± 0.21 |
| CAFFE-FC6 | 78.65 ± 0.36 | 81.27 ± 0.39 |
| Cheng et al. [26] | 87.15 ± 0.45 | 90.36 ± 0.18 |
| Cheng et al. [36] | 82.65 ± 0.31 | 84.32 ± 0.17 |
| Liu and Huang [34] | 92.33 ± 0.20 | |
| LGCF | 91.07 ± 0.17 | 94.10 ± 0.09 |
| LGFF | 93.61 ± 0.10 | 96.37 ± 0.05 |
| Method | Classification Accuracy (%) | False-Positive Rate | False-Negative Rate |
|---|---|---|---|
| SITI (global) | 58.94 ± 1.12 | ||
| MSBoVW (local) | 71.98 ± 0.68 | ||
| CAFFE-FC6 (deep) | 81.27 ± 0.39 | 0.0042 | 0.1852 |
| LGFBOVW (global-local) | 81.67 ± 0.27 | 0.0041 | 0.1819 |
| Global-deep | 89.47 ± 0.31 | ||
| Deep-local | 94.73 ± 0.23 | ||
| LGFF (deep-local-global) | 96.37 ± 0.05 | 0.0008 | 0.0363 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Q.; Zhong, Y.; Liu, Y.; Zhang, L.; Li, D. A Deep-Local-Global Feature Fusion Framework for High Spatial Resolution Imagery Scene Classification. Remote Sens. 2018, 10, 568. https://doi.org/10.3390/rs10040568
Zhu Q, Zhong Y, Liu Y, Zhang L, Li D. A Deep-Local-Global Feature Fusion Framework for High Spatial Resolution Imagery Scene Classification. Remote Sensing. 2018; 10(4):568. https://doi.org/10.3390/rs10040568
Chicago/Turabian StyleZhu, Qiqi, Yanfei Zhong, Yanfei Liu, Liangpei Zhang, and Deren Li. 2018. "A Deep-Local-Global Feature Fusion Framework for High Spatial Resolution Imagery Scene Classification" Remote Sensing 10, no. 4: 568. https://doi.org/10.3390/rs10040568
APA StyleZhu, Q., Zhong, Y., Liu, Y., Zhang, L., & Li, D. (2018). A Deep-Local-Global Feature Fusion Framework for High Spatial Resolution Imagery Scene Classification. Remote Sensing, 10(4), 568. https://doi.org/10.3390/rs10040568