1. Introduction
Hyperspectral imaging systems are nowadays considered as one of the most powerful remote sensing tools for acquiring precise information of the Earth’s surface. These optical systems are able to provide images in which single pixels have information from across the electromagnetic spectrum of the scene under observation. In other words, whereas the human eyes see colors of visible light in mostly three bands (red, green, and blue), hyperspectral imaging divides the spectrum into many contiguous bands (typically hundreds), which may be even out of the visible part of the electromagnetic spectrum. The main advantage of this technique is that certain objects leave unique ‘fingerprints’ in the electromagnetic spectrum, which are known as spectral signatures. These ‘fingerprints’ enable the identification of the materials that make up a scanned object, providing a much better understanding of the scene under analysis [
1].
However, the dimensionality of the space spanned by the pixels of a particular hyperspectral image is generally much lower than its number of spectral bands, which means that some bands of hyperspectral images usually provide redundant information that can be reduced by identifying an appropriate subspace. This allows for carrying on a spectral reduction of the captured hyperspectral data [
2]. Dimensionality reduction algorithms have been extensively used in the literature because of two equally relevant main reasons. First, because it represents an essential processing step to reduce the huge amount of information of hyperspectral images. Effectively, raw data captured from current hyperspectral imaging sensors require, for their representation, a space whose number of dimensions equals the number of spectral bands provided, which is typically several hundreds. Such a value oversizes the minimum number of dimensions of the intrinsic supporting subspace. Therefore, to avoid the computational complexity that is derived from dealing with large dimensional spaces, the original hyperspectral data should be shrunk to keep the most relevant information. Second, because it has been demonstrated in the literature that such an isolation of the most significant information contained in the targeted image clearly benefits the results that are achieved by the ulterior hyperspectral image processing steps, such as unmixing, classification and target detection, just to name some [
3,
4,
5].
Among the different techniques for decorrelating and reducing the amount of spectral information in hyperspectral images, the Principal Component Analysis (PCA) algorithm has become one of the most popular options [
6]. PCA is based on projections techniques seeking for the best subspace for representing the collected hyperspectral data. Specifically, the PCA algorithm seeks the projections that best represent the hyperspectral data in terms of its variance. For this, it is necessary to calculate the eigenvalue decomposition of the covariance matrix, usually after centering the data in the average of each spectral observation. Then, by selecting only the eigenvectors that correspond to the largest eigenvalues, a reduction of the dimensionality of the original data is achieved while retaining a wealth of information (variance) in the data.
Although this PCA dimensionality reduction has proven to bring the aforementioned benefits to the whole hyperspectral image processing chain, it is also true that its utilization is not exempt from a formidable computational effort, which may compromise its use in time-sensitive (real-time or near real-time) applications. In these applications, the algorithms that are required for processing the data are typically implemented onto high-performance computing architectures in which the operations involved are executed in parallel devices [
7,
8,
9]. In this sense, different research groups have published works that deal with the implementation of the PCA algorithm onto different high-performance computer architectures, such as Field Programmable Gate Arrays [
10], graphic processing units (GPUs) [
11], and cloud computing infrastructures [
12], which represent the most recent efforts in the literature toward this goal. Unfortunately, none of these works provides comparisons between the different high-performance computing devices, and their benefits and weaknesses, according to the characteristics of the different applications remain unknown for the reader. To the best of the authors’ knowledge, this work represents the first step towards this goal, in the sense that it compares the performance that is achieved by different high-performance computing platforms when applying the PCA algorithm to a set of hyperspectral images. Precisely, this work is focused on two main aspects. First, on efficiently implementing, by means of the Jacobi technique, the PCA algorithm onto two popular high-performance computing platforms, such as a GPU from NVIDIA and a manycore from Kalray, which represents the main innovation that is introduced in this work. Second, on providing a comprehensive comparison of the suitability of the implementation of the Jacobi algorithm on the previously mentioned platforms and a third one, collected form the state-of-the-art, which represents the most recent work in the literature in which the PCA algorithm, also through the Jacobi technique, is implemented onto an FPGA [
10]. Last but not least, we would like to recognize the existence in the state-of-the-art of other hyperspectral dimensionality reduction techniques, such as the ones published in [
13,
14,
15,
16], which have demonstrated to outperform PCA in terms of dimensionality reduction and computational complexity capabilities. However, we have decided to focus our efforts in the implementation of the PCA algorithm as nowadays represent the
de facto technique that is utilized in many hyperspectral image processing chains so far published.
The rest of the paper is organized as follows.
Section 2 reviews the PCA algorithm and the Jacobi method.
Section 3 introduces the main characteristics of the high-performance computing devices that are considered in this work, i.e., GPUs and manycores, while
Section 4 and
Section 5 give a detailed explanation about how the Jacobi-based PCA algorithm has been efficiently implemented onto an NVIDIA GPU and a Kalray manycore, respectively. Finally,
Section 6 presents, analyzes, and compares the results that were obtained with both devices and with the FPGA-based implementation published in [
10], while
Section 7 draws the main conclusions of this work.
2. Dimensionality Reduction by Means of the PCA Algorithm
Principal Component Analysis (PCA) is a popular method that is used to spectrally compact high dimensional datasets [
2]. In order to capture most of the variation of the targeted dataset, PCA projects the data onto an orthogonal subspace with a smaller dimension, which represents a very efficient technique to eliminate the existing redundancies among adjacent highly correlated bands. With PCA, an optimal dimension subspace in which the data volume lies can be discovered. PCA is optimal in the sense that it finds a number of orthogonal directions, smaller than the data space dimension, that, once the data volume is projected onto them, maximizes the total variance of the projections, i.e., maximizes the total variance from the original image, which is retained within the built-in subspace. Furthermore, the variance of the different projections is rearranged as a decreasing function of the sequence of selected orthogonal directions.
PCA consists of four main stages. The pseudocode is provided in Algorithm 1, together with an approximation of the number of Floating Point Operations (FLOPs) that each computing step involves. First, the data volume is moved to be recentered around the reference origin point. This data preprocessing is achieved by computing and removing the average value of each spectral band (see line 2 of Algorithm 1). Secondly, the covariance matrix of the data volume is computed as the product of the preprocessed data matrix and its transpose (line 3). Next, the eigenvectors that are associated to the covariance matrix are extracted (line 4). Finally, every pixel of the original image is projected onto a subset of eigenvectors to achieve the dimensionality reduction (lines 5 and 6).
| Algorithm 1: Principal Component Analysis | Number of FLOPS |
| 1 | Input: Hyperspectral image Y (N × M matrix), N pixels, M bands | |
| 2 | X = BandAverageRemoval (Y) | 2(N × M) + M |
| 3 | Covariance matrix, C = XT·X | 2 × N2 × M2 |
| 4 | E = EigenvectorDecomposition (C), e eigenvectors computed | 4 × M3 |
| 5 | Projection Matrix, Q = Y·E | e × N(2 × M − 1) |
| 6 | Q’ = MatrixColumnRemoval (Q, p), p principal components | |
| 7 | Output: Reduced hyperspectral image Q’ (N × p matrix) | |
According to the rightmost column in Algorithm 1, the number of FLOPS required for the dimensionality reduction of a hyperspectral image composed by 512 × 512 pixels (N = 262,144) and 224 bands (M = 224) can reach the total amount of more than 1015 FLOPS, which reinforces the crucial role that is played by high-performance computing facilities for applications under real-time constraints.
As stated in Algorithm 1, one of the most computationally demanding processes within the PCA algorithm is the eigenvector decomposition of the covariance matrix. A naive method to find an eigenvector decomposition of a matrix consists of finding the roots of the characteristic polynomial of the matrix, and then, solving a set of systems of linear equations using, for instance, Gaussian elimination [
17]. However, this procedure is not feasible for matrices as large as those that are involved in hyperspectral image processing.
Iterative algorithms have been extensively employed to compute eigenvalues and eigenvectors. This class of algorithms refines an approximation of the eigenvectors until a convergence criterion is satisfied. Different iterative methods have been described in the literature [
17]. Among them, the Jacobi method [
18,
19,
20] is distinguished. In this method, the sequential nature of the iterative process is balanced with the possibility to exploit its inherent parallelism. In addition, the method extracts all of the eigenvectors of the matrix, a relevant feature for the computation of the PCA algorithm. Its main objective is to approximate the input image to a diagonal matrix by iteratively zeroing all of the off-diagonal elements thanks to the application of successive planar rotations, known as Jacobi rotations. It should be noted that this methodology only applies to real and symmetric matrices. To better understand this method, a toy example with an input matrix of 2 × 2 is provided.
Given a real and symmetric matrix
, and a rotation matrix
, the Jacobi method finds a value of
α such that the operation shown in (1) results in a diagonal matrix,
B.
By substituting
A and
P in Equation (1) and operating, the values of
and
can be deduced, obtaining the expressions (2) to (5). After applying these expressions, the element
b in matrix
A would be zeroed, thus converting the original matrix in a diagonal one.
Extending this method to matrices of greater dimension is just a matter of generalizing these expressions. As can be inferred from (1), the rotation matrix
P must present the same dimensions as the input matrix, which in the case under study is the covariance matrix of the original hyperspectral image,
C. Hence, its structure is similar to that shown in (6). As it can be inferred from (6),
P is similar to an identity matrix, except for the
Pii,
Pij,
Pji, and
Pjj values.
Furthermore, as of now, there are more off-diagonal elements,
α should depend on the element selected to be zeroed,
Cij, where
i represents the rows of the covariance matrix and
j represents the columns. As a result, expression (2) is generalized as shown in (7). On the contrary, expressions (3) to (5) remain unchanged.
This process nulls one element of the matrix at a time, so in each iteration (
k) the operation shown in (8), which is a generalization of that shown in (1), must be performed. Specifically, each iteration recalculates the rotation matrix and generates
Ck, where the element
Cij is now zeroed, as well as its symmetric counterpart. Then, the next iteration will consider this matrix as its input.
Although it can be deduced that each iteration can undo some of the zeros that were previously achieved, it has been demonstrated that the magnitude of all off-diagonal elements is reduced after each iteration. As a result, these operations are iteratively repeated until a provided stop condition,
ε, is reached, that is, until all of the off-diagonal elements are smaller than this stop factor. Equation (9) summarizes the complete Jacobi method, where
K represents the total amount of iterations,
CK is a diagonal matrix containing the eigenvalues of the input image, and
Pi are the successive Jacobi rotation matrices. Similarly, the associated eigenvectors can easily be computed, as shown in (10), where the eigenvectors are stored in a column-wise order.
The convergence of Jacobi method has been successfully proven for two different strategies [
18], depending on the order in which the elements are selected to be zeroed. The classical method selects the largest off-diagonal element in each rotation, whereas the cyclic method chooses the elements in a given order, e.g., row by row or column by column. Although the former minimizes the number of iterations, the latter is faster, since it bypasses the location of the largest element in each iteration, which is a quadratic-order operation. For that reason, the latter is the method that is selected in this study.
The main advantage of the Jacobi method is that it is inherently parallelizable. After the computation of each iteration, matrix Ck matches with Ck−1, except in rows and columns i and j. As a result, several rotations can be computed simultaneously. Specifically, two elements can be zeroed in parallel as long as they do not share any position, i.e., they are not located in the same row or column. However, the computation of all the eigenvectors in large matrices like the ones that are involved in hyperspectral imaging applications is still a computationally intensive problem, although it can benefit from parallelization techniques, like the Jacobi method. Hence, for time-sensitive applications, it is advisable to use high-performance computing platforms in which the whole process is effectively accelerated by means of their internal parallel computing structure.
3. High Performance Computing in Graphics Processing Units and Manycores
Hyperspectral imaging applications under timing constraints require to rapidly process a huge amount of data. In these applications, the algorithms used for processing the data, like the dimensionality reduction step targeted in this paper, are typically implemented onto high-performance computing platforms in which the operations that are involved can be executed in parallel as far as these algorithms exhibit an inherent parallelism. Among the different high-performance computing devices that are currently available in the market, graphic processing units (GPUs) and manycores have gained popularity since their multiple processors are easier to program than field programmable gate arrays (FPGAs) and dedicated hardware circuits.
In the past, one way to improve processor performance was to increase the processor clock rate. However, this technique generated excessive power dissipation. A suitable solution is to increase the number of cores in the processor, and consequently, to provide support for a larger number of threads. In this context, a single-chip multiprocessor is currently known as a multi-core processor. More specifically, a manycore processor is a type of multi-core processor containing a large number of independent cores, typically several hundreds, which are designed to achieve the execution of a large number of tasks in parallel. Key factors that impact the performance of manycore processors are the internal core communication methods and the mechanisms to interact with the world outside of the processor. It is worth noting that, besides the number of cores, multi-core processors are differentiated from manycores in the number of resources devoted to figure out the implicit parallelism available in a single thread.
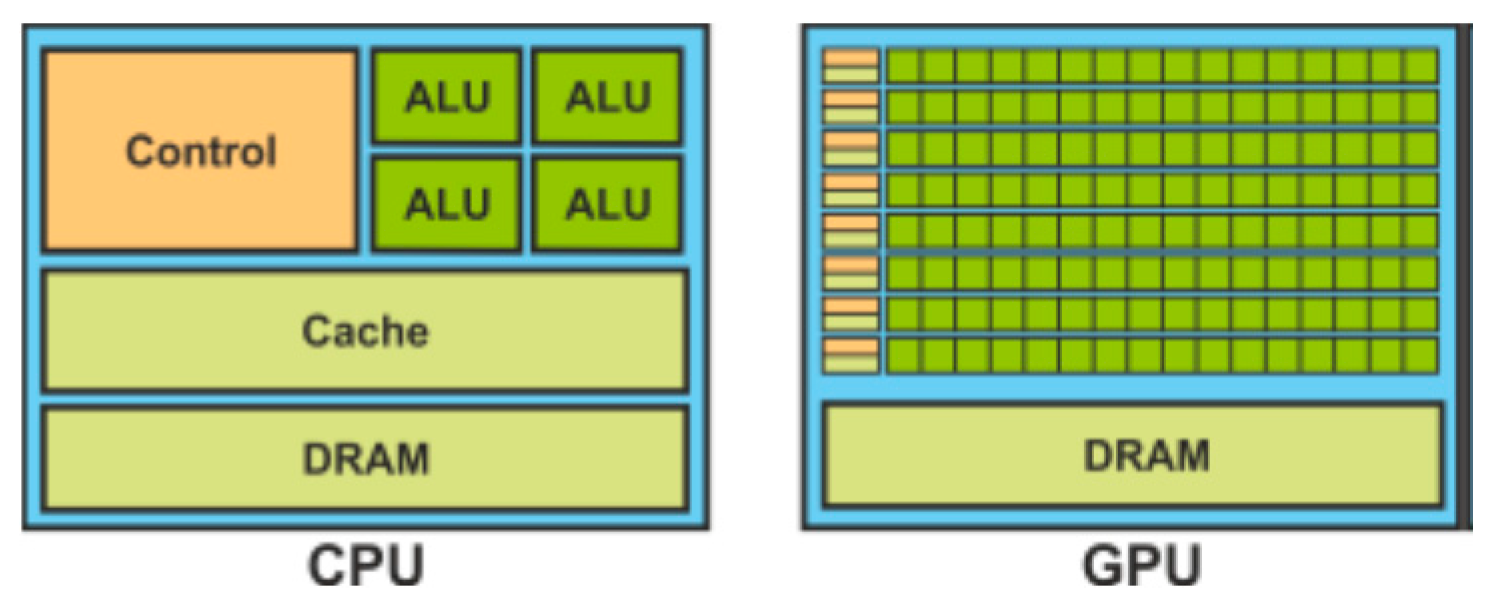
GPUs provide much larger availability of processing cores than standard CPU processing, with smaller processing capability of the cores and small control units that are associated to each core (see
Figure 1). Hence, GPUs are appropriate for algorithms that need to execute many repetitive tasks with fine grain parallelism and little coordination between tasks.
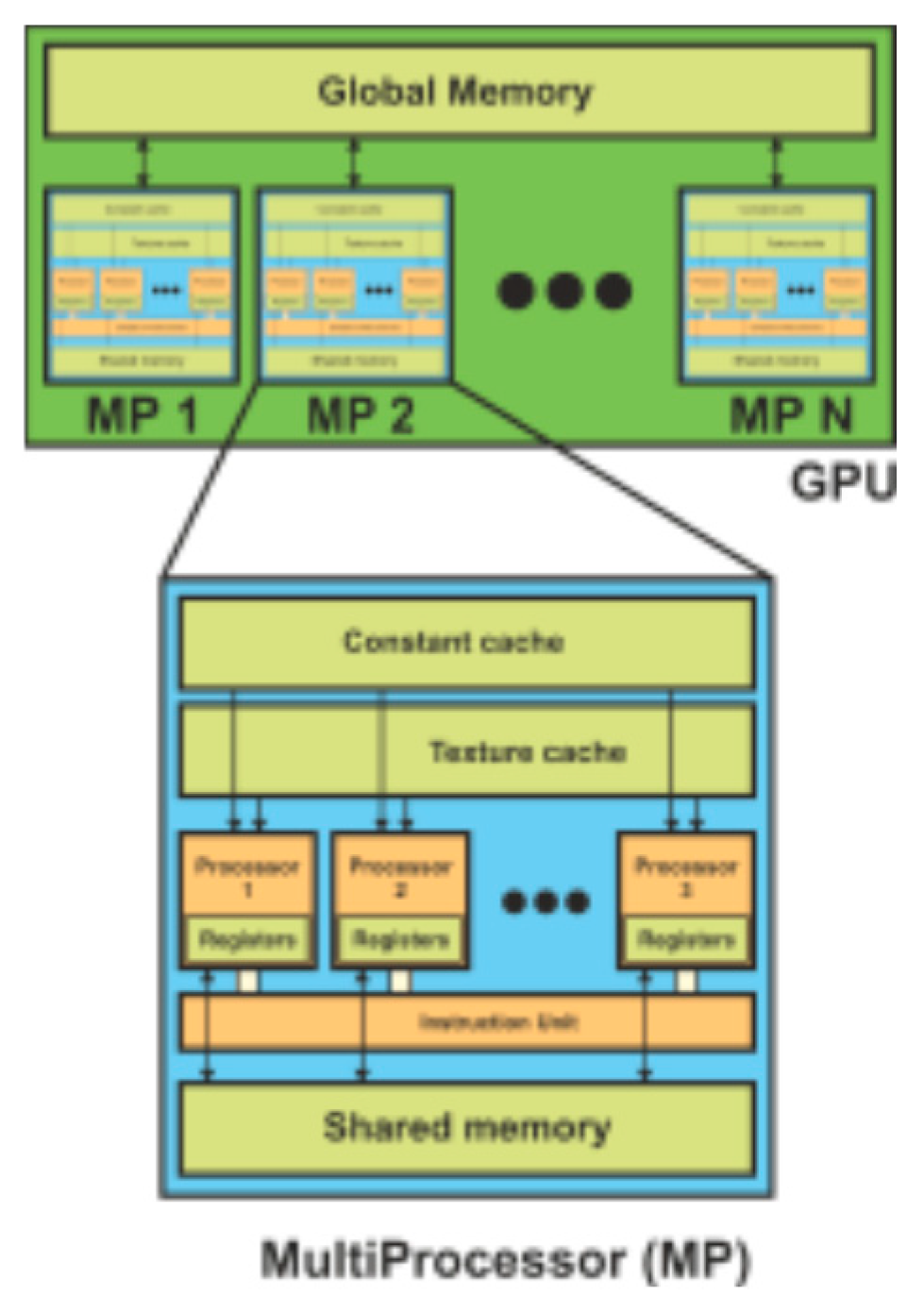
Figure 2 shows the architecture of the GPU, which can be seen as a set of multiprocessors. Each multiprocessor is characterized by a single instruction multiple data (SIMD) architecture, i.e., in each clock cycle each processor of the multiprocessor executes the same instruction, but operating on multiple data streams. Each processor has access to a local shared memory and also to local cache memories in the multiprocessor, while the multiprocessors have access to the global GPU (device) memory.
Within manycore processors, a typical architecture consists of a hierarchical structure that groups
M processing elements in
N clusters, which in turn, communicate with the external world through an Input/Output (I/O) subsystem. In addition, a Network-on-Chip (NoC) is usually employed for cluster interconnection. A clear example of this architecture is described in [
21]. The Kalray MPPA-256-N (where MPPA stands for
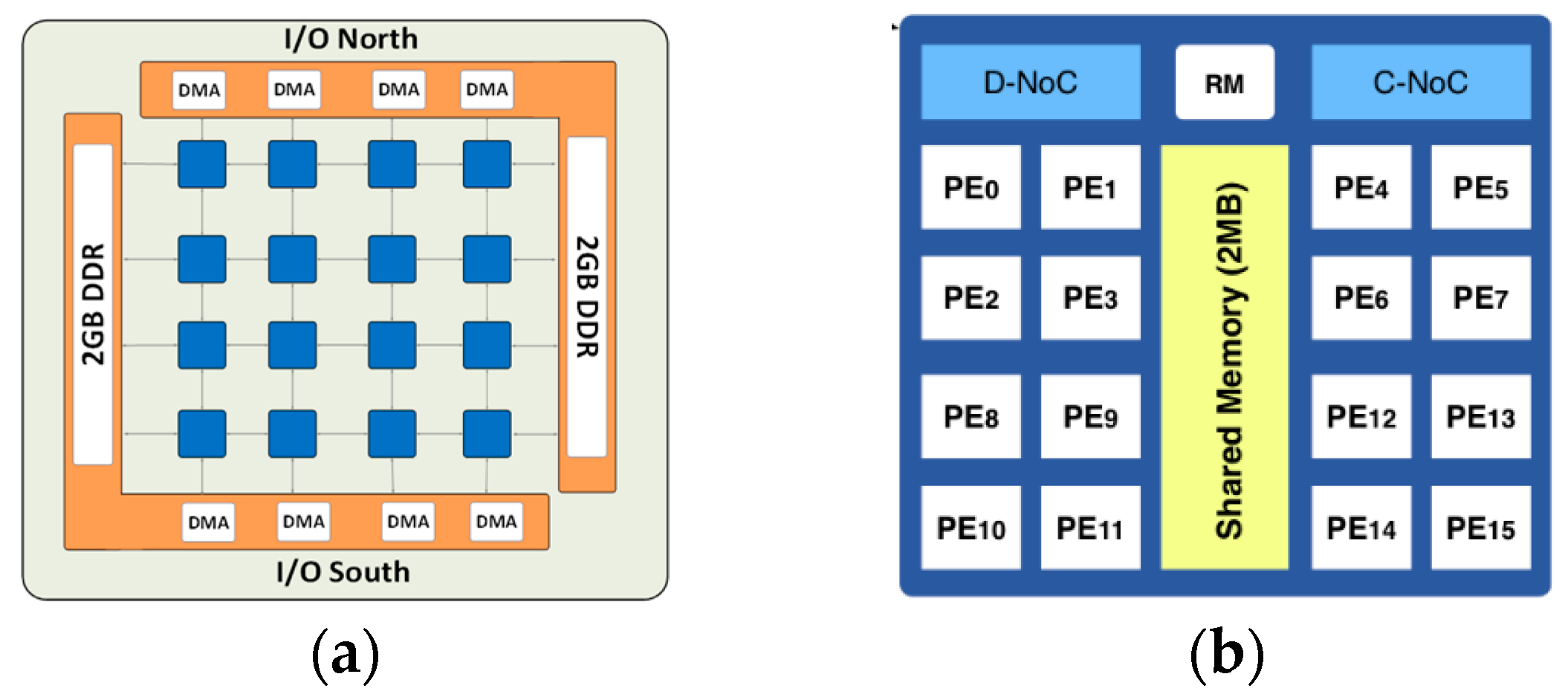
Massively Parallel Processor Array) is a single-chip manycore processor that targets low to medium volume applications with requirements such as low energy per operation and time predictability. This architecture is a homogeneous Multiprocessor System-on-Chip (MpSoC) mainly composed of 256 Very Long Instruction Word (VLIW) Processing Elements (PEs) distributed over 16 clusters and running at 400 MHz—see
Figure 3. All of the clusters are interconnected through two NoCs, one for control information (C-NoC) and another for data communications (D-NoC) [
22]. Likewise, external communications are handled with two I/O subsystems. Each of them contains a quad-core processor with a shared D-cache, four Direct Memory Accesses (DMAs), on-chip memory and a Double Data Rate (DDR) controller to access up to 64GB of external Double Data Rate (DDR) memory banks. Additionally, they run either a rich Operating System (OS) as Linux or a Real-Time Operating System (RTOS).
The clusters are the basic processing unit of the MPPA architecture. Besides the 16 PEs, they contain one Resource Management (RM) core responsible for running NodeOS operating system and handling, events, and interruptions. They also contain 2 MB of shared memory organized in 16 parallel banks of 128 KB each. This shared memory provides a bandwidth of 38.4 GB/s, providing a fair trade-off between power, area, latency, and bandwidth [
21], although it has been demonstrated to be the main limitation in data-intensive applications [
23]. Each cluster also gathers a DMA engine for handling the communications between the NoC and the shared memory.
Finally, as described in [
21], each PE or RM core implements a five-way VLIW architecture, including a multiply and accumulate floating-point unit, two arithmetic and logic units, together with a load/store unit and a branch and control unit, which allows up to 800 MFLOPS on 32-bit data at 400 MHz. These five execution units are interconnected through 64 32-bit general-purpose registers (GPRs). Furthermore, each PE also includes a Memory Management Unit (MMU) for virtual memory support and process isolation.
6. Materials
The performance of the proposed implementations of the Jacobi-based PCA algorithm has been evaluated with synthetically generated hyperspectral images as well as with different real hyperspectral images.
The synthetic images have been generated with data extracted from the United States Geological Survey (USGS) database [
27], which provides a library of spectral signatures from hundreds of different materials. The objective of using these images is to study the effect of the variation of the image dimensions on the performance that is given by both implementations. In this sense, two different sets of images have been created: in the first one the spatial resolution is varied while the spectral one remains unchanged (100 × 100 × 50, 200 × 200 × 50, 300 × 300 × 50, 400 × 400 × 50 and 500 × 500 × 50), whereas in the second one, the opposite procedure has been carried out (300 × 300 × 20, 300 × 300 × 30, 300 × 300 × 100 and 300 × 300 × 200). Specifically, these images have been generated by combining 10 different signatures that were randomly extracted from the USGS database and an additive noise drawn from a Gaussian distribution with an SNR set to 70 dB.
Figure 7 shows properly scaled pseudo-color versions of the synthetic images that were generated with different spatial size.
The real images utilized in this work were collected by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS). This sensor captures 224 spectral bands in the wavelength range of 0.4 to 2.5 μm. The first image used was taken over the region of
Cuprite, Nevada, in 1997. The selected scenes consist of 250 × 191 pixels and 350 × 350 pixels. Several bands have been removed due to water absorption and low SNR, resulting in a total of 188 spectral bands. The site is well understood mineralogically, and it has several exposed minerals of interest, including alunite, buddingtonite, calcite, kaolinite and muscovite. The second hyperspectral image used in this work was recorded by AVIRIS over the standard scenes of
Jasper Ridge Biological Preserve in California (1989). Water absorption and low SNR bands were removed prior to the analysis. The full data consists of a total amount of 512 × 614 pixels. The last hyperspectral image used was captured over the
World Trade Center (WTC) area in New York City on 16 September 2001, five days after the terrorist attacks that collapsed the two main towers and other buildings in the WTC complex. The full data consists of a total amount of 614 × 512 pixels.
Table 1 summarizes the features of the real hyperspectral images considered in this work while
Figure 8 shows the pseudo-color versions of these images.
These two sets of images (synthetic and real) represent a heterogeneous test bench, according to the different spatial and spectral resolution of the images as well as different content, which allows for studying the behavior of the proposed implementations of the PCA algorithm under different situations.
7. Experimental Results
The experimental results have been measured for the hyperspectral images that are mentioned in the previous section and two different architectures, a NVIDIA GPU and a manycore platform from Kalray. In this section, the results that were achieved by both platforms are presented. Furthermore, to provide a comparison with a sequential implementation, the results have also been measured in a CPU.
7.1. Performance of the Sequential PCA Jacobi Algorithm
Before assessing the performance of the implementations that are described in
Section 4 and
Section 5, first the algorithm has been evaluated executing a C implementation on an Intel
® Core™ i7-4790 CPU with 32GB of external memory and four 3.6 GHz cores running an Ubuntu 14.04 LTS distribution. As the objective of this test is to serve as a sequential version, the implementation has been run using one core and one thread of the processor.
Table 2 presents the results measured when executing the algorithm without the optimization flag (–O3) for obtaining the first principal component with the AVIRIS images.
7.2. Performance of the CUDA PCA Jacobi Algorithm
The CUDA PCA Jacobi has been run in the NVIDIA GeForce GTX 680 GPU, which has a Kepler architecture.
Table 3 summarizes the main features of this GPU.
Table 4 provides the execution times of the CUDA PCA Jacobi algorithm for the aforementioned synthetic hyperspectral images. In this table, the processing times for obtaining 1, 3, and 5 principal components are also provided to analyze the effect of obtaining more than one component. The results in
Table 4 show that the eigenvector decomposition is, by far, the most time consuming stage. This is due to the first part of this stage, which is calculated sequentially on the host side. The second most time consuming stage is the preprocessing due to the fact that it includes the transfer from the host to the device in order to load the initial hyperspectral image onto the global memory of the device. These transfers are carried out over the PCI express bus, taking a considerable amount of time, but thanks to this strategy, the execution time of the rest of the stages is much lower because they work over data stored on the device, which avoids the need of new transfers from the host to the device. Furthermore, the results that are provided in
Table 4 prove that, in this implementation, increasing the spectral resolution of the image has a larger impact on the performance than augmenting the spatial one.
Certainly, this table shows that, when increasing 25 times the spatial resolution of the image (i.e., comparing 100 × 100 × 50 and 500 × 500 × 50), the processing time is approximately multiplied by 1.3. However, when the spectral resolution is increased 10 times, the processing time is multiplied by an approximate factor of 2.25. This agrees with the fact that the eigenvector decomposition of the covariance matrix (which is a BANDS × BANDS matrix) represents the main bottleneck of this implementation.
Table 5 outlines the results that were obtained when processing the real hyperspectral images mentioned in the previous section, where the data in brackets in the rightmost column of the table represents the speedup factor that is achieved with respect to the sequential implementation. From this table, we can extract the same conclusions than with the previous one about the critical stage of the design (eigenvector decomposition) and about the greater impact that has an increase in the spectral resolution than in the spatial resolution of the images under processing.
7.3. Performance of the MPPA PCA Jacobi Algorithm
The PCA Jacobi has also been run in the MPPA-256-N architecture described before.
Table 6 summarizes the main features of this platform, which is composed of 16 clusters with 16 cores each.
Likewise,
Table 7 and
Table 8 show the execution time of the PCA Jacobi algorithm running on the MPPA-256-N manycore architecture for the hyperspectral images that are presented before. In addition, the processing times for obtaining 1, 3, and 5 principal components are also provided to analyze the effect of computing more than one component.
The results provided in
Table 7 and
Table 8 show that, as expected, the main bottleneck of the system is still the covariance matrix computation, regardless of the image used as input. Effectively, clusters memories have the capacity for only one image band. In addition, there are only 16 clusters at the MPPA-256-N. Consequently, since memory is a scarce resource at the cluster level, a costly iterative process is required. From these tables, it can also be inferred that the impact of increasing the number of principal components to compute is almost negligible. Additionally, these tables show that, for images with the same resolution but with very different contents—i.e., AVIRIS Jasper Ridge and WTC—similar processing times are obtained. This means that, although the PCA algorithm is data-dependent, the effect of the features (hyperspectral signatures) of the image under processing on the global execution time is almost negligible.
Furthermore, the results that are provided in
Table 7 prove that, as it happens with the GPU implementation, in the MPPA implementation, increasing the spectral resolution of the image has a larger impact on the performance than augmenting the spatial one. This table shows that, when increasing 25 times the spatial resolution of the image (i.e., comparing 100 × 100 × 50 and 500 × 500 × 50), the processing time is approximately multiplied by 2. However, when the spectral resolution is increased 10 times, the processing time is multiplied by almost 56. This agrees with the covariance matrix being the main bottleneck, as described before, computing the covariance matrix involves multiplying the image by itself, generating as a result a
BANDS ×
BANDS matrix. Hence, the greater the number of bands, the greater the number of elements that need to be computed in this step and the greater the processing time needed for this step, as shown in
Table 7. Moreover, it is also coherent with Jacobi step behavior: as previously described, the Jacobi step is in charge of diagonalizing the covariance matrix; as a result, the complexity of this task will increase with the size of the covariance matrix, and thus with the number of bands, as shown in the execution times that were measured for this step.
7.4. Comparisons
When comparing these results with those that were obtained with the NVIDIA GPU, it is clear that the results obtained with the GPU for the images considered in this work are much faster than those that were obtained with the manycore architecture. In addition, it can also be observed that, for the smallest synthetic image in terms of spectral resolution (300 × 300 × 20), the MPPA is faster than the GPU. This demonstrates that, as expected, the memory is the main limitation of the MPPA. Effectively, for small images, the processing times can be even better than those of the GPU; however, when the memory limit is exceeded, the performance drops. Additionally, other features should be considered when comparing both implementations: for instance, GPU implementations have higher power consumption than MPPA. When huge amounts of data are just transmitted and then off-line processed on Earth, power dissipation does not represent a problem, being the preferred platform the one that is able to process the information in the shortest period of time. On the other hand, Earth Observation applications that demand on-board computing should have less power consumption and PCA Jacobi implementation on a NVIDIA GPU would not be the best choice indeed. In this sense, NVIDIA is doing huge research efforts in the consumption power field and last NVIDIA GPUs have improved it without decreasing their performance. For example, the maximum power dissipation for the NVIDIA GeForce GTX 1030, which follows the Pascal architecture, is 30 W and its recommended system power is 300 W.
In those cases in which power consumption becomes a tight constraint, architectures, like the MPPA, provide a fair trade-off between performance and energy efficiency. This architecture is designed for timing predictability and energy efficiency [
29,
30], achieving a typical power consumption of 10–20 W. As power efficiency requirements are gaining momentum, Kalray is also focusing its efforts towards this field. Specifically, the third generation of the MPPA processor will be launched soon, targeting critical embedded high-performance applications, and doubling the computing capabilities while maintaining the power consumption below 20 W.
As shown in
Table 3 and
Table 6, the volume of resources of each piece of architecture is very different, so it should be taken into consideration when comparing both implementations. To do so, this paper proposes normalization with respect to the number of processing cores and the frequency to provide a fair comparison between the two implementations. This comparison is based on the number of hyperspectral cubes per second that each system can process. This metric—hereafter,
CPS,
Cubes Per Second—is obtained by computing the inverse of the total execution time of the algorithm for each platform, and provides a general idea of the throughput of the system. Nevertheless, this throughput is still highly dependent on the volume of resources of the platform; as a result, dividing this throughput by the number of processing cores and the operating frequency provides a fair metric to compare two implementations of the same algorithm that use a very different volume of resources. Consequently, this metric gives an idea of the efficiency of the implementation, independently of the available resources, as it provides the number of processed cubes per second and per core and MHz.
In this sense,
Table 9 and
Table 10 gather the comparison of the two implementations for both the synthetic images and the AVIRIS ones, respectively. This table provides the number of hyperspectral cubes per second,
CPS, when obtaining one principal component and the comparison parameter, measured in CPS per processing core and per MHz. As can be observed, the number of CPS is much higher for the GPU for both types of images. On the other hand, when considering the frequency and the number of cores, the MPPA proves to be more efficient (in terms of the figure of merit expressed in the rightmost column of
Table 9 and
Table 10) when dealing with images with a low number of spectral bands (100 or less), being the efficiency of both implementations is very similar when processing images with a high number of spectral bands (AVIRIS images and the synthetic image with 200 spectral bands). Again, it is worth noting that, for smaller images, MPPA efficiency is considerably increased. This is coherent with what has been previously described, as the MPPA-256-N is memory bounded, and therefore, its throughput worsens when the memory usage is more intensive.
Additionally,
Figure 9 shows the first principal component that was obtained for the AVIRIS images with both implementations, which demonstrate their functional equivalence in terms of dimensionality reduction.
After comparing the implementation of the PCA Jacobi algorithm, both on a GPU and on manycore architecture, a comparison with an implementation extracted from the state of the art of the same algorithm on a different platform has been also carried out in this work.
Specifically, in [
10], Fernandez et al. present an implementation of PCA Jacobi on a Xilinx Virtex XC7VX690T FPGA, which is evaluated with two of the images used in this research work: AVIRIS Cuprite (large) and AVIRIS Jasper Ridge. The main characteristics of the FPGA targeted in the aforementioned work are summarized in
Table 11.
To compare this implementation with the two ones presented here, a metric that is similar to the one described in the previous section will be applied. Since the criterion of the number of processing cores does not make sense in the FPGA case, only the operating frequency is included in the comparison metric. This comparison is presented in
Table 12 and
Figure 10, and it has been conducted using two AVIRIS images –Cuprite (large) and Jasper Ridge—as input, since they are the ones analyzed in [
10].
Although the most efficient implementation is the FPGA one, as its operating frequency is smaller when compared with the other two (76 MHz), it is worth noting that this advantage is achieved at the expense of a smaller number of CPS when compared to a GPU and a design-time and power consumption increase (more complex programmability and up to 60 W of typical power consumption [
31]) when compared to an MPPA. To delve into this triple comparison,
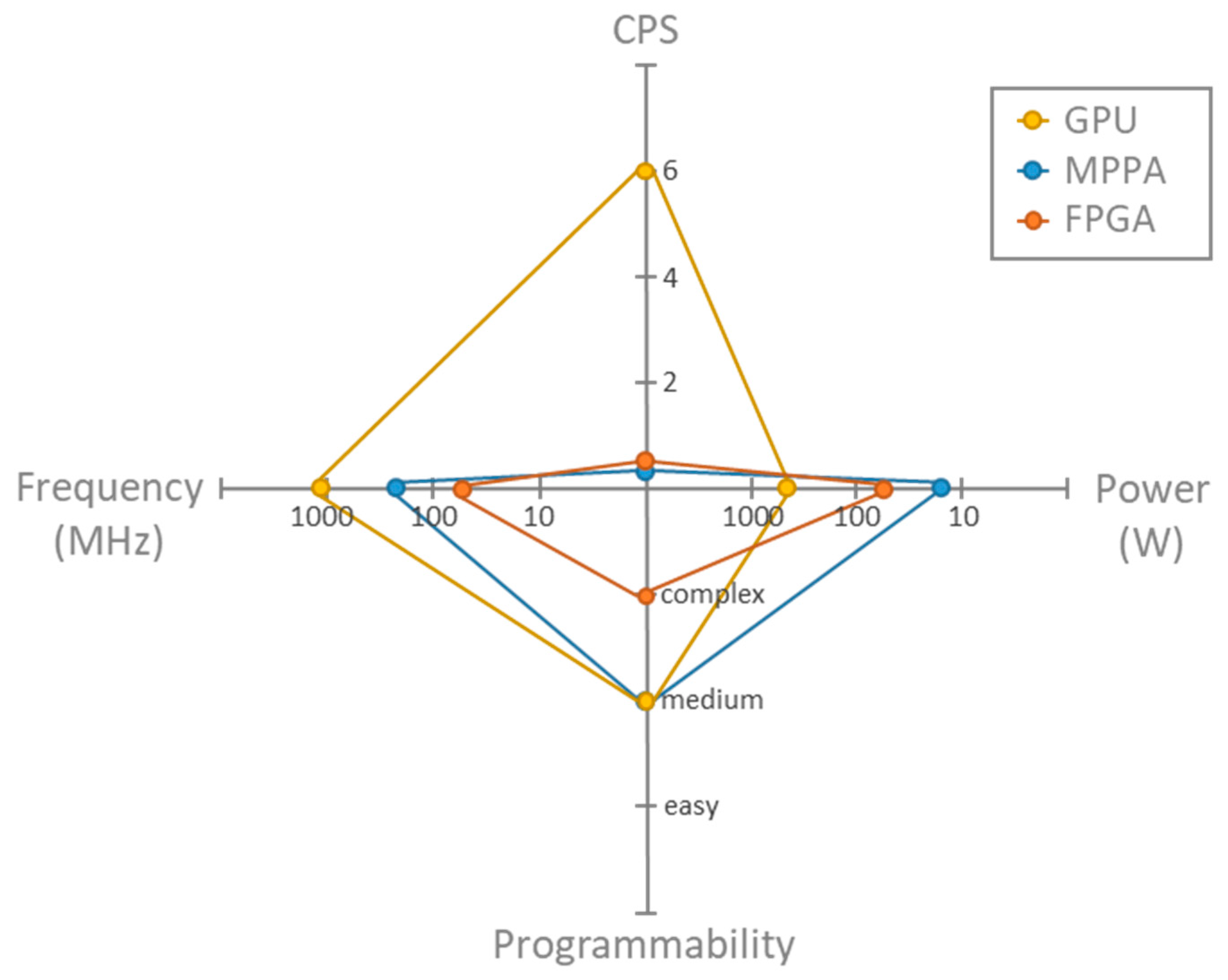
Figure 8 presents a spider chart in which four key indicators are evaluated for each implementation: frequency, CPS (for simplicity purposes, only the values for the Cuprite image are included), power consumption, and programmability complexity. As can be observed, the GPU implementation stands out in terms of CPS; likewise, the MPPA one stands out in terms of energy efficiency. On the contrary, while the FPGA implementation stands out in terms of frequency, it is also the one that presents higher programmability complexity. Finally,
Table 13 collects the processing times that were reported in papers [
11,
12], with similar images than the ones used in this work. Although these two works do not implement the Jacobi method, the processing times reported by their authors allow for checking the efficiency of our proposals in terms of the time that is required to process a given hyperspectral image.
8. Conclusions
In this paper, the implementation of the PCA algorithm onto a NVIDIA GPU and onto a Kalray manycore has been presented. In particular, the Jacobi method has been selected in both implementations in order to obtain the eigenvalue decomposition that is required by the PCA algorithm, as this method allows for exploiting the parallelism that is offered by both high-performance architectures. The procedure for accelerating the Jacobi-based PCA algorithm onto the two targeted devices has been exhaustively described and the main results that were obtained with a heterogeneous set of hyperspectral images have been reported. Moreover, a thorough analysis of the results that were achieved for each platform has been performed, introducing a novel comparison between them and with respect to an FPGA implementation recently published in the literature of the Jacobi-based PCA algorithm. Additionally, these results have also been compared with (1) similar algorithms in the recent literature, and (2) a sequential implementation of the algorithm. Last, but not least, the impact of the input image dimensions on the performance has been assessed by modifying both the spatial and the spectral resolution.
These comparisons have uncovered the pros and cons of each of the considered options in terms of the time that is required for processing a hyperspectral image, the power consumed for this processing, and the ease of programming of each platform, which provides crucial information for the potential designers of the next generation of hyperspectral imaging systems. Specifically, the results obtained prove that, although in general lines GPUs provide better performance rates, when features like power consumption are key decision factors, manycore architectures—such as MPPA—also provide efficient results. Its main limitation has also proven to be the internal memory, since for the smallest images it even outperforms the GPU under study. However, once this limit is exceeded, its performance drops substantially. As a result, the trade-off that is required for each application between performance, power consumption, and memory usage can help in deciding which is the most suitable platform.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









