1. Introduction
A hyperspectral image (HSI) is acquired by hyperspectral remote sensors and composed of hundreds of bands over the same spatial area. It can provide high spectral resolution and rich spatial information. These features of HSIs contain a wealth of information to identify land covers of interest effectively. As a fundamental problem, HSI classification has been paid more and more attention recently, partially due to its widely successful applications in various fields, such as precision agriculture [
1], urban planning [
2], environment monitoring [
3], target detection [
4], and anomaly detection [
5].
HSI classification is to assign each pixel to a meaningful and physical class based on their spectral features and the land coverage surface. During the last decades, plenty of HSI classification methods have been proposed. Some typical approaches; for example, support a vector machine (SVM)-based method [
6,
7,
8,
9], multinomial logistic regression-based techniques [
10,
11], various feature selection-based methods [
12,
13], and sparse representation-based methods [
14,
15], have been demonstrated to be very successful techniques. The aforementioned methods make full use of the spectral features of hyperspectral data in the process of classification. Generally, the classification results obtained by those above-mentioned methods that do not consider the spatial information of HSI are often not ideal. To further improve the classification performance, a large number of methods combining spectral information with spatial information have been investigated in recent years [
16,
17,
18,
19,
20,
21,
22].
Among of the spectral–spatial based approaches, some spatial filtering techniques are developed [
23,
24,
25,
26,
27,
28]. The purpose of applying these techniques to HSI classification is to denoise HSI in the pre-processing task or improve the classification accuracy in post-processing. Several popular methods are discontinuity preserving relaxation (DPR) [
28], Markov random fields (MRF) [
29,
30], probabilistic relaxation (PR) [
31], the local binary pattern filter [
32], the edge-preserving filter [
33], Gabor filter [
34], the extended morphological profiles filter [
35] and so on.
Although the application of spatial filtering techniques in HSI classification can effectively reduce some noise pixels and provide a better classification result, the adopted spatial region is fixed in size and shape. In other words, the spatial information of HSI may be exploited insufficiently. Recent research shows that superpixel segmentation provides a powerful way to address this problem, as a superpixel is with adaptive shape and size. According to the techniques used to generate a superpixel, the known superpixel segmentation methods can be categorized into graph-based methods [
36,
37,
38], gradient-ascent-based methods [
39,
40] and cluster-based methods [
41]. Among of these segmentation algorithms, simple linear iterative clustering (SLIC) algorithm seems to be more popular because it is fast to compute, simple to use and good to adhere to boundaries [
41].
Over the past decade, superpixel segmentation methods have also been extended to HSI classification [
42,
43,
44,
45,
46,
47,
48,
49,
50], aiming at making full use of spectral information and spatial structure in hyperspectral data. By the combination of different segmentation techniques with various classification methods, a number of approaches for HSI classification have been developed, such as ER with sparse representation [
42,
51,
52,
53], SVM [
54] or extreme learning machines [
55], SLIC with multi-morphological method [
56], SVM [
57] or convolutional neural network [
58] and so on. These HSI classification methods based on superpixel segmentation display good performance in experiments. Generally, when using SLIC algorithms to segment HSI, the principal component analysis (PCA) method must be adopted previously and the first three components are taken as the Lab color space. However, it will still inevitably encounter the difficulties of selecting the optimal weight in SLIC algorithms. To address the above-mentioned problems, therefore, it is necessary to improve SLIC used in color image segmentation so that it can be directly applied to segment HSI.
In this study, a novel technique to measure the similarity of a pair of pixels in HSI is suggested. The proposed similarity is designed especially for the SLIC algorithm so that SLIC can be used to segment HSI directly without adopting PCA in advance. The advantages of the proposal lie in: on the one hand, we can better measure the similarity between two pixels since the spectral distance, spectral correlation and spatial distance are considered simultaneously; on the other hand, it cleverly avoids the problem of optimal parameter setting in SLIC.
In addition, the acquired HSIs contain a large number of noise data for a variety of reasons. There is no doubt that the presence of a multiple of noise will seriously affect the accurate classification and interpretation of HSIs. Furthermore, the high-dimensional and big data features of HSI also bring great difficulties to the accurate classification of land cover. Therefore, it is very urgent and important to put forward effective methods to tackle the above-mentioned problems in the field of remote sensing. Based on the improved SLIC algorithm and DPR strategy, this study develops an effective semi-supervised HSI classification scheme. The DPR method is adopted to preserve the class boundary information well in the process of denoising. In post-processing, the use of the superpixels with adaptive shape and size can effectively improve the classification accuracy.
The main contributions of the proposal are summarized as follows.
An effective classification scheme for HSI is developed based on DPR strategy, SVM and the improved SLIC method.
A novel technique to measure the similarity of a pair of pixels in HSI is proposed to improve the SLIC algorithm.
The improved SLIC algorithm can be directly applied to superpixel segmentation of hyperspectral data and is free of parameters.
2. The Proposed Classification Scheme for HSI
We first introduce some notations used in this study.
Let be a hyperspectral image with n pixels; indicate the spectral vector with regard to the pixel xi; B is the number of bands.
denotes a set of spatial neighbors of the pixel
xi. We herein adopt the Moore neighbor, which is defined as
where
) is the spatial coordinate of the pixel
xi.
2.1. Discontinuity Preserving Relaxation
In hyperspectral data, it is possible that the same class ground objects are with different spectra and the same spectrum may be corresponding to different ground objects. This feature of HSI leads to a lot of noise pixels. In addition, the acquired spectral reflectance values are also affected by water vapor and atmospheric radiation, also resulting in noisy pixels that remain despite the atmospheric compensation step. Noise pixels in hyperspectral data will obviously affect the final classification accuracy. One of the effective ways to solve this problem is to denoise hyperspectral data by using a fixed size moving window technique. The use of this technique will make smooth areas smoother and smoother, but at the same time, it blurs the boundary of the class. Fortunately, the DPR method provides a good solution to this problem, due to the fact that the DPR method preserves the class boundary information well while de-noising.
In HSI preprocessing, DPR, initially developed by Li et al. [
28], adopts the local spatial relation among adjacent pixels to denoise the hyperspectral data, and attempts to preserve the class boundary information as much as possible. It is in fact an iterative relaxation procedure.
Specifically, the DPR method can be depicted as follows.
For a given HSI, let
,
;
is the probability of pixel
xi belonging to the
j-th class. The probability matrix
,
can be obtained by solving the following optimization problem
where
is a weight to balance the first term and the second term in Equation (2);
is a value of the pixel
xj of the edge image.
is calculated by Equation (3)
where Sobel() represents the Sobel filter that detects the discontinuities in a band image.
bi denotes the
i-th band of the original hyperspectral data cube.
Our earlier work [
59] showed that using Roberts cross operator instead of Sobel filter operator in Equation (3) can provide better relaxation effect. The reason of doing so is that Roberts cross operator is simple, easy to calculate, and more accurate to find the class boundary information. Thus, in this study, we still use the Roberts cross operator in Equation (3), and experimental results confirm the effectiveness of this substitution again.
While applying DPR in preprocessing stage, appropriate changes are to be made since it is impossible to know previously for a given HSI.
The Sobel filter is replaced by the Roberts cross operator in Equation (3), i.e.,
For each band
b, we use Equation (5) to update it constantly
where
is the value of the bth band of the pixel
xi in the
t-th iteration.
The update process will terminate if Equation (6) is satisfied
where
indicates the
b-th band image;
is a predetermined threshold.
2.2. Superpixel Segmentation
The superpixel algorithm partitions an image into small non-overlapping homogeneous regions with adaptive shape and size. Previous works show that superpixel segmentation has achieved great success in computer vision and image analysis. Among of the popular superpixel algorithms, the simple linear iterative cluster (SLIC) [
41] is a more powerful method because of its advantages of simple use, fast computing and better preservation of the class boundary. SLIC adopts the k-means cluster technique to segment an image according to the spatial structure and color.
The distance between two pixels is defined as follows,
where
dc and
ds denote the color distance and spatial distance of a pair of pixels, respectively;
Nc is the maximum color distance;
s is the segmentation scale.
As pointed out in [
41], determining the maximum color distance
Nc is nontrivial as color distances can vary significantly from cluster to cluster and image to image. To tackle this problem, the authors fixed
Nc to a constant
m and rewrote Equation (7) in the following form
where
m is a weight balancing color similarity and spatial proximity.
To achieve better segmentation effect, the CIELAB color space (instead of RGB color space) was adopted in the classical SLIC algorithm. Euclidean distance was taken in the computation of the color distance
dc and spatial distance
ds. In this case,
m can be in the range [
1,
40].
2.3. The Improved SLIC Algorithm
In SLIC method, the segmentation effect of HSI obviously depends on the choice of the weight
m. In general, it is inappropriate to use the SLIC algorithm and the suggested parameter value directly in superpixel segmentation of HSI, as significant differences in reflectance among hundreds of bands would result in a tremendous difference between spectral distance and spatial distance. In addition, it can be seen from
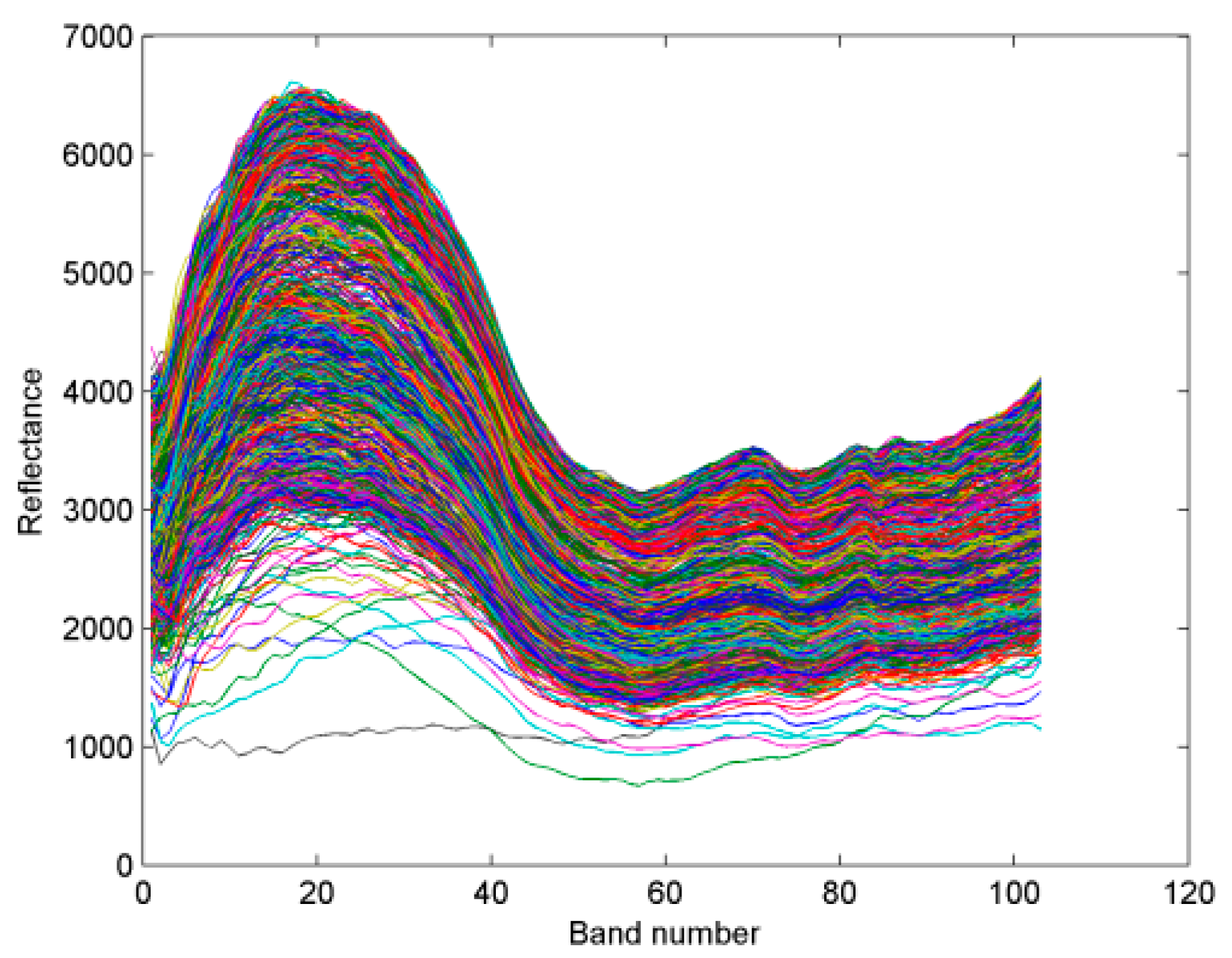
Figure 1 that even for two pixels in the same class, there still is a distinctive difference in spectral distance if only Euclidean distance is adopted. This obviously increases the possibility of misclassification in hyperspectral data processing.
To address the aforementioned problem, a novel technique to measure the similarity of a pair of pixels in HSI is suggested, aiming at applying SLIC algorithm handily in superpixel segmentation of HSI.
The spectral distance
dspec, the spatial distance
dspat and the correlation coefficient
are defined as follows.
The Manhatten distance is adopted in the calculation of spectral distance in Equation (9). The value of is obvious in the range [0,1] as all components of xi and xj are positive.
For the convenience of narration, we define
in the following form:
The proposed strategy to measure the similarity of a pair of pixels in HSI is as follows.
Suppose that there are
k cluster centroids,
c1,
c2, …,
ck, around the tested pixel
xi. By using Equations (9), (10) and (12), the spectral distance
dspec(
xi,
cj), the spatial distance
dspat(
xi,
cj) and
from
xi to
cj (
j=1, 2, …,
k) is calculated, respectively. In each group, we rank them in ascending order, i.e.,
where
,
and
is a permutation of
, respectively.
The tested pixel xi will be assigned to j-th cluster, if among of dspec (xi, cj), dspat(xi, cj) and , at least two of them are the smallest in the corresponding groups. Otherwise, spatial distance is considered only.
This strategy can be thought of as the generalization of Equation (8). When all of them, or spectral distance and spatial distance are minimal, this is exactly the case of Equation (8). When spectral distance and are minimal, it indicates that the spectral curves of the pixel xi and centroid cj are similar both in shape and reflectance. The assignment of pixel xi to j-th cluster is propitious to enhance the homogeneity of superpixels. As for the case of dspat(xi, cj) and , it can be regarded as the supplement of the case of spectral distance and spatial distance. The difference is that they are very similar in shape, but there are some differences in their reflection values. If there is only one smallest among of dspec(), dspat() and , it is reasonable to assign pixel xi to the closest cluster according to the first law of geography.
The proposed technique not only measures the similarity between two pixels better, but also gets rid of the trouble of choosing optimal weight m in Equation (8). It is worth noting that you can choose the distance you like to calculate the spectral distance between two pixels because the comparison takes place within each group.
The improved SLIC algorithm can be summarized as follows.
Initialize the cluster centers by sampling pixels at scale s. Move cluster center to the pixel with the lowest gradient in a neighborhood.
Assign each pixel to the nearest cluster in a region by using Equations (9), (10) and (12) and the proposed strategy.
Update each cluster center.
Repeat clustering until a given threshold is met.
2.4. An Effective Classification Scheme for HSI
In what follows, an effective classification scheme for HSI is presented based on the DPR method, SVM and improved SLIC algorithm. The proposed scheme can be divided into three steps.
Step 1. Data preprocessing.
There is no doubt that a large number of noise pixels in hyperspectral data will affect the HSI classification result. In order to get a better classification result, it is very necessary to preprocess hyperspectral data before classification. In this work, we prefer to take DPR as the data preprocessing method to denoise a given HSI. Specifically, we use Equations (4)–(6) to do this work.
Step 2. Classification at pixel wise.
Previous studies have demonstrated that SVM is a more powerful classifier in machine learning and hyperspectral data analysis. In this step, SVM with five-fold cross-validation (SVM-5) is used to classify the preprocessed HSI in a pixel-wise fashion. To enhance the performance of SVM-5, the Gaussian radial basis function (RBF) kernel is taken as its kernel function. The optimization process of the parameters used in SVM-5 is implemented by means of five-fold cross-validation.
Step 3. Post-proprecessing
After data preprocessing, we have also used the improved SLIC algorithm to carry out the superpixel segmentation of HSI. The obtained superpixels are herein used to improve the classification result provided in step 2.
The superpixel segmentation of HSI is based on the assumption that the spatial adjacent pixels in the remote sensing image have similar spectral properties and, thus, should fall into the same class. This assumption allows us to apply superpiexls to the post-processing of HSI classification. Unlike the MRF method with fixed-size window, superpixels have adaptive shapes and sizes. This feature of a superpixel makes it favorable for its application in the post-processing of HSI classification. Experimental results of this study confirm this idea.
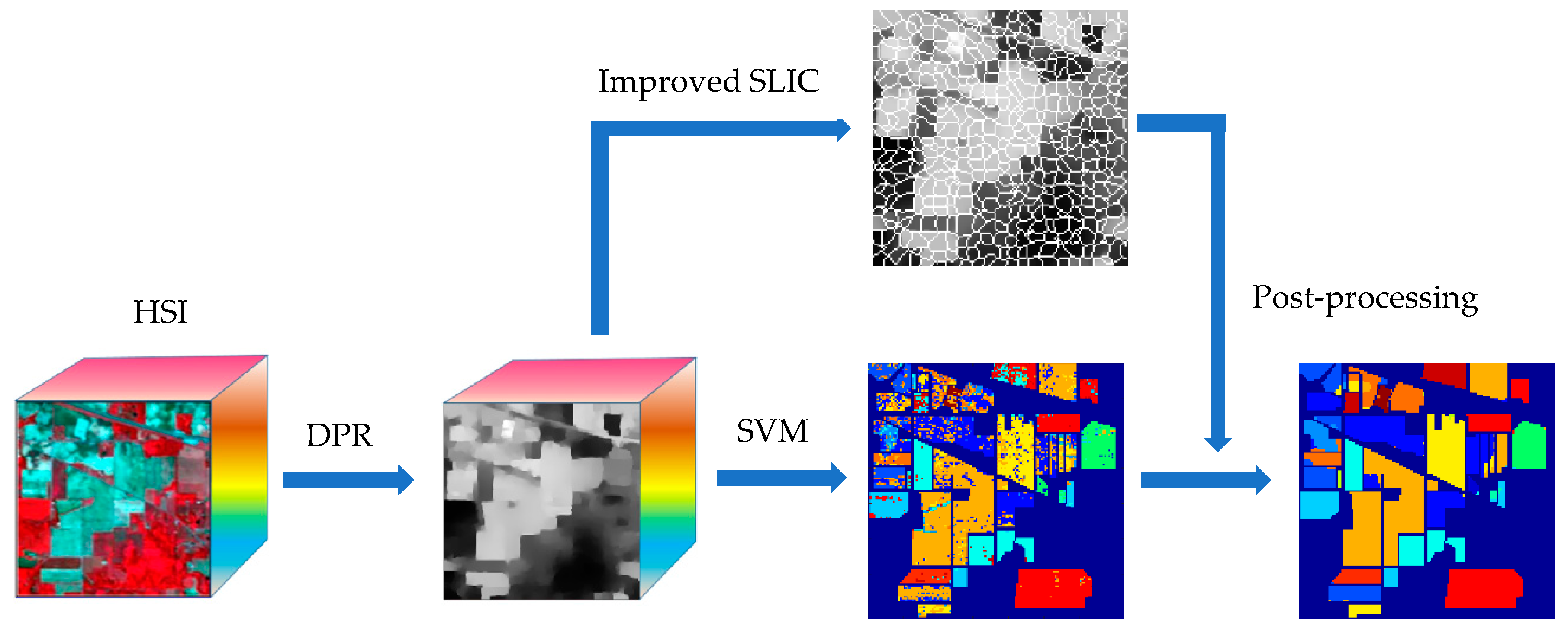
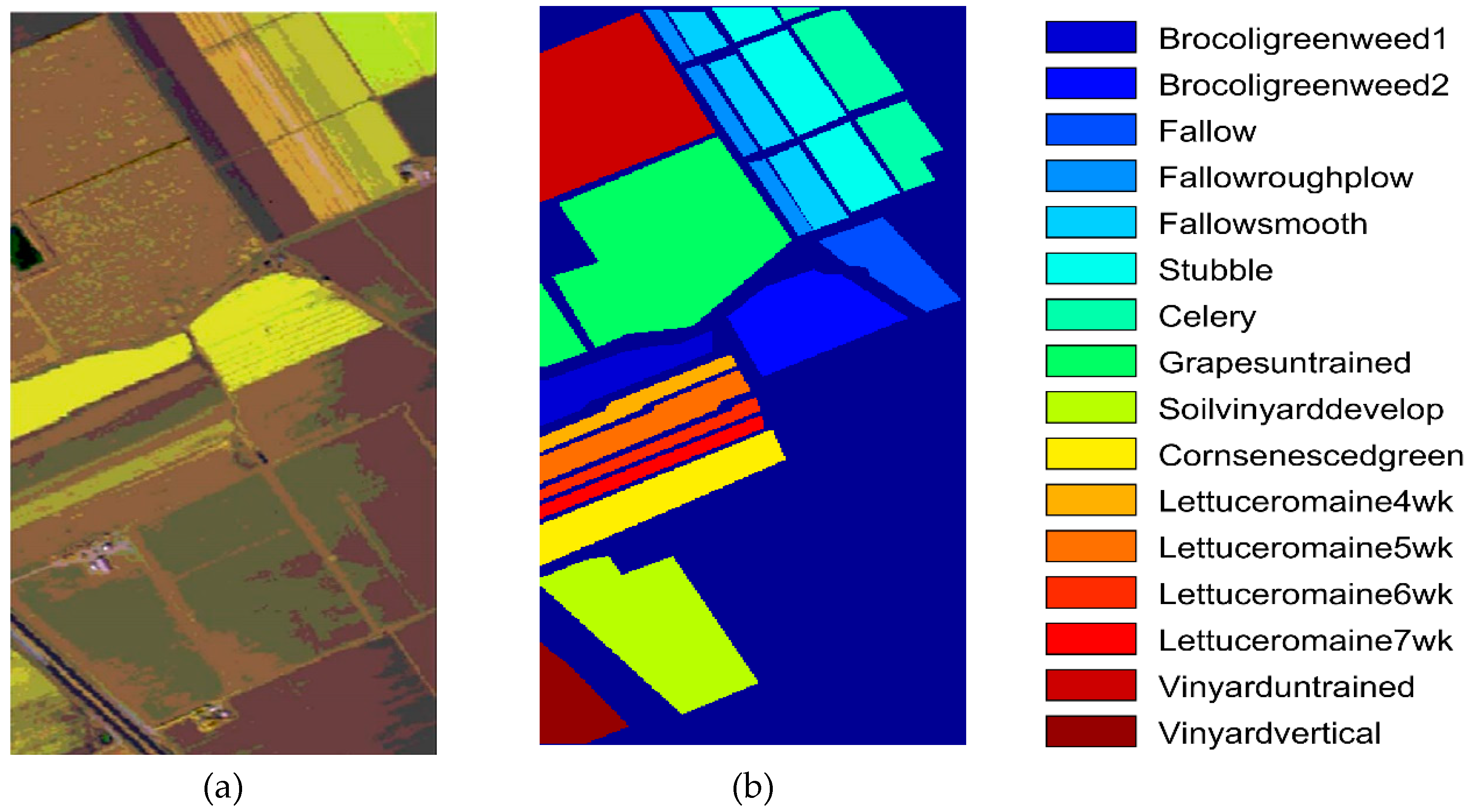
To better understand the proposed classification scheme, the overall workflow of the integration of DPR, SVM and superpixel segmentation is elaborated in
Figure 2. In this scheme, the DPR technique is responsible for denoising, while retaining the class boundary information better. The SVM method has good classification performance for high-dimensional data with small labeled samples. Similar to the other two-step classification methods, the use of a superpixel in post-processing can significantly improve the classification accuracy. The proposed approach effectively integrates their strengths, and the experimental results also confirm the effectiveness of the proposal.
4. Parameter Analysis
In this section, we discuss the effects of the parameters adopted in the proposed scheme on classification results on the three hyperspectral datasets. Parameter β controls the contribution of discontinuity calculated by edge detection operator to the smooth image in the DPR method. Segmentation scale s dominates the size of superpixels in SLIC algorithm. Furthermore, the effects of different edge detection operators on the classification results are also analyzed.
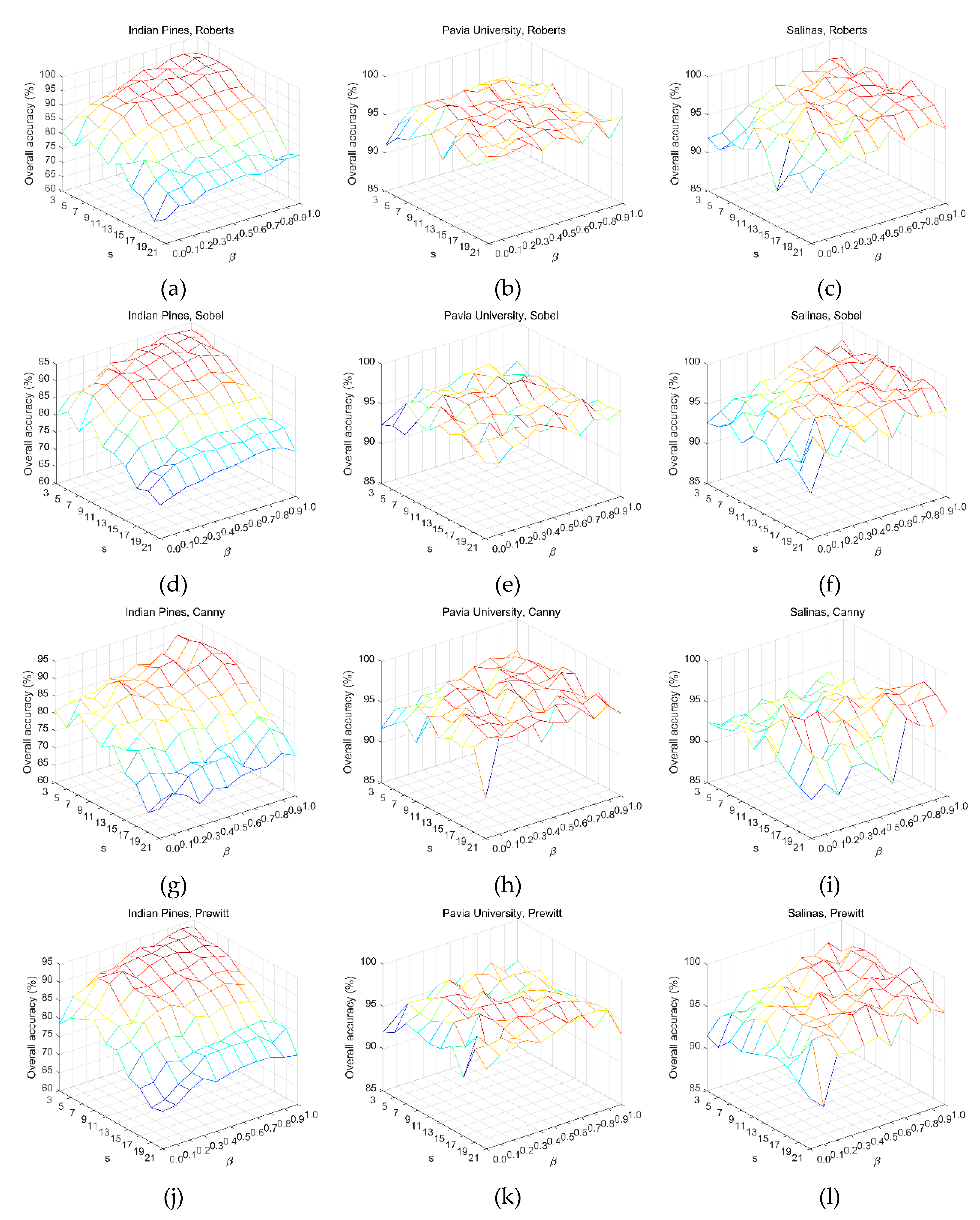
Figure 9 shows the classification results on three hyperspectral datasets for four different edge detection operators. For Indian Pines dataset, with the increase of superpixel volume, the classification accuracy of the four operators shows an obvious downward trend. This may be due to the fact that the number of object classes contained in large superpixels exceeds the number of clusters, thus undermining the homogeneity of superpixels. All the four operators show better classification performance on Pavia University dataset, and almost all classification accuracies are more than 90%, especially Robert operator and Sobel operator. The reason should be that Pavia University dataset has only nine classes and that they have significant spatial separation. The satisfactory classification results can be obtained on Salinas dataset by using Robert, Sobel and Prewitt operators, most of which are above 95%. The best results achieved by these four operators on different datasets are recorded in
Table 6.
It is easy to see from table 6 that Robert operator provides two of the three best classification accuracy. In particular, compared with the other three operators, Robert operator has an obvious advantage on Indian Pines dataset. Almost perfect classification result is obtained by using Robert operator on Salinas dataset. Canny operator outperforms the other three operators on Pavia University dataset. This is because the Canny operator is a second-order differential operator and has a good ability to recognize irregular boundaries. Unlike Indian Pines and Salinas datasets, the difference of classification accuracy among the four operators on Pavia University dataset is less than 0.3%. In other words, it is acceptable to adopt Robert operator in the proposed method.
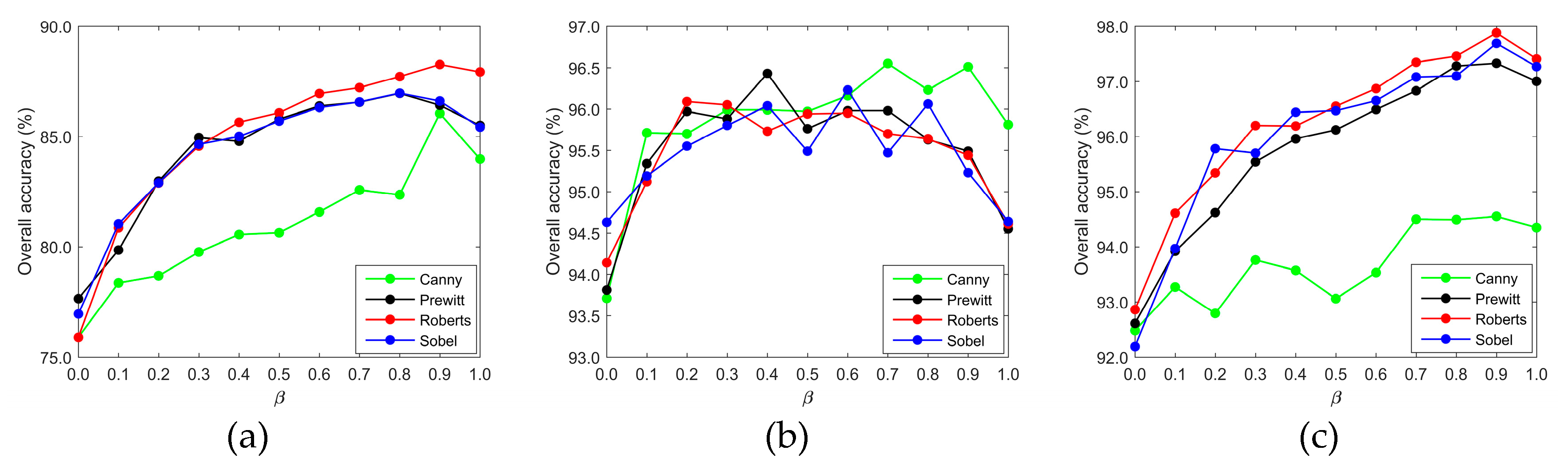
Figure 10 exhibits the variation of the average classification accuracy with the increase of β. Each point in
Figure 10 is the average of the classification results obtained by the proposed scheme on ten different superpixel segmentation scales
s and with the same β. Furthermore, the classification accuracy for the fixed segmentation scale
s is the average of the classification results of the training set generated randomly for ten times. It is known from Equation (5) that β = 0 means to classify HSI on the original dataset without data smoothing; β = 1 represents to denoise HSI completely using the boundary information contained in the neighbors of the tested pixel, while neglecting the spectral band information of the tested pixel itself.
For two AVIRIS datasets, the Indian Pines and Salinas, the average classification accuracy becomes better and better as β value increase. This indicates that all the other three operators, except canny operators, can detect effectively class boundary, and this information plays a dominant role in the DPR method. The reason may be that, as shown in
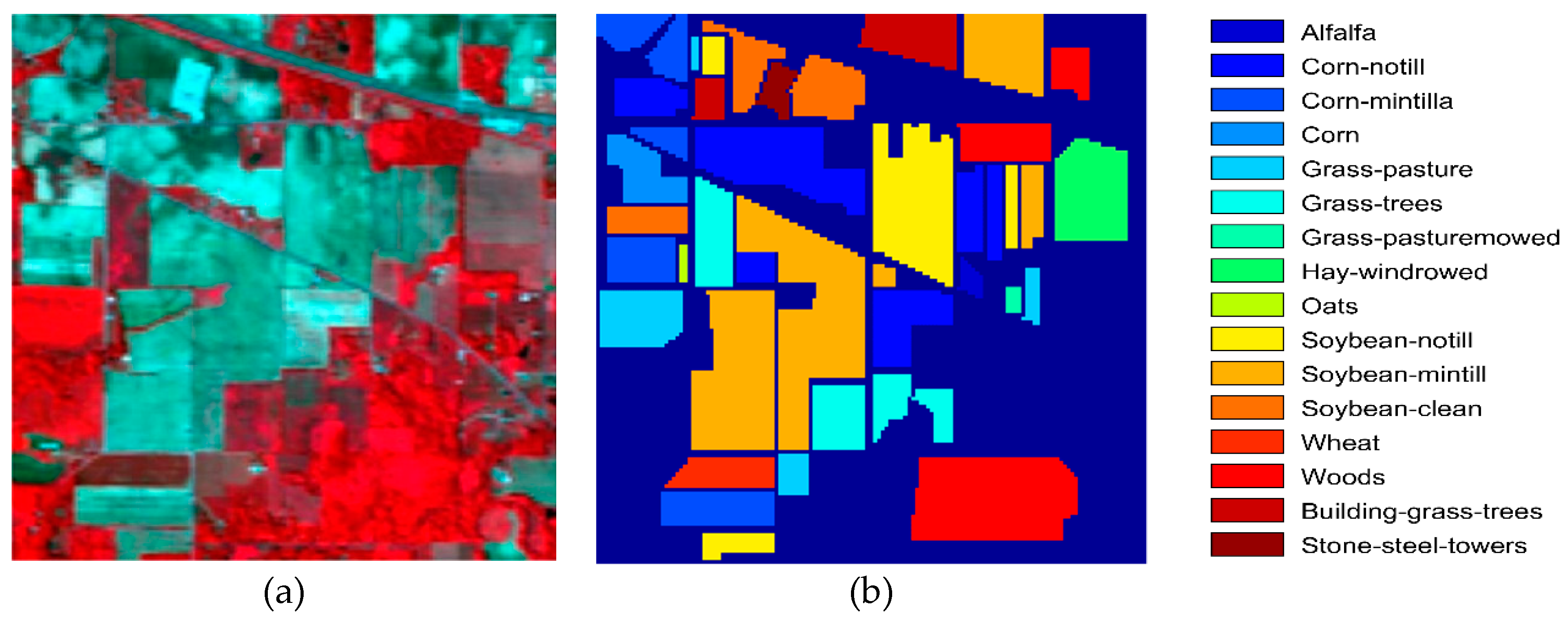
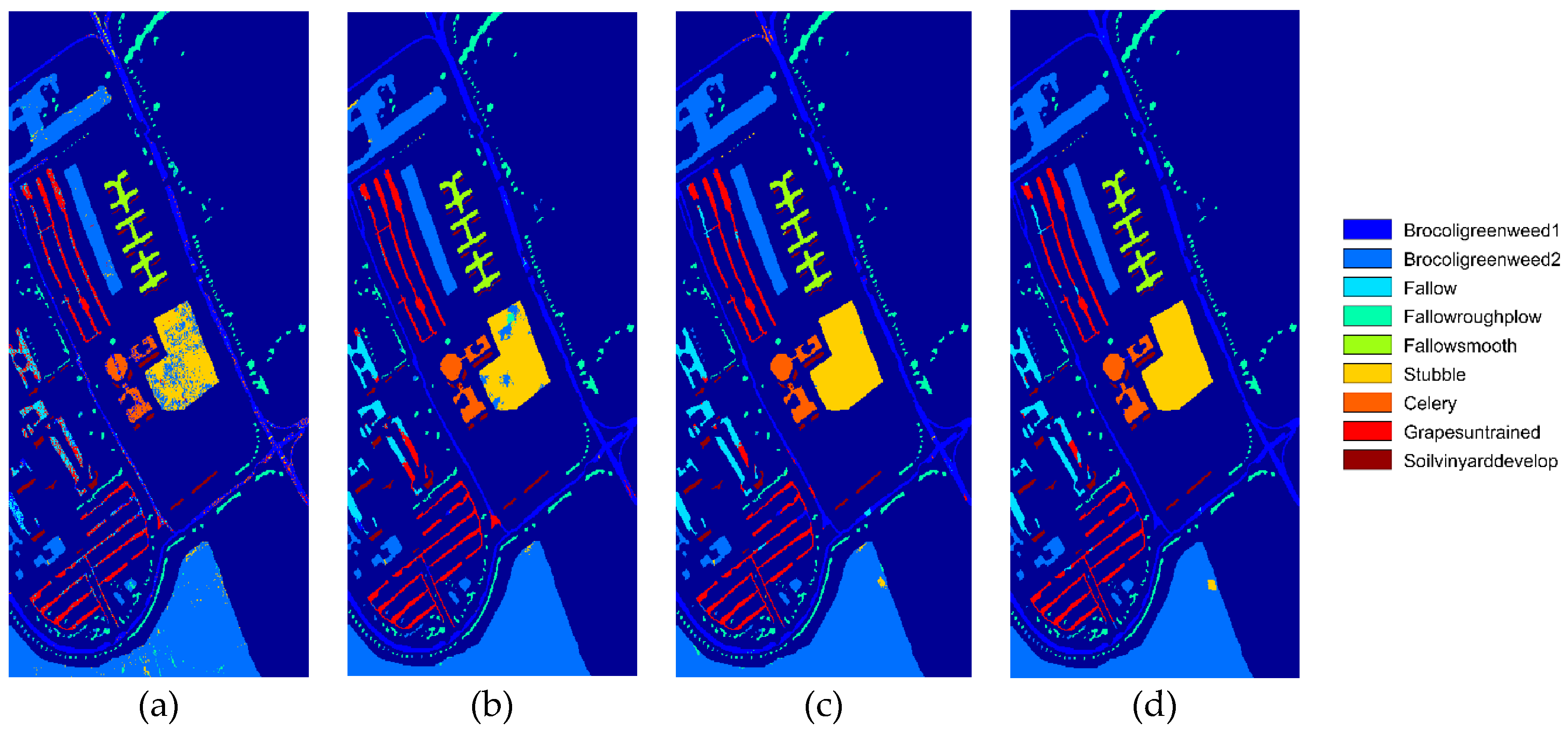
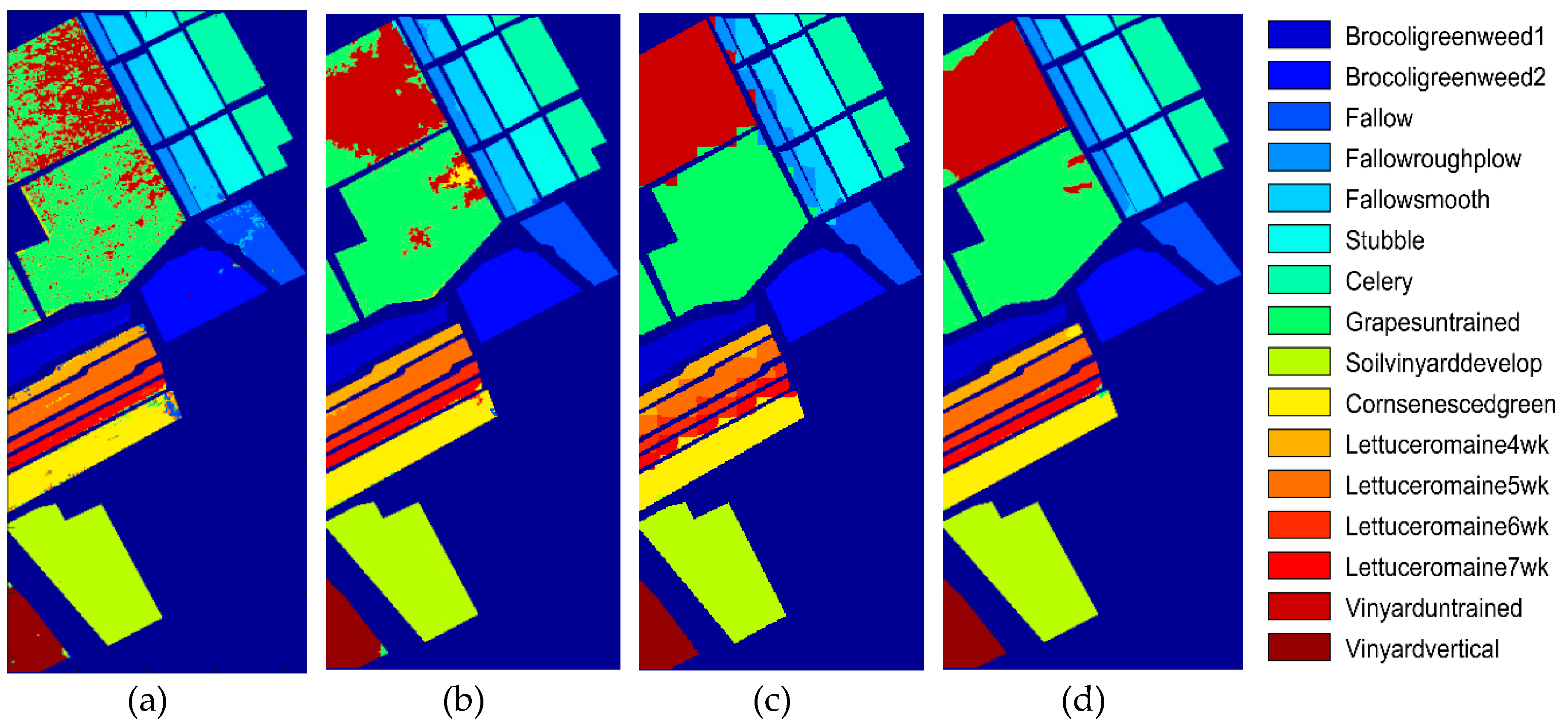
Figure 3b and
Figure 5b, the boundary of each category in these two datasets is essentially regular, but the acquirement of the best β value (0.8 or 0.9) depends on the operator used in the DPR strategy. Although the classification results obtained by using the three operators are not much different, the Robert operator still has some advantage.
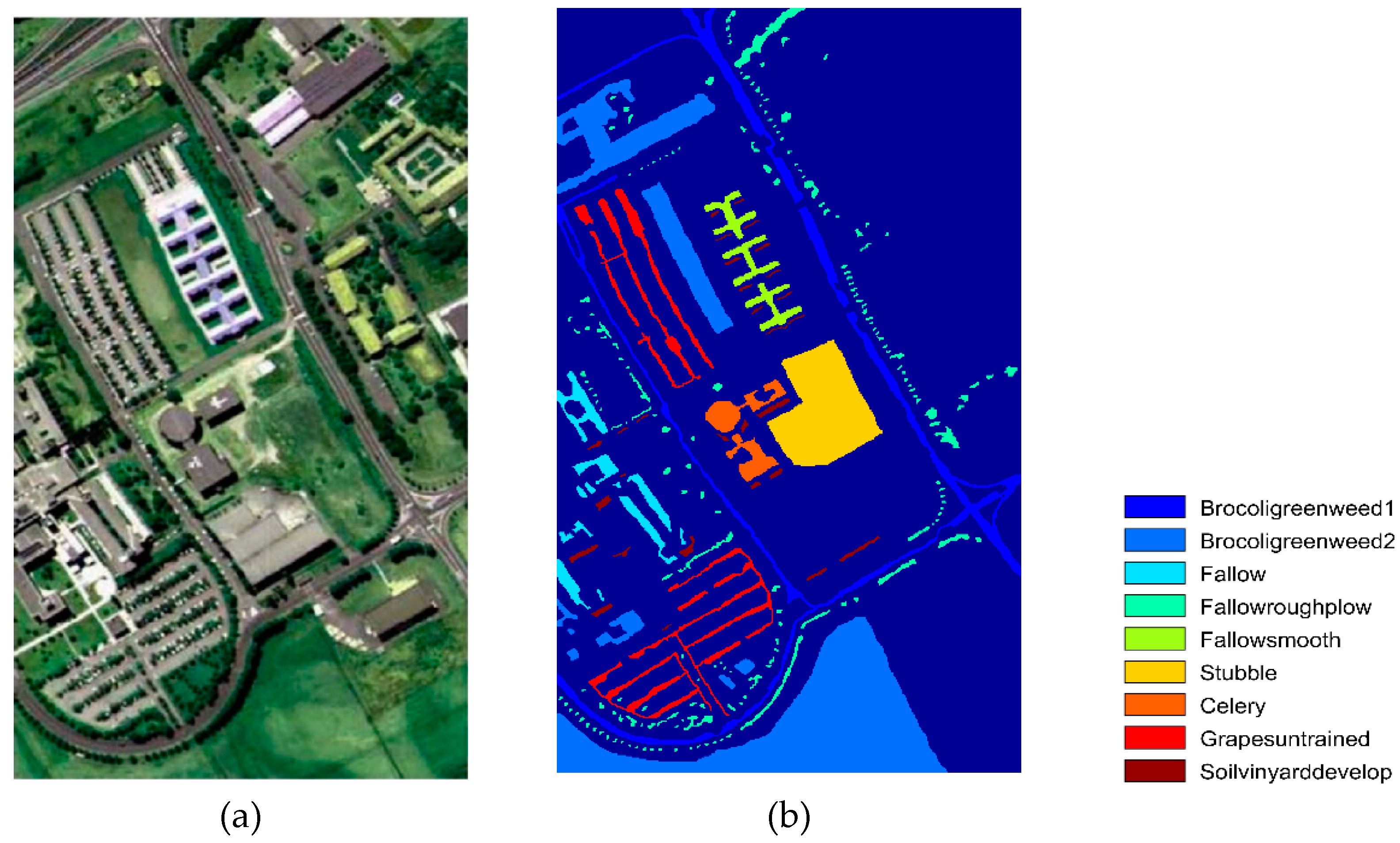
The variation of average classification accuracy does not show obvious regularity on the Pavia University dataset. The great increasing of the average classification accuracy with the increase of β value from 0 to 0.1 or 0.2 explains that it is necessary to adopt edge detection operators in DPR method. While β value varies from 0.7 to 1, the classification accuracy obtained by Canny operator is still superior, because of its good ability to extract an irregular class boundary. On this dataset, the acquirement of the best β is seriously depended on the operator applied in DPR strategy.
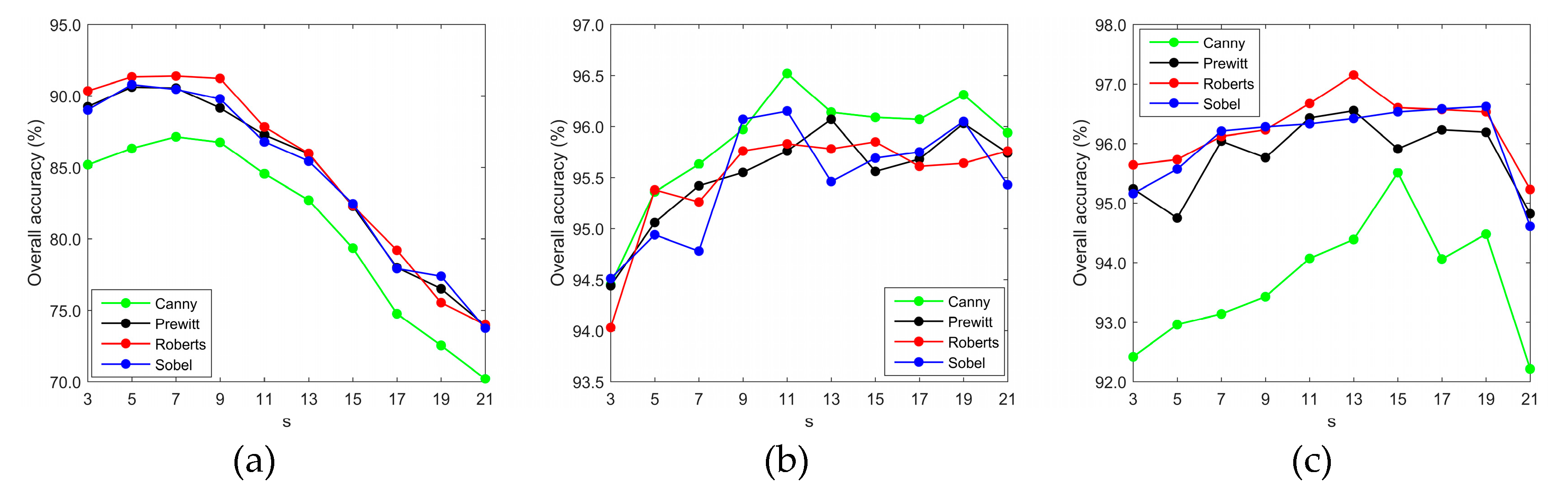
Each datum in
Figure 11 is the average of the classification results obtained by the proposal for 11 different β values and with the same segmentation scale
s. For the Indian pines dataset, the average classification accuracy shows a significant downward trend as the segmentation scale
s changes from 9 to 21. Since the Indian Pines dataset with size 145 × 145 has 16 classes, large-scale segmentation will inevitably reduce the homogeneity of superpixels. In post-processing, the heterogeneity of superpixels obviously leads to a distinctive decrease in classification accuracy. Contrary to the case of the Indian Pines dataset, satisfactory classification results have been obtained on the Pavia University dataset when
s was from 9 to 21. One can see from
Figure 8b that all the average classification accuracies are over 95.5%. As shown in
Figure 4b, a great difference in spatial structure of the objects in the same class implies that using large scales in the SLIC algorithm will achieve a better segmentation effect on this dataset. In superpixel addition, the advantage of the Canny operator in detecting an irregular boundary is proved again. On the Salinas dataset, the Sobel operator shows good stability with the increase of the volume of. There is no significant difference in average classification accuracy among Sobel operator, Robert operator and Prewitt operator when the segmentation scale
s varies from 7 to 19. The reason behind this lies in that in this hyperspectral dataset, the regular class shape and the absence of the class with a very small volume make the proposed method insensitive to the segmentation scale.
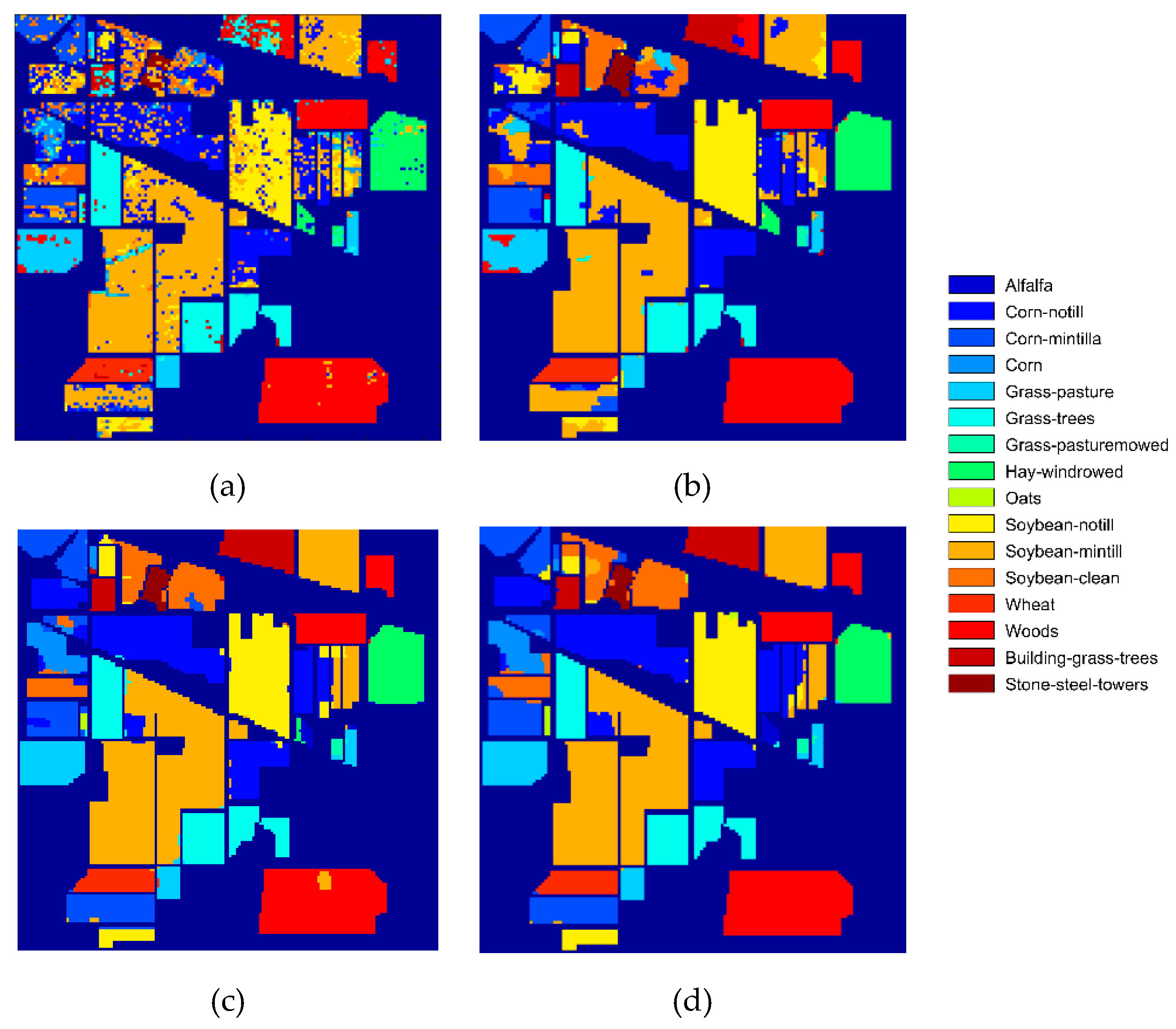
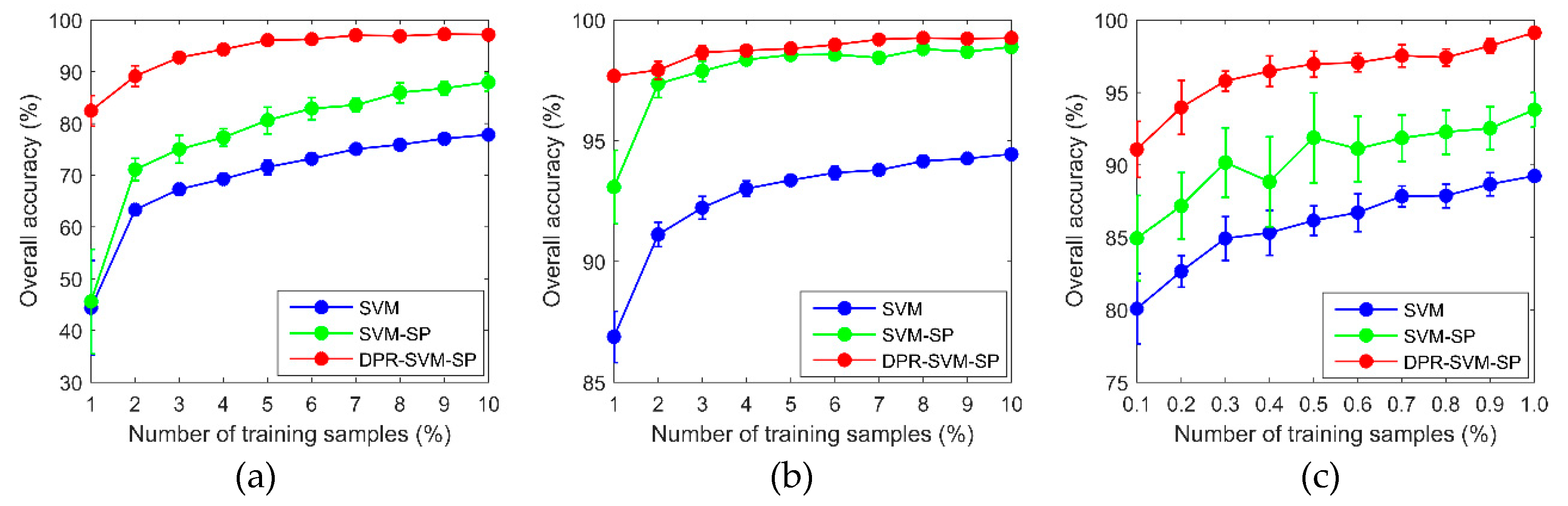
Table 7 shows how the average classification accuracy on three datasets varies with the increasing of the number of training samples. The visualization of result in
Table 7 is displayed in
Figure 12. As seen from
Table 7 and
Figure 12, the classification accuracy has been greatly improved by using spatial information in pre-processing or post-processing. For the Pavia University dataset, the classification accuracy of SVM-SP and DPR-SVM-SP increases slightly as the number of training samples is changed from 2 to 10%. This is because the classification accuracy is so high that there is no room for improvement. The classification accuracy of DPR-SVM-SP on AVIRIS dataset Salinas is more than 95% when the labeled ratio is great than or equal to 0.3%. It indicates that the proposed method can achieve the satisfactory classification result with small training samples. The classification results on the Indian Pines dataset have not shown the growth we expect, when the labeled ratio is greater than 6%. Maybe, most of the pixels that are correctly newly classified are in the superpixels that have already been correctly classified previously.
5. Conclusions
In this study, a technique for measuring the similarity of two pixels in HSI is proposed to address the problem of dividing HSI into superpixels directly by using the SLIC algorithm without using a PCA method. The adoption of this new similarity in the SLIC algorithm will also make it a non-parametric algorithm and easy to use. The experimental results of this work confirm the success of this attempt. Based on the improved SLIC algorithm, SVM and DPR methods, an effective classification scheme for hyperspectral data is developed. The classification accuracy can be significantly improved by utilizing DPR method in preprocessing and superpixel in post-processing. Experimental results on three real hyperspectral datasets widely used to test the performance of HSI classification approaches demonstrate the effectiveness of the proposed method.
In the proposed classification scheme, the DPR strategy, SVM and superpixels obtained by the improved SLIC can be replaced with other denoising techniques, classification algorithms or superpixels detected by other methods. That is to say that among the many combinations, only one of them has been considered in this paper. To an extent, the proposal is a general semi-supervised classification scheme. The DPR method with Robert operator has a good denoising effect on the hyperspectral data with relatively regular class boundary. However, for the HSI in which some classes are composed of many very small fragments, DPR with Canny operator seems to have a good de-noising performance. In summary, one can see from
Table 6 and
Table 7 that the proposal can achieve good classification results.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}