2.1. Study Area
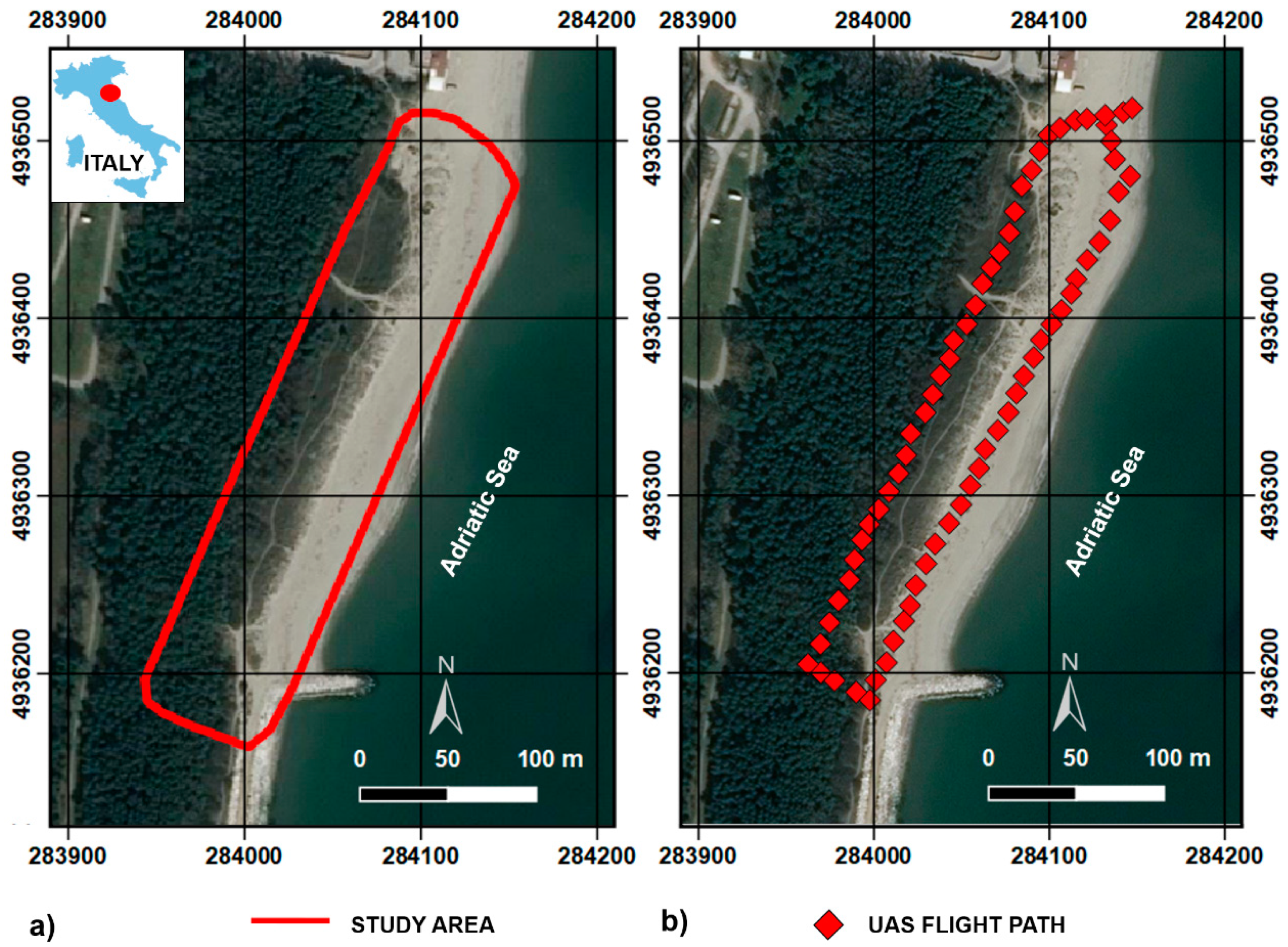
The investigated dune is located near the small touristic village of Casal Borsetti (Ravenna, Italy;
Figure 1a). In light of the complexity, variability, and vulnerability of the small dune belt considered, a detailed description of both the regional settings and the study area is required.
The territory surrounding the city of Ravenna has been strongly anthropized and industrialized, and in the relevant natural areas, intensive agriculture and tourist facilities coexist [
30]. Since the 1960s, the establishment of tourist infrastructures directly along the coastline of this area has resulted in widespread dune damage and destruction. Where the dunes have not been completely flattened to the ground, they have undergone huge fragmentation [
4,
31]. The natural coastal system has been substituted with the new structures that are directly exposed to climate-change effects, such as a rise in the level of the sea, sea storms, flooding events, and marine erosion [
32]. As reported by Sytnik et al. [
6], the sector where the study area lies has shown the highest rates of coastal erosion of the last six decades.
Nowadays, all of the remaining dunes are included within the Po Delta Regional Park, as a Special Protection Area (Directive 2009/147/EC “Birds”) and a Site of Community Importance (Directive 92/43/EEC “Habitat”). The Regional Park is also included in the UNESCO World Heritage list.
The dune investigated is 350 m long and 60 m wide. The mean dune elevation is 2.5 m above sea level (a.s.l.), and the maximum elevation is 3.5 m a.s.l. (to the north of the site). It is one of the last stretches of dunes with psammophytic vegetation, which is very important for the conservation of coastal biodiversity [
33,
34].
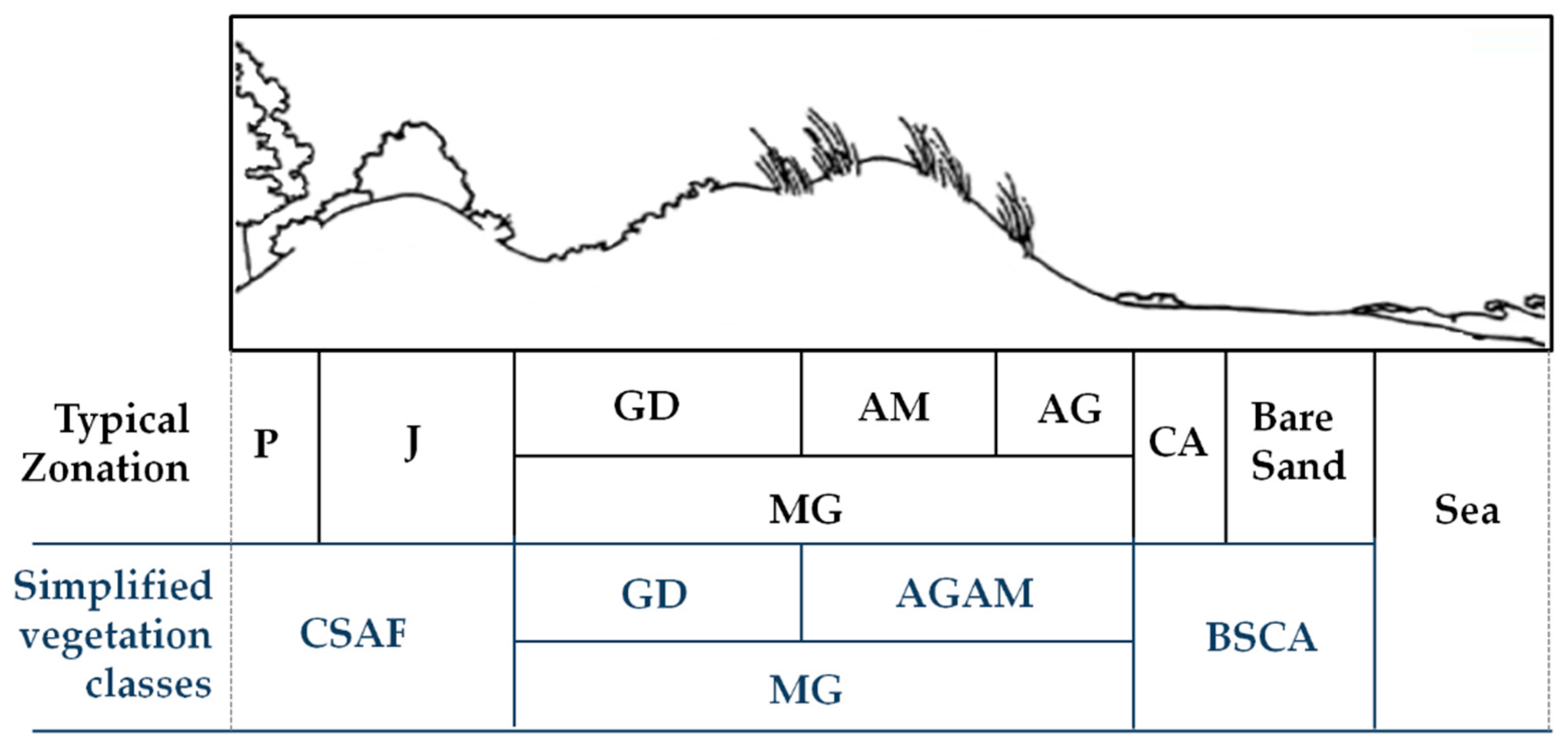
While limiting themselves to the vegetation, many authors have described the typical zonation for the north Adriatic coastal dunes based on strips parallel to the coastline [
35,
36]. In agreement with the definitions of Directive 92/43/EEC “Habitat”, and in light of the recent publication of Merloni et al. [
37], from the sea going inland, the zonation consists of annual pioneer species, embryo dunes, white dunes,
Malcolmietalia grassland, grey dunes, shrubby plant communities, and coastal pine woods (
Figure 2).
The annual pioneer species described as
Salsolo kali–Cakiletum maritimae (EUNIS Code B1.12; hereafter referred to as CA) grow close to the shoreline (within a few meters), and they aid in the formation of the dunes where the organic matter brought by the sea accumulates. The main ephemeral species are
Cakile maritima,
Salsola tragus, and
Chamaesyce peplis [
37,
38]. Moving inland, the dunes start to become semi-stable, and the embryo dune vegetation described as
Agropyretum (
Echinophoro spinosae–Elymetum farcti; EUNIS Code B1.3; hereafter referred to as AG) includes psammophilous perennial plants, such as
Elytrigia juncea (=
Agropyron junceum),
Echinophora spinosa, and
Calystegia soldanella, and these capture the sand as it is moved by the winds, providing the vertical growth of the dune. The white dune community is present in the inner areas where the dunes become more stable, which is also described as
Echinophoro spinosae–Ammophiletum australis (EUNIS Code B1.3; hereafter referred to as AM). This habitat usually covers 50% to 60% of the total area, and represents a semi-permanent stage, as the roots of
Ammophila arenaria,
Echinophora spinosa, and
Eryngium maritimum form dense felts that promote dune consolidation. Behind the white dunes, where salt winds, coastal erosion, and burial by sand do not affect the vegetation, there are the grey dunes (
Tortulo–Scabiosetum; EUNIS Code B1.4; hereafter referred to as GD), which are colonized by perennial species, such as
Lomelosia argentea,
Fumana procumbens, and
Teucrium polium, and which have a significant carpet of mosses and lichens (e.g.,
Tortula ruraliformis,
Cladonia convoluta).
A complication with respect to the theoretical distribution so far described is seen here by
Malcolmietalia grassland (EUNIS Code B1.4; hereafter referred to as MG), which arises where trampling, salty winds, and disturbance occur. This plant community is mixed with AG, AM, and GD, and it can cover large surfaces [
35]. The main diagnostic species are the annual plants
Silene canescens and
Vulpia membranacea, which are typically found alongside allochthonous species, such as
Ambrosia coronopifolia.
A rapid change occurs when moving further inland, where shrubby plant communities settle into depressions where they replace the grey dune vegetation (EUNIS Code B1.63; hereafter referred to as the J habitat), e.g., Juniperus communis and Phillyrea angustifolia. This narrow belt of shrub is in continuity with the coastal pine woods (EUNIS Code B1.7; hereafter referred to as the P habitat), where Pinus pinaster and Pinus pinea are the dominant species.
Along the Casal Borsetti dunes in particular, this vegetation succession is often fragmented, with each becoming interspersed with the others; this has generated an atypical vegetation mosaic. Consequently, five vegetation classes were established for the technical classification requirements here, which represent the most significant evolutionary stages of these dunes. For graphical reasons, the previously reported EUNIS Codes are henceforth substituted by the following vegetation community abbreviations: “Bare sand and
Cakiletum” (BSCA), “
Agropyretum and
Ammophyletum” (AGAM), GD, MG, and “Coastal shrub and arboreal formations” (CSAF) (
Figure 2).
The BSCA class represents the merging of bare sand areas and Cakiletum, where Cakiletum species are always <5% of the entire coverage, even under conditions of naturalness and in the absence of disturbance. Moreover, Cakiletum habitats are systematically swept during summer beach cleaning operations, which destroys all of the growing plants.
Agropyretum has a relatively high presence, even if it also partly suffers from cleaning and trampling activities. Due to these anthropic disturbances, its main species (i.e.,
Agropyron junceum) grows into the next formation, the
Ammophiletum. These two communities have thus been merged into the "Perennial herbaceous vegetation of the embryonic and white dunes" class (i.e., AGAM).
Ammophyletum is not abundant, even if
Ammophila arenaria grows luxuriantly in small areas. This union is also justified from an ecological point of view, because these two represent the perennial herbaceous vegetation that is typical of both embryonal and white dunes distributed along all Mediterranean littoral areas (
Ammophiletalia australis) [
33].
The GD is the third class considered. GD is found as a homogeneous strip that is almost totally covered in mosses (Tortulo–Scabiosetum).
The MG vegetation species are widespread within different habitats, both for AGAM and GD, and they tend to cover even large surfaces, because of both natural and anthropogenic disturbance. Indeed, the MG settlement is mainly linked to the frequent passage of people, which creates erosion of the perennial vegetation cover.
Finally, the J and P habitats have been merged into the CSAF, which mainly includes Pinus pinaster, Juniperus communis, Eleagnus sp., Pyracantha coccinea, Tamarix gallica, and Quercus ilex. An example of a Populus × canadensis tree (located in the northern area of the dunes) is also included in this class. This tree is considered to be a naturalized neophytic species that mostly grows in sandy soils that are damp for most of the year, such as riverbeds or around sandy quarries. However, it can sometimes also be found in ‘back-dune’ environments, although it is not typical of this kind of environment.
2.2. Data Acquisition and Analysis
This analysis of the vegetation communities was based on a three-band orthoimage obtained through a photogrammetric pipeline from a dataset acquired using a UAV. The UAV platform used was an ESAFLY A2500 hexacopter (SAL Engineering, Modena, Italy). It was equipped with a commercial multispectral camera (Tetracam ADC Micro) that acquired images in the green, red, and near-infrared (NIR) bands, centered respectively at 550, 650, and 800 nm. The camera had only one sensor (Aptina CMOS; 6.55 mm × 4.92 mm; pixel size, 3.12 micron), which was screened with a filter array (Bayer RGB) in a ‘checkerboard’ pattern [
39]. Moreover, the lens on the multispectral camera had an optical low-pass filter that stopped the blue band, but it did not have a filter to stop NIR. Through the combination of the filter in the lens with the filter array, each pixel can capture only one band between the green, red, and NIR bands, relating to its position in the checkerboard. For each pixel, it was possible to reconstruct the values of the two missing bands by interpolation of the corresponding measured values in the adjacent pixels [
39]. The proprietary software PixelWrench2 (PW2) provided with the multispectral camera was used to manage this operation.
As the camera was based on the rolling-shutter acquisition system with a total frame creation time of a few milliseconds, the images were acquired with a drone translation speed of 4 m/s and with a constant flight altitude of 80 m above ground level, giving a ground sample distance of 0.03 m. These technical choices avoided blur-motion effects, thus avoiding subsequent problems in the image processing. Furthermore, the UAV had a stabilization system that consisted of a gimbal stabilized with two brushless motors on two axes (i.e., roll, pitch), with mechanical and magnetic cardanic damping and inertial reference with high speed, which allowed for stable framing [
40].
The hexacopter was equipped with a single-frequency global navigation satellite system (GNSS) receiver with a code solution. It was used for both the control and definition of the programmed flight path (with longitudinal overlapping and side slap of 80%), and for the coordinate definition of the multispectral chamber centers of acquisition (
Figure 1b). These approximate camera positions were used as estimated solutions for the reconstruction of the exterior image orientation in the photogrammetric pipeline, using the approach based on the structure from motion algorithms [
41]. Five ground control points (GCPs) were positioned on the ground (i.e., four targets plus the master station), to optimize and increase the accuracy of the self-calibration process for an estimation of the camera interior orientation parameters (i.e., focal length, main point, lens distortion parameters), for a definition of the parameters of the external orientation, and also to obtain more accurate georeferencing. The five targets were sufficient for the optimization process through the bundle adjustment algorithms. Indeed, as recently published by Sanz-Ablanedo et al. [
42], to reach a maximum level of relative accuracy, assessed in terms of the root mean squared error/ground sample distance, 2.5 GCPs are sufficient for every 100 images. In this case, the total number of images used was <100, and of these, <30 images were aligned longitudinally and consecutively. The target coordinates were measured using a geodetic dual-frequency GNSS receiver (Topcon GB500) in rapid-static mode. The International GPS Service for Geodynamics permanent station of Medicina (Bologna, Italy) and the European Reference for Quality Assured Breast Screening and Diagnostic Services permanent station of Porto Garibaldi (Ferrara, Italy) were used to define the positions of the GCPs in the WGS84 system. The chosen projection system is UTM 33N [
43].
The data obtained from the survey were raster images (ground sample distance, 0.03 m) which were composed of a single matrix of digital numbers (DN) and stored in a raw format. These files were pre-processed in PW2 to reconstruct the information for the three bands, and exported as single tri-band TIFF (Tagged Image File Format) images. The PW2 was calibrated to account for the actual exposure conditions using a RAW image of the calibration tag, acquired under the same lighting conditions as the studied images. This procedure does not convert the sensor output to reflectance [
40], and therefore, the subsequent analysis was based on the DN values. The tri-band TIFF images were then processed using the photogrammetric pipeline implemented in Agisoft Photoscan Professional (Agisoft LLC, St. Petersburg, Russia). In the first step, the approximate position and orientation from the GNSS and inertial measurement unit of the drone were associated with each image. In this way, a sparse point cloud model of the scene was created. Through this model, the external orientation parameters of each individual frame were recalculated. A preliminary dense cloud model was then created. The information relating to photogrammetric GCPs was then entered, with manual collimation of each GCP identified for each individual image. The dense cloud model was linearly transformed using seven similarity transformation parameters, which only compensated for linear model misalignment. The next optimization phase then removed non-linear deformations of the model and provided accurate geo-referencing based on the known GCP coordinates [
24]. Through the constraints defined by the GCPs by means of the bundle adjustment algorithm, this step allowed a recalculation of the parameters of external and internal (self-calibration) orientation. The dense cloud model was then recreated. The optimization was used to ensure correct scaling and geo-location, to improve the camera interior and exterior parameters, and to correct for any systematic error and/or block deformation. Successively, a polygon mash was generated based on the previously built dense point cloud. Finally, the digital surface model and the orthoimage were generated with a resolution of 0.15 m. The orthoimage produced maintained the three channels (i.e., green, red, NIR) that were essential for the later vegetation analysis [
43].
To perform the classification, the areas of interest of five vegetation classes were defined by both direct botanical field surveys and photo-interpretation. The areas of interest surveyed in the field were measured with dual-frequency GNSS instrumentation (Leica GPS1200) using the real-time kinematic (RTK) technique. The differential corrections were received through the ItalPoS Network service [
44]. The ItalPos network provides a network-based (N)RTK system, and specifically, the real-time service is based on the master-auxiliary approach, MAX [
45]. The adopted cartographic reference system for all of the data produced is WGS84-UTM33N.
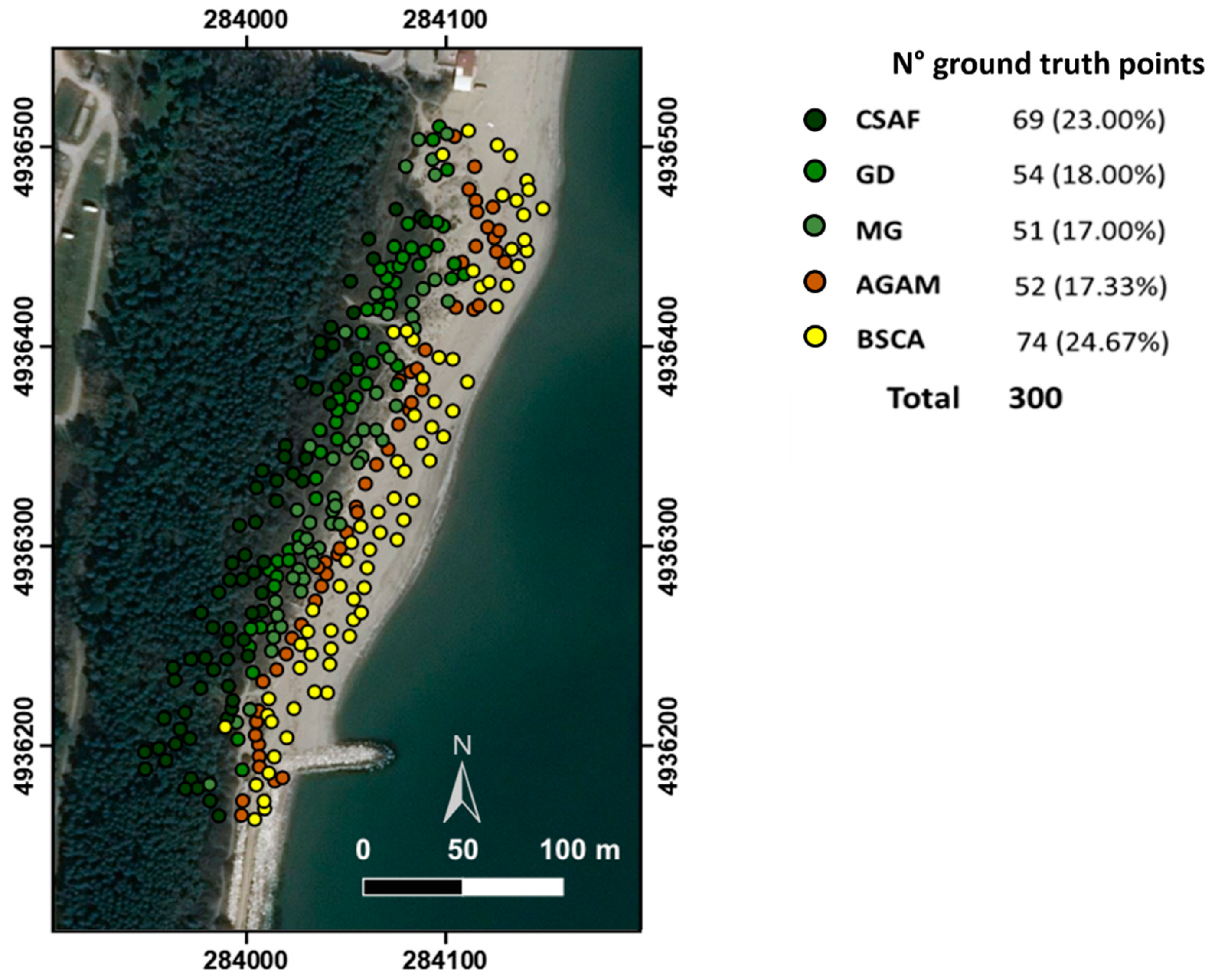
Finally, to collect the ground truth control points for the map classification validation, another NRTK survey (same equipment and procedure as described above) with botanical support was conducted in-situ, with the identification of 300 points of defined vegetation classes (
Figure 3). The final accuracy of the NRTK coordinates was 6 cm to 8 cm in planimetry and 8 cm to 10 cm in altimetry. These values are very acceptable considering that the size of the image cell was 15 cm × 15 cm.
2.3. Classification Methods
In this study, both pixel-based and object-based classification methods were applied to define the dune vegetation communities. The pixel-based classifier considers the information for the spectral signature of the individual pixels. In contrast, the object-based method classifies objects, i.e., groups of pixels with relatively homogeneous properties, that are created in a preliminary phase known as segmentation. These have intrinsic features, like information derived from the direct spectral observation and geometric properties, and contextual features that describe the relationships between multiple objects [
46]. In both approaches, supervised classification algorithms were used. They both required previous knowledge of the vegetation in the study area. Beyond the complicated real field situation, the class selection was also driven by the technical feasibility of discrimination with automatic methods.
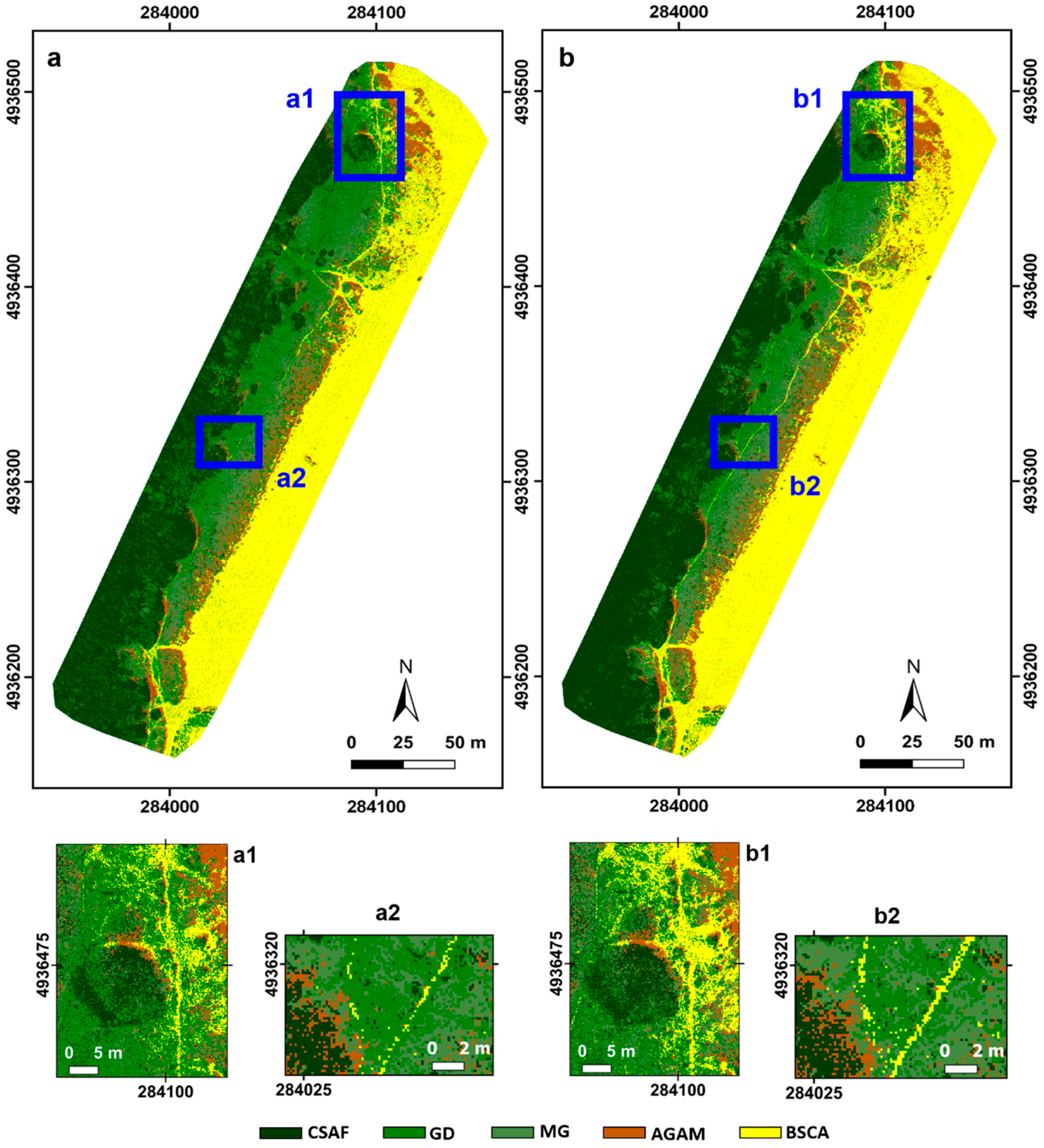
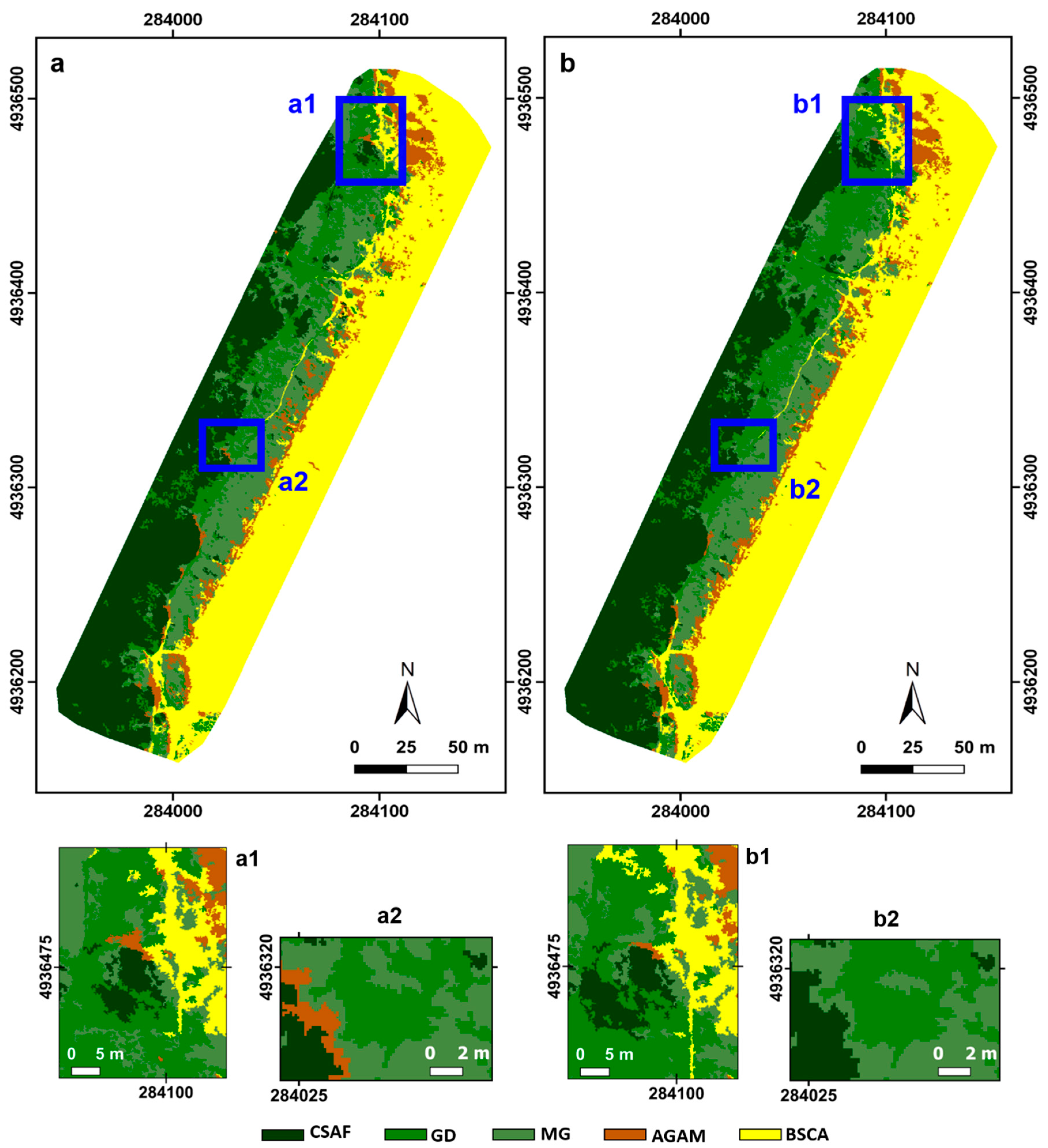
The normalized difference vegetation index was extracted from the multi-band orthoimages before the classification. The analysis started by applying the most used pixel and object classifiers, as the maximum-likelihood (ML) and nearest-neighbor (NN) algorithms [
47,
48], respectively, using the same areas of interest. The pixel-based classifications were conducted using the ENVI software, and the object classifications using the eCognition software.
The ML method assumes that pixels of each class belong to a multivariate normal distribution and defines the probability density function for each class. Each pixel is assigned to the class that it has the highest probability of being in [
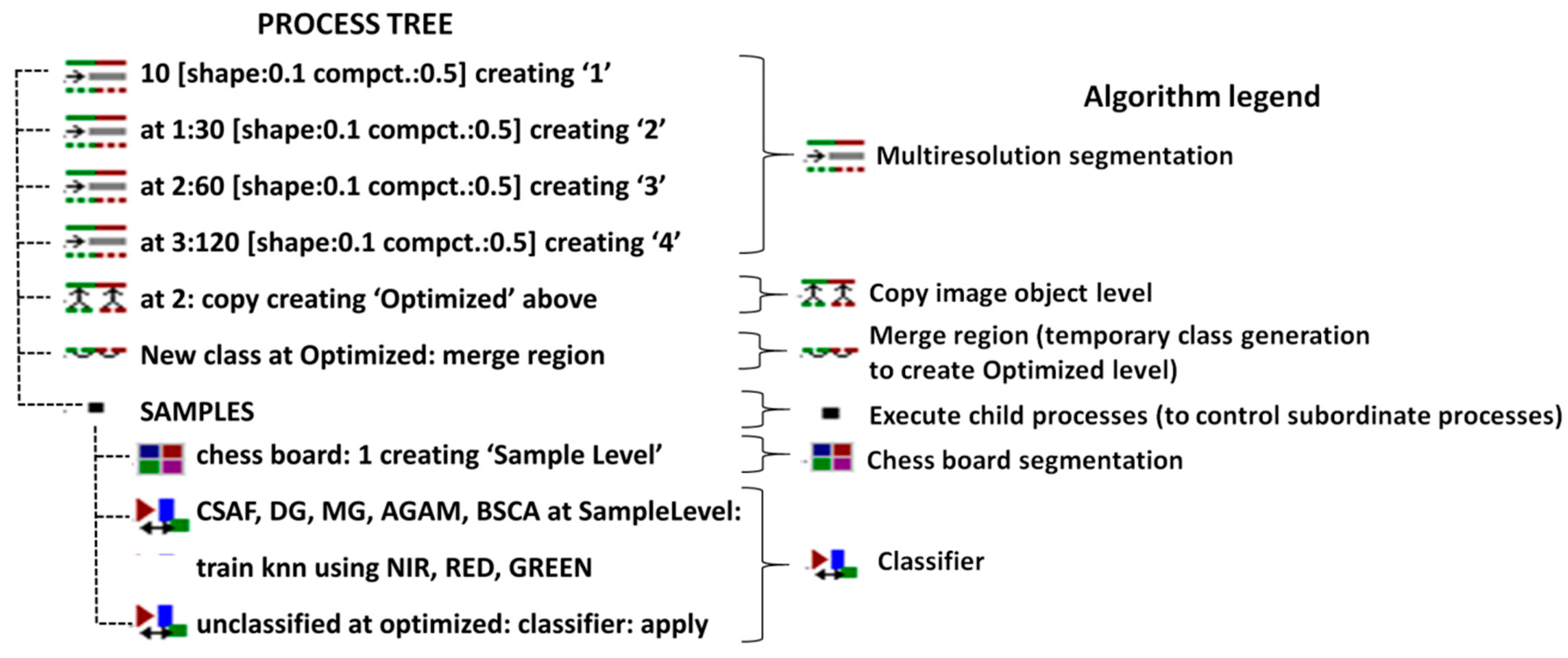
49]. Comparatively, the NN classifier uses spatial features to classify the object, based on the closest training examples and on the class in which its neighbors have been classified. The NN classification required a previous segmentation step. This phase was performed using a multilevel segmentation approach, and in addition to the tri-bands orthoimage, the normalized difference vegetation index and digital surface models were used as input layers. The multiresolution segmentation algorithm was used to generate the image objects. Four levels of segmentation were applied, which defined the color and shape parameters, with the scale parameter increased at each level (
Figure 4). The scale parameter was set to define the level of heterogeneity. Each level was evaluated by photo-interpretation. The optimized level was generated by combining the object levels. The optimized level comprised large segments in homogeneous areas and distinctively smaller image objects that represented small-scale structures and heterogeneous regions [
50,
51]. The class sample shapes were imported in the eCognition software to identify the objects that corresponded to the areas of interest. Therefore, the sample level was created by chess-board segmentation. Finally, the classification procedure was applied to image objects at the optimized level.
To create a comparable classification with pixel-based products, only the mean green, mean red, and mean NIR features were used.
To improve the comparison quality, the support vector machine (SVM) algorithm was applied for both pixel-based and object-based classifiers. The SVM method seeks to determine the optimal separating hyperplane between classes by focusing on the training cases (vector support) that are placed at the edge of the class descriptors [
52]. Training cases other than support vectors are discarded. In this way, fewer training samples are effectively used. Therefore, a high classification accuracy is achieved with small training sets [
53]. The SVM used for classification has the advantages of solving sparse sampling and nonlinear and global optimum problems, compared to other classifiers for satellite imagery classification [
54].
The implementation of SVM in the ENVI software based on the pairwise classification strategy is a multiclass classification method that combines all of the comparisons for each pair of classes [
55]. The SVM pixel (SVMPi) classification output represents the decision values of each pixel for each class, which are used for the probability estimations. Among the available mathematical kernel functions, the linear function was applied. For the penalty parameter field (Harris Geospatial solution, ENVI 5.2), the value of 100 was used, which represents a parameter that controls the trade-off between allowing training errors and forcing rigid margins. Based on the same theoretical approach, using the eCognition software, the equal function and parameters were applied at the optimized level to perform the corresponding object classification (SVMObj).
Once the classifications were performed, their accuracies were evaluated. The agreement between each classification and ground truth was assessed, as represented by 300 control points.
The pixel-by-pixel comparison provided the confusion matrix with dimensions equal to the number of classes, the overall accuracy, and the Kappa coefficient (
K). For the object-based approach, the classification result was exported in a raster format to carry out the comparison. The
K compares global accuracy with an expected global accuracy, taking into account random chance.
K >0.80 represents strong agreement and
K <0.40 represents poor agreement [
56]. The user accuracy, producer accuracy, and
K-Conditional were also calculated from a single confusion matrix. The first provides the probability that a random pixel extracted from among those belonging to class
i in the reference belongs to class
i in the classification. The producer accuracy, instead, defines whether a randomly chosen pixel among those belonging to class
j in the classification also belongs to class
j in the reference data [
57]. As for
K,
K-Conditional represents the agreement between the reference pixels and those classified, as calculated for each class.
2.4. Statistical Classification Comparison
To determine the better performing classification method between pixel-based and object-based classification, three tests were carried out: TEST 1, TEST 2, and TEST 3.
TEST 1 established the significance of the difference in the accuracy between two maps with independent Kappa coefficients. Once establishing the null hypothesis, that the expected
K values of the two statistics considered for each comparison (1 = first algorithm; 2 = second algorithm) were the same (i.e., no significant difference), the Student’s
t was applied [
47,
58], as in Equation (1):
where
and
represent the estimated variances of the derived
K coefficients.
To calculate the required variance values associated with the
K and
K-Conditional coefficients, a Fortran program was implemented using the
σ formula proposed by Rossiter (2004) [
59]. Considering that
z follows a normal normalized distribution and the significance level
α = 0.10, with a consequently confidence limit of 1.65, the hypothesis was accepted for the test statistic
z of |
z| ≤1.65.
TEST 2 evaluated the significance of the difference between two independent proportions [
60], using Equation (2), which takes into account the correction for continuity [
58]:
where
and
are the numbers of correctly allocated cases in two samples of size
and
, respectively, and
. The statistical significance of the difference between two classification maps is verified through
z, which follows a normal normalized distribution, in the same way as with the previous comparison of
K.TEST 3 was based on McNemar’s test [
60], which is suitable for comparisons of related samples. Equation (3) takes into account the correction for continuity [
61]:
This non-parametric test uses a confusion matrix, of 2 × 2 dimensions, in which
fij indicates the frequency of sites lying in confusion element
i, j, as reported in the example in
Table 1.
The McNemar statistic follows a chi-squared distribution with one degree of freedom, and its square root follows a normal normalized distribution. Therefore, the statistical significance of the difference between the two classification maps is evaluated as with the previous tests.
The continuity correction that is considered in TEST 2 and TEST 3 is particularly important when the sample size used is small [
62].
In the first step, these tests were applied for the same classification technique at both the global and single class levels. Then, the tests were applied to compare the statistical significance of the accuracy between the two algorithms that demonstrated smaller errors in previous comparisons.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}