1. Introduction
Remote sensing satellites, which observe objects on the ground from outer space, are widely used in various real applications, such as environmental monitoring, resource exploration, disaster warning, and military applications. The observed images from satellites generally have low-resolution (LR) due to the limitations of spaceborne imaging equipment (Charge-coupled Device (CCD) sensors) and communication bandwidth. In addition, satellite images are affected by atmospheric turbulence, transmission noise, motion blur, and undersampling optical sensors. The quality and resolution of images from remote sensing satellites cannot meet the requirements of real satellite image analysis. Super-resolution (SR) technology can overcome hardware limitations and improve the spatial resolution of images through software manner. The first SR algorithm [
1] was developed to improve the resolution of Landsat remote sensing images by fusing multi-frame complementary information. In the last decades, SR has been successfully applied to enhance the resolution and quality of remote sensing satellite images. A well known example is SPOT-5, which reaches 2.5 m resolution through the SR of two 5 m images that are sampled from shifting a double CCD array by subpixel sampling interval [
2,
3]. Traditional SR image generation methods usually require multiple spatial/spectral/temporal low-resolution images of the same scene [
4,
5].
Existing image SR algorithms are divided into two categories, namely reconstruction- and learning-based algorithms [
6]. Reconstruction-based algorithms fuse subpixel LR multi-frame information and reconstruct their latent high-resolution (HR) images. Previous satellite SR methods utilize reconstruction-based methods in solving the inverse problem of the degradation process. Reconstruction-based methods model the degradation process of imaging with mathematical formulas by using degradation factors, such as downsampling, optical blur, atmospheric disturbance, registration error, geometric deformation, and motion compensation [
7,
8,
9]. Although reconstruction-based methods are simple and intuitive and can be flexibly combined with prior constraints, they rely on accurate subpixel precision estimation.
Inspired by the immense success of machine learning in object recognition and other tasks, learning-based SR methods have been highly valued and have become the mainstream direction of research. They aim to learn a mapping function between LR and HR image/patches through the prior information provided by a training dataset. Learning-based SR algorithms can obtain better subjective and objective reconstruction performance than reconstruction-based methods because external training databases provide considerable a priori information. In terms of the usage of prior training samples, learning-based SR algorithms can be divided into three categories, namely regression-, representation-, and deep-learning-based algorithms. Some representative regression-based [
10,
11,
12] and representation-based SR algorithms [
13,
14,
15] yield decent subjective and objective performance. These methods are efficient with flexible framework for using regularization terms.
Deep-learning-based approaches provide an end-to-end solution for learning complex mapping functions and are rapidly and successfully applied on SR tasks. A complex nonlinear mapping relationship between LR and HR patches is learned through convolutional neural networks (CNNs) [
16,
17], considering their excellent learning capability. Shi et al. [
18] constructed a subpixel CNN, which provides a novel manner of directly and efficiently learning the mapping function from LR to HR images, which is further efficient. Kim et al. [
19] stated that the construction of a deep network can effectively alleviate training difficulty with deep residual learning. Lai et al. [
20] built a pyramid network for fusing multi-scale residuals in the feature domain. A generative adversarial network (GAN) [
21,
22], which comprises generator and discriminative networks, was used to generate fake details for simulating a good visual output. For satellite images, Luo et al. [
23] replaced zero-padding with self-similarity to avoid the addition of unusable information and achieved good results. Wang et al. [
24] proposed a multi-memory CNN for video SR to retain inter-frame temporal correlations.
The above-mentioned SR approaches mainly focus on the general nature images. As for satellite image, the object scale in the image is relatively different due to wide-range imaging, and it has important roles in vision tasks, such as segmentation, feature extraction, and object tracking. Some deep-learning algorithms designed for general images cannot efficiently handle satellite images because they do not specially consider the multi-scale nature of satellite images. Moreover, adequate high-frequency information, such as edges and textures, are crucial for satellite image detection [
25] and object recognition [
26,
27,
28,
29,
30]. The use of a single structure network in predicting and reconstructing objects without considering their different scales results in poor reconstruction performance. One practical solution is to explore the multi-scale information into deep neural networks. Zhang et al. [
31] used multi-scale spatial structural self-similarity to learn multi-scale dictionaries. Fu et al. [
32] utilized the multi-scale regions of an image to train a recurrent attention network for fine-grained recognition. Liu et al. [
33] used multi-scale and multi-level network in a holistic manner to obtain hierarchical edge information. Similar to the inception network [
34], Du et al. [
35] fused different scale features from three varying filters.
The aforementioned CNN-based SR models build fine networks and have advanced the state-of-the-art performance on learning significant local detail information. The approach in [
36] points out that too small receptive field resulting in the lack of enough global information to yield good visual results. To obtain fine local detail information, they often use small image patches for training (e.g.,
for SRCNN [
17],
for VDSR [
19],
for LapSRN [
20], and
for SRResnet/SRGAN [
21]). A small receptive field only considers a limited range of information during SR tasks. This model lacks the capability of obtaining global and contextual information for SR. On the contrary, Zeiler et al. [
37] visualized convolutional network to indicate that different network layers have varying roles in representing the features that simulate the ventral pathway to enhance their performance [
38,
39,
40,
41,
42]. They indicated that hierarchical features of different scales effectively improve the capability of acquiring global information.
Inspired by the observation of “look closer to see better” [
32], we propose a flexible and versatile multi-scale residual deep neural network for satellite image SR, named MRNN, for the hierarchical reconstruction of satellite imagery with HR detail information. In this network, multi-scale receptive fields are similar to the observation from different distances by human eyes. We extract three scales of the image at large- (large-kernel-size network, for global information), middle- (middle-kernel-size network, for contextual information) and small-scale (small-kernel-size network, for fine local information) features to represent the multi-scale information of images. In comparison with traditional neural networks, MRNN fuses the residual information rather than intermediate features. Thus, the fusion network fuses all scales of residual information to improve the high-frequency details.
The contributions of this study are highlighted as follows: (i) The use of MRNN is proposed for satellite image SR. The proposed network contains three parts, namely multi-scale feature extraction; parallel small-, middle-, and large-scale; and residual fusion networks. The proposed multi-scale neural network leverages SR performance on the basis of “look in multi-scale to see better”. (ii) The proposed residual enhancement and fusion networks effectively enhance the high-frequency information of satellite images in SR tasks. The fusion network refines fine edge/detail textures, thereby improving the details of the satellite image.
The remainder of this paper is organized as follows. In
Section 2, we describe the framework of the proposed method. In
Section 3, comparison is presented among the proposed method and some representative SR methods. The discussion and conclusion of this study are given in
Section 4 and
Section 5, respectively.
2. Satellite Imagery SR Based on Multi-Scale Residual Neural Network
We use image saliency to show the difference among various image sizes and emphasize the role of multi-scale images. Image saliency [
43] is an important visual feature in an image and emphasizes the importance degree of a region for human eye perception. The brightness of a saliency map represents the importance of object parts. The saliency map
S is formulated as:
where
is the mean image feature vector, and
is the corresponding image pixel vector value at position
in the Gaussian blurred version (using a
separable binomial kernel) of the original image.
Figure 1 displays three sizes of image patches, namely large- (
), middle- (
), and small-sized (
) image patches. In the
image patch, the saliency map focuses on the global information in the image, such as the outline of a building. For the
image patch, which contains further contextual information, the saliency map focuses on building parts and street lines. For the
image patch, which has a small receptive field, only local information is observed, and global information is neglected. Here, long-distance observation experience can be reviewed; global configuration information, such as position and outward appearance, can be observed when we are far from the observed objects, and no detailed information is included. For additional details, we focus on local information, such as the decoration and color of a building, as we approach. This observation is a good illustration of the role of multi-scale information in visual observation. Therefore, image reconstruction on only single-scale image patches cannot simultaneously and effectively recover the global and local information of the object.
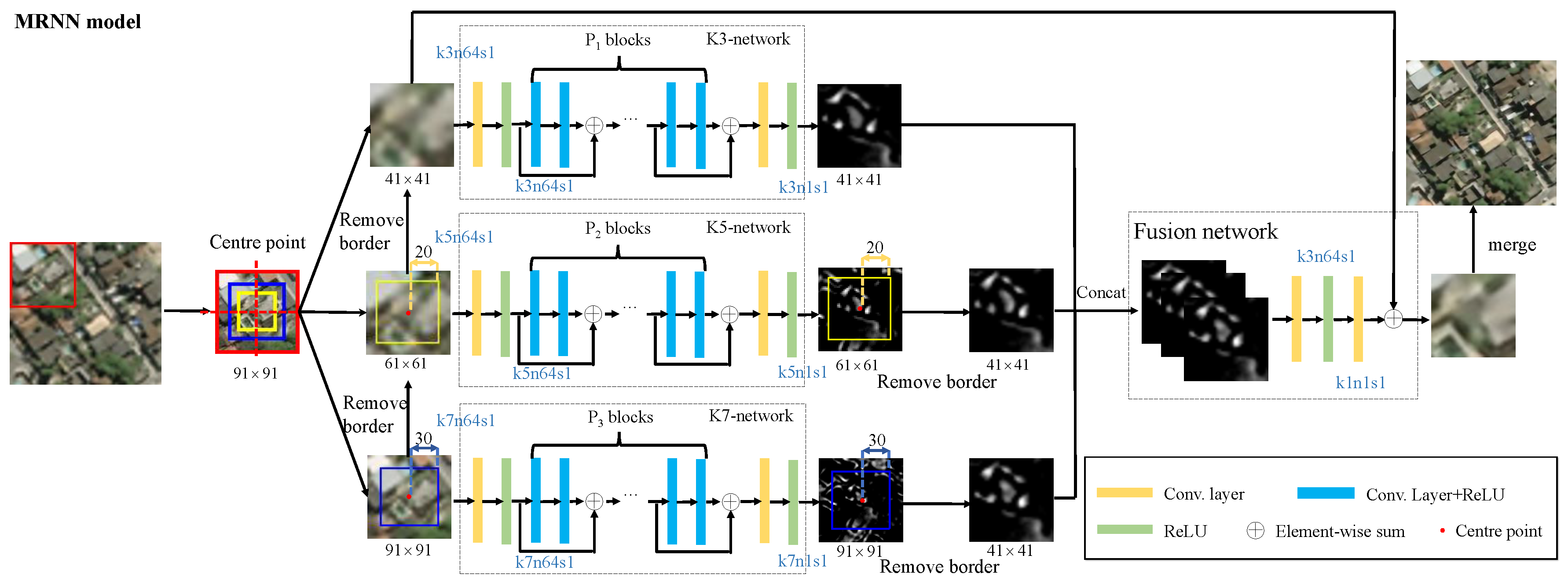
We propose a novel multi-scale residual network, whose structure is shown in
Figure 2. We establish three adaptive networks with different scale features to predict their high-frequency residual information in different scales for satellite images. Thus, we use residual images with varying scales to merge their high-frequency by utilizing a residual fusion network. As the pixel value in the residual image is small, we use the ImageEnhance module of Python Imaging Library
https://github.com/python-pillow/Pillow to conduct enhanced contrast processing of images. The enhanced image
is given by
where
is the original image, and the enhancement factor
represents the weight of the image blend.
is a generated image, whose pixel value is 0.5 plus the average value of
. The greater is the
, the greater is the contrast of the image.
For a pair of training datasets
, where LR image
and HR image
,
t is the amplification factor,
i denotes the sample index, and
M refers to the number of training samples. The LR image
is interpolated to the HR image size with bicubic kernel as
, and the tensor version of the training dataset is rewritten as
. The superscript represents the type of network, and the subscript indicates the number of layers. Superscripts K3, K5, K7, C, and F represent the K3-network, K5-network, K7-network, Concat operation, and residual fusion network, respectively. The sampling of patches with different sizes results in various numbers of patches in each scale. However, all training sample sets share the same training set
. The number of image patches is calculated as follows:
where
is the floor function and
indicates the size of receptive field of the D-layer network. Image patches
and
are acquired on the basis of the center point of the
image patch (for additional details, see
Figure 2). LR and HR image patch pairs with different scales are defined as
,
, and
, which have patch sizes of
,
and
pixels, respectively.
j is the index of the image patches, and
,
, and
denote the numbers of patches. Considering residual fusion, we use the patch center point to anchor three different size patches; thus,
.
2.1. Multi-Scale SR
We use three different scales of networks to simulate SR with different depths. The network depths are
,
, and
. Parameter
D is fine tuned according to the method in
Section 3. In the K3-network, the convolution filter is defined as
. The residual map of the K3-network at the patch level is defined as follows:
where
is the predicted residual patch with size
;
indicates the weight matrix with size
;
denotes the bias with size
;
represents the generated feature maps of the 19th layers by an activation ReLU, which is composed of 64 feature maps; and
j refers to the index of image patches.
For the K5-network, the size of its convolution kernel is
pixels. For K7-network, the filter kernel size is
pixels. We use the same method to calculate the size of the input image patch. Their residual maps are calculated as follows:
where
has a size of
;
has a size of
; the size of
and
is
; and
j denotes the index of the image patches.
and
represent the feature maps of the 14th layers by the K5- and K7-networks, respectively.
2.2. Residual Fusion Network
To realize the complementarity of different scales of information, the global information of an object is described by large-scale information, and, the closer you look, the better the hierarchical details become. We use a fusion network for multi-scale residual fusion.
where
,
, and
are the residual maps with the removal of border from the outputs of the three differently scaled networks.
represents the combined three layers of residual maps. The Concat function cascades the multi-scale residual maps in the third dimension (connect three tensors). Regardless of the same input
, the outputs of K3-, K5-, and K7-networks are different because they reconstruct their residual information through their own scales. To fuse different scales of residual information, we use a simple two-layer network to fuse three channel information. A
convolution kernel is a linear combination of each pixel on different channels. The
convolution kernel is used to fuse the residual feature maps. The cross-channel information interaction among different scales of information is consistent with the hierarchical visual cognition mechanism. We can obtain the final fusion residual as follows:
where
is the second layer weight matrix,
represents its bias,
denotes the input multi-scale residual maps, and
indicates the final fused output residual map. Thus, the final HR image
is as follows:
2.3. Loss Function
We define the loss function with mean squared error (MSE) as the objective function. In MRNN, we formulate the overall loss function as follows:
where the first three terms are the losses of the multi-scale residual networks (K3-, K5-, and K7-networks). The last term represents the residual fusion loss. We simply set
. We use a two-step method to train the network. Initially, we parallel-train three SR networks with differently-scaled patches. Then, we determine the fusion loss for the second time on the basis of the contacted residual maps.
A gradient descent method is used to optimize the network parameters by back propagation. Convolution operations reduce the size of the feature map. We maintain many edge pixels by padding zero to infer the center pixel accurately and ensure that all feature maps have the same size to preserve the information on the edge of the image patch.
3. Experiments
3.1. Experimental Data
The learning-based super-resolution methods learn the missing high-frequency information of LR images from the prior information provided in the training data. Generally, the more training data there are, the better reconstruction effect can be obtained by SR methods. In addition, the performance of the SR reconstruction method is also related to the similarity of the test image to the training image. If the test image is close to the statistical characteristics of the training images, it is more likely to get a good reconstruction result. At this point, there may be fewer training samples to get good results. On the contrary, when the statistical characteristics of the test image and the training image are greatly different, it is difficult to achieve a satisfactory result even using a large-scale training set. To verify the performance of MRNN, we conducted experiments on two satellite image datasets, namely, SpaceNet image and NWPU-RESISC45, to ensure that all algorithms used the same amount of training data. The SpaceNet satellite image dataset
https://spacenetchallenge.github.io/AOI_Lists/AOI_1_Rio.html includes five areas in Rio de Janeiro, Paris, Las Vegas, Shanghai, and Khartoum, which are collected from DigitalGlobe’s WorldView-2 satellite and published publicly at Amazon. The complete satellite image of Rio de Janeiro (the spatial resolution is 0.5 m) has the highest resolution image with 2.8 M × 2.6 M pixels, and is divided into 6540 non-overlapping HR image patches with
pixels, and the main contents of interest in the image are buildings and roads. In total, 2080 images of buildings were randomly selected from these image patches, of which 2000, 40, and 40 images were used as the training set, validation set, and test samples, respectively.
The NWPU-RESISC45 dataset
http://pan.baidu.com/s/1mifR6tU [
44] is a publicly available benchmark for remote sensing image scene classification (RESISC), created by Northwestern Polytechnical University (NWPU). This dataset covers 45 classes with 700 images in each class. We randomly selected 52 images from each class, of which 50 were used for training and the rest for testing. The HR image size is
pixels. The spatial resolution of NWPU-RESISC45 varies from approximately 30 m to 0.2 m [
44]. Images in the NWPU-RESISC45 dataset, compared with the SpaceNet dataset, have complicated and erratic imaging conditions, including various weather, seasons, and lighting conditions. These factors pose a huge difficulty for SR methods.
Image degradation is a very complex process to be modeled by some filter and down-sampling operators. Here, we interpolated the HR image with bicubic kernel into its LR version with scaling factor
t. In the current works (for example, all the comparison methods in our work [
17,
20,
21,
23,
45]), the most commonly used image degradation is the bicubic downsampling. Since learning-based super-resolution algorithms learn the mapping relationship between low-resolution and high-resolution images, the bicubic degradation is the fairest approach for comparison. Complex imaging degradation model will be investigated in future research. In the testing process, the images did not need to be partitioned.
Peak signal to noise ratio (PSNR) and structural similarity (SSIM) [
46] (with default parameters) describe the similarity between the reconstructed and original images in terms of the image. Recent studies [
47] have shown that feature similarity (FSIM) [
47] and visual information fidelity (VIF) [
48] are further consistent with the subjective results. Rectangular-normalized superpixel entropy index (RSEI) [
49] (with default parameters)
https://github.com/jiaming-wang/RSEI obtains further accurate image evaluation results by introducing the spatial structure of the image. Mutual information (MI) can express the dependence degree of the information between the images in terms of information. The higher is the MI score, the more substantial is the dependence and the higher is the similarity between images. The mutual information between patches
and
is defined as follows:
where
q and
g represent the gray-scale values,
denotes the ratio of the number of pixels of the gray value that is
g to the increased image, and
is the joint distribution function of
q and
g.
We define the information gain between SR image
and LR image
relative to HR image
as follows:
All image quality assessment metrics only consider the Y component of the YCbCr color space.
3.2. Training Parameters
The proposed network is an end-to-end network, where each sub-network must train for 80 epochs as the pre-training network. The entire network is trained for 10 epochs.
Considering the deep network layer, the algorithm uses learning rate attenuation. We followed Kim et al. [
19] for setting hyper-parameters: the learning rate was initialized to 0.1, the learning rate decreased by 1/10 every 20 epochs, and the network’s momentum was 0.9. To avoid over-fitting, we used regularized
-norm, and its weight decay was 0.0001. For the K3-residual learning network, we set the step size to 1 with a padding size of 1. For the K5-network, the step size was equal to 1 with a padding size of 2. For the K7-network, we set the step size to 1 and padding size to 3. We applied the MSRA method [
50] to initialize the weights, that is, satisfying the Gaussian distribution whose mean value is 0, utilizing a variance of
(
n is the batch size), and a constant to initialize the bias term with initial value 0. We initially converted the RGB image to the YCbCr color space and then reconstructed the Y channel. After the reconstruction, the Y channel image was restored to the RGB color space. We implemented the MRNN model using the Caffe library [
51]. Training the MRNN roughly took 10 h with four 1080Ti GPUs.
3.3. Complementarity Analysis of Multi-Scale Residual
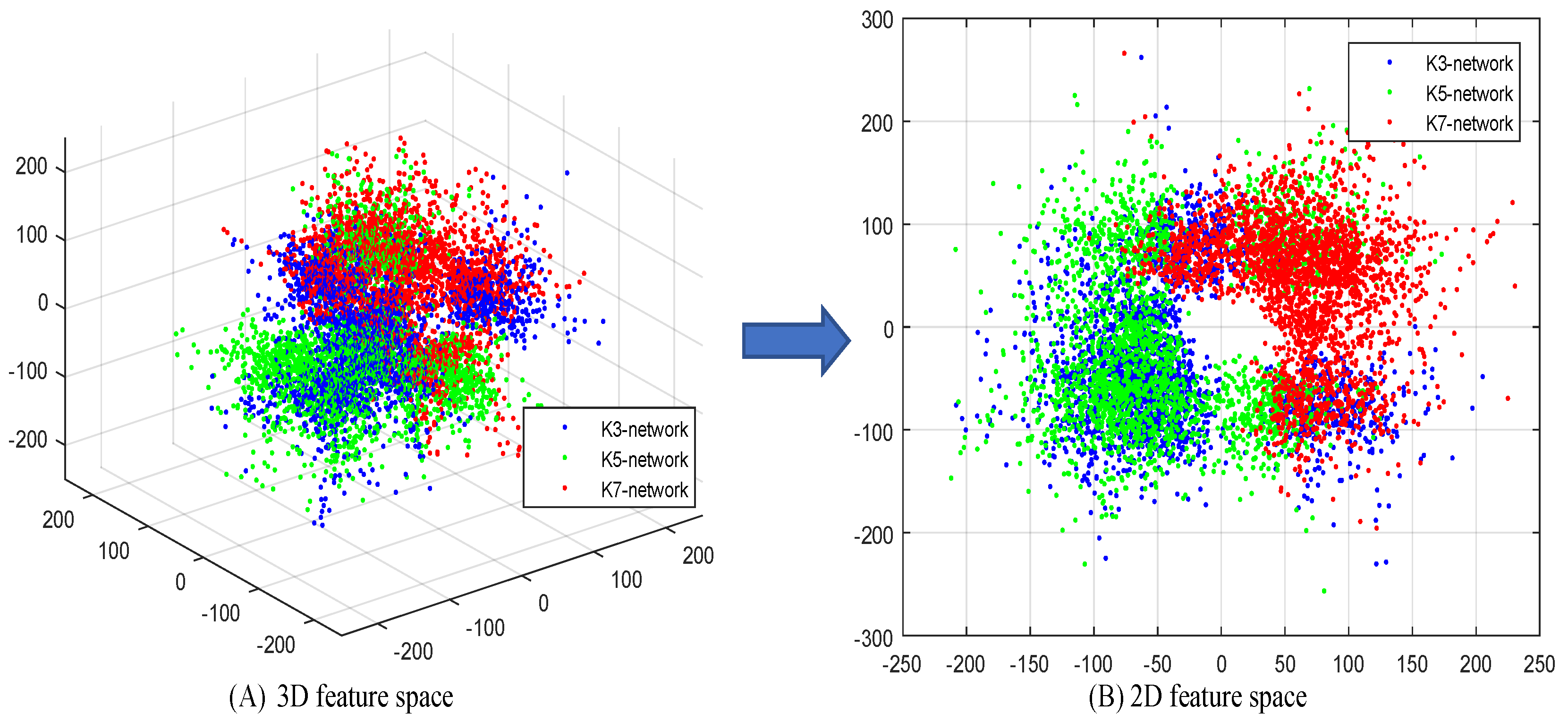
If there were less overlap between different scale residual information, it would mean that the complementarity of residual information between different scales is better [
52]. Therefore, in this section, we show the distributions of residual information on different scales. We selected 15 representative LR images
and corresponding HR image
from SpaceNet image datasets with the same configuration of
Section 3.6. The reconstruction residual maps of multi-scale networks are
for a total of 45 residual images. The estimation residual error map was defined as
, and we projected them into 3D and 2D residual feature spaces through principal component analysis (PCA), as shown in
Figure 3. The distribution maps of 2D and 3D feature space show that multi-scale networks provide different estimation residual errors. This observation also proved that they are complementary. The overlap observed in
Figure 3B covers a sufficiently large feature space, even if only three parallel networks are used. Therefore, additional parallel networks would only increase overlap.
The distribution maps in
Figure 3 cannot clearly describe the complementary patterns of multi-scale residual. Therefore, we implemented the clustering of data by k-means and obtained their distribution of 2D feature space, as shown in
Figure 4. We name the four patterns as “
”, “
”, “
”, and “
”. Pattern “
” represents the best case, that is, the high-frequency information of three scales is complementary between any two. The latter three patterns can be classified as: the information of two scales is considerably common, but a complementary relationship also exists, whereas the other scale complements them. This behavior effectively demonstrates the complementarity between multi-scale residuals.
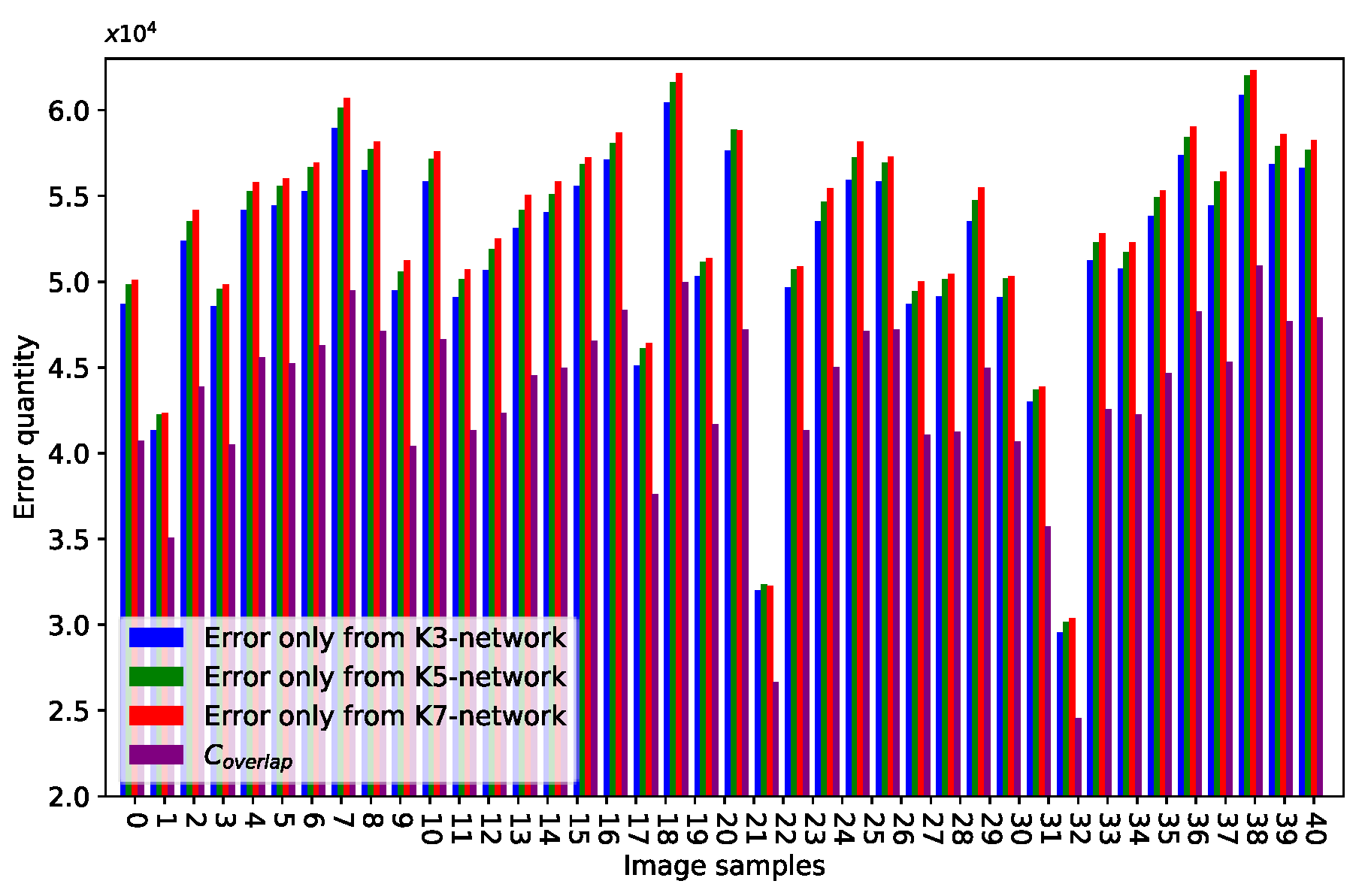
We performed quantitative validation as follows:
where
represents the absolute value of the matrix in an element-wise manner. The function
can count the number of nonzero elements in a matrix.
represents the number of elements whose values are greater than threshold
t.
denotes the number of above elements at the same locations in three error residual maps. We refer to Wang et al. [
52] and set
to represent high-value components (high-frequency information signals).
Figure 5 plots the bar. The blue bar represents the error only from the K3-network, and the green and red bars indicate the errors only from the K5- and K7-networks, respectively.
is the purple bar.
, and networks of different scales play different roles in the proposed method.
Statistical data and qualitative assessments prove that high-frequency information learned by multi-scale networks is complementary. This case is the reason we fuse multi-scale residual maps for improving reconstruction performance.
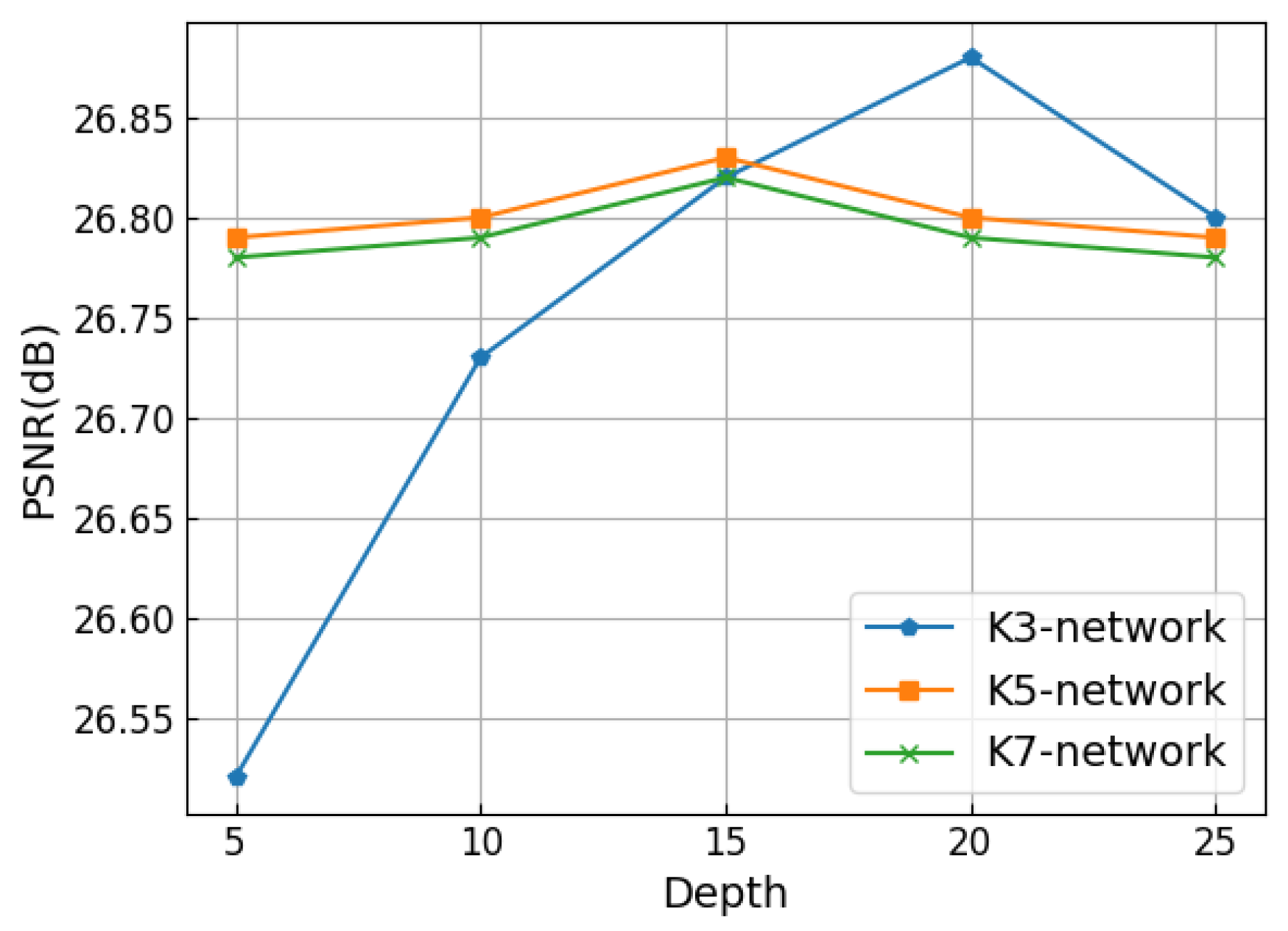
3.4. Performance and Model Trade-Offs
We configured the multi-scale residual network to different depths and compared their performance. We set
D at 5, 10, 15, 20, and 25 to test the network performance. The input image patch size changed when the network depth changed. We used PSNR to measure the network performance, as shown in
Figure 6. For the K3-network, the performance was optimal when
D was 20. For K5- and K7- networks, the performance of networks was optimal when
D was 15. The receptive field
of the D-layer network is defined as
, and
k is the kernel size.
3.5. Visualizing the Learned Filters and Feature Maps
The experiments presented in the previous section showed that three different depths of networks can replace MRNN. The results prove that “deeper is not better” in certain low-level vision tasks. We would like K5- and K7-networks to learn contextual and global information to compensate for the lack of information in the K3-network. Therefore, we visualize the networks to consider the role of differently-scaled networks in this section.
In the recognition task, the features learned by the network exhibit hierarchical features. Deep features are more discriminative than shallow features, such as color and edge. Therefore, horizontal visualization is suitable for describing the recognition process from low to high level. The image restoration is different from the recognition task. To explore the role of differently scaled networks, we longitudinally visualize the MRNN, that is, the filters and feature maps of the penultimate layer of the differently scaled networks.
A large difference is observed in the complexity of patterns from the filters.
Figure 7 represents the feature maps. The larger the filters are, the less local detail information is represented in the feature maps. The smaller are the filters, the more apparent is the detail information in the feature maps.
Overall, we observe that differently scaled networks have their own advantages on various scale objects. For example, a large-scale network performs efficiently on global configuration, a middle-scale network is good at contextual information, and a small-scale network performs well in local detail information. K3-, K5-, and K7-networks have different levels of functionality in the network. A single-scale network cannot simultaneously learn different scales of information. Thus, the multi-scale information should be fused to improve image reconstruction performance.
3.6. Performance Comparison with State-Of-The-Art SR Algorithms
We conducted subjective qualitative and quantitative analyses on the reconstructed images by using PSNR, SSIM, FSIM, VIF, RSEI, and GMI. To verify the effectiveness of our algorithm, we compared MRNN with the following state-of-the-art SR algorithms:
SelfExSR [
45] is the best performing algorithm based on self-similarity based SR.
SRCNN [
17] is a classic deep-learning based approach, which first uses CNN for SR task.
LapSRN [
20] is the most famous multi-scale SR algorithm based on deep learning.
VISR [
23] is the best performing of satellite image SR algorithm via CNN.
SRResnet [
21] is an excellent depth network algorithm with high computing efficiency and high visual fidelity.
These algorithms were implemented using their public source codes and available parameters provided by the authors, and all images were down-sampled by using the same bicubic kernel of MATLAB. For a fair comparison, we trained all these algorithms with the same database configuration and evaluated the same satellite images with the proposed network.
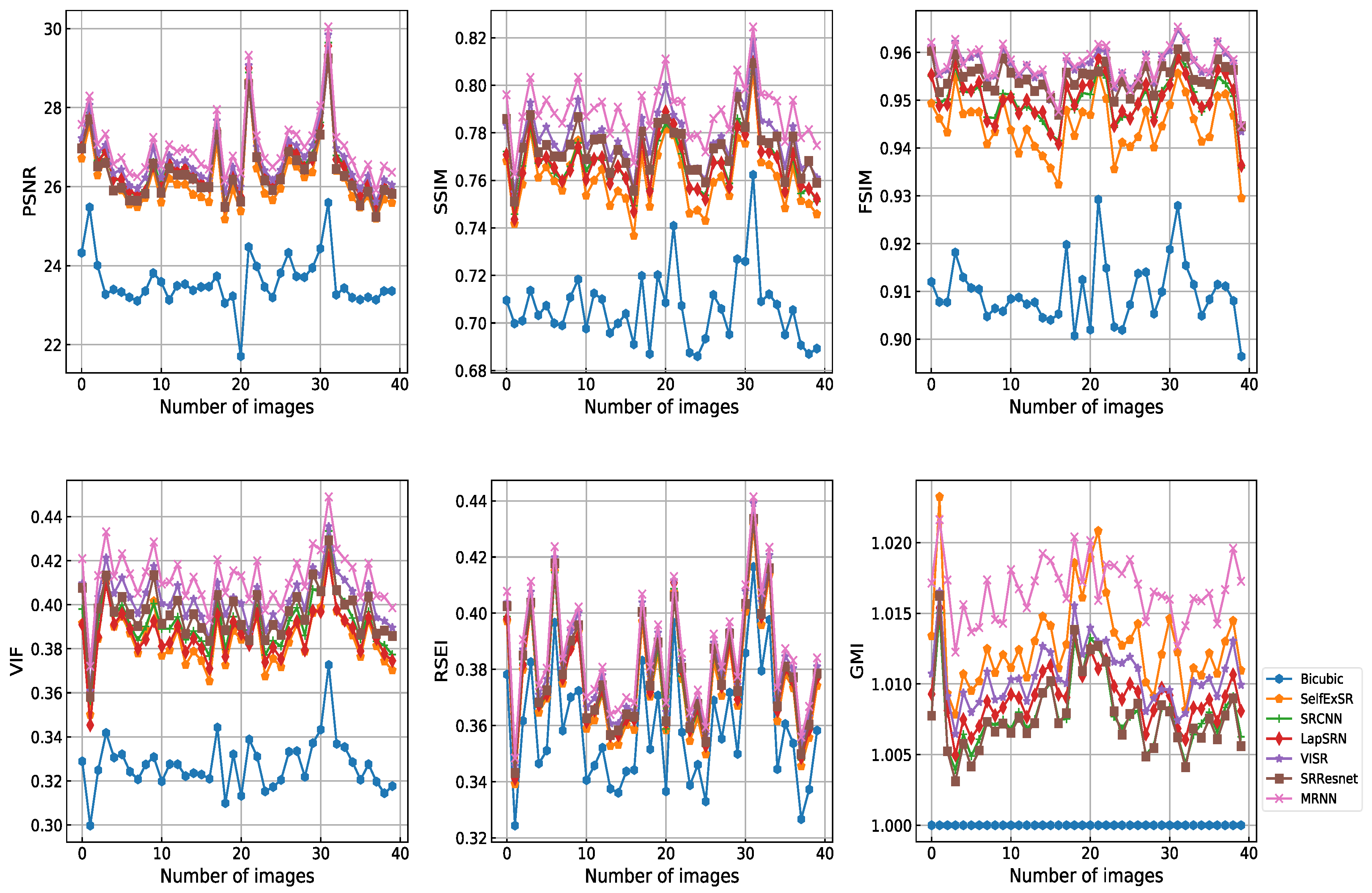
Figure 8 shows the PSNR, SSIM, FSIM, VIF, RSEI, and GMI of all 40 testing images. MRNN obtained improved reconstruction results. The corresponding significance levels were 100%, 100%, 97.5%, 100%, 100%, and 95%, respectively. The difference in score between MRNN and other methods was statistically significant.
Table 1 and
Table 2 show a considerable quantitative advantage of the proposed method compared with cutting-edge deep learning based algorithms. This finding indicates that residual multi-scale networks are relatively effective in learning different scales of content and structure, and they restore image information effectiveness by using a deeper and flatter network than those used by competing algorithms.
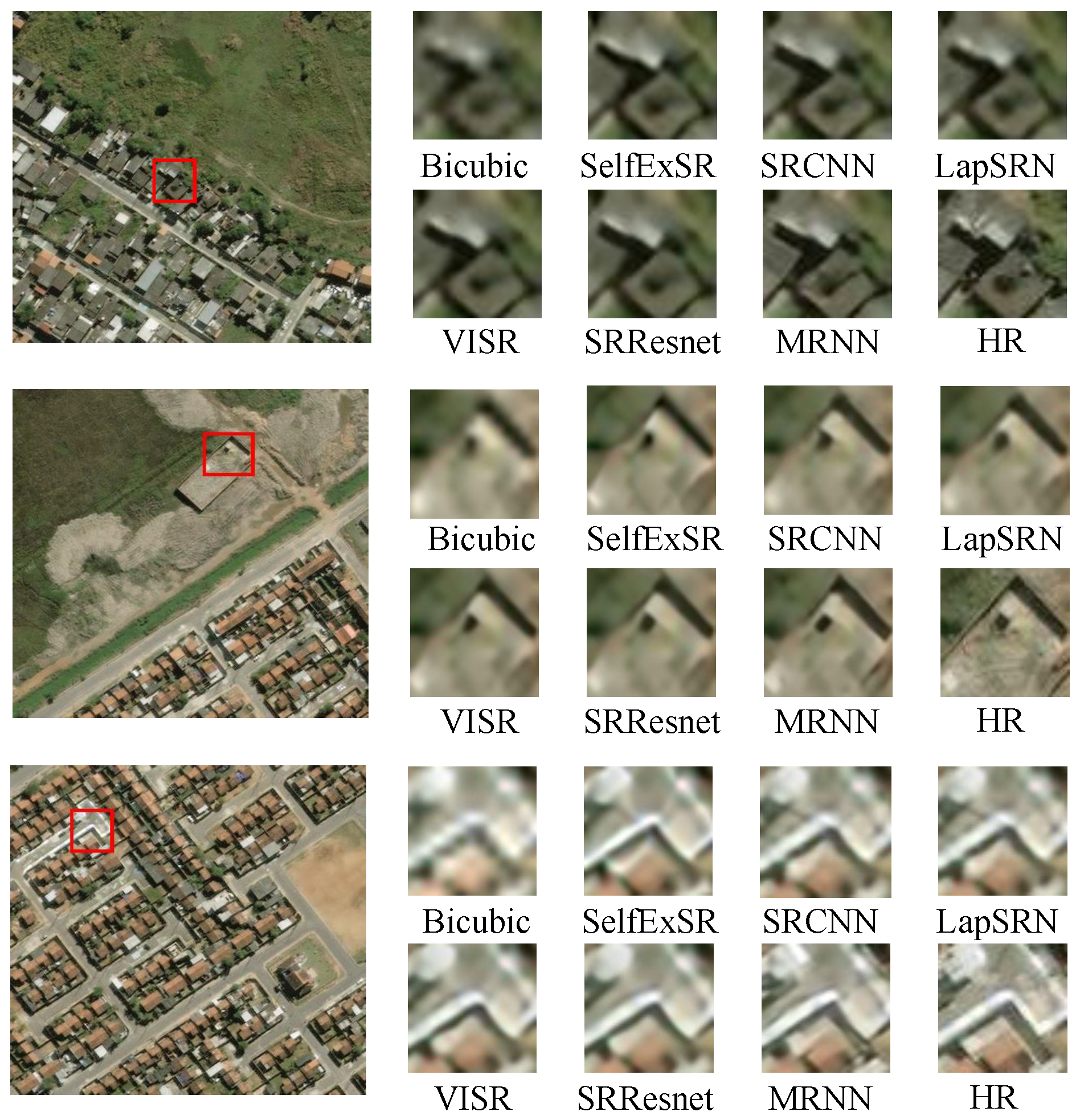
For simple observation, we amplified the representative scale object in randomly selected reconstructed image for comparison. As shown in
Figure 9, we selected a roof (small-scale object), building (middle-scale object), and street corner (large-scale object) to show the SR performance. For the examples shown in
Figure 9, our method produced sharper edges and finer details than the other methods for all object scales. In addition, our method produced sharper edges and finer details than LapSRN for all object scales. This condition confirms that MRNN fuses multi-scale residual information to enhance visual performance.
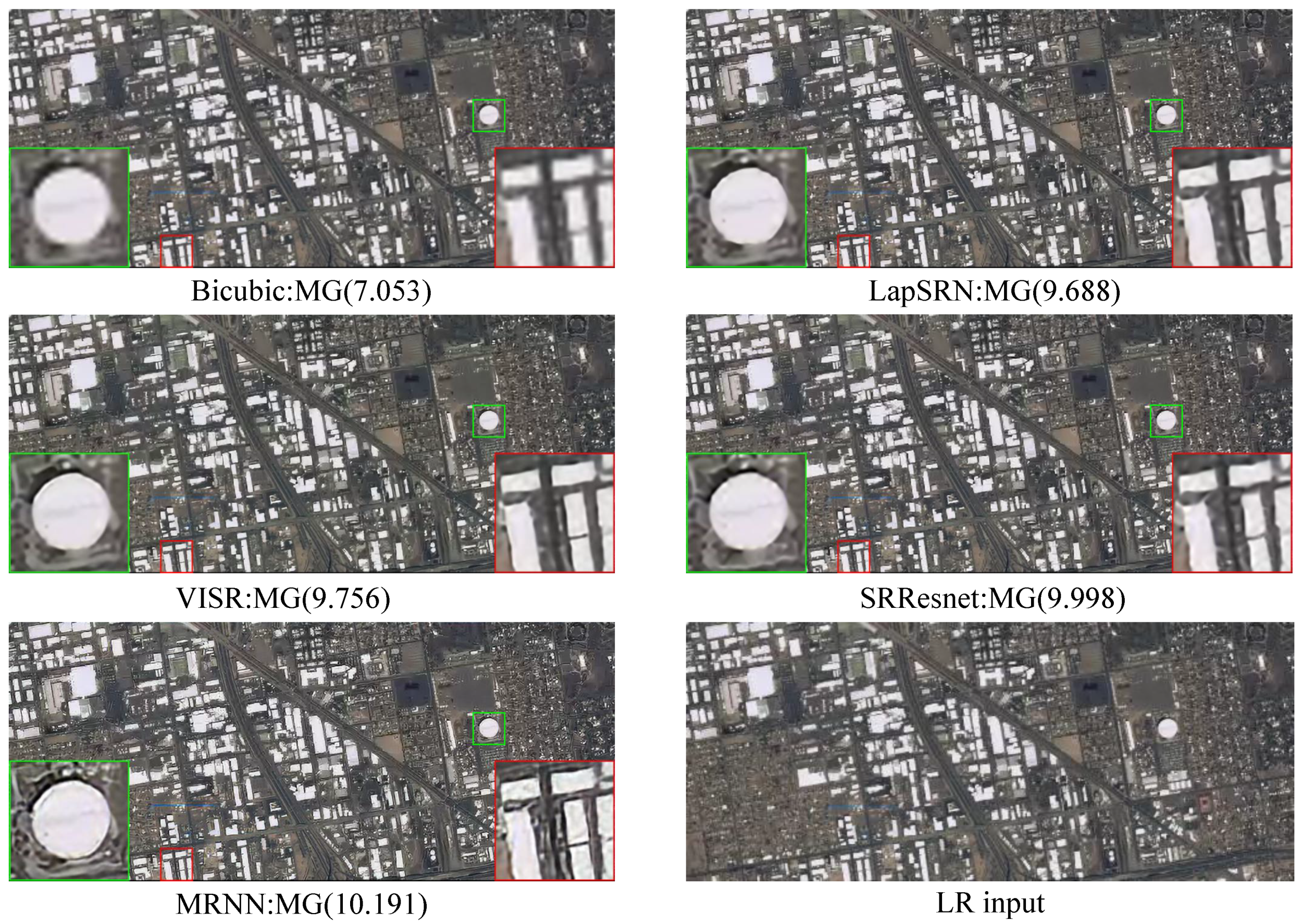
Figure 10 shows a further intuitive result that only our method can restore a clear outline.
3.7. Time Complexity
Figure 11 shows the running time of all algorithms. The running time of the traditional algorithm is longer than that of deep learning algorithms and has no training phase. MRNN is a parallel network with three different scales and does not increase the time complexity of the network, especially when the network is complex. Although LapSRN has a better running time performance, its PSNR is lower than that of MRNN. Our method is slightly slower than VISR in terms of running time. However, MRNN has improved PSNR, SSIM, FSIM, VIF, RSEI, and GMI. We implemented all algorithms in the experiments under the same hardware configuration: Intel Core i7-6700 K CPU @4.00 GHz, NVIDIA GTX1080 8 GB RAM.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}