SmokeNet: Satellite Smoke Scene Detection Using Convolutional Neural Network with Spatial and Channel-Wise Attention



Abstract
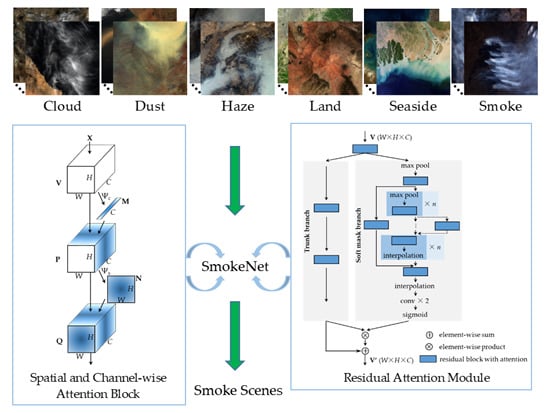
:
1. Introduction
- We construct a new satellite imagery dataset based on MODIS data for smoke scene detection. It consists of 6225 RGB images from six classes. This dataset will be released as the benchmark dataset for smoke scene detection with satellite remote sensing.
- We improve the spatial attention mechanism in a deep learning network for scene classification. The SmokeNet model with spatial and channel-wise attention is proposed to identify the smoke scenes.
- Experimental results on the new dataset show that the proposed model outperforms the state-of-the-art methods.
2. Materials and Methods
2.1. Dataset
2.1.1. Data Source
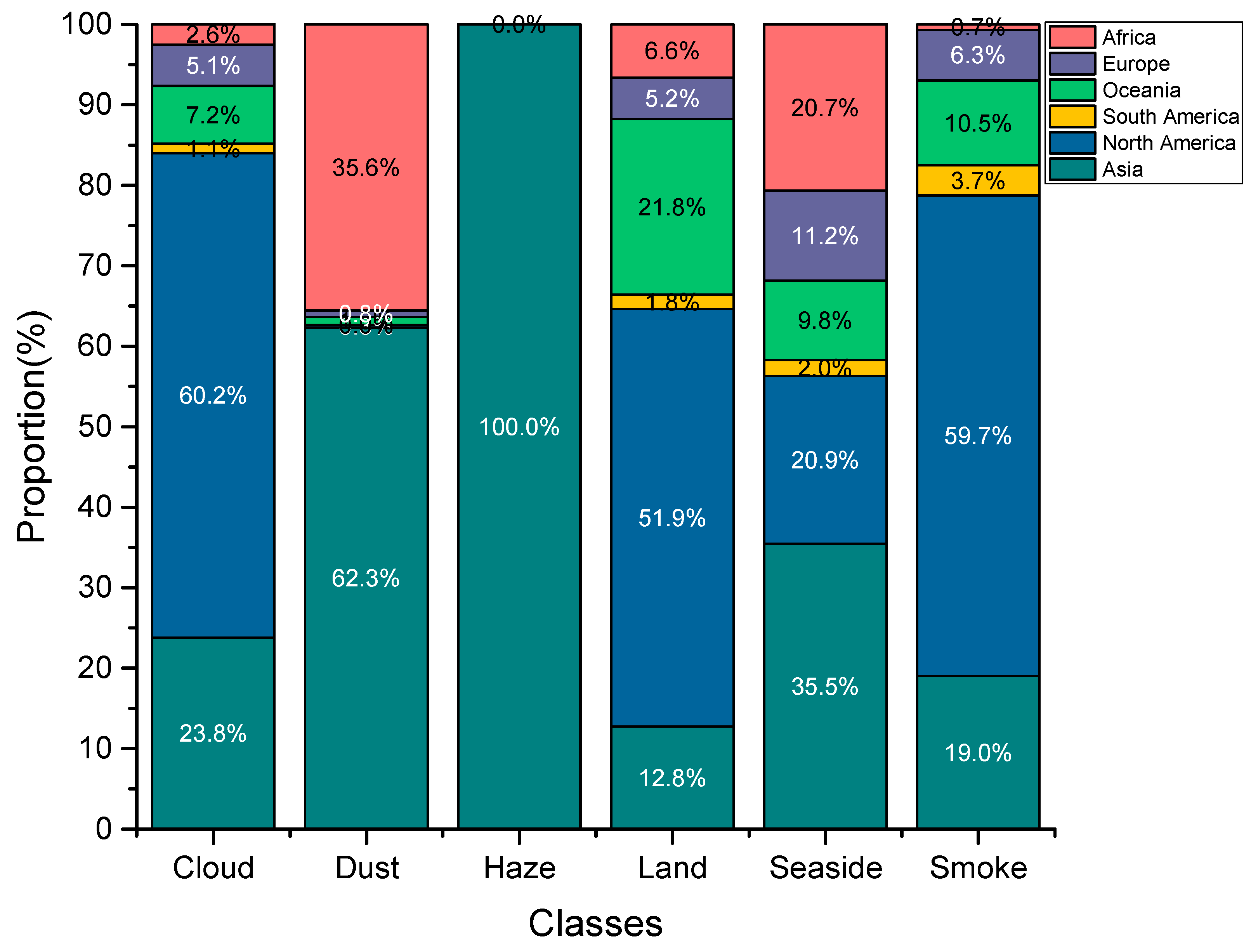
2.1.2. Classes
2.1.3. Data Collection and Annotation
2.1.4. USTC_SmokeRS Dataset
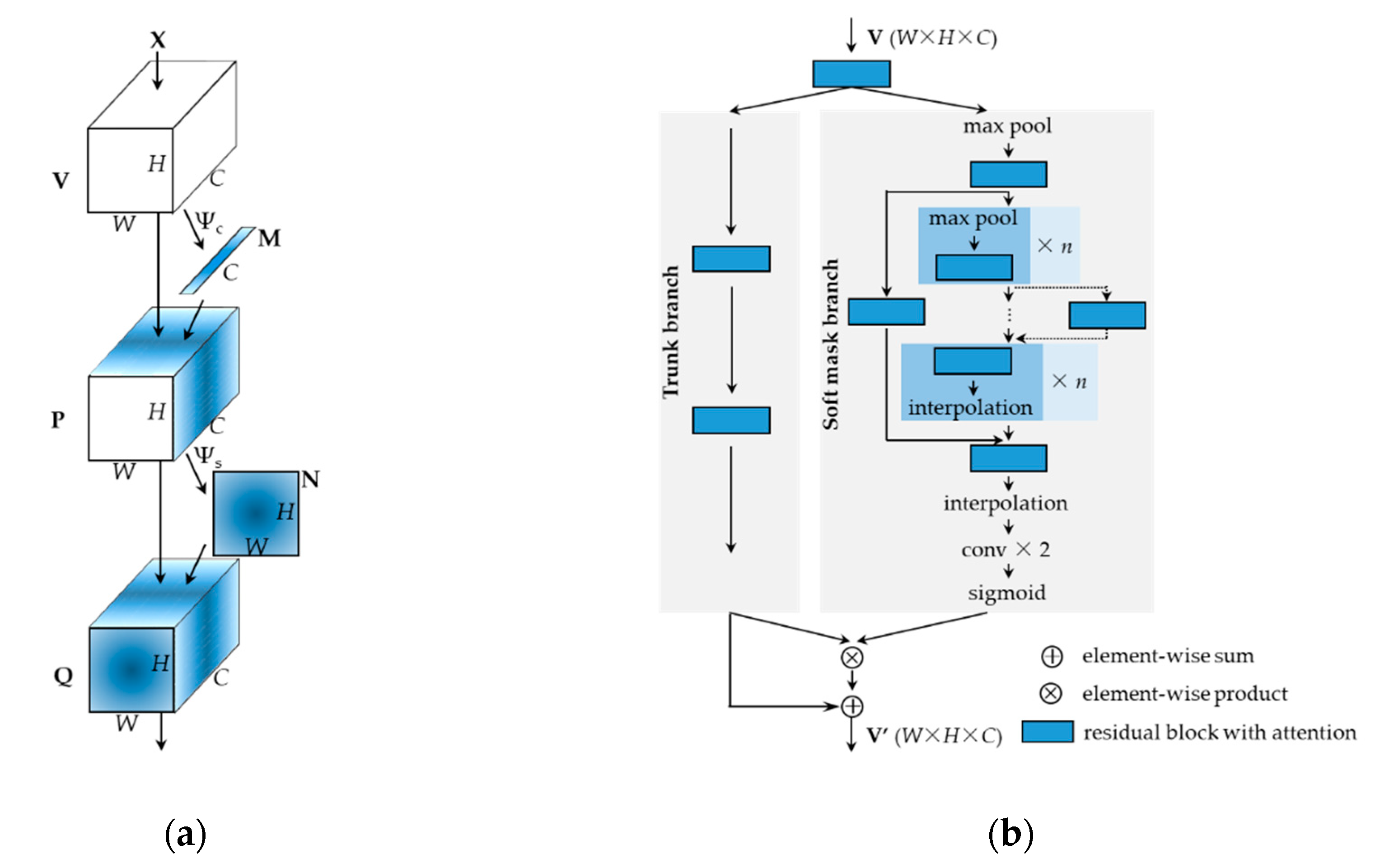
2.2. Method
2.3. Implementation Details
2.4. Evaluation Protocols
3. Results
3.1. Accuracy Assessment
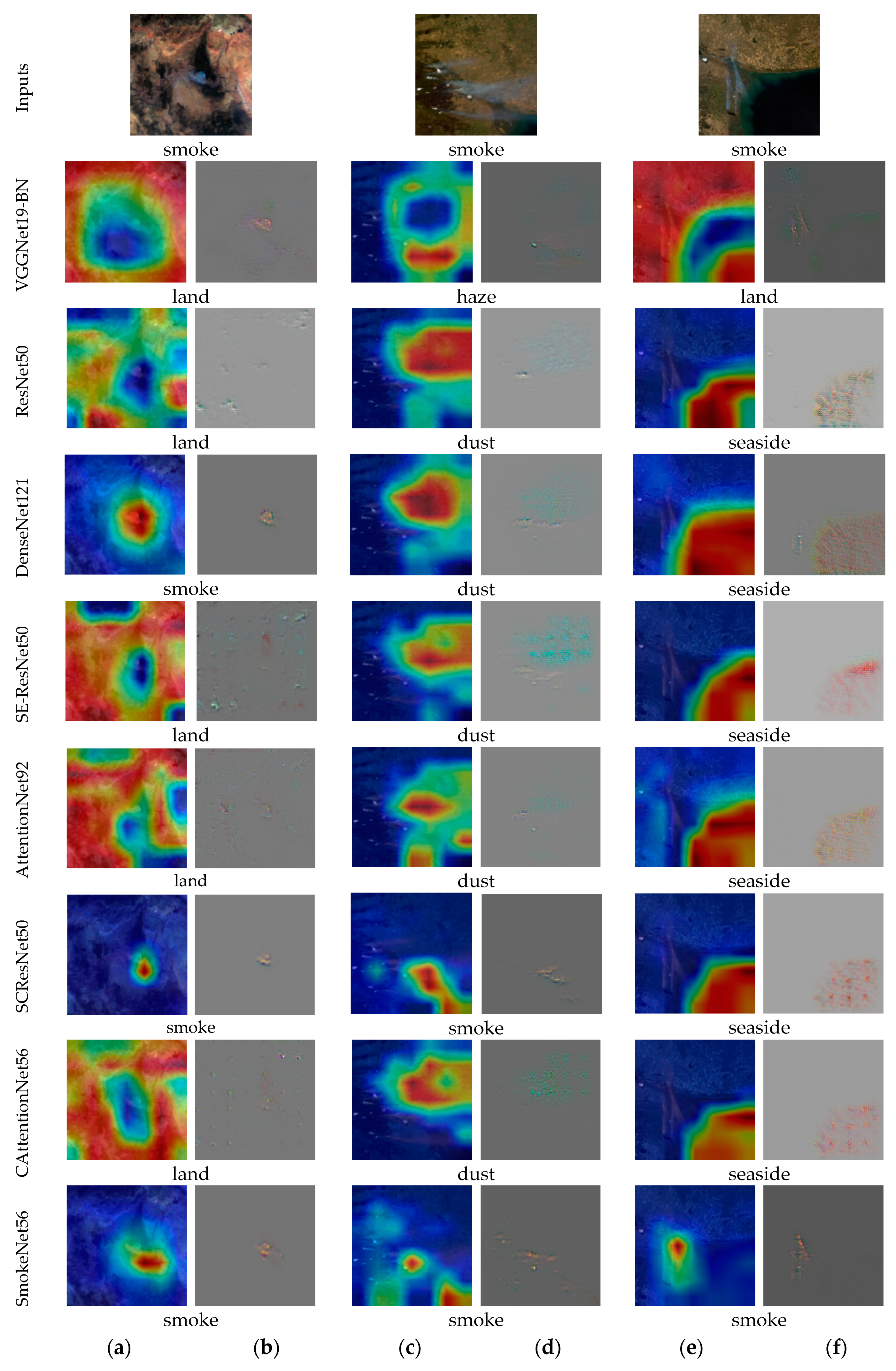
3.2. Visualization Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MODIS | Moderate Resolution Imaging Spectroradiometer |
| AVHRR | Advanced Very High Resolution Radiometer |
| BT | brightness temperature |
| BOVW | bag-of-visual-words |
| SIFT | scale invariant feature transform |
| DBN | deep belief network |
| SA | sparse autoencoder |
| CNN | convolutional neural network |
| SE | squeeze-and-excitation |
| TIR | thermal infrared |
| LAADS | Level-1 and Atmosphere Archive & Distribution System |
| DAAC | Distributed Active Archive Center |
| UTM | Universal Transverse Mercator |
| RA module | residual attention module |
| OE | omission error |
| CE | commission error |
| K | Kappa coefficient |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| AHI | Advanced Himawari Imager |
| OLI | Operational Land Imager |
| VIIRS | Visible Infrared Imaging Radiometer Suite |
| S-NPP | Suomi National Polar-orbiting Partnership |
| GOES | Geostationary Operational Environmental Satellite |
| GF | GaoFen |
Websites
| Google search | https://www.google.com/ |
| Baidu search | https://www.baidu.com/ |
| NASA Visible Earth | https://visibleearth.nasa.gov/ |
| NASA Earth Observatory | https://earthobservatory.nasa.gov/ |
| Monitoring Trends in Burn Severity (MTBS) | https://www.mtbs.gov/ |
| Geospatial Multi-Agency Coordination (GeoMAC) | https://www.geomac.gov/ |
| Incident Information System (InciWeb) | https://inciweb.nwcg.gov/ |
| China Forest and Grassland Fire Prevention | http://www.slfh.gov.cn/ |
| DigitalGlobe Blog | http://blog.digitalglobe.com/ |
| California Forestry and Fire Protection | http://www.calfire.ca.gov/ |
| MyFireWatch—Bushfire map information Australia | https://myfirewatch.landgate.wa.gov.au/ |
| World Air Quality Index Sitemap | https://aqicn.org/ |
References
- Ryu, J.-H.; Han, K.-S.; Hong, S.; Park, N.-W.; Lee, Y.-W.; Cho, J. Satellite-Based Evaluation of the Post-Fire Recovery Process from the Worst Forest Fire Case in South Korea. Remote Sens. 2018, 10, 918. [Google Scholar] [CrossRef]
- Li, Z.Q.; Khananian, A.; Fraser, R.H.; Cihlar, J. Automatic detection of fire smoke using artificial neural networks and threshold approaches applied to AVHRR imagery. IEEE T. Geosci. Remote Sens. 2001, 39, 1859–1870. [Google Scholar] [Green Version]
- Zhao, T.X.-P.; Ackerman, S.; Guo, W. Dust and smoke detection for multi-channel imagers. Remote Sens. 2010, 2, 2347–2368. [Google Scholar] [CrossRef]
- Chrysoulakis, N.; Herlin, I.; Prastacos, P.; Yahia, H.; Grazzini, J.; Cartalis, C. An improved algorithm for the detection of plumes caused by natural or technological hazards using AVHRR imagery. Remote Sens. Environ. 2007, 108, 393–406. [Google Scholar] [CrossRef]
- Xie, Z.; Song, W.; Ba, R.; Li, X.; Xia, L. A Spatiotemporal Contextual Model for Forest Fire Detection Using Himawari-8 Satellite Data. Remote Sens. 2018, 10, 1992. [Google Scholar] [CrossRef]
- Li, X.L.; Song, W.G.; Lian, L.P.; Wei, X.G. Forest Fire Smoke Detection Using Back-Propagation Neural Network Based on MODIS Data. Remote Sens. 2015, 7, 4473–4498. [Google Scholar] [CrossRef] [Green Version]
- Chrysoulakis, N.; Opie, C. Using NOAA and FY imagery to track plumes caused by the 2003 bombing of Baghdad. Int. J. Remote Sens. 2004, 25, 5247–5254. [Google Scholar] [CrossRef]
- Randriambelo, T.; Baldy, S.; Bessafi, M.; Petit, M.; Despinoy, M. An improved detection and characterization of active fires and smoke plumes in south-eastern Africa and Madagascar. Int. J. Remote Sens. 1998, 19, 2623–2638. [Google Scholar] [CrossRef]
- Kaufman, Y.J.; Setzer, A.; Justice, C.; Tucker, C.; Pereira, M.; Fung, I. Remote sensing of biomass burning in the tropics. In Fire in the Tropical Biota; Springer: Berlin/Heidelberg, Germany, 1990; pp. 371–399. [Google Scholar]
- Xie, Y.; Qu, J.J.; Xiong, X.; Hao, X.; Che, N.; Sommers, W. Smoke plume detection in the eastern United States using MODIS. Int. J. Remote Sens. 2007, 28, 2367–2374. [Google Scholar] [CrossRef]
- Giglio, L.; Descloitres, J.; Justice, C.O.; Kaufman, Y.J. An Enhanced Contextual Fire Detection Algorithm for MODIS. Remote Sens. Environ. 2003, 87, 273–282. [Google Scholar] [CrossRef]
- Xie, Y.; Qu, J.; Hao, X.; Xiong, J.; Che, N. Smoke plume detecting using MODIS measurements in eastern United States. In Proceedings of the EastFIRE Conference, Fairfax, VA, USA, 11–13 May 2005; pp. 11–13. [Google Scholar]
- Wang, W.T.; Qu, J.J.; Hao, X.J.; Liu, Y.Q.; Sommers, W.T. An improved algorithm for small and cool fire detection using MODIS data: A preliminary study in the southeastern United States. Remote Sens. Environ. 2007, 108, 163–170. [Google Scholar] [CrossRef]
- Li, X.L.; Wang, J.; Song, W.G.; Ma, J.; Telesca, L.; Zhang, Y.M. Automatic Smoke Detection in MODIS Satellite Data based on K-means Clustering and Fisher Linear Discrimination. Photogramm. Eng. Remote Sens. 2014, 80, 971–982. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.-S.; Yang, W.; Delon, J.; Gousseau, Y.; Sun, H.; Maître, H. Structural high-resolution satellite image indexing. In Proceedings of the ISPRS TC VII Symposium-100 Years ISPRS, Vienna, Austria, 5–7 July 2010; pp. 298–303. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE T. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Yuan, F. Video-based smoke detection with histogram sequence of LBP and LBPV pyramids. Fire Saf. J. 2011, 46, 132–139. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, J. Deep domain adaptation based video smoke detection using synthetic smoke images. Fire Saf. J. 2017, 93, 53–59. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.-x.; Lin, G.-h.; Zhang, Y.-m.; Xu, G.; Wang, J.-j. Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images. Proc. Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Q.; Liu, D.; Lin, G.; Wang, J.; Zhang, Y.J.I.A. Adversarial Adaptation From Synthesis to Reality in Fast Detector for Smoke Detection. IEEE Access 2019, 7, 29471–29483. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Zhang, Q.; Jia, Y.; Xu, G.; Wang, J. Smoke detection in video sequences based on dynamic texture using volume local binary patterns. KSII Trans. Internet Inf. Syst. 2017, 11, 5522–5536. [Google Scholar] [CrossRef]
- Toreyin, B.U. Computer Vision Based Fire Detection Software & Dataset. Available online: http://signal.ee.bilkent.edu.tr/VisiFire/ (accessed on 10 March 2019).
- Péteri, R.; Fazekas, S.; Huiskes, M.J. DynTex: A comprehensive database of dynamic textures. Patt. Recogn. Lett. 2010, 31, 1627–1632. [Google Scholar] [CrossRef]
- Bansal, R.; Pundir, A.S.; Raman, B. Dynamic Texture Using Deep Learning. In Proceedings of the TENCON 2017–2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017. [Google Scholar]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.-S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 4700–4708. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. IJCV 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; No. 4. Technical Report; University of Toronto: Toronto, ON, Canada, 2009; Volume 1. [Google Scholar]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. 2001, 2, 194. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, ON, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y.J. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Ba, J.; Mnih, V.; Kavukcuoglu, K.J. Multiple object recognition with visual attention. arXiv 2014, arXiv:1412.7755. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.-S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Miech, A.; Laptev, I.; Sivic, J. Learnable pooling with context gating for video classification. arXiv 2017, arXiv:1706.06905. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, ON, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honululu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Ba, R.; Song, W.; Li, X.; Xie, Z.; Lo, S. Integration of Multiple Spectral Indices and a Neural Network for Burned Area Mapping Based on MODIS Data. Remote Sens. 2019, 11, 326. [Google Scholar] [CrossRef]
- Wang, J.; Song, W.; Wang, W.; Zhang, Y.; Liu, S. A new algorithm for forest fire smoke detection based on modis data in heilongjiang province. In Proceedings of the 2011 International Conference on Remote Sensing, Environment and Transportation Engineering (RSETE), Nanjing, China, 24–26 June 2011; pp. 5–8. [Google Scholar]
- Melchiorre, A.; Boschetti, L. Global Analysis of Burned Area Persistence Time with MODIS Data. Remote Sens. 2018, 10, 750. [Google Scholar] [CrossRef]
- Terra. The EOS Flagship. Available online: https://terra.nasa.gov/ (accessed on 4 May 2019).
- Aqua Earth-Observing Satellite Mission. Aqua Project Science. Available online: https://aqua.nasa.gov/ (accessed on 4 May 2019).
- Pagano, T.S.; Durham, R.M. Moderate resolution imaging spectroradiometer (MODIS). In Proceedings of the Sensor Systems for the Early Earth Observing System Platforms, Orlando, FL, USA, 25 August 1993; pp. 2–18. [Google Scholar]
- Axel, A.C. Burned Area Mapping of an Escaped Fire into Tropical Dry Forest in Western Madagascar Using Multi-Season Landsat OLI Data. Remote Sens. 2018, 10, 371. [Google Scholar] [CrossRef]
- Allison, R.S.; Johnston, J.M.; Craig, G.; Jennings, S. Airborne optical and thermal remote sensing for wildfire detection and monitoring. Sensors 2016, 16, 1310. [Google Scholar] [CrossRef] [PubMed]
- Su, Q.; Sun, L.; Di, M.; Liu, X.; Yang, Y. A method for the spectral analysis and identification of Fog, Haze and Dust storm using MODIS data. Atmos. Meas. Tech. Discuss. 2017, 2017, 1–20. [Google Scholar] [CrossRef]
- Li, R.R.; Kaufman, Y.J.; Hao, W.M.; Salmon, J.M.; Gao, B.C. A technique for detecting burn scars using MODIS data. IEEE Trans. Geosci. Remote 2004, 42, 1300–1308. [Google Scholar] [CrossRef]
- Continent. Wikipedia. Available online: https://en.wikipedia.org/wiki/Continent (accessed on 10 July 2019).
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NIPS 2017 Autodiff Workshop: The Future of Gradient-based Machine Learning Software and Techniques, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Stroppiana, D.; Azar, R.; Calo, F.; Pepe, A.; Imperatore, P.; Boschetti, M.; Silva, J.M.N.; Brivio, P.A.; Lanari, R. Integration of Optical and SAR Data for Burned Area Mapping in Mediterranean Regions. Remote Sens. 2015, 7, 1320–1345. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 618–626. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-World Anomaly Detection in Surveillance Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spectral Bands | Bandwidth (µm) | Spectral Domain | Primary Application |
|---|---|---|---|
| 1 | 0.620–0.670 | red | Land/Cloud Boundaries |
| 3 | 0.459–0.479 | blue | Land/Cloud Properties |
| 4 | 0.545–0.565 | green |
| Class | Cloud | Dust | Haze | Land | Seaside | Smoke |
|---|---|---|---|---|---|---|
| Number | 1164 | 1009 | 1002 | 1027 | 1007 | 1016 |
| Output Size | SCResNet | CAttentionNet | SmokeNet |
|---|---|---|---|
| 112 × 112 | conv, 7 × 7, 64, stride 2 | ||
| 56 × 56 | max pool, 3 × 3, stride 2 | ||
| 56 × 56 | × 3 | × 1 RA-C module1 1 × 1 | × 1 RA-SC module1 2 × 1 |
| 28 × 28 | × 4 | × 1 RA-C module2 × 1 | × 1 RA-SC module2 × 1 |
| 14 × 14 | × 6 | × 1 RA-C module3 × 1 | × 1 RA-SC module3 × 1 |
| 7 × 7 | × 3 | × 3 | × 3 |
| 1 × 1 | global average pool | average pool, 7 × 7, stride 1 | |
| fc, softmax, 6 | |||
| Image Set | Number of Images | Proportion |
|---|---|---|
| Training set | 994 | 16% |
| 1988 | 32% | |
| 2985 | 48% | |
| 3984 | 64% | |
| Validation set | 999 | 16% |
| Testing set | 1242 | 20% |
| USTC_SmokeRS | 6225 | 100% |
| Class | Predicted Class 1 | Predicted Class t | Omission Error (OE) | Commission Error (CE) |
|---|---|---|---|---|
| Actual Class 1 | N11 | N1t | ||
| Actual Class t | Nt1 | Ntt | ||
| Accuracy | ||||
| Kappa coefficient (K) | ||||
| Model | Layers | Accuracy (%) | K | OE (%) | CE (%) | Params (Million) |
|---|---|---|---|---|---|---|
| VGGNet-BN [33] | 19 | 54.67 | 0.4572 | 87.68 | 65.28 | 143.68 |
| ResNet [35] | 50 | 73.51 | 0.6821 | 53.20 | 36.67 | 25.56 |
| DenseNet [36] | 121 | 78.10 | 0.7371 | 34.48 | 31.79 | 7.98 |
| AttentionNet [47] | 92 | 77.86 | 0.7342 | 41.87 | 32.18 | 83.20 |
| SE-ResNet [48] | 50 | 80.11 | 0.7612 | 43.84 | 22.97 | 28.07 |
| CAttentionNet | 56 | 83.57 | 0.8028 | 31.03 | 21.79 | 50.57 |
| SCResNet | 50 | 83.25 | 0.7988 | 35.96 | 15.58 | 28.58 |
| SmokeNet | 56 | 85.10 | 0.8212 | 29.56 | 10.06 | 53.52 |
| Class | Cloud | Dust | Haze | Land | Seaside | Smoke | OE (%) | CE (%) |
|---|---|---|---|---|---|---|---|---|
| Cloud | 227 | 0 | 1 | 3 | 0 | 1 | 2.16 | 2.99 |
| Dust | 0 | 174 | 15 | 5 | 1 | 6 | 13.43 | 10.77 |
| Haze | 0 | 13 | 183 | 3 | 0 | 1 | 8.50 | 13.68 |
| Land | 4 | 4 | 3 | 193 | 0 | 1 | 5.85 | 9.39 |
| Seaside | 0 | 0 | 2 | 1 | 197 | 1 | 1.99 | 1.50 |
| Smoke | 3 | 4 | 8 | 8 | 2 | 178 | 12.32 | 5.32 |
| Accuracy | 92.75% | |||||||
| K | 0.9130 | |||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ba, R.; Chen, C.; Yuan, J.; Song, W.; Lo, S. SmokeNet: Satellite Smoke Scene Detection Using Convolutional Neural Network with Spatial and Channel-Wise Attention. Remote Sens. 2019, 11, 1702. https://doi.org/10.3390/rs11141702
Ba R, Chen C, Yuan J, Song W, Lo S. SmokeNet: Satellite Smoke Scene Detection Using Convolutional Neural Network with Spatial and Channel-Wise Attention. Remote Sensing. 2019; 11(14):1702. https://doi.org/10.3390/rs11141702
Chicago/Turabian StyleBa, Rui, Chen Chen, Jing Yuan, Weiguo Song, and Siuming Lo. 2019. "SmokeNet: Satellite Smoke Scene Detection Using Convolutional Neural Network with Spatial and Channel-Wise Attention" Remote Sensing 11, no. 14: 1702. https://doi.org/10.3390/rs11141702
APA StyleBa, R., Chen, C., Yuan, J., Song, W., & Lo, S. (2019). SmokeNet: Satellite Smoke Scene Detection Using Convolutional Neural Network with Spatial and Channel-Wise Attention. Remote Sensing, 11(14), 1702. https://doi.org/10.3390/rs11141702