An Integrated Land Cover Mapping Method Suitable for Low-Accuracy Areas in Global Land Cover Maps



Abstract
:1. Introduction
2. Study Sites and Datasets
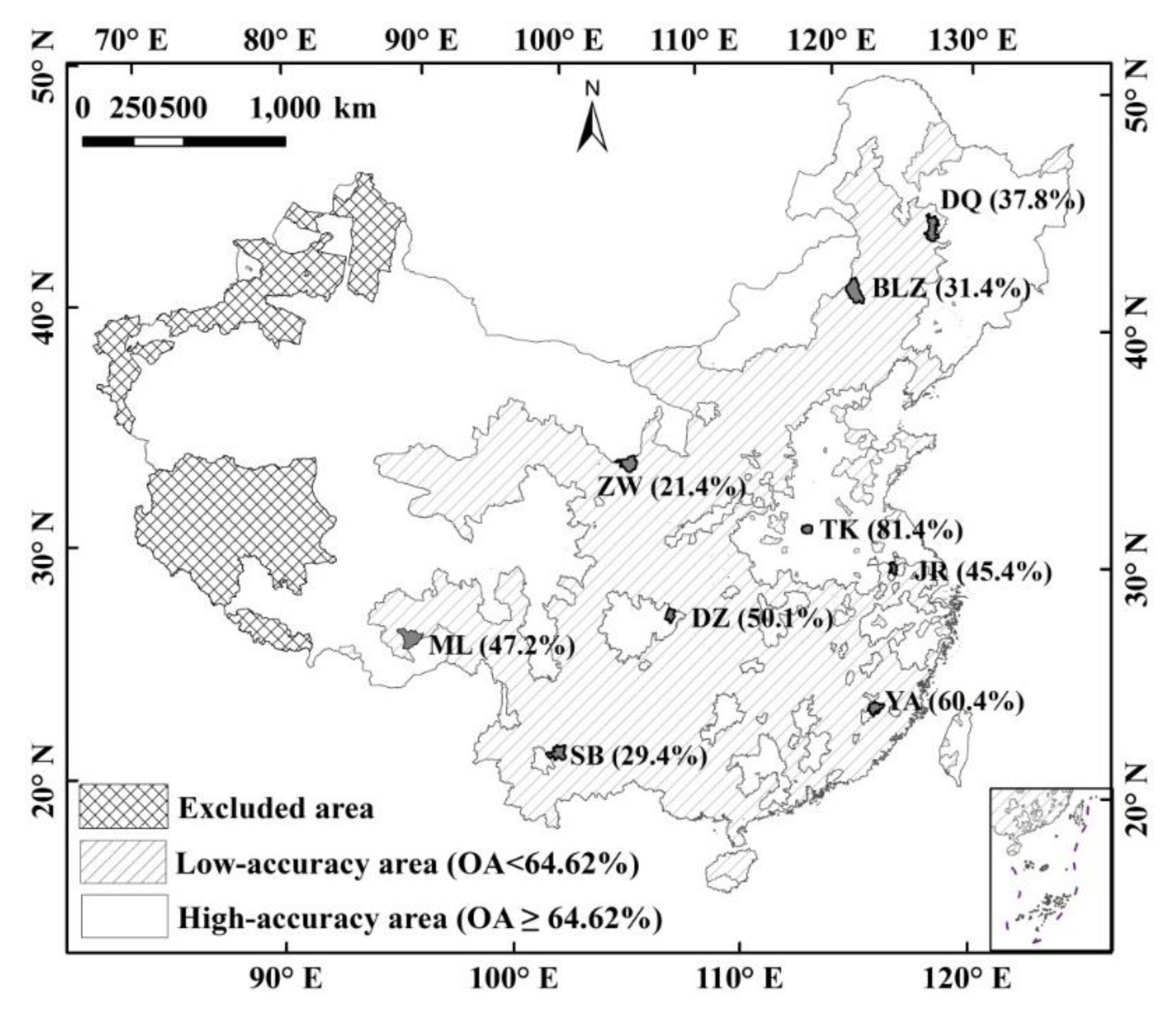
2.1. Low-Accuracy Area and Study Sites
2.2. Datasets
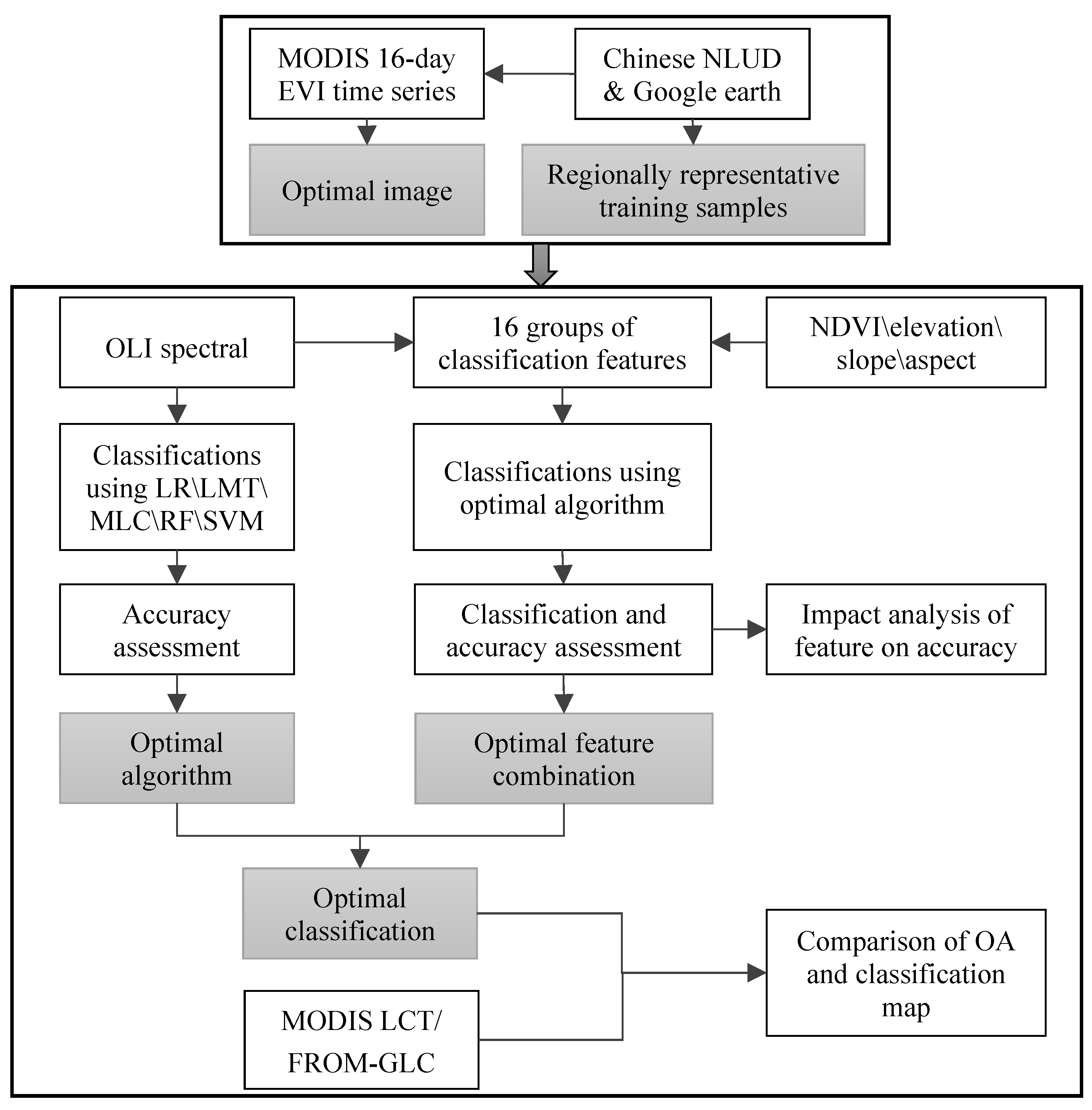
3. Method
3.1. Image Selection
3.2. Land-Cover Classification System
3.3. Training and Testing
3.4. Classification Algorithms and Features
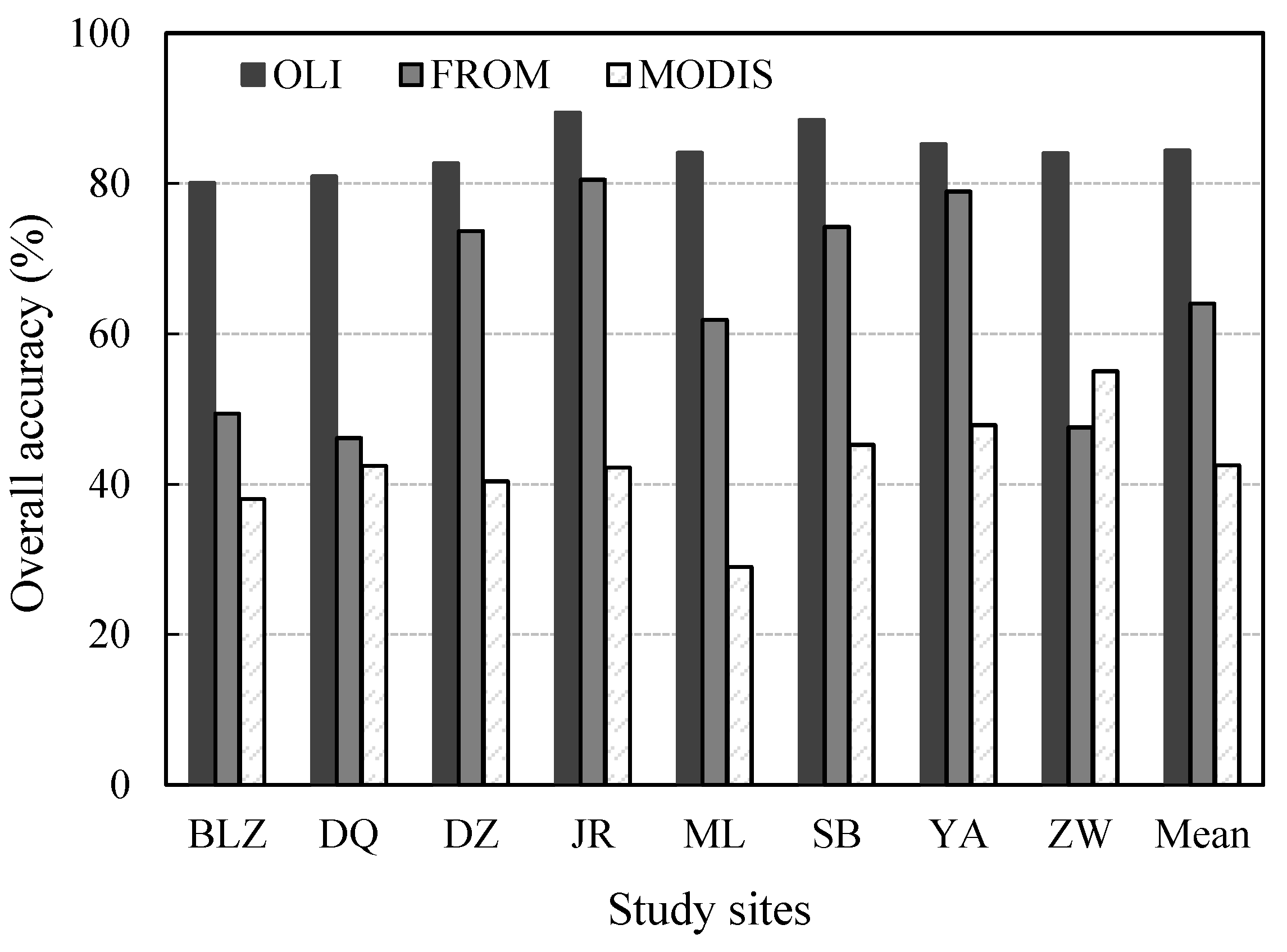
3.5. Comparison Analysis
4. Results
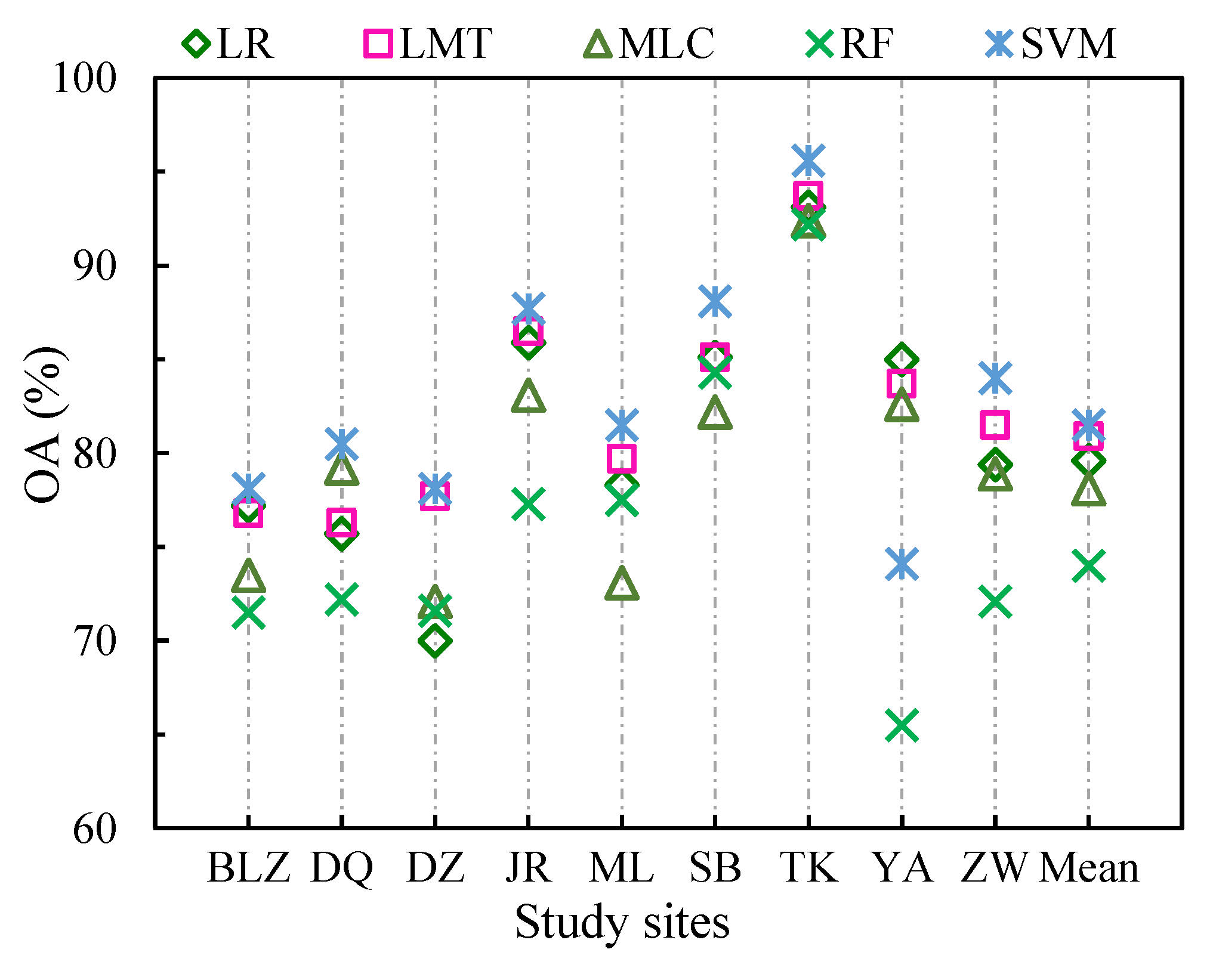
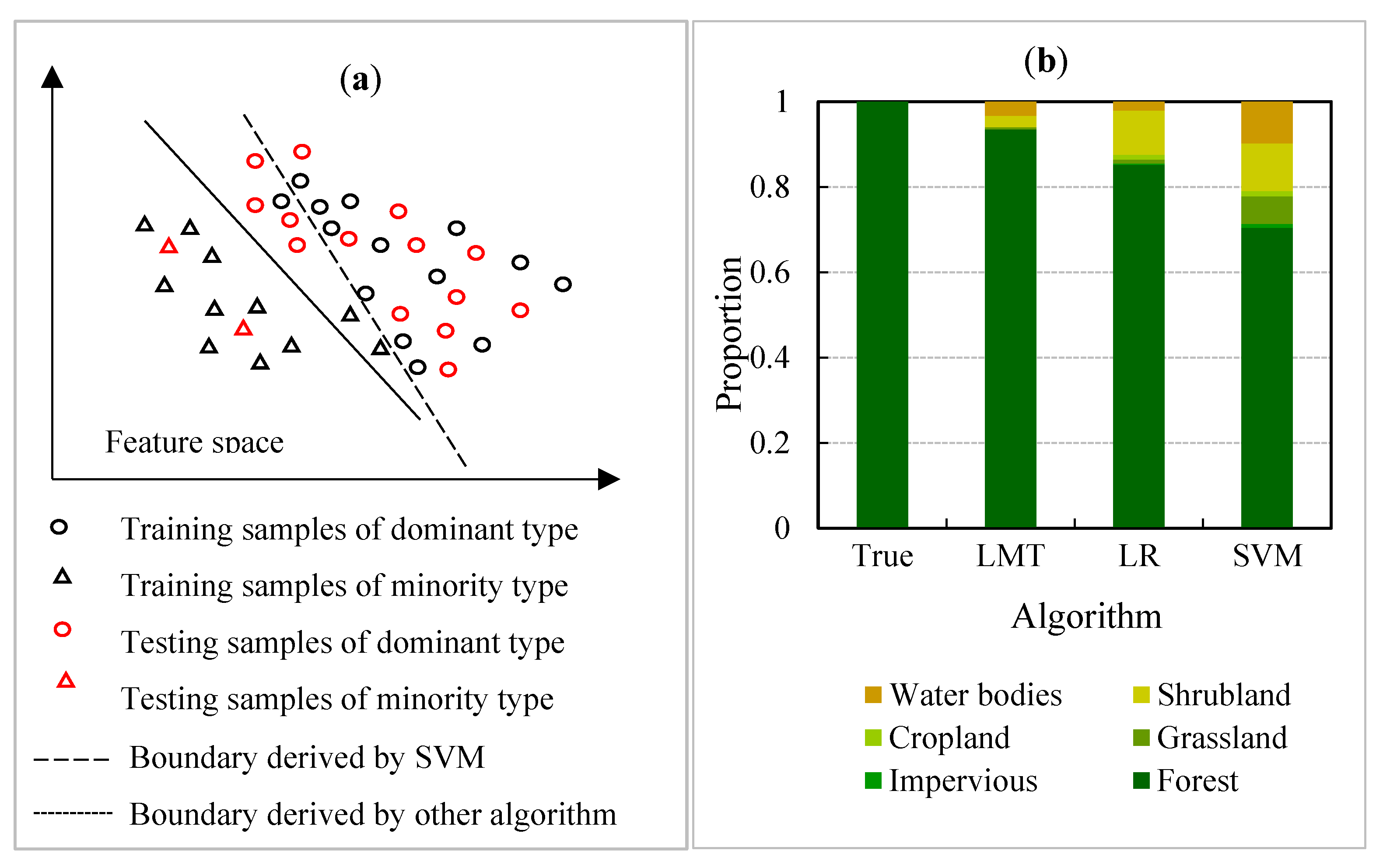
4.1. Optimal Algorithm
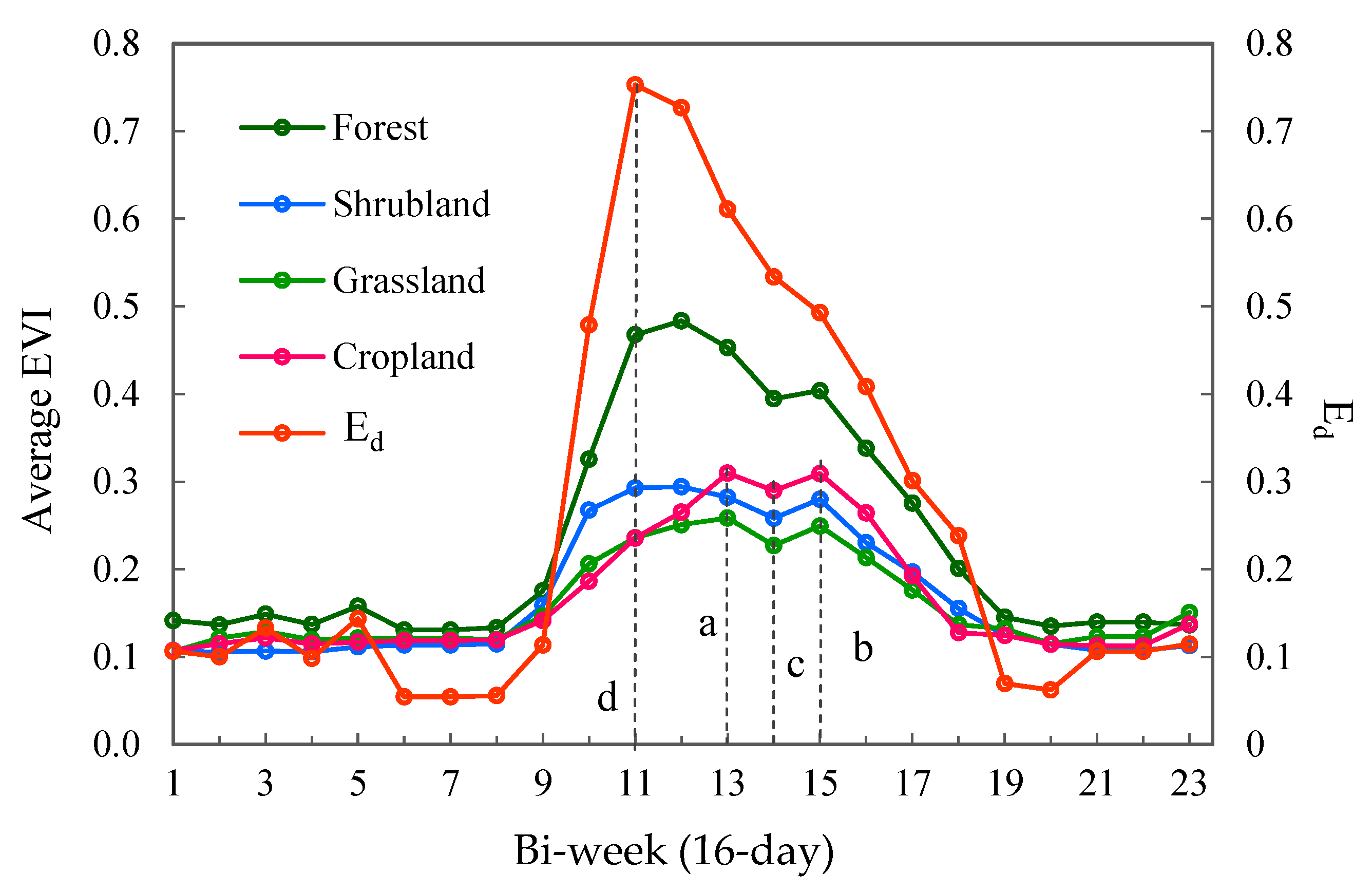
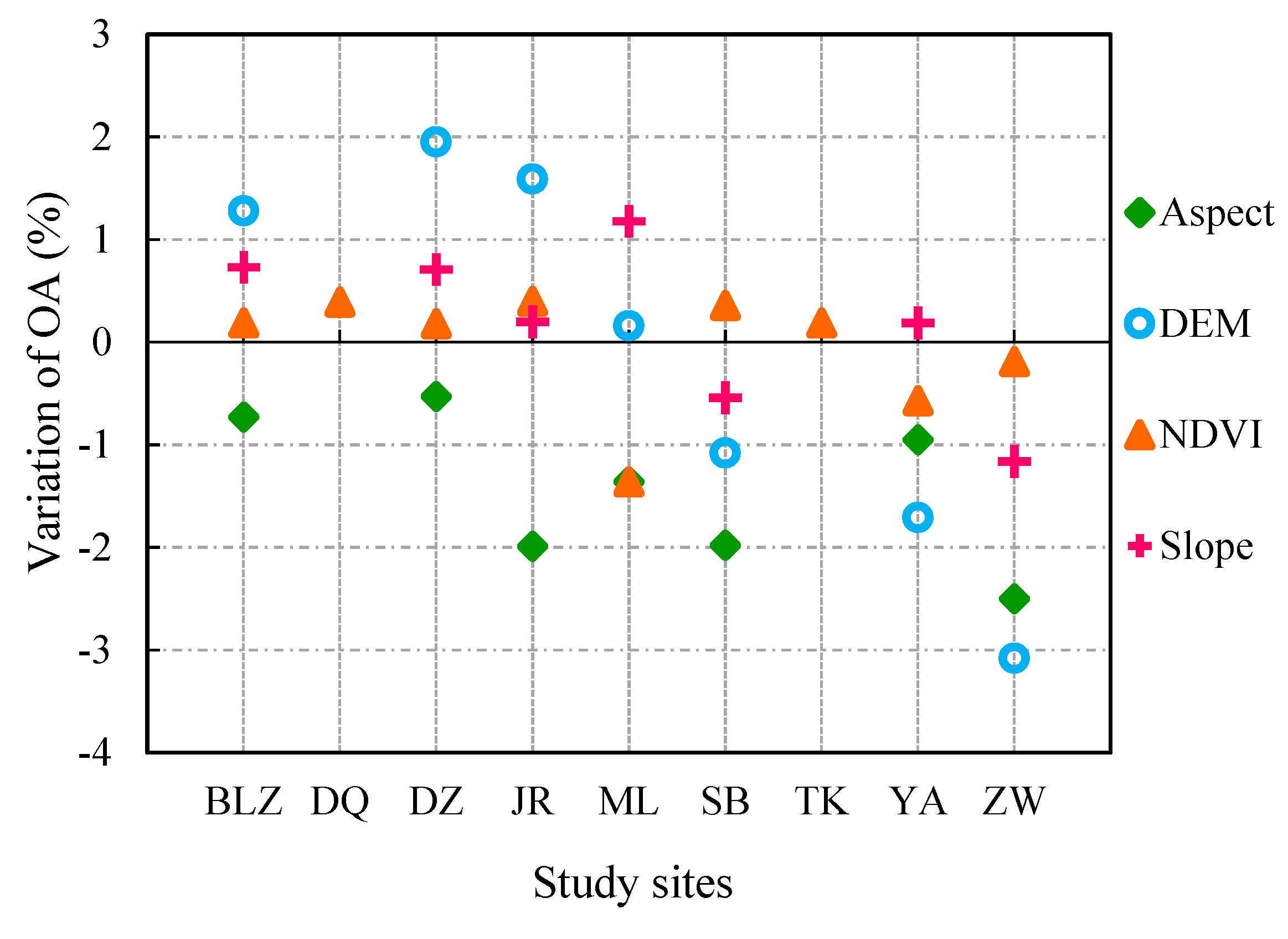
4.2. Impact of Class Features on Accuracy
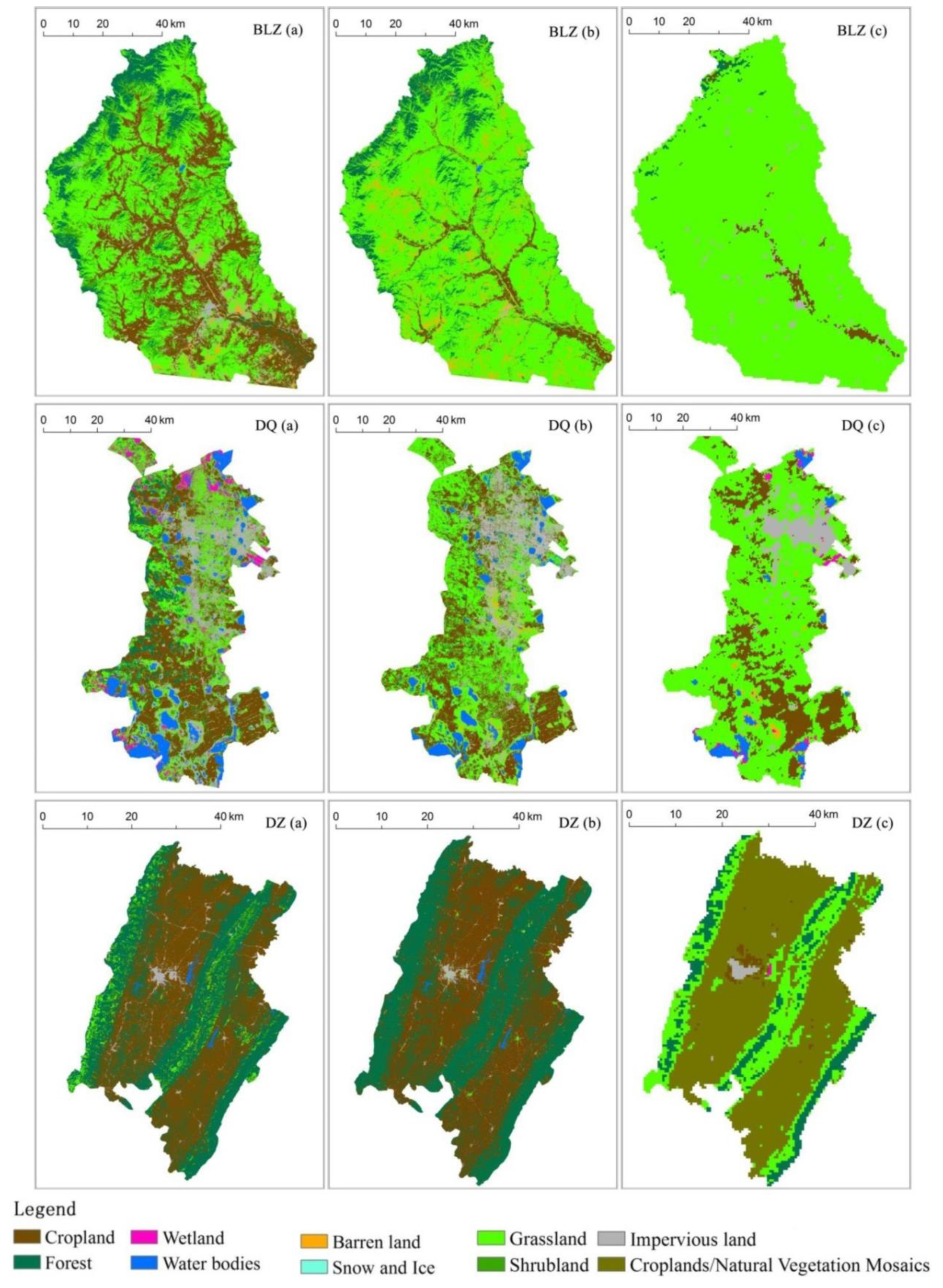
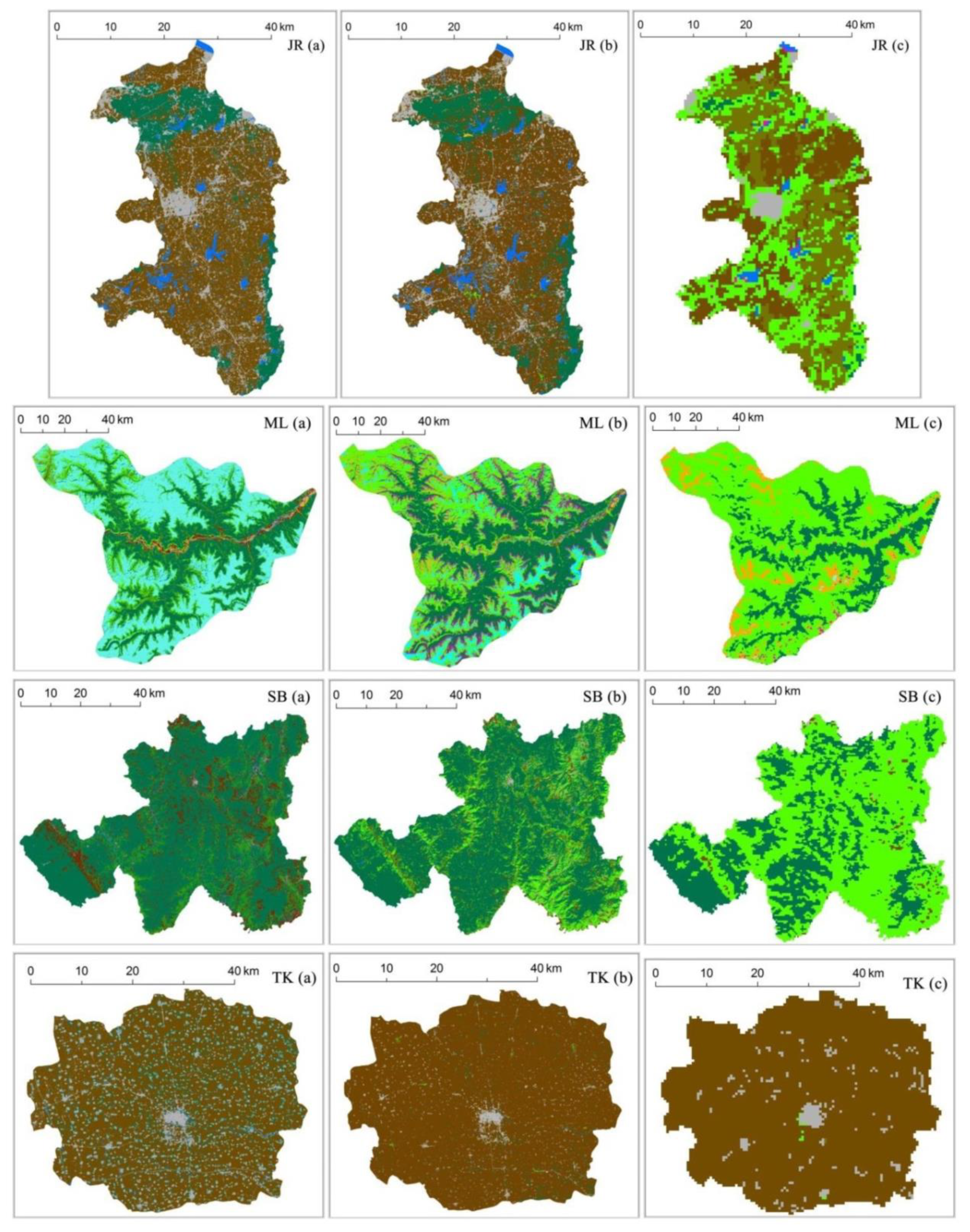
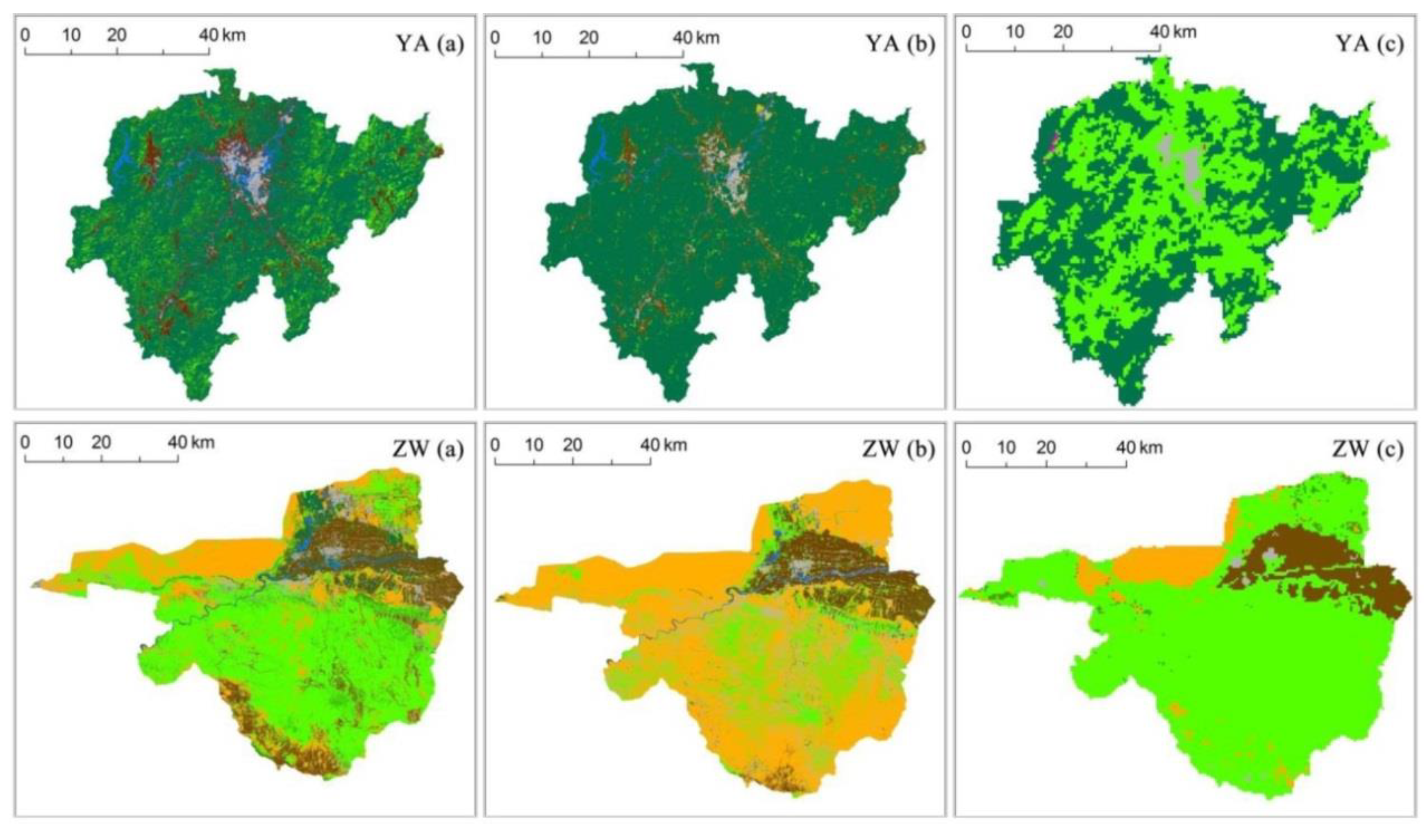
4.3. Optimal Combination of Class Features and Classification Results
5. Discussion
5.1. The Trait and Identification of Low-Accuracy Areas
5.2. The Contribution of Existent Visually-Interpreted LCC Data in Classification Process
5.3. Classification Algorithm and Features for the Low-accuRacy Areas in China
5.4. The Applicability and Limitation of the Integrated LCC Method
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A



References
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Foley, J.A.; Defries, R.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K. Global Consequences of Land Use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grimm, N.B.; Faeth, S.H.; Golubiewski, N.E.; Redman, C.L.; Wu, J.; Bai, X.; Briggs, J.M. Global change and the ecology of cities. Science 2008, 319, 756–760. [Google Scholar] [CrossRef] [PubMed]
- Tian, J.; Zhang, B.Q.; He, C.S.; Yang, L.X. Variability in soil hydraulic conductivity and soil hydrological response under different land covers in the mountainous area of the Heihe River Watershed, Northwest China. Land Degrad. Dev. 2017, 28, 1437–1449. [Google Scholar] [CrossRef]
- Sellers, P.J.; Meeson, B.W.; Hall, F.G.; Asrar, G.; Murphy, R.E.; Schiffer, R.A.; Bretherton, F.P.; Dickinson, R.E.; Ellingson, R.G.; Field, C.B. Remote sensing of the land surface for studies of global change: Models–algorithms–experiments. Remote Sens. Environ. 1995, 39, 3–26. [Google Scholar] [CrossRef]
- Zhang, Z.X.; Chang, J.; Xu, C.Y.; Zhou, Y.; Wu, Y.H.; Chen, X.; Jiang, S.S.; Duan, Z. The response of lake area and vegetation cover variations to climate change over the Qinghai-Tibetan Plateau during the past 30 years. Sci. Total Environ. 2018, 635, 443–451. [Google Scholar] [CrossRef] [PubMed]
- Bontemps, S.; Defourny, P.; Bogaert, E.; Arino, O.; Kalogirou, V.; Perez, J. GLOBCOVER 2009—Products Description and Validation Report. Available online: http://due.esrin.esa.int/globcover/LandCover2009/GLOBCOVER2009_Validation_Report_2.2.pdf (accessed on 5 June 2016).
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.C.; Zhao, Y.Y.; Liang, L.; Niu, Z.G.; Huang, X.M.; Fu, H.H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Hansen, M.C.; Defries, R.S.; Townshend, J.R.G.; Sohlberg, R. Global land cover classification at 1 km spatial resolution using a classification tree approach. Int. J. Remote Sens. 2000, 21, 1331–1364. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W.; Defries, R.S.; Belward, A.S. Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data. Int. J. Remote Sens. 1999, 21, 1303–1330. [Google Scholar] [CrossRef]
- Tateishi, R. Production of global land cover data—GLCNMO. Int. J. Digit. Earth 2011, 4, 22–49. [Google Scholar] [CrossRef]
- Yu, L.; Wang, J.; Li, X.; Li, C.; Zhao, Y.; Gong, P. A multi-resolution global land cover dataset through multisource data aggregation. Sci. China Earth Sci. 2014, 57, 2317–2329. [Google Scholar] [CrossRef]
- Ran, Y.; Li, X.; Lu, L. Evaluation of four remote sensing based land cover products over China. J. Glaciol. Geocryol. 2010, 31, 391–401. [Google Scholar] [CrossRef]
- Zeng, T.; Zhang, Z.; Zhao, X.; Wang, X.; Zuo, L. Evaluation of the 2010 MODIS Collection 5.1 Land Cover Type Product over China. Remote Sens. 2015, 7, 1981–2006. [Google Scholar] [CrossRef] [Green Version]
- Townshend, J.R.G.; Justice, C.O. Towards operational monitoring of terrestrial systems by moderate-resolution remote sensing. Remote Sens. Environ. 2002, 83, 351–359. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Goward, S.N.; Masek, J.G.; Irons, J.R.; Herold, M.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Landsat continuity: Issues and opportunities for land cover monitoring. Remote Sens. Environ. 2008, 112, 955–969. [Google Scholar] [CrossRef]
- Gomez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Giri, C.; Pengra, B.; Long, J.; Loveland, T.R. Next generation of global land cover characterization, mapping, and monitoring. Int. J. Appl. Earth Obs. Geoinf. 2013, 25, 30–37. [Google Scholar] [CrossRef]
- Hansen, M.C.; Loveland, T.R. A review of large area monitoring of land cover change using Landsat data. Remote Sens. Environ. 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Irons, J.R.; Dwyer, J.L.; Barsi, J.A. The next Landsat satellite: The Landsat Data Continuity Mission. Remote Sens. Environ. 2012, 122, 11–21. [Google Scholar] [CrossRef] [Green Version]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Moran, C.J. The AmericaView classification methods accuracy comparison project: A rigorous approach for model selection. Remote Sens. Environ. 2015, 170, 115–120. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. Assessment of the effectiveness of support vector machines for hyper-spectral data. Future Gener. Comput. Syst. 2004, 20, 1215–1225. [Google Scholar] [CrossRef]
- Yu, L.; Liang, L.; Wang, J.; Zhao, Y.; Cheng, Q.; Hu, L.; Liu, S.; Yu, L.; Wang, X.; Zhu, P. Meta-discoveries from a synthesis of satellite-based land-cover mapping research. Int. J. Remote Sens. 2014, 35, 4573–4588. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Peng, G. Comparison of Classification Algorithms and Training Sample Sizes in Urban Land Classification with Landsat Thematic Mapper Imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef] [Green Version]
- Clinton, N.; Yu, L.; Gong, P. Geographic stacking: Decision fusion to increase global land cover map accuracy. ISPRS J. Photogramm. Remote Sens. 2015, 103, 57–65. [Google Scholar] [CrossRef]
- Lesiv, M.; Moltchanova, E.; Schepaschenko, D.; See, L.; Shvidenko, A.; Comber, A.; Fritz, S. Comparison of Data Fusion Methods Using Crowdsourced Data in Creating a Hybrid Forest Cover Map. Remote Sens. 2016, 8, 17. [Google Scholar] [CrossRef]
- Perez-Hoyos, A.; Garcia-Haro, F.J.; San-Miguel-Ayanz, J. A methodology to generate a synergetic land-cover map by fusion of different land-cover products. Int. J. Appl. Earth Obs. Geoinf. 2012, 19, 72–87. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, X.; Zhao, X.; Liu, B.; Yi, L.; Zuo, L.; Wen, Q.; Liu, F.; Xu, J.; Hu, S. A 2010 update of National Land Use/Cover Database of China at 1:100000 scale using medium spatial resolution satellite images. Remote Sens. Environ. 2014, 149, 142–154. [Google Scholar] [CrossRef]
- Yang, L.; Homer, C.; Hegge, K.; Huang, C.; Wylie, B.; Reed, B. A Landsat 7 scene selection strategy for a national land cover database. In Proceedings of the IEEE 2001 International Geoscience and Remote Sensing Symposium, Sydney, Australia, 9–13 July 2001; Volume 1, pp. 1123–1125. [Google Scholar] [CrossRef]
- Piper, J. Variability and bias in experimentally measured classifier error rates. Pattern Recognit. Lett. 1992, 13, 685–692. [Google Scholar] [CrossRef]
- Van Niel, T.G.; McVicar, T.R.; Datt, B. On the relationship between training sample size and data dimensionality: Monte Carlo analysis of broadband multi-temporal classification. Remote Sens. Environ. 2005, 98, 468–480. [Google Scholar] [CrossRef]
- Shackelford, A.K.; Davis, C.H. A hierarchical fuzzy classification approach for high-resolution multispectral data over urban areas. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1920–1932. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cessie, S.L.; Houwelingen, J.C.V. Ridge Estimators in Logistic Regression. Journal of the Royal Statistical Society. Ser. C Appl. Stat. 1992, 41, 191–201. [Google Scholar] [CrossRef]
- Hsu, C.W. A Practical Guide to Support Vector Classification. Available online: https://www.researchgate.net/publication/288023219_A_Practical_Guide_to_Support_Vector_Classification (accessed on 5 June 2016).
- Landwehr, N.; Hall, M.; Frank, E. Logistic Model Trees. Mach. Learn. 2005, 59, 161–205. [Google Scholar] [CrossRef] [Green Version]
- Richards, J.A. Remote Sensing Digital Image Analysis, 5th ed.; Springer-Verlag: Berlin/Heidelberg, Germany, 2013; pp. 247–318. ISBN 13: 9783642300615. [Google Scholar]
- Mathur, A.; Foody, G.M. Multiclass and Binary SVM Classification: Implications for Training and Classification Users. IEEE Geosci. Remote Sens. Lett. 2008, 5, 241–245. [Google Scholar] [CrossRef]
- CORINE L and Cover. Available online: https://www.eea.europa.eu/publications/COR0-landcover#tab-related-publications (accessed on 1 July 2019).
- Vogelmann, J.E.; Sohl, T.L.; Campbell, P.V.; Shaw, D.M. Regional Land Cover Characterization Using Landsat Thematic Mapper Data and Ancillary Data Sources. Environ. Monit. Assess. 1998, 51, 415–428. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
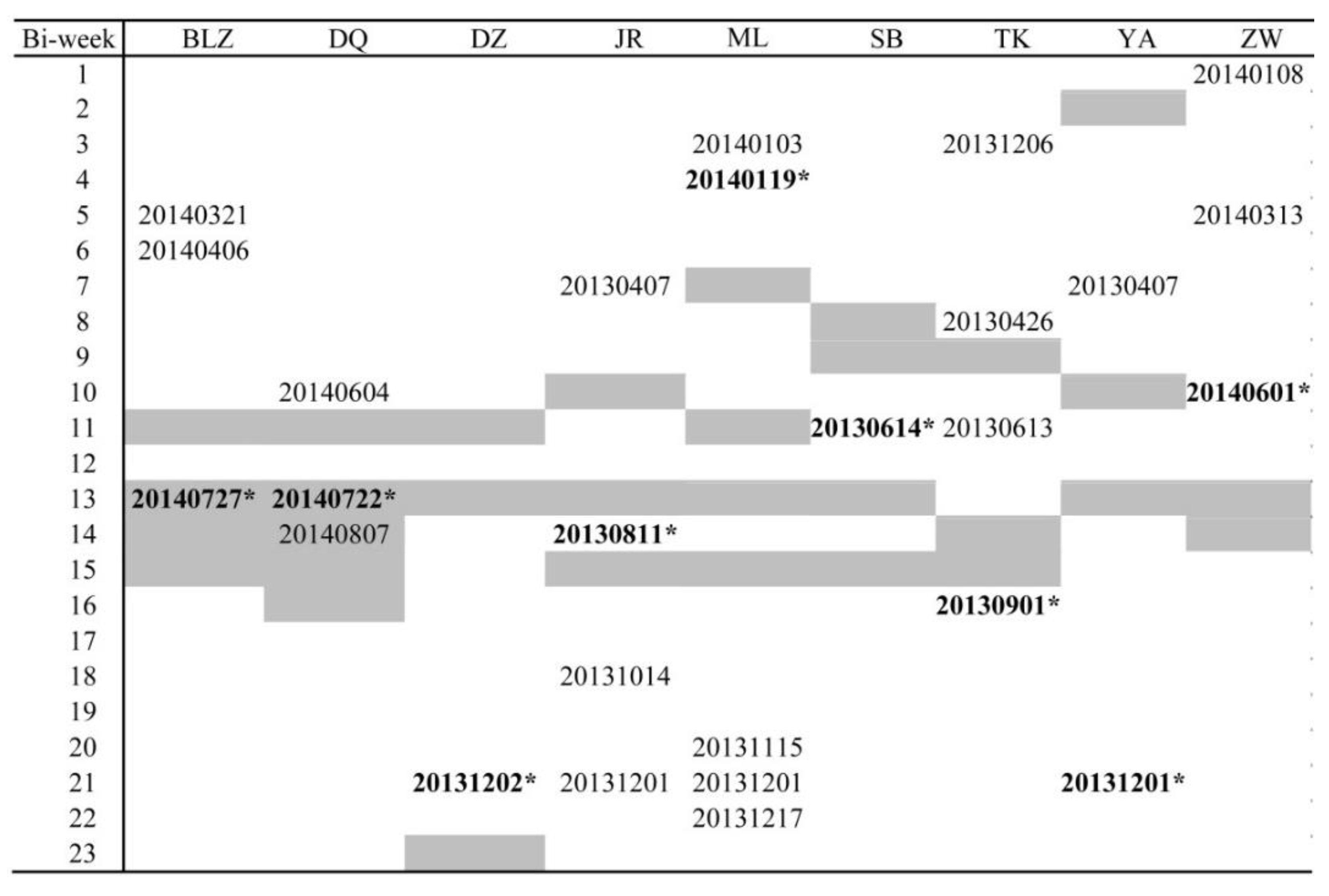
| Study Site | Location | Area (km2) | Image (Path/Row) | Image Time |
|---|---|---|---|---|
| BLZ | Agro-pastoral zone | 6418 | 122/29 | 20140727 |
| DQ | Northeast Plain | 5065 | 119/28 | 20140722 |
| DZ | Sichuan Basin | 2083 | 127/39 | 20131202 |
| JR | Middle and Lower Yangtze Valley Plain | 1390 | 120/38 | 20130811 |
| ML | Southeast of Tibetan Plateau | 9045 | 136/40 | 20140119 |
| SB | Yunnan and Guizhou Plateau | 4114 | 130/43 | 20130614 |
| TK | North Plain | 1766 | 123/36 | 20130901 |
| YA | Southeast Hilly Area | 2944 | 120/42 | 20131201 |
| ZW | Inner Mongolia Plateau | 4529 | 130/34 | 20140601 |
| Dataset | Use for | Spatial Resolution (m) | Data Source |
|---|---|---|---|
| Landsat OLI | classification | 30 | www.glovis.usgs.gov/ |
| GDEM v2 | classification | 30 | www.reverb.echo.nasa.gov/ |
| MOD13Q1 | Image selection | 250 | https://ladsweb.modaps.eosdis.nasa.gov/search/ |
| FROM-GLC | Accuracy comparison | 30 | http://data.ess.tsinghua.edu.cn/ |
| MODIS LCT | Accuracy comparison | 500 | https://ladsweb.modaps.eosdis.nasa.gov/search/ |
| Code | Name | Definition |
|---|---|---|
| 1 | Cropland | Land with cultivated crops growing on it in growing season |
| 2 | Forest | Natural or planted forests |
| 3 | Grassland | Natural or planted Grassland |
| 4 | Shrubland | Shrub cover identifiable in the image, having a texture finer than tree canopies but coarser than Grassland. |
| 5 | Wetland | Perennial or seasonal inundated land with hygrophytes growing on it. |
| 6 | Water bodies | All inland water bodies. |
| 7 | Tundra | Located at high mountains above tree line and high latitude regions with low height vegetation. |
| 8 | Impervious land | Primarily based on artificial cover such as asphalts, concrete, sand and stone, bricks, glasses and other cover materials. |
| 9 | Barren land | Vegetation is hardly observable, while dominated by exposed soil, sand, gravel and rock backgrounds. |
| 10 | Snow and ice | Distributed in the polar areas and high mountains. |
| Study Site | BLZ | DQ | DZ | JR | ML | SB | TK | YA | ZW |
|---|---|---|---|---|---|---|---|---|---|
| The number of classes | 7 | 7 | 6 | 4 | 8 | 6 | 4 | 6 | 7 |
| Cropland | 141 | 173 | 311 | 282 | 40 | 91 | 340 | 69 | 82 |
| Forest | 90 | 30 | 135 | 105 | 205 | 296 | 30 | 339 | 30 |
| Grassland | 189 | 102 | 30 | 0 | 53 | 78 | 0 | 30 | 212 |
| Shrubland | 37 | 0 | 30 | 0 | 36 | 30 | 0 | 30 | 30 |
| Wetland | 0 | 30 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Water bodies | 30 | 48 | 30 | 30 | 56 | 30 | 30 | 30 | 30 |
| Impervious | 30 | 49 | 30 | 85 | 48 | 30 | 124 | 30 | 30 |
| Barren land | 30 | 82 | 0 | 0 | 33 | 0 | 0 | 0 | 106 |
| Snow and ice | 0 | 0 | 0 | 0 | 123 | 0 | 0 | 0 | 0 |
| Total | 547 | 514 | 566 | 502 | 590 | 555 | 524 | 528 | 520 |
| Algorithm | Abbreviation | Parameter Type | Values of Parameter | SOURCE |
|---|---|---|---|---|
| Maximum-likelihood classification | MLC | prior probability | The same for all classes. | ENVI |
| Logistic regression | LR | Log likelihood edge value | 0, 10-10, …,10-1, 1 | Weka |
| Logistic model tree | LMT | Minimal instances for splitting | 5, 10, 15, 20, 25, 30 | Weka |
| Weight trimming | 0, 0.01, …, 0.34, 0.35 | |||
| Support vector machine | SVM | Penalty factor C | 1, 10, 20, …, 300 | Libsvm |
| Kernel function Parameter | 0.1, 0.2, …,0.9, 1, 2, 3, …, 39, 40 | |||
| Random forest | RF | numFeature | From 1 to the number of features | Weka |
| numTrees | 20, 40, 60, 80, 100 |
| Classification Input | Classification Accuracy (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BLZ | DQ | DZ | JR | ML | SB | TK | YA | ZW | |
| Spectral bands | 78.8 | 80.5 | 78.1 | 87.7 | 81.5 | 88.1 | 95.6 | 85.0 | 84.0 |
| N | 79.0 | 80.9 | 78.3 | 88.1 | 80.2 | 88.5 | 95.8 | 84.5 | 83.9 |
| E | 80.1 | 80.0 | 89.2 | 81.7 | 87.0 | 83.3 | 81.0 | ||
| S | 79.5 | 78.8 | 87.9 | 82.7 | 87.6 | 85.2 | 82.9 | ||
| A | 78.1 | 77.6 | 85.7 | 80.2 | 86.1 | 84.1 | 81.5 | ||
| NE | 79.2 | 82.7 | 89.4 | 83.2 | 87.8 | 82.8 | 81.2 | ||
| NS | 79.0 | 78.8 | 87.7 | 82.4 | 84.5 | ||||
| NA | 78.1 | 77.0 | 85.5 | 82.7 | 85.2 | 83.7 | 81.5 | ||
| ES | 79.5 | 80.2 | 89.4 | 81.7 | 86.0 | 82.2 | 80.4 | ||
| EA | 78.8 | 79.2 | 89.2 | 81.5 | 85.2 | 82.6 | 79.8 | ||
| SA | 78.1 | 77.9 | 87.1 | 82.0 | 85.8 | 84.5 | 81.7 | ||
| NES | 79.3 | 82.7 | 89.2 | 82.9 | 86.7 | 81.6 | 80.6 | ||
| NEA | 78.8 | 79.2 | 89.0 | 82.7 | 85.2 | 81.3 | 79.6 | ||
| NSA | 78.2 | 78.1 | 86.1 | 83.4 | 85.6 | 81.8 | 81.5 | ||
| ESA | 78.8 | 79.3 | 88.7 | 83.4 | 84.5 | 81.8 | 79.8 | ||
| NESA | 79.2 | 80.4 | 89.2 | 84.1 | 84.3 | 81.1 | 80.2 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, T.; Wang, L.; Zhang, Z.; Wen, Q.; Wang, X.; Yu, L. An Integrated Land Cover Mapping Method Suitable for Low-Accuracy Areas in Global Land Cover Maps. Remote Sens. 2019, 11, 1777. https://doi.org/10.3390/rs11151777
Zeng T, Wang L, Zhang Z, Wen Q, Wang X, Yu L. An Integrated Land Cover Mapping Method Suitable for Low-Accuracy Areas in Global Land Cover Maps. Remote Sensing. 2019; 11(15):1777. https://doi.org/10.3390/rs11151777
Chicago/Turabian StyleZeng, Tian, Lei Wang, Zengxiang Zhang, Qingke Wen, Xiao Wang, and Le Yu. 2019. "An Integrated Land Cover Mapping Method Suitable for Low-Accuracy Areas in Global Land Cover Maps" Remote Sensing 11, no. 15: 1777. https://doi.org/10.3390/rs11151777
APA StyleZeng, T., Wang, L., Zhang, Z., Wen, Q., Wang, X., & Yu, L. (2019). An Integrated Land Cover Mapping Method Suitable for Low-Accuracy Areas in Global Land Cover Maps. Remote Sensing, 11(15), 1777. https://doi.org/10.3390/rs11151777