1. Introduction
Satellite image time series capture the temporal evolution of the optical properties of land surfaces, and their use allows certain land cover classes, such as crops, to be classified with a high accuracy. Several studies [
1,
2,
3,
4], show that the time series of each pixel is a rich source of discriminatory features for producing land cover
classification maps. These are maps where each pixel bears a categorical label describing the land cover of the corresponding area. However, certain classes remain difficult to identify correctly, even with multi-temporal and multi-spectral information. For example, shrublands are often confused with forests, as the difference between the two classes is the density of tree cover. In the same way, continuous urban fabric, roads, and industrial and commercial units all present high confusion rates [
5]. Indeed, the main difference between buildings situated in a dense city center and buildings in a suburban residential area lies in the quantity of vegetation surrounding each building. In other words, it is the spatial arrangement of the buildings and vegetation in the proximity, more than the characteristics of each building itself, which is discriminatory.
Over the past decades, there has been a steady increase in the availability of high spatial resolution satellite imagery, bringing to light new details that were previously inaccessible with lower spatial resolution images. For example, fine elements such as roads, lone trees or houses, as well as their textures can be captured at a 10 m spatial resolution with Sentinel-2 images. Using such images, it seems relevant to seek to describe groups of adjacent pixels in the image rather than individual pixels. Indeed, at such a spatial resolution, the pixels are often smaller than the objects containing them, so the spatial arrangement of these pixels can help to describe and to distinguish the various objects present in the image. In this paper, features that describe a group of adjacent pixels in an image are called contextual features, and the group of pixels in question is called the spatial support of the feature.
A very common approach is to consider a sliding window around each pixel as spatial support. The central pixel is often described with contextual information like textures, a common example being the Haralick textures [
6], which are based on the Gray Level Co-Occurence Matrix, and have previously been used in Remote Sensing classification problems [
7,
8]. These contextual features are then included into a classification scheme by using a classifier adapted for multi-modal inputs, like a Composite Kernel SVM [
9,
10], or a Random Forest [
11].
In other recent works, Convolutional Neural Networks have been applied to land cover mapping problems [
12,
13,
14]. In such approaches, the contextual information is directly included in the classification model, through the convolutional layers of the network. These networks either assign one label to the central pixel of each input patch (networks such as AlexNet [
15]), or provide a dense labeling of the entire patch (e.g., U-Net [
16]).
While using a sliding window brings an interesting characterization of the neighboring pixels, it also can lead to a smoothing of the sharp corners and fine elements in the output map. Indeed, when using a square support, there is a risk of the relevant context being drowned out by the description of neighboring image objects, especially if the pixel is surrounded by very different objects. This may lead to confusion between the pixel class and its neighboring classes, as the pixel would adopt a very similar contextual characterization as the neighbors. Generally speaking, pixels belonging to sharp corners, or fine elements such as roads and rivers in land cover mapping are sensitive to this phenomenon. This is demonstrated in the experiments in
Section 5.
Another approach is to consider a spatial support adaptive to the nearby image content, which leads to methods based on image segmentation, such as Object Based Image Analysis (OBIA) [
17], which is also commonly used in remote sensing [
18,
19]. However, this comes at the risk of not including a sufficient diversity of pixels to characterize the context, especially in textured areas, due to over-segmentation. For this reason, superpixels [
20], which offer an intermediate representation between sliding windows and objects, have also been used in other studies [
21,
22]. More details about this trade-off and about superpixels can be found in
Section 3.3.
In any case, evaluating the quality of a contextual classification must be done with care, as some methods have the tendency to alter the geometry of the output map. The usual statistical performance indicators (Overall Accuracy, Cohen’s , and F-score) are naturally biased towards the most common samples in the validation data set, meaning that high spatial frequency elements, such as corners and fine elements, are usually poorly represented in the validation. This implies that errors in such areas have a low influence on the overall statistical performance indicators. In other words, the deterioration of high spatial frequency areas can be overshadowed by other effects, such as the smoothing of noisy pixels in homogeneous areas.
One way to evaluate the quality of the geometry of a classification map is to split the validation set in several subsets, where each subset contains pixels of a certain geometric category, such as corners, edges, or central areas, as is done in [
23], and later in [
24]. This allows a specific measurement of the deterioration of the various geometric entities in the image, but requires dense reference data to categorize the validation labels as corners, edges, etc. Another commonly used metric, the Intersection over Union (IoU) [
25] also requires dense reference data to calculate the areas of intersection and union. Moreover, it is subject to the same biases as Overall Accuracy and
, as it measures an average error on the target object or segment. The more sophisticated Overall Geometric Accuracy (OGA) proposed by [
26] also uses the areas of intersection and union, in combination with the position of the center of gravity of the reference and target objects. However, using such metrics is only possible if the validation data set is dense, in other words, if every pixel of the training area is labeled. Indeed, without this information, there is no way to split the validation data into geometric categories, or to extract the reference objects.
Unfortunately, dense validation data is not available in most practical land cover problems. Indeed, there are many cases where training data is manually collected in the field, or comes from a combination of existing data bases, which are all incomplete, or for which certain classes are out of date. A small, dense validation set could be manually constructed, but this would limit the metric to a reduced region, and would be a very time-consuming process.
Figure 1 illustrates the sparse reference data used later in the Experimental Section, which is similar to the database used in [
5] for time series mapping over France. The validation data contains polygons that unfortunately do not contain a full description of the geometry. First of all, the polygons have been eroded, to limit the negative impact of spatial co-registration errors between different images at dates. Second of all, the edges and corners of the polygons can not be used as reference geometry, because there is no guarantee that each polygon edge truly separates elements of two different classes.
The objective of this study is therefore to present a metric that can measure the geometric quality of a classification map, even when the validation data is sparsely distributed across the image, as is the case in many land cover mapping problems [
5,
13,
14].
By comparing a contextual classification to a pixel-based classification, instead of a dense reference data set, it is possible to measure how well certain geometric elements, which are usually well recognized by pixel-based classifiers, are preserved. In other words, the pixel-based classification can be used as an approximation of the dense reference data set, at least for some class borders. Sharp corners are commonly subject to the smoothing effects visible in many contextual classification maps, and are relatively simple to identify in a such a map using currently existing corner extraction methods. For this reason, the precise localization of sharp corners is considered as an indicator of the quality of the geometry in the output map. Further details about the supervised corner extraction method, and about its validation, are given in
Section 2.
This study proposes a new metric called the Pixel Based Corner Match (PBCM), which is evaluated on classification results generated with contextual features from three different spatial supports: sliding windows, objects from an object segmentation, and superpixels. A precise definition and more information regarding each method is given in
Section 3. In a previous study [
27], these three spatial supports were compared in terms of how much they influenced the classification accuracy, especially of classes that depend heavily on context. The performance of the methods was evaluated using only the standard classification accuracy metrics and on a unique area of 110 km × 110 km. The authors concluded that the geometric precision of the result should be analyzed quantitatively, as some of the contextual classification methods have a tendency to deform the geometry of the output.
The case study is the challenging problem of satellite image time series classification, based on Sentinel-2 imagery, which presents several practical difficulties, in particular, a very high number of features in the original feature space due to the combined use of multi-spectral and multi-temporal information, a certain degree of label noise, and a lack of densely available reference data [
5,
28]. Therefore, care must be taken when selecting which contextual classification method to apply, which is the underlying motivation behind this study.
The rest of the paper is organized as follows. The details of the new Pixel Based Corner Match (PBCM) geometric accuracy metric, are provided in
Section 2. Then, the various strategies for defining the spatial support are detailed in
Section 3. Next,
Section 4 focuses on the two types of contextual features used in the experiments. The experimental setup is given in
Section 5, and the results in
Section 6. Finally,
Section 7 draws conclusions and suggests perspectives for future studies.
2. Pixel Based Corner Match to Measure Geometric Precision
In this section, a new metric that aims to quantify the geometric precision of a contextual method, with respect to a pixel-based method is presented. This metric relies on the output of a pixel-based classifier to extract sharp corners, which are compared to the corners from a contextual classification map. This is based on the assumption that the pixel-based classification map respects the high spatial frequency areas, and the target geometry. Indeed, a pixel-based classification map can be sensitive to noise and to errors in context dependent classes, but it should preserve the corners and fine elements in the image. On the other hand, context-based classifiers can alter the geometry of the result. An example of this phenomenon is given later, in the Experimental Section in Figure 14c, in which many of the sharp corners originally present in the pixel-based classification are smoothed when using a contextual method. For these reasons, the PBCM is based on corner detection alone, with the pixel-based classification map used as a reference.
The image itself should not be used to detect the reference corners, because highly textured areas contain many corners which should not be present in the target classification maps. In other words, the corners that should be preserved by a contextual classifier are the ones at the intersections of the different classes, which are not necessarily the same as the corners in the actual image.
Using successive steps of line detection and corner detection, the objective is to calculate the percentage of corners in the target classification that are situated near at least one corner in the pixel-based classification. The notion of proximity is given by a radius parameter, which is taken to be very small (1 pixel). This gives a quantitative indication of how many corners were displaced or lost, when using a contextual method.
It is important to note that the metric is intended to be used in a relative manner, in other words, to compare the geometry of results from various possible choices of spatial support, feature, or parameters on a given problem. Indeed, the absolute values of the corner matching must not be interpreted directly, as they depend strongly on the parameters of the corner detection, which should be calibrated according to the type of imagery, and to the target classes. The absolute values also may depend on other unknown factors, such as the level of noise in the classification map.
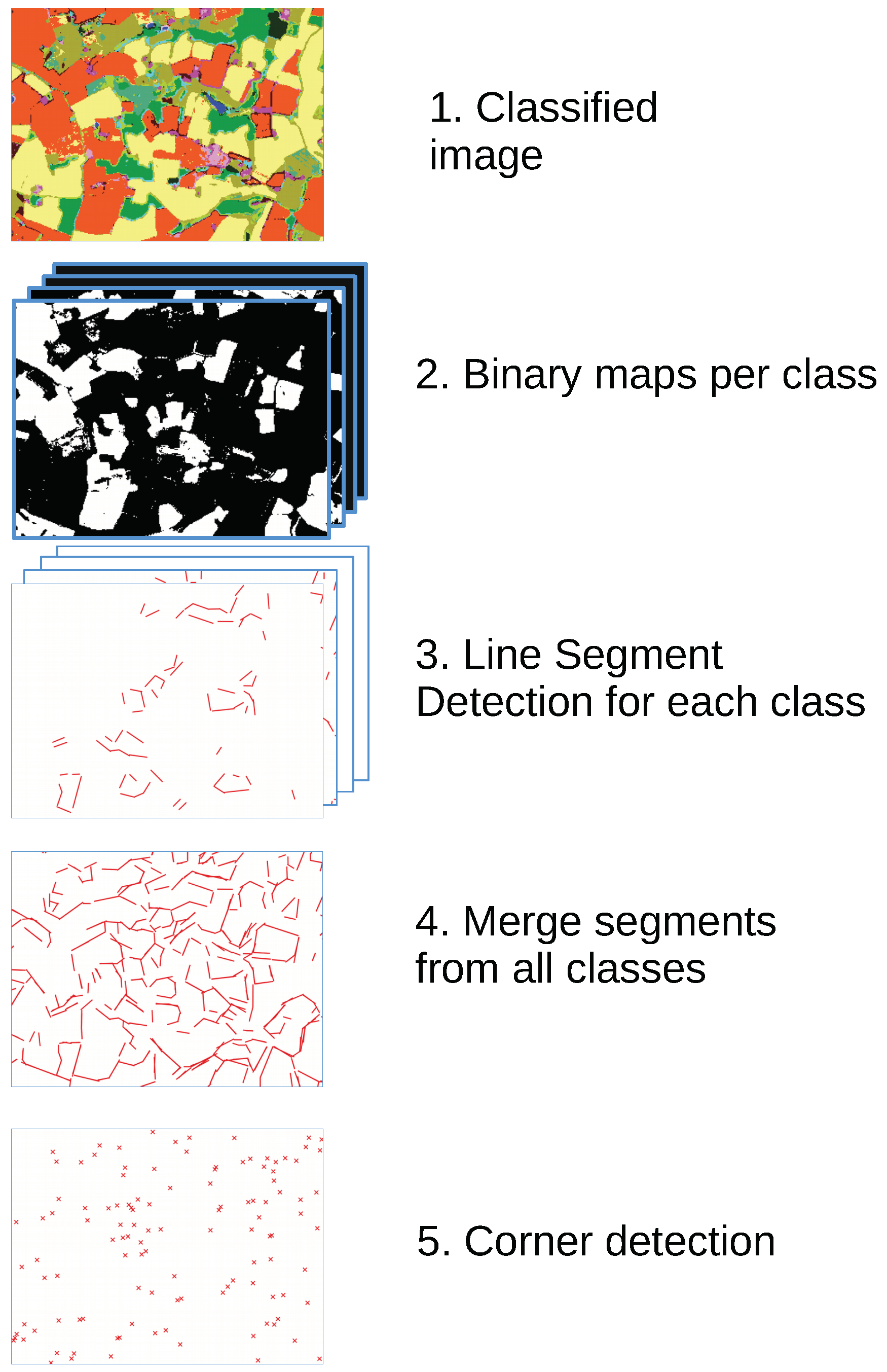
2.1. Corner Detection
Detecting the corners in a classification map can be done by extracting straight line segments in the map, and by calculating the position and angle of the intersection between pairs of lines. For this, first of all, the classification map is split into a set binary maps (one binary map for each class). Then, an unsupervised Line Segment Detector (LSD), based on [
29], is applied to the map, generating a set of segments for each class. In order to find corners on the edges of areas of various classes, all of the segments of the different classes are merged together. A corner is detected if the angle of the two segments is within a certain range (30°–120°), and if their extremities are close enough. This is shown in
Figure 2.
2.2. Corner Matching
After the corners have been extracted in both the target classification map and the reference classification map, the ratio of corners that match up in both maps to the number of corners in the target classification is used as a performance metric. In other words, let
be the set of corners of the reference image (the pixel-based classification), and
be the set of corners of the classification map of which geometry is being measured. The set of matching corners is defined in Equation (
1), where
is the standard Euclidean distance, and
t is a threshold parameter. This is also illustrated in
Figure 3.
From here, the geometric precision metric
can be defined, as is shown in Equation (
2).
A high ratio means that many of the corners detected in the target are also present in the pixel-based classification, and reversely, a low ratio means than many of the corners in the pixel-based classification have been lost. When comparing two pixel-based classifications generated with a different sampling of training data, and therefore a different Random Forest, an average matching ratio of 51.3% is measured, see Figure 5. This seemingly low number is due to imperfections in line and corner detection, which are sensitive to the label noise present in the pixel-based classification.
In order to increase the robustness of the metric, each target classification can be compared to several pixel-based results, which are generated by classifiers trained on various random samplings of the training data. This reduces the contribution of noise, in the same manner as a cross-validation scheme. Then, the average value and standard deviation of the metric can be calculated, in order to provide an indication of the confidence of the metric, when different sub-samplings of the training data are used.
The PBCM metric also has its limits, as it only measures the smoothing of corners, and not of other high spatial resolution features, such as fine elements. Furthermore, it is biased by the corners of the majority classes, in this case, the two crop classes (summer and winter crops), which account for the wide majority of corners detected in these maps. The geometry of other classes, such as the urban classes, which are unfortunately the most challenging to classify, might not be measured in this case. The metric might also overlook the geometry of minority classes, which do not generate many corners in the first place. However, it still can play the role of an indicative metric, as these biases are known and can be accounted for in the interpretation. Moreover, it would be possible to add weights to the different corners, according to the classes that form them, and in this way to reduce the biases linked to class proportions. However, this would be application dependent and is not developed further in this work.
2.3. Impact of Regularization
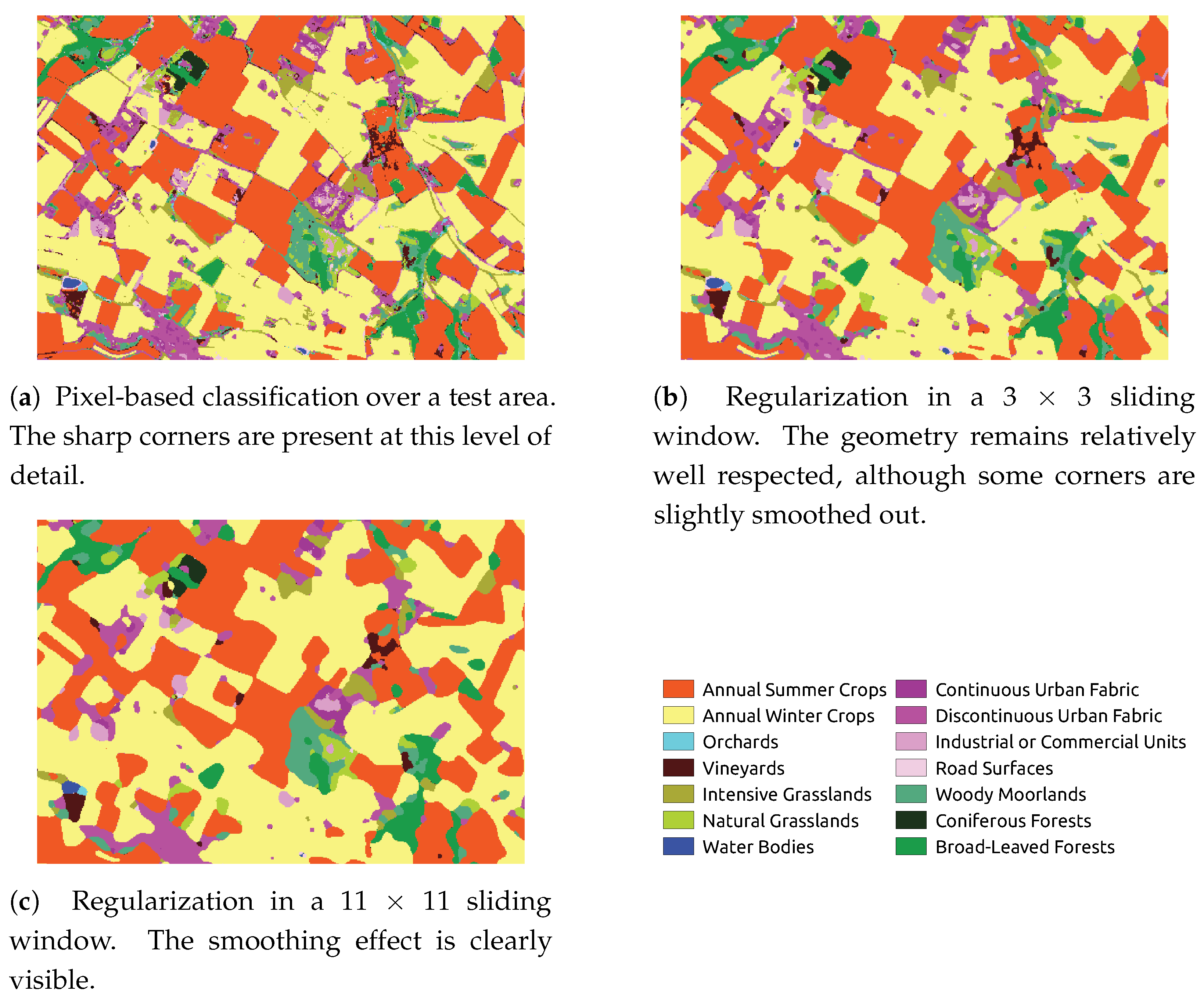
To demonstrate the pertinence of the metric, a majority vote filter, also known as regularization filter, is applied in a sliding window to the result of a pixel-based classification. This common post-processing step consists in replacing the label of the central pixel of the sliding window by the most frequent label in the neighborhood. It is known to increase the statistical accuracy by removing isolated pixels in the final result. This is illustrated in
Figure 4.
Figure 4a shows the result of a pixel-based classification, which contains sharp corners, and a certain amount of isolated pixels, that can be attributed to noise. As
Figure 4b demonstrates, this noise is largely reduced by the regularization filter. However, the corners are slightly smoothed. In
Figure 4c, a larger neighborhood of 11 × 11 pixels was chosen for the regularization filter, which has a heavy smoothing effect on the previously sharp corners.
The impact of the regularization on the statistical accuracy is shown in
Figure 5. In this figure, the vertical axis shows the difference in Overall Accuracy with respect to the pixel-based classification, while the horizontal axis represents the PBCM. The labels above the points indicate the size of the sliding window, in pixels. Clearly, regularizing the classification result using a sliding window has a positive impact on the classification accuracy metric (Overall Accuracy). This remains true, even for very large sliding window sizes. In fact, the most accurate performances are achieved for the large windows (11 × 11, 13 × 13, 15 × 15), where the geometric deformation is very visible, as is shown in
Figure 4c.
Figure 5 also shows that when applying a majority vote filter in a sliding window neighborhood, like in
Figure 4b, the PBCM decreases as the size of the filter increases. Indeed, the metric reaches 30% for a window of 5 × 5, and passes under 10% for a window of 11 × 11. These results give a first indication that the corner matching metric is indeed sensitive to a deterioration of the geometric quality, and allows for an initial quantitative evaluation of this effect. This also shows that measuring the Overall Accuracy or the Kappa alone is not sufficient to fully evaluate the quality of a map, and that a specific metric for evaluating the quality of the geometry is indeed necessary.
2.4. Calibration of the Metric
Extracting the corners involves several parameters that need to be calibrated to the type of imagery used. In particular, the Line Segment Detector depends on 7 parameters, which all have a significant influence on how well the line segments are extracted. The advised parameters given in [
29] have been selected for computer vision problems, and do not always provide coherent results when applied on binary maps at a 10 m resolution. Indeed, at such a resolution, each desired segment is made up of a relatively small number of pixels, when compared to computer vision images. Secondly, the contrast along the lines in binary maps is stronger than in natural images. For this reason, a calibration step is used before applying the metric. This involves maximizing the average number of matching corners between pairs of pixel-based classification maps, while minimizing the number of matching corners between a pixel-based classification map and a regularized classification map. In practice, the difference between the two is used as a cost function for a grid search optimization over the parameters, around their default values. Pixel-based results from several samplings of the training data are used to increase the robustness of the PBCM metric at each step of the calibration. The resulting values of the calibration are given in
Table 1 and
Table 2.
5. Experimental Setup
For the evaluation, the benchmark problem is the 17-class land cover mapping of Sentinel-2 time series, as described in [
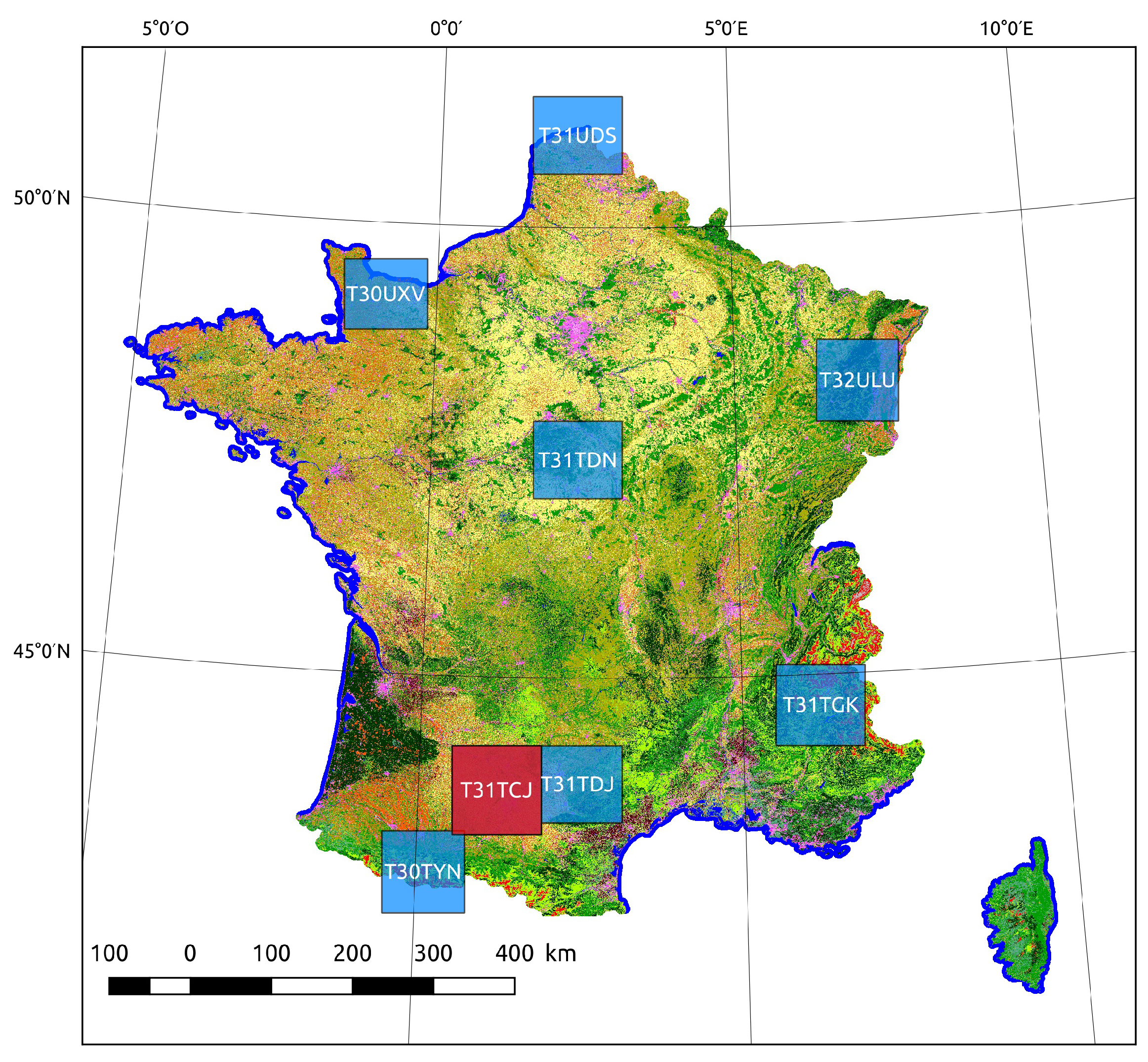
5]. The data set is comprised of 33 dates of 10 band optical images at a 10 m spatial resolution. A total of 7 different tiles of 110 × 110 km covering a variety of landscapes across France were chosen for the evaluation. The different tiles and their geographic layout is shown in
Figure 11, and the number of training samples taken for each tile is shown in
Table 3. Each tile contains quite different class proportions. Most illustrations and detailed analysis are based on the tile
T31TCJ, which contains the city of Toulouse.
Figure 12 and
Figure 13 respectively show the RGB bands of the first date of the time series, over this area, as well as the reference data used for the training and validation of these experiments. Results for all 8 tiles in
Section 6. The classifier used for the evaluation is a Random Forest [
11] with 100 trees, and a maximal depth of 25.
This region was chosen among the others as it covers a wide area, including large urban agglomerations as well as a variety of forests and agricultural lands.
Figure 14a shows a small area of this data set. Three spectral indices, namely the Normalized Differential Vegetation Index (NDVI), the Normalized Differential Water Index (NDWI) and Brightness, are also calculated from these images, which gives the full time series a total dimension of 489 features. A detailed description of the training data is also given in [
5]. In the selected region, the nomenclature contains 14 classes, which range from agricultural classes such as summer or winter crops, to natural covers like forests and water, as well as artificial surfaces, roads and urban areas, as shown in
Figure 14b. For the evaluation, the reference data is split into training and testing sets, at the polygon level, to avoid correlation between the two data sets, and to provide measurement of the generalization error, as is recommended by [
43]. Each data set is comprised of 15,000 samples per class, except for the Natural Grasslands class, where around 10,000 samples are selected, as there are fewer samples available for this class. The same number of samples was chosen for the testing sets. The benchmark classification is the pixel-based Random Forest classification [
11], an example the of benchmark result is given in
Figure 14b.
The performance of the different methods is evaluated by the following criteria.
The experiments are run on two sets of features, the mean/variance features, and the edge density features. In each case, the object shape information is included if it is pertinent to the spatial support, so for objects and superpixels.
The performance of the baseline classification method, the pixel-based Random Forest classifier is given in the first column of
Table 4, in
Section 6.
6. Results
The experimental results are obtained by including contextual features calculated in a spatial support around the pixel that is being classified. This can be either a sliding window, a superpixel, or an object. First, a detailed analysis of the results on the tile T31TCJ is provided. This includes the class scores of the four main candidate methods, as well as graphs showing their Overall Accuracy and Pixel Based Corner Match. Next, the results on the other tiles are shown, which gives an indication of the performance of the various methods in different situations, each with unique class proportions and class behaviour.
6.1. Detailed Results on T31TCJ
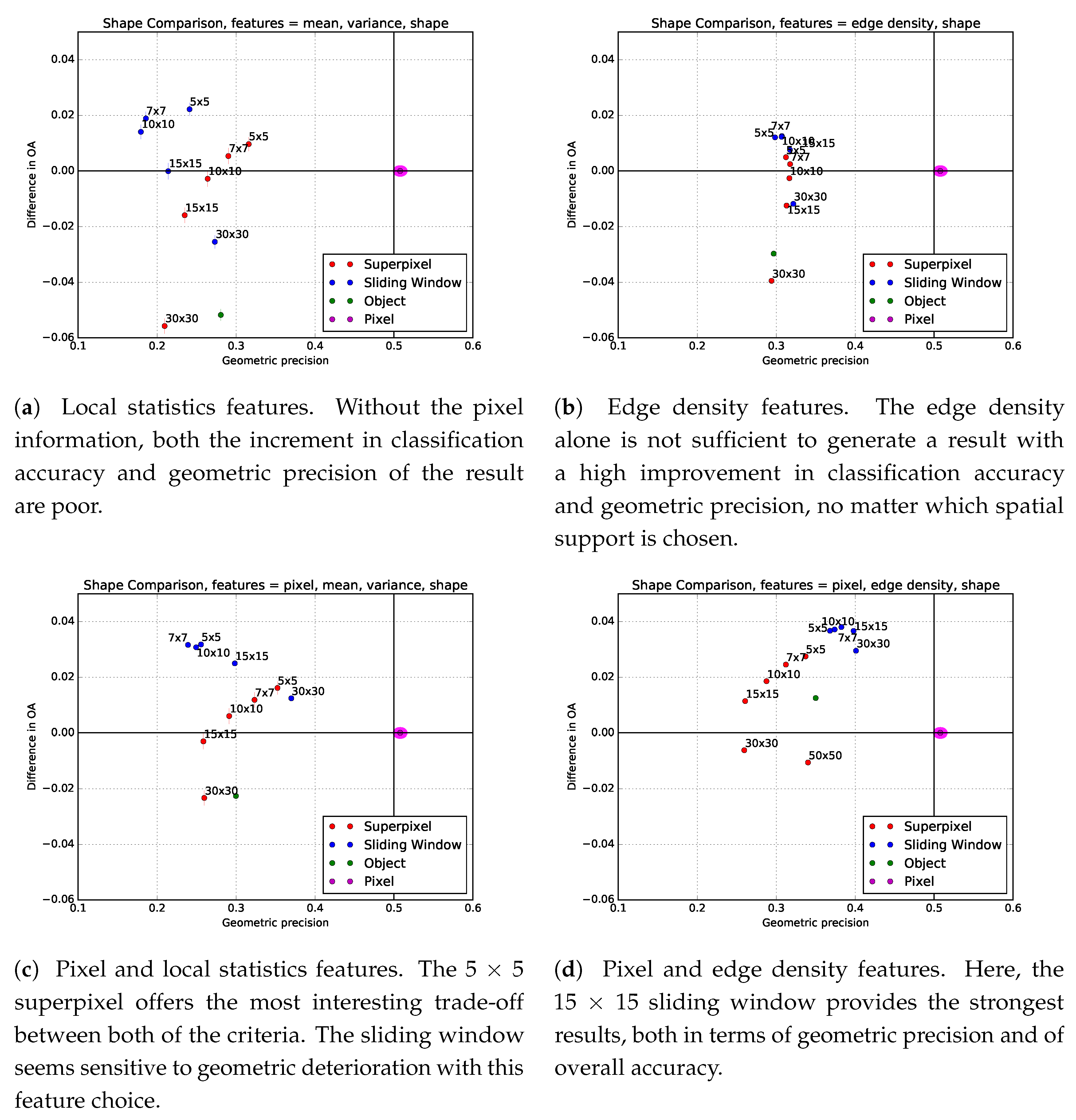
Figure 14 shows an extract of the classification maps, generated with different combinations of spatial support shape and feature choice, on an urban area with a small dense center and its surroundings. In
Figure 15, the different shapes and feature choices are compared according to two criteria:
The horizontal axis shows the difference between the Overall Accuracy of the contextual method and of the pixel-based method, which is also given in the second column of
Table 4. The vertical axis represents the ratio of matching corners between the pixel-based classification and the contextual classification. To obtain a reference value for the pixel-based classification, the PBCM metric was calculated on pixel-based results that were generated using different sub-samples of the training set. The labels above the points represent the scale factor, which is the diameter of the window for a sliding window, expressed in pixels, or the square root of the average size for a superpixel.
Finally
Table 4 shows the detailed per-class results for different combinations of features and spatial supports. This table shows that strong improvements are made for textured classes: the four urban classes, as well as orchards and vineyards. Only the crop classes seem to suffer from the inclusion of context, as these features are mainly irrelevant for them. However, their recognition rate remains very high.
6.1.1. Sliding Window
Figure 14c,d show the result of the classification when including respectively local statistics, and edge density features, in a sliding window neighborhood of size 11 × 11. Visually, it appears that the amount of noise is reduced, compared to the pixel-based classification result. However, in the case of the local statistics features, some of the corners seem quite rounded, and fine elements like the river are deformed, and at some places even lost. Using a structured texture feature like edge density, this effect is largely reduced. On the other hand, round-shaped artifacts appear in the urban area, due to the isotropic nature of the square neighborhood.
Figure 15 confirms several of these conclusions. In particular,
Figure 15c shows that the sliding window neighborhoods can provide an increase in classification accuracy, but at the cost of a deterioration of the geometric precision. Surprisingly, when the window size is very large (30 × 30), the geometric precision increases. To understand this it is necessary to analyze the Random Forest variable importance, as defined in [
11]. It appears that when the window size is too large, the contextual information is mostly discarded by the classifier. This explains why when increasing the window size, the geometric precision increases, but the statistical accuracy decreases, because the classification gets closer to the pixel-based prediction. Furthermore,
Figure 15a,b show that both the classification accuracy and geometric precision of the sliding window neighborhood result are quite low when the pixel information is not included. Finally,
Figure 15d shows that using edge density features in combination with pixel features provides the best results, both in terms of classification accuracy and geometry.
6.1.2. Mean Shift Object
The result using features calculated in a object from a Mean Shift segmentation is shown in
Figure 14g. The high-frequency elements are conserved, but the noise smoothing effect in the urban area is clearly less present than when using superpixels. This is due to the fact that segmentation methods like Mean Shift create very small segments in urban areas, because of the high spectral variability. Calculating contextual features in objects does therefore not bring much information when compared to pixel-based classification. This is confirmed by
Figure 15a,d, as the increment in classification accuracy is quite limited, regardless of the feature choice.
6.1.3. Superpixel
When using superpixel features with an initial segment size of 11 × 11,
Figure 14e,f the noise seems filtered out and the high spatial frequency elements remain in the final result. The class edges in the urban areas have the tendency to follow the superpixel edges, which adhere to strong gradients in the image.
Figure 15 shows that when using a superpixel as a spatial support, the pixel-based information once again has a positive effect, increasing both the classification accuracy and geometric precision. Furthermore, with the local statistics features,
Figure 15a,c, superpixels offer the best trade-off between the two evaluation criteria, although the optimal superpixel size is 5 × 5, which shows that this choice of feature and support is only relevant at smaller scales, for capturing a local context. When using the edge density and pixel information, the increase in overall accuracy is positive, and the PBCM is decent, but they remain slightly lower than when using sliding windows.
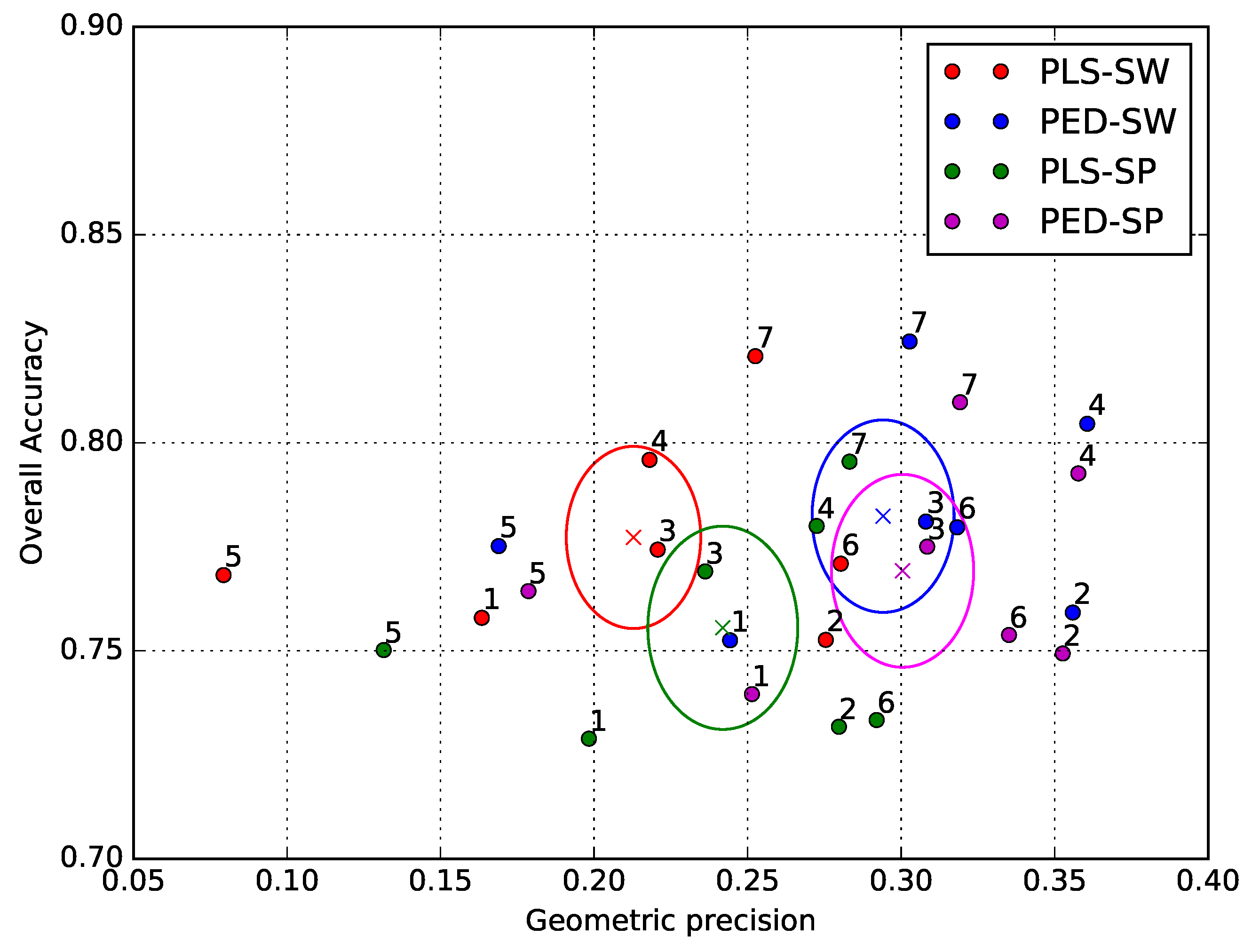
6.2. Results on Other Tiles
Figure 16 shows the Overall Accuracy and geometric precision scores for the 7 tiles present in the evaluation data set. Each point represents the performance on one tile. The scores show some variability, due to the unique class proportions of each tile. Tiles 1 and 5 (T30TYN and T30TGK) show a far lower absolute PBCM than the other tiles, no matter which method is considered. This is linked to the low number of crop classes in these tiles, which cover mountainous areas, respectively, the Alps and the Pyrenees. However, the absolute value of the geometric precision metric is not very important, as it is meant to be used as a relative metric to compare different methods. The ellipses in
Figure 16 show the mean and standard deviation of the scores, over all 7 tiles. The center of the ellipse is placed on the mean value, while the length of the semi-minor and semi-major axes are equal to the standard deviation of the two scores.
The graph shows that the edge density feature systematically gives a higher geometric precision, for both superpixels and sliding windows, relative to the local statistic features. While this result may seem intuitive, the PBCM metric provides quantitative evidence to this conclusion. This might be due to the fact that the edge density is a structured feature, which takes into account local variations, and not only the overall behavior in the spatial support.
It is interesting to note that the relative values of the scores for a given method are relatively similar from one tile to another. This shows that the relative geometric precision metric is quite robust to diversity in tile content, in other words, it provides a reliable indication of the geometric degradation of a contextual classification method.
In terms of Overall Accuracy, the sliding window seems to provide the highest performance, especially in combination with the edge density feature. However, the difference with the superpixel spatial support is not that large, and the superpixel support seems to provide a slightly higher geometric precision.
The results show that the choice of spatial support and the choice of features cannot be made independently. Indeed, in the case of the local statistics features (mean and variance), the sliding windows have a strong tendency to deteriorate the geometry of the output map, particularly by smoothing out sharp corners and erasing fine elements. This phenomenon could be linked to the fact that the local statistics features are “unstructured”, meaning that they do not depend on the arrangement of pixels in the spatial support, and are therefore akin to a low-pass filter. It is interesting to note that these features are best combined with a superpixel support, which provides a modest improvement in classification accuracy, while maintaining a higher level of geometric precision. It is possible that the averaging nature of unstructured features implies that they run the risk of smoothing the output geometry, and therefore should be applied in combination with an image segmentation technique.
However, when using the edge density feature, the conclusion is quite different. Sliding windows provide the highest classification improvement, while generating a geometrically precise map, at least in the corners of the majority crop classes. Meanwhile, with these same features, superpixels seem to capture less valuable contextual information than sliding windows, although they also preserve the geometry, and do improve the context-dependent classes. This could be explained by the “structured” aspect of the edge density feature, which is based on the average of a local gradient, and therefore depends on the spatial arrangement of the pixels in the context, making corners and fine elements easier to characterize. This feature being more similar to a high-pass filter, is therefore adapted for use with a sliding window.
Finally, these experiments show that the presence of pixel information is key for providing maps with both a higher classification accuracy and a sharp geometry, especially when an unstructured feature like the edge density is used. Purely object-based methods like OBIA, whether they be used with superpixels or object segments from Mean Shift, provide inferior results on this problem.
7. Conclusions
In this paper, the Pixel Based Corner Match (PBCM), a new metric for measuring the geometric precision of a context-based classification map, in the absence of dense validation data, is presented. This metric uses the output of a pixel-based classification map to simulate dense validation data, under the assumption that the corners formed by the edges between different classes are relatively well respected by the pixel-based classifier. By matching these corners with the corners in the contextual classification map, the degradation of these high spatial frequency elements can be quantified. Experiments using regularization (majority vote in a sliding window) show that this metric provides a quantitative indication of the amount of smoothing and loss of corners that occurs when using such a post-processing step. Indeed, when increasing the size of the regularization window, the metric decreases significantly. However, it is important to keep in mind that this metric is far from perfect, as it only measures the degradation of corners, and not of fine elements. Secondly, it is strongly biased by the classes that contain the most corners, in this study, the summer and winter crops.
The PBCM metric is used to demonstrate the ability of three different spatial supports (superpixel, sliding window, and object) to improve class recognition at a 10m spatial resolution, while maintaining a precise geometry. This experimental study serves as a demonstration of how the metric can guide the choice of spatial support and features to use. Two types of contextual features, the second order local statistics (mean and variance), and the density of edges are also compared, to understand how the choice of spatial support and contextual feature can be linked.
For this land cover mapping problem, the most viable solution (in terms of both statistical and geometrical accuracy) among those evaluated here seems to be the combination of pixel features with the edge density, calculated in a sliding window. On the other hand, superpixels provide results with a high geometric accuracy, but seem to provide a less pertinent characterization of the context than sliding windows, in this case.
In conclusion, this paper shows that the geometric precision of a classification map can be evaluated efficiently over wide areas without dense reference data. This metric is meant to be used in a multi-criteria evaluation of various contextual classification methods.
Further studies could investigate the use of a dense reference data on a small area to locally validate the metric, by comparing it to other well known dense geometrical degradation indicators, such as Hoover metrics, and category specific metrics like the ones used in [
23,
24]. Further improvements could also include the detection of fine elements, in order to measure the degradation in such areas. It would be equally interesting to intersect the validation data with a buffer around each corner detected on a pixel-based classification result, to provide a class-specific metric of the deterioration in the corner areas. Moreover, it could be interesting to incorporate weights to the different corners, according to the classes that form them. For instance, the weights might be inversely proportional to the class frequencies, to balance the contribution of the different classes to the metric, in case of very unbalanced class proportions.
The source code of the PBCM metric uses Orfeo ToolBox, and is freely accessible [
44].



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}