Figure 1.
Airborne laser scanning system (ALS) datasets (the colors are rendered according to the true labels): (a) Training set; (b) site I of the test set; (c) site II of the test set; (d) site III of the test set.
Figure 1.
Airborne laser scanning system (ALS) datasets (the colors are rendered according to the true labels): (a) Training set; (b) site I of the test set; (c) site II of the test set; (d) site III of the test set.
Figure 2.
The location of datasets. (a) Training set; (b) site I of the test set; (c) site II of the test set; (d) site III of the test set. The base map is from Google Earth. The yellow plus sign denotes the pylon location. The polygon with red border indicates the extent of the dataset. The blue line is the center line of the dataset range and is the connection line of the pylon.
Figure 2.
The location of datasets. (a) Training set; (b) site I of the test set; (c) site II of the test set; (d) site III of the test set. The base map is from Google Earth. The yellow plus sign denotes the pylon location. The polygon with red border indicates the extent of the dataset. The blue line is the center line of the dataset range and is the connection line of the pylon.
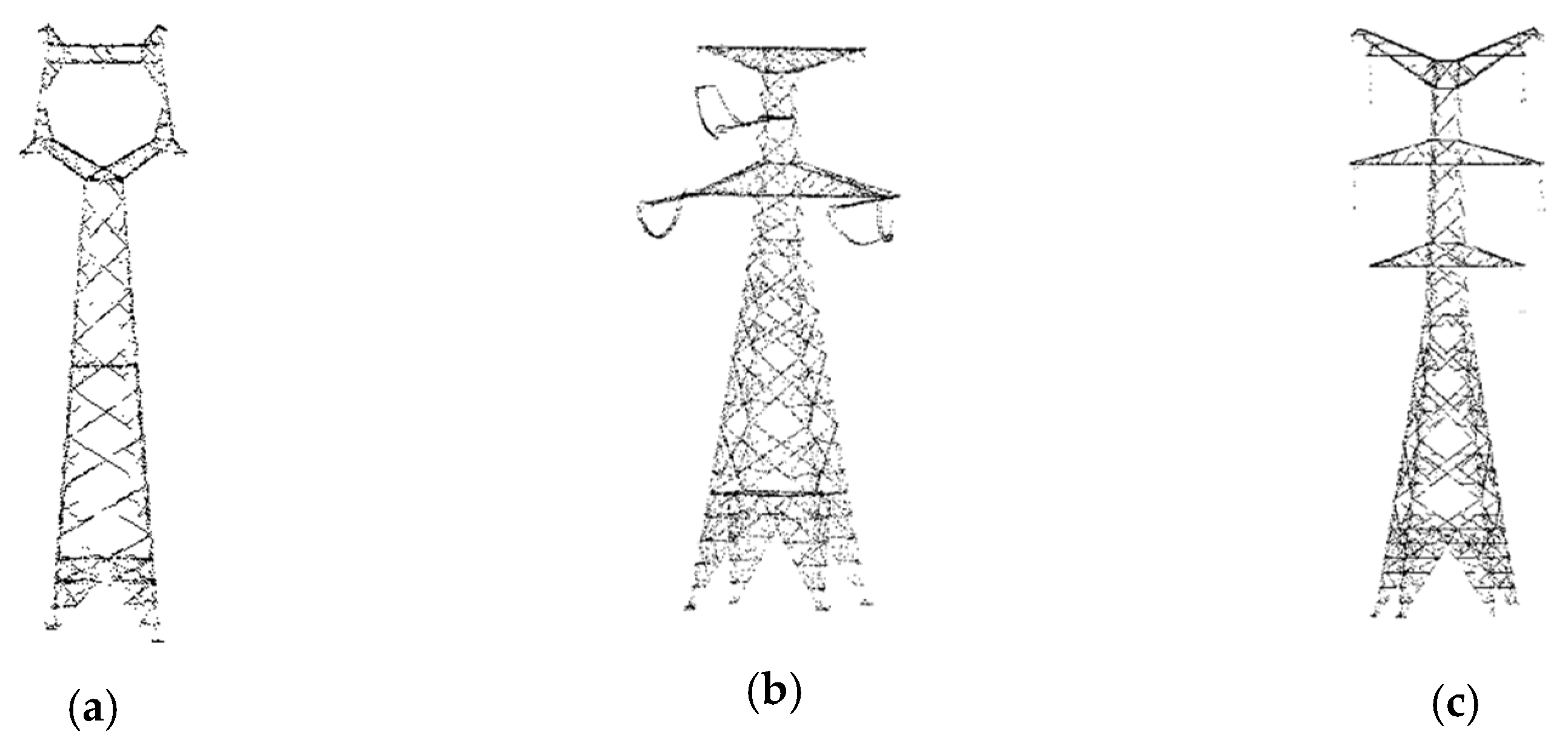
Figure 3.
The pylon types of datasets: (
a) Pylon belongs to the line in
Figure 1a; (
b) pylon belongs to the line in
Figure 1c; (
c) pylon belongs to the line in
Figure 1d. Three different types of pylon are included.
Figure 3.
The pylon types of datasets: (
a) Pylon belongs to the line in
Figure 1a; (
b) pylon belongs to the line in
Figure 1c; (
c) pylon belongs to the line in
Figure 1d. Three different types of pylon are included.
Figure 4.
The complete flowchart of our study. This flowchart has been divided into two parts. The left box is the basic classification framework and the right box lists the main experiments, including comparison among classifiers, balanced versus unbalanced learning, comparison between feature sets, and sensitivity analysis of neighborhood radius. All classifiers, feature sets and class distribution tested are listed in the dotted box.
Figure 4.
The complete flowchart of our study. This flowchart has been divided into two parts. The left box is the basic classification framework and the right box lists the main experiments, including comparison among classifiers, balanced versus unbalanced learning, comparison between feature sets, and sensitivity analysis of neighborhood radius. All classifiers, feature sets and class distribution tested are listed in the dotted box.
Figure 5.
Neighborhood types used in feature extraction: (a) Cylinder neighborhood C, (b) spherical neighborhood S (hollow point: Center point, r: Neighborhood radius).
Figure 5.
Neighborhood types used in feature extraction: (a) Cylinder neighborhood C, (b) spherical neighborhood S (hollow point: Center point, r: Neighborhood radius).
Figure 6.
The classification results of site I with different classifiers: (a) the point clouds colored by the true labels; (b) the point clouds colored by the KNN prediction results; (c) the point clouds colored by the LR prediction results; (d) the point clouds colored by the RF prediction results; (e) the point clouds colored by the GBDT prediction results. The black box is an area of obvious misclassification.
Figure 6.
The classification results of site I with different classifiers: (a) the point clouds colored by the true labels; (b) the point clouds colored by the KNN prediction results; (c) the point clouds colored by the LR prediction results; (d) the point clouds colored by the RF prediction results; (e) the point clouds colored by the GBDT prediction results. The black box is an area of obvious misclassification.
Figure 7.
The classification results of site II with different classifiers. (a) The point clouds colored by the true labels; (b) the point clouds colored by the KNN prediction results; (c) the point clouds colored by the LR prediction results; (d) the point clouds colored by the RF prediction results; (e) the point clouds colored by the GBDT prediction results. The black box is an area of obvious misclassification.
Figure 7.
The classification results of site II with different classifiers. (a) The point clouds colored by the true labels; (b) the point clouds colored by the KNN prediction results; (c) the point clouds colored by the LR prediction results; (d) the point clouds colored by the RF prediction results; (e) the point clouds colored by the GBDT prediction results. The black box is an area of obvious misclassification.
Figure 8.
The classification results of site III with different classifiers: (a) The point clouds colored by the true labels; (b) the point clouds colored by the KNN prediction results; (c) the point clouds colored by the LR prediction results; (d) the point clouds colored by the RF prediction results; (e) the point clouds colored by the GBDT prediction results. The black box is an area of obvious misclassification.
Figure 8.
The classification results of site III with different classifiers: (a) The point clouds colored by the true labels; (b) the point clouds colored by the KNN prediction results; (c) the point clouds colored by the LR prediction results; (d) the point clouds colored by the RF prediction results; (e) the point clouds colored by the GBDT prediction results. The black box is an area of obvious misclassification.
Figure 9.
The pylons are colored by the true labels: (a) Pylon type in the training set; (b) pylon type-I in site II; (c) pylon type-III in site III.
Figure 9.
The pylons are colored by the true labels: (a) Pylon type in the training set; (b) pylon type-I in site II; (c) pylon type-III in site III.
Figure 10.
The classification results of pylon type-I with different classifiers (feature set = , class distribution = unbalanced, R = 1.5 m): (a) The pylon is colored by the KNN prediction results; (b) the pylon is colored by the LR prediction results; (c) the pylon is colored by the RF prediction results; (d) the pylon is colored by the GBDT prediction results.
Figure 10.
The classification results of pylon type-I with different classifiers (feature set = , class distribution = unbalanced, R = 1.5 m): (a) The pylon is colored by the KNN prediction results; (b) the pylon is colored by the LR prediction results; (c) the pylon is colored by the RF prediction results; (d) the pylon is colored by the GBDT prediction results.
Figure 11.
The classification results of pylon type-II with different classifiers( feature set = , class distribution = unbalanced, R = 1.5 m): (a) The pylon is colored by the KNN prediction results; (b) the pylon is colored by the LR prediction results; (c) the pylon is colored by the RF prediction results; (d) the pylon is colored by the GBDT prediction results.
Figure 11.
The classification results of pylon type-II with different classifiers( feature set = , class distribution = unbalanced, R = 1.5 m): (a) The pylon is colored by the KNN prediction results; (b) the pylon is colored by the LR prediction results; (c) the pylon is colored by the RF prediction results; (d) the pylon is colored by the GBDT prediction results.
Figure 12.
Oversampling results of the building, pylon and power line class: (a) Oversampled building, (b) oversampled pylon, (c) oversampled power line. The original points are colored with blue, while the synthetic points are colored with red.
Figure 12.
Oversampling results of the building, pylon and power line class: (a) Oversampled building, (b) oversampled pylon, (c) oversampled power line. The original points are colored with blue, while the synthetic points are colored with red.
Figure 13.
The sensitivity analysis of neighborhood radius for different classes based on the RF classifier.
Figure 13.
The sensitivity analysis of neighborhood radius for different classes based on the RF classifier.
Table 1.
Details about data acquisition.
Table 1.
Details about data acquisition.
| Sensor | Flight Height | Swath | Flight Speed | Field of View | Scanning Speed | Laser Pulse Rate | Laser Beam Divergence | Number of Returns |
|---|
RIEGL
VUX-1 | 200 m | 400 m | 30 km/h | 330° | 200 lines/s | 550 kHz | 0.5 mrad | 4 |
Table 2.
Overview of the Datasets.
Table 2.
Overview of the Datasets.
| Dataset | Area/m2 | Density (pt/m2) | Points |
|---|
| Ground | Vegetation | Pylon | Power Line | Building | SUM |
|---|
Training
Set | 907 × 90 | 52 | 3,763,849 | 2,345,327 | 321,306 | 26,877 | 49,912 | 6,199,950 |
| 60.71% | 37.83% | 5.18% | 0.43% | 0.81% | 100% |
Test
Set | I | 535 × 90 | 44 | 1,782,922 | 1,004,471 | 5850 | 15,391 | 10,381 | 2,819,021 |
| 63.25% | 35.63% | 0.21% | 0.55% | 0.37% | 100% |
| II | 397 × 90 | 73 | 1,586,186 | 1,848,031 | 20,509 | 20,688 | 222,033 | 3,697,447 |
| 42.90% | 50.00% | 0.60% | 0.60% | 6.00% | 100% |
| III | 937 × 80 | 41 | 2,464,418 | 1,246,571 | 62,074 | 162,771 | 43,777 | 3,979,611 |
| 61.93% | 31.32% | 1.56% | 4.09% | 1.10% | 100% |
Table 3.
Feature vector description. The first column represents the basis of feature computing, the second column is the feature name, the third column is the feature abbreviation, the fifth column is the feature computing method, and the last column is the description of the feature meaning.
Table 3.
Feature vector description. The first column represents the basis of feature computing, the second column is the feature name, the third column is the feature abbreviation, the fifth column is the feature computing method, and the last column is the description of the feature meaning.
| Category | Feature | Abbreviation | Equation | Description |
|---|
| Eigenvalue | Sum | SU | | The sum of the eigenvalues |
| Omnivariance | OM | | - |
| Eigenentropy | EI | | The entropy of eigen |
| Anisotropy | AN | | The homogeneity distribution of points in three directions |
| Planarity | PL | | A measure of planar-likeness |
| Linearity | LI | | A measure of linear-likeness |
| Surface Variation | SUV | | A measure of surface roughness |
| Sphericity | SP | | A measure of spherical-likeness |
| Verticality | VE | | A measure of vertical-likeness |
| Density | Point Density | PD | | The density of points within S |
| Density Ratio | DR | | The ratio of the point density in S and in its projection plane |
| Height | Vertical Range | VR | | Height difference in C |
| Height Above | HA | | The height difference between the current point and the lowest point in C |
| Height Below | HB | | The height difference between the current point and the highest point in C |
| Sphere Variance | SPV | | Standard deviation of height difference in S |
| Cylinder Variance | CV | | Standard deviation of height difference in C |
| Vertical Profile | ContiOffSegment | CFS | - | Maximum number of discrete segments |
| ContiOnSegment | COS | - | Maximum number of consecutive segments |
| MaxHeightDev | MHD | | Maximum height difference of the barycenter |
| MaxPtsNumDev | MPD | | Maximum height difference of the mean height |
| OnSegmentNum | OS | - | Number of segments containing points |
Table 4.
Classification performance for the different classifiers (feature set = , class distribution = unbalanced, R = 1.5 m). Three performance measures are shown in this table. P denotes the macro precision, R denotes the macro recall, and F denotes the macro F1. Bold denotes best results for each performance metric in each test set.
Table 4.
Classification performance for the different classifiers (feature set = , class distribution = unbalanced, R = 1.5 m). Three performance measures are shown in this table. P denotes the macro precision, R denotes the macro recall, and F denotes the macro F1. Bold denotes best results for each performance metric in each test set.
| Dataset | Classifiers | Performance Measures |
|---|
| Macro Precision (P, %) | Macro Recall (R, %) | Macro F1 (F, %) |
|---|
| Site I | KNN | 77.76 | 81.36 | 78.24 |
| LR | 80.05 | 69.93 | 73.71 |
| RF | 82.16 | 83.15 | 82.33 |
| GBDT | 79.99 | 82.80 | 80.45 |
| Site II | KNN | 86.59 | 78.55 | 81.00 |
| LR | 89.87 | 65.58 | 69.78 |
| RF | 92.70 | 84.60 | 87.72 |
| GBDT | 91.88 | 83.12 | 86.34 |
| Site III | KNN | 81.34 | 70.11 | 73.50 |
| LR | 78.29 | 62.52 | 68.47 |
| RF | 74.71 | 67.00 | 66.01 |
| GBDT | 78.52 | 76.35 | 76.59 |
| Average | KNN | 81.90 | 76.67 | 77.58 |
| LR | 82.74 | 66.01 | 70.65 |
| RF | 83.19 | 78.25 | 78.69 |
| GBDT | 83.46 | 80.76 | 81.13 |
Table 5.
The confusion matrix and performance measures of site I (classifier = RF, feature set = , class distribution = unbalanced, R = 1.5 m).
Table 5.
The confusion matrix and performance measures of site I (classifier = RF, feature set = , class distribution = unbalanced, R = 1.5 m).
| Class | Ground | Vegetation | Pylon | Power Line | Building | PRECISION RATE (PRE, %) |
|---|
| Ground | 1,685,297 | 165,815 | 151 | 0 | 3098 | 90.88 |
| Vegetation | 97,524 | 834,939 | 2,005 | 69 | 6,215 | 88.75 |
| Pylon | 0 | 1 | 3,655 | 30 | 0 | 99.16 |
| Power line | 0 | 57 | 22 | 15,287 | 0 | 99.49 |
| Building | 101 | 3,659 | 17 | 11 | 1068 | 21.99 |
| Recall rate (REC, %) | 94.52 | 83.12 | 62.48 | 99.29 | 10.29 | |
Table 6.
The confusion matrix and performance measures of site II (classifier = RF, feature set = , class distribution = unbalanced, R = 1.5 m).
Table 6.
The confusion matrix and performance measures of site II (classifier = RF, feature set = , class distribution = unbalanced, R = 1.5 m).
| Class | Ground | Vegetation | Pylon | Power Line | Building | PRE (%) |
|---|
| Ground | 1,537,494 | 366,825 | 43 | 1 | 35,103 | 79.27 |
| Vegetation | 45,978 | 1,474,955 | 3844 | 1 | 31,213 | 94.79 |
| Pylon | 0 | 3 | 15,813 | 196 | 0 | 98.76 |
| Power line | 0 | 16 | 809 | 20,490 | 0 | 96.13 |
| Building | 2,714 | 6232 | 0 | 0 | 155,717 | 94.57 |
| REC(%) | 96.93 | 79.81 | 77.1 | 99.04 | 70.13 | |
Table 7.
The confusion matrix and performance measures of site III (classifier = RF, feature set = , class distribution = unbalanced, R = 1.5 m).
Table 7.
The confusion matrix and performance measures of site III (classifier = RF, feature set = , class distribution = unbalanced, R = 1.5 m).
| Class | Ground | Vegetation | Pylon | Power Line | Building | PRE (%) |
|---|
| Ground | 2,427,197 | 327,024 | 499 | 0 | 18,829 | 87.51 |
| Vegetation | 36,798 | 915,267 | 16,302 | 53,945 | 17,513 | 88.02 |
| Pylon | 411 | 1,192 | 41,800 | 3,601 | 0 | 88.93 |
| Power line | 0 | 97 | 1,187 | 91,748 | 0 | 98.62 |
| Building | 12 | 2,991 | 2,286 | 13,477 | 7,435 | 28.38 |
| REC(%) | 98.49 | 73.42 | 67.34 | 56.37 | 16.98 | |
Table 8.
Classification performance for different sampling references (feature set = F0, classifier = RF, R = 1.5 m).
Table 8.
Classification performance for different sampling references (feature set = F0, classifier = RF, R = 1.5 m).
| Sampling Reference Value | Performance Measures |
|---|
| Mean Score (%) | Time/s |
|---|
| Original training set | 91.28 | 3284 |
| 50,000 | 93.46 | 77 |
| 100,000 | 97.24 | 179 |
| 150,000 | 97.32 | 291 |
Table 9.
The resampled training dataset. Table shows the number of points and proportion per class after resampling.
Table 9.
The resampled training dataset. Table shows the number of points and proportion per class after resampling.
| Class | Resampled Dataset |
|---|
| Ground | 100,000 | 19.26% |
| Vegetation | 100,000 | 19.26% |
| Pylon | 111,880 | 21.55% |
| Power line | 107,508 | 20.71% |
| Building | 99,824 | 19.23% |
| SUM | 519,212 | 100% |
Table 10.
Classification performance for different class distributions (classifier = RF, feature set = , R = 1.5 m). Three performance measures are shown in the table. The symbol Δ denotes the difference between the measures obtained by balanced and unbalanced learning. P denotes macro precision, R denotes macro recall, and F denotes the macro F1.
Table 10.
Classification performance for different class distributions (classifier = RF, feature set = , R = 1.5 m). Three performance measures are shown in the table. The symbol Δ denotes the difference between the measures obtained by balanced and unbalanced learning. P denotes macro precision, R denotes macro recall, and F denotes the macro F1.
| Dataset | Class Distribution | Performance Measures |
|---|
| P (%) | R (%) | F (%) |
|---|
| Site I | Unbalanced | 82.16 | 83.15 | 82.16 |
| Balanced | 75.81 | 87.34 | 76.95 |
| Δ | −6.35 | +4.19 | −5.21 |
| Site II | Unbalanced | 89.87 | 65.58 | 89.87 |
| Balanced | 84.59 | 87.38 | 85.58 |
| Δ | −5.28 | +21.80 | −4.29 |
| Site III | Unbalanced | 74.71 | 67.00 | 74.71 |
| Balanced | 67.81 | 72.68 | 64.10 |
| Δ | −6.9 | +5.68 | −10.61 |
Table 11.
Variation of F1 values for different classes and class distributions (classifier = RF, feature set = , R = 1.5 m). Δ denotes the difference between the measures obtained by balanced and unbalanced learning.
Table 11.
Variation of F1 values for different classes and class distributions (classifier = RF, feature set = , R = 1.5 m). Δ denotes the difference between the measures obtained by balanced and unbalanced learning.
| Dataset | Class Distribution | F1 (%) |
|---|
| Ground | Vegetation | Pylon | Power Line | Building |
|---|
| Site I | Unbalanced | 93.54 | 87.74 | 97.89 | 99.93 | 32.54 |
| Balanced | 92.38 | 86.71 | 94.14 | 99.91 | 11.6 |
| Δ | −1.16 | −1.03 | −3.75 | −0.02 | −20.94 |
| Site II | Unbalanced | 87.22 | 86.66 | 86.6 | 97.56 | 80.54 |
| Balanced | 87.81 | 87.04 | 81.13 | 95.82 | 76.09 |
| Δ | +0.59 | +0.38 | −5.47 | −1.74 | −4.45 |
| Site III | Unbalanced | 93.15 | 82.9 | 49.62 | 51.03 | 53.38 |
| Balanced | 92.67 | 83.22 | 47.99 | 60.53 | 36.07 |
| Δ | −0.48 | +0.32 | −1.63 | +9.50 | −17.31 |
Table 12.
The classification performance for different feature sets (classifier = RF, class distribution = unbalanced, R = 1.5 m). Three performance measures are shown in the table. P denotes the macro precision, R denotes the macro recall, and F denotes the macro F1. Bold denotes best results for each performance metric in each test set.
Table 12.
The classification performance for different feature sets (classifier = RF, class distribution = unbalanced, R = 1.5 m). Three performance measures are shown in the table. P denotes the macro precision, R denotes the macro recall, and F denotes the macro F1. Bold denotes best results for each performance metric in each test set.
| Dataset | Feature Set | Performance Measures |
|---|
| P (%) | R (%) | F (%) |
|---|
| Site I | | 82.16 | 83.15 | 82.33 |
| 77.67 | 79.01 | 77.62 |
| 81.62 | 82.37 | 81.66 |
| Site II | | 89.87 | 65.58 | 89.87 |
| 88.24 | 77.71 | 81.51 |
| 92.14 | 82.86 | 86.36 |
| Site III | | 74.71 | 67.00 | 74.71 |
| FPCA | 70.69 | 62.92 | 65.04 |
| 74.48 | 63.32 | 63.36 |
Table 13.
The sensitivity analysis of neighborhood radius for feature extraction about each class (classifier = RF, class distribution = unbalanced, test set = site III). Bold denotes best results for each class.
Table 13.
The sensitivity analysis of neighborhood radius for feature extraction about each class (classifier = RF, class distribution = unbalanced, test set = site III). Bold denotes best results for each class.
| | Radius/m | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|
| F1(%) | |
|---|
| Ground | 86.85 | 85.37 | 85.08 | 84.14 | 84.45 |
| Vegetation | 86.22 | 83.86 | 83.40 | 82.30 | 82.86 |
| Pylon | 80.18 | 81.14 | 85.48 | 89.95 | 67.65 |
| Power line | 96.74 | 97.70 | 96.65 | 96.57 | 95.65 |
| Building | 81.69 | 84.21 | 85.29 | 84.84 | 83.89 |
| Mean | 86.34 | 86.46 | 87.18 | 87.56 | 82.90 |























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}