Extracting Raft Aquaculture Areas from Remote Sensing Images via an Improved U-Net with a PSE Structure

Abstract
:
1. Introduction
- The improved U-Net is designed to capture multiscale feature maps, which contains detailed boundary and contextual information of raft aquaculture areas.
- The pyramid upsampling module and the squeeze-excitation module were combined for the first time into the PSE structure, which can adaptively fuse the multiscale feature maps.
2. Related Works
2.1. FCN and U-Net
2.2. Spatial Pyramid Pooling
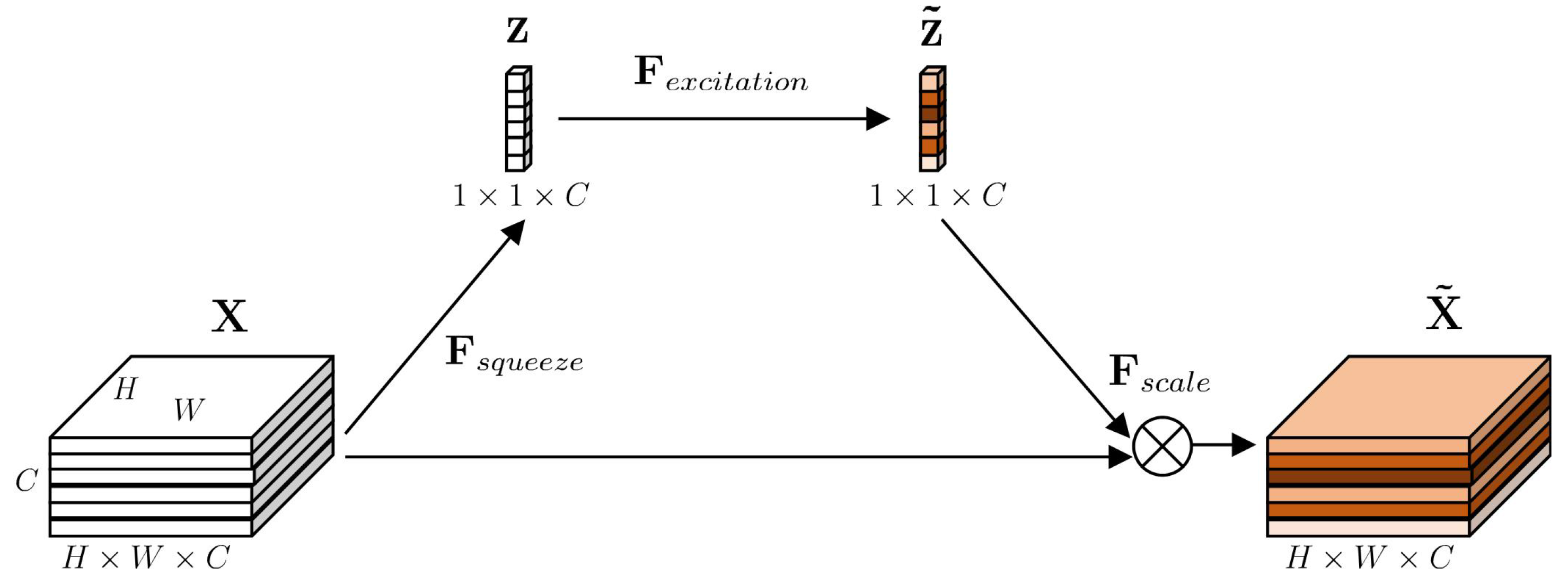
2.3. Squeeze-Excitation Module
3. Methods
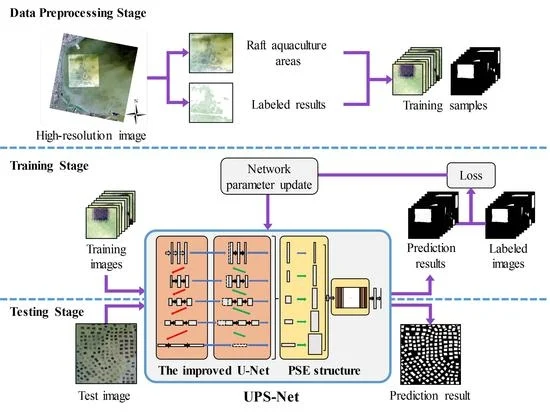
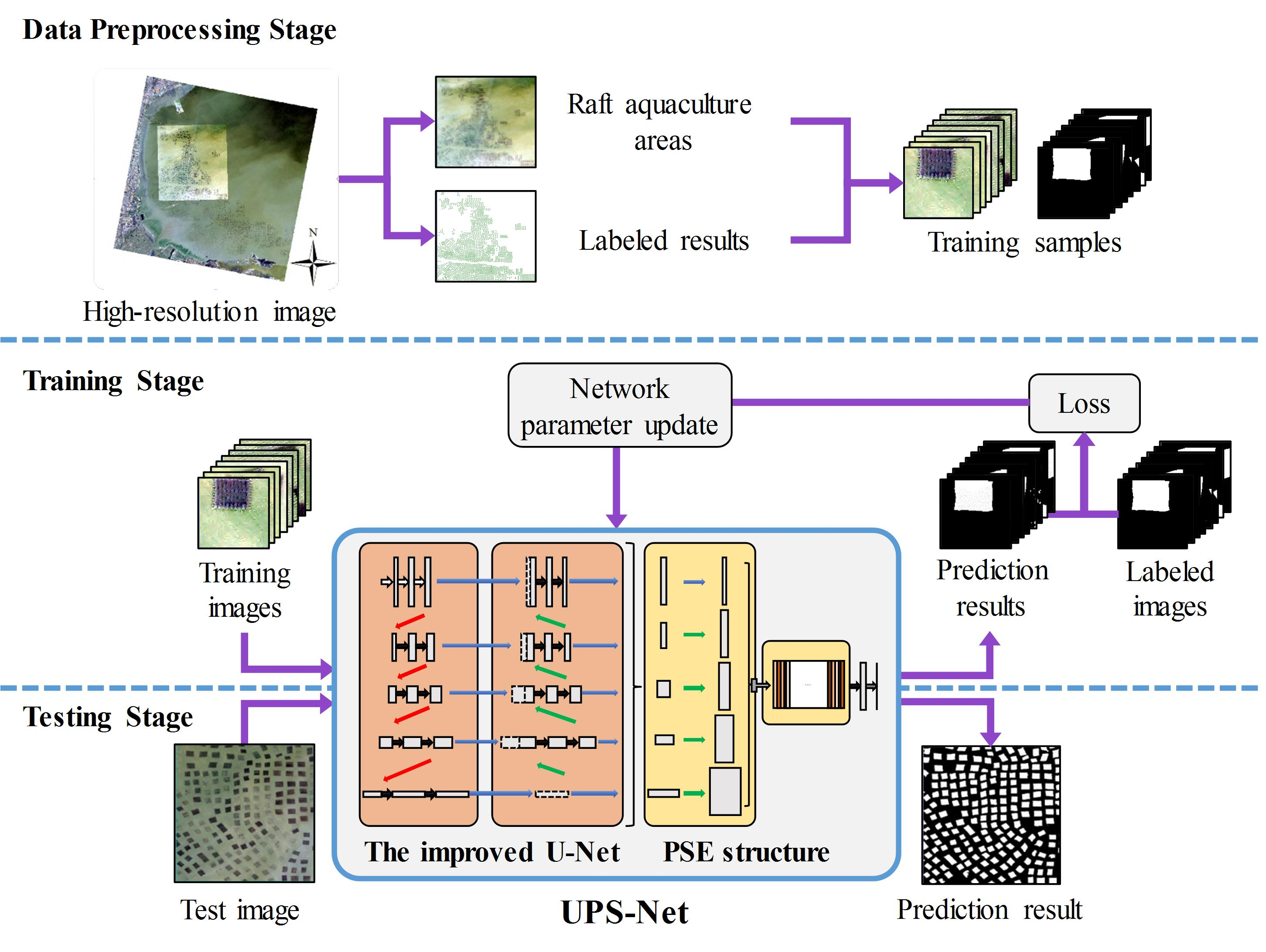
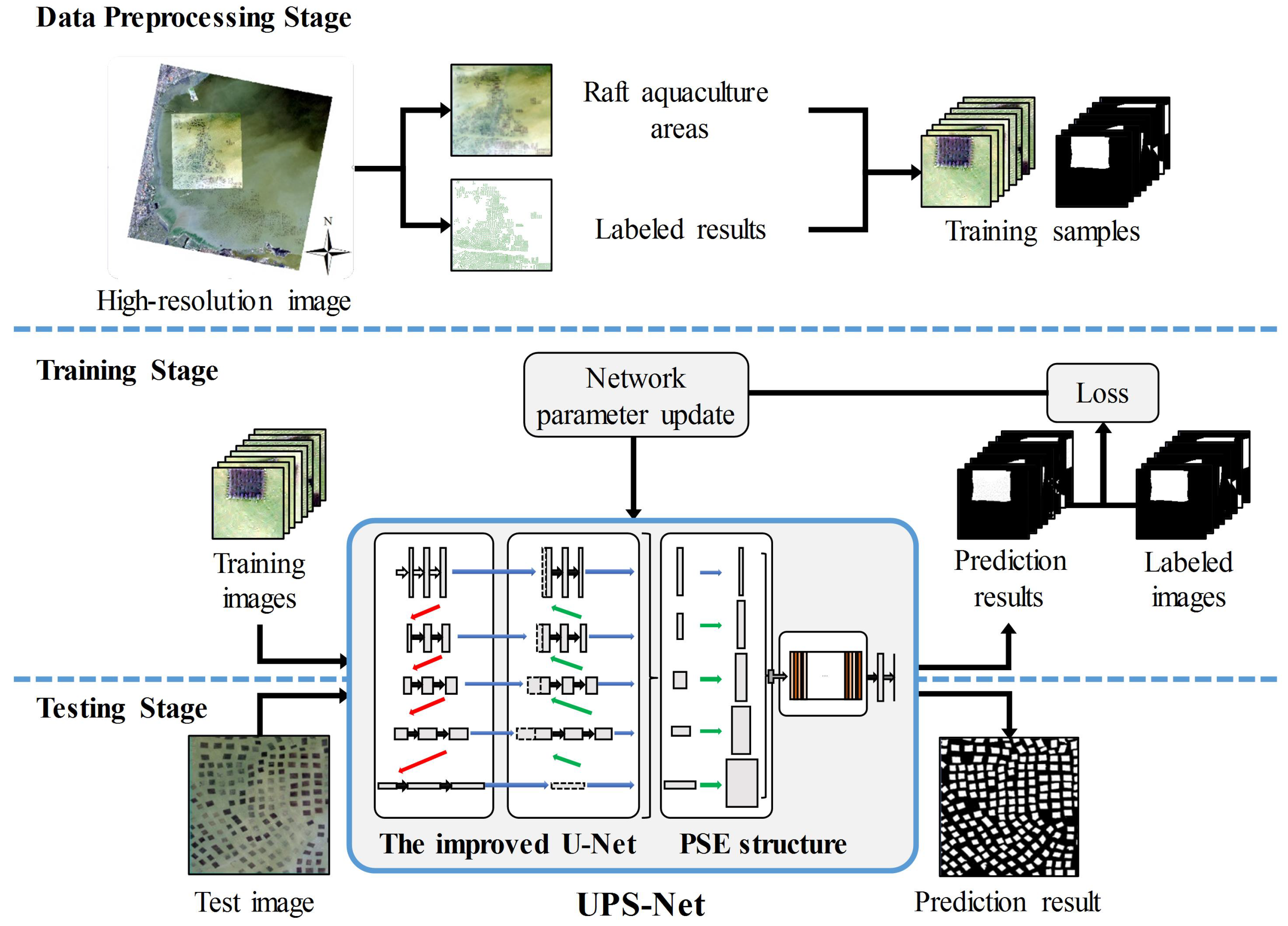
3.1. The General Process of Raft Aquaculture Areas Extraction
| Algorithm 1: Raft aquaculture areas extraction by using the proposed UPS-Net. |
| Input: the high-resolution images I, the parameter k of cross-validation, the iteration m, the initial hyperparameter h, the threshold of loss . 1. Data preprossessing: Input high-resolution images I and label raft aquaculture areas. Convert the labeled results to binary ground truth maps. Crop the images I and ground truth map to make raft aquaculture areas dateset. Split the dataset to generate training set, validation set and test set. Shuffle the training set and validation set randomly and split the dataset into k groups for cross-validation. 2. Training: Build the UPS-Net model and input hyperparameter h. Input training set and validation set of the raft aquaculture areas. while Loss L > do Tune the hyperparameter h. for do Implement forward propagation and extract raft aquaculture areas on training set. Compute loss between the extraction results and the ground truth on training set. Implement backward propagation to get the gradients. Update parameters of the UPS-Net model. end for Implement forward propagation and compute Loss L on validation set. end while 3. Cross-validation: Repeat step 2. Training by using k-fold cross-validation. 4. Testing: Input test set of the raft aquaculture areas. Extract raft aquaculture areas on test set by UPS-Net. |
3.2. The Proposed UPS-Net
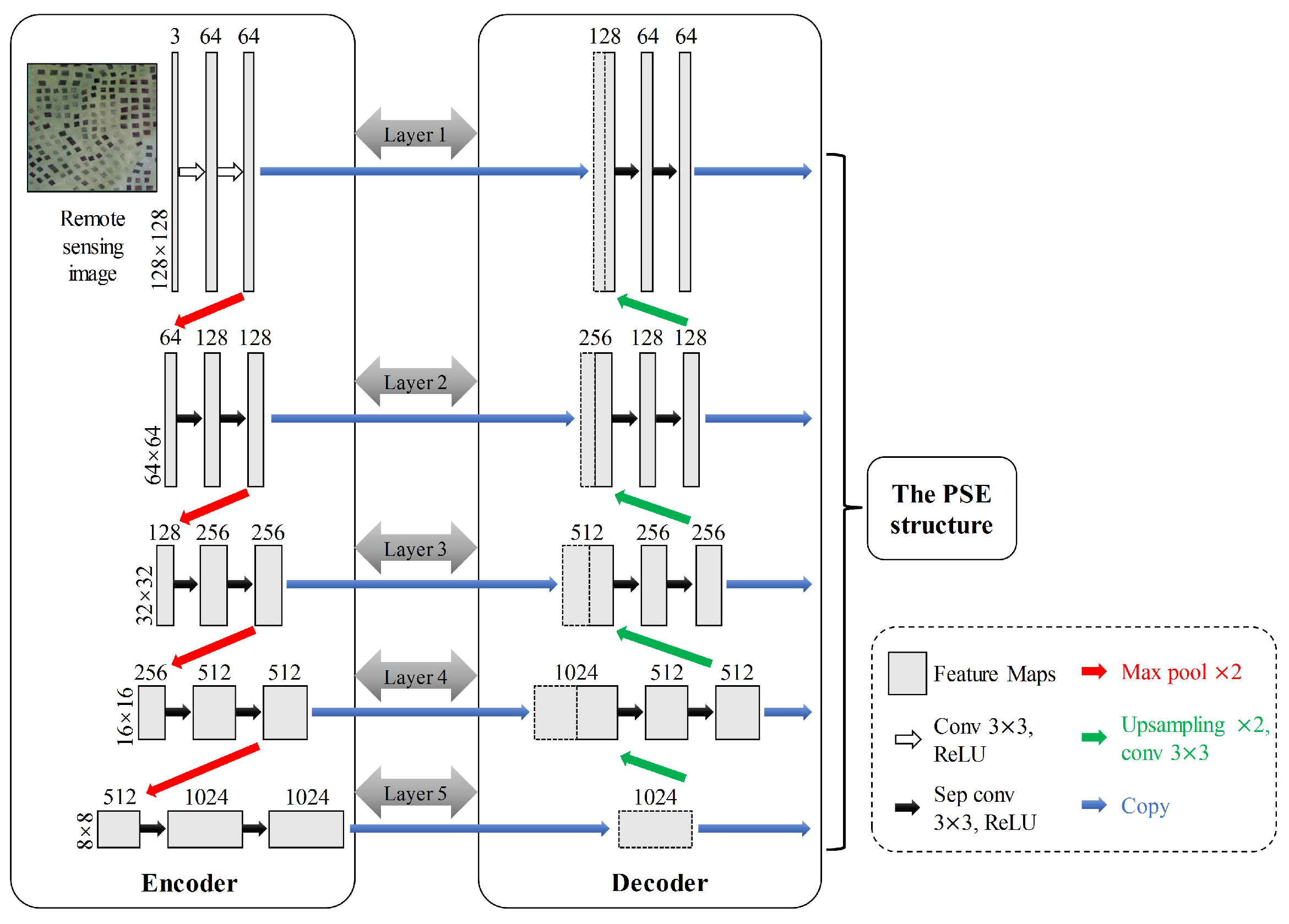
3.2.1. The Improved U-Net
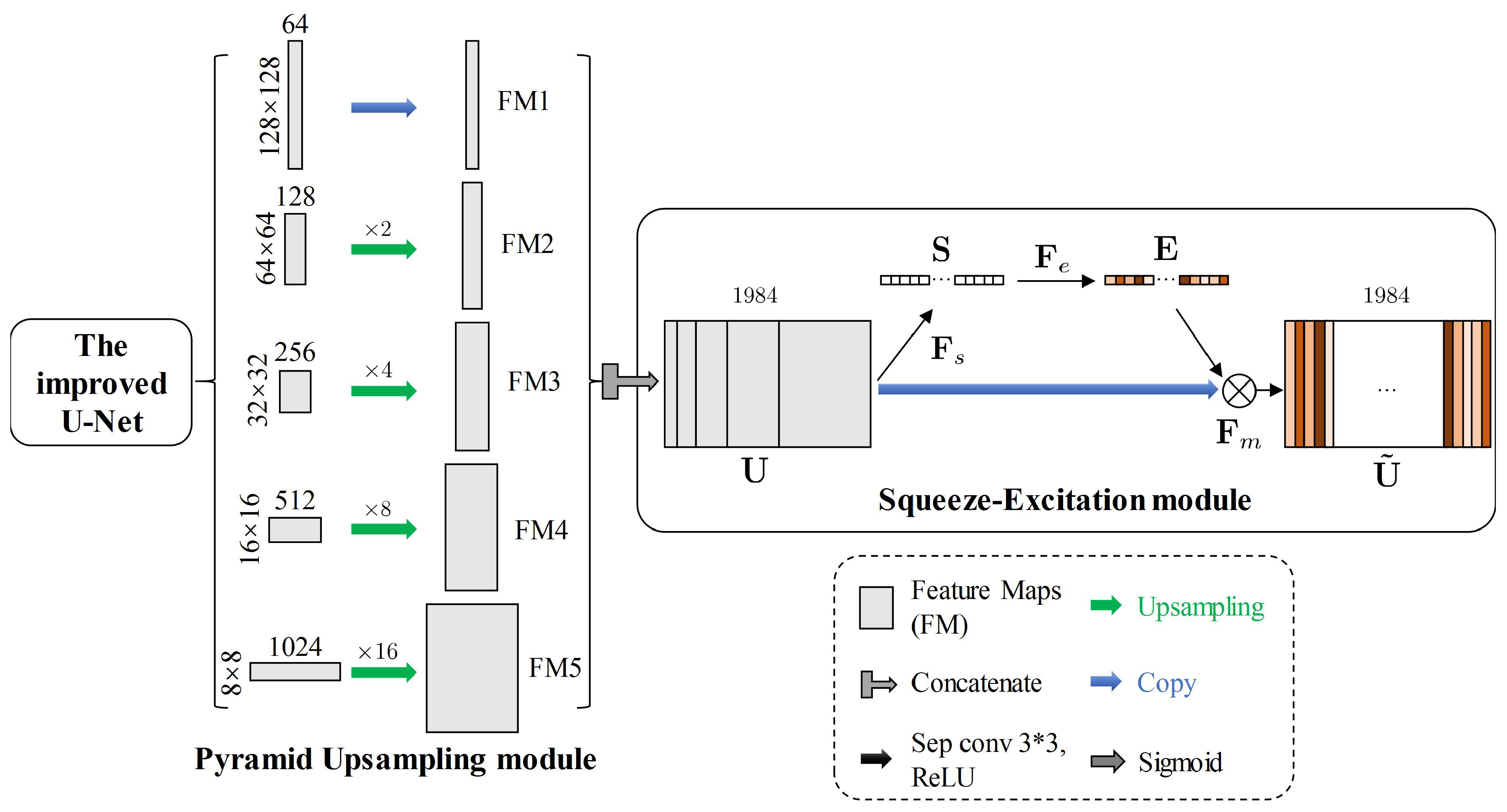
3.2.2. The PSE Structure
4. Experiments and Evaluation
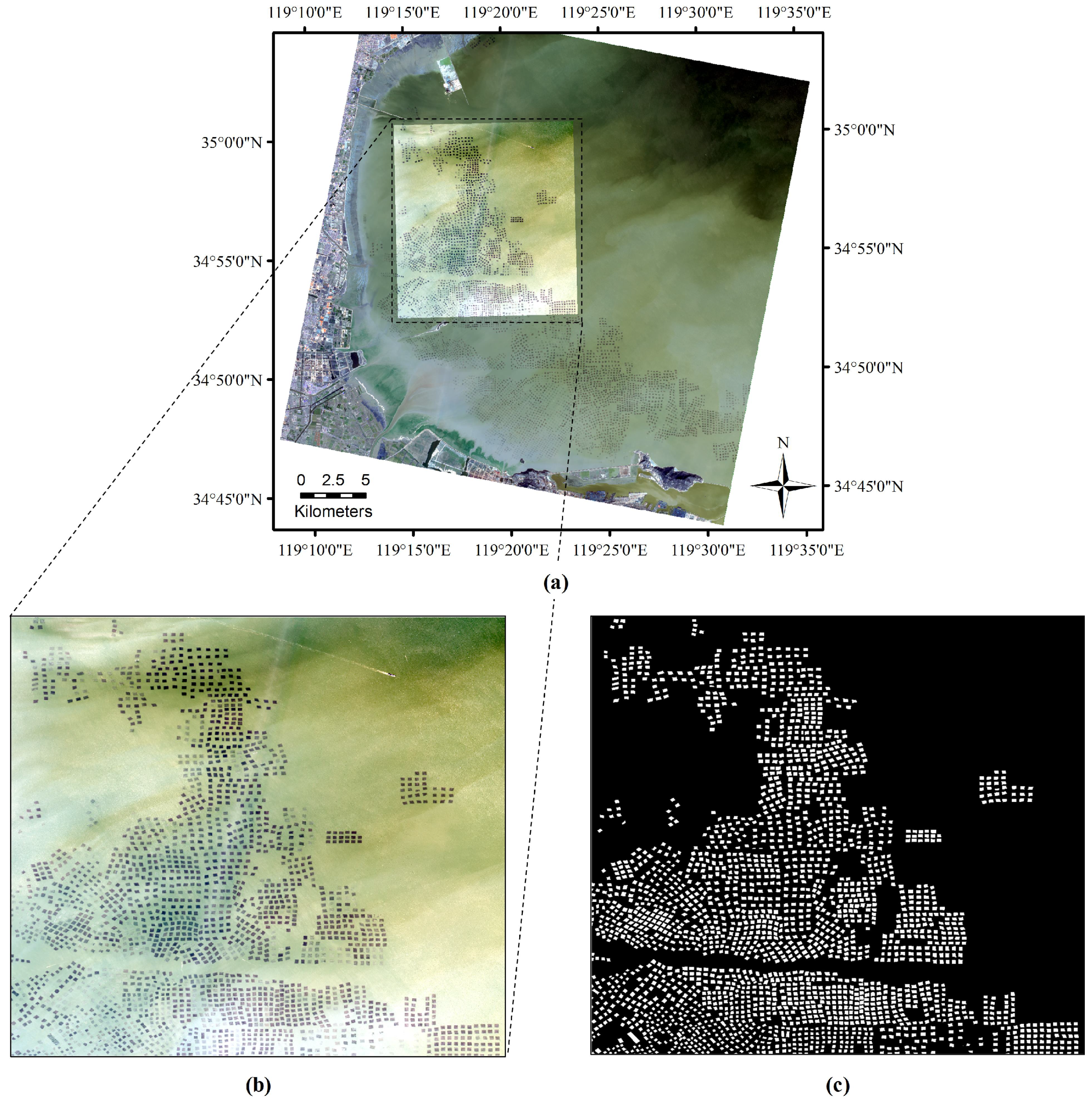
4.1. Experimental Dataset and Evaluation Metrics
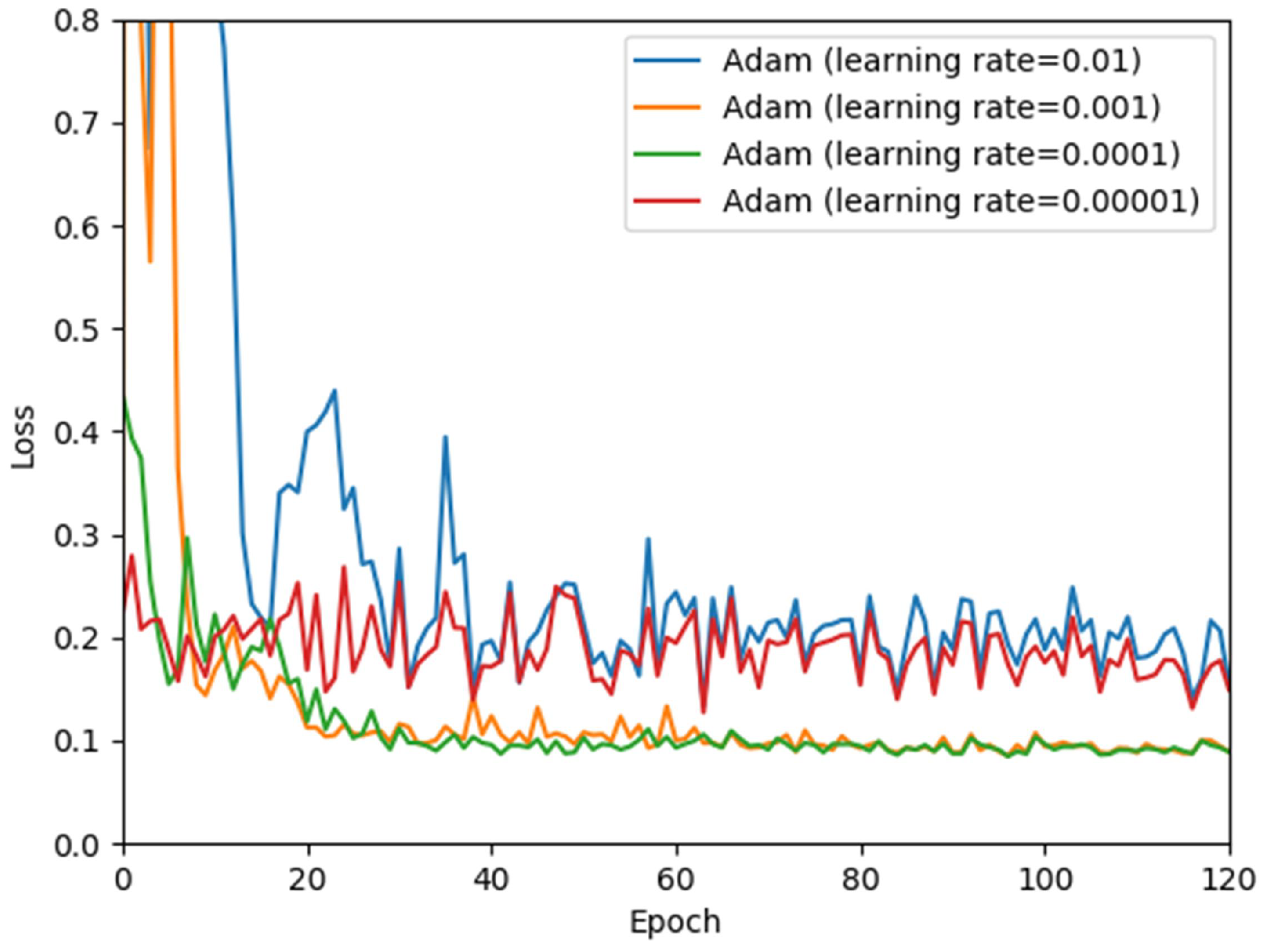
4.2. The Process of Hyperparameter Tuning and Setting
4.3. Experimental Results and Comparison
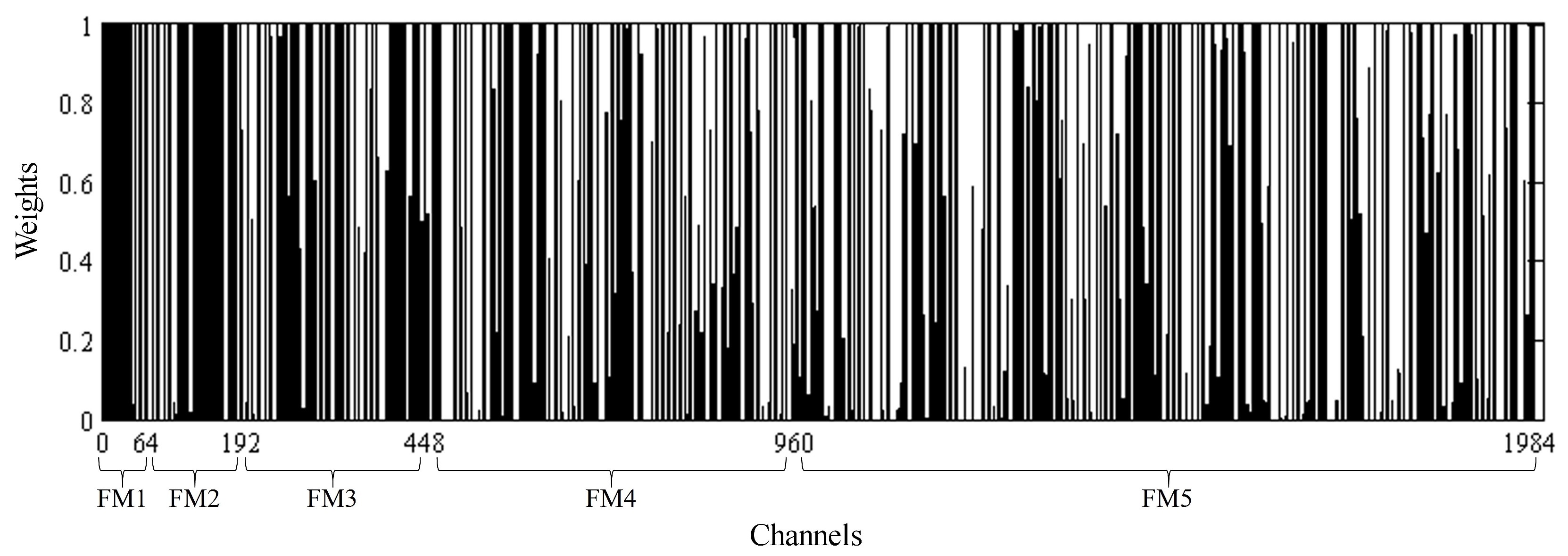
4.4. The Evaluation of the PSE Structure
5. Discussion
5.1. Compared with Some Popular FCN-Based Models
5.2. Compared with DS-HCN
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| FCN | Fully Convolutional Network |
| R-CNN | Regions with Convolutional Neural Network features |
| UPS-Net | Improved U-Net with a PSE structure |
| GLCM | Gray-Level Co-occurrence Matrix |
| SPP | Spatial Pyramid Pooling |
| PSPNet | Pyramid Scene Parsing Network |
| RCF | Richer Convolutional Features network |
| DS-HCN | Dual-Scale Homogeneous Convolutional Neural Network |
| PSE | Pyramid upsampling and Squeeze-Excitation |
| FM | Feature Maps |
| ReLU | Rectified Linear Unit |
| FC | Fully Connected layer |
| TP | True Positives |
| FP | False Positives |
| FN | False Negatives |
| SVM | Support Vector Machine |
References
- Gentry, R.R.; Froehlich, H.E.; Grimm, D.; Kareiva, P.; Parke, M.; Rust, M.; Gaines, S.D.; Halpern, B.S. Mapping the global potential for marine aquaculture. Nat. Ecol. Evol. 2017, 1, 1317. [Google Scholar] [CrossRef] [PubMed]
- FAO. The State of World Fisheries and Aquaculture; FAO: Rome, Italy, 2018. [Google Scholar]
- Bell, F.W. Food from the Sea: The Economics and Politics of Ocean Fisheries; Routledge: New York, NY, USA, 2019. [Google Scholar]
- Yucel-Gier, G.; Eronat, C.; Sayin, E. The Impact of Marine Aquaculture on the Environment; the Importance of Site Selection and Carrying Capacity. Agric. Sci. 2019, 10, 259–266. [Google Scholar] [CrossRef] [Green Version]
- Grigorakis, K.; Rigos, G. Aquaculture effects on environmental and public welfare–the case of Mediterranean mariculture. Chemosphere 2011, 85, 899–919. [Google Scholar] [CrossRef] [PubMed]
- Volpe, J.V.; Gee, J.L.; Ethier, V.A.; Beck, M.; Wilson, A.J.; Stoner, J.M.S. Global Aquaculture Performance Index (GAPI): The first global environmental assessment of marine fish farming. Sustainability 2013, 5, 3976–3991. [Google Scholar] [CrossRef]
- Pham, T.D.; Yokoya, N.; Bui, D.T.; Yoshino, K.; Friess, D.A. Remote Sensing Approaches for Monitoring Mangrove Species, Structure, and Biomass: Opportunities and Challenges. Remote Sens. 2019, 11. [Google Scholar] [CrossRef]
- Aneece, I.; Thenkabail, P. Accuracies Achieved in Classifying Five Leading World Crop Types and their Growth Stages Using Optimal Earth Observing-1 Hyperion Hyperspectral Narrowbands on Google Earth Engine. Remote Sens. 2018, 10. [Google Scholar] [CrossRef]
- Pham, T.D.; Yoshino, K.; Kaida, N. Monitoring mangrove forest changes in cat ba biosphere reserve using ALOS PALSAR imagery and a GIS-based support vector machine algorithm. In Proceedings of the International Conference on Geo-Spatial Technologies and Earth Resources, Hanoi, Vietnam, 5–6 October 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 103–118. [Google Scholar]
- Fan, J.C.; Chu, J.L.; Geng, J.; Zhang, F.S. Floating raft aquaculture information automatic extraction based on high resolution SAR images. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 3898–3901. [Google Scholar]
- Wang, M.; Cui, Q.; Wang, J.; Ming, D.; Lv, G. Raft cultivation area extraction from high resolution remote sensing imagery by fusing multi-scale region-line primitive association features. ISPRS J. Photogramm. Remote. Sens. 2017, 123, 104–113. [Google Scholar] [CrossRef]
- Hu, Y.; Fan, J.; Wang, J. Target recognition of floating raft aquaculture in SAR image based on statistical region merging. In Proceedings of the 2017 Seventh International Conference on Information Science and Technology (ICIST), Da Nang, Vietnam, 16–19 April 2017; pp. 429–432. [Google Scholar]
- Shi, T.; Xu, Q.; Zou, Z.; Shi, Z. Automatic Raft Labeling for Remote Sensing Images via Dual-Scale Homogeneous Convolutional Neural Network. Remote Sens. 2018, 10. [Google Scholar] [CrossRef]
- Durand, T.; Mehrasa, N.; Mori, G. Learning a Deep ConvNet for Multi-label Classification with Partial Labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 647–657. [Google Scholar]
- Li, P.; Chen, X.; Shen, S. Stereo r-cnn based 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7644–7652. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for High Resolution Remote Sensing Imagery Using a Fully Convolutional Network. Remote Sens. 2017, 9. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Yueming, L.; Xiaomei, Y.; Zhihua, W.; Chen, L. Extracting raft aquaculture areas in Sanduao from high-resolution remote sensing images using RCF. Haiyang Xuebao 2019, 41, 119–130. [Google Scholar]
- Pan, B.; Shi, Z.; Xu, X. Hierarchical guidance filtering-based ensemble classification for hyperspectral images. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 4177–4189. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Kaiser, L.; Gomez, A.N.; Chollet, F. Depthwise separable convolutions for neural machine translation. arXiv 2017, arXiv:1706.03059. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances IN Neural Information Processing Systems, Stateline, NV, USA, 5–10 December 2012; pp. 1097–1105. [Google Scholar]
- Hien, D.H.T. A Guide to Receptive Field Arithmetic for Convolutional Neural Networks. Available online: https://medium.com/mlreview/a-guide-to-receptive-field-arithmetic-for-convolutional-neural-networks-e0f514068807/ (accessed on 6 April 2017).
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 421–429. [Google Scholar]
- Hu, Y.; Wen, G.; Luo, M.; Dai, D.; Ma, J.; Yu, Z. Competitive inner-imaging squeeze and excitation for residual network. arXiv 2018, arXiv:1807.08920. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Hsiao, T.Y.; Chang, Y.C.; Chou, H.H.; Chiu, C.T. Filter-based deep-compression with global average pooling for convolutional networks. J. Syst. Archit. 2019, 95, 9–18. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Law, M.; Collins, A. Getting to Know ArcGIS for Desktop; ESRI Press: Redlands, CA, USA, 2013. [Google Scholar]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; De Freitas, N. Learning to learn by gradient descent by gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3981–3989. [Google Scholar]
- Ketkar, N. Introduction to keras. In Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; pp. 97–111. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI’16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kuo, B.C.; Ho, H.H.; Li, C.H.; Hung, C.C.; Taur, J.S. A kernel-based feature selection method for SVM with RBF kernel for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2013, 7, 317–326. [Google Scholar]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network. Remote Sens. 2019, 11. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Layer Name | Kernel Size | Kernel Number | Connect to |
|---|---|---|---|---|
| Encoder | Conv1_1 (Input) | 3 × 3 | 64 | Conv1_2 |
| Conv1_2 | 3 × 3 | 64 | Maxpooling1 & SepConv6_1 | |
| MaxPooling1 | 2 × 2 | - | SepConv2_1 | |
| SepConv2_1 | 3 × 3 | 128 | SepConv2_2 | |
| SepConv2_2 | 3 × 3 | 128 | Maxpooling2 & SepConv7_1 | |
| MaxPooling2 | 2 × 2 | - | SepConv3_1 | |
| SepConv3_1 | 3 × 3 | 256 | SepConv3_2 | |
| SepConv3_2 | 3 × 3 | 256 | Maxpooling3 & SepConv8_1 | |
| MaxPooling3 | 2 × 2 | - | SepConv3_1 | |
| SepConv4_1 | 3 × 3 | 512 | SepConv4_2 | |
| SepConv4_2 | 3 × 3 | 512 | Maxpooling4 & SepConv9_1 | |
| MaxPooling4 | 2 × 2 | - | SepConv5_1 | |
| SepConv5_1 | 3 × 3 | 1024 | SepConv5_2 | |
| SepConv5_2 | 3 × 3 | 1024 | SepConv10_1 | |
| Dncoder | SepConv6_1 | 3 × 3 | 64 | SepConv6_2 |
| SepConv6_2 | 3 × 3 | 64 | UpSampling11_1 | |
| SepConv7_1 | 3 × 3 | 128 | SepConv7_2 | |
| SepConv7_2 | 3 × 3 | 128 | UpPooling7 & UpSampling11_2 | |
| UpSampling7 | 2 × 2 | - | SepConv6_1 | |
| SepConv8_1 | 3 × 3 | 256 | SepConv8_2 | |
| SepConv8_2 | 3 × 3 | 256 | UpPooling8 & UpSampling11_3 | |
| UpSampling8 | 2 × 2 | - | SepConv9_1 | |
| SepConv9_1 | 3 × 3 | 512 | SepConv9_2 | |
| SepConv9_2 | 3 × 3 | 512 | UpPooling9 & UpSampling11_4 | |
| UpSampling9 | 2 × 2 | - | SepConv10_1 | |
| SepConv10_1 | 3 × 3 | 1024 | UpSampling11_5 | |
| Pyramid upsampling module | UpSampling11_1 | 2 × 2 | 64 | Concatenate12 |
| UpSampling11_2 | 2 × 2 | 128 | Concatenate12 | |
| UpSampling11_3 | 2 × 2 | 256 | Concatenate12 | |
| UpSampling11_4 | 2 × 2 | 512 | Concatenate12 | |
| UpSampling11_5 | 2 × 2 | 1024 | Concatenate12 | |
| Squeeze-Excitation module | Concatenate12 | - | - | FC12_1 & Multiplication12 |
| FC12_1 | - | - | sigmoid12 | |
| sigmoid12 | - | - | FC12_1 | |
| FC12_2 | - | - | Multiplication12 | |
| Multiplication12 | - | - | SepConv13_1 | |
| SepConv13_1 | 3 × 3 | 1984 | SepConv13_2 | |
| SepConv13_2 | 3 × 3 | 2 | sigmoid13 | |
| Sigmoid13 | - | - | (Output) |
| The Data Set | Number of Images | Size of Images | |
|---|---|---|---|
| Training set | The experimental images | 2263 | |
| The ground truth map | 2263 | ||
| Validation set | The experimental images | 564 | |
| The ground truth map | 564 | ||
| Test set | The experimental images | 5 | |
| The ground truth map | 5 | ||
| Method | Precision (%) | Recall (%) | F1 (%) | Parameter |
|---|---|---|---|---|
| SVM | 84.6 ± 2.61 | 77.9 ± 1.32 | 81.1 ± 1.93 | |
| Mask R-CNN | 85.9 ± 2.07 | 87.5 ± 2.30 | 86.7 ± 2.15 | 67.3 M |
| FCN | 89.2 ± 2.18 | 79.3 ± 1.40 | 83.6 ± 1.79 | 55.5 M |
| U-Net | 87.5 ± 0.76 | 87.1 ± 0.83 | 87.3 ± 0.80 | 31.0 M |
| PSPNet | 85.5 ± 1.26 | 87.4 ± 2.13 | 86.4 ± 1.70 | 46.7 M |
| DeepLabv3+ | 87.2 ± 3.81 | 86.5 ± 1.77 | 86.8 ± 3.29 | 41.3 M |
| DS-HCN | 87.8 ± 0.84 | 84.7 ± 1.98 | 86.2 ± 1.41 | 11.2 M |
| UPS-Net (ours) | 89.1 ± 1.52 | 88.7 ± 1.17 | 89.0 ± 1.35 | 4.6 M |
| Method | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| The improved U-Net | 88.5 ± 1.38 | 86.3 ± 1.61 | 87.4 ± 1.53 |
| UPS-Net (ours) | 89.1 ± 1.52 | 88.7 ± 1.17 | 89.0 ± 1.35 |
| U-Net | 87.6 ± 0.76 | 87.1 ± 0.83 | 87.6 ± 0.80 |
| U-Net + PSE | 87.4 ± 0.88 | 89.0 ± 1.29 | 88.2 ± 1.13 |
| PSPNet | 85.5 ± 1.26 | 87.4 ± 2.13 | 86.4 ± 1.70 |
| PSPNet + PSE | 87.8 ± 1.31 | 87.2 ± 1.93 | 87.6 ± 1.82 |
| DeepLabv3+ | 87.2 ± 3.81 | 86.8 ± 1.77 | 86.9 ± 3.29 |
| DeepLabv3+ + PSE | 87.6 ± 2.25 | 87.5 ± 2.06 | 87.5 ± 1.88 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, B.; Fei, D.; Shao, G.; Lu, Y.; Chu, J. Extracting Raft Aquaculture Areas from Remote Sensing Images via an Improved U-Net with a PSE Structure. Remote Sens. 2019, 11, 2053. https://doi.org/10.3390/rs11172053
Cui B, Fei D, Shao G, Lu Y, Chu J. Extracting Raft Aquaculture Areas from Remote Sensing Images via an Improved U-Net with a PSE Structure. Remote Sensing. 2019; 11(17):2053. https://doi.org/10.3390/rs11172053
Chicago/Turabian StyleCui, Binge, Dong Fei, Guanghui Shao, Yan Lu, and Jialan Chu. 2019. "Extracting Raft Aquaculture Areas from Remote Sensing Images via an Improved U-Net with a PSE Structure" Remote Sensing 11, no. 17: 2053. https://doi.org/10.3390/rs11172053
APA StyleCui, B., Fei, D., Shao, G., Lu, Y., & Chu, J. (2019). Extracting Raft Aquaculture Areas from Remote Sensing Images via an Improved U-Net with a PSE Structure. Remote Sensing, 11(17), 2053. https://doi.org/10.3390/rs11172053