3.3. Survey Data
To test the integration of survey information with RS data we selected seven municipalities that were part of a larger evaluation completed by DEval [
14]. The evaluation included 100 municipalities, of which 44 formed the intervention group, and 56 the control group. Control municipalities were selected from all available municipalities in the two study regions (Eastern Visayas and Western Visayas) using a propensity-score matching technique [
50]. Base- and endline survey data were collected by DEval for 10 households in three randomly selected barangays per municipality, resulting in 3000 interviewed households.
The intervention evaluated by DEval was a comprehensive LU planning program known as SIMPLE (Sustainable Integrated Management and Planning for Local Government Ecosystems) that received funding and administrative support from the German agency for technical cooperation (GIZ) over a 10-year period (2006–2015). The SIMPLE intervention included training schemes, technical assistance, and the development of participatory planning tools. The DEval evaluation found that the SIMPLE intervention significantly improved land-use planning quality and comprehensiveness, and led to an increased number of protected areas [
14]. The DEval evaluation investigated the general effectiveness of the SIMPLE intervention on land-use planning approaches in the Philippines but did not evaluate post-disaster recovery, the focus of this article.
During the DEval impact evaluation extensive panel survey data were collected at the household, barangay, and municipal levels. Base- and endline data were collected in 2012 and 2016, respectively. Due to budget constraints we were unable to perform the remote sensing analysis for all surveyed municipalities for the study reported in this paper. The seven municipalities were purposefully chosen for two reasons: (i) we selected municipalities that were affected to different degrees by Haiyan, to capture sufficient variation in damage and recovery; and (ii) we further ensured that both treated (receipt of SIMPLE intervention) and untreated municipalities were represented in our sample. From each of the seven municipalities three barangays (villages) were randomly selected, resulting in a sample of
N = 21 barangays. However, data limitations (e.g., cloud coverage in some of the RS data) led to a reduction in the analytic sample to
N between 13–18, depending on the geographic variable.
Figure 2 shows the seven municipalities that contained the barangays included in this study.
3.4. RS Data Analsyis
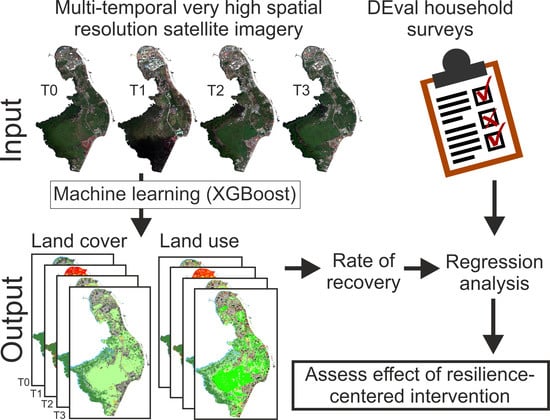
We developed a conceptual framework to assess recovery based on the extraction of image-based proxies. The approach consisted of two main steps: (i) to generate the damage map, and (ii) to generate recovery maps at the required times after the disaster. To do so, suitable proxies needed to be identified and extracted for each of the required time steps (e.g., pre-disaster, event time, and post-disaster). Proxies for separate dimensions, i.e., built-up, social, and economic [
19] are needed to cover the entire damage and recovery process comprehensively. The proxies listed for the pre-disaster (T0) and event (T1) times support the damage assessment, and subsequently the damage map was compared with the proxies listed for two post-disaster time epochs approximately 2 and 3 years after Haiyan (T2 and T3, respectively) to assess recovery at each time. The changes in the state of each proxy between two epochs demonstrate the damage to the indicators, and subsequently the degree of recovery.
Table 2 shows the selected proxies and their use to evaluate recovery in the selected study area. To assess the full scope of damages we employed proxies that measure the structural damages to buildings, bridges, and transportation facilities, but also textural proxies and evidence of blow-out debris. To assess the recovery process we employ proxies that measure the reconstruction of buildings and impervious surface. Once the proxy-based damage map has been produced, monitoring changes through the built-up proxies indicates the degree of recovery at a given point in time following the disaster. Among the economic proxies, LU information indicates the types of economic activity, while the presence of vehicles and boats provides an indication of the extent and frequency of its use. Arable land is a proxy for the potential for farming. In addition, roof color and material helps to differentiate between types of buildings (e.g., industrial facilities vs. residential housing). We use the share of population residing in informal settlements (i.e., slums) as a proxy for the socio-economic status of the area.
Machine learning methods such as support vector machines (SVM) and random forest (RF) have been widely used in remote sensing data processing, particularly for satellite image processing, due to their efficiency and accurate results. Several researchers also studied their applicability in producing accurate LC and LU maps from remote sensing optical images [
20,
51,
52,
53,
54]. Recent advances in computer science motivated researchers to use deep learning and convolutional neural network (CNN) approaches as superior classification methods [
55]. However, CNN-based models must be trained with a large number of samples to give appropriate results, which also require substantially more computational power and complex models.
Other advanced ML methods have been developed to support challenging image classification tasks at low computational costs, such as logistic model trees, and rotation forest ensembles. The gradient boosting method (GBM) is a supervised classification technique and belongs to regression and classification trees models [
56,
57]. Tree boosting is an ensemble learning algorithm that is very effective in the classification of even weak trees [
58], as has been shown in scene classification [
59,
60]. However, traditional GBMs require the tuning of a number of parameters and are thus more susceptible to overfitting than other ML algorithms, such as SVM. In 2008, Chen and Guestrin [
61] developed the extreme gradient boosting (XGBoost) method, which is the regularized version of GBM and overcomes most of the limitations. Since then XGBoost has been successfully used for different classification problems. Its superiority for LC and LU classification from very high resolution images was also shown in recent studies [
58,
62].
Both urban and rural LU classes in most cases cannot be distinguished using only spectral information (e.g., slum areas), and require the addition of spatial features (i.e., texture) [
63]. Local Binary Patterns (LBP) have been shown to be an effective textural information extraction method [
20,
64,
65]. LBP are based on the gray level co-occurrence matrix, which contains simple textural computations such as mean, variance, homogeneity and entropy. Therefore, in this study the LBP of each image, using a 5 × 5 kernel, were computed and used as input in addition to the image bands in the XGBoost classification. The implementation of the XGBoost classifier was based on the default parameter values, and the calculation of the LBP and XGBoost was performed in Python.
The LC map contains the following classes: building, impervious surface, bare land, inland water, trees/flattened trees, non-tree vegetation, and rubble for the event time images. In addition, the LU maps include large-scale industry, informal settlement (slums), formal buildings, trees/flattened trees, crop land, grass land, inland water, bare land, impervious surface, and rubble for event time images. In the first step of the classification the training areas were selected for each class, separately for the LC and LU classifications. In addition, the accuracy of the results was computed based on standard measurements, overall, user’s, and producer’s accuracy (OA, UA, and PA, respectively) for Barangay 69. Stratified random sampling was used to generate random reference points for the evaluation. Considering the size of the test area, a minimum of 30 sample pixels per class for both the LC and LU classification maps were selected to produce reference data.
Figure 3 shows the general framework of the implemented steps for the proxy extraction based on LCLU maps. Before starting to select the training areas for the classification, three pre-processes were implemented: (i) improving the geo-referencing of the images; since the final recovery map/proxy extraction was conducted based on a pixel-by-pixel comparison of the maps for each time step, the images required a good matching in terms of geo-referencing. Accordingly, one of the images was selected as a base image, and the geo-referencing of the other images refined using image-to-image registration/rectification, as is commonly done in pixel-based change detection techniques [
66]. However, satellite inclination angles vary, and in particular the time-critical post-disaster response phase tends to be dominated by images taken at large off-nadir angles. This leads to errors in the change assessment, in particular for vertical features such as building façades; (ii) image mosaicking to match and merge different satellite images to cover the entire area. The merging operation, and thus the provided merged images, challenge the classification approach and lead to inaccuracies in the LCLU maps, particularly for images collected in different seasons or with large gaps between acquisitions; (iii) region of interest (ROI)/barangay image extraction, which was conducted using ArcGIS based on the barangay boundaries by the United Nation’s Office for Humanitarian Affairs (OCHA) based on information provided by the Philippine Statistical Authority (PSA) [
67].
The computed class characteristics were used for the proxy extraction and interpretations. The LCLU classification was implemented on multi-spectral satellite images, while due to their small size compared to other LCLU classes vehicles and boats were extracted using both panchromatic and multispectral images. The boats inside the barangays (on inland water), as well as the boats close to the selected barangays (on open water) were counted. The proxies were extracted based on the LCLU class area sizes and their changes from T0–T3, except for the number of boats and vehicles that were counted manually. For example, the building land cover change from the pre-disaster time (T0) to just after the disaster (T1) shows the change in the overall size of the area covered by buildings in the area and, consequently, the damaged buildings. Furthermore, roof color was calculated based on the extraction of the brightness values of the pixels for the building class using MATLAB.
We implemented the developed approach on the images of the four epochs considered (T0–T3) to extract the selected proxies.
3.5. Statistical Modelling of the Recovery Assessment
Outcome variables. In this study, we focused on building reconstruction and industry recovery as our outcomes of interest. Results from the semi-automated classification of LCLU patterns at the three post-disaster time points (T1–T3) allowed us to compute recovery rates (in %). Positive values indicate an increase in the building stock, while negative values suggest that (possibly damaged) structures were removed.
Survey variables. A selection of relevant variables from the DEval survey was employed in this analysis to investigate the influence of development interventions and various socio-demographic and structural characteristics on recovery rates. We grouped survey variables into donor support, structural characteristics, DRM-related characteristics, and local governance. Donor support was measured with focus on the Germany-funded SIMPLE intervention. A dichotomous variable indicates whether SIMPLE was implemented (1 = yes, 0 = no) in a given barangay, and whether the intervention started early (pre-2009) or late (2009–2012). In addition, we employed a variable measuring whether the barangay had received support from other donors (1 = yes, 0 = no).
Structural characteristics included information on average annual municipal income classified as high (income = 1: ≥500,000 US$) and low (income = 0: <500,000 US$), whether a barangay was located in the city (urban area = 1) or the rural countryside (urban area = 0), and amount of IRA (Internal Revenue Allotment) subsidies (in million $US) that a municipality received during the previous year.
DRM-related characteristics included perceived disaster preparedness, ranked by the barangay captain on a scale from 1 (low) to 10 (high), and whether the barangay had experienced a disaster in the preceding 5 years (1 = yes, 0 = no). In addition, a variable indicated the amount of reconstruction support received by the municipality from government authorities (in million US$), as well as a rating by the barangay captain regarding the number of ongoing DRM-related activities (0 = low, 10 = high).
Finally, the quality of local governance was measured through the political experience level of the barangay captain (1 = more than one completed term as captain, 0 = less than one term as captain), the work experience level of the mayor (years in office), and how corrupt the barangay captain considered the local system to be (0 = low corruption, 10 = high corruption).
Table 3 provides summary statistics for the relevant survey variables.
Statistical approach. Due to the very small sample size the statistical analysis had to be limited to simple bivariate ordinary least squares (OLS) regression models. The primary goal of this analysis was to demonstrate the use of combining RS data with survey data to answer substantively meaningful questions regarding post-disaster recovery processes. Equation (1) formally describes the employed models.
We modeled changes in recovery rates (y) at the barangay level, with α representing the intercept or average recovery rate. The parameter β
1 constitutes the effect of a given predictor variable x
1 (e.g., experience of barangay captain), and
constituting the normally distributed error term. To account for the small N, significance tests use robust standard errors. Computations were performed using the R statistical environment [
68].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}