1. Introduction
The world is rapidly urbanizing. Fifty-four percent of the world’s population was living in cities by 2014, and 2.5 billion more people were projected to be city dwellers by 2050 [
1]. It is also predicted that the global urban area may triple, from the year 2000, by 2030 [
2]. Information on land use (LU, the social function of land) is important to understand the dynamics and complexity of urban systems. Specifically, the intra-city land use structure can benefit models of carbon emission estimations [
3,
4], hazard resilience [
5], and transportation [
6,
7]. However, information on the extent of urban sprawl (i.e., uncoordinated city growth [
8]) is often missing or outdated. Official zoning maps or land use maps based on land surveying are often not updated frequently, due to financial and time costs, and thus do not capture the rapid land changes accompanying urbanization.
Remote sensing has been successfully applied to map urban land cover over large areas (e.g., national scale [
9]). The spatial and temporal information in historical satellite data has also contributed to our understanding of urban sprawl, e.g., Reference [
10]. In urban areas, land cover change is mostly a direct result of human use patterns. However, remotely sensed imagery can only characterize the biophysical properties of the land surface (i.e., land cover, such as impervious surface cover), but not how humans use land (i.e., land use or the social function of land, such as residential or commercial lands) [
10,
11]. Other forms of data that can contribute information about human land use activities are needed to reconstruct detailed land use (instead of land cover) history of urban areas.
Recently, socially-sensed geographical data have been studied to model the spatial-temporal patterns of detailed human activities [
12]. Previous studies in the GIScience field have explored the applications of solely using different socially sensed data sources to model land use or the function of places in cities, including call detailed records (CDRs) [
13], georeferenced Tweets [
14], taxi trajectories [
15], wireless data requests [
16], Foursquare check-in data [
17], and photos from Google Street View [
18].
However, socially-sensed data often lack a historical archive as these data rely on the recent prevalence of GPS-embedded devices, e.g., smartphones. Thus, they are unable, on their own, to reveal the evolution of long-term land change. Methodologically, the pre-defined geographic units from static GIS layers to aggregate socially-sensed data (e.g., Reference [
19]) could change over time, making it difficult to obtain an up-to-date representation. In addition, only a few sources, such as georeferenced Tweets, are freely accessible by researchers. Location accuracy of these data is subject to the GPS-embedded device and the environmental context (e.g., open outdoor space vs. indoor spaces [
20]), which introduces uncertainty into modeling spatial-temporal patterns of land uses at fine spatial resolutions, i.e., buildings or land parcels. Lastly, and perhaps most importantly, the demographic bias [
21] present in socially-sensed data may limit their applications to certain urban areas that fit the demographics, e.g., only certain cities.
The complementary information combining remotely sensed and socially sensed data together offers new opportunities to study long-term urban land use change in large urban areas. Previous studies in the remote sensing literature have employed socially-sensed data as the reference for validating satellite-based land cover maps [
22,
23] or as an indicator for targeting interested regions for subsequent remote sensing analysis [
24]. However, there have been few attempts to fuse remote sensing imagery and socially-sensed data to identify urban land use [
25].
The primary objective of this research is to combine a remote-sensing-based land cover change product and georeferenced Tweets to identify the detailed land use of newly developed areas. We chose Washington D.C. as our study area. We associated Tweets with land parcels derived from the land cover map by the spatial relationship, and then modeled spatial-temporal patterns of how the parcels were used. We identified the newly-added residential and non-residential lands within the study area. Based on the results of the primary objective, our secondary objective was to estimate the geographic pattern of urban sprawl over the past three decades (i.e., the time span of satellite data) for residential and non-residential uses.
2. Study Area and Data
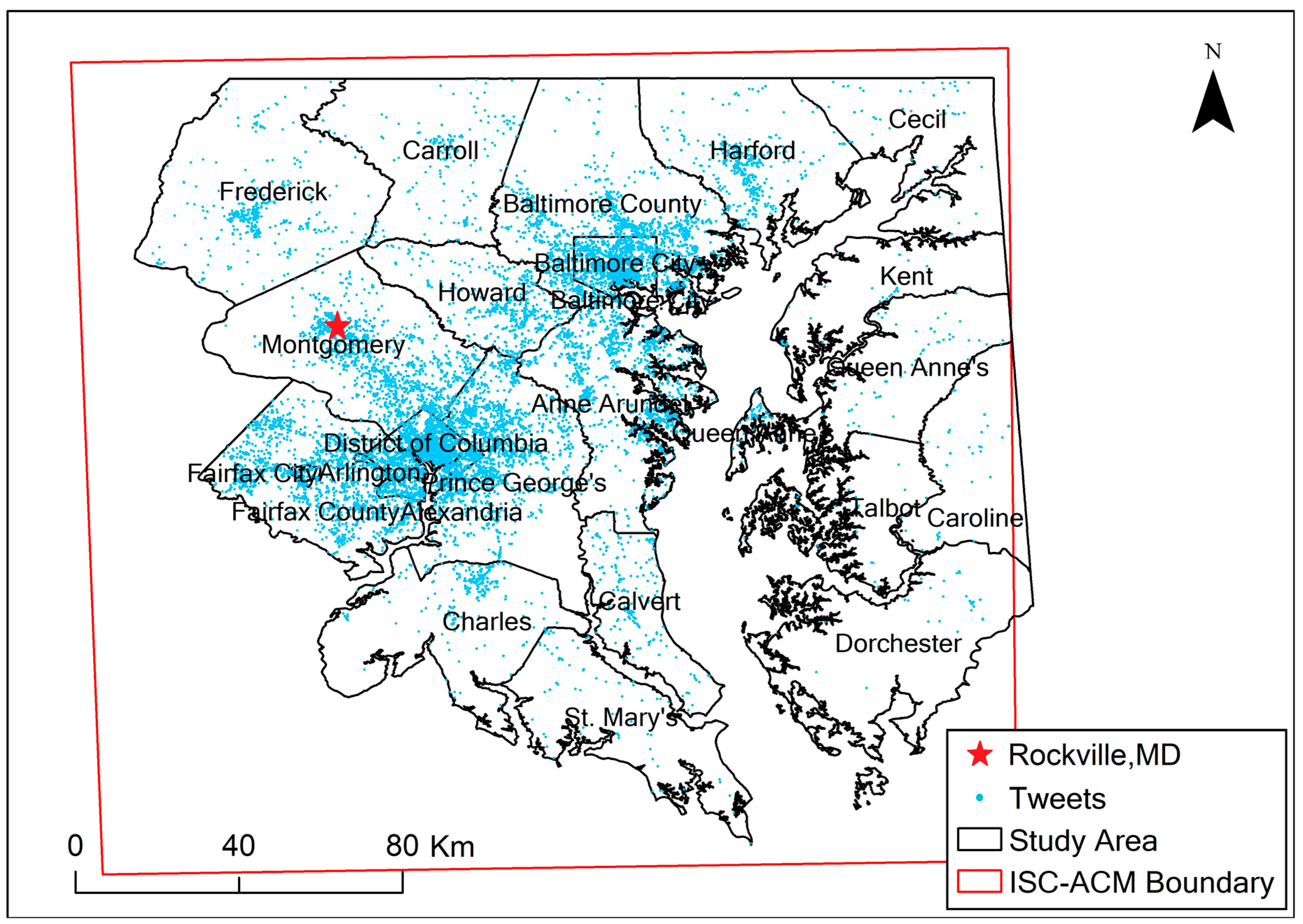
The Washington D.C.–Baltimore metropolitan area was selected as the study area, including the District of Columbia, four municipalities/counties in Virginia, and 17 counties in Maryland (
Figure 1). The region is the capital of the United States and has experienced continued urban sprawl between 1984 and 2008 [
10,
26,
27].
Five main data sources were used to model land use. The first source was a satellite-based Impervious Surface Cover Annual Change Map (ISC-ACM), generated at the University of Maryland [
10]. The second data source was georeferenced Tweets from Twitter that are widely used for modeling human activities (e.g., References [
28,
29]). The third data source was zoning or land use maps collected from local urban planning departments for this region. The final two data sources were Google Maps and Google Street View, which were also used for the study region.
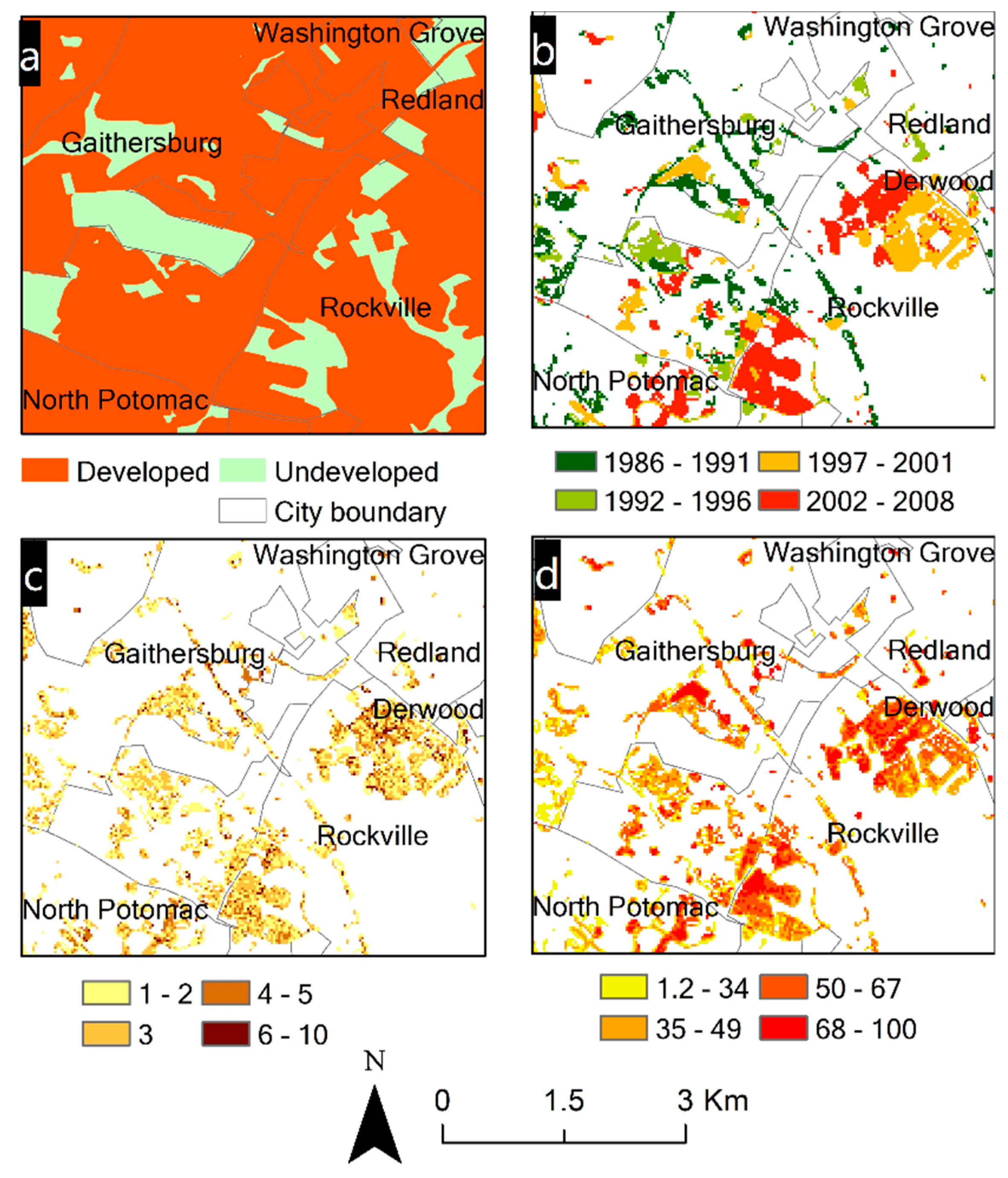
The Impervious Surface Cover Annual Change Map (ISC-ACM) is a suite of raster maps characterizing long-term urban land expansion at an annual frequency over the Washington DC–Baltimore metropolitan region. A complete description of this dataset is reported in References [
10,
27]. Here, we provide a concise summary of its key characteristics and the major steps of its development. The ISC-ACM consists of three map layers representing (1) the percentage increase of impervious surface cover per 30 × 30 m pixel for the period from 1986 to 2008; (2) the year during this period when the most significant impervious surface change occurred; and (3) the duration (unit: years) that a 30 m pixel was converted from undeveloped to developed (
Figure 2b–d). These three change layers were simultaneously derived by applying an innovative change detection algorithm on a stack of annual percent impervious surface cover maps [
10]. The stack of the annual impervious surface maps was in turn created using all available Landsat Thematic Mapper (TM) and Enhanced Thematic Mapper Plus (ETM+) imagery acquired during the 23 year period. Landsat images were converted in a series of processing steps to surface reflectance, seasonal composites, and annual percent impervious surface cover using regression tree and vector-based high-resolution training data obtained from the municipalities [
27]. The overall accuracy of the change-year layer was 99.7%, as reported.
The second major data source used in this study, the georeferenced Tweets, were collected from October 2014 to April 2015 via the Twitter Public Streaming Application Program Interfaces (APIs). The final data set had about 11.12 million records. Given a small enough region, almost all georeferenced Tweets can be retrieved via the Twitter APIs [
30]. There is no information about the position error of Tweets; however, as a reference, the median horizontal position error of a smartphone is reported to be between 5.0 and 8.5 m [
20].
We also used available zoning maps or land use maps from planning departments that were the closest to 2008 as the reference for the actual land use. For counties in Maryland, this was the 2010 Maryland Land Use Land Cover Map [
31]; for Washington D.C., it was the 2006 Land Use Map [
32]; for counties in Virginia, we used 2015 zoning maps for each county [
33,
34,
35,
36]. The detailed land use types were re-categorized into two major land use classes: Undeveloped and developed. Undeveloped land use included forest, water, pasture, cropland, and other natural lands, while developed land use included two mutually exclusive sub-types: Residential and non-residential. Non-residential use included commercial, educational, hospital, industrial, etc. The official land use maps were used as a reference rather than the ground truth of land use as they were also not frequently updated, and therefore may not have reflected the actual land cover and land use after the time period we studied, as we discussed in
Section 5.2 of this paper.
The final two data sources, Google Maps and Google Street View, were snapshots of land use ground truth in 2015 for the validation data sets and referred to land use in 2008.
It is noticeable that, for this study, the data products spanned different and non-overlapping time periods. The remote sensing data products were for 1986–2008, while the Tweets and Google data were for 2014 and 2015, respectively. Even though the Tweets were collected more recently than the physical signature data, any shifts to developed land (residential and non-residential), even those that occurred prior to 2008, were still expected to be in place since once land became developed, it was unlikely to revert back again to an undeveloped state. We discuss this issue of different data source timelines in more detail in
Section 5.2.
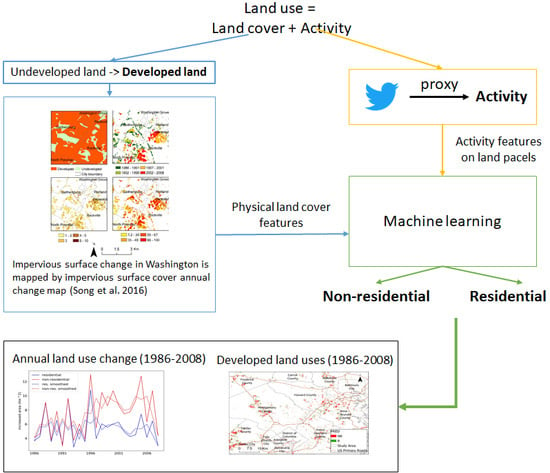
3. Methodology
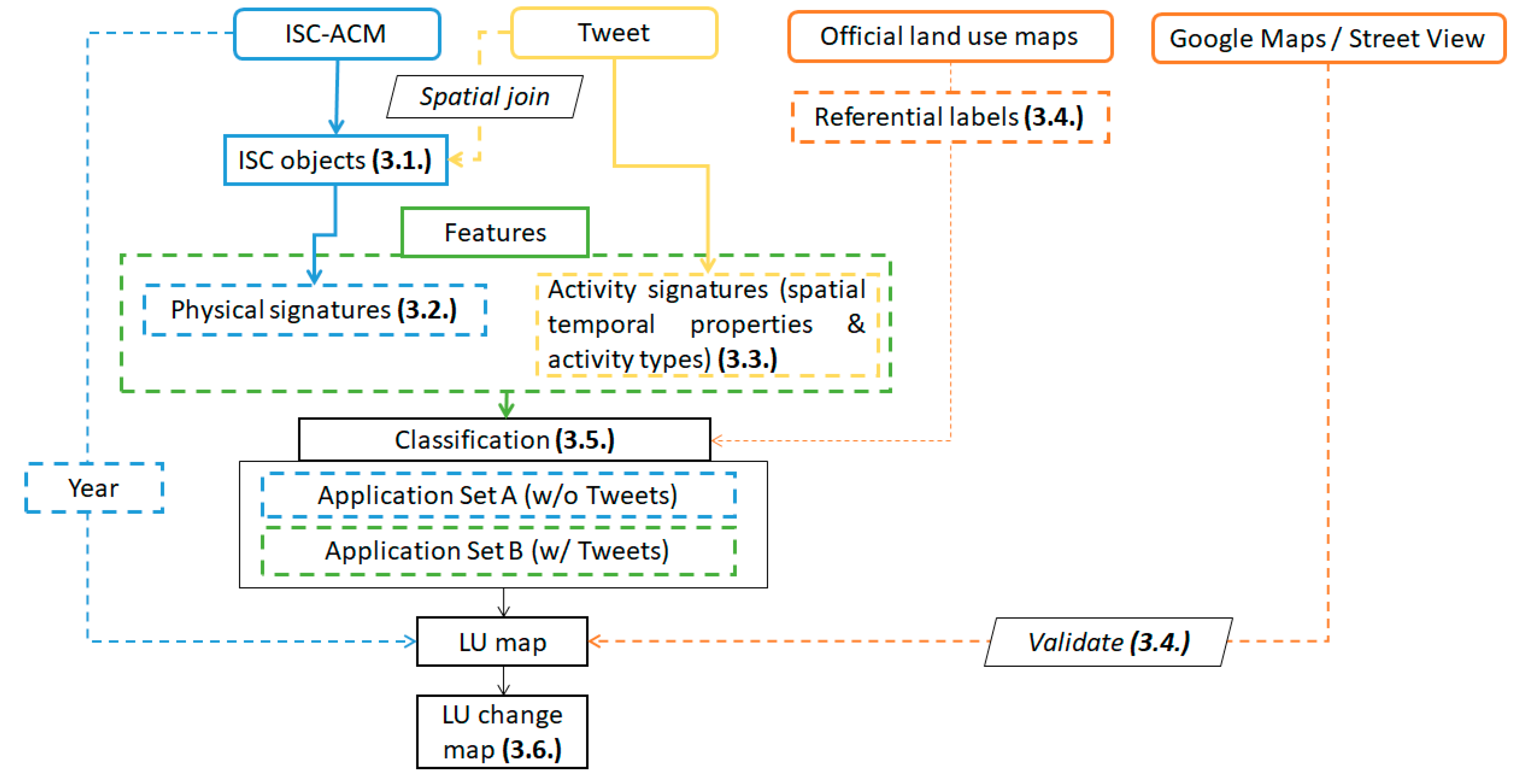
To identify land use change via our workflow (
Figure 3), the change-detected pixels from the ISC-ACM were first grouped into parcels (denoted as ISC objects to differentiate them from parcels in the official land use maps) as the basic geographic units for aggregating and classifying physical vs. activity features. Georeferenced Tweets containing information about activities and their geolocations were spatially joined with all the ISC objects (
Figure 3). Therefore, for each ISC object, a set of physical properties were derived from pixels in the ISC-ACM data as the physical signatures, and a set of activity properties were derived from associated Tweets as the activity signatures; together, these were combined to form the feature set of the ISC object. ISC objects were then associated with the official land use maps as a basis for categorizing if an ISC object would be included in the training set or not. Classification models were trained using the training set and were then applied to determine the land use type of the unlabeled ISC objects for 2008. Google Maps and Google Street View were used to validate the results. As the change year layer of the ISC-ACM (
Figure 2b) showed the year land cover change for a pixel happened for 1986–2008, the classified results used this information to infer when land use changed and represented these changes in the land use change map (
Figure 3). The following subsections discuss these steps in more detail.
3.1. Deriving Impervious Surface Cover Objects
Following an object-based image processing approach [
37], connected component segmentation [
38] was applied to adjacent group pixels in the ISC-ACM change-year layer classifying the pixels into objects. An object can be treated as a place or an area-of-interest (AOI, [
39]), such as a plaza or a residential community occupying several pixels in the satellite images. It was also assumed that the construction of AOIs was continuous in time and space and thus adjacent pixels belonging to the same AOI should be labeled as the same year or adjacent years in the ISC-ACM change-year layer. Due to the
year uncertainty of the ISC-ACM [
10], a two-year search radius was designed for the implementation of connected component segmentation using the image processing package Orfeo [
40]. That is, if the change-year of two adjacent pixels was within
years, the two pixels were grouped into the same land parcel as an ISC object.
3.2. Building Physical Signatures for Impervious Surface Cover Objects
As an ISC object corresponds to a set of pixels in each ISC-ACM layer, five basic statistical metrics for pixel values of ISC objects in each layer were calculated as the physical signatures: minimum, maximum, mean, median, and standard deviation. In addition, the change magnitudes and change durations for each object were grouped by the change years, and the same five statistical metrics were calculated for these two properties for each year. Three morphological metrics of ISC objects were also included as part of the physical signature: perimeter, area, and the perimeter-area ratio [
41].
3.3. Building Activity Signatures for Impervious Surface Cover Objects
Georeferenced Tweets were utilized as the proxy for human activities co-located with ISC objects. These activities provided another way to gain insights into different land uses. A key assumption that is discussed more fully in
Section 5, and mentioned previously, was that although the Tweets were more recently collected than the physical signature data, any shifts to developed land that occurred even prior to 2008 were still expected to be in place. For preprocessing, Tweets from user accounts that potentially used location spoofing [
42], and for this reason possibly falsified activity locations, were removed, excluding approximately 8% of the data set. The remaining Tweets were associated with the derived ISC objects by their location relationships.
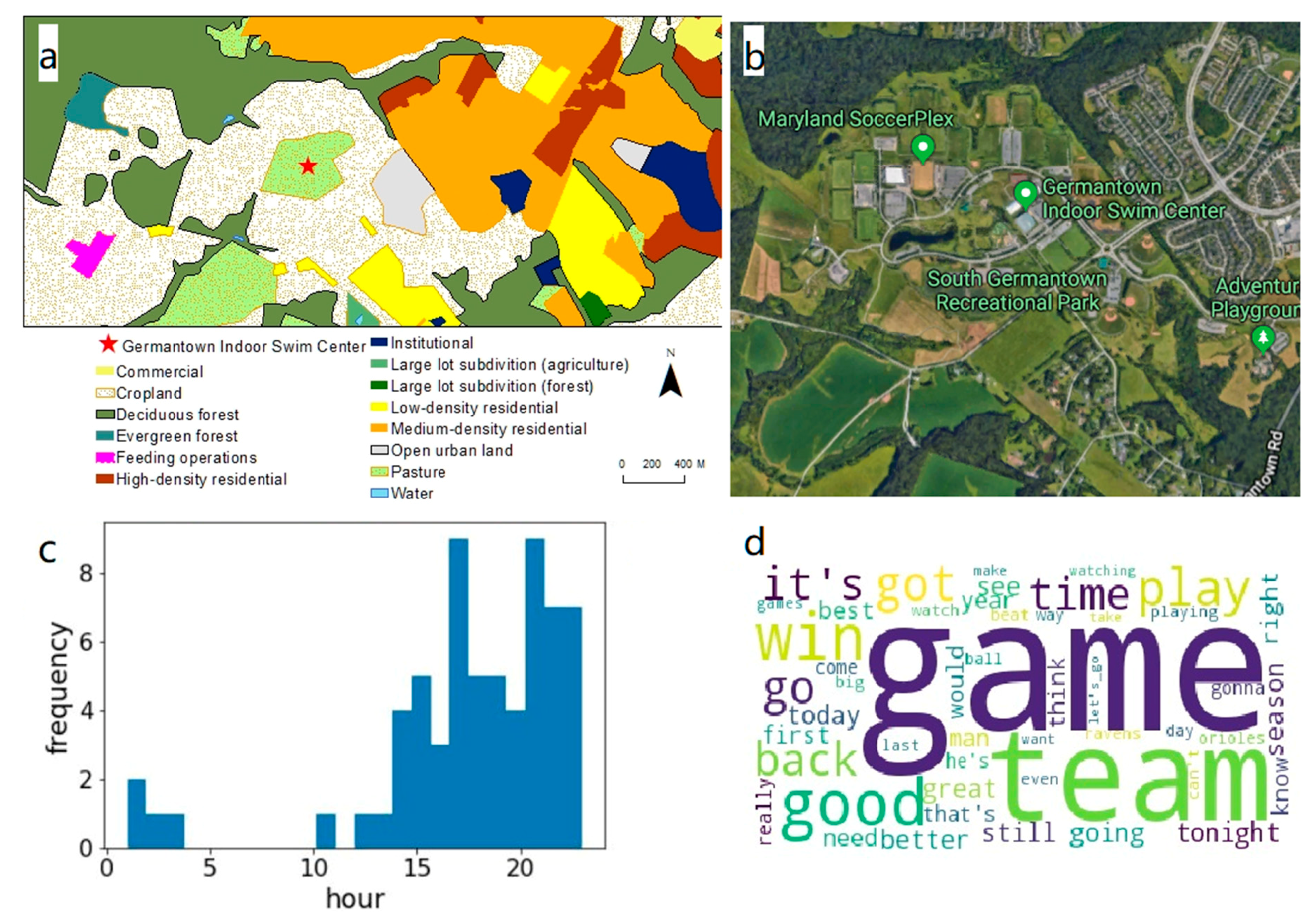
Two types of activity patterns: Temporal patterns and topic patterns were derived by aggregating the Tweets for each ISC object. The time-varying number of Tweets in an average week has been frequently used as the activity signatures to characterize land use [
14]. The temporal bin for aggregation was determined to be one hour. Tweets for an ISC object were aggregated by the day of the week first, regardless of the calendar date. Three metrics were then derived: hourly tweet volume, hourly user entropy, and hourly user volume to characterize temporal patterns.
The hourly tweet volume was defined as:
where
o is the ID of an ISC object;
u is the ID of a Twitter user;
U is the set of user IDs;
d is a day of the week;
h ranges from 0 to 23 such that 0 represents the one-hour interval between 0:00–1:00 a.m.;
represents the total number of Tweets from a unique user for an ISC object within the one-hour interval; and
represents the hourly tweet volume. Residential places generally had lower volumes during week hours, while non-residential places had the opposite pattern.
It has been observed, however, that human behavior has a bursty nature, e.g., posting a large number of Tweets in a short time and then waiting for a period of time before tweeting again [
43,
44]. Therefore, a Shannon entropy measure [
45] was employed to better profile the bursty phenomenon. Similar to the hourly tweet volume, hourly user entropy was thus defined as:
where
is the Shannon entropy of users located at an ISC object
o during the hourly interval
h on the day of week
d.
is the proportion of Tweets from a user among the total Tweets at the same ISC object during the same hourly interval on the same day of the week. It was expected that non-residential locations would have higher Shannon entropy values than residential locations since a greater number of people could stop by and leave their digital footprint online at non-residential places.
Hourly user volume counts user presence at a place within an hourly interval only once and thus represented both volume and diversity. It was defined as:
where
is the hourly user volume and
represents whether a user Tweets in an ISC object within a specific time interval. This index is not sensitive to the possible bursty pattern of tweeting activities and can differentiate situations involving no Tweets versus having all Tweets from one single user that cannot be characterized by the Shannon entropy.
Topic modeling derives a set of abstract hidden topics that occurs in a set of texts [
46]. For deriving the topic pattern, Single Topic Latent Dirichlet Allocation (ST-LDA) [
47] was utilized in this study as it is particularly designed to model topics in the Tweet text and has been used for analyzing human activities [
29]. ST-LDA associates each Tweet with a single latent thematic topic that achieves the maximum probability to match the Tweet text. Each latent topic is represented as a weighted vector of vocabulary whose theme can be inferred by the word weights. We conceptualize that the latent thematic topics are also related to certain activities. For example, students may post Tweets with a topic whose top-weighted words are related to teachers, exams, and cohorts, which can be generalized as a “School Study” topic. The vector of topic counts for an ISC object formed the topic pattern for the object. We employed the same natural language processing (NLP) workflow integrating the ST-LDA model in a previous study of the Washington D.C. area [
48].
3.4. Preparing Training, Validation and Undetermined Sets
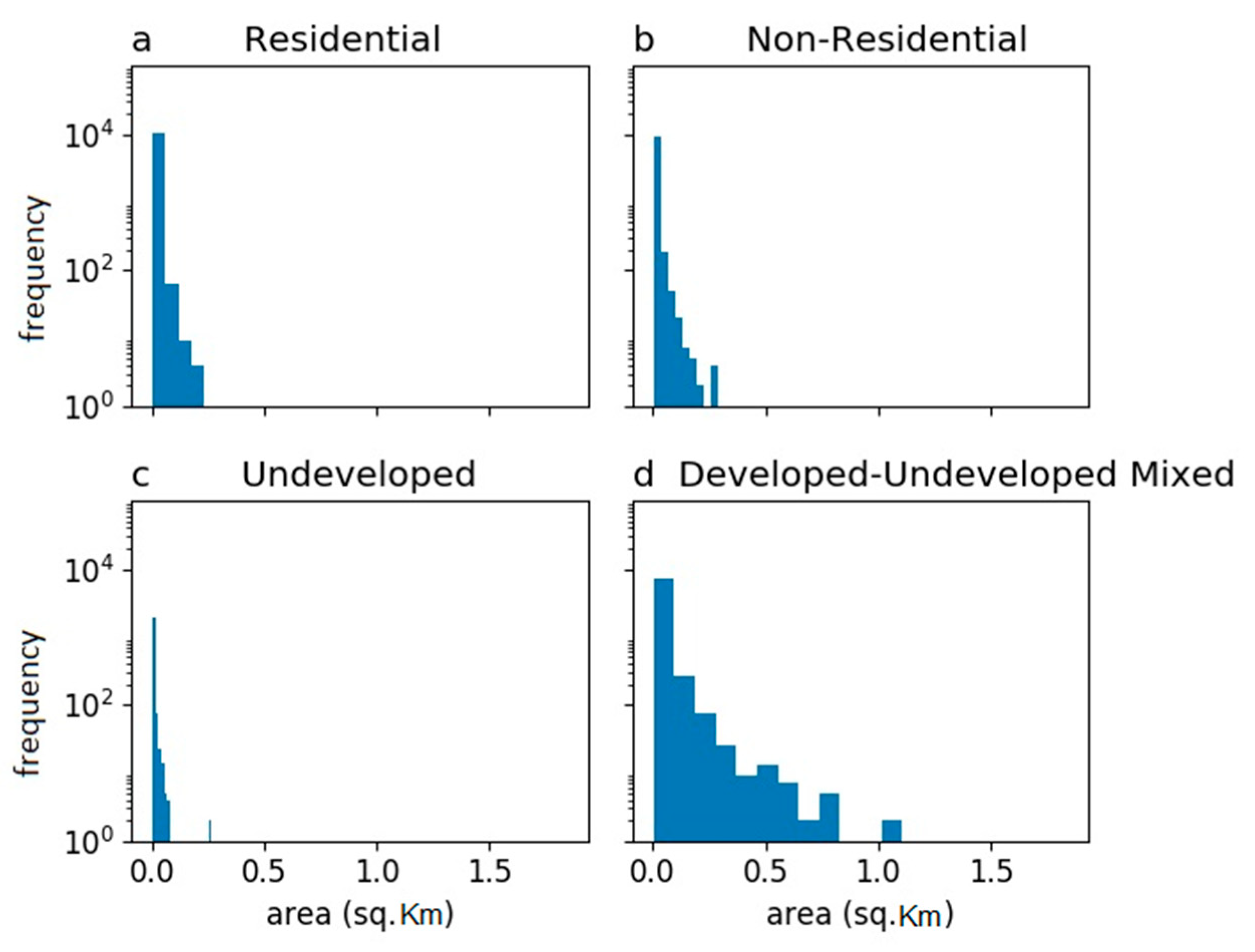
The categorized official land use maps were used to determine training and validation sets. If an ISC object was completely within a developed land use parcel, i.e., a residential or non-residential parcel, the object was assumed to be correctly labeled on the official land use map and was categorized as an entry of the Training Set for building the classification model in the next step. If an ISC object was partially or fully co-located with an undeveloped land parcel, or it was associated with two different types of developed land use, these objects were categorized as undetermined for predicting, by the classification model, as their land use type might have been mislabeled on the official land use maps. These undetermined ISC objects were further categorized into two sets: ISC objects with more than seven Tweets were categorized as Application Set A, the rest were categorized as an independent set denoted as Application Set B. As the smaller number of Tweets associated with objects in Application Set B did not allow for building a reliable activity signature, objects in this set were labeled by another classifier using the same training set, but only used the physical signature for classification. Among the unidentified ISC objects, 100 objects were randomly selected from both Application Set A and Application Set B, and these were denoted as Validation Set A and Validation Set B, respectively. The actual land use of the ISC objects as Validation Set A and B was visually checked using Google Maps and Google Street View to determine ground truth.
3.5. Training and Classification
We implemented the random forests algorithm [
49] in
scikit-learn [
50] as the main classifier since this algorithm is robust for high-dimensional feature datasets and has better performance over other classifiers, as reported in Reference [
51].
Ten-fold cross-validation [
52] was used to evaluate the performance of the classification models building on the training dataset. Ten-fold cross-validation splits the training set into 10 equal-size folds and uses nine folds to build a classification model and one remaining fold to evaluate and then select the best model. Accuracy, Cohen’s Kappa coefficient [
53], precision, recall, F1-score, and the area under the receiver operating characteristics curve (AUC) were used to undertake a comprehensive evaluation of the classifier. Precision is the percentage of true positive records in the dataset that are predicted as positive by the classifier. Recall is the percentage of records that are correctly predicted as positive in all positive records. The F1-score is the harmonic average of precision and recall [
54]. AUC shows the probability that a classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance [
55].
Two training processes were conducted on the same training set with different signature combinations: Both physical signatures and activity signatures (
Appendix A for detailed attributes) were used for the first classification model to identify Application Set A; only physical signatures were used for the second classification model to identify Application Set B (no Tweets were associated with this set). In this analysis, each random forests model was composed of 256 trees [
56]. The classification performances of the two models were evaluated by the 10-fold cross-validation. After the two application sets were classified, their corresponding testing sets were also applied to evaluate the two models, respectively, as the proxy for all objects.
3.6. Inferring Sprawl of Residential and Non-Residential Land Use in the Study Area
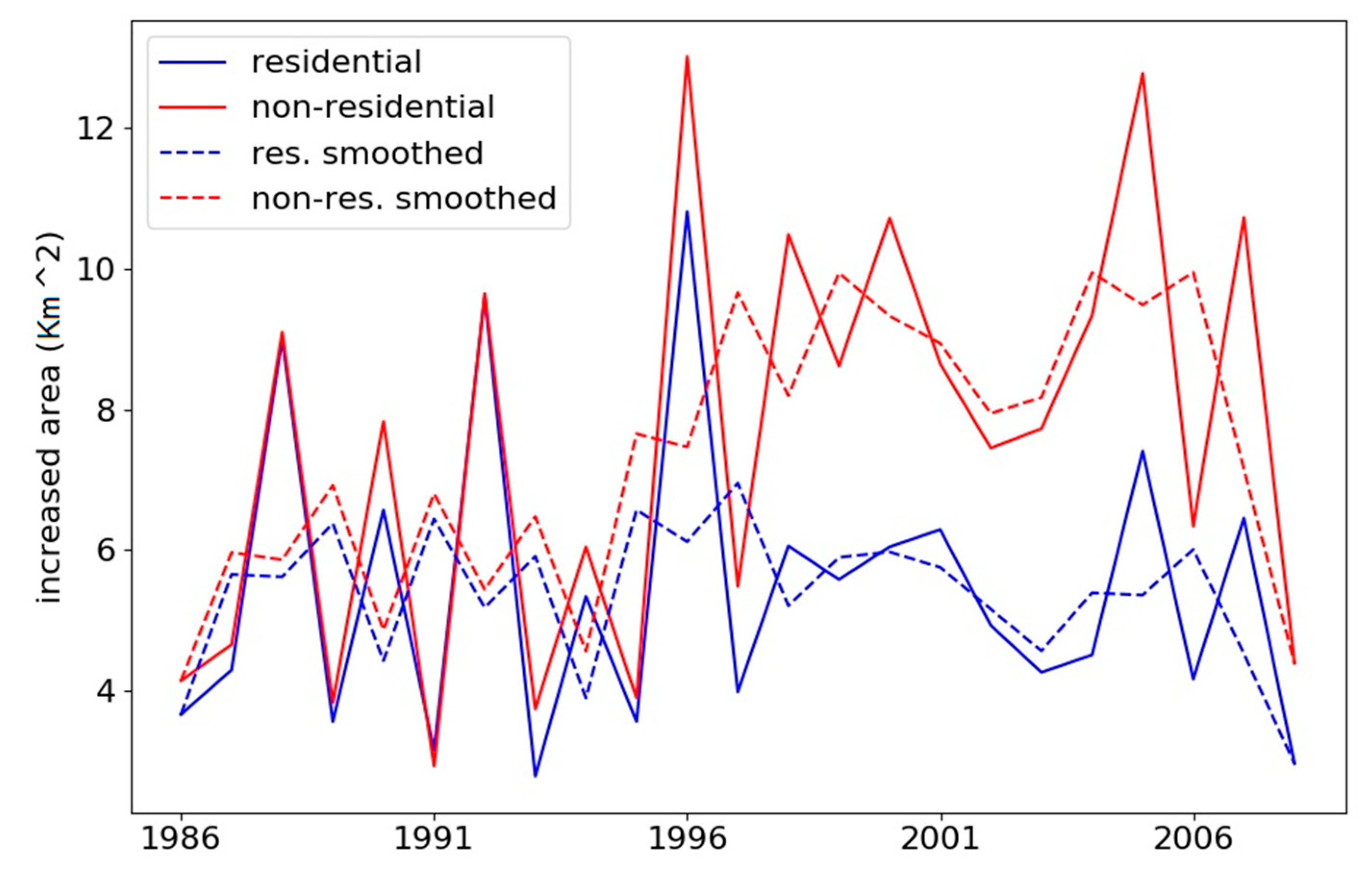
Once all unlabeled ISC objects in the two application sets were labeled by the classifier, the change from undeveloped land to developed land, including residential and non-residential uses in the period modeled by the ISC-ACM, was determined by counting the total area of pixels in a certain year labeled in the change-year layer of the map for each land use type.
5. Discussion
5.1. Contribution
In this study, we developed a framework that integrates socially-sensed human activities data and remotely sensed imagery as model inputs to identify detailed urban land use for the period 1986–2008. The output of the framework not only maps the spatial details of land use change but also profiles the trajectories of different land use types over time, which contributes to an understanding of the evolution of urban development as a complex system. The framework minimizes the dependence on traditional GIS data sets that may not be surveyed regularly and which are costly to undertake, such as land parcel footprint maps and street network maps. Since the original data sources, the Landsat imagery and georeferenced Tweets are both currently free to access, and the framework has the potential to be applied to other cities, especially those in developing countries, where cities are undergoing fast urbanization on a massive scale. For municipalities or counties in the US with zoning or land use maps, the output of this framework may help to address mapping errors in current maps.
This framework utilizes remote sensing imagery to model the physical signatures of land cover and georeferenced Tweets to model activity signatures associated with different land use types. The comparison of classification models shows the accuracy of the modeling using both signatures together is 0.04 and 0.06 higher than the model with the physical signature (i.e., remotely-sensed data) or the activity signature alone, respectively. After area adjustment, the former improvement increases to 0.10. The improvement is based on the distinguishable residential vs. non-residential landscape pattern found in the Washington D.C.–Baltimore region. This region has been experiencing suburbanization at a high rate where single-house communities with cul-de-sac designs are significantly different from commercial parcels in terms of morphology and the magnitude of impervious surfaces is increasing. This is not necessarily true for cities in other regions with more compact urban land parcel patterns, e.g., New York City, Beijing, and Manila. Activity signatures are expected to bring more value to these cases when differentiating the land use of parcels. In addition, different types of non-residential uses often have similarly high impervious surface cover that may be more difficult to distinguish using the physical signatures alone.
The higher values returned by the area-adjusted estimator compared to the object-based estimator in
Section 4.4 was likely due to the large number of small objects in Application Set B and Validation Set B (objects with less than two pixels were 60% of the count, but accounted for 17% of the overall area in Validation Set B). Therefore, the area-adjusted accuracy of using a physical signature alone was a little better than the non-adjusted result, but still much lower than the result of the model utilizing both physical and activity signatures.
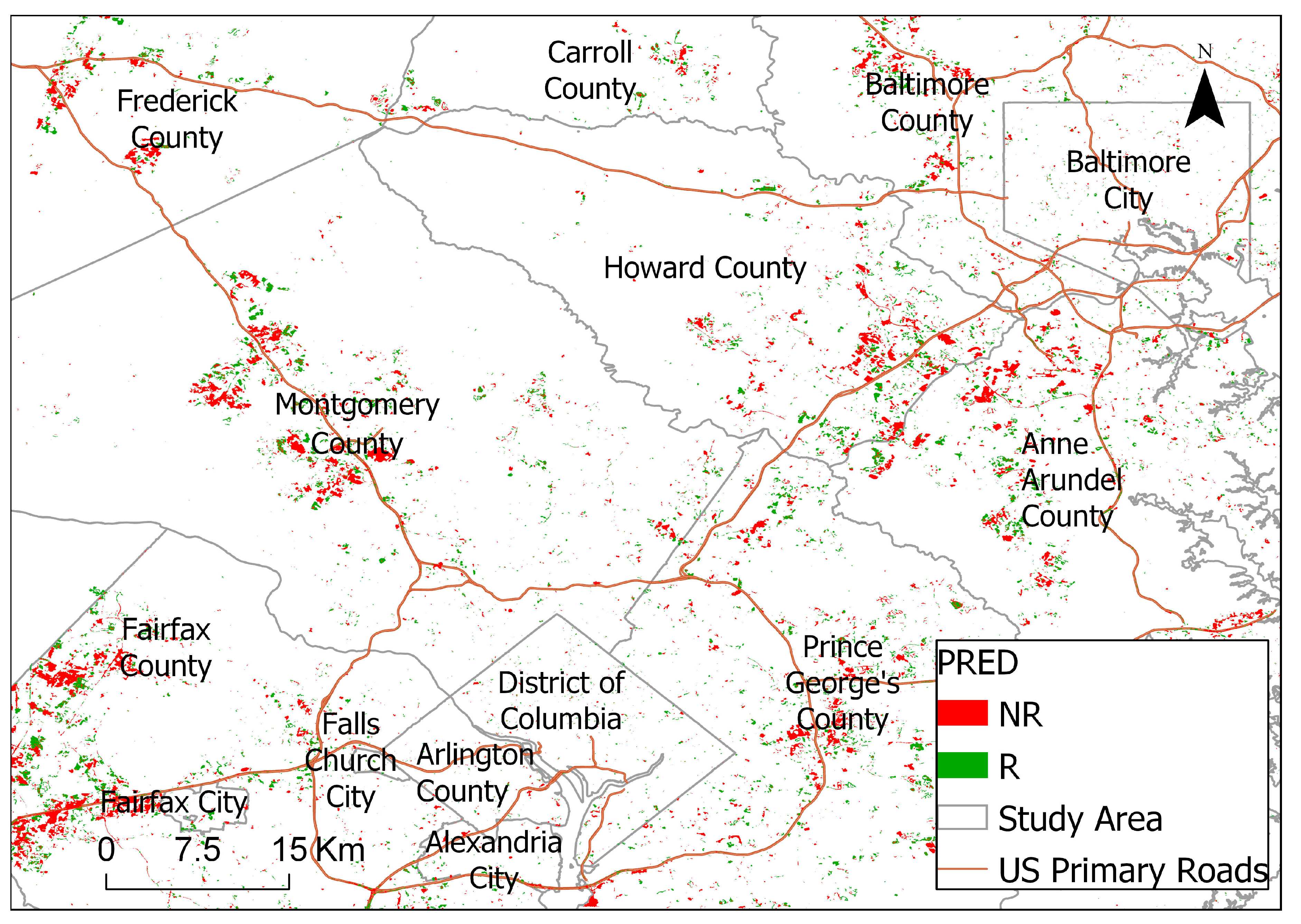
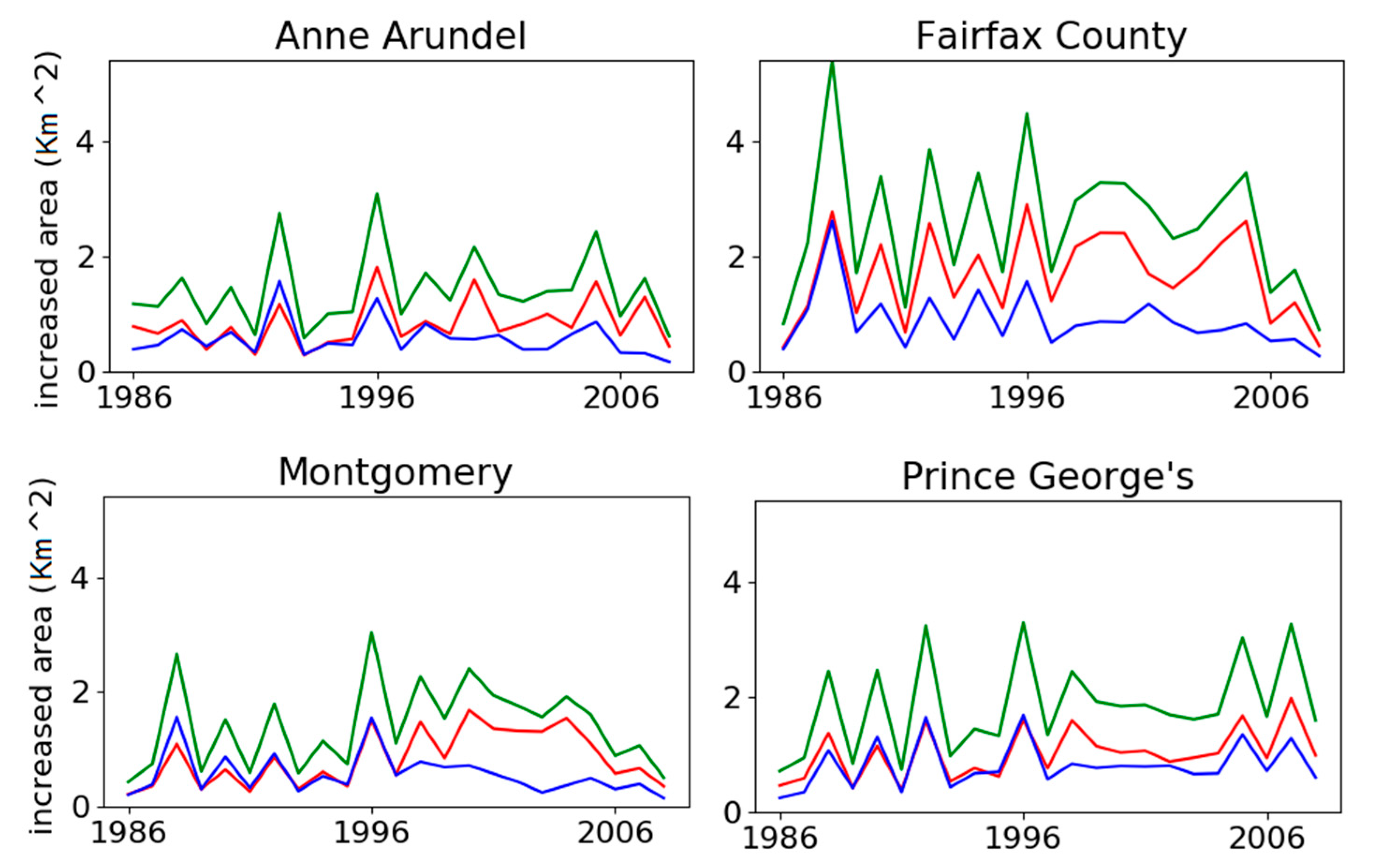
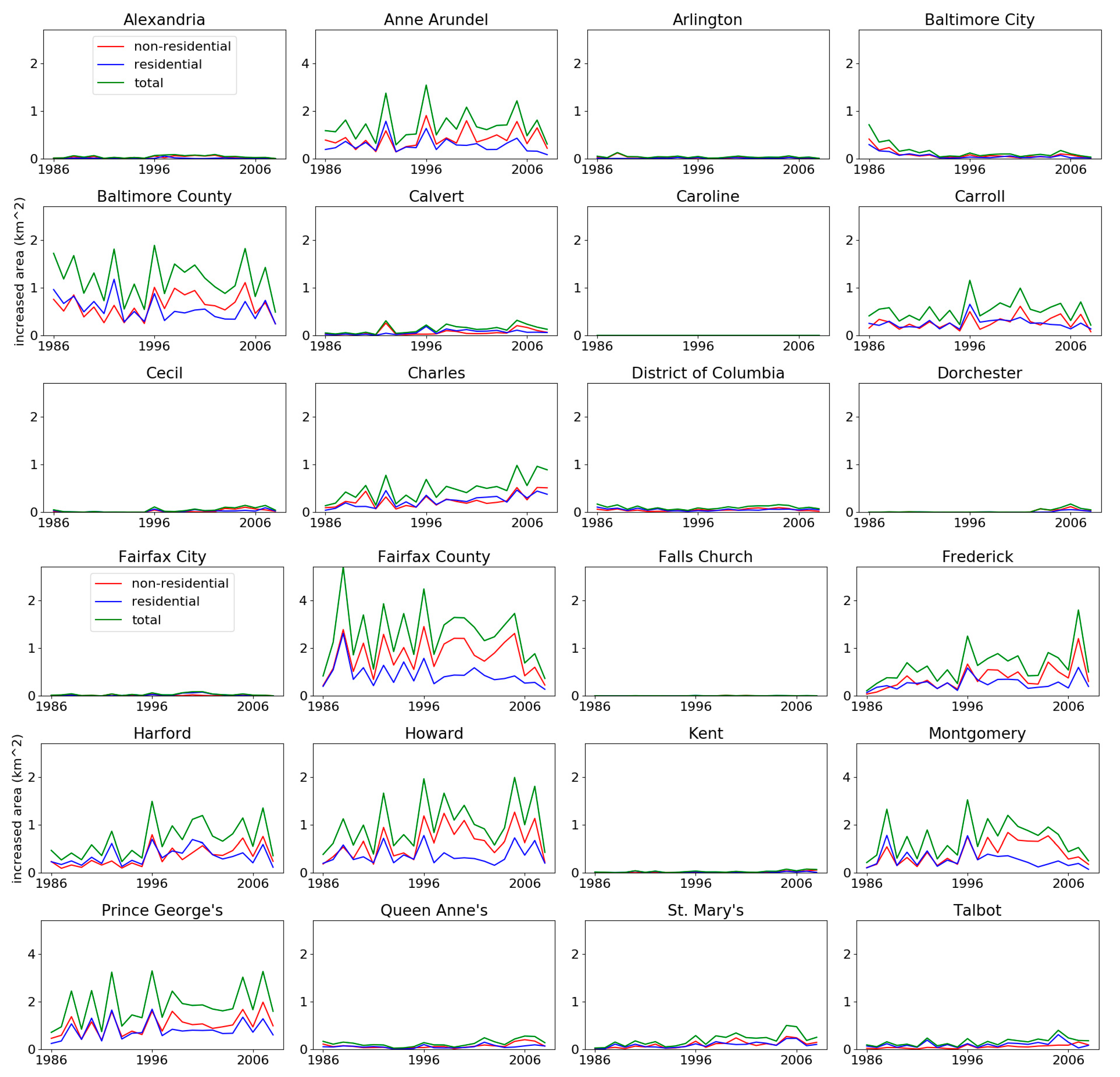
For modeling the sprawl of developed land, the higher the amount of non-residential over residential use in
Section 4.5 for Montgomery County, MD, can be explained by the I-270 Technology Corridor stretching from the city of Bethesda to the city of Rockville, both within Montgomery County, MD. According to a local government report [
61], this corridor is where over 18,000 business establishments have located, offering 72% of Montgomery County’s total employment, while 30% of the employees lived outside of the county, and most housing growth was estimated to be multi-family as of 2007. For Fairfax County, VA, the amount of increase could be explained by similar reasons, as there is the Dulles Technology Corridor connecting cities in Fairfax County and involve communities such as Tysons Corner, Reston, Herndon, Sterling, and Ashburn.
5.2. Source of Uncertainty
It should be acknowledged that temporal differences existed between the five different data sources employed in this study, which is a common issue for multi-source data fusion. Specifically, the most recent year of the remote sensing-based impervious surface map product was 2008, whereas Twitter data were collected for the year 2015. The seven-year gap between these two datasets may inevitably introduce some errors and differences, as land-use change between residential and non-residential on the newly developed land may occur. However, we believe that the temporal gap did not significantly alter the results of our study for the following reason. Potential errors could only be caused by the changes from residential to non-residential and vice versa on new urban land between 2008 and 2015. The amount of these specific types of land-use change was expected to be much less than general land-use conversions from undeveloped to developed between 1986 and 2008. Our independent validation using Google Maps and Google Street View supported this fact. We manually checked some ISC objects where Google Street View’s historical archive is available. The historical archive covers the period between 2007 and 2017, although the spatial coverage and the availability for certain years vary by location. We found no visual change for the ISC objects where the historical street views were available during the 2007–2017 period. Nevertheless, future research should focus on how more up-to-date remote sensing datasets could minimize the temporal difference between remote sensing and social sensing data and the impacts on reasoning with these data.
The tradeoff of this study was to define the spatial footprint of places from segmenting only remotely sensed imagery. Currently, image segmentation-based place footprints do not perfectly match the ground truth. As an example, using Application set A, parcel A, a commercial complex, and parcel C, a residential community with cul-de-sacs, were well identified (
Figure 9). However, parcel B was based on a combination of commercial buildings in the North and some residential buildings in the South, and was labeled as non-residential. If a pixel in the commercial buildings part had been selected as a testing pixel, the label would be correct, but the attribution would be incorrect for other pixels. Unlike land cover objects, it is difficult to define the ground truth of a land use object, as a land use object may involve several land cover types. The boundary of a land use object may also be subjective, based on a person’s feelings about a place [
62].
The topic features extracted as part of the activity signature analyses were observed to have high feature importance in random forests. This implies that topic features could be further investigated to classify more detailed non-residential land use types. Conceptually, each type of non-residential land use had unique corresponding activity types, for example, teaching or learning in schools and shopping in malls. If such activity information can be retrieved, it would be possible to use this information to identify more detailed non-residential land use types.
However, we should investigate a better model to associate the georeferenced Tweets with the land parcels to address the uncertainty from the positioning inaccuracy. In this study, we used the point-in-polygon spatial join to assign the Tweets to ISC objects, which may be sensitive to the positioning inaccuracy. In addition, due to the spatial bias of the georeferenced Tweets, as mentioned in the Introduction, further applications may still be limited to certain metropolitan areas that fit these demographics. The amount of available georeferenced Tweets in a study area may also influence the classification results.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
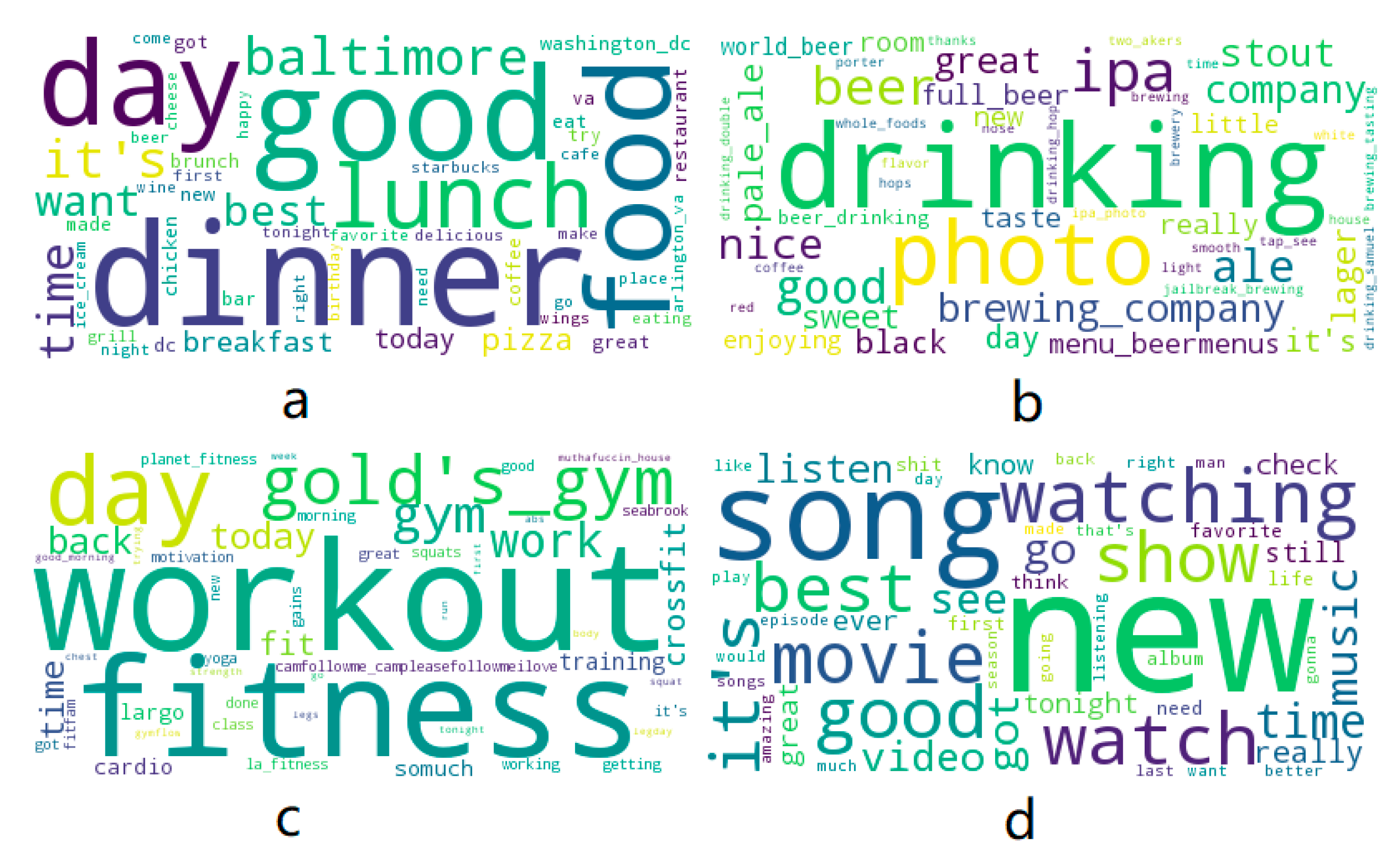{kind=link}
{kind=link}










