1. Introduction
With rich spectral information contained in tens or hundreds of spectral bands, hyperspectral images (HSI) has been successfully applied in a wide range of remote sensing applications such as land cover analysis [
1,
2,
3], military surveillance [
4,
5], object detection [
6], and precision agriculture [
7,
8,
9,
10,
11], etc. Among these applications, image classification is an active topic, which aims to assign each pixel in the HSI into one unique semantic category or class.
During the past few years, a number of discriminative methods have been developed for pixel-based classification of HSI. Within these techniques, the Support vector machine (SVM) is a basic but efficient classifier [
12]. Due to the advantage of handling different features, the random forest has also attracted wide attraction [
13]. The neural network-based methods have proved to be an effective tool for classification, which has also been applied into the HSI [
14]. However, the aforementioned methods focus more on the spectral information only, where the spatial information has not been adequately considered. Recently, some improved approaches have also been proposed, such as the composite kernel SVM [
15], the ensemble-based random forest [
16], and the random field-based method [
17,
18]. Furthermore, effective feature extraction techniques have developed for HSI classification, such as the principal component analysis (PCA) and its variations [
19,
20]. By defining a sequence of morphological operations on the first principal component of the HSI, the extended morphological profile (EMP) [
21] can be acquired, which is found to be an advanced feature for HSI classification. Recently, Ghamisi et al. have also designed extinction profiles (EP) [
22] for extracting the contextual information from remote sensing data.
The sparse representation classification (SRC)-based method has been found to be a powerful tool for numerous computer vision tasks. Originally proposed by Wright et al. in face recognition [
23], the SRC has also been successfully applied into the HSI classification [
24]. Assume that one test pixel in the HSI image can be reconstructed by a sparse dictionary using a few training samples, the corresponding sparse coefficients can determine correlation between the test pixel and the selected training samples in the dictionary. After the reconstruction of the test pixel based on the sparse coefficients and the selected training samples, the class of the test pixel can be labelled through identifying the one with the minimum reconstruction residual. To cope the spectral information with the spatial context, a Joint SRC (JSRC) model is proposed [
24]. A fixed-size local region is predefined for each pixel and all the pixels within this region can share the same sparse representation from the dictionary. With the joint sparsity model, the SRC can improve its robustness against to the outliers and improve the classification accuracy. To improve the non-linear separability of the model, a kernel based JSRC (JKSRC) has also been proposed [
25]. In [
26], NLW-JSRC is developed by adding a nonlocal weight (NLW) to the neighbouring pixel around the test pixel. Furthermore, the multiscale adaptive model (MASR) [
27] has been used to exploit the spatial information with differently sized regions, where a better performance than JSRC has been achieved.
For HSI data, the high dimensionality of the pixel vector often leads to huge computational burden. For SRC-based framework, the computational complexity can be even higher due to the large size of the dictionary to be constructed from the training samples in most circumstance. Thus, it is crucial to improve the efficacy of the SRC while maintaining the classification accuracy. Within the aforementioned methods, the spatial information of HSI is usually extracted from a fixed-size window or multiscale square windows, which also increases the computational burden. Recently, the utilization of superpixel [
28] and other shape-adaptive filters [
29] are used to find the homogeneous regions instead of square windows. In [
30], Superpixel-based classification framework with multiple kernels (SC-MK) has been designed, and the experimental results indicate the efficacy of the approach. The superpixel-based SRC method [
31] has also shown the superiority in terms of high classification accuracy and efficient computational speed.
The lack of sufficient training samples is another common problem in practical applications, which is also addressed in the proposed framework. For improving the classification accuracy, effective fusion of spectral and spatial features in the SRC-based classification framework have attracted increasing attention. Most of current SRC-based methods [
32,
33,
34,
35] utilize adaptive strategies to estimate the sparse coefficients and determine the label of the test pixel by the sum of residuals from all extracted features. In [
32], a collaborative representation-based multitask learning framework is introduced for fusion of multiple extracted features, where the significance of each feature is represented by an adaptive weight. Zhang et al. have built a joint SRC-based multisource classification framework (ALWMJ-SRC) [
33], where an locality adaptive weighting strategy is employed to improve the feature fusion from different data. In [
34], a multiple feature adaptive SRC framework (MFASR) has been proposed, where the generated sparse coefficients are obtained adaptively to keep the feature-specific pattern for multiple feature learning. Moreover, the similar kernel version of the multiple feature SRC [
35] has also been introduced and shown the significance of the non-linear separability. Although these approaches have shown relative good performance, the mechanism for fusion of multiple features needs be further analysed to derive a more robust strategy.
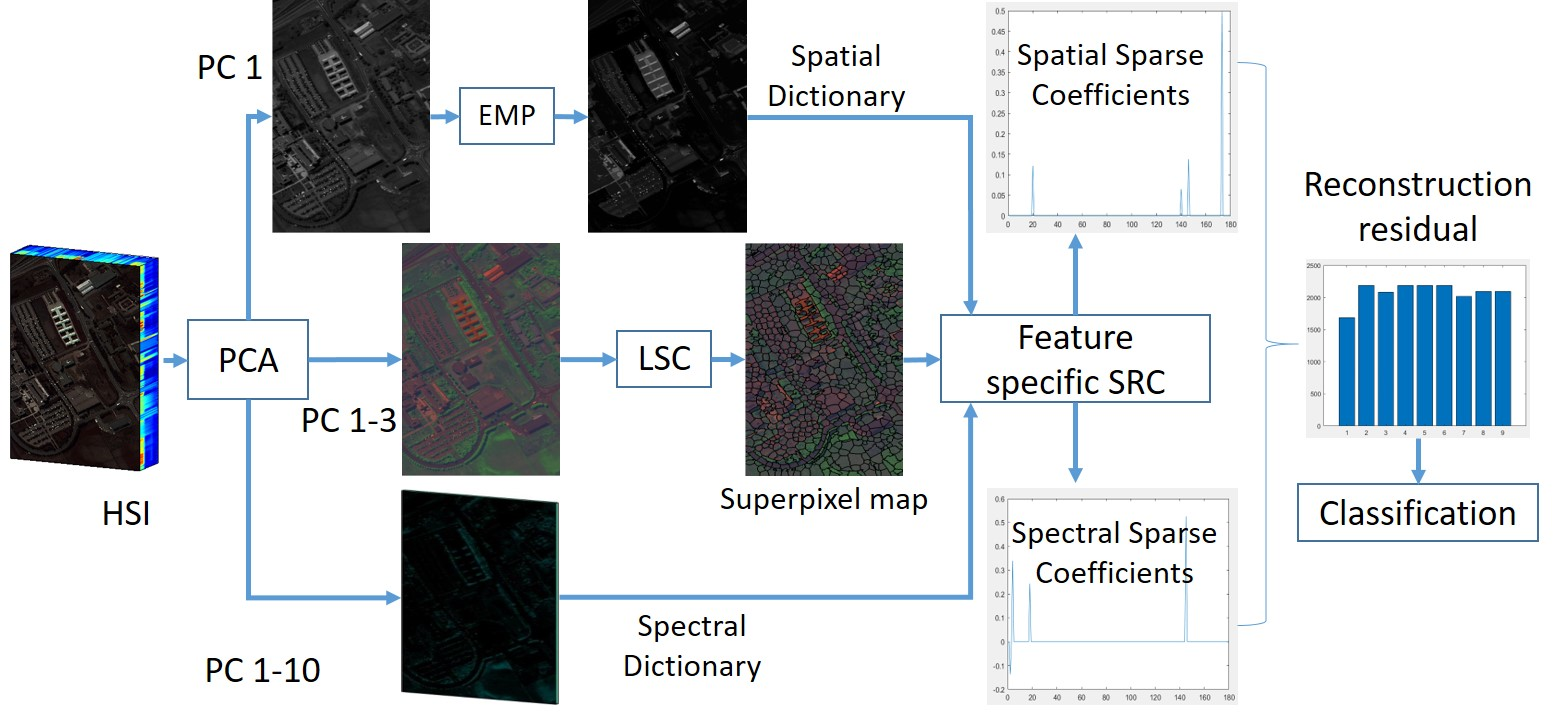
To improve the efficiency and maintain the classification accuracy under the circumstance of insufficient training samples, a superpixel-based feature specific sparse representation framework (SPFS-SRC) is proposed in this paper for the classification of HSI. First, the PCA analysis [
19] is used to reduce the dimension of HSI. Second, the extended morphological profiles (EMPs) [
21] are extracted as spatial features from the 1st principle component. Afterwards, the linear spectral clustering (LSC) oversegmentation approach [
36] is applied on the first three principle components to generate superpixels of the HSI. Pixels in each superpixel is assumed to share similar spatial-spectral characteristics. Before the classification, an online metric learning step is used for weighting each atom in the dictionary. With the kernel based sparse regularization, the sparse coefficients are obtained. Finally, instead of labelling each pixel in the superpixel, the recovered sparse coefficients can be jointly utilized to calculate the reconstruction residual and assign the class label for the whole superpixel, which can reduce the computational cost.
The main contributions of this paper can be highlighted as follows: (1) A superpixel-based sparse representation (SR) model is proposed for effective classification of HSIs with insufficient training samples; (2) By introducing the superpixel into the SRC model, the computational cost has been significantly reduced whilst maintaining the classification accuracy; (3) an online metric learning strategy is applied to exploit the discrimination of spatial and spectral features to further improve the classification accuracy.
The rest of this paper is organized as follows.
Section 2 introduces the proposed SPFS-SRC method, along with a brief discussion of generic SRC-based HSI classification in
Section 2.1.
Section 3 details the experimental results on two commonly used remote sensing datasets, including the selection of key parameter and comparison with other state-of-the-art algorithms. Finally, further discussion and concluding remarks about our work are given in the
Section 4.
4. Discussion and Conclusion
During the last several years, various approaches have been proposed to improve the performance of HSI classification. In this paper, we propose a superpixel-based feature specific SRC framework to fully exploit the spectral-spatial features of the HSI. A superpixel map is generated to acquire better spatial information and save computational cost. After the superpixel generation, a SRC-based classifier is designed to assign each superpixel into certain category. With our proposed SRC-based classifier, it can be noticed that our approach achieves a better performance than other methods in both datasets.
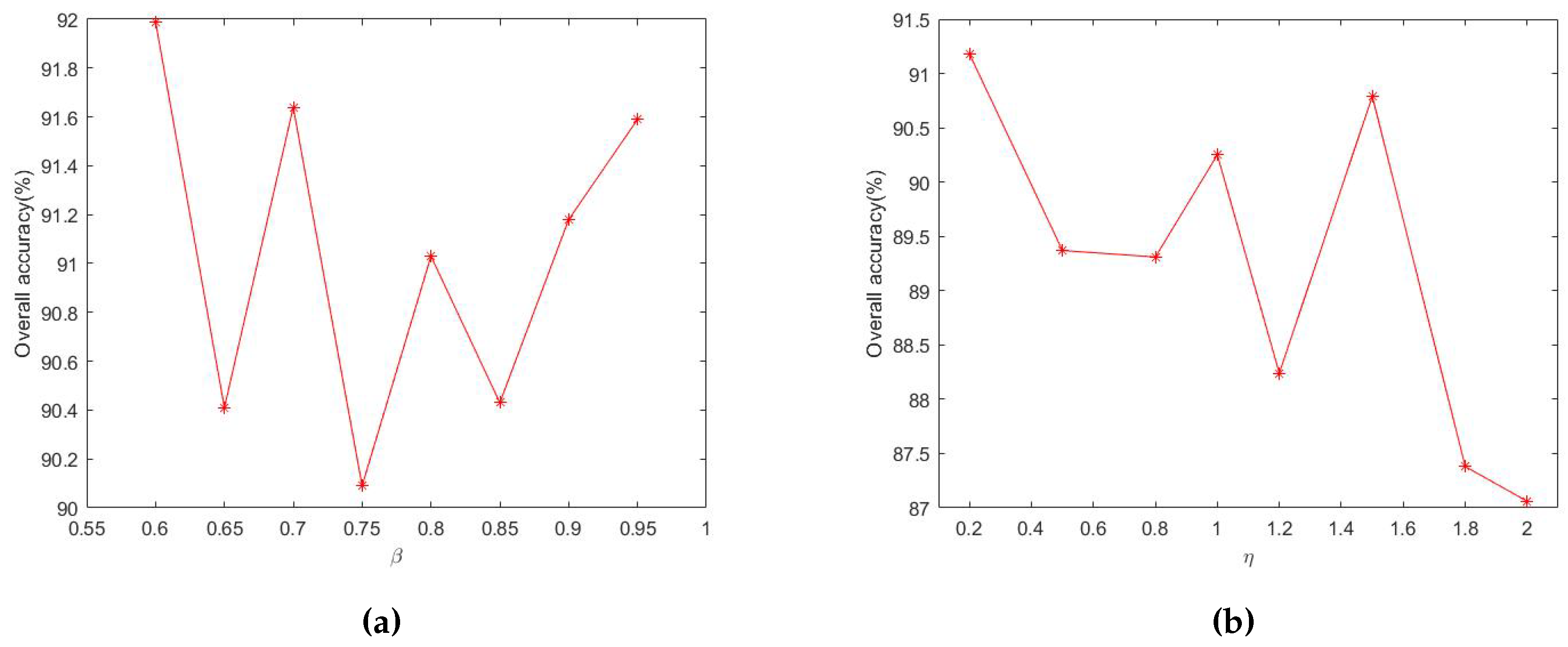
In this paper, we have also designed an online Mahalanobis-based metric learning strategy to acquire better matching between the training and test samples. With this mechanism, we have achieved the best performance in both datasets, and we also improve the OA in the PaviaU dataset from the baseline method’s 88.98% to 91.51%, and in Indian Pine dataset from 82.38% to 83.71%. From the experimental reuslts, the learned metric can improve the discriminative ability of the SRC without high computational burden. For the learned metric, four determined parameters are discussed. For the discounting parameter and regularization parameter , corresponding results show that these two parameters are robust to the OA. As for the two thresholds and that determined the defined statement, they were set by empirically. By searching the value from 0.5 to 2, optimal parameters were chosen. From the confusion matrix of PaviaU dataset, we have found that quite a number of samples from class 6 ’bare soil’ have been misclassified into the class 2 as ‘meadows’. However, less samples from class 2 ‘meadows’ are misclassified as ’bare soil’ in class 6. This is possibly due to inaccurate ground truth caused by spectral mixing as there can be grasses grown in regions labeled as ‘bare soil’. On the other hand, there may be also small regions of ’bare soil’ in labelled ’meadows’ regions. This explains the high error rate from class 6 to class 2, yet the low error rate from class 2 to class 6.
The future work can be summarized as follows: firstly, we will work on a more reliable superpixel generation approach, aiming to produce superpixels for classification and maintain the superpixel boundaries to adhere well to the natural boundaries. Especially for small images like the Indian Pine dataset, a more accurate superpixel map is desirable. Secondly, we will dedicate to design a more robust online metric learning strategy, which can reduce the number of parameters and provide even better matching between training samples and test sample. Thirdly, for our framework, more features will be explored in the future, even with an automatic feature selection method such as band selection [
41,
42,
43].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}