A Novel Multi-Model Decision Fusion Network for Object Detection in Remote Sensing Images



Abstract
:
1. Introduction
2. Related Work
2.1. Geospatial Object Detection
2.2. Contextual Information Fusion
2.3. The RoIAlign Layer
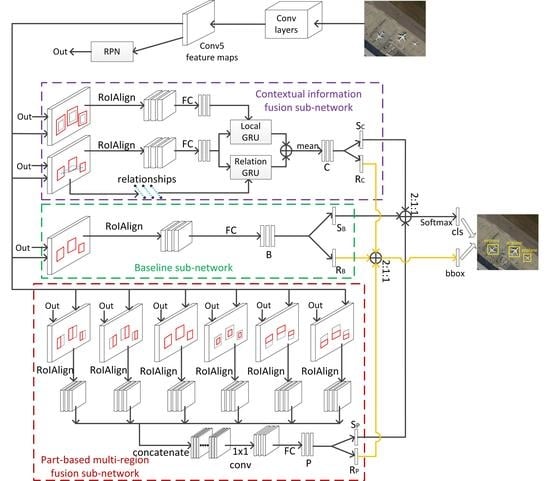
3. Proposed Framework
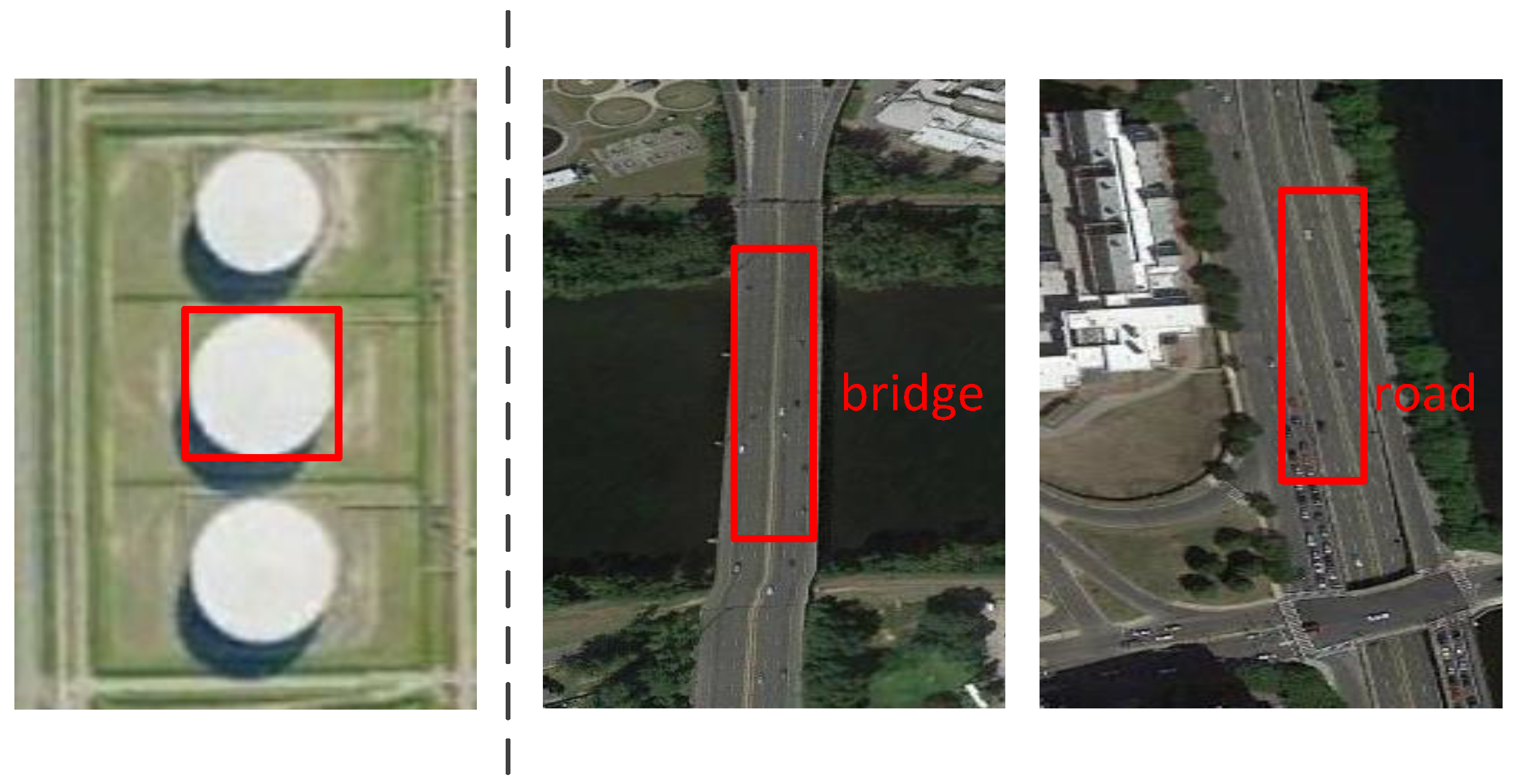
3.1. Local Contextual Information and Object-Object Relationship Contextual Information Fusion Sub-Network
3.2. Part-Based Multi-Region Fusion Sub-Network
3.3. Multi-Model Decision Fusion Strategy
4. Experiments and Results
4.1. Data Set
4.2. Evaluation Metrics
4.2.1. Precision-Recall Curve (PRC)
4.2.2. Average Precision (AP)
4.3. Implementation Details and Parameter Settings
4.4. Evaluation of Local Contextual Information and Object-Object Relationship Contextual Information Fusion Sub-Network
4.5. Evaluation of Part-Based Multi-Region Fusion Network
4.6. Evaluation of Multi-model Decision Fusion Strategy
4.7. Comparisons with Other Detection Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ahmad, K.; Pogorelov, K.; Riegler, M.; Conci, N.; Halvorsen, P. Social media and satellites. Multimed. Tools Appl. 2019, 78, 2837–2875. [Google Scholar] [CrossRef]
- Ahmad, K.; Pogorelov, K.; Riegler, M.; Ostroukhova, O.; Halvorsen, P.; Conci, N.; Dahyot, R. Automatic detection of passable roads after floods in remote sensed and social media data. arXiv, 2019; arXiv:1901.03298. [Google Scholar]
- Sirmacek, B.; Unsalan, C. Urban-Area and Building Detection Using SIFT Keypoints and Graph Theory. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1156–1167. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef]
- Tuermer, S.; Kurz, F.; Reinartz, P.; Stilla, U. Airborne Vehicle Detection in Dense Urban Areas Using HoG Features and Disparity Maps. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2327–2337. [Google Scholar] [CrossRef]
- Shi, Z.; Yu, X.; Jiang, Z.; Li, B. Ship Detection in High-Resolution Optical Imagery Based on Anomaly Detector and Local Shape Feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Gidaris, S.; Komodakis, N. Object Detection via a Multi-region and Semantic Segmentation-Aware CNN Model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1134–1142. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Xiao, Z.; Gong, Y.; Long, Y.; Li, D.; Wang, X.; Liu, H. Airport Detection Based on a Multiscale Fusion Feature for Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1469–1473. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Deformable Faster R-CNN with Aggregating Multi-Layer Features for Partially Occluded Object Detection in Optical Remote Sensing Images. Remote Sens. 2018, 10, 1470. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-Insensitive and Context-Augmented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2337–2348. [Google Scholar] [CrossRef]
- Yang, Y.; Zhuang, Y.; Bi, F.; Shi, H.; Xie, Y. M-FCN: Effective Fully Convolutional Network-Based Airplane Detection Framework. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1293–1297. [Google Scholar] [CrossRef]
- Xu, Y.; Zhu, M.; Li, S.; Feng, H.; Ma, S.; Che, J. End-to-End Airport Detection in Remote Sensing Images Combining Cascade Region Proposal Networks and Multi-Threshold Detection Networks. Remote Sens. 2018, 10, 1516. [Google Scholar] [CrossRef]
- Guo, W.; Yang, W.; Zhang, H.; Hua, G. Geospatial Object Detection in High Resolution Satellite Images Based on Multi-Scale Convolutional Neural Network. Remote Sens. 2018, 10, 131. [Google Scholar] [CrossRef]
- Chen, S.; Zhan, R.; Zhang, J. Geospatial Object Detection in Remote Sensing Imagery Based on Multiscale Single-Shot Detector with Activated Semantics. Remote Sens. 2018, 10, 820. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Z.; Zhong, R.; Chen, D.; Ke, Y.; Peethambaran, J.; Chen, C.; Sun, L. Multilevel Building Detection Framework in Remote Sensing Images Based on Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3688–3700. [Google Scholar] [CrossRef]
- Wang, G.; Wang, X.; Fan, B.; Pan, C. Feature Extraction by Rotation-Invariant Matrix Representation for Object Detection in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 851–855. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, Z.; Wu, J. A Hierarchical Oil Tank Detector With Deep Surrounding Features for High-Resolution Optical Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4895–4909. [Google Scholar] [CrossRef]
- Zhang, W.; Sun, X.; Wang, H.; Fu, K. A generic discriminative part-based model for geospatial object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2015, 99, 30–44. [Google Scholar] [CrossRef]
- Zhang, W.; Sun, X.; Fu, K.; Wang, C.; Wang, H. Object Detection in High-Resolution Remote Sensing Images Using Rotation Invariant Parts Based Model. IEEE Geosci. Remote Sens. Lett. 2013, 11, 74–78. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Qian, X.; Zhou, P.; Yao, X.; Hu, X. Object detection in remote sensing imagery using a discriminatively trained mixture model. ISPRS J. Photogramm. Remote Sens. 2013, 85, 32–43. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Scalable multi-class geospatial object detection in high-spatial-resolution remote sensing images. In Proceedings of the IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 2479–2482. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object Detection in Optical Remote Sensing Images Based on Weakly Supervised Learning and High-Level Feature Learning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3325–3337. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; He, X.; Li, X. Locality and Structure Regularized Low Rank Representation for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 911–923. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef] [Green Version]
- Fei-Fei, L.; Perona, P. A Bayesian hierarchical model for learning natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 2, pp. 524–531. [Google Scholar]
- Zhang, D.; Han, J.; Cheng, G.; Liu, Z.; Bu, S.; Guo, L. Weakly Supervised Learning for Target Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2014, 12, 701–705. [Google Scholar] [CrossRef]
- Xu, S.; Fang, T.; Li, D.; Wang, S. Object Classification of Aerial Images with Bag-of-Visual Words. IEEE Geosci. Remote Sens. Lett. 2010, 7, 366–370. [Google Scholar]
- Han, J.; Zhou, P.; Zhang, D.; Cheng, G.; Guo, L.; Liu, Z.; Bu, S.; Wu, J. Efficient, simultaneous detection of multi-class geospatial targets based on visual saliency modeling and discriminative learning of sparse coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 37–48. [Google Scholar] [CrossRef]
- Li, Z.; Itti, L. Saliency and Gist Features for Target Detection in Satellite Images. IEEE Trans. Image Process. 2011, 20, 2017–2029. [Google Scholar] [PubMed] [Green Version]
- Ma, W.; Zhang, J.; Wu, Y.; Jiao, L.; Zhu, H.; Zhao, W. A Novel Two-Step Registration Method for Remote Sensing Images Based on Deep and Local Features. IEEE Trans. Geosci. Remote Sens. 2019, 1–10. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene Classification With Recurrent Attention of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Nogueira, K.; Fadel, S.G.; Dourado, Í.C.; Werneck, R.D.O.; Muñoz, J.A.V.; Penatti, O.A.B.; Calumby, R.T.; Li, L.T.; dos Santos, J.A.; Torres, R.D.S. Exploiting ConvNet Diversity for Flooding Identification. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1446–1450. [Google Scholar] [CrossRef]
- Wiewiora, E.; Galleguillos, C.; Vedaldi, A.; Belongie, S.; Rabinovich, A. Objects in Context. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar]
- Chen, Q.; Song, Z.; Dong, J.; Huang, Z.; Hua, Y.; Yan, S. Contextualizing Object Detection and Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 13–27. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Wei, Y.; Liang, X.; Dong, J.; Xu, T.; Feng, J.; Yan, S. Attentive Contexts for Object Detection. IEEE Trans. Multimed. 2017, 19, 944–954. [Google Scholar] [CrossRef]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2874–2883. [Google Scholar]
- Chen, X.; Gupta, A. Spatial Memory for Context Reasoning in Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4086–4096. [Google Scholar]
- Liu, Y.; Wang, R.; Shan, S.; Chen, X. Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6985–6994. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar]
- Marcu, A.; Leordeanu, M. Dual Local-Global Contextual Pathways for Recognition in Aerial Imagery. arXiv, 2016; arXiv:1605.05462. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv, 2014; arXiv:1406.1078. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, ND, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C | P | mAP | Airplane | Ship | Storage Tank | Baseball Diamond | Tennis Court | Basketball Court | Ground Track Field | Harbor | Bridge | Vehicle | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C-Gl | C-Lo | C-Re | |||||||||||||
| Faster R-CNN (Baseline) | 0.8980 | 1.0000 | 0.9225 | 0.9415 | 0.9521 | 0.9267 | 0.8429 | 1.0000 | 0.8788 | 0.6899 | 0.8254 | ||||
| ours | √ | 0.9242 | 1.0000 | 0.9106 | 0.9523 | 0.9593 | 0.9554 | 0.9116 | 1.0000 | 0.9235 | 0.7419 | 0.8873 | |||
| ours | √ | √ | 0.9404 | 0.9999 | 0.9184 | 0.9898 | 0.9757 | 0.9545 | 0.9484 | 0.9994 | 0.9497 | 0.7605 | 0.9072 | ||
| ours | √ | √ | √ | 0.9504 | 0.9934 | 0.9227 | 0.9918 | 0.9668 | 0.9632 | 0.9756 | 1.0000 | 0.9740 | 0.8027 | 0.9136 | |
| ours | √ | √ | √ | 0.9264 | 0.9999 | 0.9139 | 0.9618 | 0.9630 | 0.9493 | 0.9424 | 1.0000 | 0.9172 | 0.7051 | 0.9115 | |
| Fusion Ratio | mAP | Airplane | Ship | Storage Tank | Baseball Diamond | Tennis Court | Basketball Court | Ground Track Field | Harbor | Bridge | Vehicle |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1:1:1 | 0.9386 | 1.0000 | 0.9303 | 0.9741 | 0.9740 | 0.9439 | 0.9506 | 1.0000 | 0.9689 | 0.7406 | 0.9029 |
| 1:1:2 | 0.9337 | 1.0000 | 0.9104 | 0.9616 | 0.9617 | 0.9421 | 0.9471 | 1.0000 | 0.9686 | 0.7421 | 0.9032 |
| 1:1:3 | 0.9345 | 1.0000 | 0.9061 | 0.9557 | 0.9748 | 0.9420 | 0.9459 | 1.0000 | 0.9715 | 0.7414 | 0.9079 |
| 1:2:1 | 0.9416 | 1.0000 | 0.9142 | 0.9921 | 0.9758 | 0.9557 | 0.9631 | 1.0000 | 0.9381 | 0.7603 | 0.9169 |
| 1:2:2 | 0.9320 | 1.0000 | 0.8993 | 0.9756 | 0.9528 | 0.9422 | 0.9506 | 1.0000 | 0.9601 | 0.7359 | 0.9033 |
| 1:2:3 | 0.9313 | 1.0000 | 0.9107 | 0.9696 | 0.9438 | 0.9414 | 0.9471 | 1.0000 | 0.9693 | 0.7285 | 0.9031 |
| 1:3:1 | 0.9403 | 1.0000 | 0.9131 | 0.9717 | 0.9774 | 0.9628 | 0.9500 | 1.0000 | 0.9607 | 0.7656 | 0.9012 |
| 1:3:2 | 0.9339 | 1.0000 | 0.9304 | 0.9762 | 0.9512 | 0.9412 | 0.9500 | 1.0000 | 0.9535 | 0.7345 | 0.9022 |
| 1:3:3 | 0.9330 | 1.0000 | 0.9315 | 0.9752 | 0.9583 | 0.9413 | 0.9462 | 1.0000 | 0.9576 | 0.7174 | 0.9028 |
| 2:1:1 | 0.9504 | 0.9934 | 0.9227 | 0.9918 | 0.9668 | 0.9632 | 0.9756 | 1.0000 | 0.9740 | 0.8027 | 0.9136 |
| 2:1:2 | 0.9391 | 1.0000 | 0.9204 | 0.9623 | 0.9743 | 0.9445 | 0.9495 | 1.0000 | 0.9705 | 0.7641 | 0.9053 |
| 2:1:3 | 0.9356 | 1.0000 | 0.9103 | 0.9564 | 0.9748 | 0.9440 | 0.9495 | 1.0000 | 0.9716 | 0.7476 | 0.9015 |
| 2:2:1 | 0.9379 | 0.9999 | 0.8866 | 0.9680 | 0.9661 | 0.9599 | 0.9512 | 1.0000 | 0.9598 | 0.7814 | 0.9059 |
| 2:2:3 | 0.9355 | 1.0000 | 0.9357 | 0.9710 | 0.9373 | 0.9436 | 0.9495 | 1.0000 | 0.9685 | 0.7465 | 0.9032 |
| 2:3:1 | 0.9352 | 1.0000 | 0.9136 | 0.9762 | 0.9621 | 0.9430 | 0.9512 | 1.0000 | 0.9502 | 0.7536 | 0.9025 |
| 2:3:2 | 0.9363 | 1.0000 | 0.9306 | 0.9762 | 0.9646 | 0.9426 | 0.9500 | 1.0000 | 0.9567 | 0.7398 | 0.9029 |
| 2:3:3 | 0.9337 | 1.0000 | 0.9281 | 0.9727 | 0.9436 | 0.9429 | 0.9506 | 1.0000 | 0.9598 | 0.7356 | 0.9032 |
| 3:1:1 | 0.9381 | 0.9934 | 0.9468 | 0.9768 | 0.9660 | 0.9798 | 0.9512 | 1.0000 | 0.9326 | 0.7674 | 0.8671 |
| 3:1:2 | 0.9405 | 1.0000 | 0.9325 | 0.9615 | 0.9741 | 0.9456 | 0.9495 | 1.0000 | 0.9705 | 0.7704 | 0.9014 |
| 3:1:3 | 0.9314 | 1.0000 | 0.8675 | 0.9605 | 0.9735 | 0.9447 | 0.9495 | 1.0000 | 0.9714 | 0.7459 | 0.9016 |
| 3:2:1 | 0.9383 | 1.0000 | 0.9142 | 0.9704 | 0.9734 | 0.9453 | 0.9500 | 1.0000 | 0.9662 | 0.7611 | 0.9023 |
| 3:2:2 | 0.9399 | 1.0000 | 0.9309 | 0.9699 | 0.9746 | 0.9447 | 0.9500 | 1.0000 | 0.9705 | 0.7554 | 0.9029 |
| 3:2:3 | 0.9405 | 1.0000 | 0.9344 | 0.9659 | 0.9740 | 0.9445 | 0.9495 | 1.0000 | 0.9707 | 0.7636 | 0.9029 |
| 3:3:1 | 0.9361 | 1.0000 | 0.9216 | 0.9762 | 0.9601 | 0.9445 | 0.9506 | 1.0000 | 0.9486 | 0.7565 | 0.9027 |
| 3:3:2 | 0.9371 | 1.0000 | 0.9298 | 0.9762 | 0.9676 | 0.9443 | 0.9500 | 1.0000 | 0.9591 | 0.7408 | 0.9033 |
| mAP | Airplane | Ship | Storage Tank | Baseball Diamond | Tennis Court | Basketball Court | Ground Track Field | Harbor | Bridge | Vehicle | Time per Image (Second) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| COPD [31] | 0.5489 | 0.6225 | 0.6937 | 0.6452 | 0.8213 | 0.3413 | 0.3525 | 0.8421 | 0.5631 | 0.1643 | 0.4428 | 1.16 |
| Transferred CNN [58] | 0.5961 | 0.6603 | 0.5713 | 0.8501 | 0.8093 | 0.3511 | 0.4552 | 0.7937 | 0.6257 | 0.4317 | 0.4127 | 5.09 |
| RICNN [17] | 0.7311 | 0.8871 | 0.7834 | 0.8633 | 0.8909 | 0.4233 | 0.5685 | 0.8772 | 0.6747 | 0.6231 | 0.7201 | 8.47 |
| RICAOD [20] | 0.8712 | 0.9970 | 0.9080 | 0.9061 | 0.9291 | 0.9029 | 0.8031 | 0.9081 | 0.8029 | 0.6853 | 0.8714 | 2.89 |
| Faster R-CNN [10] | 0.8980 | 1.0000 | 0.9225 | 0.9415 | 0.9521 | 0.9267 | 0.8429 | 1.0000 | 0.8788 | 0.6899 | 0.8254 | 0.09 |
| ours | 0.9504 | 0.9934 | 0.9227 | 0.9918 | 0.9668 | 0.9632 | 0.9756 | 1.0000 | 0.9740 | 0.8027 | 0.9136 | 0.75 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, W.; Guo, Q.; Wu, Y.; Zhao, W.; Zhang, X.; Jiao, L. A Novel Multi-Model Decision Fusion Network for Object Detection in Remote Sensing Images. Remote Sens. 2019, 11, 737. https://doi.org/10.3390/rs11070737
Ma W, Guo Q, Wu Y, Zhao W, Zhang X, Jiao L. A Novel Multi-Model Decision Fusion Network for Object Detection in Remote Sensing Images. Remote Sensing. 2019; 11(7):737. https://doi.org/10.3390/rs11070737
Chicago/Turabian StyleMa, Wenping, Qiongqiong Guo, Yue Wu, Wei Zhao, Xiangrong Zhang, and Licheng Jiao. 2019. "A Novel Multi-Model Decision Fusion Network for Object Detection in Remote Sensing Images" Remote Sensing 11, no. 7: 737. https://doi.org/10.3390/rs11070737
APA StyleMa, W., Guo, Q., Wu, Y., Zhao, W., Zhang, X., & Jiao, L. (2019). A Novel Multi-Model Decision Fusion Network for Object Detection in Remote Sensing Images. Remote Sensing, 11(7), 737. https://doi.org/10.3390/rs11070737