1. Introduction
Crop type maps deliver essential information for agricultural monitoring and are likewise relevant for other fields such as environmental assessments. Respective classification approaches using Earth Observation (EO) stand to benefit from the availability of high-resolution Sentinel-1 and Sentinel-2 dense time series. Particularly, the synergistic use of these optical and Synthetic-Aperture Radar (SAR) datasets bears high potential. In previous research, single-sensor approaches based on optical and SAR data were used the most to map crop types at different scales. A larger share of research was based on optical data [
1,
2,
3,
4,
5]. The classification of crop types using only SAR data has also been successfully implemented in several studies [
6,
7,
8,
9]. Optical data that makes use of the visible, near-infrared, and short-wave-infrared portion of the electromagnetic spectrum, provides valuable information about leaf pigments, water content, and plants’ overall health condition.; whereas SAR data, dependent on the frequency and polarization, delivers a complex representation of canopy structure, surface roughness, soil moisture, and topography [
10].
The first studies that focused on optical-SAR data fusion date back to the 80s [
11,
12]. However, starting from 2000, the number of studies on this topic gradually increased, which can be partially explained by the launch of new space-borne radar (ERS, RADARSAT, ENVISAR, ASAR, etc.) and optical (Landsat, SPOT, IRS, MODIS, QuickBird, etc.) satellites [
13]. The launch of Sentinel-1 (2014/2016) and Sentinel-2 (2015/2017), operated by the European Space Agency (ESA), boosted the interest in using these freely available SAR and optical datasets for crop type mapping in a synergistic way. Optical and SAR data’s complementary nature gives the possibility to simultaneously utilize information on plants’ structural and bio-physical conditions. This explains that most previous fusion studies reported improvements in crop classification accuracy when optical and SAR data were combined compared to single sensor experiments [
14,
15,
16]. Commonly, optical-SAR fusion studies used several cloud-free optical and available SAR scenes for their studies [
13]. The use of dense time-series of both became more common in recent studies [
17,
18]. However, for large-scale studies, it is still a challenge to combine these two datasets since vast volumes of diverse datasets demand higher processing power and resources.
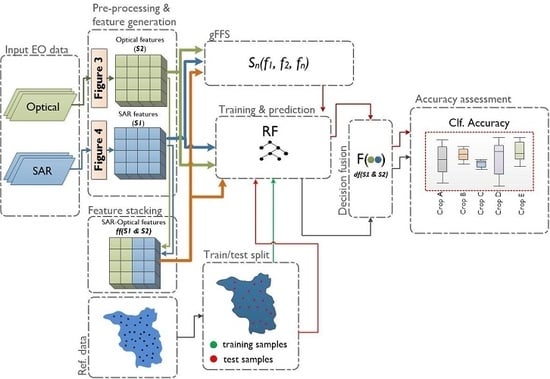
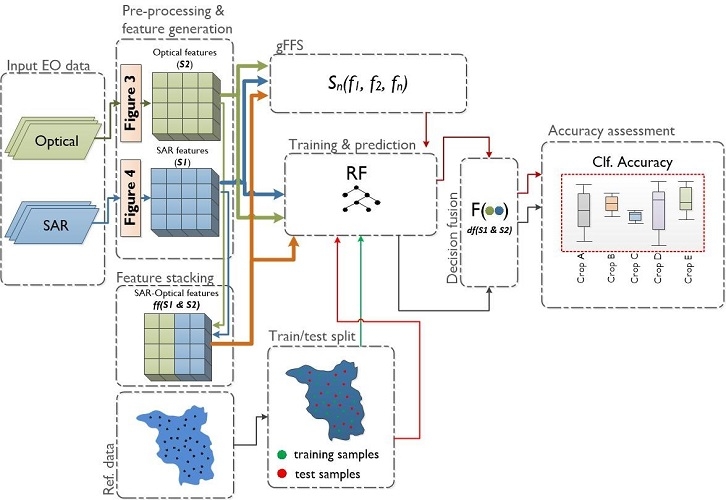
There are three primary data fusion levels: pixel-level, feature-level (further, feature stacking), and decision-level [
19] (for details see
Section 2.4.1). Among crop type classification studies, Gibril et al. [
20] compared pixel-level fusion techniques (Brovey Transform, Wavelet Transform, Ehlers) with feature stacking results. To the best of our knowledge, the comparison between optical-SAR feature stacking and optical-SAR fusion at decision-level was not subject to any study even though decision fusion was successfully applied [
21]. Multi-sensor feature stacking may result in high dimensional feature space, which may negatively affect the classification accuracy. While decision fusion, based on classification confidences derived from single sensor predictions, might profit from less complex models. It could be valid to expect that optical-SAR fusion at the decision-level could be more performant than simple feature stacking. To test this hypothesis, in this study, we compare the classification results derived from optical-SAR feature stacking and optical-SAR fusion at decision-level (further, decision fusion).
Combining dense optical and SAR time series features can quickly result in a high-dimensional feature space that can pose challenges for pattern recognition and machine learning. In terms of classification accuracy, earlier methods such as the parametric maximum likelihood classifier are more susceptible to high-dimensional feature spaces than to state-of-the-art classifiers, such as Support Vector Machines and Random Forest (RF). Nevertheless, studies have shown that these classifiers’ accuracy can also be increased by feature selection [
22], particularly when the amount of training samples is limited [
23]. Elaborated pre-processing, feature generation, and selection of suitable features are needed for many classification algorithms. Commonly derived features as spectral-temporal variability metrics [
24], time-weighted interpolation [
5], or computationally more expensive approaches such as time-weighted dynamic time warping [
25] are being used less often for large-scale applications. This happens probably due to, among other reasons, high computational complexity, particularly over very large areas.
Feature selection methods have a long tradition in pattern recognition analysis of remote sensing data [
26,
27], alleviating the challenges mentioned earlier. It helps to train more accurate models, decrease computational complexity, and improve the understanding of the used features [
28,
29]. Data and model understanding is essential in the development of operational products [
30] and in scientific research where feature importance and rankings are often essential elements [
28,
31,
32]. The main groups of feature selection are filters and wrappers methods [
33]. Filter methods use various statistical measures (e.g., Chi-square test, Pearson’s correlation) to score the relevance of features. Whereas, wrapper methods perform feature selection based on the chosen classifiers’ performance, which enables to select most performant features with low correlation. The main drawback of the wrapper approaches is the high computational costs. In crop type classification studies, embedded methods such as classifier specific RF feature importance is often used to select the most important features [
34]. It is a fast approach, but a drawback is that features with correlating information content can show similarly high importance scores.
To alleviate the limitations of wrapper methods concerning high computing efforts, in this study, we perform a group-wise forward feature selection (gFFS). gFFS allows focusing the analysis and interpretation on useful feature sets like spectral bands, vegetation indices (VIs), or data acquisition dates (for details see
Section 2.4.3). A similar approach was followed by Defourny et al. [
35]. The grouping strategies of features in the gFFS have two important benefits: (1) gFFS allows to tailor the feature selection towards better interpretability and supports a more efficient feature selection process. For example, the time-steps with most discriminative power can be better analyzed by considering all information available at a particular time-step as a group and not only as single features. (2) gFFS allows the substantially reduced computational time of the feature selection step while considering all features at hand.
In addition to an appropriate feature selection, the quality of the satellite data features concerning data availability and gaps are crucial aspects that can influence classification accuracy. Croplands are typically characterized by management activities such as tilling, sowing, and harvesting or cutting and are, therefore, amongst the most dynamic land cover elements. Their successful identification via remote sensing data often requires dense time-series information capable of capturing critical plant development phases and the mentioned land management activities [
36]. The comparison of seasonal, monthly composites, and gap-filled Harmonized Landsat and Sentinel-2 [
37] time-series (10-days interval) data by Griffiths et al. [
4] showed that the highest classification performance was achieved with gap-filled 10-day time-series data. However, the quality of the gap-filled data depends on the duration and number of gaps. Gaps originate mainly from cloud cover, cloud shadows, and other atmospheric effects from which optical data are often suffering. In this sense, combining dense time series of SAR features and gap-filled optical data could result in more accurate classifications.
In summary, despite the large number of studies focusing on the combination of optical and SAR features for crop type mapping, the following aspects were not sufficiently investigated: (1) combined performance of a comparably high number of relevant Sentinel-2 and Sentinel-1 dense time-series features for larger areas covering more than one sensor swath, where the derivation of spatially homogeneous features across all the study area is required; (2) impact of optical-SAR feature stacking and decision fusion on classification accuracies; (3) analysis and interpretation of feature importance and ranking based on dates, bands, and VIs instead of single features and their effect on classification accuracies; (4) the performance of respective classification approaches to differentiate 16 crop types; (5) analysis of the influence of the optical data availability, parcel size, and pixel location within the parcel on the classification results.
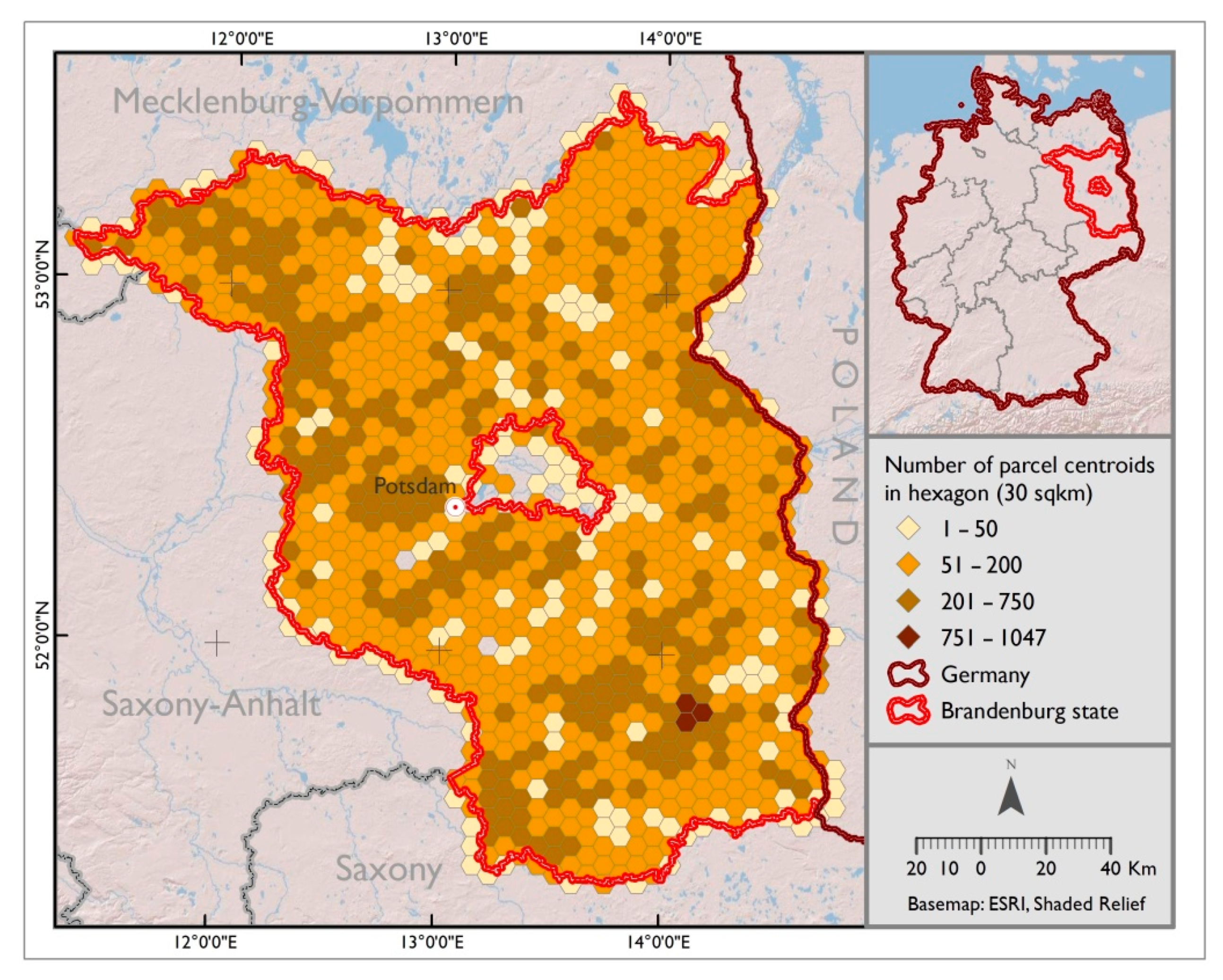
This study aims to contribute to these open issues by evaluating how the synergetic use of dense optical and SAR time-series data derived from Sentinel-1 and Sentinel-2 improves the classification accuracy of typical crop types of Central Europe. The study site covers the Brandenburg state, located in northern Germany. In this context, we investigate how a large number of optical and SAR features affect the performance of RF models and evaluate the relevance of various feature-sets and time-steps to the classifier. It is also analyzed how agricultural parcel size, mixed pixels occurrence at parcel borders, and the non-availability of optical satellite data at specific dates of the year affect the classification accuracy. More explicitly, the following questions were addressed:
How do the usage of single-sensor dense time-series data and the fusion of Sentinel-1 and Sentinel-2 data affect the classification accuracy? Do classification accuracies based on optical-SAR feature stacking differ from decision fusion?
How does a high dimensionality of optical-SAR feature stack impact on the performance of RF? Which features are most relevant, and which dates and bands or VIs lead to the highest accuracies?
What is the influence of cloud-related gaps in optical data, how do parcel sizes, and the pixel location within a parcel affect classification accuracy?
3. Results
3.1. Classification Accuracies (Overall and Class-Specific)
The f1-scores obtained from the predictions based on all features and the best-performing feature subsets selected using time-wise gFFS and variable-wise gFFS are shown in
Table 2. The gFFS did not have any effect on the accuracy values for the experiments based on only SAR features (
S1), optical features (S2), and decision fusion (
df(S1&S2)). The decrease of f1-score by only 0.01 was recorded with time-wise gFFS for experiments based on optical-SAR features stacks (
ff(S1&S2)). Also, in the class-specific accuracies, no significant changes were recorded (
Supplementary Materials B). Based on these outcomes, we continue reporting classification accuracies based on the results when all the existing features were used.
The f1-score of the predictions based on S2 and S1 was equal to 0.61 and 0.67, respectively, without class-grouping. After grouping cereal and legume classes, f1-score derived from S2, and S1 classifications increased to 0.73 and 0.76, respectively. There was no significant difference in the mean precision and recall values for single sensor experiments (S2: precision—0.62, recall—0.61; S1: precision—0.68, recall—0.67).
The classifications based on ff(S1&S2) resulted in an f1-score of 0.72 with a precision of 0.73 and a recall of 0.72 without class-grouping. Decision fusion showed similar results (f1-score—0.71, precision—0.72, recall—0.72). Considering the grouped cereal and legume classes, f1-scores of both fusion approaches increased to 0.81, 0.80 for ff(S1&S2) and df(S1&S2) accordingly. Thus, both considered fusion approaches outperformed the single sensor accuracies.
Figure 7 gives an overview of the class-specific accuracies for a single sensor and fused feature results. In general, class-specific accuracies showed higher diversity compared to overall accuracies. Winter rape and sugar beet classes showed the best accuracy results (f1-score > 0.90), with only minor differences between the used sensors or fusion types.
Most crop types showed the highest accuracies when using
ff(S1&S2), and were better classified with
S1 compared to
S2. For example, this applies to all winter cereals (winter rape, winter wheat, winter rye, winter barley, and winter triticale) with f1-scores > 0.70. The same pattern could be seen for summer cereals (summer barley and summer oat) and potatoes. Nevertheless, f1-scores remained below 0.6 for both summer cereals. Potatoes and maize had the highest f1-score with
ff(S1&S2), which were 0.75 and 0.79. For classes such as sunflowers, lupins, and peas-beans, the performance of models built using
S1 was quite close to the performance of the models built using
ff(S1&S2) (f1-scores: ∆ = 0.03, ∆ = 0.03, ∆ = 0.01, accordingly) while using
S2 resulted in slightly lower accuracies (f1-scores: ∆ = 0.18, ∆ = 0.21, ∆ = 0.19, accordingly). In contrast, the two considered grassland classes had higher classification accuracies when using
S2 (f1-scores: temporal grasslands—0.42, permanent grasslands—0.62) compared to
S1 (f1-scores: temporal grasslands—0.38, permanent grasslands—0.51). This can also be seen from the map presented in
Figure 8. Nonetheless, for these classes, the maximum accuracy score is reached with fused datasets (f1-scores
ff(S1&S2): temporal grasslands—0.45, permanent grasslands—0.64).
Permanent and temporal grasslands had a high within-group confusion rate (
Figure 9). The test samples of legume mixture and temporal grasslands were often predicted as permanent grasslands, reflecting low precision and high recall values. Maize samples were often predicted correctly (recall = 86), but false predictions of sunflower, potato, and lupin samples as maize affected the precision, which was equal to 73. Summer and winter cereals formed two groups with high intra-group confusion. For winter cereals, higher confusion was present among classes such as winter wheat, winter rye, and winter triticale. Whereas, summer cereals were not only confused within the group but also often were classified as one of the legume classes. The confusion between summer cereals and legume classes are higher when using only optical feature compared to SAR only features.
Supplementary Materials C includes all confusion matrices for all experiments.
After combing summer barley and summer oat (which were heavily confused, see
Figure 10) into a single class of summer cereals, the f1-score increased to 0.78 with
ff(S1&S2) (
Figure 8). The classes lupins, peas-beans, and legume mixture, when grouped to one legumes class, got the highest f1-score of 0.77 with
ff(S1&S2). The f1-score of class winter cereals raised above 0.90 with
ff(S1&S2) after grouping. However, when merging classes, the general pattern, that optical-SAR feature combination and decision fusion were outperforming single sensor information, remained unchanged.
3.2. gFFS Rankings and Feature Importance
The RF model with the highest accuracy (f1-score: 0.7) was achieved using a variable-wise gFFS at the 5th sequence with 100 features with
ff(S1&S2) (
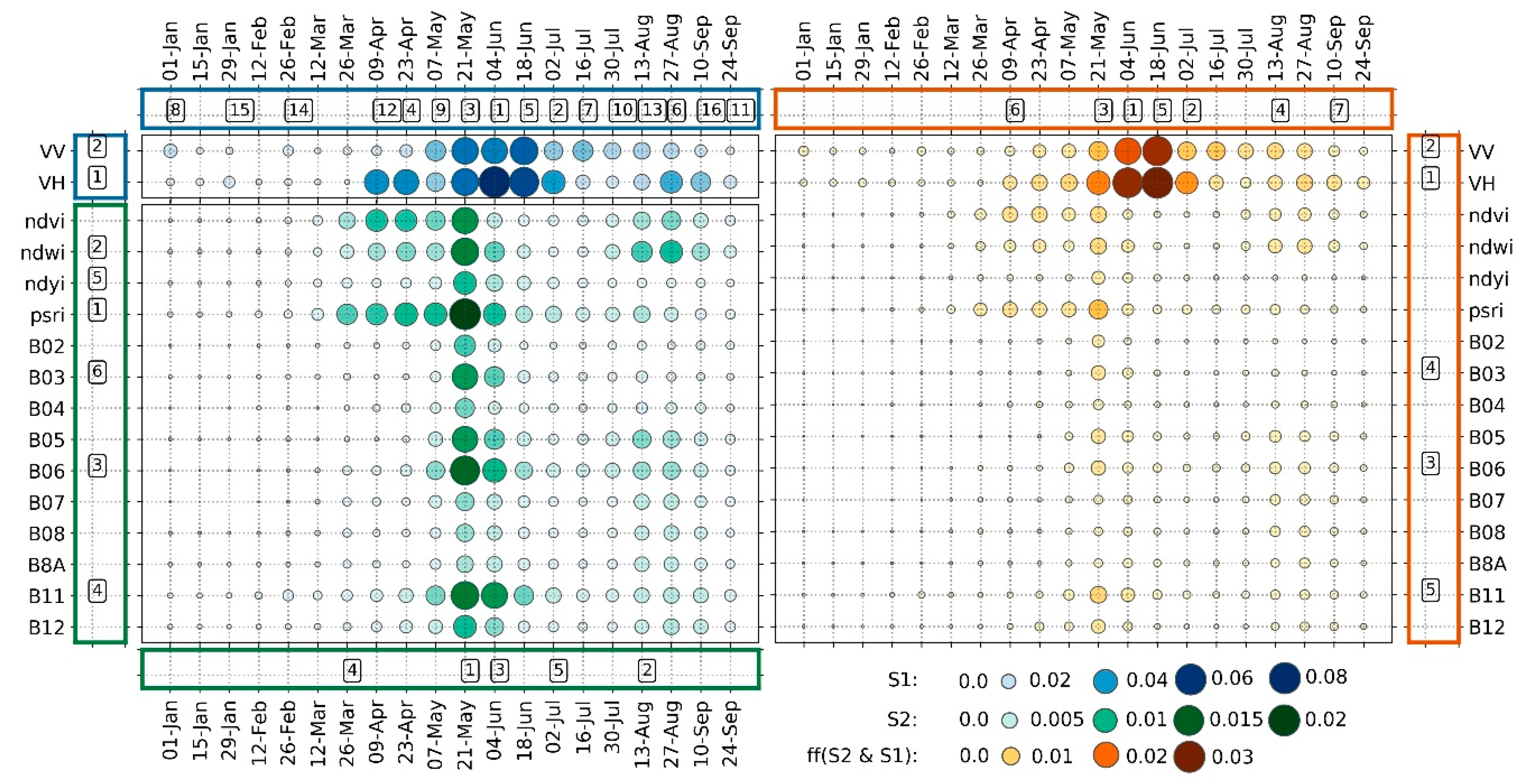
Figure 11). By variable-wise gFFS, the full time-series of VH, VV, red-edge (B06), green (B03), and SWIR (B11) were identified as the most performant feature-sets (
Figure 12, border axis). The f1-score difference at the point with the maximum performance (100 features) and the last sequence (320 features) was only 0.01.
The time-wise gFFS showed the maximum performance (f1-score: 0.69) with 112 features at the 7th sequence with
ff(S1&S2). The dates chosen as being most crucial by time-wise gFFS are shown in the border axis of
Figure 12. No significant difference was observed between the maximum performance value and the f1-score at the last sequence with 320 features (∆ = 0.001).
When applied to only optical features, time-wise and variable-wise gFFS showed identical maximum accuracy results with f1-score of 0.58. The difference was in the number of features, where time-wise gFFS peaked at the 5th sequence with 70 features, and variable-wise gFFS peaked at the 6th sequence with 120 features.
The use of both, VH and VV feature-sets (40 features), showed the highest performance (f1-score: 0.65) of the variable-wise gFFS when applied to only SAR features. The maximum performance (f1-score: 0.66) of the time-wise gFFS for VV and VH features was achieved at the 16th sequence.
The RF importance scores derived from the RF models trained using optical (greens), SAR (blues), and optical-SAR feature stack (orange-brown) are illustrated in
Figure 12. The experiments using only SAR features showed that data from April until mid-September were the most valuable for the classifier. The highest importance scores were given to the features acquired in June when the majority of crops are close to their full development stage. The results of those experiments that were based on only optical features showed that information obtained from three VIs (psri, ndwi, ndvi), red-edge (B06), and SWIR (B11) bands had higher importance scores compared to other features. The features acquired at the end of May had a distinct significance to the classifier. When optical and SAR data were used simultaneously, SAR features received higher ranking compared to optical features. Notably, none of the VIs were selected by variable-wise gFFS when using the stacked features.
3.3. Potential Influences of Parcel Size, Optical Data Availability, and Pixel Location within the Parcel on the Classification Accuracy
For mis- and correctly-classified pixels, we analyzed the information on parcel sizes, the distance of pixels to parcel borders, optical data availability, their NDVI, and VH temporal profiles to assess their influence classification outcomes.
Except for winter triticale and winter rye, all crops with f1-score below 0.70 at
ff(S1&S2) have average field sizes below 9 ha (see,
Table 1). Among winter cereals, winter triticale and winter rye have the smallest average parcel sizes.
Figure 13 shows, for each class, the distribution of field sizes of correctly and incorrectly classified pixels. For most classes, the parcel size distribution of correctly classified records is much broader than from misclassified records. Also, differences in medians suggest that pixels coming from large parcels were more often correctly classified. The medians’ differences derived from the parcel size distributions of correctly and misclassified records are smaller for the classes with the smallest average parcel sizes. For example, classes such as permanent grasslands (0.29 ha), temporal grasslands (0.33 ha), winter rye (0.85 ha), summer oat (1.03 ha), lupins (1.71 ha) show differences in medians of less than 2 ha. Whereas the highest differences in median parcel sizes were recorded for the following classes: winter wheat (7.44 ha), winter rape (6.15 ha), winter barley (5.80 ha), potatoes (5.14 ha), and peas-beans (5.12 ha).
The variations of f1-scores depending on a pixel’s distance to parcel border are illustrated in
Figure 14. Plots for all remaining crop types can be found in
Supplementary Materials E.
As can be seen from
Figure 14, border pixels have lower accuracy than those located 6–8 pixels away from the parcel borders. Predictions based on only optical features seem to have a higher variation of f1-scores even for classes with overall high accuracy values (e.g., winter rape, peas-beans, sunflowers) except for maize and sugar beets classes (see
Supplementary Materials E). The classifications based on optical-SAR stacked features and decision fusion, in most of the cases, showed the highest accuracy, even for mixed pixels close to parcel border, compared to classifications based on one sensor only.
As various atmospheric conditions can considerably influence optical data quality, the effect of optical data availability on the classification accuracy was assessed based on the invalid pixel mask (see
Section 2.3.1.). We analyzed monthly optical data availability for correctly classified and misclassified pixels predicted by
S2 (
Figure 15). Further plots showing all crop types are available as
Supplementary Materials F.
Correctly predicted pixels have, on average, more valid optical observations compared to misclassified pixels. For example, the class maize had the highest difference in optical data availability for correctly and incorrectly classified pixels in May and August. In May, 94.4% of the correctly predicted pixels had one or more valid optical observations, whereas for misclassified pixels, this number was equal to 65.2%. In August, only 20.1% of all misclassified maize test pixels had one or more valid optical observations, while for the correctly classified pixels, it was 70%. For winter cereals, the maximum differences in the percentages occurred in July for winter barley and winter triticale; in May for winter rape and winter rye, in August for winter wheat. No significant differences were observed for summer cereals, temporal grasslands, and legume classes. In August, the difference for correctly- and misclassified pixels was the highest for classes such as sugar beets (77.1% vs. 37.6%), potatoes (58.9% vs. 38.2%), and sunflowers (41.2% vs. 21.3%). Consequently, such optical data scarcity influenced the temporal profile curves.
NDVI temporal profiles of mis- and correctly classified samples deviate considerably in the month, where we also observed large differences in optical data availability reported in the previous paragraph (
Figure 15). Optical data scarcity can also be seen from the NDVI temporal profiles of misclassified and correctly classified pixels (
Figure 16).
Supplementary Materials G gives an overview of NDVI temporal profiles for all crop types. The months when misclassified pixels had the lowest amount of valid optical observations, apparent discrepancies in the NDVI curves can be identified. For example, the lowest percentage of optical data availability for misclassified pixels in August (
Figure 15) is reflected in the lower NDVI values in August for the class maize. Surely, climatological, meteorological, and biological factors should also be taken into account when interpreting the alterations seen in these NDVI profiles. Smaller differences were present between the VH temporal profiles of correctly- and misclassified pixels (
Figure 16). These profiles are presented in
Supplementary Materials H.
4. Discussion
We evaluated the classification accuracies of RF models built using dense time-series features of only optical data (Sentinel-2), only SAR data (Sentinel-1), their combination, and decision fusion. Time-wise and variable-wise gFFS was employed to investigate the relevance of specific bands, Vis, and time-steps. To understand further influences on misclassifications, we additionally analyzed parcel sizes, optical data availability, and pixel distance to polygon borders.
The results acquired for the example of Brandenburg (year 2017) showed that the combination of optical and SAR features and decision fusion leads to better overall classification accuracy (f1 score: 0.81) compared to single-sensor approaches. These findings are in line with several previous studies [
57,
58,
59]. In the presented study, no significant differences in accuracy were found between optical-SAR feature-stacking and decision fusion. When considering class-specific accuracies, several crop types were classified more accurately with only SAR features (e.g., lupins, peas-beans), while fewer crop types showed higher accuracies when using only optical features (e.g., permanent grasslands, sugar beets). However, in most cases, crop-specific accuracy based on a combination of sensors was insignificantly higher than the better-performing single sensor accuracy. Respectively, the increase of overall accuracy in the fusion approaches is an expected consequence as each target class could achieve higher accuracies using best performing optical or SAR features. These results suggest that if the remote sensing data availability for the study region is not a subject of concern, the decision to use optical-SAR fusion or single sensor data should be considered depending on the crop types being investigated. Data fusion is an attractive option for the classification of a broad range of diverse crop classes, but it also comes with more significant computational expenses.
For the majority of investigated classes, classification accuracies derived from only SAR features showed higher values compared to only optical features. These results are contrasting to those where the performance of optical features was higher than SAR [
16,
18]. However, several reasons can serve as a possible explanation for these outcomes. First, a large number of crop classes show similar phenological patterns. Existing crop type mapping studies often focus on few and partly merged classes such as maize, grasslands, winter cereals (one class), summer cereals (one class), and sugar beets. These classes have distinct phenological development profiles, which are well reflected in optical data. As our grouped class-specific accuracy showed (
Figure 10), the accuracy values based on only optical features increases when both cereals and legumes are grouped into single classes. Nonetheless, when predicting individual cereal classes, the SAR data were more successful in capturing the important short term differences in phenological development phases (see
Supplementary Materials H, for VH temporal profiles) for those crops which optical data could not separate (see
Supplementary Materials G, for NDVI temporal profiles). We assume that this is most likely due to the data gaps in optical data. It surely depends on the quality and amount of optical and SAR data used for feature generation, as seen in [
17]. Second, in the presented study, we focus purely on the crop type classification, but no other land cover class was considered. The majority of crop type mapping studies often include land cover and land use classes such as urban areas, water bodies, forest, etc. e.g., [
4,
17,
21]. When differentiating, e.g., maize pixels from water, built-up, or forest pixels, it could be the case that optical features are more relevant for the classifier rather than SAR features.
When looking at
Figure 11, we may notice that the feature learning curve of
S2 has a higher starting point than
S1. However, with the increasing number of grouped features, the accuracy for
S1 increases much stronger than the accuracy of
S2. It could, thus be concluded that single optical features are more informative than single SAR features; nevertheless, dense time-series of SAR data are able to reach higher accuracies compared to dense time-series of optical features.
No significant accuracy differences were recorded among classifications based on full time-series data (320 features) and their subsets selected using gFFS. This supports that RF algorithm is robust to a large number of input features as stated also by other authors [
34]. However, it is also shown that dimensionality reduction of input features improves the stability of RF classification accuracies [
60]. Only in the last sequences of gFFS, we recorded an insignificant decline in accuracies (f1-score: ∆ = 0.01). But at the same time, the gFFS proved that based on a selection of the most relevant feature subsets (here: 120 features), it was possible to reach the peak accuracy.
Feature selection is used not only to improve the classification accuracy but also to better understand and interpret the input dataset [
29,
31,
32], leading to explainable classification outcomes [
28]. In this context, combining the information of RF feature importance and the rankings of the gFFS allows more profound insights into the relevance of individual features and groups of features for mapping typical crop types of Germany. It enables the identification of features that have high RF feature importance values but are correlated with other features in their information content. For example, many
S2 based features of 21 May show very high RF feature importance values. However, many of these features are not needed to reach maximum accuracy with the gFFS (see
Figure 12). Thus, their information content for the classification must be highly correlated with one of the already-selected features. Similarly, the RF feature importance of the psri from 9 April, 23 April, and 7 May are high, but they are not needed to reach maximum accuracy in case of time-wise gFFS on
S2. Instead, the date 2 July is selected where the Gini feature importance is relatively low for all single features. However, concerning the information already selected in previous sequences, it seems to include some unique additional details. The combination of this information shows a certain limitation of the RF feature importance when the goal is to select a minimum of features with the maximum amount of information for the classification tasks. It also shows that the combination of both feature relevance information sources (Gini feature importance and gFFS ranking) increases the understanding and insight in feature relevance.
Group-wise FFS allowed to substantially reduce the computational costs of a feature selection step while receiving meaningful outcomes. Usage of such feature grouping strategies could be an alternative choice for studies where computational expenses of feature selection were considered as one of the main challenges [
22,
61]. For studies investigating the spatial-temporal transferability of machine learning models [
62,
63], where the feature selection methods as FFS were extensively used, the application of gFFS might make this process more performant in large input feature-set cases.
The feature learning curve of time-wise gFFS applied on optical-SAR feature combination (
Figure 11) shows high accuracy increases in the first five sequences, which correspond to 4 June, 2 July, 21 May, 13 August, and 18 July (
Figure 12). These time frames cover critical phenological phases such as full stem development of most of the cereals, flowering, and land management events like harvest and hay cut. The following two time-steps, 9 April and 10 September improved the f1-score only by 0.01 each. According to the German National Weather Service data [
39], these two time-steps are associated with significant plant height development for winter cereals. As for summer crops, it is the phase of the first plant emergence above ground. The beginning of September is a time of harvest for classes such as maize, sunflowers, and pre-harvest phase for sugar beets. Thus, all time steps selected by time-wise gFFS reflect significant phenological developments or management actions on the ground. The results we acquired from time-wise gFFS and RF feature importance scores enable us to infer that the temporal coverage from the beginning of April until the end of September is sufficient to classify the classes under consideration, including winter cereals in our study region.
The results of variable-wise gFFS (
Figure 12) applied on the optical-SAR combination, together with our results on the comparison of single-sensor performances (
Section 3.1.), showed the high importance of SAR features. These outcomes were reaffirmed by the highest RF importance scores of VH and VV. This result was different from the findings of some studies, where optical features turned out to be more relevant for crop type classification [
16,
18]. In our variable-wise gFFS results, VH and VV were followed by the red-edge band (B06) as the next most relevant feature set. A recent study by Griffiths et al. 2019 [
4] also pointed out that adding the red-edge band to other optical bands improved crop-specific accuracy while it had a lower impact on the accuracy of non-cropland cover classes. The last feature sets that finally raised the feature learning curve to maximum were the green and SWIR bands, which improved the f1-score by only 0.01 each (
Figure 11). This supports the finding of previous studies stating that green and SWIR bands also contain important information for crop type mapping tasks [
64].
The crop-specific accuracies were influenced by the parcel sizes (
Figure 13). The results showed that classes with small average parcel sizes (
Table 1) were classified with lower f1-scores. This issue was similarly discussed in recently published studies [
3,
65]. One of the reasons for this effect is the influence of mixed pixels at parcel borders. Often, small parcels have elongated shapes, which would result in an increased number of mixed pixels. As it was seen from
Figure 14, in the majority of cases (all except sugar beets and winter rape), border pixels were classified with lower accuracies almost until the 4th pixel away from parcel border. However, some studies successfully employ information from mixed pixels in their classification tasks [
66].
Apart from the effect of border pixels, differences in the field management practices (e.g., tillage practices, fertilization, time, and frequency of weeding, water management) for small and large parcels certainly influence the spectral response. Based on this, we explicitly built our sampling strategy in a way that all training and testing pixels were equally distributed among all polygons. We assumed that the differences in classification accuracy for large and small parcels could have been bigger if we had not adjusted our sampling strategy.
It was also shown how optical data availability affected the performance of the classifier. As we saw from
Figure 15 (for all crop types, see
Supplementary Materials F), predictability of all crop types suffered from a scarcity of optical observations. Nonetheless, some crops appeared to be more sensitive to the lack of optical data at specific months. For example, for the winter rape, it was May, which was associated with the flowering phase. The high RF importance scores (
Figure 12) of feature ‘21 May’ in the experiments based on only optical features could also be explained by the optical data availability, as the number of optical observations was much higher in May compared to all other months (
Figure 15). Therefore, it is suggested to consider the aspect of data availability when concluding the importance of specific features or time-steps.
Further steps could include testing spectral-temporal variability metrics such as medians, percentiles of optical and SAR features. The spatial transferability of machine learning models would also be considered in future research.
5. Conclusions
The present study investigated the advantages of using the fusion of optical (Sentinel-2) and SAR (Sentinel-1) dense time-series data over the single sensor features. The importance of the features was evaluated using variable- and time-wise grouped forward feature selection (gFFS). Additionally, the effects of optical satellite data gaps and parcel size were analyzed to understand the reasons for misclassifications.
The classification accuracy based on only SAR features outperformed those based on optical features alone. Optical-SAR feature stacking showed the highest accuracies, while no significant difference was found between feature stacking and decision fusion.
The combined assessment of feature ranking based on gFFS and RF feature importance enabled a better interpretation of the results and selecting the most relevant features from both data sources. The question of selecting time-steps with most discriminative power for a classification task is better analyzed by considering all the information available at a particular time step compared to single features.
With optical-SAR feature combination, the peak accuracy of the RF model was achieved when using the full time-series of VH, VV, red-edge (B06), green (B03), and short-wave infrared (B11) bands. As for temporal information, the classifier’s performance was the highest when the full feature-sets acquired on 9 April, 21 May, 4 June, 2–18 July, 13 August, and 10 September were used.
The analysis of the parcel sizes showed that these had a high impact on classification accuracies. Crop classes with a large number of small parcels are harder to classify than large parcels. One reason for this is that border pixels had lower classification accuracy than those in the center of the agricultural parcels.
Also, it was shown that for most of the crop classes, the classification accuracy drops when a lower amount of valid optical observations is available at specific months.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}