Full Convolutional Neural Network Based on Multi-Scale Feature Fusion for the Class Imbalance Remote Sensing Image Classification

 ,
,
Abstract
:
1. Introduction
- (1)
- The improved DeepLab V3 + image segmentation model facilitates the alleviation of samples imbalance problem by proposed function-based solution.
- (2)
- Mixed precision mode was introduced into training for the improvement model training efficiency, and it performed well.
- (3)
- The experimental results on self-constructed dataset and GID dataset show the proposed model obtains significant performance when compared with existing state-of-the-art approaches.
2. Materials and Methods
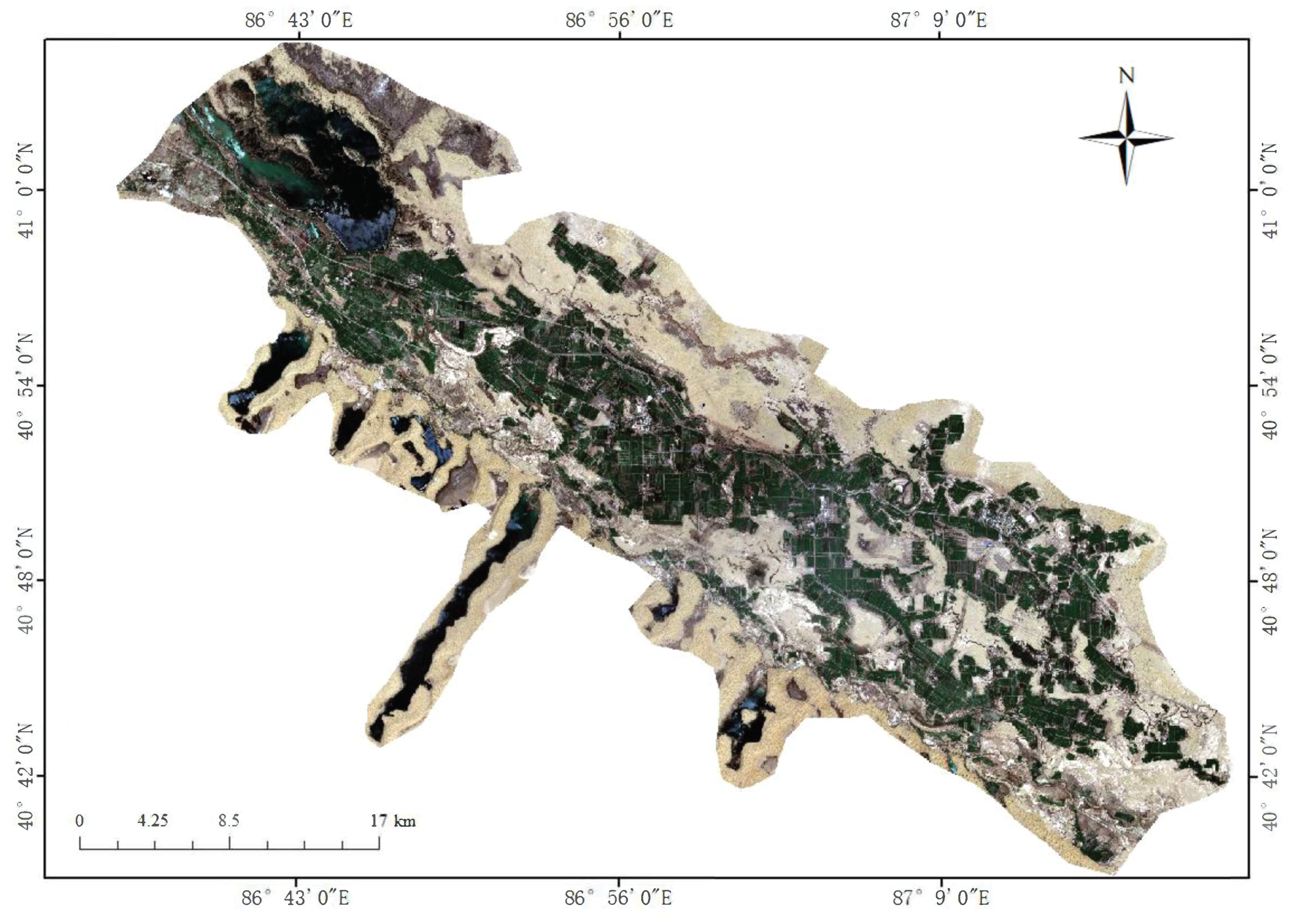
2.1. Study Area
2.2. Data and Samples
2.3. Dataset Preparation
2.4. Data Set Sample Distribution
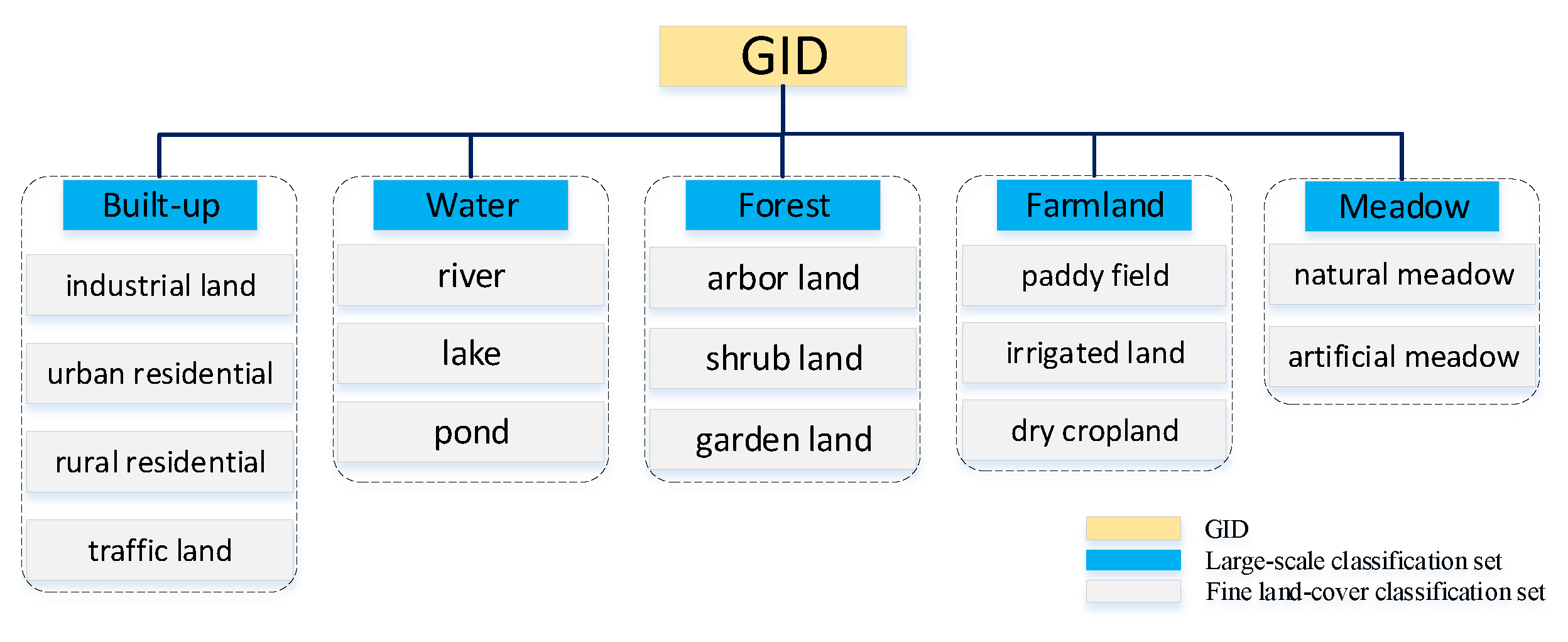
2.5. GID Dataset
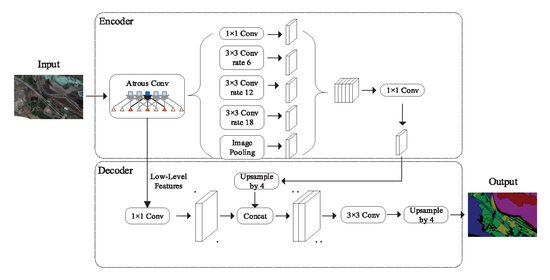
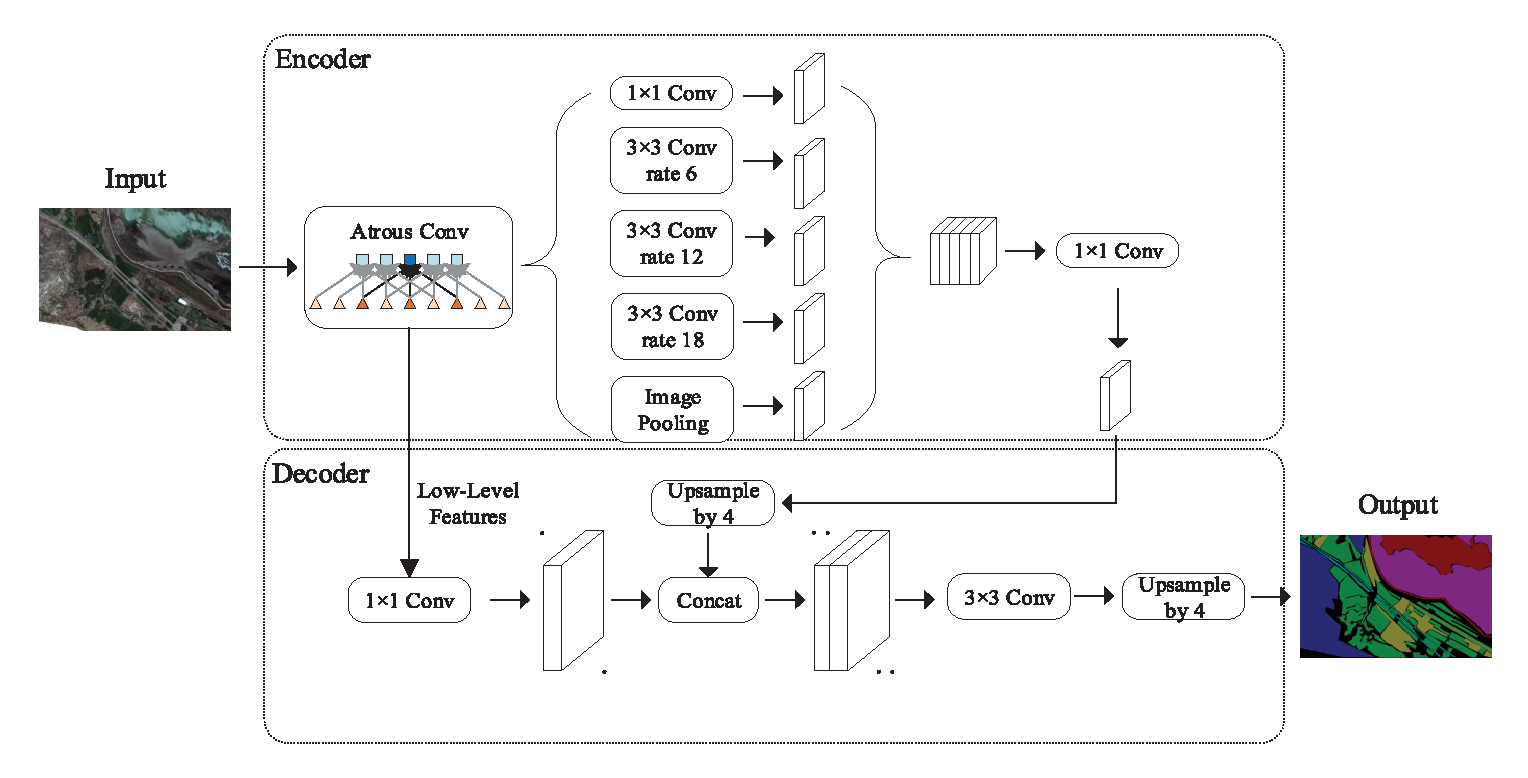
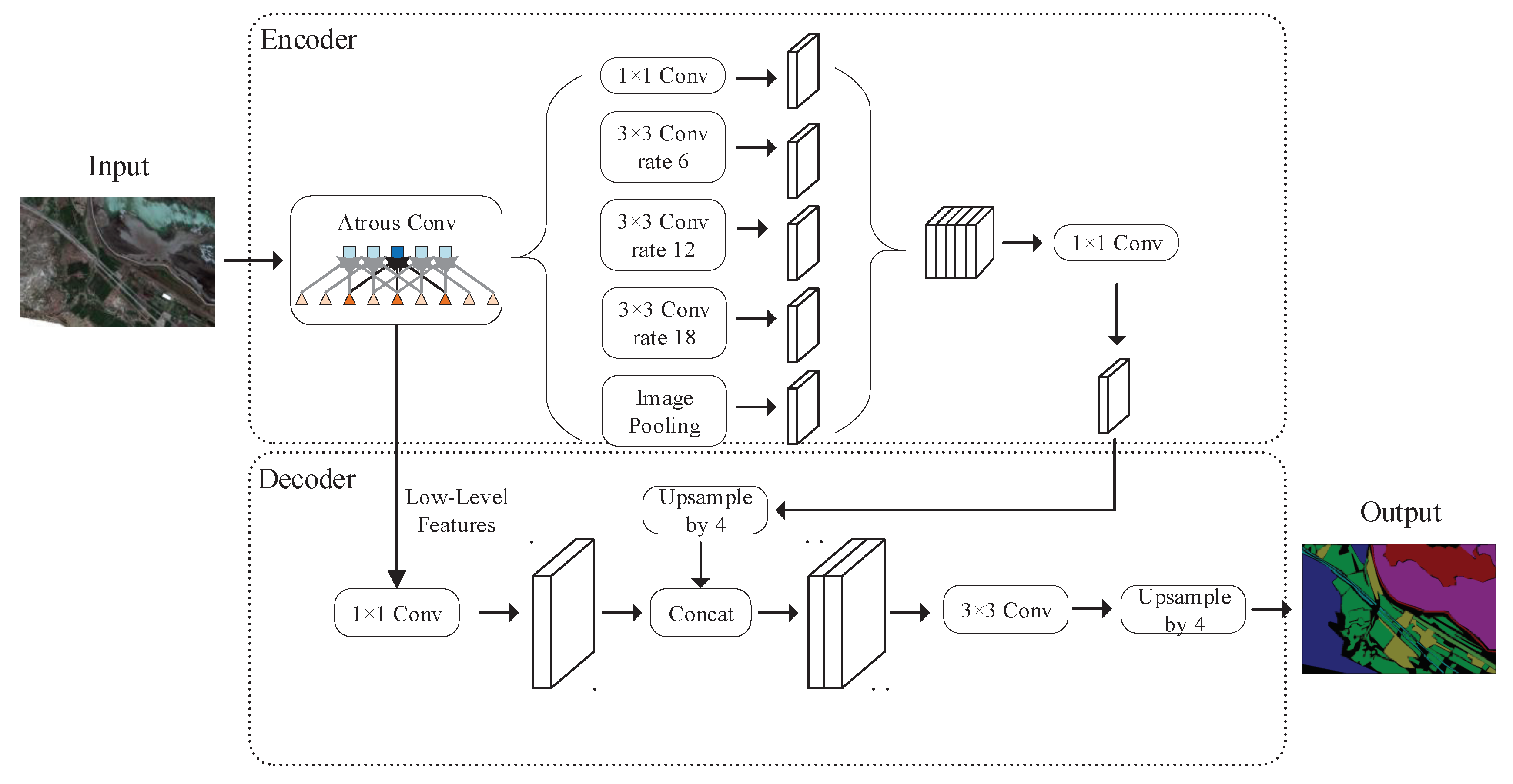
2.6. DeepLab v3+ Model
2.6.1. Overview
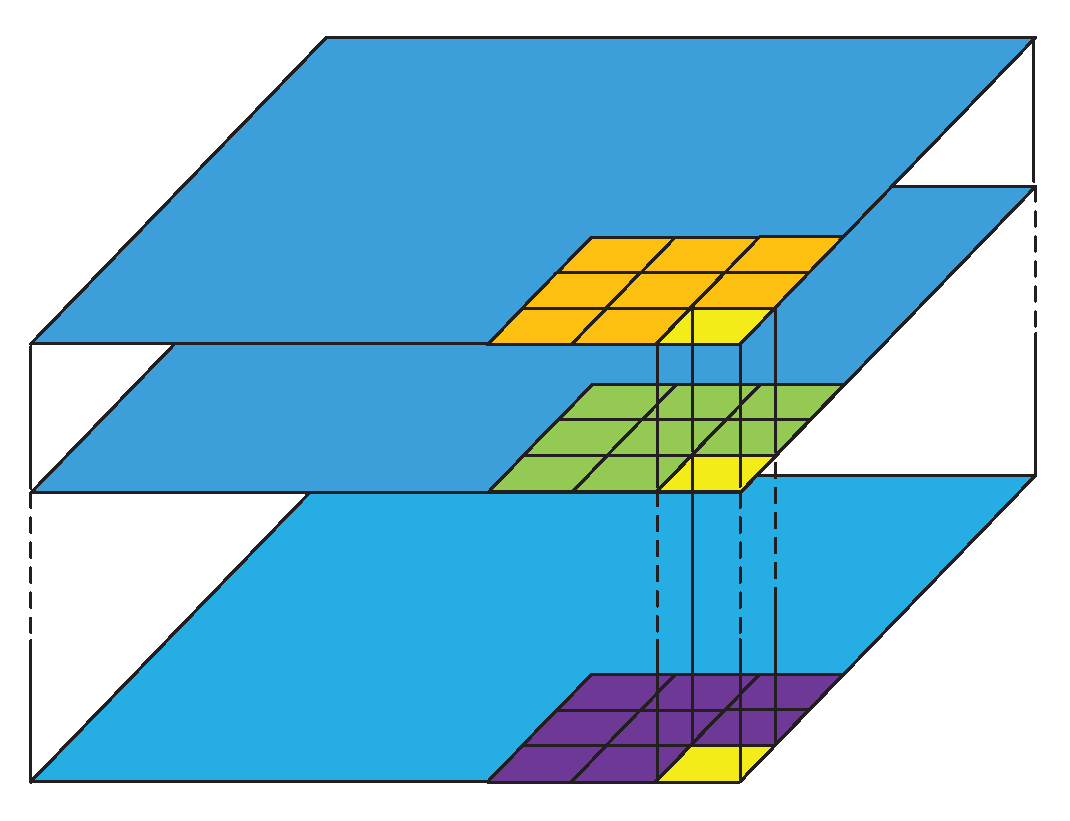
2.6.2. Atrous Spatial Pyramid Pooling with Depthwise Separable Convolution
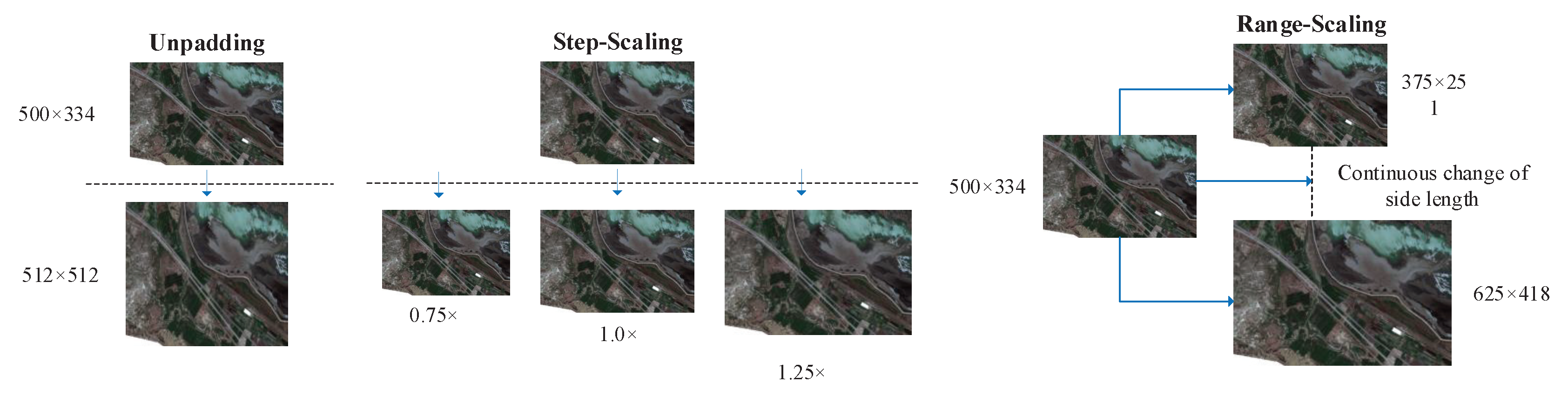
2.6.3. Data Augmentation
2.6.4. Loss Function-Based Solution of Samples Imbalance
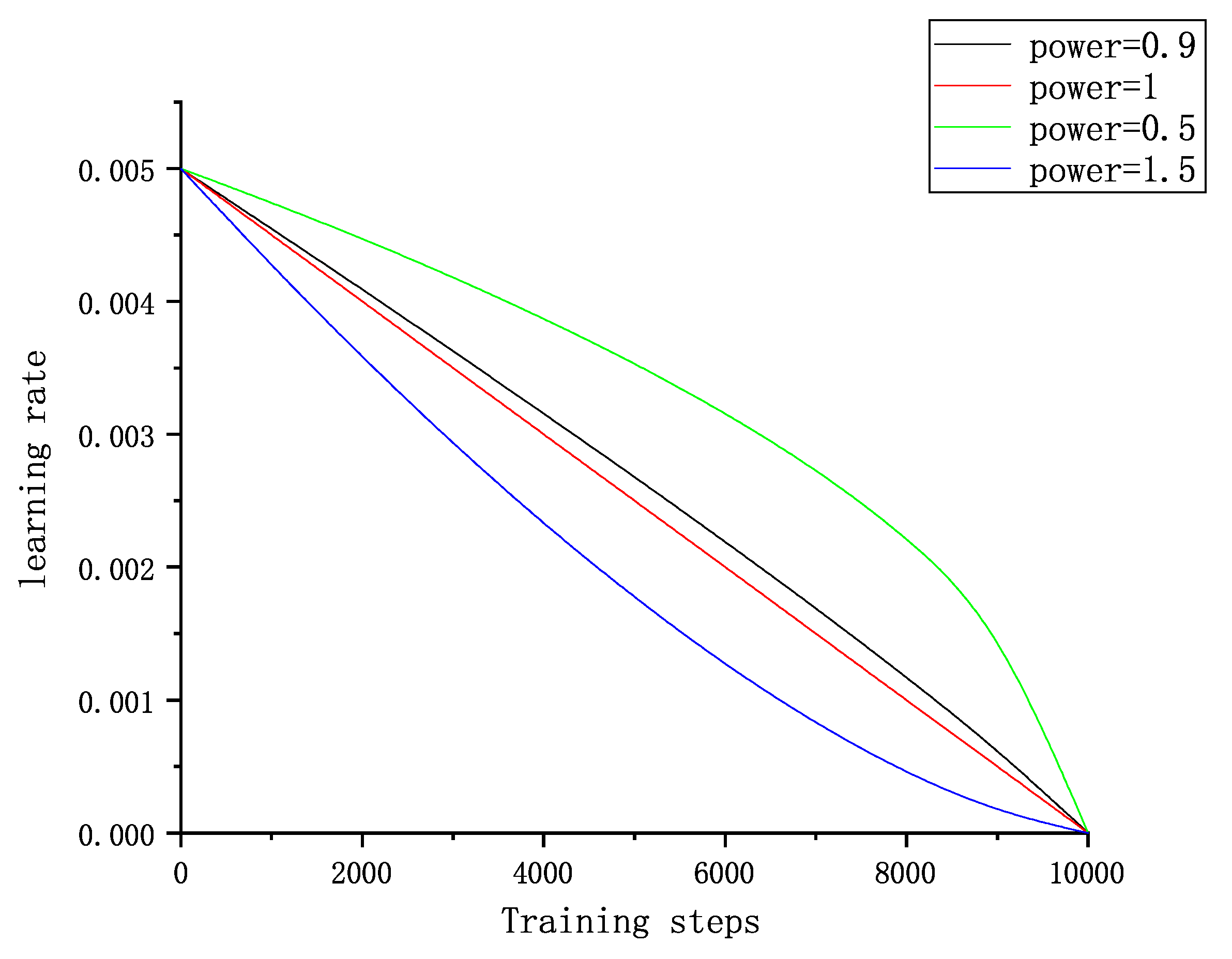
2.6.5. Model Training
3. Results
3.1. Experimental Environment and Model Training
3.2. Evaluating Indicator
3.3. Training Protocol
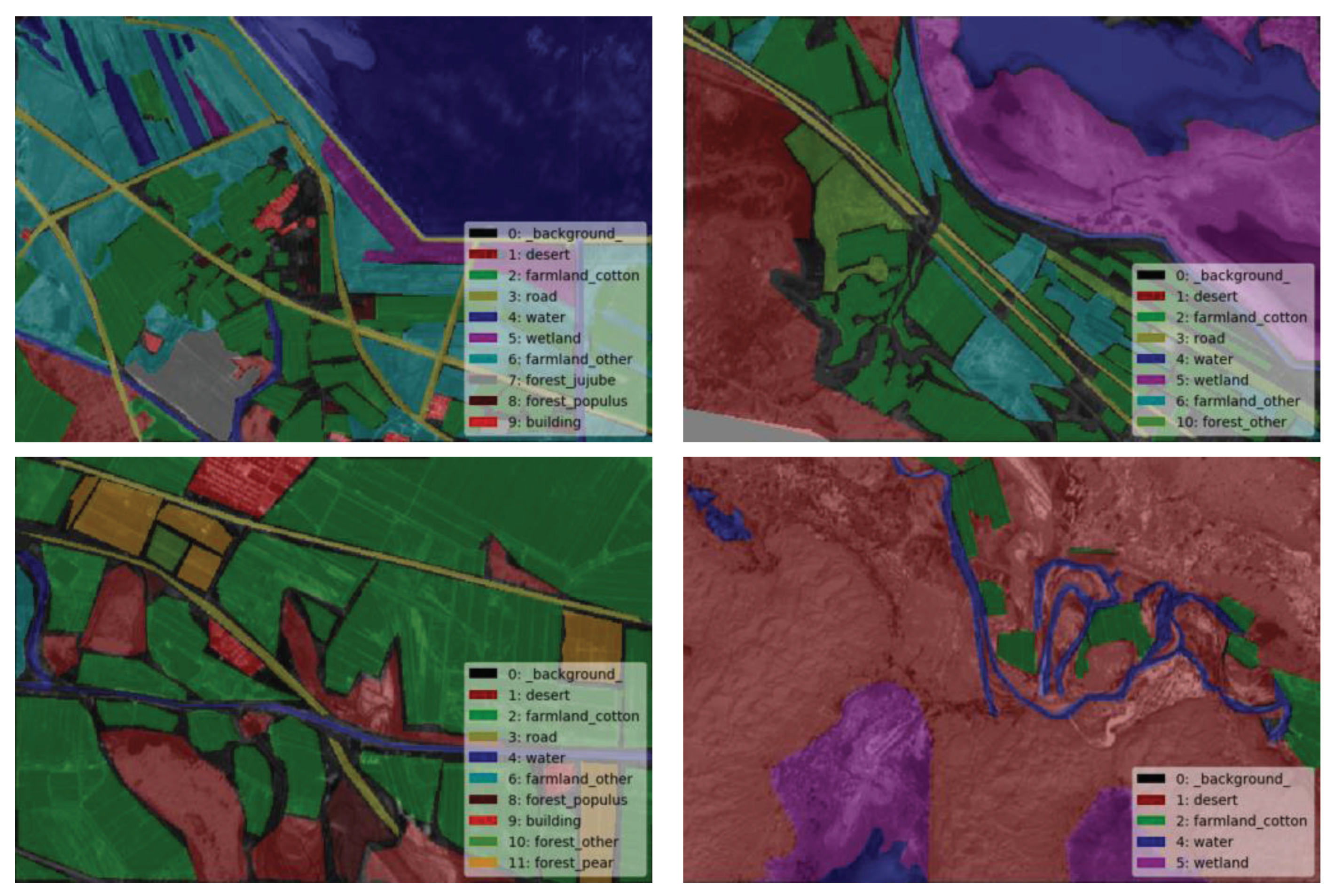
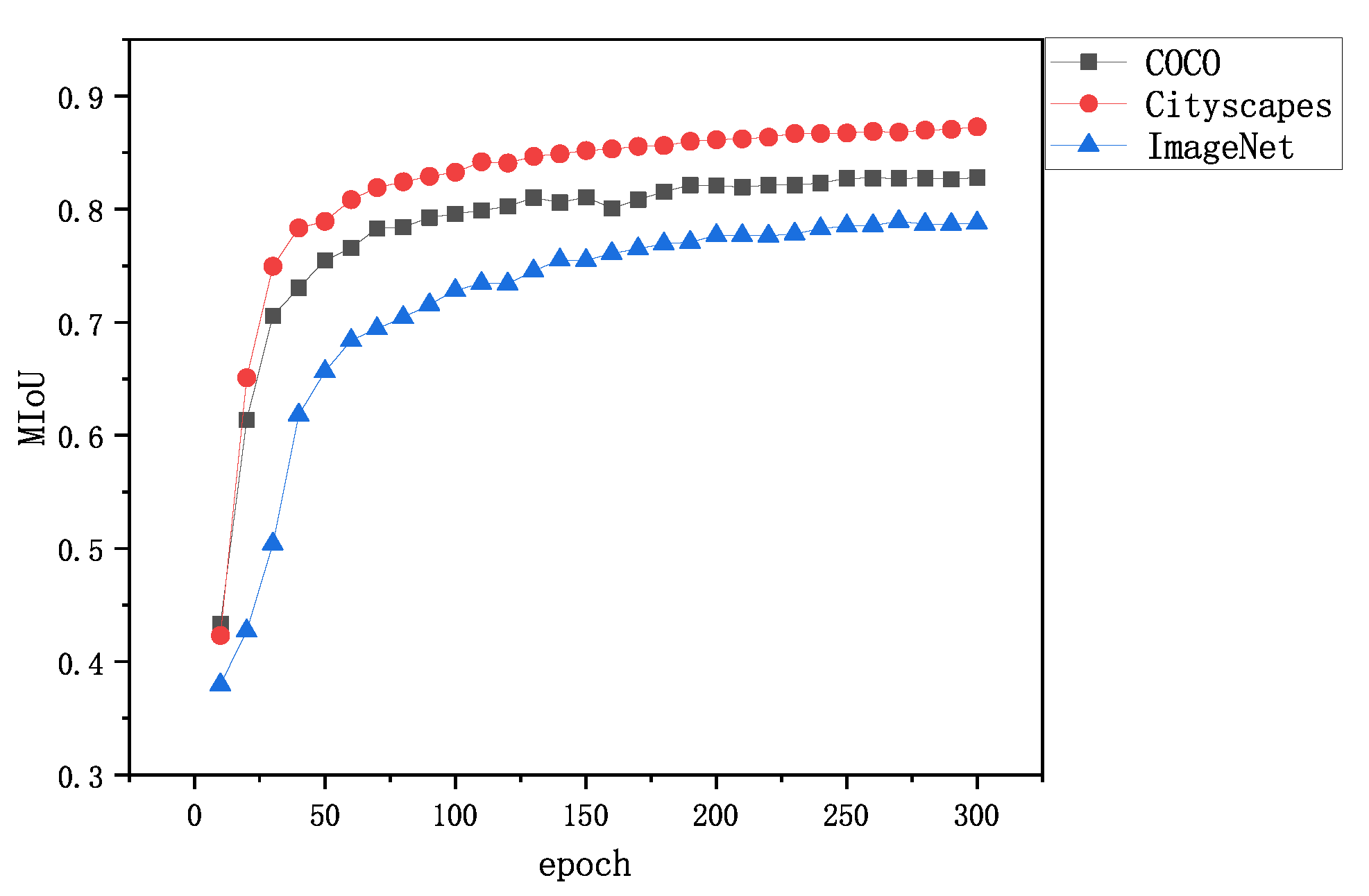
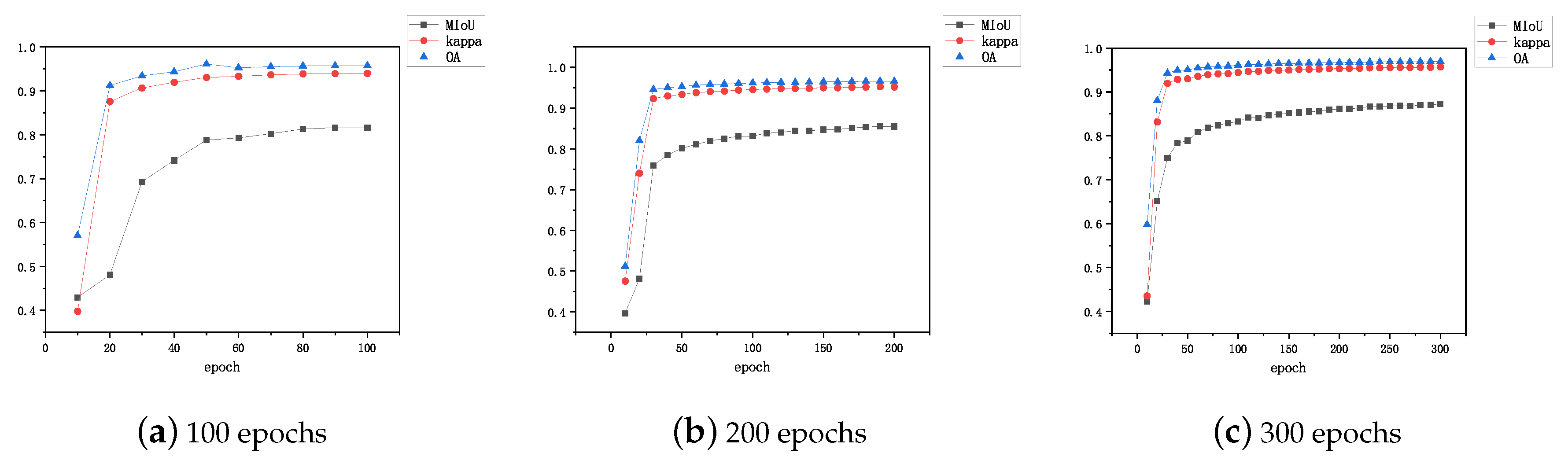
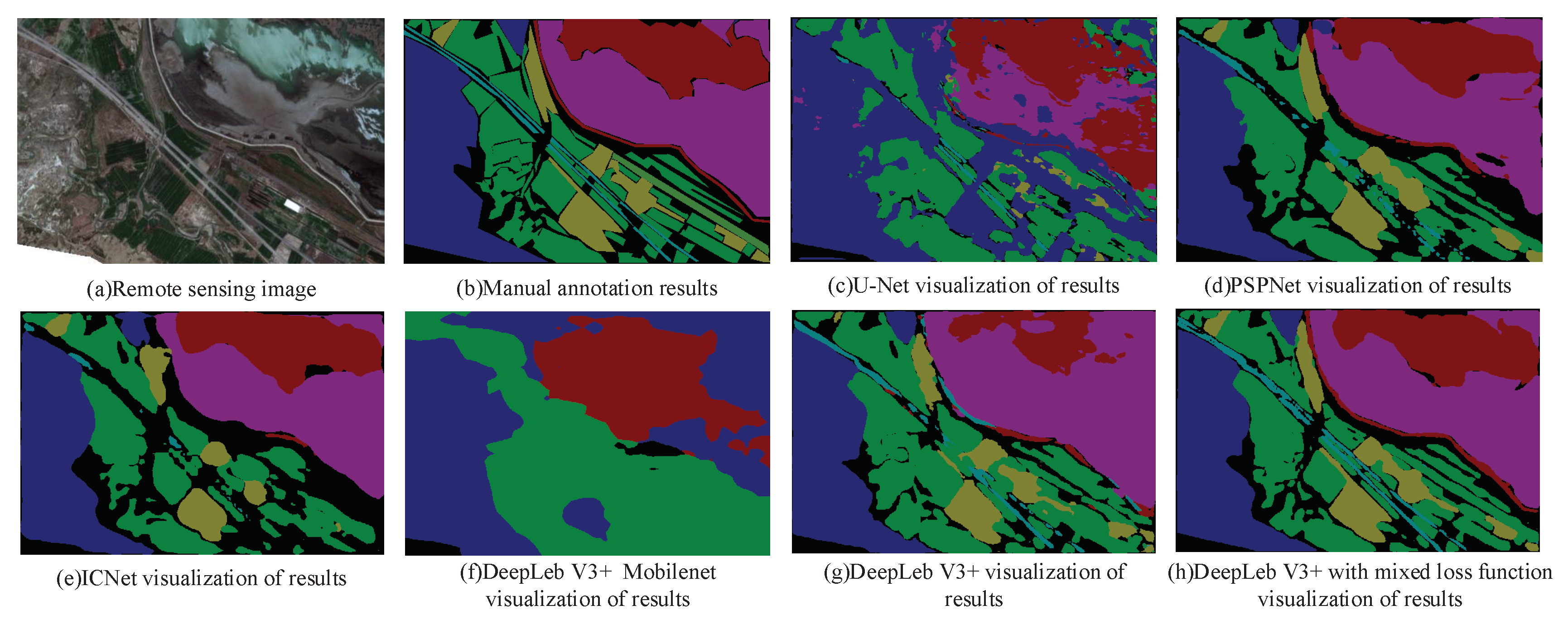
3.4. Experiment Result Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, C.; Chen, Y.; Yang, X.; Gao, S.; Li, F.; Kong, A.; Zu, D.; Sun, L. Improved remote sensing image classification based on multi-scale feature fusion. Remote Sens. 2020, 12, 213. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning aerial image segmentation from online maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Du, S.; Du, S.; Liu, B.; Zhang, X. Context-Enabled Extraction of Large-Scale Urban Functional Zones from Very-High-Resolution Images: A Multiscale Segmentation Approach. Remote Sens. 2019, 11, 1902. [Google Scholar] [CrossRef] [Green Version]
- Kavzoglu, T.; Erdemir, M.Y.; Tonbul, H. Classification of semiurban landscapes from very high-resolution satellite images using a regionalized multiscale segmentation approach. J. Appl. Remote Sens. 2017, 11, 035016. [Google Scholar] [CrossRef]
- Na, X.; Zhang, S.; Zhang, H.; Li, X.; Yu, H.; Liu, C. Integrating TM and ancillary geographical data with classification trees for land cover classification of marsh area. Chin. Geogr. Sci. 2009, 19, 177–185. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Lu, T.; Zhou, K.; Wang, M.; Bao, H. A new method for region-based majority voting CNNs for very high resolution image classification. Remote Sens. 2018, 10, 1946. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Zhao, S.; Qin, X.; Zhao, N.; Liang, L. Mapping of urban surface water bodies from Sentinel-2 MSI imagery at 10 m resolution via NDWI-based image sharpening. Remote Sens. 2017, 9, 596. [Google Scholar] [CrossRef] [Green Version]
- Jia, K.; Liang, S.; Wei, X.; Yao, Y.; Su, Y.; Jiang, B.; Wang, X. Land cover classification of Landsat data with phenological features extracted from time series MODIS NDVI data. Remote Sens. 2014, 6, 11518–11532. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Chen, Y. A Genetic Algorithm-based urban cluster automatic threshold method by combining VIIRS DNB, NDVI, and NDBI to monitor urbanization. Remote Sens. 2018, 10, 277. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object detection in optical remote sensing images based on weakly supervised learning and high-level feature learning. IEEE Trans. Geosci. Remote Sens. 2014, 53, 3325–3337. [Google Scholar] [CrossRef] [Green Version]
- Kavzoglu, T.; Tonbul, H. An experimental comparison of multi-resolution segmentation, SLIC and K-means clustering for object-based classification of VHR imagery. Int. J. Remote Sens. 2018, 39, 6020–6036. [Google Scholar] [CrossRef]
- Molada-Tebar, A.; Marqués-Mateu, Á.; Lerma, J.L.; Westland, S. Dominant Color Extraction with K-Means for Camera Characterization in Cultural Heritage Documentation. Remote Sens. 2020, 12, 520. [Google Scholar] [CrossRef] [Green Version]
- Hengst, A.M.; Armstrong, W., Jr. Automated Delineation of Proglacial Lakes At Large Scale Utilizing Google Earth Engine Maximum-Likelihood Land Cover Classification. AGUFM 2019, 2019, C31A–1481. [Google Scholar]
- Wang, K.; Cheng, L.; Yong, B. Spectral-Similarity-Based Kernel of SVM for Hyperspectral Image Classification. Remote Sens. 2020, 12, 2154. [Google Scholar] [CrossRef]
- Guo, Y.; Jia, X.; Paull, D. Effective sequential classifier training for SVM-based multitemporal remote sensing image classification. IEEE Trans. Image Process. 2018, 27, 3036–3048. [Google Scholar]
- Bazi, Y.; Melgani, F. Convolutional SVM networks for object detection in UAV imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3107–3118. [Google Scholar] [CrossRef]
- Zhu, X.; Li, N.; Pan, Y. Optimization performance comparison of three different group intelligence algorithms on a SVM for hyperspectral imagery classification. Remote Sens. 2019, 11, 734. [Google Scholar] [CrossRef] [Green Version]
- Paoletti, M.E.; Haut, J.M.; Tao, X.; Miguel, J.P.; Plaza, A. A new GPU implementation of support vector machines for fast hyperspectral image classification. Remote Sens. 2020, 12, 1257. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Wu, G.; Ding, K.; Shi, T.; Li, Q.; Wang, J. Improving land use/land cover classification by integrating pixel unmixing and decision tree methods. Remote Sens. 2017, 9, 1222. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Zafari, A.; Zurita-Milla, R.; Izquierdo-Verdiguier, E. Evaluating the performance of a random forest kernel for land cover classification. Remote Sens. 2019, 11, 575. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2881–2890. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Zhao, W.; Du, S. Learning multiscale and deep representations for classifying remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Wang, E.; Qi, K.; Li, X.; Peng, L. Semantic Segmentation of Remote Sensing Image Based on Neural Network. Acta Opt. Sin. 2019, 39, 1210001. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Wang, S.; Yang, D.; Shuyang, W.; Liu, X. An road extraction method for remote sensing image based on Encoder-Decoder network. Acta Geod. Cartogr. Sin. 2019, 48, 330. [Google Scholar]
- Zhang, H.; Wang, B.; Han, W.; Yang, J.; Pu, P.; Wei, J. Extraction of Irrigation Networks in Irrigation Area of UAV Orthophotos Based on Fully Convolutional Networks. Trans. Chin. Soc. Agric. Mach. 2019, 27. [Google Scholar]
- Wu, Z.; Gao, Y.; Li, L.; Xue, J. Fully Convolutional Network Method of Semantic Segmentation of Class Imbalance Remote Sensing Images. Acta Opt. Sin. 2019, 39, 0428004. [Google Scholar]
- Zhu, T.; Dong, F.; Gong, H. Remote Sensing Building Detection Based on Binarized Semantic Segmentation. Acta Opt. Sin. 2019, 39, 1228002. [Google Scholar]
- Yang, J.; Zhou, Z.; Du, Z.; Xu, Q.; Yin, H.; Liu, R. Rural construction land extraction from high spatial resolution remote sensing image based on SegNet semantic segmentation model. Trans. Chin. Soc. Agric. Eng. 2019, 35, 251–258. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Niu, Z.; Liu, W.; Zhao, J.; Jiang, G. Deeplab-based spatial feature extraction for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2018, 16, 251–255. [Google Scholar] [CrossRef]
- Wasikowski, M.; Chen, X.W. Combating the small sample class imbalance problem using feature selection. IEEE Trans. Knowl. Data Eng. 2009, 22, 1388–1400. [Google Scholar] [CrossRef]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Special issue on learning from imbalanced data sets. ACM SIGKDD Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Su, W.; Zhang, M.; Jiang, K.; Zhu, D.; Huang, J.; Wang, P. Atmospheric Correction Method for Sentinel-2 Satellite Imagery. Acta Opt. Sin. 2018, 38, 0128001. [Google Scholar] [CrossRef]
- GitHub—Wkentaro/Labelme: Image Polygonal Annotation with Python (Polygon, Rectangle, Circle, Line, Point and Image-Level Flag Annotation). Available online: https://github.com/wkentaro/labelme (accessed on 27 October 2020).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Papandreou, G.; Kokkinos, I.; Savalle, P.A. Modeling local and global deformations in deep learning: Epitomic convolution, multiple instance learning, and sliding window detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 390–399. [Google Scholar]
- Grauman, K.; Darrell, T. The pyramid match kernel: Discriminative classification with sets of image features. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 2, pp. 1458–1465. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Sifre, L.; Mallat, S. Rigid-Motion Scattering for Image Classification. Ph.D. Thesis, Ecole Polytechnique, Paleso, France, 2014. [Google Scholar]
- Vanhoucke, V. Learning visual representations at scale. ICLR Invit. Talk 2014, 1, 2. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed precision training. arXiv 2017, arXiv:1710.03740. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Acquisition Date | Satellite | Number of Bands | Cloud Coverage |
|---|---|---|---|---|
| A | 28 June 2019 | S2B | 13 | 13% |
| B | 28 July 2019 | S2B | 13 | 3.5% |
| C | 30 July 2019 | S2A | 13 | 0% |
| D | 29 August 2019 | S2A | 13 | 2% |
| E | 29 August 2019 | S2A | 13 | 2.9% |
| Class Name | Number of Pixels | Number of Pictures | Class Frequency | Weight |
|---|---|---|---|---|
| desert | 46,963,290 | 775 | 0.3628610392118988 | 0.13304701 |
| cotton | 21,022,970 | 505 | 0.24927930278057747 | 0.19366861 |
| roads | 845,340 | 260 | 0.01946890833717181 | 2.27707261 |
| water | 4,672,470 | 460 | 0.06082361364228066 | 0.7937308 |
| wetland | 4,061,970 | 165 | 0.1474131736526946 | 0.32749838 |
| uncultivated arable land | 4,780,315 | 430 | 0.0665689319036346 | 0.72522683 |
| jujube trees | 678,805 | 130 | 0.0211086199693636 | 1.54404602 |
| populus euphratica | 555,585 | 140 | 0.022732784431137725 | 1.596573 |
| buildings | 1,790,150 | 300 | 0.024234483414124132 | 1.35111947 |
| woodland | 684,185 | 185 | 0.022145492798187408 | 1.63891363 |
| pear trees | 631,290 | 160 | 0.021537724550898203 | 1.68516176 |
| backgrounds | 42,588,115 | 775 | 0.3290563260575623 | 0.14671523 |
| Loss Function | OA(%) | MIoU(%) | Kappa |
|---|---|---|---|
| softmax loss | 97.44 | 73.62 | 0.6598 |
| dice loss | 97.40 | 75.99 | 0.6933 |
| bce loss | 97.44 | 73.94 | 0.6581 |
| dice loss+bce loss | 97.47 | 76.02 | 0.6908 |
| Type | Bits | Representable Maximum | Kappa |
|---|---|---|---|
| Single-precision floating-point number | 32 | 3.4 × | 6 digits after the decimal point |
| Half-precision floating point | 16 | 65,504 | cannot accurately represent all integers in the range |
| Model Category | U-Net | PSPNet | ICNET | DeepLab V3+ Mobilenet | DeepLab V3+ | DeepLab V3+ Mixed Loss Function | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CA/% | IoU/% | CA/% | IoU/% | CA/% | IoU/% | CA/% | IoU/% | CA/% | IoU/% | CA/% | IoU/% | |
| desert | 84.64 | 81.57 | 97.77 | 96.15 | 97.41 | 94.39 | 81.98 | 77.17 | 98.06 | 96.07 | 98.69 | 97.38 |
| cotton | 73.42 | 70.49 | 92.80 | 88.36 | 90.35 | 83.46 | 57.46 | 54.87 | 92.88 | 88.27 | 95.03 | 90.94 |
| roads | 50.85 | 6.71 | 77.92 | 58.71 | 57.05 | 33.91 | 0.00 | 0.00 | 74.36 | 57.45 | 97.47 | 76.02 |
| water | 78.81 | 63.15 | 93.55 | 85.37 | 89.22 | 80.62 | 61.40 | 46.72 | 91.15 | 85.61 | 93.51 | 89.87 |
| wetland | 55.33 | 22.92 | 89.81 | 85.92 | 94.28 | 82.66 | 0.00 | 0.00 | 92.47 | 88.16 | 95.13 | 91.90 |
| uncultivated arable land | 40.68 | 7.99 | 90.07 | 81.45 | 84.02 | 72.59 | 0.00 | 0.00 | 85.43 | 80.19 | 91.19 | 86.63 |
| jujube trees | 0.00 | 0.00 | 86.00 | 77.86 | 66.01 | 58.40 | 0.00 | 0.00 | 86.22 | 77.25 | 89.75 | 85.41 |
| populus euphratica | 12.09 | 0.05 | 85.92 | 77.18 | 70.47 | 63.75 | 0.00 | 0.00 | 85.61 | 75.40 | 87.94 | 81.63 |
| buildings | 77.22 | 57.40 | 89.19 | 84.09 | 86.28 | 77.21 | 0.00 | 0.00 | 86.13 | 82.76 | 92.03 | 88.83 |
| woodland | 0.00 | 0.00 | 86.74 | 83.89 | 70.88 | 66.22 | 0.00 | 0.00 | 84.55 | 81.72 | 87.89 | 83.46 |
| pear trees | 33.21 | 0.87 | 89.02 | 79.03 | 70.82 | 65.31 | 0.00 | 0.00 | 91.46 | 81.14 | 92.93 | 87.43 |
| backgrounds | 97.24 | 88.72 | 97.15 | 93.07 | 94.88 | 90.53 | 98.35 | 87.73 | 97.16 | 92.70 | 97.94 | 94.58 |
| OA(%) | 86.16 | 95.88 | 93.97 | 81.79 | 95.77 | 97.97 | ||||||
| MIOU(%) | 33.32 | 82.59 | 72.44 | 22.21 | 82.23 | 87.74 | ||||||
| Kappa coefficient | 0.8000 | 0.9415 | 0.9144 | 0.7367 | 0.9401 | 0.9587 | ||||||
| Methods | 5 Classes | 15 Classes | ||
|---|---|---|---|---|
| OA(%) | Kappa | OA(%) | Kappa | |
| MLC | 65.48 | 0.504 | 22.65 | 0.134 |
| RF | 68.73 | 0.526 | 23.79 | 0.164 |
| SVM | 46.11 | 0.103 | 22.72 | 0.024 |
| MLP | 60.93 | 0.442 | 14.19 | 0.082 |
| U-Net | 62.68 | 0.421 | 56.59 | 0.439 |
| PSPNet | 66.11 | 0.498 | 60.73 | 0.458 |
| DeepLab V3+ Mobilenet | 66.79 | 0.508 | 54.64 | 0.357 |
| DeepLab V3+ | 72.86 | 0.604 | 62.19 | 0.478 |
| DeepLab V3+ Mixed loss function | 74.98 | 0.636 | 69.16 | 0.598 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Zhang, X.; Ma, Y.; Yang, Q.; Wang, C.; Liu, H.; Qi, Q. Full Convolutional Neural Network Based on Multi-Scale Feature Fusion for the Class Imbalance Remote Sensing Image Classification. Remote Sens. 2020, 12, 3547. https://doi.org/10.3390/rs12213547
Ren Y, Zhang X, Ma Y, Yang Q, Wang C, Liu H, Qi Q. Full Convolutional Neural Network Based on Multi-Scale Feature Fusion for the Class Imbalance Remote Sensing Image Classification. Remote Sensing. 2020; 12(21):3547. https://doi.org/10.3390/rs12213547
Chicago/Turabian StyleRen, Yuanyuan, Xianfeng Zhang, Yongjian Ma, Qiyuan Yang, Chuanjian Wang, Hailong Liu, and Quan Qi. 2020. "Full Convolutional Neural Network Based on Multi-Scale Feature Fusion for the Class Imbalance Remote Sensing Image Classification" Remote Sensing 12, no. 21: 3547. https://doi.org/10.3390/rs12213547
APA StyleRen, Y., Zhang, X., Ma, Y., Yang, Q., Wang, C., Liu, H., & Qi, Q. (2020). Full Convolutional Neural Network Based on Multi-Scale Feature Fusion for the Class Imbalance Remote Sensing Image Classification. Remote Sensing, 12(21), 3547. https://doi.org/10.3390/rs12213547