Multi-Label Remote Sensing Image Scene Classification by Combining a Convolutional Neural Network and a Graph Neural Network



Abstract
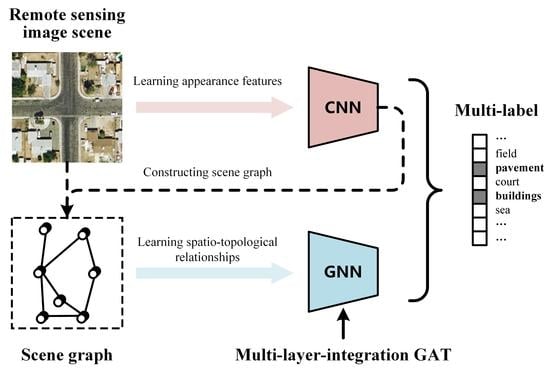
:
1. Introduction
- We propose a novel MLRSSC-CNN-GNN framework that can simultaneously mine the appearances of visual elements in the scene and the spatio-topological relationships of visual elements. The experimental results on two public datasets demonstrate the effectiveness of our framework.
- We design a multi-layer-integration GAT model to mine the spatio-topological relationship of the RS image scene. Compared with the standard GAT, the recommended multi-layer-integration GAT benefits fusing multiple intermediate topological representations and can further improve the classification performance.
2. Related Work
2.1. MLRSSC
2.2. GNN-Based Applications
3. Method
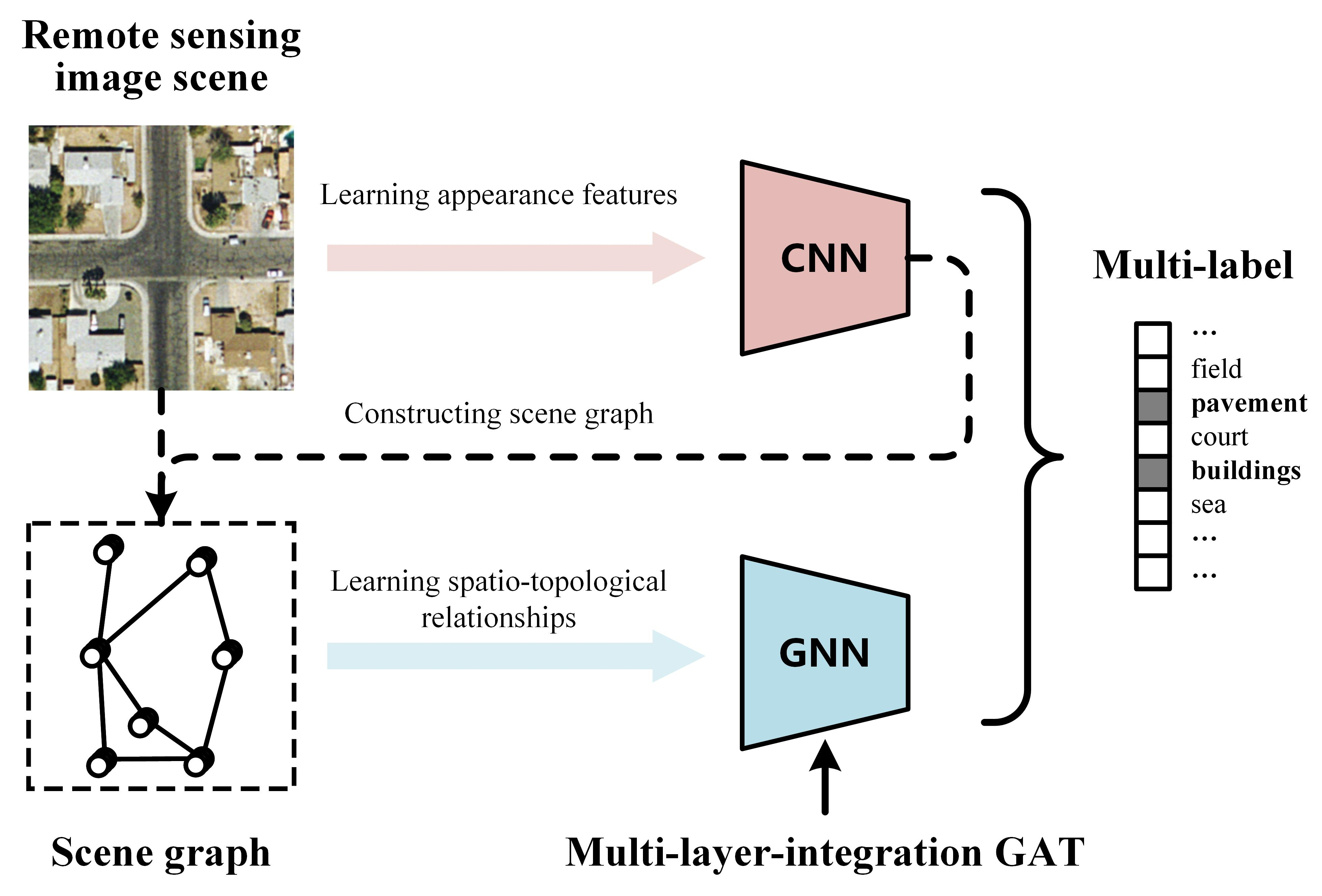
3.1. Using CNN to Generate Appearance Features
3.2. Constructing Scene Graph
3.3. Learning GNN to Mine Spatio-Topological Relationship
| Algorithm 1 Algorithm to construct the scene graph of an RS image |
| Input: RS image . |
| Output: Node feature matrix and adjacency matrix . |
| 1: for each do |
| 2: Extract deep feature maps from image ; |
| 3: Segment into superpixel regions ; |
| 4: for each do |
| 5: Obtain the max values of according to the boundary of in channels, and update the vector of the matrix ; |
| 6: Calculate the mean value of in the HSV color space; |
| 7: Obtain the adjacent regions list of ; |
| 8: end for |
| 9: for each do |
| 10: ; |
| 11: Calculate color distance between and ; |
| 12: if do |
| 13: ; |
| 14: end if |
| 15: end for |
| 16: end for |
3.3.1. Graph Attention Convolution Layer
3.3.2. Graph Pooling Layer
3.3.3. Classification Layer
4. Experiments
| Algorithm 2 Training process of the proposed MLRSSC-CNN-GNN framework |
| Input: RS images and ground truth multi-labels in training set. |
| Output: Model parameters and . Step 1: Learning CNN |
| 1: Take and as input, and train CNN to optimize according to Equation (1); |
| 2: Extract deep feature maps of according to Equation (2); Step 2: Constructing scene graph |
| 3: Construct node feature matrix and adjacency matrix of according to Algorithm 1; Step 3: Learning GNN |
| 4: for do |
| 5: Initialize parameters of the network in the first iteration; |
| 6: Update using graph attention convolution layers according to Equation (4)–(6); |
| 7: Fuse from graph attention convolution layers according to Equation (7); |
| 8: Cover to a fixed-size output via the graph pooling layer according to Equation (8-9); |
| 9: Flatten and generate the classification probability after the classification layer according to Equation (10-11); |
| 10: Calculate the loss based on the output of the network and according to Equation (12); |
| 11: Update by back-propagation; |
| 10: end for |
4.1. Dataset Description
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Comparison with the State-of-the-Art Methods
4.4.1. Results on the UCM Multi-Label Dataset
4.4.2. Results on the AID Multi-Label Dataset
5. Discussion
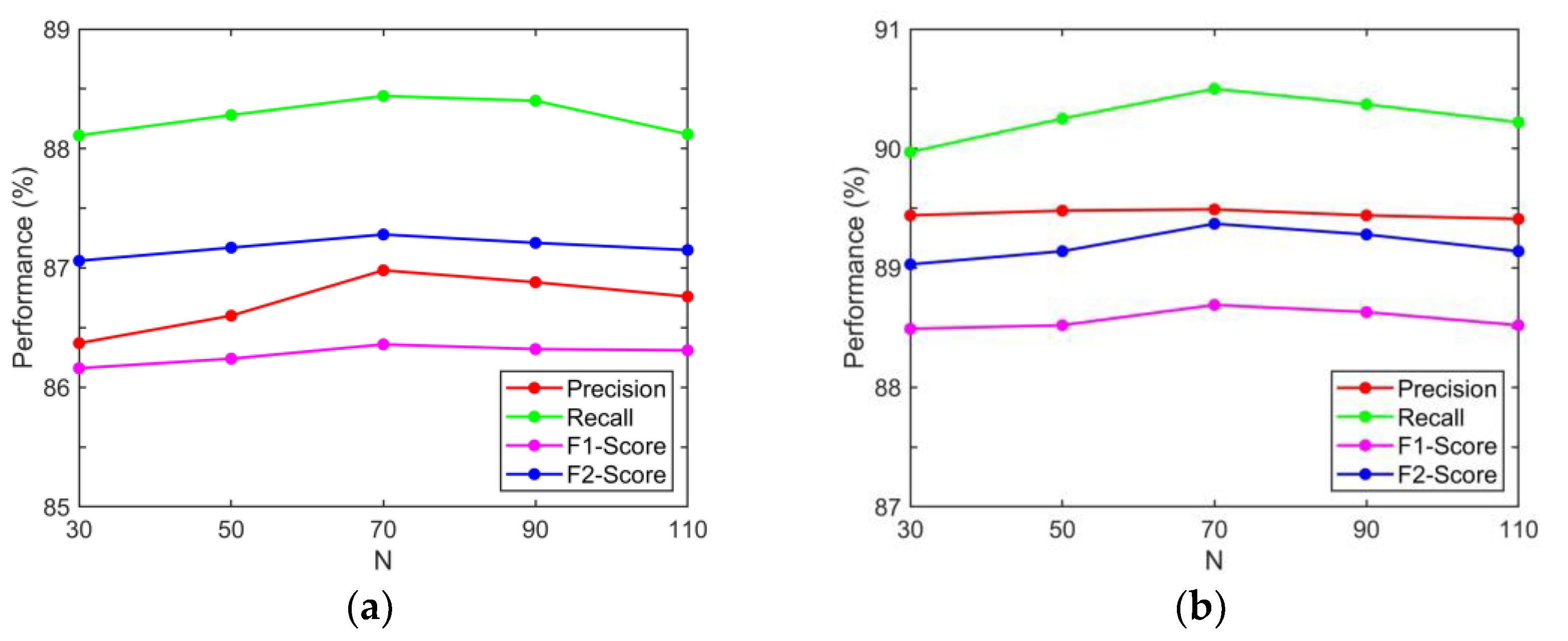
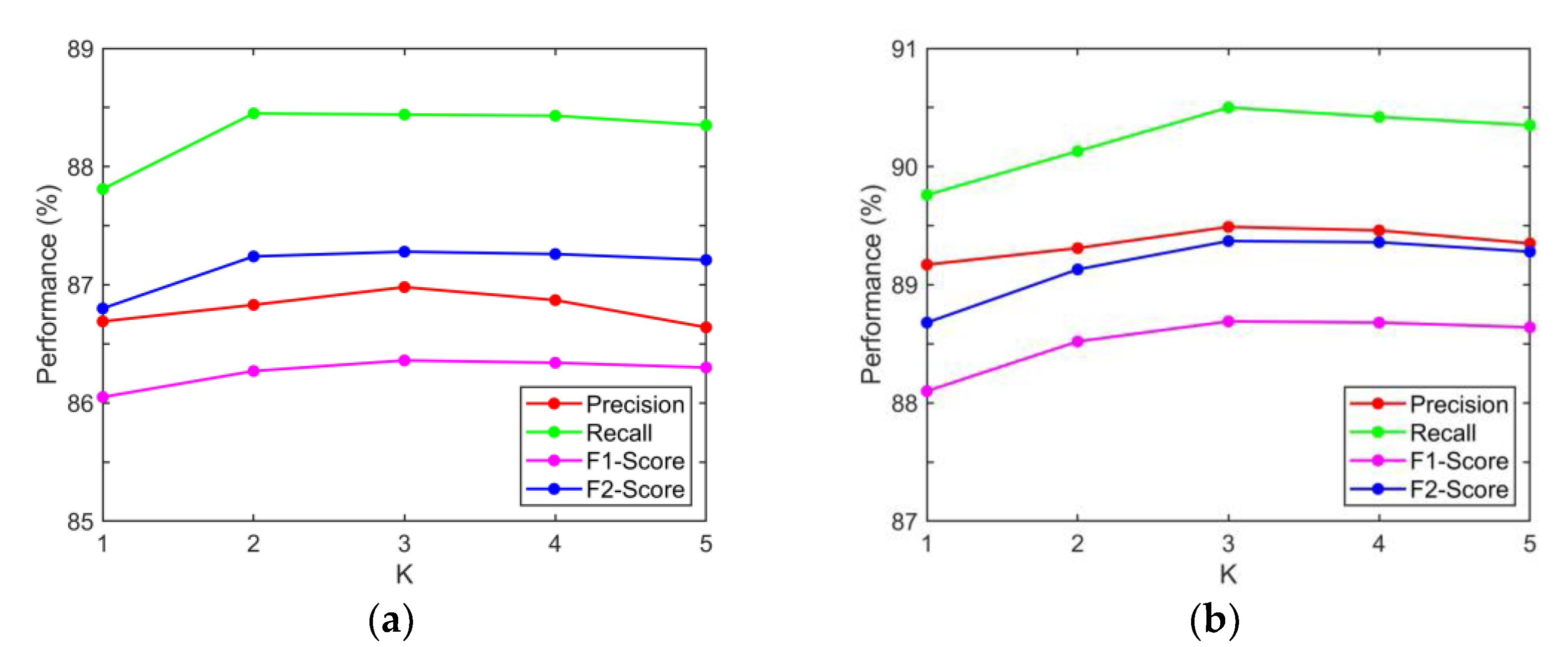
5.1. Effect on the Number of Superpixel Regions
5.2. Sensitivity Analysis of the Multi-Head Attention
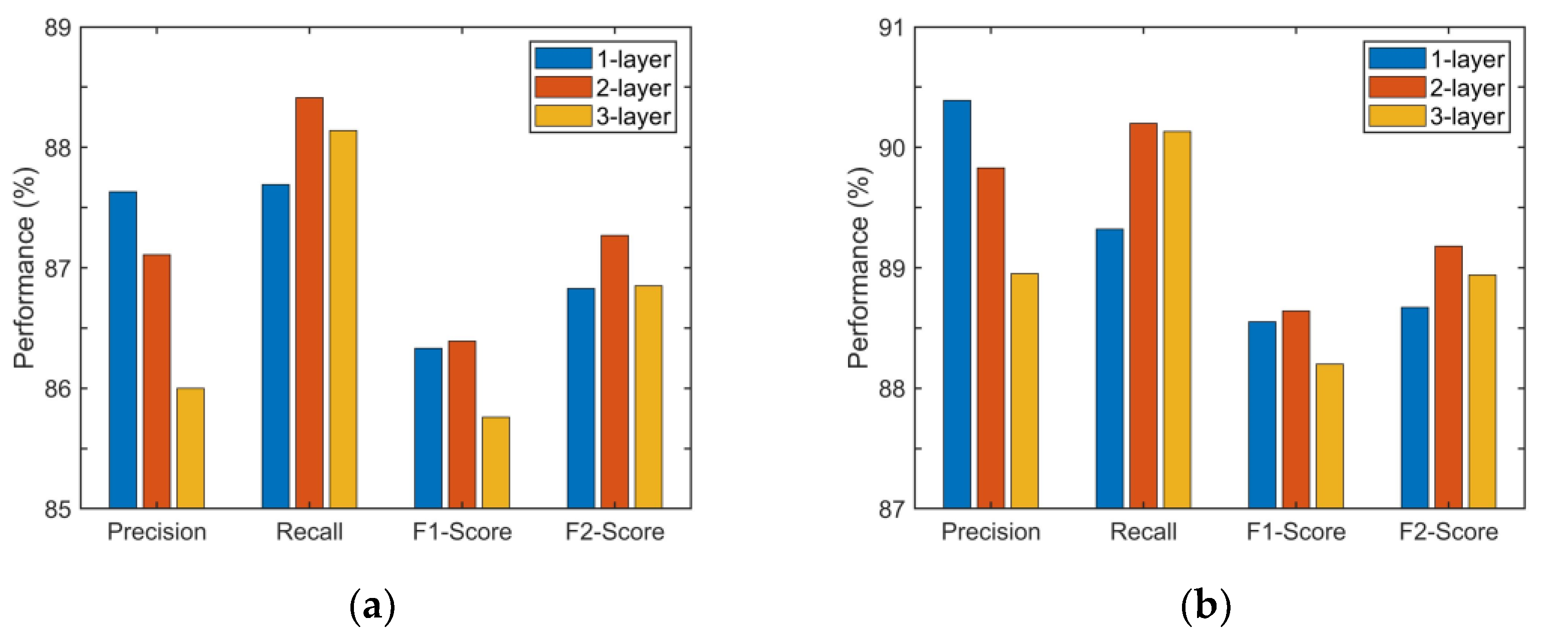
5.3. Discussion on the Depth of GNN
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and efficient midlevel visual elements-oriented land-use classification using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Tao, C.; Tan, Y.; Shang, K.; Tian, J. Unsupervised multilayer feature learning for satellite image scene classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 157–161. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Zhu, Z. Error-tolerant deep learning for remote sensing image scene classification. IEEE Trans. Cybern 2020, in press. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Zhou, P.; Zhang, D.; Cheng, G.; Guo, L.; Liu, Z.; Bu, S.; Wu, J. Efficient, simultaneous detection of multi-class geospatial targets based on visual saliency modeling and discriminative learning of sparse coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 37–48. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Xiao, R.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Tao, C.; Mi, L.; Li, Y.; Qi, J.; Xiao, Y.; Zhang, J. Scene context-driven vehicle detection in high-resolution aerial images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7339–7351. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Ma, J. Learning source-invariant deep hashing convolutional neural networks for cross-source remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6521–6536. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Zhu, H.; Ma, J. Large-scale remote sensing image retrieval by deep hashing neural networks. IEEE Trans. Geosci. Remote Sens. 2018, 56, 950–965. [Google Scholar] [CrossRef]
- Li, Y.; Ma, J.; Zhang, Y. Image retrieval from remote sensing big data: A survey. Inf. Fusion. 2021, 67, 94–115. [Google Scholar] [CrossRef]
- Jian, L.; Gao, F.; Ren, P.; Song, Y.; Luo, S. A noise-resilient online learning algorithm for scene classification. Remote Sens. 2018, 10, 1836. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 82–96. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.-S. Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Chen, K.; Jian, P.; Zhou, Z.; Guo, J.; Zhang, D. Semantic Annotation of High-Resolution Remote Sensing Images via Gaussian Process Multi-Instance Multilabel Learning. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1285–1289. [Google Scholar] [CrossRef]
- Han, X.-H.; Chen, Y. Generalized aggregation of sparse coded multi-spectra for satellite scene classification. ISPRS Int. J. Geo-Inf. 2017, 6, 175. [Google Scholar] [CrossRef] [Green Version]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- Chaudhuri, B.; Demir, B.; Chaudhuri, S.; Bruzzone, L. Multilabel Remote Sensing Image Retrieval Using a Semisupervised Graph-Theoretic Method. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1144–1158. [Google Scholar] [CrossRef]
- Tan, Q.; Liu, Y.; Chen, X.; Yu, G. Multi-label classification based on low rank representation for image annotation. Remote Sens. 2017, 9, 109. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the 2014 European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.-J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Yang, H.; Zhou, J.T.; Zhang, Y.; Gao, B.-B.; Wu, J.; Cai, J. Exploit bounding box annotations for multi-label object recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 280–288. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. CNN-RNN: A unified framework for multi-label image classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2285–2294. [Google Scholar]
- Zhang, J.; Wu, Q.; Shen, C.; Zhang, J.; Lu, J. Multilabel image classification with regional latent semantic dependencies. IEEE Trans. Multimedia 2018, 20, 2801–2813. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Lobry, S.; Marcos, D.; Murray, J.; Tuia, D. RSVQA: Visual question answering for remote sensing data. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8555–8566. [Google Scholar] [CrossRef]
- Stivaktakis, R.; Tsagkatakis, G.; Tsakalides, P. Deep learning for multilabel land cover scene categorization using data augmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1031–1035. [Google Scholar] [CrossRef]
- Zeggada, A.; Melgani, F.; Bazi, Y. A deep learning approach to UAV image multilabeling. IEEE Geosci. Remote Sens. Lett. 2017, 14, 694–698. [Google Scholar] [CrossRef]
- Hua, Y.; Mou, L.; Zhu, X.X. Recurrently exploring class-wise attention in a hybrid convolutional and bidirectional LSTM network for multi-label aerial image classification. ISPRS J. Photogramm. Remote Sens. 2019, 149, 188–199. [Google Scholar] [CrossRef]
- Lee, J.; Lee, I.; Kang, J. Self-attention graph pooling. In Proceedings of the 2019 International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 6661–6670. [Google Scholar]
- Such, F.P.; Sah, S.; Dominguez, M.A.; Pillai, S.; Zhang, C.; Michael, A.; Cahill, N.D.; Ptucha, R. Robust spatial filtering with graph convolutional neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 884–896. [Google Scholar] [CrossRef]
- Zhang, M.; Cui, Z.; Neumann, M.; Chen, Y. An end-to-end deep learning architecture for graph classification. In Proceedings of the 2018 AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018; pp. 4438–4445. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 2017 International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Li, Y.; Zemel, R.; Brockschmidt, M.; Tarlow, D. Gated graph sequence neural networks. In Proceedings of the 2014 International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. In Proceedings of the 2018 International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the 2017 International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 2053–2070. [Google Scholar]
- Chen, T.; Xu, M.; Hui, X.; Wu, H.; Lin, L. Learning semantic-specific graph representation for multi-label image recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 522–531. [Google Scholar]
- Chen, Z.-M.; Wei, X.-S.; Wang, P.; Guo, Y. Multi-label image recognition with graph convolutional networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5172–5181. [Google Scholar]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef] [Green Version]
- Dai, O.E.; Demir, B.; Sankur, B.; Bruzzone, L. A novel system for content-based retrieval of single and multi-label high-dimensional remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2473–2490. [Google Scholar] [CrossRef] [Green Version]
- Sumbul, G.; Demir, B. A novel multi-attention driven system for multi-label remote sensing image classification. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 5726–5729. [Google Scholar]
- Senge, R.; del Coz, J.J.; Hüllermeier, E. On the problem of error propagation in classifier chains for multi-label classification. In Proceedings of the 36th Annual Conference of the German Classification Society on Data Analysis, Machine Learning and Knowledge Discovery, Hildesheim, Germany, 1–3 August 2012; pp. 163–170. [Google Scholar]
- Hua, Y.; Mou, L.; Zhu, X.X. Relation network for multilabel aerial image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4558–4572. [Google Scholar] [CrossRef] [Green Version]
- Kang, J.; Fernandez-Beltran, R.; Hong, D.; Chanussot, J.; Plaza, A. Graph relation network: Modeling relations between scenes for multilabel remote-sensing image classification and retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 1–15. [Google Scholar] [CrossRef]
- Wang, H.; Xu, T.; Liu, Q.; Lian, D.; Chen, E.; Du, D.; Wu, H.; Su, W. MCNE: An end-to-end framework for learning multiple conditional network representations of social network. In Proceedings of the 2019 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1064–1072. [Google Scholar]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-based recommendation with graph neural networks. Proc. AAAI Conf. Artif. Intell. 2019, 33, 346–353. [Google Scholar] [CrossRef]
- Nathani, D.; Chauhan, J.; Sharma, C.; Kaul, M. Learning attention-based embeddings for relation prediction in knowledge graphs. In Proceedings of the 2019 Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019; pp. 4710–4723. [Google Scholar]
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. Auto-encoding scene graphs for image captioning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10677–10686. [Google Scholar]
- Chaudhuri, U.; Banerjee, B.; Bhattacharya, A. Siamese graph convolutional network for content based remote sensing image retrieval. Comput. Vis. Image Underst. 2019, 184, 22–30. [Google Scholar] [CrossRef]
- Gong, L.; Cheng, Q. Exploiting edge features for graph neural networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9203–9211. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the 2018 Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018; pp. 4800–4810. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Ying, R.; You, J.; Morris, C.; Ren, X.; Hamilton, W.L.; Leskovec, J. Hierarchical graph representation learning with differentiable pooling. Adv. Neural Inf. Process. Syst. 2018. [Google Scholar]
- Shao, Z.; Yang, K.; Zhou, W. Performance evaluation of single-label and multi-label remote sensing image retrieval using a dense labeling dataset. Remote Sens. 2018, 10, 964. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.Z.; Zhou, Z.H. A unified view of multi-label performance measures. In Proceedings of the 2017 International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 6–11 August 2017; pp. 5778–5791. [Google Scholar]
- Tsoumakas, G.; Vlahavas, I. Random k-labelsets: An ensemble method for multilabel classification. In Proceedings of the 2007 European Conference on Machine Learning (ECML), Warsaw, Poland, 17–21 September 2007; pp. 406–417. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 2015 International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Precision | Recall | F1-Score | F2-Score |
|---|---|---|---|---|
| CNN [63] | 80.09 ± 0.25 | 81.78 ± 0.41 | 78.99 ± 0.10 | 80.18 ± 0.09 |
| CNN-RBFNN [33] | 78.18 | 83.91 | 78.80 | 81.14 |
| CA-CNN-BiLSTM [34] | 79.33 | 83.99 | 79.78 | 81.69 |
| AL-RN-CNN [48] | 87.62 | 86.41 | 85.70 | 85.81 |
| Our MLRSSC-CNN-GNN via standard GAT | 86.41 ± 0.22 | 88.17 ± 0.09 | 86.09 ± 0.07 | 87.03 ± 0.02 |
| Our MLRSSC-CNN-GNN via multi-layer-integration GAT | 87.11 ± 0.09 | 88.41 ± 0.10 | 86.39 ± 0.04 | 87.27 ± 0.07 |
| Methods | Precision | Recall | F1-Score | F2-Score |
|---|---|---|---|---|
| CNN [63] | 87.62 ± 0.14 | 86.13 ± 0.15 | 85.31 ± 0.09 | 85.36 ± 0.07 |
| CNN-RBFNN [33] | 84.56 | 87.85 | 84.58 | 85.99 |
| CA-CNN-BiLSTM [34] | 88.68 | 87.83 | 86.68 | 86.88 |
| AL-RN-CNN [48] | 89.96 | 89.27 | 88.09 | 88.31 |
| Our MLRSSC-CNN-GNN via standard GAT | 89.78 ± 0.24 | 89.52 ± 0.10 | 88.32 ± 0.05 | 88.66 ± 0.05 |
| Our MLRSSC-CNN-GNN via multi-layer-integration GAT | 89.83 ± 0.27 | 90.20 ± 0.22 | 88.64 ± 0.06 | 89.18 ± 0.13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Chen, R.; Zhang, Y.; Zhang, M.; Chen, L. Multi-Label Remote Sensing Image Scene Classification by Combining a Convolutional Neural Network and a Graph Neural Network. Remote Sens. 2020, 12, 4003. https://doi.org/10.3390/rs12234003
Li Y, Chen R, Zhang Y, Zhang M, Chen L. Multi-Label Remote Sensing Image Scene Classification by Combining a Convolutional Neural Network and a Graph Neural Network. Remote Sensing. 2020; 12(23):4003. https://doi.org/10.3390/rs12234003
Chicago/Turabian StyleLi, Yansheng, Ruixian Chen, Yongjun Zhang, Mi Zhang, and Ling Chen. 2020. "Multi-Label Remote Sensing Image Scene Classification by Combining a Convolutional Neural Network and a Graph Neural Network" Remote Sensing 12, no. 23: 4003. https://doi.org/10.3390/rs12234003
APA StyleLi, Y., Chen, R., Zhang, Y., Zhang, M., & Chen, L. (2020). Multi-Label Remote Sensing Image Scene Classification by Combining a Convolutional Neural Network and a Graph Neural Network. Remote Sensing, 12(23), 4003. https://doi.org/10.3390/rs12234003