Learned Representation of Satellite Image Series for Data Compression


Abstract
:
1. Introduction
2. Related Work
2.1. Compression Method on Satellite Videos
2.2. Compression Method of Image Series
2.3. Image-to-Image Translation Method
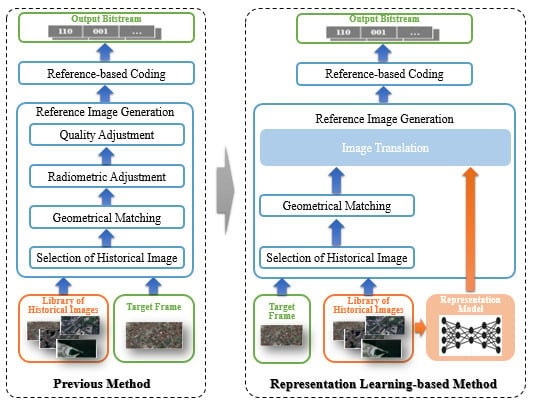
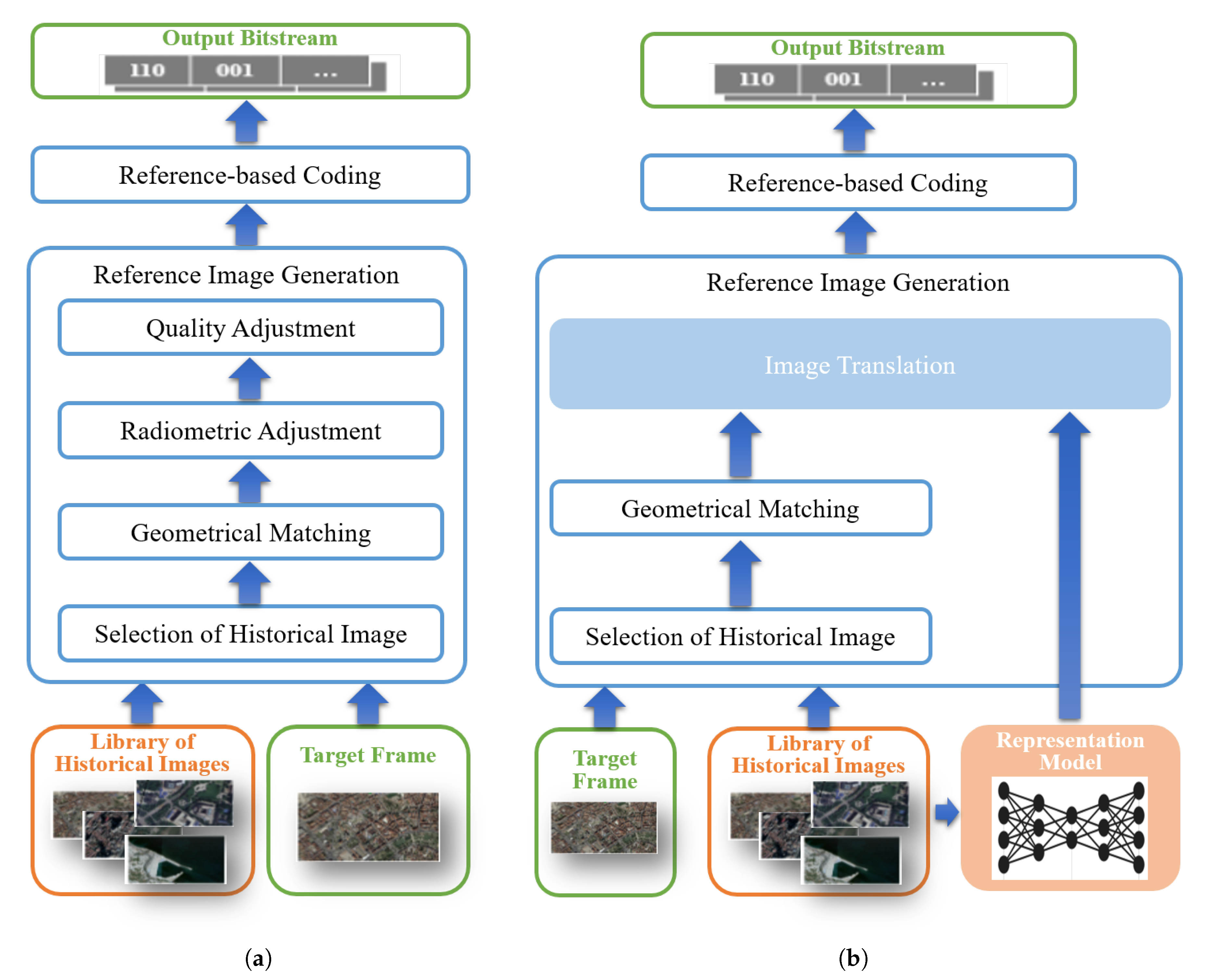
3. Method
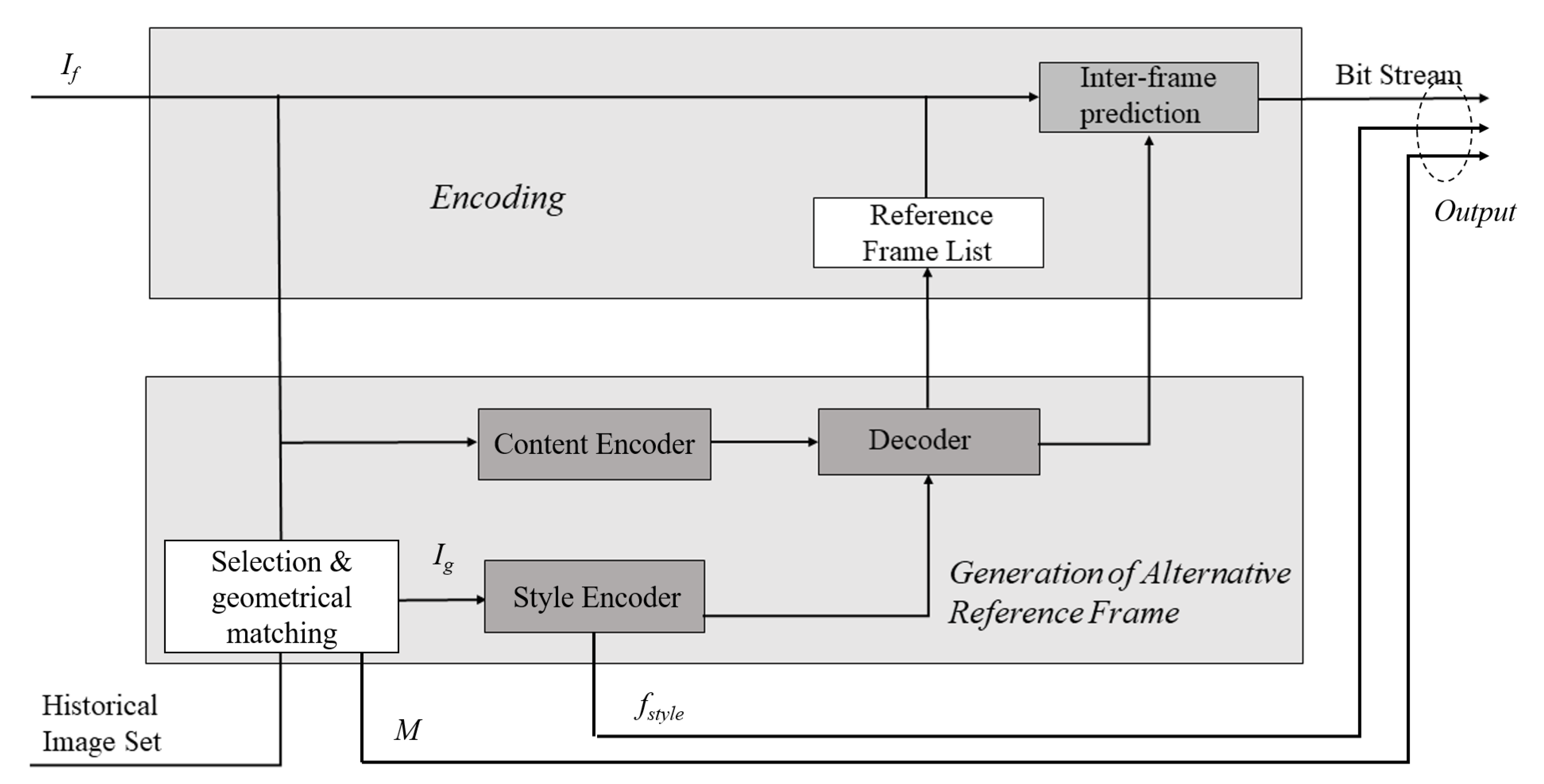
3.1. Preliminary on Reference Image Generation
3.2. Representation Learning-Based Reference Image Generation
3.2.1. Network Architecture
3.2.2. Objective Function
- Shared content feature loss: As for the shared content features, and must be identical, i.e., . Therefore, our goal is to minimize the distance between them. The loss function of the content encoder is defined as:
- Reconstruction loss: The reconstruction loss contains two meanings. The first is that the disentangled image x can be reconstructed by its content feature and its style feature . In this case, the encoder and decoder form an auto-encoder model. The first term of reconstruction loss is the self-reconstruction of each image. Taking x for example, the self-reconstruction loss is defined as:Image y is the same.The second term for reconstruction loss is a cross-reconstruction loss. The exclusive feature only contains the particular information of each image. Therefore, the reconstruction of image x, should be similar to x. For the sake of disentangled representation, the reconstruction loss of x is:Therefore, the overall reconstruction loss is the sum of two reconstruction loss terms:
- Adversarial loss: In order to force the distribution of reconstruction to be close to the distribution of the real image, PatchGAN [36] was adopted for our model. The decoder can be regarded as the generator, and it is trained to reconstruct images, which can be classified as true by the discriminator, i.e., , while the discriminator is trained to tell the reconstructed images from the real images, i.e., . The loss of GAN is defined as:The generator tries to maximize the loss while the discriminator tries to minimize it. The overall adversarial loss is the sum of both reconstructed images x and y:
- Total loss: Our model is trained jointly in an end-to-end learning manner. The objective is to minimize the following total loss defined as:where and are the constant weights of corresponding losses.
3.2.3. Representation Learning-Based Image Translation
3.3. Improvement of the Compression Scheme
4. Experimental Results and Discussion
4.1. Experimental Setup
4.1.1. Implementation Details
| Algorithm 1 Training procedure of our proposed model. |
|
4.1.2. Datasets
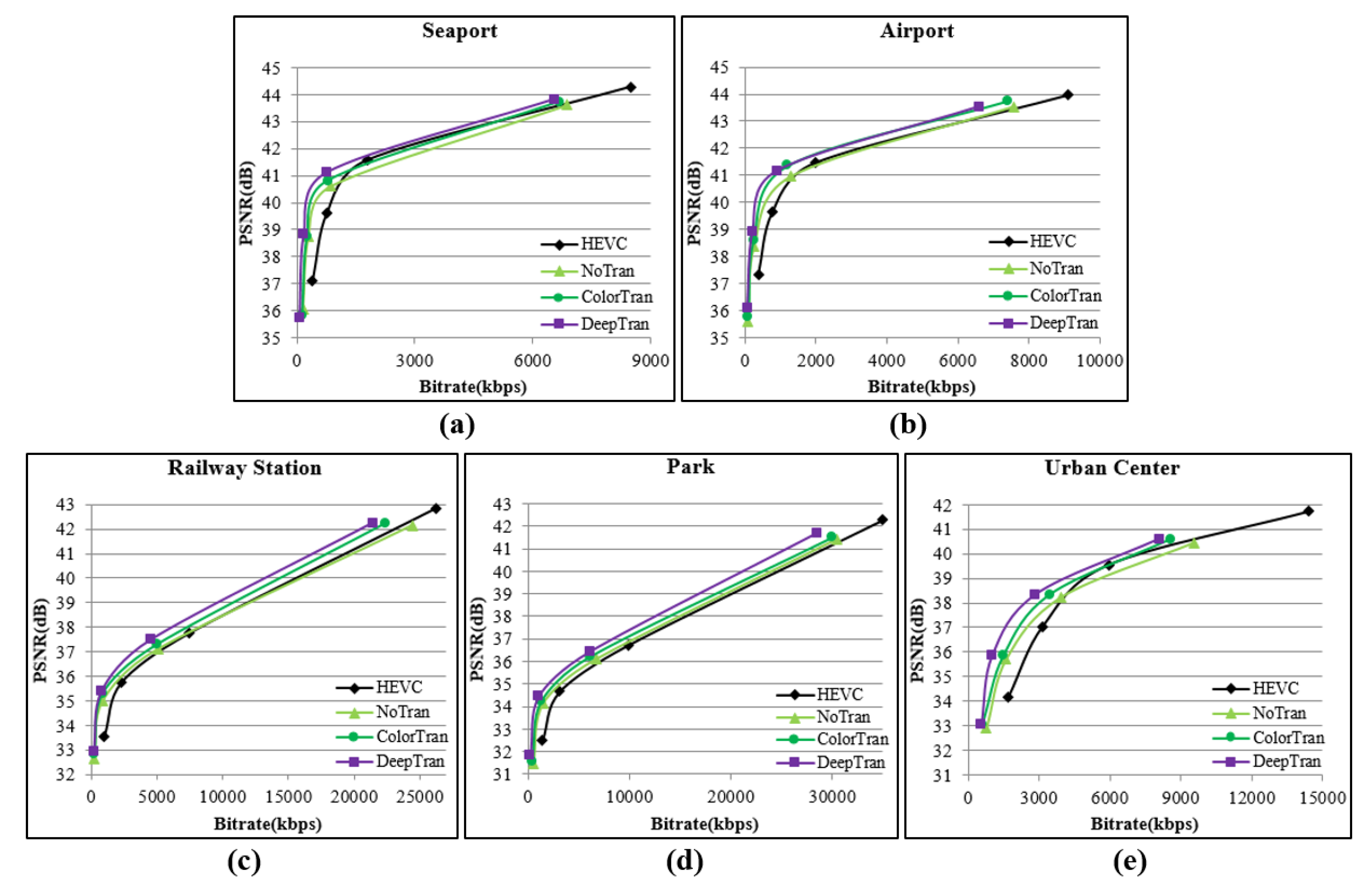
- Video clips from satellites: There were five video clips from the satellite Jilin-1 over the seaport of Valencia (Figure 6a), the airport of Atlanta (Figure 6b), a railway station of Munich (Figure 6c), a park of Madrid (Figure 6d) m and the urban center of Valencia (Figure 6e). Those video clips were cut out from the original 12,000 × 5000 resolution and had a unified size of with 300 frames, 10 fps.
- Image series from historical Google images: To show the evolution of the landscape, we employed the historical images of the same landscape from Google Earth as the training data. The image series contained 5000 images, which included an average of ten images for each landscape. The example images of the test landscape from the last five years are shown in Figure 7. They showed that the structure of the same landscape was almost unchanged, but the appearance was changed due to the environment.
4.2. Results
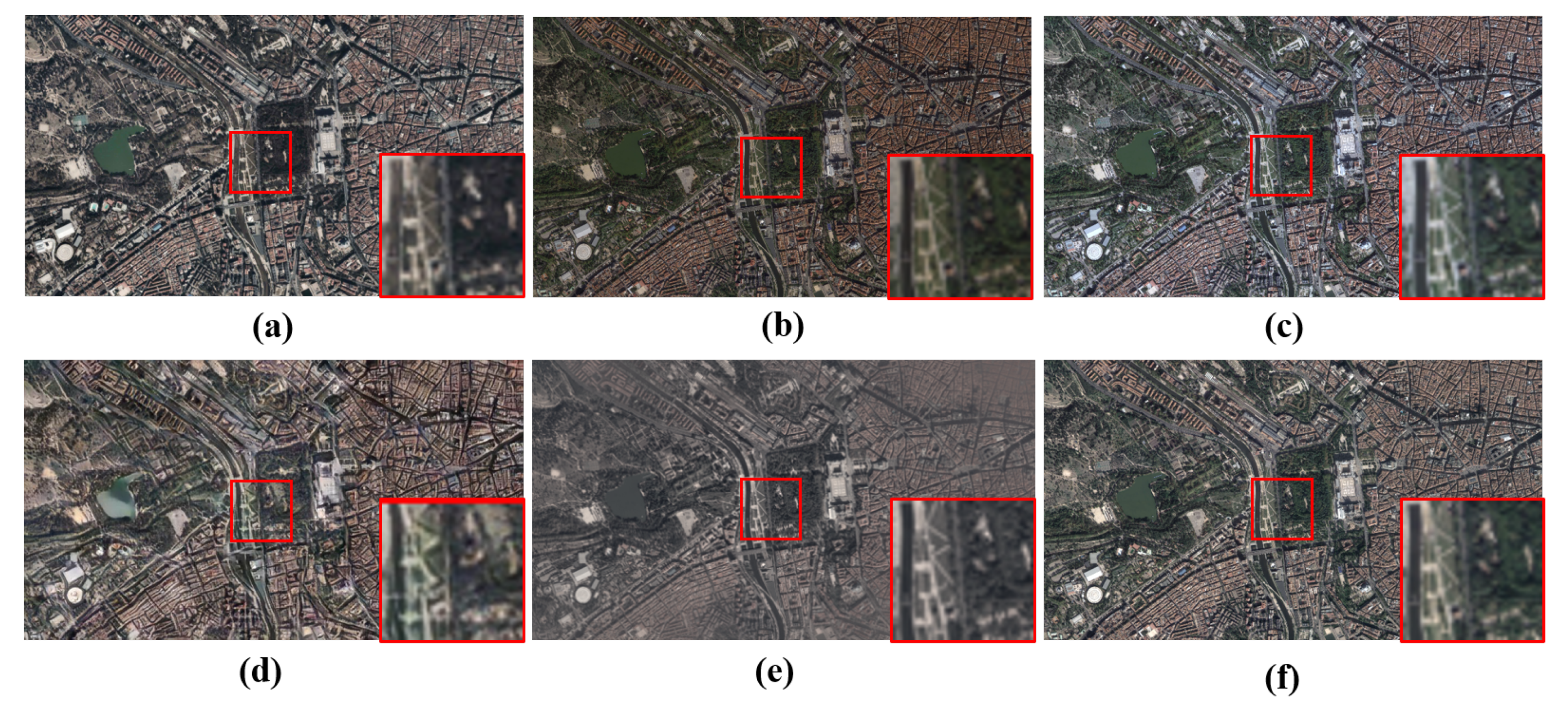
4.2.1. Intermediate Results from the Background Reference Generation
- Color transform [2]: manipulating the color image by imposing the mean and standard deviation of the style image onto the content image.
- AdaIN [40]: aligning the mean and variance of the content features with those of the style features by the adaptive instance normalization (AdaIN) layer.
- PhotoWCT [43]: transferring the style of the reference image to the content image by a pair of feature transforms, whitening, and coloring.
4.2.2. Experiments with Satellite Video Clips
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sjoberg, R.; Chen, Y.; Fujibayashi, A.; Hannuksela, M.M.; Samuelsson, J.; Tan, T.K.; Wang, Y.K.; Wenger, S. Overview of HEVC high-level syntax and reference picture management. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1858–1870. [Google Scholar] [CrossRef]
- Xiao, J.; Zhu, R.; Hu, R.; Wang, M.; Zhu, Y.; Chen, D.; Li, D. Towards Real-Time Service from Remote Sensing: Compression of Earth Observatory Video Data via Long-Term Background Referencing. Remote Sens. 2018, 10, 876. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Lu, K.; Liu, P.; Ranjan, R.; Chen, L. IK-SVD: dictionary learning for spatial big data via incremental atom update. Comput. Sci. Eng. 2014, 16, 41–52. [Google Scholar] [CrossRef]
- Song, W.; Deng, Z.; Wang, L.; Du, B.; Liu, P.; Lu, K. G-IK-SVD: parallel IK-SVD on GPUs for sparse representation of spatial big data. J. Supercomput. 2017, 73, 3433–3450. [Google Scholar] [CrossRef]
- Ke, H.; Chen, D.; Shi, B.; Zhang, J.; Liu, X.; Zhang, X.; Li, X. Improving Brain E-health Services via High-Performance EEG Classification with Grouping Bayesian Optimization. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef]
- Ke, H.; Chen, D.; Shah, T.; Liu, X.; Zhang, X.; Zhang, L.; Li, X. Cloud-aided online EEG classification system for brain healthcare: A case study of depression evaluation with a lightweight CNN. Software Pract. Exper. 2018. [Google Scholar] [CrossRef]
- Jing, X.Y.; Zhu, X.; Wu, F.; You, X.; Liu, Q.; Yue, D.; Hu, R.; Xu, B. Super-resolution person re-identification with semi-coupled low-rank discriminant dictionary learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 695–704. [Google Scholar]
- Wu, F.; Jing, X.Y.; You, X.; Yue, D.; Hu, R.; Yang, J.Y. Multi-view low-rank dictionary learning for image classification. Pattern Recognit. 2016, 50, 143–154. [Google Scholar] [CrossRef]
- Liu, X.; Tao, X.; Ge, N. Remote-sensing image compression using priori-information and feature registration. In Proceedings of the 2015 IEEE 82nd Vehicular Technology Conference (VTC2015-Fall), Glasgow, Scotland, 11–14 May 2015; pp. 1–5. [Google Scholar]
- Tao, X.; Li, S.; Zhang, Z.; Liu, X.; Wang, J.; Lu, J. Prior-Information-Based Remote Sensing Image Compression with Bayesian Dictionary Learning. In Proceedings of the 2017 IEEE 85th Vehicular Technology Conference (VTC Spring), Sydney, Australia, 4–7 June 2017; pp. 1–6. [Google Scholar]
- Wang, X.; Hu, R.; Wang, Z.; Xiao, J. Virtual background reference frame based satellite video coding. IEEE Signal Process. Lett. 2018, 25, 1445–1449. [Google Scholar] [CrossRef]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Chen, D.; Tang, Y.; Zhang, H.; Wang, L.; Li, X. Incremental factorization of big time series data with blind factor approximation. IEEE Trans. Knowl. Data Eng. 2019. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, D.; Wang, L.; Zomaya, A.; Chen, J.; Liu, H. Bayesian tensor factorization for multi-way analysis of multi-dimensional EEG. Neurocomputing 2018, 318, 162–174. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef] [Green Version]
- Corporation, S.I. SkySat-C Generation Satellite Sensors. Available online: https://www.satimagingcorp.com/satellite-sensors/skysat-1/ (accessed on 28 December 2019).
- Yue, H.; Sun, X.; Yang, J.; Wu, F. Cloud-based image coding for mobile devices—Toward thousands to one compression. IEEE Trans. Multimed. 2013, 15, 845–857. [Google Scholar]
- Shi, Z.; Sun, X.; Wu, F. Feature-based image set compression. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Wu, H.; Sun, X.; Yang, J.; Zeng, W.; Wu, F. Lossless compression of JPEG coded photo collections. IEEE Trans. Image Process. 2016, 25, 2684–2696. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Tian, T.; Ma, M.; Wu, J. Joint compression of near-duplicate Videos. IEEE Trans. Multimed. 2016, 19, 908–920. [Google Scholar] [CrossRef]
- Song, X.; Peng, X.; Xu, J.; Shi, G.; Wu, F. Cloud-based distributed image coding. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1926–1940. [Google Scholar] [CrossRef]
- Xiao, J.; Hu, R.; Liao, L.; Chen, Y.; Wang, Z.; Xiong, Z. Knowledge-based coding of objects for multisource surveillance video data. IEEE Trans. Multimed. 2016, 18, 1691–1706. [Google Scholar] [CrossRef]
- Xiao, J.; Liao, L.; Hu, J.; Chen, Y.; Hu, R. Exploiting global redundancy in big surveillance video data for efficient coding. Clust. Comput. 2015, 18, 531–540. [Google Scholar] [CrossRef]
- Chen, Y.; Hu, R.; Xiao, J.; Xu, L.; Wang, Z. Multisource surveillance video data coding with hierarchical knowledge library. Multimed. Tools Appl. 2019, 78, 14705–14731. [Google Scholar] [CrossRef]
- Chen, Y.; Hu, R.; Xiao, J.; Wang, Z. Multisource surveillance video coding with synthetic reference frame. J. Vis. Commun. Image Represent. 2019, 65, 102685. [Google Scholar] [CrossRef]
- Sanchez, E.; Serrurier, M.; Ortner, M. Learning Disentangled Representations of Satellite Image Time Series. arXiv 2019, arXiv:1903.08863. [Google Scholar]
- Gonzalez-Garcia, A.; van de Weijer, J.; Bengio, Y. Image-to-image translation for cross-domain disentanglement. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 2–8 December 2018; pp. 1287–1298. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27 October–3 Novemver 2017; pp. 2223–2232. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2017; pp. 465–476. [Google Scholar]
- Auli-Llinas, F.; Marcellin, M.W.; Sanchez, V.; Serra-Sagrista, J.; Bartrina-Rapesta, J.; Blanes, I. Coding scheme for the transmission of satellite imagery. In Proceedings of the 2016 Data Compression Conference (DCC), Snowbird, UT, USA, 29 March–1 April 2016; pp. 427–436. [Google Scholar]
- Aulí-Llinàs, F.; Marcellin, M.W.; Sanchez, V.; Bartrina-Rapesta, J.; Hernández-Cabronero, M. Dual link image coding for earth observation satellites. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5083–5096. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, T.; Tian, Y.; Gao, W. Background-modeling-based adaptive prediction for surveillance video coding. IEEE Trans. Image Process. 2013, 23, 769–784. [Google Scholar] [CrossRef] [PubMed]
- Reinhard, E.; Adhikhmin, M.; Gooch, B.; Shirley, P. Color transfer between images. IEEE Comput. Graph. Appl. 2001, 21, 34–41. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Wang, X.; Hu, R.; Wang, Z.; Xiao, J.; Satoh, S. Long-Term Background Redundancy Reduction for Earth Observatory Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef]
- Welch, T.A. A technique for high-performance data compression. Computer 1984, 6, 8–19. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27 October–3 Novemver 2017; pp. 1501–1510. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Institute, F.H.H. High Efficiency Video Coding (HEVC). Available online: https://hevc.hhi.fraunhofer.de/ (accessed on 28 December 2019).
- Li, Y.; Liu, M.; Li, X.; Yang, M.-H.; Kautz, J. A closed-form solution to photorealistic image stylization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 453–468. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Frame structure | Low Delay IPPP | GOP size | 4 |
| QP | 22, 27, 32, 37 | Max partition depth | 4 |
| Fast search | Enable | Search range | 64 |
| Intra-period | 20 | GOP size | 4 |
| SAO | 1 | Rate control | -1 |
| Method | Satellite Jilin-1 | BD-PSNR (dB) | BD-Rate (%) |
|---|---|---|---|
| NoTran | Seaport | 0.11 | −27.73 |
| Airport | 0.35 | −25.57 | |
| Railway Station | 0.27 | −10.59 | |
| Park | 0.36 | −9.33 | |
| Urban Center | 0.36 | −17.12 | |
| Average | 0.29 | −18.07 | |
| ColorTran | Seaport | 0.45 | −39.28 |
| Airport | 0.80 | −42.38 | |
| Railway Station | 0.59 | −22.18 | |
| Park | 0.64 | −22.52 | |
| Urban Center | 0.86 | −28.38 | |
| Average | 0.67 | −30.95 | |
| DeepTran | Seaport | 0.81 | −53.33 |
| Airport | 0.97 | −52.34 | |
| Railway Station | 0.89 | −36.72 | |
| Park | 0.94 | −34.46 | |
| Urban Center | 1.27 | −44.27 | |
| Average | 0.98 | −44.22 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, L.; Xiao, J.; Li, Y.; Wang, M.; Hu, R. Learned Representation of Satellite Image Series for Data Compression. Remote Sens. 2020, 12, 497. https://doi.org/10.3390/rs12030497
Liao L, Xiao J, Li Y, Wang M, Hu R. Learned Representation of Satellite Image Series for Data Compression. Remote Sensing. 2020; 12(3):497. https://doi.org/10.3390/rs12030497
Chicago/Turabian StyleLiao, Liang, Jing Xiao, Yating Li, Mi Wang, and Ruimin Hu. 2020. "Learned Representation of Satellite Image Series for Data Compression" Remote Sensing 12, no. 3: 497. https://doi.org/10.3390/rs12030497
APA StyleLiao, L., Xiao, J., Li, Y., Wang, M., & Hu, R. (2020). Learned Representation of Satellite Image Series for Data Compression. Remote Sensing, 12(3), 497. https://doi.org/10.3390/rs12030497