1. Introduction
Remote-sensing image classification has gained in popularity as a research area, due to the increase in availability of satellite imagery and advancements in deep-learning methods for image classification. A typical image contains objects and natural scenery, and the algorithms must understand which parts of the image are important and relate to the class, and which parts are unrelated to the class. Scene classification has been applied to various industrial products such as drones and autonomous robots, to improve their predictability at understanding scenes.
Much early work concentrated on using hand-crafted methods such as color histograms, texture features, scale-invariant feature transform (SIFT) or histograms of oriented gradient (HOG). Color histograms were very simple to implement but, though translation- and rotation-invariant, they were unable to take advantage of spatial information in an image [
1]. For the analysis and classification of aerial and satellite images, texture features were commonly used, including Gabor features, co-occurrence matrices and binary patterns [
2]. SIFT used the gradient information about important keypoints to describe regions of the image. There are different types of SIFT (sparse SIFT, PCA-SIFT and SURF) which are all highly distinctive and are scale-, illumination- and rotation-invariant [
3]. HOG calculates the distribution of the intensities and directions of the gradients of regions in the image, and has had great success at edge detection and identifying shape details in images [
4]. Both SIFT and HOG use features to represent local regions of an image, and therefore reduce their effectiveness by not taking important spatial information into account. To improve these methods, creating global feature representation
bag of visual word models were introduced [
5]. Advances in these models included using pooling techniques such as spatial pyramid matching [
6].
Several unsupervised approaches have been explored for remote sensing classification problems. Principal component analysis (PCA) and k-means clustering were successful early methods. More recently, auto-encoders have been used in the area as an unsupervised model, which involve reconstructing an image after forcing it through a bottleneck layer. These unsupervised methods improved on hand-crafted features techniques, but distinct class boundaries were hard to define because the data was unlabeled. For this reason, supervised learning was more attractive, especially for convolutional neural networks (CNNs) from the field of deep learning, which have been responsible for state-of-the-art results in image classification [
7,
8].
Given the unmatched power of deep learning for image classification, it is natural to investigate the usefulness of CNNs on remote sensing data problems [
9,
10]. CNN models such as AlexNet [
11] and VGG16 [
12] have demonstrated their ability to extract relevant informative features that are more discriminative than extracted hand-crafted features. [
13,
14] used a promising strategy of extracting the CNN activations of the variously scaled local regions, and pooling them together into a bag of local features. Their networks were pre-trained on ImageNet, similar to [
15], demonstrating how using a good initialization of parameters can increase network classification accuracy. Other related works show that by avoiding pooling and instead focusing on multi-scale CNN structures, competitive results can be achieved [
16].
This type of image classification is very challenging for several reasons. First, although remote-sensing datasets are increasing in size, most are still considered small in deep-learning terms. This means that we often have insufficient training data to obtain high classification accuracy. To have a fair comparison between our method and related work in this area, we set up the experiments in the same manner. This meant that the training dataset had a very limited number of samples, adding to the problem difficulty. To tackle this problem we use
transfer learning, which uses other data to provide a good initialization point for the network parameters. A second problem is that images from the same class can have very different scales and/or orientation. To address this issue, we apply a standard method from deep-learning image recognition:
data augmentation. A third problem is that high-resolution satellite images can contain overlapping classes, which can have an inverse effect on classification accuracy [
17]. Although the method in [
17] has had great success, it is very dependent on how the initial low-level hand-crafted features are extracted, which in turn relies greatly on domain knowledge. Using CNNs to extract the relevant features eliminates the need for domain knowledge and hand-crafted features. A fourth problem is that training a CNN on images can lead to very large networks that are prone to overfitting, and unsuitable for deployment on memory- and energy-limited devices.
A current trend in deep learning is network size reduction, but this often uses computationally expensive supervised learning techniques. We propose a novel unsupervised learning approach, based on k-means clustering, for pruning neural networks of unwanted redundant filters and nodes. We find optimal clusters within the filters/nodes of each layer, and discard those furthest from the center along with all their associated parameters. Our new method, which we call PulseNetOne, combines these techniques with fine-tuning phases to recover from any loss in accuracy. Extensive experiments with various datasets and neural networks were carried out to illustrate the performance and robustness of our proposed pruning technique. We compare it with other state-of-the-art remote-sensing classification algorithms, and experiments show that it significantly outperforms them in classification accuracy and regularization while generating much less complex networks.
The rest of this paper is organized as follows.
Section 2 discusses the related work on various methods of remote-sensing image classification. The datasets and CNNs used are described in
Section 3, and we explain our proposed method in
Section 4. The results are given in
Section 5 as well as their evaluation and discussions. Finally,
Section 6 concludes the paper.
2. Related Work
A well-established method that has been very successful for satellite image recognition is the
bag of visual words (BOVW) approach. This usually involves (i) extracting hand-made features (properties derived from the information present in the image itself), using algorithms like SIFT and HOG; (ii) using a clustering algorithm to group the features, thus creating a BOVW with a defined center; and (3) forming feature representations using histograms, by mapping the learned features onto the nearest cluster center [
18,
19,
20,
21,
22,
23]. Both the authors of [
24,
25] have employed this technique to remote-sensing classification. To obtain more meaningful features, spatial pyramids and randomized spatial partitions were used. The authors of [
26] used a CNN, originally trained on the ImageNet dataset, with spatial pyramid pooling, and only fine-tuned the fully connected layers of the network. The spatial pyramid was inserted between the convolutional and fully connected layers to automatically learn multi-scale deep features, which are then pooled together into subregions.
To remove the need for domain-knowledge hand-crafted features, unsupervised learning was used to learn basis functions to encode the features. By constructing the features using the training images instead of hand-crafted ones, better discriminative features are learned to represent the data. Some of the more popular unsupervised methods implemented in this research area include k-means, PCA and auto-encoders [
17,
27,
28].
The authors of [
29] claimed that an important part of remote-sensing classification was to overcome the problems of within-class diversity and between-class similarity, which are both major challenges. The authors proposed to train a CNN on a new discriminative objective function that imposes a metric learning regularization term on the features. At each training iteration random image samples are used to construct similar and dissimilar pairs, and by applying a constraint between the pairs a hinge loss function is obtained. Unlike our proposed algorithm, which is unsupervised and fast, their method requires several parameters to be selected, which most likely will vary depending on the data, and has a complex training procedure that is relatively inefficient. Their results reinforce the idea that unlike most other approaches that only use the CNN for feature extraction, better performance is achieved by training all the layers within the network.
The authors of [
30] designed a type of dual network in which features were extracted from the images based on both the objects and the scene of the image, and fused them together, hence the name FOSNet (fusion of object and scene). The authors trained their network using a novel loss function (scene coherence loss) based on the unique properties of the scene. The authors of [
31] fused both local and global features by first partitioning the images into dense regions, which were clustered using k-means. A spatial pyramid matching method was used to connect local features, while the global features were extracted using multi-scale completed local binary patterns which were applied to both gray scale and Gabor filter feature maps. A filter collaborative representation classification approach is used on both sets of features, local and global, and images are classified depending on the minimal approximation residual after fusion. The authors of [
32] also used a spatial pyramid idea with the AlexNet CNN as its main structure. The authors find that although AlexNet has shown great success in scene classification and as a feature extractor, because of limited training datasets it is prone to overfitting. By using a technique of side supervision on the last three convolutional layers, and spatial pyramid pooling before the first fully connected layer, the authors claim that this unique AlexNet structure, named AlexNet-SPP-SS, helps to counteract overfitting and improve classification. Our work also shows how both AlexNet and VGG16 are prone to overfitting due to lack of training data, but by pruning redundant filters/nodes we add a strong regularization to the networks, which prevents overfitting and increases model efficiency.
The authors of [
33] argue that using a deeper network (GoogLeNet) and extracting features at three stages helps to improve the robustness of the model, allowing low-, mid- and high-level features to contribute more directly to the classification. Instead of the usual additive approach to pooling features, they show that a product principle works better. Their work includes experiments on Scene15, MIT67 and SUN397 datasets, which we shall also use, and show achieve better accuracy using smaller networks and without pooling. We claim that our approach is also more efficient.
The authors of [
16] found that scaling scene images induced bias between training and testing sets, which significantly reduces performance. They proposed scale-specific networks in a multi-scale architecture. They also introduce a novel approach to combine pre-training on both the ImageNet and Places datasets, showing that more accurate classification is achieved. The authors mentioned the idea of redundant features by removing redundancy within the network, making it more efficient and forcing stronger regularization, thus improving generalization. Our proposed method develops this idea.
The authors of [
34] combined two pre-trained CNNs in a hybrid collaborative representation method. One side of the hybrid model extracted shared features, while the other extracted class-specific features. They extended and improved their method by using various kernels: linear, polynomial, Hellinger and radial basis function. The authors of [
35] also used ImageNet networks pre-trained on VGG16 and Inception-v3 as feature extractors, before introducing a novel 3-layer additional network called CapsNet. The first layer is a convolutional layer that converts the input image into feature maps. The next layer consists of 2 reshape functions along with a squash function that transforms it into a 1-D vector before it enters the final layer, which has a node for each class, and is used for classification. Both these works use pre-trained networks, which our work shows can be significantly reduced in size.
The authors of [
36] used VGG16 to extract important features, then used a method based on feature selection and feature fusion to merge relevant features into a final layer for classification. Following the work of the authors of [
37] on canonical correlation analysis CCA, [
36] improved their work by proposing discriminant correlation analysis, which overcame the limitation of CCA that ignored the relationship between class structures in the data by maximizes the correlation between two feature sets while also maximizing the difference between the classes. The authors of [
38] adopted a Semantic Regional Graph model to select discriminant semantic regions in each image. The authors used a graph convolutional network originally proposed by the authors of [
39], pre-trained on the COCO-Stuff dataset. This type of classification model showed great promise, especially on the difficult SUN397 data on which it achieved 74% classification accuracy.
The authors of [
40] introduced a novel way to tackle limited training data, which causes overfitting in state-of-the-art CNNs such as AlexNet and VGG16. They used transfer learning, but also applied traditional augmentation on the original dataset, and collected images from the internet that were most similar to the desired classes. This greatly increased the number of training examples and helped to prevent overfitting. The authors showed that increasing the number of samples in the training data enables state-of-the-art networks to be trained on small datasets, such as scene-recognition data. Our proposed method can be fine-tuned on the original data alone, with standard augmentation due to the strong regularization our pruning approach imposes on the networks.
The authors of [
41] evaluated three common methods of using CNNs for remote-sensing datasets with limited data: training a network from scratch, fine-tuning a pre-trained network, and using a pre-trained network as a feature extractor. The preferred method is training a network from scratch as it tends to generate better features and allows for better control of the network. However, this approach is only feasible when adequate training data is available, otherwise either fine-tuning or feature extraction is more appropriate. The authors found that fine-tuning tends to lead to more accurate classification, especially when combined using a linear support vector machine as the classifier. Although our method uses a pre-trained network, we create more informative features by fine-tuning the full network, while applying our novel pruning approach to create a much smaller and more efficient network that helps to overcome overfitting.
The authors of [
42], on which this work is based, proposed an iterative CNN pruning algorithm called
PulseNet which used an absolute filter/node measurement as the decision metric on which filters and nodes to prune. Similar to the authors of [
42], PulseNetOne pruned all parts of the network but, unlike our proposed method, [
42] repeatedly pruned all parts reducing the rate of compression as the network converged to being fully pruned. Also, in this work, we use a more intelligent decision pruning metric based on
k-means. Both methods extract a smaller, more efficient network, and demonstrate their classification accuracy and computational speed during inference testing.
4. Results
PulseNetOne was applied to the AID dataset and its performance compared with other state-of-the-art results.
Table 2 shows that training the networks on the target dataset from scratch yielded poor results:
and
on AlexNet and VGG16 respectively. The accuracy of both networks improved greatly when using transfer learning and fine-tuning the transferred model. For transfer learning the weights and parameters of networks trained on ImageNet, on both AlexNet and VGG16, were re-initialized and used as a starting point for the weights of our networks. The fully-connected layers of the pre-trained networks were removed and replaced by fully-connected layers of the same size initialized using a
He normal weight distribution, with the number of final layer outputs being the number of classes in the dataset.
PulseNetOne takes the fine-tuned network and, as described in
Section 3.1, prunes the original network to a much smaller version, which not only reduces the storage size and number of floating point operations per second (FLOPs), but also improves classification accuracy. The accuracy of AlexNet improves by nearly
and VGG16 by
. The confusion matrices of both networks (available on request) show that very few errors were made, and as they were quite randomly distributed they might simply be a poor representation of the class within wrongly-classified images. The precision, recall and F1 scores of both networks are in their descriptions for further comparison.
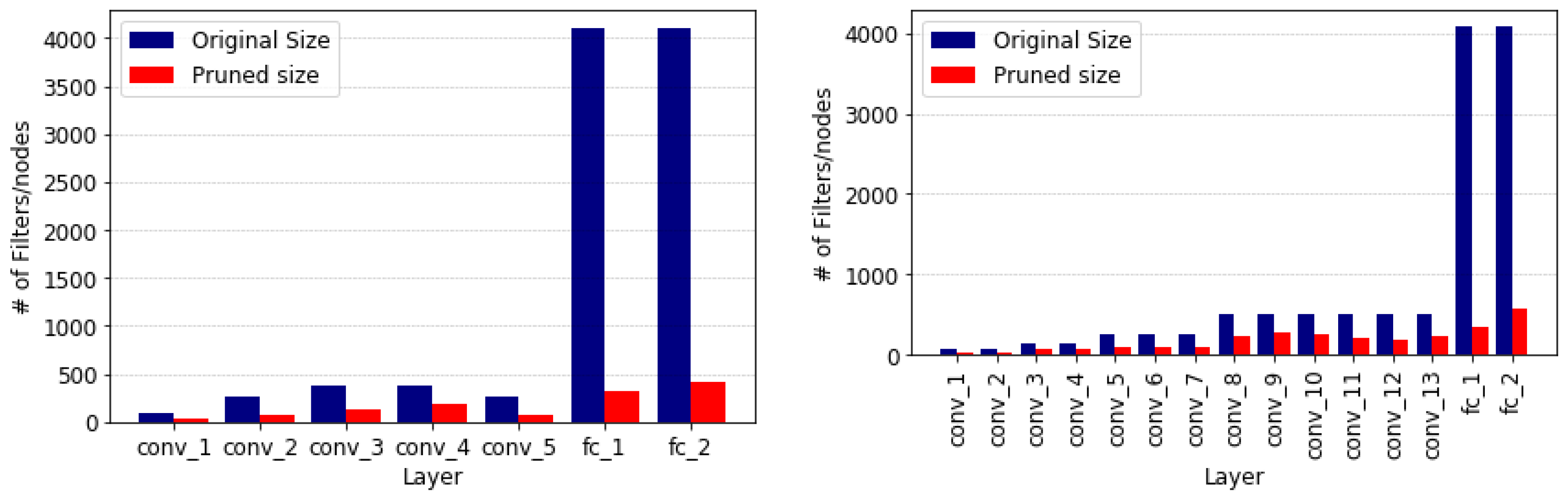
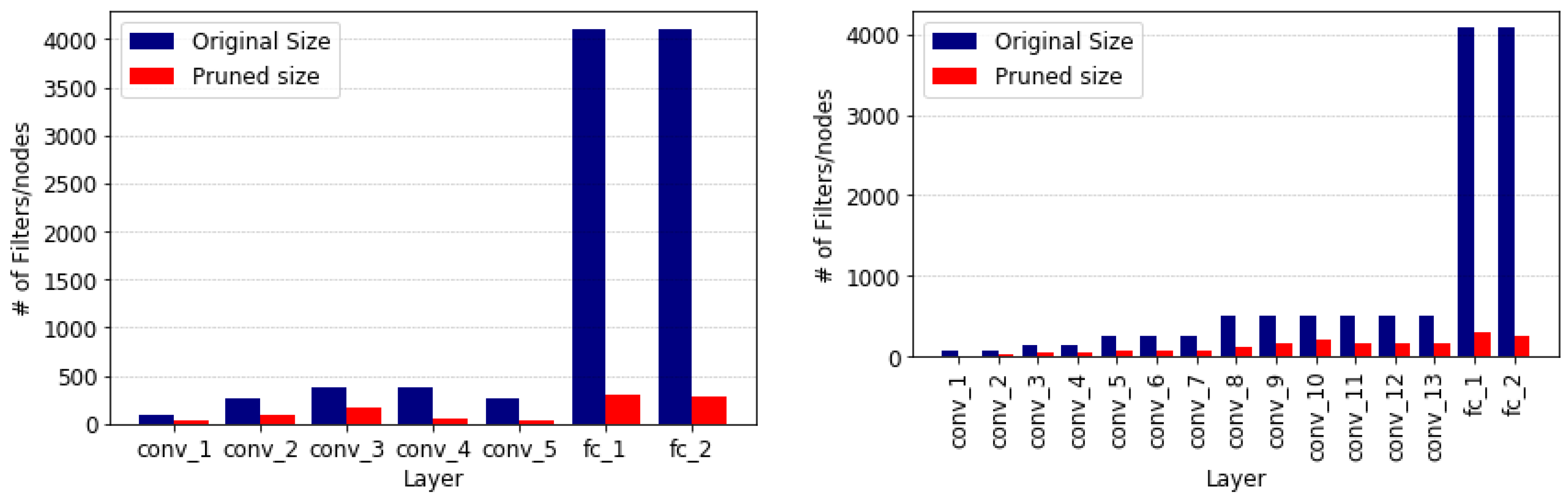
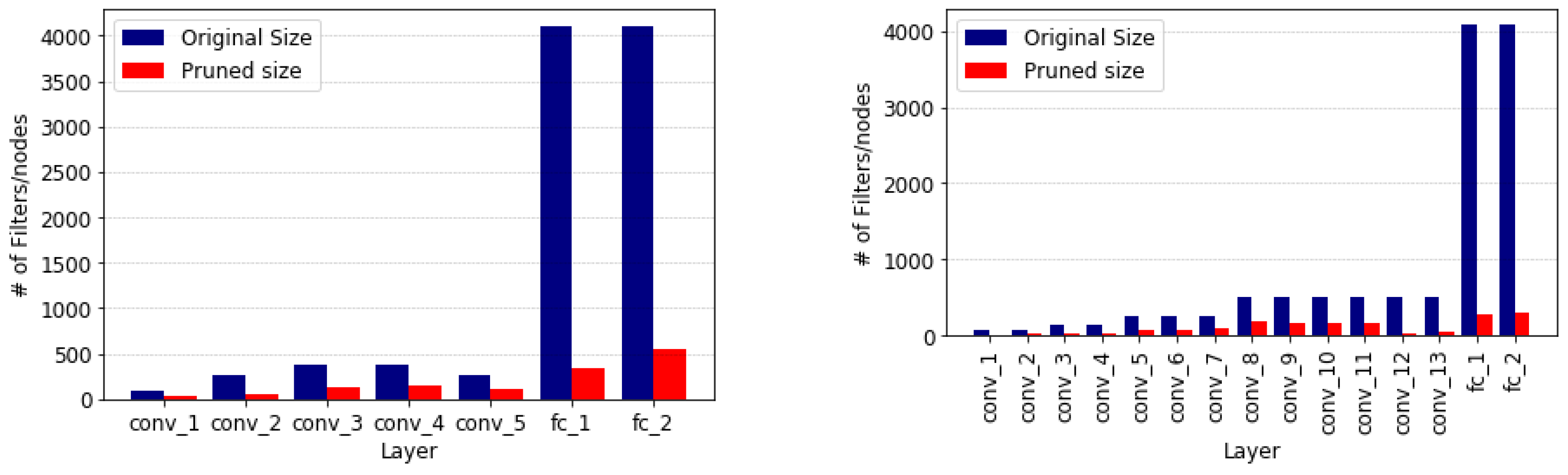
Figure 1 shows the number of filters pruned in each layer of the networks. As expected, the layers pruned most are the fully-connected layers, as it is well documented that these are over-parameterized. It is interesting to see that the first and last few convolutional layers are pruned more than the intermediate layers. A reason for this is that the first few layers are edge detectors and filters based on colour and shapes which can contain a lot of duplicate or similar filters, while the last convolutional layers are more class-related and, because the networks were pre-trained on the 1000-class ImageNet dataset, these layers contained many redundant filters.
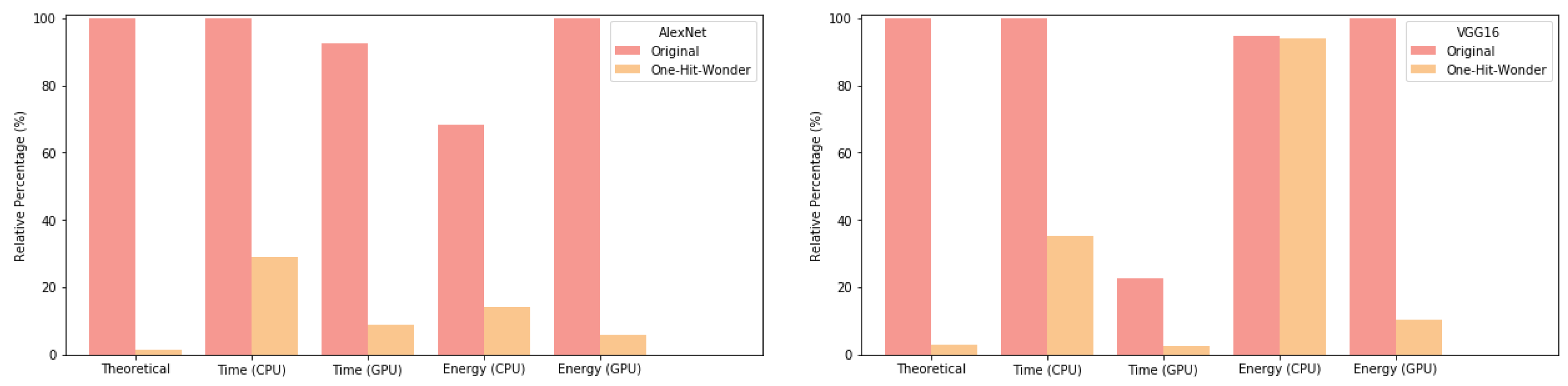
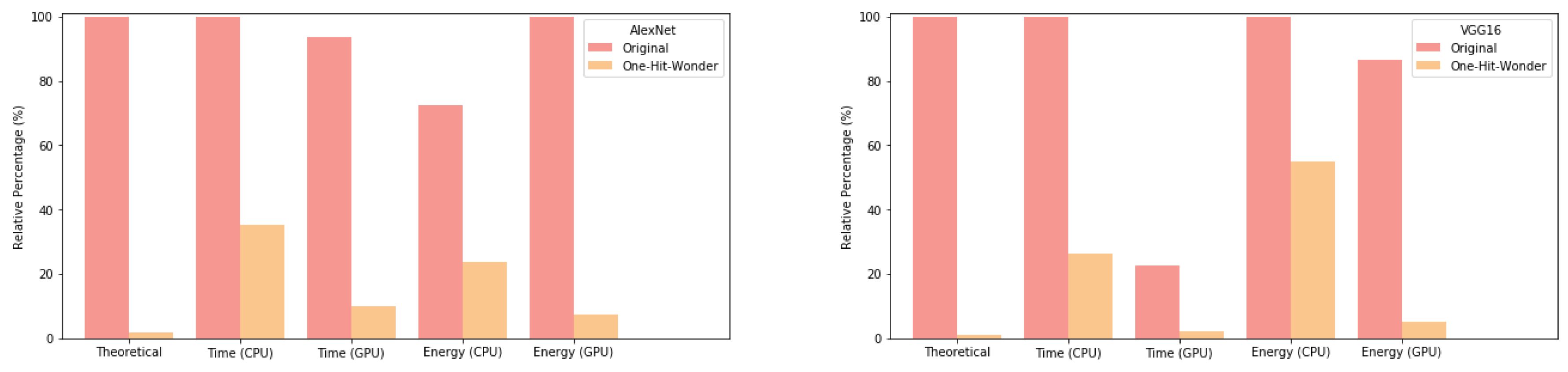
The barcharts in
Figure 2 clearly show that, although in most cases the theoretical improvements are not reached (except for the GPU timings for both networks, and the GPU energy for AlexNet), the results come close in most cases. Comparing our work with state-of-the-art results in
Table 3, it can be seen that our approach using VGG16 achieves the best classification accuracy with
, and our AlexNet version ranks in second place with
, which outperforms both Discriminative CNNs VGG16 [
29] and GCFs+LOFs [
48] by nearly
.
Next the dataset MIT67 is analysed, on which (similarly to the AID dataset) CNNs achieve poor classification accuracy when trained from scratch:
accuracy on AlexNet and
on VGG16. The explanation is believed to be the lack of training samples: a deep learning network has millions of parameters to tune and is therefore quite data-hungry.
Table 4 shows that simply transferring learning was not as effective as on the previous dataset, reaching a maximum accuracy of nearly
, but after fine-tuning on the targeted dataset, it reached a more reasonable
. PulseNetOne reduces AlexNet down to
and VGG16 down to
of their original sizes, and improves their performances to
and
respectively.
The confusion matrices for both networks (available on request) show that most mistakes were made when distinguishing between the bathroom and bedroom, and the grocery store and toy store classes. The precision, recall and F1 scores of both networks are in their descriptions for further transparency, and can be seen to be between
and
. Details of how PulseNetOne pruned the layers of the networks are shown in
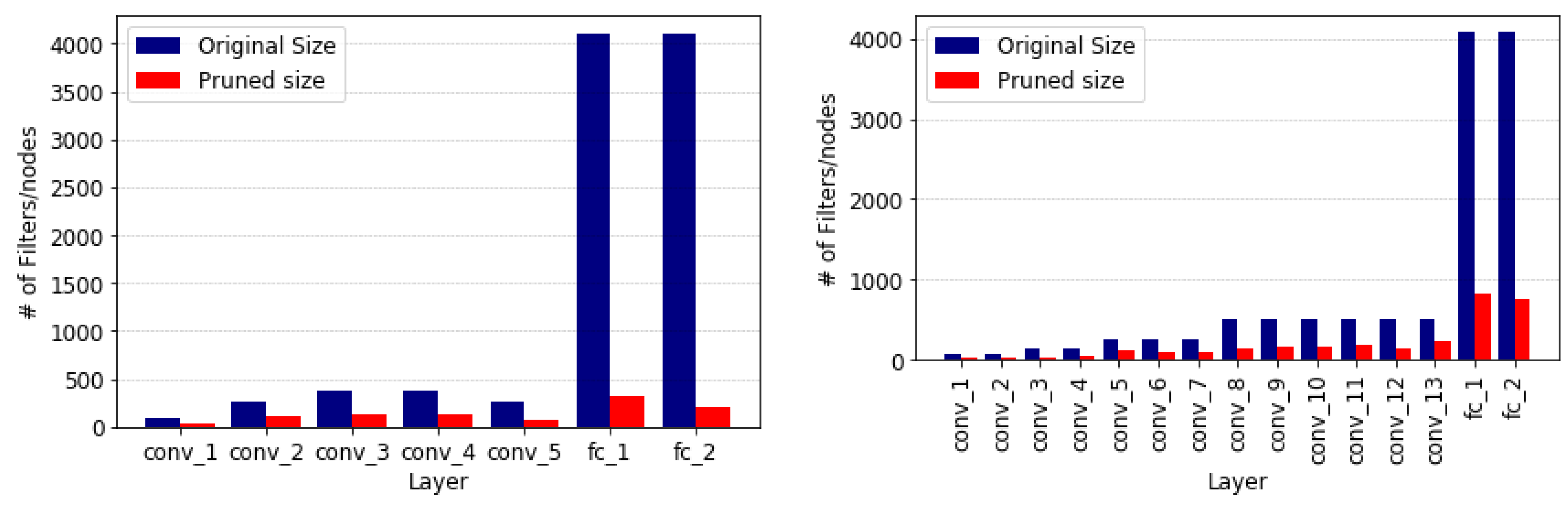
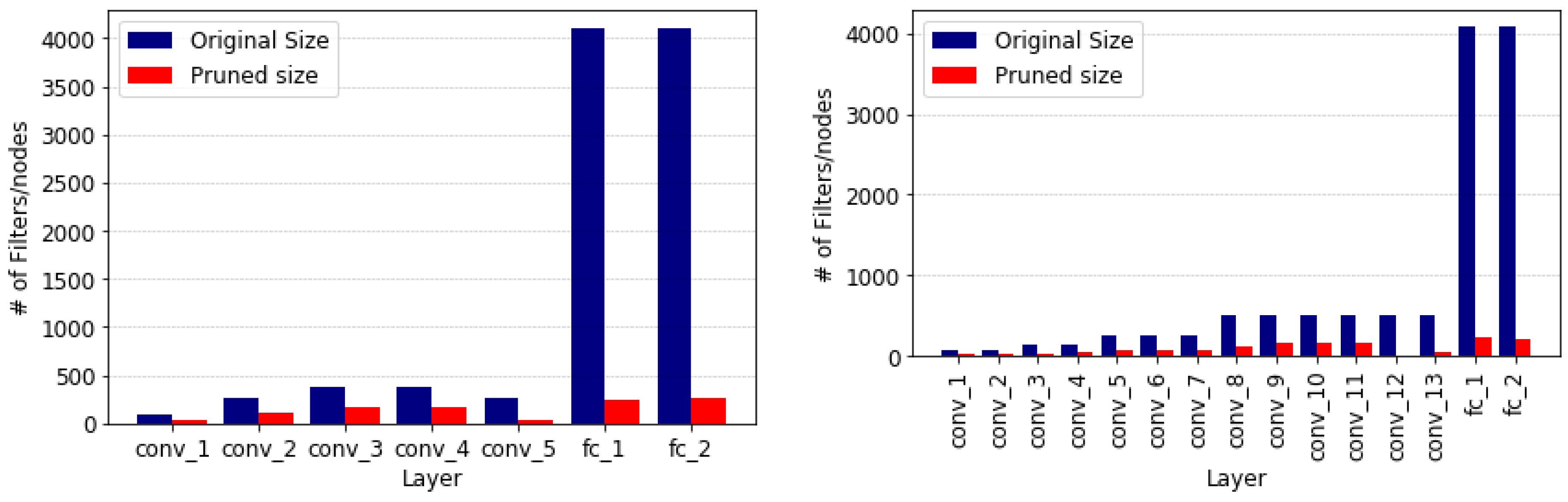
Figure 3, and agree with the analysis of the AID dataset. However, the VGG16 network retained more nodes in the fully-connected layers, which could be caused by the MIT67 dataset having more than twice the number of target classes.
Table 5 compares PulseNetOne to the related work in this area, and it can be seen that both networks pruned by PulseNetOne outperform the state-of-the-art by over
. FOSNet CCG [
30] and SOSF+CFA+GAF [
50] were the current best published results on the MIT67 dataset, achieving
and
respectively, but were significantly beaten by PulseNetOne.
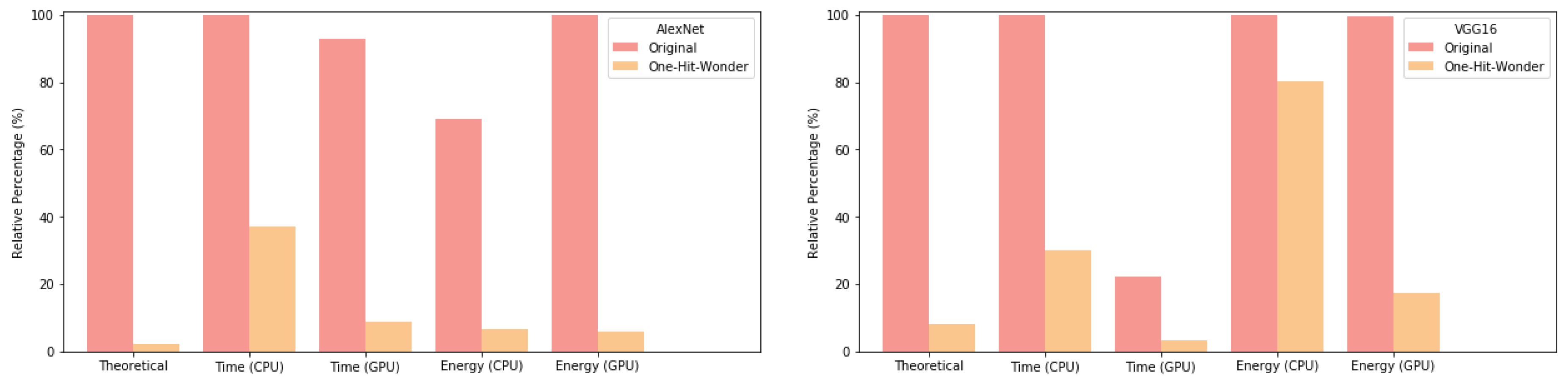
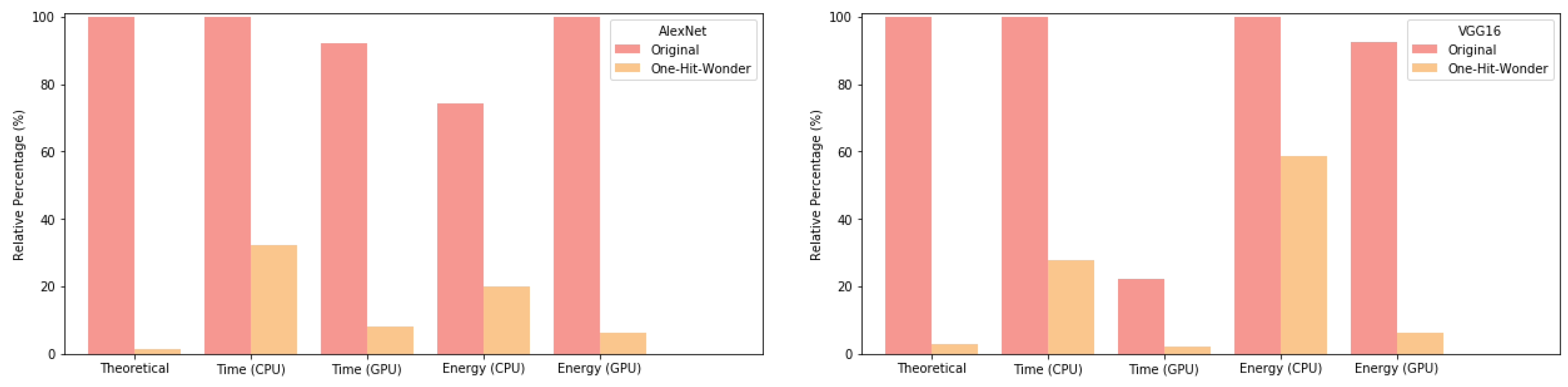
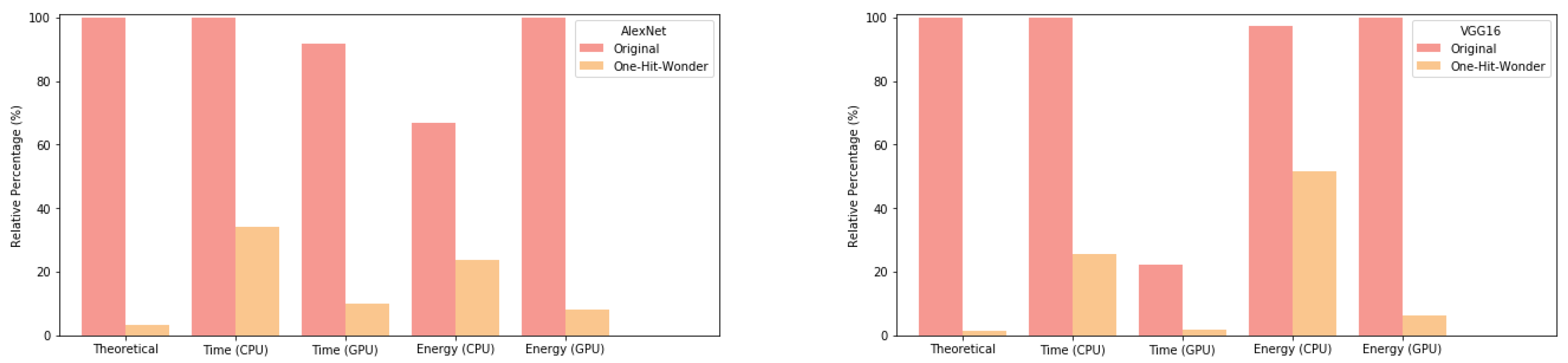
Figure 4 shows that AlexNet almost achieved its theoretical performance on all experiments except for CPU inference timing, while the pruned network was approximately
faster than the original network. VGG16 results were more mixed, with the CPU timing beating the theoretical result, but the CPU energy usage being quite high, though still slightly less than the original network structure.
The NWPU-RESISC45 dataset accuracy was only able to score
on AlexNet and
on VGG16 when trained from scratch.
Table 6 shows that transfer learning boosted their performances up to approximately
accuracy, while fine-tuning increased both to approximately
. PulseNetOne was able to increase their classification accuracy by over
, with AlexNet scoring
and VGG16
. This was the result of network pruning reducing overfitting: AlexNet was reduced by
and VGG16 by
.
The confusion matrices for both networks (available on request) show that both networks found it hard to distinguish between the freeway and railway, medium and dense residential, and meadow and forest classes. Other publications have commented on these classes being difficult to separate also. Again, the precision, recall and F1 scores of both networks are given in their descriptions, and can be seen to be between
and
. The way in which PulseNetOne pruned the layers of the networks, shown in
Figure 5, is more similar to that of the AID dataset than the MIT67 dataset, possibly because of its 45 classes.
Figure 6 shows that once again AlexNet achieved close to its theoretical performance on all experiments except for the CPU inference timing. The VGG16 results were not quite as impressive, with the GPU timing beating the theoretical result, while the CPU energy usage was close to that of the original network. It can be seen from
Figure 6 that in the other experiments the pruned network is much more efficient than the original.
PulseNetOne again beats the current state-of-the-art on the NWPU-RESISC45 dataset, as seen in
Table 7, by just over
. Inception-v3-CapsNet [
35] and Triple networks [
59] achieve
and
respectively, which is quite close to our results, but it should be noted that PulseNetOne creates an extremely efficient version of the networks, while both the related works approaches use complex networks that increase computational expense.
The accuracy achieved on Scene15 dataset, when trained from scratch, was quite reasonable when compared to the previous datasets, with AlexNet scoring
and VGG16 scoring
. Transfer learning increased classification accuracy by 10–
, while fine-tuning further increased it by 2–
as seen in
Table 8. PulseNetOne was able to increase the classification accuracy of AlexNet to
and VGG16 to
. AlexNet was reduced to
and VGG16 to
of their original sizes. The confusion matrices of both networks (available on request) show no particular pattern in their errors, with both networks making random misclassifications. The precision, recall and F1 scores of both networks are given in their descriptions, and can be seen to be between
and
.
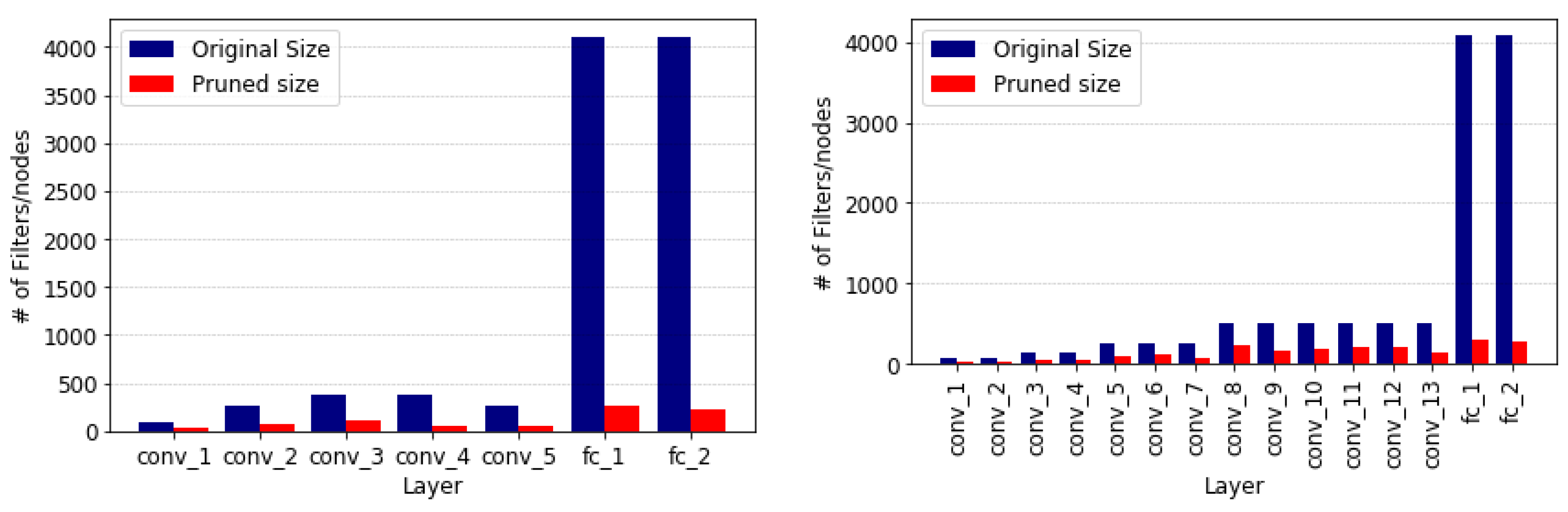
The layers of both networks, as shown in
Figure 7, are pruned in the same pattern as with the other datasets, fully-connected layers being heavily pruned, along with the beginning and ending of the convolutional layers, while the intermediate convolutional layers are less pruned.
Figure 8 shows that on AlexNet the pruned network performs better on the GPU, but for real-world situations where a CPU would be more commonly used for analysis, the pruned network easily outperforms the original structure in all cases. On VGG16 the CPU energy usage are unimpressive, but are almost twice as energy efficient as the original network. Following the same analysis as for the previous datasets, we compare PulseNetOne to the current state-of-the-art on the Scene15 dataset, shown in
Table 9. The Dual CNN [
16] was state-of-the-art since 2016, with a classification accuracy of
, the next in line being G-MS2F [
33] with
. PulseNetOne achieves almost a
greater accuracy, with AlexNet beating VGG16 on this dataset with
. Again, PulseNetOne’s closest competition uses 2 deep learning CNNs which is much less efficient.
The SUN397 dataset was the most difficult dataset to train from scratch, possible because of its large number of classes and its limited amount of training data: AlexNet reached
and VGG16
accuracy. Transfer learning with the ImageNet dataset helped increased AlexNet’s accuracy to
and VGG16 to
. Fine-tuning all the layers for either network had less effect than with the other datasets, only improving AlexNet to
and VGG16 to
. However, PulseNetOne was able to pass
classification accuracy on both networks, as seen in
Table 10: AlexNet reached
accuracy and VGG16
.
Confusion matrices for both networks (available on request) showed no real surprises in either of them, similar classes being mis-classified. The PulseNetOne-pruned AlexNet model had a precision score of
, recall score
and F1-score
, and the VGG166 version had precision score
, recall score
and a F1-score
. The layers of both networks, as seen in
Figure 9, are similar to previous results, but show that AlexNet’s last convolution layer was heavily pruned: slightly surprising given the dataset’s large number (397) of classes. A possible explanation is that the classes in the ImageNet dataset, on which the model was initially trained, were quite different to the classes on the target dataset SUN397. The PulseNetOne-pruned VGG16 also had a convolutional layer that was heavily pruned (the
layer or second-to-last layer), which reaffirms our hypothesis.
Figure 10 shows that the PulseNetOne version of both networks use considerably less energy and are in all cases noticeably faster at inference time.
Table 11 shows previous state-of-the-art results, and our method advances the best by approximately
. SOSF+CFA+GAF [
50] achieves the closest to our results, but whereas we use an input image of size
, their method uses an input size of
which is signifcant larger and therefore more computationally expensive. FOSNet [
30] is once again close to the state-of-the-art, with
.
The final dataset is UC Merced, which (as mentioned earlier) is relatively easy to classify accurately. VGG16 and AlexNet achieve
and
respectively, while transfer learning applied only to the new fully-connected layers resulted in accuracies of approximately
. Further fine-tuning increased the accuracies of both networks to just over
, and the current state-of-the-art uses fine-tuning with a Support Vector Machine as the classifier. PulseNetOne added
accuracy to both networks, and though this is small it makes our proposed method state-of-the-art.
Table 12 shows that VGG16 achieved classification accuracy
, and AlexNet
. We attribute this improvement to the high degree of pruning reducing overfitting: the AlexNet parameters and FLOPS were reduced by
, and those of VGG16 by
.
The confusion matrices of both networks (available on request) show that between both networks there was only 3 misclassifications. The precision, recall and F1 scores of both networks are in their descriptions, and can be seen to be
–
. As expected, the GPU performance was close to theoretical, while CPU times were significantly better on the pruned networks compared to the original networks, as shown in
Table 12.
Figure 11 shows that the second-last layer in VGG16 is again the most pruned, as in the SUN397 dataset, with the other layers being pruned in the same pattern as the other datasets.
Figure 12 shows that the GPU was more energy efficient and also had a faster inference time, but the PulseNetOne versions of the networks were both faster and consumed less energy on the CPU than the original networks. PulseNetOne slightly outperforms the current state-of-the-art on the UC Merced dataset by almost
, as shown in
Table 13. Inception v3 CapsNet [
35] had, once again, one of the best accuracies with
, narrowly beaten by Fine-tuned GoogLeNet with SVM [
41] with
which, though quite close to our results, comes at the cost of more complex and expensive networks.
Table 14 shows inference time and energy consumed per image on both a CPU and GPU processor, along with the storage size of the original and pruned networks. To ensure that the work was applicationally related, we used a test batch of just one image, which is more applicable to real-world testing. Looking at the results on the AID dataset, the storage sizes of both networks are greatly reduced by PulseNetOne, and on a CPU inference is approximately
faster, and approximately
faster on a GPU. The energy saving for the networks ranges from
to
fewer milli-Joules. Next the results for the MIT67 dataset, where the storage size of AlexNet was reduced in size by nearly
while VGG16 was reduced by
. The energy saved on the CPU and GPU was
and
–
respectively, while the speed-up in inference time on AlexNet was 3–
and on VGG16 3–
.
The results for the NWPU-RESISC45 dataset show the storage sizes of AlexNet and VGG16 were reduced by
and
respectively, as shown in
Table 14. The speed-up in inference time on both networks were between
and
on the CPU and GPU, respectively. We see from the results on the SCENE15 dataset that the storage sizes of AlexNet and VGG16 were reduced by
and
respectively, as seen in
Table 14. The improvement of the inference timing on both neworks were
and
for the CPU and GPU, respectively.
Table 14 also shows that the CPU energy saving is between
and
, and between
and
for the GPU.
Next looking at the SUN397 dataset, we see that the storage sizes of AlexNet and VGG16 were reduced
and
respectively, as shown in
Table 14. The improvement in inference timing on both networks were
and
for the CPU and GPU, respectively. As shown in
Table 14 the CPU energy saving is 2–
while the GPU’s energy saving is
–
. Finally on the UCM dataset, it can be seen that the storage sizes of AlexNet and VGG16 were reduced from
MB to
MB and
MB to
MB, respectively. The speed-up in inference time on both networks were
and
on the CPU and GPU, respectively.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}