Multi-Label Remote Sensing Image Classification with Latent Semantic Dependencies




Abstract
:
1. Introduction
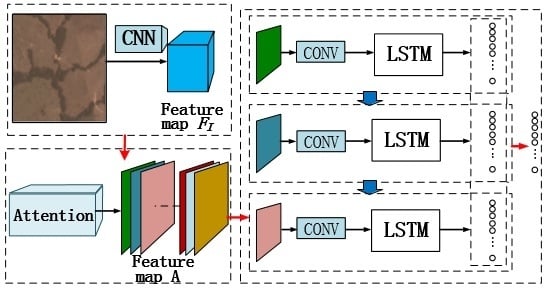
- We propose a novel framework for multi-label remote sensing image classification. By introducing the attention module into the CNN-RNN structure, the RNN can notice some small targets which might be neglected and easier to extract the correlation between labels.
- We propose a new loss function, which solves the problem of imbalance in the proportion of labels in the dataset. It helps to improve the classification results of rare labels, thereby improving the overall classification performance.
- We conduct experiments and evaluations on the dataset of the Amazon rainforest and prove that our proposed model is superior to other leading multi-label image classification methods in scores.
2. Related Works
3. Methodology
3.1. Densenet for Feature Extraction
3.2. Attention Module
3.3. Lstm for Latent Semantic Dependencies
3.4. Max-Pooling and Loss Function
3.5. Data Augmentation
- The size of original images from our dataset is 256 × 256, they are then cropped to 224 × 224 to fit the network input size. We take five crops for each image(four in the corners and one in the center);
- Unlike ordinary images such as what is in the ImageNet, satellite images can preserve semantic information after flipping and rotation, accordingly we applied both horizontal and vertical flips;
- We rotate each image to 90, 180, and 270 degrees.
4. Experiment
4.1. Dataset
4.2. Evaluation
4.3. Classification Performance
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sun, Y.; Song, H.; Jara, A.J.; Bie, R. Internet of things and big data analytics for smart and connected communities. IEEE Access 2016, 4, 766–773. [Google Scholar] [CrossRef]
- Refice, A.; Capolongo, D.; Pasquariello, G.; D’Addabbo, A.; Bovenga, F.; Nutricato, R.; Lovergine, F.P.; Pietranera, L. Sar and insar for flood monitoring: Examples with cosmo/skymed data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2711–2722. [Google Scholar] [CrossRef]
- Chen, K.S.; Serpico, S.B.; Smith, J.A. Remote sensing of natural disasters. Proc. IEEE 2012, 100, 2794–2797. [Google Scholar] [CrossRef]
- Losik, L. Using satellites to predict earthquakes, volcano eruptions, identify and track tsunamis from space. In Proceedings of the 2012 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2012; pp. 1–16. [Google Scholar]
- Levander, O. Autonomous ships on the high seas. IEEE Spectrum. 2017, 54, 26–31. [Google Scholar] [CrossRef]
- Zou, W.; Jing, W.; Chen, G.; Lu, Y.; Song, H. A Survey of Big Data Analytics for Smart Forestry. IEEE Access 2019, 7, 46621–46636. [Google Scholar] [CrossRef]
- Gilbert, A.; Flowers, G.E.; Miller, G.H.; Rabus, B.T.; Wychen, W.V.; Gardner, A.S.; Copland, L. Sensitivity of barnes ice cap, baffin island, canada, to climate state and internal dynamics. J. Geophys. Res. Earth Surf. 2016, 121, 1516–1539. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks; Morgan Kaufmann Press: San Francisco, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.H.; Karpathy, A.; Khosla, K.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Du, S. Learning multiscale and deep representations for classifying remotely sensed imagery. Isprs J. Photogramm. Remote. Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Jing, W.P.; Song, H.B.; Chen, G.S. High-resolution remote sensing image change detection combined with pixel-level and object-level. IEEE Access 2019, 7, 78909–78918. [Google Scholar] [CrossRef]
- Peng, J.T.; Zhou, Y.C. Ideal regularized kernel for hyperspectral image classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3274–3277. [Google Scholar]
- Fang, Y.; Xu, L.L.; Sun, X.; Yang, L.S.; Chen, Y.J.; Peng, J.H. A novel unsupervised classification approach for hyperspectral imagery based on spectral mixture model and Markov random field. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2450–2453. [Google Scholar]
- Yao, X.; Han, J.; Cheng, G.; Qian, X.; Guo, L. Semantic Annotation of High-Resolution Satellite Images via Weakly Supervised Learning. IEEE Trans. Geosci. Remote. Sens. 2016, 54, 3660–3671. [Google Scholar] [CrossRef]
- Chen, Q.; Song, Z.; Dong, J.; Huang, Z.; Hua, Y.; Yan, S. Contextualizing Object Detection and Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 13–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Q.; Song, Z.; Dong, J.; Hua, Y.; Huang, Z.Y.; Yan, S.C. Hierarchical matching with side information for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3426–3433. [Google Scholar]
- Dong, J.; Xia, W.; Chen, Q.; Feng, J.S.; Huang, Z.Y.; Yan, S.C. Subcategory-aware object classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 827–834. [Google Scholar]
- Harzallah, H.; Jurie, F.; Schmid, C. Combining efficient object localization and image classification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 237–244. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A Library for Support Vector Machines. Acm Trans. Intell. Syst. Technol. 2011, 2, 27:1–27:27. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Gong, Y.; Jia, Y.; Toshev, A.; Leung, T.; Ioffe, S. Deep Convolutional Ranking for Multilabel Image Annotation. Available online: https://arxiv.org/pdf/1312.4894 (accessed on 17 December 2013).
- Li, Y.; Song, Y.; Luo, J. Improving pairwise ranking for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3617–3625. [Google Scholar]
- Yang, H.; Tianyi Zhou, J.; Zhang, Y.; Gao, B.B.; Wu, J.; Cai, J. Exploit bounding box annotations for multi-label object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 280–288. [Google Scholar]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. Cnn-rnn: A unified framework for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2285–2294. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, Makuhari, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Zhang, J.; Wu, Q.; Shen, C.; Zhang, J.; Lu, J. Multilabel Image Classification With Regional Latent Semantic Dependencies. IEEE Trans. Multimed. 2018, 20, 2801–2813. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Zhu, F.; Li, H.; Ouyang, W.; Yu, N.; Wang, X. Learning spatial regularization with image-level supervisions for multi-label image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5513–5522. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | Training | Validition | Test |
|---|---|---|---|
| baseline | 0.859 | 0.851 | 0.849 |
| VGG16 | 0.915 | 0.912 | 0.909 |
| ResNet-50 | 0.921 | 0.917 | 0.915 |
| VGG16-LSTM | 0.918 | 0.914 | 0.913 |
| ResNet50-LSTM | 0.924 | 0.920 | 0.919 |
| DenseNet121-LSTM | 0.926 | 0.923 | 0.922 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, J.; Jing, W.; Chen, G.; Lin, J.; Song, H. Multi-Label Remote Sensing Image Classification with Latent Semantic Dependencies. Remote Sens. 2020, 12, 1110. https://doi.org/10.3390/rs12071110
Ji J, Jing W, Chen G, Lin J, Song H. Multi-Label Remote Sensing Image Classification with Latent Semantic Dependencies. Remote Sensing. 2020; 12(7):1110. https://doi.org/10.3390/rs12071110
Chicago/Turabian StyleJi, Junchao, Weipeng Jing, Guangsheng Chen, Jingbo Lin, and Houbing Song. 2020. "Multi-Label Remote Sensing Image Classification with Latent Semantic Dependencies" Remote Sensing 12, no. 7: 1110. https://doi.org/10.3390/rs12071110
APA StyleJi, J., Jing, W., Chen, G., Lin, J., & Song, H. (2020). Multi-Label Remote Sensing Image Classification with Latent Semantic Dependencies. Remote Sensing, 12(7), 1110. https://doi.org/10.3390/rs12071110