Improving 3-m Resolution Land Cover Mapping through Efficient Learning from an Imperfect 10-m Resolution Map


 and
and
Abstract
:
1. Introduction
2. Data
2.1. Image Data Source
2.2. Label Data Source and Classification System
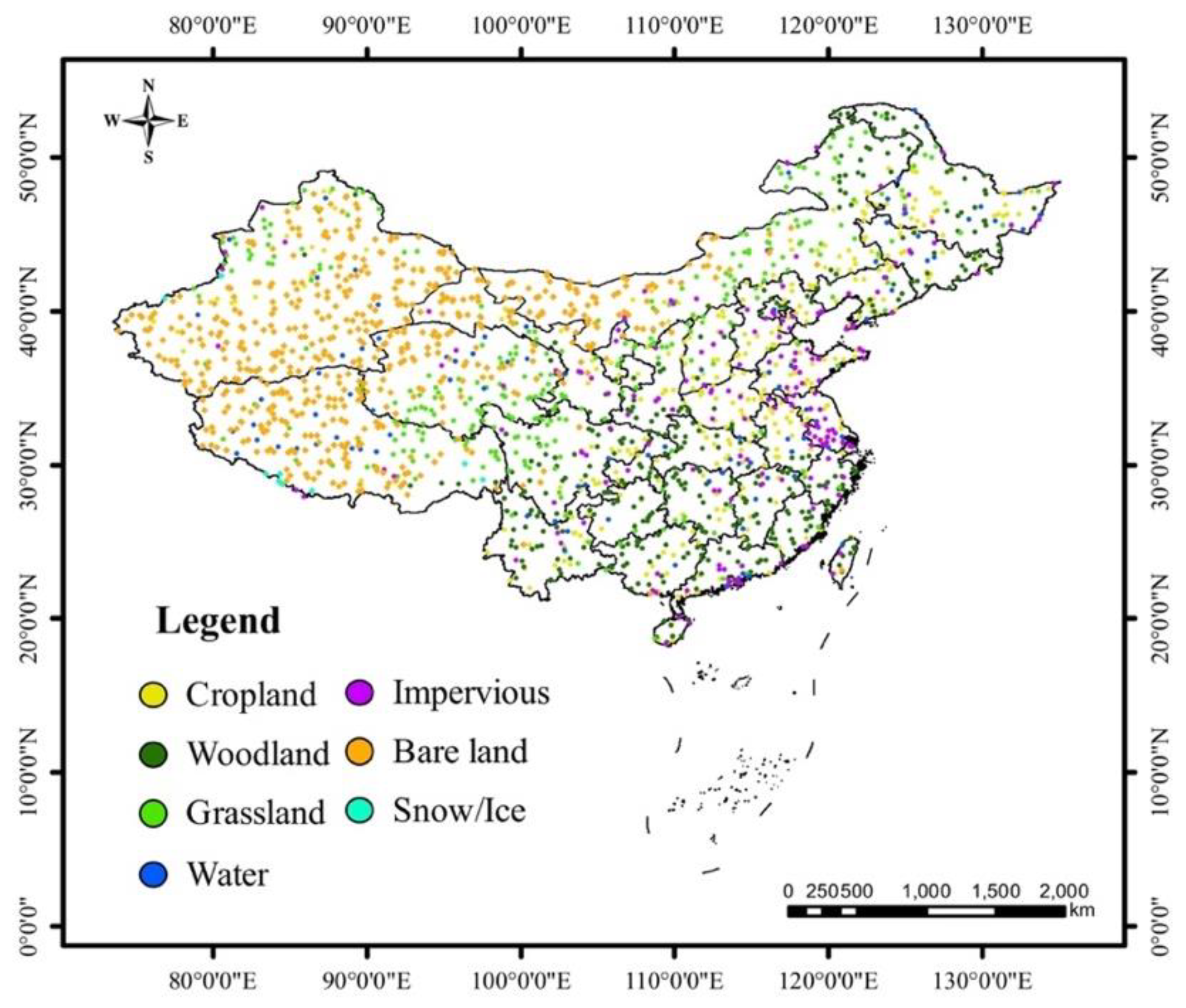
2.3. Datasets
3. Methods
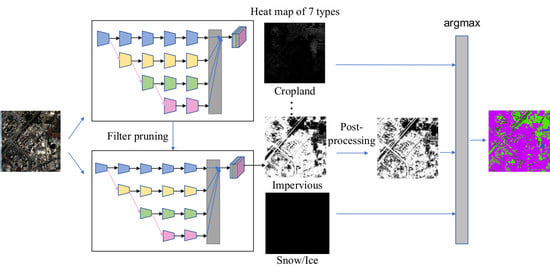
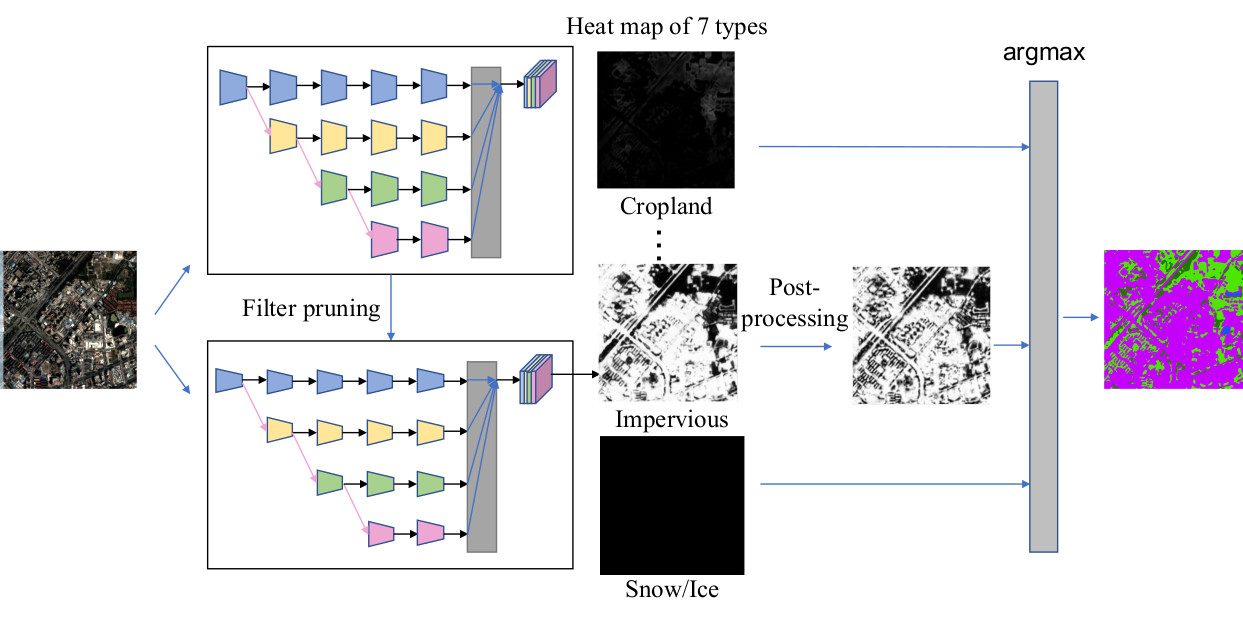
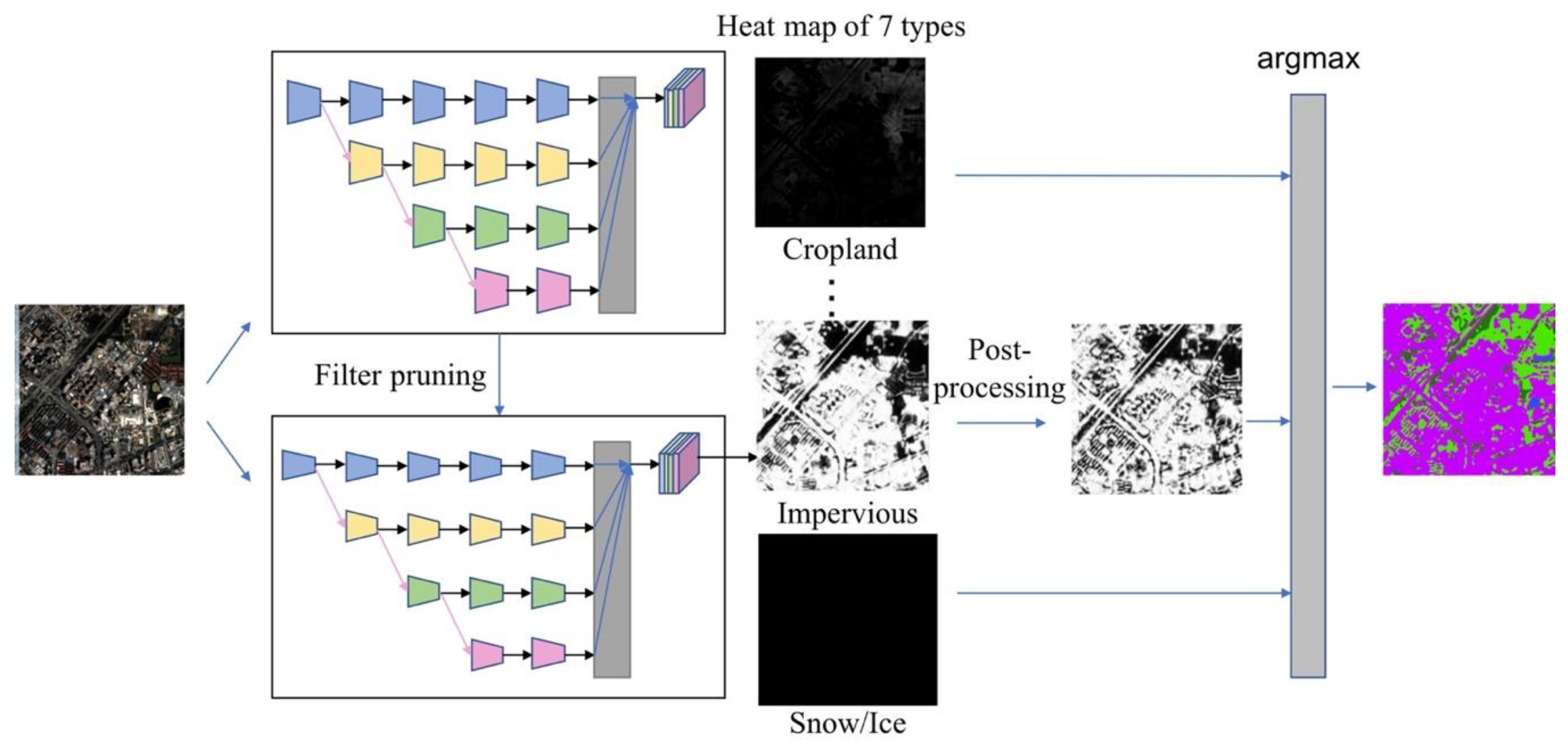
3.1. Overview of the Proposed Method
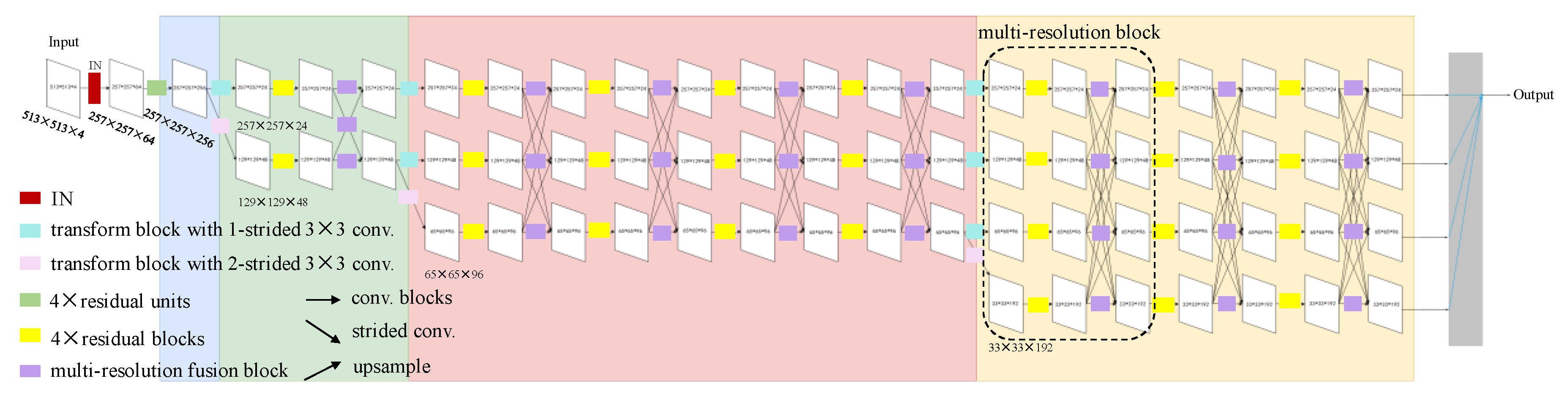
3.2. Neural Network Model
3.3. Contrast Limited Adaptive Histogram Equalization Post-Processing
3.4. Filter Pruning for Feature Dimension Reduction and Neural Network Acceleration
| Algorithm 1. Algorithm Description of FPGM |
| Input: training data: X. |
| 1: Given: pruning rate 40% |
| 2: Initialize: model parameter |
| 3: for epoch = 1; do |
| 4: Update the model parameter W based on X |
| 5: for do |
| 6: Find filters that satisfy Equation (1) |
| 7: Zeroize selected filters |
| 8: end for |
| 9: end for |
| 10: Obtain the compact model from |
| Output: The compact model and its parameters |
4. Experimental Results
4.1. The Quantitative Results of the 3-m Resolution Land Cover Maps of China
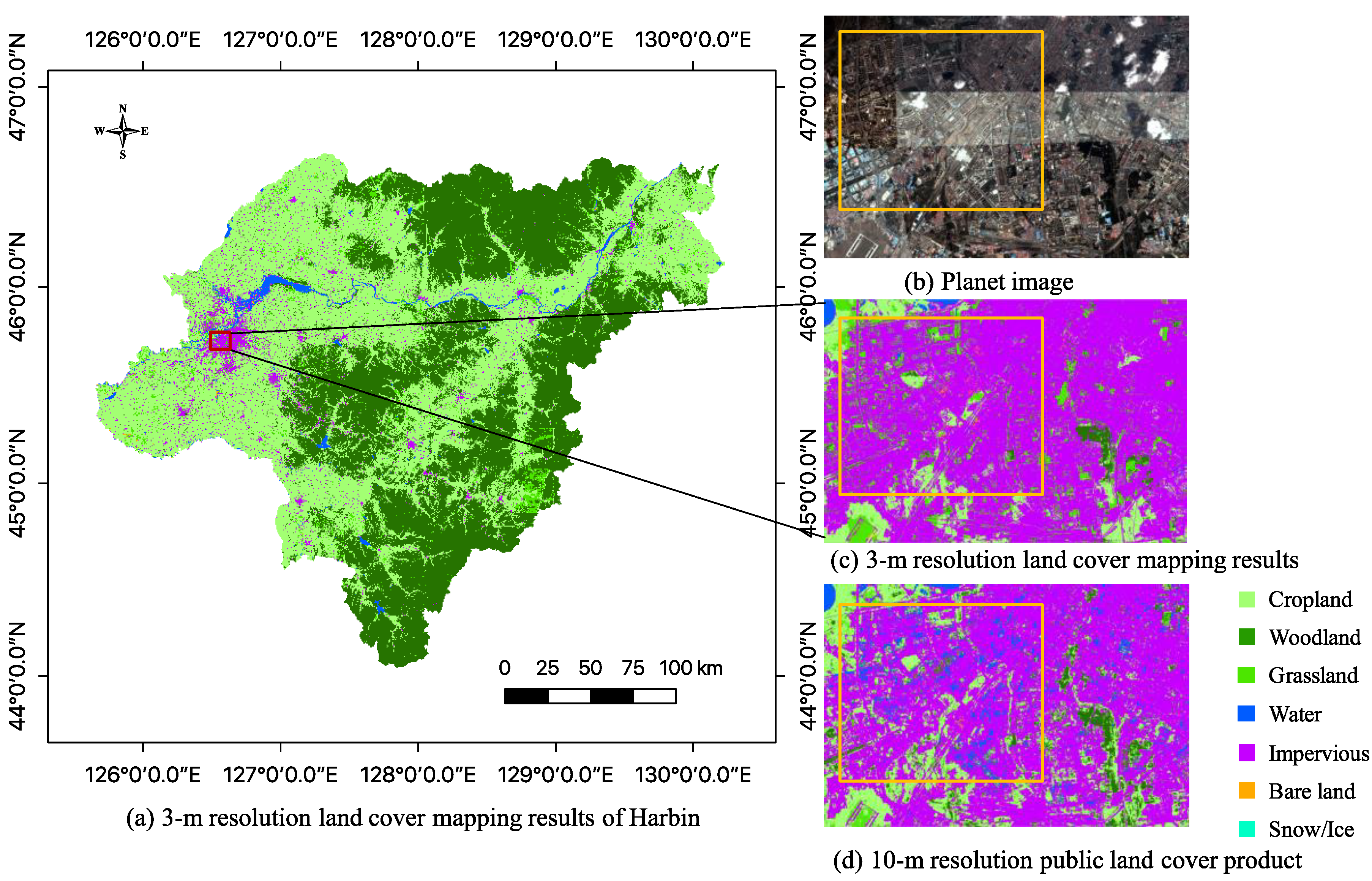
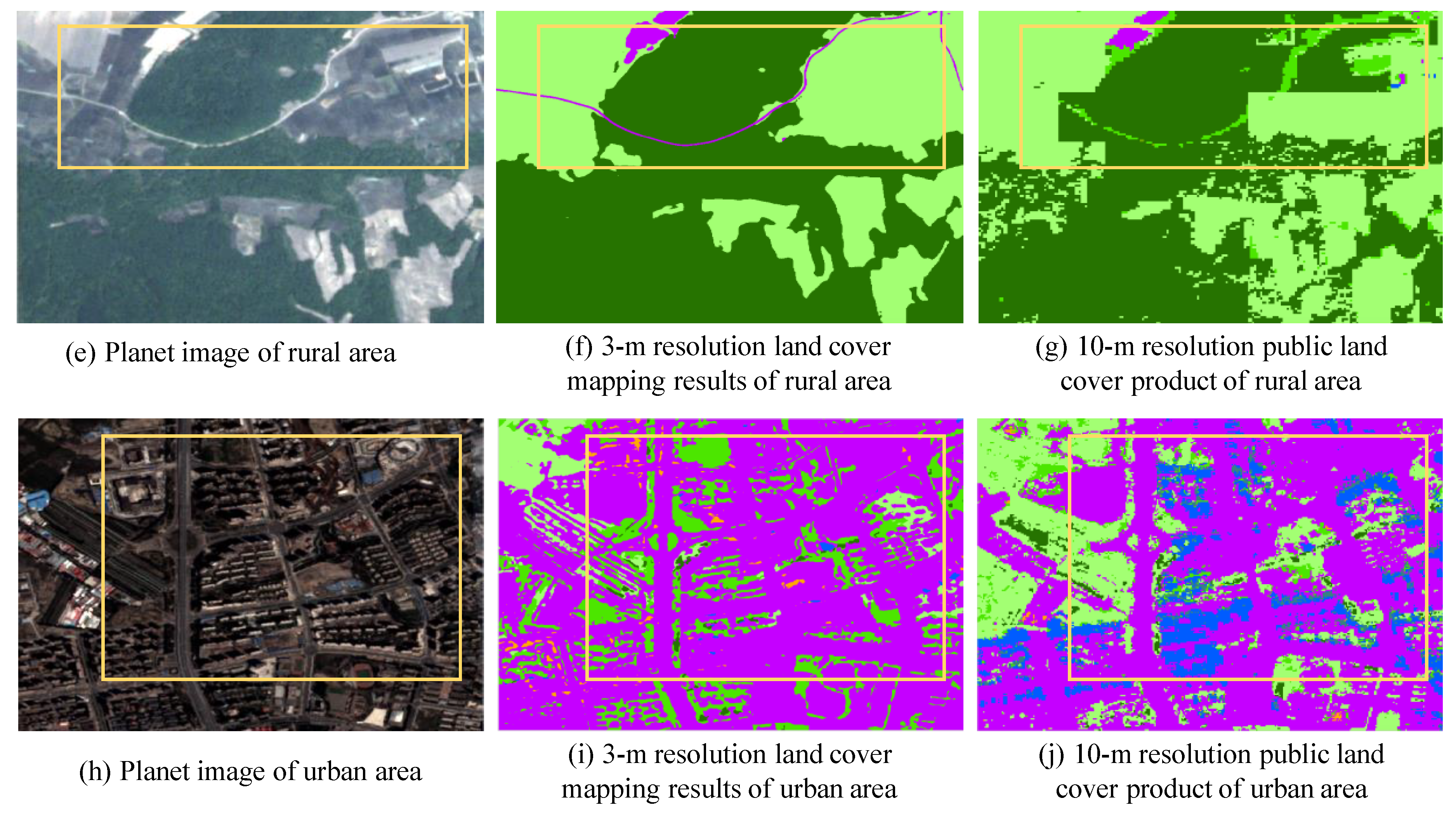
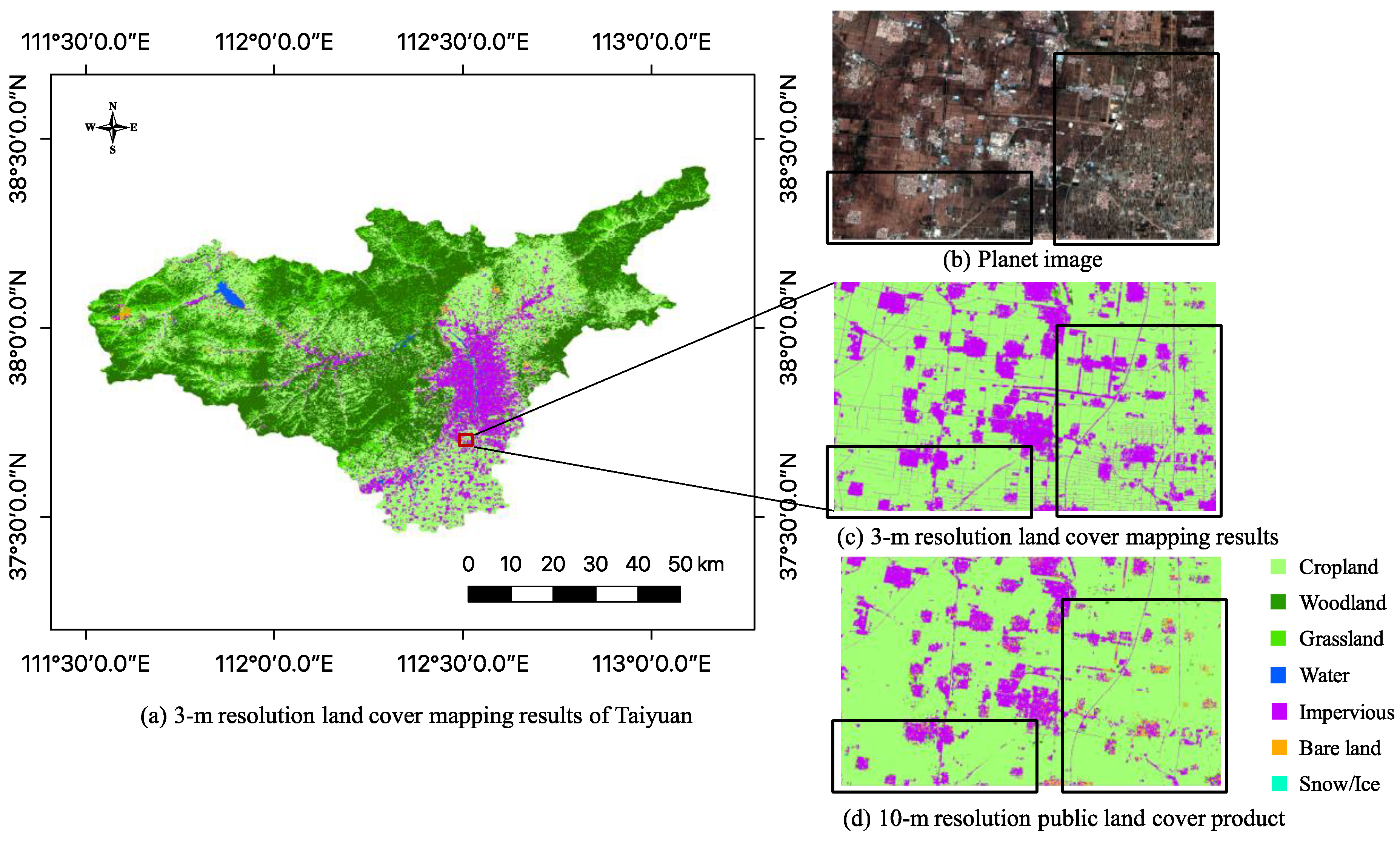
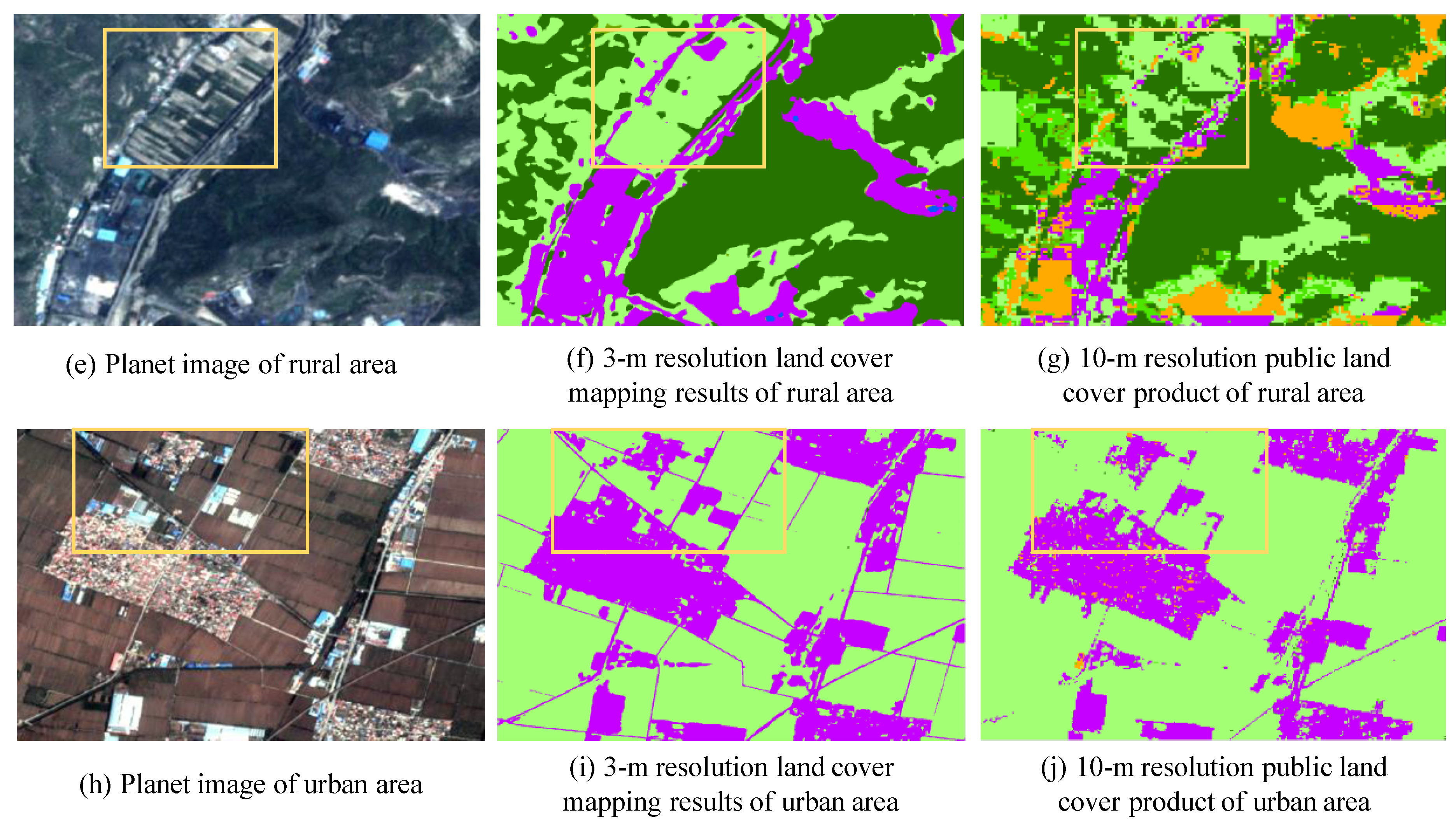
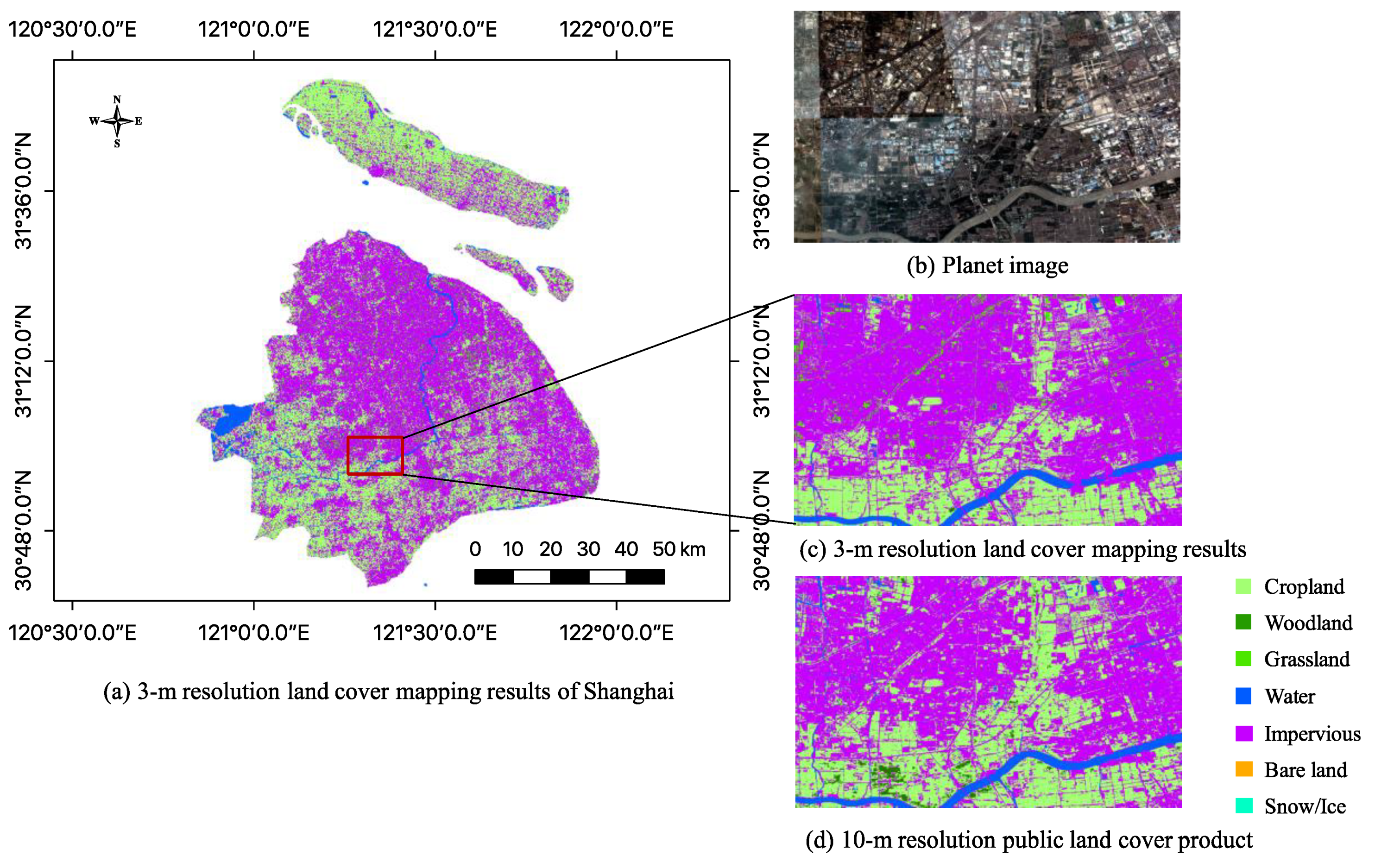
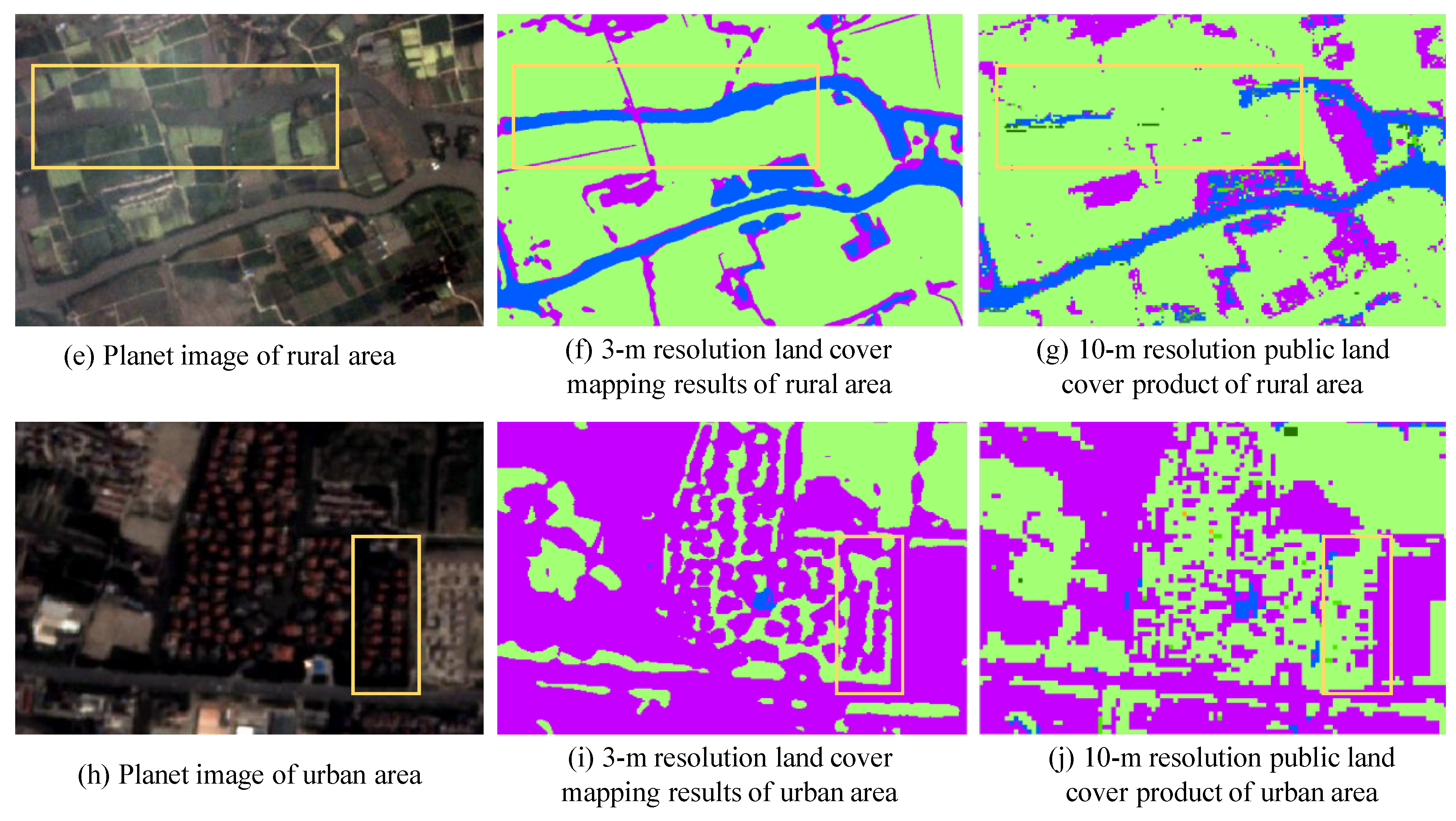
4.2. Examples of Land Cover Mapping in China
5. Discussion
5.1. Analysis of Accuracies between 3-m and 10-m Resolution Land Cover Maps
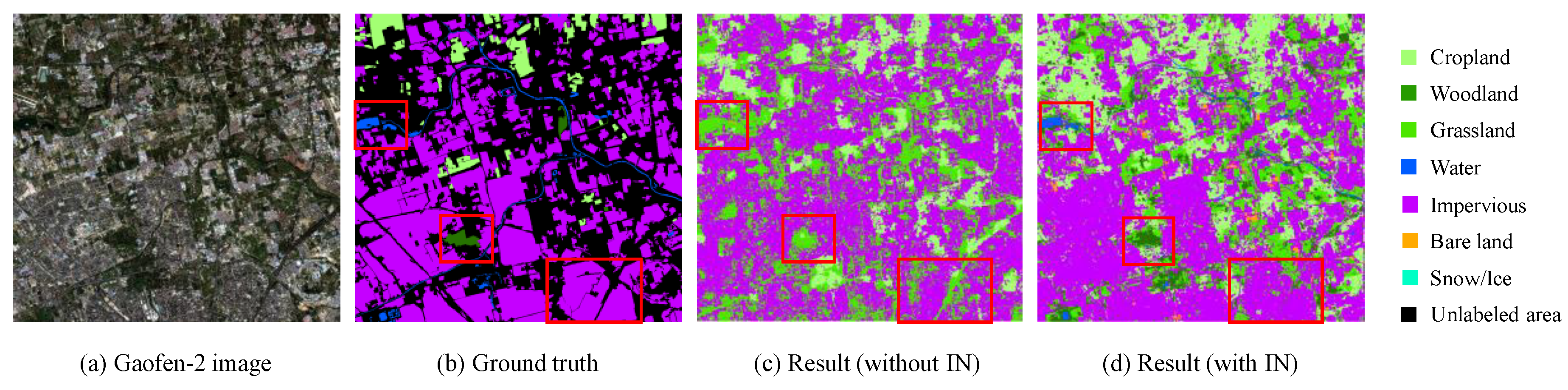
5.2. The Effectiveness of Our Proposed Network and Post-Processing
5.3. The Computational Efficiency of Our Proposed Method in Large-Scale Land Cover Mapping
5.4. Shortcomings with 3-m Resolution Land Cover Map and Potential Strategies for Further Research
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Robinson, C.; Hou, L.; Malkin, K.; Soobitsky, R.; Czawlytko, J.; Dilkina, B.; Jojic, N. Large Scale High-Resolution Land Cover Mapping with Multi-Resolution Data. In Proceedings of the IEEE Conference on CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 12726–12735. [Google Scholar]
- Tong, X.; Zhao, W.; Xing, J.; Fu, W. Status and development of China High-Resolution Earth Observation System and application. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016. [Google Scholar]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [Green Version]
- Hansen, M.; DeFries, R.; Townshend, J.; Sohlberg, R. Global land cover classification at 1 km spatial resolution using a classification tree approach. Int. J. Remote Sens. 2000, 21, 1331–1364. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and igbp discover from 1 km avhrr data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Friedl, M.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. Modis collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Gray, J.M.; Abercrombie, S.P.; & Friedl, M.A. Hierarchical mapping of annual global land cover 2001 to present: The modis collection 6 land cover product. Remote Sens. Environ. 2019, 222, 183–194. [Google Scholar] [CrossRef]
- Arino, O.; Bicheron, P.; Achard, F.; Latham, J.; Witt, R.; Weber, J.-L. GLOBCOVER: The most detailed portrait of Earth. Eur. Space Agency Bull. 2008, 136, 25–31. [Google Scholar]
- Bontemps, S.; Defourny, P.; Van Bogaert, E.; Arino, O.; Kalogirou, V.; Perez, J.R. GLOBCOVER 2009 Products Description and Validation Report. 2011. Available online: http://ionia1.esrin.esa.int/docs/GLOBCOVER2009_Validation_Report_2,2 (accessed on 30 April 2018).
- Land Cover CCI: Product User Guide Version 2.0. 2017. Available online: www.esa-landcover-cci.org (accessed on 30 April 2018).
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on CVPR, Miami, FL, USA, 20–26 June 2009; pp. 248–255. [Google Scholar]
- Tong, X.; Xia, G.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Learning Transferable Deep Models for Land-Use Classification with High-Resolution Remote Sensing Images. arXiv 2018, arXiv:1807.05713. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Raska, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on CVPRW, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–17209. [Google Scholar]
- Zhang, H.K.; Roy, D.P. Using the 500 m MODIS land cover product to derive a consistent continental scale 30 m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Lee, J.; Cardille, J.A.; Coe, M.T. BULC-U: Sharpening Resolution and Improving Accuracy of Land-Use/Land-Cover Classifications in Google Earth Engine. Remote Sens. 2018, 10, 1455. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Liu, L.; Wang, Y.; Hu, Y.; Zhang, B. A SPECLib-based operational classification approach: A preliminary test on China land cover mapping at 30 m. Int. J. Appl. Earth Obs. Geoinfor. 2018, 71, 83–94. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, H.L.; Qiu, C.; Zhu, X.X. SEN12MS–A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. arXiv 2019, arXiv:1906.07789. [Google Scholar] [CrossRef] [Green Version]
- Schmitt, M.; Prexl, J.; Ebel, P.; Liebel, L.; Zhu, X.X. Weakly supervised semantic segmentation of satellite images for land cover mapping–challenges and opportunities. arXiv 2020, arXiv:2002.08254. [Google Scholar]
- Kaiser, P.; Wegner, J.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning aerial image segmentation from online maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Gong, P.; Chen, B.; Li, X.; Liu, H.; Wang, J.; Bai, Y.; Chen, J.; Chen, X.; Fang, L.; Feng, S.; et al. Mapping essential urban land use categories in China (EULUC-China): Preliminary results for 2018. Sci. Bull. 2020, 65, 182–187. [Google Scholar] [CrossRef] [Green Version]
- Ren, M.; Zeng, W.; Yang, B.; Urtasun, R. Learning to reweight examples for robust deep learning. arXiv 2018, arXiv:1803.09050. [Google Scholar]
- Kim, Y.; Yim, J.; Yun, J.; Kim, J. Nlnl: Negative learning for noisy labels. In Proceedings of the IEEE Conference on CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 101–110. [Google Scholar]
- Dong, R.; Li, W.; Fu, H.; Gan, L.; Yu, L.; Zheng, J.; Xia, M. Oil palm plantation mapping from high-resolution remote sensing images using deep learning. Int. J. Remote Sens. 2019, 41, 2022–2046. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 180–196. [Google Scholar]
- Liu, Z.; Mu, H.; Zhang, X.; Guo, Z.; Yang, X.; Cheng, T.K.T.; Sun, J. MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning. arXiv 2019, arXiv:1903.10258. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Zhuang, B.; Shen, C.; Tan, M.; Liu, L.; Reid, I. Towards effective low-bitwidth convolutional neural networks. In Proceedings of the IEEE Conference on CVPR, Salt Lack City, UT, USA, 18–22 June 2018; pp. 7920–7928. [Google Scholar]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Yan, S.; Feng, J. Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution. arXiv 2019, arXiv:1904.05049. [Google Scholar]
- Ye, J.; Wang, L.; Li, G.; Chen, D.; Zhe, S.; Chu, X.; Xu, Z. Learning compact recurrent neural networks with block-term tensor decomposition. In Proceedings of the IEEE Conference on CVPR, Salt Lack City, UT, USA, 18–22 June 2018; pp. 9378–9387. [Google Scholar]
- You, Z.; Yan, K.; Ye, J.; Ma, M.; Wang, P. Gate Decorator: Global Filter Pruning Method for Accelerating Deep Convolutional Neural Networks. arXiv 2019, arXiv:1909.08174. [Google Scholar]
- Zhou, Y.; Zhang, Y.; Wang, Y.; Tian, Q. Accelerate CNN via Recursive Bayesian Pruning. In Proceedings of the IEEE Conference on CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 3306–3315. [Google Scholar]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. arXiv 2018, arXiv:1808.06866. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. arXiv 2019, arXiv:1902.09212. [Google Scholar]
- Cheng, W.; Liu, H.; Zhang, Y.; Zhou, C.; Gao, Q. Classification System of Land-Cover Map of 1:1,000,000 in China. Resour. Sci. 2004, 26, 2–8. [Google Scholar]
- Li, C.; Gong, P.; Wang, J.; Zhu, Z.; Biging, G.S.; Yuan, C.; Hu, T.; Zhang, H.; Wang, Q.; Li, X.; et al. The first all-season sample set for mapping global land cover with landsat-8 data. Sci. Bull. 2017, 62, 508–515. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zuiderveld, K. Contrast limited adaptive histogram equalization. In Graphics gems IV; Academic Press Professional, Inc.: San Diego, CA, USA, 1994; pp. 474–485. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE Conference on CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 4340–4349. [Google Scholar]
- Li, W.; Dong, R.; Fu, H.; Wang, J.; Yu, L.; Peng, G. Integrating Google Earth imagery with Landsat data to improve 30-m resolution land cover mapping. Remote Sens. Environ. 2019, 237, 111563. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Jégou, S.; Drozdzal, M.; Vazquez, D. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on CVPRW, Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the MICCAI, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
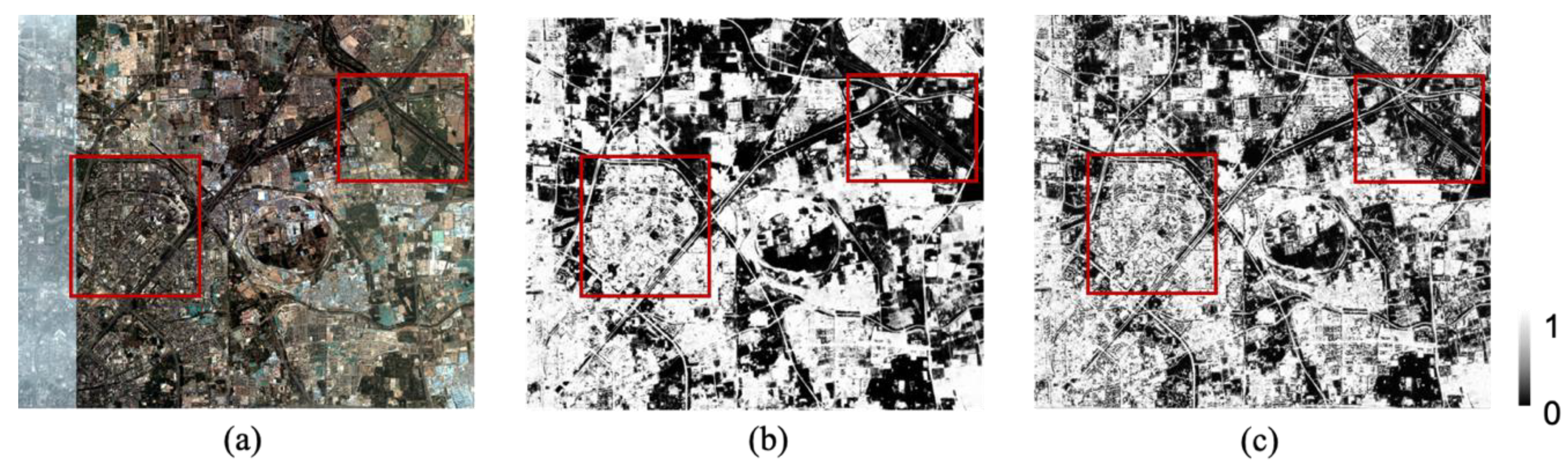{kind=link}
| Land Cover Type | Cropland | Woodland | Grassland | Water |
| Number of samples | 336 | 437 | 303 | 97 |
| Land Cover Type | Impervious | Bare land | Snow/Ice | Total Number |
| Number of samples | 191 | 566 | 10 | 1940 |
| Name | Cropland | Woodland | Grassland | Water | Impervious | Bare Land | Snow/Ice | SUM | UA (%) |
|---|---|---|---|---|---|---|---|---|---|
| Cropland | 263 | 34 | 32 | 3 | 36 | 1 | 0 | 369 | 71.27 |
| Woodland | 27 | 373 | 30 | 0 | 2 | 0 | 0 | 432 | 86.34 |
| Grassland | 32 | 17 | 188 | 1 | 12 | 32 | 0 | 282 | 66.67 |
| Water | 0 | 3 | 1 | 89 | 1 | 3 | 2 | 99 | 89.90 |
| Impervious | 9 | 1 | 2 | 2 | 132 | 1 | 0 | 147 | 89.80 |
| Bare land | 5 | 9 | 49 | 2 | 8 | 526 | 3 | 602 | 87.38 |
| Snow/Ice | 0 | 0 | 1 | 0 | 0 | 3 | 5 | 9 | 55.56 |
| SUM | 336 | 437 | 303 | 97 | 191 | 566 | 10 | 1940 | |
| PA (%) | 78.27 | 85.35 | 62.05 | 91.75 | 69.11 | 92.93 | 50.00 | 81.24 * |
| Name | Cropland | Woodland | Grassland | Water | Impervious | Bare Land | Snow/Ice | SUM | UA (%) |
|---|---|---|---|---|---|---|---|---|---|
| Cropland | 282 | 27 | 20 | 3 | 20 | 1 | 0 | 353 | 79.89 |
| Woodland | 21 | 391 | 26 | 2 | 6 | 0 | 1 | 447 | 87.47 |
| Grassland | 22 | 10 | 223 | 1 | 7 | 19 | 0 | 282 | 79.08 |
| Water | 1 | 1 | 0 | 84 | 2 | 2 | 0 | 90 | 93.33 |
| Impervious | 8 | 1 | 2 | 4 | 150 | 2 | 0 | 167 | 89.82 |
| Bare land | 2 | 7 | 32 | 3 | 6 | 542 | 6 | 598 | 90.64 |
| Snow/Ice | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 100.00 |
| SUM | 336 | 437 | 303 | 97 | 191 | 566 | 10 | 1940 | |
| PA (%) | 83.93 | 89.47 | 73.60 | 86.60 | 78.53 | 95.76 | 30.00 | 86.34 * |
| Models | PA (%) | OA (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Cropland | Woodland | Grassland | Water | Impervious | Bare Land | Snow/Ice | ||
| 10-m resolution map | 78.27 | 85.35 | 62.05 | 91.75 * | 69.11 | 92.93 | 50.00 * | 81.24 |
| U-Net | 73.21 | 88.79 | 70.96 | 86.60 | 75.92 | 95.05 | 20.00 | 83.40 |
| FC-DenseNet | 81.55 | 91.08 * | 68.32 | 84.54 | 68.59 | 94.52 | 0.00 | 83.87 |
| HRNet (ours) | 83.93 * | 89.47 | 73.60 * | 86.60 | 78.53 * | 95.76 * | 30.00 | 86.34 * |
| Models | Overall Accuracy (%) | Number of Parameters | Model Size (MB) | Theoretical Acceleration (%) |
|---|---|---|---|---|
| Baseline model | 86.34 | 16,812,946 | 130 | - |
| Pruned model | 86.04 | 9,720,660 | 39 | 52.63 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, R.; Li, C.; Fu, H.; Wang, J.; Li, W.; Yao, Y.; Gan, L.; Yu, L.; Gong, P. Improving 3-m Resolution Land Cover Mapping through Efficient Learning from an Imperfect 10-m Resolution Map. Remote Sens. 2020, 12, 1418. https://doi.org/10.3390/rs12091418
Dong R, Li C, Fu H, Wang J, Li W, Yao Y, Gan L, Yu L, Gong P. Improving 3-m Resolution Land Cover Mapping through Efficient Learning from an Imperfect 10-m Resolution Map. Remote Sensing. 2020; 12(9):1418. https://doi.org/10.3390/rs12091418
Chicago/Turabian StyleDong, Runmin, Cong Li, Haohuan Fu, Jie Wang, Weijia Li, Yi Yao, Lin Gan, Le Yu, and Peng Gong. 2020. "Improving 3-m Resolution Land Cover Mapping through Efficient Learning from an Imperfect 10-m Resolution Map" Remote Sensing 12, no. 9: 1418. https://doi.org/10.3390/rs12091418
APA StyleDong, R., Li, C., Fu, H., Wang, J., Li, W., Yao, Y., Gan, L., Yu, L., & Gong, P. (2020). Improving 3-m Resolution Land Cover Mapping through Efficient Learning from an Imperfect 10-m Resolution Map. Remote Sensing, 12(9), 1418. https://doi.org/10.3390/rs12091418