3.1. Preprocessing
Preprocessing included the following main steps: radiometric calibration, orthographical correction, and geometric correction.
(1) Radiometric calibration. This is used to obtain the Top of Atmosphere (TOA) reflectance. TOA reflectance is the essential attribute of ground objects, which can avoid the influence of solar radiation intensity and solar altitude angle. Absolute radiometric calibration can be performed by taking the absolute calibration coefficients provided by the China Center for Resources Satellite Data and Application. The equivalent radiation brightness is calculated as follows:
where Le is the equivalent radiation brightness at the entrance pupil of the satellite loading channel; its unit is W·m
−2·sr
−1·um
−1. Gain and Bias means the gain and offset of the calibration coefficient, respectively. Their unit is W·m
−2·sr
−1·um
−1, too. DN is the digital number of a pixel. If we wish to calculate the TOA reflectance, it is necessary to consider the solar irradiance (ESUN) at the outer atmospheric for the GF-4 satellite. However, the China Center For Resources Satellite Data and Application did not provide these data. We then calculated the ESUN using the following equation:
where E(λ) means the solar spectral radiation energy outside the atmosphere. This is obtained from the solar constant and solar spectral irradiance under zero air mass, which was published in 2016 as a meteorological industry standard of the People’s Republic of China. S(λ) means the spectral response function of the sensor at a certain band, and λ1 and λ2 mean the beginning and ending locations of a certain band spectrum, respectively. After determining the Le and ESUN, we finally calculated the TOA reflectance as follows:
where
means the TOA reflectance,
is pi (3.1415926), d means the distance between the Sun and the Earth in astronomical units, and
means the solar elevation angle.
(2) Orthographical correction and geometric correction. The GSWO data used in the RTD method are derived from Landsat products. These data are in the UTM-WGS84 projected coordinate system and have been radiometrically and geometrically corrected. The downloaded GF-4 data are a level 1A product and are in the GCS-WGS-1984 geographic coordinate system and have not been radiometrically or geometrically corrected. There will be a huge positional deviation if the Landsat and GF-4 images are directly combined, and accordingly orthographical correction and geometric correction should be performed in advance. Orthographical correction was firstly performed using the rational polynomial coefficient (RPC) model [
31]. GF-4 provides the PRC values in its metadata. Geometric correction was performed using Landsat images as reference images. In order to ensure that the correction was accurate, we performed geometric correction three times. Geometric correction was firstly performed between two GF-4 images and the Landsat reference image separately, and then geometric correction was performed again between the two corrected GF-4 images. Thus, we ensured that the geometric corrections had a high matching accuracy. We performed these correction operations using the ENVI 5.3 software and controlled all the RMSEs to less than 2 pixels.
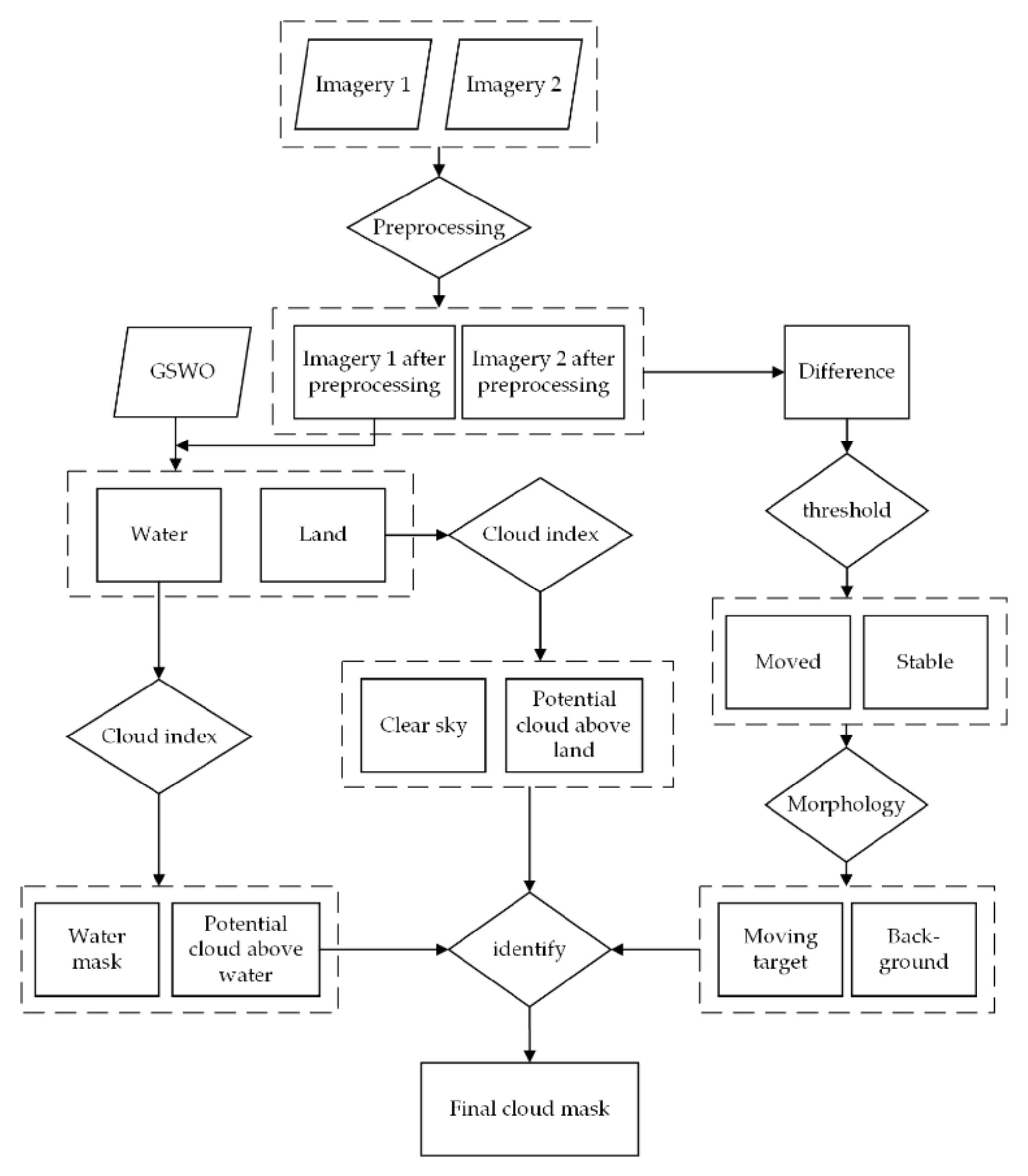
3.2. Potential Cloud Pixels Detection from Single Image
- (1)
Separate land and water with GSWO data
As land and water surfaces have very different spectral characteristics, it is essential to determine whether the underlying surface type is land or water before cloud detection can be achieved [
11,
16,
18]. Cloud indexes are commonly calculated separately for land and water surfaces [
18]. In previous cloud detection methods, a water mask was obtained through several spectral tests [
19]. This approach can separate land and water pixels well when they are clear-sky or thin cloud pixels; however, it does not work for areas covered by thick clouds [
16]. It is necessary to develop a water mask that can separate water and land precisely. In recent years, many water products have been developed and used, such as a 30 m water mask from a Landsat-based global land-cover product and a 250 m global water mask from MODIS data [
16,
18].
GSWO provides water occurrence from 0% to 100% for each pixel [
16,
30]. A value of 0 means land and a value of 100 means water. The water occurrence is changeable in intertidal zones located near coastlines or terrestrial rivers; however, the value is commonly less than 40%. As such, we can roughly divide the GF-4 images into water and land parts according to Equation (4) as follows:
It should be noted that this water and land segmentation provides an effective way to guide the subsequent threshold setting. However, GSWO cannot be used to construct an accurate water map for every GF-4 image since the image acquisition time may be different.
The RTD algorithm combines several spectral tests (as does Fmask) to identify Potential Cloud Pixels (PCPs) [
19]. However, only four visible and near-infrared bands were used for GF-4 images. Due to the lack of thermal infrared, cirrus, and short infrared bands, many important spectral parameters cannot be calculated, such as Brightness Temperature (BT), the Normalized Difference Snow Index (NDSI), and the Normalized Difference Built-up Index (NDBI). In the RTD algorithm, six spectral tests of the visible light band were performed.
Clouds have high reflectance in the visible light band, so their values are higher than those of ordinary objects. Setting a threshold in the visible band is the simplest way to separate clouds. In our experiment, we firstly used the TOA reflectance of the blue band to separate clouds as follows:
The spectral test in a single spectral band can classify most clouds; however, it cannot separate high-reflectance objects, such as sand, rocks, ice, snow, built-up area, etc.
The Whiteness Index was originally proposed by [
32]. As clouds always appear white due to their flat reflectance in the visible spectrum, these authors used the sum of the absolute difference between the intensity of the visible bands and the overall brightness to calculate the Whiteness Index [
19]. Zhu et al. divided this difference by the average value of the intensity of the visible bands and proposed a new Whiteness Index [
19]. We examined the index proposed in [
19] and found that it works well for distinguishing clouds in GF-4 imagery. As such, we adopted this index in our experiment. It was calculated as follows:
where
band_Blue, band_Green, and band_Red mean the TOA reflectance in the blue, green, and red channels, respectively. The Whiteness Test can be used to remove those pixels whose spectra are not sufficiently flat relative to cloud. However, neither the original Whiteness Index nor the new Whiteness Index of Zhu et al. can distinguish certain pixels of bare soil, sand, built-up area, and snow/ice, since these are also very bright and have a “flat” reflectance in the visible bands.
The Haze Optimized Transformation (HOT) was firstly developed and assessed for the detection and characterization of the spatial distribution of haze/cloud in Landsat scenes [
33]. It is based on the idea that, for most land surfaces under clear-sky conditions, the visible bands are highly correlated but the spectral response to haze and thin cloud is different between the blue and red wavelengths [
19]. It is described as
where
k and
b are the correlation coefficient and intercept of the TOA reflectance of the blue and red bands, respectively. These were derived from the images in the clear-sky area. However, in real experiments, it is not easy to calculate
k and
b for every image. Zhu et al. proposed the new format of HOT [
19]. It pre-defines several parameters so that it is not necessary to calculate the parameters separately for each image. In this study, we adopted the HOT index proposed in [
19], which is described as follows:
The HOT is useful for detecting clouds, and especially thin clouds; however, it cannot be applied to identify water, snow, or bare soil surfaces due to the irregularity of these surfaces in the red and blue bands.
The Normalized Difference Vegetation Index (NDVI) can be used to describe the vegetation situation in an image. The NDVI is calculated as follows:
where band_NIR and band_Red mean the TOA reflectance of the near-infrared and red channels, respectively. Chlorophyll in vegetation is a strong absorber of red light; however, it strongly reflects in the near-infrared. As such, vegetation presents a high value of NDVI. Meanwhile, clouds present similar reflective features in the red and NIR bands, so their NDVI values fluctuate around 0.
It should be noted that the NDVI test is used to remove the influence of vegetation; however, it cannot be used to remove water, snow, etc., since their NDVI values are also near zero.
The Normalized Difference Water Index (NDWI) can be used to describe the water situation in an image [
34]. The NDWI is calculated as follows:
where band_NIR and band_Green mean the TOA reflectance of the near-infrared and green channels, respectively. Water has a strong absorption in the NIR; however, it strongly reflects green light. As such, water commonly presents high values of NDWI. Meanwhile, clouds present similar reflective features in the green and NIR bands, and their NDWI value is commonly lower than 0.3. As such, NDWI test is given by the following equation:
Similar to the NDVI test for vegetation, the NDWI test is only used to remove the influence of water. The clear_sky pixels were probably water to a large extent.
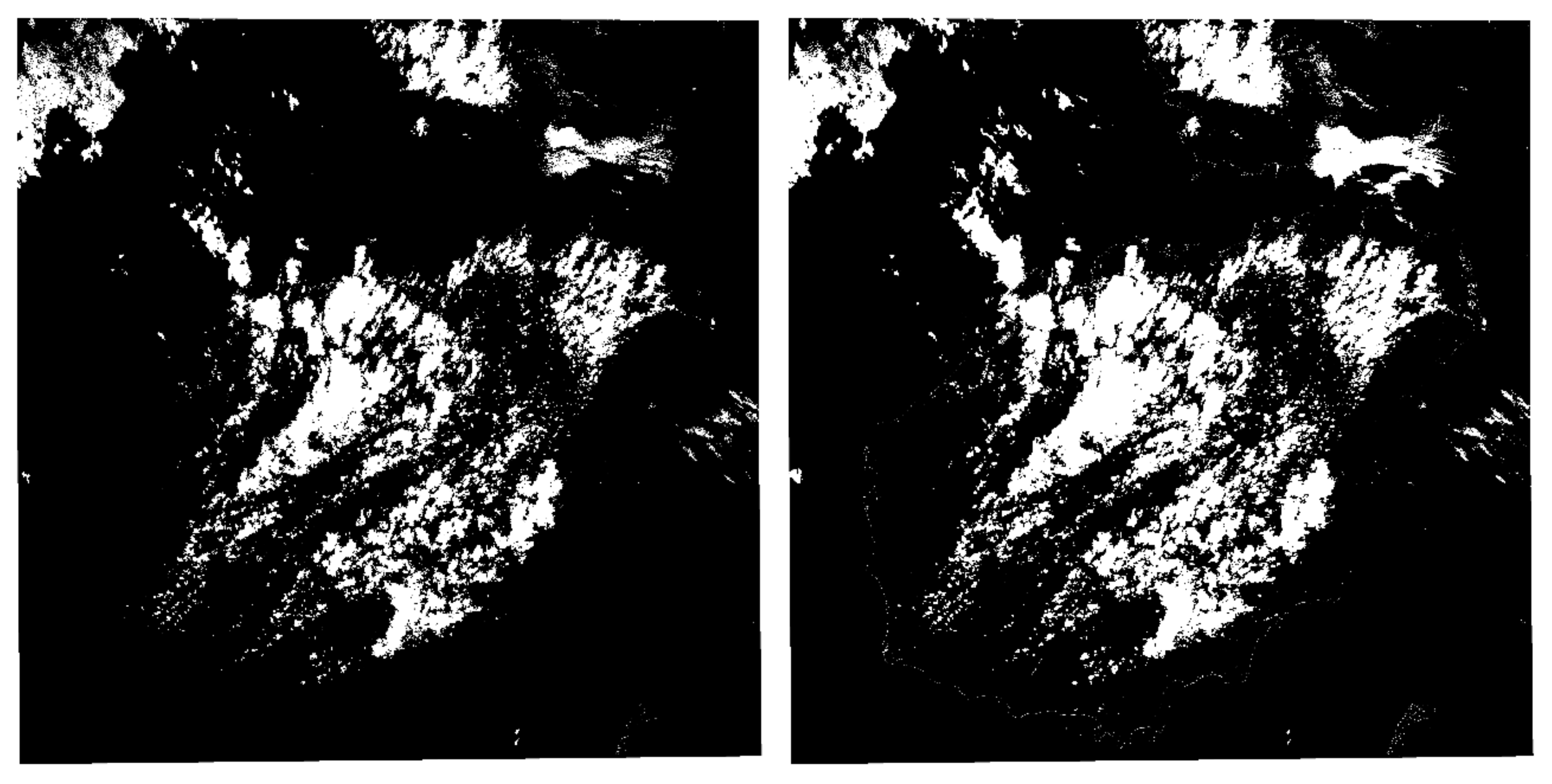
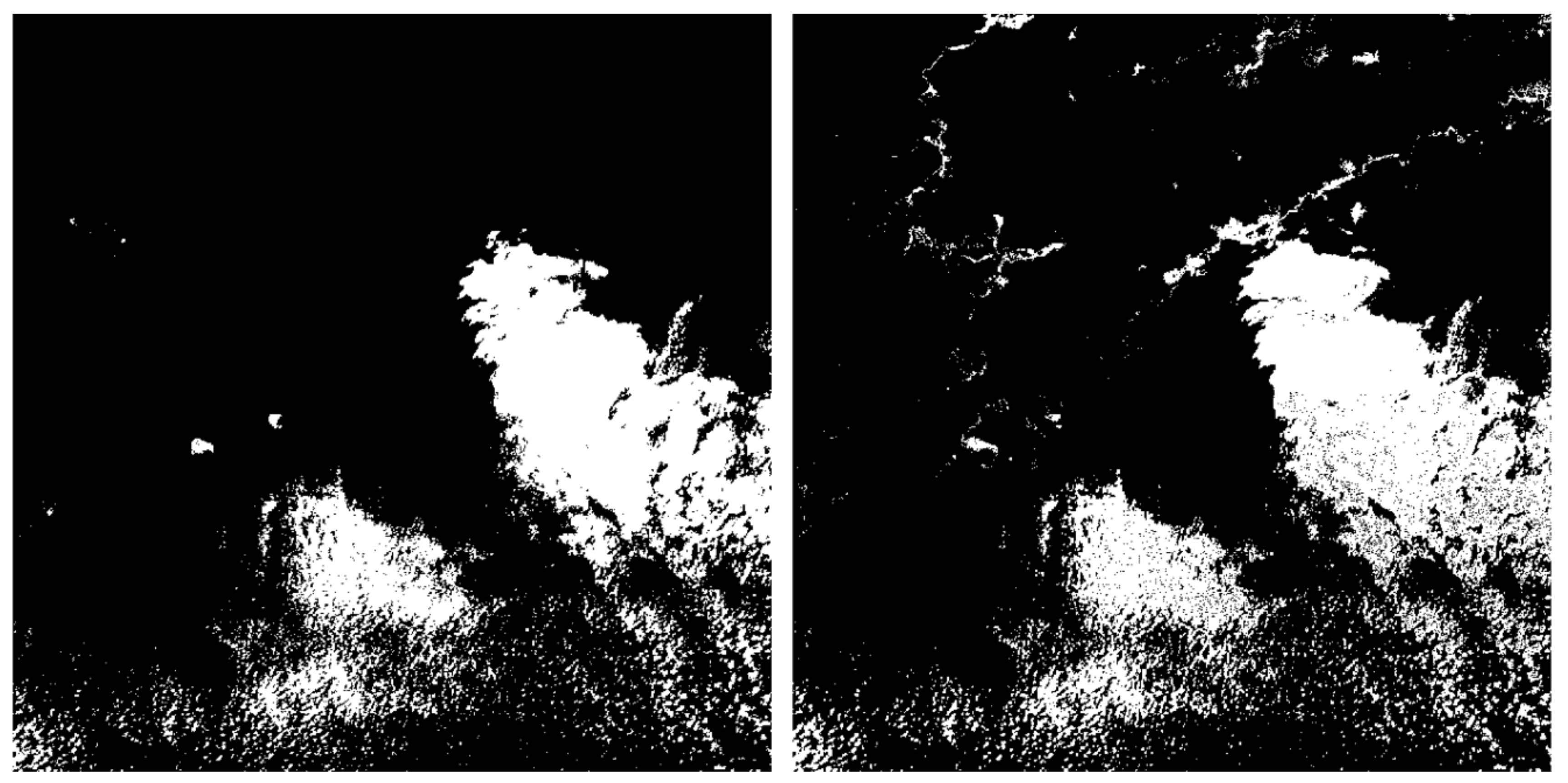
Clouds result in a single image can be finally obtained through the following equation:
3.3. The Difference between a Pair of Real-Time Images
Clouds are masses of condensed water vapor floating in the atmosphere. They may be in a liquid or solid state and may consist of a mixture of water and ice, and their dynamics, growth, motion, and dissipation are very complex [
35]. Clouds are spatial features that evolve over time [
36]. Generally, the height of clouds is more than 600 m above the ground surface. The wind speed is more than 20 m/s at such a height. In the stratosphere, the wind speed greatly increases due to the airstream. The time interval between two GF-4 images can reach 20 s. Assume that two images are obtained two minutes apart. In such a time, it is reasonable to assume that changes in the land surface are negligible. However, clouds can move by at least 240 m in this time. The spatial resolution of GF-4 is 50 m pixel. As such, it is theoretically possible to detect the movement of clouds using GF-4 images. In real experiments, geometric correction errors should be considered. Generally, the geometric correction errors can be controlled to within two pixels.
For the purpose of moving target detection, clouds can be regarded as the moving target that should be detected. Moving objects can be identified using the difference between two images if the difference is larger than a given threshold. The moving test can be described as follows:
where
x and
y refer to the row and column number of a pixel, respectively;
Ik(
x,y) refers to the pixel value of pixel (
x,y) at time
k;
Ik+1(
x,y) refers to the pixel value of pixel (
x,y) at time
k+1; and
Dk(
x,y) refers to the difference between the two images. The moving test can be used to identify moving clouds by comparing two consecutive images. Due to the images’ coarse resolution, most other moving objects on the Earth cannot be directly detected in GF-4 images, such as buses, trains, and airplanes. Therefore, clouds can be regarded as the only moving targets in GF-4 images. However, there are some problems in real cloud detection experiments. The first one is due to the errors caused by the geometric correction. Second, clouds which overlap in two images can easily be identified as background due to “holes”—i.e., pixels which contain clouds in the first image but which still contain clouds in the second image—produced in the difference process. In order to overcome these two problems, we applied some morphological algorithms, including corrosion, dilation, and flood-fill algorithms [
37]. Firstly, a corrosion process was performed to reduce the errors caused by geometric correction and isolated noise caused by system errors. Then, an image segmentation was performed. The eroded images were taken as starting points and the segmentation result was taken as the boundary to use in the flood-fill algorithm. Thus, we obtained a rough cloud result. Dilation was then performed to expand the cloud boundary in order to obtain nearly all of the moved clouds. Finally, the dilated clouds were intersected with the cloud result that was obtained from the cloud index to obtain the final cloud mask.
3.4. Evaluation of RTD by Comparison with SVM
In order to demonstrate the accuracy and effectiveness of the proposed RTD method, this method was compared with the SVM classifier. SVM has been proven to be a highly accurate machine-learning method. Therefore, SVM can be considered as an important benchmark to assess the performance of RTD. A brief description of SVM is presented in the following equation. Assume there are
l observations from two classes:
where
denotes the samples;
yi is a collection of labels that represent the category of
, and
is the
i-th sample. Let us assume that two classes are linearly separable. This means that it is possible to find at least one hyperplane (linear surface), defined by the vector
and bias
, that can separate the two classes without errors. Finding the optimal hyperplane involves solving a constrained optimization problem using a quadratic equation. The optimization criterion is the width of the margin between the classes. The discrimination hyperplane is defined as follows [
38]:
where
is a kernel function and where the sign of
denotes the membership of
. Constructing the optimal hyperplane is equivalent to finding all nonzero
values, which are called Lagrange multipliers. Any data point
corresponding to a nonzero
is a support vector of the optimal hyperplane [
39].
In the process of implementing SVM, we used the same reference images as in RTD to obtain the best parameters for the SVM. We tested the linear, polynomial, radial basis, and sigmoid kernel functions, and selected the radial basis kernel function. We then further tested the gamma and penalty parameters. The value of gamma was set to 0.2 and the penalty parameter was set to 100 to classify the cloud.
At the same time, SVM and RTD were compared using the same validation data. We adopted six commonly used indicators to assess the accuracy of the results, namely the overall accuracy (OA), Kappa coefficient, commission error (CE), omission error (OE), producer’s accuracy (PA), and user’s accuracy (UA) [
40]. By using the same reference images and validation set, we guaranteed the fairness of the comparison between SVM and RTD.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}