Rethinking the Random Cropping Data Augmentation Method Used in the Training of CNN-Based SAR Image Ship Detector




Abstract
:
1. Introduction
- A hidden source of training gradient noise introduced by the traditional random cropping data augmentation method is pointed out for the first time, which can lead to inaccurate target bounding box regression results and false alarm targets.
- A simple training method is proposed to suppress the gradient noise introduced by the traditional random cropping algorithm. This method uses a feature map mask to prevent pixels that generate gradient noise from participating in the calculation of training loss. The proposed method is proven to effectively improve the performance of the CNN-based SAR image ship detector, especially for high-precision bounding box regression tasks.
2. Materials and Methods
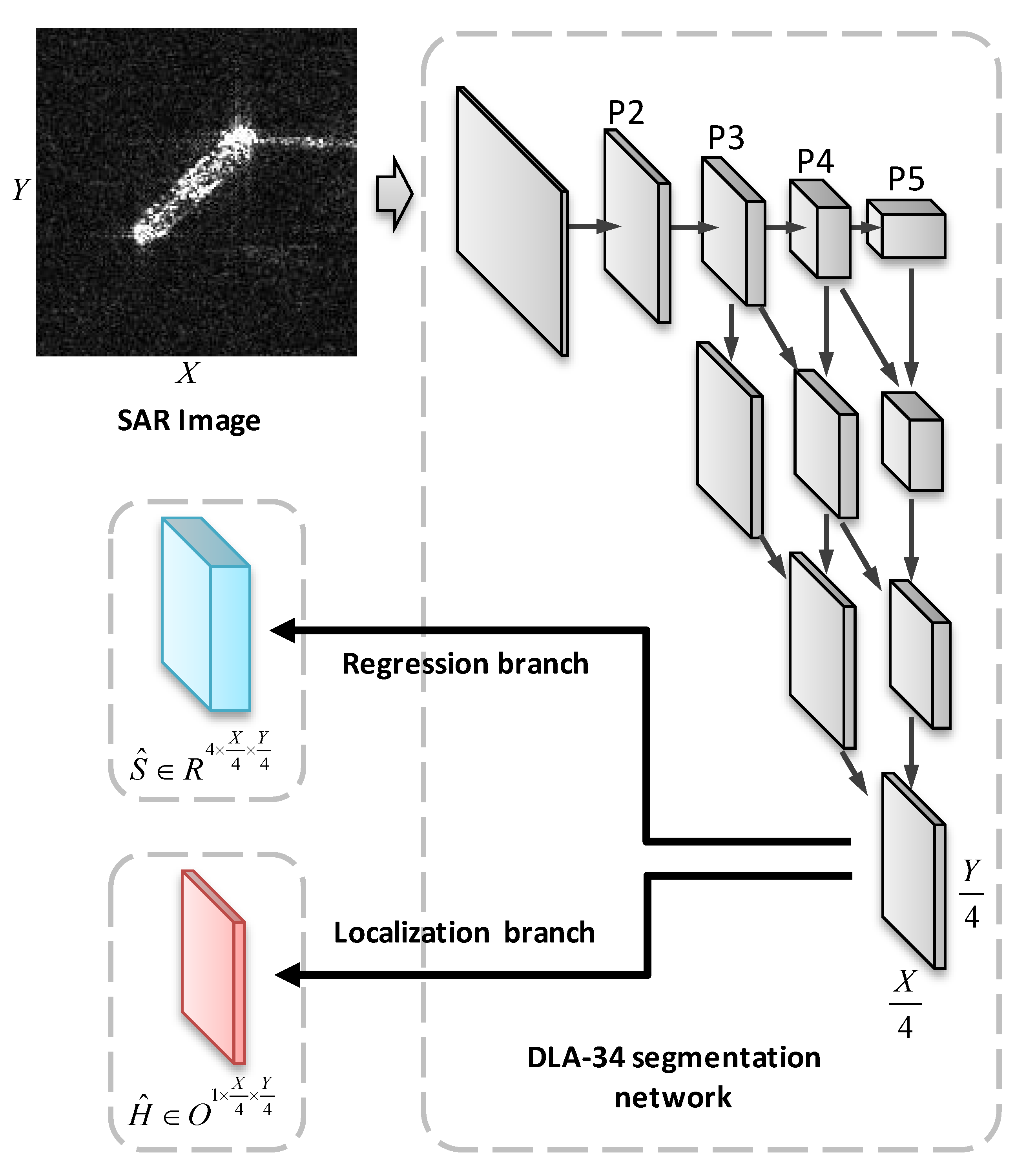
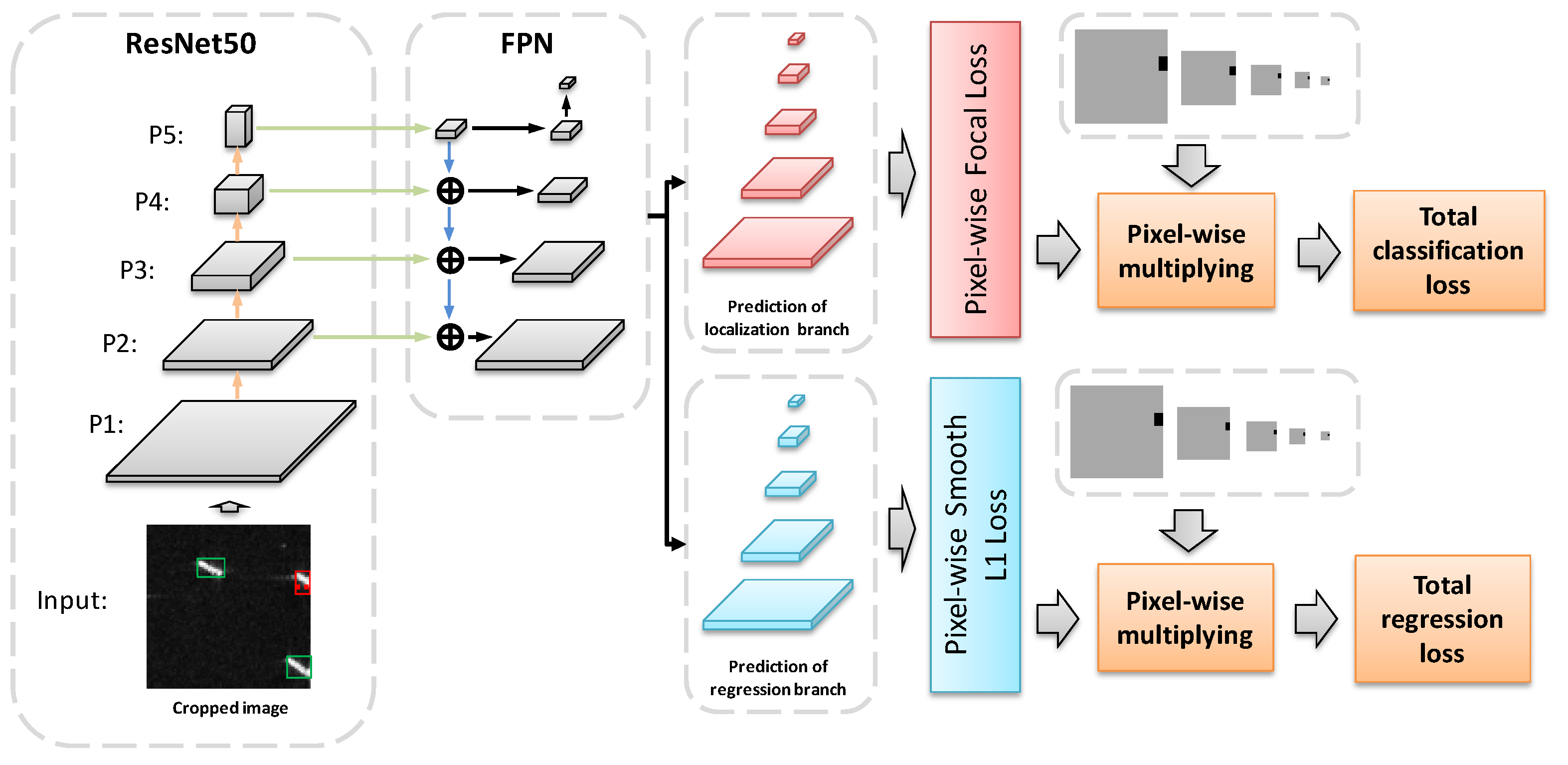
2.1. Basic Detection Model
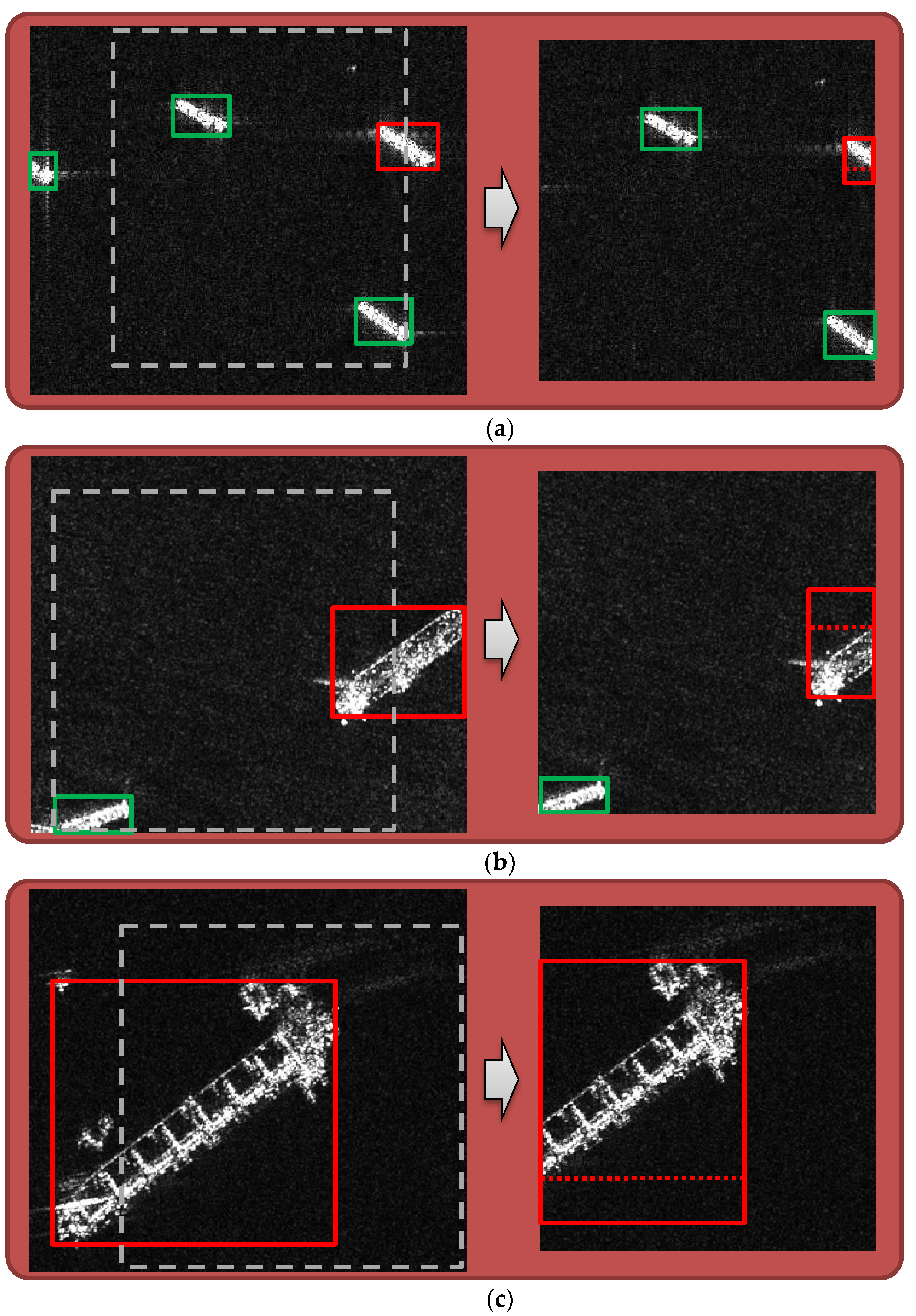
2.2. Training Gradient Noise Introduced by Random Cropping
2.3. Training Method Proposed for SAR Ship Detection Models That Use Random Cropping as Data Augmentation
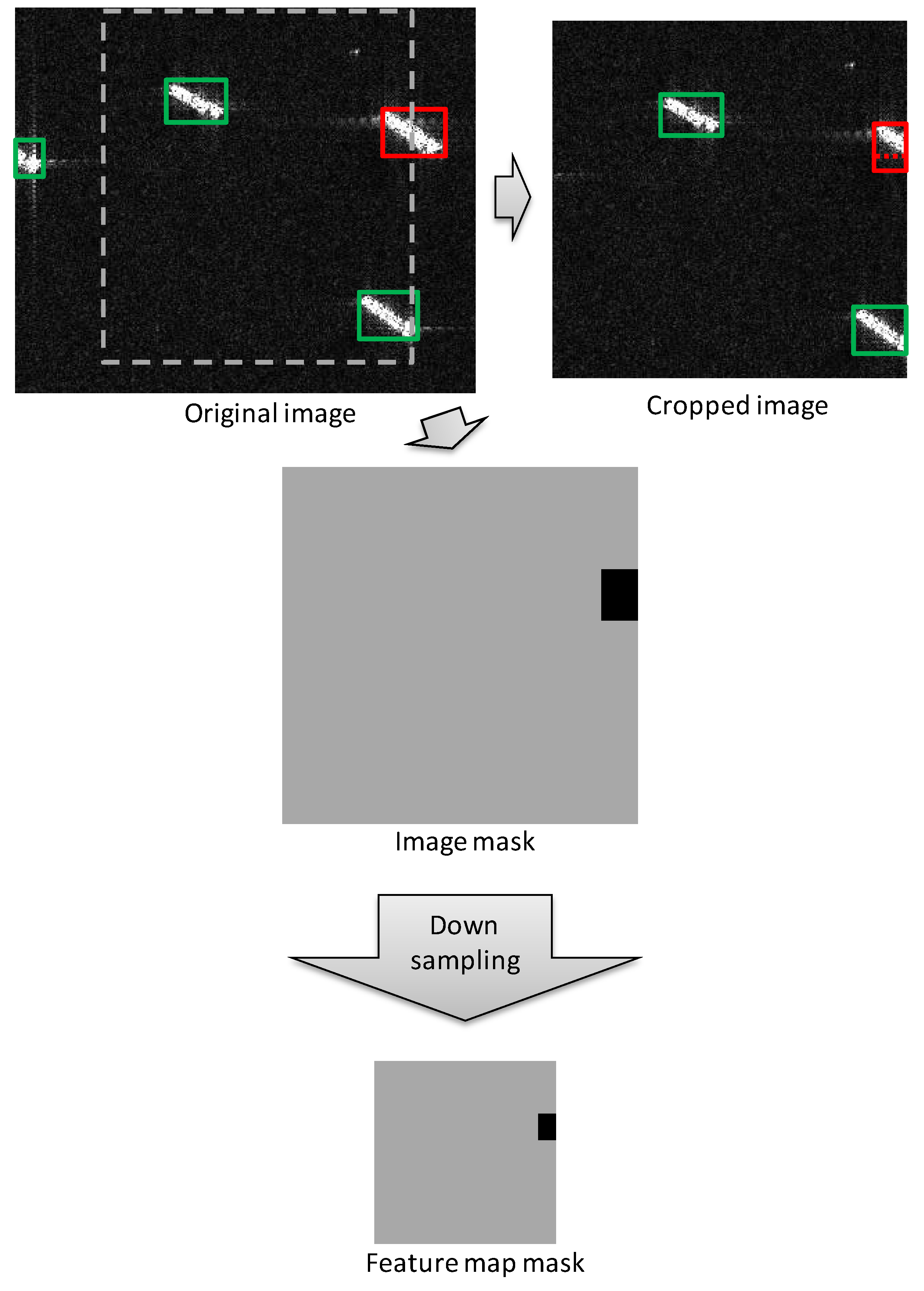
2.3.1. Feature Map Mask Used for the Guidance of Loss Calculation
2.3.2. Loss Calculation with Feature Map Mask
2.4. Implementation Details
2.4.1. Data Preprocessing and Post-Processing
2.4.2. Optimizer Setting
3. Results
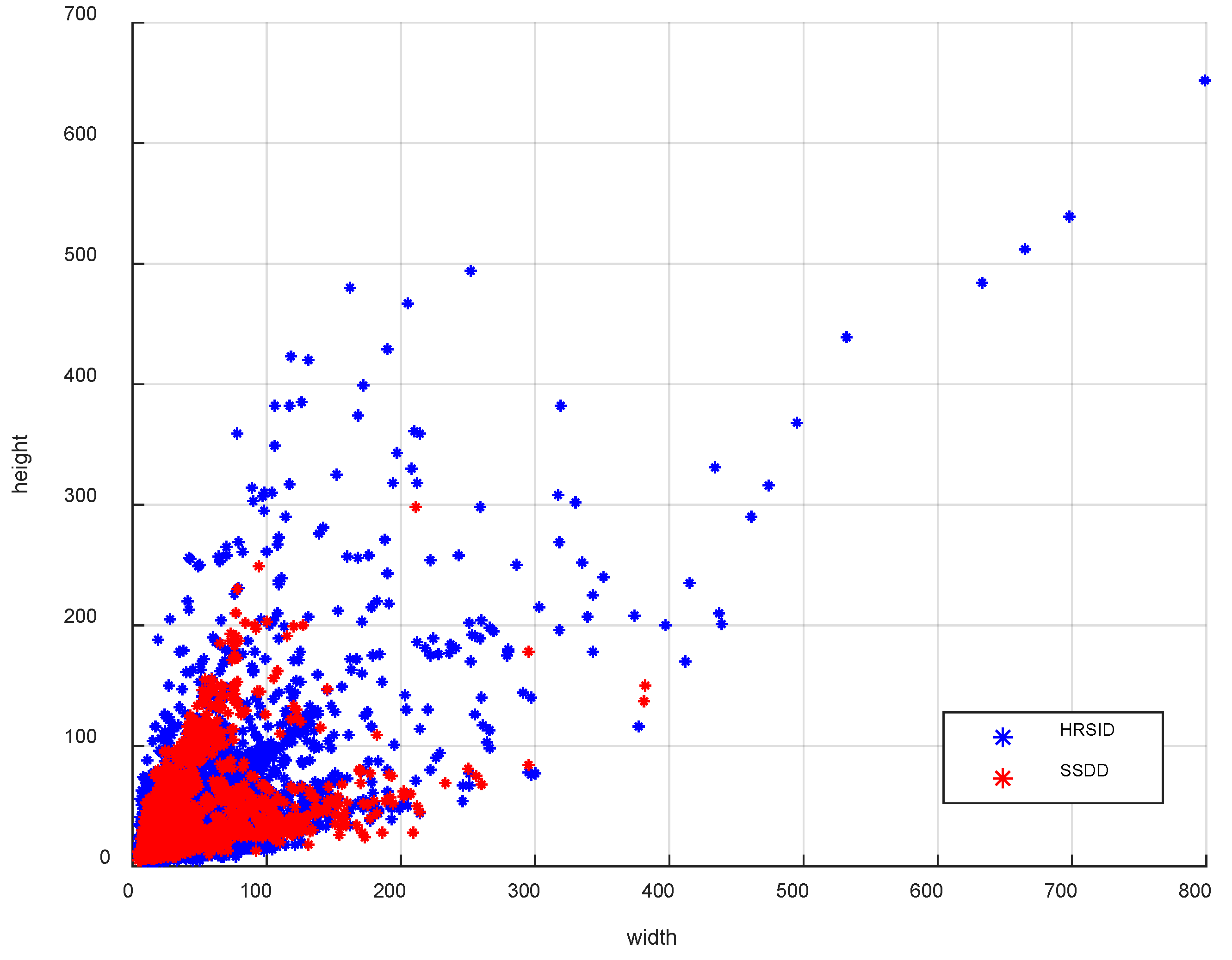
3.1. Experimental Data
3.2. Evaluation Criteria
3.3. Evaluation Results of the Proposed Method
4. Discussion
4.1. Analysis of the Proposed Method under Different Metrics
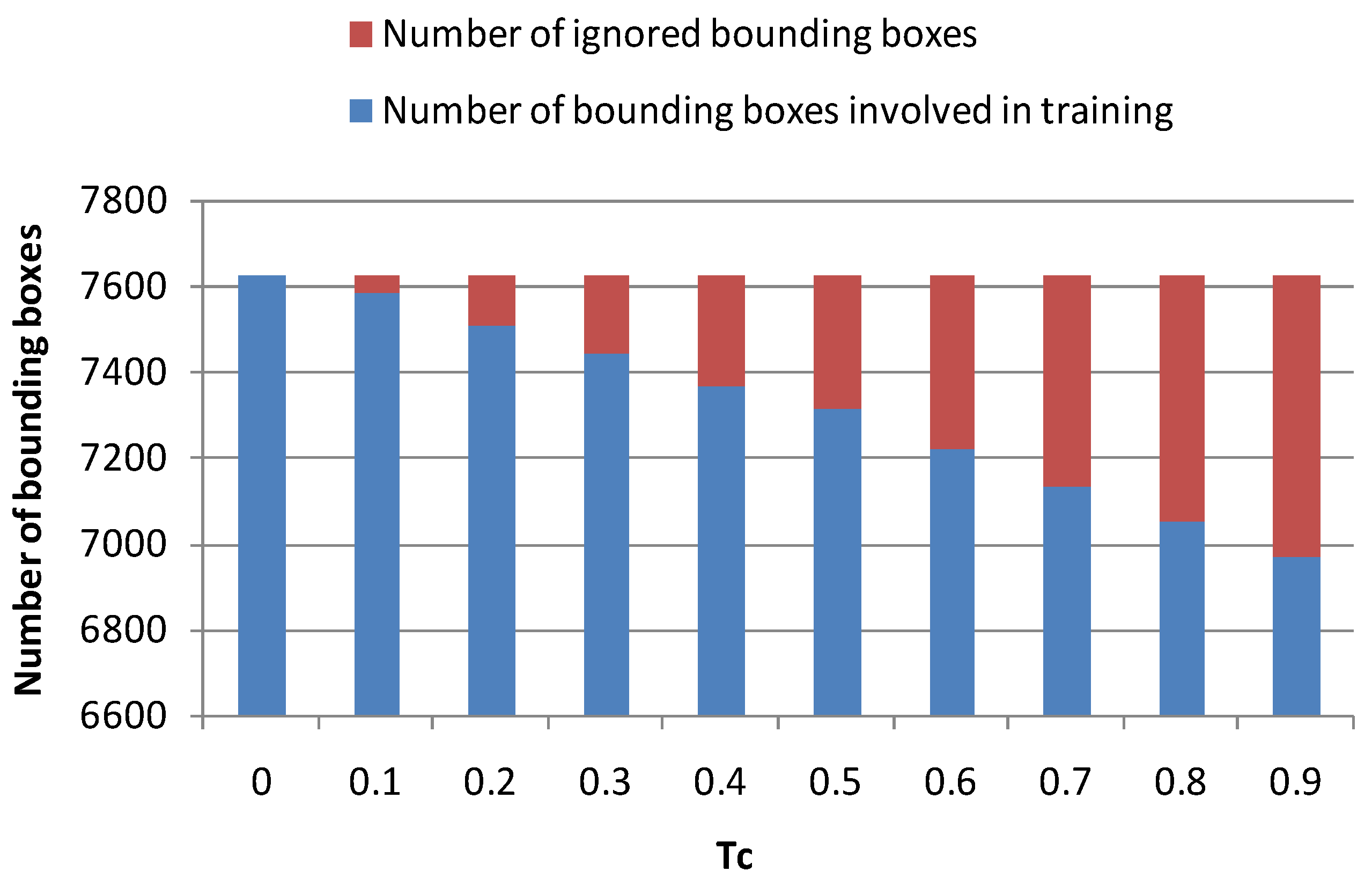
4.2. The Influence of Different on the Performance of the Proposed Method
4.3. Analysis of the Ship Detection Results
4.4. The Significance of theProposed Method for SAR Image Ship Detection Task
4.5. Applicability of the Proposed Method in Other Fields
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multi box detector. In European Conference On computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- An, Q.; Pan, Z.; Liu, L.; You, H. Drbox-v2: An improved detector with rotatable boxes for target detection in sar images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic ship detection based on retinanet using multi-resolution gaofen-3 imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef] [Green Version]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and robust ship detection for high-resolution sar imagery based on hr-sdnet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depth wise separable convolution neural network for high-speed sar ship detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef] [Green Version]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in sar images. In IEEE Transactions on Geoscience and Remote Sensing; IEEE: Piscataway, NJ, USA, 2019; Volume 57, pp. 8983–8997. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. Available online: https://arxiv.org/abs/2004.10934 (accessed on 29 April 2020).
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6023–6032. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. Available online: https://arxiv.org/abs/1904.07850 (accessed on 16 April 2020).
- Chen, C.; He, C.; Hu, C.; Pei, H.; Jiao, L. A deep neural network based on an attention mechanism for sar ship detection in multi scale and complex scenarios. IEEE Access 2019, 7, 104848–104863. [Google Scholar] [CrossRef]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar]
- Liu, Z.; Zheng, T.; Xu, G.; Yang, Z.; Liu, H.; Cai, D. Training-Time-Friendly Network for Real-Time Object Detection; AAAI: Menlo Park, CA, USA, 2020; pp. 11685–11692. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. Hrsid: A high-resolution sar images dataset for ship detection and instan cesegmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in sar images based on an improved faster r-cnn. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge 2007 (voc2007) Results. 2007. Available online: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/ (accessed on 29 April 2020).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
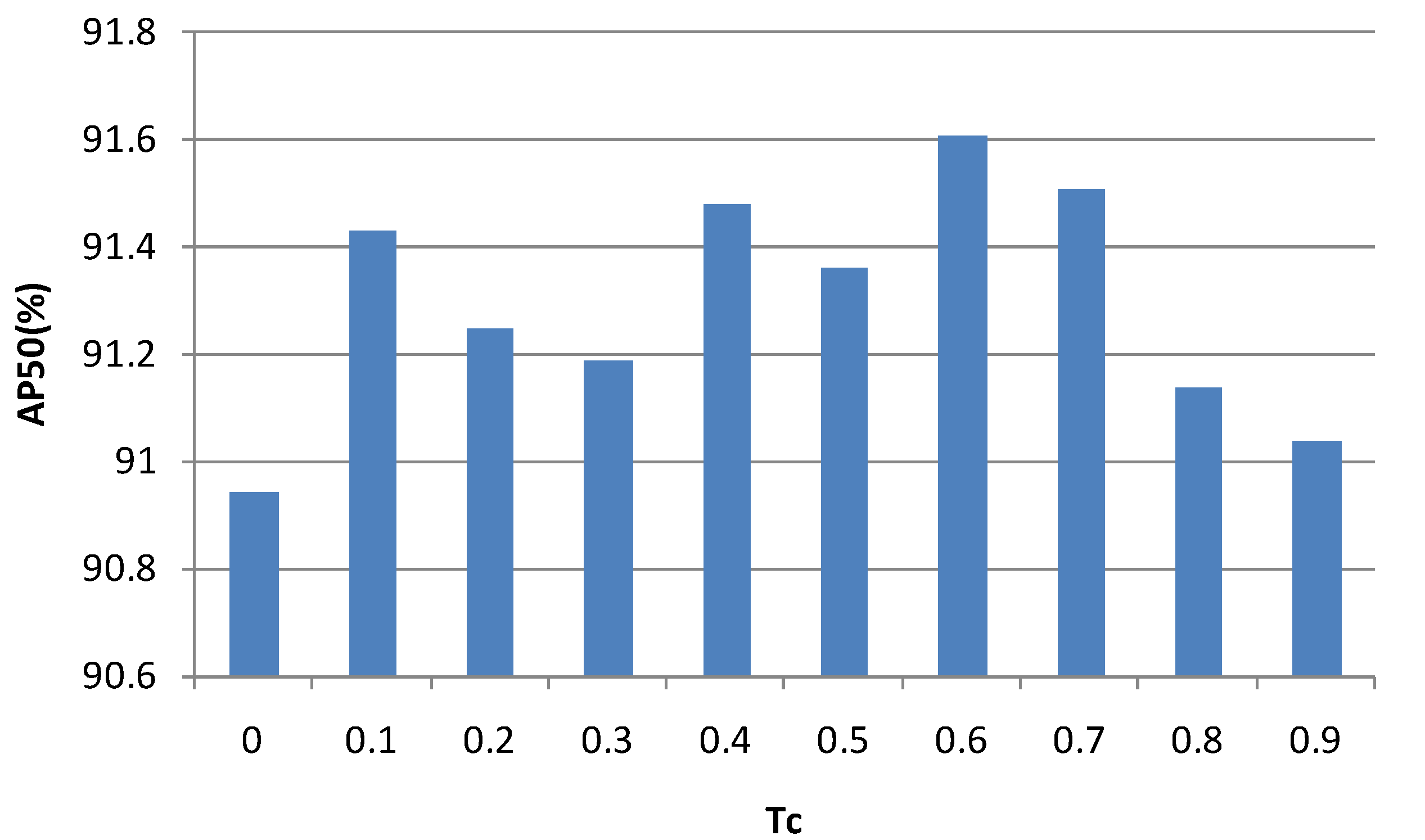{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Size of images (Pixel) | |
| Number of training images | 3642 |
| Number of testing images | 1962 |
| Resolution (m) | 0.5∼3 |
| Polarization | HH, VV, HV |
| Satellite | Sentinel-1B, TerraSAR-X, TanDEM |
| Range of incident angle (◦) | 20∼60 |
| Background type | Inshore, Offshore |
| Total number of ships | 16,906 |
| Metrics | Metrics Meaning |
|---|---|
| mAP | AP average from IoU = 0.50: 0.05: 0.95 |
| AP50 | AP at IoU = 0.50 |
| AP75 | AP at IoU = 0.75 |
| Crop Size | Method | mAP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|---|
| 800 | No random crop | 66.43 | 88.61 | 76.86 |
| 704 | Traditional method | 67.36 | 90.16 | 78.13 |
| Proposed method | 68.21 | 91.61 | 79.70 | |
| 608 | Traditional method | 67.18 | 91.04 | 77.60 |
| Proposed method | 68.17 | 91.99 | 79.38 | |
| 512 | Traditional method | 67.40 | 90.94 | 78.09 |
| Proposed method | 68.50 | 91.51 | 79.29 | |
| 416 | Traditional method | 67.30 | 91.31 | 77.49 |
| Proposed method | 68.23 | 91.47 | 78.85 |
| mAP (%) | AP50 (%) | AP75 (%) | |
|---|---|---|---|
| 0 | 67.4 | 90.94 | 78.09 |
| 0.1 | 67.65 | 91.43 | 77.63 |
| 0.2 | 67.66 | 91.25 | 78.03 |
| 0.3 | 67.51 | 91.19 | 77.88 |
| 0.4 | 67.79 | 91.36 | 78.42 |
| 0.5 | 67.88 | 91.36 | 79.04 |
| 0.6 | 68.04 | 91.61 | 78.77 |
| 0.7 | 68.50 | 91.51 | 79.29 |
| 0.8 | 67.75 | 91.14 | 78.53 |
| 0.9 | 67.50 | 91.04 | 78.07 |
| Crop Size | Method | mAP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|---|
| 800 | No random crop | 63.61 | 88.59 | 74.64 |
| 512 | Traditional method | 66.22 | 91.20 | 76.68 |
| Proposed method () | 67.61 | 91.89 | 78.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, R.; Wang, R.; Deng, Y.; Jia, X.; Zhang, H. Rethinking the Random Cropping Data Augmentation Method Used in the Training of CNN-Based SAR Image Ship Detector. Remote Sens. 2021, 13, 34. https://doi.org/10.3390/rs13010034
Yang R, Wang R, Deng Y, Jia X, Zhang H. Rethinking the Random Cropping Data Augmentation Method Used in the Training of CNN-Based SAR Image Ship Detector. Remote Sensing. 2021; 13(1):34. https://doi.org/10.3390/rs13010034
Chicago/Turabian StyleYang, Rong, Robert Wang, Yunkai Deng, Xiaoxue Jia, and Heng Zhang. 2021. "Rethinking the Random Cropping Data Augmentation Method Used in the Training of CNN-Based SAR Image Ship Detector" Remote Sensing 13, no. 1: 34. https://doi.org/10.3390/rs13010034
APA StyleYang, R., Wang, R., Deng, Y., Jia, X., & Zhang, H. (2021). Rethinking the Random Cropping Data Augmentation Method Used in the Training of CNN-Based SAR Image Ship Detector. Remote Sensing, 13(1), 34. https://doi.org/10.3390/rs13010034