
Knowledge-Driven GeoAI: Integrating Spatial Knowledge into Multi-Scale Deep Learning for Mars Crater Detection


Abstract
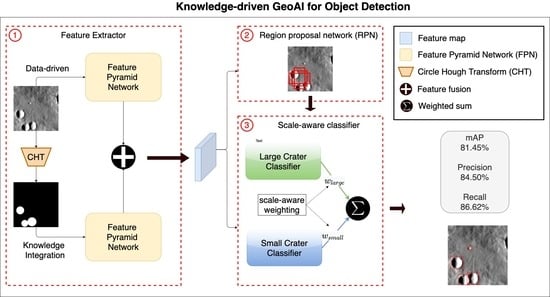
:
1. Introduction
2. Literature Review
2.1. Automated Crater Detection
2.2. Multi-Scale Object Detection
3. Methodology
3.1. Data Preparation
3.2. Baseline Deep Learning Model for Crater Detection
3.3. Feature Pyramid Network (FPN)-Based Feature Extractor
3.4. Domain Knowledge Integration with the Data-Driven Model
3.5. Scale-Aware Object Classification
4. Experiments
4.1. Experiment Setup
4.2. Model Comparison
4.3. Detection Threshold
4.4. Computational Efficiency
4.5. Detection Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| GeoAI | Geospatial Artificial Intelligence |
| DEM | digital elevation model |
| CDA | Crater detection algorithm |
| CNN | Convolutional neural network |
| mAP | Mean Average Precision |
| BBOX | Bounding box |
| THEMIS | Thermal Emission Imagining System |
| DIR | Daytime infrared |
| RPN | Region proposal network |
| NMS | Non-maximum suppression |
| RoI | Region of interest |
| FPN | Feature pyramid network |
| CHT | Circular Hough Transform |
References
- Barlow, N.G. A review of Martian impact crater ejecta structures and their implications for target properties. Large Meteor. Impacts III 2005, 384, 433–442. [Google Scholar]
- Barlow, N.G.; Perez, C.B. Martian impact crater ejecta morphologies as indicators of the distribution of subsurface volatiles. J. Geophys. Res. Planets 2003, 108. [Google Scholar] [CrossRef] [Green Version]
- Hartmann, W.K.; Malin, M.; McEwen, A.; Carr, M.; Soderblom, L.; Thomas, P.; Danielson, E.; James, P.; Veverka, J. Evidence for recent volcanism on Mars from crater counts. Nature 1999, 397, 586–589. [Google Scholar] [CrossRef]
- Hawke, B.; Head, J. Impact melt on lunar crater rims. In Impact and Explosion Cratering: Planetary and Terrestrial Implications; Pergamon Press: New York, NY, USA, 1977; pp. 815–841. [Google Scholar]
- Neukum, G.; Wise, D. Mars—A standard crater curve and possible new time scale. Science 1976, 194, 1381–1387. [Google Scholar] [CrossRef] [PubMed]
- Hartmann, W.K. Martian cratering. Icarus 1966, 5, 565–576. [Google Scholar] [CrossRef]
- Schon, S.C.; Head, J.W.; Fassett, C.I. Recent high-latitude resurfacing by a climate-related latitude-dependent mantle: Constraining age of emplacement from counts of small craters. Planet. Space Sci. 2012, 69, 49–61. [Google Scholar] [CrossRef]
- Schaber, G.; Strom, R.; Moore, H.; Soderblom, L.A.; Kirk, R.L.; Chadwick, D.; Dawson, D.; Gaddis, L.; Boyce, J.; Russell, J. Geology and distribution of impact craters on Venus: What are they telling us? J. Geophys. Res. Planets 1992, 97, 13257–13301. [Google Scholar] [CrossRef]
- Wilhelms, D.E.; John, F.; Trask, N.J. The Geologic History of the Moon; Technical Report; U.S. Geological Survey, 1987. Available online: https://pubs.er.usgs.gov/publication/pp1348 (accessed on 27 May 2021).
- Martín-Torres, F.J.; Zorzano, M.P.; Valentín-Serrano, P.; Harri, A.M.; Genzer, M.; Kemppinen, O.; Rivera-Valentin, E.G.; Jun, I.; Wray, J.; Madsen, M.B.; et al. Transient liquid water and water activity at Gale crater on Mars. Nat. Geosci. 2015, 8, 357–361. [Google Scholar] [CrossRef]
- Ruff, S.W.; Farmer, J.D. Silica deposits on Mars with features resembling hot spring biosignatures at El Tatio in Chile. Nat. Commun. 2016, 7, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Losiak, A.; Wilhelms, D.; Byrne, C.; Thaisen, K.; Weider, S.; Kohout, T.; O’Sullivan, K.; Kring, D. A new lunar impact crater database. In Lunar and Planetary Science Conference; 2009; p. 1532. Available online: https://www.lpi.usra.edu/meetings/lpsc2009/pdf/1532.pdf (accessed on 27 May 2021).
- Robbins, S.J. A global lunar crater database, complete for craters 1 km, ii. In Proceedings of the 48th Lunar and Planetary Science Conference, The Woodlands, TX, USA, 20–24 March 2017; pp. 20–24. [Google Scholar]
- Robbins, S.J.; Hynek, B.M. A new global database of Mars impact craters ≥1 km: 1. Database creation, properties, and parameters. J. Geophys. Res. Planets 2012, 117. [Google Scholar] [CrossRef]
- Schaber, G.G.; Chadwick, D.J. Venus’ impact-crater database: Update to approximately 98 percent of the planet’s surface. In Proceedings of the Lunar and Planetary Science Conference XXIV, Houston, TX, USA, 15–19 March 1993; Volume 24, p. 1241. [Google Scholar]
- Edwards, C.; Nowicki, K.; Christensen, P.; Hill, J.; Gorelick, N.; Murray, K. Mosaicking of global planetary image datasets: 1. Techniques and data processing for Thermal Emission Imaging System (THEMIS) multi-spectral data. J. Geophys. Res. Planets 2011, 116. [Google Scholar] [CrossRef]
- Di, K.; Li, W.; Yue, Z.; Sun, Y.; Liu, Y. A machine learning approach to crater detection from topographic data. Adv. Space Res. 2014, 54, 2419–2429. [Google Scholar] [CrossRef]
- Honda, R.; Konishi, O.; Azuma, R.; Yokogawa, H.; Yamanaka, S.; Iijima, Y. Data mining system for planetary images-crater detection and categorization. In Proceedings of the International Workshop on Machine Learning of Spatial Knowledge in Conjunction with ICML, Stanford, CA, USA, 2000; pp. 103–108. Available online: http://citeseerx.ist.psu.edu/viewdoc/versions?doi=10.1.1.28.1172 (accessed on 27 May 2021).
- Jahn, H. Crater detection by linear filters representing the Hough Transform. In Proceedings of the ISPRS Commission III Symposium: Spatial Information from Digital Photogrammetry and Computer Vision, Munich, Germany, 5–9 September 1994; International Society for Optics and Photonics: Bellingham, WA, USA, 1994; Volume 2357, pp. 427–431. [Google Scholar]
- Kim, J.R.; Muller, J.P.; van Gasselt, S.; Morley, J.G.; Neukum, G. Automated crater detection, a new tool for Mars cartography and chronology. Photogramm. Eng. Remote Sens. 2005, 71, 1205–1217. [Google Scholar] [CrossRef] [Green Version]
- Lee, C. Automated crater detection on Mars using deep learning. Planet. Space Sci. 2019, 170, 16–28. [Google Scholar] [CrossRef] [Green Version]
- Palafox, L.F.; Hamilton, C.W.; Scheidt, S.P.; Alvarez, A.M. Automated detection of geological landforms on Mars using Convolutional Neural Networks. Comput. Geosci. 2017, 101, 48–56. [Google Scholar] [CrossRef]
- Wetzler, P.G.; Honda, R.; Enke, B.; Merline, W.J.; Chapman, C.R.; Burl, M.C. Learning to detect small impact craters. In Proceedings of the 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05)-Volume 1, Breckenridge, CO, USA, 5–7 January 2005; Volume 1, pp. 178–184. [Google Scholar]
- Li, W. GeoAI: Where machine learning and big data converge in GIScience. J. Spat. Inf. Sci. 2020, 2020, 71–77. [Google Scholar] [CrossRef]
- Li, W.; Hsu, C.Y. Automated terrain feature identification from remote sensing imagery: A deep learning approach. Int. J. Geogr. Inf. Sci. 2020, 34, 637–660. [Google Scholar] [CrossRef]
- Li, W.; Hsu, C.Y.; Hu, M. Tobler’s First Law in GeoAI: A spatially explicit deep learning model for terrain feature detection under weak supervision. Ann. Am. Assoc. Geogr. 2021. [Google Scholar] [CrossRef]
- DeLatte, D.; Crites, S.T.; Guttenberg, N.; Yairi, T. Automated crater detection algorithms from a machine learning perspective in the convolutional neural network era. Adv. Space Res. 2019, 64, 1615–1628. [Google Scholar] [CrossRef]
- Tewari, A.; Verma, V.; Srivastava, P.; Jain, V.; Khanna, N. Automated Crater Detection from Co-registered Optical Images, Elevation Maps and Slope Maps using Deep Learning. arXiv 2020, arXiv:2012.15281. [Google Scholar]
- Li, H.; Jiang, B.; Li, Y.; Cao, L. A combined method of crater detection and recognition based on deep learning. Syst. Sci. Control Eng. 2020, 9, 132–140. [Google Scholar] [CrossRef]
- Lee, C.; Hogan, J. Automated crater detection with human level performance. Comput. Geosci. 2021, 147, 104645. [Google Scholar] [CrossRef]
- Wang, H.; Jiang, J.; Zhang, G. CraterIDNet: An end-to-end fully convolutional neural network for crater detection and identification in remotely sensed planetary images. Remote Sens. 2018, 10, 1067. [Google Scholar] [CrossRef] [Green Version]
- Hsu, C.Y.; Li, W. Learning from counting: Leveraging temporal classification for weakly supervised object localization and detection. arXiv 2021, arXiv:2103.04009. [Google Scholar]
- Ghorbanzadeh, O.; Tiede, D.; Wendt, L.; Sudmanns, M.; Lang, S. Transferable instance segmentation of dwellings in a refugee camp-integrating CNN and OBIA. Eur. J. Remote Sens. 2021, 54, 127–140. [Google Scholar] [CrossRef]
- Li, Y.; Ouyang, S.; Zhang, Y. Collaboratively boosting data-driven deep learning and knowledge-guided ontological reasoning for semantic segmentation of remote sensing imagery. arXiv 2020, arXiv:2010.02451. [Google Scholar]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Yu, M.; Cui, H.; Tian, Y. A new approach based on crater detection and matching for visual navigation in planetary landing. Adv. Space Res. 2014, 53, 1810–1821. [Google Scholar] [CrossRef]
- Arvidson, R.E. Morphologic classification of Martian craters and some implications. Icarus 1974, 22, 264–271. [Google Scholar] [CrossRef]
- Cintala, M.J.; Head, J.W.; Mutch, T.A. Martian crater depth/diameter relationships-Comparison with the moon and Mercury. Lunar Planet. Sci. Conf. Proc. 1976, 7, 3575–3587. [Google Scholar]
- Emami, E.; Bebis, G.; Nefian, A.; Fong, T. Automatic crater detection using convex grouping and convolutional neural networks. In International Symposium on Visual Computing; Springer: Berlin, Germany, 2015; pp. 213–224. [Google Scholar]
- Stepinski, T.F.; Mendenhall, M.P.; Bue, B.D. Machine cataloging of impact craters on Mars. Icarus 2009, 203, 77–87. [Google Scholar] [CrossRef]
- Hough, P.V. Method and Means for Recognizing Complex Patterns. U.S. Patent 3,069,654, 18 December 1962. [Google Scholar]
- Silburt, A.; Ali-Dib, M.; Zhu, C.; Jackson, A.; Valencia, D.; Kissin, Y.; Tamayo, D.; Menou, K. Lunar crater identification via deep learning. Icarus 2019, 317, 27–38. [Google Scholar] [CrossRef] [Green Version]
- Yoo, J.C.; Han, T.H. Fast normalized cross-correlation. Circuits Syst. Signal Process. 2009, 28, 819–843. [Google Scholar] [CrossRef]
- Emami, E.; Ahmad, T.; Bebis, G.; Nefian, A.; Fong, T. Crater detection using unsupervised algorithms and convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5373–5383. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Yang, J.; Kang, Z. Bayesian network-based extraction of lunar impact craters from optical images and DEM data. Adv. Space Res. 2019, 63, 3721–3737. [Google Scholar] [CrossRef]
- Zuo, W.; Li, C.; Yu, L.; Zhang, Z.; Wang, R.; Zeng, X.; Liu, Y.; Xiong, Y. Shadow–highlight feature matching automatic small crater recognition using high-resolution digital orthophoto map from Chang’E Missions. Acta Geochim. 2019, 38, 541–554. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Barata, T.; Alves, E.I.; Saraiva, J.; Pina, P. Automatic recognition of impact craters on the surface of Mars. In International Conference Image Analysis and Recognition; Springer: Berlin, Germany, 2004; pp. 489–496. [Google Scholar]
- Plesko, C.; Brumby, S.; Asphaug, E. A Comparison of Automated and Manual Surveys of Small Craters in Elysium Planitia. In Proceedings of the 36th Annual Lunar and Planetary Science Conference, The Woodlands, TX, USA, 16–20 March 2005; p. 1971. [Google Scholar]
- Barlow, N.G. Crater size-frequency distributions and a revised Martian relative chronology. Icarus 1988, 75, 285–305. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Honari, S.; Yosinski, J.; Vincent, P.; Pal, C. Recombinator networks: Learning coarse-to-fine feature aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5743–5752. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Pinheiro, P.O.; Lin, T.Y.; Collobert, R.; Dollár, P. Learning to refine object segments. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 75–91. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 354–370. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Xiao, T.; Zhang, J.; Yang, K.; Zhang, Z. Scale-invariant convolutional neural networks. arXiv 2014, arXiv:1411.6369. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin, Germany, 2014; pp. 740–755. [Google Scholar]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 304–311. [Google Scholar]
- Bandeira, L.; Ding, W.; Stepinski, T. Automatic detection of sub-km craters using shape and texture information. In Proceedings of the Lunar and Planetary Science Conference, The Woodlands, TX, USA, 1–5 March 2010; p. 1144. [Google Scholar]
- McEwen, A.S.; Eliason, E.M.; Bergstrom, J.W.; Bridges, N.T.; Hansen, C.J.; Delamere, W.A.; Grant, J.A.; Gulick, V.C.; Herkenhoff, K.E.; Keszthelyi, L.; et al. Mars reconnaissance orbiter’s high resolution imaging science experiment (HiRISE). J. Geophys. Res. Planets 2007, 112. [Google Scholar] [CrossRef] [Green Version]
- Smith, D.E.; Zuber, M.T.; Frey, H.V.; Garvin, J.B.; Head, J.W.; Muhleman, D.O.; Pettengill, G.H.; Phillips, R.J.; Solomon, S.C.; Zwally, H.J.; et al. Mars Orbiter Laser Altimeter: Experiment summary after the first year of global mapping of Mars. J. Geophys. Res. Planets 2001, 106, 23689–23722. [Google Scholar] [CrossRef]
- Zuber, M.T.; Smith, D.; Solomon, S.; Muhleman, D.; Head, J.; Garvin, J.; Abshire, J.; Bufton, J. The Mars Observer laser altimeter investigation. J. Geophys. Res. Planets 1992, 97, 7781–7797. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ballard, D.H. Generalizing the Hough transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Galloway, M.J.; Benedix, G.K.; Bland, P.A.; Paxman, J.; Towner, M.C.; Tan, T. Automated crater detection and counting using the Hough transform. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1579–1583. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Predictions | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|---|
| Faster R-CNN [72] | 88,125 | 71.53 | 65.97 | 72.18 |
| FPN [59] | 105,539 | 74.13 | 81.87 | 78.09 |
| FPN + D | 115,121 | 69.70 | 83.97 | 76.16 |
| FPN + S | 97,231 | 82.63 | 84.08 | 79.72 |
| FPN + D + S | 97,956 | 84.50 | 86.62 | 81.45 |
| Models | Threshold | Predictions | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|---|---|
| FPN [59] | 0 | 140,864 | 55.92 | 85.97 | 78.09 |
| 0.3 | 109,001 | 69.96 | 83.22 | ||
| 0.5 | 105,539 | 74.13 | 81.87 | ||
| FPN + D + S | 0 | 128,524 | 68.40 | 92.01 | 81.45 |
| 0.3 | 103,907 | 81.09 | 88.18 | ||
| 0.5 | 97,956 | 84.50 | 86.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, C.-Y.; Li, W.; Wang, S. Knowledge-Driven GeoAI: Integrating Spatial Knowledge into Multi-Scale Deep Learning for Mars Crater Detection. Remote Sens. 2021, 13, 2116. https://doi.org/10.3390/rs13112116
Hsu C-Y, Li W, Wang S. Knowledge-Driven GeoAI: Integrating Spatial Knowledge into Multi-Scale Deep Learning for Mars Crater Detection. Remote Sensing. 2021; 13(11):2116. https://doi.org/10.3390/rs13112116
Chicago/Turabian StyleHsu, Chia-Yu, Wenwen Li, and Sizhe Wang. 2021. "Knowledge-Driven GeoAI: Integrating Spatial Knowledge into Multi-Scale Deep Learning for Mars Crater Detection" Remote Sensing 13, no. 11: 2116. https://doi.org/10.3390/rs13112116
APA StyleHsu, C. -Y., Li, W., & Wang, S. (2021). Knowledge-Driven GeoAI: Integrating Spatial Knowledge into Multi-Scale Deep Learning for Mars Crater Detection. Remote Sensing, 13(11), 2116. https://doi.org/10.3390/rs13112116