
Improving Parcel-Level Mapping of Smallholder Crops from VHSR Imagery: An Ensemble Machine-Learning-Based Framework



Abstract
:
1. Introduction
2. Materials and Process
2.1. Study Site
2.2. Data and Preprocessing
2.2.1. WorldView-2 Imagery
2.2.2. Parcel Boundary Vector Data
2.2.3. Ground-Truth Data
3. Experimental Design and Methods
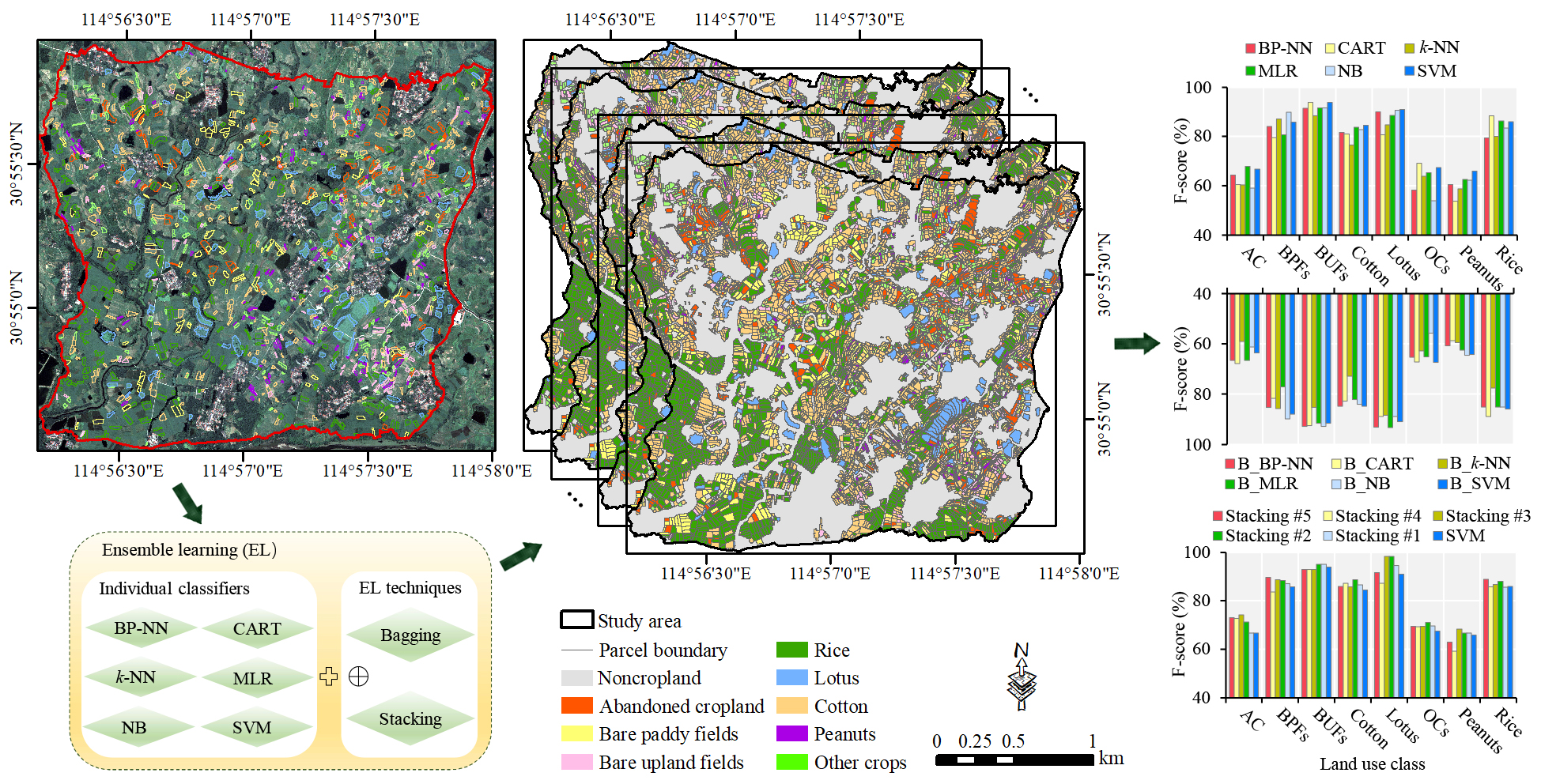
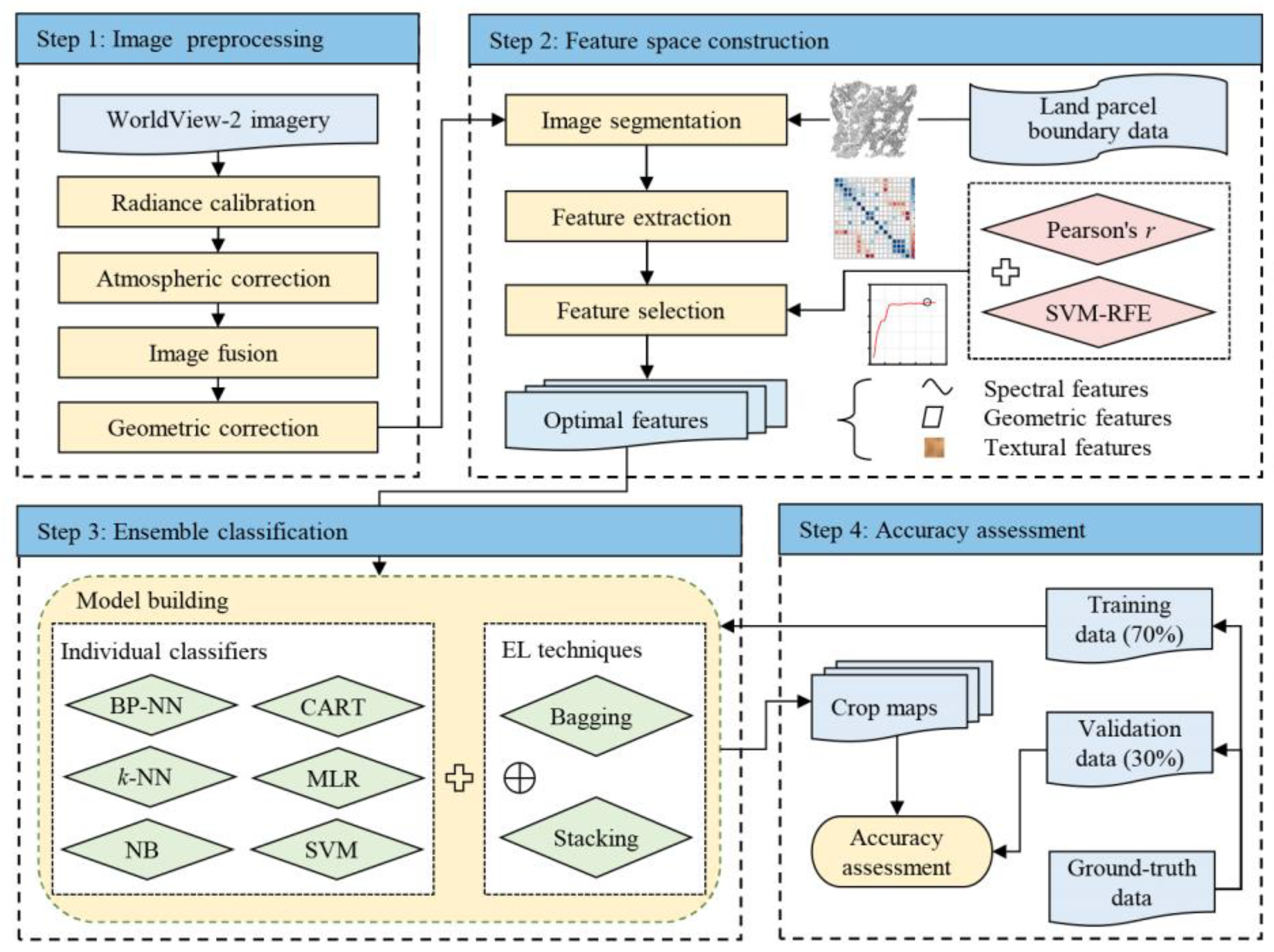
3.1. Crop Mapping Framework
3.2. Feature Space Construction
3.2.1. Image Segmentation
3.2.2. Feature Extraction and Selection
3.3. Ensemble Classification
3.3.1. Bagging and Stacking Methods
3.3.2. Machine Learning Classifiers
3.4. Accuracy Assessment
4. Implementation and Results
4.1. Model Performance Evaluation and Comparison
4.1.1. Performance of the Individual Classifiers
4.1.2. Performance of the Bagging Models
4.1.3. Performance of the Stacking Models
4.1.4. Comparison of the Stacking with Other Models
4.1.5. Comparison under Different Feature Sets
4.2. Predicted Crop Type Maps
4.2.1. Spatial Pattern of the Crop Types
4.2.2. Agreement Analysis of the Prediction Maps
4.2.3. Error Analysis of the Prediction Maps
5. Discussions
5.1. Advantages of the Stacking Ensemble
5.2. Effect of the Bagging Ensemble
5.3. Contribution of the Spatial Features
5.4. Benefits/Drawbacks of Our Approach
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Texture Metrics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Texture Measures | Formula |
|---|---|---|
| 1 | Homogeneity | |
| 2 | Contrast | |
| 3 | Dissimilarity | |
| 4 | Entropy | |
| 5 | Ang. 2nd moment | |
| 6 | Mean | |
| 7 | Standard deviation | |
| 8 | Correlation |
Appendix B. Model’s Parameter Configuration
Appendix C. Comparison under Different Meta-Classifiers
| Meta-Classifiers | Base Classifiers | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| #1 | #2 | #3 | #4 | #5 | ||||||
| OA (%) | Kappa | OA (%) | Kappa | OA (%) | Kappa | OA (%) | Kappa | OA (%) | Kappa | |
| SVM * | 82.04 | 0.790 | 83.91 | 0.812 | 83.11 | 0.803 | 80.97 | 0.778 | 82.57 | 0.796 |
| MLR | 80.97 | 0.777 | 82.04 | 0.79 | 79.62 | 0.762 | 77.21 | 0.735 | 75.07 | 0.710 |
| CART | 74.26 | 0.699 | 74.26 | 0.699 | 76.14 | 0.722 | 75.34 | 0.712 | 78.28 | 0.747 |
| NB | 68.36 | 0.635 | 78.28 | 0.747 | 68.10 | 0.633 | 67.29 | 0.624 | 67.83 | 0.630 |
| BP-NN | 80.43 | 0.772 | 81.50 | 0.783 | 80.70 | 0.774 | 80.43 | 0.771 | 80.16 | 0.768 |
| k-NN | 80.70 | 0.744 | 81.23 | 0.78 | 80.16 | 0.768 | 81.50 | 0.784 | 80.70 | 0.775 |
References
- ETC Group. Who Will Feed Us? Questions for the Food and Climate Crisis; ETC Group Communiqué: Ottawa, ON, Canada, 2009. [Google Scholar]
- Wolfenson, K.D.M. Coping with the Food and Agriculture Challenge: Smallholders’ Agenda; FAO: Rome, Italy, 2013. [Google Scholar]
- Bermeo, A.; Couturier, S.; Pizaña, M.G. Conservation of traditional smallholder cultivation systems in indigenous territories: Mapping land availability for milpa cultivation in the Huasteca Poblana, Mexico. Appl. Geogr. 2014, 53, 299–310. [Google Scholar] [CrossRef]
- Lambert, M.J.; Traoré, P.C.S.; Blaes, X.; Baret, P.; Defourny, P. Estimating smallholder crops production at village level from Sentinel-2 time series in Mali’s cotton belt. Remote Sens. Environ. 2018, 216, 647–657. [Google Scholar] [CrossRef]
- Zhang, P.; Hu, S.; Li, W.; Zhang, C. Parcel-level mapping of crops in a smallholder agricultural area: A case of central China using single-temporal VHSR imagery. Comput. Electron. Agric. 2020, 175, 105581. [Google Scholar] [CrossRef]
- Kamal, M.; Schulthess, U.; Krupnik, T.J. Identification of mung bean in a smallholder farming setting of coastal south asia using manned aircraft photography and sentinel-2 images. Remote Sens. 2020, 12, 3688. [Google Scholar] [CrossRef]
- Morton, J.F. The impact of climate change on smallholder and subsistence agriculture. Proc. Natl. Acad. Sci. USA 2007, 104, 19680–19685. [Google Scholar] [CrossRef] [Green Version]
- Lei, Y.; Liu, C.; Zhang, L.; Luo, S. How smallholder farmers adapt to agricultural drought in a changing climate: A case study in southern China. Land Use Pol. 2016, 55, 300–308. [Google Scholar] [CrossRef]
- Chandra, A.; Mcnamara, K.E.; Dargusch, P.; Maria, A.; Dalabajan, D. Gendered vulnerabilities of smallholder farmers to climate change in conflict-prone areas: A case study from Mindanao, Philippines. J. Rural Stud. 2017, 50, 45–59. [Google Scholar] [CrossRef]
- Jin, Z.; Azzari, G.; You, C.; Di, S.; Aston, S.; Burke, M.; Lobell, D.B. Smallholder maize area and yield mapping at national scales with Google Earth Engine. Remote Sens. Environ. 2019, 228, 115–128. [Google Scholar] [CrossRef]
- Piiroinen, R.; Heiskanen, J.; Mõttus, M.; Pellikka, P. Classification of crops across heterogeneous agricultural landscape in Kenya using AisaEAGLE imaging spectroscopy data. Int. J. Appl. Earth Obs. Geoinf. 2015, 39, 1–8. [Google Scholar] [CrossRef]
- Lebourgeois, V.; Dupuy, S.; Vintrou, É.; Ameline, M.; Butler, S.; Bégué, A. A combined random forest and OBIA classification scheme for mapping smallholder agriculture at different nomenclature levels using multisource data (simulated Sentinel-2 time series, VHRS and DEM). Remote Sens. 2017, 9, 259. [Google Scholar] [CrossRef] [Green Version]
- Breunig, F.M.; Galvão, L.S.; Dalagnol, R.; Santi, A.L.; Della-Flora, D.P.; Chen, S. Assessing the effect of spatial resolution on the delineation of management zones for smallholder farming in southern Brazil. Remote Sens. Appl. Soc. Environ. 2020, 100325. [Google Scholar]
- Conrad, C.; Löw, F.; Lamers, J.P.A. Mapping and assessing crop diversity in the irrigated Fergana Valley, Uzbekistan. Appl. Geogr. 2017, 86, 102–117. [Google Scholar] [CrossRef]
- Liu, X.; Zhai, H.; Shen, Y.; Lou, B.; Jiang, C.; Li, T.; Hussain, S.B.; Shen, G. Large-Scale Crop Mapping from Multisource Remote Sensing Images in Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 414–427. [Google Scholar] [CrossRef]
- Leroux, L.; Jolivot, A.; Bégué, A.; Lo Seen, D.; Zoungrana, B. How reliable is the MODIS land cover product for crop mapping Sub-Saharan agricultural landscapes? Remote Sens. 2014, 6, 8541–8564. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Xiao, X.; Qin, Y.; Wang, J.; Xu, X.; Hu, Y.; Qiao, Z. Mapping cropping intensity in China using time series Landsat and Sentinel-2 images and Google Earth Engine. Remote Sens. Environ. 2020, 239, 111624. [Google Scholar] [CrossRef]
- Planque, C.; Lucas, R.; Punalekar, S.; Chognard, S.; Hurford, C.; Owers, C.; Horton, C.; Guest, P.; King, S.; Williams, S.; et al. National Crop Mapping Using Sentinel-1 Time Series: A Knowledge-Based Descriptive Algorithm. Remote Sens. 2021, 13, 846. [Google Scholar] [CrossRef]
- Alganci, U.; Sertel, E.; Ozdogan, M.; Ormeci, C. Parcel-level identification of crop types using different classification algorithms and multi-resolution imagery in Southeastern Turkey. Photogramm. Eng. Remote Sensing. 2013, 79, 1053–1065. [Google Scholar] [CrossRef]
- Kussul, N.; Lemoine, G.; Gallego, F.J.; Skakun, S.V.; Lavreniuk, M.; Shelestov, A.Y. Parcel-Based Crop Classification in Ukraine Using Landsat-8 Data and Sentinel-1A Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2500–2508. [Google Scholar] [CrossRef]
- Sitokonstantinou, V.; Papoutsis, I.; Kontoes, C.; Arnal, A.L.; Andrés, A.P.A.; Zurbano, J.A.G. Scalable parcel-based crop identification scheme using Sentinel-2 data time-series for the monitoring of the common agricultural policy. Remote Sens. 2018, 10, 911. [Google Scholar] [CrossRef] [Green Version]
- Das, K.; Pramanik, D.; Santra, S.C.; Sengupta, S. Parcel wise crop discrimination and web based information generation using remote sensing and open source software. Egypt. J. Remote Sens. Sp. Sci. 2019, 22, 117–125. [Google Scholar] [CrossRef]
- Neigh, C.S.R.; Carroll, M.L.; Wooten, M.R.; McCarty, J.L.; Powell, B.F.; Husak, G.J.; Enenkel, M.; Hain, C.R. Smallholder crop area mapped with wall-to-wall WorldView sub-meter panchromatic image texture: A test case for Tigray, Ethiopia. Remote Sens. Environ. 2018, 212, 8–20. [Google Scholar] [CrossRef]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Hay, G.J.; Castilla, G. Geographic Object-Based Image Analysis (GEOBIA): A new name for a new discipline. In Object-Based Image Analysis; Springer: Berlin/Heidelberg, Germany, 2008; pp. 75–89. [Google Scholar]
- Arvor, D.; Durieux, L.; Andrés, S.; Laporte, M.A. Advances in Geographic Object-Based Image Analysis with ontologies: A review of main contributions and limitations from a remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2013, 82, 125–137. [Google Scholar] [CrossRef]
- Vaudour, E.; Noirot-Cosson, P.E.; Membrive, O. Early-season mapping of crops and cultural operations using very high spatial resolution Pléiades images. Int. J. Appl. Earth Obs. Geoinf. 2015, 42, 128–141. [Google Scholar] [CrossRef]
- Wu, M.; Huang, W.; Niu, Z.; Wang, Y.; Wang, C.; Li, W.; Hao, P.; Yu, B. Fine crop mapping by combining high spectral and high spatial resolution remote sensing data in complex heterogeneous areas. Comput. Electron. Agric. 2017, 139, 1–9. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, H.; Li, X.; Li, X.; Cai, W.; Han, C. An object-based approach for mapping crop coverage using multiscale weighted and machine learning methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1700–1713. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Peña, J.M.; Gutiérrez, P.A.; Hervás-Martínez, C.; Six, J.; Plant, R.E.; López-Granados, F. Object-based image classification of summer crops with machine learning methods. Remote Sens. 2014, 6, 5019–5041. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Zhao, J.; Liu, T.; Zhang, H.; Zhang, Z.; Guo, X. Crop Type Identification and Mapping Using Machine Learning Algorithms and Sentinel-2 Time Series Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3295–3306. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, H.; Wang, C.; Zhang, B.; Liu, M. Crop classification based on temporal information using Sentinel-1 SAR time-series data. Remote Sens. 2019, 11, 53. [Google Scholar] [CrossRef] [Green Version]
- Feyisa, G.L.; Palao, L.K.; Nelson, A.; Gumma, M.K.; Paliwal, A.; Win, K.T.; Nge, K.H.; Johnson, D.E. Characterizing and mapping cropping patterns in a complex agro-ecosystem: An iterative participatory mapping procedure using machine learning algorithms and MODIS vegetation indices. Comput. Electron. Agric. 2020, 175, 105595. [Google Scholar] [CrossRef]
- Pal, M. Ensemble learning with decision tree for remote sensing classification. World Acad. Sci. Eng. Technol. 2007, 36, 258–260. [Google Scholar]
- Feng, L.; Zhang, Z.; Ma, Y.; Du, Q.; Williams, P.; Drewry, J.; Luck, B. Alfalfa yield prediction using UAV-based hyperspectral imagery and ensemble learning. Remote Sens. 2020, 12, 2028. [Google Scholar] [CrossRef]
- Khosravi, I.; Safari, A.; Homayouni, S.; McNairn, H. Enhanced decision tree ensembles for land-cover mapping from fully polarimetric sar data. Int. J. Remote Sens. 2017, 38, 7138–7160. [Google Scholar] [CrossRef]
- Man, C.D.; Nguyen, T.T.; Bui, H.Q.; Lasko, K.; Nguyen, T.N.T. Improvement of land-cover classification over frequently cloud-covered areas using landsat 8 time-series composites and an ensemble of supervised classifiers. Int. J. Remote Sens. 2018, 39, 1243–1255. [Google Scholar] [CrossRef]
- Zhou, Z.-H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012; ISBN 1439830037. [Google Scholar]
- Wang, G.; Hao, J.; Ma, J.; Jiang, H. A comparative assessment of ensemble learning for credit scoring. Expert Syst. Appl. 2011, 38, 223–230. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Watkins, B.; Van Niekerk, A. A comparison of object-based image analysis approaches for field boundary delineation using multi-temporal Sentinel-2 imagery. Comput. Electron. Agric. 2019, 158, 294–302. [Google Scholar] [CrossRef]
- Hong, R.; Park, J.; Jang, S.; Shin, H.; Kim, H.; Song, I. Development of a Parcel-Level Land Boundary Extraction Algorithm for Aerial Imagery of Regularly Arranged Agricultural Areas. Remote Sens. 2021, 13, 1167. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Ursani, A.A.; Kpalma, K.; Lelong, C.C.D.; Ronsin, J. Fusion of textural and spectral information for tree crop and other agricultural cover mapping with very-high resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 225–235. [Google Scholar] [CrossRef]
- Ma, L.; Cheng, L.; Li, M.; Liu, Y.; Ma, X. Training set size, scale, and features in Geographic Object-Based Image Analysis of very high resolution unmanned aerial vehicle imagery. ISPRS J. Photogramm. Remote Sens. 2015, 102, 14–27. [Google Scholar] [CrossRef]
- Jordan, C.F. Derivation of Leaf-Area Index from Quality of Light on the Forest Floor. Ecology. 1969, 50, 663–666. [Google Scholar] [CrossRef]
- Rouse, J.W., Jr.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the great plains with erts; NASA Special Publication: Washington, DC, USA, 1974. [Google Scholar]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Löw, F.; Michel, U.; Dech, S.; Conrad, C. Impact of feature selection on the accuracy and spatial uncertainty of per-field crop classification using Support Vector Machines. ISPRS J. Photogramm. Remote Sens. 2013, 85, 102–119. [Google Scholar] [CrossRef]
- Song, Q.; Xiang, M.; Hovis, C.; Zhou, Q.; Lu, M.; Tang, H.; Wu, W. Object-based feature selection for crop classification using multi-temporal high-resolution imagery. Int. J. Remote Sens. 2019, 40, 2053–2068. [Google Scholar] [CrossRef]
- Lee Rodgers, J.; Alan Nice Wander, W. Thirteen ways to look at the correlation coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Wen, L.; Hughes, M. Coastal wetland mapping using ensemble learning algorithms: A comparative study of bagging, boosting and stacking techniques. Remote Sens. 2020, 12, 1683. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 8, 1–26. [Google Scholar]
- Ha, N.T.; Manley-Harris, M.; Pham, T.D.; Hawes, I. A comparative assessment of ensemble-based machine learning and maximum likelihood methods for mapping seagrass using sentinel-2 imagery in Tauranga Harbor, New Zealand. Remote Sens. 2020, 12, 355. [Google Scholar] [CrossRef] [Green Version]
- Ting, K.M.; Witten, I.H. Issues in stacked generalization. J. Artif. Intell. Res. 1999, 10, 271–289. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H. The optimality of Naive Bayes. In Proceedings of the Seventeenth International Florida Artificial Intelligence Research Society Conference, FLAIRS 2004, Miami Beach, FL, USA, 12–14 May 2004. [Google Scholar]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Srivastava, S. Weka: A tool for data preprocessing, classification, ensemble, clustering and association rule mining. Int. J. Comput. Appl. 2014, 88. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Van Rijsber, C.J. Information Retrieval, 2nd ed.; Butterworth-Heinemann: Newton, MA, USA, 1979. [Google Scholar]
- Foody, G.M. Thematic map comparison: Evaluating the statistical significance of differences in classification accuracy. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Ross, Q.J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.J.; Kang, D.K. Ensemble with neural networks for bankruptcy prediction. Expert Syst. Appl. 2010, 37, 3373–3379. [Google Scholar] [CrossRef]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-use/cover classification in a heterogeneous coastal landscape using RapidEye imagery: Evaluating the performance of random forest and support vector machines classifiers. Int. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar] [CrossRef]
- Kim, H.O.; Yeom, J.M. Effect of red-edge and texture features for object-based paddy rice crop classification using RapidEye multi-spectral satellite image data. Int. J. Remote Sens. 2014, 35, 7046–7068. [Google Scholar] [CrossRef]
- O’Reilly, P. Mapping the Complex World of the Smallholder: An Approach to Smallholder Research for Food and Income Security With Examples from Malaysia, India and Sri Lanka. Procedia Food Sci. 2016, 6, 51–55. [Google Scholar] [CrossRef] [Green Version]
- Watkins, B.; Van Niekerk, A. Automating field boundary delineation with multi-temporal Sentinel-2 imagery. Comput. Electron. Agric. 2019, 167, 105078. [Google Scholar] [CrossRef]








| Types (Code) | Number of Parcels | Total Area (ha) | Average Parcel Size (ha) | ||
|---|---|---|---|---|---|
| Training (70%) | Validation (30%) | Total | |||
| Abandoned cropland (AC) | 66 | 28 | 94 | 6.87 | 0.073 |
| Bare paddy fields (BPFs) | 78 | 34 | 112 | 7.24 | 0.065 |
| Bare upland fields (BUFs) | 95 | 41 | 136 | 4.52 | 0.033 |
| Cotton | 189 | 81 | 270 | 11.57 | 0.043 |
| Lotus | 67 | 29 | 96 | 13.37 | 0.139 |
| Other crops (OCs) | 115 | 49 | 164 | 4.85 | 0.030 |
| Peanuts | 92 | 40 | 132 | 3.16 | 0.024 |
| Rice | 167 | 71 | 238 | 15.10 | 0.063 |
| Total | 869 | 373 | 1242 | 66.68 | —— |
| Type | Subtype | Variables | References |
|---|---|---|---|
| Spectral features | Mean | Coastal, blue, green, yellow, red, red-edge, NIR1, and NIR2 bands | [12] |
| Maximum difference | Maximum difference (Max-Diff) | [48] | |
| Brightness | Brightness | [12] | |
| Indices | NDVI, RVI, and EVI | [49,50,51] | |
| Geometric features | —— | Area, border length (Bor. Len.), length, length/width (L/W), width, density, and shape index (Sha. Ind.) | [5,48] |
| Textural features | GLCM | Homogeneity (G-hom), contrast, dissimilarity, entropy, ang. 2nd moment (G-ASM), mean (G-mean), standard deviation (G-SD), and correlation (G-cor) | [12,46] |
| BP-NN | CART | k-NN | MLR | NB | SVM | |
|---|---|---|---|---|---|---|
| OA (%) | 76.41 | 78.02 | 75.07 | 79.36 | 77.21 | 80.70 |
| Kappa | 0.725 | 0.743 | 0.707 | 0.759 | 0.734 | 0.775 |
| Weighted-F | 0.765 | 0.776 | 0.752 | 0.792 | 0.773 | 0.808 |
| B_BP-NN | B_CART | B_k-NN | B_MLR | B_NB | B_SVM | |
|---|---|---|---|---|---|---|
| OA (%) | 79.89 | 79.89 | 73.46 | 78.82 | 78.55 | 80.16 |
| Kappa | 0.766 | 0.764 | 0.688 | 0.753 | 0.750 | 0.769 |
| Weighted-F | 0.799 | 0.797 | 0.738 | 0.787 | 0.786 | 0.804 |
| Stacking #1 | Stacking #2 | Stacking #3 | Stacking #4 | Stacking #5 | |
|---|---|---|---|---|---|
| OA (%) | 82.04 | 83.91 | 83.11 | 80.97 | 82.57 |
| Kappa | 0.790 | 0.812 | 0.803 | 0.778 | 0.796 |
| Weighted-F | 0.821 | 0.839 | 0.830 | 0.807 | 0.824 |
| Stacking #2 | SVM | MLR | CART | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UA (%) | PA (%) | F (%) | UA (%) | PA (%) | F (%) | UA (%) | PA (%) | F (%) | UA (%) | PA (%) | F (%) | |
| AC | 67.74 | 75.00 | 71.19 | 60.00 | 75.00 | 66.67 | 64.52 | 71.43 | 67.80 | 64.00 | 57.14 | 60.38 |
| BPFs | 88.24 | 88.24 | 88.24 | 83.33 | 88.24 | 85.71 | 81.82 | 79.41 | 80.60 | 74.36 | 85.29 | 79.45 |
| BUFs | 97.44 | 92.68 | 95.00 | 95.00 | 92.68 | 93.83 | 90.48 | 92.68 | 91.57 | 95.00 | 92.68 | 93.83 |
| Cotton | 86.05 | 91.36 | 88.62 | 85.00 | 83.95 | 84.47 | 82.14 | 85.19 | 83.64 | 80.49 | 81.48 | 80.98 |
| Lotus | 100.00 | 96.55 | 98.25 | 96.15 | 86.21 | 90.91 | 84.38 | 93.10 | 88.52 | 82.14 | 79.31 | 80.70 |
| OCs | 75.00 | 67.35 | 70.97 | 72.09 | 63.27 | 67.39 | 69.77 | 61.22 | 65.22 | 63.79 | 75.51 | 69.16 |
| Peanuts | 65.85 | 67.50 | 66.67 | 64.29 | 67.50 | 65.85 | 62.50 | 62.50 | 62.50 | 66.67 | 45.00 | 53.73 |
| Rice | 88.57 | 87.32 | 87.94 | 85.92 | 85.92 | 85.92 | 88.24 | 84.51 | 86.33 | 86.49 | 90.14 | 88.28 |
| OA (%) | 83.91 | 80.70 | 79.36 | 78.02 | ||||||||
| SGTF-Stacking #2 | SGF-Stacking #2 | STF-Stacking #2 | SF-Stacking #2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UA (%) | PA (%) | F (%) | UA (%) | PA (%) | F (%) | UA (%) | PA (%) | F (%) | UA (%) | PA (%) | F (%) | |
| AC | 67.74 | 75.00 | 71.19 | 63.33 | 67.86 | 65.52 | 56.76 | 75.00 | 64.62 | 51.35 | 67.86 | 58.46 |
| BPFs | 88.24 | 88.24 | 88.24 | 86.11 | 91.18 | 88.57 | 90.63 | 85.29 | 87.88 | 85.29 | 85.29 | 85.29 |
| BUFs | 97.44 | 92.68 | 95.00 | 97.30 | 87.80 | 92.31 | 86.36 | 92.68 | 89.41 | 94.74 | 87.80 | 91.14 |
| Cotton | 86.05 | 91.36 | 88.62 | 83.72 | 88.89 | 86.23 | 81.18 | 85.19 | 83.13 | 80.46 | 86.42 | 83.33 |
| Lotus | 100.00 | 96.55 | 98.25 | 100.00 | 96.55 | 98.25 | 96.30 | 89.66 | 92.86 | 96.55 | 96.55 | 96.55 |
| OCs | 75.00 | 67.35 | 70.97 | 72.09 | 63.27 | 67.39 | 61.22 | 61.22 | 61.22 | 55.22 | 75.51 | 63.79 |
| Peanuts | 65.85 | 67.50 | 66.67 | 62.22 | 70.00 | 65.88 | 58.62 | 42.50 | 49.28 | 50.00 | 20.00 | 28.57 |
| Rice | 88.57 | 87.32 | 87.94 | 89.71 | 85.92 | 87.77 | 88.57 | 87.32 | 87.94 | 90.77 | 83.10 | 86.76 |
| OA (%) | 83.91 | 82.04 | 78.28 | 76.68 | ||||||||
| Kappa | 0.812 | 0.790 | 0.746 | 0.727 | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Hu, S.; Li, W.; Zhang, C.; Cheng, P. Improving Parcel-Level Mapping of Smallholder Crops from VHSR Imagery: An Ensemble Machine-Learning-Based Framework. Remote Sens. 2021, 13, 2146. https://doi.org/10.3390/rs13112146
Zhang P, Hu S, Li W, Zhang C, Cheng P. Improving Parcel-Level Mapping of Smallholder Crops from VHSR Imagery: An Ensemble Machine-Learning-Based Framework. Remote Sensing. 2021; 13(11):2146. https://doi.org/10.3390/rs13112146
Chicago/Turabian StyleZhang, Peng, Shougeng Hu, Weidong Li, Chuanrong Zhang, and Peikun Cheng. 2021. "Improving Parcel-Level Mapping of Smallholder Crops from VHSR Imagery: An Ensemble Machine-Learning-Based Framework" Remote Sensing 13, no. 11: 2146. https://doi.org/10.3390/rs13112146
APA StyleZhang, P., Hu, S., Li, W., Zhang, C., & Cheng, P. (2021). Improving Parcel-Level Mapping of Smallholder Crops from VHSR Imagery: An Ensemble Machine-Learning-Based Framework. Remote Sensing, 13(11), 2146. https://doi.org/10.3390/rs13112146