1. Introduction
Maps of Land Use and Land Cover (LULC) are an elementary tool for environmental planning and decision-making. As the name implies, the term comprises two related, but different pieces of information about a geographical location, the land use (LU) according to its function in terms of human use (such as farm, airport, road, etc.), and the land cover (LC) according to the physical/chemical material (such as vegetation, bare soil, etc.). Both LC and LU classes, normally defined in hierarchical schemes, play an important role for planning and management of the natural and built environment at different granularities [
1]. A primary data source to generate LULC maps is remotely sensed imagery, which serves as a basis for either photo-interpretation by a human operator, or automated classification with suitable classification algorithms. Remote sensing imagery at different wavelengths of the electromagnetic spectrum has proven effective for environmental monitoring at various spatial and spectral resolutions [
2,
3]. In particular, recent satellites observe the Earth’s surface with small ground sampling distances (GSD) and high temporal revisit rates [
4], which makes them suitable for environmental monitoring of remote territories, where other data sources are difficult to sustain the monitoring.
A case in point is New Caledonia, a biodiversity hotspot [
5,
6] whose monitoring on a regular, periodic basis is essential for environmental management and conservation. New Caledonia is a tropical high-island with a comparatively small population distributed unevenly across its territory, large areas of dense vegetation, and considerable, intense mining activities that have led to significant erosion phenomena [
7]. The resulting complex environment [
8,
9,
10] requires environmental monitoring at a fine scale by the use of very high spatial resolution satellite imagery. The Government of New Caledonia has commissioned the production of an LU map of the entire territory from the New Caledonia Environmental Observatory, using 2014 SPOT6 satellite images [
11]. That map, available at medium resolution (minimum mapping unit 0.01 km
), is widely used by the country’s decision makers to monitor the environmental impact of mining and the decline of tropical forests over the entire territory. However, the product at present covers only the southern part of New Caledonia. Moreover, its creation, requiring a lot of human input, was time-consuming and costly. No updates are foreseen for several years, for lack of resources. Consequently, there is a need for automation.
Among comparisons of methods to classify LULC from satellite images on several benchmark datasets, Deep Learning has recently stood out as a particularly effective framework for automatic image interpretation [
12]. Given large amounts of training data, Deep Learning is able to extract very complex decision rules [
13]. In image processing in particular, Deep Learning is at the top of the state-of-the-art semantic image analyses [
14] (described in the Methods section), greatly enhanced by the particular design of the convolutional deep networks. Indeed, on some tasks its performance matches or even exceeds that of humans [
15]. Additionally in optical satellite remote sensing, Deep Learning has become a standard tool, as it appears to cope particularly well with the continuously varying imaging conditions (illumination, sensor properties, atmospheric composition, etc.) [
16,
17,
18]. Deep Learning has been widely employed for remote sensing, including tasks such as object recognition, scene type recognition or pixel-wise classification [
19,
20].
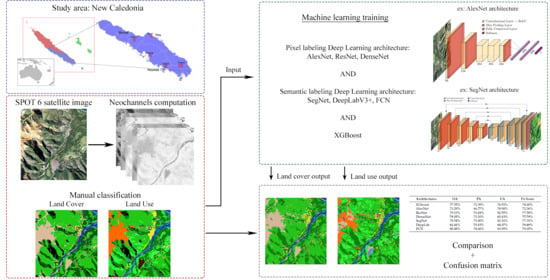
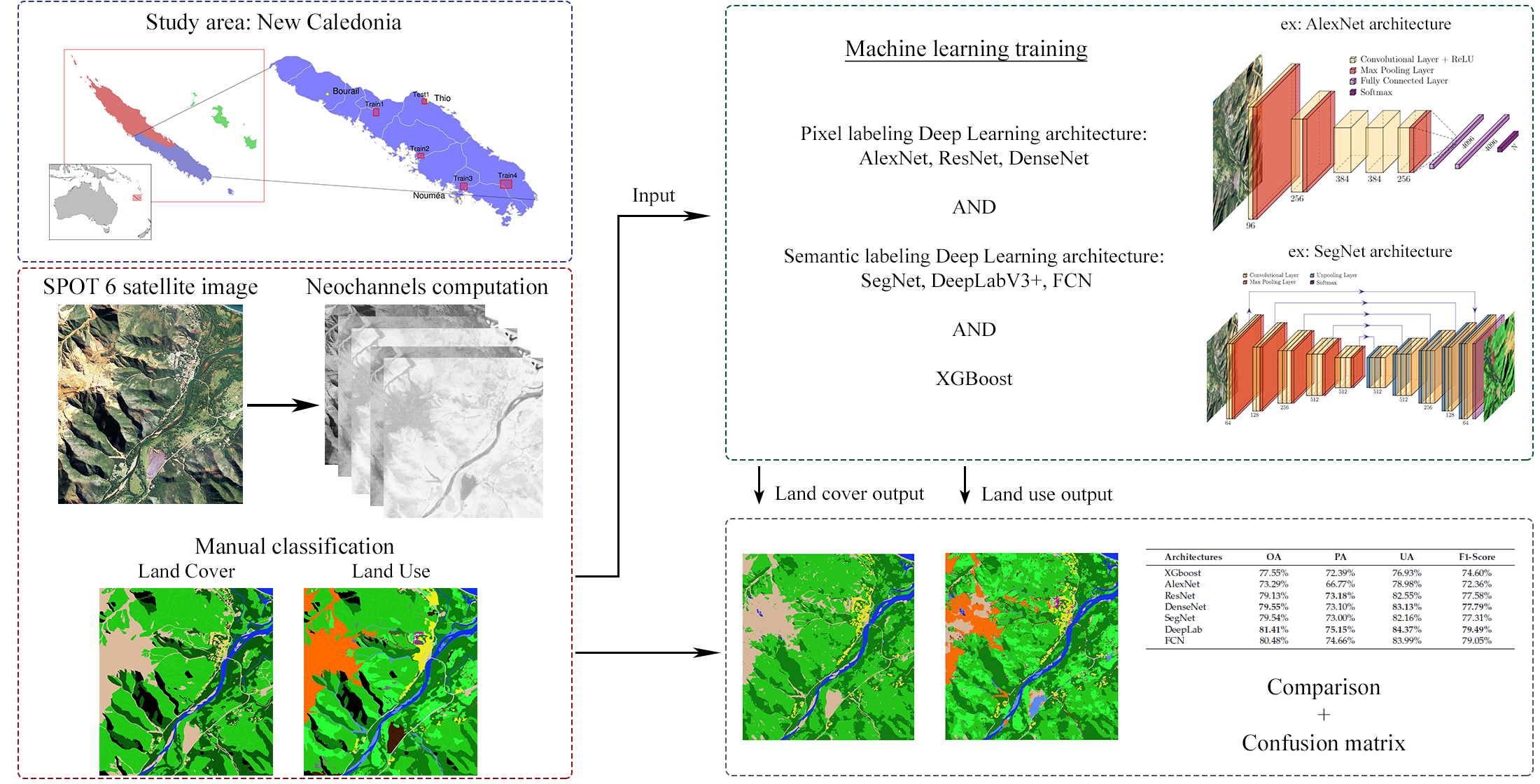
In this article, several Deep Learning architectures for LULC classification are compared across five specific regions of South Province of New Caledonia. The goal is to prepare an operational system for LULC monitoring for the South Province territory, since its natural environment is subject to significant human pressures [
21,
22]. Many powerful Deep Learning architectures in the field of remote sensing use two possible strategies: “central-pixel labeling” or “semantic segmentation” (described in the Methods section).
We empirically compare a number of these promising Deep Learning architectures. Moreover we also include a standard machine learning baseline, XGboost, which has shown very good performances in several benchmarks related to classification [
23]. Since “neo-channels”, which are non-linear combinations of the raw channels, and texture filters derived by arithmetic combinations of the raw image channels are widely used in the field of remote sensing [
24], we also assess the interest of such additional information when using XGboost and Deep Learning, even if in the latter case, the technique is able to build its own internal features by combining the raw information.
Finally, LU mapping is a considerably harder task than LC mapping. LC mapping is generally obtained by photo-interpretation of satellite and/or aerial images, while LU mapping typically requires the integration of exogenous data (road network map, flood zones, agricultural areas, etc.) and ground surveys due to the difficulty of interpreting satellite images. However, for this study these exogenous data sources are not available and the LU mapping is also created by photo-interpretation. In addition, in this study, the LU nomenclature has a higher number of distinct classes than the LC nomenclature. We construct a two-step architecture and show that LU retrieval can be improved by first classifying LC and then using its class labels as an additional input.
3. Methods
3.1. Use of Neo-Channels
The four raw channels of SPOT 6 used in this study were recorded in the R, G, B and NIR wavelengths, respectively. On the basis of the characteristics of the raw channels, neo-channels were calculated to highlight the particularity of certain land types in remote sensing [
30,
31] or complex objects such as urban infrastructures [
32]. For example, NDVI [
33] was used to highlight vegetation cover. Neo-channels are potentially important for XGBoost because the technique does not have the feature learning capabilities like Deep Learning. The neo-channels used in this study were as follows:
The luminance
L from the colour system HSL (Hue, Saturation, Luminance)
from the colour system
[
34].
NDVI (Normalized Difference Vegetation Index) [
33]
MSAVI (Modified Soil-Adjusted Vegetation Index) [
35]
ExG (Excess Green Index) [
36]
MNDWI (Modified Normalized Difference Water Index) [
37]
The NDVI, MSAVI and ExG [
38] highlighted vegetation.
L and
provided information about contrast and illumination [
34]. These neo-channels as well as the raw channels were used as inputs for the model training.
3.2. XGBoost
To serve as baseline, we used a standard machine learning method called XGboost (“Extreme Gradient Boosting”, [
39]). It is a boosting scheme with decision trees as base (weak) learners that are combined into a strong learner. XGBoost iteratively builds an ensemble of trees on subsets of the data; weighting their individual predictions according to their performance. An ensemble prediction is then computed by taking the weighted sum of all base learners. The library is designed to be highly efficient and provides parallel algorithms for tree boosting (also known as GBDT, GBM) that are very well suited for the big data of remote sensing. XGboost is a state-of-the-art technique in supervised classification that showed very strong performance on a wide variety of benchmark tasks [
39].
To run an XGBoost model, neo-channels and multiple texture filters were used. The filters were: dissimilarity, entropy, homogeneity and mean. Input of windows were used for labeling the central pixel. The training data were the same as for the Deep Learning architectures.
3.3. Deep Learning Architectures
The internal parameters of the employed Convolutional Neural Network (CNN) architectures were not changed with regards to the originally proposed ones. A CNN [
40] is a machine learning technique based on sequences of layers of three different types: convolutional, pooling or fully connected layers. Convolution and fully connected layers are usually followed by an element-wise, non-linear activation function.
In the frame of classification of visible satellite data into l classes, the first layer of a Deep Learning architecture receives an input, generally an image of k channels of pixels. The convolutional layers act as filters that extract relevant features from the image. Pooling layers then allow sub-sampling the filter responses to a lower resolution to extract higher-level features with larger spatial context. The last layers map the resulting feature maps to class scores. There are two possible strategies: “central-pixel labeling”, where a fully connected layer maps the features computed over an entire image patch to a vector of (pseudo-)probabilities for only the central pixel of the patch; or “semantic segmentation”, where the high-level features are interpreted as a latent encoding and decoded back to a map of per-pixel probabilities for the entire patch, where the decoder is a further sequence of (up-)sampling and convolution layers. The objective of this coding-decoding sequence is to extract informative data from the inputs, remove the noise signal and combine the information for classification purposes.
All architectures were trained with stochastic gradient descent using a similar protocol, with a momentum of 0.9 and starting from an initial learning rate of . Every 20 epochs, the learning rate is divided by 10 until reaching .
Neural networks do not perform well when trained with unbalanced data sets [
41]. In the case of “central-pixel labeling” architectures it is possible to make balanced data sets with the initial pixels selection used for the learning. In the case of “semantic labeling” the composition of the images makes it more difficult to precisely control the number of pixels per class. We tried several methods, but found negligible differences in performance. All reported experiments use the median frequency balancing method.
3.3.1. Central-Pixel Labeling
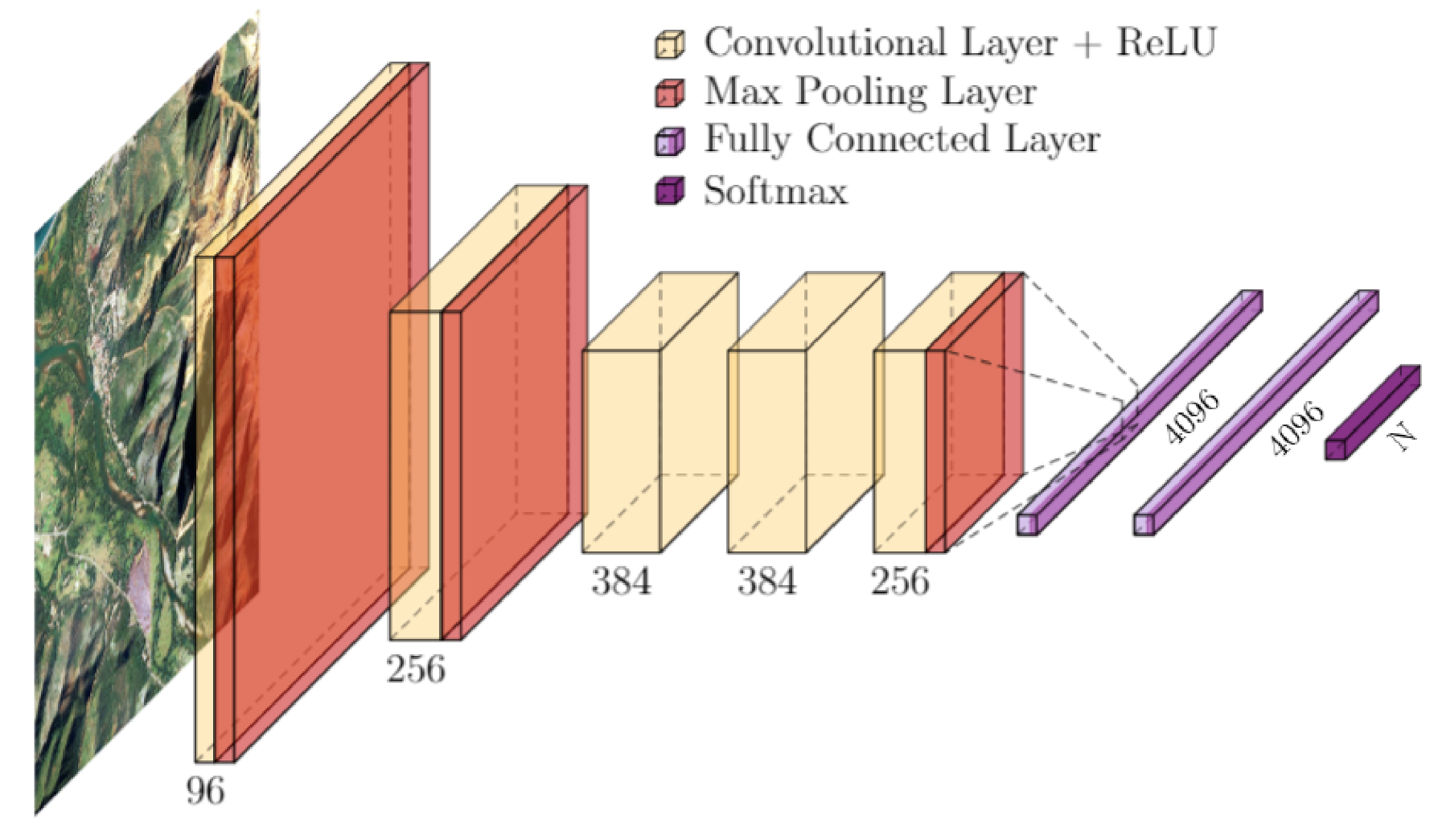
AlexNet, an architecture introduced by Alex Krizhevsky [
42], is one of the first Deep Learning architectures to appear on the scene. Inspired by the LeNet architecture introduced by Yann LeCun [
40], AlexNet is deeper with eight layers, the first five being convolutional layers whose parameters are shown in
Table 5, interleaved with max-pooling layers (
Figure 3). The sequence finishes with two fully connected layers before the final classification with a softmax. A ReLu type activation function is used for each layer. Data augmentation and drop-out are used to limit overfitting.
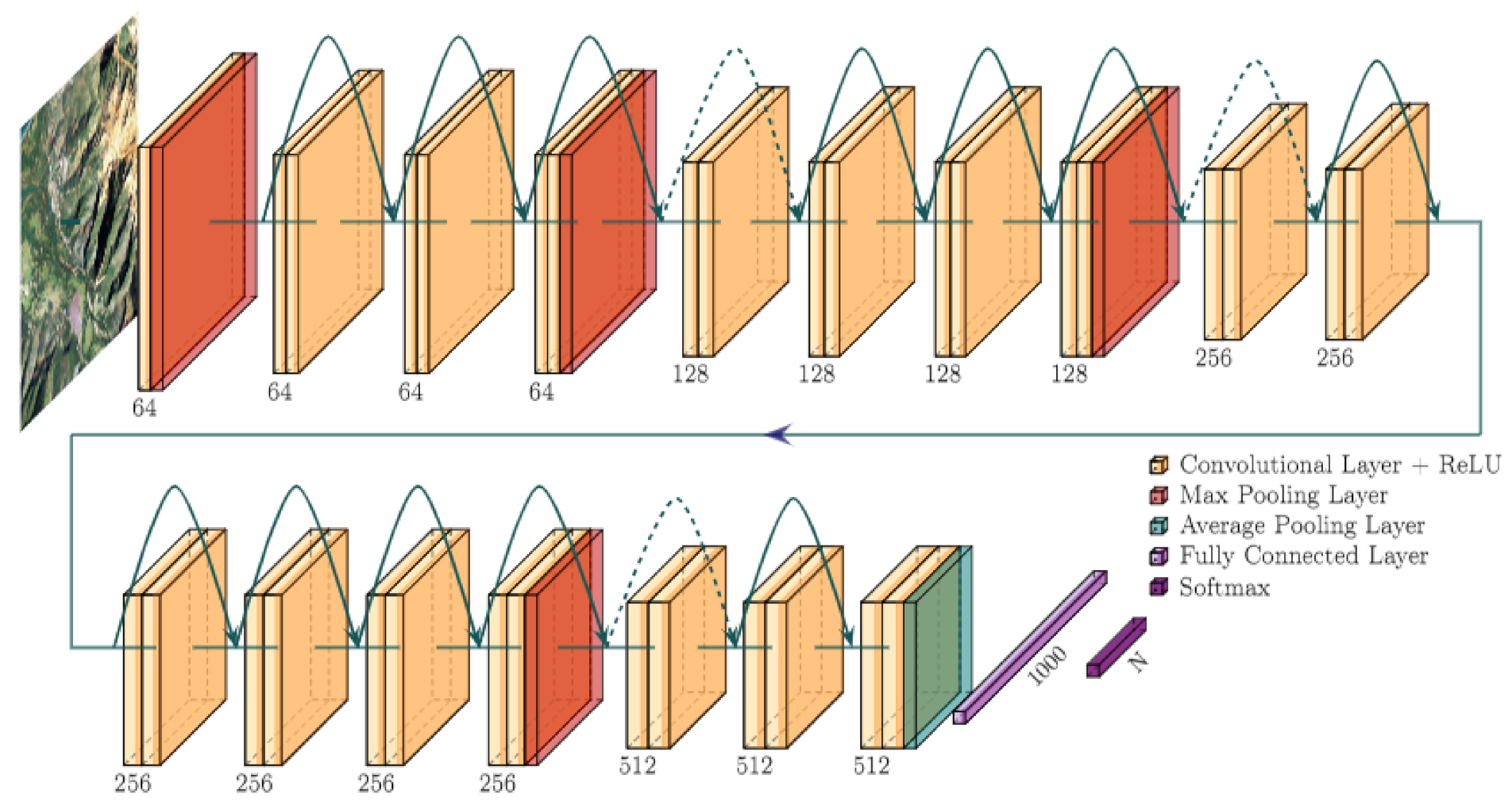
ResNet (Deep Residual Network, [
43]) is a Deep Learning architecture with many layers that use skip connections, as illustrated in
Figure 4. These skip connections allow the bypassing of layers and add their activations to those of the skipped layers further down the sequence. The dotted arrows in
Figure 4 denote skip connections through a linear projection to adapt to the channel depth.
By skipping layers and thus shortening the back-propagation path, the problem of the “vanishing gradient” can be mitigated.
Figure 4 represents a 34-layer ResNet architecture. The first layer uses
convolutions, the remaining ones
.
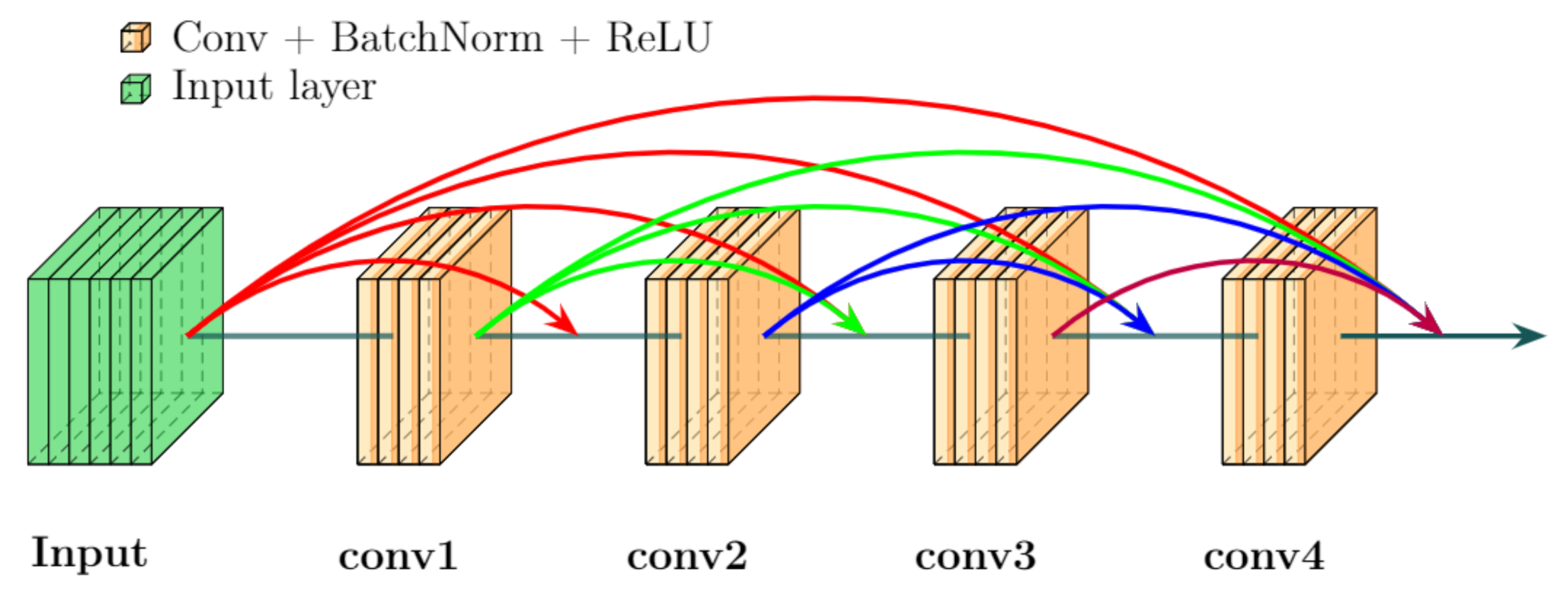
The DenseNet architecture [
44] extends the principle of ResNet, with skip connections to all following layers in a module called a “dense block”, as shown in
Figure 5. The activation maps of the skipped layers are concatenated as additional channels. The architecture then consists of a succession of convolution layers, dense blocks and average pooling.
3.3.2. Semantic Labelling
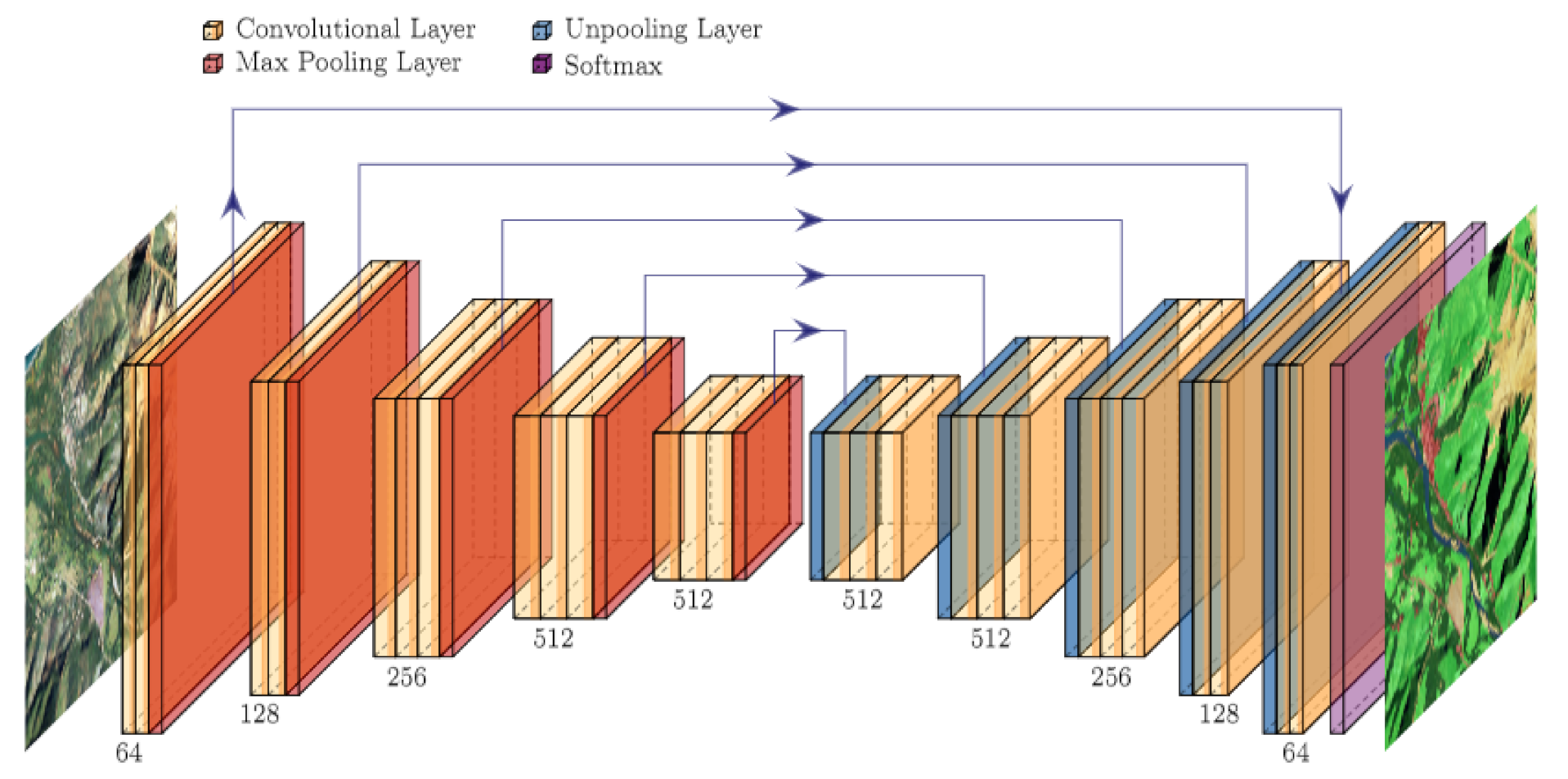
Unlike “pixel labelling”, the
“Semantic Labelling” approach classifies all pixels of an image patch to obtain a corresponding label map. For this purpose, the architectures SegNet, DeepLabV3+, and FCN are used. SegNet [
45] is a neural network of encoder-decoder types like DeconvNet [
46] or U-Net [
47]. The encoder in the Deep Learning architecture is a series of convolutional and max pooling layers that encode the image into a latent “feature representation”. Before each pooling step, the activations are also passed to the corresponding up-convolution layer in the decoder, to preserve high-frequency detail (see
Figure 6).
The Fully Convolutional Networks (FCNs) [
48] have convolution layers instead of fully connected ones, preserving some degree of locality throughout. These layers include two parts: the first part consisting of convolutional and max pooling to fulfil the function of the encoder, and the second part comprises an up-convolution to recover the initial dimensions of the image and a softmax to classify all pixels. In order to maximize recovery of all the information during the encoding, skip connections are included similar to [
43] architecture.
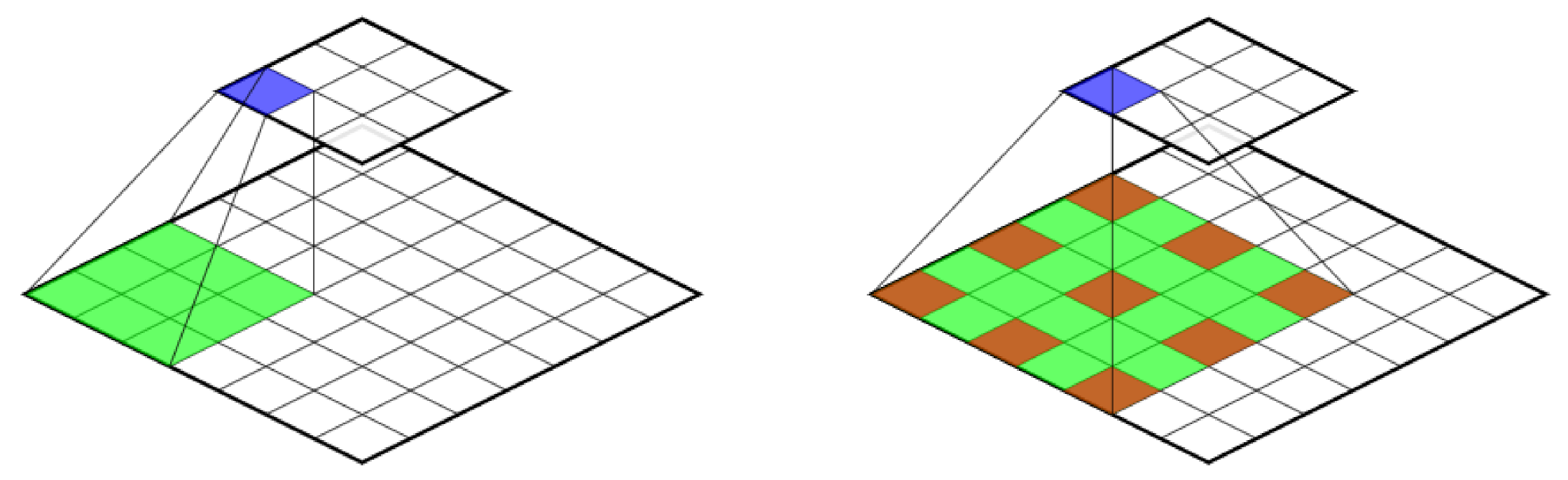
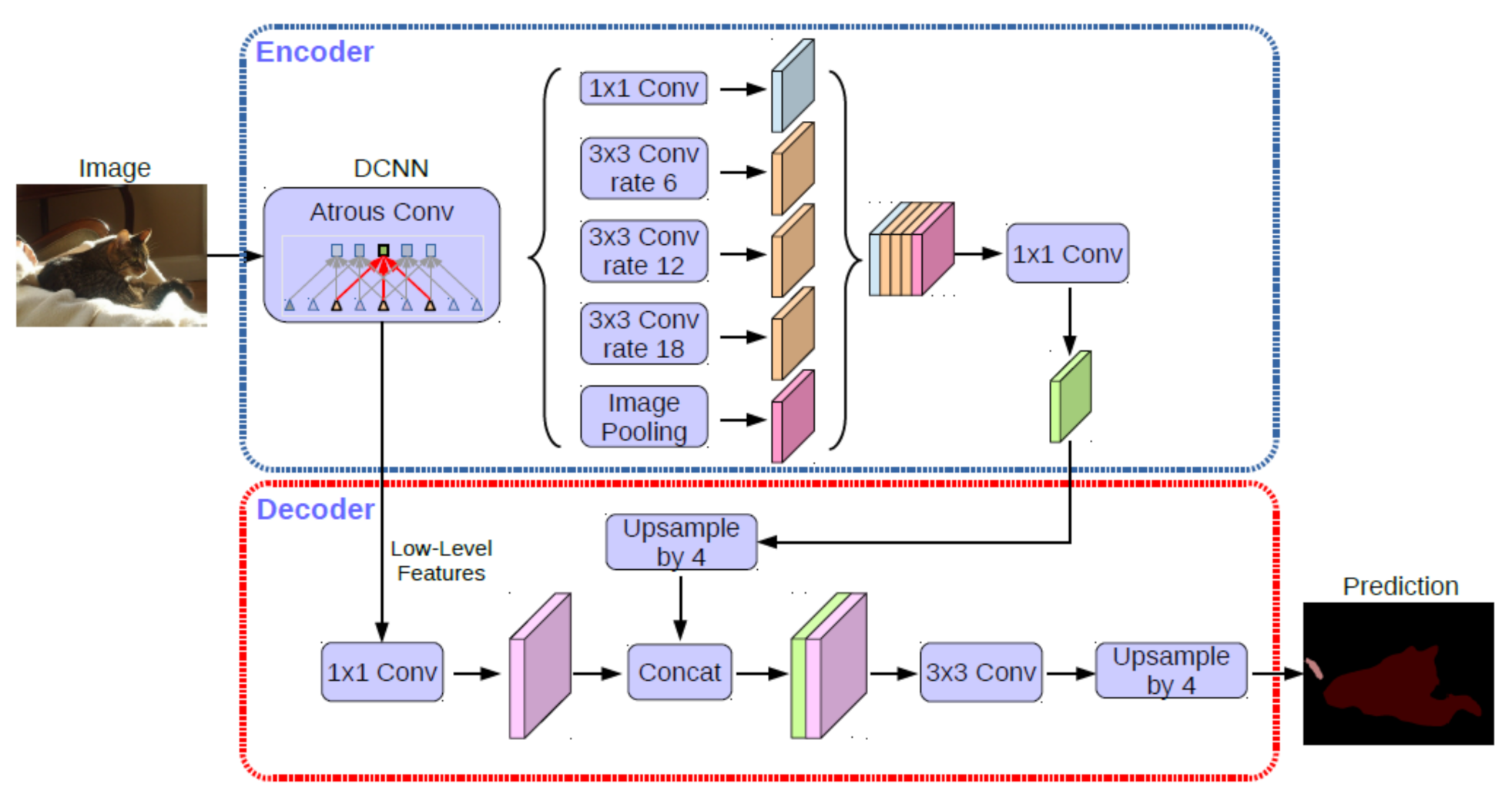
The DeepLab V3+ architecture [
49] uses so-called “Atrous Convolution” in the encoder. This makes it possible to apply a convolution filter with “holes”, as shown in
Figure 7, covering a larger field of view without smoothing.
Atrous convolution is embedded in a ResNet-101 [
50] or Xception [
51] architecture, delivering a pyramid of activations with different atrous rates (see
Figure 8). This pyramid accounts for objects of different scales and thus increases the expressive power of the model. After appropriate resampling in the decoder, a semantic segmentation is obtained.
3.4. Sampling Method
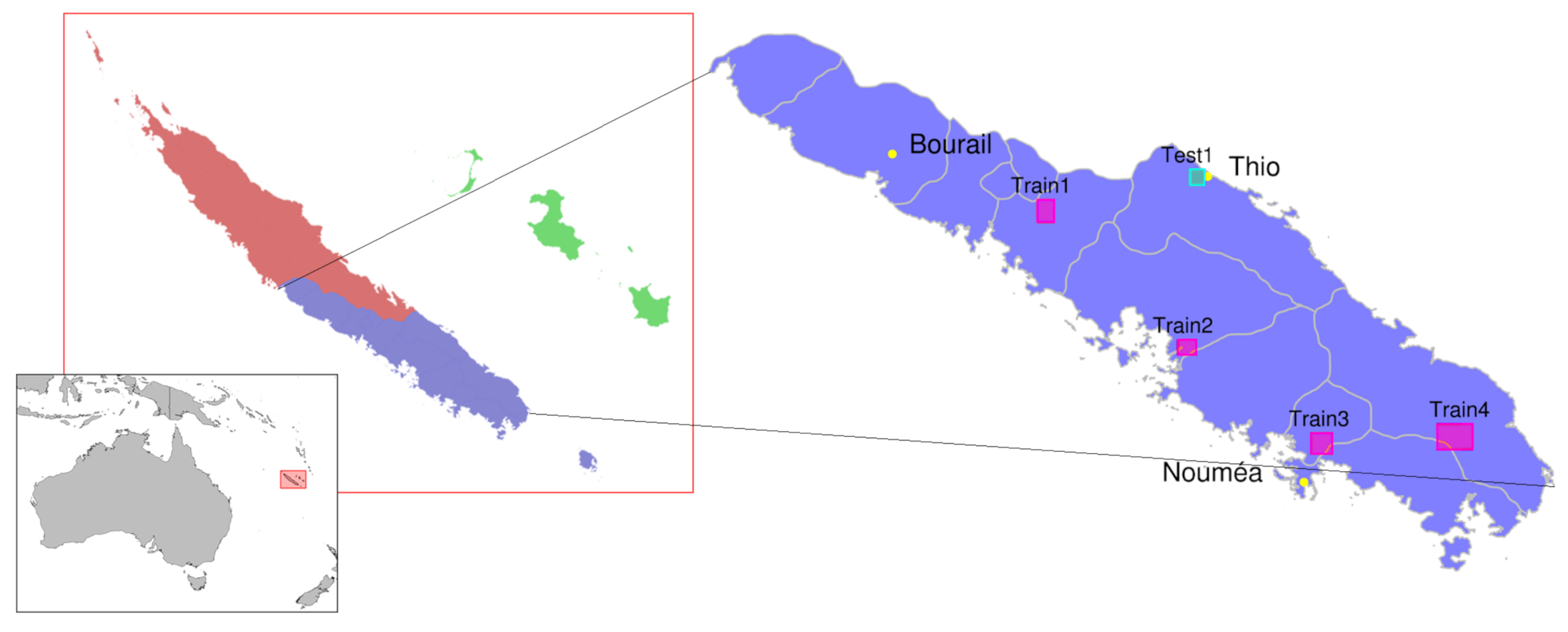
The SPOT6 satellite data for our five study areas were preprocessed to be fed into the different Deep Learning architectures and the XGBoost model. First, the data were split into three mutually exclusive parts: a learning set, a validation set and a test set totally independent of the two previous ones.
Four of the five areas were used for learning and validation. The last, isolated scene was then used as the test set. It contained all the classes for the two nomenclatures, the five LC classes, and the 12 LU classes. In addition, this image contained all the environments representing the New Caledonian landscape: urban, mining, mountainous and forest environment with variations from the coastline to the inland mountain areas. It is on this entire scene that the final confusion matrix and quality metrics were computed.
Several possible input channel combinations were tested for both XGBoost and Deep Learning. For both LU and LC classification, a set of data consisting only of the four SPOT6 channels (Red, Green, Blue and Near Infra-Red), was used as a basis. The other data sets were composed of these raw channels with six additional neo-channels: NDVI, MSAVI, MNDWI, L, , and ExG.
In addition to these inputs, LC information can also be used to assess whether additional LC information can improve LU classification. To that end we first performed LC mapping, then added the max-likelihood LC label as an input channel for the LU mapping. The different variants are summarized in
Table 6.
3.5. Mapping and Confusion Matrix
After fitting the parameters of the different Deep Learning architectures as well as XGBoost on the training set, they were run on the test set to obtain a complete mapping of LC and LU as described above. Confusion matrices were extracted from these results. Four quality metrics are used: Overall Accuracy (OA), Producer Accuracy (PA), User Accuracy (UA) and the F1-score. The OA takes the sum of the diagonal of the confusion matrix. The PA takes the number of well-ranked individuals divided by the sum of the column in the confusion matrix. The UA takes the number of well-ranked individuals divided by the sum of the line. Finally, the F1-score is calculated as the harmonic mean of precision and recall. This last metric allows calculating the accuracy of a model by giving an equal importance between the PA and the UA. Note that the shadow and cloud areas were not taken into account in the confusion matrix.
For architectures using a “central-pixel labeling” method, the mapping was done pixel by pixel using a sliding window with step size 1. In each window only the central pixel (i.e., row 33, column 33 of the window) was classified. To sidestep boundary effects, a buffer of 32 pixels at the boundary of the scene was not classified.
For “semantic labeling” architectures, we empirically used a sliding window with step size 16. With bigger steps the results deteriorated, and smaller ones did not bring further improvements. Every pixel was thus classified multiple times, and we averaged the resulting per-class probabilities. Finally, the class with the highest score was retained as a pixel label.
5. Discussion
In New Caledonia, for both LC detection and LU detection, the best Deep Learning techniques show good performance in overall detection accuracy on the test set relative to a human operator (respectively 81.41% and 63.61%). The two baseline techniques: XGBoost and AlexNet, are easy to implement and require low CPU time consumption. They achieved satisfactory performance on the LC classification (respectively 77.55% and 73.29%) task in New Caledonia but, as expected, showed their limitations for the challenging LU classification task (respectively 51.56% and 45.79%), with XGBoost performing slightly better on both tasks. In this particular case, standard remote sensing classification techniques using neo-channels and textures were slightly more effective than a basic deep learning architecture (AlexNet) using raw channels as input.
When using more advanced Deep Learning architectures, a clear improvement appeared. While the differences were rather small for LC classification, quite important gains could be obtained for LU by selecting the right architecture. In this study, two types of architectures were tested: “semantic labelling” architecture and “pixel labelling” architecture. Among them, DeepLab (“semantic labelling”) and DenseNet (“pixel labelling”) stood out and showed similar results. The “pixel labeling” architectures outperform the “semantic labeling” ones on the training set presented in the appendix. However, these architectures have equal performances on the test set. The “pixel labeling” architectures seem to be more sensitive to overfitting, especially the ResNet architecture.
Nevertheless, due to lower CPU time consumption, it could be interesting to use a “semantic labeling” approach when dealing with very high resolution remote sensing images. Furthermore, the resulting LULC maps from the “pixel labelling” architectures are usually noisy with many isolated pixels surrounded by pixels from a different class. The resulting frontiers between classes can look fuzzy. On the contrary, the maps generated by the “semantic labelling” are much more homogeneous, though the surfaces of the predicted classes depend on the size of the chosen sliding window for subsampling the area and do not respect the observed frontiers between classes.
In this study, even if we used a balanced data set for training, none of the four training areas contained all classes of the LULC nomenclature; only the area Test1 (
Table 1) included all possible labels. Indeed, there are great inequalities in the distribution of classes, with the vegetation class covering more than 90% of the New Caledonian territory. The test set was used as is, without any class balancing, so as to correspond to a realistic, complete mapping task.
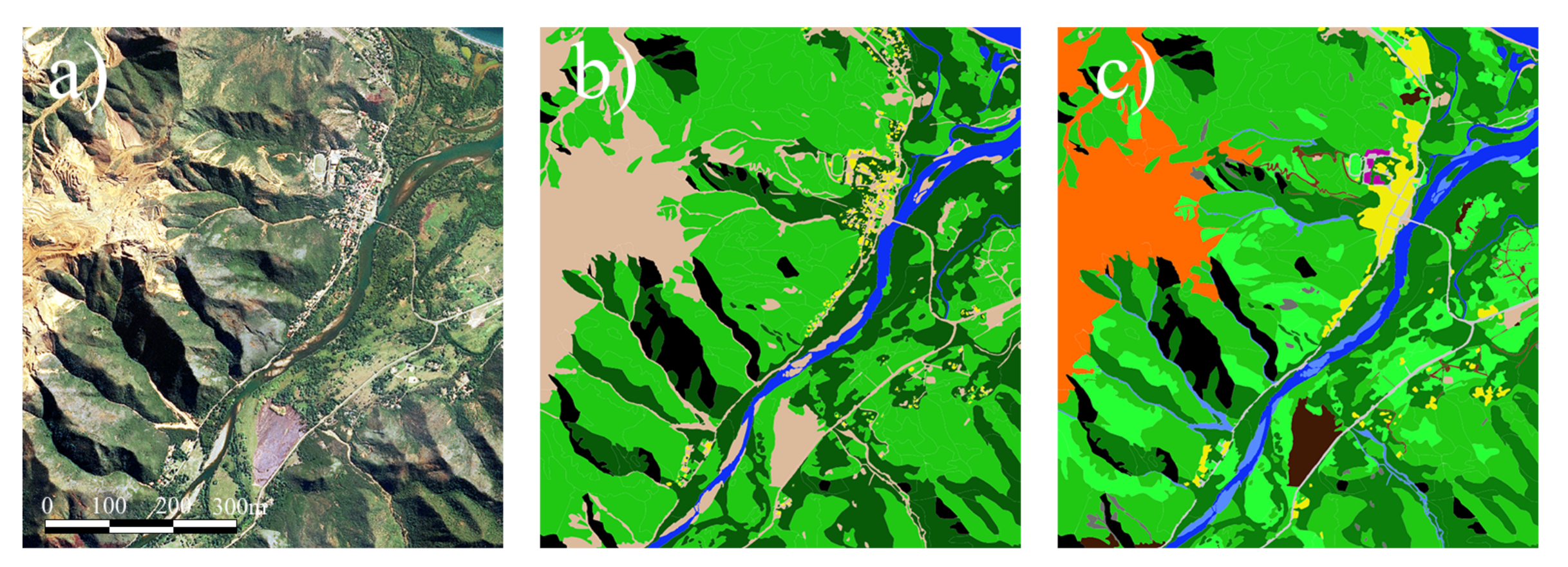
The accuracy of LC classification was globally high with a global accuracy of 81.41% on the test set for the best model.
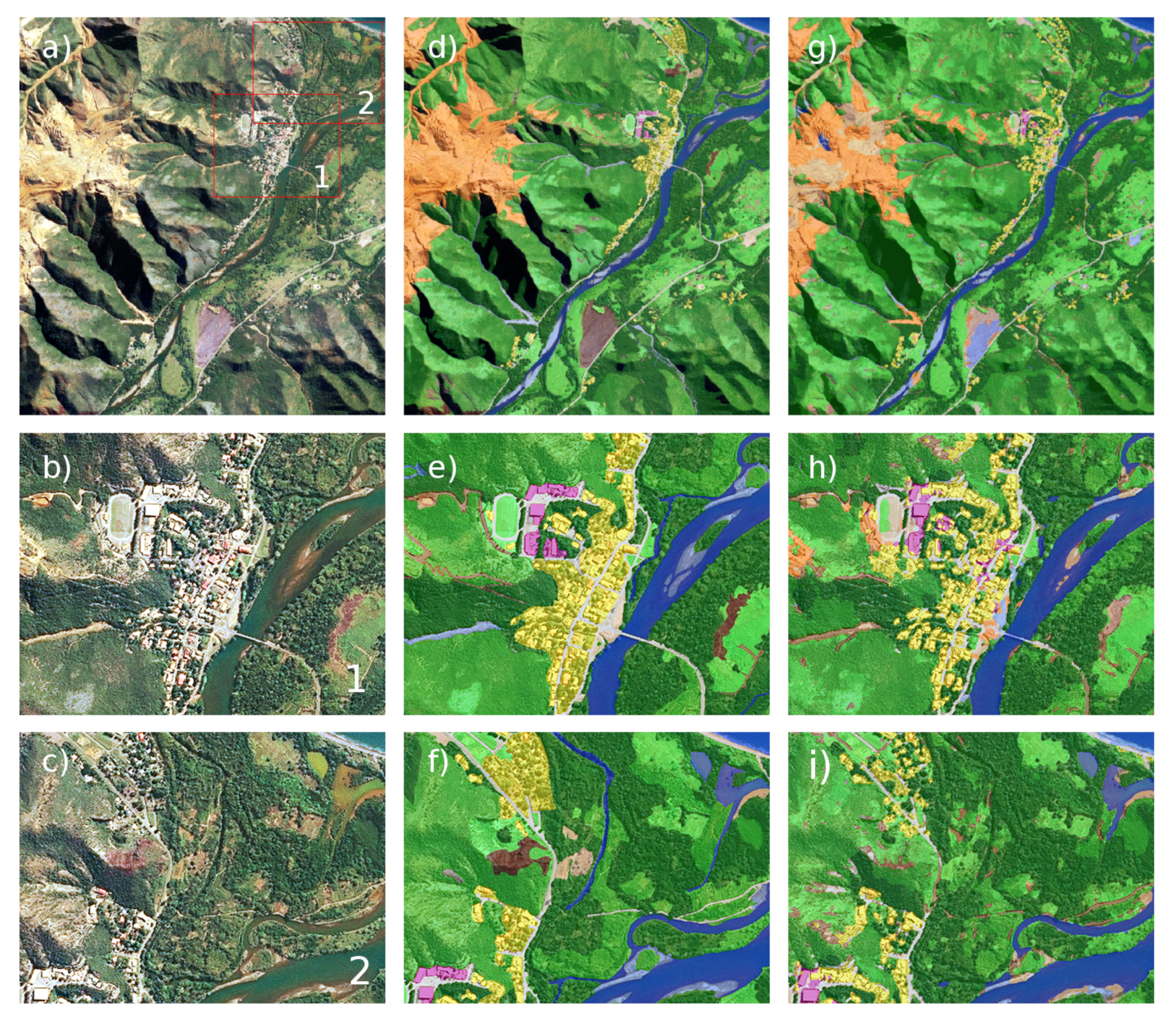
Table 10 showed that the building class detection was the most difficult task in this study. The model tended to overestimate the extent of this class, creating many false positives on other classes, especially on bare soil. This could be explained by the proximity of these classes around buildings (
Figure 9).
A slight confusion between forest and low density vegetation, as well as between bare soil and low density vegetation was also noted. However, distinguishing these classes is a difficult task even for a human operator. It should be noted that at this scale it was not possible to provide accurate field data. Most of the boundaries between classes were established by photo-interpretation. Unlike other learning tasks that are rely on perfectly controlled data, the train and test data sets for LULC classification are never error-free. It is therefore difficult to know whether classification errors are due to a lack of model performance or to mislabeling.
The LU and LC were fairly similar because of the many areas not subject to direct human use. The main differences occurred in the division of the urban fabric. It is far more complex to qualify this type of area, and human expertise is often necessary but subjective. For example, the difference in urban fabric between residential and industrial areas is open to misinterpretation. One might think that buildings with very large roofs, such as warehouses, belong to the industrial class, but this classification quickly becomes subjective, as schools, sports complexes, etc. also correspond to this criterion but, belong to the residential area. Only on-the-ground knowledge would remove these ambiguities.
The LU classification remained a very challenging task with the score of 63.61% on the test set for the best deep learning architecture with a clear improvement compared to XGBoost (51.56%). The water surfaces and worksites were well detected by the model, but the other classes such as trails, bare rocks, and bare soil had very low recognition rates (see
Table 11). Indeed, from a radiometric point of view, it is difficult to distinguish a trail from bare ground. Distinguishing between these classes requires a broad knowledge of the ground and a high level of cognitive reasoning (a trail is a bare ground 3 to 5 m wide with a particular wire form). We hoped that Deep Learning models would be able to distinguish this type of class, but it seems that there was not enough extra information in our data set to handle this task accurately (such as exogenous information or large-scale vision). The same difficulty then stood for engravement and bare soil classes. Moreover, the Deep Learning techniques barely distinguished mines and bare soil classes, but this task is very difficult to perform, even for a human operator, without contextual information and based only on a small picture (
pixels).
As stated in the introduction, a major challenge is to monitor the forest area, as a spatial understanding of biomass and carbon stock in tropical forests. It is crucial for assessing the global carbon budget. Similarly, detecting the bare soil area changes is an important task in order to limit the erosion. The accuracy of detection for the Forest class reached 0.78 as detailed in
Table 10. This class can be confused with the Low-density vegetation class (19% of mislabeling between those two classes) and the Bare Soil class was similarly confused with the Low-density vegetation class (14% of mislabeling). For those specific classes, these results are significantly better than those obtained with the machine learning techniques (gain around 10% of accuracy) and the monitoring of forest and bare soil areas would be significantly improved using deep learning techniques.
Even with all these imperfections on the train and test set, the results showed there is a real added value in using Deep Learning techniques in the frame of LULC detection in a complex environment such as a tropical island. The Deep Learning architectures were applied to a completely different geographic region in the Southern Province and with a different climate (area located east of the mountain range and exposed to rain and wind), they overcame these challenges with up to 80% accuracy for the LC classification task. Other Deep Learning applications on LC manage to achieve similar results [
52,
53].
Unlike the “Corine Land Cover” classification, the agriculture areas class do not appear in the Level 1 (L1) and Level 2 (L2) nomenclature since this class could not be distinguished using standard deep learning approaches from low-density vegetation class. Likely, this is due to the size of the sliding window, not large enough to catch the features that can be computed to distinguish the two classes. Further work based on a multiscale approach could be useful to overcome this issue.
Our findings also showed that adding the LC output as input for the LU classification can improve the accuracy, suggesting that it could be interesting to perform a hierarchical approach for the LULC task. This hierarchy of concept could also be used to improve the interpretability and explicability of results. Indeed, understanding how Deep Learning combines information to effectively classify land use classes remains a challenging task, but recent research using ontologies could be useful to achieve this goal [
54]. This idea could also highlight missing exogenous information (elevation, cadastre, etc.) in addition to remote sensing data to improve LULC detection. Unifying the most difficult classes to detect could improve the performance of the LU classification results. The difficult classes would then be moved to a different, more accurate level of the classification, for example, an L3 level in
Table 4. Another path for improvement consists in including cloud and shadow detection in the classifier and using post-processing filters [
55] and heuristics (object-oriented rules…).
These results presented here seem robust since, at a resolution of 1.5 meters and for an image of pixels, the receptive field equals approximately 0.01 km. At this resolution and area, it is possible for a human operator to identify the type of land and its use. We investigated alternative sizes of pixels or pixels, with step size 8, and dimilar results were obtained. Due to hardware limitations of the graphic card, implying a drastic reduction of the batch size, we did not further pursue the pixel configuration. The larger number of individual samples at size did not seem to make much difference. Hence, we settled for pixels, striking a compromise between image size and number of samples.
6. Conclusions
In this study, machine learning techniques such as Deep Learning and XGBoost were compared for LULC classification in a tropical island environment. For this purpose, a specific data set based on SPOT6 satellite data was created and made available for the scientific community, comprised of five representative areas of New Caledonia labelled by a human operator: four used as training set, and the fifth one as test set [
26]. The performance of XGBoost managed to stand up to Deep Learning for LC classifications but, as for many applications in image processing, the best deep learning architectures provided the best performances. The standard machine learning approach is clearly behind on the more complex LU domains which require a higher level of conceptualization of the surroundings to obtain good results. Though the framework can be complex to handle, the Deep Learning approach for LULC detection was easy to implement since there is no significant gain to pre-process the data by computing neo-channel or texture-based input in contrast to conventional remote sensing techniques.
Specific to the deep learning approach, the two methods: “semantic” labeling and “pixel labeling” provided equivalent performances for the most efficient architectures: DeepNet and DeepLab, whose internal structure was not modified.
Our findings also showed that adding the LC output as input for the LU classification improved the accuracy, suggesting that a hierarchical approach could be interesting to perform the LULC task. Further work on this classification is necessary to obtain better results, but it is a step forward towards the development of an automatic system allowing the monitoring of the impact of human activities on the environment by the detection of the forest surface change and bare soil areas.
In future work, we aim to apply the classifier to the rest of New Caledonia, including the Northern Province and the Islands Province. Additional information will be necessary to cover the specific conditions in those new regions. In terms of mapping area, it may be interesting to also include the maritime environment, in particular the many islets and reefs of the New Caledonian lagoon. We also plan to adapt the classification to use Sentinel-2 instead of SPOT6 as input for LULC classification. While the Sentinel-2 sensor has lower spatial resolution, its spectral resolution is better and it offers a revisit times of only 5 days.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




























