
Near-Real-Time Flood Mapping Using Off-the-Shelf Models with SAR Imagery and Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Description and the Test Area
2.1.1. Sen1Floods11 Dataset
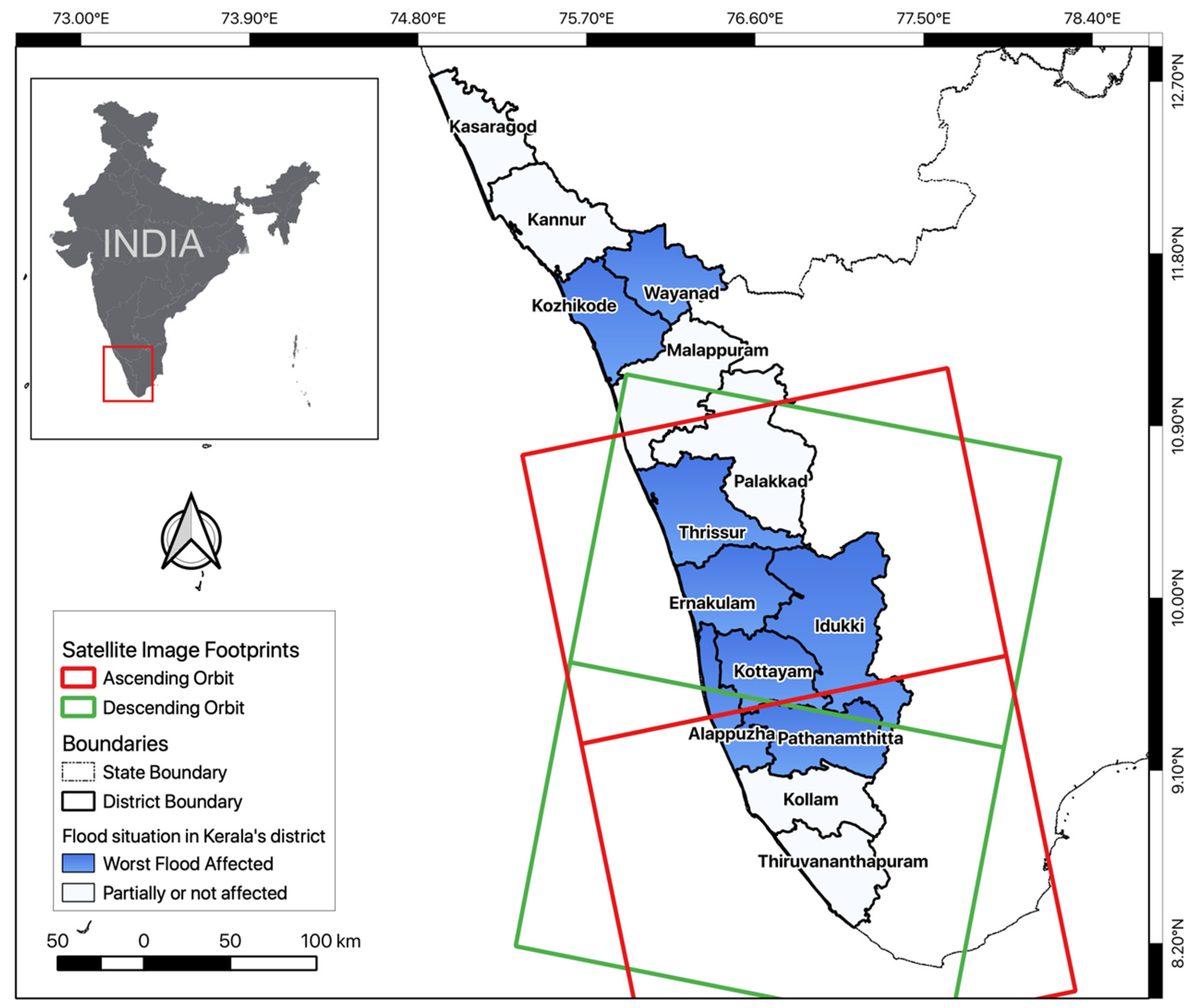
2.1.2. Test Area
2.2. Networks and Hyperparameters
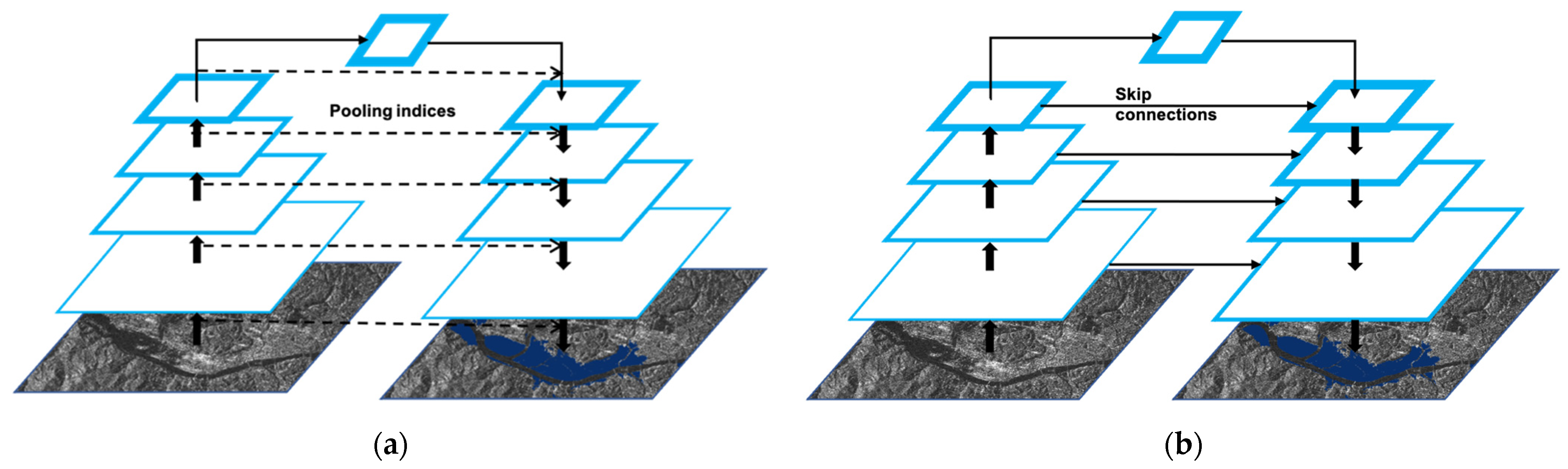
2.2.1. Networks Used
2.2.2. Hyperparameters
2.3. Training Strategy
2.4. Testing
2.4.1. Testing on the Test Dataset
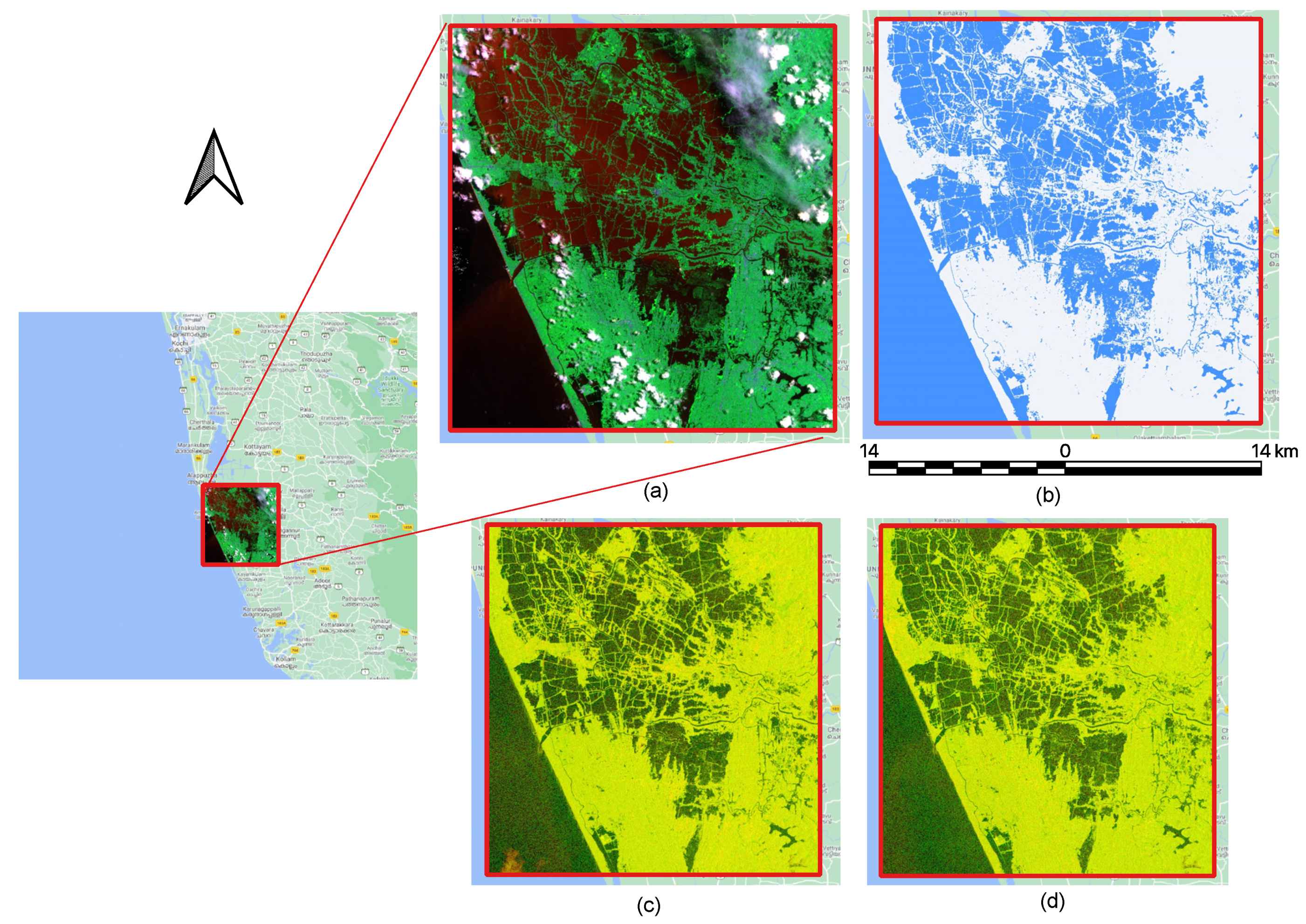
2.4.2. Testing as an off-the-Shelf Model on the Whole Image during the 2018 Kerala Floods
2.5. Accuracy Evaluation
3. Results
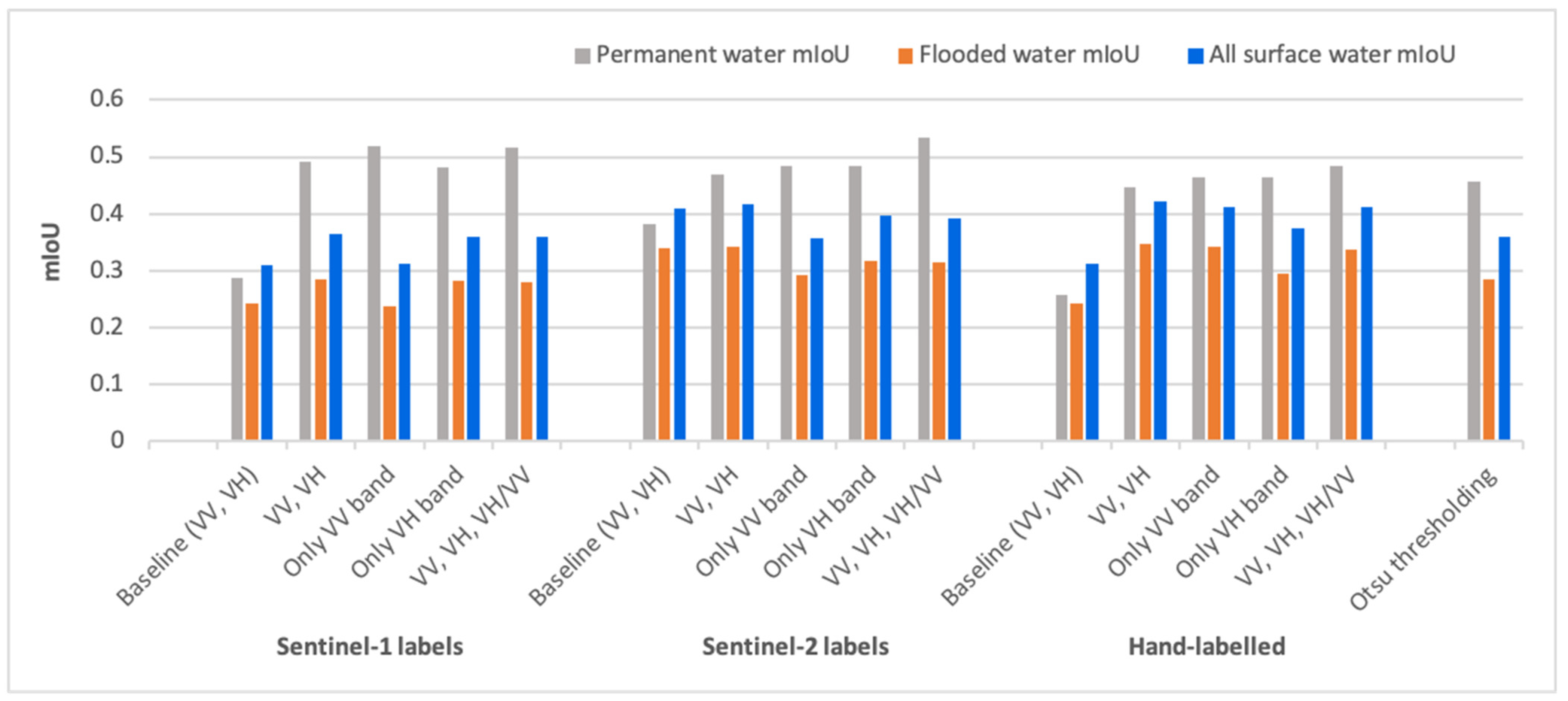
3.1. Results on the Test Dataset
3.2. Results on Test Site
4. Discussion
- (1)
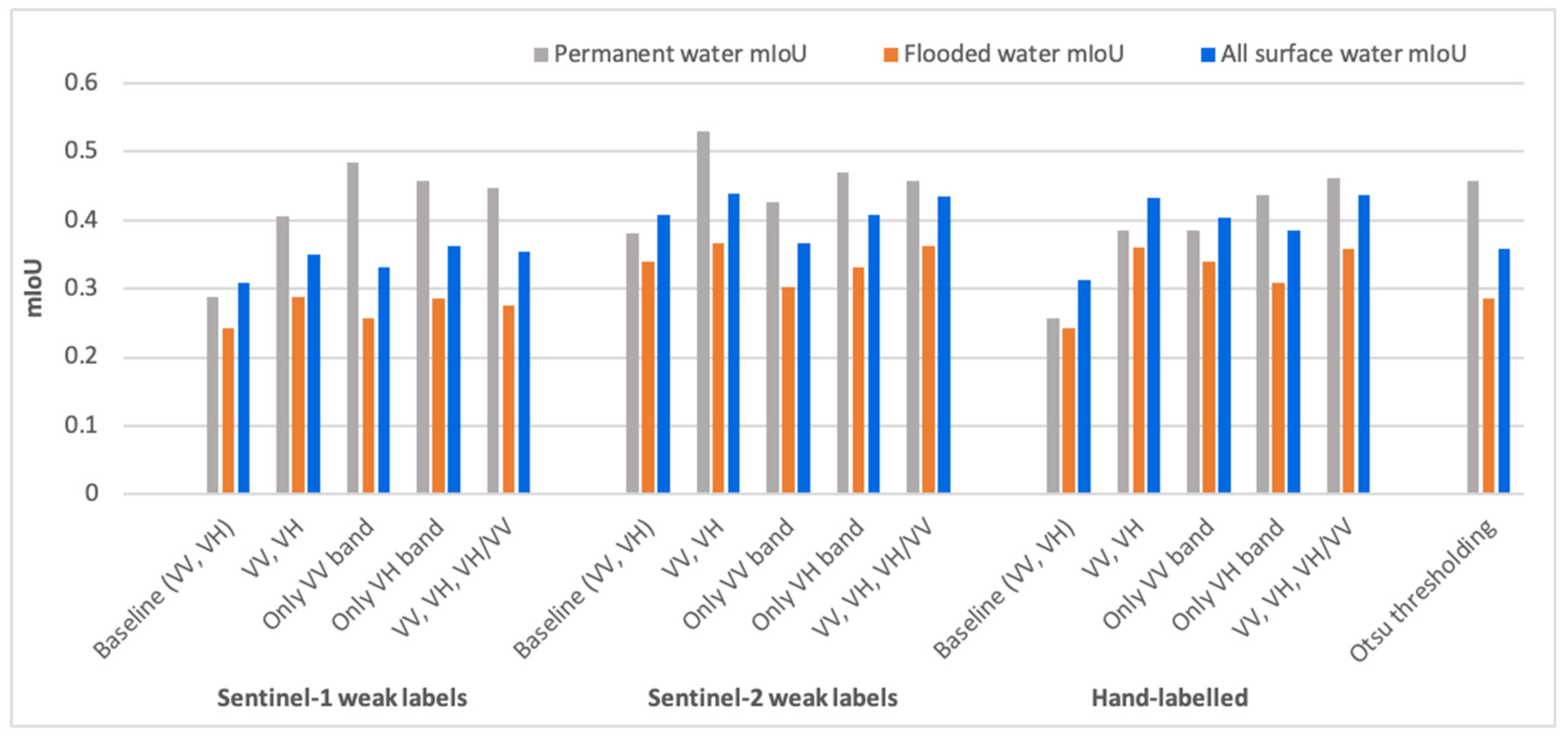
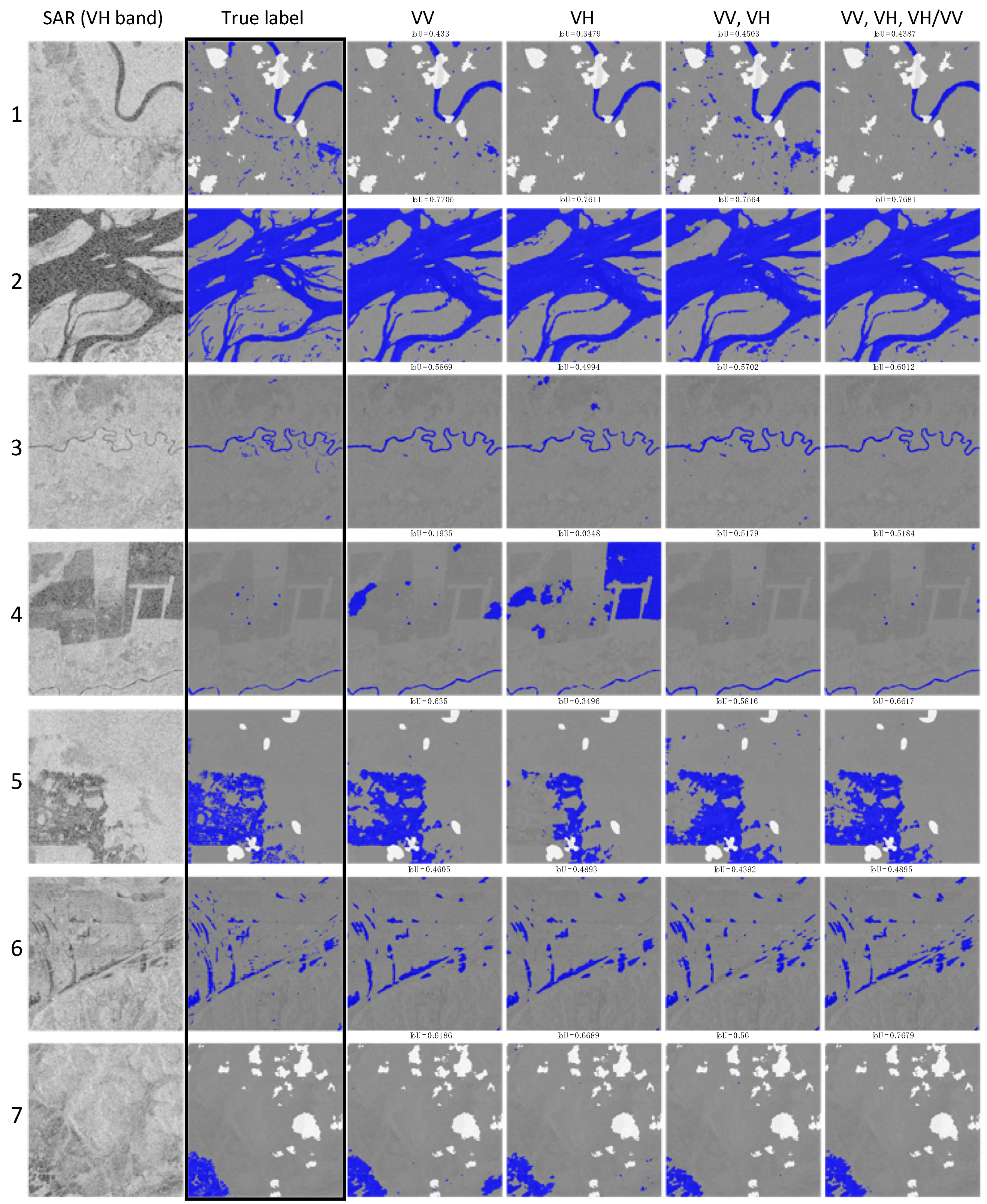
- When the labels are weak, models trained on the co-polarization VV band performed poorly in comparison to models trained on the cross-polarization VH band. One of the reasons can be the high sensitivity of co-polarization towards rough water surfaces, for example, due to wind, as described by Manjushree et al. [41] and Clement et al. [26]. However, for hand-labeled data, VV performs better than VH, especially for flooded areas. Figure 7 shows the results from the models trained on different band combinations. Because the training set here was hand-labeled, VV performed mostly better than VH bands except in the rows 6 and 7. One of the interesting outcomes was that the three bands combined (VV, VH, and their ratio) gave the best results, except for the first row in Figure 7. This combination provided very good improvement in some of the difficult test cases, as in rows 5–7. This was particularly interesting as no new information is provided in the third band, it is just the ratio of already present input bands.
- (2)
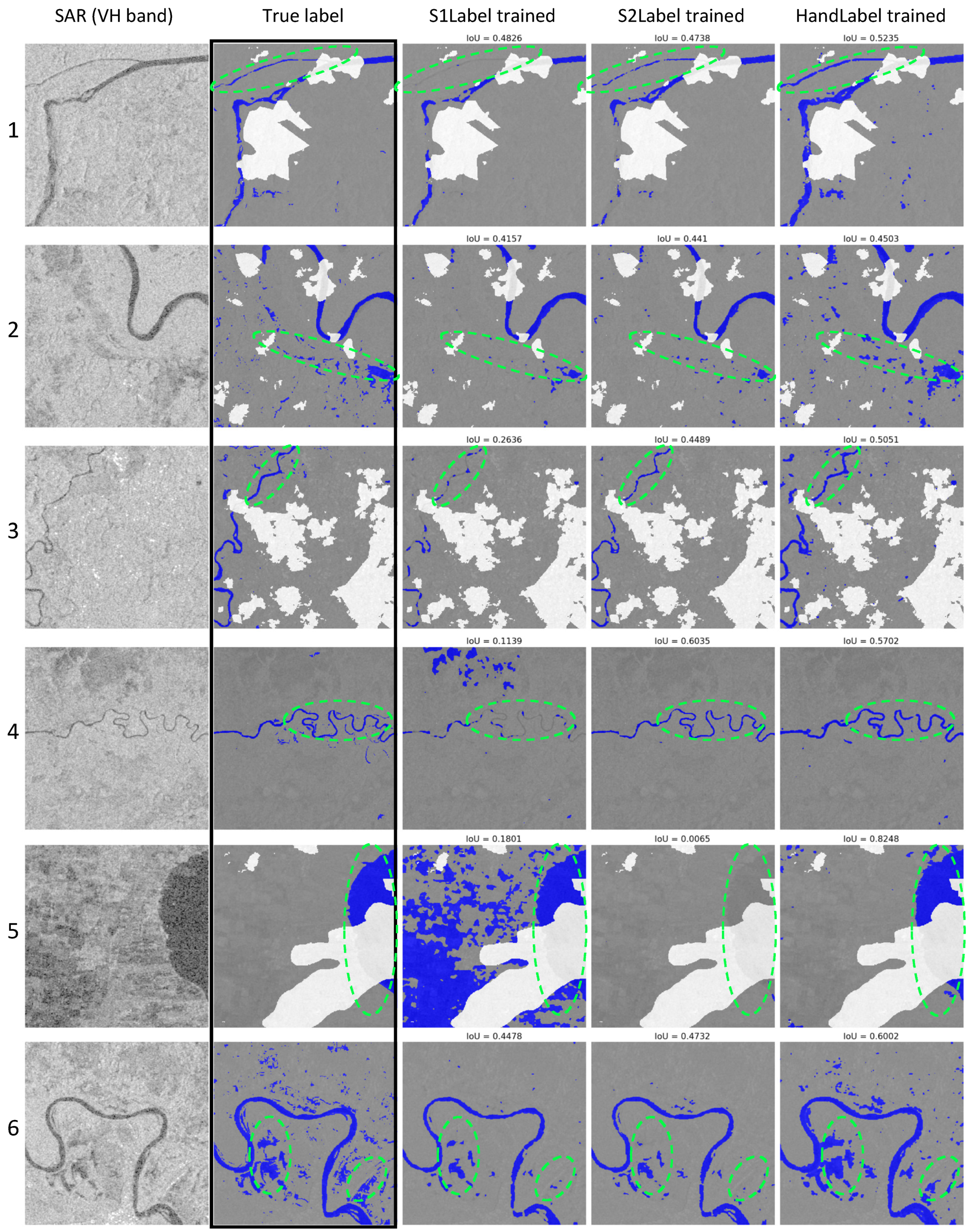
- Models trained on Sentinel-2 weakly labeled data gave better results in comparison to Sentinel-1 weakly labeled data, which is consistent with the results of Bonafilia et al. [23]. Moreover, the models trained on hand-labeled data approximately matches the accuracy of the models trained with Sentinel-2 data and sometimes even beat them despite limited samples, which goes against the results of Bonafilia et al. [23], who concluded that hand-labeled data are not necessary for training fully convolutional neural networks to detect flooding. We have demonstrated that models trained with hand-labeled data perform better throughout, as shown in Table 2 and Table 3. Figure 8 shows a few examples of the improvement achieved by hand-labeled data. However, sometimes models trained with hand-labeled data give over-detection, as can be seen in the red circled areas in the first and last rows of the figure.
- (3)
- Successful implementation of transfer learning proves two things: first, there is no substitute for more accurate labels (hand-labeled data) as can be seen by the improved results. Second, that it is a good approach to generate many training samples automatically and a model trained on it gives better generalization. This is because more samples help in covering diverse cases and varieties of landcover. Further, we can use transfer learning to tune the model for our given test set. However, another interesting result is that, for finding surface water in SAR images, general features play a larger role than do specific features. As explained by Yosinski et al. [42], layers close to the input, encoder blocks in our case, are responsible for general feature extraction, and deep layers are responsible for obtaining specific features. In our experiments, freezing the expansion phase and retraining the contraction phase gave the most favorable result. This can be further explored with different architectures; if the same behavior persists, then we may use many shallow layer networks, making an ensemble to detect water areas from SAR images without wasting too many resources. The enhancement in water area detection using transfer learning is presented in Figure 9. Some of the examples, such as rows 1, 2, and 5, show significant improvement.
- (4)
- If we look only at mIoU in the test dataset, then its value, which was less than 0.5, does not present a good picture of the surface water detection. However, if we see some examples of the test set true labels along with the detected mask, such as in Figure 8, where we can see that the detection is quite accurate, especially by the model trained on hand-labeled data. Similar accuracy is seen in Figure 9, which shows the results of transfer learning models. Some of the reasons for low mIoU can be understood in Figure 10. In rows 1 and 2 of Figure 10, where a very narrow stream has been labeled, this stream is either not visible in SAR image due to mountainous terrain (row 1) or trees growing along with it (row 2), and it becomes difficult to identify any significant water pixels in the SAR image. Here we also need to take care of the SAR imagery geometric effects due to the side looking imaging principle, this may miss the water bodies such as river or small lakes behind the shadow or under the layover effect in the mountainous region [43]. Another issue is having very small water bodies containing very few pixels scattered over the whole image (row 3). We need to consider that spatial resolution of Sentinel-1 IW-GRD images is 5 m × 22 m in range and azimuth respectively, so smaller water bodies cannot be detected [43]. In this case, even though very few numbers of pixels were miss detected but the IoU will be near zero, affecting the mIoU of the whole test dataset. A few incorrect labels are present in the test dataset. Some examples of this are shown in rows 5 and 6, where the red ellipses show the locations of incorrect labels. In these situations, even though our model is performing quite well, the IoU becomes very low or in some case goes to zero, such as in the last row. Whereas, according to the given label, there are no water bodies, so the intersection will be zero and the union will be the detected water body pixels, which will result in an IoU of zero. Moreover, there are also many possible scenarios where, due to the special properties of the SAR, the detection is not accurate, such as in the case of row 4 in Figure 10. This area was flooded in a field with sparse vegetation, as can be seen in the true-color image in the last row of Figure 11. This creates a double bounce from the specular surface of the water and vegetation in the co-polarized band (VV). This anomaly is the reason that the model is not able to identify it as a flooded field. A similar example is shown in the first row of Figure 11, where sand deposits in the river have high backscatter in the VV band. One possible reason for the high backscatter is the presence of moisture in the sand which increase the dielectric constant, so the reflectivity. In addition, the VV band is in general more susceptible to surface roughness, so higher reflectivity along with roughness may be the reason for high backscatter [40]. These special cases can be detected by the model if there are enough training samples that also have similar properties.





- Further classification of the flooded areas as the type of floods, such as open flood, flooded vegetation, and urban flood.
- Ensuring that the test set is error-free and that enough samples are provided for a variety of flooded area types.
- Removing the training sets that have less than a certain number of water pixels, as our main target is to learn to identify water pixels. In their absence, models do not learn anything significant, no matter how many samples are processed.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
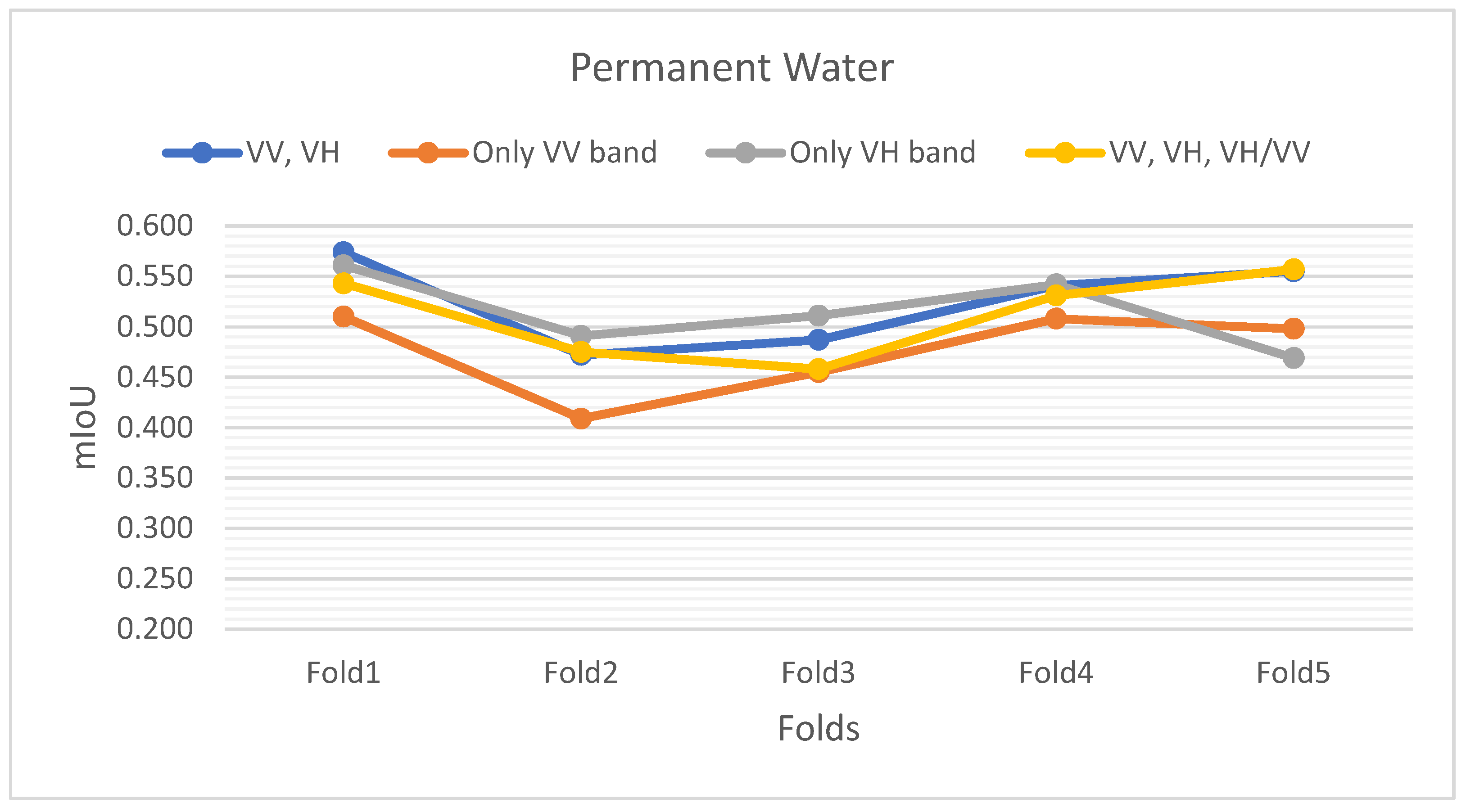
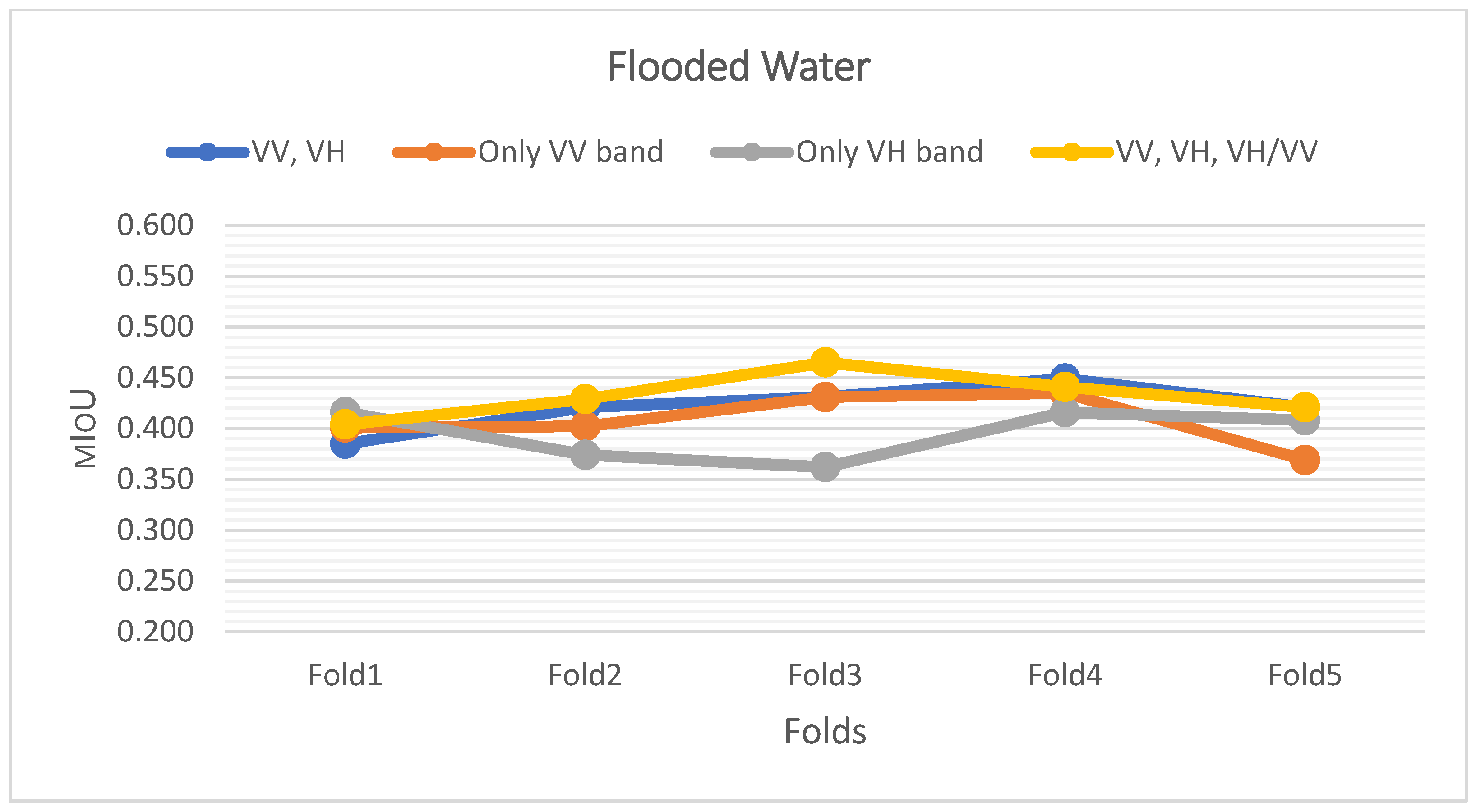
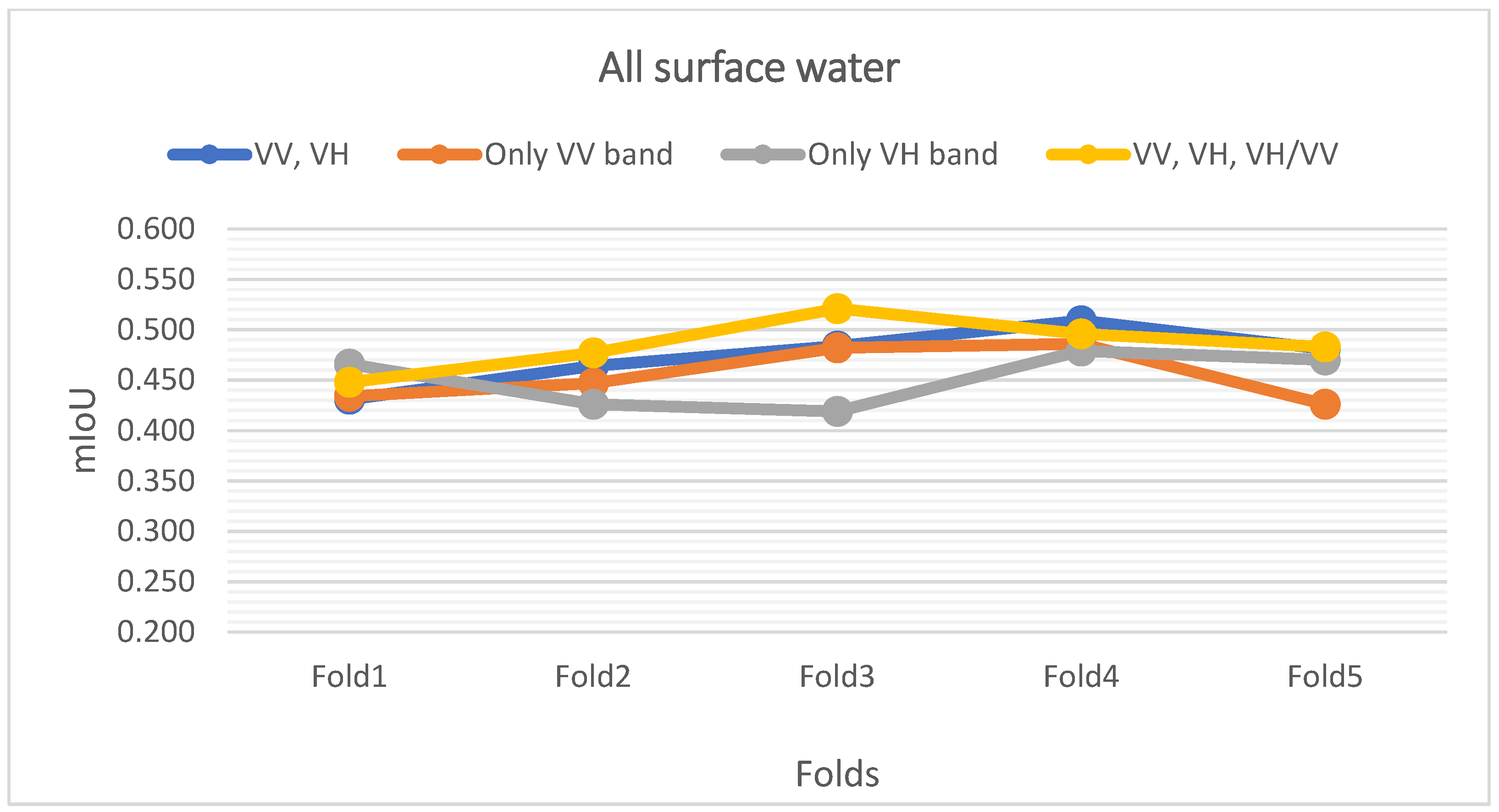
Appendix A. K-Fold Cross-Validation Result




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Permanent Water | Flooded Water | All Surface Water | ||||
|---|---|---|---|---|---|---|
| Band Used | Average mIoU | Std. Dev. | Average mIoU | Std. Dev. | Average mIoU | Std. Dev. |
| VV, VH | 0.524 | 0.040 | 0.421 | 0.021 | 0.473 | 0.026 |
| Only VV band | 0.474 | 0.039 | 0.407 | 0.024 | 0.454 | 0.025 |
| Only VH band | 0.514 | 0.033 | 0.395 | 0.023 | 0.451 | 0.025 |
| VV, VH, VV/VH | 0.511 | 0.039 | 0.432 | 0.020 | 0.484 | 0.024 |
References
- UNEP Goal 11: Sustainable Cities and Communities. Available online: https://www.unep.org/explore-topics/sustainable-development-goals/why-do-sustainable-development-goals-matter/goal-11 (accessed on 16 January 2021).
- Yang, H.; Wang, Z.; Zhao, H.; Guo, Y. Water body extraction methods study based on RS and GIS. Procedia Environ. Sci. 2011, 10, 2619–2624. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Chen, Y.; Zhang, S.; Wu, J. Detecting, extracting, and monitoring surface water from space using optical sensors: A review. Rev. Geophys. 2018, 56, 333–360. [Google Scholar] [CrossRef]
- Schumann, G.J.P.; Moller, D.K. Microwave remote sensing of flood inundation. Phys. Chem. Earth 2015, 83, 84–95. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated water extraction index: A New technique for surface water mapping using landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Yang, X.; Qin, Q.; Grussenmeyer, P.; Koehl, M. Urban surface water body detection with suppressed built-up noise based on water indices from sentinel-2 MSI imagery. Remote Sens. Environ. 2018, 219, 259–270. [Google Scholar] [CrossRef]
- Herndon, K.; Muench, R.; Cherrington, E.; Griffin, R. An Assessment of surface water detection methods for water resource management in the Nigerien sahel. Sensors 2020, 20, 431. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water Body Extraction from very high-resolution remote sensing imagery using deep U-Net and a superpixel-based conditional random field model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 618–622. [Google Scholar] [CrossRef]
- Schumann, G.J.P.; Brakenridge, G.R.; Kettner, A.J.; Kashif, R.; Niebuhr, E. Assisting flood disaster response with earth observation data and products: A critical assessment. Remote Sens. 2018, 10, 1230. [Google Scholar] [CrossRef] [Green Version]
- Assad, S.E.A.A. Flood Detection with a Deep Learning Approach Using Optical and SAR Satellite Data. Master’s Thesis, Leibniz University Hannover, Hannover, Germany, 2019. [Google Scholar]
- Rambour, C.; Audebert, N.; Koeniguer, E.; le Saux, B.; Crucianu, M.; Datcu, M. Flood detection in time series of optical and SAR images. Int. Arch. Photogramm. Remote Sens. Spat. Inform. Sci. 2020, 43, 1343–1346. [Google Scholar] [CrossRef]
- Bioresita, F.; Puissant, A.; Stumpf, A.; Malet, J.P. Fusion of sentinel-1 and sentinel-2 image time series for permanent and temporary surface water mapping. Int. J. Remote Sens. 2019, 40, 9026–9049. [Google Scholar] [CrossRef]
- Shen, X.; Anagnostou, E.N.; Allen, G.H.; Robert Brakenridge, G.; Kettner, A.J. Near-real-time non-obstructed flood inundation mapping using synthetic aperture radar. Remote Sens. Environ. 2019, 221, 302–315. [Google Scholar] [CrossRef]
- Huang, X.; Wang, C.; Li, Z. A near real-time flood-mapping approach by integrating social media and post-event satellite imagery. Ann. GIS 2018, 24, 113–123. [Google Scholar] [CrossRef]
- Landuyt, L.; van Wesemael, A.; Schumann, G.J.P.; Hostache, R.; Verhoest, N.E.C.; van Coillie, F.M.B. Flood mapping based on synthetic aperture radar: An assessment of established approaches. IEEE Trans. Geosci. Remote Sens. 2019, 57, 722–739. [Google Scholar] [CrossRef]
- Hostache, R.; Matgen, P.; Wagner, W. Change detection approaches for flood extent mapping: How to select the most adequate reference image from online archives? Int. J. Appl. Earth Obs. Geoinform. 2012, 19, 205–213. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Kittler, J.; Illingworth, J. Minimum error thresholding. Pattern Recognit. 1986, 19, 41–47. [Google Scholar] [CrossRef]
- Martinis, S.; Twele, A.; Voigt, S. Towards operational near real-time flood detection using a split-based automatic thresholding procedure on high resolution TerraSAR-X data. Nat. Hazards Earth Syst. Sci. 2009, 9, 303–314. [Google Scholar] [CrossRef]
- Zhang, P.; Chen, L.; Li, Z.; Xing, J.; Xing, X.; Yuan, Z. Automatic extraction of water and shadow from SAR images based on a multi-resolution dense encoder and decoder network. Sensors 2019, 19, 3576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Katiyar, V.; Tamkuan, N.; Nagai, M. Flood area detection using SAR images with deep neural. In Proceedings of the 41st Asian Conference of Remote Sensing—Asian Association of Remote Sensing, Deqing, China, 9–11 November 2020. [Google Scholar]
- Bonafilia, D.; Tellman, B.; Anderson, T.; Issenberg, E. Sen1Floods11: A georeferenced dataset to train and test deep learning flood algorithms for sentinel-1. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 835–845. [Google Scholar] [CrossRef]
- Li, Y.; Martinis, S.; Wieland, M.; Schlaffer, S.; Natsuaki, R. Urban flood mapping using SAR intensity and interferometric coherence via bayesian network fusion. Remote Sens. 2019, 11, 2231. [Google Scholar] [CrossRef] [Green Version]
- Twele, A.; Cao, W.; Plank, S.; Martinis, S. Sentinel-1-based flood mapping: A fully automated processing chain. Int. J. Remote Sens. 2016, 37, 2990–3004. [Google Scholar] [CrossRef]
- Clement, M.A.; Kilsby, C.G.; Moore, P. Multi-temporal synthetic aperture radar flood mapping using change detection. J. Flood Risk Manag. 2018, 11, 152–168. [Google Scholar] [CrossRef]
- Tiwari, V.; Kumar, V.; Matin, M.A.; Thapa, A.; Ellenburg, W.L.; Gupta, N.; Thapa, S. Flood inundation mapping-Kerala 2018—Harnessing the power of SAR, automatic threshold detection method and Google Earth engine. PLoS ONE 2020, 15, e0237324. [Google Scholar] [CrossRef]
- Caballero, I.; Ruiz, J.; Navarro, G. Sentinel-2 satellites provide near-real time evaluation of catastrophic floods in the west mediterranean. Water 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Sekou, T.B.; Hidane, M.; Olivier, J.; Cardot, H. From patch to image segmentation using fully convolutional networks—Application to retinal images. arXiv 2019, arXiv:1904.03892. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; ISBN 3463353563306. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. Lect. Notes Comput. Sci. 2015, 9351, 234–241. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Bahl, G.; Daniel, L.; Moretti, M.; Lafarge, F. Low-power neural networks for semantic segmentation of satellite images. In Proceedings of the International Conference on Computer Vision Workshop, ICCVW, Seoul, Korea, 27 October–2 November 2019; pp. 2469–2476. [Google Scholar] [CrossRef] [Green Version]
- Jadon, S. A Survey of loss functions for semantic segmentation. In Proceedings of the IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Viña del Mar, Chile, 27–29 October 2020. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015—Conference Track Proceedings), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Li, L.; Yan, Z.; Shen, Q.; Cheng, G.; Gao, L.; Zhang, B. Water body extraction from very high spatial resolution remote sensing data based on fully convolutional networks. Remote Sens. 2019, 11, 1162. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Pan, Z.; Lei, B. What, where, and how to transfer in SAR target recognition based on deep CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2324–2336. [Google Scholar] [CrossRef] [Green Version]
- Flores-Anderson, A.I.; Herndon, K.E.; Thapa, R.B.; Cherrington, E. Sampling designs for SAR-assisted forest biomass surveys. In The SAR Handbook—Comprehensive Methodologies for Forest Monitoring and Biomass Estimation; SAR: Santa Fe, NM, USA, 2019; pp. 281–289. [Google Scholar] [CrossRef]
- Manjusree, P.; Prasanna Kumar, L.; Bhatt, C.M.; Rao, G.S.; Bhanumurthy, V. Optimization of threshold ranges for rapid flood inundation mapping by evaluating backscatter profiles of high incidence angle SAR Images. Int. J. Disaster Risk Sci. 2012, 3, 113–122. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 4, 3320–3328. [Google Scholar]
- Schmitt, M. Potential of large-scale inland water body mapping from sentinel-1/2 data on the example of Bavaria’s lakes and rivers. PFG J. Photogramm. Remote Sens. Geoinf. Sci. 2020, 88, 271–289. [Google Scholar] [CrossRef]






| Satellite Image Name | Acquisition Date (yyyy/mm/dd) | Flight Direction | Processing Level |
|---|---|---|---|
| S1A_IW_GRDH_1SDV_20180821T004109_20180821T004134_023337_0289D5_B2B2 | 2018/08/21 | Descending | L1-GRD (IW) |
| S1A_IW_GRDH_1SDV_20180821T130602_20180821T130631_023345_028A0A_C728 | 2018/08/21 | Ascending | L1-GRD (IW) |
| S1A_IW_GRDH_1SDV_20180821T004044_20180821T004109_023337_0289D5_D07A | 2018/08/21 | Descending | L1-GRD (IW) |
| S1A_IW_GRDH_1SDV_20180821T130631_20180821T130656_023345_028A0A_E124 | 2018/08/21 | Ascending | L1-GRD (IW) |
| S2B_MSIL1C_20180822T050649_N0206_R019_T43PFL_20180822T085140 | 2018/08/22 | Descending | Level 1C |
| SegNet/Dataset and Band Used | Permanent Water | Flooded Water | All Surface Water | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mIoU | Om. | Comm. | mIoU | Om. | Comm. | mIoU | Om. | Comm. | |
| Sentinel-1 weak labels | |||||||||
| VV, VH | 0.492 | 0.008 | 0.046 | 0.286 | 0.378 | 0.044 | 0.364 | 0.249 | 0.044 |
| Only VV band | 0.519 | 0.255 | 0.032 | 0.238 | 0.474 | 0.037 | 0.313 | 0.397 | 0.037 |
| Only VH band | 0.482 | 0.009 | 0.048 | 0.282 | 0.382 | 0.049 | 0.359 | 0.251 | 0.049 |
| VV, VH, VH/VV | 0.515 | 0.011 | 0.043 | 0.281 | 0.41 | 0.042 | 0.360 | 0.269 | 0.043 |
| Sentinel-2 weak labels | |||||||||
| VV, VH | 0.469 | 0.008 | 0.024 | 0.342 | 0.365 | 0.021 | 0.417 | 0.239 | 0.020 |
| Only VV band | 0.484 | 0.315 | 0.021 | 0.292 | 0.434 | 0.016 | 0.357 | 0.393 | 0.016 |
| Only VH band | 0.483 | 0.006 | 0.025 | 0.318 | 0.382 | 0.021 | 0.396 | 0.252 | 0.020 |
| VV, VH, VH/VV | 0.534 | 0.014 | 0.018 | 0.315 | 0.438 | 0.014 | 0.392 | 0.290 | 0.014 |
| Hand labelling | |||||||||
| VV, VH | 0.447 | 0.005 | 0.029 | 0.347 | 0.341 | 0.024 | 0.421 | 0.223 | 0.024 |
| Only VV band | 0.463 | 0.285 | 0.031 | 0.342 | 0.355 | 0.023 | 0.412 | 0.331 | 0.023 |
| Only VH band | 0.463 | 0.011 | 0.032 | 0.296 | 0.429 | 0.021 | 0.374 | 0.283 | 0.021 |
| VV, VH, VH/VV | 0.484 | 0.007 | 0.024 | 0.336 | 0.404 | 0.019 | 0.411 | 0.265 | 0.019 |
| Benchmark from [23] | |||||||||
| Otsu thresholding | 0.457 | 0.054 | 0.085 | 0.285 | 0.151 | 0.085 | 0.359 | 0.143 | 0.085 |
| Baselines from [23] | |||||||||
| Sentinel-1 weak labels (VV, VH) | 0.287 | 0.066 | 0.135 | 0.242 | 0.119 | 0.100 | 0.309 | 0.112 | 0.997 |
| Sentinel-2 weak labels (VV, VH) | 0.382 | 0.121 | 0.053 | 0.339 | 0.268 | 0.078 | 0.408 | 0.248 | 0.078 |
| Hand labeling (VV, VH) | 0.257 | 0.095 | 0.152 | 0.242 | 0.135 | 0.106 | 0.313 | 0.130 | 0.106 |
| UNet/Dataset and Band Used | Permanent Water | Flooded Water | All Surface Water | ||||||
| mIoU | Om. | Comm. | mIoU | Om. | Comm. | mIoU | Om. | Comm. | |
| Sentinel-1 weak labels | |||||||||
| VV, VH | 0.406 | 0.006 | 0.052 | 0.288 | 0.352 | 0.050 | 0.349 | 0.231 | 0.050 |
| Only VV band | 0.485 | 0.285 | 0.035 | 0.257 | 0.445 | 0.038 | 0.332 | 0.389 | 0.038 |
| Only VH band | 0.457 | 0.008 | 0.021 | 0.285 | 0.390 | 0.043 | 0.362 | 0.256 | 0.043 |
| VV, VH, VH/VV | 0.446 | 0.006 | 0.039 | 0.275 | 0.396 | 0.037 | 0.353 | 0.259 | 0.037 |
| Sentinel-2 weak labels | |||||||||
| VV, VH | 0.529 | 0.009 | 0.017 | 0.366 | 0.358 | 0.014 | 0.439 | 0.236 | 0.014 |
| Only VV band | 0.427 | 0.293 | 0.021 | 0.303 | 0.402 | 0.019 | 0.367 | 0.364 | 0.019 |
| Only VH band | 0.469 | 0.004 | 0.025 | 0.332 | 0.362 | 0.021 | 0.407 | 0.236 | 0.021 |
| VV, VH, VH/VV | 0.458 | 0.004 | 0.029 | 0.362 | 0.313 | 0.024 | 0.434 | 0.205 | 0.024 |
| Hand labelling | |||||||||
| VV, VH | 0.386 | 0.005 | 0.042 | 0.361 | 0.274 | 0.035 | 0.432 | 0.181 | 0.035 |
| Only VV band | 0.386 | 0.289 | 0.038 | 0.339 | 0.315 | 0.029 | 0.404 | 0.306 | 0.029 |
| Only VH band | 0.436 | 0.005 | 0.035 | 0.309 | 0.363 | 0.029 | 0.386 | 0.236 | 0.029 |
| VV, VH, VH/VV | 0.462 | 0.003 | 0.027 | 0.359 | 0.309 | 0.024 | 0.436 | 0.202 | 0.024 |
| Benchmark from [23] | |||||||||
| Otsu thresholding | 0.457 | 0.054 | 0.085 | 0.285 | 0.151 | 0.085 | 0.359 | 0.142 | 0.085 |
| Baseline from [23] | |||||||||
| Sentinel-1 weak labels (VV, VH) | 0.287 | 0.066 | 0.135 | 0.242 | 0.119 | 0.100 | 0.309 | 0.1124 | 0.997 |
| Sentinel-2 weak labels (VV, VH) | 0.382 | 0.120 | 0.053 | 0.339 | 0.268 | 0.078 | 0.408 | 0.2482 | 0.078 |
| Hand labeling (VV, VH) | 0.257 | 0.094 | 0.152 | 0.242 | 0.135 | 0.105 | 0.312 | 0.1297 | 0.105 |
| Transfer Learning/Dataset | Permanent Water | Flooded Water | All Surface Water | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mIoU | Om. | Comm. | mIoU | Om. | Comm. | mIoU | Om. | Comm. | |
| Hand labelling | |||||||||
| Whole model | 0.530 | 0.0051 | 0.0264 | 0.409 | 0.3494 | 0.0207 | 0.483 | 0.2287 | 0.0207 |
| Whole decoder | 0.531 | 0.0054 | 0.0324 | 0.366 | 0.3745 | 0.0238 | 0.443 | 0.2451 | 0.0238 |
| Whole encoder | 0.532 | 0.0041 | 0.0243 | 0.420 | 0.3086 | 0.0204 | 0.494 | 0.2042 | 0.0204 |
| Otsu thresholding (OT) | 0.457 | 0.054 | 0.0849 | 0.285 | 0.151 | 0.0849 | 0.3591 | 0.1427 | 0.0849 |
| % improvement over OT | +16.4 | −92.4 | −71.37 | +47.3 | +104.3 | −75.9 | +37.6 | +43.1 | −75.9 |
| Method | Images | IoU | F1 Score | Om. Error | Comm. Error |
|---|---|---|---|---|---|
| Minimum and Otsu thresholding | Merged images of ascending flight direction | 0.8394 | 0.9127 | 0.1328 | 0.0367 |
| Our model (after transfer learning) | Merged images of ascending flight direction | 0.8849 | 0.9389 | 0.0587 | 0.0635 |
| Minimum and Otsu thresholding | Merged images of descending flight direction | 0.8214 | 0.9019 | 0.1535 | 0.0347 |
| Our model (after transfer learning) | Merged images of descending flight direction | 0.8776 | 0.9348 | 0.0661 | 0.0642 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Katiyar, V.; Tamkuan, N.; Nagai, M. Near-Real-Time Flood Mapping Using Off-the-Shelf Models with SAR Imagery and Deep Learning. Remote Sens. 2021, 13, 2334. https://doi.org/10.3390/rs13122334
Katiyar V, Tamkuan N, Nagai M. Near-Real-Time Flood Mapping Using Off-the-Shelf Models with SAR Imagery and Deep Learning. Remote Sensing. 2021; 13(12):2334. https://doi.org/10.3390/rs13122334
Chicago/Turabian StyleKatiyar, Vaibhav, Nopphawan Tamkuan, and Masahiko Nagai. 2021. "Near-Real-Time Flood Mapping Using Off-the-Shelf Models with SAR Imagery and Deep Learning" Remote Sensing 13, no. 12: 2334. https://doi.org/10.3390/rs13122334
APA StyleKatiyar, V., Tamkuan, N., & Nagai, M. (2021). Near-Real-Time Flood Mapping Using Off-the-Shelf Models with SAR Imagery and Deep Learning. Remote Sensing, 13(12), 2334. https://doi.org/10.3390/rs13122334