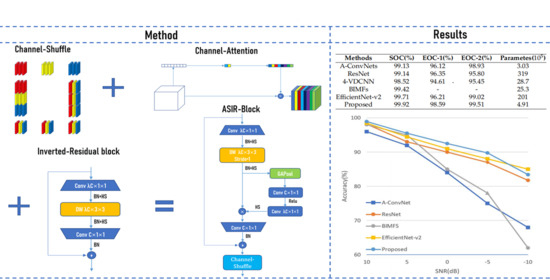
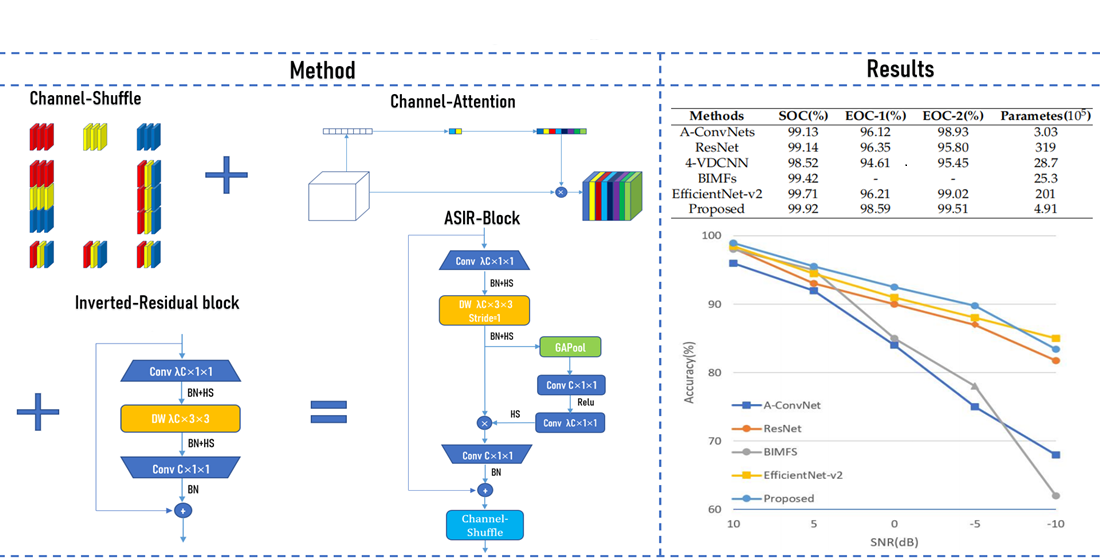
2.1. Inverted-Residual Block
ResNet [
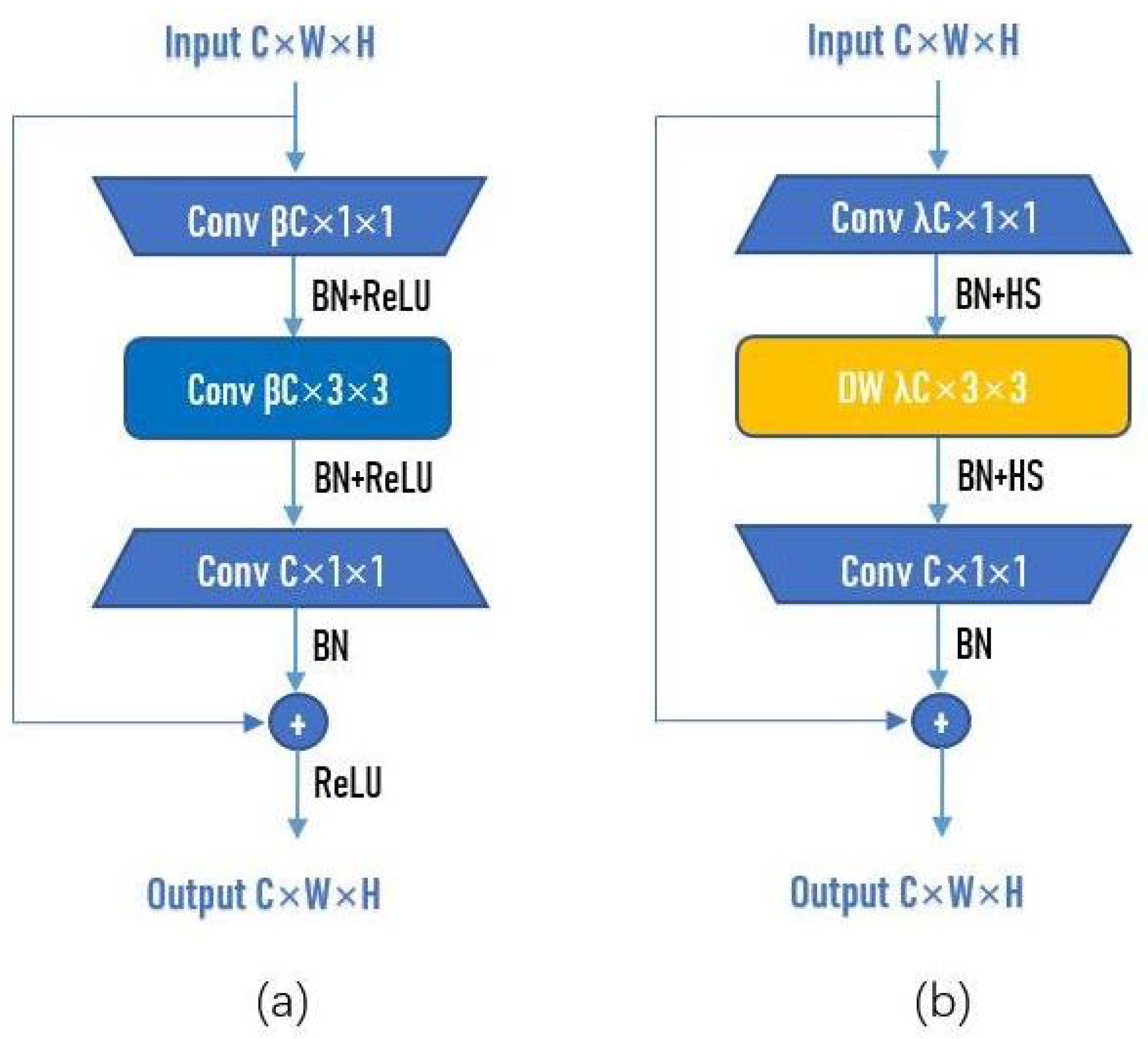
25] was proposed in 2015 and won the championship in the classification task of the ImageNet competition. Because it is simple and practical, many methods are built on the basis of ResNet. It is widely used in recognition, detection, segmentation, and other fields. The Residual block is the main structure in ResNet, as shown in
Figure 1a. Input C × W × H means that the number of channels of the input is C, and the width and height of channels of the input are W and H, respectively. Conv
C × 1 × 1 means that the number of 1 × 1 convolutional kernels is
C. After passing the first 1 × 1 convolutional layer, the width and height of the channel remain unchanged, and the number of channels becomes
C.
is a hyperparameter-scaling factor, usually set as
= 0.25. The main purpose of the first 1 × 1 convolutional layer is to fusion the channels, thereby reducing the amount of calculation. After dimensionality reduction, parameters training and feature extraction can be performed more effectively and intuitively. The function of the middle 3 × 3 convolutional layer is to perform feature extraction in low-dimensional space. Set stride = 1 and padding = 1 to ensure that the width and height of the channel do not change. Finally, a 1 × 1 convolutional layer is used to restore the same dimensionality as the input.
However, a 1 × 1 convolutional layer is first used to increase the dimensionality of the input in the Inverted-Residual block. After passing the first 1 × 1 convolutional layer, the width and height of the channel remain unchanged, and the number of channels becomes C. is a hyperparameter-scaling factor, and set = 4 or 6 in this paper. Then, use depthwise convolution (DW) for feature extraction. Finally, for more effective use of information of different channels at the same spatial position, a 1 × 1 convolutional layer is utilized to fuse channels and restore the same dimensionality as the input.
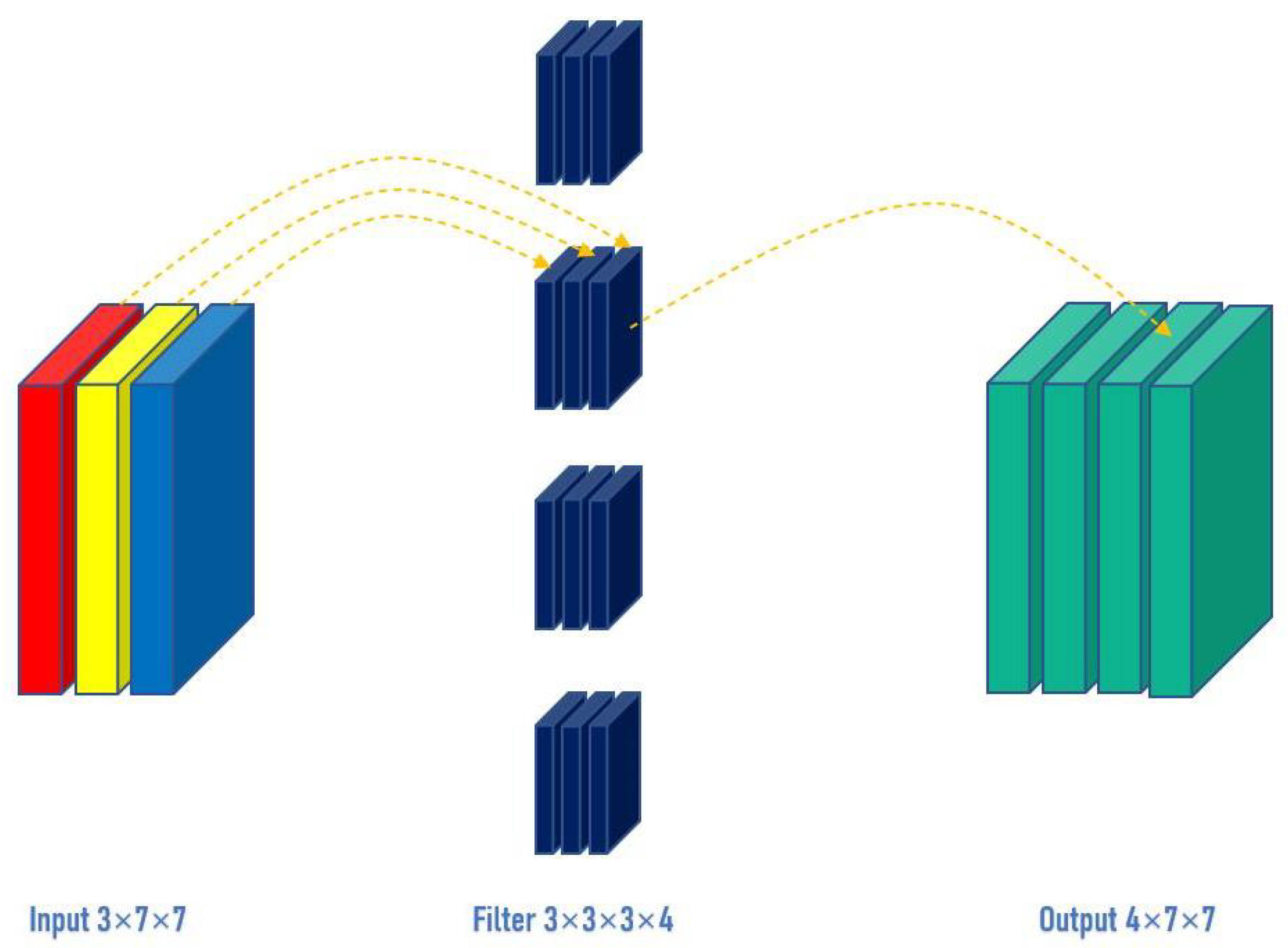
For conventional convolution, input a three-channel, and 7 × 7 pixel image (shape: 3 × 7 × 7), after passing the 3 × 3 convolutional layer (assuming the number of convolutional kernels is 4, the shape of the convolutional kernel is 3 × 3 × 3 × 4), and, finally, 4 channels are output. If the same padding is set, the size of the output is the same as the input (7 × 7); if not, the size of the output becomes 5 × 5, as shown in
Figure 2.
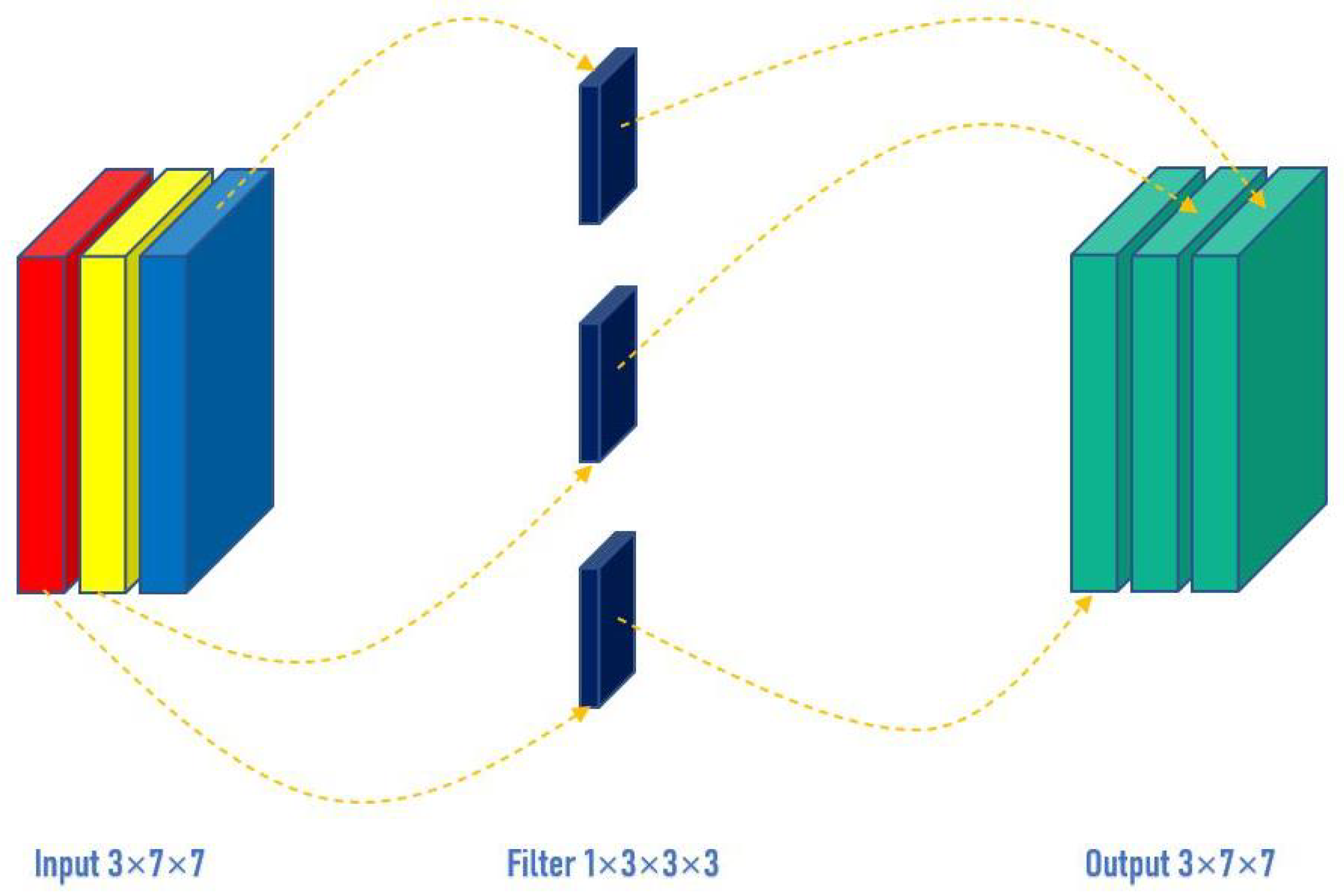
However, for depthwise convolution (DW), one channel is convolved by one convolutional kernel, and one convolutional kernel is only responsible for one channel. For the aforementioned conventional convolution, each convolutional kernel is to operate all channels of the input image at the same time. Similarly, input a three-channel, and 7 × 7 pixel image (shape: 3 × 7 × 7), DW is completely convolved in two-dimensional space. The number of channels of the input and the number of convolutional kernels are the same, and there is a one-to-one correspondence between channels and convolutional kernels. So, a three-channel image generates three channels after passing the DW layer. If the same padding is set, the size of the output is the same as the input (7 × 7); if not, the size of the output becomes 5 × 5, as shown in
Figure 3. By keeping the number of trainable weight parameters required at a low level, DW can reduce network complexity while maintaining high recognition accuracy. DW can separate the channel and the convolution area, and connect the input and output channels one-to-one through the convolution operation.
In both the Residual block and Inverted-Residual block, when the shape of the ouput is the same as that of the input, a shortcut connection can be used. The formula of the shortcut connection can be summarized as:
where
represents the feature extraction process,
u represents the input, and
represents the output. Many neural network experiments before the emergence of ResNet show that an appropriate increase in the depth of the network will strengthen its performance, but, after a certain level, the opposite effect may be achieved. Due to the divergence of the gradient, the network may be degraded. However, the shortcut connection in Residual block cleverly solves this problem.
A batch normalization (BN) operation is required between each convolutional layer and activation function. Before the nonlinear transformation, the input value of the deep convolutional neural network is gradually moved or changed as the network deepens, which results in the gradient disappearance of the deeper neural layer during the back propagation process. This is the root cause of the slower and slower training speed of deep convolutional neural networks. BN can avoid the gradient explosion and gradient disappear by modifying the distribution of the input data, thereby pulling most of the input data into the linear part of the activation function. Suppose a batch of input data is
, the process of BN can be divided into 3 steps, as follows. Step 1: the average and variance of the batch
D can be obtained by:
where
is the variance of the batch
D, and
is the average of the batch
D. Step 2: the batch
D is normalized by
and
to get the 0–1 distribution:
where
is a very small positive number to prevent the divisor from becoming 0. Step 3: scale and translate the normalized batch
D by:
where
and
are scale factor and translation factor, respectively [
27].
represents the operation of BN.
In Residual block, ReLU which has much less computation than sigmoid [
28] is used as the activation function. It can improve the convergence speed and alleviate the problem of gradient disappearance. The formula of the ReLU is presented as:
In the Inverted-residual block, Hard-Swish (HS) [
29] is used as the activation function. In deep neural networks, the Swish activation function has been shown to perform better than ReLU [
30]. The function has the good characteristics of lower bound, no upper bound, non-monotonic, and smooth, which is presented as:
where
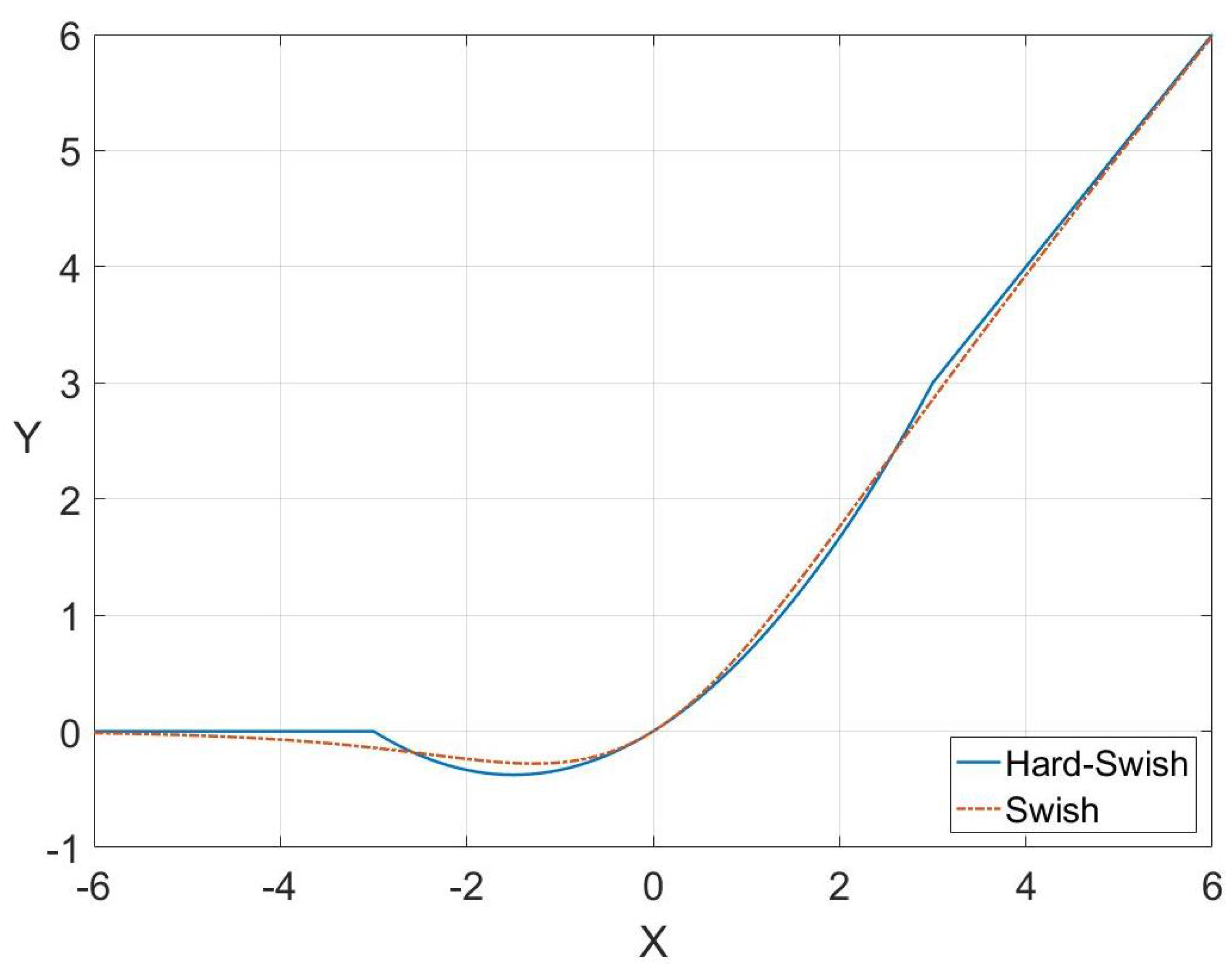
is a trainable parameter or constant. But, compared to ReLU, its calculation is more complicated because of the sigmoid function. Therefore, the sigmoid function is replaced with the ReLU6 function so as to reduce the amount of calculation, and the Hard-Swish (HS) is obtained. Hard-Swish is presented as:
The graphics of Swish and Hard-Swish are similar, but the amount of calculation of Hard-Swish is much smaller in the back propagation process. The comparison of Swish and Hard-Swish is shown in
Figure 4.
2.2. Channel-Attention Mechanism
A traditional CNN includes feature extraction modules and a classifier. Each channel of the same layer has the same status to the next layer in a traditional feature extract module. But this assumption is often proven wrong in practice [
31]. In our previous experiments, we used multiple Inverted-Residual block in series to extract feature maps, and SoftMax as a classifier.
Figure 5 displays the 16 feature maps which are extracted by the second DW layer. It is obvious that some feature maps only extract background clutter and contain less target structure information, such as the first and fourth feature maps in the third row.
In the aforementioned traditional CNN, all channels which contain different information in the same convolutional layer pass through the next convolutional layer equally. Therefore, their contribution to recognition is equal, and this equal mechanism interferes with the use of important channels which contain more useful information. So, we try to introduce the Channel-Attention mechanism. Channel-Attention mechanism can allocate different weights to channels of different importance levels in the same convolutional layer to strengthen channels that contain important information and stifle channels that contain useless information.
Figure 6 illustrates the principle of the Channel-Attention module.
C × W × H means that the width and height of the input U are W and H, respectively, and the number of channels of the input U is C. GAPool represents global average pooling, which is presented as:
where
represents the
kth channel of U. After passing GAPool, the dimensionality of U becomes C × 1 × 1. Then, two 1 × 1 convolutional layers are used instead of the fully connected layer of common attention modules, which can effectively reduce the parameters of the attention module. After passing the two 1 × 1 convolutional layers, U becomes an automatically updated weight vector, representing the importance of different channels. The activation functions of the first convolutional layer and the second convolutional layer are ReLU and Hard-Swish, respectively. Finally, the
kth channel generated by the Channel-Attention module is expressed as:
where
represents the weight of
, and
represents the product of them.
2.3. Channel-Shuffle Mechanism
Although DW can extract features in high-dimensional space with fewer parameters, DW will hinder the exchange of information between different channels. The 1 × 1 convolutional layer can alleviate this shortcoming, but it is not enough. So, we try to introduce the Channel-Shuffle mechanism to the Inverted-Residual block. The Channel-Shuffle mechanism can make the output of a channel not only related to its corresponding input, which can promote the exchange of information between channels and describe more detailed features.
Channel-Shuffle mechanism was first proposed in ShuffleNet [
32]. In ShuffleNet, the author uses Channel-Shuffle mechanism to overcome the problem of low information flow rate between channels in group convolution. The specific operation steps of Channel-Shuffle mechanism are shown in
Figure 7. Step 1: divide the input C channels into g groups equally, each group contains n channels (C = 9, g = 3, n = 3 in
Figure 7); Step 2: reshape the dimensionality of input from [N, g × n, W, H ] to [N, g, n, W, H]; Step 3: transpose the g and n; Step 4: restore the dimensionality of the data to [N, n × g, W, H]. After passing Channel-Shuffle module, each group of channels finally obtained contains the channels of other groups before the Channel-Shuffle module.
2.4. Network Architecture of ASIR-Net
After adding Channel-Attention mechanism and Channel-Shuffle mechanism to the Inverted-Residual block and using the 1 × 1 convolutional layers instead of the fully connected layers, we get a fully convolutional network, namely ASIR-Net.
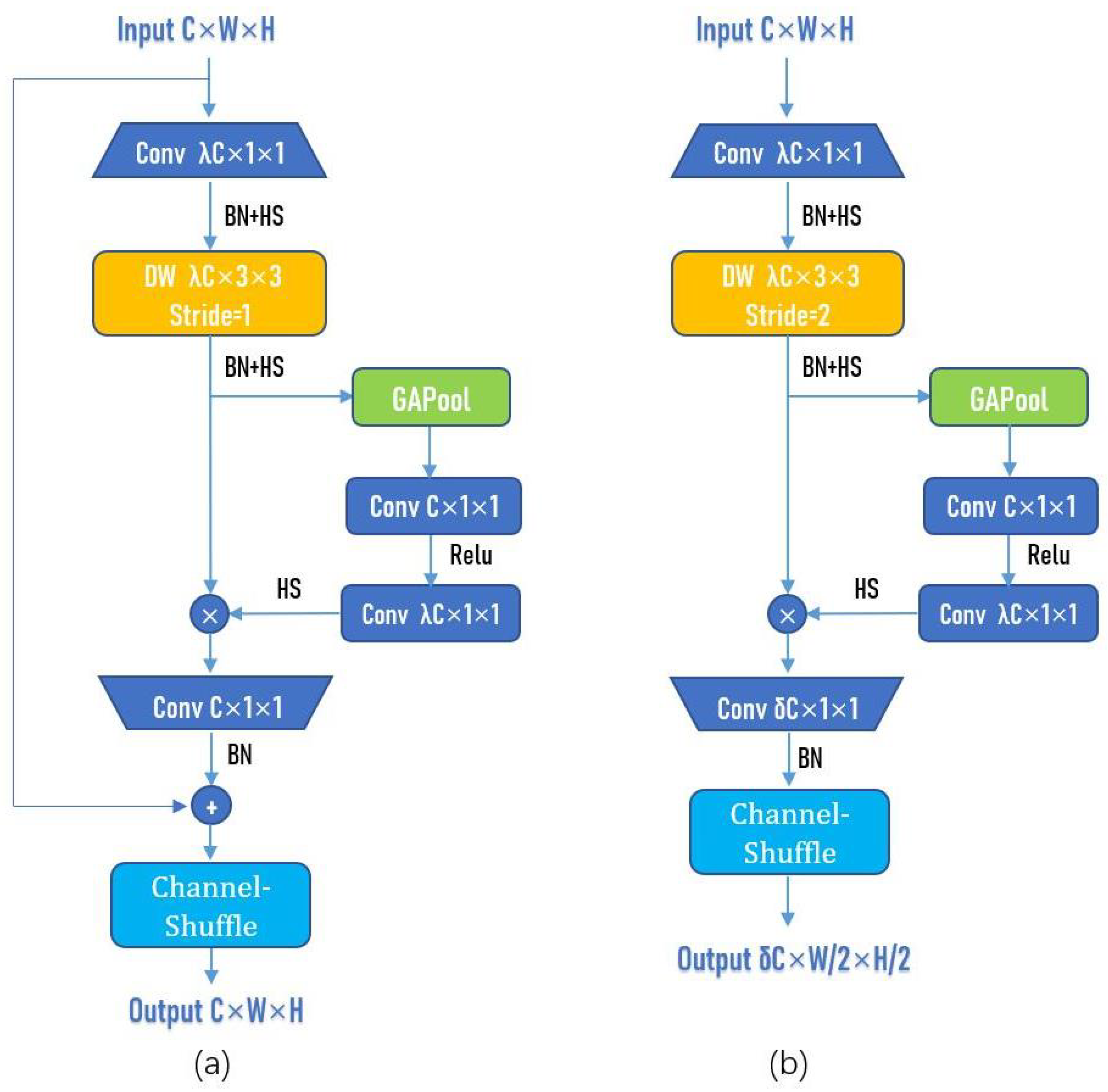
Next, we will discuss the features and overall structure of the proposed ASIR-Net. There are two blocks in ASIR-Net, namely ASIR-Block (stride = 1) and ASIR-Block (stride = 2), as shown in
Figure 8a,b.
In the ASIR-Block (stride = 1), the stride of DW is set as 1, the pooling is set as the same, and the number of convolutional kernels in the last 1 × 1 convolutional layer and the number of channels of the input are the same, so as to ensure that the shape of the output is the same as that of the input, and a shortcut connection can be used. The ASIR-Block (stride = 1) is used in the second half of the ASIR-Net to ensure the training effect and accelerate the training speed. In the ASIR-Block (stride = 2), the stride of DW is set as 2, the pooling is set as the same, and the number of convolutional kernels in the last 1 × 1 convolutional layer is set as C; is a hyperparameter, generally set as 2 or 3. The width and height of the output have become half of the input, and the number of channels of the output has become times that of the input. The ASIR-Block (stride = 2) is used in the first half of the network to compress the width and height of the channel and increase the number of channels.
With referencing to the network structure and hyperparameters of ShuffleNet [
32] and EfficientNet-v2 [
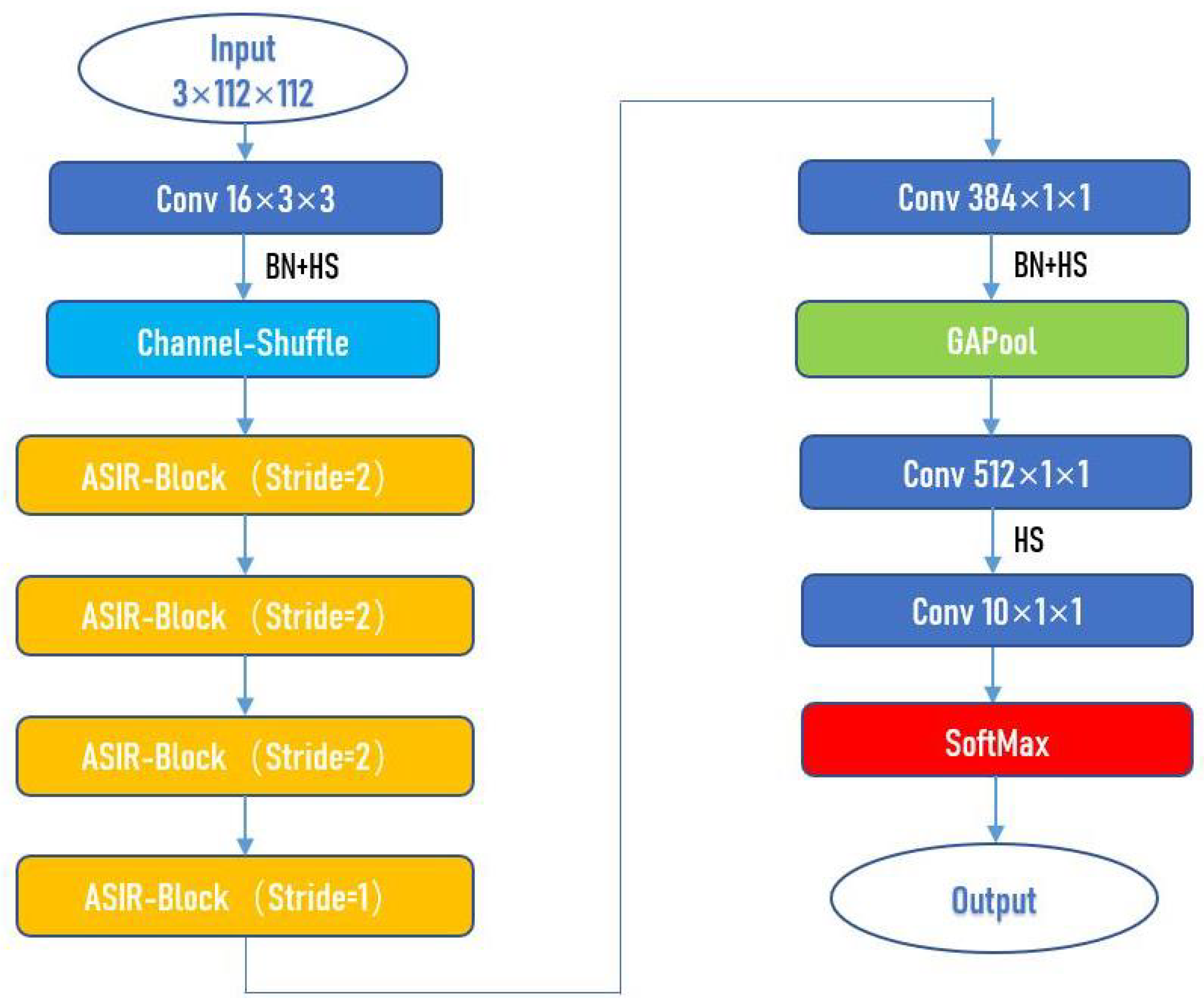
26] and doing a lot of experiments based on the structure and hyperparameters of these networks, we finally determined the structure and hyperparameters of our network. See
Table 1 and
Figure 9 for the complete specifications of ASIR-Net, where Out denotes the number of output channels, BN denotes whether to perform Batch-Normalization after the convolutional layer, NL denotes the type of nonlinear activation function used, and s denotes stride.
2.5. Training of ASIR-Net
We use SoftMax as the classifier. Softmax can map output values to the values in the interval (0,1), and the sum of the transformed values is 1, so we can understand the transformed values as probabilities. Suppose the vector which inputs to SoftMax is
, the formula of SoftMax is expressed as:
where
is the power of
e,
is the one-hot probability vector corresponding to the target types, and
C represents the number of target types. After passing the SoftMax, we can obtain the probability of each element corresponding to various targets from the output vector.
We use Cross-entropy as the loss function. Suppose a batch of samples in dataset is
, where
is the true label of
. The Cross-entropy can be presented as:
Adam [
33] is used to update the trainable parameters of the proposed ASIR-Net. For the weight
, we can update it in this way:
where
t denotes number of updates,
is the correction of
,
is the correction of
, and the formula of
and
can be presented as:
where
and
are constants and control exponential decay.
is the exponential moving average of the gradient, which is obtained by the first moment of the gradient.
is the square gradient, which is obtained by the second moment of the gradient. The updates of
and
can be expressed as:
where
is the first derivative. The aforementioned parameters are set as:
,
= 0.9,
= 0.999,
= 0.001.
2.6. Dataset Description
Unlike the rapid development of optical image recognition research, in the field of SAR ATR, it is very difficult to get sufficient publicly available datasets because of the difficulty of target detection means. Among them, the MSTAR publicly available in the United States is one of the few datasets that can identify ground vehicle targets. MSTAR was launched by the Defense Advanced Research Projects Agency (DARPA) in the mid-1990s [
34]. High resolution focused SAR is used to collect SAR images of various military vehicles in the former Soviet Union. MSTAR plans to conduct SAR field tests on ground targets, including target occlusion, camouflage, configuration changes, and other scalability conditions, to form a relatively comprehensive and systematic field test database. The international research on SAR ATR is basically based on this dataset, up to now.
The MSTAR dataset consists of ten types of targets: ZSU234, ZIL131, T72, T62, D7, BTR70, BTR60, BRDM2, BMP2, and 2S1. The x-band imaging radar works in HH polarization mode and obtains a serious of images with a size of 158 × 158 pixels and a resolution of 0.3 × 0.3 m [
35].
Figure 10 depicts optical images and corresponding SAR images of targets at a similar angle.
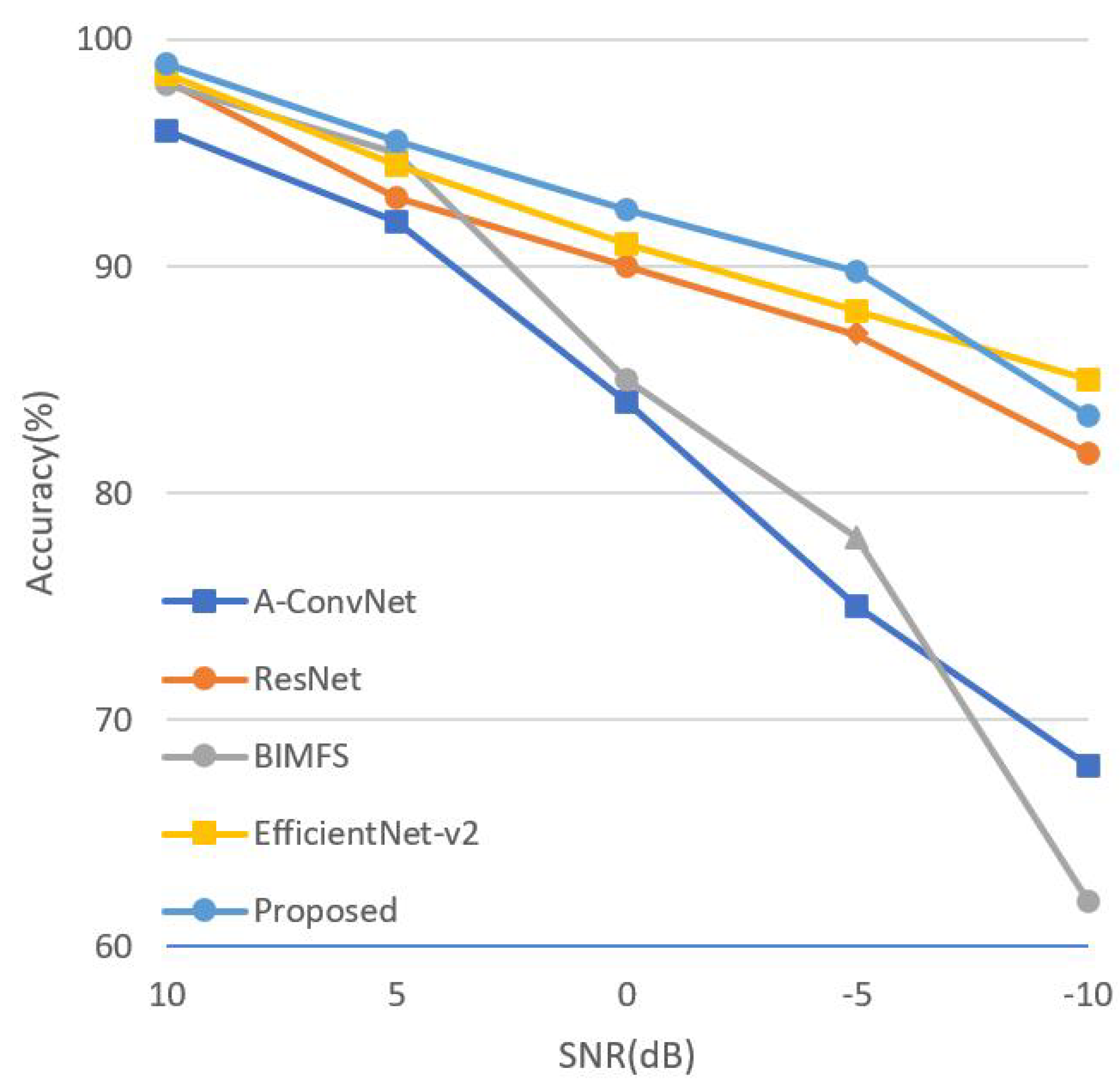
There are two categorise of collection conditions in MSTAR dataset: Standard Operating Condition (SOC) and Extended Operating Conditions (EOCs). These SAR images are generated based on a variety of acquisition conditions, such as changing the imaging depression angle, target posture, or target serial number. SOC means that the sequence number and target configuration of training dataset are the same as that of testing dataset, but the depression angles are different. EOCs consist of three experiments: depression angle variant, configuration variant, and noise corruption. Unlike some papers which only verify the performance of the network under SOC [
19,
36], to evaluate the generalization performance of the proposed ASIR-Net, this paper also measure the recognition accuracy rates of the proposed ASIR-Net under EOCs.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}