
MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery



Abstract
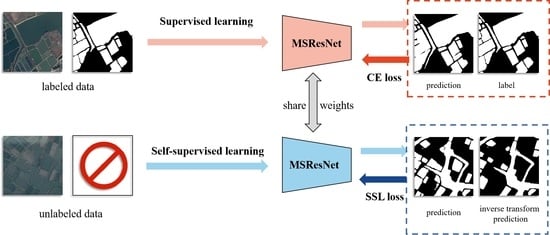
:
1. Introduction
- According to the special characteristics of water bodies, this paper proposes the novel MSResNet which includes two well-designed modules: MSDC and MKMP. More specifically, MSDC benefits the encoding of high-level semantic feature maps and the gathering of different levels of context information, and MKMP helps capture the scale-invariant characteristics of water bodies;
- In the water-body detection background, this paper, for the first time, explores an SSL strategy to train the DSSN model by fully leveraging unlabeled data. More specifically, four kinds of SSL strategies (e.g., geometric transformation learning, noise disturbance learning, image resolution learning and image context fusion learning) are comprehensively explored and evaluated, providing references for further applications;
- Our proposed water-body detection method in which MSResNet is combined with the SSL strategy demonstrates improved results compared with state-of-the-art methods operating on two publicly open datasets.
2. Related Work
2.1. Handcrafted Feature-Based Water-Body Detection Methods
2.2. Deep Learning-Based Water Body Detection Methods
3. Methodology
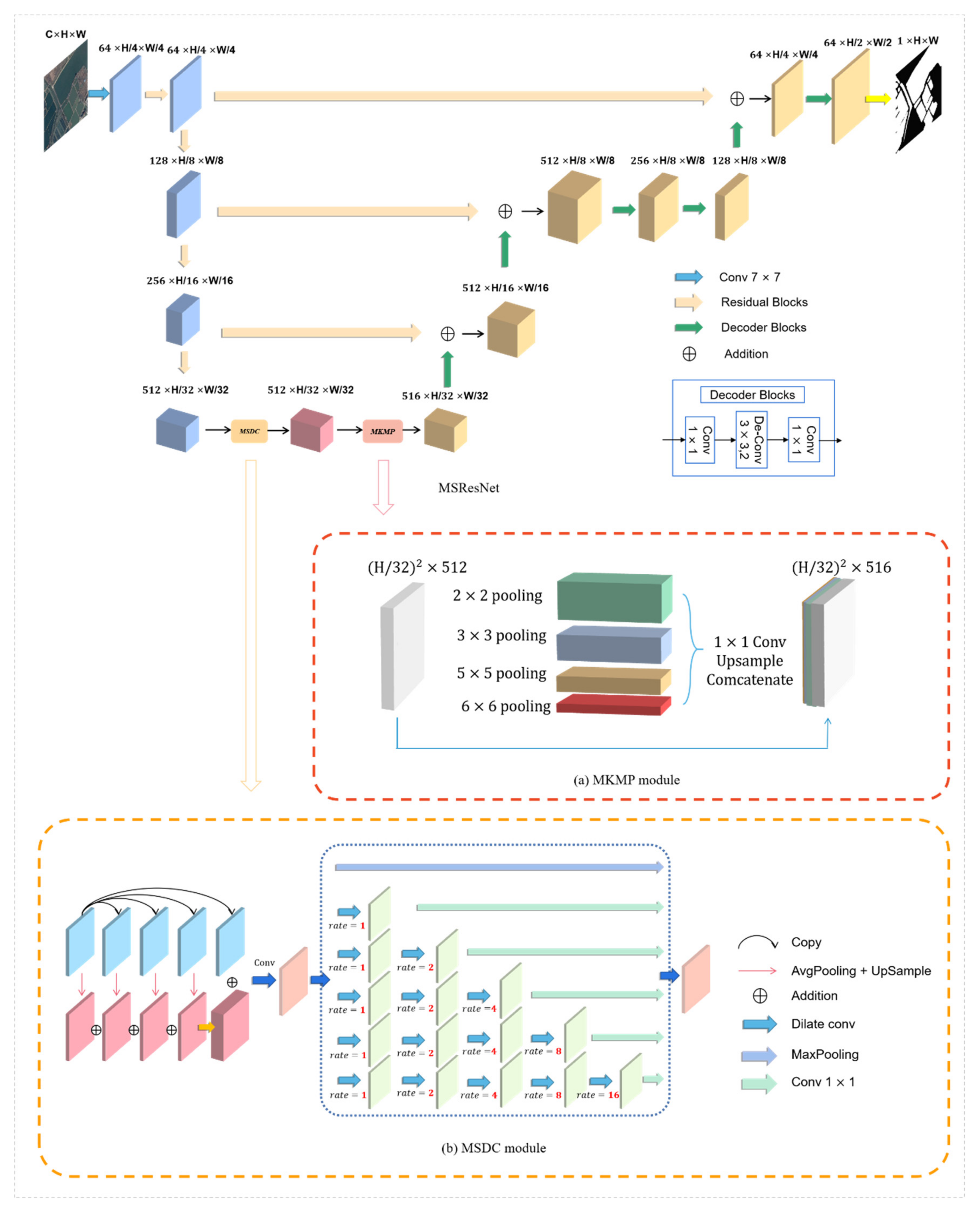
3.1. Multiscale Residual Network (MSResNet) for Water-Body Detection
3.1.1. The Multiscale Dilated Convolution (MSDC) Module
3.1.2. The Multikernel Max Pooling (MKMP) Module
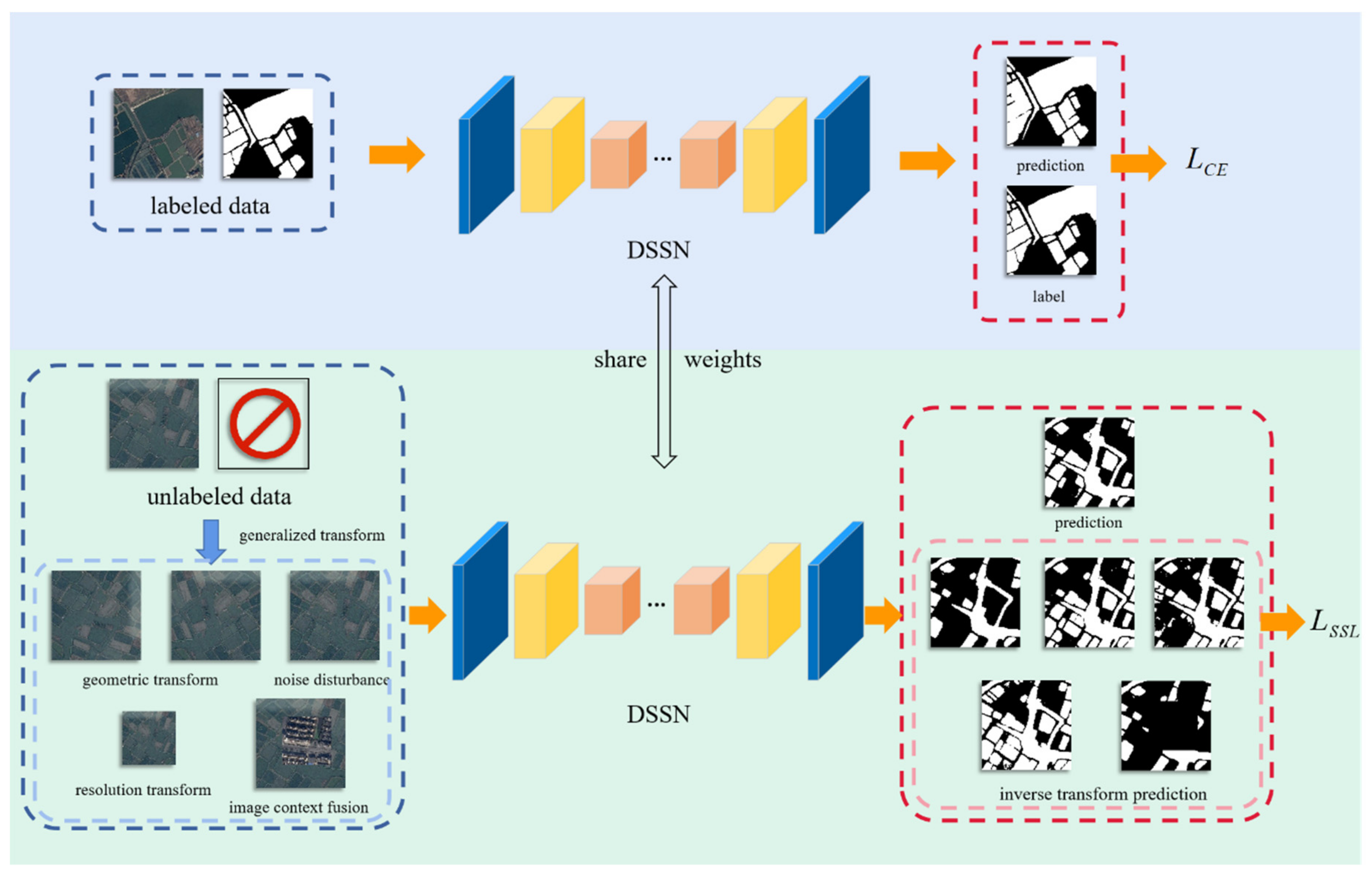
3.2. Self-Supervised Learning (SSL) Strategy for Optimizing MSResNet
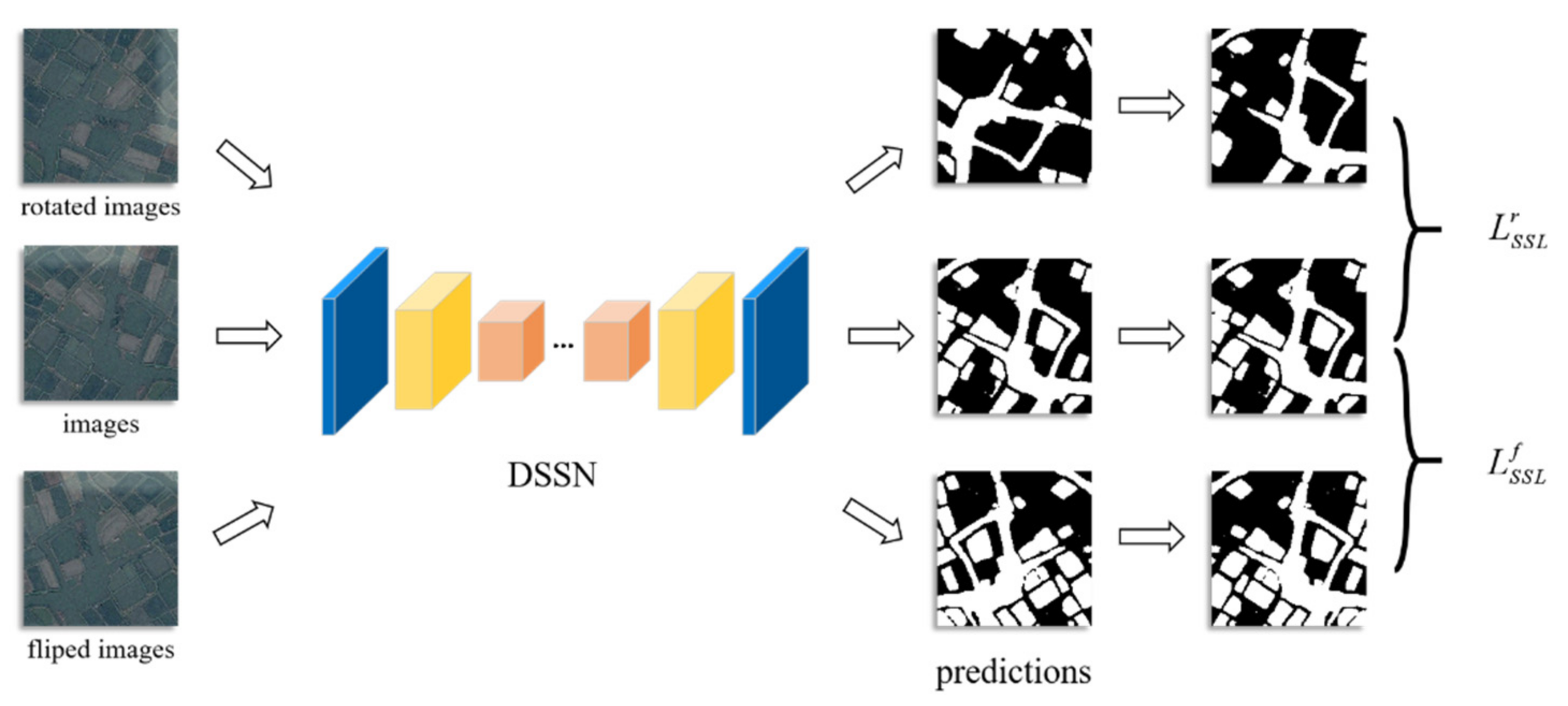
3.2.1. Geometric Transformation Learning
3.2.2. Noise Disturbance Learning
3.2.3. Image Resolution Learning
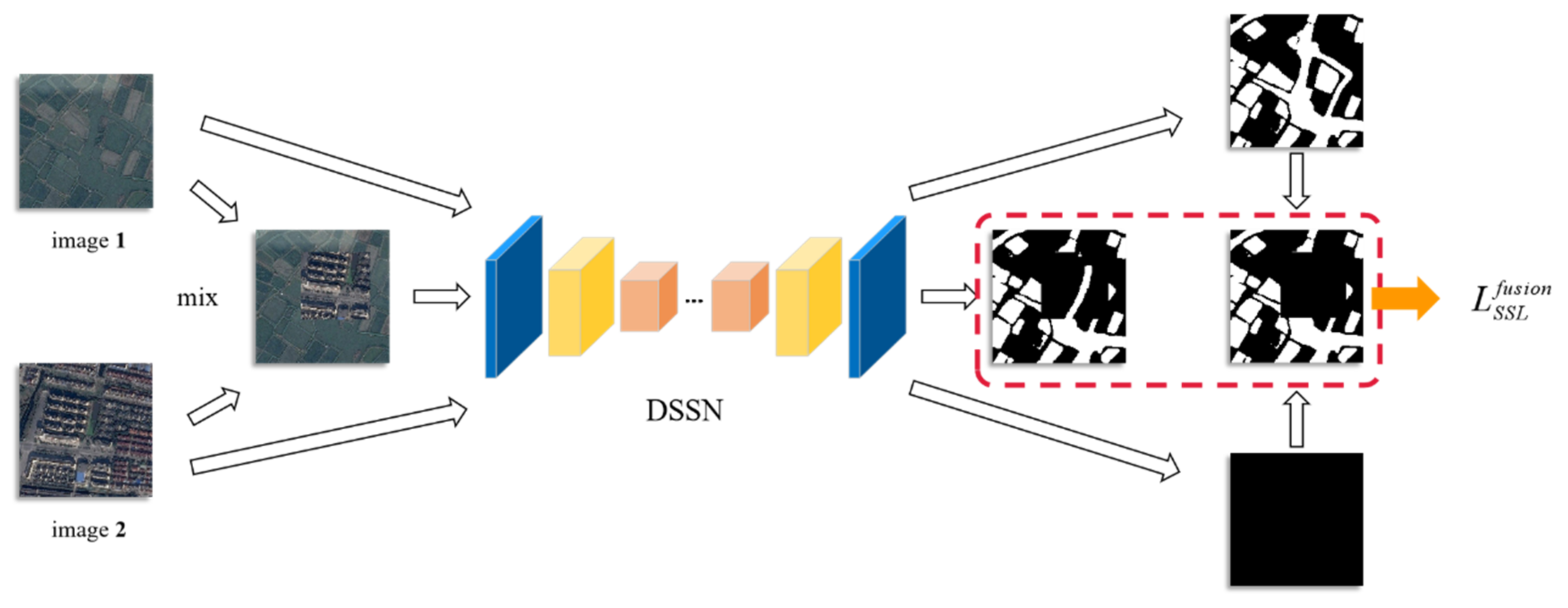
3.2.4. Image Context Fusion Learning
4. Experimental Results
4.1. Evaluation Datasets
4.2. Evaluation Metrics
4.3. Experiment Settings
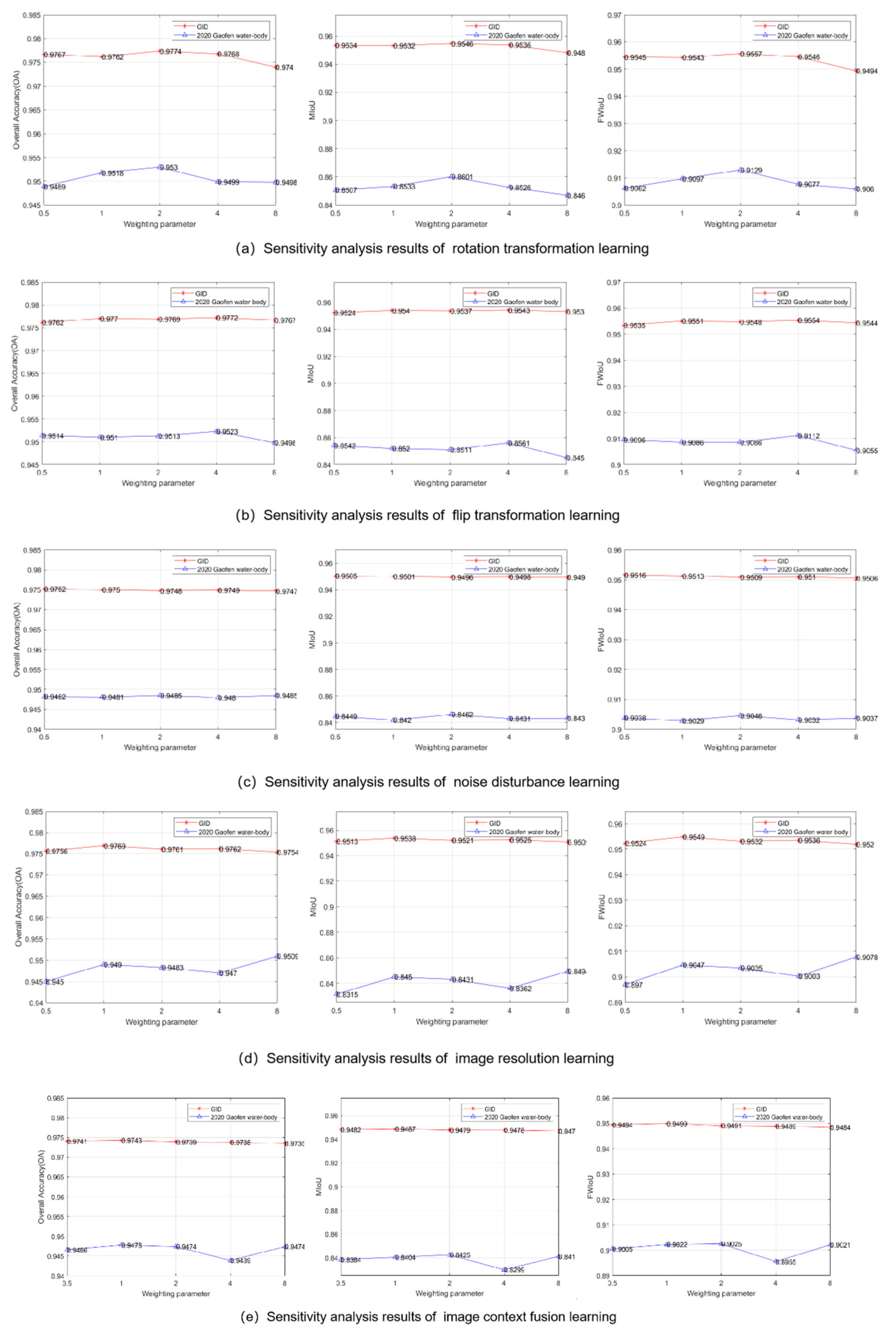
4.4. Sensitivity Analysis of the Weighting Parameter
4.5. Ablation Study
4.6. Comparison with the State-of-the-Art Methods
4.6.1. Results for the 2020 Gaofen Challenge Water-Body Segmentation Dataset
4.6.2. Results for the GID Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Ma, J.; Zhang, Y. Image retrieval from remote sensing big data: A survey. Inf. Fusion 2021, 67, 94–115. [Google Scholar] [CrossRef]
- Chi, M.; Plaza, A.; Benediktsson, J.A.; Sun, Z.; Shen, J.; Zhu, Y. Big data for remote sensing: Challenges and opportunities. Proc. IEEE 2016, 104, 2207–2219. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Chen, Y.; Zhang, S.; Wu, J. Detecting, extracting, and monitoring surface water from space using optical sensors: A review. Rev. Geophys. 2018, 56, 333–360. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, P.; Xing, J.; Li, Z.; Xing, X.; Yuan, Z. A multi-scale deep neural network for water detection from SAR images in the mountainous areas. Remote Sens. 2020, 12, 3205. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, M.; Sun, G.-C.; Chen, J.; Li, M.; Hu, Y.; Bao, Z. Water body detection in high-resolution SAR images with cascaded fully-convolutional network and variable focal loss. IEEE Trans. Geosci. Remote Sens. 2021, 59, 316–332. [Google Scholar] [CrossRef]
- Balajee, J.; Durai, M.A.S. Detection of water availability in SAR images using deep learning architecture. Int. J. Syst. Assur. Eng. Manag. 2021, 1–10. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Frazier, P.S.; Page, K.J. Water body detection and delineation with Landsat TM data. Photogrammetric engineering and remote sensing. Photogramm. Eng. Remote Sens. 2000, 66, 1461–1468. [Google Scholar]
- Lv, W.; Yu, Q.; Yu, W. Water extraction in SAR images using GLCM and support vector machine. In Proceedings of the IEEE 10th International Conference on Signal Processing, Beijing, China, 24–28 October 2010. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 9 October 2015; pp. 234–241. [Google Scholar]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water Body Extraction from Very High-Resolution Remote Sensing Imagery Using Deep U-Net and a Superpixel-Based Conditional Random Field Model. IEEE Geosci. Remote Sens. Lett. 2018, 16, 618–622. [Google Scholar] [CrossRef]
- Guo, H.; He, G.; Jiang, W.; Yin, R.; Yan, L.; Leng, W. A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2020, 9, 189. [Google Scholar] [CrossRef] [Green Version]
- Duan, L.; Hu, X. Multiscale Refinement Network for Water-Body Segmentation in High-Resolution Satellite Imagery. IEEE Geosci. Remote Sens. Lett. 2019, 17, 686–690. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 649–666. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative unsupervised feature learning with convolutional neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 766–774. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Larsson, G.; Shakhnarovich, M.M.G.; Learned-Miller, E. Self-supervised relative depth learning for urban scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 19–35. [Google Scholar]
- Li, Y.; Paluri, M.; Rehg, J.M.; Dollár, P. Unsupervised learning of edges. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1619–1627. [Google Scholar]
- Jing, L.; Tian, Y. Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Shangri-La, China, 11–13 September 2020; pp. 1597–1607. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS44Net: Boundary-aware semi-supervised semantic segmentation network for very high resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Learning transferable deep models for land-use classification with high-resolution remote sensing images. arXiv 2018, arXiv:1807.05713. [Google Scholar]
- Han-Qiu, X. A study on information extraction of water body with the modified normalized difference water index (MNDWI). J. Remote Sens. 2005, 5, 589–595. [Google Scholar]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S. Automated Water Extraction Index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Fisher, A.; Flood, N.; Danaher, T. Comparing Landsat water index methods for automated water classification in eastern Australia. Remote Sens. Environ. 2016, 175, 167–182. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, P.; Chen, C.; Jiang, T.; Yu, Z.; Guo, B. Waterbody information extraction from remote-sensing images after disasters based on spectral information and characteristic knowledge. Int. J. Remote Sens. 2017, 38, 1404–1422. [Google Scholar] [CrossRef]
- Vélez-Nicolás, M.; García-López, S.; Barbero, L.; Ruiz-Ortiz, V.; Sánchez-Bellón, Á. Applications of unmanned aerial systems (UASs) in hydrology: A review. Remote Sens. 2021, 13, 1359. [Google Scholar] [CrossRef]
- Jakovljević, G.; Govedarica, M. Water Body Extraction and Flood Risk Assessment Using Lidar and Open Data. In Climate Change Management; Springer Science and Business Media LLC: Cham, Switzerland, 2019; pp. 93–111. [Google Scholar]
- Morsy, S.; Shaker, A.; El-Rabbany, A. Using Multispectral airborne lidar data for land/water discrimination: A case study at Lake Ontario, Canada. Appl. Sci. 2018, 8, 349. [Google Scholar] [CrossRef] [Green Version]
- Nandi, I.; Srivastava, P.K.; Shah, K. Floodplain mapping through support vector machine and optical/infrared images from Landsat 8 OLI/TIRS sensors: Case study from Varanasi. Water Resour. Manag. 2017, 31, 1157–1171. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. arXiv 2021, arXiv:2101.06085. [Google Scholar]
- Li, Y.; Zhang, Y.; Zhu, Z. Error-Tolerant Deep Learning for Remote Sensing Image Scene Classification. IEEE Trans. Cybern. 2021, 51, 1756–1768. [Google Scholar] [CrossRef] [PubMed]
- Tong, X.-Y.; Xia, G.-S.; Hu, F.; Zhong, Y.; Datcu, M.; Zhang, L. Exploiting Deep Features for Remote Sensing Image Retrieval: A Systematic Investigation. IEEE Trans. Big Data 2020, 6, 507–521. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. Cfc-net: A critical feature capturing network for arbitrary-oriented object detection in remote sensing images. arXiv 2021, arXiv:2101.06849. [Google Scholar]
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Xiao, R.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Pai, M.M.M.; Mehrotra, V.; Verma, U.; Pai, R.M. Improved semantic segmentation of water bodies and land in SAR images using generative adversarial networks. Int. J. Semant. Comput. 2020, 14, 55–69. [Google Scholar] [CrossRef]
- Li, L.; Yan, Z.; Shen, Q.; Cheng, G.; Gao, L.; Zhang, B. Water body extraction from very high spatial resolution remote sensing data based on fully convolutional networks. Remote Sens. 2019, 11, 1162. [Google Scholar] [CrossRef] [Green Version]
- Song, S.; Liu, J.; Liu, Y.; Feng, G.; Han, H.; Yao, Y.; Du, M. Intelligent object recognition of urban water bodies based on deep learning for multi-source and multi-temporal high spatial resolution remote sensing imagery. Sensors 2020, 20, 397. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, L.; Wang, Z.; Tian, S.; Ye, F.; Ding, J.; Kong, J. Convolutional neural networks for water body extraction from landsat imagery. Int. J. Comput. Intell. Appl. 2017, 16, 1750001. [Google Scholar] [CrossRef]
- Miao, Z.; Fu, K.; Sun, H.; Sun, X.; Yan, M. Automatic water-body segmentation from high-resolution satellite images via deep networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 602–606. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, L.; Kan, Z.; Bilal, M.; Li, Q. A novel water body extraction neural network (WBE-NN) for optical high-resolution multispectral imagery. J. Hydrol. 2020, 588, 125092. [Google Scholar] [CrossRef]
- Li, Z.; Wang, R.; Zhang, W.; Hu, F.; Meng, L. Multiscale features supported Deeplabv3+ optimization scheme for accurate water semantic segmentation. IEEE Access 2019, 7, 155787–155804. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, M.; Ji, S.; Yu, H.; Nie, C. Rich CNN Features for water-body segmentation from very high resolution aerial and satellite imagery. Remote Sens. 2021, 13, 1912. [Google Scholar] [CrossRef]
- Wu, Y.; Han, P.; Zheng, Z. Instant water body variation detection via analysis on remote sensing imagery. J. Real Time Image Process. 2021, 1–14. [Google Scholar] [CrossRef]
- Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. WSF-NET: Weakly Supervised feature-fusion network for binary segmentation in remote sensing image. Remote Sens. 2018, 10, 1970. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 1–26 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Shi, H.; Wang, H.; Jin, Y.; Zhao, L.; Liu, C. Automated heartbeat classification based on convolutional neural network with multiple kernel sizes. In Proceedings of the 2019 IEEE Fifth International Conference on Big Data Computing Service and Applications (BigDataService), Newark, CA, USA, 4–9 April 2019; pp. 311–315. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 6023–6032. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Architecture | SSL | OA | MIoU | FWIoU |
|---|---|---|---|---|
| Our MSResNet | - | 94.93 | 85.34 | 90.57 |
| Our MSResNet | Rotation Transformation Learning | 94.94 | 85.69 | 90.68 |
| Our MSResNet | Flip Transformation Learning | 95.10 | 85.82 | 90.88 |
| Our MSResNet | Noise Disturbance Learning | 94.87 | 85.12 | 90.45 |
| Our MSResNet | Image Resolution Learning | 94.89 | 85.62 | 90.64 |
| Our MSResNet | Image Context Fusion Learning | 95.07 | 85.58 | 90.77 |
| Network Architecture | SSL | OA | MIoU | FWIoU |
|---|---|---|---|---|
| Our MSResNet | - | 96.96 | 93.94 | 94.12 |
| Our MSResNet | Rotation Transformation Learning | 97.47 | 94.94 | 95.08 |
| Our MSResNet | Flip Transformation Learning | 97.39 | 94.76 | 94.91 |
| Our MSResNet | Noise Disturbance Learning | 97.08 | 94.17 | 94.34 |
| Our MSResNet | Image Resolution Learning | 97.36 | 94.71 | 94.86 |
| Our MSResNet | Image Context Fusion Learning | 96.93 | 93.87 | 94.05 |
| Method | OA | MIoU | FWIoU |
|---|---|---|---|
| LinkNet [12] | 93.85 | 82.68 | 88.76 |
| HR-Net [13] | 93.90 | 82.36 | 88.72 |
| FCN [11] | 92.44 | 78.99 | 86.36 |
| DeepLab V3+ [37] | 93.48 | 81.86 | 88.17 |
| MECNet [51] | 94.66 | 84.96 | 90.21 |
| Our MSResNet | 94.93 | 85.34 | 90.57 |
| Our MSResNet via Rotation Transformation Learning | 94.94 | 85.69 | 90.68 |
| Our MSResNet via Flip Transformation Learning | 95.10 | 85.82 | 90.88 |
| Method | Time of Single Image (ms) |
|---|---|
| LinkNet [12] | 89 |
| HR-Net [13] | 117 |
| FCN [11] | 86 |
| DeepLab V3+ [37] | 104 |
| MECNet [51] | 119 |
| Our MSResNet | 108 |
| Our MSResNet via Rotation Transformation Learning | 106 |
| Our MSResNet via Flip Transformation Learning | 108 |
| Method | OA | MIoU | FWIoU |
|---|---|---|---|
| LinkNet [12] | 96.17 | 92.49 | 92.64 |
| HR-Net [13] | 96.02 | 92.15 | 92.37 |
| FCN [11] | 94.26 | 88.89 | 89.19 |
| DeepLab V3+ [37] | 96.54 | 93.13 | 93.33 |
| MECNet [51] | 96.44 | 92.94 | 93.15 |
| Our MSResNet | 96.96 | 93.94 | 94.12 |
| Our MSResNet via Rotation Transformation Learning | 97.47 | 94.94 | 95.08 |
| Our MSResNet via Flip Transformation Learning | 97.39 | 94.76 | 94.91 |
| Method | Time of Single Image (ms) |
|---|---|
| LinkNet [12] | 11 |
| HR-Net [13] | 29 |
| FCN [11] | 7 |
| DeepLab V3+ [37] | 24 |
| MECNet [51] | 23 |
| Our MSResNet | 22 |
| Our MSResNet via Rotation Transformation Learning | 21 |
| Our MSResNet via Flip Transformation Learning | 21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, B.; Li, Y. MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery. Remote Sens. 2021, 13, 3122. https://doi.org/10.3390/rs13163122
Dang B, Li Y. MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery. Remote Sensing. 2021; 13(16):3122. https://doi.org/10.3390/rs13163122
Chicago/Turabian StyleDang, Bo, and Yansheng Li. 2021. "MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery" Remote Sensing 13, no. 16: 3122. https://doi.org/10.3390/rs13163122
APA StyleDang, B., & Li, Y. (2021). MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery. Remote Sensing, 13(16), 3122. https://doi.org/10.3390/rs13163122